1. Introduction
How to approach predictions/simulations by geostatistical methods in hydrostatigraphy is a still open question [
1,
2,
3,
4,
5,
6,
7,
8], since the assessment of the subsoil heterogeneity is one of the keystones in groundwater flow and transport modeling. Different approaches were proposed, e.g., the Boolean [
9,
10,
11], the truncated Gaussian [
12] and the pluri-Gaussian simulation methods [
13]. However, the most well-known lithological prediction/simulation in classical geostatistics is based on indicator kriging [
14,
15,
16]. Although this approach is very frequent in the literature, due to the availability of open-source programs, there are some intrinsic probabilistic inconsistencies typical of indicator kriging: the sum of occurrence is not exactly one, the probabilities are also not guaranteed to be between zero and one and the cumulative distribution functions may not increase monotonically.
These issues are well known in the literature as the “order relation problem” [
1]. Thus, a post-processing of the conditional probabilities is frequently needed [
17].
In the classical indicator approach, spatial variability is modeled by indicator (cross)variograms, which capture only some spatial peculiarities of geological facies. However, the approach based on indicator kriging predictions/simulations is computationally intensive because of the need to solve a large system of linear equations by enforcing linear constraints. The solution of such a system is provided by inverting a matrix that includes the covariance structure of the observed data and the linear constraints. From a computational point of view, the amount of memory required scales up with the quadratic complexity, and the amount of operations performed by the inversion algorithm increases with the cubic complexity. Providing a solution to the kriging equations becomes quickly unfeasible when dealing with many lithological categories and a large number of observations along the boreholes. Therefore, the lithologies accounted in traditional datasets rarely exceed four or five categories.
The concepts of transition probability in geostatistics and their graphical representations as probability-lag diagrams (“transiogram”) appeared in earlier articles, such as [
18,
19]. This concept depends on the distance between two locations and is able to account for more stratigraphic information than classical variograms [
20,
21,
22,
23,
24]. This concept combines juxtapositions modeled through embedded Markov chains, which are already known and used in sedimentary geology [
25,
26]. In this context, transiograms replace indicator (cross)variograms within prediction/simulation procedures. Transiograms provide some important stratigraphic information that are not considered by indicator variograms; for example, they produce information about the mean thickness of the materials, their volumetric proportions, and the lithology juxtapositional tendencies [
23,
24]. The empirical estimates of the transitional probabilities are modeled by continuous Markov-chains to obtain a theoretical transition probability function depending on the distance. However, [
20] maintained an indicator kriging-based approach in their prediction/simulation procedure, thus approximating the posterior probabilities via least-squares and taking over the related computational load.
A multiple-point geostatistics approach has also been introduced [
27,
28,
29,
30,
31], mainly by considering a better reproduction of a specific conceptual geological model, such as modeling a meandering channel system. Principal strengths and weaknesses of this geostatistical approach are summarized in [
28]. The lack of specifications for an underlying categorical random field improves its flexibility and efficiency, but, on the other hand, further inference is difficult to carry out since the underlying model (i.e., the training image) is hard to parameterize efficiently and may be difficult to acquire [
32]. The use of spatially correlated latent variables is a statistical solution to overcome the problem of formulating a parsimonious parameterization under a more general framework of generalized linear mixed models [
33]. Under this approach, the probability of an occurrence of a category in one site depends on the latent process itself (usually Gaussian). A main drawback of this method is that the posterior probability of the introduced latent variables is not available in a closed form, owing to the non-Gaussian response variables.
Thus, Markov chain Monte Carlo sampling is often used for the inference with latent variables. Alternatively, a spatial multinomial logistic mixed model [
34] was proposed for spatially correlated categorical variables with several categorical outcomes.
In hydro-stratigraphic predictions/simulations where probability values are restricted (i.e., the different lithologies) and constrained to sum up to one, a maximum entropy selection rule should be preferred to the least-squares when dealing with a categorical variable [
35].
The Bayesian Maximum Entropy principle (BME) [
36] has been applied in spatial statistics to categorical variables stored in soil data sets [
37,
38,
39,
40], but it faces the same computational limitations as the indicator kriging approach due to the number of lithologies.
In Allard et al., 2011 [
41], the maximum entropy principle is revisited and its solution presents a closed-form expression that depends only on bivariate probabilities. Thus, the posterior conditional probabilities are approximated only by the use of univariate and bivariate probabilities. This approach has been named Markovian-type Categorical Prediction (MCP).
Transition probabilities can be aggregated using a Bayesian updating formulation and interpreted as expert opinions for updating the prior marginal probabilities of categorical variables [
42,
43].
Therefore, the aim of this paper is to apply the MCP approach to study the subsoil composition in a small test area and produce consistent simulations of the subsoil heterogeneity. The studied area is located in the drinking water supply area of ACEGAS APS, a public company which supplies the city of Padua. In this area, the subsoil is particularly heterogeneous, representing the passage between the high and the middle Venetian Plain. The analyses of the studied area are performed by exploiting a recent implementation of MCP approach available in the spMC package [
44] for the R environment [
45].
