Abstract
Estimating Manning’s roughness coefficient is one of the essential factors in predicting the discharge in a stream. Present research work is focused on prediction of Manning’s in meandering compound channels by using the Group Method of Data Handling Neural Network (GMDH-NN) approach. The width ratio , relative depth , sinuosity , Channel bed slope , and meander belt width ratio are specified as input parameters for the development of the model. The performance of GMDH-NN is evaluated with two different machine learning techniques, namely the support vector regression (SVR) and multivariate adaptive regression spline (MARS) with various statistical measures. Results indicate that the proposed GMDH-NN model predicts the Manning’s satisfactorily as compared to the MARS and SVR model. This GMDH-NN approach can be useful for practical implementation as the prediction of Manning’s coefficient and subsequently discharge through Manning’s equation in the compound meandering channels are found to be quite adequate.
1. Introduction
In river engineering, the Manning’s coefficient plays a vital role in the computation of flood discharge, velocity distribution, designing structures, calculating energy losses [1,2], and other hydraulic parameters. Accurate estimation of Manning’s roughness plays an important factor in flood conveyance estimation. Manning’s not only represented bed roughness, but also signifies the resistance to flow. Various equations are used for getting the discharge in simple channels using Manning’s , Chezy’s and Darcy-Weisbach’s [3], but those equations are not adequate well, while predicting discharge in meandering compound channels. This study is focused on developing a machine learning based data-driven models for predicting Manning’s . There are various elements that affect the resistance coefficient, such as the bed roughness, slope of the bed, geometry of the channel, and other parameters of a river.
Generally, the Manning’s formula is used for calculating the discharge in open channel flow. A significant amount of research has been carried out for selecting roughness coefficients for discharge calculation in an open channel. Cowan [4] considered the irregularity of the surface geometry of the channel, obstructions, and sinuosity to propose a model for predicting Manning’s roughness coefficient in meandering channels. The Soil Conservation Service (SCS) had developed an equation for estimating Manning’s for meandering channels by considering the sinuosity of the channel [5]. Limerinos [6] established a method for estimating the roughness coefficient by considering the various hydraulic parameters. Formulation for Manning’s roughness showing the gradient effect in channels having longitudinal slopes greater than 0.002 was derived by Jarrett [7]. Due to variation in flow depth, geometry and slope, the distinction of roughness coefficient in a straight channel as compared to a meandering channel were discussed by Arcement and Schneider [8]. Yen [9] proposed Manning’s for simple uniform flows taking account for a geometric measure, such as unevenness of the edge. Further, SCS method was linearized by James [10] for a meandering channel, named the Linearized SCS (LSCS) and recommended the Manning’s roughness value for the different sinuosity channels. Shiono et al. [11] developed a model to predict discharge considering the Manning’s n in the case of longitudinal slope and the meander effect of the channel. Jena [12] proposed an equation to calculate the by considering the effect of channel width, longitudinal channel slope, and the flow depth of the channel. The variations of wetted area, wetted perimeter, and the velocity data on Manning’s roughness coefficient by considering the flow simulation and sediment transport in irrigated channels was investigated by Mailapalli et al. [13]. Khatua et al. [14,15,16] formulated a mathematical equation for roughness coefficients by varying the sinuosity and geometry of the meandering compound channel. Xia et al. [17] and Barati [18,19,20] carried out the experiments for predicting discharge by taking care of the effect of bed roughness. Dash et al. [21] modeled the Manning’s roughness coefficient by considering the aspect ratio, viscosity, slope of the bed, and sinuosity. Pradhan et al. [22] proposed an empirical formulation of predicting Manning’s by dimensional analysis for the compound meandering channel, which affects relative depth, width ratio, longitudinal channel slope, and sinuosity.
In the recent years, ML techniques have been successfully implemented for predicting complex phenomena in hydrology and hydraulics. Zhang et al. [23] used the concept of diversity in the Group Method of Data Handling (GMDH) method for the prediction of time series to improve the noise-immunity capability. Mrugalski [24] proposed a method for error estimation based on the dynamic GMDH and multiple inputs, as well as output neurons. Najafzadeh and Lim [25] optimized the neuro-fuzzy GMDH model by the particle swarm optimization process to forecast the localized scour.
Vapnik and Lerner [26] extended the generalized statistical learning theory and introduced a term representing the intensive loss function for measuring the risk intensity in the support vector machine algorithm (SVM). More details on SVM can be found from many publications [27,28,29,30]. Dibike et al. [31] appraised SVM for rainfall-runoff modeling and revealed the significance of SVM in the field of civil engineering. Pal and Goel [32] also used the SVM technique to determine the discharge and end-depth ratio for circular and semi-circular channels. Further, Han et al. [33] applied SVM methodology for flood forecasting. Genc et al. [34] used Machine learning (ML) algorithms, i.e., SVM, ANN, and k-nearest neighbor (k-NN) to predict the velocity in small streams. Samui et al. [35] compared that the multivariate adaptive regression splines (MARS) methodology with ANN and FEM model and perceived that the MARS gives best outcomes for the uplift capacity of the suction caisson. Samui and Kurup [36] used MARS and LSSVM for the prediction of the consolidation ratio of clay deposits. Samui [37] predicted the elastic modulus of rock using MARS and show the performances of the MARS model better than the ANN.
However, collecting the velocity, discharge data during high flows in rivers, especially during unsteady, non-uniform and high flows are very dangerous and difficult task. Under these circumstances, the Machine learning (ML) models are highly helpful as the alternative approach for predicting Manning’s and the discharge in hydraulics engineering.
2. Experimental Setup
Experimental investigations are carried out in meandering compound channels with different sinuosity at the hydraulics-engineering laboratory under the department of civil engineering, National Institute of Technology Rourkela (NITR), India. The meandering compound channels are cast out of perspex sheets inside the flume of 10 m long, 1.7 m wide, and 0.25 m deep. The channel surfaces consist of the roughness coefficient as 0.01. Three types of experimental channels are set up for the present research works, as shown in Figure 1, Figure 2 and Figure 3. In the first and second type of meandering compound channels (NITR Type-I and NITR Type-II), the main channel is meandering with sinuosity 1.37 and 1.035, respectively, and is flanked by straight floodplain on both sides. The third one (NITR Type-III) is a doubly meandering compound channel, where both the main channel and floodplain levee are meandering with different sinuosity. Details of the experimental setup of these compound channels shown in Table 1.
