Abstract
Screening is critical for prevention and early detection of cervical cancer but it is time-consuming and laborious. Supervised deep convolutional neural networks have been developed to automate pap smear screening and the results are promising. However, the interest in using only normal samples to train deep neural networks has increased owing to the class imbalance problems and high-labeling costs that are both prevalent in healthcare. In this study, we introduce a method to learn explainable deep cervical cell representations for pap smear cytology images based on one-class classification using variational autoencoders. Findings demonstrate that a score can be calculated for cell abnormality without training models with abnormal samples, and we localize abnormality to interpret our results with a novel metric based on absolute difference in cross-entropy in agglomerative clustering. The best model that discriminates squamous cell carcinoma (SCC) from normals gives area under operating characteristic curve (AUC) and one that discriminates high-grade epithelial lesion (HSIL) AUC. Compared to other clustering methods, our method enhances the V-measure and yields higher homogeneity scores, which more effectively isolate different abnormality regions, aiding in the interpretation of our results. Evaluation using an external dataset shows that our model can discriminate abnormality without the need for additional training of deep models.
1. Introduction
Cervical cancer screening is invaluable for the early detection and prevention of cervical cancer [1]. A pap smear is used to screen for cervical cancer by detecting morphological abnormalities [2]. While pap smear screening has been successful at reducing rates of cervical cancer mortality, incidence and mortality have increased in developing countries, owing to the lack of resources [3]. Developing quantitative and autonomous methods using computer technology can potentially improve healthcare worldwide by making the smear screening process cost-efficient.
Despite efforts expended to standardize categories of precancerous cells, interobserver reproducibility of cell classification is still a challenge, owing to the morphological diversity of cells in a pap smear [4,5]. This can lead to underdiagnoses (or overdiagnoses) characterized by false-negative (-positive) rates of the screening method that can negatively affect the health of women. Therefore, a robust and reliable computational approach should encode morphological diversity and score the abnormality of the cell. Recent efforts expended to classify cell abnormalities include the use of hand-crafted features and deep learning. These methods are based on supervised learning; models require fixed labels assuming a gold-standard interpretation that does not consider possible disagreement between observers.
The development of a robust and accurate automated pap smear screening method was motivated by the goal of reducing human errors and examination time [6]. This is achieved by quantitative assessments of either hand-crafted features [7] or the use of deep learning [8,9]. Methods using hand-crafted features are interpretable in the sense that we can calculate the importance or weights of features, unlike deep learning wherein the trained model is usually a black box. A study closely related to ours is that of Özbay et al. [10], where the authors proposed an interpretable deep-learning framework for cervical cancer detection using the “hash” layer. Unlike this method, we can determine the qualitative meaning of each feature dimension by interpreting the images generated by the decoder along a fixed direction in feature space based on the use of the Variational autoencoder (VAE) [11] formulation. This allows comparisons between images by calculating the change in latent space, which quantitatively shows how the images differ.
Most modern image-based deep learning involves a non-linear transformation of an image to a lower dimension space (compared to input), which can also be called image features, to analyze relationships between semantic properties of images [12]. In supervised learning, where the semantic property or label of each image is supplied during training, image features that best discriminate different labels are computed. In contrast, unsupervised learning involves no such additional information on the characteristics of images. Instead, features are learned from image data only and their characteristics are dependent on the inductive biases such as the choice of model and distribution features [13].
VAEs are generative models that assume distribution characteristics on the generating process of data [11]. They are similar to autoencoders [14] in that they both have an encoder that encodes image features to lower dimension and a decoder that recovers the original image using the image features but introduce latent variables that are responsible for the image generation. These latent variables have distribution characteristics, usually a multivariate standard normal distribution, from which we can sample to generate new images. By enforcing a multivariate standard normal distribution (from here on, we call this latent distribution) on the latent variables given training data, images very unlike the training data are expected to have low likelihood with respect to the latent distribution and have latent variables distant from the origin. In this work, we use the terms latent variable, latent vector, and features interchangeably and, by latent space, we mean the space where latent variables are defined.
One-class classification (OCC) [15] using VAEs has the benefit of learning features for the given class in an unsupervised manner. This method has been applied to detect deepfakes by utilizing the reconstruction loss and by comparing the latent features of the input and the reconstructed image [16]. Another study applied the same method to intrusion detection in network flow, but the anomaly score was set to the reconstruction probability [17]. The advantage of our method is that we do not require additional passes to the decoder. We analyze herein only the distribution in the latent space by using the negative likelihood in the feature space as our score. To the best of our knowledge, we are the first to train our encoder using unsupervised learning and the first to apply OCC using VAEs in pap-smear anomaly detection.
Clustering is an unsupervised method used to determine groups of related samples where interpoint distances are small compared with the points outside a cluster [18]. In the context of pap-smear classification, several clustering methods, such as K-Means and its fuzzy variant [19], have demonstrated good performance [20,21]. Unlike previous studies, our approach is unique because we do not rely on fixed points to cluster our samples. Instead, we utilize nonfixed points, mapping the data into a multidimensional latent space represented as a probability distribution. The analysis of data using nonfixed points [22] and calculating statistical distances to compare class distributions has been studied previously [23]. However, to our knowledge, we are the first to apply agglomerative clustering on nonfixed points [24] using an information-theory-based pseudometric. We also demonstrate that, with some additional assumptions, our pseudometric equals the Euclidean distance, which provides evidence for comparable but slightly better results than those obtained using the K-Means with the Euclidean distance.
