A Novel Neuro-Fuzzy Model for Multivariate Time-Series Prediction †


Abstract
1. Introduction
2. Data Description
3. Proposed Model
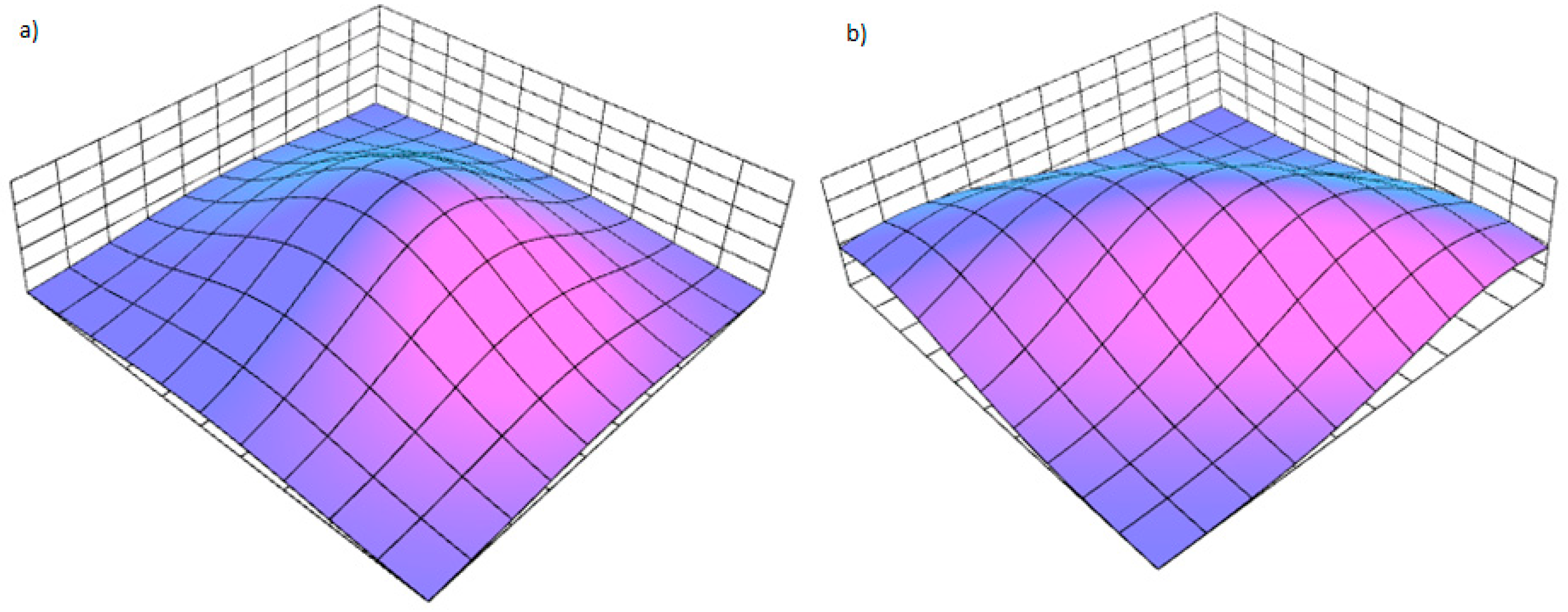
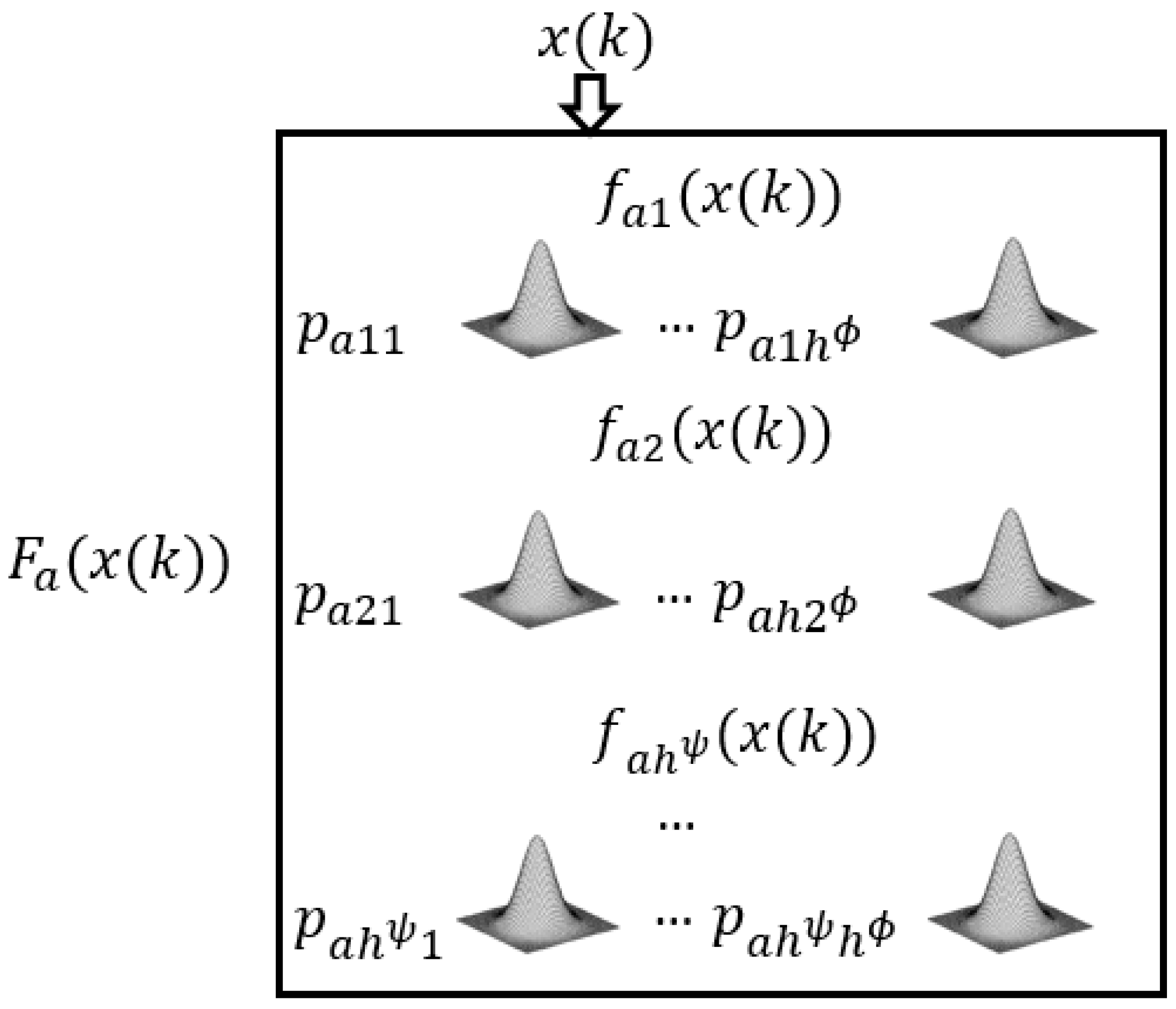
3.1. Architecture and Inference
3.2. Learning Procedure
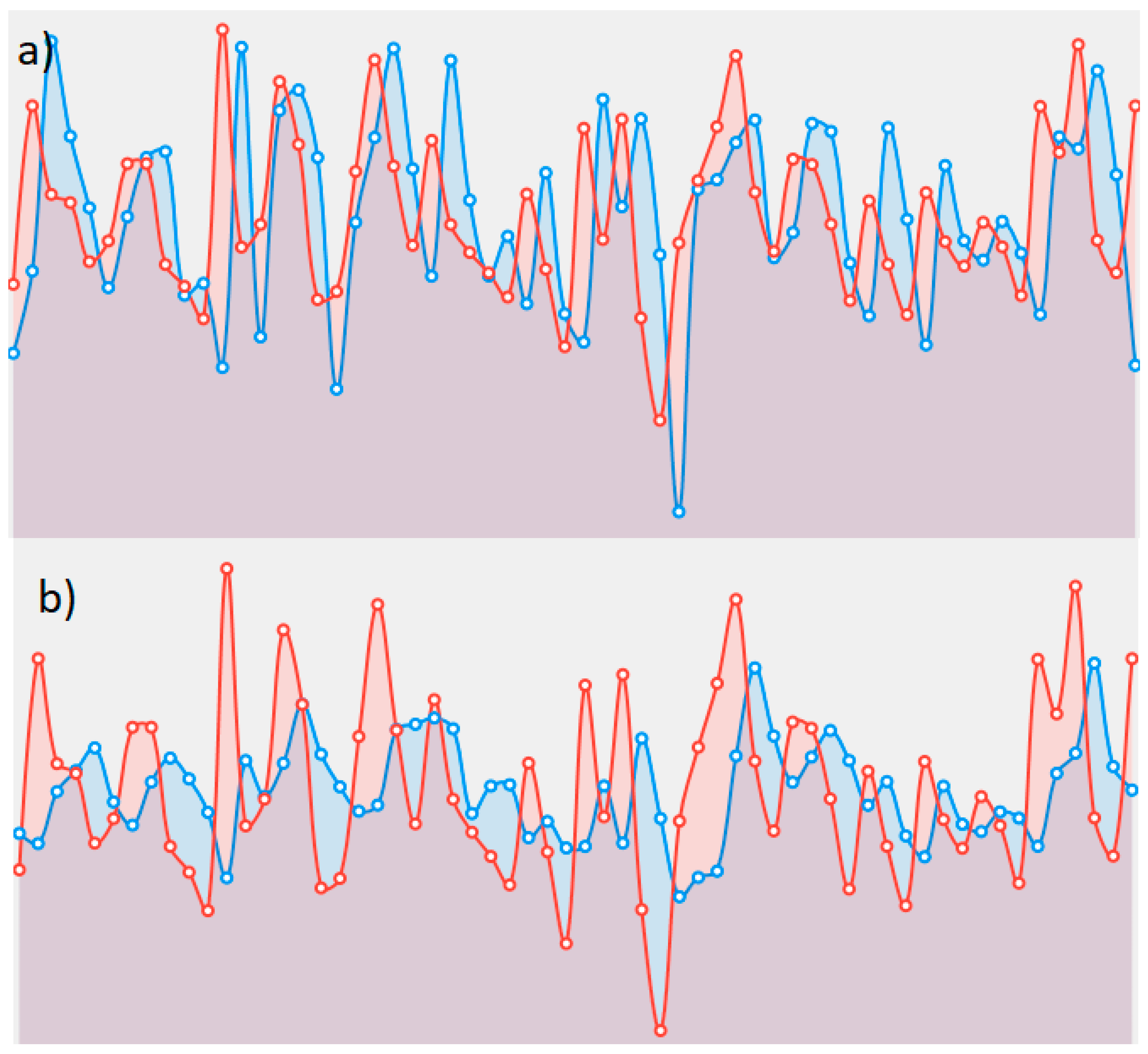
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Commandeur, J.J.; Koopman, S.J. An Introduction to State Space Time Series Analysis; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Logue, A.C. The Efficient Market Hypothesis and Its Critics. CFA Digest 2003, 33, 40–41. [Google Scholar] [CrossRef]
- Weigend, A.S.; Huberman, B.A.; Rumelhart, D.E. Predicting the future: A connectionist approach. Int. J. Neural Syst. 1990, 1, 193–209. [Google Scholar] [CrossRef]
- Crone, S.F.; Hibon, M.; Nikolopoulos, K. Advances in forecasting with neural networks? Empirical evidence from the NN3 competition on time series prediction. Int. J. Forecast. 2011, 27, 635–660. [Google Scholar] [CrossRef]
- Bodyanskiy, Y.; Popov, S. Neural network approach to forecasting of quasiperiodic financial time series. Eur. J. Oper. Res. 2006, 175, 1357–1366. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. The legacy of 50 years of fuzzy sets: A discussion. Fuzzy Sets Syst. 2015, 281, 21–31. [Google Scholar] [CrossRef]
- Dubois, D.; Prade, H. Gradualness, uncertainty and bipolarity: Making sense of fuzzy sets. Fuzzy Sets Syst. 2012, 192, 3–24. [Google Scholar] [CrossRef]
