1. Introduction
Medical imaging serves as a fundamental pillar in modern healthcare, delivering critical insights into disease detection, treatment planning, and patient monitoring. In clinical practice, medical tasks such as image classification, segmentation, automated report generation, and registration have evolved into crucial elements [
1]. While traditional machine learning techniques established the foundation for automation in these domains, they face significant challenges in processing the diverse and complex nature of clinical imaging data [
2,
3]. Additionally, the remarkable progress of modern artificial intelligence techniques has resulted in substantial improvements across various medical image analysis tasks [
4]. However, these models typically require specialized training and large annotated datasets, restricting their scalability and generalization across different clinical applications [
5,
6,
7,
8].
The emergence of cutting-edge large language models has revolutionized multiple domains, particularly in natural language processing (NLP), owing to their powerful generalization abilities and multimodal input processing capabilities [
9]. In medical imaging, LLMs, especially vision-language models, have shown considerable potential to consolidate diverse tasks within a unified framework. In the context of this review, “productivity” refers to the ability of large language models (LLMs) to efficiently and effectively perform medical image analysis tasks, such as image classification, medical report generation, and visual question answering. It is a measure of how well these models can process and integrate medical image data with textual descriptions, providing valuable outputs that assist healthcare professionals in decision-making. Productivity is assessed in terms of both the speed at which these tasks are completed and the accuracy and reliability of the model’s outputs.
With proper prompting, LLMs can analyze visual content, produce diagnostic insights, and execute various downstream tasks, potentially alleviating the workload of healthcare professionals while enhancing clinical efficiency. Traditional machine learning and LLM algorithms are generally presented in
Figure 1, in which (a) represents traditional methods and (b) illustrates medical image analysis through a large language model.
Despite increasing enthusiasm for applying LLMs to medical image analysis, a thorough and well-organized synthesis of this field is still missing. This gap hinders researchers’ ability to evaluate current progress, recognize challenges, and discover opportunities in this quickly advancing field. To bridge this gap, we conducted a systematic review documenting the current status of LLMs in medical image analysis. To offer a comprehensive perspective, we introduced an x-stage tuning paradigm encompassing zero-stage, one-stage, and multi-stage tuning, presenting a unified framework for investigating LLM applications in this domain. Several recent surveys have examined the use of large language models in healthcare, providing valuable insights into applications such as multimodal medical question answering, clinical decision support, and Transformer architectures [
10]. However, these surveys are often limited in scope focusing either on specific tasks or predominantly on text-based applications and do not extend their analysis to vision-language models or practical adaptation strategies in medical image analysis. Additionally, none provide a systematic, stage-based tuning framework to help practitioners understand how foundation models can be effectively adapted for different imaging tasks [
11,
12]. Our work addresses these gaps by offering a structured, task-oriented perspective on model tuning for medical image analysis.
The proposed X-stage tuning paradigm introduces a novel conceptual framework that categorizes adaptation strategies based on tuning complexity and domain alignment. This structure enables direct comparison of tuning approaches across various medical imaging tasks and datasets, supporting researchers and developers in selecting suitable strategies for model deployment under different constraints.
Zero-stage tuning refers to applying LLMs to medical image tasks without any additional tuning, enabling direct use with minimal resources and data.
One-stage tuning involves fine-tuning LLMs using domain-specific medical image data to capture relevant features and improve performance.
Multi-stage tuning includes a sequence of tuning phases, often leveraging both domain-agnostic and domain-specific datasets to build more robust and adaptable models [
13,
14].
Furthermore, we identify current limitations and future directions in this domain, offering critical insights and practical guidance to researchers and developers. This survey is especially timely as the field transitions from developing general-purpose foundation models to implementing domain-specific solutions in regulated clinical environments. The insights provided here are intended to support AI researchers working on model design, healthcare developers integrating AI into clinical tools, and clinicians seeking to understand the practical implications of using large language models in medical imaging workflows.
The contributions of this work are summarized as follows:
We present a detailed synthesis of the current applications of LLMs across medical imaging tasks, including automated radiology report generation, disease classification, visual question answering (VQA), and visual grounding.
We propose an x-stage tuning paradigm to systematically categorize current approaches and highlight their differences, use cases, and limitations.
We perform a thorough analysis of zero-stage, one-stage, and multi-stage fine-tuning strategies, providing insights into their comparative performance on various tasks and datasets.
We explore current trends, unresolved challenges, and promising avenues for future research in this rapidly evolving field.
This paper follows an orderly structure:
Section 2 provides background on LLMs, the x-stage tuning paradigm, and medical image tasks.
Section 3 explores the x-stage tuning framework in detail, while experimental results are discussed in
Section 4.
Section 5 discusses challenges in applying LLMs to medical image analysis.
Section 6 outlines future research directions and
Section 7 concludes the paper with key findings and next steps.
2. Background
This section outlines essential background information regarding the concept of staged fine-tuning, along with the key medical image analysis tasks handled by LLMs. To properly utilize LLMs in medical image analysis, one must first grasp how staged fine-tuning works and how LLMs can be customized for specific tasks.
2.1. Staged Fine-Tuning
Within clinical imaging applications, progressive model adaptation is a fundamental technique for customizing LLMs to specialized tasks. By gradually adjusting model parameters through multiple stages, this approach allows for better performance when addressing specialized diagnostic requirements with available imaging data.
Zero-stage fine-tuning: This method applies LLMs directly to medical image tasks without fine-tuning the model using specialized medical datasets, as illustrated in
Figure 2(1). The model utilizes its pre-trained knowledge from a broad corpus to perform the task, enabling quick deployment but potentially compromising optimal performance for medical-specific tasks. The zero-stage fine-tuning process is expressed as
where
is the output generated by the model,
is the medical image input, and
is the associated text prompt. The notation
indicates that the model’s parameters are not adjusted during this stage.
One-stage fine-tuning: In this approach, LLMs are fine-tuned using domain-specific medical image data to modify the model for medical imaging features, as presented in
Figure 2(2). This stage results in improved performance for specific tasks, such as medical image classification or report generation [
15]. The one-stage fine-tuning process is given by
where
indicates that the model is fine-tuned on medical image data to optimize its performance for specific tasks.
Multi-stage fine-tuning: The model’s refinement through multiple stages advances progressively by combining domain-specific data with general-purpose data at each stage of enhancement. This approach enhances the robustness and versatility of the model, particularly for complex medical image analysis tasks, as shown in
Figure 2(3). The multi-stage fine-tuning process is represented as
The final model after all stages is expressed as
Through multi-stage fine-tuning, the model handles diverse data across different stages, which makes it highly effective for complex multi-dimensional medical image tasks [
14].
2.2. Medical Image Analysis Tasks
LLMs have shown great promise in solving several key tasks within medical image analysis. These applications involve interpreting medical images and extracting valuable information as presented in
Figure 3 that supports clinical decision-making [
16,
17]. Below are the descriptions of four common medical image analysis tasks that LLMs can help address: report generation from images, disease classification, answering questions based on images, and identifying specific regions in images based on text descriptions.
2.2.1. Report Generation from Images
This task involves the automated creation of clinical reports from diagnostic imaging data, as shown in
Figure 3(1), encompassing X-rays, MRIs, and CT scans. The model generates a detailed textual report describing any conditions present from input images [
18,
19,
20]. This can be mathematically represented as
where
R is the generated medical report and
is the input medical image. Report generation evaluation typically utilizes BLEU [
21] and ROUGE [
21,
22], as well as Perplexity and F1-score as quality metrics for the generated reports.
2.2.2. Disease Classification
This task involves classifying medical images into different categories by identifying the presence of disease as presented in
Figure 3(2). The model outputs a classification label, which can be represented as
where
L denotes the label from a set of possible diagnostic categories and
is the medical image. This task utilizes accuracy, together with the F1 score, along with the Area Under the Curve (AUC) as key performance metrics.
2.2.3. Image-Based Question Answering (VQA)
In this task, a model answers questions related to medical images, as depicted in
Figure 3(3). Given an image and a question, such as “What condition is shown in the MRI?”, the model provides an answer based on the visual content [
23,
24,
25]. The relationship is expressed as
where
A is the model’s answer,
is the medical image, and
Q is the question. Metrics like accuracy (ACC), mean average precision (mAP), and BLEU are used to assess performance on this task.
2.2.4. Image-Text Grounding
The task of grounding requires systems to both identify locations in medical images and establish their precise positions according to text descriptions, as illustrated in
Figure 3(4). For example, a model might be tasked with identifying and highlighting a tumor in an X-ray based on a prompt. This task is mathematically represented as
where
G is the generated grounding box,
is the medical image, and
P is the phrase describing the region of interest. Various metrics, such as Intersection over Union (IoU), grounding error, and Dice coefficient, measure the performance of grounding tasks.
2.3. What Did the Previous Review on Medical Images Discuss?
With the significant progress in machine learning, particularly deep learning, its uses in medical image processing have evolved considerably. Litjens et al. [
3] offered an early synthesis of how deep learning methods influenced medical image analysis, emphasising the substantial contribution of convolutional neural networks (CNNs) and related architectures in advancing the field. Their work also outlined specific clinical applications where deep learning models have shown promise, including disease classification, organ segmentation [
26,
27], and tumor detection.
Following this foundational work, recent surveys, such as the one by Shamshad et al. [
28], have concentrated on the evolution of Transformers in medical image processing. Their work categorized applications of Transformers across different medical domains, identified the key challenges they faced, and proposed insights on addressing these obstacles. In addition, other studies have reviewed deep learning applications across various clinical domains, such as the analysis of chest X-rays, retinal fundus images, and cardiac CT scans [
29]. These efforts have served as a pivotal factor in the growth of AI technologies in the healthcare [
30] sector and facilitated the initial adoption of deep learning models in clinical settings.
While these reviews have contributed significantly to the field, there remain significant obstacles, including limited datasets and privacy issues around medical data [
31]. Chlap et al. [
32] summarized key data augmentation techniques used to address these issues in diagnostic imaging systems, including computed tomography and magnetic resonance imaging. Morid et al. [
33] focused on the application of knowledge transfer approaches in medical image analysis, outlining various strategies and their applicability in specific clinical tasks. Xie et al. [
34] reviewed the infusion of domain knowledge into machine learning models and categorised research based on clinical areas and integration techniques. Moreover, researchers have introduced three approaches, namely knowledge transfer, multiple-instance learning, and learning with partial supervision, to address data scarcity issues [
35,
36,
37].
In addition to data-related challenges, the processing of 3D medical images and improving model interpretability are also critical in clinical settings. Singh et al. [
38] conducted a systematic review of 3D deep learning models for medical image applications. These models are crucial for extracting features from complex three-dimensional medical data and ensuring safer clinical applications. Furthermore, studies have explored interpretable AI methods in medical image processing, categorizing approaches, and evaluating their potential to make AI more transparent and trustworthy for healthcare professionals [
39,
40].
Previous surveys have addressed deep learning [
3] and transformer-based methods [
28] in medical imaging, focusing mainly on CNN architectures, vision-only transformers, or text-based clinical NLP models. However, these studies lack comprehensive treatment of vision-language large models (VLMs) and do not introduce structured tuning paradigms. Furthermore, existing reviews often neglect task-specific evaluation synthesis, especially across VQA, report generation, classification, and grounding. Our work fills these gaps by providing a novel tuning framework and a unified view of task-wise performance and metrics.
2.4. Why a Survey on LLM for Medical Images?
While deep learning methods, particularly CNNs, have been extensively studied and applied to medical image analysis, this survey seeks to address the emerging literature gap concerning how LLMs contribute to analyzing medical images. As deep learning continues to advance, the increasing computational power and volume of data have enabled the creation of increasingly sophisticated network architectures. These models integrate a vast amount of contextual knowledge and uncover deeper feature representations, which have notably improved diagnostic accuracy and clinical decision-making [
41,
42].
The versatility of LLMs, driven by their capacity for cross-task generalization and multi-task learning, sets them apart from smaller, task-specific models. Their ability to process various medical imaging problems, including automated lesion detection, tissue segmentation [
43], and diagnosis classification [
44], makes them powerful tools in clinical applications. Specifically, trained on large datasets, LLMs can identify semantic relations and underlying biomedical patterns, which is an essential asset in medical imaging scenarios because annotated data are scarce.
Nevertheless, a range of challenges that should be addressed remains despite the impressive achievements of LLMs in the sphere of medical image analysis. These are the limits in datasets and metrics, issues of knowledge updating, and the necessity of multilingual models. Moreover, it has some uncertainties about how Chain-of-Thought (CoT) reasoning would be applied, the potential dangers of hallucination in the model outputs, and the safeguarding of confidential medical information.
This review is intended to give an in-depth discussion of the current LLM method in medical image analysis in light of its existing constraints. The article describes the obstacles to LLMs in this field in detail and proposes directions of future studies. In solving these problems, we would hope to offer helpful advice to researchers who deal with medical imagery and to discover other research directions that can stretch the limitations of the area further, leading to more development in medical image analytics with LLMs.
3. X-Stage Tuning Paradigm
The X-Stage Tuning Paradigm is an innovative framework for optimizing large language models (LLMs) used in medical image analysis. This framework categorizes the fine-tuning process into distinct stages: zero-stage fine-tuning, one-stage fine-tuning, and multi-stage fine-tuning. Each stage offers a distinct strategy for tailoring pre-trained models to specialized tasks, as well as specific adaptation methods that depend on the data characteristics and performance targets. This section examines each of these stages in detail, highlighting their respective strengths and challenges.
Table 1 summarizes various applications of LLMs in medical image analysis, detailing key tasks and associated challenges in each domain. It provides an overview of how LLMs are being utilized across different medical imaging tasks, as well as the primary obstacles encountered in each application [
45,
46,
47].
We introduce a novel conceptual framework, called X-stage tuning, to categorize the adaptation of LLMs in medical image analysis. This framework consists of:
Zero-stage tuning: No fine-tuning; direct model use;
One-stage tuning: Task-specific tuning using medical data;
Multi-stage tuning: Sequential adaptation combining general and domain-specific knowledge.
This is the first survey to organize adaptation strategies in this staged format, providing a practical guide for researchers selecting tuning strategies based on data availability, model complexity, and task specificity. The X-stage paradigm not only reorganizes known methods but also enables structured comparison and deployment guidance, which is missing in prior literature.
