1. Introduction
The benefit of using the results of meteorological ensemble prediction systems for hydrological purposes has been well established by now (see e.g., [
1] for an extensive review). A large number of experimental and operational hydrological ensemble prediction systems (HEPS) have already been developed and tested (e.g., [
2,
3,
4,
5]). Typically, precipitation forecasts, and also forecasts of other meteorological fields, are used as input for a hydrological model to obtain hydrological ensemble predictions.
Ensemble precipitation forecasts help to take into account uncertainties in future rainfall, but the uncertainty is certainly not fully captured. The use of raw precipitation ensembles induces biases and inaccuracies to the input of a hydrological model (errors in the forcing). The initial conditions are imperfectly known or modeled. The hydrological model itself induces further model errors. These errors can be reduced by statistical postprocessing methods [
4,
6,
7]. Such methods make use of (preferably long) sets of training data of both model forecasts and corresponding observations. This explains the need for reforecasts.
The use of postprocessed precipitation as input for hydrological ensemble forecasts has been tested [
8,
9]. The results show that the errors linked to hydrological modelling remain a key component to the total predictive uncertainty. Fundel and Zappa [
4] have demonstrated that hydrological reforecasts allow for more skillful forecasts by compensating for forecast error induced by less accurate initializations. For a good overview and further references of postprocessing hydrological ensemble forecasts, we refer to the postprocessing intercomparison of [
10]. The authors conclude that postprocessing is an important step to achieve forecasts that are unbiased, reliable, have the highest skill and accuracy possible, and that are coherent with the climatology.
Some recent work has focused on postprocessing, making use of European Centre for Medium Range Weather Forecasts (ECMWF) reforecasts [
7,
11]. Up to recently, these were produced on a weekly basis (Thursdays), and consisted of 5-member ensembles. Currently, ECMWF produces reforecasts on a bi-weekly basis, with 11-member ensembles.
In a recent study, Roulin and Vannitsem [
7] investigated the use of various postprocessing methods based on reforecasts—both on the precipitation input ensembles and discharge forecasts produced with a simple conceptual hydrological model. The authors show that postprocessing precipitation forecasts alone does not improve the resolution of the resulting hydrological ensemble predictions. This indicates the usefulness of was postprocessing directly the hydrological ensemble predictions and the development of hydrological reforecasts.
In the present study, we build further on the work of Roulin and Vannitsem [
7]. We apply a postprocessing method on our operational HEPS, which we describe further below. We apply the variance inflation method [
12,
13], estimating the calibration parameters using 5-member hydrological reforecasts over 20 years, and validate the method by applying the calibration to our archived 51-member hydrological discharge forecasts from 2012 to 2015.
In
Section 2, we give a brief overview of the hydrological model, our hydrological ensemble prediction system, and the basin used in this study. We discuss the applied postprocessing method in
Section 3, and the verification methodology in
Section 4. In
Section 5, we present and discuss the most important results. Finally, we present our conclusions in
Section 6.
4. Verification
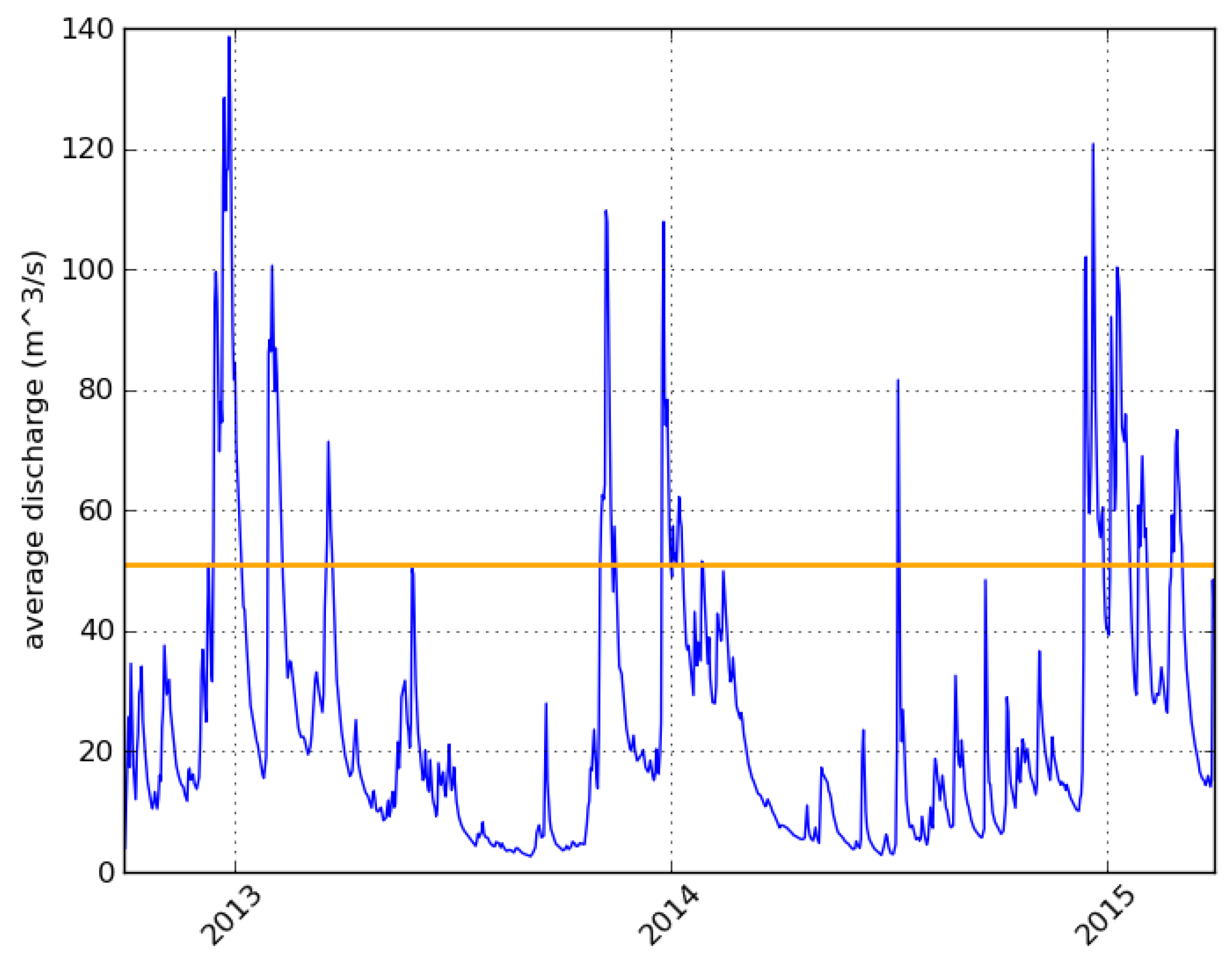
We perform a verification study for the period June 2012 until March 2015, making use of the archived ENS forecasts and observed daily discharges during this period. For each date in the verification period, the postprocessing method is calibrated based on the reforecasts from the preceding 20 years. Note that the number of ensemble members is different: the verification is performed on the postprocessed full 51-member hydrological ensemble forecasts. See
Table 1.
Our aim is to determine whether the variance inflation method is suitable for operational use in issuing exceedance probabilities for various discharge thresholds. We compare the postprocessed and raw ensemble forecasts directly with the observed discharges to check if there is an improvement.
Verification scores are also computed separately for hydrological winter (October–March) and summer (April–September) situations, due to the difference in events that typically cause high waters and flooding: mainly long periods of stratiform precipitation in winter and convective events during summer. As discussed in [
15], the HEPS typically performs much better during hydrological winter.
As an additional experiment, we also perform a calibration and verification using the “reference” discharge, which is generated by forcing the SCHEME model with observed precipitation.
We focus on the probabilistic skill scores. We evaluate the skill at forecasting discharge threshold exceedance using the Brier Score, for which we consider the P90 and P80 discharge thresholds, the discharge that is exceeded 10% and 20% of the time respectively during the verification period. We also consider the Continuous Ranked Probability Score (CRPS): a score that provides an overall measure of probabilistic skill.
The
Brier Score (BS) for a discrete set of probability forecasts and corresponding binary observations is given by
where
is the probability assigned to the event by the forecast, and
is the corresponding observation (one if the event occured, zero otherwise). The
Brier Skill Score (BSS) measures the Brier score with respect to a reference:
, where
is the BS of the reference forecast. A perfect forecast has
, while the reference forecast has
.
We use the climatological frequency of threshold exceedance in the verification sample as a reference (discharge time series June 2012–March 2015). For the postprocessed forecasts, we also consider the BS of the raw ensemble forecasts as a reference, and check for improvement ().
The CRPS is defined as the integrated square difference between the cumulated forecast and observation distributions. Its deterministic limit is the mean absolute error. For its computation, we implement the expression for the CRPS as derived in [
16]. The
Continuous Ranked Probability Skill Score (CRPSS) measures the CRPS with respect to a reference:
.
Confidence Intervals
To give an idea of the uncertainty bounds on our skill scores, we generate confidence intervals with a simple bootstrapping method.
We perform N resamplings with replacement in the set of forecast discharge and corresponding observed values (we take ). We then generate a confidence interval using the and quantiles.
The postprocessing method can be said to give a significant improvement when the BSS of the postprocessed forecast is positive with respect to the raw ensemble forecast—that is, when a BSS value of zero is outside the confidence interval.
Concerning the CRPS, we consider the significance of the improvement to the CRPSS, with the raw forecast taken as reference for the postprocessed forecast.
