
Addressing Volatility and Nonlinearity in Discharge Modeling: ARIMA-iGARCH for Short-Term Hydrological Time Series Simulation



Abstract
1. Introduction
- In addition, the dependence of ML algorithm effectiveness on input-data representation integrity can pose another challenge. Constructing features from raw data is a significant part of the modeling, and this is extremely field-specific, requiring substantial human effort [18].
2. Case Study and Data Collection

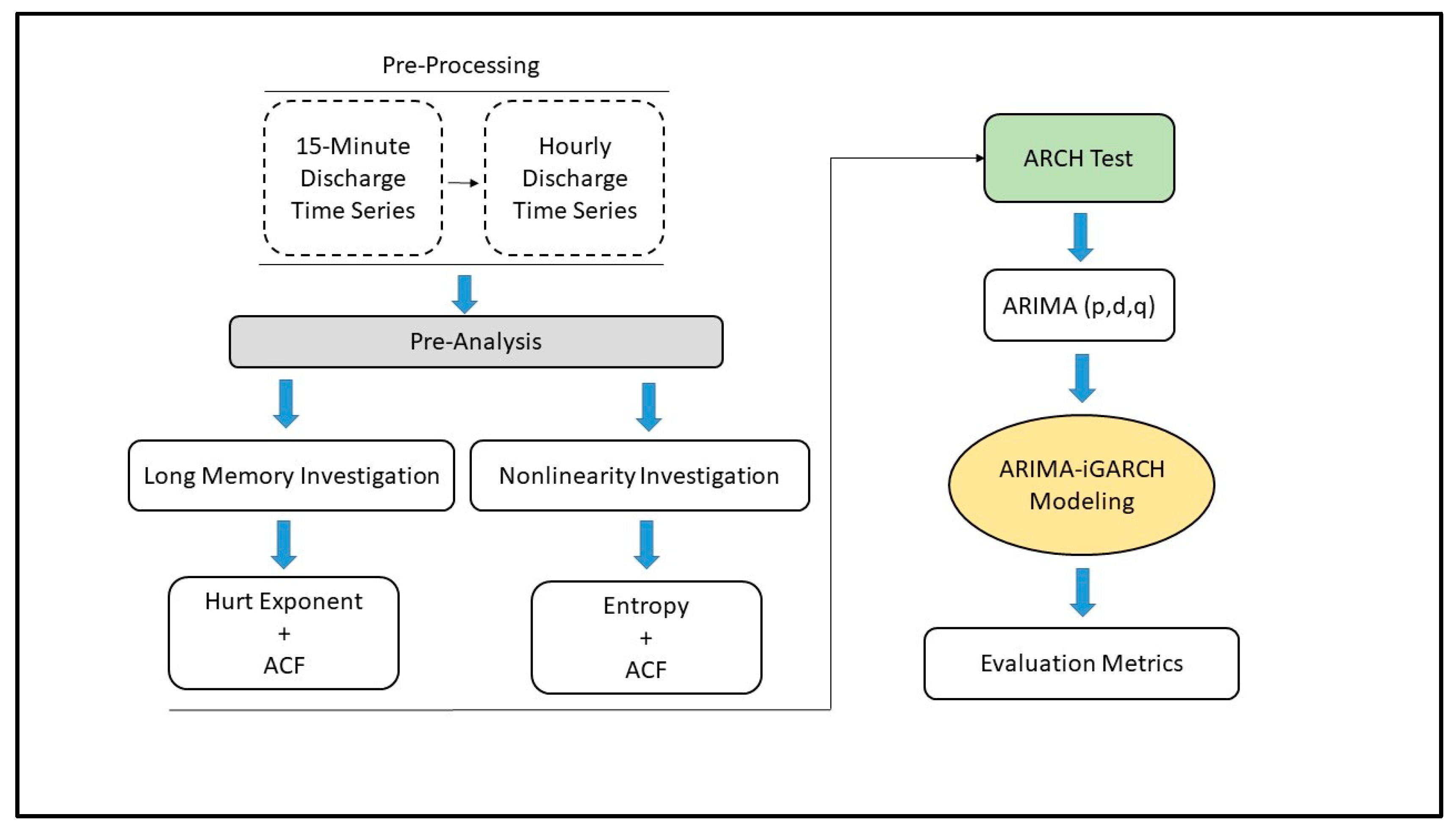
3. Methods
3.1. Long Memory Investigation
3.1.1. Autocorrelation Function (ACF)
3.1.2. Rescaled Range Analysis (Hurst Exponent)
3.2. Nonlinearity Investigation
3.2.1. Autocorrelation Function (ACF)
3.2.2. Entropy
3.3. Autoregressive Moving Average (ARIMA)
3.4. Integrated Generalized Autoregressive Conditional Heteroskedasticity (iGARCH)
3.5. Evaluation Metrics
3.5.1. Coefficient of Determination (R2)
3.5.2. Root Mean Squared Error (RMSE)
3.5.3. Mean Absolute Percentage Error (MAPE)
3.5.4. Mean Absolute Error (MAE)
3.5.5. Mean Bias Error (MBE)
3.5.6. Nash–Sutcliffe Efficiency (NSE)
3.5.7. Index of Agreement (d-Index)
3.5.8. Evaluation Approach
4. Results and Discussion
4.1. Time Series Interval Conversion
- Noise reduction and signal-to-noise ratio growth are the results from data aggregation, so it will allow us to follow the trends and patterns more clearly.
- Additionally, hourly data can better adapt to the temporal dynamics of many modeling methods.
- Furthermore, by increasing the time interval to hourly, we could decrease the computational load in order to use the data preparation techniques more effectively.
- Statistically, hourly aggregation reduces autocorrelation at short lags and improves model stability, making it more suitable for capturing conditional heteroskedasticity patterns such as those modeled by iGARCH.
- Finally, hourly data leads to more robust statistical estimates.
