

Prediction and Visual Analysis of Food Safety Risk Based on TabNet-GRA

Abstract
:1. Introduction
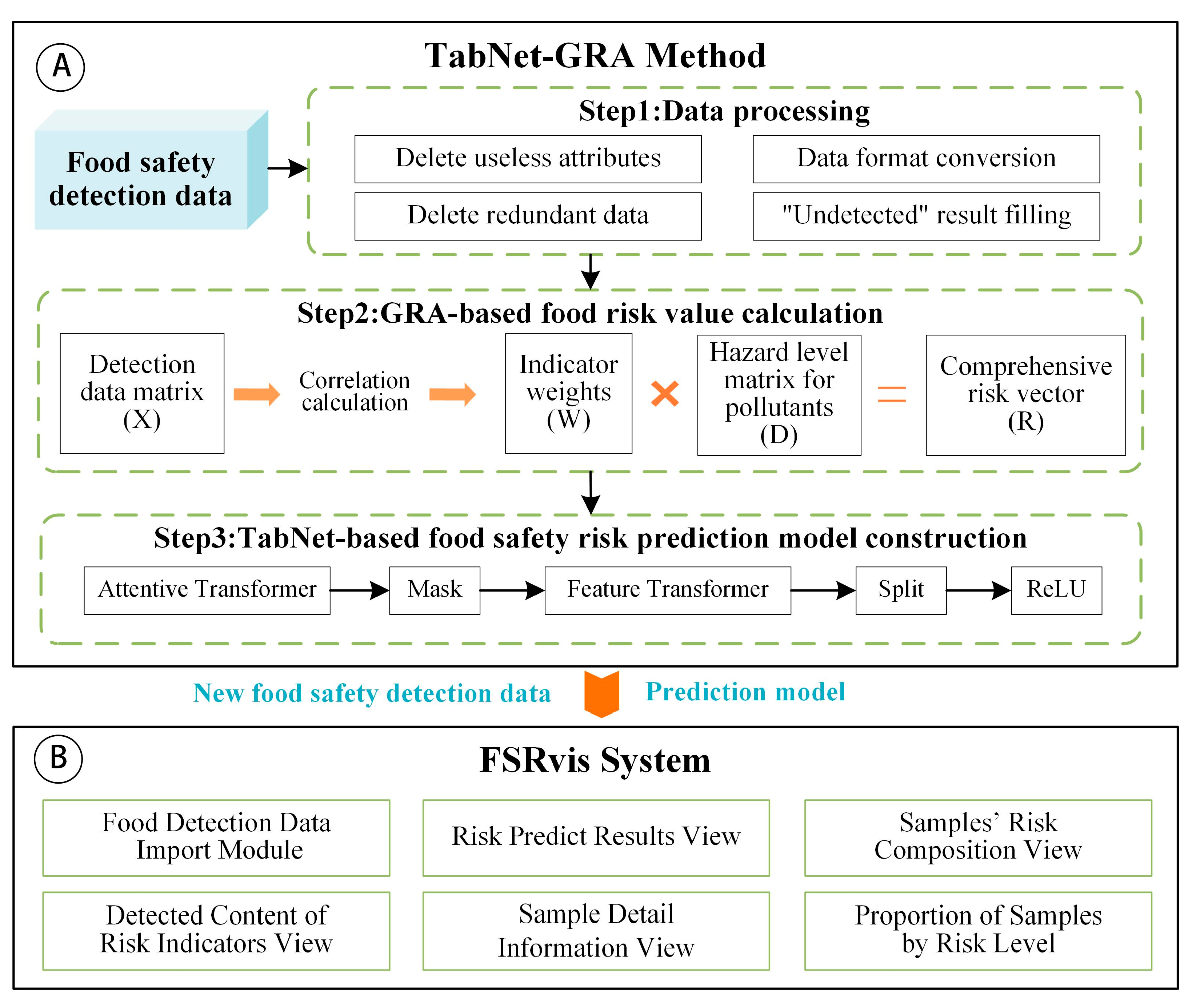
2. The Framework of TabNet-GRA Method and FSRvis System
3. The TabNet-GRA Method
3.1. The Pipeline of TabNet-GRA Method
3.2. The GRA-Based Food Risk Quantitative Assessment