5. Results and Discussion
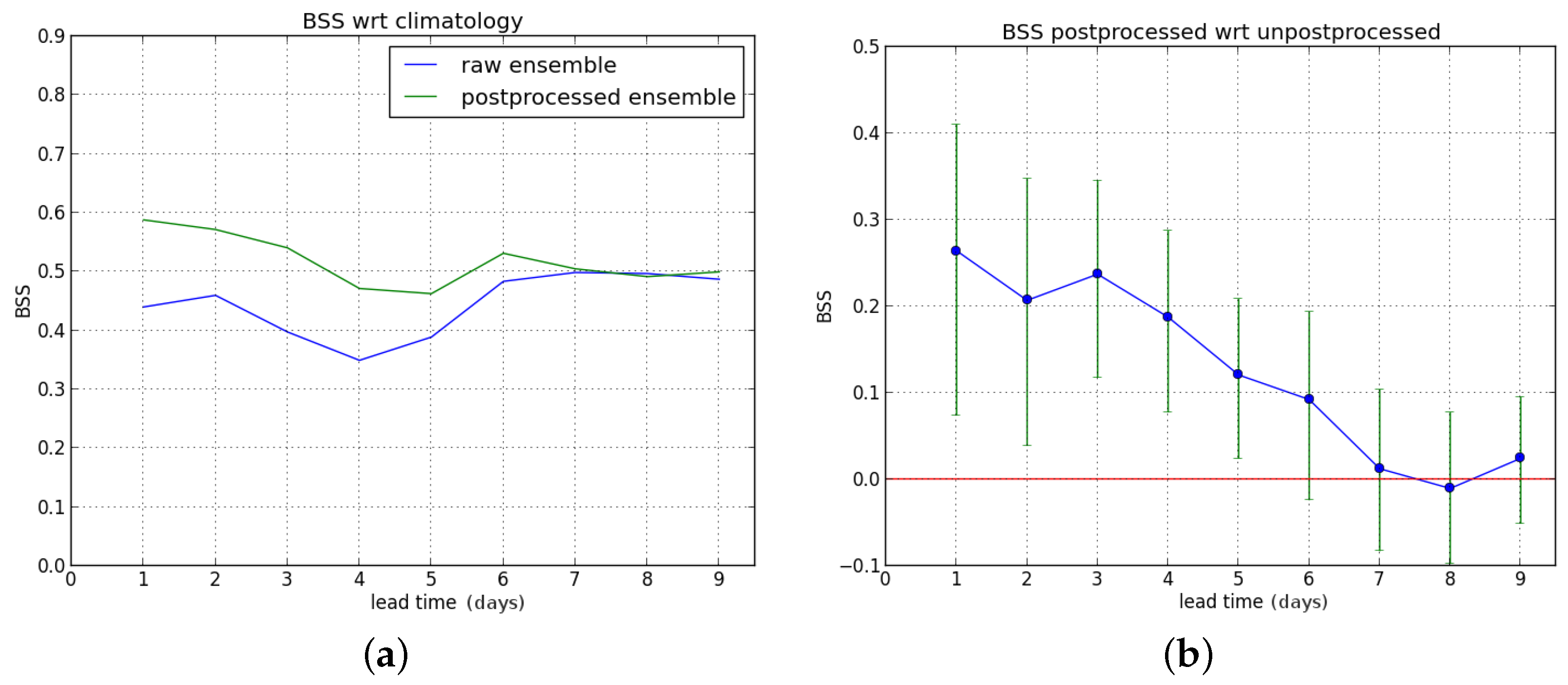
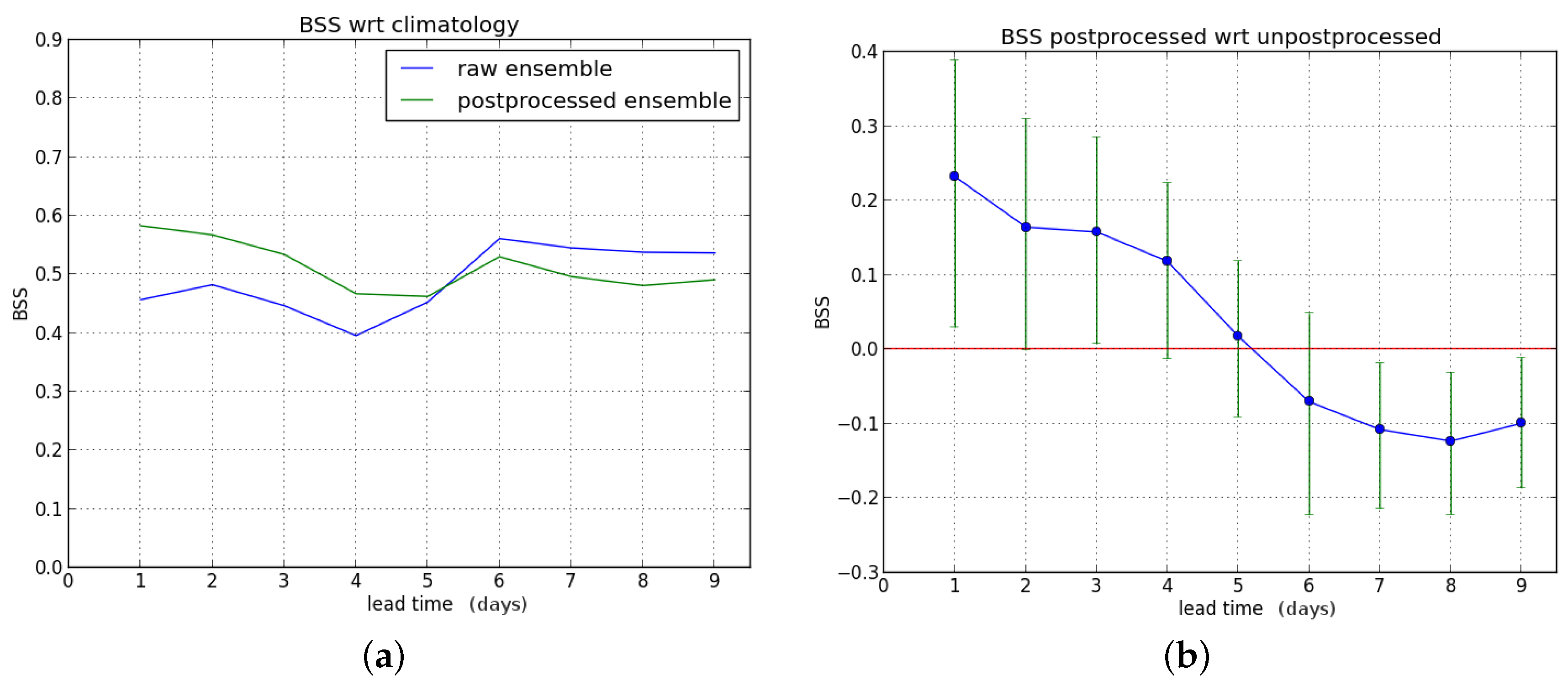
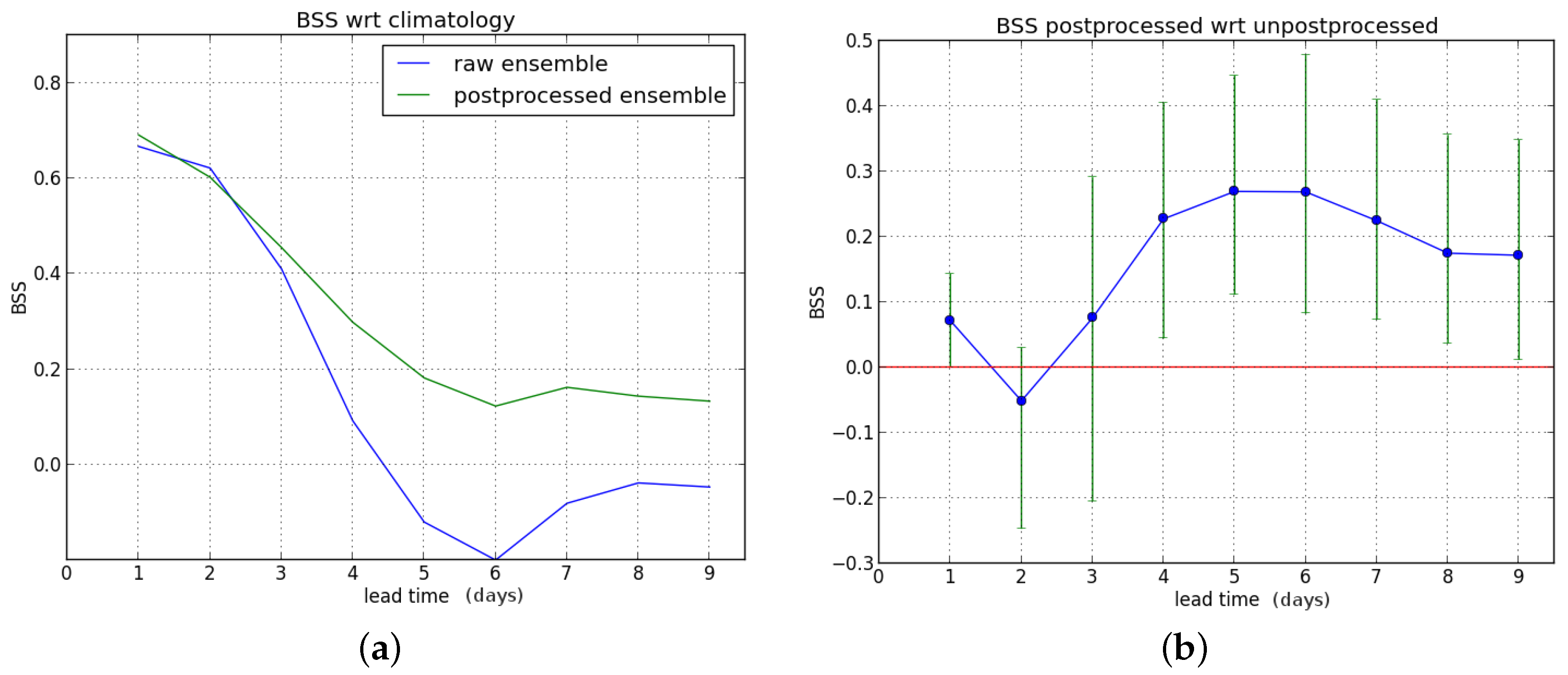
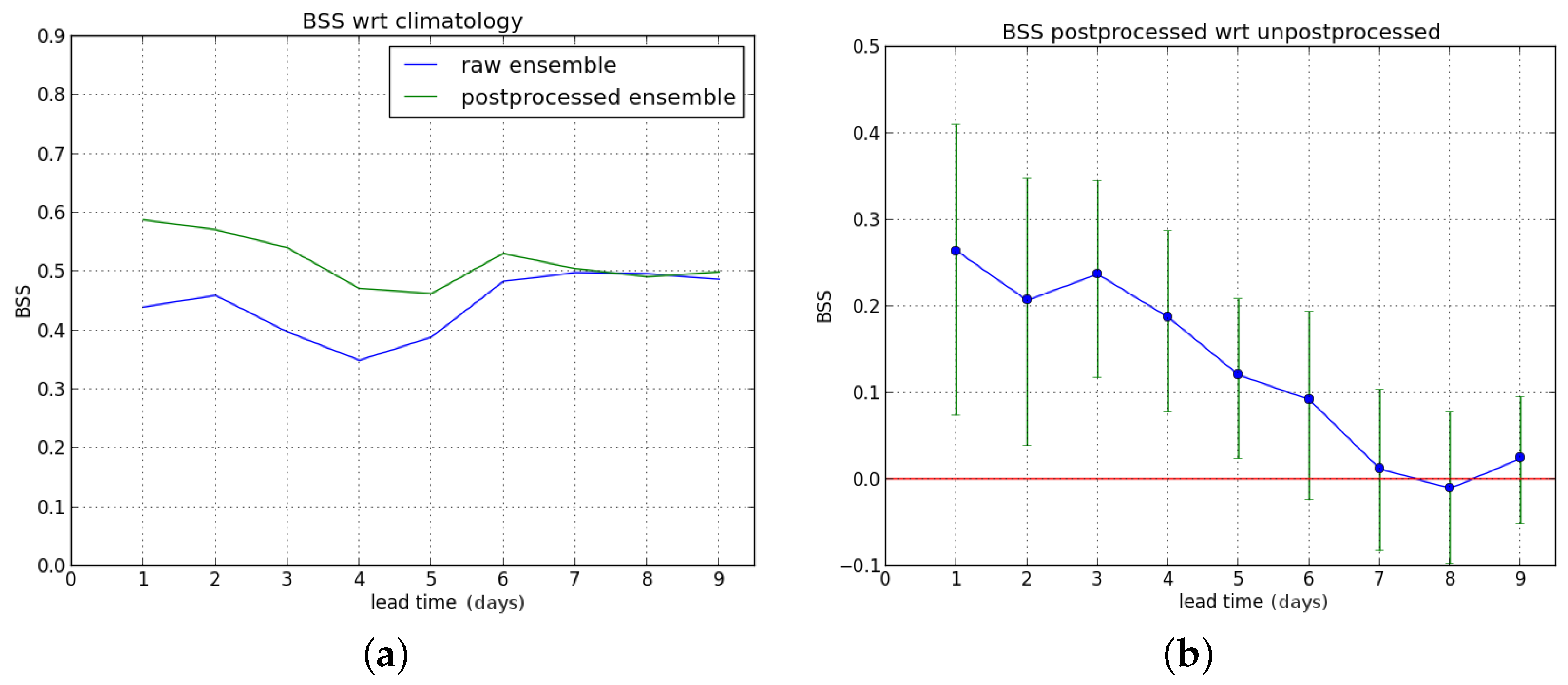
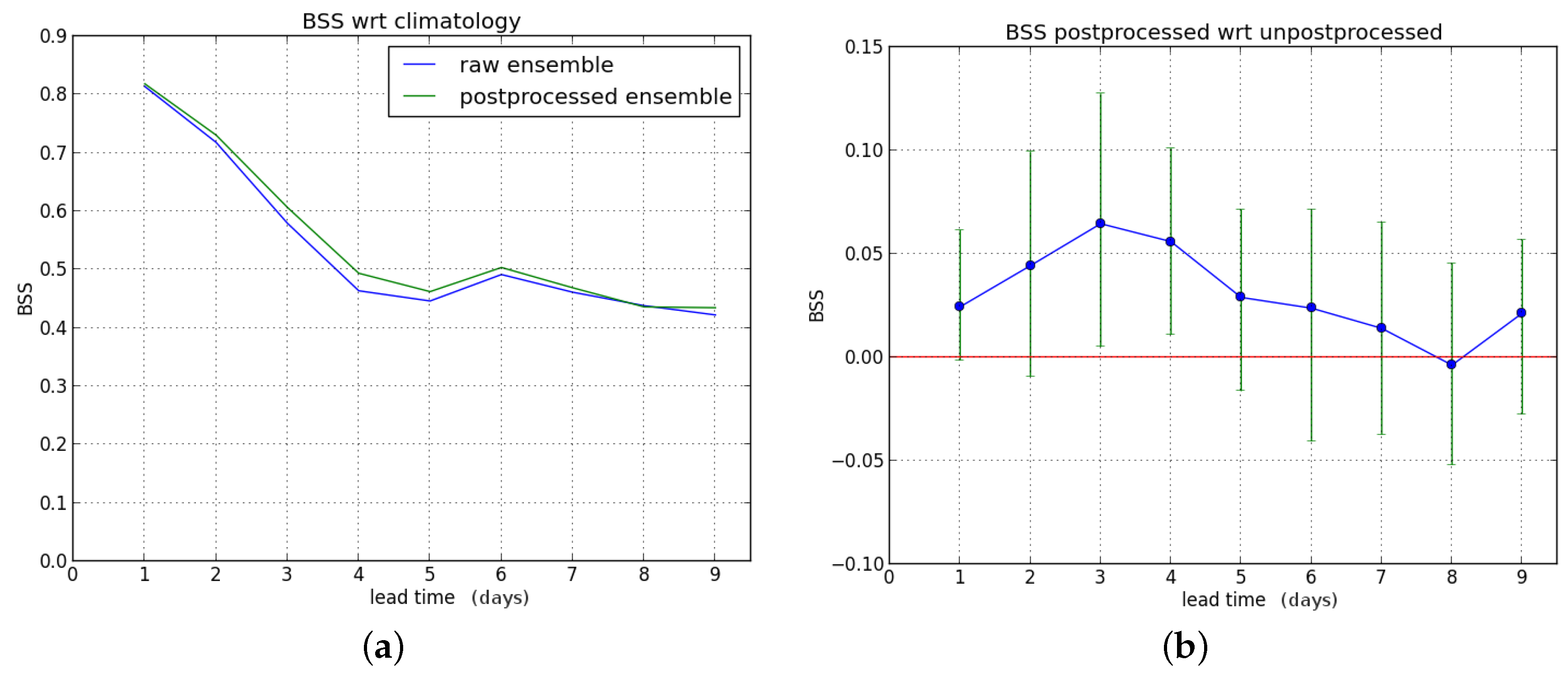
We first consider the Brier skill score (BSS) for exceedance of the P90 threshold as a function of lead time (one to nine days ahead). First, we compute the BSS of the raw and postprocessed forecasts with the sample climatology as reference, and subsequently the Brier score of the raw forecast is used as reference to compute the BSS of the postprocessed ensemble forecast.
We show the results for the entire verification period in
Figure 4.
The postprocessing leads to a significant improvement for lead times up to five days ahead. Starting from leadtime D+6, a BSS value of zero (no improvement) is within the confidence interval (see
Figure 4b).