The spMC package provides graphical tools for a better understanding of the data, and several options for parameter estimation, lithological simulations, and predictions. It allows the user to account for a non-kriging-based approach on the approximation of the conditional probabilities among lithologies and all the hydrogeological information coming from a transiograms analysis. The package provides several functions to deal with categorical spatial data, whose coordinates are either regularly or irregularly located over a multidimensional space. The main model used in the package is based on continuous-lag Markov chains and allows for a formal representation of the conditional probabilities of lithological occurrences between two sites. These probabilities depend on a multidimensional continuous lag, defined as the difference between two spatial positions. The spMC package has been partially implemented by exploiting High Performance Computing (HPC) techniques to improve its computational efficiency and allow for the processing of a larger number of the lithological categories. Since such a package has been designed for intensive geostatistical computations, part of the code deals with parallel computing via the OpenMP constructs [
46].
2. Materials and Methods
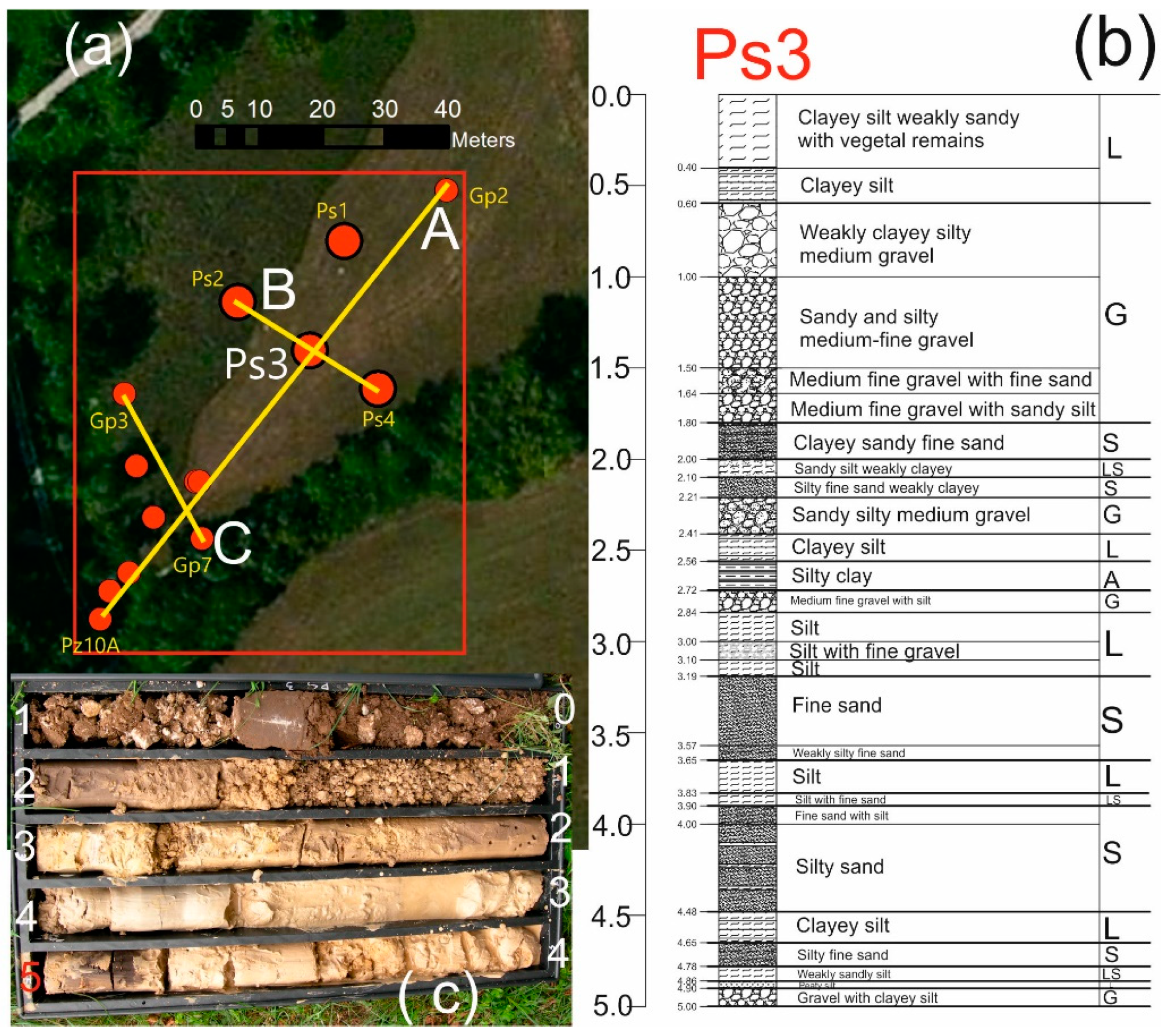
The analyses concern a hydrogeological study in an experimental site of 1.5 ha placed inside the drinking water supply area of ACEGAS APS. This site is located in the Venetian Plain (NE Italy) (
Figure 1).