4.2. Long Memory
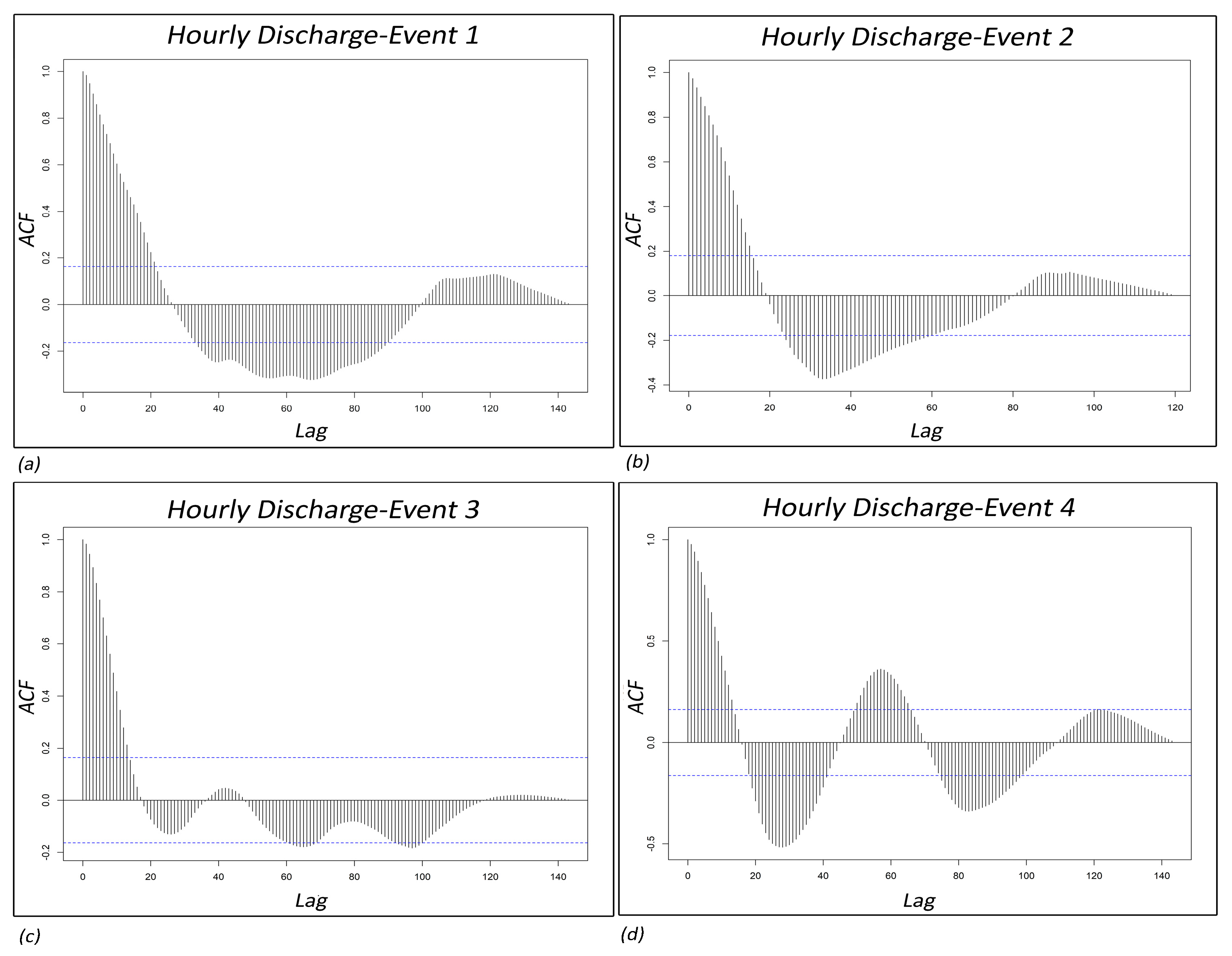
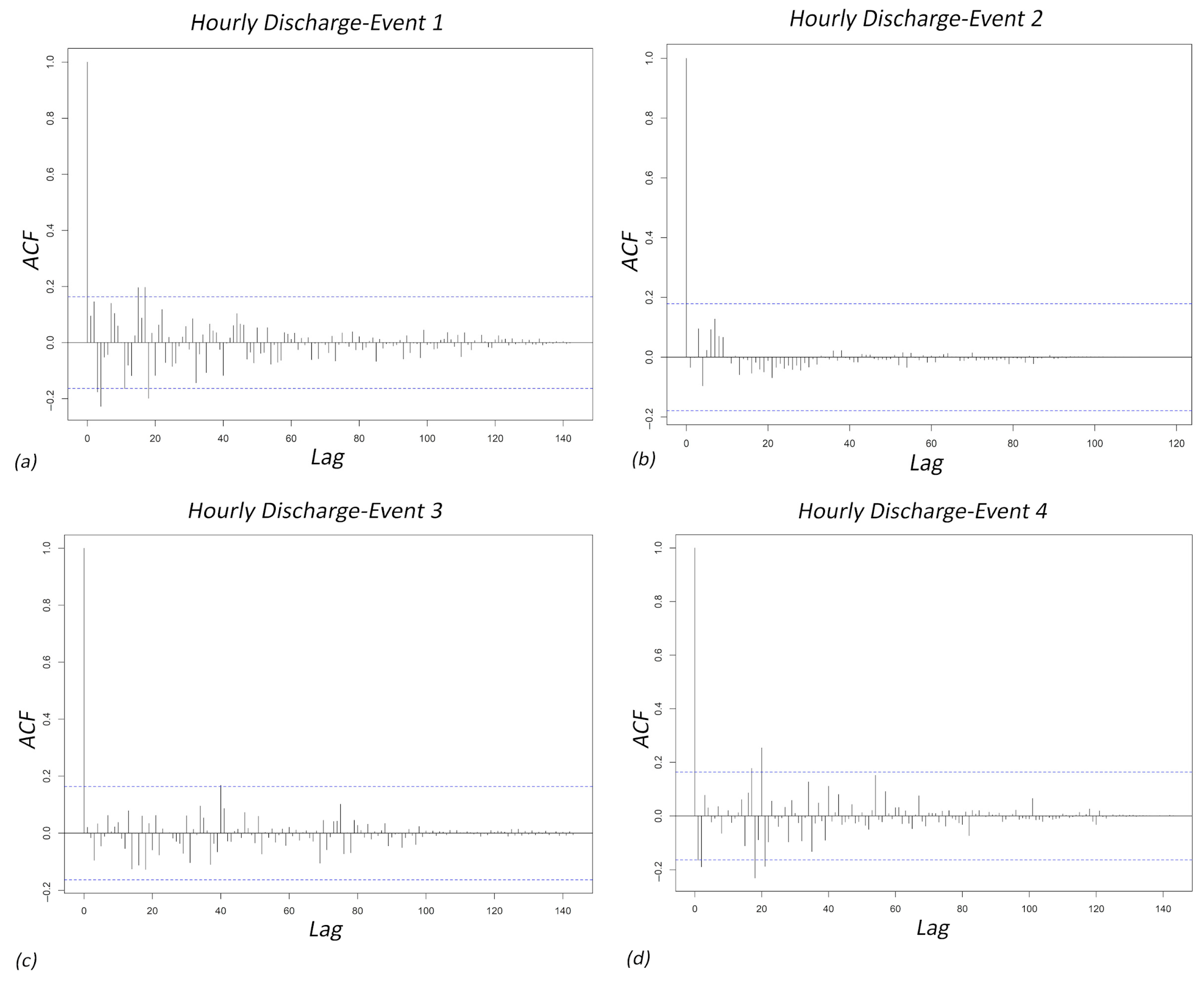
4.2.1. Autocorrelation Function (ACF)
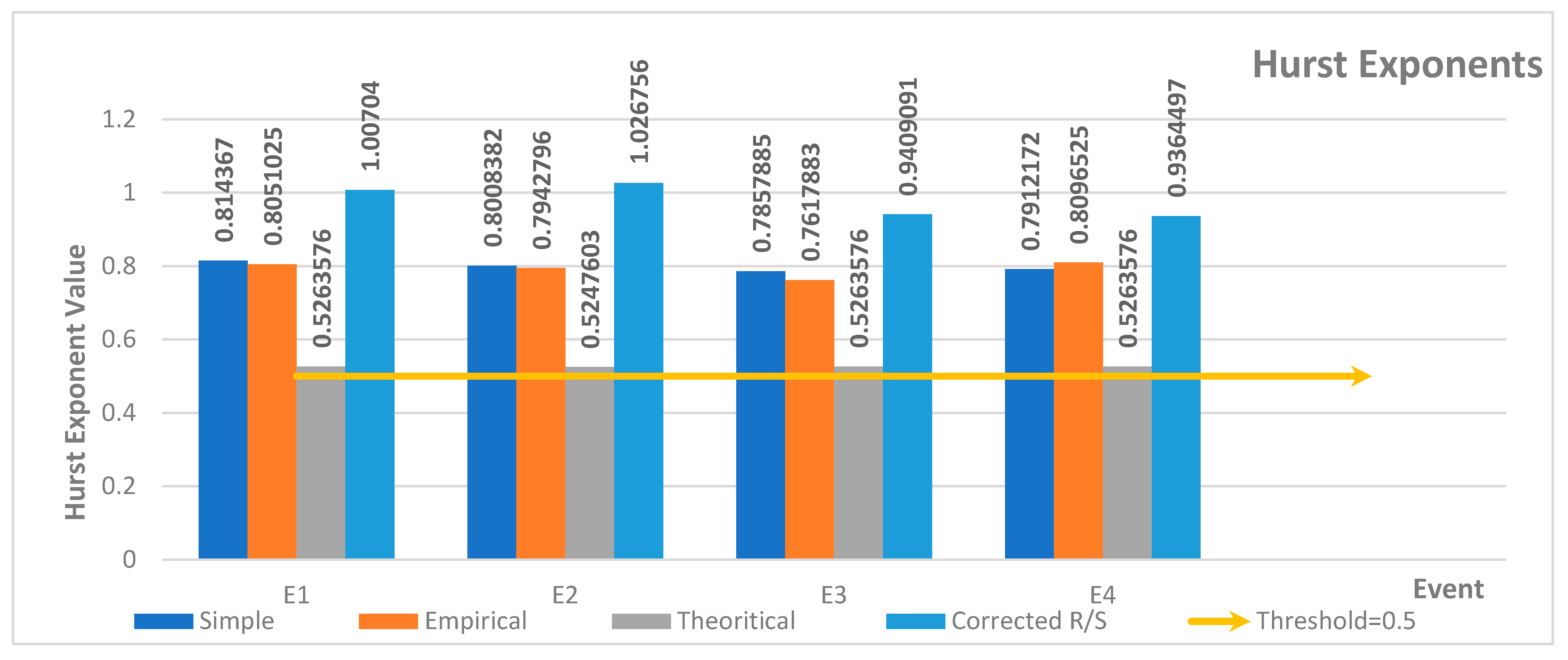
4.2.2. Hurst Exponent
4.3. Nonlinearity
4.3.1. ACF
4.3.2. Entropy
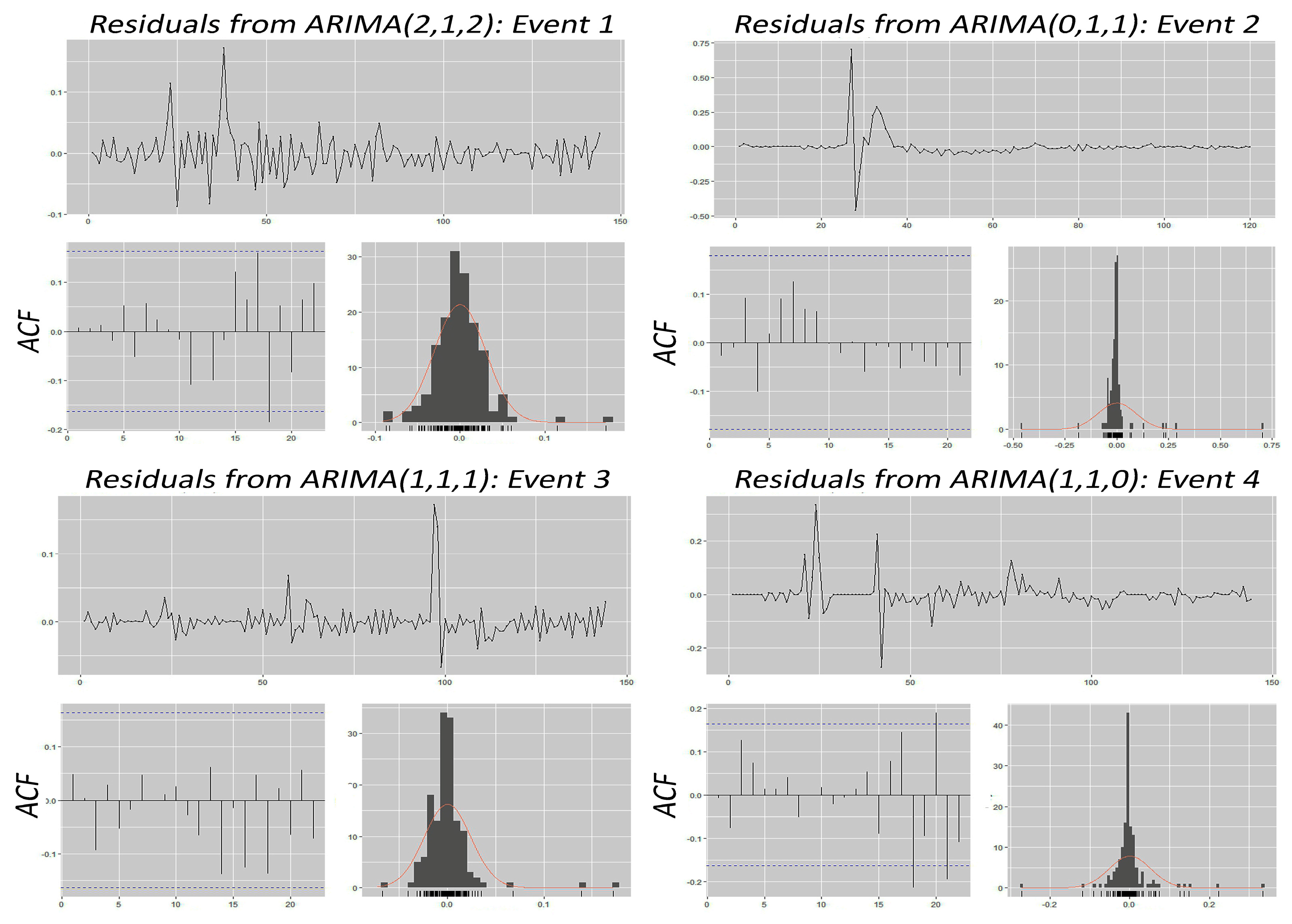
4.4. ARIMA
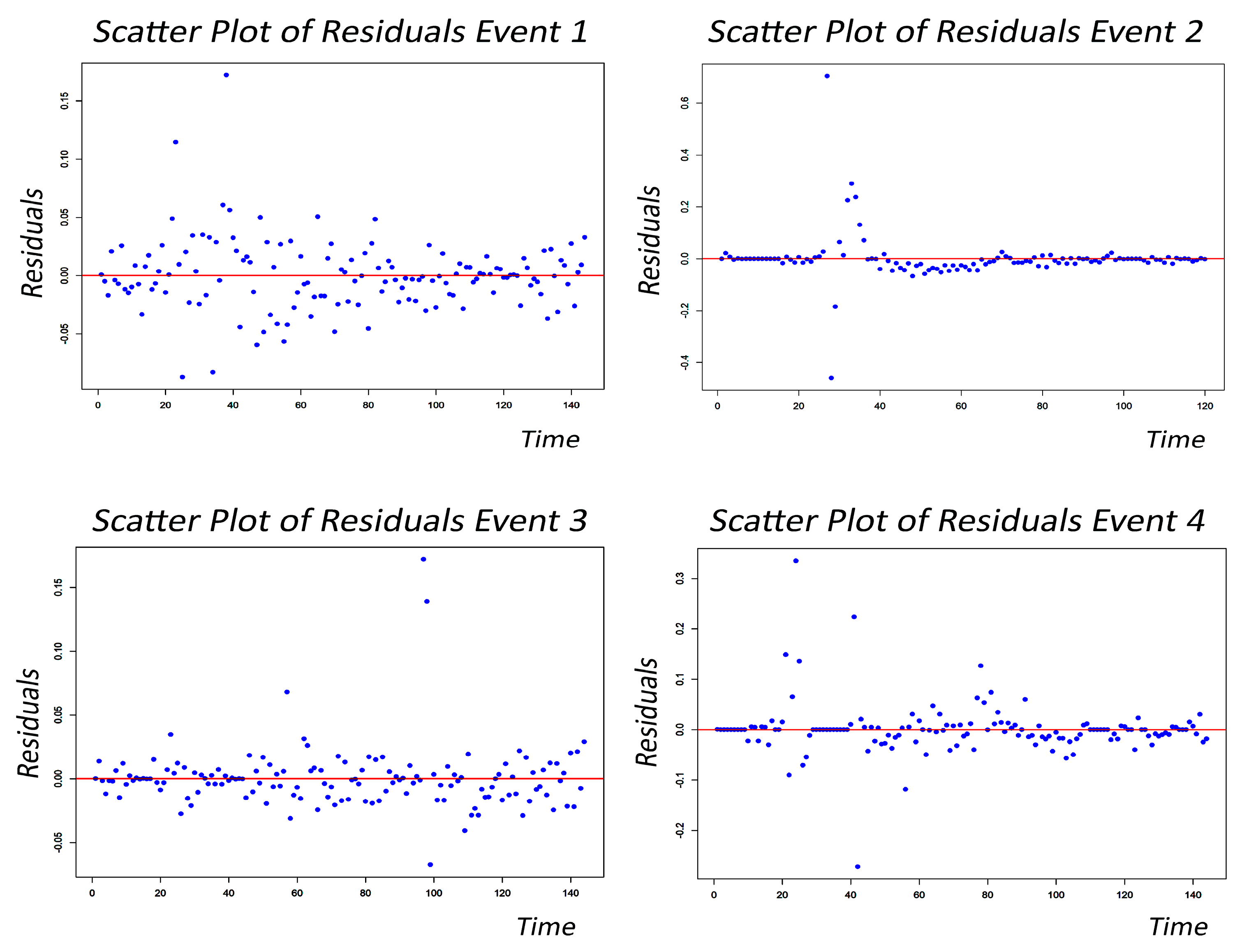
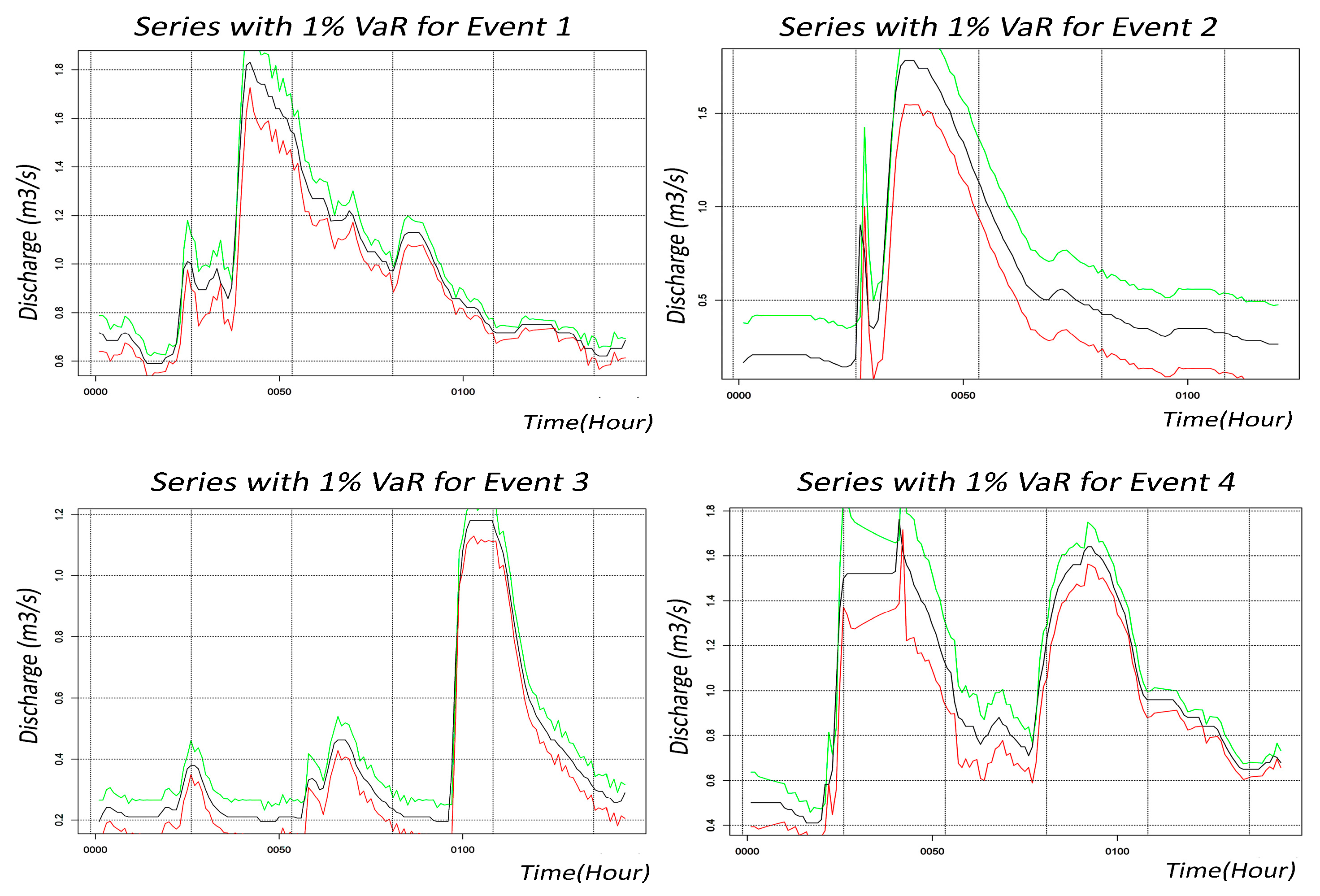
4.5. ARIMA-iGARCH
4.6. Evaluation Metrics
5. Conclusions
- Regarding long memory, the Hurst exponent method shows strong long-memory effects (values >0.5) across all events, with Event 1 exhibiting the strongest correlation.
- Regarding nonlinearity, the entropy analysis reveals notable fluctuations in hourly discharge, indicating a non-constant pattern. Event 4, with its periodic nature, displays the highest nonlinearity, underscoring the need for a fluctuation-sensitive model.
- The detection of long memory and nonlinear patterns in the streamflow data justified the application of a hybrid ARIMA-iGARCH model, which combines linear modeling for the mean and nonlinear conditional heteroskedasticity for the variance. These features improve the model’s accuracy by capturing persistent dependencies and volatility clustering that simpler models might overlook.
- Regarding the ARIMA model performance, the ARIMA model captures average value responses to nonlinearity, enhancing modeling accuracy. However, its sensitivity to sudden jumps (notably in Event 2) can lead to residual errors. Optimizing iGARCH specifications using ARIMA reduces forecast errors.
- Regarding the ARIMA-iGARCH model performance, the ARIMA-iGARCH model effectively models volatility and time-dependent fluctuations, achieving its best performance in Event 3 with high R2 and low RMSE. This model is reliable for addressing variance and improving short-term hydrological predictions.
- The ARIMA-iGARCH model improves flood forecasting and discharge assessment, making it valuable for water management. Its ability to capture variability supports early-warning systems and strengthens resilience to hydrological extremes, contributing to effective land and water management.
- This modeling approach offers scientific advancement while addressing urgent practical needs in early-warning systems, paving the way for more adaptive and resilient hydrological infrastructure under uncertain conditions.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bai, X.; Zhao, W. Impacts of climate change and anthropogenic stressors on runoff variations in major river basins in China since 1950. Sci. Total. Environ. 2023, 898, 165349. [Google Scholar] [CrossRef]
