

A Dynamic Model-Fitting Algorithm for Batch Laboratory Data: Application to Constant-Pressure Cake Filtration Experiments


Abstract
1. Introduction
Novelty Statement and Organization
- A Process Systems Engineering-based algorithm for fitting experimental data from batch experiments to dynamic models;
- A comprehensive analysis of the key steps, decision points, and available tools necessary for effective model fitting;
- An application of the algorithm to a system in the field of Chemical Engineering—specifically, constant pressure cake filtration using calcium carbonate.
2. Notation and Background
2.1. Conceptual Framework for Model Fitting from Experimental Data
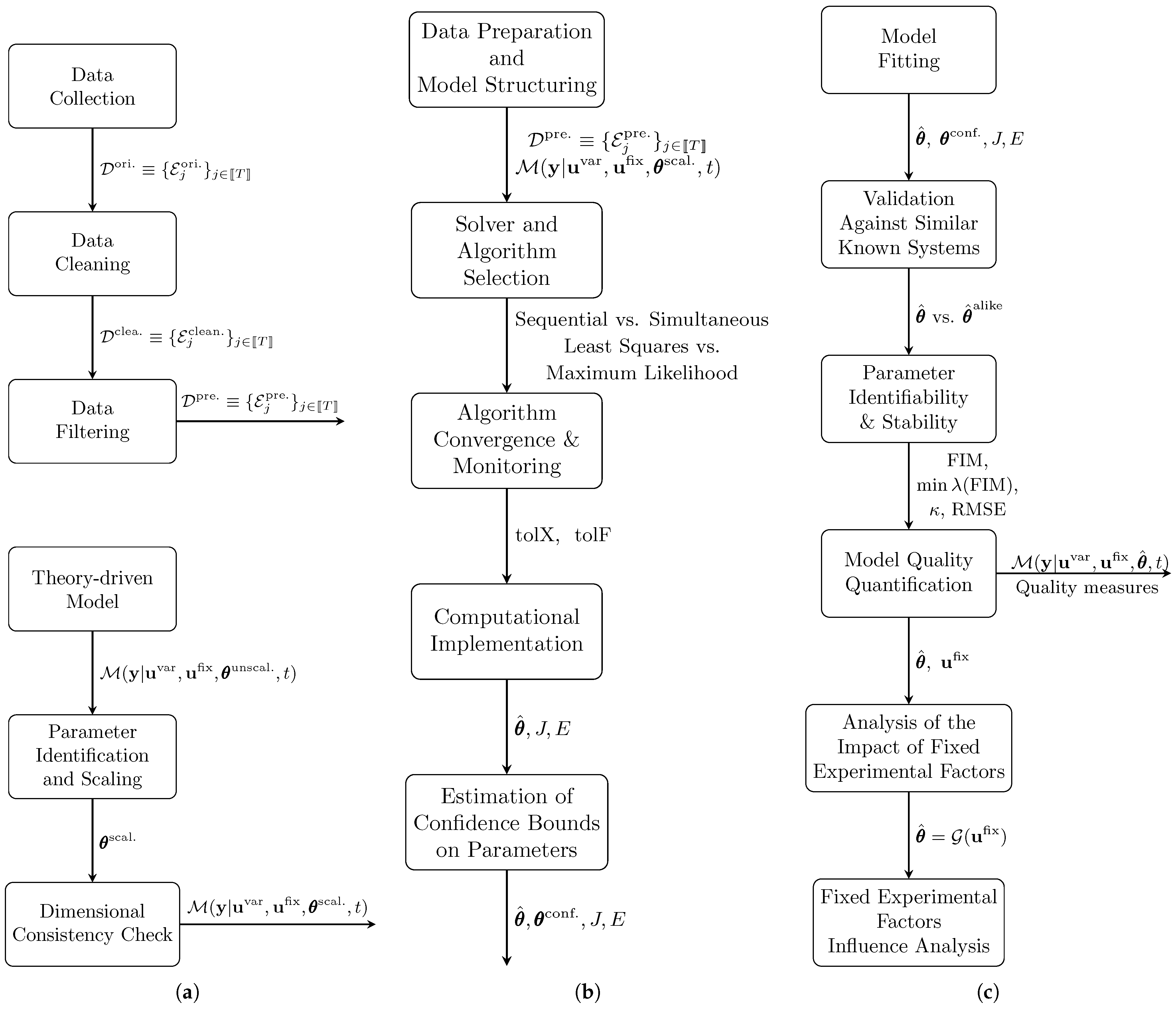
3. In-Depth Analysis of the Algorithm for Dynamic Model Fitting
3.1. Data Preparation and Model Selection
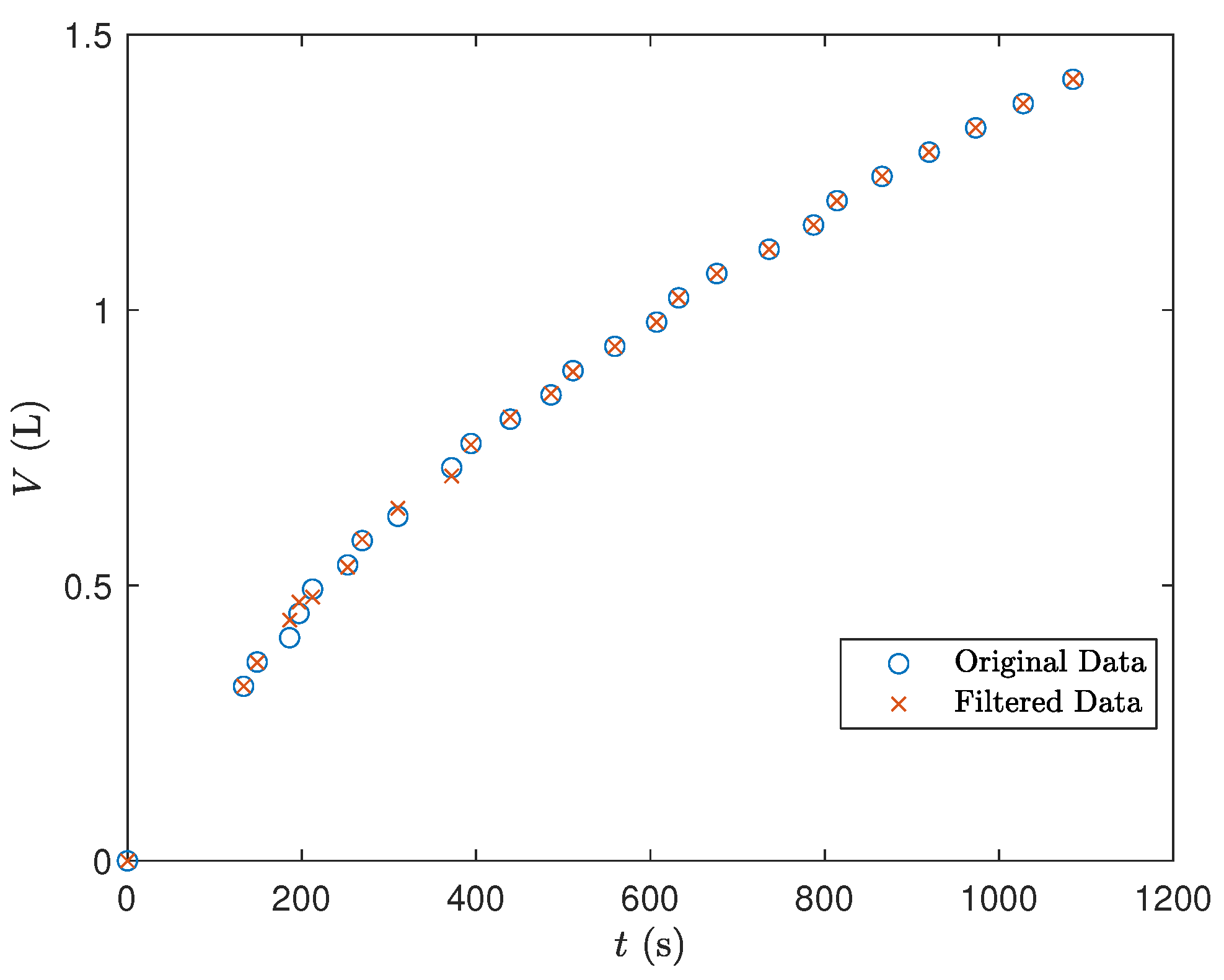
3.1.1. Data Cleaning
3.1.2. Data Filtering
3.1.3. Theory-Driven Model
3.1.4. Parameter Identification and Scaling
3.1.5. Dimensional Consistency Check
3.2. Model Fitting
- Solver and Algorithm Selection: Choose an appropriate algorithm and fitting criterion that align with the model structure and data.
