1. Introduction and Background
Academic libraries are increasingly participating in research data publication and preservation [
1,
2,
3]. However, out-of-the-box institutional repository (IR) systems like DSpace [
4] and Digital Commons [
5] are not designed to publish research data. These systems’ workflows are tailored to articles, which are published once, in a final state. Data workflows tend to be messier: Research data are often published in a preliminary state, then updated with new versions as projects progress [
6] (p. 52). Additionally, many IR systems lack data-specific features such as file-level description and data-specific metadata. Customizing IR systems to meet the needs of data may prevent upgrading to new software versions, because any customizations must be repeated for the new version.
Some repository systems are designed specifically for research data, but they are resource-intensive. Open source systems like Dataverse [
7], CKAN [
8], DKAN [
9], and Samvera [
10] require developer hours and data storage infrastructure. Vendor solutions like Figshare for Institutions [
11] and Tind [
12] require subscription payments, and the resources required to operate a data repository are expended in addition to those required for existing IRs. Many academic libraries now support two repository systems—one for publications, and another for research data. In order to support research data repositories, libraries are either increasing spending by buying vendor solutions, or replicating work by building and managing individual instances of data repository software. In addition, data repository systems require that libraries support permanent storage for the datasets stored within, and research data pose unique digital preservation challenges, including heterogeneous file types and very large file sizes [
13]. As of 2018, there are nearly a thousand data repositories in the United States [
14], many of which provide services and policies that ensure their trustworthiness and suitability for research data. We suggest that small and mid-sized institutions can both conserve their limited resources and increase the discovery of institutional research datasets by directing their researchers to one of these third-party repositories, and then providing local access to the published datasets through a searchable and discoverable index.
