The Oxford Common File Layout: A Common Approach to Digital Preservation

 , , , , and
, , , , and
Abstract
:1. Introduction
2. Lessons from the Community
2.1. Stanford University Libraries
An Introduction to Moab
2.2. University of Notre Dame Hesburgh Libraries
2.3. Emory Libraries
3. Overview of the OCFL
3.1. Digital Preservation
3.2. OCFL Objects
3.3. OCFL Storage Hierarchy
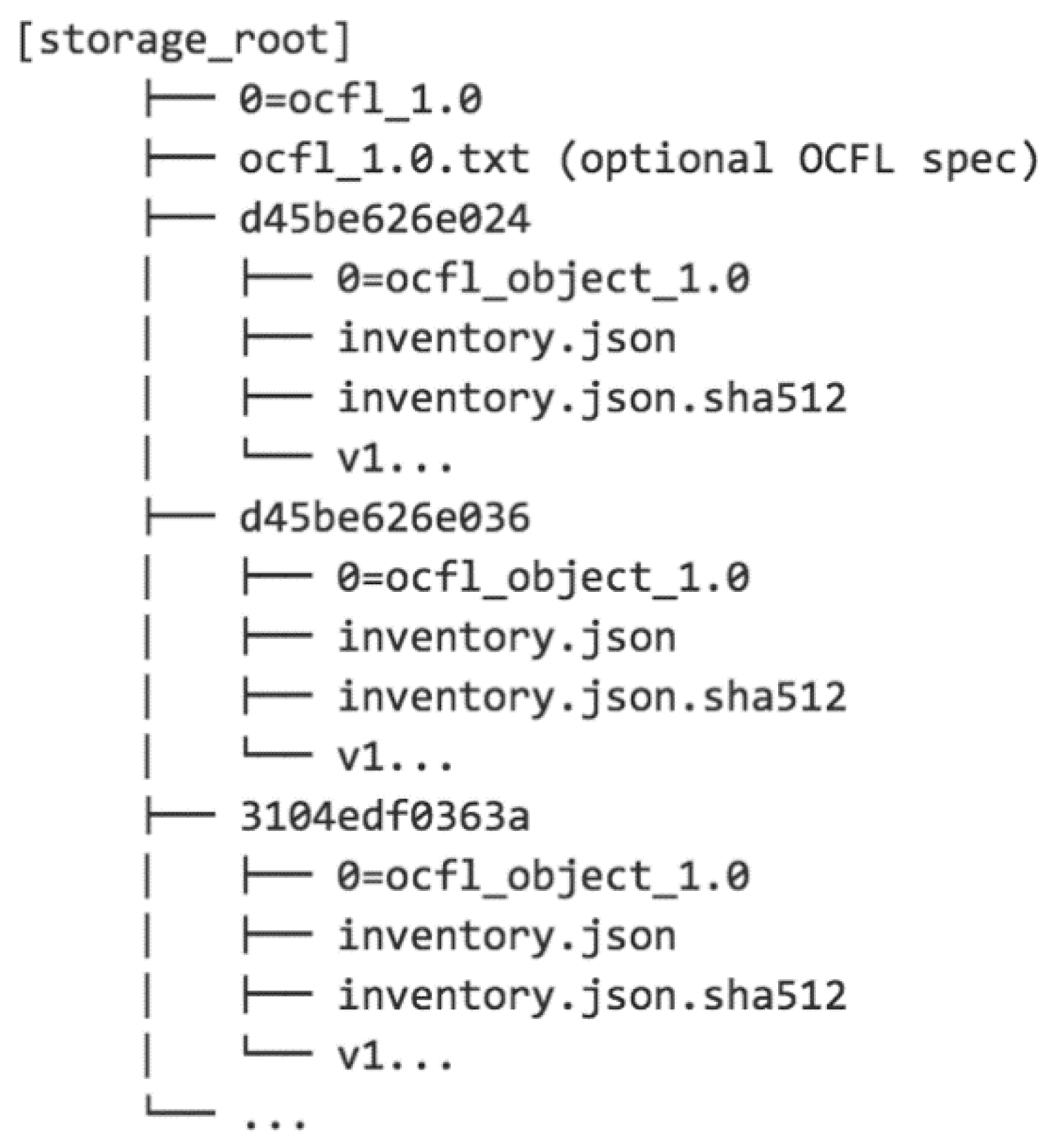
- Flat: Each object is contained in a directory with a name that is simply derived from the unique identifier of the object, possibly with the escaping/replacement of characters that are not permitted in file/directory names. This arrangement is shown in Figure 1. While this is a very simple approach, most filesystems begin to encounter performance issues when directories contain more than a few thousand files, so this arrangement is best suited to repositories with a small number of objects (or many OCFL Storage Roots).