3.1. Zero-Stage Fine-Tuning
Zero-stage fine-tuning refers to applying a pre-trained LLM directly to medical image tasks without modifying the model’s parameters. This stage leverages the model’s pre-existing knowledge from large, general-purpose datasets, such as image-text pairs or other natural language corpora, to perform medical image analysis tasks. Zero-stage tuning is shown in
Figure 4(1). Zero-stage fine-tuning is advantageous for rapid deployment and minimizing data requirements, as it does not require labeled medical datasets or any additional training for specific tasks [
48].
While zero-stage fine-tuning is efficient in terms of time and resources, it has limitations in achieving optimal performance for complex medical tasks. This is because the model has not been tailored to recognize domain-specific features and nuances in medical images, which can lead to suboptimal results when handling tasks that demand specialized medical knowledge [
49,
50].
3.2. One-Stage Fine-Tuning
The one-stage adaptation process focuses on optimizing the parameters of the pre-trained model with domain-specific medical image data. At this stage, the model undergoes task-specific training on datasets, enabling it to learn features relevant to the medical domain and enhance its performance on targeted tasks, such as disease classification, medical report generation, or image segmentation. One-stage fine-tuning is particularly useful for adapting general-purpose models to medical applications by introducing task-specific data into the training process.
This stage generally demands a substantial amount of annotated data for model training. One-stage fine-tuning needs high-quality annotated datasets to achieve successful outcomes. The model gains an enhanced understanding of medical image complexities through one-stage fine-tuning, as shown in
Figure 4(2), which leads to better accuracy and result specificity [
50,
51,
52].
One-stage fine-tuning enables significant performance improvements but relies heavily on the availability of domain-specific data. The quality and diversity of the medical datasets used in this stage play an important role in the success of fine-tuning [
51].
3.3. Multi-Stage Fine-Tuning
This staged adaptation method is an expansion of the one-stage methodology that is characterized by including more stages in the fine-tuning of the model to more focused tasks or working with distinct datasets. This approach strengthens the flexibility of the model to work well when used on different medical image analysis problems and makes the model stronger. The progressive approach is particularly beneficial for handling complex datasets that span multiple domains or require understanding different modalities (e.g., combining 2D and 3D medical images), as illustrated in
Figure 4(3).
In this phased fine-tuning, it initially trains the model on large, domain-agnostic data. The training goal at this step allows the model to learn global patterns and ideas to apply them to a wide variety of medical imaging tasks. Further phases improve the capability of the model to perform particular things by tuning the model on smaller and more specialized datasets [
53,
54].
The process of fine-tuning structures the model to be more specific regarding the complexity of medical image analysis in each stage. As an example, one stage may be training the model with a general medical image dataset, and other stages may further refine the model to perform specific tasks such as image segmentation or diagnostic report generation.
The multi-stage fine-tuning has a number of benefits such as better generalization of multiple tasks and compatibility with different types of data. Nevertheless, it is a demanding method that involves careful treatment of the training phases as well as access to comprehensive sets of data. It is also more resource-intensive to perform fine-tuning than zero-stage and one-stage fine-tuning since it requires more training steps [
53].
3.4. Benefits of X-Stage Tuning
The X-Stage Tuning Paradigm provides a flexible and scalable approach to adapting LLMs for medical image analysis. It allows researchers to select the most appropriate fine-tuning strategy based on each task’s unique demands and the available data. The main benefits of staged fine-tuning include:
Efficiency: Zero-stage fine-tuning offers a quick deployment of pre-trained models without the need for task-specific data. It is particularly useful when resources are limited or when rapid application of models is required.
Task-Specific Adaptation: One-stage fine-tuning increases the performance on target medical tasks by fine-tuning the model to the specificities of the medical field.
Robustness and Flexibility: By using a multi-stage fine-tuning, the model can work with multimodal, complex data and generalize them on a range of tasks. It gives an advantage of flexibility in the application of the model to the various fields of medicine; thus, it is applicable in various and multifaceted clinical surroundings.
Improved Generalization: Multi-stage fine-tuning improves the generalization and flexibility of LLMs to work with data across many medical domains or modes of data by continually adjusting the model to the practice of multi-stage training [
54,
55].
Table 2 and
Table 3 outlines the X-stage tuning paradigm for LLMs in medical imaging, comparing open-source (OS) approaches. Meanwhile,
Table 2 evaluates LLM performance on key medical VQA datasets (VQA-RAD, SLAKE, PathVQA), reporting accuracy for open-ended (O), closed (C), and overall (OA) questions, with top results highlighted in blue.
4. Experimental Setup
This survey paper does not conduct new experiments but systematically reviews existing works on LLMs for medical images. The experimental setup is derived from the methodologies of the analyzed studies, which typically follow the steps outlined below.
4.1. Selection of Papers, Countrywise and Yearly Roadmap
This survey covers research papers published between 2021 and 2025, presenting a comprehensive roadmap of recent advancements in the field over the past five years, as illustrated in
Figure 5a. The geographic distribution of identified papers reveals that 60–65 % of studies originate from the USA, 15–20 % from China, and 20–25% from other countries, including Vietnam, various European nations, and multinational collaborations, as illustrated in
Figure 5b. This breakdown highlights both the temporal progression of research activity and the current concentration of medical LLM research in these two leading AI hubs while underscoring the need for broader global participation in future work.
4.2. Model Selection and Tuning Paradigms
We explore model selection and tuning paradigms for large language models (LLMs) in medical imaging, categorizing them into three stages: zero-stage tuning, where pre-trained LLMs (e.g., GPT-4V, Gemini) are applied directly to medical tasks without any fine-tuning; one-stage tuning, where models (e.g., MedBLIP, RadFM) are fine-tuned on domain-specific datasets such as MIMIC-CXR; and multi-stage tuning, where models (e.g., LLaVA-Med, PeFoMed) undergo progressive training on both general and medical datasets. The models were chosen on the capability of supporting complex applications of medical image analysis, especially those with large amounts of data. We used various tuning paradigms to maximize various tasks, like automated diagnosis and report generation, among other tasks, on models. ImageNet, MIMIC-CXR, and MedicalSeg, among other datasets, were used in the training process and were chosen in a way that would facilitate a wide scope of medical imaging difficulties. The given systematic review sheds some light on the performance of every available method, giving a strategic plan of how to move forward in medical AI. By categorizing these paradigms, we aim to offer a deeper understanding of how each tuning method influences model accuracy and adaptability, which is essential for advancing the application of LLMs in healthcare.
4.3. Benchmark Tasks and Datasets
This article includes a systematic survey of LLMs on medical imaging tasks through benchmark research elements. Some of the relevant functions are automated radiology report generation, diagnosis type, visual question answering (VQA), and visual grounding tasks. In
Figure 6a, the popular datasets identified in the study include MIMIC-CXR (X-rays with reports), CheXpert (chest radiographs), and VQA-RAD/SLAKE (medical visual QA pairs). With the help of these datasets and the aspect in which they are used in assessing the quality of LLM, this work sheds light on the effectiveness of the models and the way the progress of AI-based medical services may evolve. Additionally,
Figure 6b outlines the percentage of identified papers from different journals, coneference, and arxiv. In
Figure 6c, it can be seen that we identified 272 papers from Scopus and Web of Science using keywords like “LLM for medical images” and “role of VLM in medical images” after removing duplicates. Abstract screening excluded 141 irrelevant records (books, reviews, chapters, non-English, etc.), followed by full-text screening, which excluded 7 additional papers. The final review included 124 studies, ensuring a rigorous and representative literature synthesis.
4.4. Key Tasks in Medical Image Analysis Using LLMs
LLMs have demonstrated significant potential across a variety of medical image analysis tasks. Each of these tasks supports different aspects of medical decision-making, from diagnosis to patient care. Below, we discuss the key tasks to which LLMs are applied:
Automated Radiology Report Generation: Automated radiology report generation is a critical task where LLMs analyze medical images (such as X-rays, CT scans, or MRIs) and generate detailed text descriptions, identifying abnormalities and making diagnostic suggestions. This task often uses datasets like MIMIC-CXR and CheXpert, where medical reports are paired with imaging data, providing the foundation for training models to produce clinically relevant reports.
Disease Classification: Disease classification is the process of training models in order to perform classification tasks on medical images, e.g., healthy vs. diseased classification. This activity is crucial in the early diagnosis and detection of the disease, which assists medical personnel in coming up with informed choices. Datasets such as MIMIC-CXR and CheXpert are annotated with images containing diagnostic categories, which can be used to assess the effectiveness of models in practice in clinical settings.
Visual Question Answering (VQA): The model in VQA tasks is presented with a question and answers concerning an image related to the field of medicine, e.g., what is the diagnosis of an X-ray or an MRI? Such a task involves the combination of visual and text data. Medical image datasets with clinical questions and answers, including VQA-RAD and SLAKE, are useful in training models to produce revealing and accurate responses to clinical questions using visualized information.
Visual Grounding: Visual grounding tasks require recognition of certain areas in an image given from textual descriptions or queries. This may include an analysis of medical images, such as the detection of tumors or other abnormalities in X-rays or MRIs. The model gives a bounding box or segmentation map to signify the position of the identified region. Datasets like CheXpert and Open-I facilitate such works, providing text annotations and image features that ground particular medical entities.
4.5. Datasets Used in Medical Image Analysis with LLMs
The effectiveness of LLMs in medical image analysis is heavily dependent on the datasets used for training, testing, and evaluation. Below are some of the key datasets that have been utilized in the research of LLMs for medical images.
MIMIC-CXR: The MIMIC-CXR includes more than 370,000 objects (chest X-ray images) with accompanying radiology reports. The prevalent use of this dataset includes disease categorization and report automation, in which tasks include deployment of LLMs to write coherent descriptions of the conditions detected in X-rays. Its size and diversity are good choices of data to train LLMs with in the real-world situation of clinical needs.
CheXpert: CheXpert is a rather big dataset of chest X-rays with labels of several types of diseases, including, e.g., pneumonia, tuberculosis, and cardiovascular diseases. The data also contain uncertainty labels, and on the basis of the uncertainty labels, the models are trained to be able to deal with the uncertain or unclear situations, so it is a valuable resource related to the disease classification activity. CheXpert is an important database to evaluate the out-of-sample performance of LLMs in numerous clinical circumstances.
VQA-RAD: VQA-RAD is a special dataset that is used to address medical visual question answering (VQA). It has medical pictures that are accompanied by questions and answers, where the model has to infer the visual contents. VQA-RAD can assist in training models that can process both image and text data to respond to clinical questions, and this can contribute a great deal to training AI-related systems concerning clinical decision support.
SLAKE: One more important dataset in VQA tasks is SLAKE. It comprises both medical images and question–answer pairs, covering as varied a set of clinical scenarios as possible. The data support answering open-ended and detailed medical questions with LLMs to achieve enhanced medical VQA models.
Open-I: Open-I is a collection of medical images and question–answer pairs on a wide set of images. It is heavily applied in designing and testing visual question answering systems, especially in those that involve LLMs in reading through both medical images and textual descriptions. It is useful with regard to such models that have to respond to clinical questions with reference to visual information in pictures.
4.6. Evaluation Metrics in LLMs for Medical Image Analysis
Evaluation metrics are used for LLMs in medical imaging across key tasks. The evaluative metrics for medical report generation consist of BLEU and ROUGE, together with CheXpert labels for measuring both text quality and clinical relevance. Diagnosis classification is evaluated using accuracy (ACC) and AUC-ROC, ensuring robust predictive performance [
25,
98,
99]. The accuracy metric measures both open- and closed-ended questions in Visual question answering, while visual grounding is measured using IoU and Dice coefficient for spatial alignment. This study provides a comprehensive analysis of these benchmarks to guide future advancements in AI-driven medical applications [
100,
101,
102] as presented in
Figure 7.
Table 4 sumarizes the evaluation metrics used for different tasks in medical image analysis.
4.7. Evaluation of LLMs in Medical Image Analysis
Evaluating LLMs for medical image analysis involves the use of standard metrics to assess performance across different tasks. Common evaluation metrics include:
Accuracy: Measures the percentage of correct classifications or answers generated by the model. This metric is commonly used in disease classification and VQA tasks.
F1-Score: A harmonic mean of precision and recall, the F1-score is widely used to evaluate the balance between correctly identified disease cases and false positives/negatives.
Area Under the Curve (AUC): This metric evaluates the performance of classification models, particularly in tasks with imbalanced datasets. AUC provides a measure of the model’s ability to discriminate between different classes (e.g., disease vs. healthy).
BLEU and ROUGE: These are text-based evaluation metrics used for automated report generation. BLEU measures the overlap of n-grams between the generated and reference text, while ROUGE focuses on recall-based evaluation of n-grams.
Intersection over Union (IoU): Used in visual grounding tasks, IoU measures how well the predicted bounding box matches the ground truth. It is a critical metric for evaluating the accuracy of segmentation and localization tasks.
A core contribution of this survey is the synthesis of evaluation metrics used across various LLM-driven medical imaging tasks.
Table 4 summarizes which metrics are applied to each task and how they are used.
Medical Report Generation:
BLEU: Measures n-gram overlap between generated and reference reports.
ROUGE: Evaluates recall-based n-gram similarity.
CheXpert Labels: Converts free-text reports into structured clinical labels for validation.
Disease Classification:
Accuracy (ACC): Proportion of correctly predicted diagnostic labels.
AUC-ROC: Measures the model’s ability to distinguish between classes (e.g., disease vs. healthy).
Visual Question Answering (VQA):
Accuracy: Evaluates correctness of responses to open- and closed-ended questions.
BLEU (for descriptive responses): Measures linguistic quality of generated answers.
Visual Grounding/Segmentation:
IoU (Intersection over Union): Measures overlap between predicted and actual regions.
Dice Coefficient: Measures similarity between predicted and reference segmentations.
These metrics are consistently used across benchmark datasets such as MIMIC-CXR, VQA-RAD, SLAKE, and CheXpert. Their unified synthesis helps standardize future model evaluation across medical imaging tasks.
5. Challenges
The adoption and optimization of large language models (LLMs) for medical image analysis necessitate addressing multiple existing challenges. These challenges arise from issues such as data scarcity, the evolving nature of medical knowledge, model output hallucinations, and concerns regarding privacy and security. This section examines these challenges in detail and proposes potential solutions for addressing them.
Table 5 presents the key challenges faced when applying LLMs in medical image analysis, describing the impact on model performance and potential solutions for each issue. It highlights the major obstacles that need to be overcome for LLMs to be fully utilized in clinical settings [
55,
103,
104,
105].
