Earth Observation for Citizen Science Validation, or Citizen Science for Earth Observation Validation? The Role of Quality Assurance of Volunteered Observations

 ,
,
Abstract
1. Introduction
QA Case Study Background
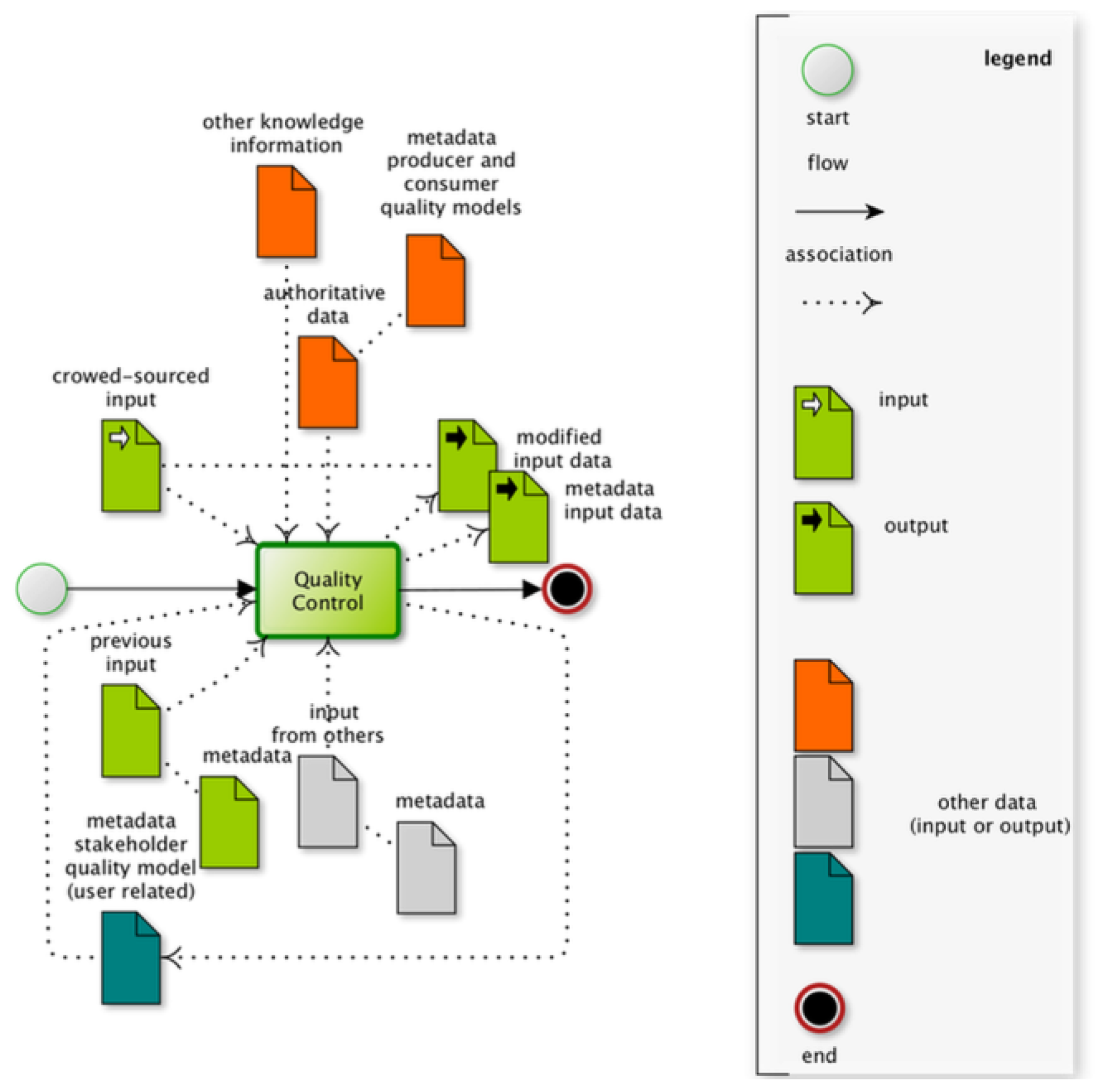
2. Quality Assurance and Quality Control Framework
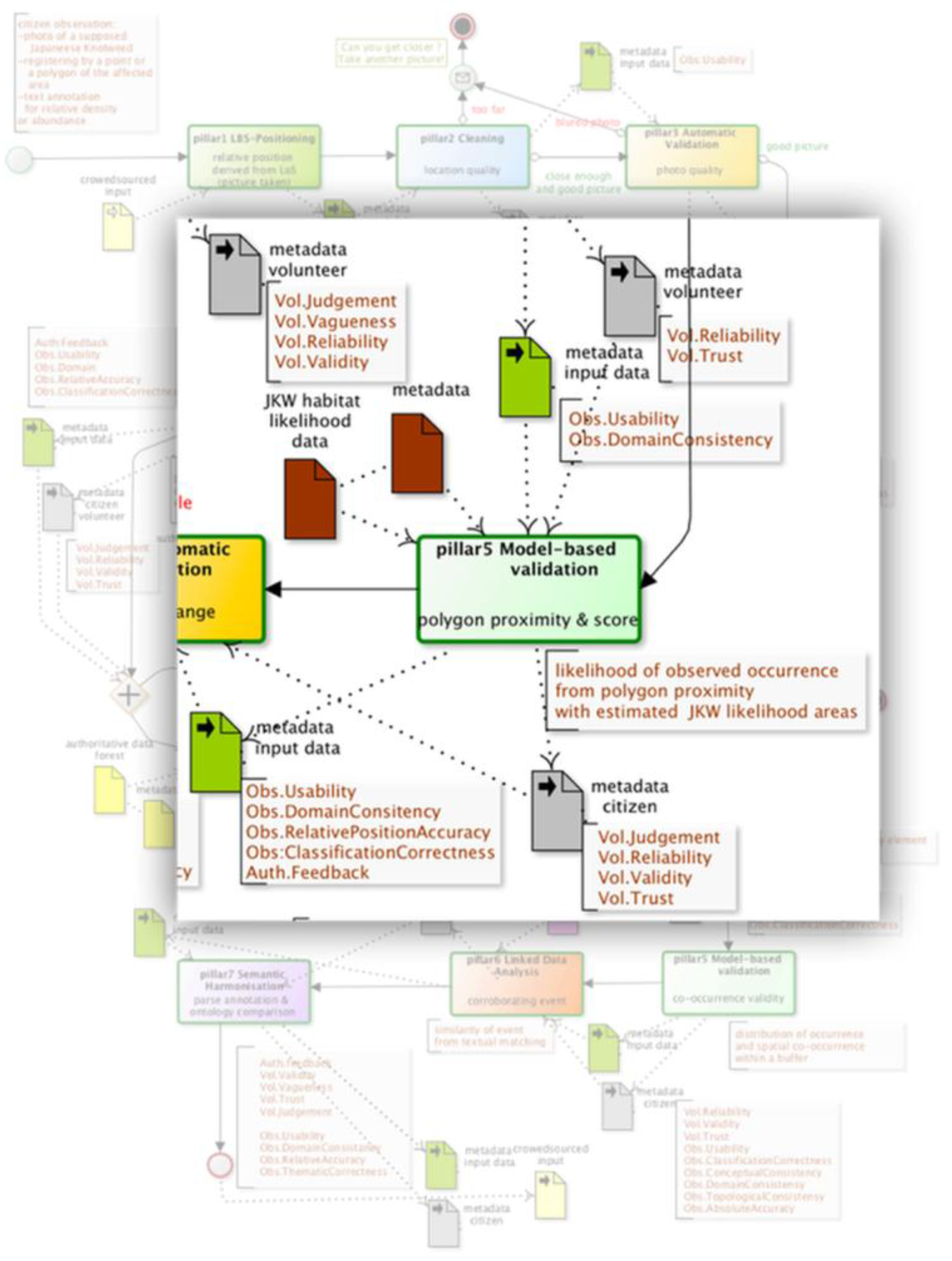
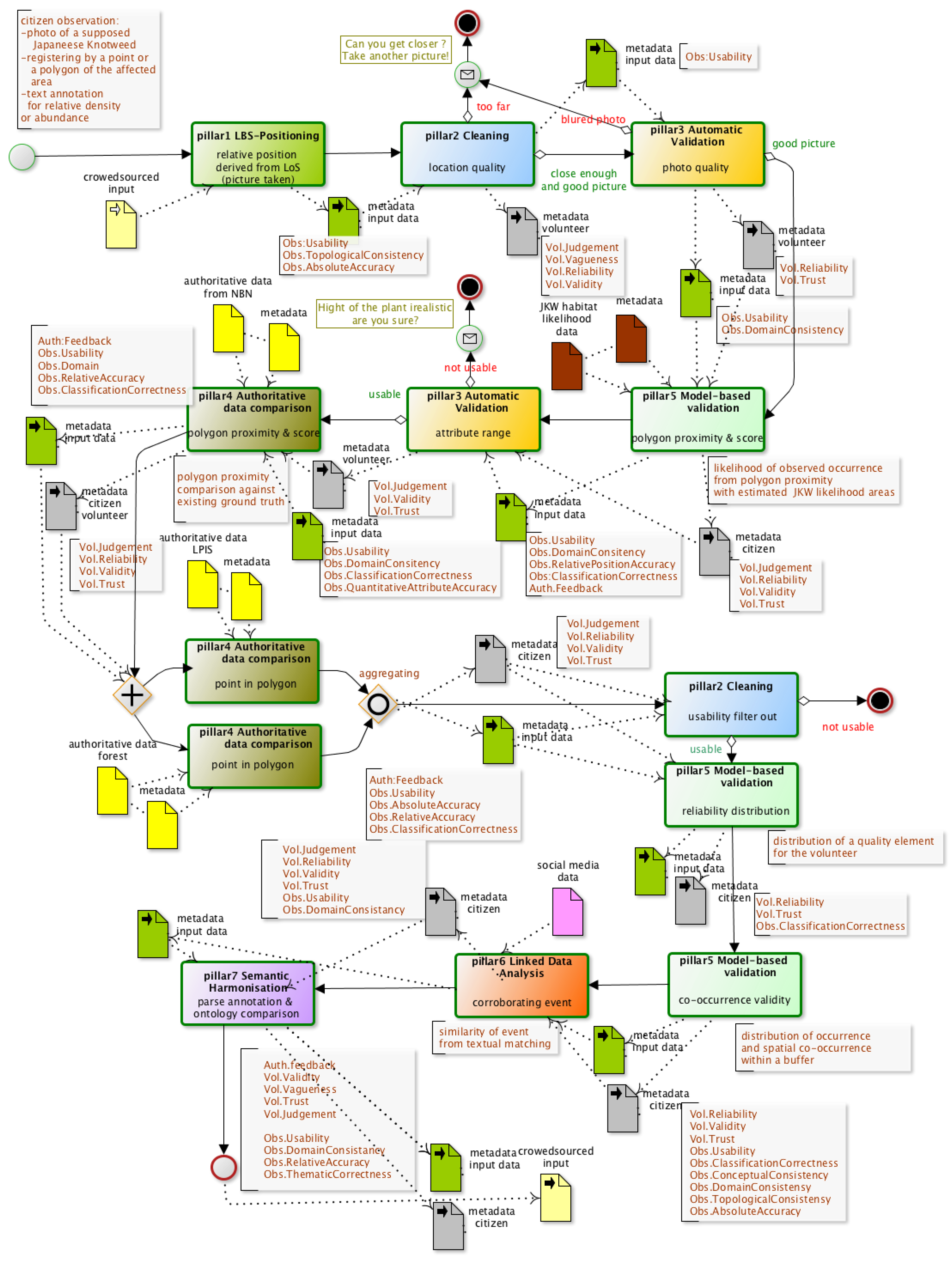
3. Designing the Japanese Knotweed Quality Assurance
4. Using Citizen Science for Earth Observation Validation
