Data Engineering for Affective Understanding Systems


Abstract
1. Introduction
2. Related Work
- A variety of data sources are used that can include images, videos, physiological data, environmental data, subjective self-evaluation, activities and text. This variation alongside with the naturally large amount of some of them and the high frequency of their generation categorizes data in these studies as “big data” according to the recent definition of this term [30].
- Data are either collected in a simulated lab environment or while performing real activities in a field environment. A lab environment is more controlled, which ensures better focus on the studied parameters; however, users’ emotions within lab experiments may suffer from exaggeration or suppression [6]. Furthermore, in real environments, users usually perform more complex tasks, which require a higher cognitive load [4]. Thus, since the goal of these applications is the detection of affects in real environments, a system can only be useable when it proves efficient in a real environment.
- Physiological features that were repeatedly reported in the literature to best predict stress are amplitude of the heart rate variability (HRV) and low frequency (LF)/high frequency (HF). In addition, electrocardiogram (ECG) and galvanic skin response (GSR) are particularly useful in the immediate identification of short-term stress events.
- Interpretation methods vary from statistical methods, to neural networks, image and video recognition, etc.
- (1)
- Collect data and assign time stamps to them.
- (2)
- Interpolate lost data.
- (3)
- Identify poor quality data and screen it out.
- (4)
- Data normalization.
- (5)
- Aggregate data into one-minute blocks.
- (6)
- Train a Support Vector Machine (SVM) [23].
