
688,112 Statistical Results: Content Mining Psychology Articles for Statistical Test Results


Abstract
:1. Summary
2. Data Description
3. Methods
4. Usage Notes
Acknowledgments
Conflicts of Interest
Appendix. Example of Statcheck Report for PubPeer
References
- Nuijten, M.B.; Hartgerink, C.H.J.; van Assen, M.A.L.M.; Epskamp, S.; Wicherts, J.M. The prevalence of statistical reporting errors in psychology (1985–2013). Behav. Res. Methods 2015. [Google Scholar] [CrossRef] [PubMed]
- Nuijten, M.B.; Epskamp, S. Statcheck: Extract Statistics from Articles and Recompute p Values (R Package Version 1.0.1); Tilburg University: Tilburg, The Netherlands, 2015. [Google Scholar]
- https://raw.githubusercontent.com/chartgerink/2016statcheck_data/master/no_result.txt.
- Hartgerink, C.H.J.; van Aert, R.C.M.; Nuijten, M.B.; Wicherts, J.M.; van Assen, M.A.L.M. Distributions of p-values smaller than .05 in psychology: What is going on? PeerJ 2016, 4, e1935. [Google Scholar] [CrossRef] [PubMed]
- Hartgerink, C.H.J.; van Assen, M.A.L.M.; Wicherts, J.M. Too Good to be False: Nonsignificant Results Revisited. 2016. Available online: http://osf.io/qpfnw (accessed on 25 June 2016).
- https://github.com/chartgerink/2016statcheck_data.
- Larivière, V.; Haustein, S.; Mongeon, P. The oligopoly of academic publishers in the digital era. PLoS ONE 2015, 10, e0127502. [Google Scholar] [CrossRef] [PubMed]
- https://github.com/chartgerink/2016statcheck_data/blob/master/scraping/journal-spiders/journal_list_old.csv.
- Hartgerink, C.H.J. Elsevier Stopped me Doing my Research. 2015. Available online: http://onsnetwork.org/chartgerink/2015/11/16/elsevier-stopped-me-doing-my-research/ (accessed on 17 May 2016).
- Bloudoff-Indelicato, M. Text-mining block prompts online response. Nature 2015, 527, 413. [Google Scholar] [CrossRef]
