From Academia to Reality Check: A Theoretical Framework on the Use of Chemometric in Food Sciences



 ,
, 

Abstract
1. Introduction
2. Chemometrics Linking the Univariate with the Multivariate World
3. The Importance of Experimental Design
4. Sampling and Samples
5. Interpretation of Results and Validation
6. The Misuse of Chemometrics
7. Final Considerations and Perspectives
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fotakis, C.; Kokkotou, K.; Zoumpoulakis, P.; Zervou, M. NMR metabolite fingerprinting in grape derived products: An overview. Food Res. Int. 2013, 54, 1184–1194. [Google Scholar] [CrossRef]
- Nunes, C.A.; Alvarenga, V.O.; Sant’Ana, A.D.S.; Santos, J.S.; Granato, D. The use of statistical software in food science and technology: Advantages, limitations and misuses. Food Res. Int. 2015, 75, 270–280. [Google Scholar] [CrossRef]
- Granato, D.; Calado, V.M.D.A.; Jarvis, B. Observations on the use of statistical methods in Food Science and Technology. Food Res. Int. 2014, 55, 137–149. [Google Scholar] [CrossRef]
- Fardet, A. New Approaches to Studying the Potential Health Benefits of Cereals: From Reductionism to Holism. Cereal Foods World 2014, 59, 224–229. [Google Scholar] [CrossRef]
- Hopke, P.K. The evolution of chemometrics. Anal. Chimi. Acta 2003, 500, 363–367. [Google Scholar] [CrossRef]
- Burlingame, B. Holistic and reductionist nutrition. J. Food Compos. Anal. 2004, 17, 585–586. [Google Scholar] [CrossRef]
- Cozzolino, D.; Daniel, C. Foodomics and infrared spectroscopy: from compounds to functionality. Curr. Opin. Food Sci. 2015, 4, 39–43. [Google Scholar] [CrossRef]
- Munck, L. A new holistic exploratory approach to Systems Biology by Near Infrared Spectroscopy evaluated by chemometrics and data inspection. J. Chemom. 2007, 21, 406–426. [Google Scholar] [CrossRef]
- Munck, L.; Møller, J.B.; Rinnan, Å.; Fast, S.H.; Møller, E.M.; Nørgaard, L.; Balling, E.S. A physiochemical theory on the applicability of soft mathematical models—Experimentally interpreted. J. Chem. 2010, 24, 481–495. [Google Scholar] [CrossRef]
- Kelly, J.G.; Trevisan, J.; Scott, A.D.; Carmichael, P.L.; Pollock, H.M.; Martin-Hirsch, P.L.; Martin, F.L. Biospectroscopy to metabolically profile biomolecular structure: A multistage approach linking computational analysis with biomarkers. J. Proteome Res. 2011, 10, 1437–1448. [Google Scholar] [CrossRef]
