
Reduction of the Number of Samples for Cost-Effective Hyperspectral Grape Quality Predictive Models

 ,
,  ,
,  ,
, 
 ,
, 
Abstract
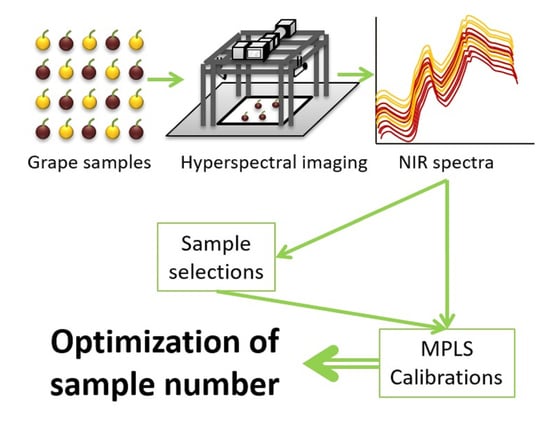
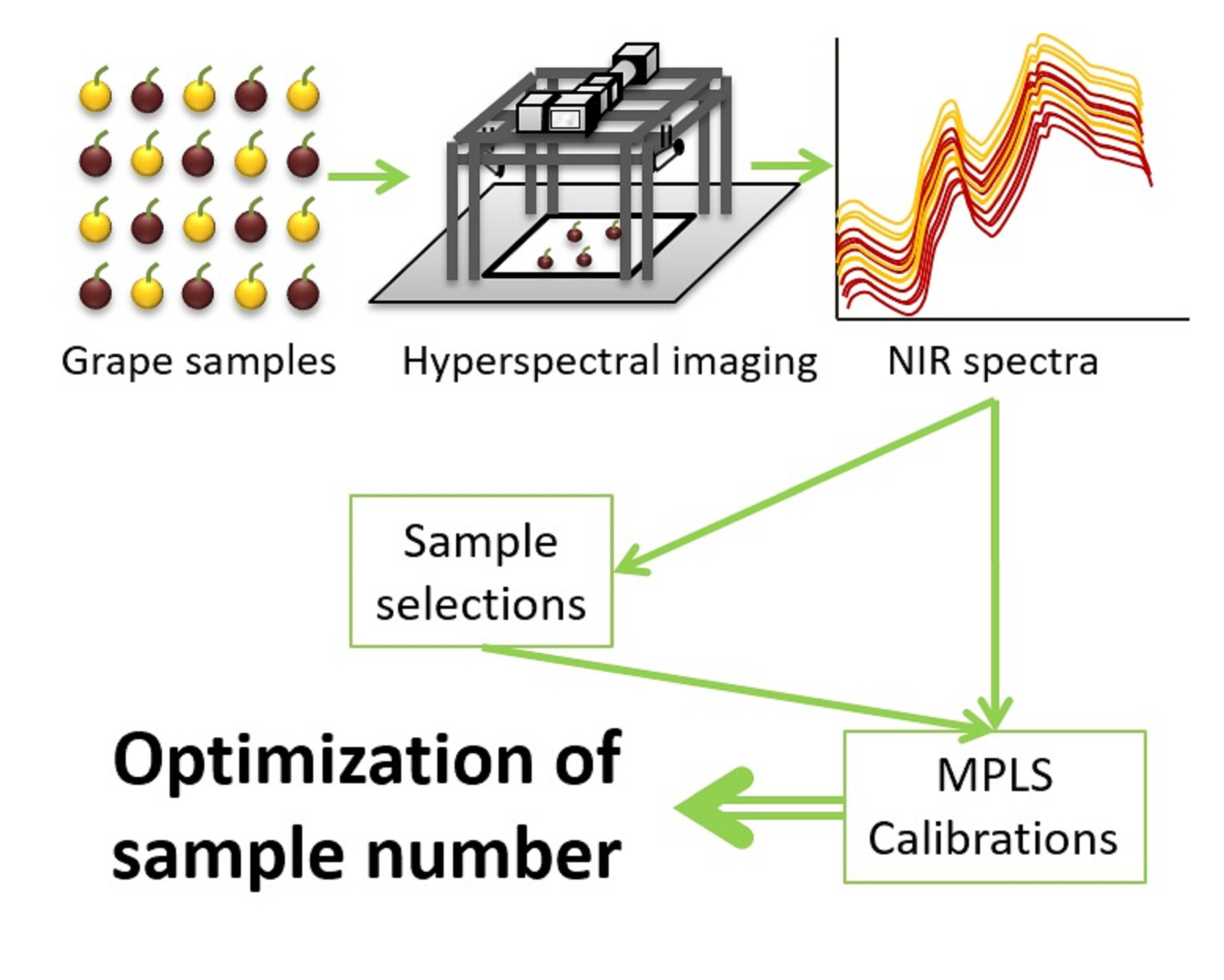
1. Introduction
2. Materials and Methods
2.1. Samples
2.2. Spectral Matrix
2.3. Reference Parameters
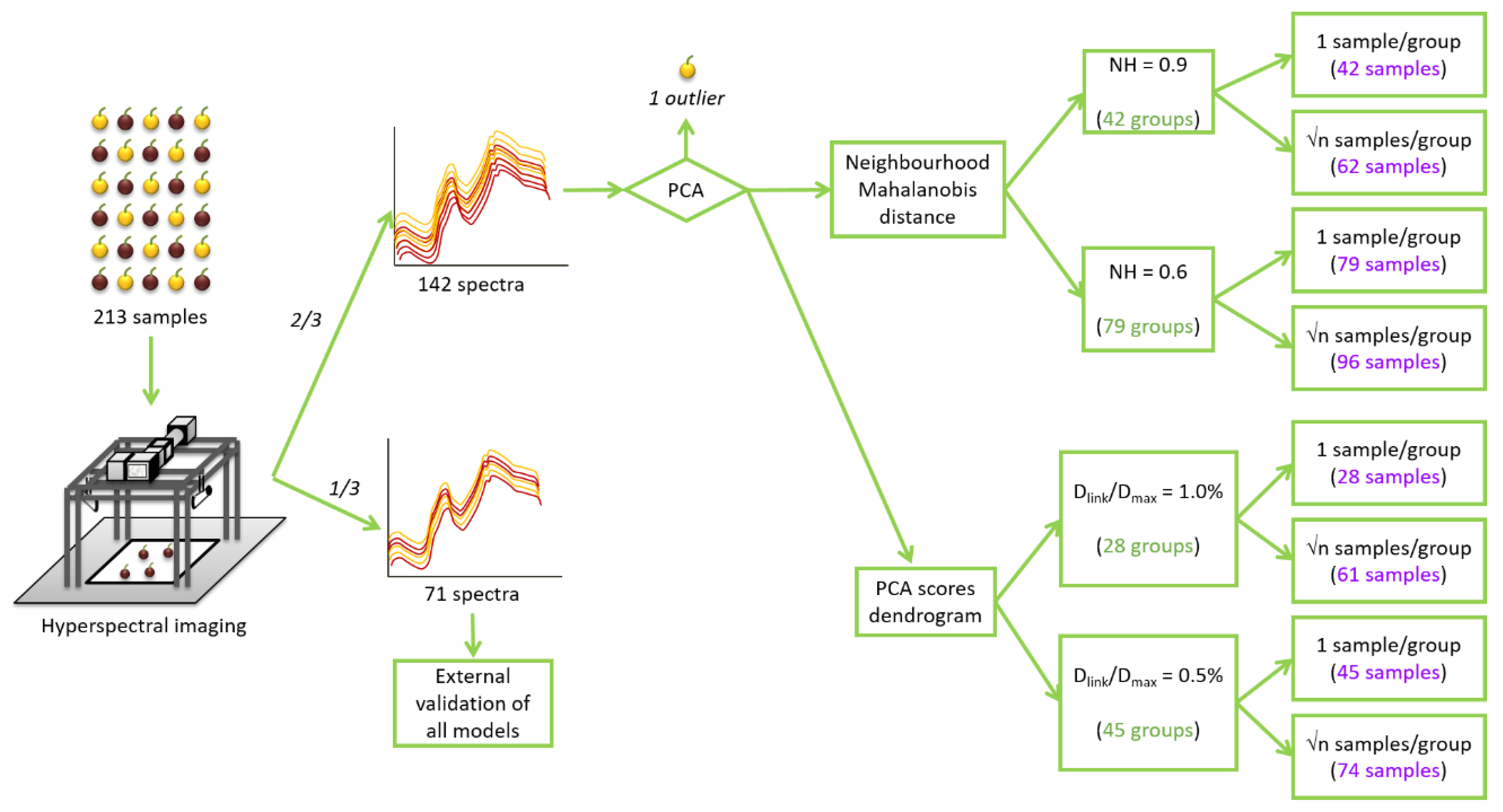
2.4. Sample Selections
2.5. Modified Partial Least Square (MPLS) Regressions on the Full Calibration (FC) Set
3. Results and Discussion
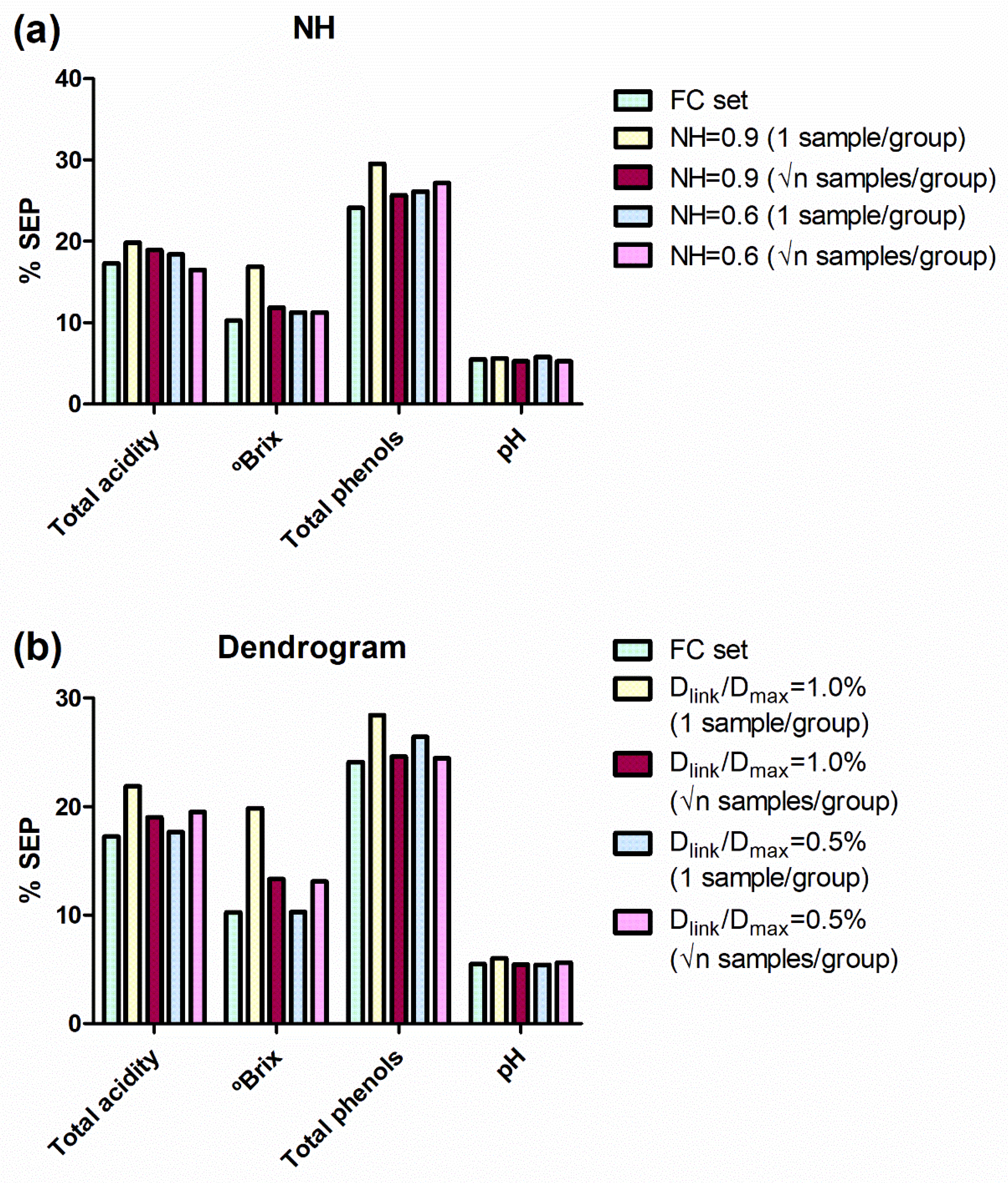
3.1. Sample Selection Using Neighbourhood Mahalanobis (NH) Distance
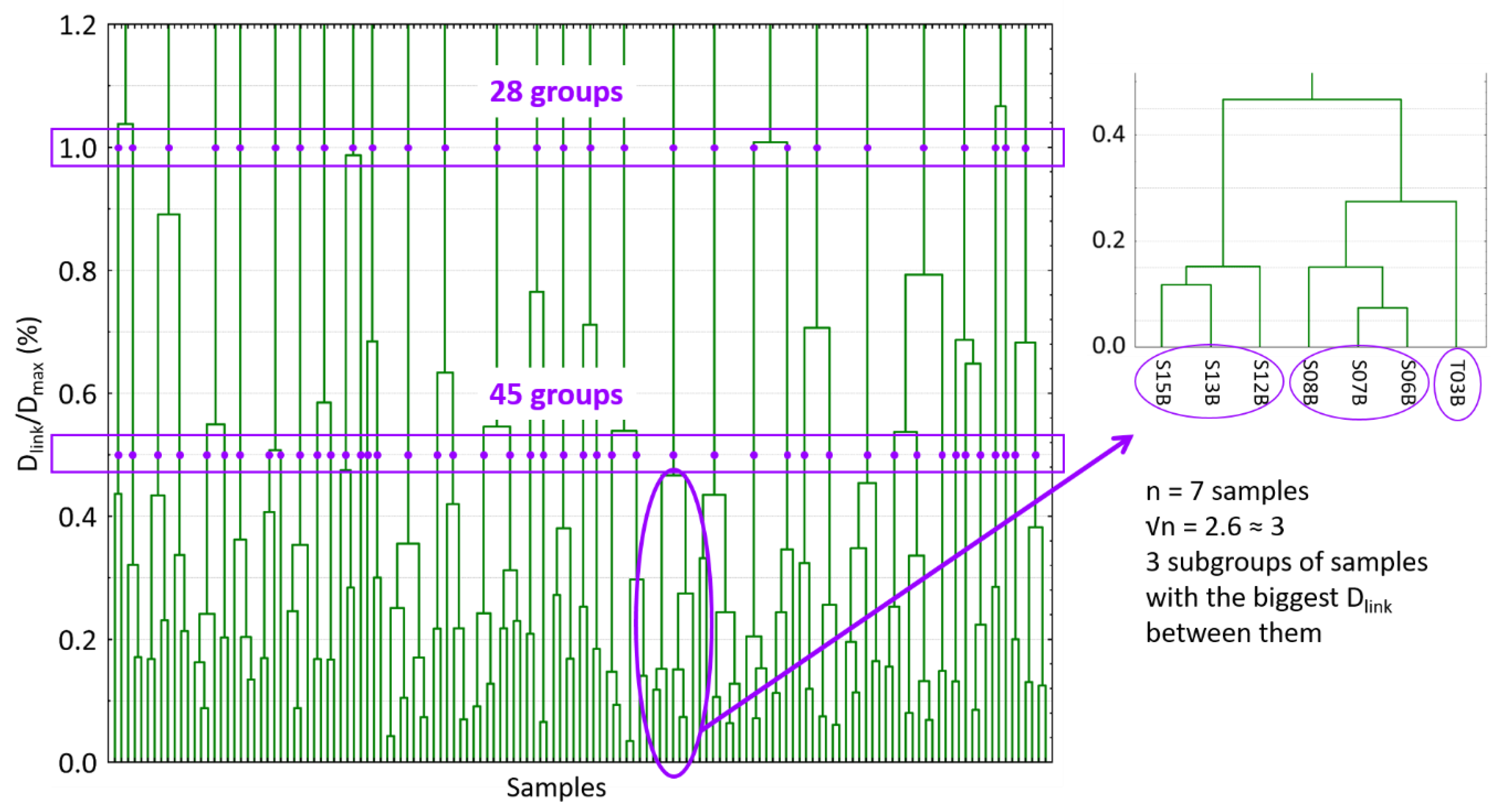
3.2. Sample Selection using Hierarchical Clustering (HC) Analysis
3.3. Modified Partial Least Square (MPLS) Regressions on the NH and HC Sets
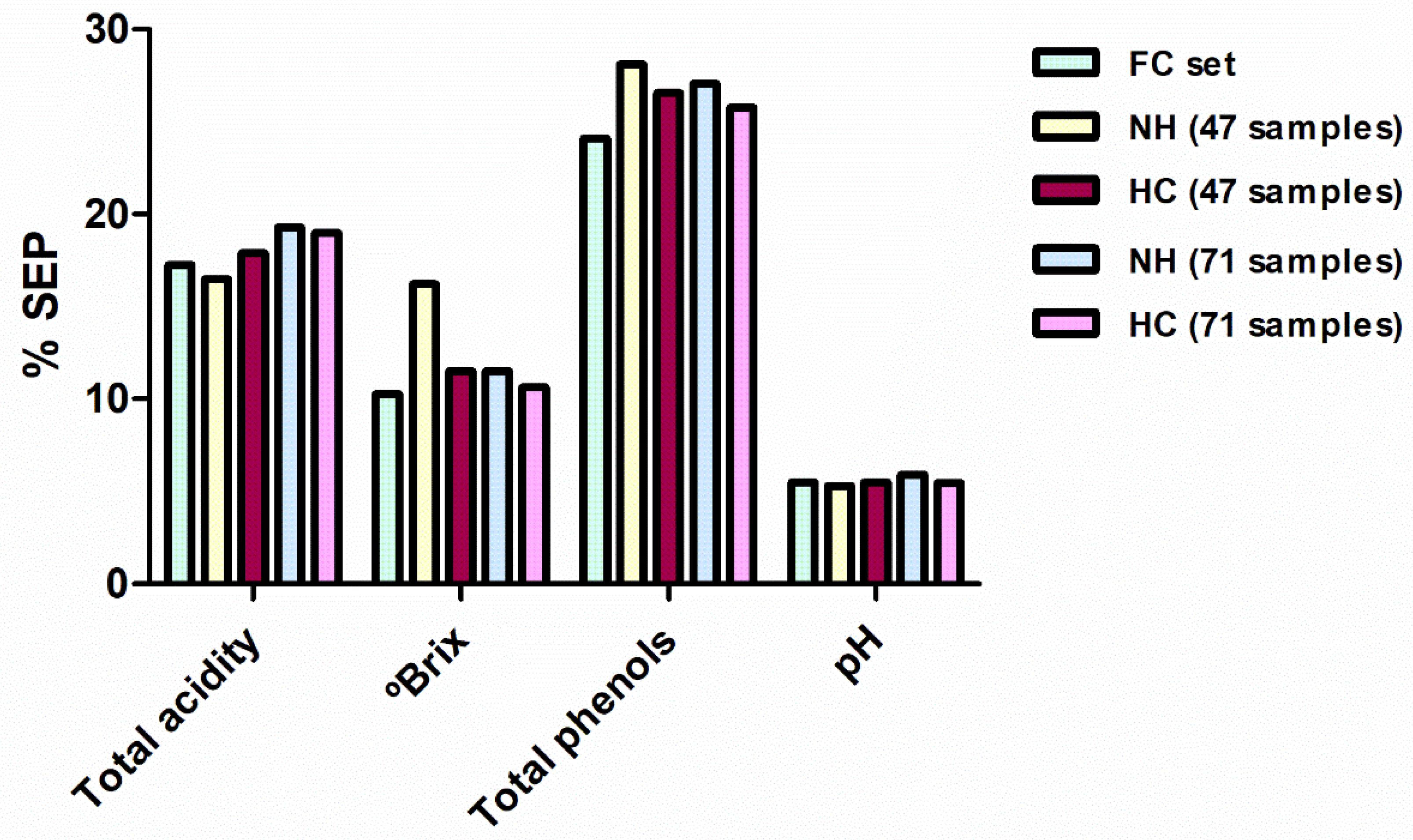
3.4. Comparison of Sample Selection Methods
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Grassi, S.; Alamprese, C. Advances in NIR spectroscopy applied to process analytical technology in food industries. Curr. Opin. Food Sci. 2018, 22, 17–21. [Google Scholar] [CrossRef]
- Cen, H.; He, Y. Theory and application of near infrared reflectance spectroscopy in determination of food quality. Trends Food Sci. Technol. 2007, 18, 72–83. [Google Scholar] [CrossRef]
- Cozzolino, D.; Degner, S.; Eglinton, J. A Review on the Role of Vibrational Spectroscopy as An Analytical Method to Measure Starch Biochemical and Biophysical Properties in Cereals and Starchy Foods. Foods 2014, 3, 605–621. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Yu, H.; Xu, H.; Ying, Y. Near infrared spectroscopy for on/in-line monitoring of quality in foods and beverages: A review. J. Food Eng. 2008, 87, 303–313. [Google Scholar] [CrossRef]
- Cozzolino, D.; Dambergs, R.G.; Janik, L.; Cynkar, W.U.; Gishen, M. Review: Analysis of grapes and wine by near infrared spectroscopy. J. Near Infrared Spectrosc. 2006, 14, 279–289. [Google Scholar] [CrossRef]
- Cozzolino, D.; Cynkar, W.; Shah, N.; Smith, P. Technical solutions for analysis of grape juice, must, and wine: The role of infrared spectroscopy and chemometrics. Anal. Bioanal. Chem. 2011, 401, 1475–1484. [Google Scholar] [CrossRef]