- Hartgerink, C.H.J. Wiley Also Stopped me Doing my Research. 2016. Available online: http://onsnetwork.org/chartgerink/2016/02/23/wiley-also-stopped-my-doing-my-research/ (accessed on 17 May 2016).
- https://github.com/chartgerink/2016statcheck_data/blob/master/scraping/journal-spiders/journal_list.csv.
- https://github.com/chartgerink/journal-spiders.
- https://github.com/chartgerink/2016statcheck_data/tree/master/scraping/journal-spiders/journal-links.
- https://github.com/chartgerink/2016statcheck_data/blob/master/tilburg_journals.ods?raw=true.
- https://github.com/contentmine/quickscrape.
- https://github.com/thewinnower/terrier.
- https://github.com/chartgerink/2016statcheck_data/blob/master/scraping/terrier.rb.
- https://github.com/michelenuijten/statcheck.
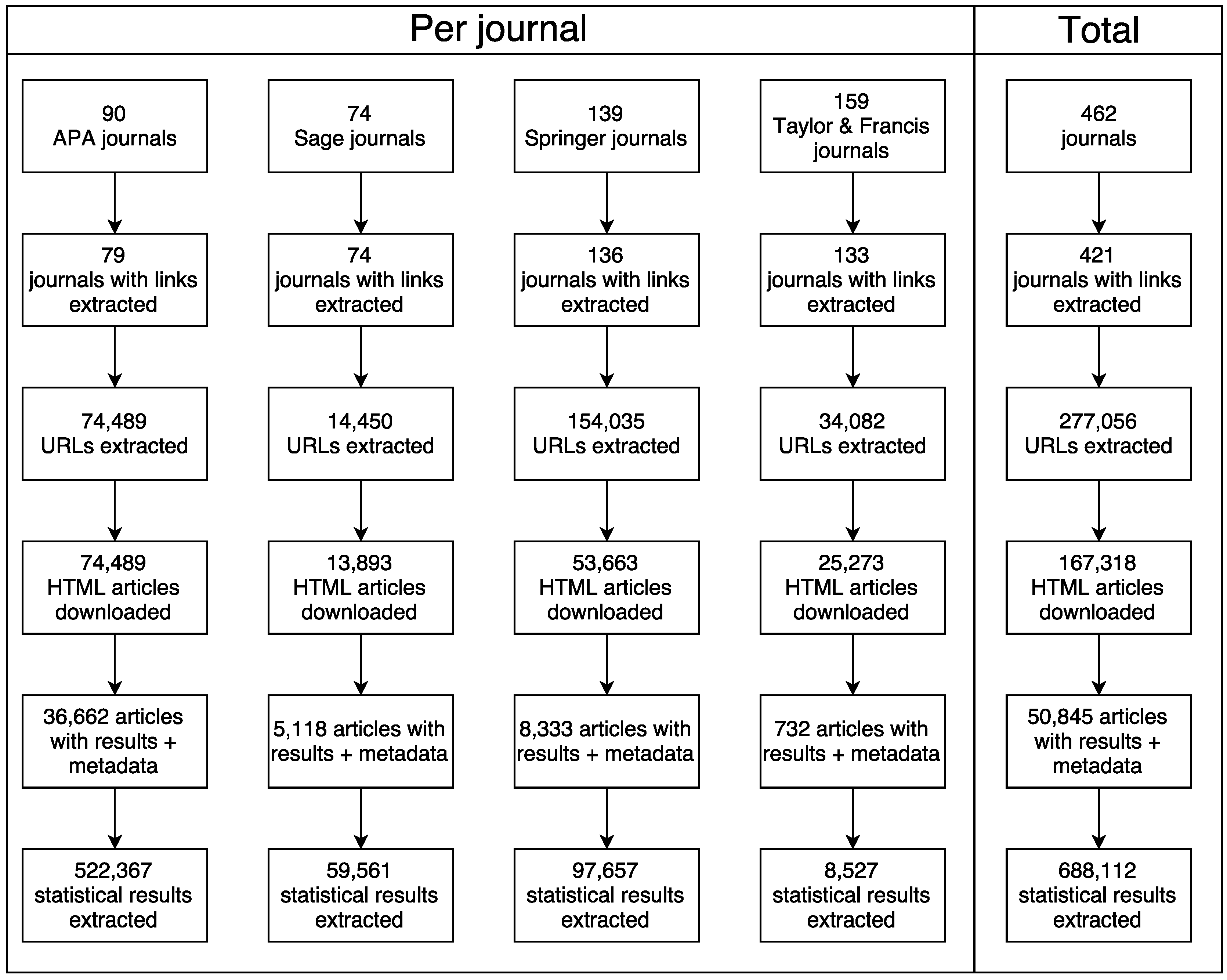

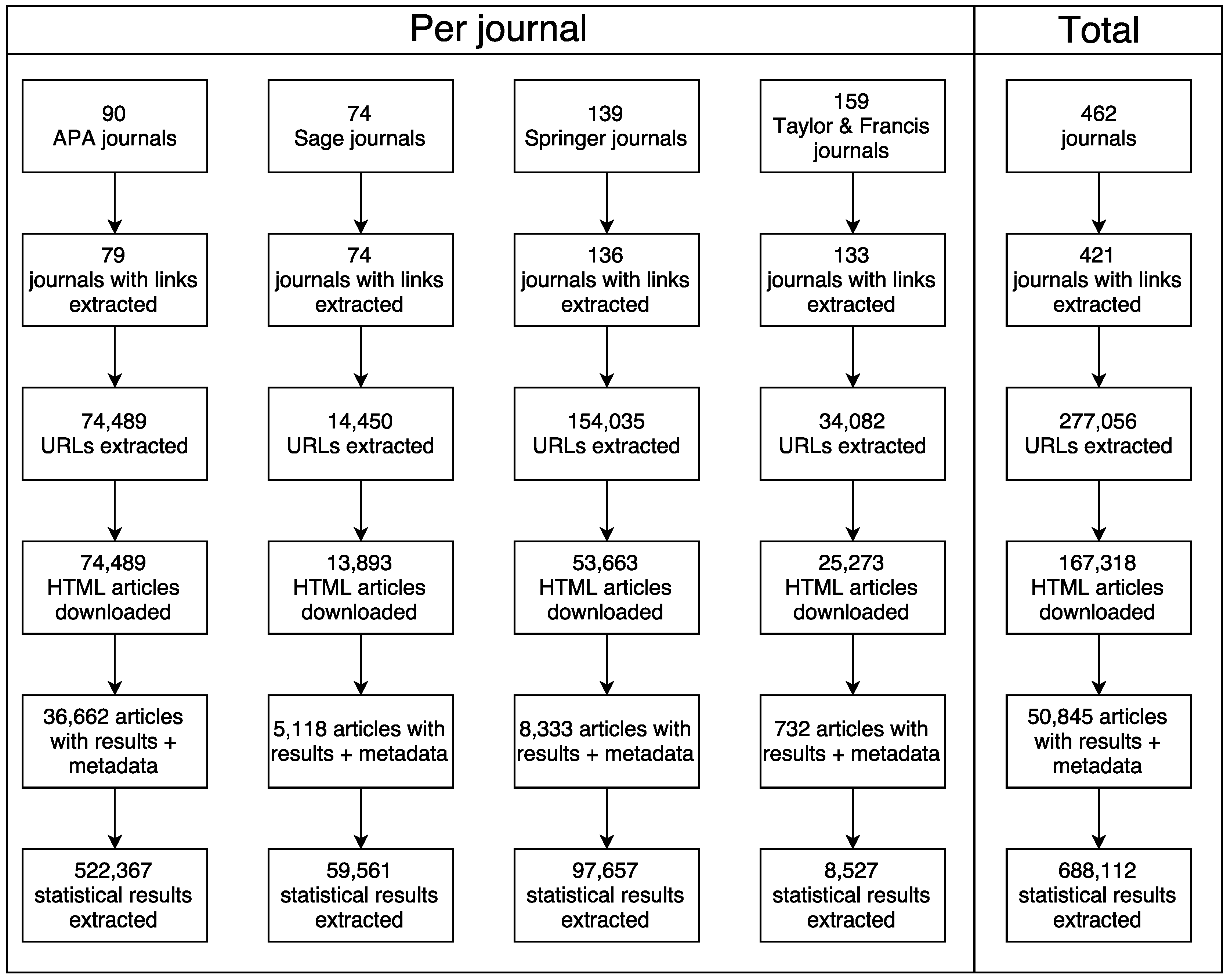{kind=link}
| Publisher | Timespan | Number of Articles | Number of Articles with Results | Result Count | Median Results per Article | Mean Reported p-Value | Mean Recalculated p-Value |
|---|---|---|---|---|---|---|---|
| American Psychological Association (APA) | 1985–2016 | 74,489 | 36,662 | 522,367 | 9 | 0.073 | 0.098 |
| Sage | 1972–2016 | 13,893 | 5118 | 59,561 | 8 | 0.101 | 0.110 |
| Springer | 2003–2016 | 53,667 | 8333 | 97,657 | 8 | 0.097 | 0.113 |
| Taylor & Francis | 2003–2016 | 25,274 | 732 | 8527 | 8 | 0.118 | 0.133 |
| Total | 1972–2016 | 167,318 | 50,845 | 688,112 | 9 | 0.080 | 0.102 |
| Variable | Type | Description |
|---|---|---|
| Source | Metadata | Digital Object Identifier (DOI) of the article |
| publisher | Metadata | Publisher of the article, as available in CrossRef |
| year | Metadata | Publication year, as available in CrossRef |
| journal | Metadata | Journal, as available in CrossRef |
| Statistic | Individual result | Type of statistical test statistic (possible values and ) |
| df1 | Individual result | First degree of freedom of the test statistic |