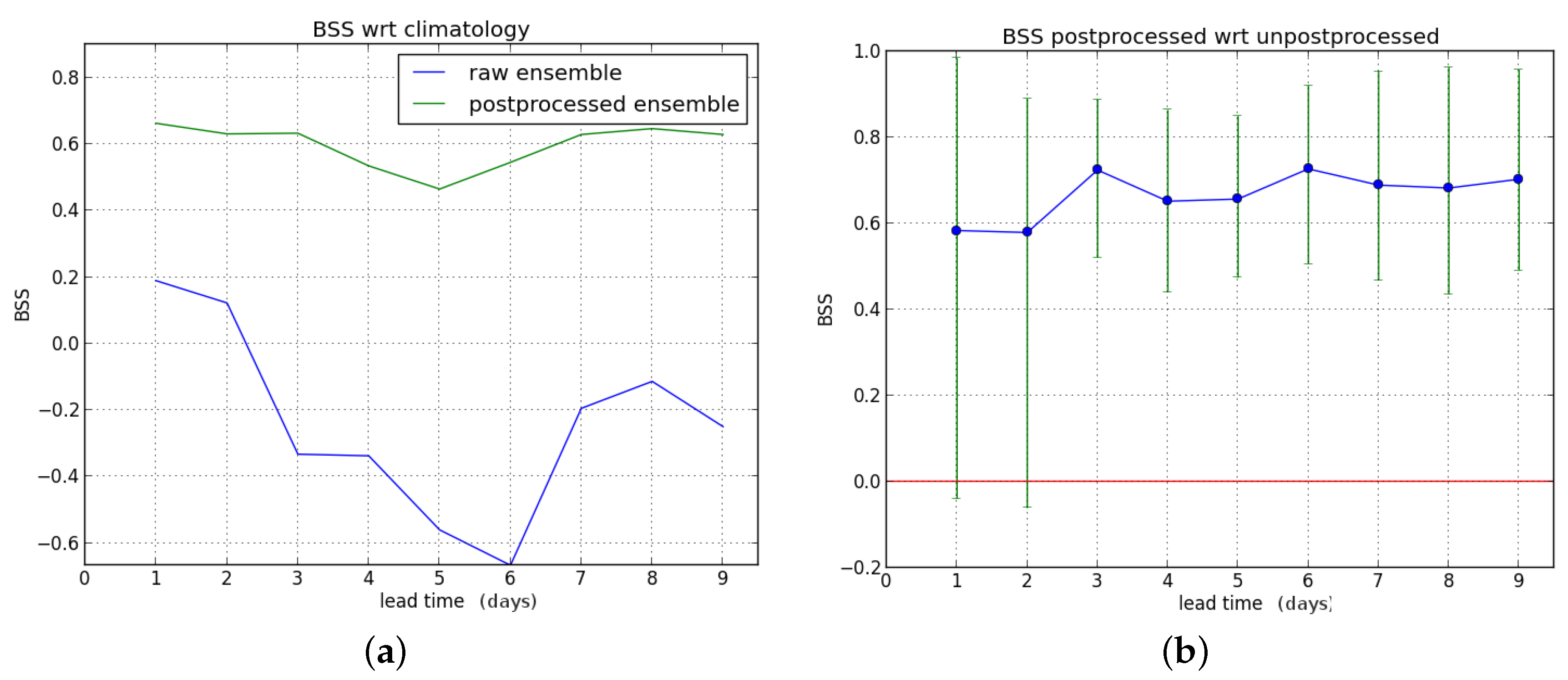
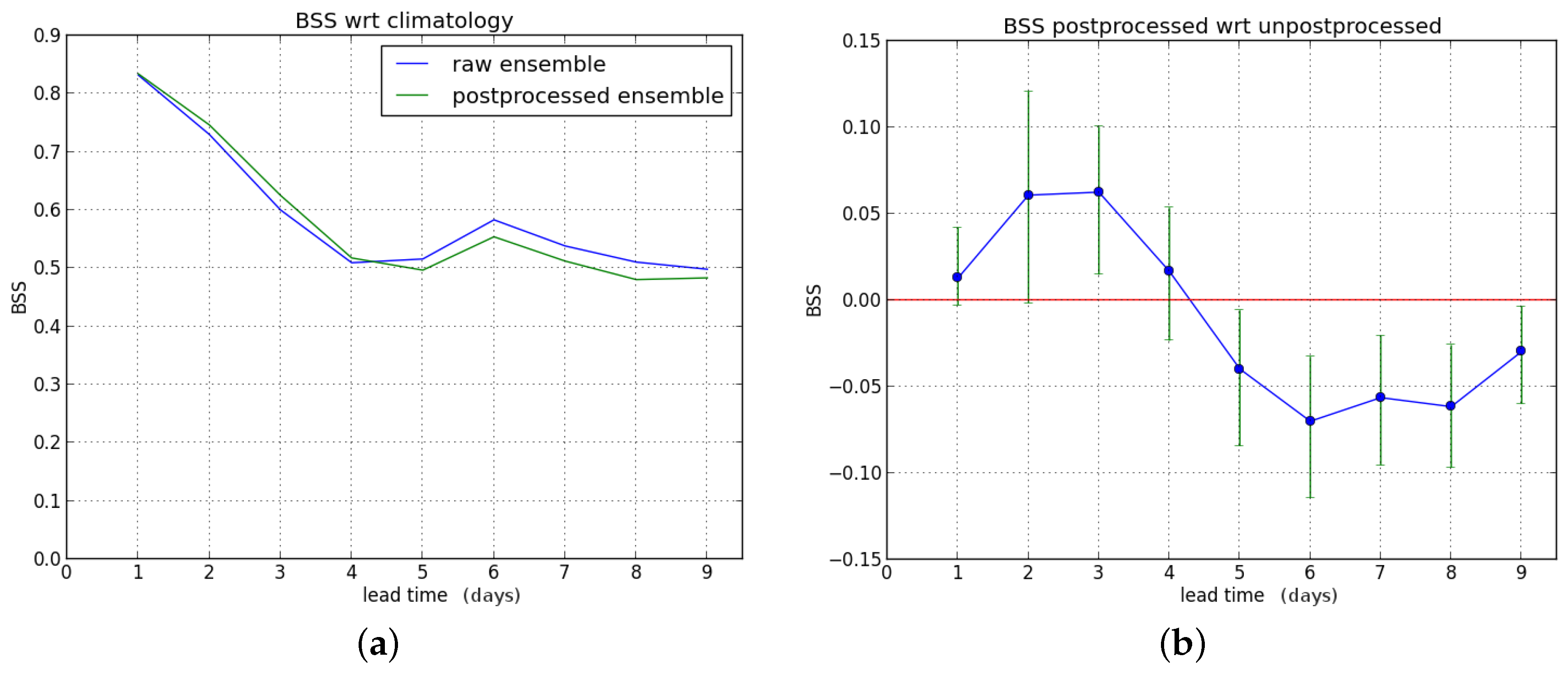
When we consider hydrological winter only, the results are given in
Figure 5. Postprocessing gives an improvement for lead times up to three days ahead, but degrades the forecasts at long lead times (seven to nine days ahead).
For hydrological summer, we refer to
Figure 6. The postprocessing method gives a significant improvement for almost the entire forecast range. Note that there are fewer exceedance events during summer. Further examination of the data reveals that the postprocessing method mainly reduces the number of “false alarm cases”. during this period: cases where no exceedance of the P90 threshold is observed, and where the raw ensemble forcast gives a non-zero probability of exceeding the threshold, which is reduced to zero by the postprocessing. Note that we use the term loosely—the actual false alarm rate would depend on the probability threshold set for acting or not acting.
We also considered the exceedance of the P80 threshold. Results (not shown here) are qualitatively similar. The only difference is that the postprocessing method gives a slightly larger improvement in BSS, significant up to six days ahead when the entire verification period is considered.
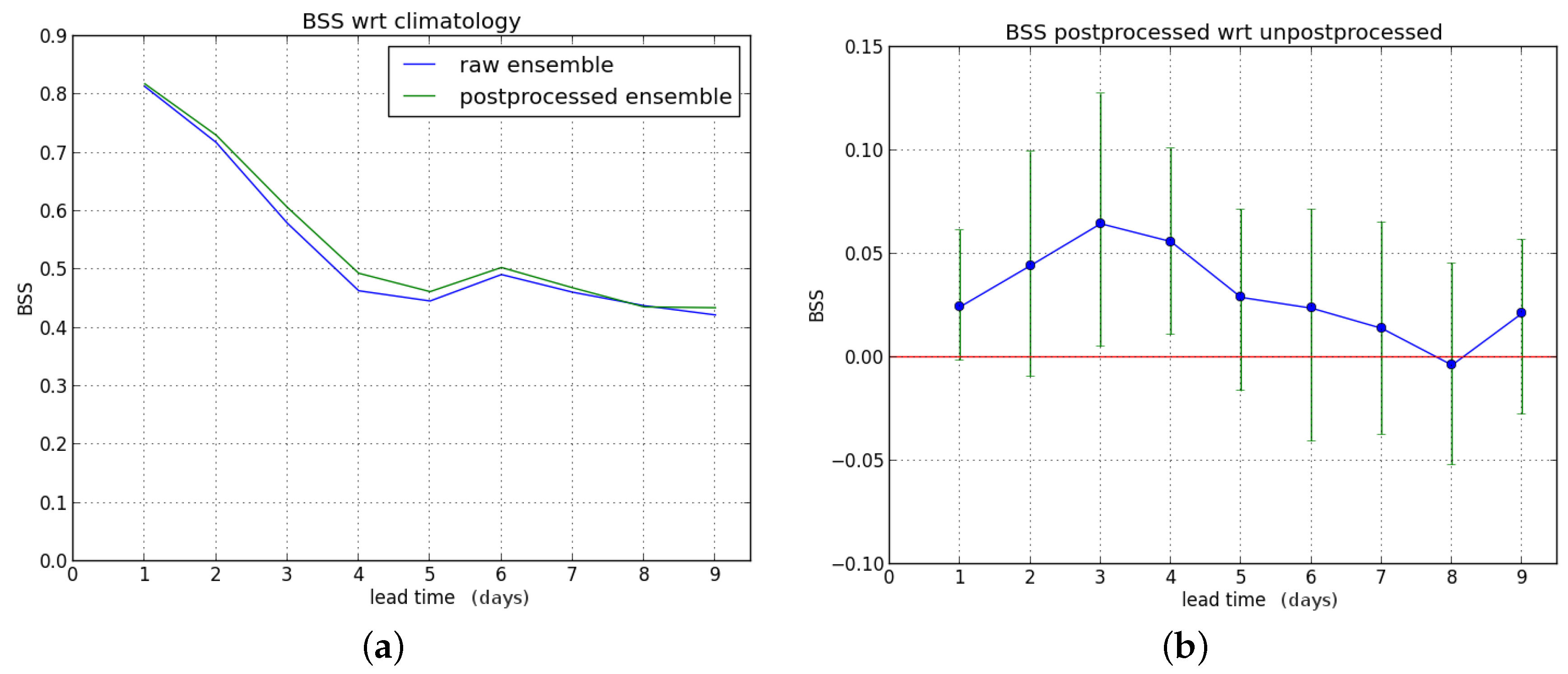
In a last experiment, we force the SCHEME model with observed precipitation and take the resulting output as the truth so that the skill of the hydrological ensemble forecast and the improvement achieved by postprocessing are evaluated in a “perfect hydrological model” setting. Results for the postprocessing with respect to this “reference discharge” are shown in
Figure 7 for the entire verification period at the P90 threshold.