The Venetian Plain is delimited on the north by the Pre Alps, on the east by the Livenza river, on the west by Lessini mountains, Berici and Euganei hills, on the south by the Adige river and the Adriatic Sea. The alpine limit of the plain is on 150–200 m a.s.l., diminishing towards SSE until the coast. From the West to the East, we can observe the hydrographical system of Leogra Timonchio, Astico Bacchiglione, Brenta and Piave; these rivers have deposited a huge amount of loose materials, forming the subsoil of the Venetian Plain. Therefore, the Venetian Plain consists of several large alluvial fans (Plio Quaternary deposits) called “megafans” whose width increases towards the SSE [
47]. The hydrogeological features of the Venetian Plain depend principally on the depositional sequences of the rivers and on their granulometric characteristics. In the upper part of the alluvial plain, near the Pre Alps, where the subsoil is composed almost totally by gravels, there is only a thick unconfined aquifer with high hydraulic conductivity (10
−1–10
−2 m/s).
Towards the south east and closer to the Adriatic Sea, the alluvial sediments move into a multi-layered system where cohesive and incohesive sediments alternate. Thus, the unconfined aquifer gradually evolves into a system of stratified, confined (or semiconfined), often artesian aquifers, which represent the lower plain [
48,
49,
50,
51,
52]. Between the upper and the lower plain, there is the middle plain that consists of progressively finer materials than the high plain. The middle plain is formed by gravely and sandy horizons alternating with clayey and silty levels, where the latter become more frequent from upstream to downstream [
53]. This area is characterized by a high quantity of plain springs (arising from the intersection between the topography surface and the water table) (
Figure 1).
This natural drainage system supplies numerous perennial stream flows (
Figure 1), e.g., the Sile river (5–6 m
3/s). This regional context affects our area of study, contributing to its heterogeneity.
In the considered area (1.5 ha), 39 piezometers are present with a depth ranging from 1.6 to 22 m and a diameter ranging from 50 to 90 mm. The structural characteristics of 29 piezometers are available. The subsurface composition, and consequently the hydrogeological features, show high heterogeneity with gravel horizons alternating with sandy, silty and clayey levels (
Figure 2b,c). The shallow unconfined aquifer of this area is essentially recharged by rainfall [
53,
54].
Figure 2a shows the red rectangle of the simulation area with the location of 13 available borehole logs that are 5 m deep and have data every 2 cm. An example of stratigraphy (Ps3) is given in
Figure 2b.
Markovian Categorical Prediction (MCP)
Traditionally, Markov chains are stochastic processes described by a probabilistic model along a single dimension (usually time) subdivided into discrete lags. The extension of this concept arises by the definition of a Markov process involving continuous lags in a
d dimensional space [
21].
By considering a stationary process, the transition probability between two lithologies (categories),
i and
j, in two locations,
s and
s +
h, is defined as:
where K is the total number of lithologies (1,…, K) that the categorical random variable Z can assume as outcomes and
h is a multidimensional lag from any observed location
s. The transition probability
is the element in the
i-th row and in the
j-th column of the matrix
T(
h) such that:
where the transition rate matrix
depends both on the length of the lag
h and its direction.
Carle and Fogg, 1997, formulated the transition rate matrix
for the direction
h by an ellipsoidal approximation, which combines the matrix
derived from the main axial directions. The vector
indicates the standard basis vector of dimension
d, whose
k-th component (corresponding to the
k-th axial direction) is one and the others are zeros. Considering our scope, the first problem consists of the estimation of the transition rate matrix components
, and the second arises from the choice of the conditional probability approximation adopted for simulating/predicting the lithologies. Different methods address the first problem and are implemented in spMC. These include the mean lengths and the maximum entropy method suggested by Carle and Fogg, 1997. The lithological simulation and prediction algorithms implemented in spMC are based on attempts proposed to solve the second problem, and consider different approximations of the conditional probability:
where
denotes the simulation/prediction spatial location without lithological information,
represents the
l th spatial position of the available data, and
corresponds to the observed lithology of the random variable
.
The classical approximation of (3) is based on the cokriging or kriging approach, while other formulations bypass the kriging formalism and its related issues. For instance, Bogaert, 2002 introduced a Bayesian procedure that exploits the maximum entropy principle, but requires a computationally intensive entropy optimization. Allard et al., 2011, avoided the entropy optimization by aggregating the transition probabilities (Markovian-type Categorical Prediction (MCP)) to approximate the optimal solution of the maximum entropy approach. The approximation of the conditional probability proposed by Allard et al., 2011, is formulated as follow:
where
denotes the proportion of the
i-th lithology considered for the location
, and
is the transition probability to the
i-th lithology in
from the
k-th lithology observed in the location
.
The sources of uncertainty in a conditional simulation setting are mainly related to the several approximations used in the computation of the final conditional probability. The estimation process consists of several steps to compute transition rates along axial directions. These steps introduce variability in the estimates of the rates by aligning the data according to a reasonable angular tolerance, and a possible model misspecification due to the ellipsoidal approximation [
21] along non-axial directions may reduce the precision of the transition probabilities. In addition, the approximation used to produce the conditional probabilities affects the accuracy of the resulting predicted lithologies. All these sources are considered together the intrinsic variability of the spatial random process, which increases as the distance between the prediction point,
, and the data becomes wider.