- MacDonald, G.; Godbout, A.; Gillcash, B.; Cairns, S. Volume-preserving Neural Networks. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–9. [Google Scholar]
- Wang, W.; Van Gelder, P.H.A.J.M.; Vrijling, J.K.; Ma, J. Testing and modelling autoregressive conditional heteroskedasticity of streamflow processes. Nonlinear Process. Geophys. 2005, 12, 55–66. [Google Scholar] [CrossRef]
- Giri, F.; Devercelli, M. Chaos arising from the hydrological behaviour of a floodplain river during the last century. River Res. Appl. 2022, 39, 241–254. [Google Scholar] [CrossRef]
- Lai, Y.; Dzombak, D.A. Use of the Autoregressive Integrated Moving Average (ARIMA) Model to Forecast Near-Term Regional Temperature and Precipitation. Weather. Forecast. 2020, 35, 959–976. [Google Scholar] [CrossRef]
- Li, Y.; Huang, C.; Ding, L.; Li, Z.; Pan, Y.; Gao, X. Deep learning in bioinformatics: Introduction, application, and perspective in the big data era. Methods 2019, 166, 4–21. [Google Scholar] [CrossRef]
- Marwan, N.; Donges, J.F.; Donner, R.V.; Eroglu, D. Nonlinear time series analysis of palaeoclimate proxy records. Quat. Sci. Rev. 2021, 274, 107245. [Google Scholar] [CrossRef]
- Bhasme, P.; Bhatia, U. Improving the interpretability and predictive power of hydrological models: Applications for daily streamflow in managed and unmanaged catchments. J. Hydrol. 2024, 628, 130421. [Google Scholar] [CrossRef]
- Naimy, V.; Haddad, O.; Fernández-Avilés, G.; El Khoury, R.; Segovia, J.E.T. The predictive capacity of GARCH-type models in measuring the volatility of crypto and world currencies. PLoS ONE 2021, 16, e0245904. [Google Scholar] [CrossRef]
- Wong, W.M.; Lee, M.Y.; Azman, A.S.; Rose, L.A.F. Development of Short-term Flood Forecast Using ARIMA. Int. J. Math. Model. Methods Appl. Sci. 2021, 15, 68–75. [Google Scholar] [CrossRef]
- Fathian, F.; Fard, A.F.; Ouarda, T.B.; Dinpashoh, Y.; Nadoushani, S.M. Modeling streamflow time series using nonlinear SETAR-GARCH models. J. Hydrol. 2019, 573, 82–97. [Google Scholar] [CrossRef]
- Izadi, A.; Zarei, N.; Nikoo, M.R.; Al-Wardy, M.; Yazdandoost, F. Exploring the potential of deep learning for streamflow forecasting: A comparative study with hydrological models for seasonal and perennial rivers. Expert Syst. Appl. 2024, 252, 124139. [Google Scholar] [CrossRef]
- Naji, A.S.M.; Yaziz, S.R.; Zakaria, R.; Mohamad, N.N.; Radi, N.F.A. Gold price forecasting using ARIMA-GARCH model during COVID-19 pandemic outbreak. AIP Conf. Proc. 2024, 2895, 090018. [Google Scholar] [CrossRef]