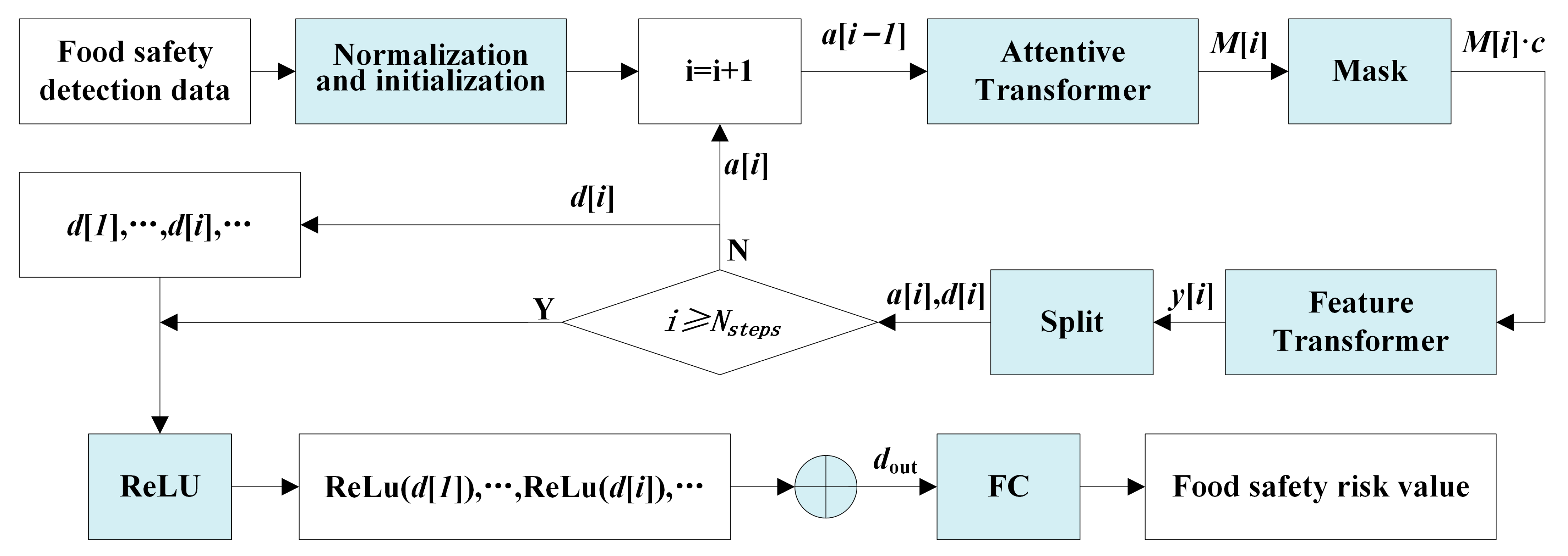
3.3. The TabNet-Based Food Safety Risk Prediction Model
4. Case Study and Model Evaluation
4.1. Data Preprocessing
4.2. Calculating the Comprehensive Risk Value
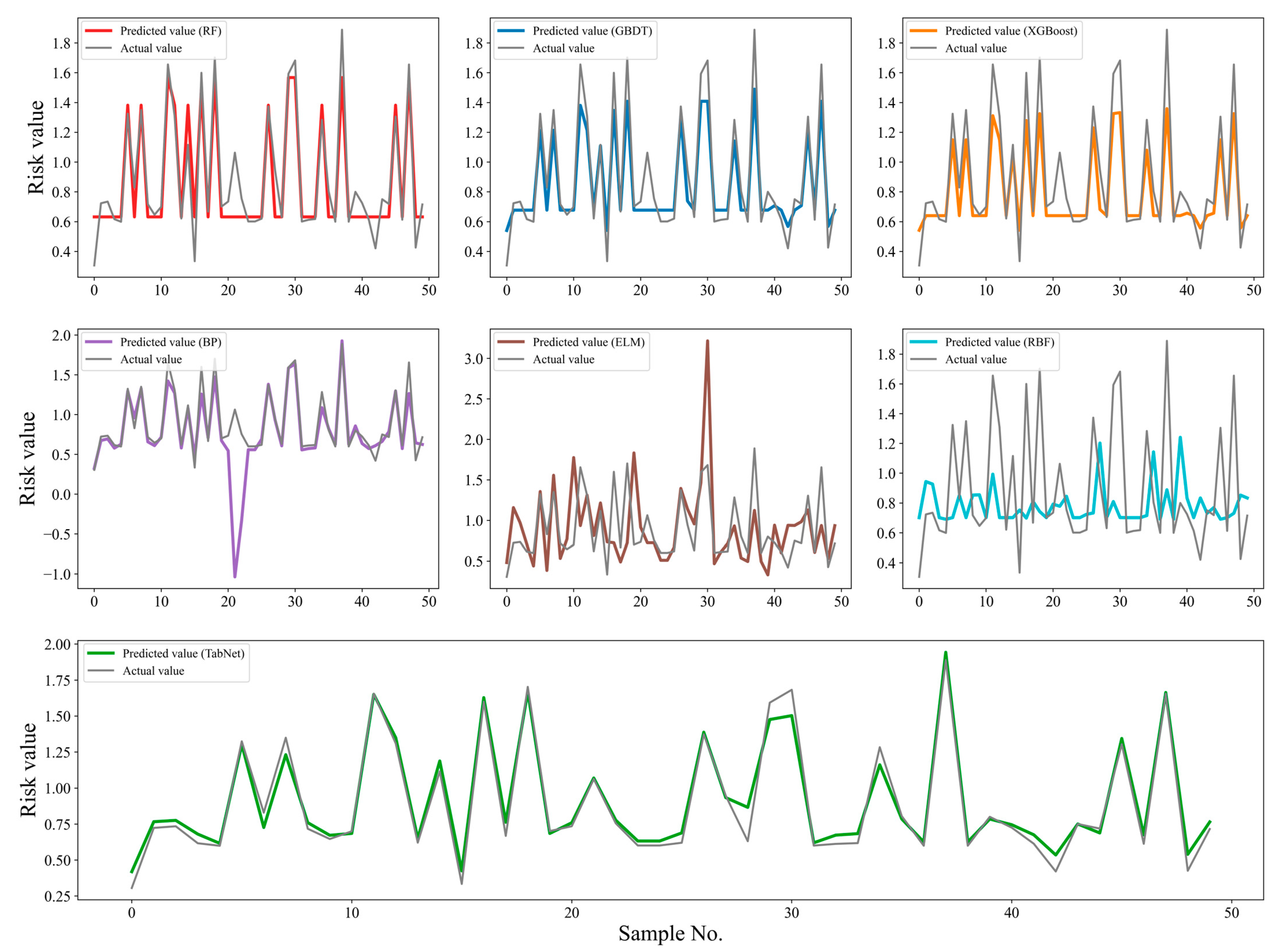
4.3. Model Construction and Evaluation
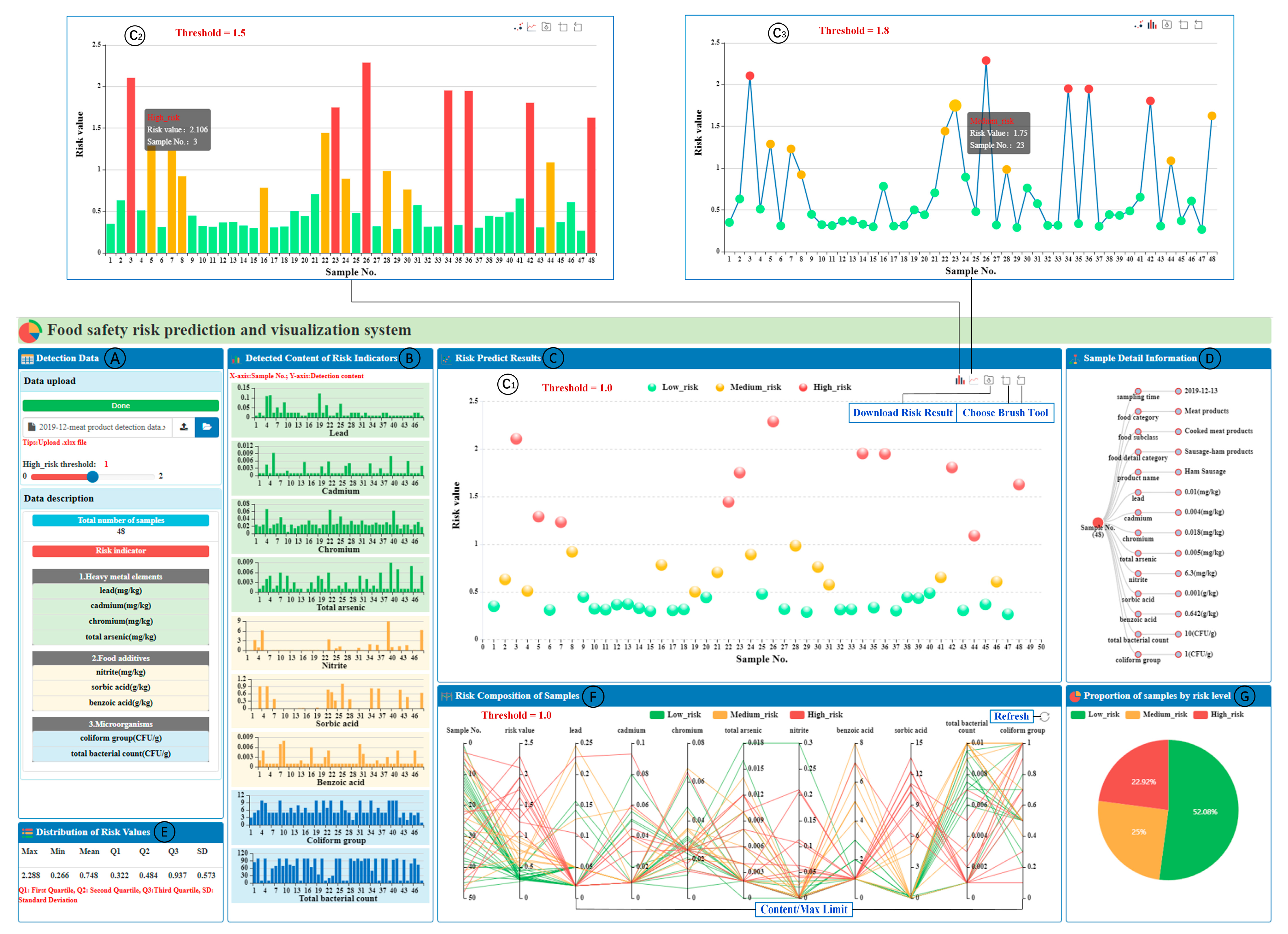
5. FSRvis System
6. Discussion
7. Conclusions and Future Work
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fukuda, K. Food safety in a globalized world. Bull. World Health Organ. 2015, 93, 212. [Google Scholar] [CrossRef]
- Wang, X.; Bouzembrak, Y.; Lansink, A.O.; van der Fels-Klerx, H.J. Application of machine learning to the monitoring and prediction of food safety: A review. Compr. Rev. Food. Sci. Saf. 2022, 21, 416–434. [Google Scholar] [CrossRef]
- World Health Organization (WHO). Food Safety. Available online: https://www.who.int/health-topics/food-safety (accessed on 15 March 2023).