- Algorithm Convergence and Monitoring: Define criteria to monitor convergence, ensuring that the optimization process reliably reaches a solution.
- Computational Implementation: Use a suitable computational tool to implement and solve the formulated optimization problem.
- Parameter Estimation and Confidence Interval Construction: Perform the optimization to estimate parameter values, along with constructing confidence intervals to assess parameter certainty.
3.2.1. Solver and Algorithm Selection
Choosing the Optimality Criterion
Selecting the Signals to Fit
- Integral Method: This approach directly utilizes the observed data (i.e., ) to fit the observations over the time horizon of the experiments. In this method, the derivatives in the state Equation (1a) are approximated using a suitable numerical rule integrated within the solver, with the observational error arising from the measurement system. This method is analogous to the integral approach for parameterizing kinetic rate laws from kinetic data, as discussed by Levenspiel [64] and Himmelblau et al. [65]. In this context, the signals to be fitted correspond to the accumulated values of the state variables, transformed through the measurement system at specified time points.Although this method can present numerical challenges, requiring an Ordinary Differential Equation (ODE) solver combined with an optimizer for the nonlinear least squares problem, it offers the significant advantage of fitting the data in a bias-free manner—without any prior treatment (see Schittkowski [66], Edsberg and Wedin [67] for relevant applications). Proper initialization of parameters is essential to ensure effective convergence of the optimizer, thus enhancing computational efficiency.
- Differential Method: Alternatively, the differential method fits the kinetic rates to increments in each reaction advance [68]. The model in this case is represented by algebraic rate equations, which can be linear or nonlinear, and generally facilitate a more straightforward least squares fitting process compared to the integral method. However, this approach necessitates numerical differentiation of the sampled data prior to fitting, a step that can be numerically challenging, especially with a large number of observed variables. This operation tends to amplify the error in the derivatives relative to the measurement error of the acquired signals [69]. Moreover, characterizing the error distribution becomes complex when the observations undergo local numerical differentiation. This method has been explored by Cremers and Hübler [70] and others.
Choosing the Numerical Solution Method
- Sequential Methods—These methods utilize an integrator to solve the state-space model, complemented by an outer optimization solver that iteratively refines the chosen optimality criterion. The integrator generates solutions based on a specified parameter set and computes parameter sensitivities, which are then used to approximate the objective function, gradient, and Hessian matrices for optimization. A Nonlinear Programming (NLP) solver—often based on techniques such as Generalized Reduced Gradient, Gradient Descent, or Sequential Quadratic Programming (SQP), iteratively adjusts the parameter vector until convergence is achieved. When the integrator’s solution grid does not match the observation times, interpolation is performed to align them. Although sequential methods are straightforward and tend to converge relatively quickly, they may struggle to maintain physically meaningful predictions for state and measurement variables, particularly when there is significant variability in state magnitudes [73].In essence, sequential methods alternate between an integrator (inner module) and an optimizer (outer module) until convergence is reached. Their main advantage lies in their simplicity; however, the convergence process can be sensitive, as predictions for states and measurements may become physically inconsistent due to the lack of constraints in the integrator. For a detailed review of sequential methods, see Vassiliadis et al. [74], Beck [75].
- Simultaneous Methods—These methods apply discretization techniques, such as orthogonal collocation on finite elements, to reformulate the differential model into algebraic equations corresponding to each experimental and observation time point. The transformed model is then solved as a single, large NLP problem [76,77,78], effectively converting it into a dynamic optimization problem focused on selecting the optimal parameter set for the desired criterion.Simultaneous methods offer improved control over state and measurement variables, ensuring that solutions remain within a physically meaningful range throughout the optimization process. However, their convergence rate is significantly influenced by the number of time points and experiments considered, as the complexity of the NLP tends to grow exponentially with additional observations, potentially leading to computational challenges due to NP-hard (Non-Polynomial time) characteristics. For an introduction to simultaneous methods, refer to Vasantharajan and Biegler [79], Tjoa and Biegler [80].
Choosing the Optimization Algorithm
- Sequential Quadratic Programming (SQP), as implemented in MATLAB R2024b’s fmincon function [84].
- Trust Region and Conjugate Gradient Methods, which are utilized in Mathematica’s FindMinimum function [85].
- Interior Point (IP) Method, available through the IPOPT solver [86].
- Generalized Reduced Gradient (GRG) Method, used in the CONOPT solver [87].
3.2.2. Algorithm Convergence and Monitoring
3.2.3. Computational Implementation
- General-Purpose Scientific Programming Languages: Languages such as Python, R, MATLAB, Julia, and Mathematica are versatile and problem-oriented. They offer a wide range of up-to-date tools and libraries specifically designed for tasks such as numerical integration and optimization. These solutions are highly flexible and can easily integrate with other software, enabling more complex analyses that combine parameter fitting with various computational tasks. However, they do require programming skills to effectively utilize their capabilities.
- Specialized Parameter Fitting Tools: These tools are explicitly designed for parameter fitting and model optimization, often providing user-friendly applications suitable for non-programmers. They are tailored for specific types of application, enhancing usability. Examples of tools in this category include the following: (i) parmest: A module of Pyomo, a Python package that employs simultaneous methods through orthogonal collocation on finite elements for process optimization [91]; (ii) pyPESTO: A Python package focused on the parameter estimation of large, complex systems [92]; (iii) NonlinearFit: A built-in function in Mathematica for fitting nonlinear models [93]; (iv) dMOD: An R package designed for dynamic modeling and parameter estimation [94]; (v) Berkeley Madonna: An intuitive environment for graphically constructing and numerically solving mathematical equations [95].
3.2.4. Estimation of Confidence Bounds on Parameters
3.3. Results Post-Analysis
- Physical Validation Against Similar Known Systems: This involves comparing the estimated parameters with those reported for similar systems in the literature.
- Parameter Identifiability and Stability Analysis: This step checks if the parameters can be estimated uniquely and measures its numerical stability and collinearity.