- Bringing together big data from different technologies (sources), sometimes more than ten sources.
- Choosing the right tool to integrate the data.
- Making sure that the data used is clean, reliable and fit for purpose.
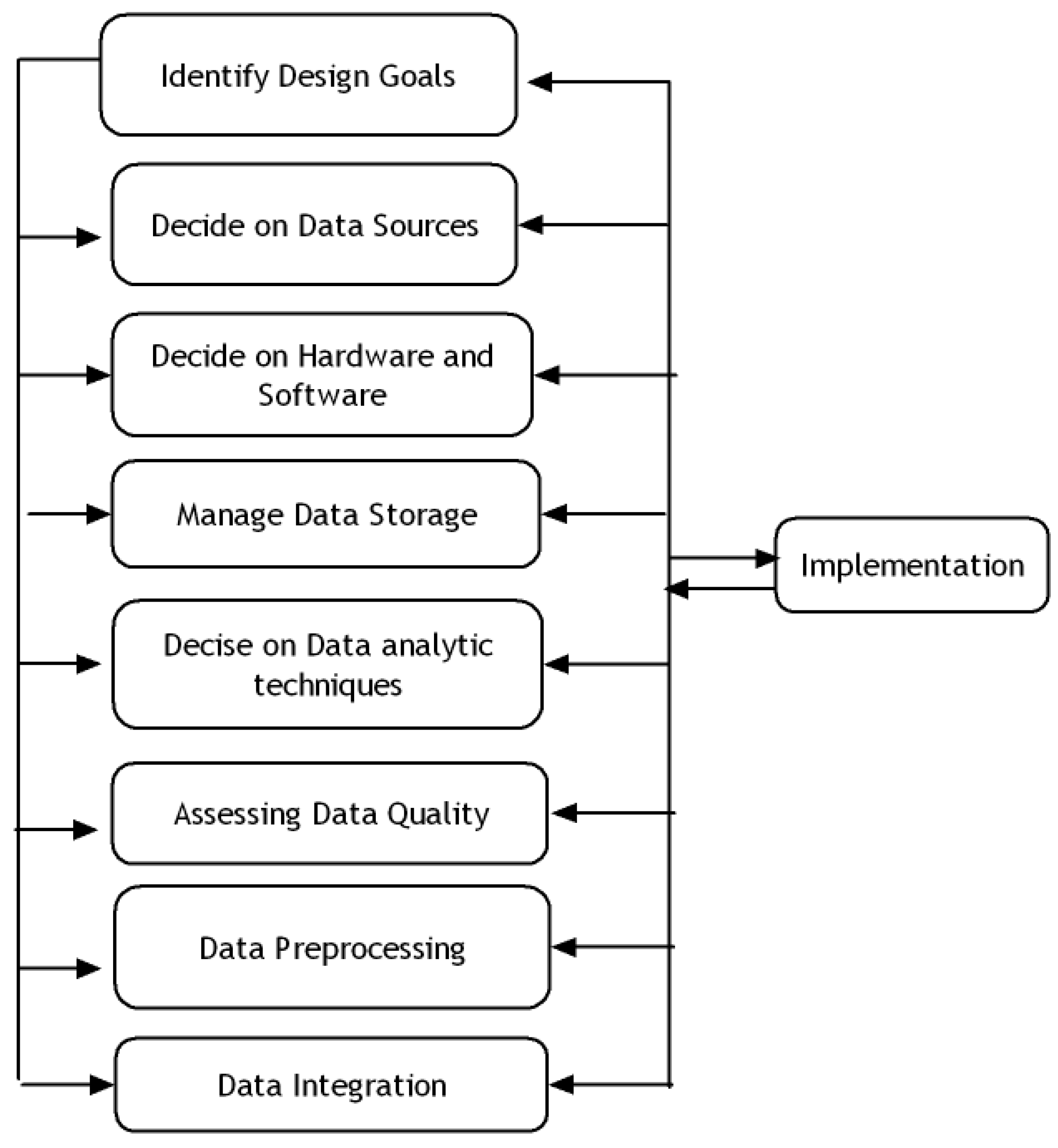
3. Design Model
3.1. Identify Design Goals
3.2. Decide on Data Sources
3.3. Decide on Hardware and Software
3.4. Manage Data Storage
3.5. Decide on Data Analytic Techniques
3.6. Assessing Data Quality
3.7. Data Preprocessing
3.8. Data Integration
- Proprietary software of devices that acquire signals may only work offline or be difficult to integrate with other components of the system.
- Availability of data at different times or rates. For example, subjective self-evaluation may not be available until the end of the experiment.
- Some signals suffer from latency and discontinuity.
- It is common to use time-stamps to correlate data, but sometimes time-space labels mismatch when devices are not synchronized.
4. Detecting Driver Stress Application
4.1. Design Goals
- No car alteration is needed. The test is conducted on the participant’s own car. Rational: Driving a new car or an altered car may introduce an additional element of stress for some people.
- All devices for measuring physiological indicators are wearable in a minimally obstructive way. Rational: Obstructive tools introduce an element of stress while driving.
- Data should be collected at different times of the day, different weather conditions, different routes, different ages, and different genders. Rational: Variations of data enhance the detection of patterns.
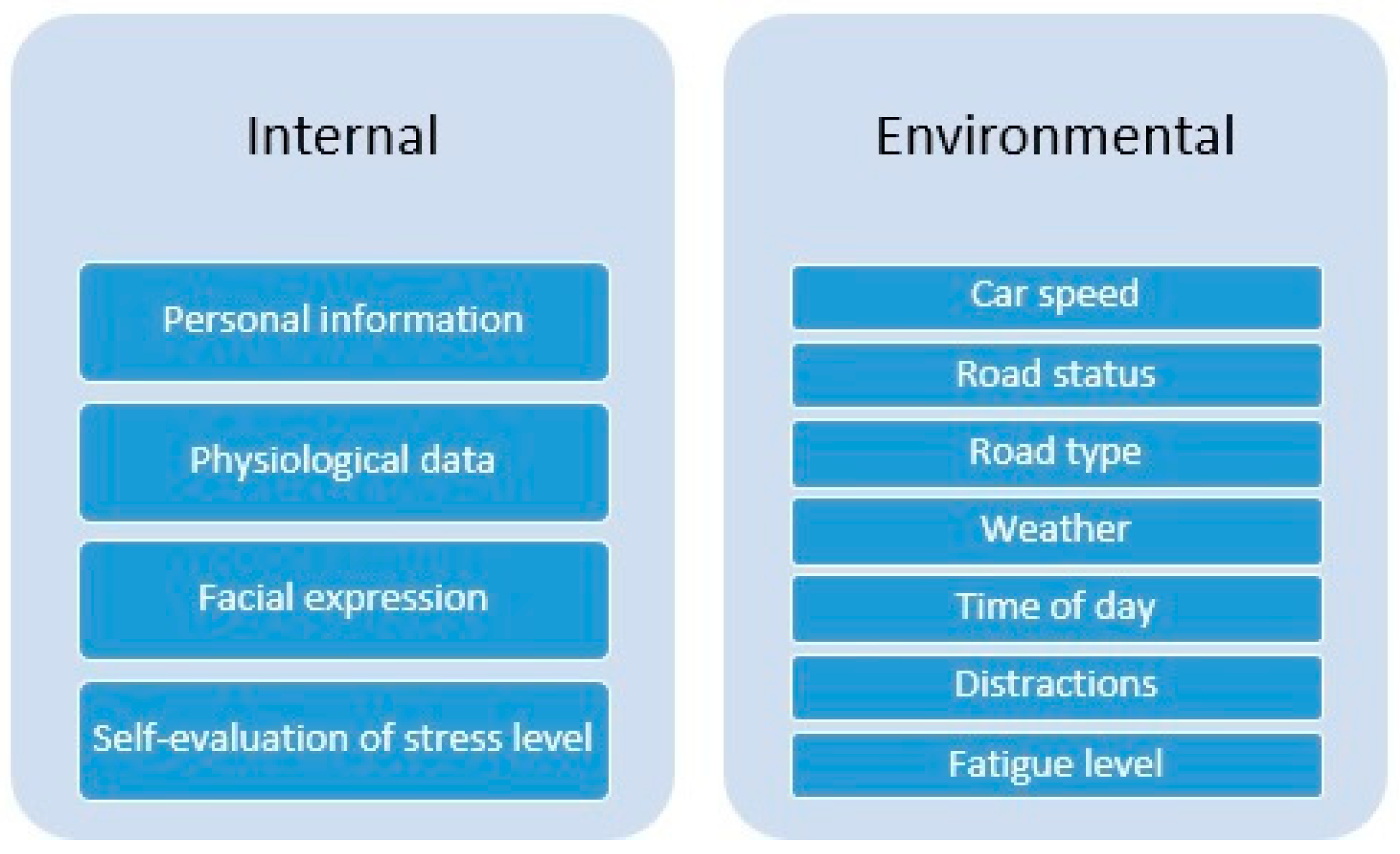
4.2. Data Sources
- (1)