- Sheta, A. Software Effort Estimation and Stock Market Prediction Using Takagi-Sugeno Fuzzy Models. In Proceedings of the 2006 IEEE International Conference on Fuzzy Systems, Vancouver, BC, Canada, 16–21 July 2006. [Google Scholar] [CrossRef]
- Chang, P.-C.; Liu, C.-H. A TSK type fuzzy rule based system for stock price prediction. Expert Syst. Appl. 2008, 34, 135–144. [Google Scholar] [CrossRef]
- Pamučar, D.; Cirovic, G. Vehicle Route Selection with an Adaptive Neuro Fuzzy Inference System in Uncertainty Conditions. Decis. Mak. Appl. Manag. Eng. 2018, 1, 13–37. [Google Scholar] [CrossRef]
- Pamučar, D.; Ljubojević, S.; Kostadinović, D.; Đorović, B. Cost and risk aggregation in multi-objective route planning for hazardous materials transportation—A neuro-fuzzy and artificial bee colony approach. Expert Syst. Appl. 2016, 65, 1–15. [Google Scholar] [CrossRef]
- Bodyanskiy, Y.; Popov, S.; Rybalchenko, T. Multilayer Neuro-fuzzy Network for Short Term Electric Load Forecasting. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; pp. 339–348. [Google Scholar]
- Otto, P.; Bodyanskiy, Y.; Kolodyazhniy, V. A new learning algorithm for a forecasting neuro-fuzzy network. Integr. Comput.-Aided Eng. 2003, 10, 399–409. [Google Scholar] [CrossRef]
- Sremac, S.; Tanackov, I.; Kopić, M.; Radović, D. ANFIS model for determining the economic order quantity. Decis. Mak. Appl. Manag. Eng. 2018, 1. [Google Scholar] [CrossRef]
- De Jesús Rubio, J. USNFIS: Uniform stable neuro fuzzy inference system. Neurocomputing 2017, 262, 57–66. [Google Scholar] [CrossRef]