- Model Quality Quantification: This measures the model’s predictive accuracy.
- 4.
- Analysis of the Impact of Fixed Experimental Factors: This task involves regressing the parameters against the fixed factors used in the experiments.
- 5.
- Fixed Experimental Factors Influence Analysis: This step analyzes the results from the regression to derive additional insights.
3.3.1. Physical Validation Against Similar Known Systems
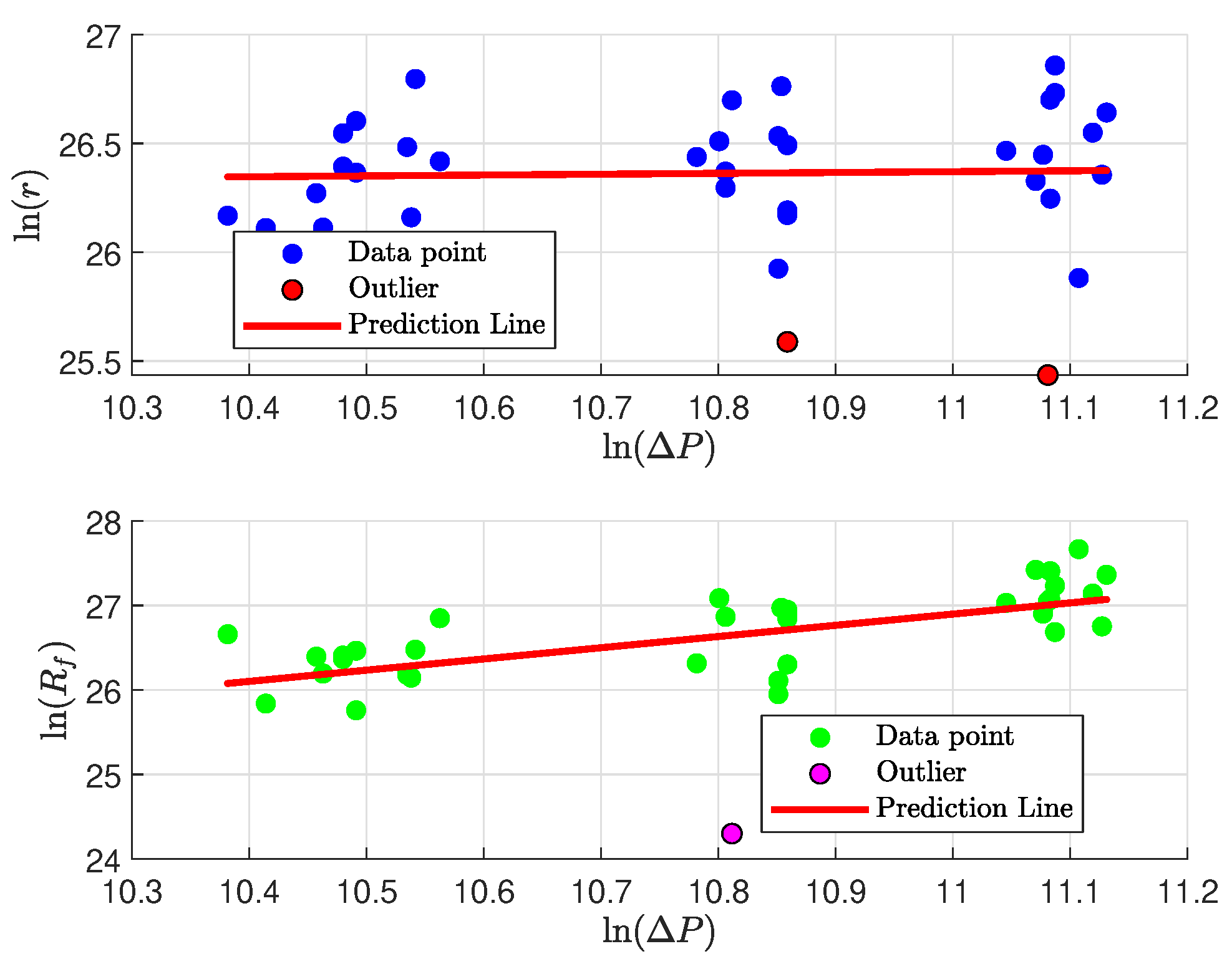
3.3.2. Parameter Identifiability and Stability Analysis
- Inter-Parameter Correlation: High correlations between parameters may indicate linear dependence or redundancy, which can lead to increased instability in parameter estimates [101].
- Variance Inflation Factor (VIF): Elevated VIF values signal that parameters are not sufficiently determined by the data, leading to increased variance in parameter estimates due to multicollinearity [103].
3.3.3. Model Quality Quantification
- Goodness-of-Fit Metrics based on prediction errors;
- Parameter Sensitivity and Identifiability Analysis, as discussed in Section 3.3.2;
- Information Criteria, such as the Akaike Information Criterion, which balance model fidelity with parsimony and are commonly used for model discrimination.
3.3.4. Analysis of the Impact of Fixed Experimental Factors
3.3.5. Influence of Fixed Experimental Factors on Parameter Estimation
4. Application of the Algorithm for Dynamic Model Fitting
4.1. Data Preparation and Model Selection
4.1.1. Model Building and Consistency Checking
- the pressure drop across the cake, ;
- the pressure drop across the filter medium, ;
4.1.2. Data Preparation
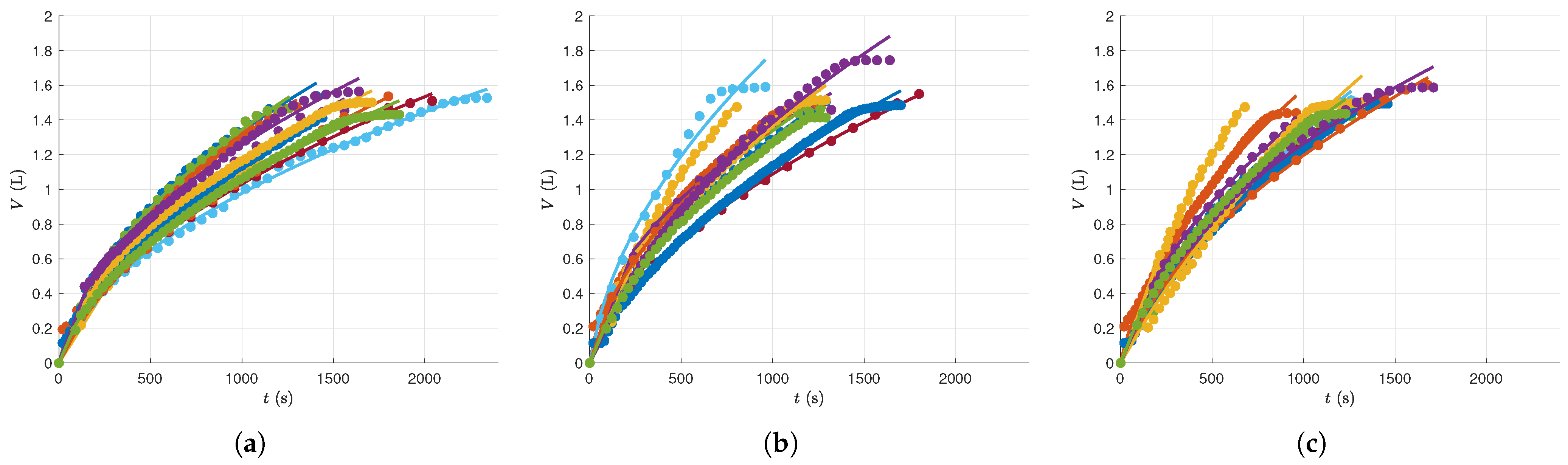
- Low-Pressure (LP) regime: spanning 32 × 103 N/m2 to 39 × 103 N/m2.