We see that the postprocessing gives a slight improvement in BSS over the whole forecast range, but only significantly for lead times of two and three days. Once again, results for the P80 threshold are similar, but with slightly larger improvement due to postprocessing.
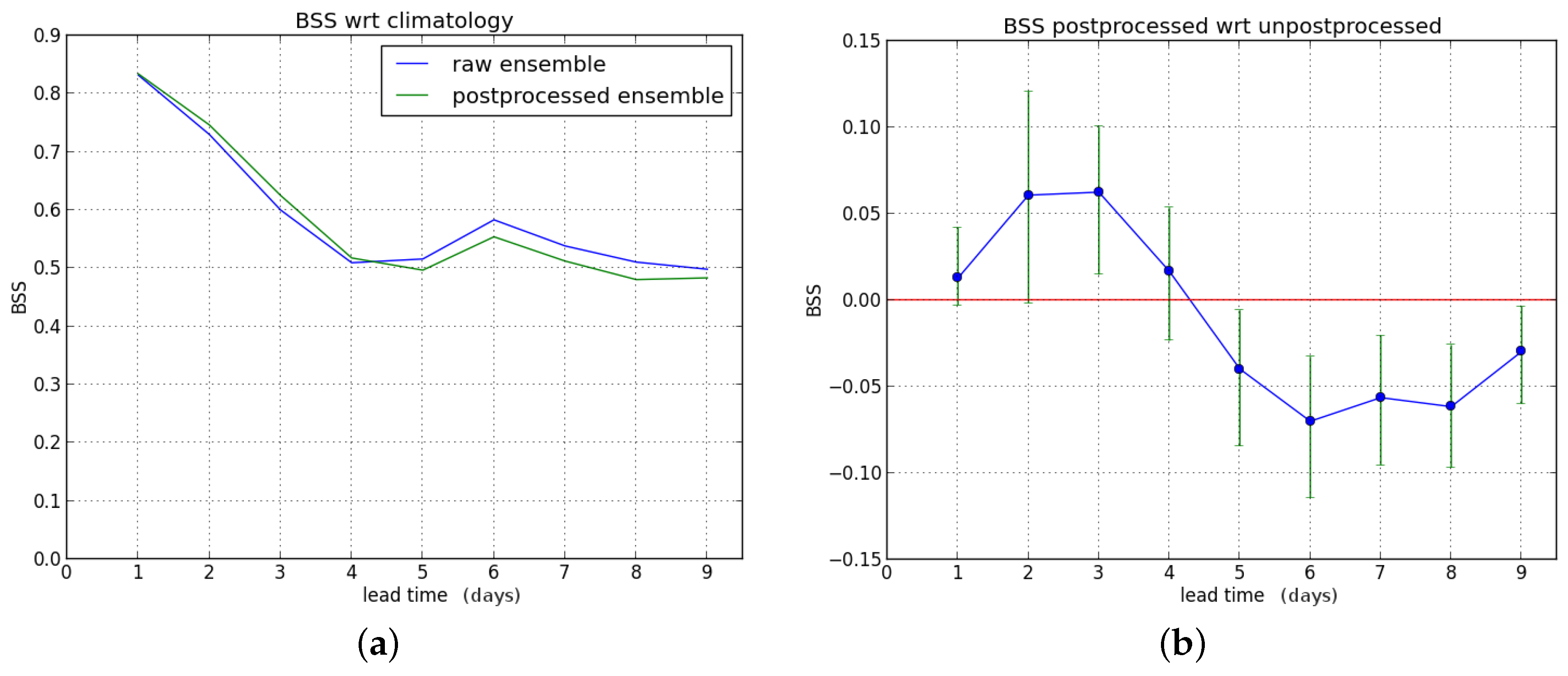
For hydrological winter and summer, the results are shown in
Figure 8 and
Figure 9, respectively. The BSS for hydrological winter is improved during the first days and degraded from the fifth forecast day. During summer, there is an improvement beyond three days. Note that the BSS of the raw ensemble forecast becomes negative after four days; after postprocessing, there is skill during the entire forecast range. Also, comparing
Figure 8 and
Figure 9 to
Figure 5 and
Figure 6, respectively, we conclude that the postprocessing partly compensates for hydrological model errors.
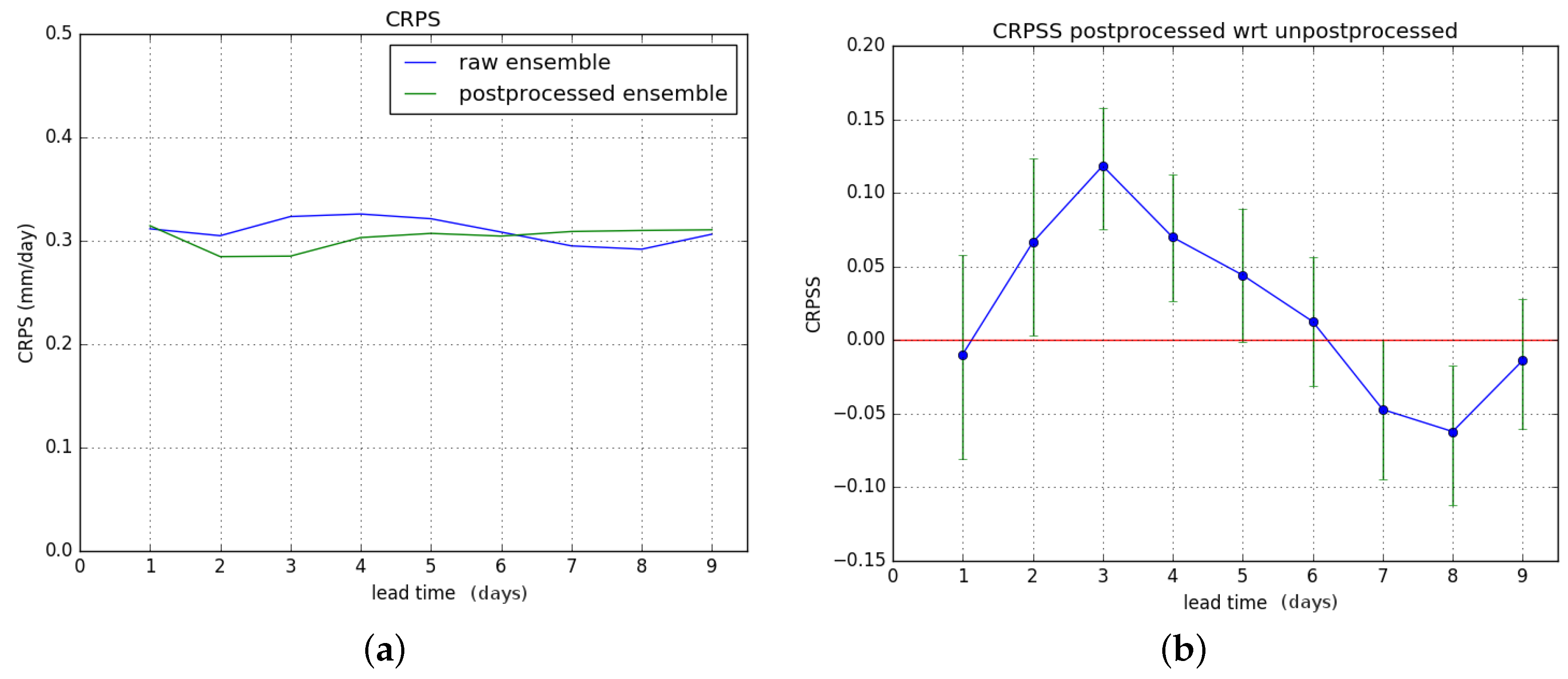
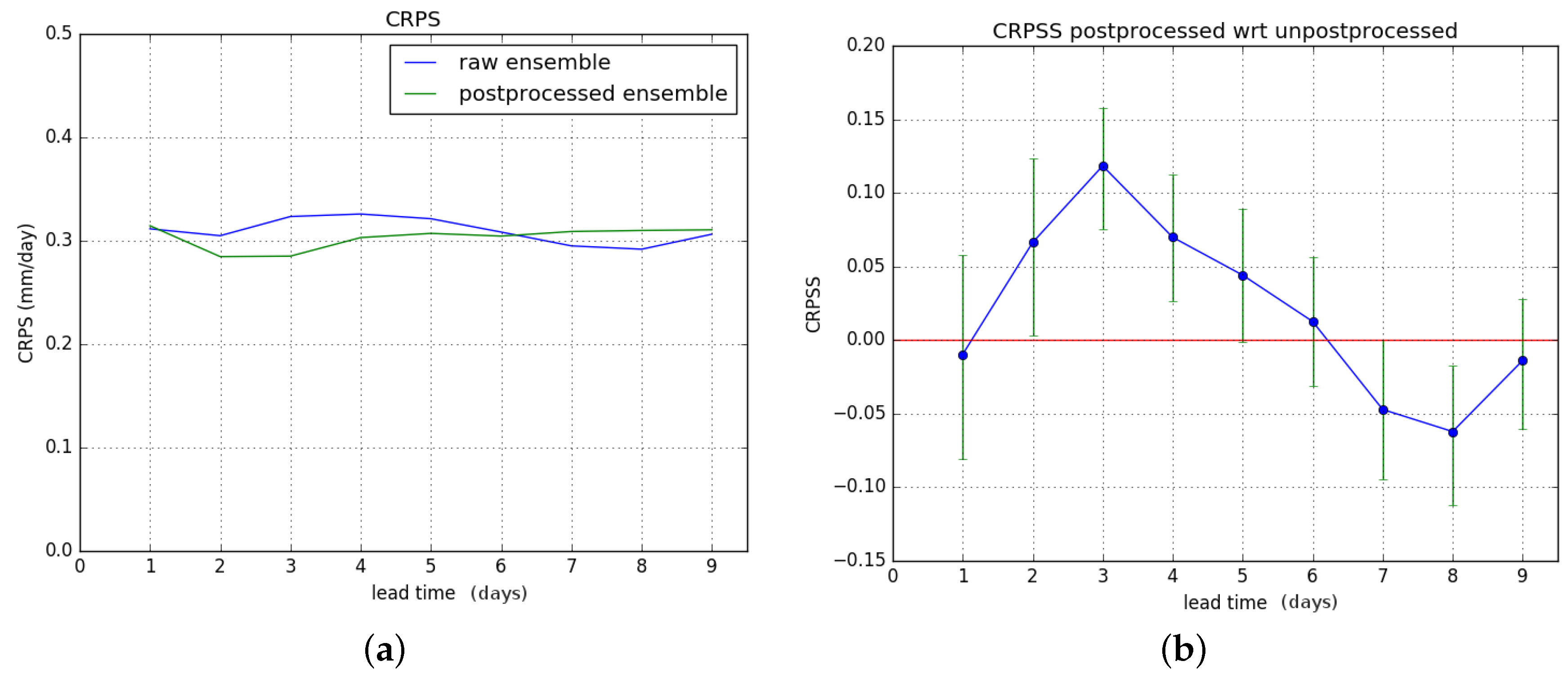
Finally, we look at the CRPS and the improvement attained by postprocessing. We compute the CRPS of the raw and postprocessed forecasts, and subsequently the CRPSS of the postprocessed forecast is computed with the CRPS of the raw forecast as the reference.