To evaluate the uncertainties of the simulation process the standardized conditional entropy [
55] is computed as:
This index allows to assess the spatial distribution of the simulations by highlighting areas that are more uncertain due to the lack of data. Other indexes, such as producer and user accuracies, can be used to assess the ability of the methodology in reproducing the correct lithology by using validation data; however, this type of analysis goes beyond the aims of this paper.
3. Data Analysis
As described in
Section 2, 39 piezometers are present in an area of 1.5 ha, but only 13 are drilled in the simulated area (70 m x 60 m) (red box in
Figure 2a).
The first step simplifies the local complex heterogeneity of the available 13 stratigraphic logs into five lithologies: A = clay, G = gravel, L = silt, LS = silty sand and S = sand. All analyses are performed by the package spMC [
44] implemented in R, which is a free software environment for statistical computing and graphics.
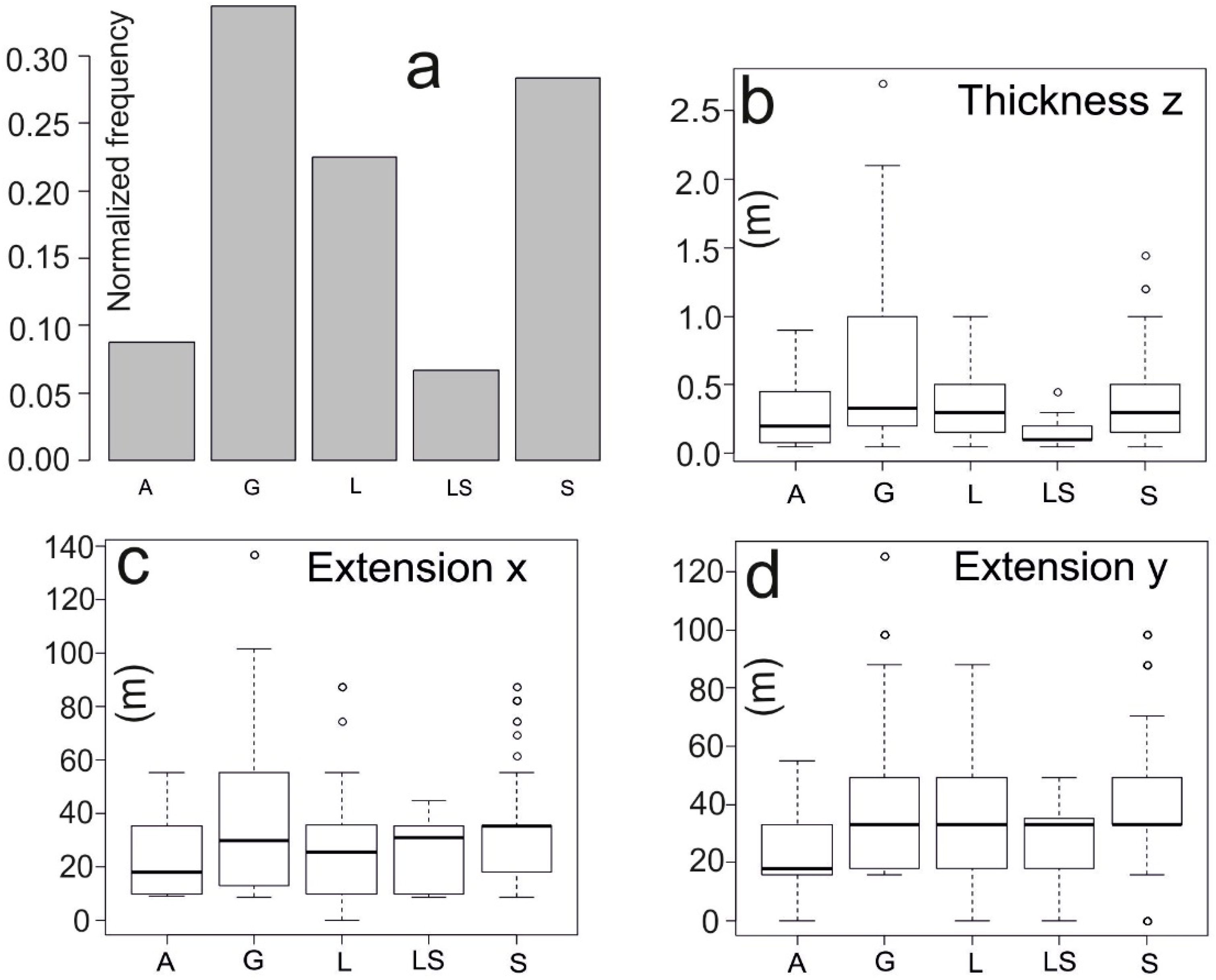
Figure 3a shows the sediment distribution indicated in the subsoil G (0.34), S (0.28) and L (0.22) as more frequent than A (0.09) and LS (0.07). The boxplots of
Figure 3b–d show the thickness/extension distribution of the lithologies along the directions Z (depth), X (longitude), and Y (latitude), and their mean values are exposed in
Table 1. The horizontal extensions are based on the 13 borehole locations that are successively considered during the simulation (
Figure 2a). The extensions in X and Y are calculated for all five lithologies through the mean lengths of spatial embedded Markov chains.