- González-Caballero, V.; Sánchez, M.-T.; Fernández-Novales, J.; López, M.-I.; Pérez-Marín, D. On-Vine Monitoring of Grape Ripening Using Near-Infrared Spectroscopy. Food Anal. Methods 2012, 5, 1377–1385. [Google Scholar] [CrossRef]
- Dambergs, R.; Gishen, M.; Cozzolino, D. A Review of the State of the Art, Limitations, and Perspectives of Infrared Spectroscopy for the Analysis of Wine Grapes, Must, and Grapevine Tissue. Appl. Spectrosc. Rev. 2015, 50, 261–278. [Google Scholar] [CrossRef]
- Power, A.; Truong, V.K.; Chapman, J.; Cozzolino, D. From the Laboratory to The Vineyard—Evolution of The Measurement of Grape Composition using NIR Spectroscopy towards High-Throughput Analysis. High-Throughput 2019, 8, 21. [Google Scholar] [CrossRef]
- Sun, D.W. Hyperspectral Imaging for Food Quality Analysis and Control; Elsevier Science & Technology: San Diego, CA, USA, 2010. [Google Scholar]
- Riccioli, C.; Pérez-Marín, D.; Guerrero-Ginel, J.E.; Fearn, T.; Garrido-Varo, A. Detection and Quantification of Ruminant Meal in Processed Animal Proteins: A Comparative Study of near Infrared Spectroscopy and near Infrared Chemical Imaging. J. Near Infrared Spectrosc. 2012, 20, 623–633. [Google Scholar] [CrossRef]
- Nogales-Bueno, J.; Rodríguez-Pulido, F.J.; Baca-Bocanegra, B.; González-Miret, M.L.; Heredia, F.J.; Hernández-Hierro, J.M. Hyperspectral Imaging—A Novel Green Chemistry Technology for the Oenological and Viticultural Sectors. In Agricultural Research Updates; Gorawala, P., Mandhatri, S., Eds.; Nova Science Publishers, Inc.: New York, NY, USA, 2016; Volume 12, pp. 45–56. [Google Scholar]
- Nogales-Bueno, J.; Hernández-Hierro, J.M.; Rodríguez-Pulido, F.J.; Heredia, F.J. Determination of technological maturity of grapes and total phenolic compounds of grape skins in red and white cultivars during ripening by near infrared hyperspectral image: A preliminary approach. Food Chem. 2014, 152, 586–591. [Google Scholar] [CrossRef] [PubMed]