- Pashazadeh, A.; Javan, M. Comparison of the gene expression programming, artificial neural network (ANN), and equivalent Muskingum inflow models in the flood routing of multiple branched rivers. Theor. Appl. Clim. 2020, 139, 1349–1362. [Google Scholar] [CrossRef]
- Wang, H.; Song, S.; Zhang, G.; Ayantoboc, O.O. Predicting daily streamflow with a novel multi-regime switching ARIMA-MS-GARCH model. J. Hydrol. Reg. Stud. 2023, 47. [Google Scholar] [CrossRef]
- HLNUG. Nauheim gauge (ID 23980353) in Hesse, Germany: Discharge Data [Data Set]. Database of Hessian Agency for Nature Conservation, Environment and Geology (Hessisches Landesamt für Naturschutz, Umwelt und Geologie). 2023. Available online: https://www.hlnug.de/static/pegel/wiskiweb3/webpublic/#/overview/Durchfluss/station/41361/Nauheim/ (accessed on 5 June 2023).
- Khazaeiathar, M.; Hadizadeh, R.; Attar, N.F.; Schmalz, B. Daily Streamflow Time Series Modeling by Using a Periodic Autoregressive Model (ARMA) Based on Fuzzy Clustering. Water 2022, 14, 3932. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Khazaiee, M.; Khalili, K.; Behmanesh, J. Investigating the relationship between physical characteristics of watersheds and nonlinearity of daily streamflow processes. Int. J. Water 2018, 12, 141. [Google Scholar] [CrossRef]
- Choi, E.; Bahadori, M.T.; Kulas, J.A.; Schuetz, A.; Stewart, W.F.; Sun, J. RETAIN: An Interpretable Predictive Model for Healthcare using Reverse Time Attention Mechanism. Adv. Neural Inf. Process. Syst. 2016, 29. Available online: http://arxiv.org/abs/1608.05745 (accessed on 21 March 2025).
- Khand, K.; Senay, G.B. Evaluation of streamflow predictions from LSTM models in water- and energy-limited regions in the United States. Mach. Learn. Appl. 2024, 16, 100551. [Google Scholar] [CrossRef]
- Roodschild, M.; Sardiñas, J.G.; Will, A. A new approach for the vanishing gradient problem on sigmoid activation. Prog. Artif. Intell. 2020, 9, 351–360. [Google Scholar] [CrossRef]
- Rawat, D.; Mishra, P.; Ray, S.; Warnakulasooriya, H.H.F.; Sati, S.P.; Mishra, G.; Alkattan, H.; Abotaleb, M. Modeling of rainfall time series using NAR and ARIMA model over western Himalaya, India. Arab. J. Geosci. 2022, 15, 1–26. [Google Scholar] [CrossRef]
- Samantaray, S.; Sahoo, P.; Sahoo, A.; Satapathy, D.P. Flood discharge prediction using improved ANFIS model combined with hybrid particle swarm optimisation and slime mould algorithm. Environ. Sci. Pollut. Res. 2023, 30, 83845–83872. [Google Scholar] [CrossRef]