5.1. Lack of Large High-Quality Datasets for Medical Images
The limited availability of extensive and accurate annotated medical image datasets stands as a major barrier in using LLMs for medical image analysis [
106]. Training LLMs requires substantial amounts of data, particularly data that are labeled with expert knowledge. However, obtaining medical image datasets with comprehensive annotations is often expensive, time-consuming, and limited by privacy concerns. Many existing medical image datasets are either small in scale or lack the diversity needed to enable robust model development that can generalize across different medical conditions and imaging modalities [
107].
To address this challenge, one potential solution is to create synthetic datasets by leveraging techniques like data augmentation or generative models. These methods can be used to generate additional training data, potentially alleviating the data scarcity problem. Another approach is to implement federated learning, which allows models to be trained across multiple institutions without sharing sensitive patient data, thus ensuring both privacy and data diversity [
108].
5.2. Knowledge Editing in LLMs for Medical Images
The field of medical knowledge evolves all the time, and each day new diseases, disease treatments, and methods of imaging are discovered. Yet, LLMs are usually trained on fixed datasets and cannot experience automatic knowledge update after training [
109]. This shortcoming implies that LLMs might not be able to use the most recent medical breakthroughs, thus producing out-of-date or even erroneous findings.
Knowledge editing could be one of the solutions to counter this problem. With knowledge editing, one can create the capability to change the knowledge database of an LLM without as many retraining procedures. Such a strategy will enable LLM to be flexible and embrace the updated medical information. One of the most essential methods of knowledge editing is a continuous learning mechanism where updating of the knowledge base is carried out by the model with little or no retraining. Moreover, integrating external databases, including those that constantly update the repositories of medical literature, enables the LLMs to keep up with the latest advances in medical science. The mechanisms of keeping LLMs up to date with relevant information, as well as keeping them in line with recent developments, also allow the LLMs to adjust to new knowledge in medicine more effectively and offer appropriate advice in the clinic [
110].
5.3. Hallucination in LLMs for Medical Images
The other important concern in using LLMs in medical image analysis is the problem of hallucinations, in which the models produce inaccurate or misleading results. Such an issue is especially alarming in the medical sphere, where a misdiagnosis or an improper suggestion might be disastrous as far as patient care is concerned. The hallucination arises frequently when the model is uncertain about its predictions or where the input data are unclear, and the interpretation becomes faulty [
111].
Hallucinations can be mitigated by a number of strategies. One of them is human feedback (RLHF) tasks in which the model is retrained using expert know-how to fix incorrect responses. This process enhances the precision and consistency of the model by enhancing the comprehension of the model, grounded in practical knowledge. Additionally, integrating external knowledge bases or reasoning modules can help the model generate more reliable and accurate responses by providing contextual support and reinforcing medical knowledge. Regular model evaluation and validation using medical experts play a critical role in detecting and preventing hallucinations, as expert oversight ensures that model outputs align with clinical expectations and are clinically accurate [
112,
113].
5.4. Privacy and Security of Medical Information in LLMs
The use of medical images often involves sensitive patient data, and privacy is a significant concern when training LLMs in healthcare settings. Traditional methods of training models require centralized access to large datasets, which raises the risk of exposing sensitive information. This issue is particularly important when handling medical data, as improper handling or breaches could lead to violations of patient confidentiality [
114].
To ensure privacy, methods such as federated learning [
115] can be employed. Federated learning allows models to be trained locally at different institutions while keeping the data secure and private. The model aggregates insights from local training without transferring raw data, minimizing the risk of data breaches. Additionally, techniques such as differential privacy can be incorporated to ensure that sensitive information is not inadvertently exposed during the training process.
5.5. Model Interpretability and Trustworthiness
Trustworthiness and interpretability of a model are also vital in the medical sphere. Healthcare professionals must be able to interpret the decision tree of LLMs in executing crucial roles in diagnostic and therapeutic planning [
116,
117]. Some LLMs, particularly large models, however, are used as a black box, which can make it challenging to interpret the decision-making process.
To make LLMs usable in a clinical setting, it is crucial to improve their interpretability. The decision-making of the model can also be made more transparent using methods such as explainable AI (XAI) or saliency mapping which display the image areas that had the greatest effect on the model. Moreover, the models may be modified to offer confidence scores and lines of argument so as to assist healthcare specialists to comprehend why the model makes the predictions.
6. Future Directions
As the development of large language models (LLMs) in medical image analysis continues to evolve, a range of interesting opportunities and possible innovations are in the cards. This section explains the major areas of study within which one can focus in the future in order to develop the abilities of the currently available ILM further, as well as solving the limitations present in the current usage. Other streams of research that should be pursued in the future include the combination of vision-language models (VLMs) in medical image interpretation. On the one hand, multimodal data integration between visual, textual, and even audio or temporal data is already an easy route to take, since the VLMs are continuously evolving towards the multimodal scope. Such integration would be able to add a lot of value to clinical decision-making, providing richer, contextually aware information. Also, a more adaptive and dynamic fine-tuning approach still would enable VLMs to adapt to new information and learn continually about new medical knowledge with real-time customized assistance to healthcare practitioners. In addition, the cross-lingual and cross-cultural flexibility will be needed for VLMs so that they can be applicable all over the world without any biases in terms of region and language. Such developments would facilitate the overall contribution of VLMs and LLMs to the change in healthcare.
6.1. Unified Evaluation Metrics for Medical Image Tasks
A major issue hindering the advancement of LLMs in medical image analysis is that studies often employ conflicting evaluation metrics. Multiple assessment metrics currently exist for evaluating model performance in automated report creation, disease classification [
44], and medical visual question answering. These metrics, including BLEU, ROUGE, accuracy, and F1-score, vary significantly depending on the task and dataset, making comparisons between models challenging and hindering the standardization of progress in the field [
118,
119,
120]. For instance, a model may achieve high accuracy on a disease classification task; however, this could be misleading if the dataset is imbalanced, with a dominant class, such as “healthy” images. In this case, the model might perform poorly on the minority class (e.g., rare diseases) but still achieve a high overall accuracy. Conversely, the F1 score, which takes both precision and recall into account, may reflect a more balanced performance across all classes, showing how the model performs on both the majority and minority classes.
A unified set of evaluation metrics is essential for facilitating fair comparisons and advancing the creation of enhanced models. Subsequent investigations should focus on establishing standardized metrics for various medical image tasks that consider both diagnostic accuracy and text generation quality. This will help streamline model development and enable more consistent and reliable performance evaluation across the field [
121,
122].
6.2. Multilingual Capabilities in LLMs for Medical Images
Currently, most large language models (LLMs) for medical image analysis are primarily trained on English-language datasets. However, healthcare is a global issue, and medical image data from non-English-speaking countries and regions are often underrepresented. The lack of multilingual support in LLMs limits their applicability and usefulness in diverse clinical settings [
123]. As medical image analysis continues to expand globally, addressing language barriers is crucial for ensuring that LLMs can be effectively applied across different linguistic and cultural contexts.
To overcome this limitation, it would be worthwhile to consider future studies in establishing multilingual LLMs that can deal with medical image analyses work across several languages. Incorporation of datasets that correspond to multiple languages potentially allows these models to ensure more inclusive healthcare solutions, as well as options that can improve the availability of diagnostic tools in areas with limited access to English content. Multilingual LLMs will help fill the high-resource-low-resource divide in medical diagnostics, allowing medical workers across the globe to access AI-based tools in their respective settings, irrespective of their linguistic or geographical belonging [
124].
Also, cross-cultural adaptability concerns the necessity of vision-language models (VLMs) to operate across various linguistic and cultural environments, as well as healthcare system environments. Although the majority of the medical image analysis models are trained on the data of the largely English-speaking world, the healthcare practice, medical terminology, and patient demographics vary significantly around the world. That is why it is necessary to design VLMs that are culture-sensitive and capable of interpreting data within the scope of various medical procedures. VLMs can give fairer and more accurate healthcare support by considering multilingual datasets and accommodating cultural differences in symptoms, diagnosis signs, and treatment strategies. This intercultural resilience can be especially effective in areas where exposure to English-speaking sources are scarce, and health technologies cannot be used to the full extent. By making sure that VLMs can be used regardless of the language and cultural background, one will be able to minimize disparities in the delivery of medical services; thus, the innovative techs will be broader and cross-nationwide.
6.3. Integration of LLMs with Medical Decision Support Systems
The best potential of further progress of the research on LLMs can be seen when applied to medical decision support systems (MDSSs). MDSSs can assist medical providers in making use of patient information in terms of clinical recommendations with the assistance of its decision-making capabilities. By means of incorporating LLMs into MDSSs, these systems would be able to gain the ability not only to generate medical reports, but also to provide suggestions for diagnoses and individual treatment plans depending on medical images.
The incorporation of LLMs in MDSSs would render a more efficient workflow in clinics, coupled with offering superior, well-informed decision making to clinicians. Subsequently, work can be performed on creating frameworks where LLMs can be used in a seamless manner, incorporated with existing MDSSs, that would have the capability of providing real-time feedback and decision-making support directly based on medical imaging data [
125,
126].
6.4. Chain-of-Thought (CoT) Reasoning for Medical Image Analysis
LLMs exhibit limited reasoning capacities for complex tasks, especially when analyzing medical images. Chain-of-Thought (CoT) reasoning is a method that can significantly enhance the interpretability and decision-making capabilities of LLMs. CoT reasoning involves breaking down a complex task into a sequence of logical steps, which helps the model produce more reliable and understandable answers. In medical image analysis, CoT reasoning could boost LLMs’ capacity to generate diagnostic explanations, allowing these systems to outline the rationale behind a diagnosis or treatment suggestion. Enhanced trust and reliability in clinical practice become possible through the implementation of CoT reasoning in LLM-based systems [
127]. The integration of CoT reasoning into medical image analysis models would enable healthcare professionals to better understand how the model arrives at specific conclusions. By providing a clear and logical breakdown of the decision-making process, CoT reasoning fosters greater transparency, leading to more informed clinical decisions. Future research should focus on methods for integrating CoT reasoning systems to improve both the accuracy and interpretability of LLMs in medical imaging procedures [
126,
128,
129].
Dynamic Fine-Tuning for Continuous Learning
One of the strategies is dynamic fine-tuning, where VLMs are constantly updated and fine-tuned using new information. Since medical information and knowledge is fast changing, especially with the entry of new diseases, remedies, and diagnostic procedures, it is imperative that VLMs be kept up to date. Dynamic fine-tuning enables process models to adjust to the latest trends in medicine and patient-specific data so that the system is valuable and feasible with time. This would not be the usual type of training where the models just learn, but in this case, the models would practically become part of the decision-making process through the inclusion of new findings and clinical experiences.
As an illustration, when new imaging modalities/diagnostic markers are discovered, the VLMs can update to be capable of identifying and embracing such findings, making sure that healthcare practitioners are informed about the latest recommendations. Dynamic fine-tuning keeps the medical image analysis models relevant because they constantly learn from the newly available data. This will aid in making the performance of the models sustainable despite the changes occurring in the medical arena, and hence these models will be effective in the clinics when the new learnings are implemented frequently.
6.5. Multimodal Learning for Comprehensive Medical Image Analysis
In medical image analysis, the analysis frequently makes use of other kinds of data as well, not just the images, which might include clinical notes, patient history, laboratory results, and genetic information, as well as others. Most existing or available large language models (LLMs) in the medical domain to date have been trained on single-modal data, where either images or just text have been used. This shortcoming limits the extent to which they might reflect a complex, multimodal nature of medical information, which could give a more comprehensive picture of the health of a patient [
128].
Improving LLMs by training them to gather and synthesize data across modalities should also be the object of future research. As an example, an additional X-ray image can be much more informative when it is accompanied by clinical notes, lab results, and patient demographics. With this kind of training, LLMs can create insights into patient diagnosis and care options that may be richer and more contextual by drawing on all of these different data points. Such practice can be implemented to enable more specific, individualized healthcare suggestions because models will be able to refer to a larger number of data sources. Multimodal learning will be also able to better simulate clinical human reasoning that can be based on integrating the information of different origins, visual, textual, and contextual when vital decisions need to be made [
130,
131]. By mimicking this process, LLMs will be able to support healthcare professionals in making more informed, reliable decisions, ultimately improving the quality of care and patient outcomes.
6.6. Federated Learning for Privacy-Preserving Medical Image Analysis
Medical image analysis using federated learning is a potentially promising area that could be used to solve privacy issues. Federated learning allows training the models in various institutions without the exchange of sensitive patient data. This will guarantee patient privacy as well as the possibility of different healthcare institutions using the model to enhance their performance [
132].
Federated learning may be instrumental in breaking the privacy challenges linked to centralized data aggregation as the use of LLMs in medical image analysis expands. Future research should focus on the best ways to integrate federated learning with LLMs, especially in healthcare, where data security and confidentiality are essential. This would cause a situation whereby the use of LLMs in the clinical setting becomes mainstream and beneficial to all, including the patients [
133].
6.7. Model Explainability and Trustworthiness
In healthcare, models must have transparency and should be trustworthy to be adopted by clinicians. Large language models (LLMs) in general and deep learning-based ones in particular are usually characterized by being a black box, so it is difficult to explain how they come to specific conclusions. Failure to explain their thought processes makes them less useful in healthcare since reliable AI advice is instrumental in clinical decision-making, where faith in the machine is the most important factor. One way to overcome this difficulty is by enhancing the interpretability of LLMs, where clinicians are able to comprehend and confirm the results of the model.
As potential future work, medical image analysis with LLM should be made explainable by means of saliency mapping, attention mechanisms, and explainable AI (XAI). Saliency mapping shows the parts of an image that are most influential when making the decision in the model, hence the visualization of what features in the image were deemed as essential. By enabling models to concentrate on certain parts of input information, attention mechanisms provide a better understanding of the way in which the model processes the information and prioritizes it as well. XAI methods are used to give a better idea of the processes within the model, so that the decision-making process of a model can be made simpler. Through these methods, clinicians may gain a clearer look at the rationale of the model and what influences its decisions, which will create more trust regarding its outputs. Altogether, an increase in interpretability and transparency of LLMs will not only stimulate their uptake by clinicians but also turn into more trustworthy tools in the practice of healthcare workers. This emphasis on transparency is the key to the production of LLMs that can eventually become an ordinary part of the medical decision-making process, helping to deliver informed, accurate, and positive clinical judgment [
134,
135].