- Medium-Pressure (MP) regime: spanning 48 × 103 N/m2 to 52 × 103 N/m2.
- High-Pressure (HP) regime: spanning 63 × 103 N/m2 to 68 × 103 N/m2.
4.2. Model Fitting
- Optimality Criterion: Chose Least Squares.
- Signal to Fit: Used the measured variable, , instead of its numerically differentiated form, employing the integral method.
- Numerical Solution Method: Adopted a simultaneous approach, with a variable-order, variable-step size integrator.
- Optimization Method: Selected the Interior Point-based NLP solver, IPOPT.
- Integrator: AbsTolX = 1 × 10−7, RelTolX = 1 × 10−6.
- Optimization Solver: AbsTolX = 1 × 10−5, RelTolX = 1 × 10−5, TolF = 1 × 10−5.
4.3. Results Post-Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Doebelin, E. Engineering Experimentation: Planning, Execution, Reporting; McGraw-Hill Series in Mechanical Engineering; McGraw-Hill: New York, NY, USA, 1995. [Google Scholar]
- Bevington, P.R.; Robinson, D.K. Data Reduction and Error Analysis for the Physical Sciences; McGraw-Hill: New York, NY, USA, 2003. [Google Scholar]
- Ljung, L. System Identification: Theory for the User; Prentice Hall: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Marquardt, W. Model-based experimental analysis of kinetic phenomena in multi-phase reactive systems. Chem. Eng. Res. Des. 2005, 83, 561–573. [Google Scholar] [CrossRef]
- Duarte, B.P.M.; Atkinson, A.C.; Granjo, J.F.O.; Oliveira, N.M.C. A model-based framework assisting the design of vapor-liquid equilibrium experimental plans. Comput. Chem. Eng. 2021, 145, 107168. [Google Scholar] [CrossRef]
- Hangos, K.; Cameron, I. Process Modelling and Model Analysis; Process Systems Engineering; Academic Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Stephanopoulos, G. Chemical Process Control: An Introduction to Theory and Practice; Prentice-Hall International Series in the Physical and Chemical Engineering Sciences; Prentice-Hall: Upper Saddle River, NJ, USA, 1984. [Google Scholar]
- Åström, K.J. Modelling and identification of power system components. In Realtime Control of Electric Power Systems: Proceedings of the Symposium on Real-Time Control of Electric Power Systems, Baden, Switzerland; Handschin, E., Ed.; Elsevier: Amsterdam, The Netherlands, 1972; pp. 1–28. [Google Scholar]
- Bard, Y. Nonlinear Parameter Estimation; Academic Press: New York, NY, USA, 1974. [Google Scholar]
- Seber, G.A.F.; Wild, C.J. Nonlinear Regression; John Wiley & Sons: New York, NY, USA, 2003. [Google Scholar]
- Stewart, G.W. Collinearity and least squares regression. Stat. Sci. 1987, 2, 68–84. [Google Scholar] [CrossRef]
- López, D.C.; Barz, T.; Korkel, S.; Wozny, G. Nonlinear ill-posed problem analysis in model-based parameter estimation and experimental design. Comput. Chem. Eng. 2015, 77, 24–42. [Google Scholar] [CrossRef]
- Danuser, G.; Stricker, M. Parametric model fitting: From inlier characterization to outlier detection. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 263–280. [Google Scholar] [CrossRef]
- Enders, C.K. Applied Missing Data Analysis; Guilford Publications: New York, NY, USA, 2022. [Google Scholar]
- Huber, P.J. Robust estimation of a location parameter. Ann. Math. Stat. 1964, 35, 73–101. [Google Scholar] [CrossRef]
- Miké, V. Efficiency-robust systematic linear estimators of location. J. Am. Stat. Assoc. 1971, 66, 594–601. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Least median of squares regression. J. Am. Stat. Assoc. 1984, 79, 871–880. [Google Scholar] [CrossRef]
- Schick, I.C.; Mitter, S.K. Robust recursive estimation in the presence of heavy-tailed observation noise. Ann. Stat. 1994, 22, 1045–1080. [Google Scholar] [CrossRef]
- Tsai, C.; Kurz, L. An adaptive robustizing approach to Kalman filtering. Automatica 1983, 19, 279–288. [Google Scholar] [CrossRef]
- Donoho, D.L.; Johnstone, I.M. Adapting to unknown smoothness via wavelet shrinkage. J. Am. Stat. Assoc. 1995, 90, 1200–1224. [Google Scholar] [CrossRef]
- Mallat, S.G. Multiresolution approximations and wavelet orthonormal bases of L2(R). Trans. Am. Math. Soc. 1989, 315, 69–87. [Google Scholar] [CrossRef]
- West, M.; Harrison, J. Bayesian Forecasting and Dynamic Models; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar] [CrossRef]
- Brown, A.; Tuor, A.; Hutchinson, B.; Nichols, N. Recurrent neural network attention mechanisms for interpretable system log anomaly detection. In Proceedings of the First Workshop on Machine Learning for Computing Systems, Tempe, AZ, USA, 12 June 2018; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- McKnight, E. Missing Data: A Gentle Introduction; The Guilford Press: New York, NY, USA, 2007. [Google Scholar]
- Curran, D.; Bacchi, M.; Schmitz, S.; Molenberghs, G.; Sylvester, R. Identifying the types of missingness in quality of life data from clinical trials. Stat. Med. 1998, 17, 739–756. [Google Scholar] [CrossRef]
- Cleophas, T.J.; Zwinderman, A.H.; Cleophas, T.J.; Zwinderman, A.H. Missing data imputation. In Clinical Data Analysis on a Pocket Calculator: Understanding the Scientific Methods of Statistical Reasoning and Hypothesis Testing; Springer: Cham, Switzerland, 2016; pp. 93–97. [Google Scholar] [CrossRef]
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for imputation of missing values in air quality data sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Zhang, S. Nearest neighbor selection for iteratively kNN imputation. J. Syst. Softw. 2012, 85, 2541–2552. [Google Scholar] [CrossRef]
- Smith, S.W. The Scientist and Engineer’s Guide to Digital Signal Processing; California Technical Publishing: San Diego, CA, USA, 1997. [Google Scholar]