- Wang, X.; Qin, Y.; Wang, Y.; Xiang, S.; Chen, H. ReLTanh: An activation function with vanishing gradient resistance for SAE-based DNNs and its application to rotating machinery fault diagnosis. Neurocomputing 2019, 363, 88–98. [Google Scholar] [CrossRef]
- Lee, K.; Lee, K.; Shin, J.; Lee, H. Overcoming catastrophic forgetting with unlabeled data in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October 2019; pp. 312–321. [Google Scholar] [CrossRef]
- Moura, R.; Mendes, A.; Cascalho, J.; Mendes, S.; Melo, R.; Barcelos, E. Predicting Flood events with Streaming Data: A Preliminary Approach with GRU and ARIMA. In Optimization, Learning Algorithms and Applications. OL2A 2023. Communications in Computer and Information Science 1981; Pereira, A.I., Mendes, A., Fernandes, F.P., Pacheco, M.F., Coelho, J.P., Lima, J., Eds.; Springer: Cham, Switzerland, 2024; pp. 319–332. [Google Scholar] [CrossRef]
- Parsaie, A.; Ghasemlounia, R.; Gharehbaghi, A.; Haghiabi, A.; Chadee, A.A.; Nou, M.R.G. Novel hybrid intelligence predictive model based on successive variational mode decomposition algorithm for monthly runoff series. J. Hydrol. 2024, 634, 131041. [Google Scholar] [CrossRef]
- Sharma, A.K.; Punj, P.; Kumar, N.; Das, A.K.; Kumar, A. Lifetime Prediction of a Hydraulic Pump Using ARIMA Model. Arab. J. Sci. Eng. 2024, 49, 1713–1725. [Google Scholar] [CrossRef]
- Mo, R.; Xu, B.; Zhong, P.-A.; Dong, Y.; Wang, H.; Yue, H.; Zhu, J.; Wang, H.; Wang, G.; Zhang, J. Long-term probabilistic streamflow forecast model with “inputs–structure–parameters” hierarchical optimization framework. J. Hydrol. 2023, 622, 129736. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Pandit, M.; Gaur, M.K.; Kumar, S. Artificial Intelligence and Sustainable Computing; Pandit, M., Gaur, M.K., Kumar, S., Eds.; Springer Nature: Dordrecht, GX, The Netherlands, 2023. [Google Scholar]
- Chukwueloka, E.; Nwosu, A. Modelling and Prediction of Rainfall in the North-Central Region of Nigeria Using ARIMA and NNETAR Model. In Climate Change Impacts on Nigeria, Springer Climate; Egbueri, J.C., Ighalo, J.O., Pande, C.B., Eds.; Springer: Cham, Switzerland, 2023; pp. 91–114. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Khandakar, Y. Automatic Time Series Forecasting: The forecast Package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef]