2. Dataset Search
This article describes an in-progress project that could provide a solution to the issues outlined above: An open source, scalable, sustainable, and standardized Dataset Search tool that will promote discovery and reuse of research datasets while expending fewer resources than those required for an institutional data repository. Unlike a data repository, the in-progress prototype for the Montana State University (MSU) Dataset Search
1 does not archive research datasets themselves. Instead, it harvests metadata from third-party data repositories that archive research datasets, and serves the metadata via an online interface. To explain further: In the same way that a library catalog does not store actual books, but rather provides metadata so that visitors can find the books, Dataset Search does not store actual datasets, but rather provides metadata so that visitors can find the repositories where the datasets are stored. Dataset Search builds on similar projects such as the Data Catalog Collaboration Project [
16,
17], NIH DataMed [
18], and SHARE [
19], adding three innovations. First, Dataset Search brings an institutional focus to the automated collection of metadata from third-party data repositories. Automated metadata collection allows the index to be populated with metadata for local research datasets with less manual effort from library employees and therefore less resource expenditure from the institution. Second, Dataset Search promotes discovery through leading commercial web search engines. Third, Dataset Search will automatically generate new descriptive metadata for individual datasets using external topic mining of scholarly profile sources like ORCID and Google Scholar Profiles.
3. Implementation
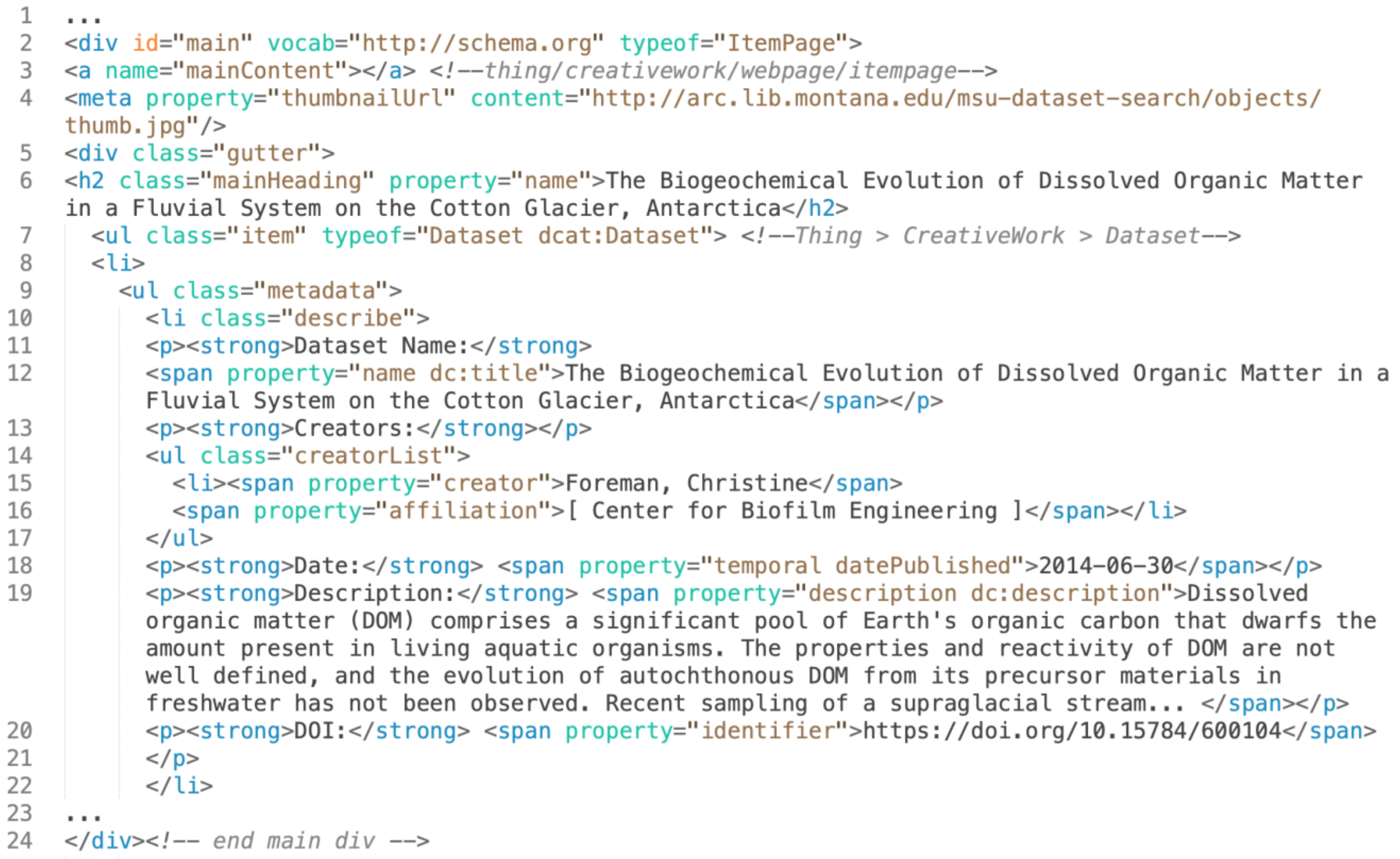
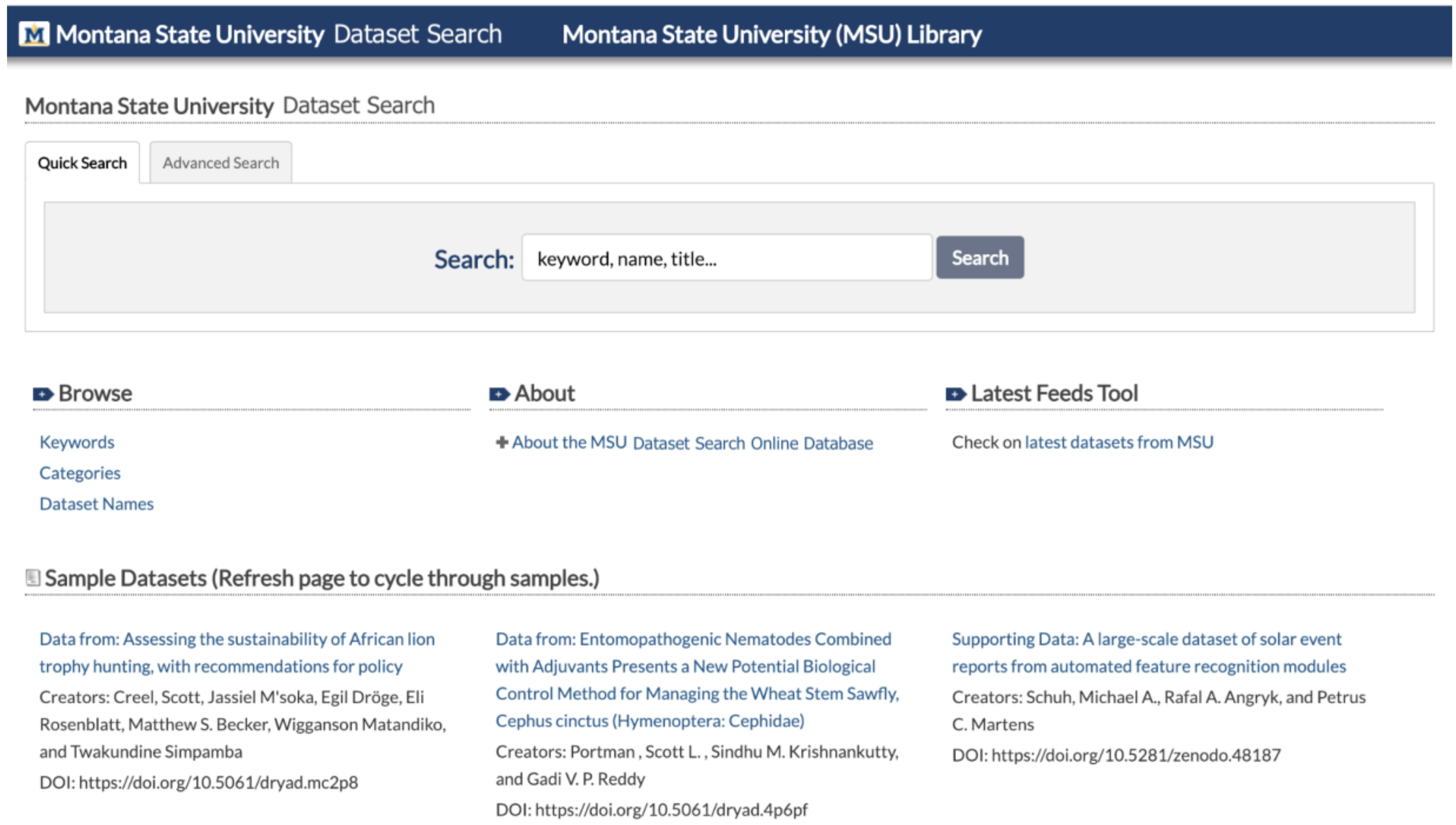
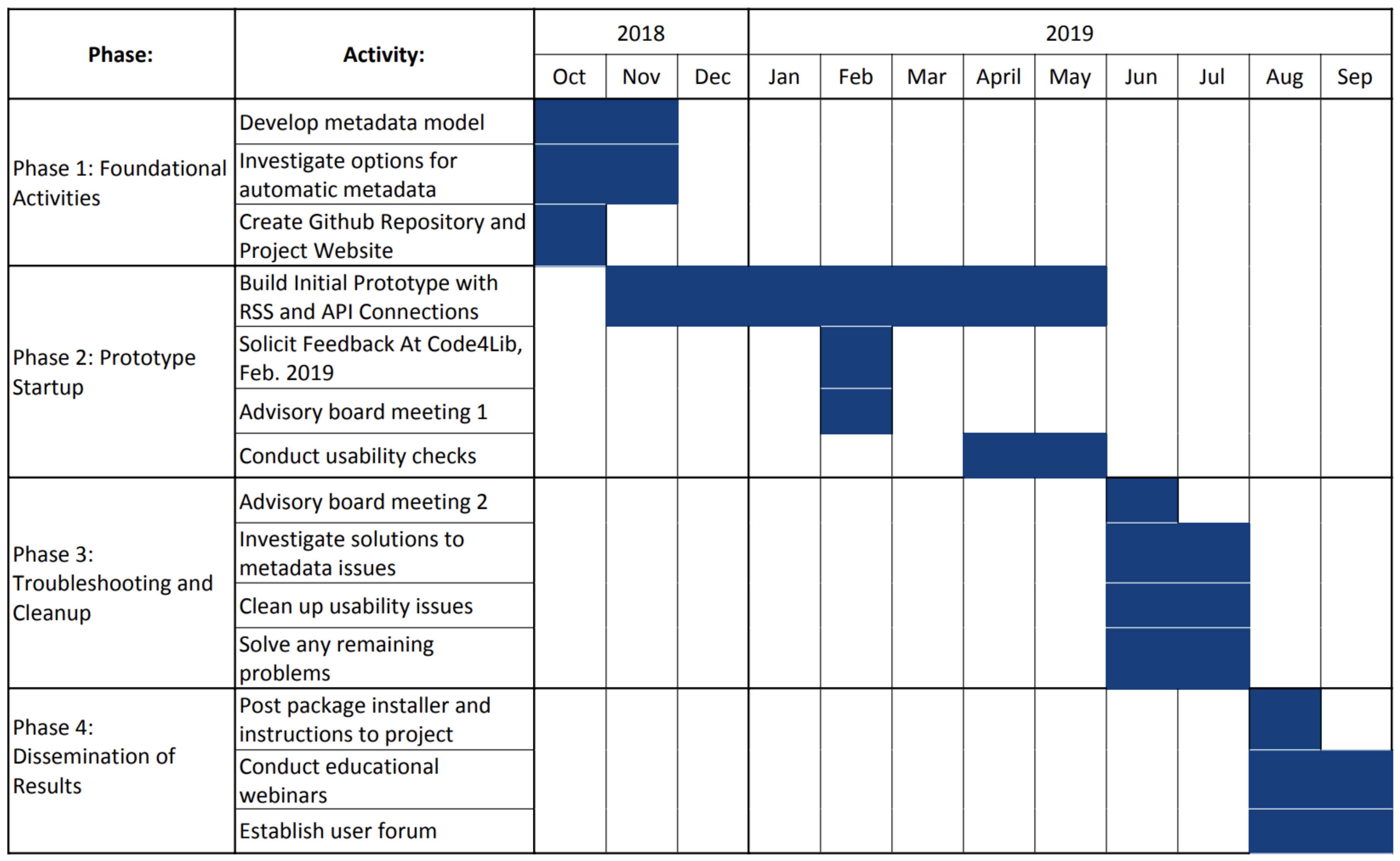
The Dataset Search tool is based on an existing system at MSU Library that harvests citation information for published journal articles [