In this study, we explore an unsupervised method for learning features of normal cells and using negative log-likelihood to quantify abnormality. To interpret our latent space, we analyze the factors of variation learned by our model and introduce a metric based on cross-entropy to cluster similar cells. We test our method against the baselines of other unsupervised clustering algorithms. Our contributions are as follows:
- We demonstrate that VAE models can learn interpretable features from pap-smear datasets;
- The trained models can detect abnormalities by estimating a Gaussian based on the latent feature space using only normal samples;
- Additional image augmentation during the training of generative models can enhance the distinction between normal and abnormal samples;
- The formulation of statistical distance based on cross-entropy enables agglomerative clustering that outperforms conventional clustering methods;
- Finally, our model can be generalized to other datasets containing images of cervical cells. It is capable of distinguishing normal and abnormal images by using the pretrained encoder.
2. Materials and Methods
In this section, we define our study’s problem of obtaining an abnormality score function on the latent space of VAEs by first reviewing them in the context of disentanglement. We then define our score function for OCC and follow up using other methods for interpreting latent space by qualitatively assessing reconstructions and using the agglomerative clustering method to obtain similar samples from the input.
2.1. VAEs and Disentanglement
Let be a random sample of size N from an unknown distribution . We assume that X is generated by an unobserved continuous random variable Z. The set contains a family of distributions parameterized by in and the true but unknown parameter .
Owing to the intractability of marginal likelihood computation and computation costs occurring from large datasets, Kingma et al. [11] proposed the autoencoding variational Bayes method, in which a recognition model is approximated to the posterior model . This allows efficient approximation of maximum likelihood or maximum a posteriori approximation for , posterior inference of the latent variable z given an observed value x given , and marginal inference of the variable x. The recognition model can be considered as a probabilistic encoder that models the distribution of latent representation z. Likewise, the generative model can be considered as a probabilistic decoder that models the distribution of the generated datapoint x with respect to a latent variable z.
We denote as the parameters for the decoder, as the parameters for the encoder, as the approximate posterior parameterized as a diagonal multivariate normal distribution, and as the true data-generating distribution with marginal latent distribution as a standard normal distribution. The evidence lower bound (ELBO) of VAE [11] is
where is the Kullback–Leibler divergence [25]. Burgess et al. [26] showed that, for curated datasets, adding an extra term ß to the ELBO helps disentangle factors of variation [27], which may help interpret features. The ELBO for -VAE is as follows:
Chen et al. [28] showed that total correlation [29], a term found by decomposing ELBO [30], is related to the disentangling property found in ß-VAE. The ELBO for their model, ß-TCVAE is as follows:
where I is the mutual information function and were the values of constants for all experiments in this study.
In this study, we explored the possibility of interpreting latent factors for cells in pap-smear images using different loss functions of VAE. By performing training using only normal samples, we hypothesized that color and morphological factors may be found in the latent space so that we can interpret results when inputs show signs of abnormality.
2.2. Score Function
The ELBO suggests that our approximate posterior should be a factorized standard normal distribution after training. However, our distribution of normal samples may differ from training samples, owing to augmentations applied during training. Instead, we also estimated our distribution of normal samples by a multivariate normal distribution. We define our scoring function s by the negative log-likelihood of a multivariate normal distribution:
where and are the estimated parameters from normal cell image examples.
2.3. Interpreting Latent Space
The formulation of VAEs suggests independent image-generating factors in latent space. By traversing along the latent entry, we can infer qualitatively the meaning of each factor in latent space.
As we modeled the image distribution as an augmented distribution, we traversed along each entry centered at the mean of the nonaugmented data distribution for 10 steps, starting from a value equal to −4 × standard deviations (with respect to the mean) to +4 × standard deviations (with respect to the mean).
Another way we can interpret latent space is to identify samples near the encoded input. The straightforward approach is to cluster samples in latent space and identify other samples in the cluster associated with the input. However, a characteristic of VAEs may allow us to use statistical distances instead of sampling approaches to this problem. The reparameterization trick [11] for a Gaussian posterior, a differentiable transformation , yields
where and are parameters for the mean and standard deviation for the latent feature z. This reveals that the latent feature vector z is modeled by with an error term with variance . Therefore, instead of using contemporary clustering methods that use the mean vector or a sample from this distribution, we can use statistical distances. Images in the same cluster should contain similar image characteristics, owing to the proximity of their locations in latent space. By incorporating statistical distances, we hypothesized that our method clusters similar images more effectively compared with contemporary methods, such as K-means with Euclidean distance, by utilizing the error of representation and factoring relative information of nearby samples.
2.4. Cross-Entropy-Based Referenced Statistical Distance
We introduce a statistical distance that is related to well-known divergences, such as the Jenson–Shannon and Jefferys, and an equality to Mahalanobis distance as a special case, as indicated in the this section. We call this cross-entropy-based referenced statistical distance (CRSD). Connnections of CRSD to other divergences are descriped in Appendix A.