7. Conclusions
In this survey, we mapped the transformational power of large language models (LLMs) as applied to medical image analysis and the associated potential of redefining the clinical workflow and automated diagnostic procedures. The capacity of LLMs to handle both image and text data allows tremendous breakthroughs in image classification, the generation of medical reports, and visual question answering tasks. Multimodal possibilities can be easily combined with the imaging data and textual description, giving better decision support that helps healthcare specialists in the diagnosis and treatment of patients. This incorporation gives a more comprehensive perspective of patient care; therefore, the LLMs are able to improve the quality, efficiency, and personalization of healthcare delivery. The versatility and applicability of LLMs to medical applications are a significant step in increasing the utilization of artificial intelligence in healthcare.
Nevertheless, although the given possibilities seem so exciting, a few issues remain in the utilization of LLMs towards the medical image examination practice. Among the main barriers are the unavailability of good-quality as well as annotated datasets, which are essential in training such models. Most of the available existing datasets that are too small or not diverse enough restrain the possibility of LLMs performing well across different medical conditions and imaging modalities. Also, it is necessary to add new information on medicine to the models continually, otherwise there is a risk of outdated information, and this is a worse problem made by the immutable nature of the current LLMs. Also, problems such as hallucinations, where the model produces reasonable yet incorrect answers, and the interpretability of the model cause concerns about the stability and trustworthiness of LLMs in real clinical settings. Moreover, when working with LLMs in real-world healthcare environments, one of the most critical concerns is the privacy and safety of confidential medical information and a high level of protection and privacy-preserving measures.
Looking ahead, there is considerable potential for overcoming these challenges through ongoing advancements in LLM architectures and training methodologies. Future research must focus on developing more efficient and effective fine-tuning strategies that allow LLMs to adapt better to medical tasks and perform across a range of specialties and domains. Improving the generalizability of LLMs is critical for ensuring their applicability in diverse clinical scenarios. Additionally, enhancing model transparency and interpretability is key to gaining the trust of healthcare providers who need to understand and validate the decisions made by AI systems. A crucial direction for future work is the integration of LLMs with medical decision support systems, which would allow for the real-time application of model outputs to assist clinicians in making informed decisions. Exploring multimodal learning approaches that incorporate other data types, such as electronic health records, genomic data, and clinical notes, will further broaden the scope and utility of LLMs in healthcare.
In conclusion, this survey lays the groundwork for future studies aimed at realizing the full potential of LLMs in medical image analysis. While there are still significant challenges to address, the continued advancements in LLM architectures, the development of more comprehensive datasets, and the integration of LLMs into clinical decision-making systems provide a clear path forward. By addressing these hurdles and leveraging the evolving capabilities of LLMs, we can contribute to more effective, accurate, and personalized patient care. This survey offers the first X-stage tuning framework for LLMs in medical image analysis, helping researchers navigate model adaptation under varying resource constraints. Unlike previous surveys, this work integrates a comprehensive evaluation metric synthesis, comparative tuning strategies, and a vision-language perspective aligned with modern multimodal LLM advances. By addressing current gaps, the survey aims to guide AI developers, support medical system designers, and educate clinicians on leveraging LLMs safely and effectively in real-world workflows. Ultimately, the successful application of LLMs in healthcare promises to revolutionize medical diagnostics, improving outcomes for patients and enhancing the efficiency of healthcare systems worldwide.
Author Contributions
B.U.: Conceptualization, Visualization, Methodology, Writing—original draft. M.F.: Conceptualization, Visualization, Methodology, Data Curation, Writing—original draft. S.A.: Data Curation, Writing—review and editing. L.M.D.: Investigation, Resources, Supervision, Writing—review and editing. K.W.K.: Formal analysis, Supervision Resources, Writing—review and editing, Funding acqisition. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is contained within the article.
Acknowledgments
This work was supported by the Institute of Information and Communications Technology Planning and Evaluation (IITP) grant (RS-2025-02219599) and Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI) grant (RS-2018-KH049509).
Conflicts of Interest
The authors claim that they have no known conflicting financial interests or personal ties that may have seemed to affect the work presented in this study.
References
- Zhou, S.K.; Greenspan, H.; Davatzikos, C.; Duncan, J.S.; Van Ginneken, B.; Madabhushi, A.; Prince, J.L.; Rueckert, D.; Summers, R.M. A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises. Proc. IEEE 2021, 109, 820–838. [Google Scholar] [CrossRef]
- Chan, H.P.; Samala, R.K.; Hadjiiski, L.M.; Zhou, C. Deep learning in medical image analysis. In Deep Learning in Medical Image Analysis: Challenges and Applications; Springer: Cham, Switzerland, 2020; pp. 3–21. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Li, Y.; Liu, Y.; Wang, Z.; Liang, X.; Wang, L.; Liu, L.; Cui, L.; Tu, Z.; Wang, L.; Zhou, L. A Systematic Evaluation of GPT-4V’s Multimodal Capability for Medical Image Analysis. arXiv 2023, arXiv:2310.20381. [Google Scholar]
- Qin, L.; Chen, Q.; Feng, X.; Wu, Y.; Zhang, Y.; Li, Y.; Li, M.; Che, W.; Yu, P.S. Large language models meet nlp: A survey. arXiv 2024, arXiv:2405.12819. [Google Scholar] [CrossRef]
- Qin, L.; Chen, Q.; Zhou, Y.; Chen, Z.; Li, Y.; Liao, L.; Li, M.; Che, W.; Yu, P.S. Multilingual large language model: A survey of resources, taxonomy and frontiers. arXiv 2024, arXiv:2404.04925. [Google Scholar] [CrossRef]
- Wang, L.; Ma, C.; Feng, X.; Zhang, Z.; Yang, H.; Zhang, J.; Chen, Z.; Tang, J.; Chen, X.; Lin, Y.; et al. A survey on large language model based autonomous agents. Front. Comput. Sci. 2024, 18, 186345. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, F.; Gu, B.; Zou, X.; Huang, J.; Wu, J.; Li, Y.; Chen, S.S.; Zhou, P.; Liu, J.; et al. A survey of large language models in medicine: Progress, application, and challenge. arXiv 2023, arXiv:2311.05112. [Google Scholar]
- Demirhan, H.; Zadrozny, W. Survey of multimodal medical question answering. BioMedInformatics 2024, 4, 50–74. [Google Scholar] [CrossRef]
- Nazi, Z.A.; Peng, W. Large language models in healthcare and medical domain: A review. Informatics 2024, 11, 57. [Google Scholar] [CrossRef]
- Chow, J.C.; Wong, V.; Li, K. Generative pre-trained transformer-empowered healthcare conversations: Current trends, challenges, and future directions in large language model-enabled medical chatbots. BioMedInformatics 2024, 4, 837–852. [Google Scholar] [CrossRef]
- Wang, Y.; Si, S.; Li, D.; Lukasik, M.; Yu, F.; Hsieh, C.J.; Dhillon, I.S.; Kumar, S. Two-stage LLM fine-tuning with less specialization and more generalization. arXiv 2022, arXiv:2211.00635. [Google Scholar]
- Zhang, B.; Liu, Z.; Cherry, C.; Firat, O. When scaling meets llm finetuning: The effect of data, model and finetuning method. arXiv 2024, arXiv:2402.17193. [Google Scholar] [CrossRef]
- Guan, C.; Huang, C.; Li, H.; Li, Y.; Cheng, N.; Liu, Z.; Chen, Y.; Xu, J.; Liu, J. Multi-Stage LLM Fine-Tuning with a Continual Learning Setting. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2025, Albuquerque, Mexico, 29 April–4 May 2025; pp. 5484–5498. [Google Scholar]
- Ma, B.; Meng, F.; Yan, G.; Yan, H.; Chai, B.; Song, F. Diagnostic classification of cancers using extreme gradient boosting algorithm and multi-omics data. Comput. Biol. Med. 2020, 121, 103761. [Google Scholar] [CrossRef]
- Ma, W.; Wu, D.; Sun, Y.; Wang, T.; Liu, S.; Zhang, J.; Xue, Y.; Liu, Y. Combining fine-tuning and llm-based agents for intuitive smart contract auditing with justifications. arXiv 2024, arXiv:2403.16073. [Google Scholar]
- Irvin, J.; Rajpurkar, P.; Ko, M.; Yu, Y.; Ciurea-Ilcus, S.; Chute, C.; Marklund, H.; Haghgoo, B.; Ball, R.; Shpanskaya, K.; et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 590–597. [Google Scholar]
- Zhang, Y.; Wang, X.; Xu, Z.; Yu, Q.; Yuille, A.; Xu, D. When radiology report generation meets knowledge graph. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12910–12917. [Google Scholar]
- Chen, L.; Han, X.; Lin, S.; Mai, H.; Ran, H. TriMedLM: Advancing Three-Dimensional Medical Image Analysis with Multi-Modal LLM. In Proceedings of the 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Lisboa, Portugal, 3–6 December 2024; IEEE: New York, NY, USA, 2024; pp. 4505–4512. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Luo, Y.; Li, W.; Chen, C.; Li, X.; Liu, T.; Niu, T.; Yuan, Y. LLM-guided Decoupled Probabilistic Prompt for Continual Learning in Medical Image Diagnosis. IEEE Trans. Med. Imaging 2025. [Google Scholar] [CrossRef]
- Boecking, B.; Usuyama, N.; Bannur, S.; Castro, D.C.; Schwaighofer, A.; Hyland, S.; Wetscherek, M.; Naumann, T.; Nori, A.; Alvarez-Valle, J.; et al. Making the most of text semantics to improve biomedical vision–language processing. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–21. [Google Scholar]
- Manjunath, P.; Lerner, B.; Dunn, T. Towards interactive and interpretable image retrieval-based diagnosis: Enhancing brain tumor classification with llm explanations and latent structure preservation. In Proceedings of the International Conference on Artificial Intelligence in Medicine, Salt Lake City, UT, USA, 9–12 July 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 335–349. [Google Scholar]
- Lee, R.W.; Lee, K.H.; Yun, J.S.; Kim, M.S.; Choi, H.S. Comparative Analysis of M4CXR, an LLM-Based Chest X-Ray Report Generation Model, and ChatGPT in Radiological Interpretation. J. Clin. Med. 2024, 13, 7057. [Google Scholar] [CrossRef]
- Hussain, A.; Ul Amin, S.; Fayaz, M.; Seo, S. An Efficient and Robust Hand Gesture Recognition System of Sign Language Employing Finetuned Inception-V3 and Efficientnet-B0 Network. Comput. Syst. Sci. Eng. 2023, 46, 3509–3525. [Google Scholar] [CrossRef]
- Kim, K.W.; Huh, J.; Urooj, B.; Lee, J.; Lee, J.; Lee, I.S.; Park, H.; Na, S.; Ko, Y. Artificial intelligence in gastric cancer imaging with emphasis on diagnostic imaging and body morphometry. J. Gastric Cancer 2023, 23, 388. [Google Scholar] [CrossRef] [PubMed]
- Shamshad, F.; Khan, S.; Zamir, S.W.; Khan, M.H.; Hayat, M.; Khan, F.S.; Fu, H. Transformers in medical imaging: A survey. Med. Image Anal. 2023, 88, 102802. [Google Scholar] [CrossRef] [PubMed]
- Çallı, E.; Sogancioglu, E.; van Ginneken, B.; van Leeuwen, K.G.; Murphy, K. Deep learning for chest X-ray analysis: A survey. Med. Image Anal. 2021, 72, 102125. [Google Scholar] [CrossRef]
- Afzal, S.; Khan, H.A.; Ali, S.; Lee, J.W. Virtual Reality Environment: Detecting and Inducing Emotions. In Proceedings of the 2025 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–14 January 2025; IEEE: New York, NY, USA, 2025; pp. 1–4. [Google Scholar]
- Wang, J.; Wang, S.; Zhang, Y. Deep learning on medical image analysis. CAAI Trans. Intell. Technol. 2025, 10, 1–35. [Google Scholar] [CrossRef]
- Chlap, P.; Min, H.; Vandenberg, N.; Dowling, J.; Holloway, L.; Haworth, A. A review of medical image data augmentation techniques for deep learning applications. J. Med. Imaging Radiat. Oncol. 2021, 65, 545–563. [Google Scholar] [CrossRef] [PubMed]
- Morid, M.A.; Borjali, A.; Del Fiol, G. A scoping review of transfer learning research on medical image analysis using ImageNet. Comput. Biol. Med. 2021, 128, 104115. [Google Scholar] [CrossRef] [PubMed]
- Xie, X.; Niu, J.; Liu, X.; Chen, Z.; Tang, S.; Yu, S. A survey on incorporating domain knowledge into deep learning for medical image analysis. Med. Image Anal. 2021, 69, 101985. [Google Scholar] [CrossRef] [PubMed]
- Guan, H.; Liu, M. Domain adaptation for medical image analysis: A survey. IEEE Trans. Biomed. Eng. 2021, 69, 1173–1185. [Google Scholar] [CrossRef]