- Personal information about the driver including (age, gender, number of driving years, daily driving hours, number of accidents in general and in the previous year, illnesses, personal stress symptoms, and personal evaluation of driving skills, driving style and general stress level while driving). This data is collected before a driving experiment.
- (2)
- Physiological data while driving (ECG, EMG of trapezius muscle, GSR skin conductance (GSR/SC), respiration rate).
- (3)
- Self-evaluation of the stress level collected offline after the experiment, with contextual cues of the road images to overcome the drawbacks of recall-based self-report method as suggested in [37].
- (4)
- Road status while driving.
- (5)
- Facial expressions while driving.
- (6)
- Environmental conditions of the experiment (weather, time of day, distractions inside the car, fatigue level and stress level before the experiment).
- (7)
- Car speed and road type while driving.
4.3. Hardware and Software
- Send road status and real-time facial expressions to a central data center requires high-quality wireless network at all locations while driving, which is impossible to ensure as network quality of services vary depending on car location, in addition to the high cost of moving intensive data such as images or videos over a wireless network.
- Alternatively, we can store the road status and facial expressions data locally on the mobile phone during the experiment then move it offline for integration.
4.4. Data Storage
4.5. Data Analytic Techniques
4.6. Assessing Data Quality
- Loose electrodes, which caused missing physiological data (e.g., ECG or EMG).
- Errors in the mobile application or shortage of internal storage or memory storage of the mobile device, which caused loss of images recording.
- Distorted images due to car movement.
- Loss of GPS signals, which cause missing GPS locations and incorrect car speeds.