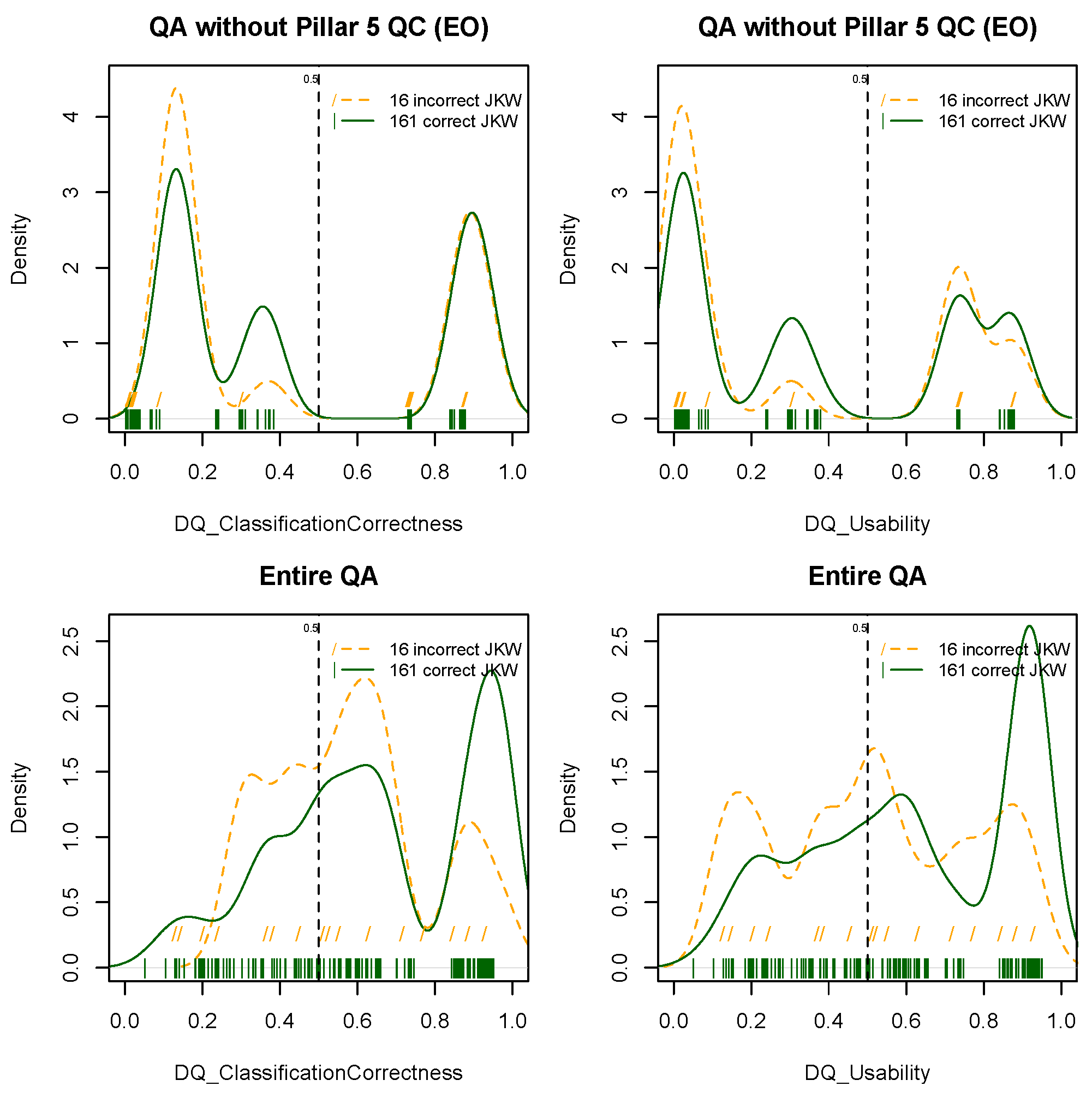
4.1. Without Quality Assurance of the Citizen Science Data
- CS data with no score (25/177) and score <0.2 (20/177) represent an omission for high-risk zones of 45/177 (25%) and correcting for ground truth gives 39/161 (24%).
- CS data with score >0.5 represent accurate areas, 120/177 (68%), but 10/120 (8%) points wrongly identified JKW so a corrected accuracy of 110/177 (62%) with a commission of 8%.
4.2. With Quality Assurance of the Citizen Science Data
- CS data with no score (10/66) or score <0.2 (9/66) represent omission areas of 19/66 (29%).
- CS data with score >0.5 represent accurate areas, 41/66 (62%).
4.3. With Line of Sight Correction in the QA for the Citizen Science Data
- CS data with no score represents omission areas, 0/72 (0%).
- CS data with score >0.5 represent accurate areas, 72/72 (100%), correcting for ground truth gives 67/72 (93%).
- CS data with score <0.2 (which was the low risk value in the EO data) represents an omission rate of 0/72 (0%).