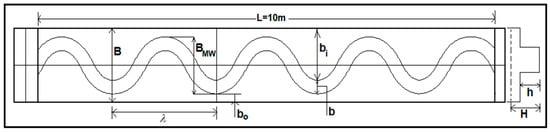
Figure 1.
Geometric Configuration of Meandering Compound Channel (National Institute of Technology Rourkela (NITR) Type-I).
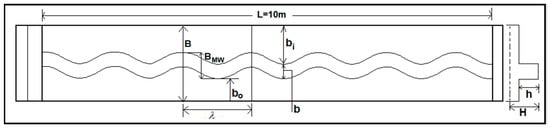
Figure 2.
Geometric Configuration of Meandering Compound Channel (NITR Type-II).

Figure 3.
Geometric Configuration of Doubly Meandering Compound Channel (NITR Type-III).

Table 1.
Description of Geometric Parameters of the three Experimental Channel setup.
The bed slope of the channel is recorded as 0.001 for all the three types of channel. A movable bridge is placed across the flume with the facility of traversing on both the directions over the flume for taking measurements at different locations in the channel section. A measuring tank is situated at the downstream end of the flume. Water from the measuring tank is collected in a sump, which again feedbacks to the overhead tank with the help of a centrifugal pump. A closure valve is fitted at the downstream volumetric tank. A schematic illustration of the experimental setup of the compound meandering channel is shown in Figure 4. For a better understanding of the experimental channel setup, the sample photograph of NITR Type I, Type II, and Type III meandering compound channels are shown in Figure 5.
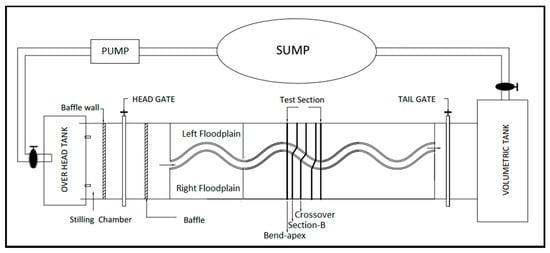
Figure 4.
Plan View of the Experimental Meandering Compound Channel.

Figure 5.
Photograph of Experimental Channel Setup (a) NITR Type-I Channel; (b) NITR Type-II Channel; and, (c) NITR Type-III Channel.
The measuring equipment involves point gauge having least count of 0.1 mm for measuring the flow depth in the channels. A Pitot tube coupled with manometer is used for measurement of pressure difference from which the point velocities of flow in the compound channels are computed. All of the readings are taken at the predefined grid points, as shown in Figure 6, at the bend apex, Section B and a geometric crossover of the three types of channels (Figure 4).
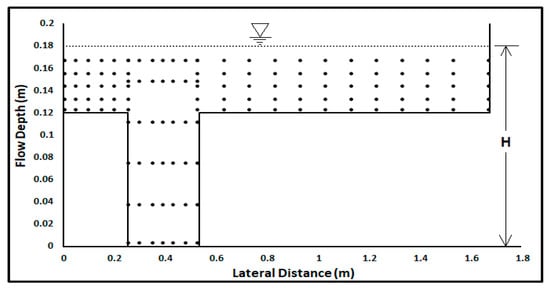
Figure 6.
Grid Arrangement of Points for experimental measurements across the channel section.
The Manning’s for the perspex sheet channel boundary is experimentally determined as 0.01. For this, the in-bank flow in the meandering main channel is collected in the volumetric tank located at its end. From the time-rise data of the water level in the volumetric tank, the discharge rate is computed. By knowing the channel cross-sectional area and the wetted perimeter, Manning’s is computed for four consecutive depths of flow, and the mean value of is computed as 0.01 [(0.0088 + 0.0096 + 0.0104 + 0.012)/4], which is found to be close to its value given various handbooks for the type of bed materials.
Traditional flow formulae are used for the estimation of discharge are Manning’s equation. From the observed discharge results, we can calculate Manning’s coefficient by the back calculation. After getting discharge, mean velocity can be computed by dividing area to the discharge. Then, from Manning’s equation, corresponding can be evaluated, which is given in the below equation:
where is indicated the mean velocity for the compound section of the compound channel, the bed slope of the compound channel, and the hydraulic radius of the compound channel. It is known that Manning’s increases slightly with the depth of flow in the channel representing a lumped response to all of the flow resistances. Since the basic purpose of the present work is to model the Manning’s for overbank flow, the variation of observed value for the compound channel is shown in figure later in the manuscript.
Besides the present work, reported data of other researchers are also used to calibrate models for predicting Manning’s value. Other experimental works from which data is used in the present work are the FCF-B; the investigational studies done in the UK, Flood Channel Facility (FCF) during 1990–1992 on large-gauge meandering channels (Phase B). The data are acquired from the Birmingham university website (http://www.birmingham.ac.uk/) and also collected from other articles [10,38,39]. Other than FCF-B, the authors have also used data from Toebes-Sooky [40], Kar [41], Das [42], Kiely [43], Patra-Kar [44], Khatua [45], Mohanty [46], and Pradhan [22] to predict the roughness coefficient, as given in Table 2. All of the experimental channel data used in the present work consists of similar hydraulic nature having smooth meandering compound channels.
Table 2.
Hydraulics Parameter of the Experimental and Collected Dataset used in Present work.
Factors Affecting Roughness Coefficient
Studies [8,11,15,16,21,22,47,48] have indicated that Manning’s not only represent the resistance to the flow in the channel, but it represents the lumped response of all the hydraulic and geometric parameters influencing the flow in the channel. Therefore, in the current study, the author considers the influencing non-dimensional factors, such as the width ratio of the channel , depth ratio or relative depth , sinuosity , longitudinal channel slope , and meander belt width ratio as the inputs to model for predicting the Manning’s value. A regular channel retains diversity in flow and surface conditions that need to be incorporated to develop a suitable model for predicting the roughness coefficient at various flood conditions. It is important to incorporate all of these variables to predict a suitable roughness coefficient at all flood conditions.
For the present work, the Group Method of Data Handling neural network (GMDH-NN) algorithm is used to predict the roughness coefficient, which is compared with machine learning methods, such as the multivariate adaptive regression spline (MARS) and the support vector machine regression (SVR) models, for developing a best alternative for modelling Manning’s value for compound channels.