4.7. Data Preprocessing
4.8. Data Integration
5. Implementation
6. Discussion
7. Future Work
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Alexandra, J.M.; Andres, L.; Ocumpaugh, J.; Baker, R.S.; Slater, S.; Paquette, L.; Jiang, Y.; Karumbaiah, S.; Bosch, N.; Munshi, A.; et al. Affect Sequences and Learning in Betty’s Brain. In Proceedings of the 9th International Conference on Learning Analytics & Knowledge, Tempe, AZ, USA, 4–8 March 2019. [Google Scholar]
- Vea, A.; Mesina, M.R.; Toriaga, R.P.; Padlan, N. Development of an Intelligent Agent that Detects Student’s Negative Affect while Making a Computer Program. In Proceedings of the International Conference on Advances in Image Processing, Bangkok, Thailand, 25–27 August 2017. [Google Scholar]
- Liu, C.; Tong, L. Developing Automatic Form and Design System Using Integrated Grey Relational Analysis and Affective Engineering. Appl. Sci. 2018, 8, 91. [Google Scholar] [CrossRef]
- Sarsenbayeva, Z.; Berkel, N.; Hettiachchi, D.; Jiang, W.; Dingler, T.; Velloso, E.; Kostakos, V.; Goncalves, J. Measuring the Effects of Stress on Mobile Interaction. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3. [Google Scholar] [CrossRef]
- Schwark, J.D. Toward a Taxonomy of Affective Computing. Int. J. Hum. Comput. Interact. 2015, 31, 761–768. [Google Scholar] [CrossRef]
- Zhalehpour, S.; Onder, O.; Akhtar, Z.; Erdem, C. BAUM-1: A Spontaneous Audio-Visual Face Database of Affective and Mental States. IEEE Trans. Affect. Comput. 2017, 8, 300–313. [Google Scholar] [CrossRef]
- Healey, J.; Picard, R.W. Detecting Stress During Real-World Driving Tasks Using Physiological Sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef]
- Schießl, C. Stress and Strain while driving. In Proceedings of the Young Researchers Seminar 2007, European Conference of Transport Research Institutes (ECTRI), Brno, Czech Republic, 27–30 May 2007. [Google Scholar]
- Taelman, J.; Vandeput, S.; Spaepen, A.; Van Huffel, S. Influence of Mental Stress on Heart Rate and Heart Rate Variability. In Proceedings of the 4th European Conference of the International Federation for Medical and Biological Engineering, IFMBE Proceedings, Antwerp, Belgium, 23–27 November 2008; Vander Sloten, J., Verdonck, P., Nyssen, M., Haueisen, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Bundele, M.; Banerjee, R. Detection of fatigue of vehicular driver using skin conductance and oximetry pulse: A neural network approach. In Proceedings of the 11th International Conference on Information Integration and Web-based Applications & Services, Kuala Lumpur, Malaysia, 14–16 December 2009; pp. 739–744. [Google Scholar]
- Wijsman, J.; Grundlehner, B.; Penders, J.; Hermens, H. Trapezius Muscle EMG as Predictor of Mental Stress. ACM Trans. Embed. Comput. Syst. 2010, 12, 155–163. [Google Scholar]
- Rigas, G.; Goletsis, Y.; Bougia, P.; Fotiadis, D. Towards Driver’s State Recognition on Real Driving Conditions. Int. J. Veh. Technol. 2011, 2011, 617210. [Google Scholar] [CrossRef]
- Bakker, J.; Pechenizkiy, M.; Sidorova, N. What’s your current stress level? In Proceedings of the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December 2011; pp. 573–580. [Google Scholar]
- Ertin, E.; Stohs, N.; Kumar, S.; Raij, A.; Al’Absi, M.; Shah, S.; Jeong, J.W. AutoSense: Unobtrusively wearable sensor suite for inferring the onset, causality, and consequences of stress in the field. In Proceedings of the 9th ACM Conference on Embedded Networked Sensor Systems (SenSys 2011), Seattle, WA, USA, 1–4 November 2011; pp. 274–287. [Google Scholar]
- Hernandez, J.; Morris, R.; Picard, R. Call Center Stress Recognition with Person-Specific Models. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction (ACII 2011), Memphis, TN, USA, 9–12 October 2011; D’Mello, S., Calvo, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 125–134. [Google Scholar]
- Paschero, M.; Vescovo, G.D.; Benucci, L.; Rizzi, A.; Santello, M.; Fabbri, G.; Mascioloi, F. A real time classifier for emotion and stress recognition in a vehicle driver. In Proceedings of the International Symposium on Industrial Electronics (ISIE), Hangzhou, China, 28–31 May 2012; pp. 1690–1695. [Google Scholar]
- Schneegass, S.; Pfleging, B.; Broy, N.; Schmidt, A.; Heinrich, F. A Data Set of Real World Driving to Assess Driver Workload. In Proceedings of the 5th International Conference on Automotive User Interfaces and Interactive Vehicular Applications (AutomotiveUI ’13), Eindhoven, The Netherlands, 28–30 October 2013. [Google Scholar]
- Marcos-Ramiro, A.; Pizarro-Perez, D.; Marron-Romera, M.; Gatica-Perez, D. Automatic Blinking Detection towards Stress Discovery. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; pp. 307–310. [Google Scholar]
- Luijcks, R.; Hermens, H.; Bodar, L.; Vossen, C.; Lousberg, R. Experimentally Induced Stress Validated by EMG Activity. PLoS ONE 2014, 9, e95215. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Ulrich, M. Listen to Your Heart: Stress Prediction Using Consumer Heart Rate Sensors. Available online: http://cs229.stanford.edu/proj2013/LiuUlrich-ListenToYourHeart-StressPredictionUsingConsumerHeartRateSensors.pdf (accessed on 4 June 2018).
