
Detection and Quantification of Botanical Impurities in Commercial Oregano (Origanum vulgare) Using Metabarcoding and Digital PCR
 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Samples
2.2. DNA Extraction
2.3. PCR Primers
- Oregano (Origanum vulgare) primers (Orvu EF1 F/R) target the gene for Elongation factor 1, and were adopted from [23]. A matching probe was developed in house.
- Olive tree (Olea europaea)-specific primers (Oleu SADbis F/R) were designed in house and target the Stearoyl-acyl carrier protein desaturase gene (SAD1), which is associated with the oleic acid composition of olives [24].
- White goosefoot (Chenopodium album) primers (Chal pc-1E1p1 F/R) were designed in house and target the phosphoenolpyruvate carboxylase (ppc-1E1) gene (KJ161681.1), a key enzyme of both the CAM and C4 pathways [25].
- Bindweed (Convolvulus arvensis) primers (Coar HSSp2 F/R) were designed in house and target the phi1 Homospermidine synthase (HSS) pseudogene (HF911513.1) [26].
- Myrtle (Myrtus communis) primers (MyrtusP1 F/R) were designed in house and target an isoprene synthase gene.
- Cistus (Cistus incanus) primers (Cistus S13593 F/R) were designed in house and target a geranylgeranyl pyrophosphate synthase (GGPPS1) gene.
2.4. PCR Methods
2.5. ddPCR-Based Quantification
2.6. Sequencing and Metabarcoding
2.7. Data Processing
3. Results and Discussion
3.1. Workflow
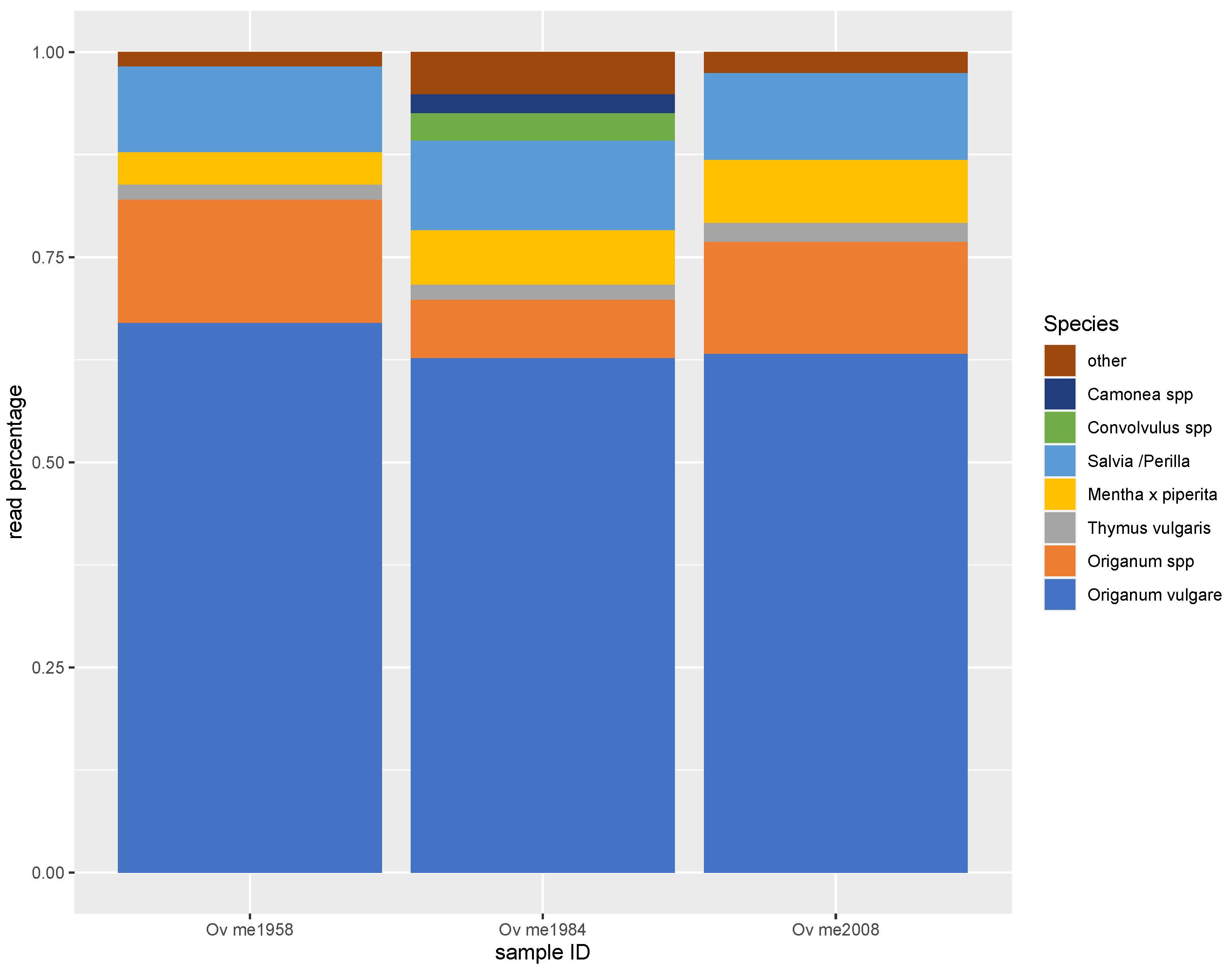
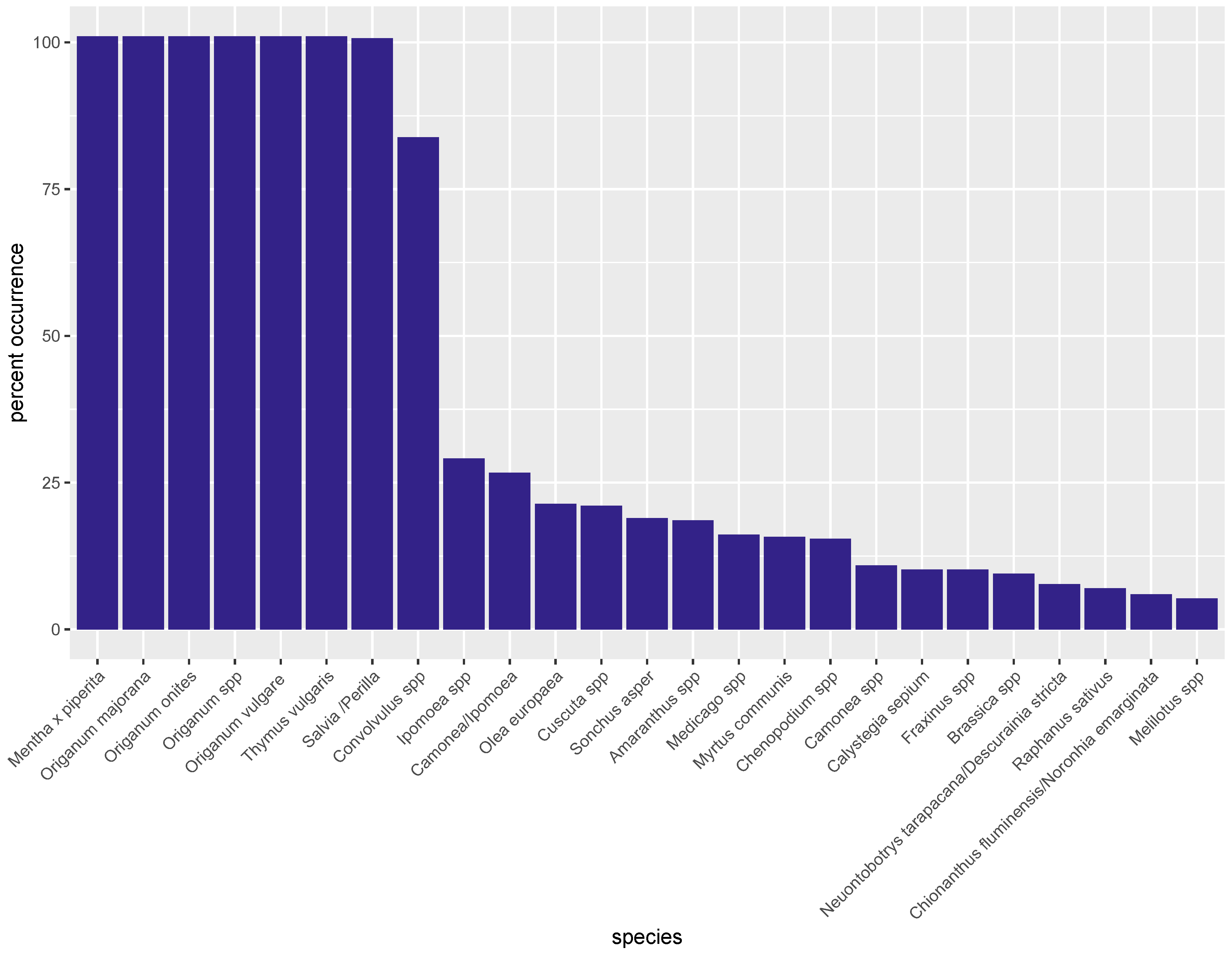
3.2. Metabarcoding by NGS
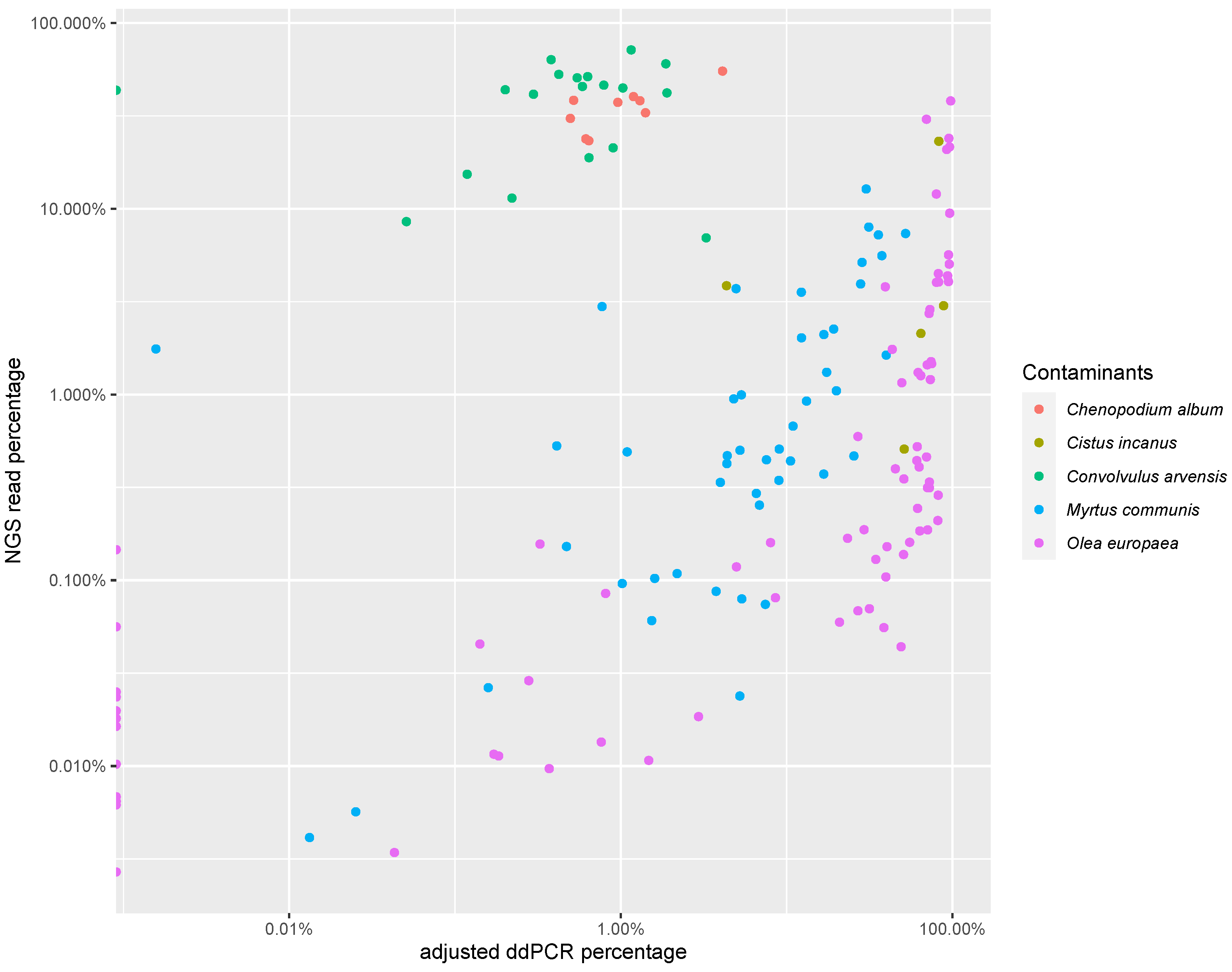
3.3. PCR-Based Quantification
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BLAST | Basic Local Alignment Search Tool |
| CBOL | Consortium for the Barcode of Life |
| CTAB | Cetyl-Trimethyl-Ammonium Bromide |
| DNA | DeoxyriboNucleic Acid |
| ESA | European Spice Association |
| ISO | International Organization for Standardization |
| NCBI | National Center for Biotechnology Information |
| NGS | Next Generation Sequencing |
| PCR | Polymerase Chain Reaction |
| ddPCR | Droplet digital PCR |
| qPCR | Quantitative PCR (real-time PCR) |
| RAPD | Random Amplification of Polymorphic DNA |
| SCAR | Sequence-Characterized Amplified Region |
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Sample | Species | READ % | ddPCR % | Sample | Species | READ % | ddPCR % |
|---|---|---|---|---|---|---|---|
| SH00033 | C. album | 37.41 | 0.96 | SH00726 | M. communis | 0.44 | 10.56 |
| SH00047 | C. album | 38.19 | 1.3 | SH00037 | O. europaea | 0.19 | 70.81 |
| SH00052 | C. album | 38.39 | 0.52 | SH00039 | O. europaea | 4.06 | 94.56 |