3. Theoretical Background
3.1. Group Method of Data Handling Neural Network (GMDH-NN)
GMDH-NN is a machine learning algorithm based methodology that works by the principle of termination [49,50,51]. The principle of termination is a process where the data seeding, rearing, hybridizing, selection, and rejection of seeds relate to the determination of the input variables, structure, and parameters of the model. The GMDH-NN algorithm consists of a set of neurons wherein altered pairs of the neurons are connected through a quadratic polynomial in each layer, resulting in the new neurons for the further layer. For number of observations with multiple input variables, the required output of the dataset is defined as:
where is the actual output for a given input of actual function . For system identification problem, the function is approximately used instead of an actual function , to predict the output value as close as possible to its actual output .
A GMDH-NN network is trained to predict the output values for any given input , that is
GMDH-NN constructs some mathematical functions between each output and input parameter. The particular GMDH-NN function is decided by calculating the mean squared error (MSE) to minimize the square of the difference between the actual and predicted output from the relation
The algorithm, namely the Kolmogorov–Gabor polynomial, a distinct form of the real value function is used for the relation function between the inputs and an output variable [49,50,52,53] is described as:
The coefficient is determined while using Equation (5). The regression is used to reduce the variation between the actual and predicted output for each pair of input variables [50,54].
3.2. Multivariate Adaptive Regression Spline (MARS)
Another databased method from the machine-learning field is the Multivariate Adaptive Regression Spline (MARS), which is adopted here to obtain a model for the prediction of Manning’s in compound meandering channels. The MARS is a type of non-parametric regression model first introduced by Friedman [55]. It combines the nonlinearities and interactions between variables automatically, for predicting continuous outputs. It also divides the data into several splines in the corresponding interval, wherein each spline split the predictors into subgroups and knots for non-linear relationships [56]. According to Leathwick [57], MARS splits the input variables into piecewise linear segments for relating the non-linear associations between the dependent (output) and the independent (input) variables. Formulation of MARS is written in the following form:
where is the dependent output variable, the constant term, the coefficient vector of the non-constant basis functions, the truncated power basis function, the index of the independent input variable of the term and product, and the order of interaction limit. The definition of the spline is given as:
where is the loop of the spline. The MARS model works through two steps: a forward pass process, followed by a backward pass. In the forward pass process, basis functions are chosen to develop (Equation (6)). This process causes a large expression of the model, which typically overfit the data. Therefore, there is a need for backward deletion procedure to reduce the overfitting and complexity of the model. In the backward process, the least effective basis function terms are deleted one by one to get the best function by calculating the residual sum of squares (RSS) error in the training dataset. The small value of RSS shows the best-fit model to the data. Equation (9) is used to compute the value of RSS given as
where is the observed value of predictor , the predicted value of predictor . The performance of basis function is measured by the generalized cross-validation (GCV) criterion [58]. The lower values of GCV shows better predictor functions. The GCV criterion is defined as
where is the number of data and a function of penalty that increases with an increase in the number of basic function and also is considered as a smoothing parameter, which is defined as
where is the number of the basis functions and the penalty for each basis function term included into the model. A detailed study of the penalty term is stated by Friedman [55]. Finally, MARS model is developed by selecting basis function in a forward pass process and by tuning the basis functions by using backward pass algorithm.
3.3. Support Vector Regression (SVR)
A regression methodology adopted by using Support Vector Machine (SVM) is termed as support vector regression (SVR). The SVR uses the algorithms equivalent as the SVM model. The support vector machines (SVM) was introduced principally by Vapnik et al. [59,60]. The formulation represents the structural risk minimization (SRM) principle [61,62]. The SVR is applied as a regression methodology and formulated, as in Equation (12). In SVR, the input is first mapped onto sample space using nonlinear mapping, and then a linear model is constructed in this feature space. The linear model in the feature space is given by
where and . represents the dot product in the space . The optimization of SVR as in Equation (13) is based on the theory that exists a function that provides an error less than for all training datasets.
where states a nonlinear function, and is the “bias” term. In the preprocessing step, the bias term is dropped as the data are assumed zero. The loss function is used to measure the quality of estimation. Generally, SVR uses -insensitive loss function [59,60], described as
Now, the empirical risk is defined as
SVR executes linear regression in the high-dimension feature space using -intensive loss function which is accomplished by minimizing the Euclidean norm, as defined by [63]. It is described by introducing a non-negative slack variable , to quantify the deviation of training datasets outside -insensitive zone. Thus, the SVR algorithm is described by minimizing the following function
Now, the optimization problem can be solved by using the following equation
where is the number of Support Vectors, the meta parameters, and are the Lagrangian Multipliers and the kernel function, which is defined as
If the Lagrange multipliers ( and ) will be zero, implying that the training data are considered to be irrelevant for the final solution. The training data with non-zero Lagrange multipliers are called support vectors. Generally, the performance of SVR depends on a setting of meta-parameters parameters C, , and the kernel parameters .
4. Development of Predictive Models
The core objective of the study is to explore the practicality of the GMDH-NN methodologies in the prediction of the Manning’s . Thus, a foremost task is to determine the relevant testing and training data subset to construct a predictive model and to evaluate its performance. The dataset that was used in this study is achieved by small scaled model experimental setup, performed at NIT Rourkela, India, and some collected data of previous researchers that has similar geometrical conditions.
Here, in the ML modeling, the normalized value of independent variables is taken as input variables, such as , , , , and . The output of the GMDH, MARS, and SVR models is the normalized value. Researchers have used different data division between testing and training data and generally, it varies with problems. There is no particular rule for the divisional process of training and testing data. In this study, about 75% of data are designated for training, and another 25% of data are used for testing the proposed model. The training and testing data have been chosen randomly form the original dataset. The data is scaled between 0 and 1. It has been done by using the following equation:
where = any finite data, = minimum value of the data, = maximum value of the data, and = normalized value of the data. This paper shows a comparative study of suggested models for prediction of in the meandering compound channels with the observed data.
GMDH algorithm was established while using GMDH Shell software [49] to find non-linear relationships between the inputs and output variables. The algorithm is characterized as a set of neurons in which various pairs of the neurons are related through a quadratic polynomial of GMDH-NN network. The data was trained while using the quadratic neural function and consequently resulting new neurons in the subsequent layer [8].