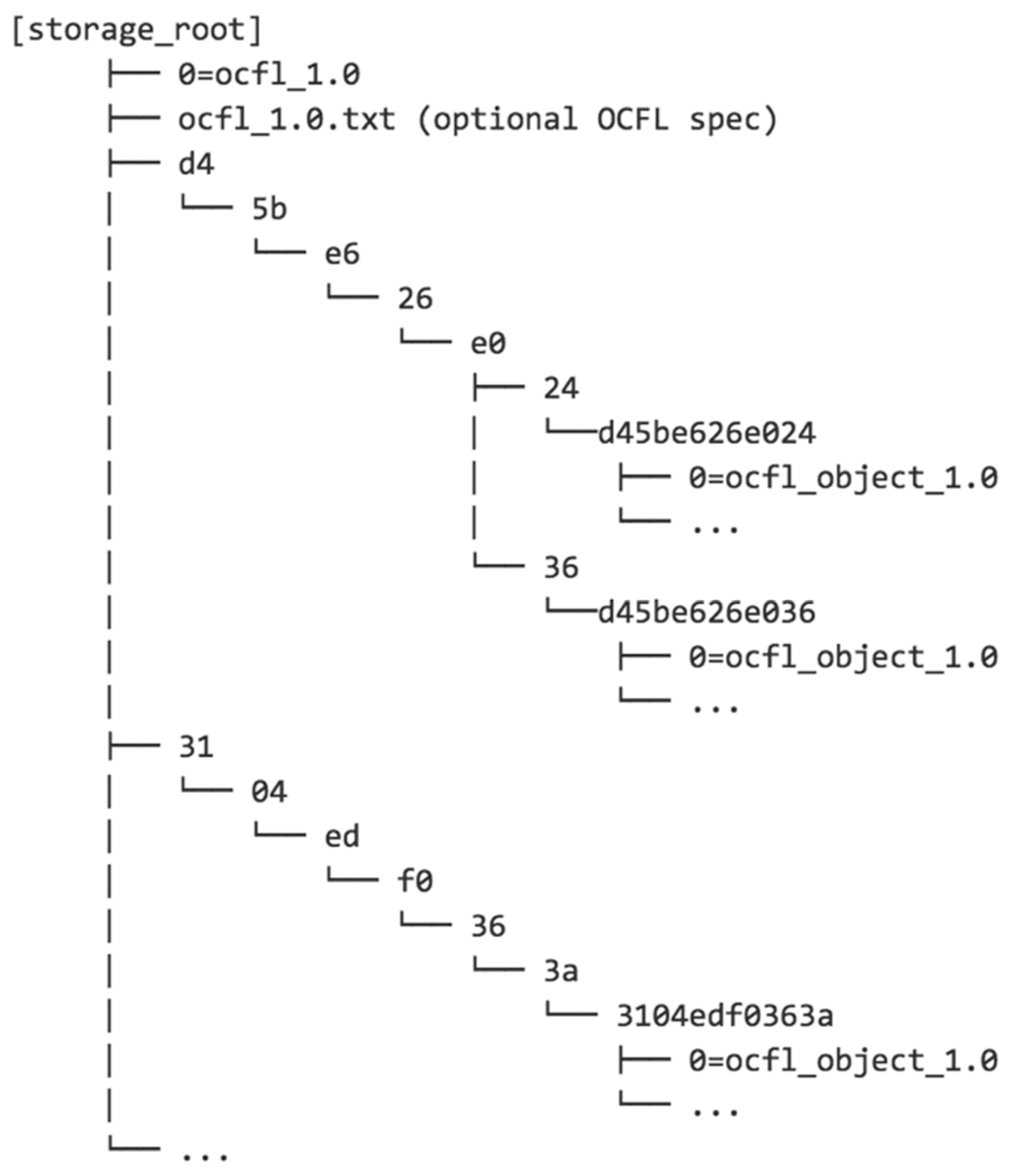
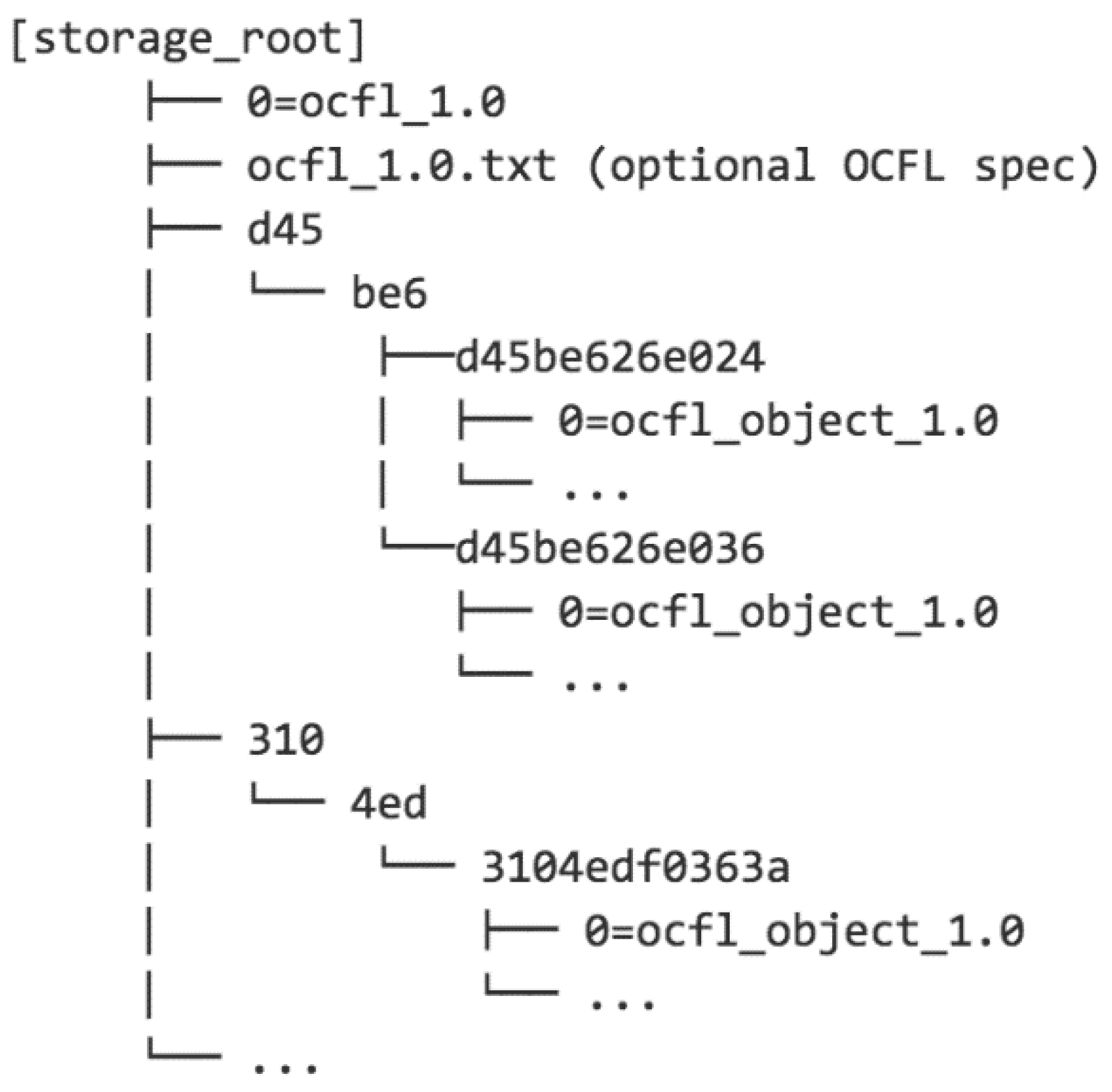
- Pairtree: Designed to overcome the limitations on the number of files in a directory that most filesystems have. It creates a heirarchy of directories by mapping identifier strings to directory paths two characters at a time, as shown in Figure 2. For numerical identifiers specified in hexadecimal, this means that there are a maximum of 256 items in any directory, which is well within the capacity of any modern filesystem. However, for long identifiers, Pairtree creates a large number of directories, which will be sparsely populated unless the number of objects is very large. Traversing all these directories during validation or rebuilding operations can be slow.
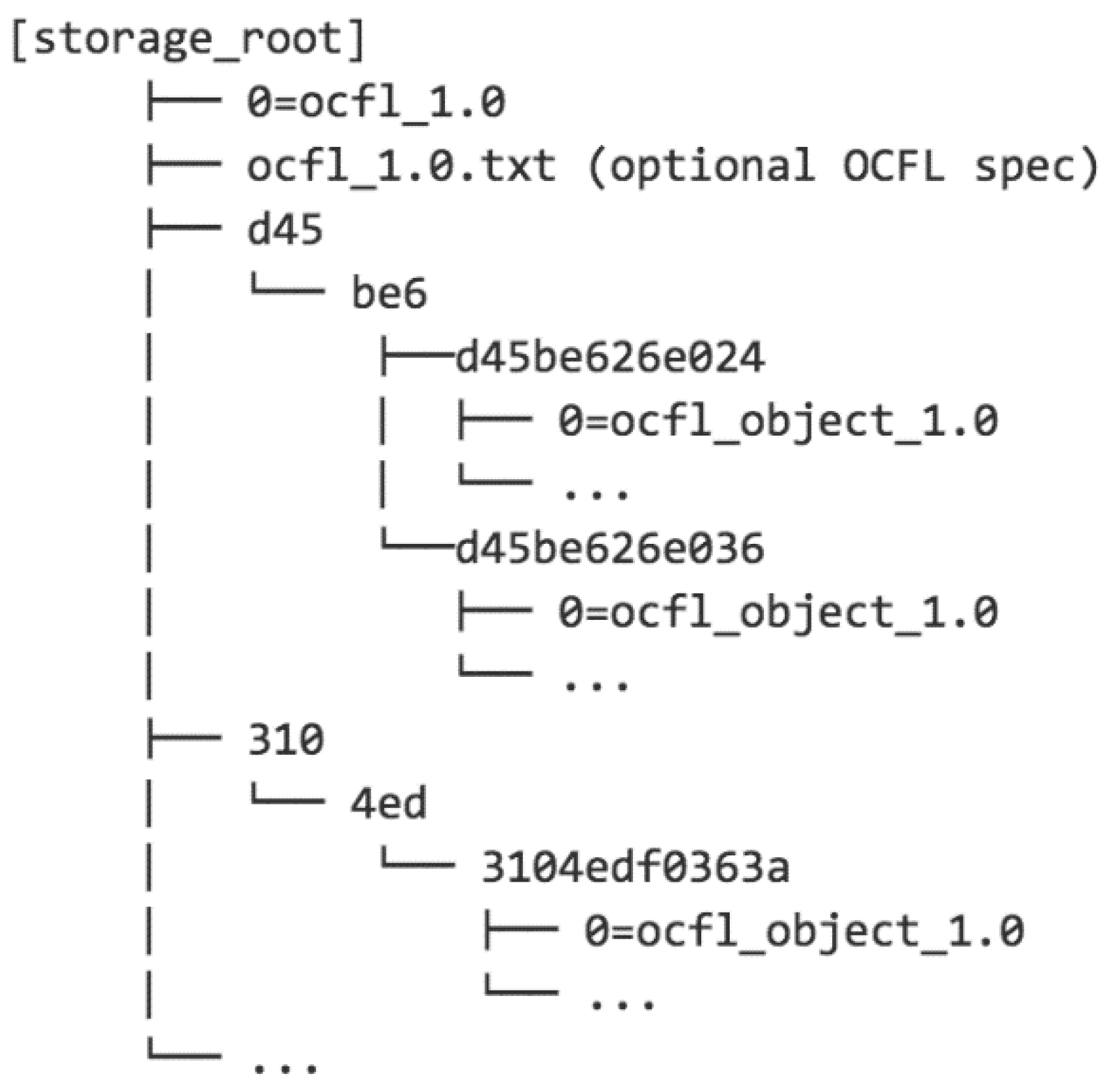
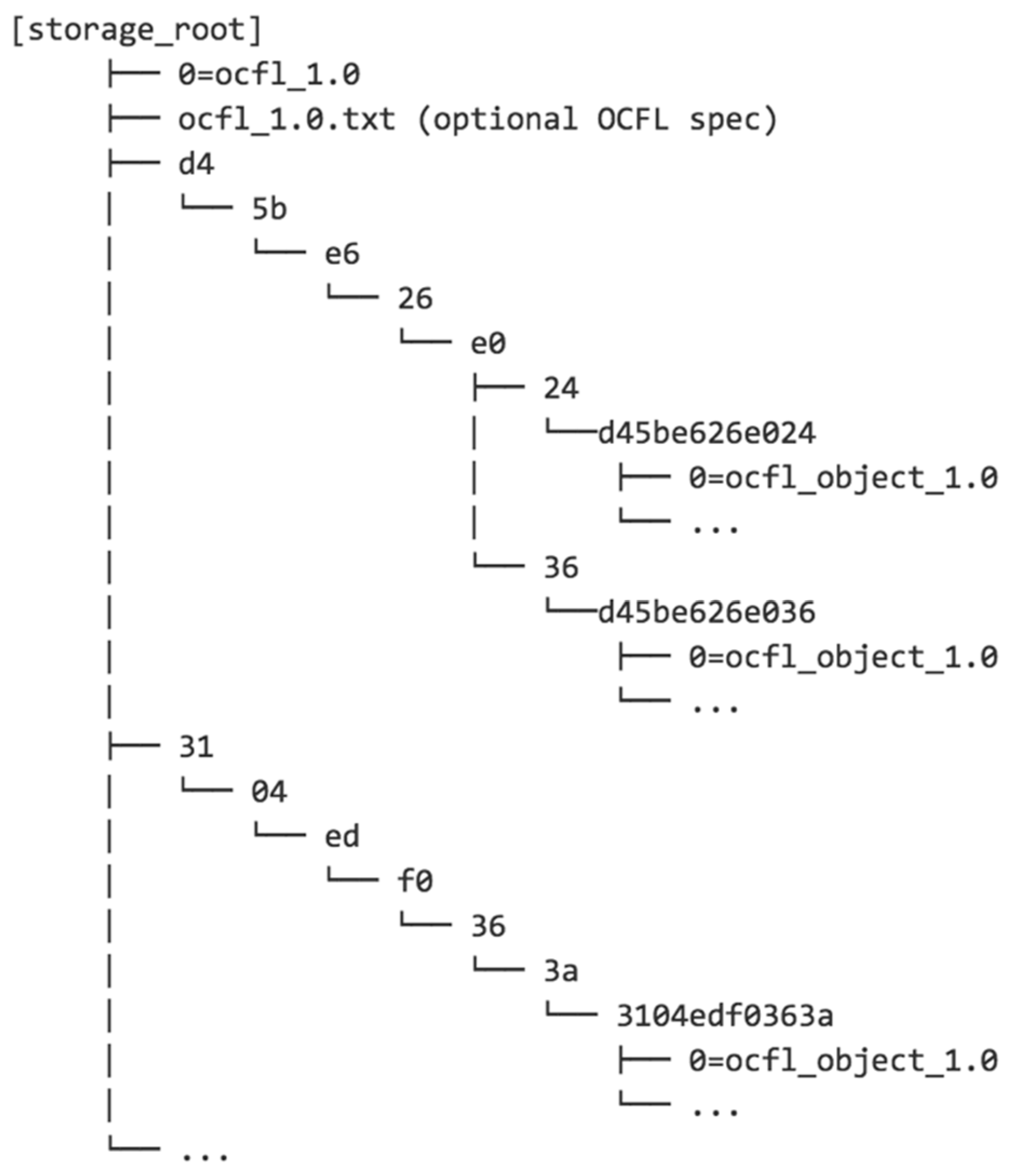