- Holt, C.C. Forecasting seasonals and trends by exponentially weighted moving averages. Int. J. Forecast. 2004, 20, 5–10. [Google Scholar] [CrossRef]
- Maybeck, P.S. Stochastic Models, Estimation, and Control; Academic Press: Cambridge, MT, USA, 1982. [Google Scholar]
- Simon, D. Optimal State Estimation: Kalman, H-Infinity, and Nonlinear Approaches; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Bowman, A.; Azzalini, A. Applied Smoothing Techniques for Data Analysis; Clarendon Press: Oxford, UK, 1997. [Google Scholar]
- Savitzky, A.; Golay, M.J.E. Smoothing and differentiation of data by simplified least squares procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Huang, T.S.; Yang, G.J.; Tang, G.Y. A fast two-dimensional median filtering algorithm. IEEE Trans. Acoust. Speech Signal Process. 1979, 27, 13–18. [Google Scholar] [CrossRef]
- Orfanidis, S.J. Introduction to Signal Processing; Prentice Hall: New Brunswick, NJ, USA, 1996; p. 798. [Google Scholar]
- Simonoff, J.S. Smoothing Methods in Statistics; Springer: New York, NY, USA, 1996. [Google Scholar]
- Haykin, S.; Van Veen, B. Signals and Systems, 2nd ed.; Wiley: New York, NY, USA, 2007. [Google Scholar]
- Harris, F.J. On the use of windows for harmonic analysis with the discrete Fourier transform. Proc. IEEE 1978, 66, 51–83. [Google Scholar] [CrossRef]
- Strang, G.; Nguyen, T. Wavelets and Filter Banks; Wellesley-Cambridge Press: Wellesley, MA, USA, 1996; p. 520. [Google Scholar]
- Julier, S.J.; Uhlmann, J.K. Unscented filtering and nonlinear estimation. Proc. IEEE 2004, 92, 401–422. [Google Scholar] [CrossRef]
- Ahnert, K.; Abel, M. Numerical differentiation of experimental data: Local versus global methods. Comput. Phys. Commun. 2007, 177, 764–774. [Google Scholar] [CrossRef]
- Van Breugel, F.; Kutz, J.N.; Brunton, B.W. Numerical differentiation of noisy data: A unifying multi-objective optimization framework. IEEE Access 2020, 8, 196865–196877. [Google Scholar] [CrossRef] [PubMed]
- Letzgus, S.; Müller, K.R. An explainable AI framework for robust and transparent data-driven wind turbine power curve models. Energy AI 2024, 15, 100328. [Google Scholar] [CrossRef]
- Alabduljabbar, R.; Alshareef, M.; Alshareef, N. Time-aware recommender systems: A comprehensive survey and quantitative assessment of literature. IEEE Access 2023, 11, 45586–45604. [Google Scholar] [CrossRef]
- Benvenuti, L.; De Santis, A.; Farina, L. On model consistency in compartmental systems identification. Automatica 2002, 38, 1969–1976. [Google Scholar] [CrossRef]
- Biegler, L. Nonlinear Programming: Concepts, Algorithms, and Applications to Chemical Processes; MOS-SIAM Series on Optimization; Society for Industrial and Applied Mathematics: University City, PA, USA, 2010. [Google Scholar]
- Himmelblau, D.M.; Bischoff, K.B. Process Analysis and Simulation: Deterministic Systems; Wiley: New York, NY, USA, 1968. [Google Scholar]
- Villaverde, A.F.; Banga, J.R. Reverse engineering and identification in systems biology: Strategies, perspectives, and challenges. J. R. Soc. Interface 2014, 11, 20130505. [Google Scholar] [CrossRef]
- Heermann, D.W.; Burkitt, A.N. (Eds.) Computer Simulation Methods. In Parallel Algorithms in Computational Science; Springer: Berlin/Heidelberg, Germany, 1991; pp. 5–35. [Google Scholar] [CrossRef]
- Chow, S.M. Practical tools and guidelines for exploring and fitting linear and nonlinear dynamical systems models. Multivar. Behav. Res. 2019, 54, 690–718. [Google Scholar] [CrossRef]
- Shin, S.; Venturelli, O.S.; Zavala, V.M. Scalable nonlinear programming framework for parameter estimation in dynamic biological system models. PLoS Comput. Biol. 2019, 15, e1006828. [Google Scholar] [CrossRef] [PubMed]
- Huang, Y.; Wu, H. A Bayesian approach for estimating antiviral efficacy in HIV dynamic models. J. Appl. Stat. 2006, 33, 155–174. [Google Scholar] [CrossRef]
- Lawson, C.L.; Hanson, R.J. Solving Least Squares Problems; SIAM: Philadephia, PA, USA, 1995. [Google Scholar]
- Maiwald, T.; Timmer, J. Dynamical modeling and multi-experiment fitting with PottersWheel. Bioinformatics 2008, 24, 2037–2043. [Google Scholar] [CrossRef] [PubMed]
- Ratkowsky, D. Nonlinear Regression Modeling; Central Book Company: New York, NY, USA, 1983. [Google Scholar]
- Singer, A.B.; Taylor, J.W.; Barton, P.I.; Green, W.H. Global dynamic optimization for parameter estimation in chemical kinetics. J. Phys. Chem. A 2006, 110, 971–976. [Google Scholar] [CrossRef] [PubMed]
- Gábor, A.; Banga, J.R. Robust and efficient parameter estimation in dynamic models of biological systems. BMC Syst. Biol. 2015, 9, 1–25. [Google Scholar] [CrossRef] [PubMed]
- Houska, B.; Logist, F.; Diehl, M.; Van Impe, J. A tutorial on numerical methods for state and parameter estimation in nonlinear dynamic systems. In Identification for Automotive Systems; Alberer, D., Hjalmarsson, H., del Re, L., Eds.; Springer: London, UK, 2012; pp. 67–88. [Google Scholar] [CrossRef]
- Duarte, B.P.M.; Moura, M.J. Using rheological monitoring to determine the gelation kinetics of chitosan-based systems. Math. Biosci. Eng. (MBE) 2023, 20, 1176–1194. [Google Scholar] [CrossRef] [PubMed]
- Granjo, J.F.O.; Duarte, B.P.M.; Oliveira, N.M.C. Systematic development of kinetic models for the glyceride transesterification reaction via alkaline catalysis. Ind. Eng. Chem. Res. 2018, 57, 9903–9914. [Google Scholar] [CrossRef]
- Gernaey, K.; Vanrolleghem, P.; Lessard, P. Modeling of a reactive primary clarifier. Water Sci. Technol. 2001, 43, 73–81. [Google Scholar] [CrossRef]