20]. Dataset Search automatically harvests metadata for MSU-affiliated research datasets using data repository feeds and APIs, which are parsed using PHP scripts. After undergoing deduplication and human curatorial review, metadata records are saved in a local database. A user interface allows users to search and access the metadata records (see
Figure 1). Once the Dataset Search tool is finished, code will be made available in Github [
21] and the project will be shared more widely with the community. Dataset Search is funded by an Institute of Museum and Library Services (IMLS) National Leadership Grant [
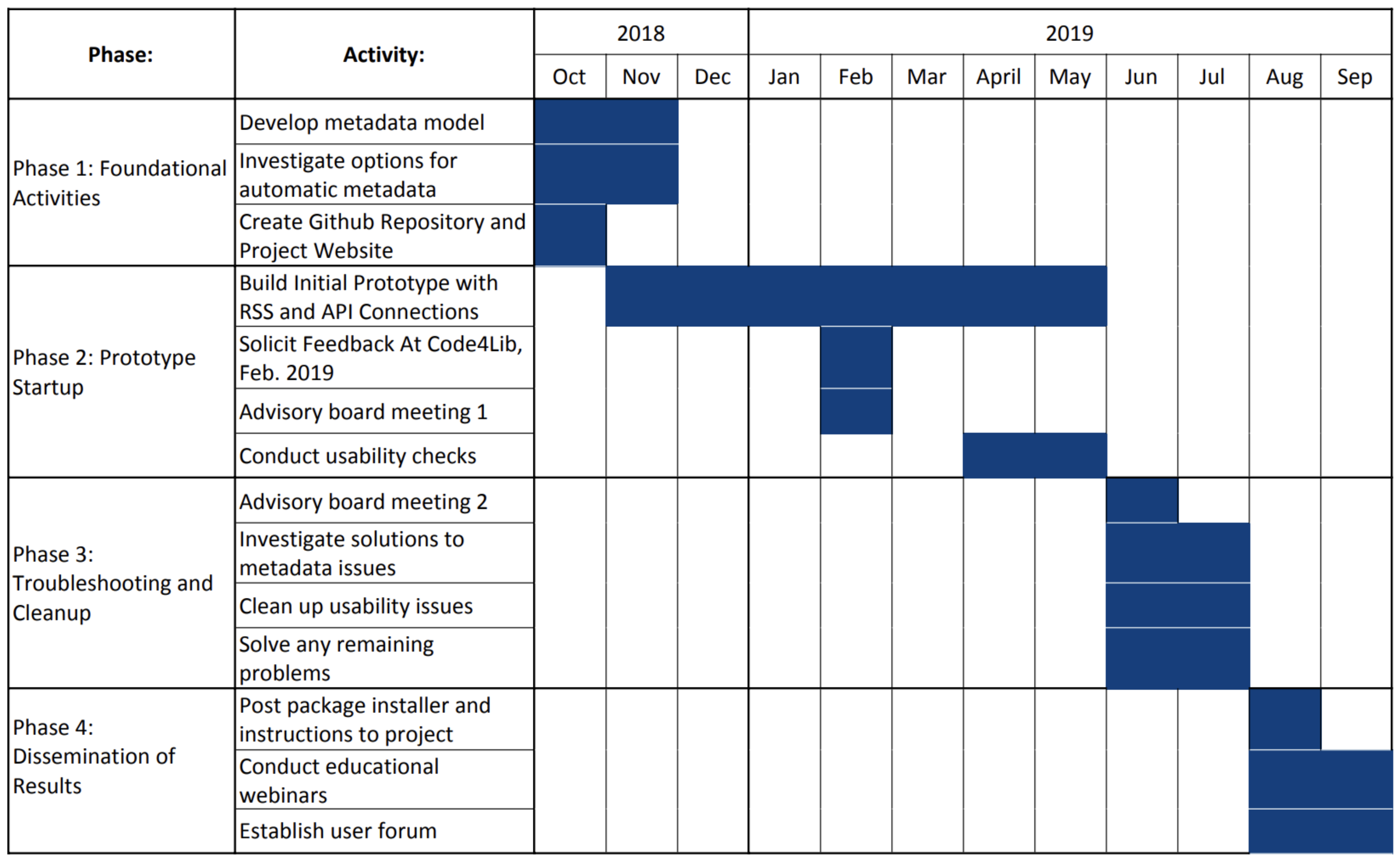
22], with a funding period of one year. As shown in
Figure 2, the project began in October 2018, and will continue until September 2019. As of the writing of this article, the project is approximately at its mid-point.
3.1. Data Repository Automated Feed Harvesting
As of this halfway point in the project, we have created a workflow that programmatically harvests dataset metadata using feed data from various data repositories. As the project continues to progress, a similar workflow will be developed for APIs. For feed data, a list of feed URLs is stored in a “feeds” table in the database and AJAX calls are used to fetch the contents of each feed upon demand. Since the structure of the feed data varies from one feed to another, the Dataset Search tool uses an XML file that contains a map of the XML tag structure of each unique feed to guide it through the harvesting of metadata. This XML file informs the Dataset Search tool of the location within the feed of seven key metadata fields: Repository name, title, description, author, publication date, link (web link to the dataset), and UID (universal ID such as DOI). These seven fields are not mandatory, and metadata records will still be created if some of these fields are not present. Human curators will review each record and fill in missing information if it is available. We are also experimenting with some autogeneration of metadata to help with missing information which we take up in more detail in
Section 3.4.