- Hernández-Hierro, J.M.; Nogales-Bueno, J.; Rodríguez-Pulido, F.J.; Heredia, F.J. Feasibility study on the use of near-infrared hyperspectral imaging for the screening of anthocyanins in intact grapes during ripening. J. Agric. Food Chem. 2013, 61, 9804–9809. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez-Pulido, F.J.; Hernández-Hierro, J.M.; Nogales-Bueno, J.; Gordillo, B.; González-Miret, M.L.; Heredia, F.J. A novel method for evaluating flavanols in grape seeds by near infrared hyperspectral imaging. Talanta 2014, 122, 145–150. [Google Scholar] [CrossRef] [PubMed]
- Fernandes, A.M.; Oliveira, P.; Moura, J.P.; Oliveira, A.A.; Falco, V.; Correia, M.J.; Melo-Pinto, P. Determination of anthocyanin concentration in whole grape skins using hyperspectral imaging and adaptive boosting neural networks. J. Food Eng. 2011, 105, 216–226. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, F.; Ning, J.; Liu, X.; Zhang, Z.; Yang, S. Predicting the anthocyanin content of wine grapes by NIR hyperspectral imaging. Food Chem. 2015, 172, 788–793. [Google Scholar] [CrossRef]
- Gutiérrez, S.; Tardaguila, J.; Fernández-Novales, J.; Diago, M.P. On-the-go hyperspectral imaging for the in-field estimation of grape berry soluble solids and anthocyanin concentration. Aust. J. Grape Wine R 2018. [Google Scholar] [CrossRef]
- Forina, M.; Lanteri, S.; Casale, M. Multivariate calibration. J. Chromatogr. A 2007, 1158, 61–93. [Google Scholar] [CrossRef]
- OIV. Recuil de Methods Internationals d´Analyse des Vins; OIV: Paris, France, 1990. [Google Scholar]
- Jackson, R.S. Chemical Constituents of Grapes and Wine. In Wine Science: Principles, Prectice and Perception; Jackson, R.S., Ed.; Academic Press: San Diego, CA, USA, 2000; pp. 232–280. [Google Scholar]
- Minasny, B.; McBratney, A.B. A conditioned Latin hypercube method for sampling in the presence of ancillary information. Comput. Geosci. 2006, 32, 1378–1388. [Google Scholar] [CrossRef]
- Ramirez-Lopez, L.; Schmidt, K.; Behrens, T.; van Wesemael, B.; Demattê, J.A.M.; Scholten, T. Sampling optimal calibration sets in soil infrared spectroscopy. Geoderma 2014, 226, 140–150. [Google Scholar] [CrossRef]