- Liu, Z.; Meng, L.Y.; Zhao, W.; Yu, F.Q. Application of ANN in food safety early warning. In Proceedings of the 2010 2nd International Conference on Future Computer and Communication, Wuhan, China, 21–24 May 2010; IEEE: Piscataway, NJ, USA, 2010; Volume 3, pp. V3-677–V3-680. [Google Scholar] [CrossRef]
- Marvin, H.J.P.; Janssen, E.M.; Bouzembrak, Y.; Hendriksen, P.J.M.; Staats, M. Big data in food safety: An overview. Crit. Rev. Food Sci. Nutr. 2017, 57, 2286–2295. [Google Scholar] [CrossRef]
- Nogales, A.; Díaz-Morón, R.; García-Tejedor, Á.J. A comparison of neural and non-neural machine learning models for food safety risk prediction with European Union RASFF data. Food Control 2022, 134, 108697. [Google Scholar] [CrossRef]
- Bouzembrak, Y.; Marvin, H.J.P. Impact of drivers of change, including climatic factors, on the occurrence of chemical food safety hazards in fruits and vegetables: A Bayesian Network approach. Food Control 2019, 97, 67–76. [Google Scholar] [CrossRef]
- Ru, G.; Crescio, M.I.; Ingravalle, F.; Maurella, C. Machine Learning Techniques applied in risk assessment related to food safety. EFSA Support. Publ. 2017, 14, 1254E. [Google Scholar] [CrossRef]
- Liu, Y.H.; Qu, Y.; Jiang, J.M.; Zong, W.L.; Zhu, X.J. Prediction of unqualified index of food inspection based on optimized random forest algorithm. J. Food Saf. Qual. 2021, 12, 7467–7472. [Google Scholar] [CrossRef]
- Gao, Y.N.; Wang, W.Q.; Wang, J.X. A Food Safety Risk Prewarning Model Using LightGBM Integrated with Fuzzy Hierarchy Partition: A Case Study for Meat Products. Food Sci. 2021, 42, 197–207. [Google Scholar] [CrossRef]
- Wang, X.Y.; Wang, Z.Y.; Zhao, Z.Y.; Zhang, X.; Chen, Q.; Li, F. A food safety risk forecast model integrated with improved AHP and XGBoost algorithm: A case study of rice. J. Food Sci. Technol. 2022, 40, 150–158. [Google Scholar] [CrossRef]
- Geng, Z.Q.; Zhao, S.S.; Tao, G.C.; Han, Y.M. Early warning modeling and analysis based on analytic hierarchy process integrated extreme learning machine (AHP-ELM): Application to food safety. Food Control 2017, 78, 33–42. [Google Scholar] [CrossRef]
- Geng, Z.Q.; Liu, F.F.; Shang, D.R.; Han, Y.M.; Shang, Y.; Chu, C. Early warning and control of food safety risk using an improved AHC-RBF neural network integrating AHP-EW. J. Food Eng. 2021, 292, 110239. [Google Scholar] [CrossRef]
- Geng, Z.Q.; Shang, D.R.; Han, Y.M.; Zhong, Y.H. Early warning modeling and analysis based on a deep radial basis function neural network integrating an analytic hierarchy process: A case study for food safety. Food Control 2018, 96, 329–342. [Google Scholar] [CrossRef]
- Niu, B.; Zhang, H.; Zhou, G.Y.; Zhang, S.W.; Yang, Y.F.; Deng, X.J.; Chen, Q. Safety risk assessment and early warning of chemical contamination in vegetable oil. Food Control 2021, 125, 107970. [Google Scholar] [CrossRef]
- Xie, T.T.; Yu, H.; Wilamowski, B. Comparison between traditional neural networks and radial basis function networks. In Proceedings of the 2011 IEEE International Symposium on Industrial Electronics (ISIE 2011), Gdansk, Poland, 27–30 June 2011; pp. 1194–1199. [Google Scholar] [CrossRef]
- Arik, S.Ö.; Pfister, T. TabNet: Attentive Interpretable Tabular Learning. AAAI Conf. Artif. Intell. 2021, 35, 6679–6687. [Google Scholar] [CrossRef]