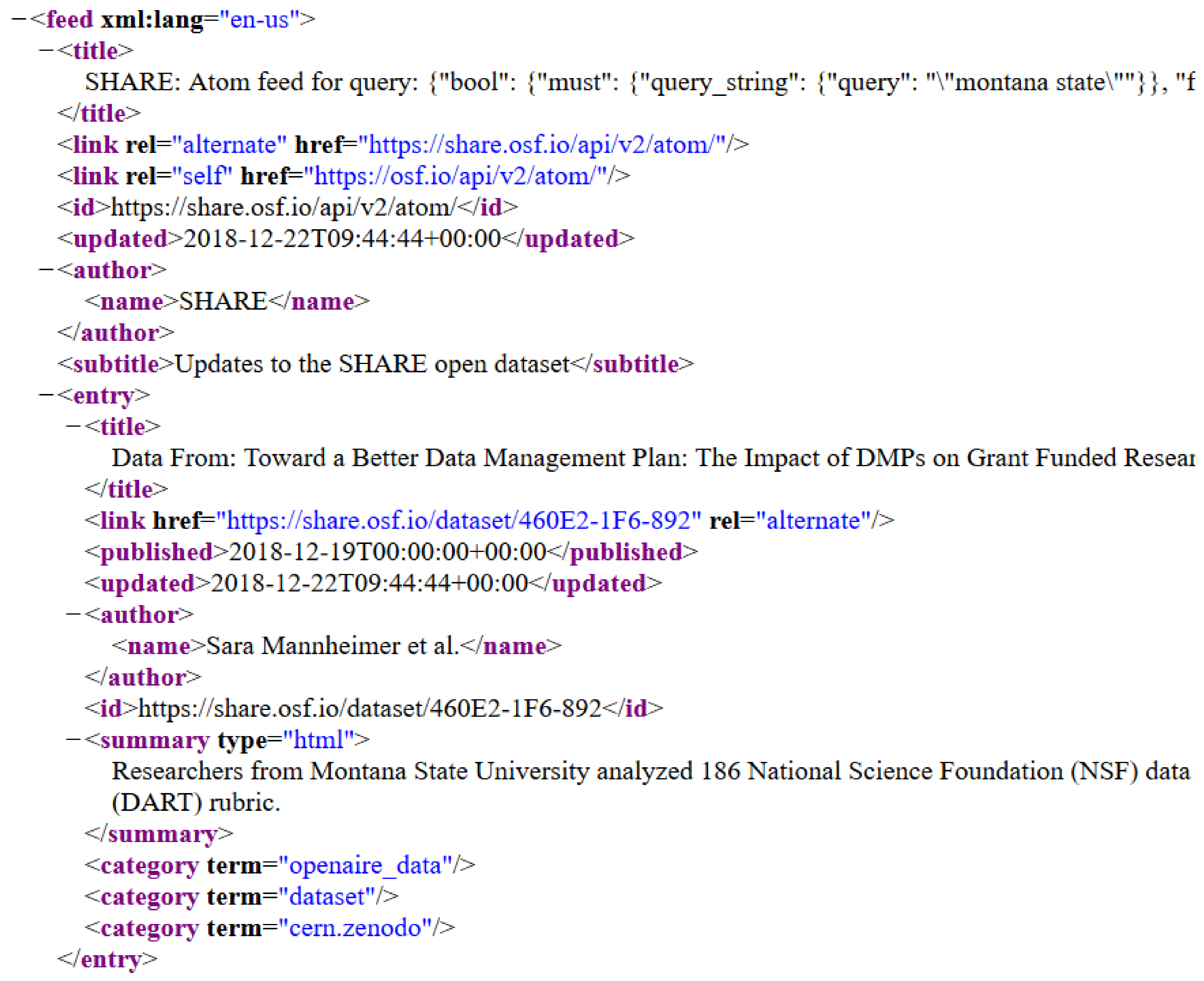
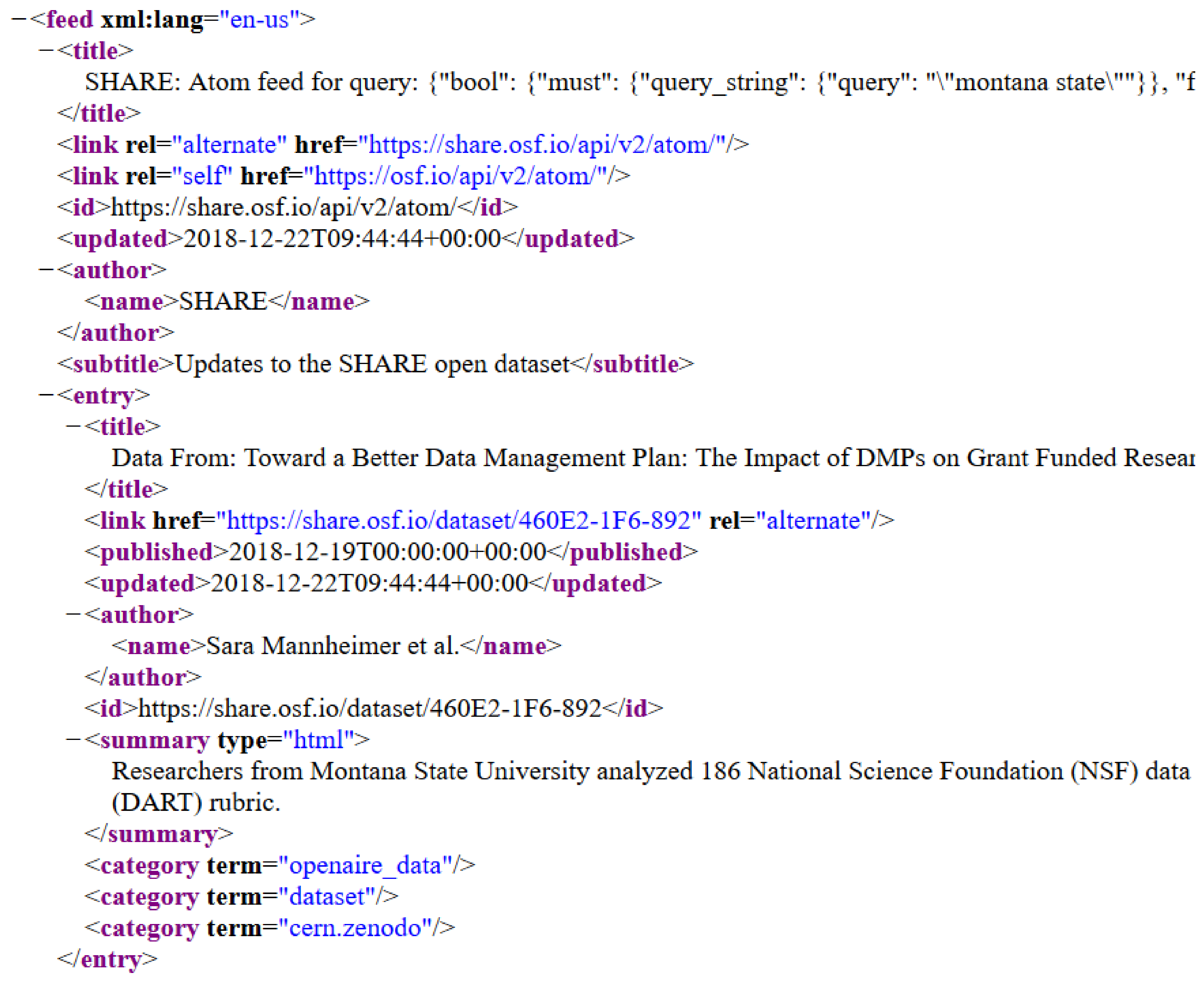
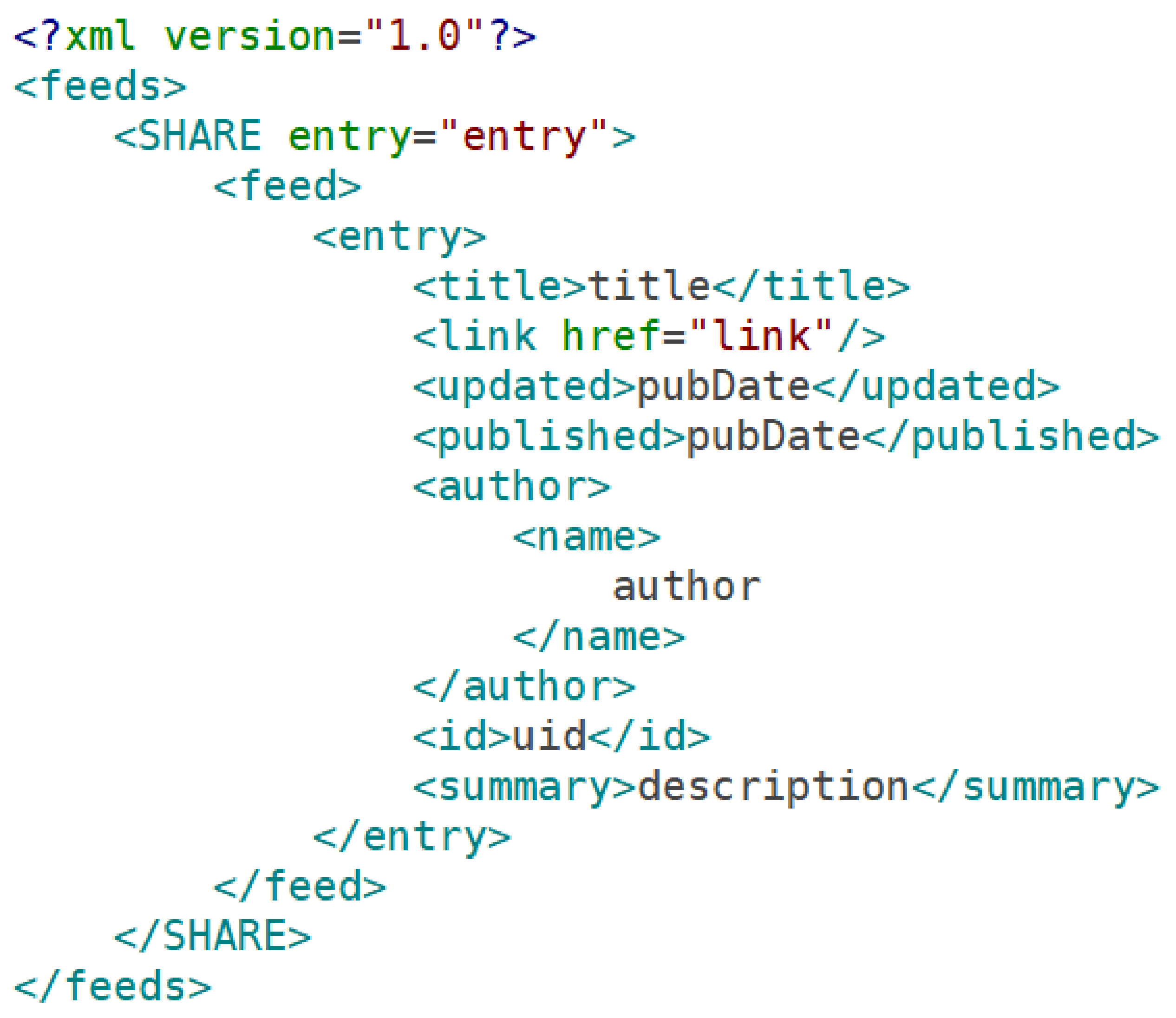
By way of example, consider the excerpt from a SHARE atom feed shown in
Figure 3.
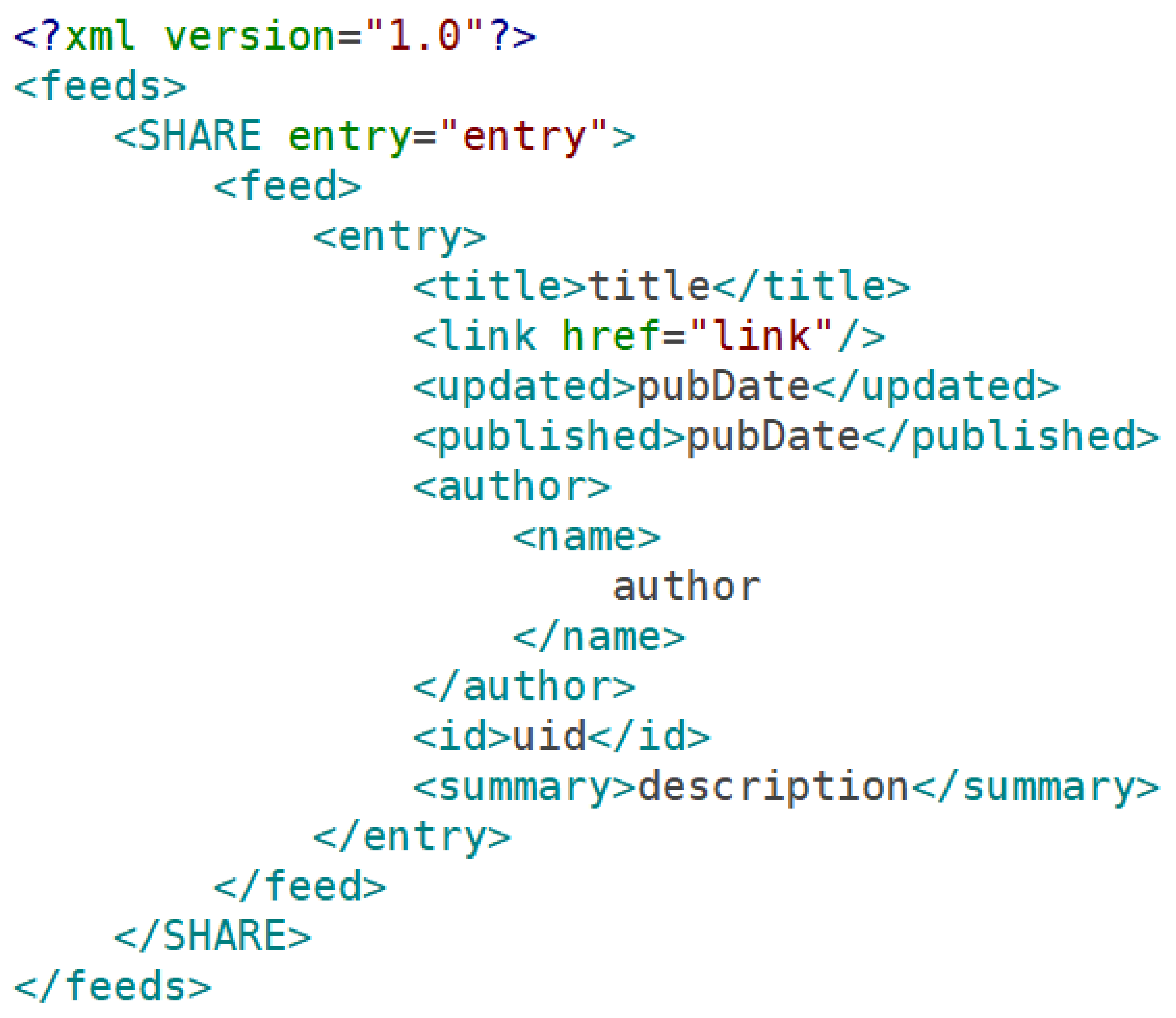
The feed structure shown in
Figure 4, below, maps the locations of the desired metadata elements in the SHARE feed. The Dataset Search tool uses the feed structure XML map to locate each metadata element in the SHARE feed and extract this data into a database record. Before the record is entered into the database, a deduplication process will be performed to ensure that each dataset is entered into the database only once. Since DOIs are unique identifiers, presence of DOI metadata could be used to filter out duplicates. In the absence of DOIs, a dataset title could be used to assist with duplicate detection. Normalization of the titles might be necessary to account for differences involving capitalization, use of ‘and’ versus ‘&’, and use of non-alphanumeric characters. The team has not yet finalized the deduplication process, but has plans to finalize the process by August 2019.