- Capozzi, F.; Bordoni, A. Foodomics: A new comprehensive approach to food and nutrition. Genes Nutr. 2013, 8, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Granato, D.; Putnik, P.; Bursać Kovačević, D.; Sousa Santos, J.; Calado, V.; Silva Rocha, R.; Gomes Da Cruz, A.; Jarvis, B.; Rodionova, O.Y.; Pomerantsev, A. Trends in Chemometrics: Food Authentication, Microbiology, and Effects of Processing. Compr. Rev. Food Sci. Food Saf. 2018, 17, 663–677. [Google Scholar] [CrossRef]
- Castro-Puyana, M.; Mendiola, J.A.; Ibáñez, E. Strategies for a cleaner new scientific discipline of green foodomics. TrAC Trends Anal. Chem. 2013, 52, 23–35. [Google Scholar] [CrossRef]
- Cevallos-Cevallos, J.M.; Reyes-De-Corcuera, J.I.; Etxeberria, E.; Danyluk, M.D.; Rodrick, G.E. Metabolomic analysis in food science: A review. Trends Food Sci. Technol. 2009, 20, 557–566. [Google Scholar] [CrossRef]
- Wishart, D.S. Metabolomics: Applications to food science and nutrition research. Trends Food Sci. Technol. 2008, 19, 482–493. [Google Scholar] [CrossRef]
- Buco, S.M. How good are your results? An approach to qualitative and quantitative statistical analysis for food monitoring and process control systems. Food Control 1990, 1, 40–46. [Google Scholar] [CrossRef]
- Matero, S.; vanDen Berg, F.; Poutiainen, S.; Rantanen, J.; Pajander, J. Towards Better Process Understanding: Chemometrics and Multivariate Measurements in Manufacturing of Solid Dosage Forms. J. Pharm. Sci. 2013, 102, 1385–1403. [Google Scholar] [CrossRef]
- Massart, D.L.; Vandegiste, B.G.M.; Deming, S.N.; Michotte, Y.; Kaufman, L. Chemometrics: A Textbook. Elsevier: Amsterdam, The Netherlands, 1988. [Google Scholar]
- Mutihac, L.; Mutihac, R. Mining in chemometrics. Anal. Chim. Acta 2008, 612, 1–18. [Google Scholar] [CrossRef]
- Wold, S. Chemometrics; what do we mean with it, and what do we want from it? Chemom. Intell. Lab. Syst. 1995, 30, 109–115. [Google Scholar] [CrossRef]
- Martens, H.M.A.M. Multivariate Analysis of Quality. An Introduction. Meas. Sci. Technol. 2001, 12, 1746. [Google Scholar] [CrossRef]
- Adams, M.J. Chemometrics in analytical spectroscopy. In RSC Spectroscopy Monographs; Barnett, N.W., Ed.; The Royal Society of Chemistry: Cambridge, UK, 1995; p. 216. [Google Scholar]
- Otto, M. Chemometrics: Statistics and Computer Application in Analytical Chemistry; Wiley-VCH: Leipzig, Germany, 1999; p. 314. [Google Scholar]
- Esbensen, K.H. Multivariate Data Analysis in Practice. CAMO Process AS: Oslo, Norway, 2002. [Google Scholar]