- Truncated n-tuple tree: This approach aims to achieve some of the scalability benefits of Pairtree while limiting the depth of the resulting directory hierarchy. To achieve this, the source identifier can be split at a higher level of granularity and only a limited number of the identifier digits are used to generate directory paths. For example, using triples and two levels with the example above yields the example shown in Figure 3.
3.4. Client Behaviors
- Inheritance: By default, a new version of an OCFL Object inherits all the filenames and file content from the previous version. This serves as the basis against which changes are applied to create a new version. A newly created OCFL Object inherits no content and is populated by file additions.
- Addition: Adds a new logical file path and corresponding new content with a physical file path to an OCFL Object. The logical path cannot exist in the previous version of the object, and the content cannot have existed in any earlier versions of the object.
- Updating: Changes the content pointed to by a logical file path. The path must exist in the previous version of the OCFL Object, and the content cannot have existed in any earlier versions of the object.
- Renaming: Changes the logical file path of existing content. The path cannot exist in the previous version of the OCFL Object, and the content cannot have existed in any earlier versions of the object.
- Deletion: Removes a logical file path (and hence the corresponding content) from the current version of an OCFL Object. The path and content remain available in earlier versions of the object.
- Reinstatement: Makes content from a version earlier than the previous version available in the current version of an OCFL Object. The content must exist in an earlier version and not the previous version. The logical file path may exist in the previous version, effectively updating the file path with older content, or it may not, effectively adding the older content as a new file.
- Purging: Purging, as distinct from deletion, covers the complete removal of content from all versions of an OCFL Object. This is a special case that is not supported as part of regular OCFL versioning operations. An approach to implementing this is covered below.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Oxford Common File Layout Specification. Available online: https://ocfl.io/0.1/spec (accessed on 27 February 2019).
- The Archive Ingest and Handling Test. Available online: http://www.digitalpreservation.gov/partners/aiht.html (accessed on 27 February 2019).
- National Geospatial Digital Archive Project. Available online: http://www.digitalpreservation.gov/partners/ngda.html (accessed on 27 February 2019).
- Cramer, T.; Kott, K. Designing and Implementing Second Generation Digital Preservation Services: A Scalable Model for the Stanford Digital Repository. D-Lib Magazine 2010, 2010; Volume 16, Number 9/10. [Google Scholar] [CrossRef]
- 6.3.1 Archival Information Package (AIP). Available online: https://www.iasa-web.org/tc04/archival-information-package-aip (accessed on 27 February 2019).
- Anderson, R. The Moab Design for Digital Object Versioning. Code4Lib J. 2013. Available online: https://journal.code4lib.org/articles/8482 (accessed on 27 February 2019).