- Nazeri-Tahroudi, M.; Ramezani, Y.; De Michele, C.; Mirabbasi, R. Bivariate Simulation of Potential Evapotranspiration Using Copula-GARCH Model. Water Resour. Manag. 2022, 36, 1007–1024. [Google Scholar] [CrossRef]
- Dos Santos, C.F.G.; Papa, J.P. Avoiding Overfitting: A Survey on Regularization Methods for Convolutional Neural Networks. ACM Comput. Surv. 2022, 54, 1–25. [Google Scholar] [CrossRef]
- Brito, G.R.A.; Villaverde, A.R.; Quan, A.L.; Pérez, M.E.R. Comparison between SARIMA and Holt–Winters models for forecasting monthly streamflow in the western region of Cuba. SN Appl. Sci. 2021, 3, 1–12. [Google Scholar] [CrossRef]
- Golpaygani, A.; Keshtkar, A.; Mashhadi, N.; Hosseini, S.M.; Afzali, A. Optimal selection of cost-effective biological runoff management scenarios at watershed scale using SWAT-GA tool. J. Hydrol. Reg. Stud. 2023, 49. [Google Scholar] [CrossRef]
- Hurst, H.E. Long-Term Storage Capacity of Reservoirs. Trans. Am. Soc. Civ. Eng. 1951, 116, 770–808. [Google Scholar] [CrossRef]
- Li, Y.; Ding, L.; Gao, X. On the Decision Boundary of Deep Neural Networks. arXiv 2018, arXiv:1808.05385. [Google Scholar] [CrossRef]
- Mohanty, A.; Sahoo, B.; Kale, R.V. A hybrid model enhancing streamflow forecasts in paddy land use-dominated catchments with numerical weather prediction model-based meteorological forcings. J. Hydrol. 2024, 635, 131225. [Google Scholar] [CrossRef]
- Abbasi, A.; Khalili, K.; Behmanesh, J.; Shirzad, A. Estimation of ARIMA model parameters for drought prediction using the genetic algorithm. Arab. J. Geosci. 2021, 14, 841. [Google Scholar] [CrossRef]
- Chen, X.; Jiang, Z.; Cheng, H.; Zheng, H.; Cai, D.; Feng, Y. A novel global average temperature prediction model—Based on GM-ARIMA combination model. Earth Sci. Inform. 2024, 17, 853–866. [Google Scholar] [CrossRef]
- Wu, M.; Liu, P.; Liu, L.; Zou, K.; Luo, X.; Wang, J.; Xia, Q.; Wang, H. Improving a hydrological model by coupling it with an LSTM water use forecasting model. J. Hydrol. 2024, 636. [Google Scholar] [CrossRef]
- Khan, M.M.H.; Mustafa, M.R.U.; Hossain, M.S.; Shams, S.; Julius, A.D. Short-Term and Long-Term Rainfall Forecasting Using ARIMA Model. Int. J. Environ. Sci. Dev. 2023, 14, 292–298. [Google Scholar] [CrossRef]
- Noh, S.-H. Analysis of Gradient Vanishing of RNNs and Performance Comparison. Information 2021, 12, 442. [Google Scholar] [CrossRef]
- Retike, I.; Bikše, J.; Kalvāns, A.; Dēliņa, A.; Avotniece, Z.; Zaadnoordijk, W.J.; Jemeljanova, M.; Popovs, K.; Babre, A.; Zelenkevičs, A.; et al. Rescue of groundwater level time series: How to visually identify and treat errors. J. Hydrol. 2022, 605, 127294. [Google Scholar] [CrossRef]