In
Figure 10, we consider the entire verification period.
Figure 10a shows the CRPS for the raw and postprocessed forecasts. Note that unlike the previous figures,
Figure 10a doesn’t show skill scores but the CRPS with units of discharge, and which is a negatively oriented measure (lower is better).
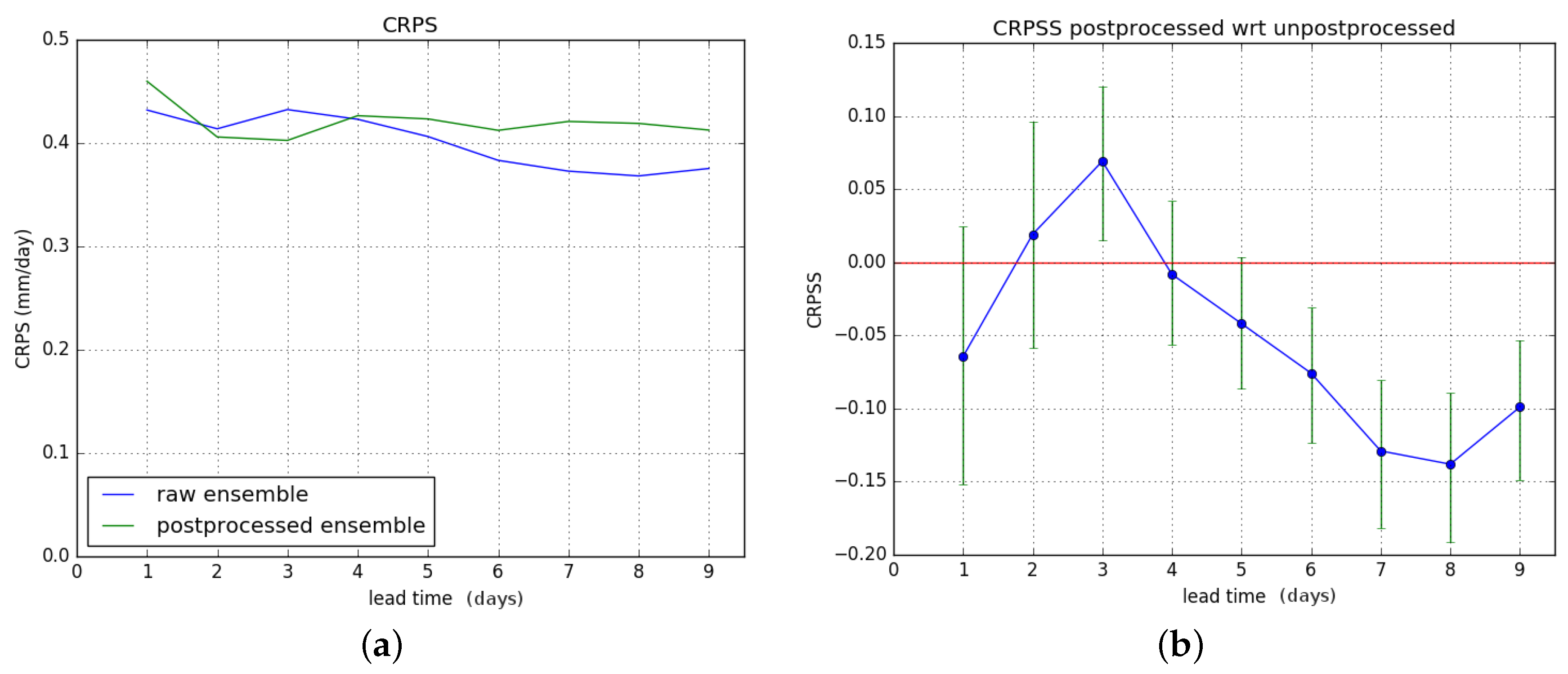
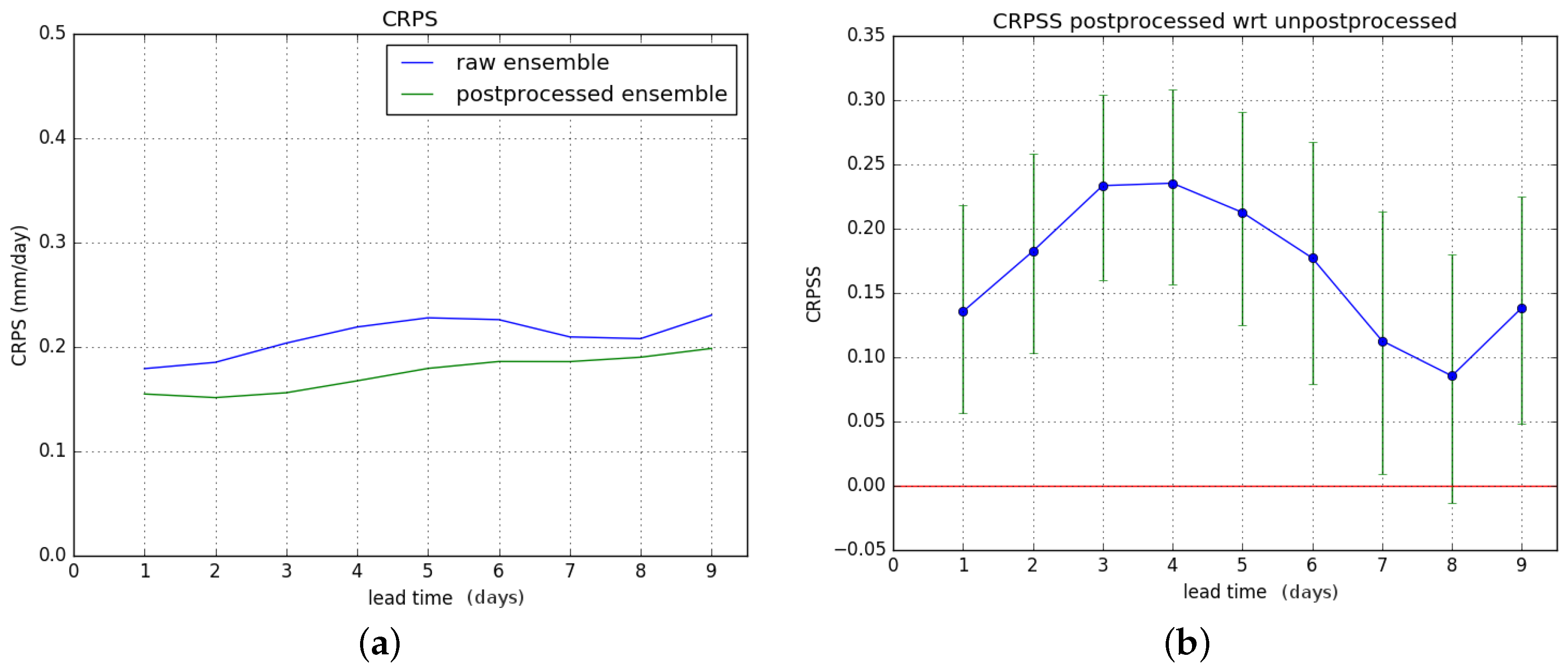
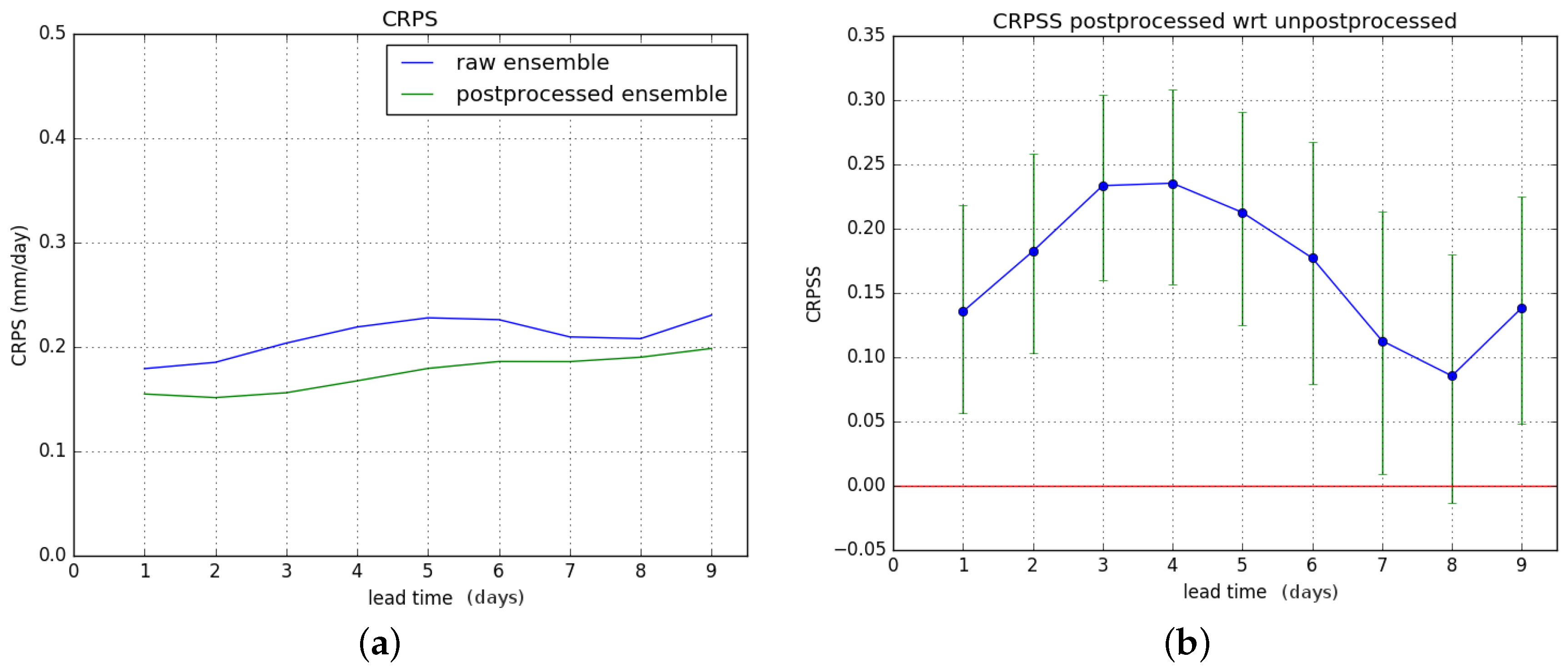
Figure 10b shows the CRPSS of the postprocessed forecasts with respect to the raw ones. The results for hydrological winter and hydrological summer are shown in
Figure 11 and
Figure 12 respectively.