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The Mahalanobis distance. Chemom. Intellig. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Shenk, J.S.; Westerhaus, M.O. Analysis of Agriculture and Food Products by Near Infrared Reflectance Spectroscopy. Monograph; NIR Systems: Silver Spring, MD, USA, 1995. [Google Scholar]
- Shenk, J.S.; Westerhaus, M.O. Population Definition, Sample Selection, and Calibration Procedures for Near Infrared Reflectance Spectroscopy. Crop Sci. 1991, 31, 469–474. [Google Scholar] [CrossRef]
- Pérez-Marín, D.; Garrido-Varo, A.; Guerrero, J.E. Implementation of LOCAL Algorithm with Near-Infrared Spectroscopy for Compliance Assurance in Compound Feedingstuffs. Appl. Spectrosc. 2005, 59, 69–77. [Google Scholar] [CrossRef] [PubMed]
- Garrido-Varo, A.; Sánchez-Bonilla, A.; Maroto-Molina, F.; Riccioli, C.; Pérez-Marín, D. Long-Length Fiber Optic Near-Infrared (NIR) Spectroscopy Probes for On-Line Quality Control of Processed Land Animal Proteins. Appl. Spectrosc. 2018, 72, 1170–1182. [Google Scholar] [CrossRef]
- Kennard, R.W.; Stone, L.A. Computer Aided Design of Experiments. Technometrics 1969, 11, 137–148. [Google Scholar] [CrossRef]
- He, Z.; Li, M.; Ma, Z. Design of a reference value-based sample-selection method and evaluation of its prediction capability. Chemom. Intellig. Lab. Syst. 2015, 148, 72–76. [Google Scholar] [CrossRef]
- He, Z.; Ma, Z.; Li, M.; Zhou, Y. Selection of a calibration sample subset by a semi-supervised method. J. Near Infrared Spectrosc. 2018, 26, 87–94. [Google Scholar] [CrossRef]
- Shetty, N.; Rinnan, Å.; Gislum, R. Selection of representative calibration sample sets for near-infrared reflectance spectroscopy to predict nitrogen concentration in grasses. Chemom. Intellig. Lab. Syst. 2012, 111, 59–65. [Google Scholar] [CrossRef]
- Moros, J.; Martínez-Sánchez, M.J.; Pérez-Sirvent, C.; Garrigues, S.; de la Guardia, M. Testing of the Region of Murcia soils by near infrared diffuse reflectance spectroscopy and chemometrics. Talanta 2009, 78, 388–398. [Google Scholar] [CrossRef]
- Singleton, V.L.; Rossi, J.A. Colorimetry of Total Phenolics with Phosphomolybdic-Phosphotungstic Acid Reagents. Am. J. Enol. Vitic. 1965, 144–158. [Google Scholar]