| SH00061 | C. album | 55.1 | 4.1 | SH00061 | O. europaea | 0.03 | 0.28 |
| SH00092 | C. album | 40.16 | 1.19 | SH00088 | O. europaea | 0.01 | 1.47 |
| SH00098 | C. album | 32.88 | 1.41 | SH00126 | O. europaea | 0.01 | 0.37 |
| SH00131 | C. album | 23.25 | 0.64 | SH00131 | O. europaea | 0.04 | 48.99 |
| SH00207 | C. album | 30.66 | 0.5 | SH00132 | O. europaea | 0.18 | 63.54 |
| SH00519 | C. album | 23.8 | 0.61 | SH00135 | O. europaea | 0.06 | 38.58 |
| SH01166 | C. incanus | 0.51 | 51.19 | SH00207 | O. europaea | 1.2 | 73.56 |
| SH01371 | C. incanus | 2.13 | 64.48 | SH00241 | O. europaea | 0.31 | 72.55 |
| SH01433 | C. incanus | 3.86 | 4.34 | SH00243 | O. europaea | 1.44 | 70.44 |
| SH01661 | C. incanus | 23.1 | 82.76 | SH00248 | O. europaea | 23.95 | 95.10 |
| SH01844 | C. incanus | 3.01 | 88.4 | SH00256 | O. europaea | 0.13 | 34.47 |
| SH00052 | C. arvensis | 8.53 | 0.05 | SH00262 | O. europaea | 0.16 | 55.21 |
| SH00059 | C. arvensis | 21.29 | 0.9 | SH00280 | O. europaea | 0.32 | 70.65 |
| SH00072 | C. arvensis | 43.73 | 0.2 | SH00281 | O. europaea | 20.85 | 92.33 |
| SH00098 | C. arvensis | 11.42 | 0.22 | SH00289 | O. europaea | 1.75 | 43.32 |
| SH00131 | C. arvensis | 6.97 | 3.27 | SH00291 | O. europaea | 0.14 | 50.70 |
| SH00135 | C. arvensis | 41.37 | 0.3 | SH00349 | O. europaea | 0.46 | 69.74 |
| SH00137 | C. arvensis | 43.48 | <LOQ | SH00416 | O. europaea | 0.003 | <LOQ |
| SH00162 | C. arvensis | 46.32 | 0.79 | SH00495 | O. europaea | 12.01 | 79.95 |
| SH00180 | C. arvensis | 42.07 | 1.9 | SH00518 | O. europaea | 1.16 | 49.46 |
| SH00236 | C. arvensis | 63.53 | 0.38 | SH00519 | O. europaea | 0.12 | 4.98 |
| SH00243 | C. arvensis | 52.89 | 0.42 | SH00523 | O. europaea | 0.35 | 50.95 |
| SH00321 | C. arvensis | 51.47 | 0.63 | SH00539 | O. europaea | 0.19 | 29.30 |
| SH00350 | C. arvensis | 60.32 | 1.87 | SH00550 | O. europaea | 2.87 | 73.14 |
| SH00387 | C. arvensis | 18.84 | 0.64 | SH00561 | O. europaea | 0.4 | 45.25 |
| SH00519 | C. arvensis | 15.35 | 0.12 | SH00573 | O. europaea | 0.16 | 8.00 |
| SH00637 | C. arvensis | 71.65 | 1.15 | SH00662 | O. europaea | 0.08 | 8.55 |
| SH00657 | C. arvensis | 50.72 | 0.55 | SH00723 | O. europaea | 4.03 | 82.45 |
| SH00935 | C. arvensis | 44.71 | 1.03 | SH00725 | O. europaea | 0.21 | 81.61 |
| SH01866 | C. arvensis | 45.55 | 0.59 | SH00726 | O. europaea | 0.24 | 61.60 |
| SH00037 | M. communis | 0.09 | 3.75 | SH00743 | O. europaea | 0.29 | 82.04 |
| SH00039 | M. communis | 1.63 | 39.86 | SH00798 | O. europaea | 5.04 | 95.67 |
| SH00061 | M. communis | 0 | 0.01 | SH00804 | O. europaea | 38.1 | 97.56 |