Given two probability distributions p and q, the CRSD with respect to a probability distribution r is defined as
where the cross-entropy of q relative to p is defined by . Henceforth, for brevity purposes, we eliminate the acronym. Based on this definition, it can be inferred that the function is symmetric, , non-negative, and zero if . However, does not imply that , and this can easily be demonstrated by Gaussian distributions with centered r values; p and q have means equal to and . The triangular inequality is also satisfied and proven using simple algebra. We also define for multiple reference probability densities: if R is a set of probability densities, the CRSD with respect to R is defined by
In this study, we substituted the Euclidean distance for CRSD in the agglomerative clustering algorithm [24] when we used nonfixed points. We restricted R to be finite in our experiments to define the latent distributions in a given piece of data related to training, validation, or test fold.
2.5. Dataset
A publicly available conventional pap-smear dataset provided by the CRIC platform [31] was chosen for our experiment. This dataset contained 400 pap-smear images and 11,534 classified cells, which contained more classified cells than other open datasets [32,33]. The dataset contained six classes according to the Bethesda system [4], namely, NILM, LSIL, HSIL, ASC-US, ASC-H, and SCC. As the classified cells were annotated rather than cropped, different views of cells (achieved by rotation and displacement) could be obtained during training without introducing background elements generated by augmentation on cropped images. In addition, we removed some annotations that were close to the boundary of the image (within 128 pixels with respect to either the x- or y-axis). The numbers of cropped images used in our experiment are shown in Table 1.

Table 1.
Number of samples per class from each dataset used in this study.
To check for the generalizability of our model, we used another publicly available SIPAKMED [33] dataset to compare scores between abnormal and normal cells. The SIPAKMED dataset contained information on cell morphological information, which we used to determine the cell coordinates. The dimension of all cell images was 256 × 256; these images were center-cropped to 64 × 64 before they were input into the model. This limited the field of view of our model and allowed focus on the nucleus of a single cell and its immediate surroundings.
2.6. Experiments
Our study comprises four parts: training of VAEs and the estimation of normal sample distribution in latent space, abnormality scoring, interpretation method for latent representations, and clustering. An overview is shown in Figure 1.
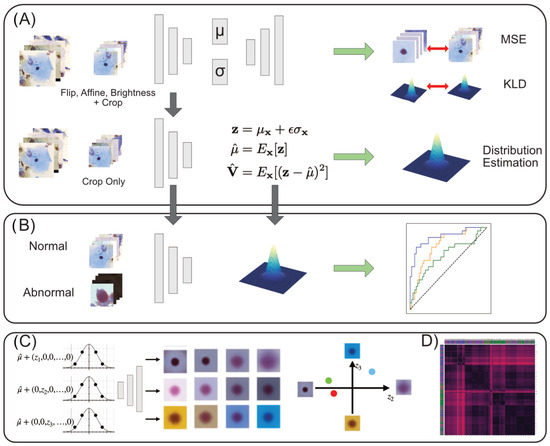
Figure 1.
Overview. (A) The process of training VAEs and estimation of the latent normal distribution. See Appendix B for details on the model architecture. (B) Using the estimated normal latent distribution, we compare likelihoods between normal and abnormal latent vectors to calculate ROC curves for performance evaluation. (C) The latent space is traversed to assess the morphological meaning of each dimension, after which the latent feature can be interpreted quantitatively for each image. (D) Clustering is performed to analyze the local characteristics in latent space and to obtain similar image examples.
We trained VAE, -VAE, and -TCVAE using normal samples (NILM) in the CRIC dataset to learn disentangled features and to calculate a simple scoring function to discern abnormal samples. Our implementation was based on Subramanian [34]. Five-fold cross-validation was performed on a two-class classification task (NILM vs. abnormal) to identify the best hyperparameters. The hyperparameters were varied using = 1, 4, 16, and the latent dimensions 8, 32, and 128.
Additionally, image-augmentation techniques were varied to determine if additional image preprocessing had a positive effect on model performance. In generative models, severe augmentations tend to distort the learned data distribution; thus, we selected plausible augmentations, such as rotation, translation, and brightness adjustment, that mimic possible variations in the usual data acquisition process using an optical microscope. Three methods were tested as hyperparameters in the cross-validation process: none; random flip, rotation, and translation (FA); and random flip, rotation, translation, and brightness (FAB). For each abnormal class, scores were then compared against NILM to assess the per-class performance of our model. Finally, clustering algorithms were compared to our best model. Clustering algorithms included agglomerative clustering [24], K-means [35], spectral clustering [36], and DBSCAN [37]. We chose homogeneity, completeness, and V-measure [38] as metrics for comparison. We conducted tests using 100 clusters, and other parameters were set to default using sci-kit learn implementation [39].
We experimented on an additional external dataset, SIPAKMED, to see if our model could score abnormality with comparable or better performance. The model was fixed to only encode images to latent space. The distribution of normal images was estimated using the same procedure as that used for the CRIC dataset. We estimated the Gaussian using different folds of normal data (5-fold split on training datasets). Abnormal data were split into 5 folds, and each sub-dataset was evaluated against normal data to calculate the ROC curve.
