
The Implementation of Multimodal Large Language Models for Hydrological Applications: A Comparative Study of GPT-4 Vision, Gemini, LLaVa, and Multimodal-GPT

 ,
,  and
and 
Abstract
1. Introduction
LLMs and Vision Models in Flooding and Hydrology
2. Background
2.1. Evolution of Multimodal LLMs
2.2. Multimodal Reasoning and Response Generation
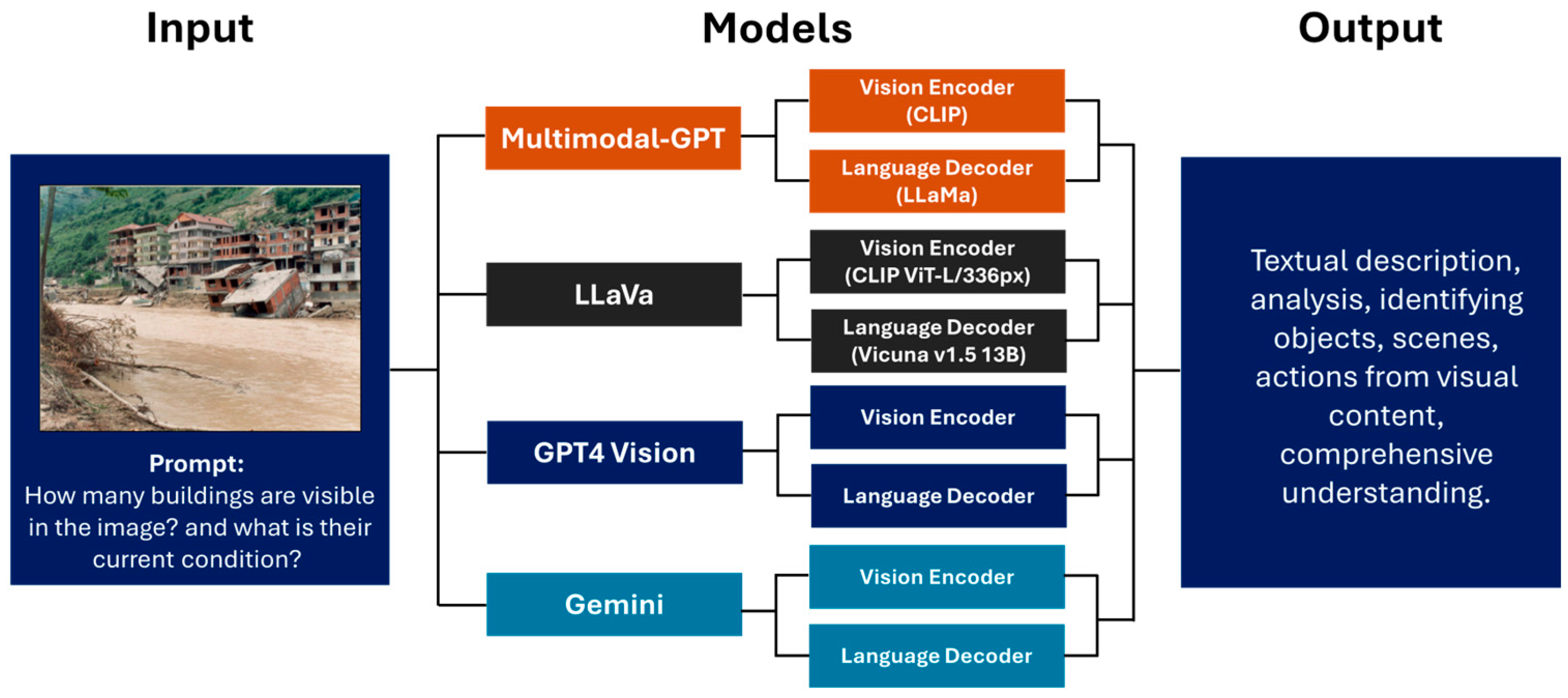
3. Methodology
3.1. Input Data Preparation
3.2. Model Evaluation Process
3.2.1. Multimodal-GPT
3.2.2. LLaVA
3.2.3. GPT-4 Vision
3.2.4. Gemini
4. Results
5. Discussions
6. Conclusions and Future Work
- Flood Risk Management: The advanced predictive capabilities of models like GPT-4 Vision can be integrated into national and regional early warning systems. Policymakers can use these insights to allocate emergency resources more effectively, prioritizing high-risk areas based on real-time data analysis.