- Sun, D.; Paredes, P.; Canny, J. MouStress: Detecting Stress from Mouse Motion. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systemss, Toronto, ON, Canada, 26 April–1 May 2014; ACM: New York, NY, USA, 2014; pp. 61–70. [Google Scholar]
- Różanowski, K.; Truszczyński, O.; Filipczak, K.; Madeyski, M. The level of driver personality and stress experienced as factors influencing behavior on the road. In Sustainable Development; WIT Transactions on The Built Environment; WIT Press: Southampton, UK, 2015; Volume 168, pp. 1009–1019. [Google Scholar]
- Hovsepian, K.; Al’Absi, M.; Ertin, E.; Kamarck, T.; Nakajima, M.; Kumar, S. cStress: Towards a Gold Standard for Continuous Stress Assessment in the Mobile Environment. In Proceedings of the ACM International Conference on Ubiquitous Computing (UbiComp 2015), Osaka, Japan, 7–11 September 2015; pp. 493–504. [Google Scholar]
- EL Haouij, N.; Ghozi, R.; Poggi, J.; Ghalila, S.; Jaidane, M. Feature extraction and selection of electrodermal reaction towards stress level recognition: Two real-world driving experiences. In Proceedings of the 47e Journées de Statistique de la Société Française de Statistique, Lille, France, 1–5 June 2015. [Google Scholar]
- Chen, M.; Zhang, Y.; Li, Y.; Hassan, M.M.; Alamri, A. AIWAC: Affective interaction through wearable computing and cloud technology. IEEE Wirel. Commun. 2015, 22, 20–27. [Google Scholar] [CrossRef]
- Rodrigues, J.; Kaiseler, M.; Aguiar, A.; Cunha, J.; Barros, J. A mobile sensing approach to stress detection and memory activation for public bus drivers. IEEE Trans. Intell. Transp. Syst. 2015, 16, 3294–3303. [Google Scholar] [CrossRef]
- Boateng, G.; Kotz, D. StressAware: An App for Real-Time Stress Monitoring on the Amulet Wearable Platform. In Proceedings of the IEEE MIT Undergraduate Research Technology Conference (URTC), Cambridge, MA, USA, 4–6 November 2016; pp. 1–4. [Google Scholar]
- Aigrain, J.; Spodenkiewicz, M.; Dubuisson, S.; Detyniecki, M.; Cohen, D.; Chetouani, M. Multimodal stress detection from multiple assessments. IEEE Trans. Affect. Comput. 2016, 99. [Google Scholar] [CrossRef]
- Mottelson, A.; Hornbæk, K. An Affect Detection Technique using Mobile Commodity Sensors in the Wild. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing UbiComp’16, Heidelberg, Germany, 12–16 September 2016; pp. 781–792. [Google Scholar]
- Yanga, C.; Huangb, Q.; Lic, Z.; Liua, K.; Hua, F. Big Data and cloud computing: innovation opportunities and challenges. Int. J. Digit. Earth 2017, 10, 13–53. [Google Scholar] [CrossRef]
- Rostaminia, S.; Lamson, A.; Maji, S.; Rahman, T.; Ganesan, D. W!NCE: Unobtrusive Sensing of Upper Facial Action Units with EOG-based Eyewear. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 23. [Google Scholar] [CrossRef]
- Clay, A.; Couture, N.; Nigay, L. Engineering affective computing: A unifying software architecture. In Proceedings of the Affective Computing and Intelligent Interaction and Workshops, Amsterdam, The Netherlands, 10–12 September 2009. [Google Scholar]
- Kandel, S.; Paepcke, A.; Hellerstein, J.; Heer, J. Wrangler: Interactive Visual Specification of Data Transformation Scripts. In Proceedings of the ACM CHI Conference on Human Factors, Vancouver, BC, Canada, 7–12 May 2011. [Google Scholar]
- Nnebedum, V. Data Engineering: Using Data Analysis Techniques in Producing Data Driven Products. Int. J. Comput. Appl. 2017, 161, 13–16. [Google Scholar]
- Mohino-Herranz, I.; Gil-Pita, R.; Ferreira, J.; Rosa-Zurera, M.; Seoane, F. Assessment of Mental, Emotional and Physical Stress through Analysis of Physiological Signals Using Smartphones. Sensors 2015, 15, 25607–25627. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Niu, K.; Xiong, J.; Jin, B.; Gu, T.; Jiang, Y.; Zhang, D. Towards a Diffraction-based Sensing Approach on Human Activity Recognition. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 33. [Google Scholar] [CrossRef]