When adding a new data repository for metadata harvest, a new feed structure must be generated. The Dataset Search system will provide a guided interface to lead the user through this process. Once a feed has been introduced to the system, PHP scripts will parse out the relevant tags that contain desired metadata fields. When prompted, users can visually identify these fields, building the feed structure automatically.
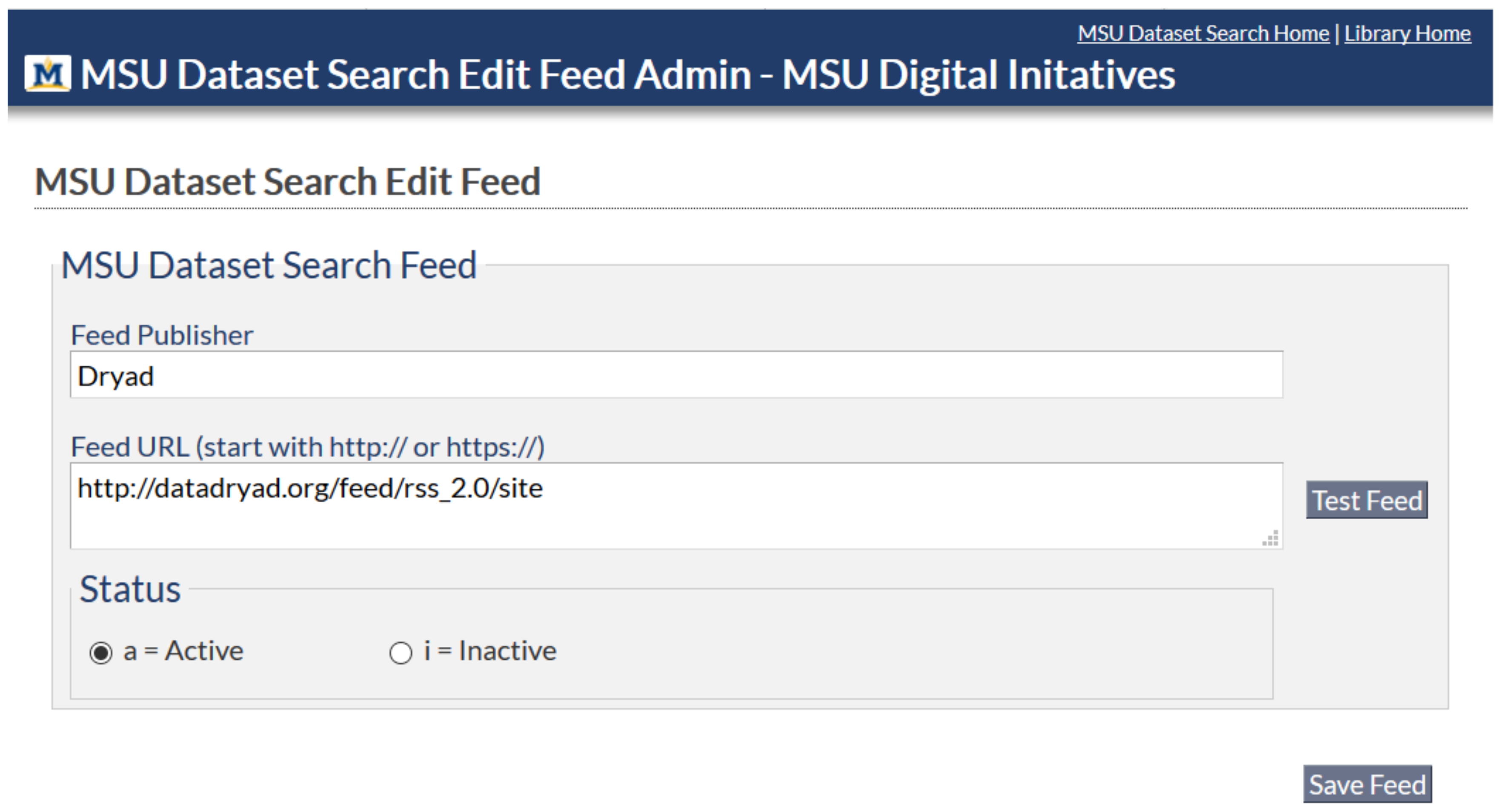
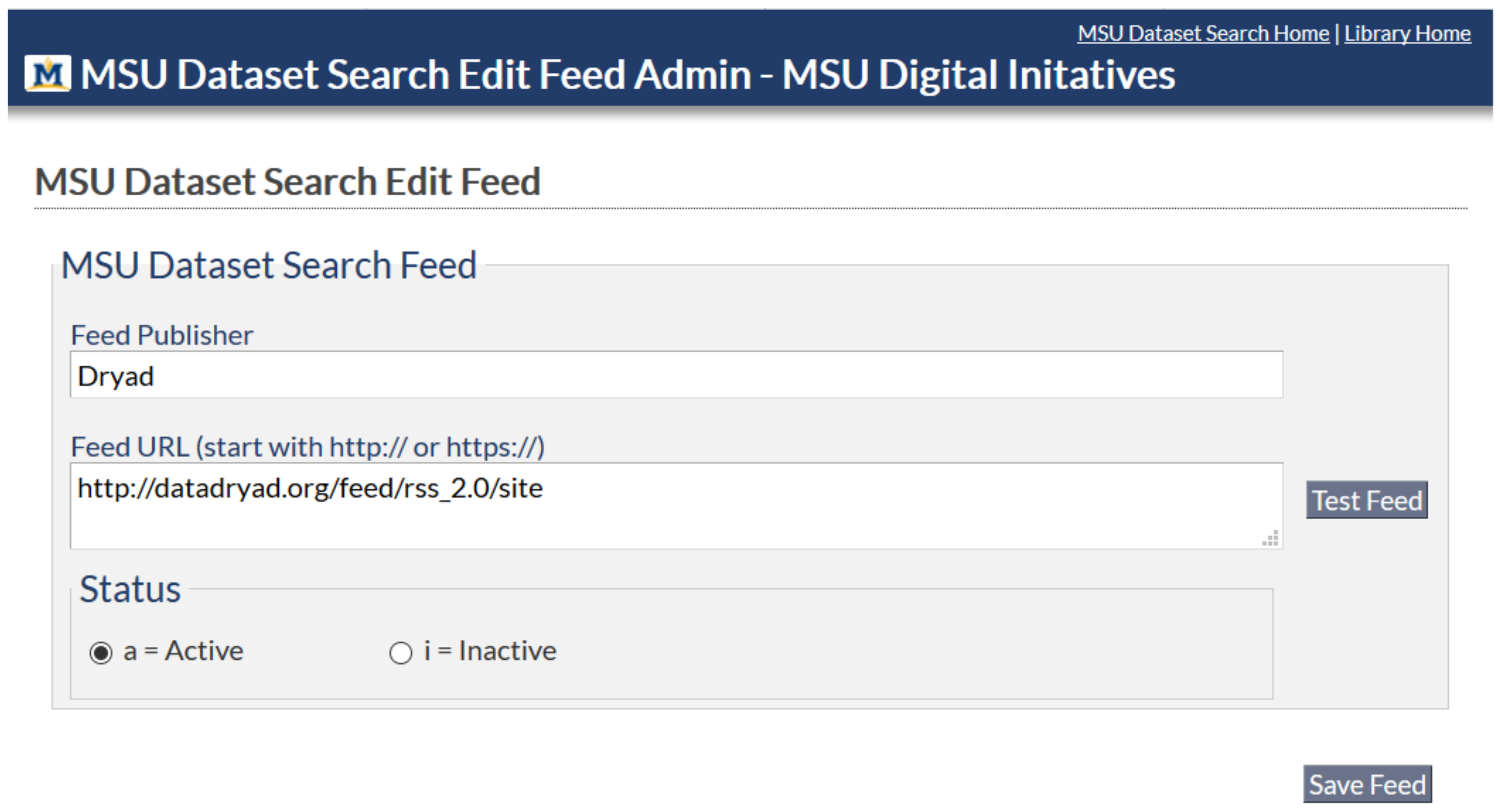
Users wishing to adopt the Dataset Search open source code will first add a selected feed using the Edit Feed web form, as shown in
Figure 5.
Users will then use the guided interface to add an entry to the XML feed structure file (see sample of XML feed structure in
Figure 4). The guided interface is a web form that will assist a user in identification of relevant feed tags and creation of the new entry for the XML feed structure file.
3.2. Repository Selection
It would be impossible for the Dataset Search tool to harvest the nearly one thousand data repositories in the United States. The project team will initially focus on harvesting other data repository aggregation sites such as DataCite, SHARE, and DataMed, in an effort to access more repositories with fewer APIs. In addition, we will create selection criteria for harvesting repositories that are most likely to include MSU-affiliated research datasets. The project team will conduct a survey of researchers at MSU to ask where they publish data, and will include the most commonly-used repositories in our prototype. The Dataset Search homepage will include a form where users can suggest additional repositories to be harvested, or send links to published datasets that were missed by the automatic harvesting.
3.3. Metadata Model
The system includes a metadata model informed by Schema.org [
23], DataCite [
24], DATS [
25], and Project Open Data [
26] metadata schemas. For reference, the complete metadata model is available in our MSU Library GitHub repository for the Dataset Search [
21]. Our goal was to build the metadata for two purposes: Inventory and discovery. Given the aggregating goals of the Dataset Search, our first metadata goal was to create a data model that allowed us to collect and analyze dataset production by MSU faculty and researchers. A “Creators” table allows us to collect author data and accommodates an arbitrary number of authors for datasets with multiple authors. An “Affiliations” table includes an ID field to help disambiguate our faculty and a discipline/department field to help us understand where common research that involves data is occurring. We also included a “Datasets” table to help catalog and describe the characteristics of the dataset itself.
Figure 6, below, shows all of the present fields in the “Datasets” table. Of note here, are the ‘dataset_RepositoryName’ and ‘dataset_doi’ fields which allow us to understand the provenance of the dataset and where our faculty and researchers are depositing data. We are also watching for times when we can control the vocabulary of our metadata fields. For example, repository names can be variable, and we are considering a level of human review to standardize this metadata or using the prefix of the DOI [