3. Results
3.1. Latent Space Captures Morphological and Color Characteristics of Cervical Pap-Smear Cells
In supervised learning, incorporating additional augmentations tends to enhance the performance of deep models, but this may not directly translate to generative models (such as VAEs) because augmented samples distort the target data distribution that is required to be learned. Therefore, our experiments were conducted on relatively plausible augmentations: rotation of cells, systematic error in centering a cell in an image, and brightness configuration, which depends on the light source of the microscope. Three augmentation methods were tested: no augmentation (None), rotation and translation (FA, flip, and affine), and FA with brightness adjustment (FAB, flip, affine, and brightness). Figure 2 shows that, for any hyperparametric combination, using the full augmentation (FAB) yields the best area under the receiver operating characteristic curve (AUROC) on average. The best model was found to be -TCVAE with = 4 and with a latent dimension equal to eight. Further performance analyses were performed using this model.
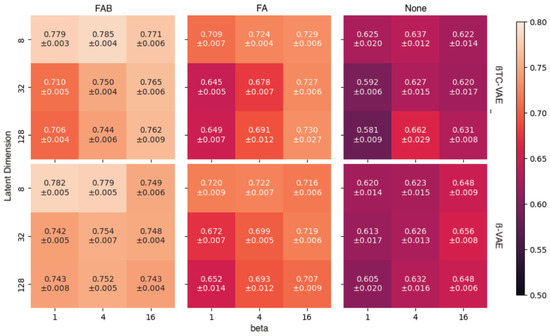
Figure 2.
Area under receiver operating characteristic curve (AUROC) for combinations of data augmentation and hyperparameters (ß and latent dimension).
Morphological and color-related features were learned by the model using unsupervised training. Figure 3 shows features learned by the ß-VAE model with ß = 4 and 32 latent dimensions. The reconstructed images were obtained by calculating the mean of latent features of normal samples and traversing from −4 to 4 standard deviations from the mean in 10 steps. The top seven rows correspond to the morphology of the cell image concerning the locations, shapes, and sizes of the nuclei. The bottom two rows correspond to color. Images in the second row from the bottom correspond to brightness adjustment, and images in the last row correspond to hue adjustment from gold-brownish to blue.

Figure 3.
Latent traversals across different dimensions of the ß-variational autoencoder (VAE) (ß = 4 and latent dimension = 32).
Pairwise latent distribution contour plots between latent dimensions of the best model (ß-TCVAE, ß = 4, and a latent dimension equal to 8) were drawn for the Center for Recognition and Inspection of Cells (CRIC) dataset. Figure 4 shows that each abnormal class contains different image characteristics, even though the encoder/decoder model was trained only based on normal examples, namely, the negative intraepithelial lesion or malignancy (NILM). Each row from top to bottom (left to right columns) corresponds to the latent dimension index (ranging from zero to seven). The following abnormal classes were merged for clarity in the pairwise KDE plots: low-grade intraepithelial lesion (LSIL) with atypical squamous cell with undetermined significance, and high-grade intraepithelial lesion (HSIL) with atypical squamous cell—cannot exclude HSIL (ASC-H). As aforementioned, we observed a shift in the data distribution from the standard normal for NILM in latent space. Scoring based on the NILM latent distribution should account for this shift instead of relying on the formulation of the latent distribution as a standard normal according to the VAE formulation.
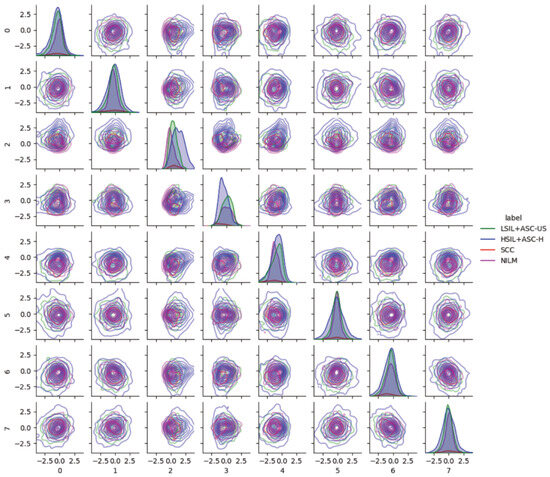
Figure 4.
Pairwise latent distribution estimation plots obtained using latent vectors of different classes in the Center for Recognition and Inspection of Cells (CRIC) dataset in conjunction with the use of the best model.
3.2. Negative Log-Likelihood Is in Line with the Progressive Severity of Precancerous Stages
As atypical cells should be different from normal cells, a score was devised based on negative log-likelihood to quantify the degree of departure from a fixed set of normal cells. NILM latent normal distribution parameters were estimated separately from NILM images that were obtained from model training. We calculated the performances of our scoring function by comparing each abnormal class against normal samples. Table 2 lists accuracy, AUC, F1 scores, and sensitivity and specificity outcomes for each abnormal class. The model performed well at discerning squamous cell carcinoma (SCC) and HSIL from normal cell states followed by the ASC-H, LSIL, and atypical squamous cell of undetermined significance (ASC-US). The AUC scores correspond to the severity of the lesion; AUC scores are ordered from high grades (HSIL, SCC, and ASC-H) to low grades (LSIL and ASC-US).