5. Using Earth Observation to Improve Citizen Science Data Quality
5.1. CS Data Validation
5.2. Iterative Paradigm
6. Discussion
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| CIR | Colored Infra-Red |
| COBWEB | Citizen OBservatory WEB |
| CS | Citizen Science |
| DEM | Digital Elevation Model |
| EO | Earth Observation |
| FP7 | Framework Program 7 |
| IAS | Invasive Alien Species |
| JKW | Japanese KnotWeed |
| INNS | Invasive Non-Native Species |
| LiDAR | Light Detection And Ranging |
| LoS | Line of Sight |
| QA | Quality Assurance |
| QAwAT | Quality Assurance workflow Authoring Tool |
| QC | Quality Controls |
| SNP | Snowdonia National Park |
| VGI | Volunteered Geographic Information |
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pseudo Code | Short Description | Quality elements metadata created or updated: DQ ISO19157 producer model GVQ GeoViQUA’s feedback model (simplified) CSQ COBWEB’s stakeholder model |
|---|---|---|
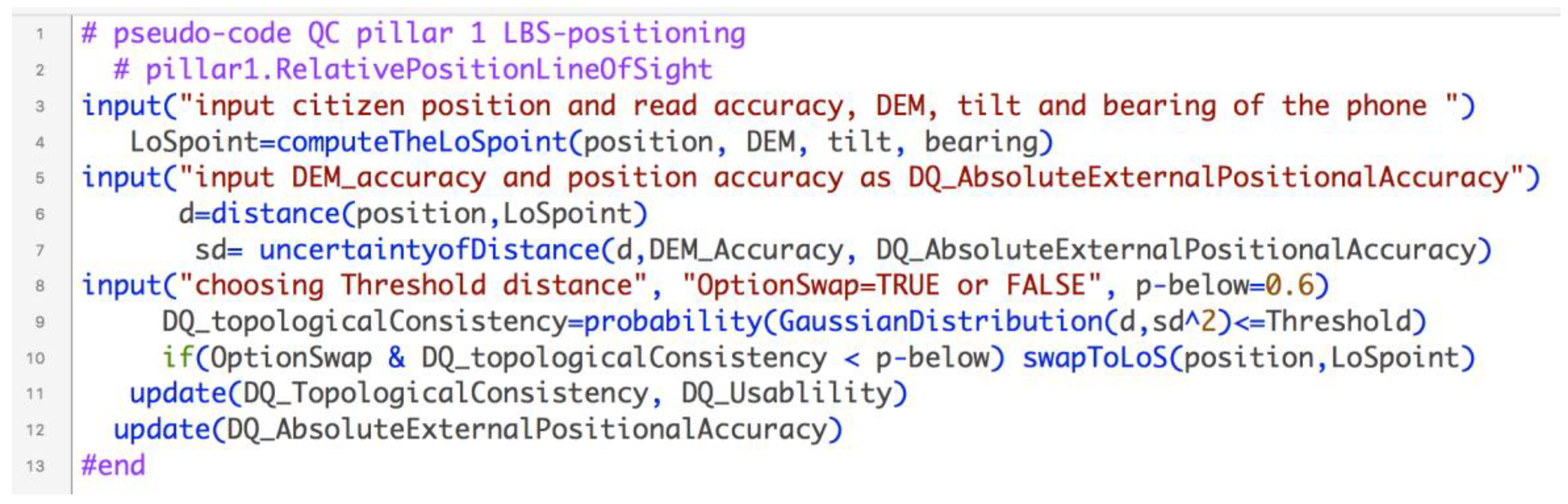
| pillar1.LocationBasedServicePosition.RelativePositionLineOfSight | ||
| #start input("citizen position, DEM, tilt and bearing of the phone ") LoSpt=computeTheLoSpoint(position, DEM, tilt, bearing) input("input DEM uncertainty and position uncertainty") d=distance(position,LoSpoint) sd= uncertaintyofDistance(d,DEM_Accuracy, DQ_AbsoluteExternalPositionalAccuracy) input("choosing Threshold distance", "OptionSwap=TRUE or FALSE", p-below=0.6) DQ_topologicalConsistency=probability(GaussianDistribution(d,sd^2)<=Threshold) if(OptionSwap & DQ_topologicalConsistency < p-below) swapToLoS(position,LoSpoint) update(DQ_TopologicalConsistency, DQ_Usablility) update(DQ_AbsoluteExternalPositionalAccuracy) #end | ||
| Compute the line of sight, aiming point and distance to it. Swap to LoS point under certain conditions DEM ThresholdDistance p-below OptionSwap | DQ_UsabilityElement DQ_TopologicalConsistency -LoS.point / DQ_AbsoluteExternalPositionalAccuracy with scope defined as “LoS” . | |
| pillar2.Cleaning.LocationQuality | ||
| #start input("input citizen position, DQlevelThreshold, PosUnThreshold, methods") for each observation { for each method in methods { DQ_usability=evaluateRule(DQ_AbsoluteExternalPositionalAccuracy, DQ_usability, DQ_topologicalconsistency, DQ_conceptualconsistency) } } update(CSQs) #end | ||
| According to the study requirement check if position is correct and/or can be corrected methods: “pillar1.WithinPoly”, ”pillar1.LineOFSight”, “pillar1,ContainsPoly”, “pillar1.GetSpatialAccuracy”,” pillar4.or pillar1.DistanceTo” DQlevelThreshold PosUncertaintyThreshold | DQ_UsabilityElement CSQ_Vagueness CSQ_Judgement CSQ_Reliability CSQ_Validity | |
| pillar3.AutomaticValidation.PhotoQuality | ||
| #start input("input citizen captured photo, blurThreshold," ) edgeImage=LaplaceTrasnform(photo) usable=evaluateRule(edgeImage, blurThreshold) update(DQ_usability, DQ_DomainConsistency, CSQ_judgement, CSQ_trust) message(usable) #end | ||
| Test on sharpness of the image using the method of edge detection from Laplace transform. BlurThreshold | DQ_UsabilityElement DQ_DomainConsistency CSQ_Reliability CSQ_Trust -dynamic: <message> “Can you take another picture?” | |
| pillar5.Model-basedValidation.ProximitySuitabilityScore | ||
| #start input("input citizen position, buffersize, attribute") ProximPol=findNearby(buffersize) score=summaryMeasure(calculweightDistance(ProximPol),values(ProximPol, attribute)) updateRules(DQs,CSQs,GVQs, score) #end | ||
| Deriving the likelihood of the observed occurrence (citizen captured data) from polygon proximity to a model-estimate one (e.g. suitability likelihood) modelled data attribute buffersize | DQ_UsabilityElement DQ_ThematicClassificationCorrectness DQ_AbsoluteExternalPositionalAccuracy DQ_RelativeInternalPositionalAccuracy GVQ_PositiveFeedback GVQ_NegativeFeedback CSQ_Judgement CSQ_Reliability CSQ_Validity CSQ_Trust | |
| pillar4.AuthoritativeDataComparison.ProximitySuitabilityScore | ||
| #start input("input citizen position, buffersize, attribute") ProximPol=findNearby(buffersize) score=summaryMeasure(calculweightDistance(ProximPol) updateRules(DQs,CSQs,GVQs, score) #end | ||