| SH00135 | M. communis | 0.02 | 5.22 | SH00869 | O. europaea | 0.05 | 0.14 |
| SH00137 | M. communis | 0.5 | 5.23 | SH00874 | O. europaea | 1.47 | 74.87 |
| SH00241 | M. communis | 3.71 | 4.95 | SH00913 | O. europaea | 0.06 | 20.84 |
| SH00248 | M. communis | 5.59 | 37.51 | SH00935 | O. europaea | 0.15 | 40.30 |
| SH00262 | M. communis | 0.1 | 1.02 | SH00946 | O. europaea | 0.44 | 60.95 |
| SH00309 | M. communis | 2.25 | 19.2 | SH00992 | O. europaea | 9.47 | 96.22 |
| SH00349 | M. communis | 1.32 | 17.43 | SH00995 | O. europaea | 4.48 | 82.22 |
| SH00350 | M. communis | 0.35 | 8.97 | SH01111 | O. europaea | 2.73 | 72.35 |
| SH00351 | M. communis | 0.42 | 4.36 | SH01119 | O. europaea | 0.02 | <LOQ |
| SH00499 | M. communis | 0.95 | 4.79 | SH01166 | O. europaea | 21.51 | 96.00 |
| SH00504 | M. communis | 0.51 | 9.02 | SH01167 | O. europaea | 1.26 | 64.40 |
| SH00519 | M. communis | 0.11 | 2.18 | SH01239 | O. europaea | 0.1 | 39.69 |
| SH00523 | M. communis | 0.92 | 13.18 | SH01267 | O. europaea | 0.01 | 0.76 |
| SH00637 | M. communis | 0.07 | 7.44 | SH01302 | O. europaea | 5.65 | 94.64 |
| SH00725 | M. communis | 7.97 | 31.28 | SH01307 | O. europaea | 1.31 | 62.07 |
| SH00743 | M. communis | 3.94 | 27.94 | SH01323 | O. europaea | 0.01 | 0.17 |
| SH00804 | M. communis | 0.47 | 25.43 | SH01324 | O. europaea | 0.02 | <LOQ |
| SH00874 | M. communis | 2.1 | 16.77 | SH01335 | O. europaea | 4.35 | 93.51 |
| SH00913 | M. communis | 1 | 5.33 | SH01368 | O. europaea | 0 | 0.04 |
| SH00924 | M. communis | 0.29 | 6.56 | SH01396 | O. europaea | 0.02 | 2.94 |
| SH00926 | M. communis | 0.37 | 16.73 | SH01433 | O. europaea | 0.52 | 61.34 |
| SH00935 | M. communis | 0.06 | 1.53 | SH01467 | O. europaea | 0.07 | 31.57 |
| SH00946 | M. communis | 0.25 | 6.85 | SH01492 | O. europaea | 0.17 | 23.30 |
| SH00977 | M. communis | 1.05 | 19.95 | SH01508 | O. europaea | 0.41 | 62.99 |
| SH00992 | M. communis | 7.36 | 52.14 | SH01536 | O. europaea | 0.15 | <LOQ |
| SH01022 | M. communis | 0.08 | 5.36 | SH01560 | O. europaea | 0.02 | <LOQ |
| SH01119 | M. communis | 0.15 | 0.47 | SH01571 | O. europaea | 4.02 | 80.11 |
| SH01166 | M. communis | 7.24 | 35.74 | SH01574 | O. europaea | 1.5 | 74.30 |
| SH01167 | M. communis | 2.02 | 12.29 | SH01641 | O. europaea | 0.34 | 72.56 |
| SH01168 | M. communis | 0.45 | 7.55 | SH01656 | O. europaea | 3.8 | 39.35 |
| SH01169 | M. communis | 0.1 | 1.6 | SH01688 | O. europaea | 0.03 | <LOQ |
| SH01302 | M. communis | 5.15 | 28.49 | SH01698 | O. europaea | 0.01 | <LOQ |