- Khalili, E.; Ramazi, S.; Ghanati, F.; Kouchaki, S. Predicting protein phosphorylation sites in soybean using interpretable deep tabular learning network. Brief. Bioinform. 2022, 23, bbac015. [Google Scholar] [CrossRef] [PubMed]
- Yan, J.Z.; Xu, T.Y.; Yu, Y.C.; Xu, H.X. Rainfall Forecast Model Based on the TabNet Model. Water 2021, 13, 1272. [Google Scholar] [CrossRef]
- Wang, W.; Wu, P.; Zhao, X. Soil infiltration based on BP neural network and grey relational analysis. Rev. Bras. De Ciência Do Solo 2013, 37, 97–105. [Google Scholar] [CrossRef]
- Liu, S.; Cai, H.; Yang, Y.; Cao, Y. Research progress of grey relational analysis model. Syst. Eng. Theory Pract. 2013, 33, 2041–2046. [Google Scholar] [CrossRef]
- Han, Y.M.; Cui, S.Y.; Geng, Z.Q.; Chu, C.; Chen, K.; Wang, Y.J. Food quality and safety risk assessment using a novel HMM method based on GRA. Food Control 2019, 105, 180–189. [Google Scholar] [CrossRef]
- Lin, X.Y.; Cui, S.Y.; Han, Y.M.; Geng, Z.Q.; Zhong, Y.H. An improved ISM method based on GRA for hierarchical analyzing the influencing factors of food safety. Food Control 2018, 99, 48–56. [Google Scholar] [CrossRef]
- Liu, M.C.; Shi, J.X.; Li, Z.; Li, C.X.; Zhu, J.; Liu, S.X. Towards Better Analysis of Deep Convolutional Neural Networks. IEEE Trans. Vis. Comput. Graph. 2017, 23, 91–100. [Google Scholar] [CrossRef] [PubMed]
- Yuan, J.; Chen, C.J.; Yang, W.K.; Liu, M.C.; Xia, J.Z.; Liu, S.X. A survey of visual analytics techniques for machine learning. Comput. Vis. Media 2021, 7, 3–36. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, Q.H.; Guan, Z.L.; Zhao, Y.; Chen, W. GEMvis: A visual analysis method for the comparison and refinement of graph embedding models. Vis. Comput. 2022, 38, 3449–3462. [Google Scholar] [CrossRef]
- Wu, C.X.; Chen, Y.; Dong, Y.; Zhou, F.F.; Zhao, Y.; Liang, C.J. VizOPTICS: Getting insights into OPTICS via interactive visual analysis. Comput. Electr. Eng. 2023, 107, 108624. [Google Scholar] [CrossRef]
- Chen, Y.; Dou, H.; Chang, Q.; Fan, C. PRIAS: An Intelligent Analysis System for Pesticide Residue Detection Data and Its Application in Food Safety Supervision. Foods 2022, 11, 780. [Google Scholar] [CrossRef]
- Chen, Y.; Lv, C.; Li, Y.; Chen, W.; MA, K.L. Ordered matrix representation supporting the visual analysis of associated data. Sci. China Inf. Sci. 2020, 63, 184101. [Google Scholar] [CrossRef]
- Luo, Z.; Chen, Y.; Li, H.; Li, Y.; Guo, Y. TreeMerge: A Visual Comparative Analysis Method for Food Classification Tree in Pesticide Residue Maximum Limit Standards. Agronomy 2022, 12, 3148. [Google Scholar] [CrossRef]
- Chen, Y.; Guo, Y.; Fan, Q.; Zhang, Q.; Dong, Y. Health-Aware Food Recommendation Based on Knowledge Graph and Multi-Task Learning. Foods 2023, 12, 2079. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, Y.; Sun, Y.; Liang, J. A Multi-comparable visual analytic approach for complex hierarchical data. J. Vis. Lang. Comput. 2018, 47, 19–30. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Sample No. | Sampling Time | Product Name | Detection Item | Detection Result | Maximum Limit | Standard Detection Limit | Unit |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 3 January 2018 | Duck in sauce | lead | 0.0425 | 0.5 | 0.05 | mg/kg |
| 2 | 2 | 3 January 2018 | Beef Jerky | chromium | 0.3570 | 1.0 | 0.03 | mg/kg |
| 3 | 3 | 3 January 2018 | Ham Sausage | nitrite | 4.2 | 30 | 0.2 | mg/kg |
| 4 | 3 | 3 January 2018 | Ham Sausage | sorbic acid | 0.86 | 0.075 | 0.01 | g/kg |