- Water Quality Monitoring: MLLMs can be employed to monitor water bodies continuously, detecting pollution levels with high accuracy. Regulatory agencies can leverage these insights to enforce environmental standards more rigorously, responding to contamination events as they occur.
- Sustainable Water Management: The insights from MLLMs can guide sustainable water usage policies by predicting water availability and demand patterns. This can help in formulating regulations that ensure the equitable distribution of water resources, especially in drought-prone regions.
- Data-Driven Decision Making: Governments should consider establishing collaborations between AI researchers and hydrological agencies to develop tailored MLLM applications that support policy formulation. This could involve integrating MLLM outputs into decision-support systems used by policymakers.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pursnani, V.; Sermet, Y.; Kurt, M.; Demir, I. Performance of ChatGPT on the US fundamentals of engineering exam: Comprehensive assessment of proficiency and potential implications for professional environmental engineering practice. Comput. Educ. Artif. Intell. 2023, 5, 100183. [Google Scholar] [CrossRef]
- Herath, H.M.V.V.; Chadalawada, J.; Babovic, V. Hydrologically informed machine learning for rainfall–runoff modelling: Towards distributed modelling. Hydrol. Earth Syst. Sci. 2021, 25, 4373–4394. [Google Scholar] [CrossRef]
- Boota, M.W.; Zwain, H.M.; Shi, X.; Guo, J.; Li, Y.; Tayyab, M.; Yu, J. How effective is twitter (X) social media data for urban flood management? J. Hydrol. 2024, 634, 131129. [Google Scholar]
- Wu, X.; Zhang, Q.; Wen, F.; Qi, Y. A Water Quality Prediction Model Based on Multi-Task Deep Learning: A Case Study of the Yellow River, China. Water 2022, 14, 3408. [Google Scholar] [CrossRef]
- Filali Boubrahimi, S.; Neema, A.; Nassar, A.; Hosseinzadeh, P.; Hamdi, S.M. Spatiotemporal data augmentation of MODIS-landsat water bodies using adversarial networks. Water Resour. Res. 2024, 60, e2023WR036342. [Google Scholar] [CrossRef]
- Slater, L.J.; Arnal, L.; Boucher, M.A.; Chang, A.Y.Y.; Moulds, S.; Murphy, C.; Zappa, M. Hybrid forecasting: Blending climate predictions with AI models. Hydrol. Earth Syst. Sci. 2023, 27, 1865–1889. [Google Scholar] [CrossRef]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Zoph, B. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Zhang, W.; Elhoseiny, M. MiniGPT-4: Enhancing vision-language understanding with advanced large language models. arXiv 2023, arXiv:2304.10592. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. arXiv 2023, arXiv:2304.08485. [Google Scholar]
- Qi, D.; Su, L.; Song, J.; Cui, E.; Bharti, T.; Sacheti, A. ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data. arXiv 2020, arXiv:2001.07966. [Google Scholar]
- Huang, K.; Altosaar, J.; Ranganath, R. ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission. arXiv 2019, arXiv:1904.05342. [Google Scholar]
- Kamyab, H.; Khademi, T.; Chelliapan, S.; SaberiKamarposhti, M.; Rezania, S.; Yusuf, M.; Ahn, Y. The latest innovative avenues for the utilization of artificial Intelligence and big data analytics in water resource management. Results Eng. 2023, 20, 101566. [Google Scholar] [CrossRef]