As visible in
Figure 3b, layers made out of gravels (G) present more variation in thickness than the other four lithologies, while the variation in the lithological extension along the directions X and Y (
Figure 3c,d) is higher but comparable between them.
The analysis of the embedded transition probabilities in 3D allows for a first rough juxtapositional investigation among the five considered materials, independently of their thickness or extension.
For instance, the analysis of
Table 2 along the direction Z (depth) highlights that, among all the five lithologies, it is more probable to find a layer of sandy silt (LS) above a layer of sand (S) (0.62) than a layer of S above a layer of LS (0.36), while the probability to find a layer of gravel (G) above a layer of silt (L) (0.36) is similar to its opposite condition (0.37). It is also evident that the probabilities seeing a layer of sandy silt (LS) above a layer of clay (A) (0.07) or a layer of gravel (G) above a layer of sandy silt (LS) (0.11) are both low.
The analyses of
Table 2 along the direction X (longitude) and Y (latitude) shows the estimated probability that one lithology laterally neighbors another. For instance, it is evident that there is a high probability to pass from clay (A) to gravel (G) (0.64 along direction X and 0.66 along Y). Moreover, similar probabilities to pass from L to G (0.70) and from G to L (0.69) have been computed along Y, while the probability to pass from A to LS is the smallest (0.00 along Y and 0.05 along X).
4. Transiogram Analysis
The lithological transition probabilities are analyzed along the directions Z (depth), X (longitude) and Y (latitude) in relation to different distances (h). These probabilities are modeled through continuous lag Markov chains and used in the next section for the lithological simulation.
The theoretical transition probabilities are calculated by estimating transition rates with a maximum entropy approach that uses the trimmed mean of the lithological layers.
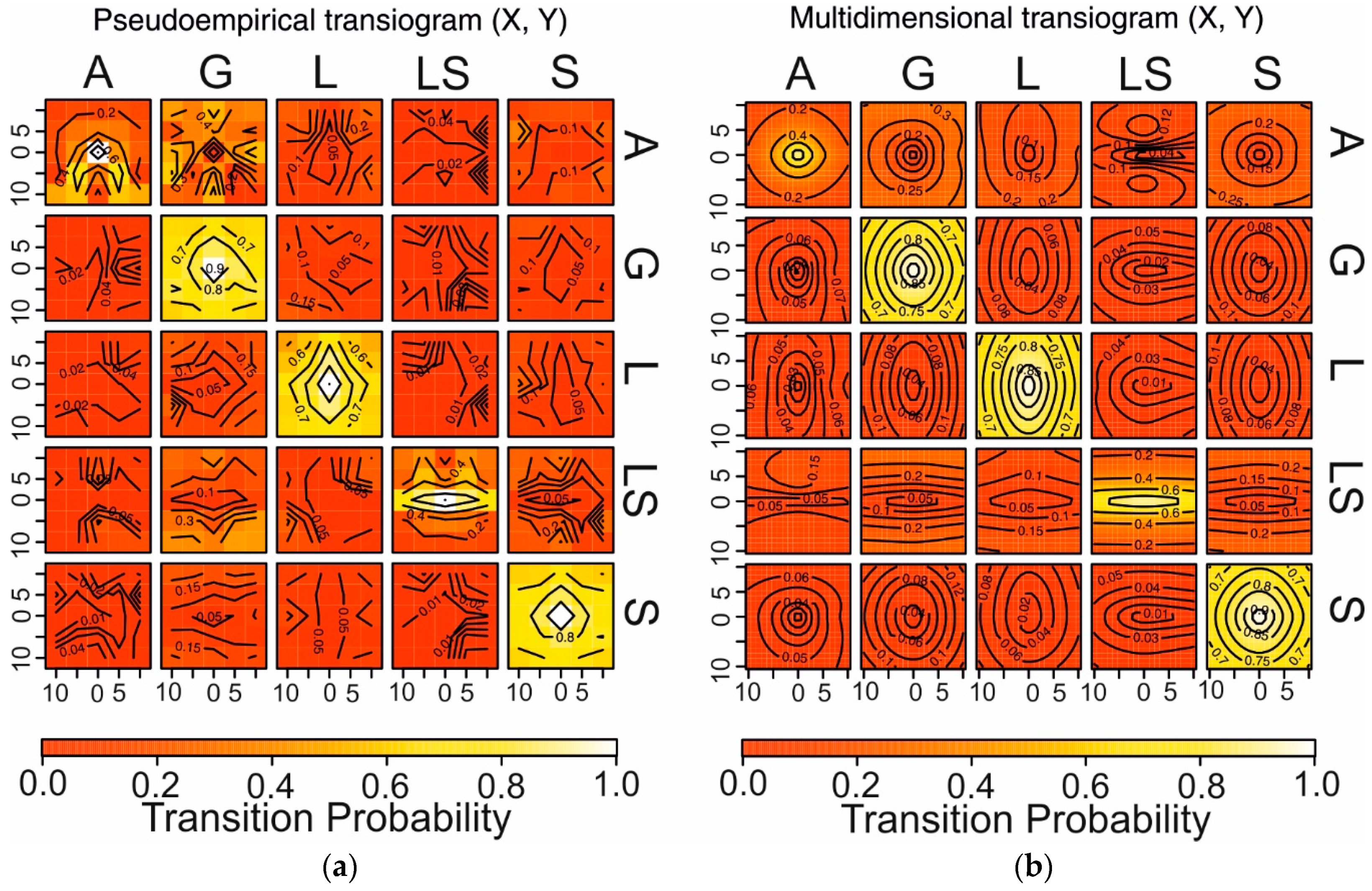
The analysis of the diagonal transiogram (e.g., A vs. A, G vs. G, etc.) in
Figure 4 gives some information about the thickness of the layers by showing the probabilities of finding the same lithologies juxtaposed every 5 cm in depth (direction Z). Along the diagonal of auto transitions, a high empirical probability is visible in sand (S), and it reaches a sill of about 0.4 at a range of 1 m (
Figure 4a). At the same time, the empirical auto transition probability in gravel (G) regularly decreases in depth down to 0 (
Figure 4b). This could mean that sandy layers are thinner (sand thickness 0.38 m) and more frequent than the gravely ones (gravel thickness 0.70 m). This is also visible in the boxplot of the length distribution for sand in
Figure 3b. The transiogram behavior (