- Rahman, T.; Zhang, M.; Voida, S.; Choudhury, T. Towards Accurate Non-Intrusive Recollection of Stress Levels Using Mobile Sensing and Contextual Recall. In Proceedings of the 8th International Conference on Pervasive Computing Technologies for Healthcare, Oldenburg, Germany, 20–23 May 2014; pp. 166–169. [Google Scholar]
- Witten, I.; Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar]
- Barua, S.; Begun, S.; Ahmed, M.U. Supervised machine learning algorithms to diagnose stress for vehicle drivers based on physiological sensor signals. In Proceedings of the 12th International Conference on Wearable Micro and Nano Technologies for Personalized Health, Västerås, Sweden, 2–4 June 2015; Studies in Health Technology and Informatics. Volume 211, pp. 241–248. [Google Scholar]
- Meiring, G.; Myburgh, H.C. A review of intelligent driving style analysis systems and related artificial intelligence algorithms. Sensors 2015, 15, 30653–30682. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Study/Year | Captured Data | Extracted Feature | Interpretation Process | Lab/Real Study |
|---|---|---|---|---|
| Healey and Picard, 2005 [7] | Electrocardiogram (EKG), electromyogram (EMG), skin conductivity, respiration, facial expression and Perceived stress | Normalized ECG, EMG, Eight skin conductivity features, Heart rate variability (HRV), … | ANOVA, confusion matrix, Correlation coefficients | Real Driving |
| Schießl, 2007 [8] | Front and back camera views, distance from front car, breaks, steering, and velocity of the car, Subjective strain using questionnaires | Fourteen types of car manoeuvers | ANOVA statistical method | Real driving + Lab simulation |
| Taelman et al., 2008 [9] | Heart Rate (HR), HRV | Mean RR-intervals low frequency (LF)/high frequency (HF) ratios | laboratory environment | |
| Bundele and Banerjee 2009 [10] | Skin conductance, Oxymetry Pulse | Eighteen features of mean, standard deviation, frequency spectrum, …, ect. | Multi-layer Neural Network. | Real driving |
| Wijsman et al., 2010 [11] | EMG | EMG Root Mean square (RMS), amplitude, Frequency, Gaps | Statistical analysis | laboratory environment |
| Rigas et al., 2011 [12] | electrocardiogram (ECG), galvanic skin response (GSR), respiration, face video, weather, traffic and road visibility | Fifteen different features (e.g., mean RR, LF/HF, Mean respiration …) | 4 classifiers: Support Vector Machine (SVM), Decision Tree, Native bayes and General Bayesian. | Real driving |
| Bakker, Pechenizkiy, and Sidorova, 2011 [13] | GSR | Change detection | Adaptive Windowing (ADWIN) | Real workplace |
| Ertin et al., 2011 [14] | ECG, respiratory, skin temperature and GSR | mean, variance, heart rate, and respiration rate | Architecture explained | Field Study |
| Hernandez, Morris, and Picard, 2011 [15] | skin conductance, subjective ratings | skin conductance | Support Vector Machines | Work environment |
| Paschero et al., 2012 [16] | Facial images | feature vector extraction, feature vector normalization and preprocessing | classification using neural networks multilayer perceptron (MLP) trained by error backpropagation (EBP) algorithm, then neuro-fuzzy algorithm | laboratory environment |
| Schneegass et al., 2013 [17] | ECG, temperature, skin conductance, Global Positioning System (GPS) acceleration, face and road images | ECG, temperature, skin conductance, GPS acceleration, face and road images | Statistical (ANOVA, t-test) | Real driving |
| Marcos-Ramiro, 2014 [18] | Face video | Shannon’s entropy of blinking events; entropy, mean, and standard deviation of time between blinks, …, etc. | per-pixel classification of extracted eye images | job interview database |