| Deriving the likelihood of the observed occurrence (citizen captured data) from polygon proximity to a given authoritative data (e.g. existing observed occurrences) Authoritative data Buffersize Note: comparing to pillar5 attribute value is 1 as authoritative data. | DQ_UsabilityElement DQ_DomainConsistency DQ_ThematicClassificationCorrectness DQ_NonQuantitativeAttributeCorrectness DQ_AbsoluteExternalPositionalAccuracy DQ_RelativeInternalPositionalAccuracy GVQ_PositiveFeedback GVQ_NegativeFeedback CSQ_Judgement CSQ_Reliability CSQ_Validity CSQ_Trust | |
| pillar4.AuthoritativeDataComparison.PointInPolygon | ||
| #start input("citizen observation, thematicAgreement, AuthData, Buffersize") InPol=evaluateIn(observation.DQ_AbsolutePositionInternalPositionalAccuracy, AuthData.DQ_AbsolutePositionInternalPositionalAccuracy, AuthData, Buffersize) IniScore=EvaluateOverlapAreas(InPol, observation, uncertainties) updateRules(DQs,CSQs,GVQs, IniScore) if(not InPol) { ProxPol=evaluateNear(Obs.DQ_AbsolutePositionInternalPositionalAccuracy, Auth.DQ_AbsolutePositionInternalPositionalAccuracy) ProxScore=Evaluate(ProxPol, Obs, uncertainties) updateRules(DQs,CSQs,GVQs, ProxScore) } #end | ||
| given the position and its uncertainty checking if a point belongs to a polygon then concluding on relative position accuracy and 'relative' semantic therefore usability and attribute accuracies Authoritative data ThematicAgreement | DQ_UsabilityElement DQ_ThematicClassificationCorrectness DQ_NonQuantitativeAttributeCorrectness DQ_QuantitativeAttributeAccuracy DQ_AbsoluteExternalPositionalAccuracy DQ_GriddedDataPositionalAccuracy DQ_RelativeInternalPositionalAccuracy GVQ_PositiveFeedback GVQ_NegativeFeedback CSQ_Judgement CSQ_Reliability CSQ_Validity CSQ_Trust | |
Appendix B
| DQ | Quality Element DQ_ | Definition Extracted from the ISO19157 |
|---|---|---|
| 01 | UsabilityElement | Degree of adherence to as specific set of data quality requirements. |
| 02 | CompletenessCommission | Excess data present in a dataset. |
| 03 | CompletenessOmission | Absence of data in a dataset. |
| 04 | ThematicClassificationCorrectness | Comparison of the classes assigned to features or their attributes to a universe of discourse (e.g., ground truth or reference data). |
| 05 | NonQuantitativeAttributeCorrectness | Whether a non-quantitative attribute is correct or incorrect. |
| 06 | QuantitativeAttributeAccuracy | Closeness of the value of a quantitative attribute to a value accepted as or known to be true. |
| 07 | ConceptualConsistency | Adherence to rules of the conceptual schema. |
| 08 | DomainConsistency | Adherence of values to the value domains. |
| 09 | FormatConsistency | Degree to which data is stored in accordance with the physical structure of the dataset. |
| 10 | TopologicalConsistency | Correctness of the explicitly encoded topological characteristics of a database. |
| 11 | AccuracyOfATimeMeasurement | Closeness of reported time measurements to values accepted as or known to be true. |
| 12 | TemporalConsistency | Correctness of the order of events. |
| 13 | TemporalValidity | Validity of data with respect to time. |
| 14 | AbsoluteExternalPositionalAccuracy | Closeness of reported coordinate values to values accepted as or being true. |
| 15 | GriddedDataPositionalAccuracy | Closeness of gridded data spatial position values to values accepted as or being true. |
| 16 | RelativeInternalPositionalAccuracy | Closeness of the relative positions of features in a dataset to their respective relative positions accepted as or being true. |
| GVQ_ | Quality Element GVQ_ | Definition |
|---|---|---|
| 01 | PositiveFeedback | Number of positive feedbacks to the used data |
| 02 | NegativeFeedback | Number of negative feedbacks to the used data |
| CSQ_ | Quality Element CSQ_ | Definition |
|---|---|---|
| 01 | Vagueness | Inability to make a clear-cut choice (i.e., lack of classifying capability). |
| 02 | Ambiguity | Incompatibility of the choices or descriptions made (i.e., lack of understanding, of clarity). |
| 03 | Judgment | Accuracy of choice or decision in a relation to something known to be true (i.e., perception capability and interpretation). |
| 04 | Reliability | Consistency in choices / decisions (i.e., testing against itself). |
| 05 | Validity | Coherence with other people’s choices (i.e., against other knowledge). |
| 06 | Trust | Confidence accumulated over other criterion concerning data captured previously (linked to reliability, validity and reputability). |
| 07 | NbControls | Total number of controls over all contributions of this volunteer. |