- Lukovac, V.; Pamučar, D.; Popović, M.; Đorović, B. Portfolio model for analyzing human resources: An approach based on neuro-fuzzy modeling and the simulated annealing algorithm. Expert Syst. Appl. 2017, 90, 318–331. [Google Scholar] [CrossRef]
- Kar, S.; Das, S.; Ghosh, P.K. Applications of neuro fuzzy systems: A brief review and future outline. Appl. Soft Comput. 2014, 15, 243–259. [Google Scholar] [CrossRef]
- Jang, J.S. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Mendes, J.; Souza, F.; Araújo, R.; Rastegar, S. Neo-fuzzy neuron learning using backfitting algorithm. Neural Comput. Appl. 2017. [Google Scholar] [CrossRef]
- Silva, A.M.; Caminhas, W.; Lemos, A.; Gomide, F. A fast learning algorithm for evolving neo-fuzzy neuron. Appl. Soft Comput. 2014, 14, 194–209. [Google Scholar] [CrossRef]
- Bodyanskiy, Y.V.; Tyshchenko, O.K.; Kopaliani, D.S. Adaptive learning of an evolving cascade neo-fuzzy system in data stream mining tasks. Evol. Syst. 2016, 7, 107–116. [Google Scholar] [CrossRef]
- Billah, M.; Waheed, S.; Hanifa, A. Stock market prediction using an improved training algorithm of neural network. In Proceedings of the 2nd International Conference on Electrical, Computer & Telecommunication Engineering (ICECTE), Rajshahi, Bangladesh, 8–10 December 2016. [Google Scholar] [CrossRef]
- Esfahanipour, A.; Aghamiri, W. Adapted Neuro-Fuzzy Inference System on indirect approach TSK fuzzy rule base for stock market analysis. Expert Syst. Appl. 2010, 37, 4742–4748. [Google Scholar] [CrossRef]
- Rajab, S.; Sharma, V. An interpretable neuro-fuzzy approach to stock price forecasting. Soft Comput. 2017. [Google Scholar] [CrossRef]