| Luijcks et al., 2014 [19] | EMG, ECG | Mean, RMS | Statistical analysis | laboratory environment |
| Liu and Ulrich, 2014 [20] | electrocardiogram (ECG) | Heart rate variability (HRV) and ECG. Fourier Transform and take the logarithm of summed total power in 10Hz bands | linear SVM | Real driving database |
| Sun, Paredes and Canny, 2014 [21] | ECG and Mouse movement | HRV, LF/HF, Power HF & LF, Mean and RMS of RR Mouse Width and distance | Statistical | Lab Simulation |
| Rozanowski, et al., 2015 [22] | Perceived stress questionnaire, personality questionnaires | Subjective stress, coping style, number of mistakes, and reaction time | Statistical | Lab Simulation |
| Hovsepian et al., 2015 [23] | Respiration, ECG, Self-reported Stress | ECG features (e.g., RR peaks) mean and median respiration, …) | Support Vector Machines algorithm | Lab and field study |
| Haouij et al., 2015 [24] | Electrodermal activity (EDA) | six features are extracted from each 1-min segment: the mean, standard deviation, and four electrodermal response characteristics | Random forest method for features ordering, the recognition analysis based on a Linear Discriminant Function (LDF). | Real Driving |
| Chen et al., 2015 [25] | electroencephalography (EEG), ECG, EMG, blood pressure, blood oxygen, respiration, facial video, social contents (text) | EEG, ECG, EMG, blood pressure, blood oxygen, respiration, facial video, social contents (text) | Not reported | Real application |
| Rodrigues et al., 2015 [26] | ECG 3 axis accelerometer GPS | of Heart Rate Variability (HRV). | Not reported | Real Driving |
| Boateng and Kotz, 2016 [27] | heart rate (HR), heartrate variability (HRV) | 14 HR and HRV | Support Vector Machine (SVM) | laboratory environment |
| Aigrain et al., 2016 [28] | EMG, GSR, skin temperature, respiration, Blood Volume Pressure (BVP) and HR. video of the face; video of the whole body. | 17 physiological features. 27 behavioral features. | SVM with a linear kernel function. Metric Learning for Kernel Regression. | laboratory environment |
| Mottelson and Hornbæk, 2016 [29] | self-assessed affect, and motion sensor measurements on a mobile | 352 features selected from motion sensor measurements (e.g., Speed, precision) | Many classification methods (e.g., k-Nearest Neighbor and SVM). | Real life |
| Zhalehpour et al., 2017 [6] | Frontal view of the face, half profile view of the face, audio | Facial features (Local Phase Quantization and Patterns of Oriented Edge Magnitudes | SVM classifier, decision level fusion technique, probability fusion approaches | laboratory environment |
| Sarsenbayeva et al., 2019 [4] | HRV, self-reported anxiety levels | HF (High-Frequency) powers of the HRV | ANOVA statistical | laboratory environment |
| Data Signal | Rate of Recording Signal Per Second (SPS) |
|---|---|
| EEG | 256 |
| EMG | 2048 |
| GSR/skin conductance (SC) | 32 |
| Respiration (RSP) | 32 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
El-Khalili, N.; Alnashashibi, M.; Hadi, W.; Banna, A.A.; Issa, G. Data Engineering for Affective Understanding Systems. Data 2019, 4, 52. https://doi.org/10.3390/data4020052
El-Khalili N, Alnashashibi M, Hadi W, Banna AA, Issa G. Data Engineering for Affective Understanding Systems. Data. 2019; 4(2):52. https://doi.org/10.3390/data4020052
Chicago/Turabian StyleEl-Khalili, Nuha, May Alnashashibi, Wael Hadi, Abed Alkarim Banna, and Ghassan Issa. 2019. "Data Engineering for Affective Understanding Systems" Data 4, no. 2: 52. https://doi.org/10.3390/data4020052
APA StyleEl-Khalili, N., Alnashashibi, M., Hadi, W., Banna, A. A., & Issa, G. (2019). Data Engineering for Affective Understanding Systems. Data, 4(2), 52. https://doi.org/10.3390/data4020052