Appendix C
| Declared Distance | N (Total 177) | LoS Distance (38/177) |
|---|---|---|
| Close (<1 m) | 73 | N = 10 out of * 73, Min. 1st Qu. Median Mean 3rd Qu. Max. 1.5 3.1 6.5 12.7 15.0 59.3 |
| Nearby (1 m–3 m) | 30 | N = 9 out of * 30, Min. 1st Qu. Median Mean 3rd Qu. Max. 3.5 5.8 14.8 213.5 516.9 687.8 |
| Far (3 m–10 m) | 39 | N = 13 out of * 39, Min. 1st Qu. Median Mean 3rd Qu. Max. 1.5 2.0 16.5 125.0 175.7 642.3 |
| Very far (>10 m) | 34 | N = 6 out of * 34, Min. 1st Qu. Median Mean 3rd Qu. Max. 1.5 2.4 5.0 11.3 6.9 47.1 |
| missing | 1 | - |
References
- DEFRA. UK Biodiversity Indicators in Your Pocket. 2015. Available online: http://jncc.defra.gov.uk/page-4229#download (accessed on 30 July 2016).
- Williams, F.; Eschen, R.; Harris, A.; Djeddour, D.; Pratt, C.; Shaw, R.S.; Varia, S.; Lamontagne-godwin, J.; Thomas, S.E.; Murphy, S.T. The Economic Cost of Invasive Non-Native Species on Great Britain; CABI Report; CABI: Wallingford, UK, 2010; p. 198. [Google Scholar]
- Silvertown, J. A new dawn for citizen science. Trends Ecol. Evol. 2009, 24, 467–471. [Google Scholar] [CrossRef] [PubMed]
- Butcher, G.S. Audubon Christmas Bird Counts; Biological Report 90(1); U.S. Fish Wildlife Service: Washington, DC, USA, 1990.
- Bonney, R.; Cooper, C.B.; Dickinson, J.; Kelling, S.; Phillips, T.; Rosenberg, K.V.; Shirk, J. Citizen Science: A Developing Tool for Expanding Science Knowledge and Scientific Literacy. BioScience 2009, 59, 977–984. [Google Scholar] [CrossRef]
- Haklay, M. Citizen Science and Volunteered Geographic Information—Overview and typology of participation. In Crowdsourcing Geographic Knowledge: Volunteered Geographic Information (VGI) in Theory and Practice, 1st ed.; Sui, D.Z., Elwood, S., Goodchild, M.F., Eds.; Springer: Berlin, Germany, 2013; pp. 105–122. [Google Scholar]
- Goodchild, M.F. Citizens as sensors: The world of volunteered geography. GeoJournal 2007, 69, 211–221. [Google Scholar] [CrossRef]
- Fonte, C.C.; Bastin, L.; See, L.; Foody, G.; Lupia, F. Usability of VGI for validation of land cover maps. Int. J. Geogr. Inf. Sci. 2015, 29, 1269–1291. [Google Scholar] [CrossRef]
- Franzoni, C.; Sauermann, H. Crowd science: The organisation of scientific research in open collaborative projects. Res. Policy 2014, 43, 1–20. [Google Scholar] [CrossRef]
- Roy, H.E.; Pocock, M.J.O.; Preston, C.D.; Roy, D.B.; Savage, J.; Tweddle, J.C.; Robinson, L.D. Understanding Citizen Science & Environmental Monitoring: Final Report on Behalf of UK-EOF; NERC Centre for Ecology & Hydrology and Natural History Museum: Bailrigg, UK, 2012. [Google Scholar]
- Adriaens, T.; Suttoncroft, M.; Owen, K.; Brosens, D.; Van Valkenburg, J.; Kilbey, D.; Groom, Q.; Ehmig, C.; Thurkow, F.; Van Hende, P.; et al. Trying to engage the crowd in recording invasive alien species in Europe: Experienced from two smartphone applications in northwest Europe. Manag. Biol. Invasions 2015, 6, 215–225. [Google Scholar] [CrossRef]
- Higgins, C.I.; Williams, J.; Leibovici, D.G.; Simonis, I.; Davis, M.J.; Muldoon, C.; Van Gneuchten, P.; O’hare, G. Citizen OBservatory WEB (COBWEB): A Generic Infrastructure Platform to Facilitate the Collection of Citizen Science data for Environmental Monitoring. Int. J. Spat. Data Infrastruct. Res. 2016, 11, 20–48. [Google Scholar] [CrossRef]
- Kotovirta, V.; Toivanen, T.; Tergujeff, R.; Häme, T.; Molinier, M. Citizen Science for Earth Observation: Applications in Environmental Monitoring and Disaster Response. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 40, 1221. [Google Scholar] [CrossRef]
- See, L.; Sturn, T.; Perger, C.; Fritz, S.; Mccallum, I.; Salk, C. Cropland Capture: A Gaming Approach to Improve Global Land Cover. In Proceedings of the AGILE 2014 International Conference on Geographic Information Science, Castellon, Spain, 3–6 June 2014. [Google Scholar]
- Sturn, T.; Pangerl, D.; See, L.; Fritz, S.; Wimmer, M. Landspotting: A serious iPad game for improving global land cover. In Proceedings of the GI-Forum 2013, Salzburg, Austria, 2–5 July 2013. [Google Scholar]
- Sparks, K.; Klippel, A.; Wallgrün, J.O.; Mark, D. Citizen science land cover classification based on ground and aerial imagery. In Spatial Information Theory (COSIT 2015), Lecture Notes in Computer Science; Fabrikant, S.I., Raubal, M., Bertolotto, M., Davies, C., Freundschuh, Z., Bell, S., Eds.; Springer: Cham, Switzerland, 2015; pp. 289–305. [Google Scholar]