Figure 4c) for silt (L) suggests that the thickness of silt layers is comparable to that of sand layers (S), but silty layers are more frequent than the sandy ones (compare
Figure 4c vs.
Figure 4a). The probabilities of auto transition for clay (A) and sandy silt (LS) (
Figure 4d,e) quickly achieve a very low sill value. This makes it less likely to find thick or frequent layers for those two lithologies.
The off-diagonal transiogram analysis of
Figure 4 gives some information about the juxtapositional tendency of the materials at different distances
h. The results are comparable with those of embedded transition probability in
Table 2, but, in this case, transition probabilities are plotted versus distances
h. A high probability of finding sandy silt (LS) in contact with and above sand (S) with a sill of approximately 0.5 and a range of about 1 m (
Figure 4f) is notable. A “hole effect” is also visible in the transition diagram from clay (A) above silt (L) (
Figure 4g), but also from silt (A) above sand (S) (
Figure 4h), indicating an irregular alternate occurrence in those two pairs of lithologies. Transiograms along the directions X and Y are calculated without considering Walther’s law of facies, stating that the vertical (along Z, i.e., depth) succession of facies reflects their lateral changes. This probably produces less interpretable experimental transiograms, but they are based on the information available from real data.
After analyzing the transiograms, the surface theoretical transiograms are studied with (
Figure 5b) or without (
Figure 5a) ellipsoidal interpolation calculated by experimental data. These diagrams highlight the anisotropies of the modeled transiograms in the X–Y plane.
The auto transition in silt (L) and gravel (G) show an anisotropy along the latitude. It is more probable to find silt and gravel along the Y direction (latitude) than the X direction (longitude). This is also confirmed from the lengths in Y and X (
Table 1), while the visible anisotropy along X related to silty sand (LS) it is not visible in
Table 1.
5. Simulation Results
After the transiogram analysis and modeling, a 3D simulation of lithologies has been performed by means of the MCP algorithm. This algorithm is implemented in the spMC package and uses a maximum entropy approach in order to approximate the posterior conditional probabilities.
A small portion (70 × 60 × 5 m) of the hydrogeological zone described before has been converted into a discrete 3D grid of 56 × 69 × 91cells [1 × 1 × 0.05 m] (
Figure 2).
An example of lithological heterogeneity in the studied area is visible in the core box of the 5 m deep borehole Ps3 exposed, also in
Figure 2c. The aim of the geostatistical simulation performed by the MCP algorithm is to reproduce such a heterogeneity.