- Levenspiel, O. Chemical Reaction Engineering; John Wiley & Sons: Hoboken, NJ, USA, 1998. [Google Scholar]
- Himmelblau, D.; Jones, C.; Bischoff, K. Determination of rate constants for complex kinetics models. Ind. Eng. Chem. Fundam. 1967, 6, 539–543. [Google Scholar] [CrossRef]
- Schittkowski, K. Parameter estimation in differential equations. In Recent Trends in Optimization Theory and Applications; World Scientific: Singapore, 1995; pp. 353–370. [Google Scholar] [CrossRef]
- Edsberg, L.; Wedin, P.A. Numerical tools for parameter estimation in ODE-systems. Optim. Methods Softw. 1995, 6, 193–217. [Google Scholar] [CrossRef]
- Fogler, H.S. Elements of Chemical Reaction Engineering, 4th ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2005. [Google Scholar]
- Wagner, J.; Mazurek, P.; Miękina, A.; Morawski, R.Z. Regularised differentiation of measurement data in systems for monitoring of human movements. Biomed. Signal Process. Control 2018, 43, 265–277. [Google Scholar] [CrossRef]
- Cremers, J.; Hübler, A. Construction of differential equations from experimental data. Z. Naturforsch. A 1987, 42, 797–802. [Google Scholar] [CrossRef]
- Vertis, C.S. Identification and Modeling of Chemical Reaction Networks—A Systematic Methodology. Ph.D. Thesis, Universidade de Coimbra, Coimbra, Portugal, 2022. [Google Scholar]
- Moura, M.J.; Vertis, C.S.; Redondo, V.; Oliveira, N.M.C.; Duarte, B.P.M. Modeling the batch sedimentation of calcium carbonate particles in laboratory experiments—A systematic approach. Materials 2023, 16, 4822. [Google Scholar] [CrossRef] [PubMed]
- Stewart, W.; Caracotsios, M.; Sorensen, J. Parameter estimation from multiresponse data. AIChE J. 1992, 38, 641–650. [Google Scholar] [CrossRef]
- Vassiliadis, V.; Sargent, R.; Pantelides, C. Solution of a class of multistage dynamic optimization problems. 1. Problems without path constraints. Ind. Eng. Chem. Res. 1994, 33, 2111–2122. [Google Scholar] [CrossRef]
- Beck, J.V. Sequential methods in parameter estimation. In Inverse Engineering Handbook; Woodbury, K., Ed.; Handbook Series for Mechanical Engineering; CRC Press: Boca Raton, FL, USA, 2002; pp. 1–41. [Google Scholar]
- Bindlich, R.; Rawlings, J.; Young, R. Parameter estimation for industrial polymerization processes. AIChE J. 2003, 49, 2071–2078. [Google Scholar] [CrossRef]
- Zavala, V.; Biegler, L. Large-scale parameter estimation in low-density polyethylene tubular reactors. Ind. Eng. Chem. Res. 2006, 45, 7867–7881. [Google Scholar] [CrossRef]
- Hoang, M.D.; Barz, T.; Merchan, V.A.; Biegler, L.T.; Arellano-Garcia, H. Simultaneous solution approach to model-based experimental design. AIChE J. 2013, 59, 4169–4183. [Google Scholar] [CrossRef]
- Vasantharajan, S.; Biegler, L. Simultaneous strategies for optimization of differential-algebraic systems with enforcement of error criteria. Comput. Chem. Eng. 1990, 14, 1083–1100. [Google Scholar] [CrossRef]
- Tjoa, I.; Biegler, L. Simultaneous solution and optimization strategies for parameter estimation of differential-algebraic equation systems. Ind. Eng. Chem. Res. 1991, 30, 376–385. [Google Scholar] [CrossRef]
- Logsdon, J.; Biegler, L. Decomposition strategies for large-scale dynamic optimization problems. Chem. Eng. Sci. 1992, 47, 851–864. [Google Scholar] [CrossRef]
- Bock, H.; Diehl, M.; Leineweber, D.; Schröder, J. A Direct Multiple Shooting Method for Real-Time Optimization of Nonlinear DAE Processes. In Nonlinear Model Predictive Control; Progress in Systems and Control Theory; Allgöwer, F., Zheng, A., Eds.; Birkhäuser: Basel, Switzerland, 2000; Volume 26. [Google Scholar] [CrossRef]
- Kühl, P.; Diehl, M.; Kraus, T.; Schlöder, J.P.; Bock, H.G. A real-time algorithm for moving horizon state and parameter estimation. Comput. Chem. Eng. 2011, 35, 71–83. [Google Scholar] [CrossRef]
- The MathWorks, Inc. MATLAB Optimization Toolbox: Fmincon Function; MathWorks: Natick, MA, USA, 2023; Available online: https://www.mathworks.com/help/optim/ug/fmincon.html (accessed on 28 November 2024).
- Wolfram Research, Inc. Mathematica, Version 14.1; Wolfram Research, Inc.: Champaign, IL, USA, 2024. Available online: https://www.wolfram.com/mathematica (accessed on 29 November 2024).
- Wächter, A.; Biegler, L.T. On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming. Math. Program. 2006, 106, 25–57. [Google Scholar] [CrossRef]
- Drud, A. CONOPT: A System for Large Scale Nonlinear Optimization; ARKI Consulting and Development A/S: Bagsværd, Denmark, 1996; Available online: https://www.gams.com/latest/docs/S_CONOPT.html (accessed on 29 November 2024).
- Sahinidis, N.V. BARON: Branch and Reduce Optimization Navigator; The Optimization Firm: Evanston, IL, USA, 2023; Available online: https://minlp.com (accessed on 30 November 2024).
- Ugray, Z.; Lasdon, L.; Plummer, J.; Glover, F.; Kelly, J.; Martí, R. A multistart scatter search heuristic for smooth NLP and MINLP problems. In Metaheuristic Optimization via Memory and Evolution; Springer: Berlin/Heidelberg, Germany, 2005; pp. 25–51. [Google Scholar] [CrossRef]
- Hairer, E.; Nørsett, S.P.; Wanner, G. Solving Ordinary Differential Equations I: Nonstiff Problems; Springer Series in Computational Mathematics; Springer: Berlin/Heidelberg, Germany, 2009; Volume 1. [Google Scholar]
- Klise, K.A.; Nicholson, B.L.; Staid, A.; Woodruff, D.L. Parmest: Parameter Estimation Via Pyomo. In Computer Aided Chemical Engineering; Muñoz, S.G., Laird, C.D., Realff, M.J., Eds.; Elsevier: Amsterdam, The Netherlands, 2019; Volume 47, pp. 41–46. [Google Scholar] [CrossRef]