27], which contains a registrant code that could be potentially used to identify the contributing repository and map it to a standardized repository name.
Beyond the inventory and analysis goal for the metadata, we looked to create metadata that would help our data become part of commercial search engine indexes. In this instance, we turned to Schema.org, a controlled vocabulary of properties and types created by commercial entities (Google, Bing, Yandex, etc.) that can be embedded in HTML to allow for search engine indexing, to inform our data model. The “Dataset” entity [
28] was our guiding principle here and you can see fields like ‘dataset_TemporalCoverage’ and ‘dataset_SpatialCoverage’ as a means to qualify the data for search and browse environments. Most importantly, we built a sitemap.xml file [
29] to list all of the data items in our catalog and embedded the Schema.org Dataset properties as RDFa structured data [
30] in our item pages as seen below in
Figure 7.
This sitemap and the RDFa structured data will allow search engines to index our Dataset Search items and we have begun benchmarking the search indexes of Google, Google Dataset Search, and Bing to record the results.
3.4. Unique Metadata Generation
During harvesting, the team also recognized one of the primary limitations of our processing: Limited and variable metadata from the source feeds. There were times during harvest where we noted missing dates, abridged titles, or limited descriptions. In
Section 3.1 above, we spoke to a set of seven key metadata fields that we built into our initial metadata records and our interest in supplementing records when data were missing. We also found another unique problem inherent to datasets: They do not exist as textual narratives to analyze. Tabular data tends toward the numerical, especially in the STEM disciplines. With both of these conditions in mind, the team talked through some additional means of creating metadata from datasets and came up with an experimental approach to conduct topic modeling on the dataset creator after the initial harvest and creation of a metadata record. The process we followed is described in detail below.
Creators could be matched to various academic social networking websites, such as ORCID.org, LinkedIn, or Google Scholar Profiles.
Once matched, each of these scholarly profiles is harvested using a web scraping routine and converted into a “bag of words” for topical analysis.
The profiles are analyzed and the topics are derived with the top 5 topics becoming an initial set of subject keywords stored in the schema.org “Keywords” property within the metadata record.
As of this writing, this automated metadata generation shows some potential, but we will continue to test and work through the utility of the method. We have some additional ideas about how entity recognition on these same scholarly profiles could be applied to populate our ‘dataset_category’ fields with linked data. All of these threads are potentially part of a metadata improvement solution. As we refine the methods, we plan on releasing the scripting routine as part of the GitHub repository [
21].