Results show an overall significant improvement of the CRPS during hydrological summer. For hydrological winter, no significant improvement is gained, and there is degrading of skill for lead times of six days or more. These results combine to give a significant overall improvement in CRPSS for lead times of two to four days for the entire verification period. The overall improvement is less than for the Brier Score.
We also looked at the CRPS for the “perfect hydrological model” setup. Results show only a significant improvement in CRPSS for the summer period, two to four days ahead.
We see that the postprocessing method helps remove some error in the precipitation forecasts during summer. In [
7], the authors considered the separate postprocessing of precipitation forecasts before using these as input to a hydrological model, and also found a significant improvement during hydrological summer.
We also compared the ensemble mean of the postprocessed ensemble to the one of the raw ensemble forecast. We find that the bias of the ensemble mean and the mean absolute error (MAE) are not significantly affected by the postprocessing method. The root mean square error (RMSE) of the ensemble mean is actually significantly degraded by the postprocessing method for lead times of two to four days.
When we look at the individual forecasts, we see that unrealistically large discharge values show up in some of the postprocessed forecasts. These outliers have a large impact on the RMSE of the ensemble average. Further investigation reveals the origin of many of these outliers. They typically arise in situations when there is an outlier in the precipitation forecasts, giving rise to mostly discharge ensemble members with no increase in discharge and one or a few giving a peak in discharge. This peak is then enhanced by the calibration, which is performed on the logarithm of the discharges. The exponentiation amplifies this effect, giving an unrealistically large discharge.
The existence of such large outliers in the postprocessed discharge forecasts is problematic if the method is to be used in an operational hydrological ensemble prediction system that also provides discharge ensemble forecasts to end users (and not just exceedance probabilities). Other transformations besides the log transform have been applied in the literature. For instance, [
17] use the log-sinh transform [
18] before “dressing” each member of an ensemble discharge prediction with a normally distributed error and converting back to real-world units. Another widely-used technique is the normal quantile transform (NQT), as used in the context of the Hydrological Uncertainty Processor (HUP, [
19]). Some authors have also discussed issues with outliers after back-transformation. For example, [
20] have shown the difficulties occurring in the inversion of the empirical NQT, if the normal random deviates lie outside the range of historically-observed range. They solve the problem by combining extreme value analysis and non-parametric regression methods. Finally, the Box–Cox transformation is used by [
6] in their truncated variant of Ensemble Model Output Statistics (EMOS). In order to avoid positive probabilities for unrealistically high runoff predictions after back-transformation, the normal distributions are right truncated at two times the maximum of the observations.
A thorough comparison of different methods to deal with the issue of outliers is outside the scope of this paper. In our study, we tested a truncation of the outliers at two times the maximum of the observations ([
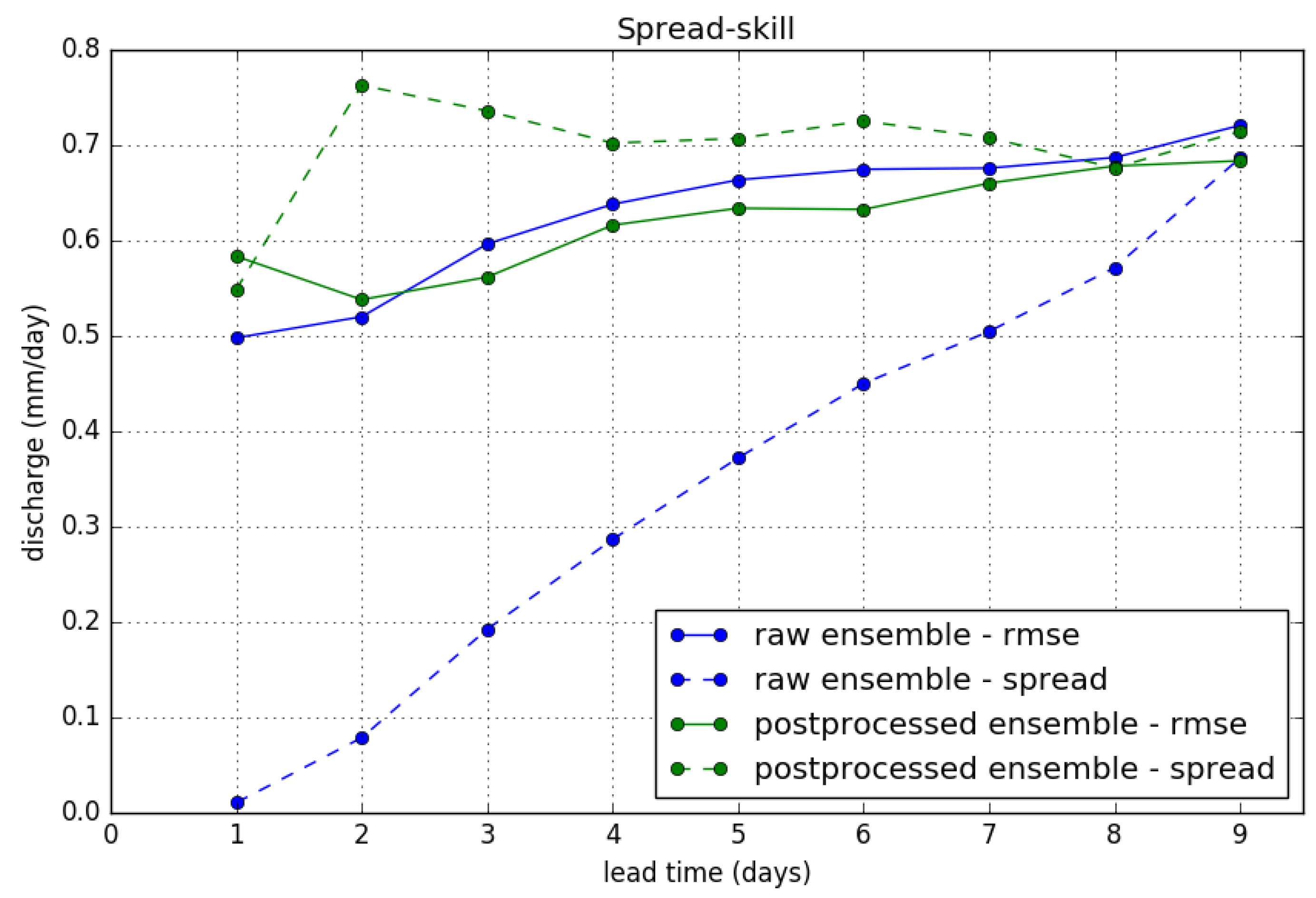
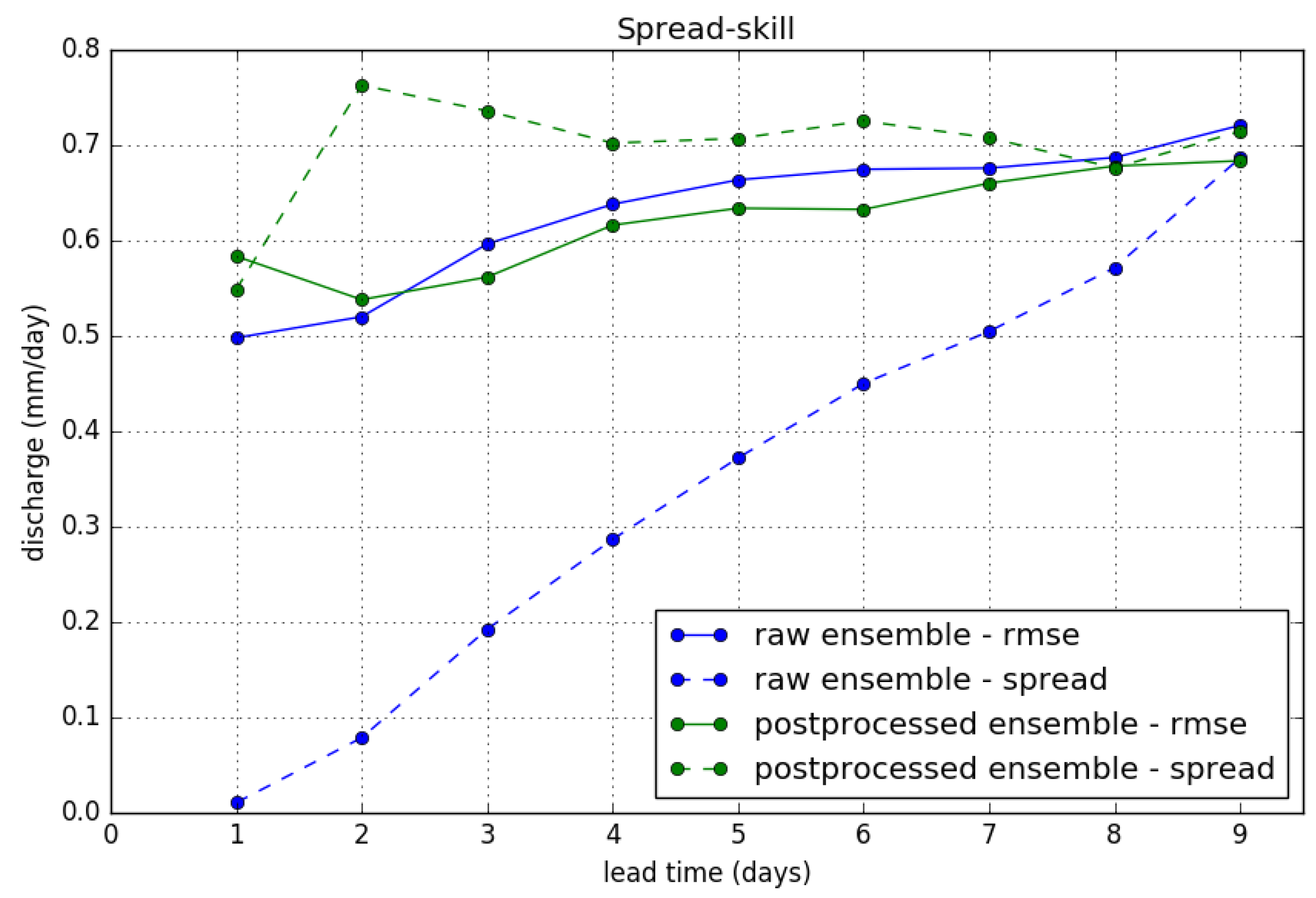
6]). Naturally, this leaves the verification results for the exceedance of the P90 threshold (Brier score) unchanged. Moreover, we find that results for the CRPS are not significantly affected. Results for the “spread-skill” relationship after truncation are presented in