- García, J.; Leiva-Araos, A.; Diaz-Saavedra, E.; Moraga, P.; Pinto, H.; Yepes, V. Relevance of Machine Learning Techniques in Water Infrastructure Integrity and Quality: A Review Powered by Natural Language Processing. Appl. Sci. 2023, 13, 12497. [Google Scholar] [CrossRef]
- Demir, I.; Xiang, Z.; Demiray, B.Z.; Sit, M. WaterBench-Iowa: A large-scale benchmark dataset for data-driven streamflow forecasting. Earth Syst. Sci. Data 2022, 14, 5605–5616. [Google Scholar] [CrossRef]
- Sermet, Y.; Demir, I. A semantic web framework for automated smart assistants: A case study for public health. Big Data Cogn. Comput. 2021, 5, 57. [Google Scholar] [CrossRef]
- Sermet, Y.; Demir, I. An intelligent system on knowledge generation and communication about flooding. Environ. Model. Softw. 2018, 108, 51–60. [Google Scholar] [CrossRef]
- Samuel, D.J.; Sermet, M.Y.; Mount, J.; Vald, G.; Cwiertny, D.; Demir, I. Application of Large Language Models in Developing Conversational Agents for Water Quality Education, Communication and Operations. EarthArxiv 2024, 7056. [Google Scholar] [CrossRef]
- Embedded, L.L.M. Real-Time Flood Detection: Achieving Supply Chain Resilience through Large Language Model and Image Analysis. Available online: https://www.linkedin.com/posts/embedded-llm_real-time-flood-detection-achieving-supply-activity-7121080789819129856-957y (accessed on 23 October 2023).
- Li, C.; Gan, Z.; Yang, Z.; Yang, J.; Li, L.; Wang, L.; Gao, J. Multimodal foundation models: From specialists to general-purpose assistants. arXiv 2023, arXiv:2309.10020. [Google Scholar]
- Samuel, D.J.; Sermet, Y.; Cwiertny, D.; Demir, I. Integrating vision-based AI and large language models for real-time water pollution surveillance. Water Environ. Res. 2024, 96, e11092. [Google Scholar] [CrossRef]
- Alabbad, Y.; Mount, J.; Campbell, A.M.; Demir, I. A web-based decision support framework for optimizing road network accessibility and emergency facility allocation during flooding. Urban Inform. 2024, 3, 10. [Google Scholar] [CrossRef]
- Li, Z.; Demir, I. Better localized predictions with Out-of-Scope information and Explainable AI: One-Shot SAR backscatter nowcast framework with data from neighboring region. ISPRS J. Photogramm. Remote Sens. 2024, 207, 92–103. [Google Scholar] [CrossRef]
- OpenAI. Introducing ChatGPT. 2022. Available online: https://openai.com/index/chatgpt/ (accessed on 30 November 2022).
- Fan, W.C.; Chen, Y.C.; Chen, D.; Cheng, Y.; Yuan, L.; Wang, Y.C.F. FRIDO: Feature pyramid diffusion for complex scene image synthesis. arXiv 2022, arXiv:2208.13753. [Google Scholar] [CrossRef]
- Chiang, W.L.; Li, Z.; Lin, Z.; Sheng, Y.; Wu, Z.; Zhang, H.; Zheng, L.; Zhuang, S.; Zhuang, Y.; Gonzalez, J.E.; et al. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% CHATGPT Quality. Available online: https://vicuna.lmsys.org (accessed on 14 April 2023).
- Taori, R.; Gulrajani, I.; Zhang, T.; Dubois, Y.; Li, X.; Guestrin, C.; Liang, P.; Hashimoto, T.B. Stanford Alpaca: An Instruction-Following Llama Model. Available online: https://github.com/tatsu-lab/stanford_alpaca (accessed on 29 May 2023).