- Kinley, L.R. Exploring the Use of Crowd Generated Geospatial Content in Improving the Quality of Ecological Feature Mapping. Master’s Thesis, The University of Nottingham, Nottingham, UK, October 2015. [Google Scholar]
- Rossiter, D.G.; Liu, J.; Carlisle, S.; Zhu, A. Can citizen science assist digital soil mapping? Geoderma 2015, 259–260, 71–80. [Google Scholar] [CrossRef]
- Walker, D.; Forsythe, N.; Parkin, G.; Gowing, J. Filling the observational void: Scientific value and a quantitative validation of hydrometeorological data from a community-based monitoring programme. J. Hydrol. 2016, 538, 713–725. [Google Scholar] [CrossRef]
- Fritz, S.; Mccallum, I.; Schill, C.; Perger, C.; Grillmayer, R.; Achard, F.; Kraxner, F.; Obersteiner, M. Geo-Wiki.Org: The Use of Crowdsourcing to Improve Global Land Cover. Remote Sens. 2009, 1, 345–354. [Google Scholar] [CrossRef]
- Flanagin, A.J.; Metzger, M.J. The credibility of volunteered geographic information. GeoJournal 2008, 72, 137–148. [Google Scholar] [CrossRef]
- Goodchild, M.F.; Li, L. Assuring the Quality of Volunteered Geographic Information. Spat. Stat. 2012, 1, 110–120. [Google Scholar] [CrossRef]
- Fowler, A.; Whyatt, J.D.; Davies, G.; Ellis, R. How Reliable Are Citizen-derived Scientific Data? Assessing the Quality of Contrail Observations Made by the General Public. Trans. GIS 2013, 17, 488–506. [Google Scholar] [CrossRef]
- Foody, G.M.; See, L.; Fritz, S.; van der Velde, M.; Perger, C.; Schill, C.; Boyd, D.S.; Comber, A. Accurate Attribute Mapping from Volunteered Geographic Information: Issues of Volunteer Quantity and Quality. Cartogr. J. 2014, 52, 336–344. [Google Scholar] [CrossRef]
- Comber, A.; See, L.; Fritz, S.; van der velde, M.; Perger, C.; Foody, G.M. Using control data to determine the reliability of volunteered geographic information about land cover. Int. J. Appl. Earth Obs. Geoinf. 2013, 23, 37–48. [Google Scholar] [CrossRef]
- Leibovici, D.G.; Evans, B.; Hodges, C.; Wiemann, S.; Meek, S.; Rosser, J.; Jackson, M. On Data Quality Assurance and Conflation Entanglement in Crowdsourcing for Environmental Studies. ISPRS Int. J. Geo-Inf. 2017, 6, 78. [Google Scholar] [CrossRef]
- Hunter, J.; Alabri, A.; Van Ingen, C. Assessing the quality and trustworthiness of citizen science data. Concurr. Comput. Pract. Exp. 2013, 25, 454–466. [Google Scholar] [CrossRef]
- Craglia, M.; Shanley, L. Data democracy–increased supply of geospatial information and expanded participatory processes in the production of data. Int. J. Digit. Earth 2015, 8, 1–15. [Google Scholar] [CrossRef]
- Aplin, P. Remote sensing: Ecology. Prog. Phys. Geogr. 2005, 29, 104–113. [Google Scholar] [CrossRef]
- Zlinsky, A.; Heilmeier, H.; Baltzter, H.; Czucz, B.; Pfeifer, N. Remote Sensing and GIS for Habitat Quality Monitoring: New Approaches and Future Research. Remote Sens. 2015, 7, 7987–7994. [Google Scholar] [CrossRef]
- Jones, D.; Pike, S.; Thomas, M.; Murphy, D. Object-Based Image Analysis for Detection of Japanese knotweed s.l. taxa (Polygonaceae) in Wales (UK). Remote Sens. 2011, 3, 319–342. [Google Scholar] [CrossRef]
- Viana, H.; Aranha, J.T.M. Mapping Invasive Species (Acacia Dealbata Link) Using ASTER/TERRA and LANDSAT 7 ETM+ Imagery. In Proceedings of the Conference of IUFRO Landscape Ecology Working Group, Bragança, Portugal, 21–27 September 2010. [Google Scholar]
- Tulloch, A.I.T.; Possingham, H.P.; Joseph, L.N.; Szabo, J.; Martin, T.G. Realising the full potential of citizen science monitoring programs. Biol. Conserv. 2013, 165, 128–138. [Google Scholar] [CrossRef]
- Alabri, A.; Hunter, J. Enhancing the Quality and Trust of Citizen Science Data. In Proceedings of the 2010 IEEE Sixth International Conference on e-Science (e-Science), Brisbane, Australia, 7–10 December 2010; pp. 81–88. [Google Scholar]
- Bordogna, G.; Carrara, P.; Criscuolo, L.; Pepe, M.; Rampini, A. A Linguistic Decision Making Approach to Assess the Quality of Volunteer Geographic Information for Citizen Science. Inf. Sci. 2014, 258, 312–327. [Google Scholar] [CrossRef]
- Meek, S.; Jackson, M.; Leibovici, D.G. A flexible framework for assessing the quality of crowdsourced data. In Proceedings of the 17th AGILE Conference, Castellon, Spain, 3–6 June 2014; Available online: https://agile-online.org/index.php/conference/proceedings/proceedings-2014 (accessed on 20 October 2017).