| SH01307 | M. communis | 3.55 | 12.26 | SH01740 | O. europaea | 0.59 | 26.90 |
| SH01318 | M. communis | 1.76 | 0 | SH01749 | O. europaea | 0.06 | <LOQ |
| SH01335 | M. communis | 12.78 | 30.16 | SH01768 | O. europaea | 0.02 | <LOQ |
| SH01411 | M. communis | 0.01 | 0.03 | SH01795 | O. europaea | 0.01 | <LOQ |
| SH01433 | M. communis | 0.53 | 0.41 | SH01798 | O. europaea | 0.01 | <LOQ |
| SH01467 | M. communis | 0.47 | 4.38 | SH01825 | O. europaea | 0.16 | 0.33 |
| SH01492 | M. communis | 0.34 | 3.98 | SH01846 | O. europaea | 30.33 | 69.69 |
| SH01574 | M. communis | 0.49 | 1.09 | SH01865 | O. europaea | 0.01 | <LOQ |
| SH01641 | M. communis | 0.68 | 10.92 | SH01866 | O. europaea | 0.01 | 0.18 |
| SH01825 | M. communis | 2.98 | 0.77 | SH01883 | O. europaea | 0.08 | 0.81 |
| SH01866 | M. communis | 0.03 | 0.16 | SH01897 | O. europaea | 0.07 | 26.91 |
| Name | Probe (5-3) | Validated | Fluorophores | nM (F/R/P) |
|---|---|---|---|---|
| Orvu EF1 Probe | TGAAGTTCTCTGAGCTTCTGACGAA | qPCR, ddPCR | FAM-QSY | 300/300/300 |
| Olea SADbis Probe | TTGCCAAGGAACACGGGGAC | qPCR, ddPCR | VIC-QSY | 300/300/500 |
| Chal pc-1E1p1 probe | TATTGGAAGCCGTCCTGCAA | - | - | -/-/- |
| Coar HSSp2 Probe | TGGTGAGGCTATTCATGCCG | - | - | -/-/- |
| Myrtus isoprene Probe | ACTTGCCGCGACGAACTTCA | - | - | -/-/- |
| Cistus S13593 | GAGCACATGACGGGGTCCAC | - | - | -/-/- |
| Species | Orvu EF1 | Oleu SADbis | Chal pc-1E1p1 | Coar HSSp2 | Myrtus Isoprene | Cistus S13593 |
|---|---|---|---|---|---|---|
| O. vulgare | 20.03 | Undetermined | Undetermined | Undetermined | Undetermined | Undetermined |
| O. europaea | Undetermined | 20.47 | Undetermined | Undetermined | Undetermined | Undetermined |
| C. album | Undetermined | Undetermined | 21.41 | Undetermined | Undetermined | Undetermined |
| C. arvensis | Undetermined | Undetermined | Undetermined | 22.10 | Undetermined | Undetermined |
| M. communis | Undetermined | Undetermined | Undetermined | Undetermined | 19.98 | Undetermined |
| C. incanus | Undetermined | Undetermined | Undetermined | Undetermined | Undetermined | 20.17 |
References
- Dafni, A.; Böck, B. Medicinal plants of the Bible-revisited. J. Ethnobiol. Ethnomed. 2019, 15, 57. [Google Scholar] [CrossRef] [PubMed]
- Veenstra, J.P.; Johnson, J.J. Oregano (Origanum vulgare) extract for food preservation and improvement in gastrointestinal health. Int. J. Nutr. 2019, 3, 43–52. [Google Scholar] [CrossRef] [PubMed]
- ISO 7925:1999; Dried Oregano (Origanum vulgare L.) —Whole and Ground Leaves—Specification. Technical Report. International Organization for Standardization: Geneva, Switzerland, 1999.