- Cheplygina, V.; De Bruijne, M.; Pluim, J.P. Not-so-supervised: A survey of semi-supervised, multi-instance, and transfer learning in medical image analysis. Med. Image Anal. 2019, 54, 280–296. [Google Scholar] [CrossRef]
- Shurrab, S.; Duwairi, R. Self-supervised learning methods and applications in medical imaging analysis: A survey. PeerJ Comput. Sci. 2022, 8, e1045. [Google Scholar] [CrossRef]
- Singh, S.P.; Wang, L.; Gupta, S.; Goli, H.; Padmanabhan, P.; Gulyás, B. 3D deep learning on medical images: A review. Sensors 2020, 20, 5097. [Google Scholar] [CrossRef]
- Van der Velden, B.H.; Kuijf, H.J.; Gilhuijs, K.G.; Viergever, M.A. Explainable artificial intelligence (XAI) in deep learning-based medical image analysis. Med. Image Anal. 2022, 79, 102470. [Google Scholar] [CrossRef]
- Singh, A.; Sengupta, S.; Lakshminarayanan, V. Explainable deep learning models in medical image analysis. J. Imaging 2020, 6, 52. [Google Scholar] [CrossRef]
- Gupta, K.; Rani, K.; Ajmani, P.; Sharma, V.; Alkhayyat, A. Integrating LLM with CNN-RNN for Optimizing Crop Production. In Proceedings of the 2024 International Conference on Intelligent & Innovative Practices in Engineering & Management (IIPEM), Singapore, 25 November 2024; IEEE: New York, NY, USA, 2024; pp. 1–6. [Google Scholar]
- VP, S.E.; Mouli S, C.; Dheepthi, R. Llm-enhanced deepfake detection: Dense cnn and multi-modal fusion framework for precise multimedia authentication. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; IEEE: New York, NY, USA, 2024; pp. 1–6. [Google Scholar]
- Dang, L.M.; Danish, S.; Khan, A.; Alam, N.; Fayaz, M.; Nguyen, D.K.; Song, H.K.; Moon, H. An efficient zero-labeling segmentation approach for pest monitoring on smartphone-based images. Eur. J. Agron. 2024, 160, 127331. [Google Scholar] [CrossRef]
- Fayaz, M.; Nam, J.; Dang, L.M.; Song, H.K.; Moon, H. Land-cover classification using deep learning with high-resolution remote-sensing imagery. Appl. Sci. 2024, 14, 1844. [Google Scholar] [CrossRef]
- van Eijk, L.F.; Beer, S.; van Es, R.M.; Kostić, D.; Nijmeijer, H. Frequency-domain properties of the hybrid integrator-gain system and its application as a nonlinear lag filter. IEEE Trans. Control Syst. Technol. 2022, 31, 905–912. [Google Scholar] [CrossRef]
- Davila, A.; Colan, J.; Hasegawa, Y. Comparison of fine-tuning strategies for transfer learning in medical image classification. Image Vis. Comput. 2024, 146, 105012. [Google Scholar] [CrossRef]
- Chiu, Y.J.; Chuang, C.C.; Hwa, K.Y. Enhancing Medical Diagnosis with Fine-Tuned Large Language Models: Addressing Cardiogenic Pulmonary Edema (CPE). In Proceedings of the 2024 11th International Conference on Biomedical and Bioinformatics Engineering, Osaka, Japan, 8–11 November 2024; pp. 66–71. [Google Scholar]
- Wei, Y.; Wang, X.; Ong, H.; Zhou, Y.; Flanders, A.; Shih, G.; Peng, Y. Enhancing disease detection in radiology reports through fine-tuning lightweight LLM on weak labels. arXiv 2024, arXiv:2409.16563. [Google Scholar] [CrossRef]
- Wortsman, M.; Ilharco, G.; Kim, J.W.; Li, M.; Kornblith, S.; Roelofs, R.; Lopes, R.G.; Hajishirzi, H.; Farhadi, A.; Namkoong, H.; et al. Robust fine-tuning of zero-shot models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7959–7971. [Google Scholar]
- Ding, N.; Qin, Y.; Yang, G.; Wei, F.; Yang, Z.; Su, Y.; Hu, S.; Chen, Y.; Chan, C.M.; Chen, W.; et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nat. Mach. Intell. 2023, 5, 220–235. [Google Scholar] [CrossRef]
- Pezzuti, F.; MacAvaney, S.; Tonellotto, N. Exploring the Effectiveness of Multi-stage Fine-tuning for Cross-encoder Re-rankers. In Proceedings of the European Conference on Information Retrieval, Lucca, Italy, 6–10 April 2025; Springer: Berlin/Heidelberg, Germany, 2025; pp. 455–462. [Google Scholar]
- Ding, W.; Zhao, X.; Zhu, B.; Du, Y.; Zhu, G.; Yu, T.; Li, L.; Wang, J. An ensemble of one-stage and two-stage detectors approach for road damage detection. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; IEEE: New York, NY, USA, 2022; pp. 6395–6400. [Google Scholar]
- Bai, A.; Yeh, C.K.; Hsieh, C.J.; Taly, A. An Efficient Rehearsal Scheme for Catastrophic Forgetting Mitigation during Multi-stage Fine-tuning. In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2025, Albuquerque, Mexico, 29 April–4 May 2025; pp. 2557–2569. [Google Scholar]
- Guefrachi, S.; Echtioui, A.; Hamam, H. Diabetic retinopathy detection using deep learning multistage training method. Arab. J. Sci. Eng. 2025, 50, 1079–1096. [Google Scholar] [CrossRef]
- Wang, P.; Lu, W.; Lu, C.; Zhou, R.; Li, M.; Qin, L. Large Language Model for Medical Images: A Survey of Taxonomy, Systematic Review, and Future Trends. Big Data Min. Anal. 2025, 8, 496–517. [Google Scholar] [CrossRef]
- Li, P.; Liu, G.; He, J.; Zhao, Z.; Zhong, S. Masked vision and language pre-training with unimodal and multimodal contrastive losses for medical visual question answering. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 374–383. [Google Scholar]
- Liu, Y.; Wang, Z.; Xu, D.; Zhou, L. Q2atransformer: Improving medical vqa via an answer querying decoder. In Proceedings of the International Conference on Information Processing in Medical Imaging, San Carlos de Bariloche, Argentina, 18–23 June 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 445–456. [Google Scholar]
- Xu, S.; Yang, L.; Kelly, C.; Sieniek, M.; Kohlberger, T.; Ma, M.; Weng, W.H.; Kiraly, A.; Kazemzadeh, S.; Melamed, Z.; et al. Elixr: Towards a general purpose x-ray artificial intelligence system through alignment of large language models and radiology vision encoders. arXiv 2023, arXiv:2308.01317. [Google Scholar] [CrossRef]
- Van Sonsbeek, T.; Derakhshani, M.M.; Najdenkoska, I.; Snoek, C.G.; Worring, M. Open-ended medical visual question answering through prefix tuning of language models. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 726–736. [Google Scholar]
- Zhang, X.; Wu, C.; Zhao, Z.; Lin, W.; Zhang, Y.; Wang, Y.; Xie, W. Pmc-vqa: Visual instruction tuning for medical visual question answering. arXiv 2023, arXiv:2305.10415. [Google Scholar] [CrossRef]
- Li, C.; Wong, C.; Zhang, S.; Usuyama, N.; Liu, H.; Yang, J.; Naumann, T.; Poon, H.; Gao, J. Llava-med: Training a large language-and-vision assistant for biomedicine in one day. Adv. Neural Inf. Process. Syst. 2023, 36, 28541–28564. [Google Scholar]
- Liu, G.; He, J.; Li, P.; He, G.; Chen, Z.; Zhong, S. PeFoMed: Parameter Efficient Fine-tuning of Multimodal Large Language Models for Medical Imaging. arXiv 2024, arXiv:2401.02797. [Google Scholar]
- Wang, S.; Zhao, Z.; Ouyang, X.; Wang, Q.; Shen, D. Chatcad: Interactive computer-aided diagnosis on medical image using large language models. arXiv 2023, arXiv:2302.07257. [Google Scholar]
- Zhao, Z.; Wang, S.; Gu, J.; Zhu, Y.; Mei, L.; Zhuang, Z.; Cui, Z.; Wang, Q.; Shen, D. Chatcad+: Towards a universal and reliable interactive cad using llms. IEEE Trans. Med. Imaging 2024, 43, 3755–3766. [Google Scholar] [CrossRef]
- Han, T.; Adams, L.C.; Nebelung, S.; Kather, J.N.; Bressem, K.K.; Truhn, D. Multimodal large language models are generalist medical image interpreters. medRxiv 2023. [Google Scholar] [CrossRef]
- Shu, C.; Chen, B.; Liu, F.; Fu, Z.; Shareghi, E.; Collier, N. Visual Med-Alpaca: A Parameter-Efficient Biomedical LLM with Visual Capabilities. 2023. Available online: https://scholar.google.com/citations?view_op=view_citation&hl=en&user=SxQjvCUAAAAJ&sortby=pubdate&citation_for_view=SxQjvCUAAAAJ:zYLM7Y9cAGgC (accessed on 23 July 2025).
- Moor, M.; Huang, Q.; Wu, S.; Yasunaga, M.; Dalmia, Y.; Leskovec, J.; Zakka, C.; Reis, E.P.; Rajpurkar, P. Med-flamingo: A multimodal medical few-shot learner. In Proceedings of the Machine Learning for Health (ML4H), PMLR, New Orleans, LA, USA, 10 December 2023; pp. 353–367. [Google Scholar]
- Shi, D.; Chen, X.; Zhang, W.; Xu, P.; Zhao, Z.; Zheng, Y.; He, M. FFA-GPT: An Interactive Visual Question Answering System for Fundus Fluorescein Angiography. npj Digit. Med. 2023, 7, 111. [Google Scholar]
- Chen, Q.; Hong, Y. Medblip: Bootstrapping language-image pre-training from 3d medical images and texts. In Proceedings of the Asian Conference on Computer Vision, Hanoi, Vietnam, 8–12 December 2024; pp. 2404–2420. [Google Scholar]
- Wu, C.; Zhang, X.; Zhang, Y.; Wang, Y.; Xie, W. Towards generalist foundation model for radiology by leveraging web-scale 2D&3D medical data. arXiv 2023, arXiv:2308.02463. [Google Scholar]
- Yang, Z.; Li, L.; Lin, K.; Wang, J.; Lin, C.C.; Liu, Z.; Wang, L. The dawn of lmms: Preliminary explorations with gpt-4v (ision). arXiv 2023, arXiv:2309.17421. [Google Scholar]
- Liu, Z.; Jiang, H.; Zhong, T.; Wu, Z.; Ma, C.; Li, Y.; Yu, X.; Zhang, Y.; Pan, Y.; Shu, P.; et al. Holistic evaluation of gpt-4v for biomedical imaging. arXiv 2023, arXiv:2312.05256. [Google Scholar] [CrossRef]
- Pal, A.; Sankarasubbu, M. Gemini goes to med school: Exploring the capabilities of multimodal large language models on medical challenge problems & hallucinations. In Proceedings of the 6th Clinical Natural Language Processing Workshop, Mexico City, Mexico, 21 June 2024; pp. 21–46. [Google Scholar]
- Gao, W.; Deng, Z.; Niu, Z.; Rong, F.; Chen, C.; Gong, Z.; Zhang, W.; Xiao, D.; Li, F.; Cao, Z.; et al. Ophglm: Training an ophthalmology large language-and-vision assistant based on instructions and dialogue. arXiv 2023, arXiv:2306.12174. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar] [CrossRef]
- Hyland, S.L.; Bannur, S.; Bouzid, K.; Castro, D.C.; Ranjit, M.; Schwaighofer, A.; Pérez-García, F.; Salvatelli, V.; Srivastav, S.; Thieme, A.; et al. Maira-1: A specialised large multimodal model for radiology report generation. arXiv 2023, arXiv:2311.13668. [Google Scholar]
- Song, M.; Wang, J.; Yu, Z.; Wang, J.; Yang, L.; Lu, Y.; Li, B.; Wang, X.; Wang, X.; Huang, Q.; et al. PneumoLLM: Harnessing the power of large language model for pneumoconiosis diagnosis. Med. Image Anal. 2024, 97, 103248. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, L.; Wang, L.; Zhou, L. R2gengpt: Radiology report generation with frozen llms. Meta-Radiology 2023, 1, 100033. [Google Scholar] [CrossRef]
- Tu, T.; Azizi, S.; Driess, D.; Schaekermann, M.; Amin, M.; Chang, P.C.; Carroll, A.; Lau, C.; Tanno, R.; Ktena, I.; et al. Towards generalist biomedical AI. NEJM AI 2024, 1, AIoa2300138. [Google Scholar] [CrossRef]
- Yang, B.; Raza, A.; Zou, Y.; Zhang, T. Customizing general-purpose foundation models for medical report generation. arXiv 2023, arXiv:2306.05642. [Google Scholar] [CrossRef]
- Yang, L.; Wang, Z.; Chen, Z.; Liang, X.; Zhou, L. MedXChat: A Unified Multimodal Large Language Model Framework towards CXRs Understanding and Generation. arXiv 2023, arXiv:2312.02233. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Zhou, J.; He, X.; Sun, L.; Xu, J.; Chen, X.; Chu, Y.; Zhou, L.; Liao, X.; Zhang, B.; Gao, X. SkinGPT-4: An interactive dermatology diagnostic system with visual large language model. arXiv 2023, arXiv:2304.10691. [Google Scholar] [CrossRef]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv 2023, arXiv:2304.10592. [Google Scholar]
- Tian, K. Towards Automated Healthcare: Deep Vision and Large Language Models for Radiology Report Generation. Ph.D. Thesis, Harvard College, Cambridge, MA, USA, 2023. [Google Scholar]
- Liu, J.; Wang, Z.; Ye, Q.; Chong, D.; Zhou, P.; Hua, Y. Qilin-med-vl: Towards chinese large vision-language model for general healthcare. arXiv 2023, arXiv:2310.17956. [Google Scholar]
- Lee, S.; Kim, W.J.; Chang, J.; Ye, J.C. LLM-CXR: Instruction-finetuned LLM for CXR image understanding and generation. arXiv 2023, arXiv:2305.11490. [Google Scholar]
- Ma, L.; Han, J.; Wang, Z.; Zhang, D. Cephgpt-4: An interactive multimodal cephalometric measurement and diagnostic system with visual large language model. arXiv 2023, arXiv:2307.07518. [Google Scholar] [CrossRef]
- Liu, F.; Zhu, T.; Wu, X.; Yang, B.; You, C.; Wang, C.; Lu, L.; Liu, Z.; Zheng, Y.; Sun, X.; et al. A medical multimodal large language model for future pandemics. npj Digit. Med. 2023, 6, 226. [Google Scholar] [CrossRef]
- Lu, Y.; Hong, S.; Shah, Y.; Xu, P. Effectively fine-tune to improve large multimodal models for radiology report generation. arXiv 2023, arXiv:2312.01504. [Google Scholar] [CrossRef]
- Thawkar, O.; Shaker, A.; Mullappilly, S.S.; Cholakkal, H.; Anwer, R.M.; Khan, S.; Laaksonen, J.; Khan, F.S. Xraygpt: Chest radiographs summarization using medical vision-language models. arXiv 2023, arXiv:2306.07971. [Google Scholar]
- Sun, Y.; Zhu, C.; Zheng, S.; Zhang, K.; Sun, L.; Shui, Z.; Zhang, Y.; Li, H.; Yang, L. Pathasst: A generative foundation ai assistant towards artificial general intelligence of pathology. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5034–5042. [Google Scholar]