- NetApp Data Compression, Deduplication, and Data Compaction. Available online: https://www.netapp.com/us/media/tr-4476.pdf (accessed on 27 February 2019).
- ZFS Deduplication. Available online: https://blogs.oracle.com/bonwick/zfs-deduplication-v2 (accessed on 27 February 2019).
- Pairtrees for Collection Storage (V0.1). Available online: https://confluence.ucop.edu/display/Curation/PairTree?preview=/14254128/16973838/PairtreeSpec.pdf (accessed on 27 February 2019).
- How Do I Use Folders in an S3 Bucket? Available online: https://docs.aws.amazon.com/AmazonS3/latest/user-guide/using-folders.html (accessed on 27 February 2019).
- MD5. Available online: https://en.wikipedia.org/wiki/MD5#Collision_vulnerabilities (accessed on 27 February 2019).
- We have Broken SHA-1 in Practice. Available online: https://shattered.io/ (accessed on 27 February 2019).
- D-flat. Available online: https://confluence.ucop.edu/display/Curation/D-flat (accessed on 27 February 2019).
- The BagIt File Packaging Format (V1.0). Available online: https://tools.ietf.org/html/rfc8493 (accessed on 27 February 2019).
- File Format Recommendations. Available online: https://wiki.service.emory.edu/display/DLPP/File+Format+Recommendations (accessed on 27 February 2019).
- Preservation Event and Workflow Recommendations. Available online: https://wiki.service.emory.edu/display/DLPP/Preservation+Event+and+Workflow+Recommendations (accessed on 27 February 2019).
- Archival Information Package Recommendations. Available online: https://wiki.service.emory.edu/display/DLPP/Archival+Information+Package+Recommendations (accessed on 27 February 2019).
- Implementation Notes, Oxford Common File Layout Specification 0.1. Available online: https://ocfl.io/0.1/implementation-notes/ (accessed on 27 February 2019).
- OAIS Reference Model (ISO 14721). Available online: http://www.oais.info/ (accessed on 27 February 2019).
- FIPS PUB 180-4 Secure Hash Standard. U.S. Department of Commerce/National Institute of Standards and Technology. Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.180-4.pdf (accessed on 27 February 2019).

{kind=link}
{kind=link}
{kind=link}
| Moab | OCFL |
|---|---|
| Enumerate all version directories in object root | Parse inventory.json in object root |
| Parse every version of manifestInventory.xml and most recent version of signartureCatalog.xml | |
| Cost = 1V+2 | Cost = 1 |
| Moab | OCFL |
|---|---|
| Enumerate all version directories in object root | Parse inventory.json in object root |
| Parse every version of versionInventory.xml, versionAdditions.xml, fileInventoryDifference.xml, and manifestInventory.xml | |
| Cost = 4V+1 | Cost = 1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hankinson, A.; Brower, D.; Jefferies, N.; Metz, R.; Morley, J.; Warner, S.; Woods, A. The Oxford Common File Layout: A Common Approach to Digital Preservation. Publications 2019, 7, 39. https://doi.org/10.3390/publications7020039
Hankinson A, Brower D, Jefferies N, Metz R, Morley J, Warner S, Woods A. The Oxford Common File Layout: A Common Approach to Digital Preservation. Publications. 2019; 7(2):39. https://doi.org/10.3390/publications7020039
Chicago/Turabian StyleHankinson, Andrew, Donald Brower, Neil Jefferies, Rosalyn Metz, Julian Morley, Simeon Warner, and Andrew Woods. 2019. "The Oxford Common File Layout: A Common Approach to Digital Preservation" Publications 7, no. 2: 39. https://doi.org/10.3390/publications7020039
APA StyleHankinson, A., Brower, D., Jefferies, N., Metz, R., Morley, J., Warner, S., & Woods, A. (2019). The Oxford Common File Layout: A Common Approach to Digital Preservation. Publications, 7(2), 39. https://doi.org/10.3390/publications7020039