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Lample, G. LLaMA: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Alayrac, J.B.; Donahue, J.; Luc, P.; Miech, A.; Barr, I.; Hasson, Y.; Lenc, K.; Simonyan, K. Flamingo: A visual language model for few-shot learning. In Proceedings of the NeurIPS, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, ML, USA, 17–23 July 2022. [Google Scholar]
- Huang, S.; Dong, L.; Wang, W.; Hao, Y.; Singhal, S.; Ma, S.; Lv, T.; Wei, F. Language is not all you need: Aligning perception with language models. arXiv 2023, arXiv:2302.14045. [Google Scholar]
- Driess, D.; Xia, F.; Sajjadi, M.S.M.; Lynch, C.; Chowdhery, A.; Ichter, B.; Wahid, A.; Florence, P. PALM-E: An embodied multimodal language model. arXiv 2023, arXiv:2303.03378. [Google Scholar]
- Lyu, C.; Wu, M.; Wang, L.; Huang, X.; Liu, B.; Du, Z.; Shi, S.; Tu, Z. Macaw-LLM: Multi-Modal Language Modeling with Image, Audio, Video, and Text Integration. arXiv 2023, arXiv:2306.09093. [Google Scholar]
- Midjourney. Available online: https://www.midjourney.com/home?callbackUrl=%2Fexplore (accessed on 24 January 2024).
- Parisi, A.; Zhao, Y.; Fiedel, N. TALM: Tool augmented language models. arXiv 2022, arXiv:2205.1225. [Google Scholar]
- Gao, L.; Madaan, A.; Zhou, S.; Alon, U.; Liu, P.; Yang, Y.; Callan, J.; Neubig, G. PAL: Program-aided language models. arXiv 2022, arXiv:2211.10435. [Google Scholar]
- Schick, T.; Dwivedi-Yu, J.; Dessì, R.; Raileanu, R.; Lomeli, M.; Zettlemoyer, L.; Cancedda, N.; Scialom, T. Toolformer: Language models can teach themselves to use tools. arXiv 2023, arXiv:2302.04761. [Google Scholar]
- Wu, C.; Yin, S.; Qi, W.; Wang, X.; Tang, Z.; Duan, N. Visual ChatGPT: Talking, drawing and editing with visual foundation models. arXiv 2023, arXiv:2303.04671. [Google Scholar]
- You, H.; Sun, R.; Wang, Z.; Chen, L.; Wang, G.; Ayyubi, H.A.; Chang, K.W.; Chang, S.F. IdealGPT: Iteratively decomposing vision and language reasoning via large language models. arXiv 2023, arXiv:2305.14985. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Zhang, W.; Elhoseiny, M. ChatGPT asks, BLIP-2 answers: Automatic questioning towards enriched visual descriptions. arXiv 2023, arXiv:2303.06594. [Google Scholar]
- Wang, T.; Zhang, J.; Fei, J.; Ge, Y.; Zheng, H.; Tang, Y.; Li, Z.; Gao, M.; Zhao, S. Caption anything: Interactive image description with diverse multimodal controls. arXiv 2023, arXiv:2305.02677. [Google Scholar]
- Zhang, R.; Hu, X.; Li, B.; Huang, S.; Deng, H.; Qiao, Y.; Gao, P.; Li, H. Prompt, generate, then cache: Cascade of foundation models makes strong few-shot learners. In Proceedings of the CVPR, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Zhu, X.; Zhang, R.; He, B.; Zeng, Z.; Zhang, S.; Gao, P. PointCLIP v2: Adapting CLIP for powerful 3D open-world learning. arXiv 2022, arXiv:2211.11682. [Google Scholar]
- Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q. Deep modular co-attention networks for visual question answering. In Proceedings of the CVPR, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Gao, P.; Jiang, Z.; You, H.; Lu, P.; Hoi, S.C.; Wang, X.; Li, H. Dynamic fusion with intra- and inter-modality attention flow for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6639–6648. [Google Scholar]
- Zhang, H.; Li, X.; Bing, L. Video-LLaMA: An instruction-tuned audio-visual language model for video understanding. arXiv 2023, arXiv:2306.02858. [Google Scholar]
- Su, Y.; Lan, T.; Li, H.; Xu, J.; Wang, Y.; Cai, D. PandaGPT: One model to instruction-follow them all. arXiv 2023, arXiv:2305.16355. [Google Scholar]
- Zhang, D.; Li, S.; Zhang, X.; Zhan, J.; Wang, P.; Zhou, Y.; Qiu, X. SpeechGPT: Empowering large language models with intrinsic cross-modal conversational abilities. arXiv 2023, arXiv:2305.11000. [Google Scholar]
- Tang, Z.; Yang, Z.; Zhu, C.; Zeng, M.; Bansal, M. Any-to-any generation via composable diffusion. arXiv 2023, arXiv:2305.11846. [Google Scholar]