- Wong, W.M. Flood Prediction using ARIMA Model in Sungai Melaka, Malaysia. Int. J. Adv. Trends Comput. Sci. Eng. 2020, 9, 5287–5295. [Google Scholar] [CrossRef]
- Ning, Y.Z.; Musa, S. Stream Flow Forcasting on Pahang River by Time Series Models, ARMA, ARIMA and SARIMA. Recent Trends Civ. Eng. Built Environ. 2023, 4, 331–341. [Google Scholar]
- Madhushani, C.; Dananjaya, K.; Ekanayake, I.; Meddage, D.; Kantamaneni, K.; Rathnayake, U. Modeling streamflow in non-gauged watersheds with sparse data considering physiographic, dynamic climate, and anthropogenic factors using explainable soft computing techniques. J. Hydrol. 2024, 631, 130846. [Google Scholar] [CrossRef]
- Nounou, M.N.; Bakshi, B.R.; Walczak, B. Multiscale Methods for Denoising and Compression; Elsevier Science BV: Amsterdam, The Netherlands, 2000; pp. 119–150. [Google Scholar] [CrossRef]
- Modarres, R.; Ouarda, T. Modeling rainfall–runoff relationship using multivariate GARCH model. J. Hydrol. 2013, 499, 1–18. [Google Scholar] [CrossRef]
- Sarhadi, A.; Modarres, R.; Vicente-Serrano, S.M. Dynamic compound droughts in the Contiguous United States. J. Hydrol. 2023, 626, 130129. [Google Scholar] [CrossRef]
- Cheng, S. Heterogeneity In Stock Price Forecasting-Based on the ARIMA-GARCH Model And PCA-LSTM Model. Highlights Sci. Eng. Technol. 2024, 88, 39–46. [Google Scholar] [CrossRef]
- Kandukuri, K. The Rainfall Forecast Models Analysis and Their Volatility. Int. J. Stat. Reli-Abil. Eng. 2023, 9, 450–460. [Google Scholar]
- Archibong, M.E.; Essi, I.D. Modelling Petroleum Prices between Garch and Intergeated Garch, (Igarch). J. Adv. Math. Comput. Sci. 2021, 36, 95–101. [Google Scholar] [CrossRef]
- Caporale, G.M.; Pittis, N.; Spagnolo, N. IGARCH models and structural breaks. Appl. Econ. Lett. 2003, 10, 765–768. [Google Scholar] [CrossRef]
- Mo, C.; Lai, S.; Yang, Q.; Huang, K.; Lei, X.; Yang, L.; Yan, Z.; Jiang, C. A comprehensive assessment of runoff dynamics in response to climate change and human activities in a typical karst watershed, southwest China. J. Environ. Manag. 2023, 332, 117380. [Google Scholar] [CrossRef]
- HLNUG. Nauheim Gauge (ID 23980353) in Hesse, Germany: Station Information. Hessian Agency for Nature Con-servation, Environment and Geology (Hessisches Landesamt für Naturschutz, Umwelt und Geologie). 2023. Available online: https://www.hlnug.de/static/pegel/wiskiweb3/webpublic/#/overview/Durchfluss/station/41361/Nauheim/stationInfoHlnug (accessed on 20 May 2025).