- Nogales-Bueno, J.; Baca-Bocanegra, B.; Rodríguez-Pulido, F.J.; Heredia, F.J.; Hernández-Hierro, J.M. Use of near infrared hyperspectral tools for the screening of extractable polyphenols in red grape skins. Food Chem. 2015, 172, 559–564. [Google Scholar] [CrossRef]
- Ward, J.H. Hierarchical Grouping to Optimize an Objective Function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Shenk, J.S.; Westerhaus, M.O. Routine Operation, Calibration, Development and Network System Management Manual; NIRSystems: Silver Spring, MD, USA, 1995. [Google Scholar]
- Lavine, B. A User-Friendly Guide to Multivariate Calibration and Classification, Tomas Naes, Tomas Isakson, Tom Fearn and Tony Davies, NIR Publications, Chichester, 2002, ISBN 0-9528666-2-5, £45.00. J. Chemom. Soc. 2003, 17, 571–572. [Google Scholar] [CrossRef]
- Massart, D.L.; Vandeginste, B.G.M.; Deming, S.N.; Michotte, Y.; Kaufman, L. Chemometrics: A Textbook. Data Handling in Science and Technology 2; Elsevier Science: Amsterdam, The Netherlands, 1988. [Google Scholar]
- Pérez-Marín, D.; Garrido-Varo, A.; Guerrero-Ginel, J.E. Remote near Infrared Instrument Cloning and Transfer of Calibrations to Predict Ingredient Percentages in Intact Compound Feedstuffs. J. Near Infrared Spectrosc. 2006, 14, 81–91. [Google Scholar] [CrossRef]
- Baca-Bocanegra, B.; Nogales-Bueno, J.; García-Estévez, I.; Escribano-Bailón, M.T.; Hernández-Hierro, J.M.; Heredia, F.J. Screening of Wine Extractable Total Phenolic and Ellagitannin Contents in Revalorized Cooperage By-products: Evaluation by Micro-NIRS Technology. Food Bioproc. Technol. 2019, 12, 477–485. [Google Scholar] [CrossRef]
- Baca-Bocanegra, B.; Nogales-Bueno, J.; Hernández-Hierro, J.M.; Heredia, F.J. Evaluation of extractable polyphenols released to wine from cooperage byproduct by near infrared hyperspectral imaging. Food Chem. 2018, 244, 206–212. [Google Scholar] [CrossRef] [PubMed]
- Moros, J.; Iñón, F.A.; Garrigues, S.; de la Guardia, M. Determination of the energetic value of fruit and milk-based beverages through partial-least-squares attenuated total reflectance-Fourier transform infrared spectrometry. Anal. Chim. Acta 2005, 538, 181–193. [Google Scholar] [CrossRef]