- Dai, J.; Zhu, Q.; Zhan, J.; Wang, B.; Qiu, X. MOSS-MED: Medical multimodal model serving medical image analysis. ACM Trans. Manag. Inf. Syst. 2024, 16, 13. [Google Scholar]
- Ji, J.; Hou, Y.; Chen, X.; Pan, Y.; Xiang, Y. Vision-language model for generating textual descriptions from clinical images: Model development and validation study. JMIR Form. Res. 2024, 8, e32690. [Google Scholar] [CrossRef]
- Zhou, W.; Ye, Z.; Yang, Y.; Wang, S.; Huang, H.; Wang, R.; Yang, D. Transferring Pre-Trained Large Language-Image Model for Medical Image Captioning. In Proceedings of the CLEF (Working Notes), Thessaloniki, Greece, 19–21 September 2023; pp. 1776–1784. [Google Scholar]
- Le-Duc, K.; Zhang, R.; Nguyen, N.S.; Pham, T.H.; Dao, A.; Ngo, B.H.; Nguyen, A.T.; Hy, T.S. LiteGPT: Large Vision-Language Model for Joint Chest X-ray Localization and Classification Task. arXiv 2024, arXiv:2407.12064. [Google Scholar]
- Alkhaldi, A.; Alnajim, R.; Alabdullatef, L.; Alyahya, R.; Chen, J.; Zhu, D.; Alsinan, A.; Elhoseiny, M. Minigpt-med: Large language model as a general interface for radiology diagnosis. arXiv 2024, arXiv:2407.04106. [Google Scholar]
- Liu, Z.; Zhong, A.; Li, Y.; Yang, L.; Ju, C.; Wu, Z.; Ma, C.; Shu, P.; Chen, C.; Kim, S.; et al. Tailoring large language models to radiology: A preliminary approach to llm adaptation for a highly specialized domain. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Vancouver, BC, Canada, 8 October 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 464–473. [Google Scholar]
- Gao, M.; Hu, X.; Yin, X.; Ruan, J.; Pu, X.; Wan, X. Llm-based nlg evaluation: Current status and challenges. Comput. Linguist. 2025, 51, 661–687. [Google Scholar] [CrossRef]
- Hartung, K.; Mallick, S.; Gröttrup, S.; Georges, M. Evaluation Metrics in LLM Code Generation. In Proceedings of the International Conference on Text, Speech, and Dialogue, Brno, Czech Republic, 9–13 September 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 214–226. [Google Scholar]
- Hu, Z.; Song, L.; Zhang, J.; Xiao, Z.; Wang, J.; Chen, Z.; Zhao, J.; Xiong, H. Rethinking llm-based preference evaluation. arXiv 2024, arXiv:2407.01085v1. [Google Scholar] [CrossRef]
- Carrington, A.M.; Manuel, D.G.; Fieguth, P.W.; Ramsay, T.; Osmani, V.; Wernly, B.; Bennett, C.; Hawken, S.; Magwood, O.; Sheikh, Y.; et al. Deep ROC analysis and AUC as balanced average accuracy, for improved classifier selection, audit and explanation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 329–341. [Google Scholar] [CrossRef]
- Ullah, E.; Parwani, A.; Baig, M.M.; Singh, R. Challenges and barriers of using large language models (LLM) such as ChatGPT for diagnostic medicine with a focus on digital pathology–a recent scoping review. Diagn. Pathol. 2024, 19, 43. [Google Scholar] [CrossRef]
- Sinha, R.K.; Roy, A.D.; Kumar, N.; Mondal, H.; Sinha, R. Applicability of ChatGPT in assisting to solve higher order problems in pathology. Cureus 2023, 15, e35237. [Google Scholar] [CrossRef] [PubMed]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef]
- Gunasekar, S.; Zhang, Y.; Aneja, J.; Mendes, C.C.T.; Del Giorno, A.; Gopi, S.; Javaheripi, M.; Kauffmann, P.; de Rosa, G.; Saarikivi, O.; et al. Textbooks are all you need. arXiv 2023, arXiv:2306.11644. [Google Scholar]
- Chen, X.; Wang, X.; Zhang, K.; Fung, K.M.; Thai, T.C.; Moore, K.; Mannel, R.S.; Liu, H.; Zheng, B.; Qiu, Y. Recent advances and clinical applications of deep learning in medical image analysis. Med. Image Anal. 2022, 79, 102444. [Google Scholar] [CrossRef]
- DuMont Schütte, A.; Hetzel, J.; Gatidis, S.; Hepp, T.; Dietz, B.; Bauer, S.; Schwab, P. Overcoming barriers to data sharing with medical image generation: A comprehensive evaluation. npj Digit. Med. 2021, 4, 141. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, N.; Tian, B.; Xi, Z.; Yao, Y.; Xu, Z.; Wang, M.; Mao, S.; Wang, X.; Cheng, S.; et al. Easyedit: An easy-to-use knowledge editing framework for large language models. arXiv 2023, arXiv:2308.07269. [Google Scholar]
- Wang, S.; Zhu, Y.; Liu, H.; Zheng, Z.; Chen, C.; Li, J. Knowledge editing for large language models: A survey. ACM Comput. Surv. 2024, 57, 1–37. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Cui, L.; Cai, D.; Liu, L.; Fu, T.; Huang, X.; Zhao, E.; Zhang, Y.; Chen, Y.; et al. Siren’s song in the AI ocean: A survey on hallucination in large language models. arXiv 2023, arXiv:2309.01219. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y.; Wang, C.; Chen, J.; Zheng, Z. Llm hallucinations in practical code generation: Phenomena, mechanism, and mitigation. arXiv 2024, arXiv:2409.20550. [Google Scholar] [CrossRef]
- Martino, A.; Iannelli, M.; Truong, C. Knowledge injection to counter large language model (LLM) hallucination. In Proceedings of the European Semantic Web Conference, Crete, Greece, 28 May–1 June 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 182–185. [Google Scholar]
- Nasr, M.; Carlini, N.; Hayase, J.; Jagielski, M.; Cooper, A.F.; Ippolito, D.; Choquette-Choo, C.A.; Wallace, E.; Tramèr, F.; Lee, K. Scalable extraction of training data from (production) language models. arXiv 2023, arXiv:2311.17035. [Google Scholar] [CrossRef]
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar] [CrossRef]
- Qin, L.; Chen, Q.; Wei, F.; Huang, S.; Che, W. Cross-lingual prompting: Improving zero-shot chain-of-thought reasoning across languages. arXiv 2023, arXiv:2310.14799. [Google Scholar]
- Yoon, D.; Jang, J.; Kim, S.; Kim, S.; Shafayat, S.; Seo, M. Langbridge: Multilingual reasoning without multilingual supervision. arXiv 2024, arXiv:2401.10695. [Google Scholar] [CrossRef]
- Gamini, S.; Kumar, S.S. Homomorphic filtering for the image enhancement based on fractional-order derivative and genetic algorithm. Comput. Electr. Eng. 2023, 106, 108566. [Google Scholar] [CrossRef]
- Bosbach, W.A.; Senge, J.F.; Nemeth, B.; Omar, S.H.; Mitrakovic, M.; Beisbart, C.; Horváth, A.; Heverhagen, J.; Daneshvar, K. Ability of ChatGPT to generate competent radiology reports for distal radius fracture by use of RSNA template items and integrated AO classifier. Curr. Probl. Diagn. Radiol. 2024, 53, 102–110. [Google Scholar] [CrossRef] [PubMed]
- Eysenbach, G. The role of ChatGPT, generative language models, and artificial intelligence in medical education: A conversation with ChatGPT and a call for papers. JMIR Med. Educ. 2023, 9, e46885. [Google Scholar] [CrossRef]
- Tang, X.; Zou, A.; Zhang, Z.; Li, Z.; Zhao, Y.; Zhang, X.; Cohan, A.; Gerstein, M. Medagents: Large language models as collaborators for zero-shot medical reasoning. arXiv 2023, arXiv:2311.10537. [Google Scholar]
- Muftić, F.; Kadunić, M.; Mušinbegović, A.; Almisreb, A. Southeast Europe Journal of Soft Computing Exploring Medical Breakthroughs: A Systematic Review of ChatGPT Applications in Healthcare. Southeast Eur. J. Soft Comput. 2023, 12, 13–41. [Google Scholar]
- García-Ferrero, I.; Agerri, R.; Salazar, A.A.; Cabrio, E.; de la Iglesia, I.; Lavelli, A.; Magnini, B.; Molinet, B.; Ramirez-Romero, J.; Rigau, G.; et al. Medical mT5: An open-source multilingual text-to-text LLM for the medical domain. arXiv 2024, arXiv:2404.07613. [Google Scholar]
- Tian, D.; Jiang, S.; Zhang, L.; Lu, X.; Xu, Y. The role of large language models in medical image processing: A narrative review. Quant. Imaging Med. Surg. 2023, 14, 1108. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Zhou, Z.; Lyu, H.; Wang, Z. Large language models-powered clinical decision support: Enhancing or replacing human expertise? Intell. Med. 2025, 5, 1–4. [Google Scholar] [CrossRef]
- Aityan, S.K.; Mosaddegh, A.; Herrero, R.; Inchingolo, F.; Nguyen, K.C.; Balzanelli, M.; Lazzaro, R.; Iacovazzo, N.; Cefalo, A.; Carriero, L.; et al. Integrated AI Medical Emergency Diagnostics Advising System. Electronics 2024, 13, 4389. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Ou, J.; Zhou, J.; Dong, Y.; Chen, F. Chain of Thought Prompting in Vision-Language Model for Vision Reasoning Tasks. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Melbourne, VIC, Australia, 25–29 November 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 298–311. [Google Scholar]
- Shi, J.; Li, C.; Gong, T.; Wang, C.; Fu, H. CoD-MIL: Chain-of-Diagnosis Prompting Multiple Instance Learning for Whole Slide Image Classification. IEEE Trans. Med. Imaging 2024, 44, 1218–1229. [Google Scholar] [CrossRef]
- Azam, M.A.; Khan, K.B.; Salahuddin, S.; Rehman, E.; Khan, S.A.; Khan, M.A.; Kadry, S.; Gandomi, A.H. A review on multimodal medical image fusion: Compendious analysis of medical modalities, multimodal databases, fusion techniques and quality metrics. Comput. Biol. Med. 2022, 144, 105253. [Google Scholar] [CrossRef]
- Duan, J.; Xiong, J.; Li, Y.; Ding, W. Deep learning based multimodal biomedical data fusion: An overview and comparative review. Inf. Fusion 2024, 112, 102536. [Google Scholar] [CrossRef]
- Adnan, M.; Kalra, S.; Cresswell, J.C.; Taylor, G.W.; Tizhoosh, H.R. Federated learning and differential privacy for medical image analysis. Sci. Rep. 2022, 12, 1953. [Google Scholar] [CrossRef] [PubMed]
- Guan, H.; Yap, P.T.; Bozoki, A.; Liu, M. Federated learning for medical image analysis: A survey. Pattern Recognit. 2024, 151, 110424. [Google Scholar] [CrossRef] [PubMed]
- Sarker, I.H. LLM potentiality and awareness: A position paper from the perspective of trustworthy and responsible AI modeling. Discov. Artif. Intell. 2024, 4, 40. [Google Scholar] [CrossRef]
- Connolly, J.; Stanton, O.; Veronica, S.; Whitmore, L. Enhancing AI Trustworthiness Through Automated Reasoning: A Novel Method for Explaining Deep Learning and LLM Reasoning. 2025. Available online: https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=Enhancing+AI+Trustworthiness+Through+Automated+Reasoning%3A+A+Novel+++Method+for+Explaining+Deep+Learning+and+LLM+Reasoning&btnG= (accessed on 23 July 2025).
Figure 1.
Traditional approaches require task-specific models to solve different tasks, as shown in (a). In contrast, LLMs can employ a unified model to handle multiple tasks, as shown in (b).
Figure 1.
Traditional approaches require task-specific models to solve different tasks, as shown in (a). In contrast, LLMs can employ a unified model to handle multiple tasks, as shown in (b).
Figure 2.
Diagram of the model tuning stage in x-stage tuning. Zero-stage tuning represents no adjustment of the model, one-stage tuning is tuning the model for one stage, and multi-stage tuning is tuning the model for more than one stage.
Figure 2.
Diagram of the model tuning stage in x-stage tuning. Zero-stage tuning represents no adjustment of the model, one-stage tuning is tuning the model for one stage, and multi-stage tuning is tuning the model for more than one stage.
Figure 3.
Medical image tasks with the application of an LLM.
Figure 3.
Medical image tasks with the application of an LLM.
Figure 4.
X-stage tuning diagram. (1) Zero-stage tuning. (2) One-stage tuning. (3) Multi-stage tuning.
Figure 4.
X-stage tuning diagram. (1) Zero-stage tuning. (2) One-stage tuning. (3) Multi-stage tuning.
Figure 5.
Roadmap of five years (a). Countrywise selection (b).
Figure 5.
Roadmap of five years (a). Countrywise selection (b).
Figure 6.
Datasets (a), journal research papers and conferences published in the selected years (b), PRISMA flow diagram illustrating the systematic literature selection process from Scopus and Web of Science databases (2021–2025). The diagram includes identification, screening, eligibility assessment, and final inclusion of studies, with documented reasons for exclusions at each stage (c).
Figure 6.
Datasets (a), journal research papers and conferences published in the selected years (b), PRISMA flow diagram illustrating the systematic literature selection process from Scopus and Web of Science databases (2021–2025). The diagram includes identification, screening, eligibility assessment, and final inclusion of studies, with documented reasons for exclusions at each stage (c).
Figure 7.
Key datasets used in medical image analysis with LLMs. This includes MIMIC-CXR (chest X-rays with reports), CheXpert (chest radiographs), VQA-RAD/SLAKE (medical visual question answering pairs), and Open-I (a variety of medical images with question-answer pairs). These datasets support various tasks, including disease classification, report generation, visual question answering, and visual grounding.
Figure 7.
Key datasets used in medical image analysis with LLMs. This includes MIMIC-CXR (chest X-rays with reports), CheXpert (chest radiographs), VQA-RAD/SLAKE (medical visual question answering pairs), and Open-I (a variety of medical images with question-answer pairs). These datasets support various tasks, including disease classification, report generation, visual question answering, and visual grounding.
Table 1.
Summary of Large Language Model (LLM) Applications in Medical Image Analysis.
Table 1.