- Meek, S.; Jackson, M.; Leibovici, D.G. A BPMN solution for chaining OGC services to quality assure location-based crowdsourced data. Comput. Geosci. 2016, 87, 76–83. [Google Scholar] [CrossRef]
- Rosser, J.; Pourabdolllah, A.; Brackin, R.; Jackson, M.J.; Leibovici, D.G. Full Meta Objects for Flexible Geoprocessing Workflows: Profiling WPS or BPMN? In Proceedings of the 19th AGILE Conference, Helsinki, Finland, 14–17 June 2016; Available online: https://agile-online.org/index.php/conference/proceedings/proceedings-2016 (accessed on 20 October 2017).
- Meek, S.; Goulding, J.; Priestnall, G. The Influence of Digital Surface Model Choice on Visibility-Based Mobile Geospatial Applications. Trans. GIS 2013, 17, 526–543. [Google Scholar] [CrossRef]
- Kimothi, M.M.; Dasari, A. Methodology to map the spread of an invasive plant (Lantana camara L.) in forest ecosystems using Indian remote sensing satellite data. Int. J. Remote Sens. 2010, 31, 3273–3289. [Google Scholar] [CrossRef]
- Groom, Q.J.; Desmet, P.; Vanderhoeven, S.; Adriaens, T. The importance of open data for invasive alien species research, policy and management. Manag. Biol. Invasions 2015, 6, 119–125. [Google Scholar] [CrossRef]
- Dodd, M. iSPot Data Quality, Metadata and Visualization. In Proceedings of the 1st European Citizen Science Association conference, Berlin, Germany, 19–21 May 2016; Available online: http://www.ecsa2016.eu/ (accessed on 20 October 2017).
- Grainger, A. Citizen Observatories and the New Earth Observation Science. Remote Sens. 2017, 9, 153. [Google Scholar] [CrossRef]




| Pillar Name | Pillar Description |
|---|---|
| Pillar 1: Positioning | Location, position and accuracy: focusing on the position of the user and of the targeted feature (if any), local condition or constraints (e.g., authoritative polygon, navigation, routing, etc.). |
| Pillar 2: Cleaning | Erroneous entries, mistakes, malicious entries: Erroneous, true mistakes, intentional mistakes, removals, corrections are checked for the position and for the attributes. Feedback mechanism can be an important part of this pillar if the mistakes can be corrected. |
| Pillar 3: Automatic Validation | Simple checks, topology relations and attribute ranges: Carries further the cleaning aspects by validating potential good contributions. Its aim is towards positive rewarding with more inclusive rules than with Pillar 2 focusing more on excluding rules. |
| Pillar 4: Authoritative Data Comparison | Comparison of submitted observations with authoritative data: Either on attributes or position performs statistical test, (fuzzy) logic rule based test qualifying the data captured or reversely qualifies the authoritative data. Knowledge of the metadata of the authoritative data is paramount. |
| Pillar 5: Model-Based Validation | Utilizing statistical and behavioral models: Extends Pillar 4 testing against modeled data (e.g., physical models, behavioral models) and other user contributed data within the same context. This may use intensively fuzzy logics and interactions with the user within a feedback mechanism of interactive surveying. (If some tests will be similar to Pillar 4 the outcome in quality elements can be different). |
| Pillar 6: Linked Data Analysis | Data mining techniques and utilizing social media outputs: Extends Pillar 5 testing to using various social media data or related data sources within a linked data framework. Tests are driven by a more correlative paradigm than in previous pillars. |
| Pillar 7: Semantic Harmonization | Conformance enrichment and harmonization in relation to existing ontologies: Level of discrepancy of the data captured to existing ontology or crowd agreement is transformed into data quality information. In the meantime, data transformation to meet harmonization can take place. |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leibovici, D.G.; Williams, J.; Rosser, J.F.; Hodges, C.; Chapman, C.; Higgins, C.; Jackson, M.J. Earth Observation for Citizen Science Validation, or Citizen Science for Earth Observation Validation? The Role of Quality Assurance of Volunteered Observations. Data 2017, 2, 35. https://doi.org/10.3390/data2040035
Leibovici DG, Williams J, Rosser JF, Hodges C, Chapman C, Higgins C, Jackson MJ. Earth Observation for Citizen Science Validation, or Citizen Science for Earth Observation Validation? The Role of Quality Assurance of Volunteered Observations. Data. 2017; 2(4):35. https://doi.org/10.3390/data2040035
Chicago/Turabian StyleLeibovici, Didier G., Jamie Williams, Julian F. Rosser, Crona Hodges, Colin Chapman, Chris Higgins, and Mike J. Jackson. 2017. "Earth Observation for Citizen Science Validation, or Citizen Science for Earth Observation Validation? The Role of Quality Assurance of Volunteered Observations" Data 2, no. 4: 35. https://doi.org/10.3390/data2040035
APA StyleLeibovici, D. G., Williams, J., Rosser, J. F., Hodges, C., Chapman, C., Higgins, C., & Jackson, M. J. (2017). Earth Observation for Citizen Science Validation, or Citizen Science for Earth Observation Validation? The Role of Quality Assurance of Volunteered Observations. Data, 2(4), 35. https://doi.org/10.3390/data2040035