Table 2.
Class-wise metrics for the best model. We calculated metrics for each abnormal class compared with those based on the normal dataset. The model was good at discerning squamous cell carcinoma (SCC) and high-grade intraepithelial lesion (HSIL) from normal followed by atypical squamous cell—cannot exclude HSIL (ASC-H), low-grade squamous intraepithelial lesion (LSIL), and atypical squamous cell with undetermined significance (ASC-US).
We tested for generalizability by estimating and evaluating the score function for additional datasets using our model. Figure 5A shows the receiver operating characteristic (ROC) curves of each abnormal class for each external dataset SIPAKMED [33]. On average, over cross-validation folds, the AUC values for dyskeratotic, metaplastic, and koilocytotic cells were 0.97, 0.89, and 0.9, respectively.
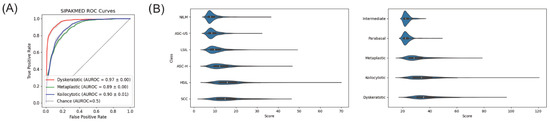
Figure 5.
(A) Receiver operating characteristic (ROC) curves for each abnormality using external dataset SIPAKMED. (B) Violin plots for the CRIC (left), SIPAKMED (right) datasets.
Figure 5B shows violin plots of scores for each class in each dataset to visualize distribution differences between normal and abnormal cases. Our best model characterizes abnormality as a departure from normality as seen by an increase in the median score with a very long tail response. This pattern is consistent with the other external datasets. However, long tails of normal cells within each dataset indicate irregularity even in normal cases, thus suggesting that score alone may not be a robust classification metric for cells.
3.3. Characteristics of External Datasets Revealed by Distributions in Latent Space
In addition to pairwise KDE visualization of the CRIC dataset, we analyzed the latent space for possible batch effects. Figure 6 show the pairwise KDE plots with the best model of the latent distributions of SIPAKMED. One observation regarding latent feature index 3 is the differences of modes among abnormal classes in SIPAKMED. We found that feature 3 was associated with color and, in turn, associated with koilocytotic, dyskeratotic, and metaplastic cells in the SIPAKMED data (orange, bluish, and lighter bluish/green). Rote interpretation based on the latent feature value is difficult because feature values are conditioned on the training data (color distribution of normal cell images in the CRIC dataset); therefore, generalization is not guaranteed. However, this strongly suggests the need for further study on batch correction methods within the latent space.
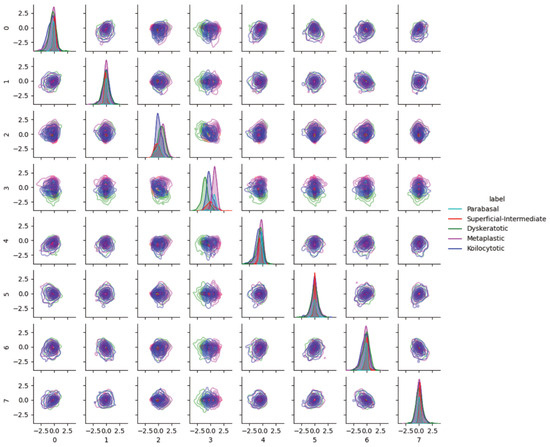
Figure 6.
Pairwise latent distribution estimation plots obtained using latent vectors of different classes in the SIPAKMED dataset and the best model.
3.4. Novel Statistical Pseudo-Distance Improves Clustering Performance
Recognizing that the latent space corresponds to varying morphological and color features, images with similar qualitative features should exist in latent space. Therefore, we applied clustering algorithms to localize similar images. Homogeneity, completeness, and V-measure [38] were calculated for each clustering algorithm to compare performances. Furthermore, as there is uncertainty associated with latent features, we developed a pseudometric known as cross-entropy-based statistical divergence (CRSD) for use in conjunction with conventional clustering algorithms. Cross-validation (fivefold) on the abnormal dataset was performed to compare different unsupervised algorithms using the best model. Table 3 shows that agglomerative methods yield higher V-measures than other methods with agglomerative clustering with CRSD (Agg-SM) as the best-performing algorithm. Homogeneity for agglomerative clustering with Euclidean distance (Agg-EM) and K-Means were similar, but K-Means yielded lower V-measures. Spectral clustering and density-based spatial clustering of applications with noise (DBSCAN) yielded very low V-measures compared with other algorithms, but DBSCAN had the highest completeness score, suggesting that the algorithm favors a smaller number of clusters.
Table 3.
Unsupervised clustering algorithm comparisons. Homogeneity (h), completeness (c), and V-measure (V) are calculated for each algorithm with number of clusters used. Values close to one indicate better performance. Our method, agglomerative clustering with CRSD (Agg-SM), yields the best V-measure, followed by K-Means. Homogeneity was similar between agglomerative clustering using Euclidean distance (Agg-EM) and K-Means.