Figure 13. We show the ensemble spread (or ensemble standard deviation) and RMSE of the ensemble mean, which are equal for a perfectly calibrated ensemble, for the raw and postprocessed ensemble forecasts. We clearly see the effect of the variance inflation method in increasing the spread of the ensemble. The RMSE of the ensemble mean is slightly reduced by the postprocessing, but note that this is dependant on the choice of truncation.
Ideally, a more refined method should be developed to deal with the issue of outliers. We briefly discuss some possible solutions and avenues for further study.
The reforecast schedule at ECMWF has evolved towards two dates per week, and the reforecast ensembles now consist of 11 members. Having more training data available should increase the chance that a specific forecast with outliers is represented in the past set of reforecasts, and should improve the calibration method. We intend to validate the use of the 11-member reforecasts as soon as enough data is available.
We are also investigating a postprocessing method with separate calibration for different river discharge regimes (rising or falling limb).
There is a trade-off between the sample size and the refinement of the calibration. It could be checked that some key characteristics of the hydrological ensemble to be postprocessed (for instance, its spread or its range) are sufficiently well-represented in the hydrological reforecast dataset used for calibration. In case they are not well represented, the postprocessing can be skipped.
6. Conclusions
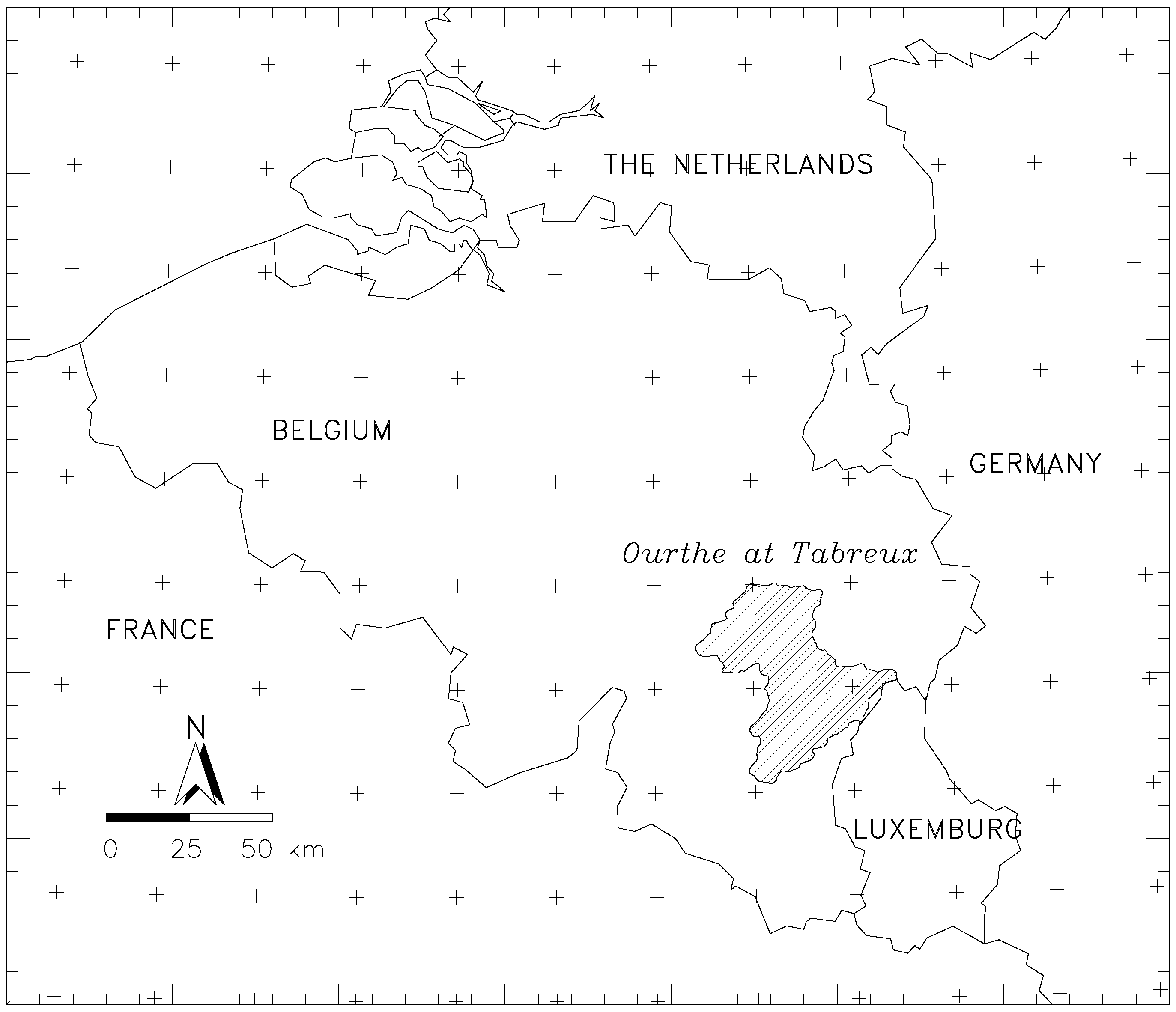
We investigated the postprocessing of our discharge forecasts for the Ourthe catchment, using archived weekly ECMWF five-member reforecasts that have been available since 2012. We used these as input to create a set of hydrological reforecasts. The implemented calibration method is the variance inflation method as adapted by [
7].
Verification results indicate that the postprocessing method gives a significant improvement in the Brier skill score for lead times of up to five days. This can be attributed to:
An improvement over the entire forecast range during hydrological summer, mainly reducing false alarms.
An improvement during winter for the first three days, and a degrading of the forecast skill for the last three days.
For the CRPS score, which measures the overall probabilistic skill, the improvement is less than for the Brier score, but still significant for the entire forecast range during hydrological summer. For hydrological winter, there is not much improvement, and a degrading of the skill for lead times of six days or more. We conclude that it is definitely valuable to apply the postprocessing method during hydrological summer. In our operational setting, where discharge exceedance probabilities for higher thresholds are forecast, the method is also useful during winter, but not for lead times beyond five days.
Finally, the postprocessed discharge forecasts contain some unrealistically large outliers. The RMSE of the ensemble mean is actually degraded by the method. This is caused by outliers in the raw ensemble discharge forecasts that are further amplified by the non-linear back-transformation to the corrected discharge values.
This leads us to conclude that the variance inflation method is suitable when the aim is to improve the forecasting of discharge exceedance probabilities. The method delivers forecasts with improved statistical properties. However, it fails to always deliver realistic ensemble forecasts when the individual members are considered. Thus, if the aim is to deliver actual postprocessed ensemble discharge forecasts (or a visualization with, for example, spaghetti plots, …) to an end user, other methods should be considered or the variance inflation method needs at least further refinement. We intend to discuss this issue further in a following study.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}