- Arantes de Carvalho, G.G.; Moros, J.; Santos, D.; Krug, F.J.; Laserna, J.J. Direct determination of the nutrient profile in plant materials by femtosecond laser-induced breakdown spectroscopy. Anal. Chim. Acta 2015, 876, 26–38. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Set | Reference Parameters | Spectral Pretreatments | N 1 | Toutliers | Min 2 | Max 3 | RSQ 4 | SECV 5 | SEP 6 |
|---|---|---|---|---|---|---|---|---|---|
| FC 7 [13] | TA 11 | MSC 14 0,0,1,1 | 141 | 7 | 0 | 45.06 | 0.96 | 2.72 | 3.89 |
| FC 7 [13] | TSS 12 | MSC 14 1,5,5,1 | 141 | 8 | 0 | 31.40 | 0.97 | 1.23 | 1.61 |
| FC 7 [13] | TSP 13 | SNV 15 2,5,5,1 | 141 | 1 | 0 | 16.34 | 0.77 | 1.77 | 1.97 |
| FC 7 [13] | pH | MSC 14 2,5,5,1 | 141 | 2 | 2.17 | 4.29 | 0.92 | 0.13 | 0.18 |
| NH-06-1 8 | TA 11 | MSC 14 0,0,1,1 | 79 | 2 | 0 | 45.42 | 0.95 | 2.92 | 4.18 |
| NH-06-1 8 | TSS 12 | MSC 14 1,5,5,1 | 79 | 4 | 0 | 29.86 | 0.93 | 1.84 | 1.68 |
| NH-06-1 8 | TSP 13 | SNV 15 2,5,5,1 | 79 | 2 | 0 | 16.15 | 0.60 | 1.96 | 2.11 |
| NH-06-1 8 | pH | MSC 14 2,5,5,1 | 79 | 1 | 2.24 | 4.21 | 0.90 | 0.15 | 0.19 |
| NH-06-√n 8,9 | TA 11 | MSC 14 0,0,1,1 | 96 | 2 | 0 | 48.37 | 0.96 | 3.01 | 3.98 |
| NH-06-√n 8,9 | TSS 12 | MSC 14 1,5,5,1 | 96 | 6 | 0 | 31.03 | 0.96 | 1.53 | 1.74 |
| NH-06-√n 8,9 | TSP 13 | SNV 15 2,5,5,1 | 96 | 0 | 0 | 17.11 | 0.78 | 1.99 | 2.32 |
| NH-06-√n 8,9 | pH | MSC 14 2,5,5,1 | 96 | 3 | 2.17 | 4.26 | 0.92 | 0.13 | 0.17 |
| NH-09-1 8 | TA 11 | MSC 14 0,0,1,1 | 42 | 2 | 0 | 45.89 | 0.93 | 3.60 | 4.56 |
| NH-09-1 8 | TSS 12 | MSC 14 1,5,5,1 | 42 | 3 | 0 | 31.57 | 0.87 | 2.24 | 2.66* |
| NH-09-1 8 | TSP 13 | SNV 15 2,5,5,1 | 42 | 2 | 0 | 16.08 | 0.79 | 1.58 | 2.37 |
| NH-09-1 8 | pH | MSC 14 2,5,5,1 | 42 | 1 | 2.25 | 4.29 | 0.94 | 0.16 | 0.18 |
| NH-09-√n 8,9 | TA 11 | MSC 14 0,0,1,1 | 62 | 0 | 0 | 45.95 | 0.93 | 3.77 | 4.36 |
| NH-09-√n 8,9 | TSS 12 | MSC 14 1,5,5,1 | 62 | 3 | 0 | 31.27 | 0.96 | 1.56 | 1.86 |
| NH-09-√n 8,9 | TSP 13 | SNV 15 2,5,5,1 | 62 | 1 | 0 | 17.04 | 0.58 | 2.13 | 2.19 |
| NH-09-√n 8,9 | pH | MSC 14 2,5,5,1 | 62 | 2 | 2.24 | 4.24 | 0.93 | 0.13 | 0.17 |
| HC-1-1 10 | TA 11 | MSC 14 0,0,1,1 | 28 | 2 | 0 | 29.34 | 0.82 | 3.68 | 3.21 |