3.5. Toward Reduced Intraobserver Variability Using Retrieved Images
Related images can be assessed to inspect images within the same cluster. Figure 7 shows two different clusters (top row and bottom) with high NILM homogeneity (first column), LSIL + ASC-US (second column), and HSIL + ASC-H (third column) in the CRIC dataset. Images with similar hue, nuclear shape, and density values are close to each other, demonstrating some consistency with the semantic meaning of latent features. The disadvantage of this approach is the fact that we cannot obtain a cluster with a high homogeneity score in cases in which certain classes have very low image counts within the dataset (such as SCC). This methodology could be improved with more cell images and additional cell labels by multiple pathologists.
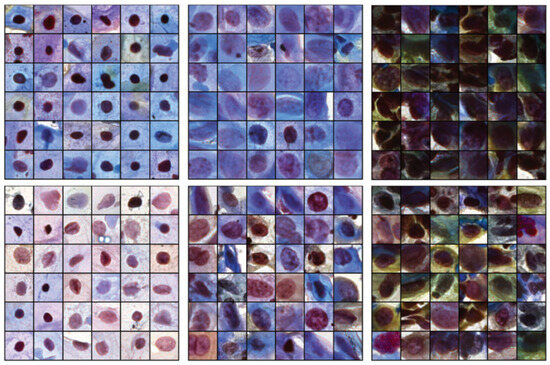
Figure 7.
Queried images from two high-homogeneity clusters for each class: negative intraepithelial lesion or malignancy (NILM) (left), low-grade intraepithelial lesion (LSIL) + atypical squamous cell of undetermined significance (ASC-US) (middle), and high-grade intraepithelial lesion (HSIL) + ASC—cannot exclude HSIL (ASC-H) (right).
4. Discussion
VAEs enable the disentanglement of latent features, which allows modeling of the latent space of cervical cells in pap-smear images. Experiments showed that we were successful in obtaining features corresponding to cytoplasmic color, nuclear shape, and image brightness in an unsupervised manner and concurrently achieved high AUROC for SCC and HSIL. More importantly, a simple Gaussian estimation of the latent feature space of normal examples produced these results without additional parameterized model-training requirements. Adding additional augmentations during the training of a generative model improved the discerning capability. However, as the generative model learns the data distribution, applying image augmentation can distort the original data distribution [40]. This is also shown in Figure 4, where the normal class (NILM) is not represented by a centered normal distribution for each latent entry. We deduce that the high discerning performance, despite the shift in latent distribution of NILM images, is due to the use of the estimate normal distribution rather than a standard normal distribution, as induced by the VAE training objective. A comparison of our results with those of other studies showed that there is a trade-off in using a limited number of labeled samples for deep feature learning. Table 4 lists the performance outcomes of other models obtained with supervised training. Despite training using only normal examples, our model was able to discern abnormality with an accuracy of 0.7 in binary classification tasks. This may be due to the low AUC scores for low-grade lesions (LSIL and ASC-US), as indicated in Table 2, which contributes to the overall lower performance.
Table 4.
Binary classification results. Supervised learning outperforms one-class classification (OCC) with variational autoencoders (VAEs).
The choice of evaluation metric for the clustering algorithm was based on the qualitative assessment of the latent space. Each class should be ideally situated in a single cluster for direct interpretation, i.e., ad hoc labeling of the cells within the cluster. However, as our latent space contains features related to position and affine transformation, abnormal classes are not characterized locally in latent space but form local clusters in some dimensions (for example, color and nuclei radii) and deviations from others (position). This suggested the use of separate metrics to quantify clusters containing only a single class; given a specific class, these quantify the capability of performing clustering using a single cluster instead of relying on a single metric such as accuracy. As expected, clustering results show that classes are locally close in the latent space, owing to the higher homogeneity and lower completeness scores, which indicate the sparsity of clusters within this space. This highlights the necessity of querying nearby images to assess new cells when applied in practice. This study was associated with some limitations. While our model can detect abnormalities for most classes, it does not discriminate effectively among abnormal classes like supervised models. To overcome this, we devised a querying method using agglomerative clustering. Images contained in some single cluster should have similar features.
5. Conclusions
VAEs provide means to interpret latent features by examining the reconstructed output and give a simple formulation for scoring abnormality. OCC of normal cells in pap-smear images can predict cell abnormality without using abnormal labels. Performance was shown to increase when additional image augmentation was applied during training. Along with interpreting latent features directly, a cross-entropy-based pseudo-metric was introduced for agglomerative clustering. The method consistently outperformed other common unsupervised clustering algorithms. We have shown that, although binary classification performance is worse than the performances of supervised methods, using OCC can discern HSIL and SCC from normal with high accuracy. We also demonstrated an implementation of an interpretable method that may contribute to the development of explainable artificial intelligence (AI) and AI trust in healthcare.
Author Contributions
Conceptualization, H.H. and J.C.; formal analysis, Y.A.; funding acquisition, H.H. and J.C.; investigation, J.C. and Y.A.; methodology J.C. and Y.A.; project administration, H.H. and J.C.; resources, N.J.-Y.P., J.C. and Y.A.; software, Y.A. and S.K.; supervision, H.H. and J.C.; validation, Y.A.; visualization, Y.A.; writing—original draft, Y.A.; writing—review & editing, J.C. and Y.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Brain Pool program, funded by the Ministry of Science and ICT through the National Research Foundation of Korea (2020H1D3A2A02102040, RS-2023-00283791).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Center for Recognition and Inspection of Cells (CRIC) Searchable Image Dataset can be obtained at https://database.cric.com.br (accessed on 1 January 2023). SIPAKMED dataset can be obtained at https://www.cs.uoi.gr/~marina/sipakmed.html (accessed on 1 January 2023).