- Schälte, Y.; Fröhlich, F.; Jost, P.J.; Vanhoefer, J.; Pathirana, D.; Stapor, P.; Lakrisenko, P.; Wang, D.; Raimúndez, E.; Merkt, S.; et al. pyPESTO: A modular and scalable tool for parameter estimation for dynamic models. Bioinformatics 2023, 39, btad711. [Google Scholar] [CrossRef] [PubMed]
- Wolfram Research, Inc. Nonlinear Regression Package; Wolfram Language Documentation; Wolfram Research, Inc.: Champaign, IL, USA, 2024. [Google Scholar]
- Kaschek, D.; Mader, W.; Fehling-Kaschek, M.; Rosenblatt, M.; Timmer, J. Dynamic modeling, parameter estimation, and uncertainty analysis in R. J. Stat. Softw. 2019, 88, 1–32. [Google Scholar] [CrossRef]
- Marcoline, F.V.; Furth, J.; Nayak, S.; Grabe, M.; Macey, R.I. Berkeley Madonna Version 10-A simulation package for solving mathematical models. CPT Pharmacomet. Syst. Pharmacol. 2022, 11, 290–301. [Google Scholar] [CrossRef] [PubMed]
- Draper, N.; Smith, H. Applied Regression Analysis; Wiley Series in Probability and Mathematical Statistics; Wiley: New York, NY, USA, 1966. [Google Scholar]
- Haraki, D.; Suzuki, T.; Ikeguchi, T. Bootstrap prediction intervals for nonlinear time-series. In Proceedings of the Intelligent Data Engineering and Automated Learning—IDEAL 2006; Corchado, E., Yin, H., Botti, V., Fyfe, C., Eds.; Universidad de Burgos: Berlin/Heidelberg, Germany, 2006; pp. 155–162. [Google Scholar] [CrossRef]
- Fernandez, J.L.; Hernandez, C. Practical Model-Based Systems Engineering; Artech House: Houston, TX, USA, 2019. [Google Scholar]
- Walter, E. Identifiability of Parametric Models; Pergamon Press, Inc.: Elmsford, NY, USA, 1987. [Google Scholar]
- Belsley, D.A.; Kuh, E.; Welsch, R.E. Regression Diagnostics: Identifying Influential Data and Sources of Collinearity; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Box, G.E.; Draper, N.R. Empirical Model-Building and Response Surfaces; John Wiley & Sons: Hoboken, NJ, USA, 1987. [Google Scholar]
- Rempel, M.F.; Zhou, J. On exact K-optimal designs minimizing the condition number. Commun. Stat.-Theory Methods 2014, 43, 1114–1131. [Google Scholar] [CrossRef]
- Marquardt, D.W. Generalized inverses, ridge regression, biased linear estimation, and nonlinear estimation. Technometrics 1970, 12, 591–612. [Google Scholar] [CrossRef]
- Atkinson, A.C.; Donev, A.N.; Tobias, R.D. Optimum Experimental Designs, with SAS; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Duarte, B.P.M.; Atkinson, A.C.; Oliveira, N.M.C. Optimum design for ill-conditioned models: K–optimality and stable parameterizations. Chemom. Intell. Lab. Syst. 2023, 239, 104874. [Google Scholar] [CrossRef]
- Riddell, E.A.; Burger, I.J.; Tyner-Swanson, T.L.; Biggerstaff, J.; Muñoz, M.M.; Levy, O.; Porter, C.K. Parameterizing mechanistic niche models in biophysical ecology: A review of empirical approaches. J. Exp. Biol. 2023, 226, jeb245543. [Google Scholar] [CrossRef] [PubMed]
- Ripperger, S.; Gösele, W.; Alt, C.; Loewe, T. Filtration, 1. Fundamentals. In Comprehensive Supramolecular Chemistry II; Wiley: New York, NY, USA, 2023; pp. 1–38. [Google Scholar] [CrossRef]
- Anlauf, H. Wet Cake Filtration: Fundamentals, Equipment, and Strategies; John Wiley & Sons: Hoboken, NJ, USA, 2019. [Google Scholar]
- Civan, F. Practical model for compressive cake filtration including fine particle invasion. AIChE J. 1998, 44, 2388–2398. [Google Scholar] [CrossRef]
- Mahdi, F.; Holdich, R. Laboratory cake filtration testing using constant rate. Chem. Eng. Res. Des. 2013, 91, 1145–1154. [Google Scholar] [CrossRef]
- Kuhn, M.; Pergam, P.; Briesen, H. Parameter estimation for incompressible cake filtration: Advantages of a modified fitting method. Chem. Eng. Technol. 2020, 43, 493–501. [Google Scholar] [CrossRef]
- Couper, J.; Penney, W.; Fair, J.; Walas, S. Chemical Process Equipment: Selection and Design; Gulf Professional Publishing: Houston, TX, USA, 2005. [Google Scholar]
- Almy Jr, C.; Lewis, W. Factors determining the capacity of a filter press. Ind. Eng. Chem. 1912, 4, 528–532. [Google Scholar] [CrossRef]
- Murugesan, S.; Hallow, D.M.; Vernille, J.P.; Tom, J.W.; Tabora, J.E. Lean filtration: Approaches for the estimation of cake properties. Org. Process Res. Dev. 2012, 16, 42–48. [Google Scholar] [CrossRef]
- Duarte, B.P.M.; Moura, M.J.; Neves, F.J.M.; Oliveira, N.M.C. A mathematical programming framework for optimal model selection/validation of process data. In 18th European Symposium on Computer Aided Process Engineering; Computer Aided Chemical Engineering, Braunschweig, B., Joulia, X., Eds.; Elsevier: Amsterdam, The Netherlands, 2008; Volume 25, pp. 343–348. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exper. | ΔP (N/m2) | r () | r CI [Low, High] () | () | CI [Low, High] () |
|---|---|---|---|---|---|
| 1 | 3.2264 | 2.3146 | [2.1606, 2.4686] | 3.7834 | [3.5016, 4.0652] |
| 2 | 3.3331 | 2.1871 | [2.0182, 2.3561] | 1.6639 | [1.2804, 2.0474] |
| 3 | 3.4797 | 2.5676 | [2.2621, 2.8732] | 2.9014 | [2.1930, 3.6098] |
| 4 | 3.4997 | 2.1913 | [2.0639, 2.3188] | 2.3740 | [2.1024, 2.6457] |
| 5 | 3.5597 | 2.9005 | [2.8345, 2.9665] | 2.8232 | [2.6849, 2.9616] |
| 6 | 3.5597 | 3.3809 | [3.2436, 3.5182] | 2.9392 | [2.6292, 3.2492] |
| 7 | 3.5997 | 3.5768 | [3.3794, 3.7741] | 3.1109 | [2.6494, 3.5725] |
| 8 | 3.5997 | 2.8216 | [2.6992, 2.9439] | 1.5366 | [1.2719, 1.8013] |
| 9 | 3.7597 | 3.1750 | [3.0389, 3.3111] | 2.3418 | [2.0218, 2.6618] |
| 10 | 3.7730 | 2.2972 | [2.1177, 2.4767] | 2.2619 | [1.8437, 2.6800] |
| 11 | 3.7864 | 4.3398 | [4.1490, 4.5306] | 3.1502 | [2.7023, 3.5981] |
| 12 | 3.8663 | 2.9726 | [2.7703, 3.1749] | 4.5729 | [4.0998, 5.0459] |