| HC-1-1 10 | TSS 12 | MSC 14 1,5,5,1 | 28 | 2 | 0 | 31.65 | 0.83 | 2.71 | 3.14 * |
| HC-1-1 10 | TSP 13 | SNV 15 2,5,5,1 | 28 | 1 | 0 | 16.11 | 0.71 | 2.32 | 2.29 |
| HC-1-1 10 | pH | MSC 14 2,5,5,1 | 28 | 1 | 2.20 | 4.25 | 0.87 | 0.20 | 0.19 |
| HC-1-√n 9,10 | TA 11 | MSC 14 0,0,1,1 | 61 | 5 | 0 | 45.94 | 0.96 | 3.01 | 4.37 |
| HC-1-√n 9,10 | TSS 12 | MSC 14 1,5,5,1 | 61 | 3 | 0 | 32.03 | 0.95 | 1.87 | 2.14 |
| HC-1-√n 9,10 | TSP 13 | SNV 15 2,5,5,1 | 61 | 0 | 0 | 16.61 | 0.72 | 1.90 | 2.04 |
| HC-1-√n 9,10 | pH | MSC 14 2,5,5,1 | 61 | 0 | 2.16 | 4.29 | 0.93 | 0.15 | 0.18 |
| HC-05-1 10 | TA 11 | MSC 14 0,0,1,1 | 45 | 1 | 0 | 50.43 | 0.95 | 3.69 | 4.46 |
| HC-05-1 10 | TSS 12 | MSC 14 1,5,5,1 | 45 | 1 | 0 | 31.24 | 0.96 | 1.87 | 1.61 |
| HC-05-1 10 | TSP 13 | SNV 15 2,5,5,1 | 45 | 0 | 0 | 16.53 | 0.77 | 2.03 | 2.18 |
| HC-05-1 10 | pH | MSC 14 2,5,5,1 | 45 | 1 | 2.12 | 4.36 | 0.91 | 0.16 | 0.18 |
| HC-05-√n 9,10 | TA 11 | MSC 14 0,0,1,1 | 74 | 4 | 0 | 44.69 | 0.95 | 3.04 | 4.36 |
| HC-05-√n 9,10 | TSS 12 | MSC 14 1,5,5,1 | 74 | 5 | 0 | 31.78 | 0.97 | 1.38 | 2.08 |
| HC-05-√n 9,10 | TSP 13 | SNV 15 2,5,5,1 | 74 | 3 | 0 | 15.66 | 0.66 | 1.80 | 1.91 |
| HC-05-√n 9,10 | pH | MSC 14 2,5,5,1 | 74 | 1 | 2.17 | 4.33 | 0.91 | 0.14 | 0.18 |
| Set | Reference Parameters | Spectral Pretreatments | N 1 | Toutliers | Min 2 | Max 3 | RSQ 4 | SECV 5 | SEP 6 |
|---|---|---|---|---|---|---|---|---|---|
| FC 7 [13] | TA 10 | MSC 13 0,0,1,1 | 141 | 7 | 0 | 45.06 | 0.96 | 2.72 | 3.89 |
| FC 7 [13] | TSS 11 | MSC 13 1,5,5,1 | 141 | 8 | 0 | 31.40 | 0.97 | 1.23 | 1.61 |
| FC 7 [13] | TSP 12 | SNV 14 2,5,5,1 | 141 | 1 | 0 | 16.34 | 0.77 | 1.77 | 1.97 |
| FC 7 [13] | pH | MSC 13 2,5,5,1 | 141 | 2 | 2.17 | 4.29 | 0.92 | 0.13 | 0.18 |
| NH-47 8 | TA 10 | MSC 13 0,0,1,1 | 47 | 2 | 0 | 52.57 | 0.96 | 3.68 | 4.33 |
| NH-47 8 | TSS 11 | MSC 13 1,5,5,1 | 47 | 1 | 0 | 30.96 | 0.90 | 2.52 | 2.51 * |
| NH-47 8 | TSP 12 | SNV 14 2,5,5,1 | 47 | 3 | 0 | 14.98 | 0.74 | 1.54 | 2.10 |
| NH-47 8 | pH | MSC 13 2,5,5,1 | 47 | 1 | 2.12 | 4.34 | 0.96 | 0.13 | 0.17 |
| NH-71 8 | TA 10 | MSC 13 0,0,1,1 | 71 | 4 | 0 | 45.78 | 0.97 | 2.73 | 4.42 |