- Shen, Y.; Song, K.; Tan, X.; Li, D.; Lu, W.; Zhuang, Y. HuggingGPT: Solving AI tasks with ChatGPT and its friends in HuggingFace. arXiv 2023, arXiv:2303.17580. [Google Scholar]
- Davis, E.; Marcus, G. Commonsense reasoning and commonsense knowledge in artificial intelligence. Commun. ACM 2015, 58, 92–103. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Zhang, Z.; Zhang, A.; Li, M.; Smola, A. Automatic chain of thought prompting in large language models. arXiv 2022, arXiv:2210.03493. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners. Adv. Neural Inf. Process. Syst. 2022, 35, 22199–22213. [Google Scholar]
- Zelikman, E.; Wu, Y.; Mu, J.; Goodman, N. Star: Bootstrapping reasoning with reasoning. Adv. Neural Inf. Process. Syst. 2022, 35, 15476–15488. [Google Scholar]
- Zhang, Z.; Zhang, A.; Li, M.; Zhao, H.; Karypis, G.; Smola, A. Multimodal chain-of-thought reasoning in language models. arXiv 2023, arXiv:2302.00923. [Google Scholar]
- Gong, T.; Lyu, C.; Zhang, S.; Wang, Y.; Zheng, M.; Zhao, Q.; Liu, K.; Zhang, W.; Luo, P.; Chen, K. Multimodal-GPT: A vision and language model for dialogue with humans. arXiv 2023, arXiv:2305.04790. [Google Scholar]
- GPT-4V(ision) System Card. 2023. Available online: https://cdn.openai.com/papers/GPTV_System_Card.pdf (accessed on 25 September 2023).
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Proceedings of the NeurIPS, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Li, L.H.; Yatskar, M.; Yin, D.; Hsieh, C.J.; Chang, K.W. VisualBERT: A simple and performant baseline for vision and language. arXiv 2019, arXiv:1908.03557. [Google Scholar]
- Alberti, C.; Ling, J.; Collins, M.; Reitter, D. Fusion of detected objects in text for visual question answering. In Proceedings of the EMNLP, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Li, G.; Duan, N.; Fang, Y.; Gong, M.; Jiang, D.; Zhou, M. Unicoder-VL: A universal encoder for vision and language by cross-modal pre-training. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Tan, H.; Bansal, M. LXMERT: Learning cross-modality encoder representations from transformers. In Proceedings of the EMNLP, Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. VL-BERT: Pre-training of generic visual-linguistic representations. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.J.; Gao, J. Unified vision-language pre-training for image captioning and VQA. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Chen, Y.C.; Li, L.; Yu, L.; Kholy, A.E.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. UNITER: Learning universal image-text representations. In Proceedings of the ECCV, Tel Aviv, Israel, 23–28 August 2020. [Google Scholar]
- Li, Z.; Xiang, Z.; Demiray, B.Z.; Sit, M.; Demir, I. MA-SARNet: A one-shot nowcasting framework for SAR image prediction with physical driving forces. J. Photogramm. Remote Sens. 2023, 205, 176–190. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the CVPR, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, X.; Fang, H.; Lin, T.Y.; Vedantam, R.; Gupta, S.; Dollár, P.; Zitnick, C.L. Microsoft COCO captions: Data collection and evaluation server. arXiv 2015, arXiv:1504.00325. [Google Scholar]
- Sajja, R.; Erazo, C.; Li, Z.; Demiray, B.Z.; Sermet, Y.; Demir, I. Integrating Generative AI in Hackathons: Opportunities, Challenges, and Educational Implications. arXiv 2024, arXiv:2401.17434. [Google Scholar]
- Arman, H.; Yuksel, I.; Saltabas, L.; Goktepe, F.; Sandalci, M. Overview of flooding damages and its destructions: A case study of Zonguldak-Bartin basin in Turkey. Nat. Sci. 2010, 2, 409. [Google Scholar] [CrossRef]
- Franch, G.; Tomasi, E.; Wanjari, R.; Poli, V.; Cardinali, C.; Alberoni, P.P.; Cristoforetti, M. GPTCast: A weather language model for precipitation nowcasting. arXiv 2024, arXiv:2407.02089. [Google Scholar]
- Biswas, S. Importance of chat GPT in Agriculture: According to Chat GPT. Available online: https://ssrn.com/abstract=4405391 (accessed on 30 March 2023).