Summary of Large Language Model (LLM) Applications in Medical Image Analysis.
| Application | Description | Key Tasks | Challenges |
|---|
| Medical Report Generation | LLMs generate comprehensive medical reports based on medical images (e.g., X-rays, MRIs). | Report generation, text summarization | Data scarcity, accuracy of generated content, hallucinations |
| Disease Classification | Classifying medical images into diagnostic categories (e.g., identifying disease presence). | Disease detection, diagnostic labeling | Data imbalance, label quality, class overlap |
| Visual Question Answering | Answering clinical questions based on medical images. | Answer generation, image-text reasoning | Ambiguity in questions, context understanding |
| Segmentation | LLMs help identify and segment specific regions (e.g., tumors, organs) in medical images. | Image segmentation, anatomical region detection | Precision in boundary detection, multimodal alignment |
| Multimodal Learning | Integration of image and text data for a unified analysis, improving task performance across domains. | Cross-modal understanding, task integration | Data alignment, computational cost, model complexity |
| Federated Learning | Privacy-preserving model training across multiple healthcare institutions without sharing data. | Distributed training, model aggregation | Privacy concerns, communication efficiency, model convergence |
Table 2.
Performance of LLM for Medical Images on Representative Downstream Tasks. VQA-RAD, SLAKE, and PathVQA are datasets for medical visual question answering. “O” refers to the accuracy of open-ended questions, “C” represents the accuracy of binary “yes/no” questions, and “OA” indicates the accuracy across all question types. The best results are highlighted in for clarity. (O = Open, C = Closed, OA = Overall).
Table 2.
Performance of LLM for Medical Images on Representative Downstream Tasks. VQA-RAD, SLAKE, and PathVQA are datasets for medical visual question answering. “O” refers to the accuracy of open-ended questions, “C” represents the accuracy of binary “yes/no” questions, and “OA” indicates the accuracy across all question types. The best results are highlighted in for clarity. (O = Open, C = Closed, OA = Overall).
| Type | Model Name | VQA-RAD | SLAKE | PathVQA |
|---|
|
O
|
C
|
OA
|
O
|
C
|
OA
|
O
|
C
|
OA
|
|---|
| Zero-stage Tuning | MUMC [56] | 71.5 | 84.2 | 79.2 | 79.5 | 82.4 | 81.1 | 39.0 | 90.4 | 65.1 |
| Q2ATransformer [57] | 79.2 | 81.2 | 80.5 | 85.1 | 80.5 | 82.8 | 54.9 | 88.9 | 74.6 |
| One-stage Tuning | ELIXR [58] | 37.9 | 69.3 | - | 73.4 | 72.1 | 72.8 | 68.0 | 86.2 | 78.6 |
| Prefix T.Medical LM [59] | - | - | - | 84.3 | 82.1 | 83.3 | 40.0 | 87.0 | 63.6 |
| Multi-stage Tuning | MedVInT-TE [60] | 69.3 | 84.2 | - | 88.2 | 87.7 | - | - | - | - |
| LLaVA-Med [61] | 64.8 | 83.1 | - | 87.1 | 86.8 | - | 39.6 | 91.1 | - |
| MedVInT-TD [60] | 73.7 | 86.8 | - | 84.5 | 86.3 | 85.2 | 72.2 | 92.0 | 79.4 |
| RadiologyGPT [61] | 78.3 | 86.2 | 82.2 | 86.9 | 85.1 | 86.0 | 65.8 | 93.2 | 79.1 |
| PeFoMed [62] | 79.9 | 87.5 | 84.4 | 83.1 | 88.7 | 85.3 | 45.7 | 91.3 | 68.6 |
Table 3.
X-stage Tuning Paradigm for LLMs in Medical Images. Large Vision-Language Model (LVLM), Open Source (OS).
Table 3.
X-stage Tuning Paradigm for LLMs in Medical Images. Large Vision-Language Model (LVLM), Open Source (OS).
| Type | Model Name | Base | No. of Parameters | Base Detail |
|---|
| | | | |
LLM
|
LVLM
|
OS
|
|---|
| Zero-stage Tuning | ChatCAD [63] | ChatGPT | - | ✓ | × | ✓ |
| ChatCAD+ [64] | ChatGPT | - | ✓ | ✓ | ✓ |
| Flamingo [65] | Flamingo | 9/80 | - | ✓ | ✓ |
| Visual Med-Alpaca [66] | LLaMA | 7 | ✓ | - | ✓ |
| Med-Flamingo [67] | OpenFlamingo | 9 | - | ✓ | ✓ |
| FFA-GPT [68] | LLaMA2 | - | ✓ | - | ✓ |
| MedBLIP [69] | BioMedLM | 2.7 | ✓ | - | ✓ |
| RadFM [70] | 3D ViT and MedLLaMA | 14 | ✓ | - | ✓ |
| RadFM [70] | LLaMA as LLM | - | - | ✓ | ✓ |
| GPT-4V [5,71,72] | GPT-4V | - | ✓ | × | ✓ |
| Gemini [73] | Gemini | - | ✓ | × | ✓ |
| VisionGPT | VisionTransformer | - | ✓ | × | ✓ |
| One-stage Tuning | OphGLM [74] | ChatGLM | 6.2 | ✓ | ✓ | ✓ |
| Visual Med-Alpaca [66] | LLaMA | 7 | ✓ | ✓ | ✓ |
| FFA-GPT [68] | LLaMA2 [75] | - | ✓ | ✓ | ✓ |
| MAIRA-1 [76] | LLaVA-1.5 | 7 | - | ✓ | ✓ |
| PneumoLLM [77] | CLIP and LLaMA-7 | 7 | - | ✓ | ✓ |
| R2GenGPT [78] | Swin Transformer and LLaMA2 | 7 | - | ✓ | ✓ |
| Med-PaLM M [79] | PaLM-E | 2/84/562 | - | ✓ | ✓ |
| Prefix T.Medical LM [59] | CLIP and BioGPT | - | - | ✓ | ✓ |
| FM for MRG [80] | BLIP-2 | 7.3 | - | ✓ | ✓ |
| MedXchat [81] | CLIP and LLaMA | - | - | ✓ | ✓ |
| MedVInT [60] | PMC-CLIP and PMC-LLaMA | - | - | ✓ | ✓ |