| 5 | 4 | 31 January 2018 | Bacon | benzoic acid | <0.005 | shall not be used | 0.005 | g/kg |
| 6 | 4 | 31 January 2018 | Bacon | cadmium | <0.008 | 0.1 | 0.003 | mg/kg |
| 7 | 5 | 4 February 2018 | Roasted leg with sauce | total bacterial count | 80; 70; 90; 50; 180 | 10,000 | / | CFU/g |
| 8 | 5 | 4 February 2018 | Roasted leg with sauce | total arsenic | Not Detected | 0.5 | 0.04 | mg/kg |
| 9 | 5 | 4 February 2018 | Roasted leg with sauce | coliform group | <10 | 10 | / | CFU/g |
| Sample No. | Lead | Cadmium | Chromium | Total Arsenic | Nitrite | Benzoic Acid | Sorbic Acid | Total Bacterial Count | Coliform Group |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0425 | 0.0025 | 0.0522 | 0.0010 | 9.600 | 0.0050 | 0.0050 | 100 | 5 |
| 2 | 0.1270 | 0.0090 | 0.3570 | 0.0450 | 0.001 | 0.0025 | 0.0050 | 85 | 10 |
| 3 | 0.0744 | 0.0057 | 0.1400 | 0.0640 | 4.200 | 0.0100 | 0.8600 | 10 | 0 |
| 4 | 0.0806 | 0.0080 | 0.4180 | 0.0875 | 3.100 | 0.0050 | 0.0050 | 100 | 5 |
| 5 | 0.0332 | 0.0015 | 0.0250 | 0.0200 | 0.100 | 0.0025 | 0.0050 | 180 | 10 |
| 6 | 0.2440 | 0.0115 | 0.7680 | 0.0111 | 6.100 | 0.0050 | 0.0050 | 100 | 5 |
| 7 | 0.1720 | 0.0015 | 0.0580 | 0.0010 | 20.00 | 0.0025 | 0.0405 | 10 | 0 |
| 8 | 0.0500 | 0.0050 | 0.2000 | 0.0400 | 4.160 | 0.0100 | 0.0050 | 70 | 10 |
| 9 | 0.0611 | 0.0015 | 0.0250 | 0.0370 | 0.100 | 0.0025 | 0.0232 | 200 | 10 |
| 10 | 0.1300 | 0.0094 | 0.0990 | 0.0010 | 5.400 | 0.1000 | 0.0050 | 100 | 5 |
| Indicator | Lead | Cadmium | Chromium | Total Arsenic | Nitrite | Benzoic Acid | Sorbic Acid | Total Bacterial Count | Coliform Group |
|---|---|---|---|---|---|---|---|---|---|
| Weight | 0.0950 | 0.1153 | 0.1080 | 0.1122 | 0.1138 | 0.1167 | 0.1073 | 0.1155 | 0.1162 |
| Sample No. | 1 | 2 | 3 | 4 | 5 | 6 | … | 7885 |
|---|---|---|---|---|---|---|---|---|
| Risk value | 0.6131 | 0.7433 | 1.5476 | 0.3113 | 0.6040 | 1.3979 | … | 0.5988 |
| Parameter | Description | Value |
|---|---|---|
| N_d | Width of the decision prediction layer | 8 |
| N_a | Width of the attention embedding for each mask | 8 |
| N_steps | Number of steps in the architecture | 3 |
| Lr | Learning rate | 0.01 |
| Max_epochs | Maximum number of epochs for training | 1000 |
| Batch_size | Number of examples per batch | 7835 |
| Virtual_batch_size | Size of the mini batches used for “GBN” | 128 |
| Optimizer_fn | Pytorch optimizer function | Adam |
| RF | GBDT | XGBoost | BP | ELM | RBF | TabNet | |
|---|---|---|---|---|---|---|---|
| 0.1435 | 0.1485 | 0.1842 | 0.3532 | 0.4533 | 0.4362 | 0.0710 | |
| 0.1038 | 0.1147 | 0.1376 | 0.1385 | 0.3088 | 0.3217 | 0.0532 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Li, H.; Dou, H.; Wen, H.; Dong, Y. Prediction and Visual Analysis of Food Safety Risk Based on TabNet-GRA. Foods 2023, 12, 3113. https://doi.org/10.3390/foods12163113
Chen Y, Li H, Dou H, Wen H, Dong Y. Prediction and Visual Analysis of Food Safety Risk Based on TabNet-GRA. Foods. 2023; 12(16):3113. https://doi.org/10.3390/foods12163113
Chicago/Turabian StyleChen, Yi, Hanqiang Li, Haifeng Dou, Hong Wen, and Yu Dong. 2023. "Prediction and Visual Analysis of Food Safety Risk Based on TabNet-GRA" Foods 12, no. 16: 3113. https://doi.org/10.3390/foods12163113
APA StyleChen, Y., Li, H., Dou, H., Wen, H., & Dong, Y. (2023). Prediction and Visual Analysis of Food Safety Risk Based on TabNet-GRA. Foods, 12(16), 3113. https://doi.org/10.3390/foods12163113