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Relationships among CRSD and Other Divergences
The distance is equal to the Kullback–Leibler, Jefferys, and Jenson–Shannon divergences, depending on which reference probability distribution or set of probabilities is chosen. We denote the divergences as , , and , respectively. The following are some relations of our formulation to well-known divergences [25]:
If p and q, are Gaussian distributions with equal covariances, we can express the squared Mahalonobis distance as
Additionally, if , where I is an identity matrix, we are then essentially calculating distances between latent distributions by the Euclidean norm between the means, i.e., . Therefore, a connection is made to our method using standard clustering algorithms and the mean vectors of the latent representations using statistical distances; the former is a special case of the latter based on assumptions on the covariances and the choice of the reference distributions.
Appendix B. Model Architecture, Training Details, and Hardware
Convolutional neural network models used in this work all had the same architecture except for the projection of the encoder/decoder output to latent space. The encoder for the VAEs consisted of 5 convolutional layers with 3 × 3 kernels, 1 padding, and a stride of 2, followed by a 2-dimensional batch normalization [43] and a leaky ReLU non-linear activation [44]. For each layer, channels were 32, 64, 128, 256, and 512, respectively. The feature output of the final convolution layer is flattened, followed by a fully connected layer reducing the dimension to 512 before projecting to latent dimensions that parameterize the mean and log standard deviation by another fully connected layer each. The decoder consisted of 5 transposed convolutional layers with 3 × 3 kernels, 1 padding, 1 output padding, and a stride of 2, followed by a 2-dimensional batch normalization and a leaky ReLU non-linear activation. Before decoding, the sampled latent vectors were projected to the same size as the output of the last layer of the encoder using a fully connected layer. The optimizer used was Adam [45] with a learning rate of 1 × 10−3 and with weight decay 1 × 10−5. Cosine annealing was applied with equal to 800 using the pytorch implementation [46]. Training was set to 4000 epochs with gradient clip value 15.0. Floating point precision was used. Models were trained in parallel during hyperparameter tuning across three Nvidia RTX A6000 graphics processing units and each training session took about 33 h.
References
- Jansen, E.E.; Zielonke, N.; Gini, A.; Anttila, A.; Segnan, N.; Vokó, Z.; Ivanuš, U.; McKee, M.; de Koning, H.J.; de Kok, I.M.; et al. Effect of organised cervical cancer screening on cervical cancer mortality in Europe: A systematic review. Eur. J. Cancer 2020, 127, 207–223. [Google Scholar] [CrossRef] [PubMed]
- Bedell, S.L.; Goldstein, L.S.; Goldstein, A.R.; Goldstein, A.T. Cervical cancer screening: Past, present, and future. Sex. Med. Rev. 2020, 8, 28–37. [Google Scholar] [CrossRef] [PubMed]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA A Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Solomon, D.; Davey, D.; Kurman, R.; Moriarty, A.; O’Connor, D.; Prey, M.; Raab, S.; Sherman, M.; Wilbur, D.; Wright, T., Jr.; et al. The 2001 Bethesda System: Terminology for reporting results of cervical cytology. JAMA 2002, 287, 2114–2119. [Google Scholar] [CrossRef] [PubMed]
- Kurtycz, D.F.; Staats, P.N.; Chute, D.J.; Russell, D.; Pavelec, D.; Monaco, S.E.; Friedlander, M.A.; Wilbur, D.C.; Nayar, R. Bethesda interobserver reproducibility Study-2 (BIRST-2): Bethesda system 2014. J. Am. Soc. Cytopathol. 2017, 6, 131–144. [Google Scholar] [CrossRef] [PubMed]
- Chitra, B.; Kumar, S. Recent advancement in cervical cancer diagnosis for automated screening: A detailed review. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 251–269. [Google Scholar] [CrossRef]
- Wang, P.; Wang, L.; Li, Y.; Song, Q.; Lv, S.; Hu, X. Automatic cell nuclei segmentation and classification of cervical Pap smear images. Biomed. Signal Process. Control 2019, 48, 93–103. [Google Scholar] [CrossRef]
- Basak, H.; Kundu, R.; Chakraborty, S.; Das, N. Cervical cytology classification using PCA and GWO enhanced deep features selection. SN Comput. Sci. 2021, 2, 369. [Google Scholar] [CrossRef]
- Manna, A.; Kundu, R.; Kaplun, D.; Sinitca, A.; Sarkar, R. A fuzzy rank-based ensemble of CNN models for classification of cervical cytology. Sci. Rep. 2021, 11, 14538. [Google Scholar] [CrossRef] [PubMed]
- Özbay, E.; Özbay, F.A. Interpretable pap-smear image retrieval for cervical cancer detection with rotation invariance mask generation deep hashing. Comput. Biol. Med. 2023, 154, 106574. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goyal, A.; Bengio, Y. Inductive biases for deep learning of higher-level cognition. Proc. R. Soc. A 2022, 478, 20210068. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Moya, M.M.; Koch, M.W.; Hostetler, L.D. One-class classifier networks for target recognition applications. NASA STI/Recon Tech. Rep. N 1993, 93, 24043. [Google Scholar]