- ISO 927:2009; Spices and Condiments—Determination of Extraneous Matter and Foreign Matter Content. Technical Report. International Organization for Standardization: Geneva, Switzerland, 2009.
- Mandrone, M.; Marincich, L.; Chiocchio, I.; Petroli, A.; Gođevac, D.; Maresca, I.; Poli, F. NMR-based metabolomics for frauds detection and quality control of oregano samples. Food Control 2021, 127, 108141. [Google Scholar] [CrossRef]
- McGrath, T.F.; Haughey, S.A.; Islam, M.; Elliott, C.T.; Kelly, S.; Suman, M.; Rindy, T.; Taous, F.; García-González, D.; Singh, D.; et al. The potential of handheld near infrared spectroscopy to detect food adulteration: Results of a global, multi-instrument inter-laboratory study. Food Chem. 2021, 353, 128718. [Google Scholar] [CrossRef] [PubMed]
- Black, C.; Haughey, S.A.; Chevallier, O.P.; Galvin-King, P.; Elliott, C.T. A comprehensive strategy to detect the fraudulent adulteration of herbs: The oregano approach. Food Chem. 2016, 210, 551–557. [Google Scholar] [CrossRef]
- Böhme, K.; Calo-Mata, P.; Barros-Velázquez, J.; Ortea, I. Review of Recent DNA-Based Methods for Main Food-Authentication Topics. J. Agric. Food Chem. 2019, 67, 3854–3864. [Google Scholar] [CrossRef]
- Corrado, G. Advances in DNA typing in the agro-food supply chain. Trends Food Sci. Technol. 2016, 52, 80–89. [Google Scholar] [CrossRef]
- Lo, Y.T.; Shaw, P.C. DNA-based techniques for authentication of processed food and food supplements. Food Chem. 2018, 240, 767–774. [Google Scholar] [CrossRef]
- Grazina, L.; Amaral, J.S.; Mafra, I. Botanical origin authentication of dietary supplements by DNA-based approaches. Compr. Rev. Food Sci. Food Saf. 2020, 19, 1080–1109. [Google Scholar] [CrossRef]
- Bayley, A. A Summary of Current DNA Methods for Herb and Spice Identification. J. AOAC Int. 2019, 102, 386–389. [Google Scholar] [CrossRef]
- Bruno, A.; Sandionigi, A.; Agostinetto, G.; Bernabovi, L.; Frigerio, J.; Casiraghi, M.; Labra, M. Food Tracking Perspective: DNA Metabarcoding to Identify Plant Composition in Complex and Processed Food Products. Genes 2019, 10, 248. [Google Scholar] [CrossRef]
- Reese, A.T.; Kartzinel, T.R.; Petrone, B.L.; Turnbaugh, P.J.; Pringle, R.M.; David, L.A. Using DNA Metabarcoding To Evaluate the Plant Component of Human Diets: A Proof of Concept. mSystems 2019, 4, e00458-19. [Google Scholar] [CrossRef] [PubMed]
- Parveen, I.; Gafner, S.; Techen, N.; Murch, S.; Khan, I. DNA Barcoding for the Identification of Botanicals in Herbal Medicine and Dietary Supplements: Strengths and Limitations. Planta Medica 2016, 82, 1225–1235. [Google Scholar] [CrossRef] [PubMed]
- Paracchini, V.; Petrillo, M.; Lievens, A.; Kagkli, D.M.; Angers-Loustau, A. Nuclear DNA barcodes for cod identification in mildly-treated and processed food products. Food Addit. Contam. Part A 2019, 36, 30633651. [Google Scholar] [CrossRef]
- Barbosa, C.; Nogueira, S.; Gadanho, M.; Chaves, S. Study on Commercial Spice and Herb Products Using Next-Generation Sequencing (NGS). J. AOAC Int. 2019, 102, 369–375. [Google Scholar] [CrossRef]
- Raclariu-Manolică, A.C.; Anmarkrud, J.A.; Kierczak, M.; Rafati, N.; Thorbek, B.L.G.; Schrøder-Nielsen, A.; de Boer, H.J. DNA Metabarcoding for Quality Control of Basil, Oregano, and Paprika. Front. Plant Sci. 2021, 12, 1–13. [Google Scholar] [CrossRef]
- Reynaud, D.H. Next-Generation DNA Testing for Botanicals. Nutr. Outlook 2016, 19, 18–19. [Google Scholar]
- Droege, G.; Barker, K.; Astrin, J.J.; Bartels, P.; Butler, C.; Cantrill, D.; Coddington, J.; Forest, F.; Gemeinholzer, B.; Hobern, D.; et al. The Global Genome Biodiversity Network (GGBN) Data Portal. Nucleic Acids Res. 2014, 42, D607–D612. [Google Scholar] [CrossRef]
- ESA. White Paper on Plant Metabarcoding Next Generation Sequencing (NGS) Analysis Applied to Culinary Herbs and Spices; Technical Report; European Spice Association: Bonn, Germany, 2021. [Google Scholar]
- Sambrook, J.; Russel, D.W. Molecular Cloning: A Laboratory Manual, 3rd ed.; Cold Spring Harbor Laboratory Press: Cold Spring Harbor, NY, USA, 2001. [Google Scholar]
- Agliassa, C.; Maffei, M.E. Origanum vulgare Terpenoids Induce Oxidative Stress and Reduce the Feeding Activity of Spodoptera littoralis. Int. J. Mol. Sci. 2018, 19, 2805. [Google Scholar] [CrossRef] [PubMed]
- Ben Ayed, R.; Ennouri, K.; Ercisli, S.; Ben Hlima, H.; Hanana, M.; Smaoui, S.; Rebai, A.; Moreau, F. First study of correlation between oleic acid content and SAD gene polymorphism in olive oil samples through statistical and bayesian modeling analyses. Lipids Health Dis. 2018, 17, 74. [Google Scholar] [CrossRef]
- Christin, P.A.; Arakaki, M.; Osborne, C.P.; Brautigam, A.; Sage, R.F.; Hibberd, J.M.; Kelly, S.; Covshoff, S.; Wong, G.K.S.; Hancock, L.; et al. Shared origins of a key enzyme during the evolution of C4 and CAM metabolism. J. Exp. Bot. 2014, 65, 3609–3621. [Google Scholar] [CrossRef]
- Kaltenegger, E.; Eich, E.; Ober, D. Evolution of Homospermidine Synthase in the Convolvulaceae: A Story of Gene Duplication, Gene Loss, and Periods of Various Selection Pressures. Plant Cell 2013, 25, 1213–1227. [Google Scholar] [CrossRef] [PubMed]