- Geladi, P. Chemometrics in spectroscopy. Part I. Classical chemometrics. Spectrochim. Acta Part B 2003, 58, 767–782. [Google Scholar] [CrossRef]
- Woodcock, T.; Downey, G.; O’Donnell, C.P.; Downey, G. Better Quality Food and Beverages: The Role of near Infrared Spectroscopy. J. Near Infared Spectrosc. 2008, 16, 1–29. [Google Scholar] [CrossRef]
- Møller, S.F.; Von Frese, J.; Bro, R. Robust methods for multivariate data analysis. J. Chemom. 2005, 19, 549–563. [Google Scholar] [CrossRef]
- Asuero, A.G.; Sayago, A.; Gonzalez, A.G. The Correlation Coefficient: An Overview. Crit. Rev. Anal. Chem. 2006, 36, 41–59. [Google Scholar] [CrossRef]
- Brereton, R.G. Applied Chemometrics for Scientist. John Wiley & Sons Ltd.: Chichester, UK, 2008. [Google Scholar]
- Naes, T.; Isaksson, T.; Fearn, T.; Davies, T. A User-Friendly Guide to Multivariate Calibration and Classification. NIR Publications: Chichester, UK, 2002; p. 420. [Google Scholar]
- Bro, R.; Smilde, A.K. Principal component analysis. Anal. Met. 2014, 6, 2812–2831. [Google Scholar] [CrossRef]
- Leardi, R. Experimental design in chemistry: A tutorial. Anal. Chim. Acta 2009, 652, 161–172. [Google Scholar] [CrossRef]
- Granato, D.; Calado, V.M.A. The use of importance of design of experiments (DOE) in process modelling in food science and technology. In Mathematical and Statistical Approaches in Food Science and Technology; Granato, D., Ares, G., Eds.; Wiley Blackwell: Oxford, UK, 2014; p. 536. [Google Scholar]
- Szczepanska, N.; Kudłak, B.; Namiesnik, J. Recent advances in assessing xenobiotics migrating from packaging material e A review. Anal. Chim. Acta 2018, 1023, 1–21. [Google Scholar] [CrossRef]
- Murray, I. NIR spectroscopy of food: simple things, subtle things and spectra. NIR News 1999, 10, 10–12. [Google Scholar] [CrossRef]
- Murray, I.; Cowe, I. Sample preparation. In Near Infrared Spectroscopy in Agriculture; Roberts, C.A., Workman, J., Reeves, J.B., Eds.; American Society of Agronomy, Crop Science Society of America, Soil Science Society of America: Madison, WI, USA, 2004; pp. 75–115. [Google Scholar]
- Cozzolino, D. Sample presentation, sources of error and future perspectives on the application of vibrational spectroscopy in the wine industry. J. Sci. Food Agric. 2014, 95, 861–868. [Google Scholar] [CrossRef]
- Nicolai, B.M.; Beullens, K.; Bobelyn, E.; Peirs, A.; Saeys, W.; Theron, K.I.; Lammertyn, J. Non-destructive measurement of fruit and vegetable quality by means of NIR spectroscopy: A review. Post Harvest Biol. Tech. 2007, 46, 99–118. [Google Scholar] [CrossRef]