In the training of each layer, the neurons are generated based on all the possible combinations of input variables. Then, these neurons are screened automatically based on their ability to predict the target variable. Only those neurons having good prediction powers (meets the criterion) are fed forward for the training of the next layer, and the rest are discarded [64]. The formulas that were obtained from the GMDH model for predicting the Manning’s are given by following equations.
where
In the MARS model, 19 basis functions are used initially by forwarding step out of which three basic functions are deleted by the backward step process. Finally, an optimum model for prediction of has restricted, given rise to 16 number of basis functions, whose constructions are brief as and in Table 3. In MARS, RSS, and GCV criteria are also performed to known the importance of the predictors by using Equations (9) and (10), respectively. Before predicting the value of , the performance ranking test of independent variables is performed by RSS and GCV criteria. Following RSS and GCV value, the independent variables are ranked consequently as , , , , and . The analysis demonstrates that the longitudinal bed slope is more sensible for predicting .
Table 3.
Basis Functions, and coefficient, used for obtaining the using the multivariate adaptive regression splines (MARS) model.
The model for predicting Manning’s is quantified by a linear arrangement of the constant 0.38 and the basis functions are presented in Table 3 superimposing with their respective coefficients that were achieved by models. The optimum model for the prediction of is from the result of Equation (26).
where denotes the Manning’s at floodplain, is the basic function, and the coefficient.
While using the Equation (26) for evaluation of Manning’s , we need the series of and values. For the present case, the value can be computed by substituting , , , , values in the column (1), Table 3. By multiplying the corresponding terms, we get the final value of MARS model that can be used for calculating Manning’s , which can be subsequently used to get a discharge in the compound channels.
For NITR Type I channel at flow depth of 0.17 m, the values of , , , , and are 5.96, 0.3, 0.7, 0.001, and 1.37, respectively, which gives as −0.3688 giving rise to values as 0.0112 and as 0.04969 m3/s for this depth of flow as against the observed value of as 0.0107 and as 0.05216 m3/s.
For SVR, is the penalty to the error that causes the generalization ability of the model. The large value assigns higher penalties to errors so that the regression is trained to minimize error with lower generalization, whereas a small assigns fewer penalties to errors, which allows for the minimization of margin with errors, thus, higher generalization ability. The higher value gives, the fewer support vectors, which leads to a decrease the final prediction performance [65]. If is too small, many support vectors are selected, which leads to the risk of overfitting. A large value of indicates a stronger smoothing of the Gaussian kernel. The SVR model is trained using the Radial Basis Function (RBF) with 36 numbers of support vectors. The best result is obtained with regularization parameter (C = 84), insensitive loss function (epsilon = 0.1), and kernel parameter .
The developed SVM gives the following equation by putting , and in Equation (16) for prediction of .
where be the Lagrange multipliers.
Model Performance Assessment
Testing of the model performance is a crucial task after its development, where comparisons between the observed and the predicted value of Manning’s are performed. Performance of the GMDH, MARS, and the SVR models are demonstrated through their standard statistical errors such as the correlation coefficient (R), root-mean-square-error (RMSE), mean absolute error (MAE), the mean absolute percentage error (MAPE), adjusted coefficient of efficiency (E), and Scatter index (SI). The value of R, RMSE, MAE, MAPE, E, and SI are determined from the following relates given as [66,67]:
where and are observed, and the predicted Manning’s values, respectively, the mean of the observed Manning’s value, the mean of the predicted Manning’s and the number of data samples.
A close value of to 1, shows a good correlation between the observed and the predicted value of the various model. MAE measures the closeness of the predicted and observed value, while RMSE shows the deviation of a predicted value from the observed value. MAE and RMSE have the unit similar to the dependent input value, i.e., a lower value of predictive variables depicts a better prediction model. An efficiency of 1, (E = 1) corresponds to a perfect match of the model to the observed data and can range from −∞ to 1. The SI is a normalized measure of error, lower value of the SI is an indication of better model performance. For anonymous consideration of the model for the various type of dataset, MAE and RMSE have converted to unitless. So, MAE and RMSE are symbolized as a percentage concerning the difference between the maximum and minimum predicted values, which are the normalized values. The normalization of MAE and RMSE are expressed as NMAE and NRMSE, respectively, which are presented as:
5. Results and Discussion
5.1. Experimental Outcomes
From the experimental data relationship between stage and discharge is shown in Figure 7a. The variation of Manning’s with the relative depth is presented in Figure 7b. The value of for overbank flow is found to increase with the increase of relative depth for the compound meandering channels, as shown in Figure 7b. Many investigators [45,68,69] have reported the increasing trend of Manning’s n with the depth of flow.
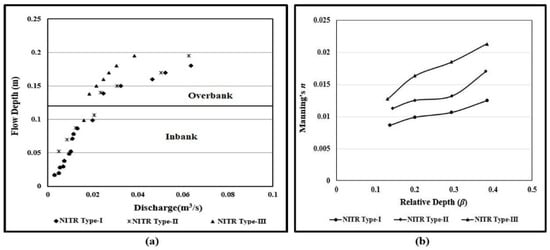
Figure 7.
The relationship of (a) Stage-discharge for experimental channels; and (b) Manning’s with relative depth.
5.2. Comparison of Predictive Models
All of the three ML models used in this study shows promising results for predicting Manning’s . Figure 8 shows the scatter plots between the predicted and the observed Manning’s . All the three models give acceptable results of Manning’s , which have been seen from Figure 8 as well as Table 4. Between these three models, the GMDH-NN model gives maximum correlation coefficient (R = 0.93) in the testing period as compared to MARS (0.86) and SVR (0.84). Table 4 gives the values of R, RMSE, MAE, and MAPE that are obtained during the training and testing period in the three developed ML models. There is an agreement of Table 4 with the result in Figure 8, GMDH-NN model gives the minimum value of RMSE for training and testing data as 0.0012 and 0.0013, respectively, as compared to the MARS and SVR model. Similarly, when the MAE and the MAPE are taken into account for performance measurement of all three ML models, a similar conclusion is drawn. SI signifies the percentage of difference in root mean square error concerning the mean observation. It gives the percentage of predictable error for parameters. Here, the GMDH model shows lower SI value, which gives the best predicting model. Also, in case of efficiency (E), GMDH-NN gives the least error both in training and testing phase. Similarly, when the MAE and the MAPE are taken into account for performance measurement of all three ML models, a similar conclusion is drawn. As also described in Table 4, the MAPE values indicate that the GMDH-NN model gives the minimum error when compared to the other two models, all through the data series for prediction of . The MAPE values are observed to be less than 7% for GMDH-NN model, whereas the MAPE values of MARS and SVR models greater than 9% in testing phase throughout the range of data. GMDH has been used for the identification of a mathematical model that has many input variables, but limited data needs by using a hierarchical structure [70]. Though we have not studied the computation time of these models used in this study, however various authors reported that SVR models required more time to train [71,72].