| df2 | Individual result | Second degree of freedom of the test statistic |
| Test.Comparison | Individual result | Sign used in reporting of test statistic (>, <, =) |
| Value | Individual result | Reported value of the test statistic |
| Reported.Comparison | Individual result | Sign used in reporting of p-value (>, <, =) |
| Reported.P.Value | Individual result | Reported p-value |
| Computed | Individual result | Recalculated p-value (two-tailed) based on Statistic and df1, df2 |
| Raw | Individual result | Raw text of extracted statistical result |
| Error | Individual result | Whether the reported p-value differs from recalculated p-value |
| DecisionError | Individual result | Whether the reported p-value differs from the recalculated p-value AND significance is different () |
| OneTail | Individual result | Whether the result would be correct if the p-value were one-tailed |
| OneTailedInTxt | Individual result | Whether the article contains “sided”, “tailed”, or “directional” |
| authors | Metadata | Author names, as available in CrossRef |
| author_count | Metadata | Number of authors |
| title | Metadata | Title, as available in CrossRef |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hartgerink, C.H.J. 688,112 Statistical Results: Content Mining Psychology Articles for Statistical Test Results. Data 2016, 1, 14. https://doi.org/10.3390/data1030014
Hartgerink CHJ. 688,112 Statistical Results: Content Mining Psychology Articles for Statistical Test Results. Data. 2016; 1(3):14. https://doi.org/10.3390/data1030014
Chicago/Turabian StyleHartgerink, Chris H. J. 2016. "688,112 Statistical Results: Content Mining Psychology Articles for Statistical Test Results" Data 1, no. 3: 14. https://doi.org/10.3390/data1030014
APA StyleHartgerink, C. H. J. (2016). 688,112 Statistical Results: Content Mining Psychology Articles for Statistical Test Results. Data, 1(3), 14. https://doi.org/10.3390/data1030014