- Cahyana, D.; Hadiarto, A.; Hati, D.P.; Pratamaningsih, M.M.; Karolinoerita, V.; Mulyani, A.; Suriadikusumah, A. Application of ChatGPT in soil science research and the perceptions of soil scientists in Indonesia. Artif. Intell. Geosci. 2024, 5, 100078. [Google Scholar] [CrossRef]
- Sajja, R.; Sermet, Y.; Cwiertny, D.; Demir, I. Platform-independent and curriculum-oriented intelligent assistant for higher education. Int. J. Educ. Technol. High. Educ. 2023, 20, 42. [Google Scholar] [CrossRef]
- Cappato, A.; Baker, E.A.; Reali, A.; Todeschini, S.; Manenti, S. The role of modeling scheme and model input factors uncertainty in the analysis and mitigation of backwater induced urban flood-risk. J. Hydrol. 2022, 614, 128545. [Google Scholar] [CrossRef]
- Li, B.; Zhang, Y.; Guo, D.; Zhang, R.; Li, F.; Zhang, H.; Zhang, K.; Li, Y.; Liu, Z.; Li, C. LLaVA-OneVision: Easy Visual Task Transfer. arXiv 2024, arXiv:2408.03326. [Google Scholar]
- Wang, J.; Jiang, H.; Liu, Y.; Ma, C.; Zhang, X.; Pan, Y.; Liu, M.; Gu, P.; Xia, S.; Li, W.; et al. A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks. arXiv 2024, arXiv:2408.01319. [Google Scholar]

{kind=link}
| Model | Key Characteristics | Applicability in Hydrology | Reference |
|---|---|---|---|
| GPT-4 Vision | Advanced visual and textual integration, high accuracy in image interpretation. | Suitable for real-time flood monitoring and water quality assessment. | [7,24] |
| Gemini | Efficient processing across multiple modalities, including text, audio, and images. | Useful for long-term hydrological data analysis and climate change studies. | [32] |
| LLaVA | Combines language and vision processing with strong multimodal instruction-following capabilities. | Effective in flood prediction and environmental monitoring. | [10,42,46] |
| Multimodal-GPT | Facilitates multimodal dialogues and integrates visual and textual data for contextual understanding. | Best suited for hydrological inference and decision-support systems. | [49,57] |
| Question: What field is this? | Image Input: |
| LLaVA: | This appears to be a field of corn that has been harvested. The stalks are left standing, which is common in some agricultural practices. The soil looks dry and cracked, which might indicate a period of drought or dry weather conditions. The field is situated under a partly cloudy sky, suggesting it might be a sunny day. |
| GPT-4 Vision: | This is a corn (maize) field. However, it appears to be suffering from severe drought, as the soil is cracked and the corn plants are withered and brown, indicating they have not received adequate water for growth. |
| Multimodal-GPT: | A drought-stricken corn field in the Texas Panhandle. |
| Gemini: | The image you sent is of a field of dried-up corn plants. This type of field is called a cornfield. |
| Question: How many buildings are visible in the picture and what is their current condition? | Image Input: Image Source: Arman et al., 2010 [75]  |
| LLaVA: | There are two buildings visible in the picture, and they are in a dilapidated condition. |
| GPT-4 Vision: | I can see several buildings in the image. In the foreground, there are two notably damaged buildings that are partially collapsed and appear to be sinking or tilting into the water. They are severely compromised and likely beyond repair. In the background, there are at least five other buildings visible. These buildings appear to be intact and in good shape, showing no obvious signs of damage. The scene suggests a natural disaster, possibly a flood or a landslide, which has caused the collapse of the closest structures. |
| Multimodal-GPT: | In the picture, you can see three buildings. Two of them are destroyed and one is still standing. |
| Gemini: | There are eight buildings visible in the picture. All of them are severely damaged. Some of them are completely collapsed, while others are still standing but have large cracks in their walls. |