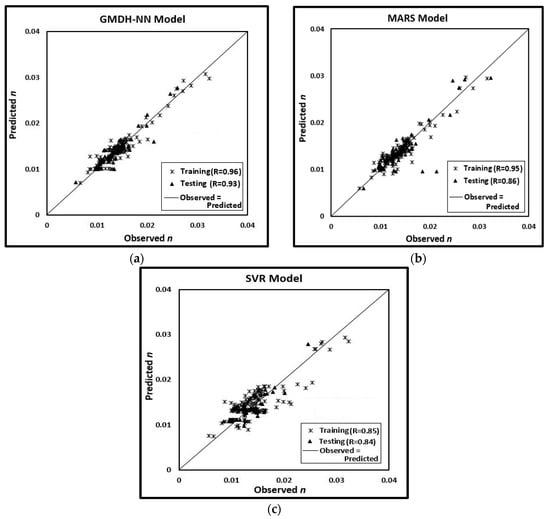
Figure 8.
The Scatter Plots show the Regression Coefficient and the 1:1 Perfect Fit Line between the Observed and Predicted Manning’s for (a) Group Method of Data Handling Neural Network GMDH-NN) Model; (b) MARS Model; and (c) support vector machine regression (SVR) Model.
Table 4.
Performance Metrics of correlation coefficient (R), mean absolute error (MAE), mean absolute percentage error (MAPE), and root-mean-square-error (RMSE) for GMDH-NN, MARS, and SVR Model.
For a better comparison of the performances of GMDH-NN, MARS, and SVR model, the normalized value of mean absolute error (NMAE) and root mean square error (NRMSE) is shown in Figure 9a,b, respectively. GMDH-NN gives the lower value of NMAE and NRMSE for testing data, as presented in Figure 9, respectively, concerning the ELM and SVR models. From the figure, it is observed that the GMDH-NN model is superior for calculating Manning’s .
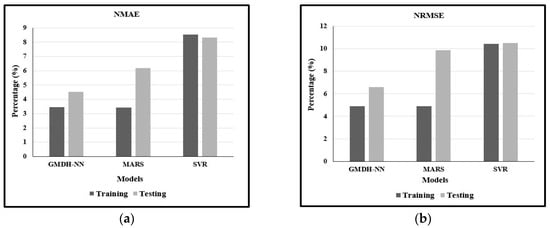
Figure 9.
Performance of Training and Testing Data Samples for Prediction of by (a) normalized value of mean absolute error (NMAE); and (b) root mean square error (NRMSE).
A box and whisker plot, which is used for graphically representing groups of numerical data through their quartiles is shown in Figure 10. In the boxplot, the lower and the upper ends lie at the lower quartile (25th percentile of the dataset ) and the upper quartile (75th percentile of the dataset ), respectively. Inside the boxplot, the 50th percentile of the dataset is the median value of the predicted Manning’s . The whisker is the two horizontal lines extended from the uppermost (top) and lowermost (bottom) of the box, whereby the lowermost whisker prolongs from to the minimum non-outlier, which is the poorest expected Manning’s value in the predicted data. The top whisker tracks from to the largest non-outlier. Based on graphical representation, the distribution statistics of the lower quartile , median , upper quartile Manning’s , mean , standard deviation , range , skewness, and kurtosis are given in Table 5. Here, denotes the predicted value of Manning’s . It is noticed that all of the quartile values obtained seems to be in almost similar range in three models for the predicted . These results are verified with the corresponding values of the distribution statistics, as shown in Table 5. The GMDH-NN model reveals the greatest degree of the range of predicted , which is also justified by the extended bottom-end of the whisker plot, as in Figure 10.
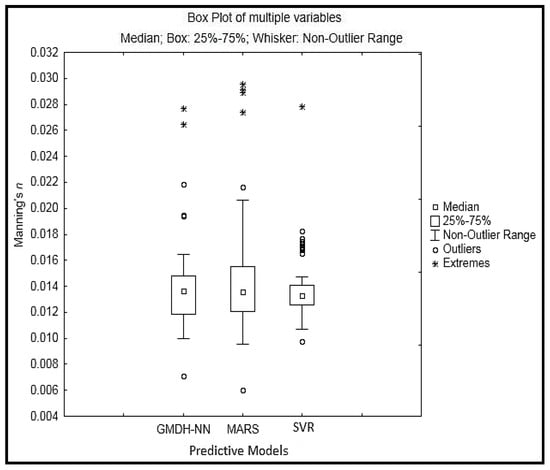
Figure 10.
Performances Statistics Established for the Prediction of Manning’s using developed GMDH-NN, MARS, and SVR Model.
Table 5.
The Distribution Statistics of Predicted Manning’s Coefficient using different Machine learning (ML) Models.
6. Application of the Model to River Data
The developed model should be adequate for its practical application, imitating the natural phenomena. The most effective hydraulic experimental solutions may not necessarily be the most globally acceptable solutions. Therefore, the proposed model is applied to river data to know its appropriateness. The Baitarani River is chosen for the application of the developed model for calculation of discharge involving meandering compound channel reach, for 7.5 m depth of flow in the year 1985 flood and 8.63 m depth of flow in the year 1975, which is located between longitude and latitude at Anandapur, Odisha, India. Figure 11 shows the plan and cross-sectional view of River Baitarani [44]. At Anandapur site, the river has developed a good meandering plan form with a drainage area of 8570 km2. The average bank full depth , the width of the main river , a top width of the main river , sinuosity , Meander Belt width , and amplitude of the river is scaled as 5.4 m, 210 m, 230 m, 1.334, 108 m, and 425 m, respectively. The surface condition for the main channel is sandy, whereas the floodplain has grass vegetation. The average longitudinal slope of the channel bed is 0.0011 for both the floodplain and main river. The river data is collected from Government of India Central Water Commission, Eastern Rivers Division, India.