- Lievens, A.; Paracchini, V.; Pietretti, D.; Garlant, L.; Maquet, A.; Ulberth, F. DNA Accounting: Tallying Genomes to Detect Adulterated Saffron. Foods 2021, 10, 2670. [Google Scholar] [CrossRef] [PubMed]
- Hollingsworth, P.M.; Forrest, L.L.; Spouge, J.L.; Hajibabaei, M.; Ratnasingham, S.; van der Bank, M.; Chase, M.W.; Cowan, R.S.; Erickson, D.L.; Fazekas, A.J.; et al. A DNA barcode for land plants. Proc. Natl. Acad. Sci. USA 2009, 106, 12794–12797. [Google Scholar] [CrossRef]
- ThermoFisher Scientific. Prepare Amplicon Libraries without Fragmentation Using the Ion Plus Fragment Library Kit, man0006846 ed.; ThermoFisher Scientific: Waltham, MA, USA; Available online: https://assets.thermofisher.com/TFS-Assets/LSG/manuals/MAN0006846_PrepAmpliconLibr_using_IonPlusFragLibraryKit_UB.pdf (accessed on 13 July 2023).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Lievens, A.; Jacchia, S.; Kagkli, D.M.; Savini, C.; Querci, M. Measuring Digital PCR Quality: Performance Parameters and Their Optimization. PLoS ONE 2016, 11, e0153317. [Google Scholar] [CrossRef]
- Huber, W.; Carey, J.; Gentleman, R.; Anders, S.; Carlson, M.; Carvalho, S.; Bravo, C.; Davis, S.; Gatto, L.; Girke, T.; et al. Orchestrating high-throughput genomic analysis with Bioconductor. Nat. Methods 2015, 12, 115–121. [Google Scholar] [CrossRef]
- Goodstein, D.M.; Shu, S.; Howson, R.; Neupane, R.; Hayes, R.D.; Fazo, J.; Mitros, T.; Dirks, W.; Hellsten, U.; Putnam, N.; et al. Phytozome: A comparative platform for green plant genomics. Nucleic Acids Res. 2012, 40, D1178–D1186. [Google Scholar] [CrossRef]
- Untergasser, A.; Cutcutache, I.; Koressaar, T.; Ye, J.; Faircloth, B.C.; Remm, M.; Rozen, S.G. Primer3: New capabilities and interfaces. Nucleic Acids Res. 2012, 40, e115. [Google Scholar] [CrossRef]
- Aranyi, T.; Varadi, A.; Simon, I.; Tusnady, G.E. The BiSearch web server. BMC Bioinform. 2006, 7, 431. [Google Scholar] [CrossRef]
- Tusnady, G.E.; Simon, I.; Varadi, A.; Aranyi, T. BiSearch: Primer-design and search tool for PCR on bisulfite-treated genomes. Nucleic Acids Res. 2005, 33, e9. [Google Scholar] [CrossRef]
- Sievers, F.; Wilm, A.; Dineen, D.; Gibson, T.J.; Karplus, K.; Li, W.; Lopez, R.; McWilliam, H.; Remmert, M.; Soding, J.; et al. Fast, scalable generation of high-quality protein multiple sequence alignments using Clustal Omega. Mol. Syst. Biol. 2011, 7, 539. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Cowley, A.; Uludag, M.; Gur, T.; McWilliam, H.; Squizzato, S.; Park, Y.M.; Buso, N.; Lopez, R. The EMBL-EBI bioinformatics web and programmatic tools framework. Nucleic Acids Res. 2015, 43, W580–W584. [Google Scholar] [CrossRef] [PubMed]
- McWilliam, H.; Li, W.; Uludag, M.; Squizzato, S.; Park, Y.M.; Buso, N.; Cowley, A.P.; Lopez, R. Analysis Tool Web Services from the EMBL-EBI. Nucleic Acids Res. 2013, 41, W597–W600. [Google Scholar] [CrossRef] [PubMed]
- Bikandi, J.; Millan, R.S.; Rementeria, A.; Garaizar, J. In silico analysis of complete bacterial genomes: PCR, AFLP-PCR and endonuclease restriction. Bioinformatics 2004, 20, 798–799. [Google Scholar] [CrossRef]
- Leitch, I.; Johnston, E.; Pellicer, J.; Hidalgo, O.; Bennett, M.D. Plant DNA C-values Database Release 7.1. New Phytol. 2020, 226, 301–305. [Google Scholar]
- Benson, D.A.; Cavanaugh, M.; Clark, K.; Karsch-Mizrachi, I.; Lipman, D.J.; Ostell, J.; Sayers, E.W. GenBank. Nucleic Acids Res. 2013, 41, D36–D42. [Google Scholar] [CrossRef]
- Maquet, A.; Lievens, A.; Paracchini, V.; Kaklamanos, G.; de la Calle, B.; Garlant, L.; Papoci, S.; Pietretti, D.; Zdiniakova, T.; Breidbach, A.; et al. Results of an EU Wide Coordinated Control Plan to Establish Theprevalence of Fraudulent Practices in the Marketing of Herbs and Spices; Technical Report; European Commission Joint Research Centre: Brussels, Belgium, 2021; ISBN 978-92-79-42979-1. [Google Scholar] [CrossRef]
- Bejar, E. Adulteration of oregano herb, and essential oil of oregano. In Botanical Adulterants Prevention Bulletin; ABC-AHP-NCNPR Botanical Adulterants Prevention Program: Austin, TX, USA, 2019; pp. 1–5. [Google Scholar]
- Marieschi, M.; Torelli, A.; Bianchi, A.; Bruni, R. Development of a SCAR marker for the identification of Olea europaea L.: A newly detected adulterant in commercial Mediterranean oregano. Food Chem. 2011, 126, 705–709. [Google Scholar] [CrossRef]
- Marieschi, M.; Torelli, A.; Poli, F.; Bianchi, A.; Bruni, R. Quality control of commercial Mediterranean oregano: Development of SCAR markers for the detection of the adulterants Cistus incanus L., Rubus caesius L. andRhus coriaria L. Food Control 2010, 21, 998–1003. [Google Scholar] [CrossRef]
- Weesepoel, Y.J.A.; van Ruth, S.M. Inventarisatie van Voedselfraude: Mondiaal Kwetsbare Productgroepen en Ontwikkeling van Analytische Methodenin Europees Onderzoek; Technical Report; RIKILT Wageningen: Wageningen, The Netherlands, 2015. [Google Scholar]
- DGCCRF. Qualité des Épices: Une Enquête de la DGCCRF Constate une Améliorationde la Qualité des Épices; Technical Report; Ministere de L’économie, des Finances et de la Relance: Paris, France, 2021.