| MedBLIP [69,82] | EVA, FLAN-T5/BioGPT | 3.4/1.5/2.7 | ✓ | ✓ | ✓ |
| BioMedGPT | BioGPT | 5.2 | ✓ | ✓ | ✓ |
| RadiologyGPT | RadiologyTransformer | 4.5 | ✓ | ✓ | ✓ |
| Multi-stage Tuning | PeFoMed [62] | MiniGPT-v2 | 7 | ✓ | ✓ | ✓ |
| SkinGPT-4 [83] | MiniGPT-4 [84] | - | ✓ | ✓ | ✓ |
| ELIXR [58] | ELIXR-C: CLIP ELIXR-B: BLIP-2 | - | - | ✓ | ✓ |
| LLaVA-Med [61] | LLaVA | 7 | - | ✓ | ✓ |
| CXR-BLIP [85] | BLIP-2 (EVA and OPT Transformer) | 2.7 | - | ✓ | ✓ |
| Qilin-Med-VL [86] | ViT and Chiese-LLaMA2-13B-Chat | 13 | - | ✓ | ✓ |
| LLM-CXR [87] | dolly-v2-3b | 3 | ✓ | ✓ | ✓ |
| CephGPT-4 [88] | MiniGPT-4 | 7 | ✓ | ✓ | ✓ |
| Med-MLLM [89] | ResNet-50 and Transformer | 8.9 | - | ✓ | ✓ |
| LMM for RRG [90] | ResNet-50 and GPT2-S | 7 | - | ✓ | ✓ |
| XrayGPT [26,91] | MedCLIP and Vicuna | - | - | ✓ | ✓ |
| PathAsst [92] | LLaVA | 13 | - | ✓ | ✓ |
| MOSS-MED [93] | LLaMA2-7B-chat as LLM | 7 | - | ✓ | ✓ |
| ClinicalBLIP [94] | InstructBLIP | - | - | ✓ | ✓ |
| LLIM for MIC [95] | BLIP-2 | - | - | ✓ | ✓ |
| RadMed-Tuning | Med-Tuning | 6.0 | ✓ | ✓ | ✓ |
| LiteGPT [96] | MiniGPT-v2 | 7 | - | ✓ | ✓ |
| MiniGPT-Med [97] | MiniGPT-v2 | 7 | - | ✓ | ✓ |
| MedGPT-3 | GPT-3 | 6.5 | ✓ | ✓ | ✓ |
Table 4.
The evaluation metrics used for different tasks in medical image analysis.
Table 4.
The evaluation metrics used for different tasks in medical image analysis.
| Task | Evaluation Metric | Description | References |
|---|
| Medical Report Generation | BLEU (Bilingual Evaluation Understudy) | Measures n-gram overlap between generated and reference text to assess fluency and informativeness | [25,98] |
| - - - | ROUGE (Recall-Oriented Understudy for Gisting) | Measures recall-based n-gram overlap between generated text and reference text | [25,98] |
| - - - | CheXpert Labels | Assesses clinical relevance of generated text based on medical domain-specific labels | [99] |
| Disease Classification | Accuracy (ACC) | Measures the overall percentage of correct predictions (e.g., disease vs. healthy) | [100] |
| - - - | AUC-ROC (Area Under Receiver Operating Curve) | Measures the ability of the model to distinguish between classes (e.g., diseased vs. healthy) | [100] |
| Visual Question Answering | Accuracy (ACC) | Measures the model’s ability to answer open- and closed-ended questions related to medical images | [101] |
| Visual Grounding | Intersection over Union (IoU) | Measures overlap between predicted and ground truth regions in image segmentation | [102] |
| - - - | Dice Coefficient | Measures the similarity between predicted and ground truth regions for segmentation tasks | [102] |
Table 5.
Key Challenges in Using Large Language Models for Medical Image Analysis.
Table 5.
Key Challenges in Using Large Language Models for Medical Image Analysis.
| Challenge | Description | Impact on Model Performance | Potential Solutions | limitations |
|---|
| Data Scarcity | Limited access to large, labeled datasets for medical images. | Hinders training and fine-tuning for medical tasks. | Data augmentation, federated learning, transfer learning. | Difficulty in obtaining annotated datasets for rare diseases. |
| Hallucinations in Generated Content | LLMs may generate plausible-sounding but incorrect medical information. | Decreases model reliability in clinical applications. | Reinforcement learning with human feedback (RLHF), continuous updates. | High risk of generating incorrect diagnoses due to unclear data. |
| Model Interpretability | Difficulty in explaining model predictions, especially for complex medical scenarios. | Reduces trust in AI-based systems, particularly in clinical use. | Explainable AI (XAI) methods, saliency mapping. | Lack of transparency makes clinical decision-making difficult. |
| Privacy and Security | Protecting patient data during training, especially when using sensitive medical data. | Legal and ethical issues, data-sharing restrictions. | Differential privacy, federated learning. | Privacy concerns remain for non-centralized data. |
| Multilingual Model Development | Lack of support for non-English medical image datasets and language diversity in clinical settings. | Limits applicability in non-English speaking regions. | Development of multilingual models, cross-lingual data augmentation. | Limited availability of diverse multilingual datasets. |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







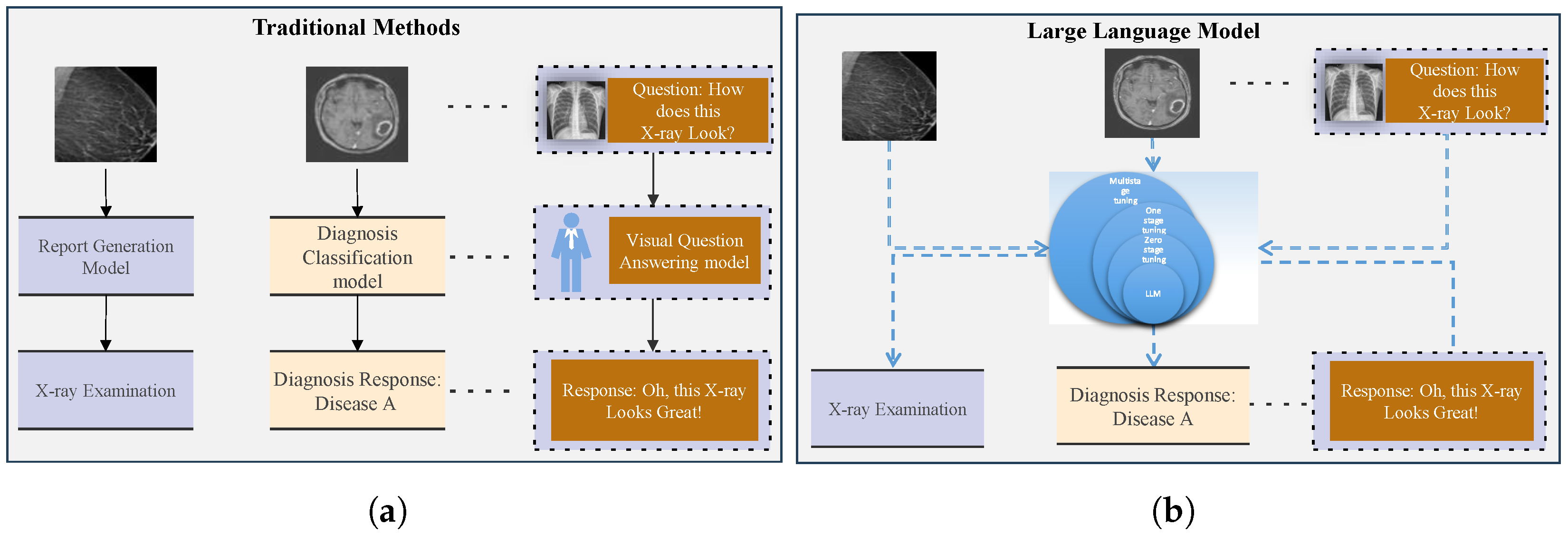

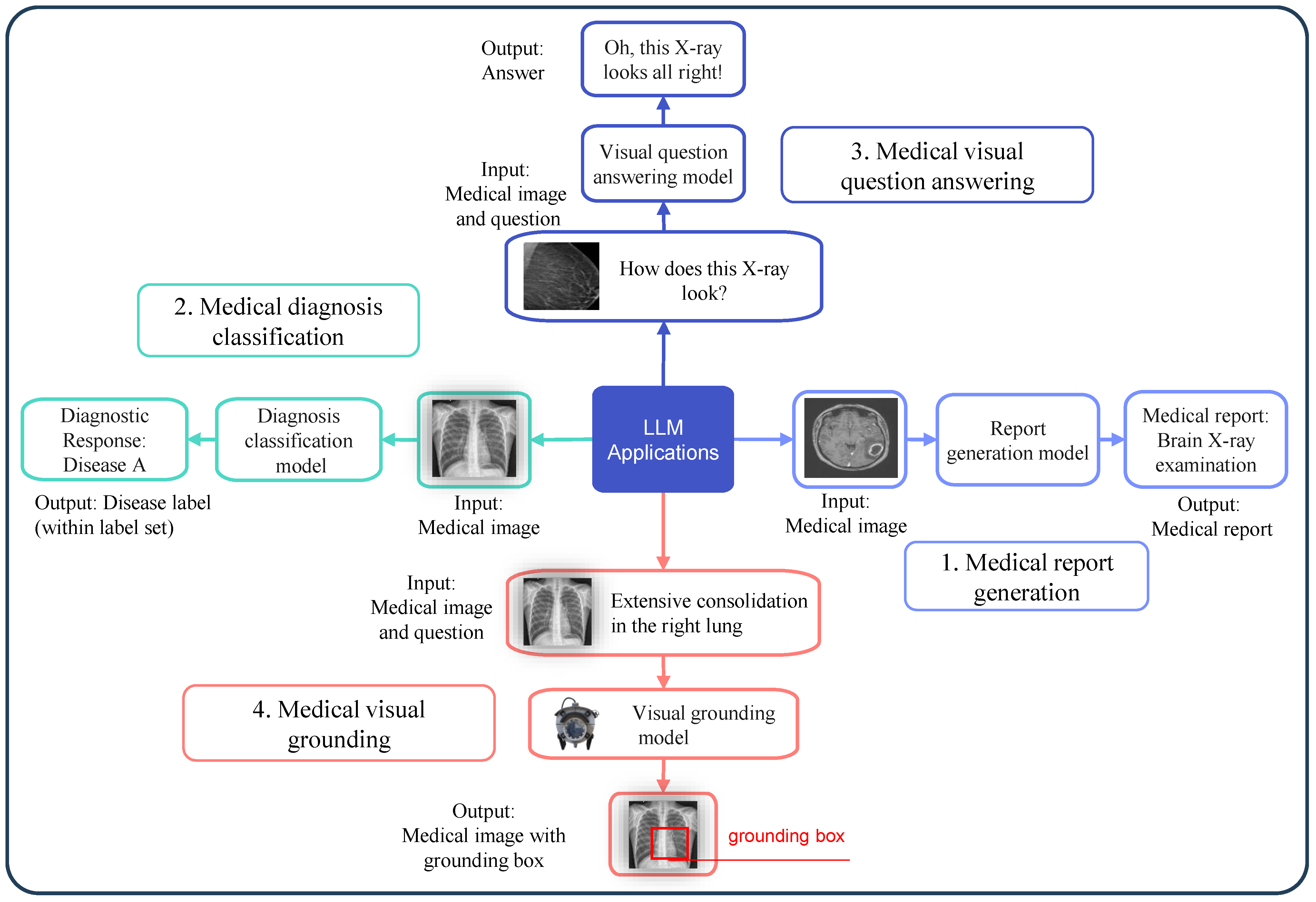
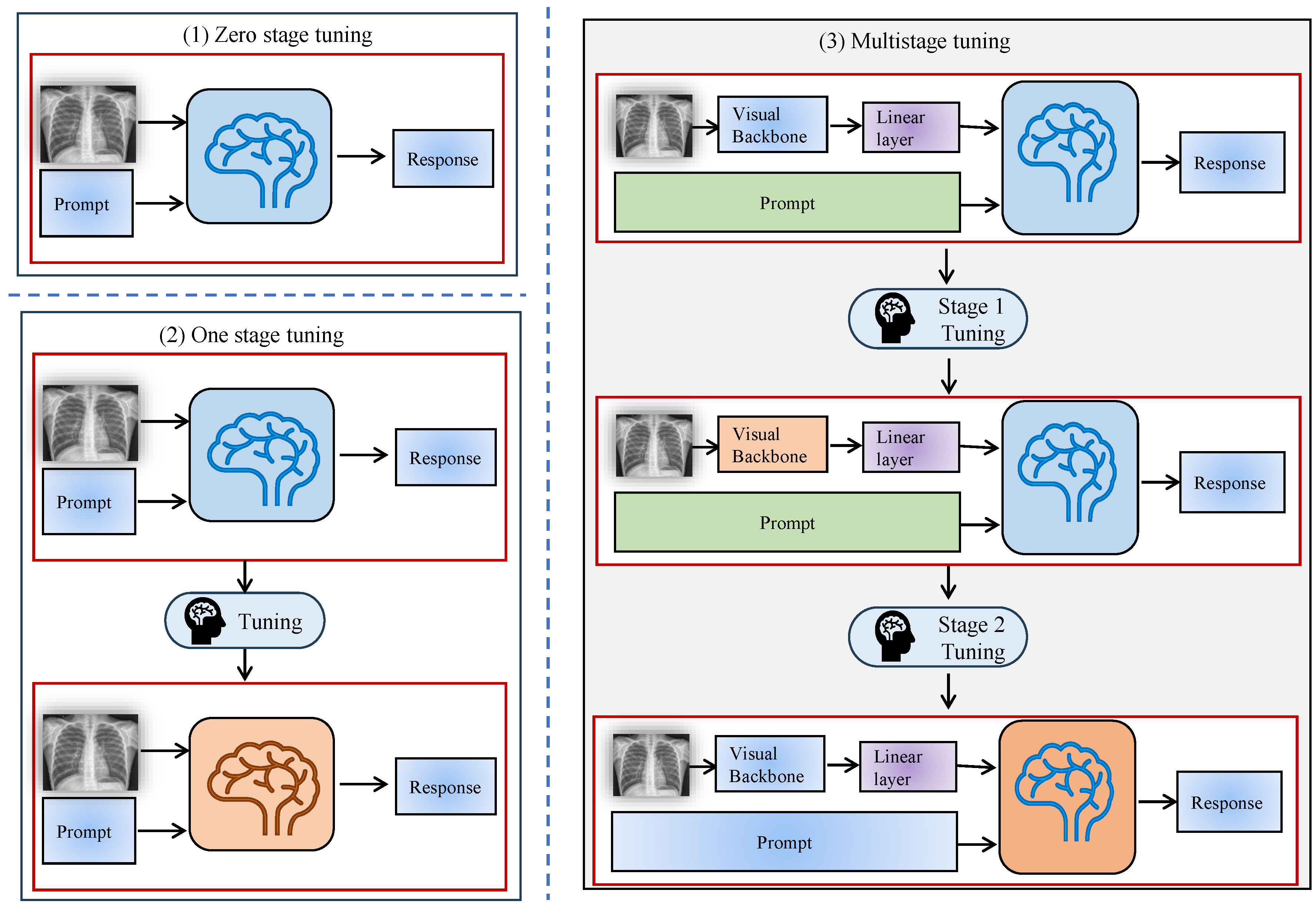

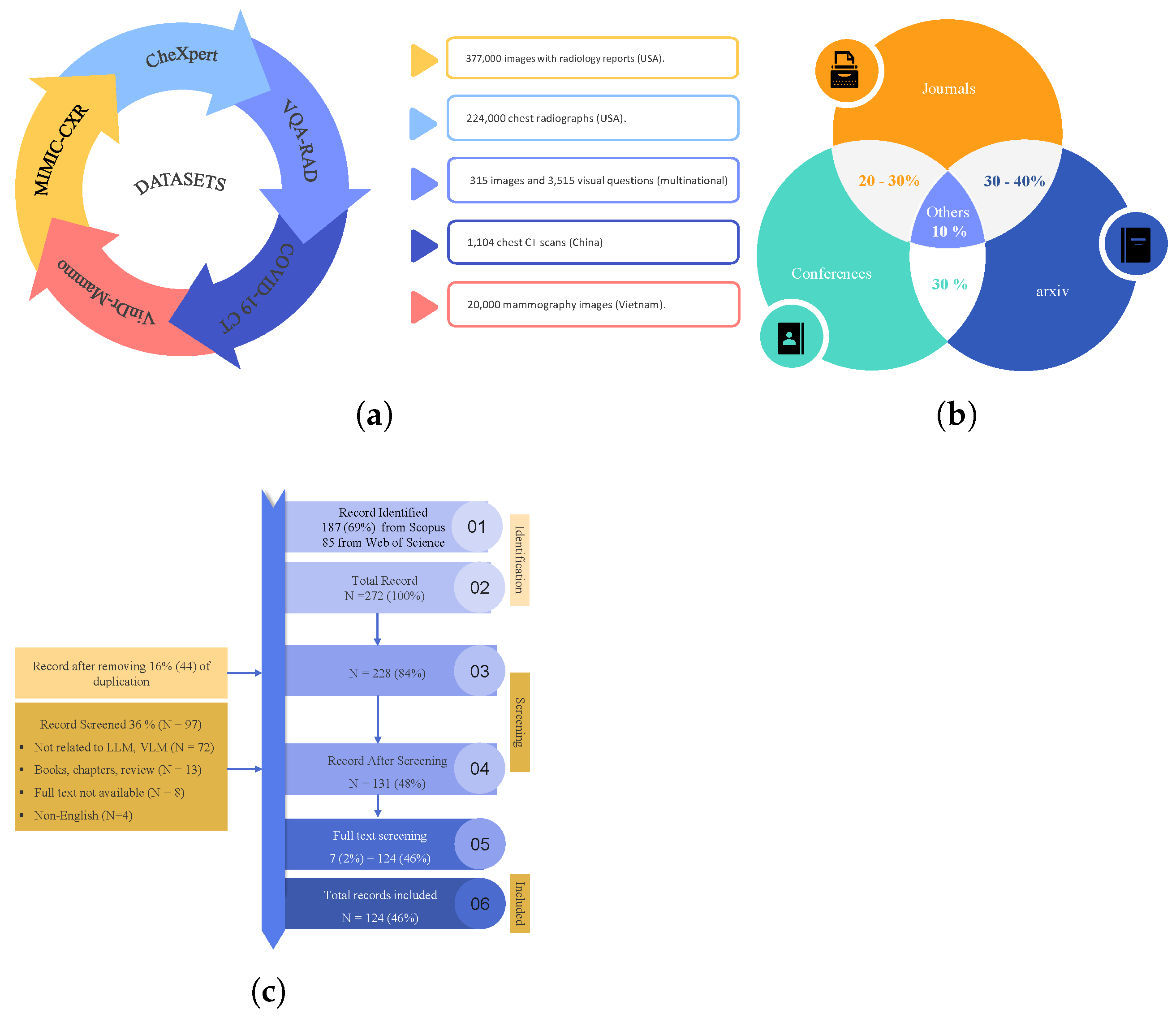
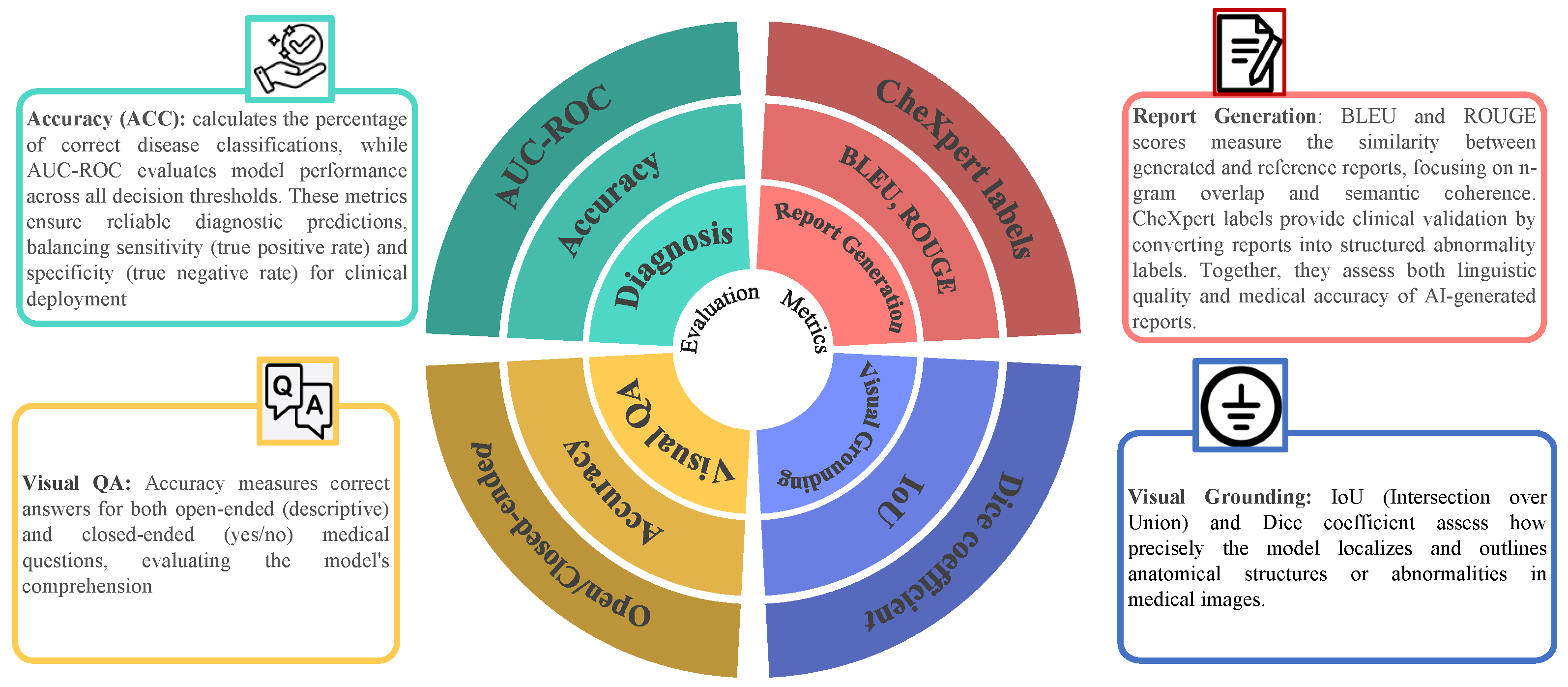

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}