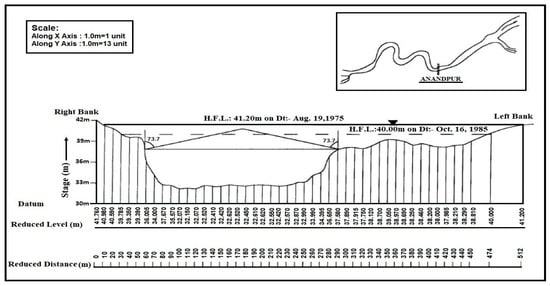
Figure 11.
Cross-section of Baitarani River at the gaging site (Anandapur, Odisha, India) [44].
While using the model equations that are provided by GMDH (Equations (20 through 25)), MARS (Equation (26)), and SVR (Equation (27)) for the evaluation of Manning’s , we need the values of input parameters. For the river Baitarani the values of , , , , are given in Table 6. By putting the corresponding values in the equations (Equations (20), (26) and (27)), we get the final value of Manning’s by three models, which can subsequently use to get a discharge in the compound channels. For 7.5 m depth of flow in the river Baitarani, the Manning’s is calculated by GMDH, MARS, SVR model as 0.0239, 0.0205, and 0.025, respectively. Similarly, for 8.63 m flow depth, the Manning’s is calculated by GMDH, MARS, SVR model as 0.0242, 0.0201, and 0.0255, respectively. The area of the river is measured as 1995 m2, 2485 m2 and perimeter as 460 m, 510 m for two different flood flow depth. Subsequently, the values of discharge are estimated by substituting value in Manning’s general equation. Discharge results that are based on the application of GMDH-NN, MARS, and SVR models are given in Table 6, which indicates the adequacy of the GMDH-NN model.
Table 6.
Testing of Model by Predicting Discharge of Baitarani River.
The percentage of mean error for prediction of by various models and their standard deviation is shown in Figure 12. The authors also accomplished the analysis of inaccuracy in terms of the root-mean-square error (RMSE), mean absolute error (MAE) and mean absolute percentage error (MAPE) as described in Table 7 for developed models. It is observed that the GMDH-NN model gives the minimum mean percentage error. It is found that the least values of respective MAE, RMSE, and MAPE as 0.00105, 0.00114, and 4.904 for GMDH-NN model. The results give a clear suggestion of the efficiency of the GMDH-NN model and its use in practical applications.
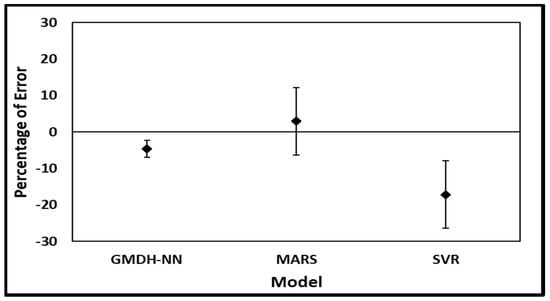
Figure 12.
Percentage of Error of Discharge for River Baitarani for Prediction values by the three Models.
Table 7.
Error Analysis of River Baitarani for Prediction of Discharge by Various Models.
7. Conclusions
The primary interest of this study is to predict the best estimation of Manning’s for meandering compound channels. Three Artificial Intelligence technics are applied for the modeling of . The fitness of the GMDH-NN model is compared with SVR and MARS machine learning methods. GMDH-NN model has a greater correlation coefficient, smaller error statistics, and fewer outliers, thus showing more promising for predicting Manning’s as compared to MARS and SVR. From various observations, it can be concluded that the computation time for predicting Manning’s of GMDH model is the least and also more flexible for data input variables as compared to MARS and SVR model. The models achieved in this study seem to be very useful for the prediction of the Manning’s of two-stage meandering channels. The model is also applied to the river data for calculating discharge by using the Manning’s equation for its practical implications. For the computing Manning’s that can hold good for all types of meandering compound channel geometry including the natural rivers irrespective of variation in the beds and floodplain surfaces. Though we have considered smooth channel surface both at the main channel and floodplain, the model is applied very successfully to the Baitarani river data giving minimum error between the computed and observed discharges. The mean percentage error accompanied by the standard deviation for the three models describes the suitability of the model for its field study. The machine-learning model achieved in this study seems to be very useful for the prediction of the Manning’s of small scale, as well as large-scale models and natural resources.
Author Contributions
A.M. has done the Experimental Investigation and collected the data. A.M. has done the analysis and validation of the experimental results. A.M. and B.B.S. developed the model and analyzed the results under the supervision of K.C.P. K.C.P. reviewed the work and provided feedback on this paper.
Funding
This research received no external funding.
Acknowledgments
The authors acknowledge the support received from the Department of Civil Engineering, National Institute of Technology Rourkela, India.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Azamathulla, H.M.; Ahmad, Z.; Ghani, A.A. An expert system for predicting manning’s roughness coefficient in open channels by using gene expression programming. Neural Comput. Appl. 2013, 23, 1343–1349. [Google Scholar] [CrossRef]
- Bilgil, A.; Altun, H. Investigation of flow resistance in smooth open channels using artificial neural networks. Flow Meas. Instrum. 2008, 19, 404–408. [Google Scholar] [CrossRef]
- Te Chow, V. Open Channel Hydraulics; McGraw-Hill Book Company, Inc.: New York, NY, USA, 1959. [Google Scholar]
- Cowan, W.L. Estimating hydraulic roughness coefficients. Agric. Eng. 1956, 37, 473–475. [Google Scholar]
- Fasken, G.B. Guide for Selecting Roughness Coefficient “N” Values for Channels; US Dept. of Agriculture, Soil Conservation Service: Washington, DC, USA, 1963.
- Limerinos, J.T. Determination of the Manning Coefficient from Measured Bed Roughness in Natural Channels; US Department of the Interior, Geological Survey, Water Resources Division: Menlo Park, CA, USA, 1969.
- Jarrett, R.D. Hydraulics of high-gradient streams. J. Hydraul. Eng. 1984, 110, 1519–1539. [Google Scholar] [CrossRef]
- Arcement, G.J.; Schneider, V.R. Guide for Selecting Manning’s Roughness Coefficients for Natural Channels and Flood Plains; US Government Printing Office: Washington, DC, USA, 1989.