- ISO 13171:2016; Essential Oil of Oregano [Origanum vulgare L. subsp. Hirtum]. Technical Report. International Organization for Standardization: Geneva, Switzerland, 2016.
- Massaro, A.; Negro, A.; Bragolusi, M.; Miano, B.; Tata, A.; Suman, M.; Piro, R. Oregano authentication by mid-level data fusion of chemical fingerprint signatures acquired by ambient mass spectrometry. Food Control 2021, 126, 108058. [Google Scholar] [CrossRef]
- Guzelsoy, N.A.; Çavuş, F.; Kaçar, O. Discrimination of Thymus, Origanum, Satureja and Thymbra species from the family Labiatae by untargeted metabolomic analysis. Czech J. Food Sci. 2020, 38, 151–157. [Google Scholar] [CrossRef]
- Marieschi, M.; Torelli, A.; Poli, F.; Sacchetti, G.; Bruni, R. RAPD-Based Method for the Quality Control of Mediterranean Oregano and Its Contribution to Pharmacognostic Techniques. J. Agric. Food Chem. 2009, 57, 1835–1840. [Google Scholar] [CrossRef] [PubMed]
- Vannozzi, A.; Lucchin, M.; Barcaccia, G. cpDNA Barcoding by Combined End-Point and Real-Time PCR Analyses to Identify and Quantify the Main Contaminants of Oregano (Origanum vulgare L.) in Commercial Batches. Diversity 2018, 10, 98. [Google Scholar] [CrossRef]
- Zhao, F.; Chen, Y.P.; Salmaki, Y.; Drew, B.T.; Wilson, T.C.; Scheen, A.C.; Celep, F.; Bräuchler, C.; Bendiksby, M.; Wang, Q.; et al. An updated tribal classification of Lamiaceae based on plastome phylogenomics. BMC Biol. 2021, 19, 2. [Google Scholar] [CrossRef]
- Chen, S.; Yao, H.; Han, J.; Liu, C.; Song, J.; Shi, L.; Zhu, Y.; Ma, X.; Gao, T.; Pang, X.; et al. Validation of the ITS2 Region as a Novel DNA Barcode for Identifying Medicinal Plant Species. PLoS ONE 2010, 5, e8613. [Google Scholar] [CrossRef] [PubMed]
- Lamb, P.D.; Hunter, E.; Pinnegar, J.K.; Creer, S.; Davies, R.G.; Taylor, M.I. How quantitative is metabarcoding: A meta-analytical approach. Mol. Ecol. 2018, 28, 420–430. [Google Scholar] [CrossRef]
- Preckel, L.; Brünen-Nieweler, C.; Denay, G.; Petersen, H.; Cichna-Markl, M.; Dobrovolny, S.; Hochegger, R. Identification of Mammalian and Poultry Species in Food and Pet Food Samples Using 16S rDNA Metabarcoding. Foods 2021, 10, 2875. [Google Scholar] [CrossRef]
- Furlan, E.M.; Davis, J.; Duncan, R.P. Identifying error and accurately interpreting environmental DNA metabarcoding results: A case study to detect vertebrates at arid zone waterholes. Mol. Ecol. Resour. 2020, 20, 1259–1276. [Google Scholar] [CrossRef] [PubMed]
- Thielecke, L.; Aranyossy, T.; Dahl, A.; Tiwari, R.; Roeder, I.; Geiger, H.; Fehse, B.; Glauche, I.; Cornils, K. Limitations and challenges of genetic barcode quantification. Sci. Rep. 2017, 7, 43249. [Google Scholar] [CrossRef]
- Robin, J.D.; Ludlow, A.T.; LaRanger, R.; Wright, W.E.; Shay, J.W. Comparison of DNA Quantification Methods for Next Generation Sequencing. Sci. Rep. 2016, 6, 24067. [Google Scholar] [CrossRef]
- Focke, F.; Haase, I.; Fischer, M. DNA-Based Identification of Spices: DNA Isolation, Whole Genome Amplification, and Polymerase Chain Reaction. J. Agric. Food Chem. 2011, 59, 513–520. [Google Scholar] [CrossRef]



| Name | Forward (5-3) | Reverse (5-3) | Length | Reference | Target |
|---|---|---|---|---|---|
| Orvu EF1 F/R | CTCCAGTTCTTGATTGCCACAC | GCTCCTTTCCAGACCTCCTATC | 87 | [23] | GU385981.1 |
| Oleu SADbis F/R | ATTTCTCATGGAAACACGGC | TTTCATGGCGCTTCTCATC | 100 | This study | KX196198.1 |
| Chal pc-1E1p1 F/R | AGGACTACCACTGAATCTGC | CTCCAAATCCAAGCCACACA | 193 | This study | KJ161681.1 |
| Coar HSSp2 F/R | CCCGGTCTAATCGTTGACAT | CAAGGATAAGCGCTCCAGTC | 174 | This study | HF911513.1 |
| Myrtus isoprene F/R | GTCCATTGAAGGTTACAGCC | CTCCATTAGTCTATCCCTCG | 171 | This study | FR692046.1 |
| Cistus S13593 F/R | GCGGAAAACCAACAAACCAC | CTACCAATCCTTCCGAACCA | 176 | This study | AF492022.1 |
| Barcode Name | Primer Name | Sequence (5-3) | Annealing Temp | Amplicon (bp) |
|---|---|---|---|---|
| RbcL | rbcL-a-F | ATGTCACCACAAACAGAGACTAAAGC | 55 °C | 560 |
| rbcL-a-R | GTAAAATCAAGTCCACCRCG | |||
| TrnL | trnL(UAA)-c | CGAAATCGGTAGACGCTACG | 50 °C | 500 |
| trnL(UAA)-d | GGGGATAGAGGGACTTGAAC | |||
| psbA | psbA-trnH –F | GTTATGCATGAACGTAATGCTC | 64 °C | 430 |
| psbA-trnH-R | CGCGCATGGTGGATTCACAATCC | |||
| MatK | matK-1RKIM-F | ACCCAGTCCATCTGGAAATCTTGGTTC | 52 °C | 800 |
| matK-3FKIM-R | CGTACAGTACTTTTGTGTTTACGAG | |||
| ITS | ITS2-F | ATGCGATACTTGGTGTGAAT | 56 °C | 460 |
| ITS2-R | GACGCTTCTCCAGACTACAAT |
| Reads | NGS Reads% | Declared Mass% | |
|---|---|---|---|
| Origanum vulgare | 1126 | 8% | 22% |
| Origanum onites | 109 | 1% | 22% |
| Origanum spp. | 564 | 4% | |
| Thymus spp. | 345 | 2% | 5% |
| Convolvulus spp. | 3771 | 27% | 1% |
| Cistus spp. | 606 | 4% | 10% |
| Myrtus communis | 25 | <1% | 10% |