- Hadavandi, E.; Shavandi, H.; Ghanbari, A. Integration of genetic fuzzy systems and artificial neural networks for stock price forecasting. Knowl.-Based Syst. 2010, 23, 800–808. [Google Scholar] [CrossRef]
- Bodyanskiy, Y.; Pliss, I.; Vynokurova, O. Adaptive wavelet-neuro-fuzzy network in the forecasting and emulation tasks. Int. J. Inf. Theory Appl. 2008, 15, 47–55. [Google Scholar]
- Chiu, D.-Y.; Chen, P.-J. Dynamically exploring internal mechanism of stock market by fuzzy-based support vector machines with high dimension input space and genetic algorithm. Expert Syst. Appl. 2009, 36, 1240–1248. [Google Scholar] [CrossRef]
- Parida, A.K.; Bisoi, R.; Dash, P.K.; Mishra, S. Times Series Forecasting using Chebyshev Functions based Locally Recurrent neuro-Fuzzy Information System. Int. J. Comput. Intell. Syst. 2017, 10, 375. [Google Scholar] [CrossRef]
- Atsalakis, G.S.; Valavanis, K.P. Forecasting stock market short-term trends using a neuro-fuzzy based methodology. Expert Syst. Appl. 2009, 36, 10696–10707. [Google Scholar] [CrossRef]
- Ebadzadeh, M.M.; Salimi-Badr, A. CFNN: Correlated fuzzy neural network. Neurocomputing 2015, 148, 430–444. [Google Scholar] [CrossRef]
- Tsay, R.S. Analysis of Financial Time Series; Wiley Series in Probability and Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar] [CrossRef]
- Monthly Log Returns of IBM Stock and the S&P 500 Index Dataset. Available online: https://faculty.chicagobooth.edu/ruey.tsay/teaching/fts/m-ibmspln.dat (accessed on 1 September 2018).