- Yen, B.C. Dimensionally homogeneous manning’s formula. J. Hydraul. Eng. 1992, 118, 1326–1332. [Google Scholar] [CrossRef]
- James, C.S.; Wark, J.B. Conveyance Estimation for Meandering Channels; Report SR 329, Hydraulic Res; HR Wallingford Ltd.: Wallingford, UK, 1992. [Google Scholar]
- Shiono, K.; Al-Romaih, J.S.; Knight, D.W. Stage-discharge assessment in compound meandering channels. J. Hydraul. Eng. 1999, 125, 66–77. [Google Scholar] [CrossRef]
- Jena, S. Stage-Discharge Relationship in Simple Meandering Channels. Master’s Thesis, Indian Institute of Technology (IIT), Kharagpur, India, 2007. [Google Scholar]
- Mailapalli, D.R.; Raghuwanshi, N.S.; Singh, R.; Schmitz, G.H.; Lennartz, F. Spatial and temporal variation of manning’s roughness coefficient in furrow irrigation. J. Irrig. Drain. Eng. 2008, 134, 185–192. [Google Scholar] [CrossRef]
- Khatua, K.K.; Patra, K.C.; Mohanty, P.K. Stage-discharge prediction for straight and smooth compound channels with wide floodplains. J. Hydraul. Eng. 2012, 138, 93–99. [Google Scholar] [CrossRef]
- Khatua, K.K.; Patra, K.C.; Nayak, P. Meandering effect for evaluation of roughness coefficients in open channel flow. WIT Trans. Ecol. Environ. 2012, 146, 213–224. [Google Scholar]
- Khatua, K.K.; Patra, K.C.; Nayak, P.; Sahoo, N. Stage-discharge prediction for meandering channels. Int. J. Comput. Methods Exp. Meas. 2013, 1, 80–92. [Google Scholar] [CrossRef]
- Xia, J.; Lin, B.; Falconer, R.A.; Wang, Y. Modelling of man-made flood routing in the lower yellow river, china. Proc. Inst. Civ. Eng. 2012, 165, 377–391. [Google Scholar] [CrossRef]
- Barati, R.; Akbari, G.H.; Rahimi, S. Flood routing of an unmanaged river basin using muskingum–cunge model; field application and numerical experiments. Casp. J. Appl. Sci. Res. 2013, 2, 8–20. [Google Scholar]
- Barati, R. Application of excel solver for parameter estimation of the nonlinear muskingum models. KSCE J. Civ. Eng. 2013, 17, 1139–1148. [Google Scholar] [CrossRef]
- Barati, R.; Rahimi, S.; Akbari, G.H. Analysis of dynamic wave model for flood routing in natural rivers. Water Sci. Eng. 2012, 5, 243–258. [Google Scholar]
- Dash, S.S.; Khatua, K.K. Sinuosity dependency on stage discharge in meandering channels. J. Irrig. Drain. Eng. 2016, 142, 04016030. [Google Scholar] [CrossRef]
- Pradhan, A.; Khatua, K.K. Assessment of roughness coefficient for meandering compound channels. KSCE J. Civ. Eng. 2017, 1–13. [Google Scholar] [CrossRef]
- Zhang, M.; He, C.; Liatsis, P. A d-gmdh model for time series forecasting. Expert Syst. Appl. 2012, 39, 5711–5716. [Google Scholar] [CrossRef]
- Mrugalski, M. An unscented kalman filter in designing dynamic gmdh neural networks for robust fault detection. Int. J. Appl. Math. Comput. Sci. 2013, 23, 157–169. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Lim, S.Y. Application of improved neuro-fuzzy gmdh to predict scour depth at sluice gates. Earth Sci. Inform. 2015, 8, 187–196. [Google Scholar] [CrossRef]
- Vapnik, V. Pattern recognition using generalized portrait method. Autom. Remote Control 1963, 24, 774–780. [Google Scholar]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Gualtieri, J.A.; Chettri, S.R.; Cromp, R.F.; Johnson, L.F. Support vector machine classifiers as applied to aviris data. In Proceedings of the Eighth JPL Airborne Geoscience Workshop, Pasadena, CA, USA, 8–11 February 1999. [Google Scholar]
- Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; Volume 3. [Google Scholar]
- Dibike, Y.B.; Velickov, S.; Solomatine, D.; Abbott, M.B. Model induction with support vector machines: Introduction and applications. J. Comput. Civ. Eng. 2001, 15, 208–216. [Google Scholar] [CrossRef]
- Pal, M.; Goel, A. Prediction of the end-depth ratio and discharge in semi-circular and circular shaped channels using support vector machines. Flow Meas. Instrum. 2006, 17, 49–57. [Google Scholar] [CrossRef]
- Han, D.; Chan, L.; Zhu, N. Flood forecasting using support vector machines. J. Hydroinform. 2007, 9, 267–276. [Google Scholar] [CrossRef]
- Genc, O.; Dag, A. A machine learning-based approach to predict the velocity profiles in small streams. Water Resour. Manag. 2016, 30, 43–61. [Google Scholar] [CrossRef]
- Samui, P.; Das, S.; Kim, D. Uplift capacity of suction caisson in clay using multivariate adaptive regression spline. Ocean Eng. 2011, 38, 2123–2127. [Google Scholar] [CrossRef]
- Samui, P.; Kurup, P. Multivariate adaptive regression spline (mars) and least squares support vector machine (lssvm) for ocr prediction. Soft Comput. 2012, 16, 1347–1351. [Google Scholar] [CrossRef]
- Samui, P. Multivariate adaptive regression spline (mars) for prediction of elastic modulus of jointed rock mass. Geotech. Geol. Eng. 2013, 31, 249–253. [Google Scholar] [CrossRef]
- Knight, D.W.; Shiono, K. Turbulence measurements in a shear layer region of a compound channel. J. Hydraul. Res. 1990, 28, 175–196. [Google Scholar] [CrossRef]
- Shiono, K.; Knight, D.W. Turbulent open-channel flows with variable depth across the channel. J. Fluid Mech. 1991, 222, 617–646. [Google Scholar] [CrossRef]
- Toebes, G.H.; Sooky, A.A. Hydraulics of meandering rivers with flood plains. J. Waterw. Harb. Div. 1967, 93, 213–236. [Google Scholar]
- Kar, S.K. A Study of Distribution of Boundary Shear in Meander Channel with and without Floodplain and River Floodplain Interaction. Ph.D. Thesis, Indian Institute of Technology Kharagpur, Kharagpur, India, 1977. [Google Scholar]
- Das, A.K. A Study of River Flood Plain Interaction and Boundary Shear Stress Distribution in a Meander Channel with One Sided Flood Plain. Ph.D. Thesis, Indian Institute of Technology Kharagpur, Kharagpur, India, 1984. [Google Scholar]