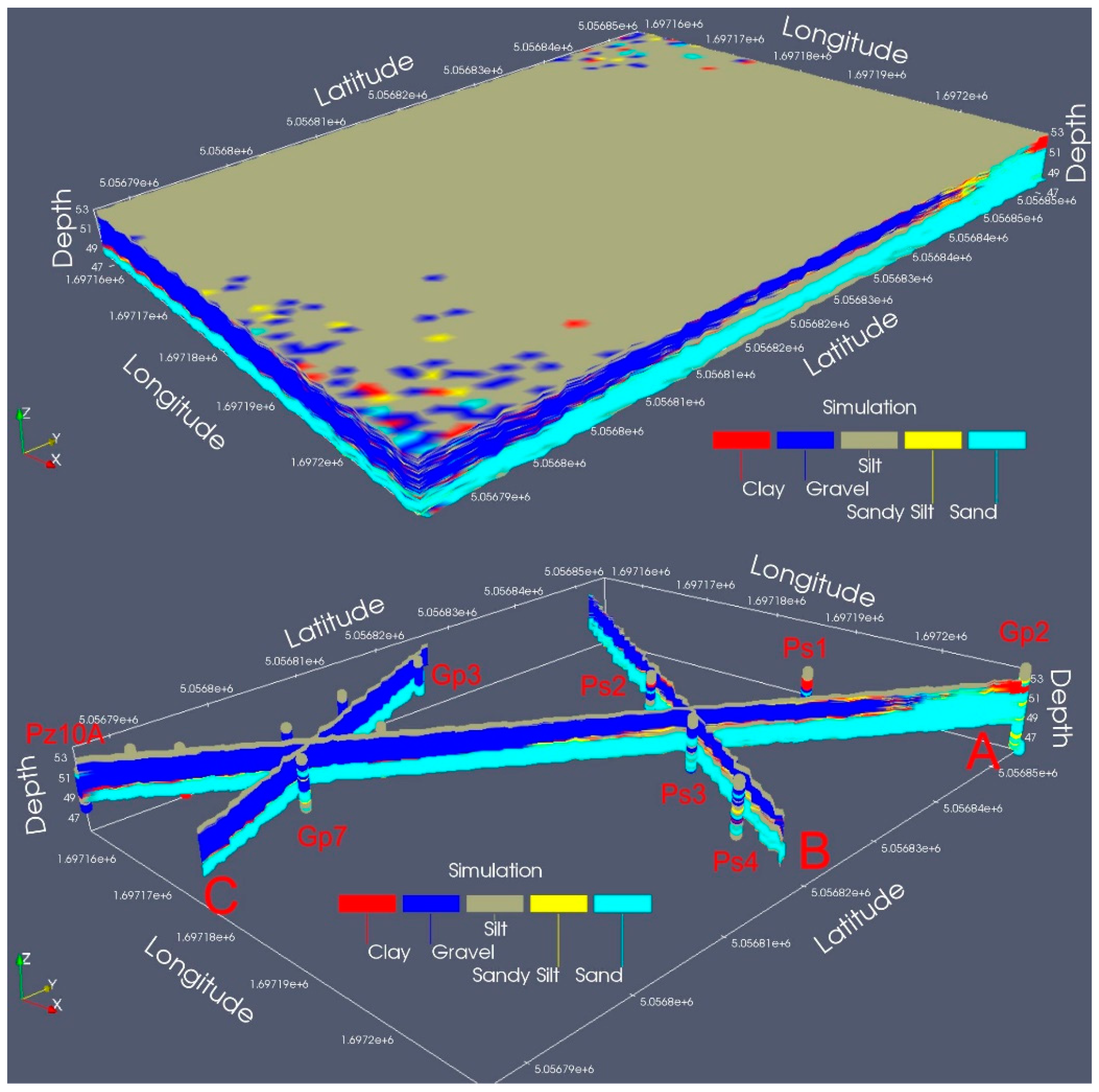
In
Figure 6, the results of lithologic simulation are visible in 3D and in three cross-sections (A, B, C) from 48.5 to 53 m a.s.l., while the latitude and longitude are expressed according to the “Monte Mario Italy 1” coordinate system.
The simulation obtained by MCP algorithm is plotted through ParaView software [
56]. ParaView is an open-source, multiplatform data analysis and visualization application.
The traces of those cross sections are also visible as yellow lines in
Figure 2a. The first cross section (A) (
Figure 6) is a diagonal obtained from the simulated area and starts from borehole Gp2 to Pz10A. The second (B) is almost perpendicular to the first one and passes through borehole Ps2 and Ps4. The third (C) passes through borehole Gp3 and Gp7.
The analysis of these simulated cross-sections confirms (compare
Table 2,
Figure 4f) as sandy silt (LS) layers are often located above sand (S) layers rather than vice versa. Moreover, sandy silt (L) layers are rarely below clay (A) layers as visible in
Figure 4m and
Table 2. A more probable situation occurs with regard to gravel (G) layers located below sandy silt (LS) layers, as shown in
Figure 4n and
Table 2.