- Vlasenko, A.; Vynokurova, O.; Vlasenko, N.; Peleshko, M. A Hybrid Neuro-Fuzzy Model for Stock Market Time-Series Prediction. In Proceedings of the IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018. [Google Scholar] [CrossRef]
- Vlasenko, A.; Vlasenko, N.; Vynokurova, O.; Bodyanskiy, Y. An Enhancement of a Learning Procedure in Neuro-Fuzzy Model. In Proceedings of the IEEE First International Conference on System Analysis & Intelligent Computing (SAIC), Kyiv, Ukraine, 8–12 October 2018. [Google Scholar] [CrossRef]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.-R. Efficient BackProp. Neural Netw. Tricks Trade 2012, 9–48. [Google Scholar] [CrossRef]
- Bottou, L.; Curtis, F.E.; Nocedal, J. Optimization Methods for Large-Scale Machine Learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Wiesler, S.; Richard, A.; Schluter, R.; Ney, H. A critical evaluation of stochastic algorithms for convex optimization. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–30 May 2013. [Google Scholar] [CrossRef]
- Kanzow, C.; Yamashita, N.; Fukushima, M. Erratum to “Levenberg–Marquardt methods with strong local convergence properties for solving nonlinear equations with convex constraints. J. Comput. Appl. Math. 2005, 177, 241. [Google Scholar] [CrossRef]
- Riedmiller, M.; Braun, H. A direct adaptive method for faster backpropagation learning: The RPROP algorithm. In Proceedings of the IEEE International Conference on Neural Networks, Rio, Brazil, 8–13 July 2018. [Google Scholar] [CrossRef]
- Souza, C.R. The Accord.NET Framework. Available online: http://accord-framework.net (accessed on 1 November 2018).
- Math.NET Numerics. Available online: https://numerics.mathdotnet.com (accessed on 1 November 2018).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IBM | SP |
|---|---|
| −8.24798 | −4.06866 |
| 6.67236 | −4.81089 |
| 4.73701 | 7.43094 |
| 0.70948 | 2.61842 |
| 3.81336 | 7.52652 |
| 0.00000 | 0.29955 |
| −4.91377 | −5.46357 |
| 8.11467 | 0.75415 |
| −4.96210 | −3.05211 |
| 8.11467 | 0.75415 |
| Model | IBM Stock Daily Log Returns and S&P 500 Index Dataset Results | ||||
|---|---|---|---|---|---|
| Execution time (ms) | IBM stock RMSE (%) | IBM stock SMAPE (%) | S&P 500 index RMSE (%) | S&P 500 index SMAPE (%) | |
| Proposed model | 64 | 8.938 | 10.049 | 4.443 | 4.594 |
| 39 | 12.956 | 20.548 | - | - | |
| 38 | - | - | 6.097 | 9.005 | |
| Proposed model | 120 | 8.878 | 10.104 | 4.356 | 4.532 |
| 63 | 12.865 | 20.138 | - | - | |
| 65 | - | - | 6.056 | 8.677 | |
| Proposed model | 257 | 8.866 | 10.013 | 4.294 | 4.463 |
| 126 | 12.693 | 20.133 | - | - | |
| 110 | - | - | 6.113 | 8.775 | |
| Bipolar Sigmoid Network RBPR | 847 | 8.91 | 10.156 | 4.66 | 4.96 |
| 514 | 13.162 | 20.876 | |||
| 545 | - | - | 6.308 | 9.139 | |
| Bipolar Sigmoid Network Levenberg-Marquart | 302 | 8.940 | 10.07 | 4.542 | 4.755 |
| 313 | 14.544 | 22.664 | - | - | |
| 297 | - | - | 7.025 | 11.019 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vlasenko, A.; Vlasenko, N.; Vynokurova, O.; Peleshko, D. A Novel Neuro-Fuzzy Model for Multivariate Time-Series Prediction. Data 2018, 3, 62. https://doi.org/10.3390/data3040062
Vlasenko A, Vlasenko N, Vynokurova O, Peleshko D. A Novel Neuro-Fuzzy Model for Multivariate Time-Series Prediction. Data. 2018; 3(4):62. https://doi.org/10.3390/data3040062
Chicago/Turabian StyleVlasenko, Alexander, Nataliia Vlasenko, Olena Vynokurova, and Dmytro Peleshko. 2018. "A Novel Neuro-Fuzzy Model for Multivariate Time-Series Prediction" Data 3, no. 4: 62. https://doi.org/10.3390/data3040062
APA StyleVlasenko, A., Vlasenko, N., Vynokurova, O., & Peleshko, D. (2018). A Novel Neuro-Fuzzy Model for Multivariate Time-Series Prediction. Data, 3(4), 62. https://doi.org/10.3390/data3040062