- LUBW: Deutsches Gewässerkundliches Jahrbuch DGJ (German Hydrological Yearbook) Rheingebiet, Teil I 2009 (Rhine Area, Part 1 2009). Landesanstalt für Umwelt, Messungen und Naturschutz Baden-Württemberg (in German). Karlsruhe. 2011. Available online: https://pd.lubw.de/38631 (accessed on 22 March 2024).
- DWD. Precipitation data from station Frankfurt/M. (Flughfn.) ID 1420 (Frankfurt Airport) [Data Set]. Germany’s National Meteorological Service (Deutscher Wetterdienst). 2023. Available online: https://cdc.dwd.de/portal/ (accessed on 5 June 2023).
- HLNUG. Overview About Water Level Monitoring Stations in Hesse. Hessian Agency for Nature Conservation, Envi-ronment and Geology (Hessisches Landesamt für Naturschutz, Umwelt und Geologie). 2022. Available online: https://www.hlnug.de/static/pegel/wiskiweb3/webpublic/#/overview/Wasserstand (accessed on 23 September 2022).
- Burud, N.B.; Kishen, J.C. Investigation of long memory in concrete fracture through acoustic emission time series analysis under monotonic and fatigue loading. Eng. Fract. Mech. 2023, 277, 108975. [Google Scholar] [CrossRef]
- Gao, S.; Zhang, S.; Huang, Y.; Han, J.; Zhang, T.; Wang, G. A hydrological process-based neural network model for hourly runoff forecasting. Environ. Model. Softw. 2024, 176, 106029. [Google Scholar] [CrossRef]
- Karimi, H.; Derr, T.; Tang, J. Characterizing the Decision Boundary of Deep Neural Networks. arXiv 2019, arXiv:1912.11460. [Google Scholar] [CrossRef]
- Le, M.T.; Le, H.M.H.; Nguyen, H.Q.; Pham, L.N.N. Geopolitical Risk, Economic Uncertainty, and Market Volatility Index Impact on Energy Price. Eng. Proc. 2025, 97, 36. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Event | Period | N(Q) * | Max. Q [m3/s (Date and Time)] | N(P) ** | Max. Precipitation Intensity [mm/h (Date and Time)] |
|---|---|---|---|---|---|
| 1 | 8–14 June 2013 | 577 | 1.83 (at 9 June 2013 16:15–18:00) | 865 | 34.8 (8 June 2013 18:00) |
| 2 | 15–20 August 2012 | 481 | 1.78 (at 16 August 2012 11:45–14:45) | 721 | 37.3 (16 August 2012 02:00) |
| 3 | 20–26 July 2004 | 577 | 1.18 (at 24 July 2004 04:45–11:45) | 865 | 37.4 (23 July 2004 19:00) |
| 4 | 1–7 May 2000 | 577 | 1.80 (at 2 May 2000 16:15–16:30) | 865 | 25.9 (4 May 2000 00:00) |
| Event | iGARCH Order | Mu | Alpha1 | Beta1 | LogLikelihood | AIC | Nyblom Stability Test Statistic | Pearson Goodness-of-Fit Test (p-Value) |
|---|---|---|---|---|---|---|---|---|
| E1 | 1,1 | 0.713 | 0.133 | 0.867 | 319.527 | −4.368 | 0.871 | 0.0001979 |
| E2 | 0,1 | 0.168 | - | 1.000 | 117.244 | −1.904 | 0.271 | 6.355 × 10−65 |
| E3 | 0,1 | 0.209 | - | 1.000 | 333.855 | −4.567 | 0.314 | 0.00001478 |
| E4 | 1,1 | 0.515 | 0.086 | 0.914 | 252.520 | −3.452 | 0.566 | 3.25 × 10−15 |
| Event | RMSE | MAPE | R2 | MAE | MBE | NSE | d-Index |
|---|---|---|---|---|---|---|---|
| E1 | 0.031 | 2.044 | 0.99 | 0.02 | −0.003 | 0.99 | 0.997 |
| E2 | 0.091 | 4.769 | 0.96 | 0.03 | −0.006 | 0.96 | 0.99 |
| E3 | 0.023 | 3.77 | 0.99 | 0.01 | −0.002 | 0.99 | 0.998 |
| E4 | 0.052 | 2.601 | 0.98 | 0.02 | −0.004 | 0.98 | 0.995 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khazaeiathar, M.; Schmalz, B. Addressing Volatility and Nonlinearity in Discharge Modeling: ARIMA-iGARCH for Short-Term Hydrological Time Series Simulation. Hydrology 2025, 12, 197. https://doi.org/10.3390/hydrology12080197
Khazaeiathar M, Schmalz B. Addressing Volatility and Nonlinearity in Discharge Modeling: ARIMA-iGARCH for Short-Term Hydrological Time Series Simulation. Hydrology. 2025; 12(8):197. https://doi.org/10.3390/hydrology12080197
Chicago/Turabian StyleKhazaeiathar, Mahshid, and Britta Schmalz. 2025. "Addressing Volatility and Nonlinearity in Discharge Modeling: ARIMA-iGARCH for Short-Term Hydrological Time Series Simulation" Hydrology 12, no. 8: 197. https://doi.org/10.3390/hydrology12080197
APA StyleKhazaeiathar, M., & Schmalz, B. (2025). Addressing Volatility and Nonlinearity in Discharge Modeling: ARIMA-iGARCH for Short-Term Hydrological Time Series Simulation. Hydrology, 12(8), 197. https://doi.org/10.3390/hydrology12080197