- Walsh, K.B.; Kawano, S. Near infrared spectroscopy. In Optical Monitoring of Fresh and Processed Agricultural Crops; Zude, M., Ed.; CRC Press: Boca Raton, FL, USA, 2009; pp. 192–239. [Google Scholar]
- Westad, F.; Marini, F. Validation of chemometric models—A tutorial. Anal. Chim. Acta 2015, 893, 14–24. [Google Scholar] [CrossRef]
- Cozzolino, D.; Cynkar, W.U.; Dambergs, R.G.; Shah, N.; Smith, P. Multivariate methods in grape and wine analysis. Int. J. Wine Res. 2009, 1, 123–130. [Google Scholar] [CrossRef]
- Cozzolino, D.; Shah, N.; Cynkar, W.; Smith, P. A practical overview of multivariate data analysis applied to spectroscopy. Food Res. Int. 2011, 44, 1888–1896. [Google Scholar] [CrossRef]
- Norris, K.H.; Ritchie, G.E. Assuring specificity for a multivariate near-infrared (NIR) calibration: The example of the Chambersburg Shoot-out 2002 data set. J. Pharm. Biomed. Anal. 2008, 48, 1037–1041. [Google Scholar] [CrossRef]
- Fearn, T. Assessing calibrations: SEP, RPD, RER and R2. NIR news 2002, 13, 12–13. [Google Scholar] [CrossRef]
- Williams, P.C. Implementation of Near-Infrared technology. In Near Infrared Technology in the Agricultural and Food Industries; Williams, P.C., Norris, K.H., Eds.; American Association of Cereal Chemist: St. Paul, MN, USA, 2011; pp. 145–169. [Google Scholar]
- Williams, P.; Dardenne, P.; Flinn, P. Tutorial: Items to be included in a report on a near infrared spectroscopy project. J. Near Infrared Spectrosc. 2017, 25, 85–90. [Google Scholar] [CrossRef]
- Badertscher, M.; Pretsch, E. Bad results from good data. Trends Anal. Chem. 2006, 25, 1131–1138. [Google Scholar] [CrossRef]
- Kjeldahl, K.; Bro, R. Some common misunderstandings in chemometrics. J. Chemom. 2010, 24, 558–564. [Google Scholar] [CrossRef]



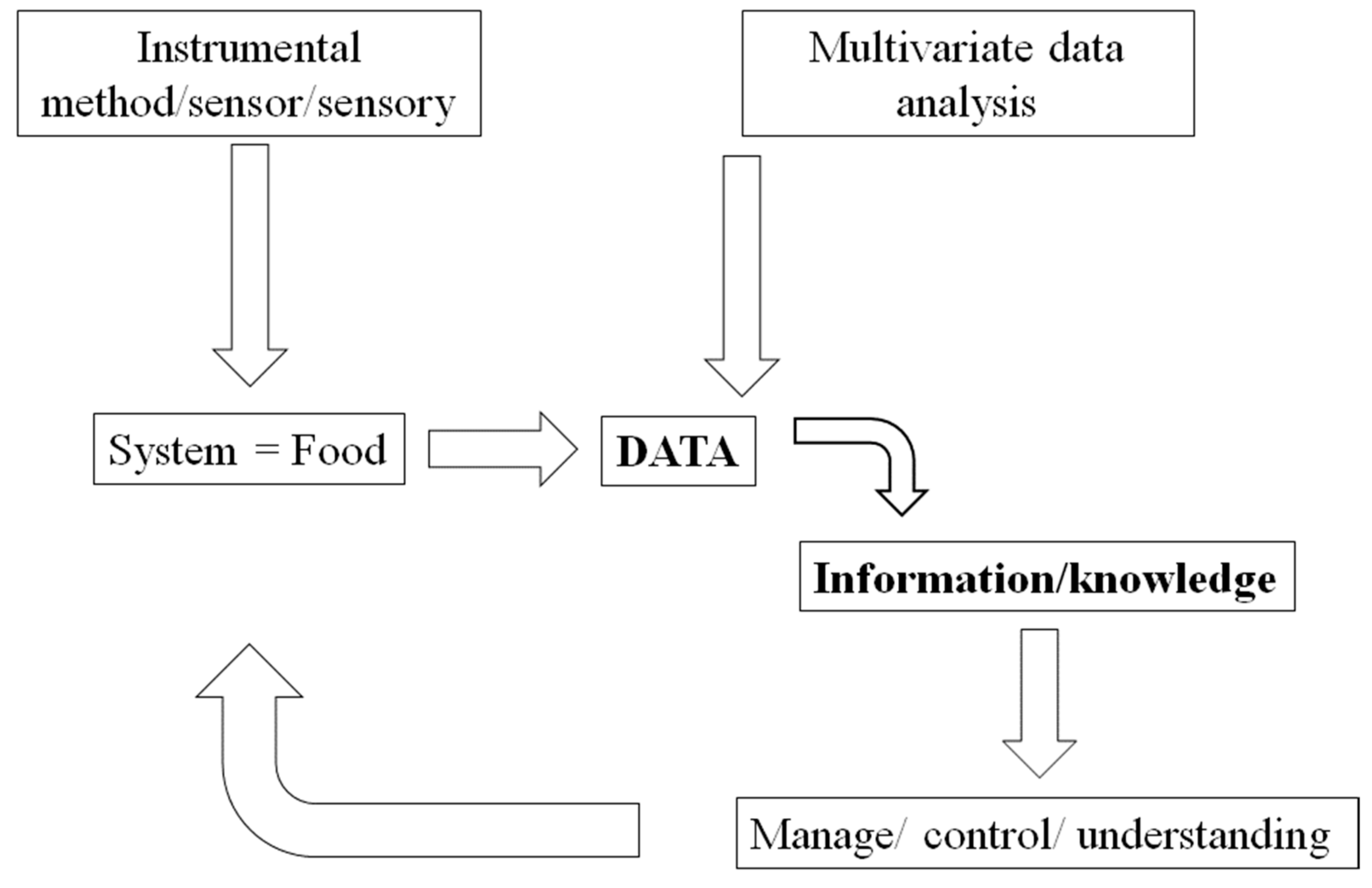{kind=link}
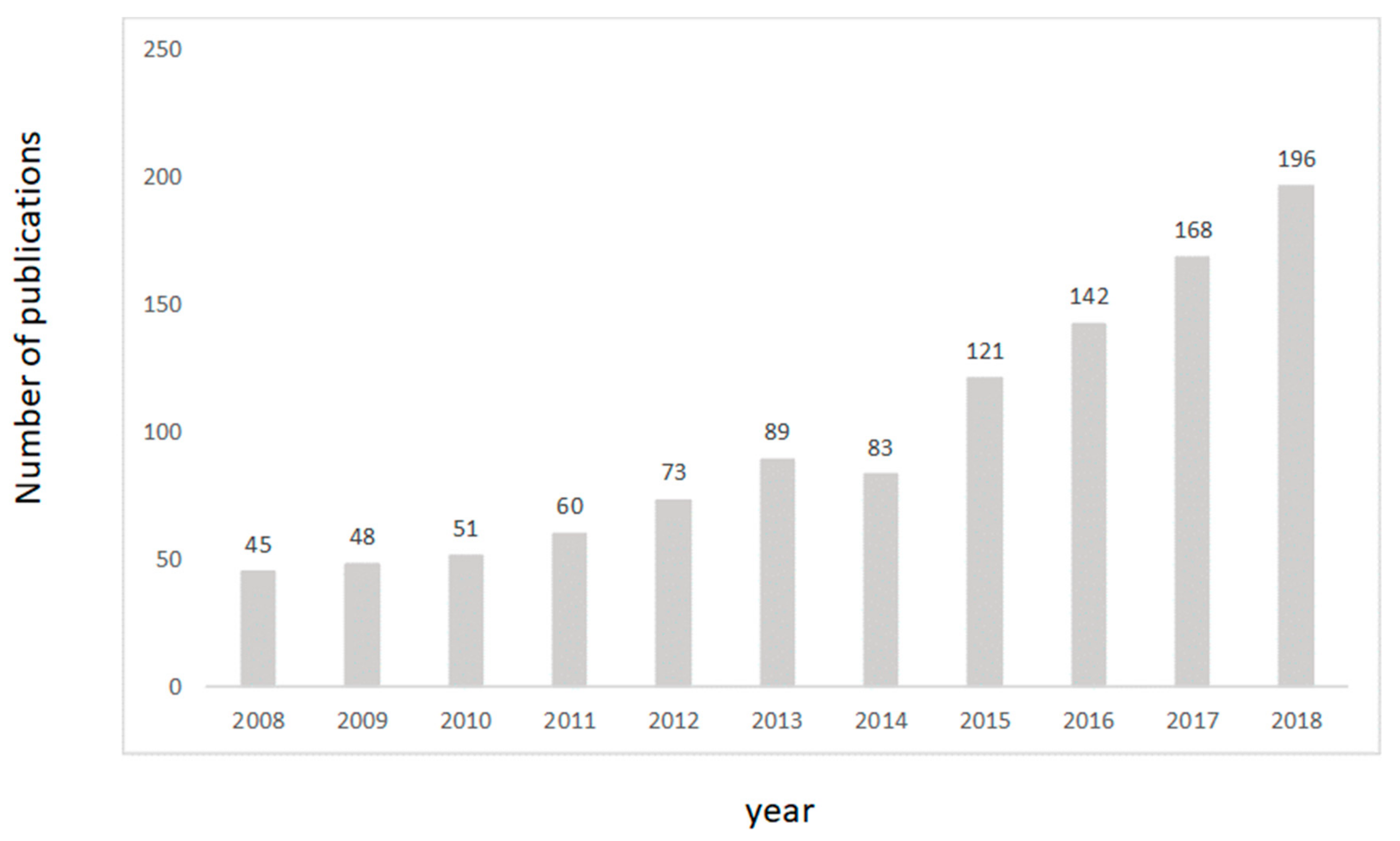{kind=link}
| Algorithm | Acronym | Application/s | Reference |
|---|---|---|---|
| Multiple Linear Regression | MLR | Calibration/modelling/prediction | [20,21,22,23,24,25,30] |
| Partial Least Squares | PLS | ||
| Principal Component Regression | PCR | ||
| Discriminant Analysis | DA | Classification | [20,21,22,23,24,25] |
| Cluster Analysis | CA | Classification | [20,21,22,23,24,25] |
| Partial Least Squares-Discriminant Analysis | PLS-DA | Classification | [20,21,22,23,24,25,30] |