- Kiely, G.K. An Experimental Study of Overbank Flow in Straight and Meandering Compound Channels. Ph.D. Thesis, Department of Civil Engineering, University College, Cork, Ireland, 1989. [Google Scholar]
- Patra, K.C.; Kar, S.K. Flow interaction of meandering river with floodplains. J. Hydraul. Eng. 2000, 126, 593–604. [Google Scholar] [CrossRef]
- Khatua, K.K. Interaction of Flow and Estimation of Discharge in Two Stage Meandering Compound Channels. Ph.D. Thesis, National Institute of Technology Rourkela, Odisha, India, 2007. [Google Scholar]
- Mohanty, P.K. Flow Analysis of Compound Channels with Wide Flood Plains Prabir. Ph.D. Thesis, National Institute of Technology Rourkela, Odisha, India, 2013. [Google Scholar]
- Ervine, D.A.; Willetts, B.B.; Sellin, R.H.J.; Lorena, M. Factors affecting conveyance in meandering compound flows. J. Hydraul. Eng. 1993, 119, 1383–1399. [Google Scholar] [CrossRef]
- Moharana, S.; Khatua, K.K. Prediction of roughness coefficient of a meandering open channel flow using neuro-fuzzy inference system. Measurement 2014, 51, 112–123. [Google Scholar] [CrossRef]
- Amanifard, N.; Nariman-Zadeh, N.; Farahani, M.H.; Khalkhali, A. Modelling of multiple short-length-scale stall cells in an axial compressor using evolved gmdh neural networks. Energy Convers. Manag. 2008, 49, 2588–2594. [Google Scholar] [CrossRef]
- Ivakhnenko, A.G. Polynomial theory of complex systems. IEEE Trans. Syst. Man Cybern. 1971, 4, 364–378. [Google Scholar] [CrossRef]
- Ivakhnenko, A.G.; Ivakhnenko, G.A. Problems of further development of the group method of data handling algorithms. Part I. Pattern Recognit. Image Anal. 2000, 10, 187–194. [Google Scholar]
- Farlow, S.J. Self-Organizing Methods in Modeling: Gmdh Type Algorithms; CRC Press: Boca Raton, FL, USA, 1984; Volume 54. [Google Scholar]
- Sanchez, E.; Shibata, T.; Zadeh, L.A. Genetic Algorithms and Fuzzy Logic Systems: Soft Computing Perspectives; World Scientific: Singapore, 1997; Volume 7. [Google Scholar]
- Iba, H.; deGaris, H.; Sato, T. A numerical approach to genetic programming for system identification. Evolut. Comput. 1995, 3, 417–452. [Google Scholar] [CrossRef]
- Friedman, J.H. Multivariate adaptive regression splines. Ann. Stat. 1991, 19, 1–67. [Google Scholar] [CrossRef]
- Friedman, J.H.; Roosen, C.B. An Introduction to Multivariate Adaptive Regression Splines; Sage Publications: Thousand Oaks, CA, USA, 1995. [Google Scholar]
- Leathwick, J.R.; Rowe, D.; Richardson, J.; Elith, J.; Hastie, T. Using multivariate adaptive regression splines to predict the distributions of new zealand’s freshwater diadromous fish. Freshw. Biol. 2005, 50, 2034–2052. [Google Scholar] [CrossRef]
- Craven, P.; Wahba, G. Smoothing noisy data with spline functions. Numer. Math. 1978, 31, 377–403. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: Berlin, Germany, 1995. [Google Scholar]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Osuna, E.; Freund, R.; Girosi, F. An improved training algorithm for support vector machines. In Proceedings of the 1997 IEEE Workshop Neural Networks for Signal Processing VII, Amelia Island, FL, USA, 24–26 September 1997; pp. 276–285. [Google Scholar]
- Gunn, S.R. Support vector machines for classification and regression. ISIS Tech. Rep. 1998, 14, 5–16. [Google Scholar]
- Smola, A.J. Regression Estimation with Support Vector Learning Machines. Master’s Thesis, Technische Universität München, München, Germany, 1996. [Google Scholar]
- Jia, X.; Zhao, M.; Di, Y.; Yang, Q.; Lee, J. Assessment of data suitability for machine prognosis using maximum mean discrepancy. IEEE Trans. Ind. Electron. 2018, 65, 5872–5881. [Google Scholar] [CrossRef]
- Thissen, U.; Pepers, M.; Üstün, B.; Melssen, W.J.; Buydens, L.M.C. Comparing support vector machines to pls for spectral regression applications. Chemom. Intell. Lab. Syst. 2004, 73, 169–179. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Yun, G.J.; Alavi, A.H. An evolutionary approach for modeling of shear strength of rc deep beams. Mater. Struct. 2013, 46, 2109–2119. [Google Scholar] [CrossRef]
- Ebtehaj, I.; Bonakdari, H.; Zaji, A.H.; Azimi, H.; Khoshbin, F. Gmdh-type neural network approach for modeling the discharge coefficient of rectangular sharp-crested side weirs. Eng. Sci. Technol. Int. J. 2015, 18, 746–757. [Google Scholar] [CrossRef]
- Knight, D.W.; Hamed, M.E. Boundary shear in symmetrical compound channels. J. Hydraul. Eng. 1984, 110, 1412–1430. [Google Scholar] [CrossRef]
- Patra, K.C. Flow Interaction of Meandering River with Flood Plains. Ph.D. Thesis, Indian Institute of Technology Kharagpur, Kharagpur, India, 1999. [Google Scholar]
- Hwang, H.-S.; Bae, S.-T.; Cho, G.-S. Container terminal demand forecasting framework using fuzzy-gmdh and neural network method. In Proceedings of the Second International Conference on Innovative Computing, Informatio and Control, Kumamoto, Japan, 5–7 September 2007; p. 119. [Google Scholar]
- Sun, J.; Cho, S. Pattern selection for support vector regression based on sparseness and variability. In Proceedings of the International Joint Conference on Neural Networks (IJCNN’06), Vancouver, BC, Canada, 16–21 July 2006; pp. 599–602. [Google Scholar]
- Wardaya, P.D. Support vector machine as a binary classifier for automated object detection in remotely sensed data. IOP Conf. Ser. Earth Environ. Sci. 2014, 18, 1–6. Available online: http://iopscience.iop.org/article/10.1088/1755-1315/18/1/012014/meta (accessed on 16 July 2018). [CrossRef]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).