| Olea europaea | 33 | <1% | 10% |
| Corylus spp. | 531 | 4% | 10% |
| Rhus coriaria | - | - | 10% |
| Amaranthus spp. | 1105 | 8% | - |
| Camonea/Ipomoea spp. | 505 | 4% | - |
| Calystegia spp. | 2974 | 21% | - |
| Chenopodium spp. | 1306 | 9% | - |
| O. majorana | 4 | <1% | - |
| Mentha x piperita | 133 | 1% | - |
| Salvia/perilla spp. | 133 | 1% | - |
| Species | Class | Species | Class | Species | Class |
|---|---|---|---|---|---|
| Origanum majorana | Adulterant | Conyza spp. | Contaminant | Olea europaea | Adulterant |
| Origanum onites | Ingredient | Corylus spp. | Contaminant | Panax stipuleanatus | Noise |
| Origanum vulgare | Ingredient | Cuminum cyminum | Contaminant | Perilla spp. | Noise |
| Aloysia spp. | Noise | Cuscuta spp. | Noise | Petroselinum crispum | Contaminant |
| Alyssum spp. | Contaminant | Cuscuta japonica | Noise | Plantago spp. | Contaminant |
| Amaranthus spp. | Contaminant | Daucus spp. | Contaminant | Raphanus sativus | Contaminant |
| Aniba hostmanniana | Noise | Descurainia sophia | Contaminant | Reseda lutea | Contaminant |
| Anisosciadium spp. | Noise | Descurainia stricta | Contaminant | Rhodamnia argentea | Noise |
| Anisosciadium lanatum | Noise | Ephedra alata | Noise | Rhodostemonodaphne rufovirgata | Noise |
| Arbutus spp. | Contaminant | Erigeron spp. | Noise | Salvia spp. | Noise |
| Artemisia spp. | Contaminant | Erysimum spp. | Noise | Saposhnikovia divaricata | Noise |
| Atriplex spp. | Contaminant | Erysimum teretifolium | Noise | Satureja spp. | Contaminant |
| Avena spp. | Contaminant | Fraxinus spp. | Noise | Sinocrassula yunnanensis | Noise |
| Bidens spp. | Contaminant | Galinsoga parviflora | Contaminant | Solanum spp. | Contaminant |
| Brassica spp. | Contaminant | Helianthemum spp. | Contaminant | Sonchus asper | Contaminant |
| Calycolpus spp. | Noise | Hypericum spp. | Contaminant | Sonchus spp. | Contaminant |
| Calycolpus moritzianus | Noise | Ipomea spp. | Contaminant | Syringa spp. | Noise |
| Calystegia sepium | Contaminant | Laurus nobilis | Contaminant | Syringa wolfii | Noise |
| Camelina spp. | Contaminant | Malva spp. | Contaminant | Tessaria spp. | Noise |
| Camonea spp. | Contaminant | Malva parviflora | Contaminant | Thymus spp. | Contaminant |
| Camonea umbrellata | Contaminant | Medicago sativa | Contaminant | Thymus vulgaris | Contaminant |
| Carpinus viminea | Noise | Medicago spp. | Contaminant | Thymus marschallianus | Contaminant |
| Carthamus tinctorius | Contaminant | Melilotus albus | Contaminant | Trifolium spp. | Contaminant |
| Chenopodium album | Contaminant | Melilotus officinalis | Contaminant | Trigonella spp. | Contaminant |
| Chenopodium spp. | Contaminant | Melilotus spp. | Contaminant | Valerianella spp. | Contaminant |
| Chionanthus spp. | Noise | Mentha x piperita | Contaminant | Vicia narbonensis | Contaminant |
| Cicer arietinum | Contaminant | Mentheae (tribe) | Contaminant | Vicia sativa | Contaminant |
| Cinnamomum spp. | Contaminant | Myrcia sylvatica | Noise | Vicia spp. | Contaminant |
| Cistus spp. | Adulterant | Myrtus communis | Adulterant | ||
| Convolvulus arvensis | Contaminant | Nama undulata | Noise | ||
| Convolvulus spp. | Contaminant | Neuontobotrys tarapacana | Noise |
| C. album | Cistus spp. | C. arvensis | M. communis | O. europaea | |
|---|---|---|---|---|---|
| n | 9 | 5 | 19 | 47 | 78 |
| Correlation coefficient | 0.82 | 0.39 | −0.05 | 0.71 | 0.68 |
| p value | p < 0.001 | p > 0.1 | p > 0.1 | p < 0.001 | p < 0.001 |
| Slope | 0.09 | 0.65 | 0 | 4.6 | 1.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lievens, A.; Paracchini, V.; Garlant, L.; Pietretti, D.; Maquet, A.; Ulberth, F. Detection and Quantification of Botanical Impurities in Commercial Oregano (Origanum vulgare) Using Metabarcoding and Digital PCR. Foods 2023, 12, 2998. https://doi.org/10.3390/foods12162998
Lievens A, Paracchini V, Garlant L, Pietretti D, Maquet A, Ulberth F. Detection and Quantification of Botanical Impurities in Commercial Oregano (Origanum vulgare) Using Metabarcoding and Digital PCR. Foods. 2023; 12(16):2998. https://doi.org/10.3390/foods12162998
Chicago/Turabian StyleLievens, Antoon, Valentina Paracchini, Linda Garlant, Danilo Pietretti, Alain Maquet, and Franz Ulberth. 2023. "Detection and Quantification of Botanical Impurities in Commercial Oregano (Origanum vulgare) Using Metabarcoding and Digital PCR" Foods 12, no. 16: 2998. https://doi.org/10.3390/foods12162998
APA StyleLievens, A., Paracchini, V., Garlant, L., Pietretti, D., Maquet, A., & Ulberth, F. (2023). Detection and Quantification of Botanical Impurities in Commercial Oregano (Origanum vulgare) Using Metabarcoding and Digital PCR. Foods, 12(16), 2998. https://doi.org/10.3390/foods12162998