- Khalid, H.; Woo, S.S. Oc-fakedect: Classifying deepfakes using one-class variational autoencoder. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 656–657. [Google Scholar]
- Zavrak, S.; İskefiyeli, M. Anomaly-Based Intrusion Detection From Network Flow Features Using Variational Autoencoder. IEEE Access 2020, 8, 108346–108358. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006; Volume 4. [Google Scholar]
- Bezdek, J.C. Fuzzy-Mathematics in Pattern Classification; Cornell University: Ithaca, NY, USA, 1973. [Google Scholar]
- Sharma, M.; Singh, S.K.; Agrawal, P.; Madaan, V. Classification of clinical dataset of cervical cancer using KNN. Indian J. Sci. Technol. 2016, 9, 28. [Google Scholar] [CrossRef]
- Sulaiman, S.N.; Mat-Isa, N.A.; Othman, N.H.; Ahmad, F. Improvement of features extraction process and classification of cervical cancer for the neuralpap system. Procedia Comput. Sci. 2015, 60, 750–759. [Google Scholar] [CrossRef]
- Löffler, M.; Phillips, J.M. Shape fitting on point sets with probability distributions. In Proceedings of the Algorithms-ESA 2009: 17th Annual European Symposium, Copenhagen, Denmark, 7–9 September 2009; Proceedings 17. Springer: Berlin/Heidelberg, Germany, 2009; pp. 313–324. [Google Scholar]
- Lu, X. Information Mandala: Statistical Distance Matrix with Clustering. IEEE Access 2021, 9, 56563–56577. [Google Scholar] [CrossRef]
- Müllner, D. Modern hierarchical, agglomerative clustering algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: New York, NY, USA, 1999. [Google Scholar]
- Burgess, C.P.; Higgins, I.; Pal, A.; Matthey, L.; Watters, N.; Desjardins, G.; Lerchner, A. Understanding disentangling in beta-VAE. arXiv 2018, arXiv:1804.03599. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Chen, R.T.; Li, X.; Grosse, R.B.; Duvenaud, D.K. Isolating sources of disentanglement in variational autoencoders. Adv. Neural Inf. Process. Syst. 2018, 31, 2615–2625. [Google Scholar]
- Watanabe, S. Information theoretical analysis of multivariate correlation. IBM J. Res. Dev. 1960, 4, 66–82. [Google Scholar] [CrossRef]
- Hoffman, M.D.; Johnson, M.J. Elbo surgery: Yet another way to carve up the variational evidence lower bound. In Proceedings of the Workshop in Advances in Approximate Bayesian Inference, NIPS, Barcelona, Spain, 5–11 December 2016; Volume 1. [Google Scholar]
- Rezende, M.T.; Silva, R.; Bernardo, F.d.O.; Tobias, A.H.; Oliveira, P.H.; Machado, T.M.; Costa, C.S.; Medeiros, F.N.; Ushizima, D.M.; Carneiro, C.M.; et al. Cric searchable image database as a public platform for conventional pap smear cytology data. Sci. Data 2021, 8, 151. [Google Scholar] [CrossRef] [PubMed]
- Martin, E.; Jantzen, J. Pap-Smear Classification; Technical University of Denmark: Lyngby, Denmark, 2003; pp. 1899–2227. [Google Scholar]
- Plissiti, M.E.; Dimitrakopoulos, P.; Sfikas, G.; Nikou, C.; Krikoni, O.; Charchanti, A. SIPAKMED: A new dataset for feature and image based classification of normal and pathological cervical cells in Pap smear images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3144–3148. [Google Scholar]
- Subramanian, A. PyTorch-VAE. 2020. Available online: https://github.com/AntixK/PyTorch-VAE (accessed on 30 January 2023).
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The k-means algorithm: A comprehensive survey and performance evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 14, 849–856. [Google Scholar]
- Ester, M. A Density-Based Algorithm for Discovering Clusters in Sarge Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 291–316. [Google Scholar]
- Rosenberg, A.; Hirschberg, J. V-measure: A conditional entropy-based external cluster evaluation measure. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 410–420. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Jun, H.; Child, R.; Chen, M.; Schulman, J.; Ramesh, A.; Radford, A.; Sutskever, I. Distribution augmentation for generative modeling. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5006–5019. [Google Scholar]
- Diniz, D.N.; Rezende, M.T.; Bianchi, A.G.; Carneiro, C.M.; Ushizima, D.M.; de Medeiros, F.N.; Souza, M.J. A hierarchical feature-based methodology to perform cervical cancer classification. Appl. Sci. 2021, 11, 4091. [Google Scholar] [CrossRef]
- Liu, W.; Li, C.; Xu, N.; Jiang, T.; Rahaman, M.M.; Sun, H.; Wu, X.; Hu, W.; Chen, H.; Sun, C.; et al. CVM-Cervix: A hybrid cervical Pap-smear image classification framework using CNN, visual transformer and multilayer perceptron. Pattern Recognit. 2022, 130, 108829. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; Volume 30, p. 3. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).