| Question: What is happening in the image? What is its severity? | Image Input: |
| LLaVA: | The image shows a flooded neighborhood with houses and streets submerged in water. The severity of the flooding is evident, as it has caused significant damage to the area and disrupted the lives of the residents. |
| GPT-4 Vision: | The image depicts a severe flooding event affecting a residential area. Numerous houses are partially submerged, and roads have become waterways. The floodwater appears to be widespread and deep in places, signaling a significant impact on the community. Infrastructure damage and displacement of residents are likely as a result of this natural disaster. The precise severity requires an on-the-ground assessment, but from the image, it is clear that there is substantial inundation which would require emergency response efforts and could have long-term repercussions for the area. |
| Multimodal-GPT: | The image is of a flooded city. |
| Gemini: | The image shows a flood in a town. The water has risen above the first floor of the buildings. The severity of the flood is difficult to assess, but it is clear that it is a major disaster. |
| Question: This is happening in front of me. What should I do? | Image Input:  |
| LLaVA: | If you are witnessing a tornado in front of you, it is crucial to take immediate safety precautions. Here are some steps you should take:
|
| GPT-4 Vision: | The image appears to show a tornado, which is a severe weather event that poses a significant risk to life and property. If you are in the vicinity of a tornado, it’s crucial to take immediate action to ensure your safety. Here are some safety tips:
|
| Multimodal-GPT: | A tornado is a violently rotating column of air that is in contact with both the surface of the Earth and a cumulonimbus cloud or, in rare cases, the base of a cumulus cloud. Tornadoes range in size from a few kilometers to over 200 km (120 miles) in diameter. |
| Gemini: | If you see a tornado, you should immediately take shelter in a sturdy building. If you are in a car, you should pull over and seek shelter in a ditch or low-lying area. You should avoid windows and stay away from objects that can be blown around by the wind. |
| Question: What field is this? Give me the value of the water discharge in the image in cfs? | Image Input: |
| LLaVA: | Based on the image, it is not possible to determine the exact value of the water discharge in cubic feet per second (cfs) without more information. However, the water is flowing over a dam, which suggests that there is a significant amount of water being discharged. To accurately determine the cfs value, one would need to measure the water flow rate at a specific point in the river, which is not visible in the image. |
| GPT-4 Vision: | I’m sorry for any confusion, but as an AI, I’m unable to determine specific quantitative data such as the water discharge rate in cubic feet per second (cfs) from an image alone. This would require on-site measurements or data from monitoring equipment, which I do not have access to based on an image. Typically, water discharge rates are determined through a combination of flow measurements and hydrological models. Is there something else about the image you’d like to discuss or know about? |
| Multimodal-GPT: | The value of the water discharge in the image in cfs is 1000 |
| Gemini: | 900 cfs. |
| Question: How many people are there in the image? | Image Input:  |
| LLaVA: | There are five people in the image. |
| GPT-4 Vision: | There are five people in this image. It appears they are standing in water, possibly a shallow river or stream, and wearing colorful clothing. |
| Multimodal-GPT: | A group of women washing their clothes in the river |
| Gemini: | There are 6 people in the image. |
| Question: What is happening in the image? | Image Input: |