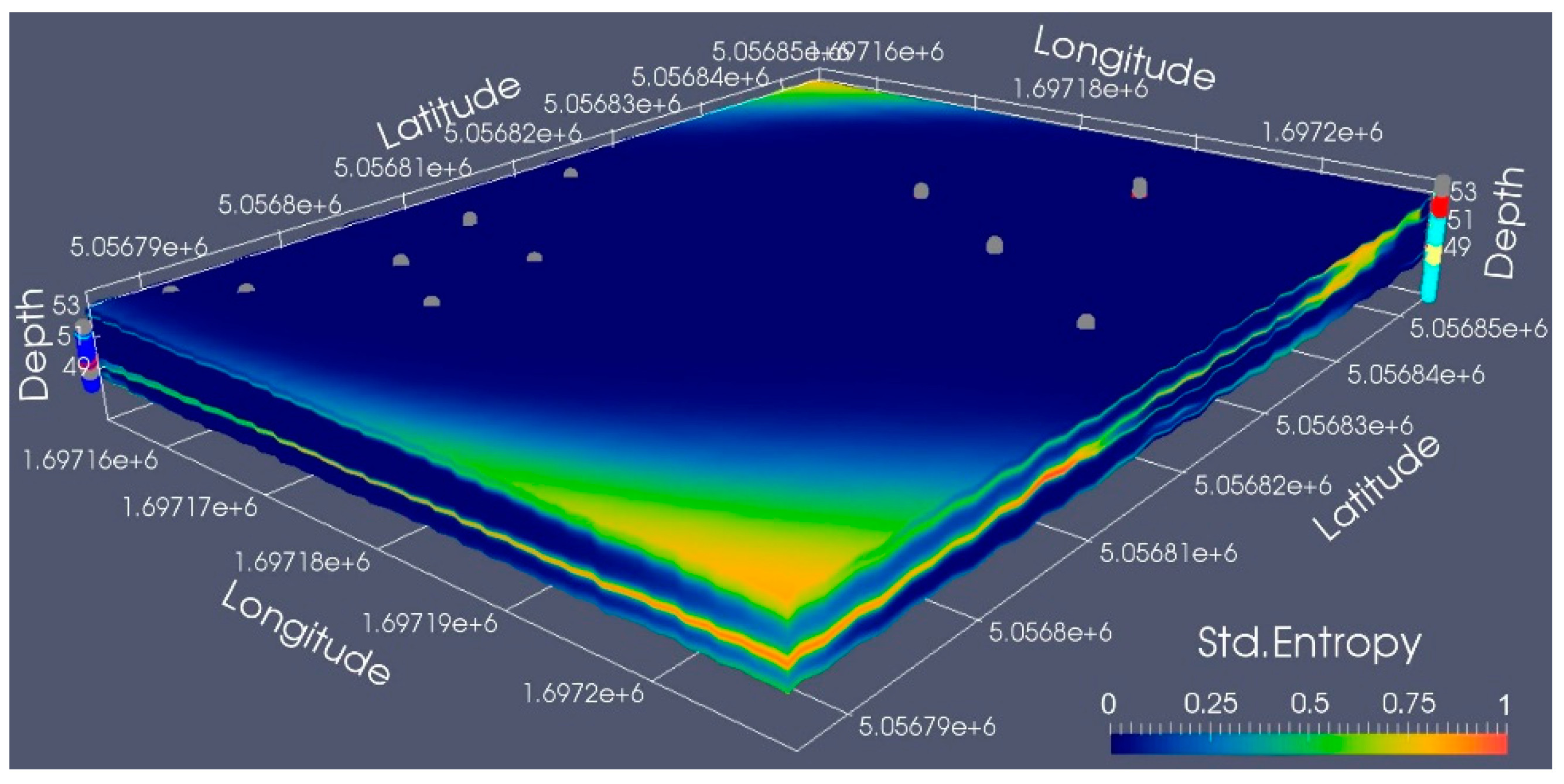
In this work, standardized conditional entropy index represents the uncertainty of the spatial information linked to the simulated lithologies. In other words, the 3D entropy index suggests both zones where the information is accurate and where lithological information should be improved. As is visible in
Figure 7, the maximum entropy (i.e., entropy ≥ 0.9) is located in zones with a lack of boreholes. Low values of entropy, instead, cover the zones where more boreholes are located. The conditional entropy map depicts good reliability in the zones where the boreholes are present. More uncertain areas are located where the boreholes are missing or sparse. In this sense, the normalized entropy volume gives us an important hint for a possible enhancement of coring, showing where new information should be acquired (i.e., zones with entropy ≥ 0.9).
6. Conclusions
In this paper, a simulation of lithological distribution in a small area located in NE Italy has been carried out. Geostatistical reconstruction of subsoil, considering categorical data, is frequently made via the indicator kriging approach, which is affected by the aforementioned conceptual issues. Along these lines, a Markovian-type Categorical Prediction (MCP) implemented in the R package spMC has been applied to show the potentialities of the software and the advantages of this new geostatistical approach. The main results of that study pointed out some important aspects, both for application purposes and computational efficiency.
From a geological perspective, the pairwise comparison of juxtapositional tendencies of the lithologies (especially in depth), regardless of their distances, provides information on the depositional correlation among materials. This also explains the spatial changes of the probability in finding other materials. Furthermore, the inspection of the diagonal transiogram (i.e., autotransiograms) supplies the associated probability of finding lithological thickness. These two types of information play an important role for both the sedimentological and hydrogeological perspectives; in fact, one can infer depositional cycles and related hydrogeological structures that control flow direction. The MCP simulation reproduces the heterogeneity of the studied area well. This fact is also corroborated by the juxtaposition tendencies that are comparable with both the estimated Embedded Transition Probabilities (ETP) and transiogram results.
From a computational point of view, MCP simulates lithologies by using only the sums and products of univariate and bivariate probabilities. This approach is in agreement with the maximum entropy approach and produces consistent results with the lithological heterogeneity of the simulated area, by avoiding the well-known “order relation problem” of the indicator kriging. This simulation method avoids high computational burden, which is typical of the indicator kriging. HPC techniques further improve the computational efficiency and also allow us to increase the number of lithological categories considered during the simulation. In conclusion, the results obtained by the spMC package suggest that this software should be considered as a good candidate for simulating the subsoil lithological distributions of limited areas. Its computational capabilities and its efficacy in modeling heterogeneity allow for a wide application of spMC in hydrogeological modeling.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}