| 13 | 4.8129 | 3.0327 | [2.6027, 3.4627] | 2.6811 | [1.6217, 3.7405] |
| 14 | 4.9063 | 3.2595 | [3.1204, 3.3986] | 5.7941 | [5.4656, 6.1227] |
| 15 | 4.9329 | 2.6321 | [2.5357, 2.7285] | 4.6420 | [4.4331, 4.8509] |
| 16 | 4.9329 | 2.8347 | [2.7071, 2.9622] | 4.6481 | [4.3633, 4.9330] |
| 17 | 4.9596 | 3.9359 | [2.9593, 4.9125] | 0.3571 | [-2.0472, 2.7614] |
| 18 | 5.1596 | 3.3371 | [3.1695, 3.5047] | 1.8606 | [1.4992, 2.2220] |
| 19 | 5.1596 | 1.8147 | [1.3492, 2.2802] | 2.1790 | [0.9469, 3.4110] |
| 20 | 5.1729 | 4.1960 | [4.0354, 4.3566] | 5.1684 | [4.7914, 5.5453] |
| 21 | 5.1996 | 1.2961 | [1.1938, 1.3985] | 4.5544 | [4.3269, 4.7819] |
| 22 | 5.1996 | 3.2009 | [3.0649, 3.3369] | 2.6465 | [2.3314, 2.9616] |
| 23 | 5.1996 | 2.3713 | [2.1951, 2.5476] | 5.0445 | [4.6145, 5.4746] |
| 24 | 5.1996 | 2.3215 | [2.1398, 2.5033] | 4.9016 | [4.4270, 5.3761] |
| 25 | 6.2662 | 3.1190 | [2.9883, 3.2497] | 5.4792 | [5.2071, 5.7512] |
| 26 | 6.4261 | 2.7145 | [2.2419, 3.1872] | 8.1022 | [6.9989, 9.2055] |
| 27 | 6.4661 | 3.0618 | [2.7875, 3.3361] | 4.8245 | [4.1954, 5.4536] |
| 28 | 6.4928 | 1.1126 | [0.9813, 1.2439] | 5.5838 | [5.2820, 5.8856] |
| 29 | 6.5061 | 2.5031 | [2.2690, 2.7372] | 7.9784 | [7.4130, 8.5439] |
| 30 | 6.5061 | 3.9471 | [3.5709, 4.3233] | 5.7260 | [4.8261, 6.6259] |
| 31 | 6.5328 | 4.0680 | [3.7871, 4.3489] | 6.7167 | [6.0106, 7.4228] |
| 32 | 6.5328 | 4.6175 | [4.2955, 4.9395] | 3.8817 | [3.1316, 4.6317] |
| 33 | 6.6661 | 1.7386 | [1.2337, 2.2435] | 10.3517 | [9.0539, 11.6495] |
| 34 | 6.7461 | 3.3915 | [3.1592, 3.6238] | 6.1191 | [5.5825, 6.6557] |
| 35 | 6.7994 | 2.7938 | [2.5258, 3.0618] | 4.1511 | [3.5564, 4.7458] |
| 36 | 6.8261 | 3.7190 | [3.5805, 3.8574] | 7.6443 | [7.3176, 7.9711] |
| Exper. | ΔP (N/m2) | VIF | RMSE | |||
|---|---|---|---|---|---|---|
| 1 | 3.2264 | −0.9748 | 20.0980 | 158.1123 | 2.9052 | 7.5145 |
| 2 | 3.3331 | −0.9608 | 13.0063 | 135.7558 | 1.3677 | 2.2602 |
| 3 | 3.4797 | −0.9550 | 11.3615 | 121.7498 | 5.1763 | 2.3446 |
| 4 | 3.4997 | −0.9421 | 8.8939 | 84.0604 | 2.8280 | 2.4280 |
| 5 | 3.5597 | −0.9534 | 10.9756 | 102.1270 | 2.2432 | 1.1274 |
| 6 | 3.5597 | −0.9549 | 11.3527 | 117.1794 | 1.5192 | 2.0411 |
| 7 | 3.5997 | −0.9534 | 10.9920 | 119.1352 | 4.0468 | 1.4116 |
| 8 | 3.5997 | −0.9431 | 9.0382 | 87.2249 | 2.6145 | 2.2809 |
| 9 | 3.7597 | −0.9576 | 12.0475 | 131.8749 | 1.6088 | 2.1467 |
| 10 | 3.7730 | −0.9587 | 12.3682 | 133.7606 | 9.9214 | 2.0488 |
| 11 | 3.7864 | −0.9515 | 10.5562 | 114.8954 | 6.9487 | 1.9417 |
| 12 | 3.8663 | −0.9558 | 11.5722 | 125.5754 | 3.7082 | 1.3586 |
| 13 | 4.8129 | −0.9804 | 25.8012 | 306.0901 | 2.4519 | 2.4891 |
| 14 | 4.9063 | −0.9561 | 11.6393 | 128.1726 | 1.5580 | 2.2008 |
| 15 | 4.9329 | −0.9506 | 10.3737 | 100.8583 | 7.8508 | 9.4579 |
| 16 | 4.9329 | −0.9581 | 12.1878 | 124.1206 | 9.9176 | 1.4923 |
| 17 | 4.9596 | −0.9721 | 18.1488 | 214.0123 | 1.7343 | 4.3067 |
| 18 | 5.1596 | −0.9426 | 8.9729 | 86.1589 | 1.8085 | 2.5913 |
| 19 | 5.1596 | −0.9542 | 11.1779 | 144.9213 | 1.3804 | 6.7857 |
| 20 | 5.1729 | −0.9549 | 11.3413 | 123.7014 | 2.1587 | 8.2544 |
| 21 | 5.1996 | −0.9608 | 13.0080 | 131.8937 | 1.5180 | 1.4230 |
| 22 | 5.1996 | −0.9559 | 11.5822 | 124.0217 | 2.8913 | 7.3362 |
| 23 | 5.1996 | −0.9603 | 12.8639 | 148.7153 | 1.2136 | 2.4571 |
| 24 | 5.1996 | −0.9504 | 10.3407 | 131.1758 | 1.7813 | 3.2612 |
| 25 | 6.2662 | −0.9520 | 10.6752 | 98.2779 | 5.0796 | 9.9417 |
| 26 | 6.4261 | −0.9636 | 13.9890 | 152.1546 | 3.0048 | 2.9569 |
| 27 | 6.4661 | −0.9729 | 18.6909 | 199.4043 | 2.1190 | 1.3565 |
| 28 | 6.4928 | −0.9705 | 17.2193 | 183.9973 | 1.0443 | 1.5392 |
| 29 | 6.5061 | −0.9593 | 12.5323 | 142.7233 | 3.9540 | 1.7501 |
| 30 | 6.5061 | −0.9559 | 11.6063 | 130.1283 | 1.7841 | 1.7123 |
| 31 | 6.5328 | −0.9559 | 11.6032 | 139.6985 | 1.8858 | 1.4147 |
| 32 | 6.5328 | −0.9477 | 9.8105 | 105.3472 | 6.9158 | 3.2597 |
| 33 | 6.6661 | −0.9638 | 14.0618 | 175.6443 | 8.3072 | 6.0948 |
| 34 | 6.7461 | −0.9585 | 12.3097 | 131.4997 | 6.3333 | 2.2281 |
| 35 | 6.7994 | −0.9541 | 11.1506 | 112.2819 | 1.2160 | 3.4642 |
| 36 | 6.8261 | −0.9569 | 11.8662 | 130.5581 | 9.0935 | 1.6653 |
| Model | Reference Resistance | Reference Resistance CI [Low, High] | Compressibility Index | Compressibility Index CI [Low, High] | R2 |
|---|---|---|---|---|---|
| Equation (12a) | 25.9396 | [25.8332, 26.0459] | 0.0391 | [−0.0672, 0.1455] | 0.0010 |
| Equation (12b) | 12.2975 | [12.1217, 12.4733] | 1.3272 | [1.1514, 1.5030] | 0.2970 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duarte, B.P.M.; Moura, M.J.; Santos, L.O.; Oliveira, N.M.C. A Dynamic Model-Fitting Algorithm for Batch Laboratory Data: Application to Constant-Pressure Cake Filtration Experiments. ChemEngineering 2025, 9, 20. https://doi.org/10.3390/chemengineering9010020
Duarte BPM, Moura MJ, Santos LO, Oliveira NMC. A Dynamic Model-Fitting Algorithm for Batch Laboratory Data: Application to Constant-Pressure Cake Filtration Experiments. ChemEngineering. 2025; 9(1):20. https://doi.org/10.3390/chemengineering9010020
Chicago/Turabian StyleDuarte, Belmiro P. M., Maria J. Moura, Lino O. Santos, and Nuno M. C. Oliveira. 2025. "A Dynamic Model-Fitting Algorithm for Batch Laboratory Data: Application to Constant-Pressure Cake Filtration Experiments" ChemEngineering 9, no. 1: 20. https://doi.org/10.3390/chemengineering9010020
APA StyleDuarte, B. P. M., Moura, M. J., Santos, L. O., & Oliveira, N. M. C. (2025). A Dynamic Model-Fitting Algorithm for Batch Laboratory Data: Application to Constant-Pressure Cake Filtration Experiments. ChemEngineering, 9(1), 20. https://doi.org/10.3390/chemengineering9010020