| Linear Discriminant Analysis | LDA | Classification | [20,21,22,23,24,25,30] |
| Soft Independent Modelling of Class Analogies | SIMCA | Classification based in PCA | [20,21,22,23,24,25,30] |
| Principal Component Analysis | PCA | Outlier detection | [31] |
| Data visualization/inspection | |||
| Revealing relationships (e.g., between variables, between samples) | |||
| Finding patterns |
| Common Drawbacks and Mistakes |
|---|
| Lack of understanding of the chemometric tools (e.g., background, limitations of the method) |
| Diverse type of algorithms and pre-processing techniques (e.g., improper selection of the appropriate tool for the task) |
| Lack of the fundamentals and information required to interpret the results |
| Incorrect use or sampling protocol |
| Lack or inappropriate experimental design |
| Inappropriate sample selection (e.g., number of samples, source) |
| Validation (e.g., cross-validation versus independent validation) |
| Issues reporting results (e.g., no information about the laboratory error associated with the reference method; Inconsistencies in reporting errors) |
| Lack or minimal training/education |
| Easy access to hardware and software |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Truong, V.K.; Dupont, M.; Elbourne, A.; Gangadoo, S.; Rajapaksha Pathirannahalage, P.; Cheeseman, S.; Chapman, J.; Cozzolino, D. From Academia to Reality Check: A Theoretical Framework on the Use of Chemometric in Food Sciences. Foods 2019, 8, 164. https://doi.org/10.3390/foods8050164
Truong VK, Dupont M, Elbourne A, Gangadoo S, Rajapaksha Pathirannahalage P, Cheeseman S, Chapman J, Cozzolino D. From Academia to Reality Check: A Theoretical Framework on the Use of Chemometric in Food Sciences. Foods. 2019; 8(5):164. https://doi.org/10.3390/foods8050164
Chicago/Turabian StyleTruong, Vi Khanh, Madeleine Dupont, Aaron Elbourne, Sheeana Gangadoo, Piumie Rajapaksha Pathirannahalage, Samuel Cheeseman, James Chapman, and Daniel Cozzolino. 2019. "From Academia to Reality Check: A Theoretical Framework on the Use of Chemometric in Food Sciences" Foods 8, no. 5: 164. https://doi.org/10.3390/foods8050164
APA StyleTruong, V. K., Dupont, M., Elbourne, A., Gangadoo, S., Rajapaksha Pathirannahalage, P., Cheeseman, S., Chapman, J., & Cozzolino, D. (2019). From Academia to Reality Check: A Theoretical Framework on the Use of Chemometric in Food Sciences. Foods, 8(5), 164. https://doi.org/10.3390/foods8050164