| NH-71 8 | TSS 11 | MSC 13 1,5,5,1 | 71 | 5 | 0 | 30.60 | 0.93 | 1.89 | 1.76 |
| NH-71 8 | TSP 12 | SNV 14 2,5,5,1 | 71 | 3 | 0 | 15.74 | 0.66 | 1.72 | 2.13 |
| NH-71 8 | pH | MSC 13 2,5,5,1 | 71 | 2 | 2.26 | 4.24 | 0.90 | 0.13 | 0.19 |
| HC-47 9 | TA 10 | MSC 13 0,0,1,1 | 47 | 1 | 0 | 49.51 | 0.95 | 3.47 | 4.43 |
| HC-47 9 | TSS 11 | MSC 13 1,5,5,1 | 47 | 2 | 0 | 30.50 | 0.94 | 1.71 | 1.76 |
| HC-47 9 | TSP 12 | SNV 14 2,5,5,1 | 47 | 1 | 0 | 16.50 | 0.78 | 1.87 | 2.19 |
| HC-47 9 | pH | MSC 13 2,5,5,1 | 47 | 4 | 2.12 | 4.38 | 0.95 | 0.12 | 0.18 |
| HC-71 9 | TA 10 | MSC 13 0,0,1,1 | 71 | 1 | 0 | 47.90 | 0.93 | 3.87 | 4.55 |
| HC-71 9 | TSS 11 | MSC 13 1,5,5,1 | 71 | 5 | 0 | 31.42 | 0.96 | 1.59 | 1.67 |
| HC-71 9 | TSP 12 | SNV 14 2,5,5,1 | 71 | 0 | 0 | 16.11 | 0.59 | 2.02 | 2.08 |
| HC-71 9 | pH | MSC 13 2,5,5,1 | 71 | 2 | 2.19 | 4.30 | 0.93 | 0.13 | 0.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nogales-Bueno, J.; Rodríguez-Pulido, F.J.; Baca-Bocanegra, B.; Pérez-Marin, D.; Heredia, F.J.; Garrido-Varo, A.; Hernández-Hierro, J.M. Reduction of the Number of Samples for Cost-Effective Hyperspectral Grape Quality Predictive Models. Foods 2021, 10, 233. https://doi.org/10.3390/foods10020233
Nogales-Bueno J, Rodríguez-Pulido FJ, Baca-Bocanegra B, Pérez-Marin D, Heredia FJ, Garrido-Varo A, Hernández-Hierro JM. Reduction of the Number of Samples for Cost-Effective Hyperspectral Grape Quality Predictive Models. Foods. 2021; 10(2):233. https://doi.org/10.3390/foods10020233
Chicago/Turabian StyleNogales-Bueno, Julio, Francisco José Rodríguez-Pulido, Berta Baca-Bocanegra, Dolores Pérez-Marin, Francisco José Heredia, Ana Garrido-Varo, and José Miguel Hernández-Hierro. 2021. "Reduction of the Number of Samples for Cost-Effective Hyperspectral Grape Quality Predictive Models" Foods 10, no. 2: 233. https://doi.org/10.3390/foods10020233
APA StyleNogales-Bueno, J., Rodríguez-Pulido, F. J., Baca-Bocanegra, B., Pérez-Marin, D., Heredia, F. J., Garrido-Varo, A., & Hernández-Hierro, J. M. (2021). Reduction of the Number of Samples for Cost-Effective Hyperspectral Grape Quality Predictive Models. Foods, 10(2), 233. https://doi.org/10.3390/foods10020233