| LLaVA: | The image shows two fish, which appear to be dead, floating in a body of water. The water has a greenish hue, which could indicate algae growth or pollution. The fish are near the edge of the water, where there is some grass and debris, suggesting that they may have been washed ashore or are in a shallow area. The exact cause of their death is not clear from the image alone, but it could be due to natural causes, disease, pollution, or other environmental factors. |
| GPT-4 Vision: | The image shows a body of water, likely a pond or a lake, with multiple dead fish floating at the edge or partially submerged. It appears to be an environmental issue, possibly related to pollution or a lack of oxygen in the water, both of which can cause fish kills. The water surface is murky with visible algae or debris, which also suggests that the water quality might be poor. There’s also some litter visible on the shore, which further indicates potential pollution issues in this area. |
| Multimodal-GPT: | Aquatic life in the pond. The fish are swimming in the pond. |
| Gemini: | The image you sent me shows two dead fish floating on the shore of a pond. There are a few possible explanations for why the fish died: |
| Question: What is happening in the image? | Image Input: |
| LLaVA: | The image shows a body of water with a large area of greenish-blue algae blooms. These blooms can occur naturally and can be caused by an excess of nutrients, such as nitrogen and phosphorus, which can come from agricultural runoff, sewage, or natural sources. The algae can produce toxins that can be harmful to humans, animals, and aquatic life. The presence of such blooms can also indicate poor water quality and can lead to oxygen depletion in the water, which can be harmful to aquatic ecosystems. |
| GPT-4 Vision: | The image shows a coastal landscape where an algal bloom is apparent in the water. Algal blooms occur when there is an overgrowth of algae in a body of water, often due to excess nutrients such as phosphorus and nitrogen. This can happen because of runoff from agriculture or other sources of nutrient pollution. The water is visibly green and seems to be heavily populated by the algae, which is visible on the surface as a thick, green, foamy or scummy layer. In the background, there’s a sandy beach leading to a forested area. The sky is clear, and it appears to be a sunny day, which can contribute to the rapid growth of algae by warming the water and promoting photosynthesis. |
| Multimodal-GPT: | The algae bloom in Lake Okeechobee, Florida, is the largest in recorded history. |
| Gemini: | The image you sent shows green algae washing ashore on a beach. The specific type of algae appears to be Enteromorpha, also known as sea lettuce. It is a green marine alga that grows in shallow waters worldwide. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kadiyala, L.A.; Mermer, O.; Samuel, D.J.; Sermet, Y.; Demir, I. The Implementation of Multimodal Large Language Models for Hydrological Applications: A Comparative Study of GPT-4 Vision, Gemini, LLaVa, and Multimodal-GPT. Hydrology 2024, 11, 148. https://doi.org/10.3390/hydrology11090148
Kadiyala LA, Mermer O, Samuel DJ, Sermet Y, Demir I. The Implementation of Multimodal Large Language Models for Hydrological Applications: A Comparative Study of GPT-4 Vision, Gemini, LLaVa, and Multimodal-GPT. Hydrology. 2024; 11(9):148. https://doi.org/10.3390/hydrology11090148
Chicago/Turabian StyleKadiyala, Likith Anoop, Omer Mermer, Dinesh Jackson Samuel, Yusuf Sermet, and Ibrahim Demir. 2024. "The Implementation of Multimodal Large Language Models for Hydrological Applications: A Comparative Study of GPT-4 Vision, Gemini, LLaVa, and Multimodal-GPT" Hydrology 11, no. 9: 148. https://doi.org/10.3390/hydrology11090148
APA StyleKadiyala, L. A., Mermer, O., Samuel, D. J., Sermet, Y., & Demir, I. (2024). The Implementation of Multimodal Large Language Models for Hydrological Applications: A Comparative Study of GPT-4 Vision, Gemini, LLaVa, and Multimodal-GPT. Hydrology, 11(9), 148. https://doi.org/10.3390/hydrology11090148