3.5. Search Engine Optimization
To promote discovery of Dataset Search metadata for commercial web search engines, we will follow the steps outlined in Arlitsch and O’Brien [
31], intended to be used to optimize search engine indexing for institutional repositories. First, sitemaps will be submitted via Google Search Console (Formerly Google Webmaster Tools). Then, through Search Console analysis, errors generated during Google crawls will be identified and improvements will be implemented such as: Improving server performance; implementing unique title and description tags containing the paper’s name and abstract; implementing “rel = canonical” tags indicating the preferred URL of each digital object. Second, metadata will be tailored to Google Scholar inclusion guidelines, including: Mapping data repository metadata to Google-supported Highwire Press tags; adding Highwire press meta tags to each index item page.
Google also avoids harvesting sites that it perceives to be “link schemes” [
32]. As an index site that provides metadata and links to research data in third-party data repositories, Dataset Search may appear to be a link scheme to Google crawlers. Google suggests two workarounds, intended to help facilitate pay-per-click advertising: Adding a “rel = nofollow” attribute to the <a> tag; redirecting the links to an intermediate page that is blocked from search engines with a robots.txt file. We plan to use a third strategy to promote content to Google crawlers: Autocreating a PDF cover page for each record harvested by the Dataset Search tool. The cover page will contain research dataset metadata and a link to both the third-party data repository and to the Dataset Search results page.
Figure 8 shows a mockup of a sample dataset cover page.
These PDF cover pages will be stored alongside the Dataset Search metadata, requiring more storage space than the simple metadata files. The team will continue to weigh these risks (increased storage requirements) and benefits (search engine optimization) once the Dataset Search tool goes live.
4. Limitations and Challenges
Over the course of the development of the Dataset Search prototype thus far, we have identified several limitations and challenges.
4.1. API Harvesting
Many data repositories provide an application programming interface (API) for harvesting instead of a feed. To guide the harvesting process from data repositories that employ APIs, we are planning to implement an XML mapping file similar to the one used for feeds. However, unlike feeds, APIs do not have a standardized structure. This could prove to be problematic. There are many possible API methods that could be employed by data repositories, and therefore many different XML maps and workflows that would need to be implemented in order to harvest APIs.
4.2. Institutional Affiliation
Another key challenge for this project is that data repositories may not require disclosure of institutional affiliation. Without institutional affiliation in the data repository metadata, it is difficult to automatically harvest institution-specific content. We are able to obtain a list of researcher names from MSU’s Office of Planning and Analysis, and we hope that we can harvest MSU-affiliated datasets by searching for these names, then using the researchers’ disciplines to filter the results. ORCID usage is also increasing, and could provide a partial solution; the data repository Zenodo is one notable adopter of ORCID integration.
4.3. Completeness of Content
The two challenges discussed above lead to a third challenge. Ideally, Dataset Search would index every research dataset available from researchers at our institution. However, the challenges with API harvesting and discovering institution-specific datasets will likely prevent the Dataset Search tool from building a fully comprehensive index. However, the Dataset Search will provide a representative sample of datasets from our institution that can be analyzed and inventoried.
4.4. Topic Modeling
We also recognize the limitations behind the methods inherent to our generation of metadata using topic modeling. Our inference of topics from academic social networks we scrape offer a potentially new view into the subjects that make up our datasets, but there are some concerns over how this a priori harvest of researcher profiles could lead to metadata that is less precise and even describing the researcher rather than the dataset. A supplementary quality control method here would be to test this initial metadata topic generation against a topic modeling of the completed metadata records for the datasets themselves. We plan to continue this line of thought and run some topic model testing, but we do maintain that even topics that modify a researcher’s primary interests will be of some value in inventory and discovery settings. Even further, researchers have noted how topic modelling methods apply a naïve model of a text as a collection of words decoupled from their syntactic and grammatical contexts of use [
33]. We can address this naïve model when we look at the generated topics and consider them in the context of the researcher profile documents (e.g., introduce an element of metadata quality control for these topics before finalization of the descriptive record). All of these challenges are within our research scope and we will look to address these questions whenever it makes sense in the project development. In the end, we still view the topic model method as valid and providing significant enhancement to our metadata generation and automation.
4.5. Local Data Publishing Needs
Another challenge for libraries is that institutional data repositories are often used to archive institutional research data that does not neatly fit into disciplinary data repositories—for example, student research data or very large datasets. Since the Dataset Search tool is not a data repository, but rather a metadata index, it is not designed to store local datasets. This complexity requires multiple solutions, depending on the data itself. For example, student data can be archived in data repositories like Zenodo or Figshare, which are free of cost and have broad collecting policies that can support a wide range of submissions. And the resources saved by foregoing building a local data repository could allow MSU to pay into membership programs for data repositories like Dryad, and to subsidize the cost of archiving large datasets in third-party repositories that can support publishing large datasets—for example, Dryad, Dataverse, and Figshare can publish more than 1TB of data for an additional fee [
34].
5. Future Work and Implications
The Dataset Search project is a work-in-progress, and our team is only at the midpoint of our development timeline. The current work of the project is focused on creating the feed and API harvesting workflows for the prototype. In the future, we hope to expand the project to create custom reporting for different MSU departments, develop user access for faculty/students to be able create and update their own records in the system, and to build a JSON-LD API to enable structured data reuse for developers [
35]. We also plan to share the prototype more widely with a package installer for local installations.
The project team is also in conversation with university IT about providing metadata records for datasets at our institution that are not publicly available. Providing access to such “invisible” datasets was identified as a challenge by Read et al. in 2015 [
36]; the Data Catalog Collaboration Project [
37] is one example of a project whose mission includes providing metadata records for nonpublic datasets. In the future, we hope that the Dataset Search tool will be able to provide metadata records as a discovery point for in-progress, sensitive, or otherwise restricted datasets. This feature would provide broader discovery and access to all datasets created by researchers at our institution, even those that are not available in data repositories.
The Dataset Search idea also has implications beyond the local tool that our team is developing. With wider adoption, Dataset Search could lead to three key impacts: (1) Increased discovery and reuse of academic research data; (2) promotion of research data as a scholarly product; and (3) potentially leveraging economies of scale through community-wide implementation. These impacts are discussed in more detail below.
First, an exploratory study conducted by the first author suggests that data are more likely to be discovered and reused if they are (1) archived in a discipline-specific repository; and (2) indexed in multiple places online [
38]. The Dataset Search tool will allow research data to be published in subject-specific repositories while additionally being discoverable in a local index. This would promote increased discovery, reuse, and citation of academic research data, ultimately leading to data reuse and potentially increased citations to associated articles [
39].
Second, the Dataset Search tool will reinforce the idea that research data is a legitimate scholarly product, both by interoperating with institutional research information management systems, and by creating a public interface where institutions can showcase data as a scholarly product.
Lastly, in a time of tight budgets in universities, economies of scale become increasingly important. The Dataset Search prototype has the potential to be adopted community-wide, creating a single system that can be used across academic libraries while requiring less resource expenditure. By working together to build a system that can be administered by the community at large, rather than building individual systems that are replicated at each university, our profession can make bigger, better systems that promote an important library mission—to provide discovery and access for scholarly products.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}