Multi-Link Fragmentation-Aware Deep Reinforcement Learning RSA Algorithm in Elastic Optical Network


Abstract
1. Introduction
- Unlike other studies that evaluate spectrum fragmentation only on the links within the current candidate path, the MFDRL-RSA algorithm focusses on multiple links along different paths. Since spectrum fragmentation of links can influence each other, focusing on the candidate path may ignore the impact of allocation decisions on subsequent requests. In contrast, the multi-link fragmentation degree offers a more holistic and effective assessment of global allocation.
- We propose a breadth-first numbering (BFN) algorithm to ensure that the network state matrix constructed based on link numbering can represent the connectivity of links. This is crucial for correlating the multi-link fragmentation degree in the MFDRL-RSA algorithm with the distribution of network resource.
2. Related Work
3. Multi-Link Fragmentation Deep Reinforcement Learning-Based Routing, Modulation, and Spectrum Allocation Algorithm
3.1. Problem Formulation
3.2. Environment Perception Information State
3.3. Action
3.4. Reward
| Algorithm 1: Breadth-first numbering |
| 1.; |
| 2. ; |
| 3. ; |
| 4. do |
| 5.; |
| 6. do |
| 7. then |
| 8. ; |
| 9. end |
| 10. based on the number of adjacent links at the other end node; |
| 11. do |
| 12. as numbered; |
| 13. ; |
| 14. end |
| 15. ; |
| 16.end |
3.5. Training
| Algorithm 2: Training process of MFDRL-RSA algorithm |
| 1.; |
| 2.for every request do |
| 3. then |
| 4.; |
| 5.; |
| 6.; |
| 7. ; |
| 8. ; |
| 9. then |
| 10. do |
| 11. ; |
| 12. end |
| 13. ; |
| 14. ; |
| 15.end |
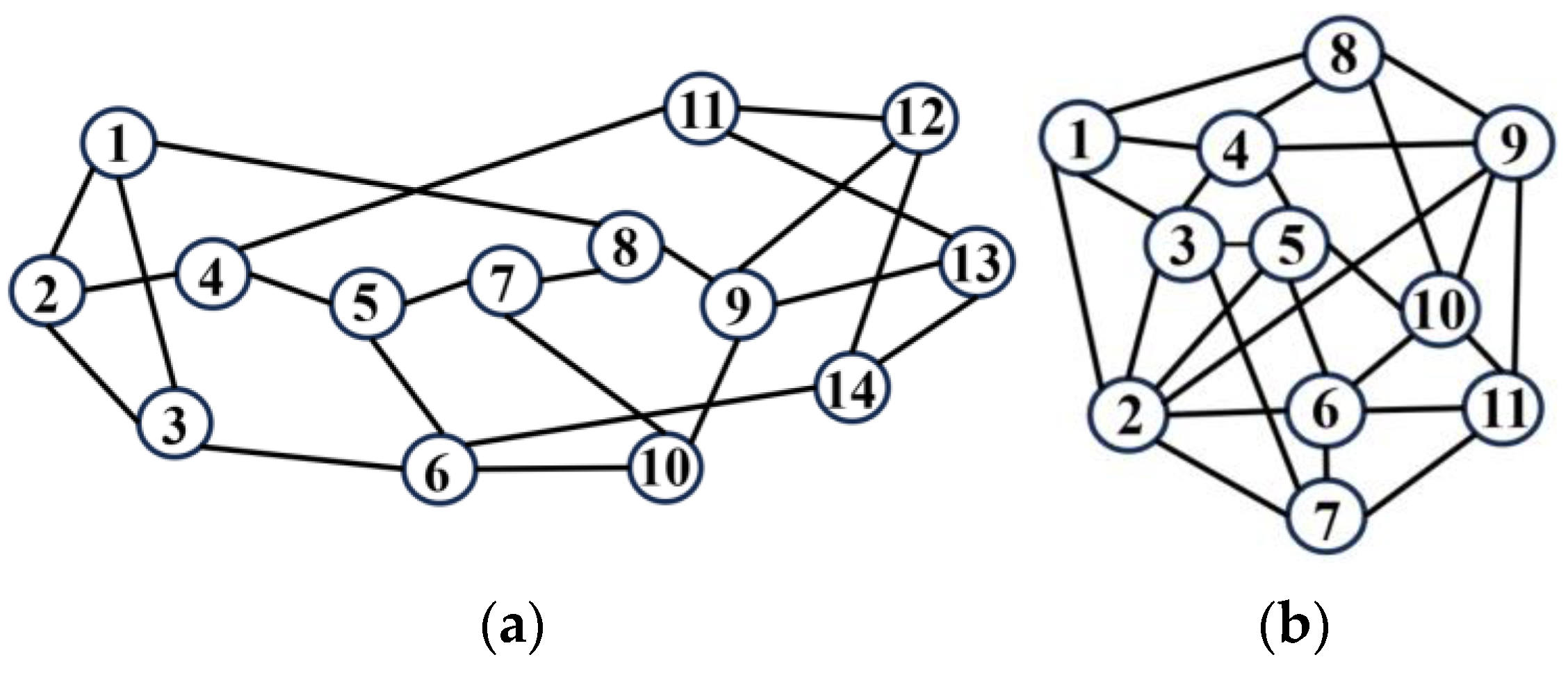
4. Simulation and Analysis
4.1. Simulation Setup
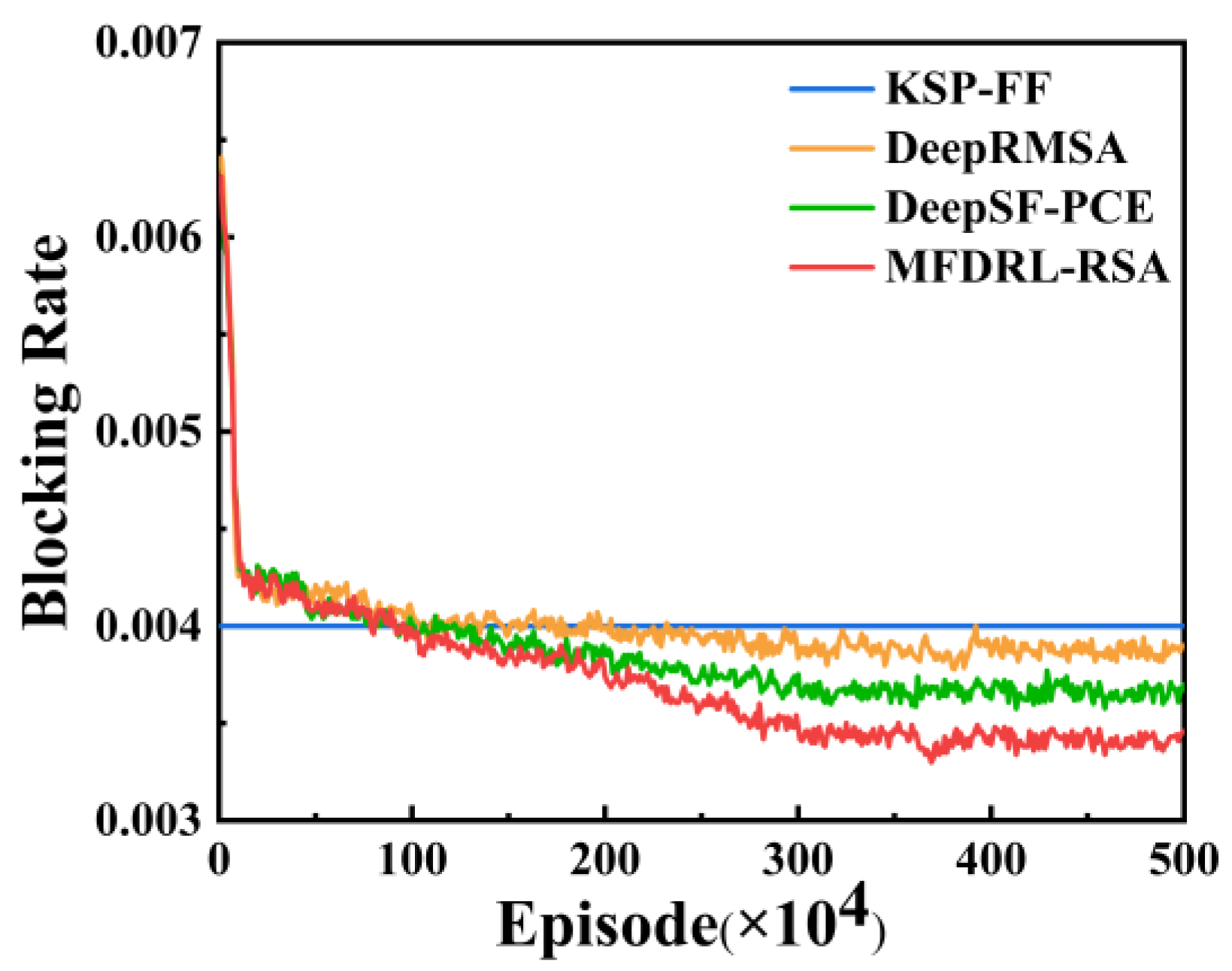
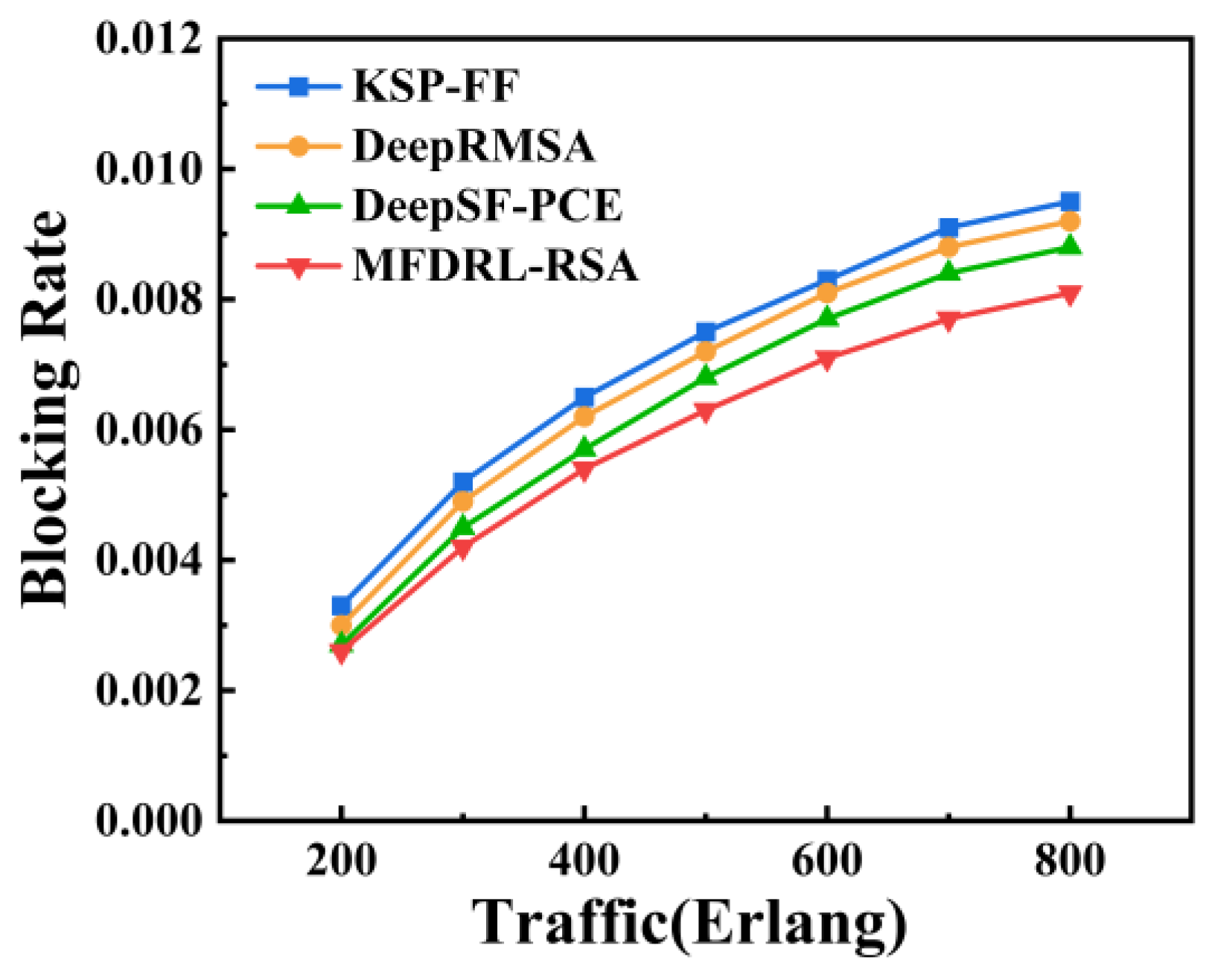
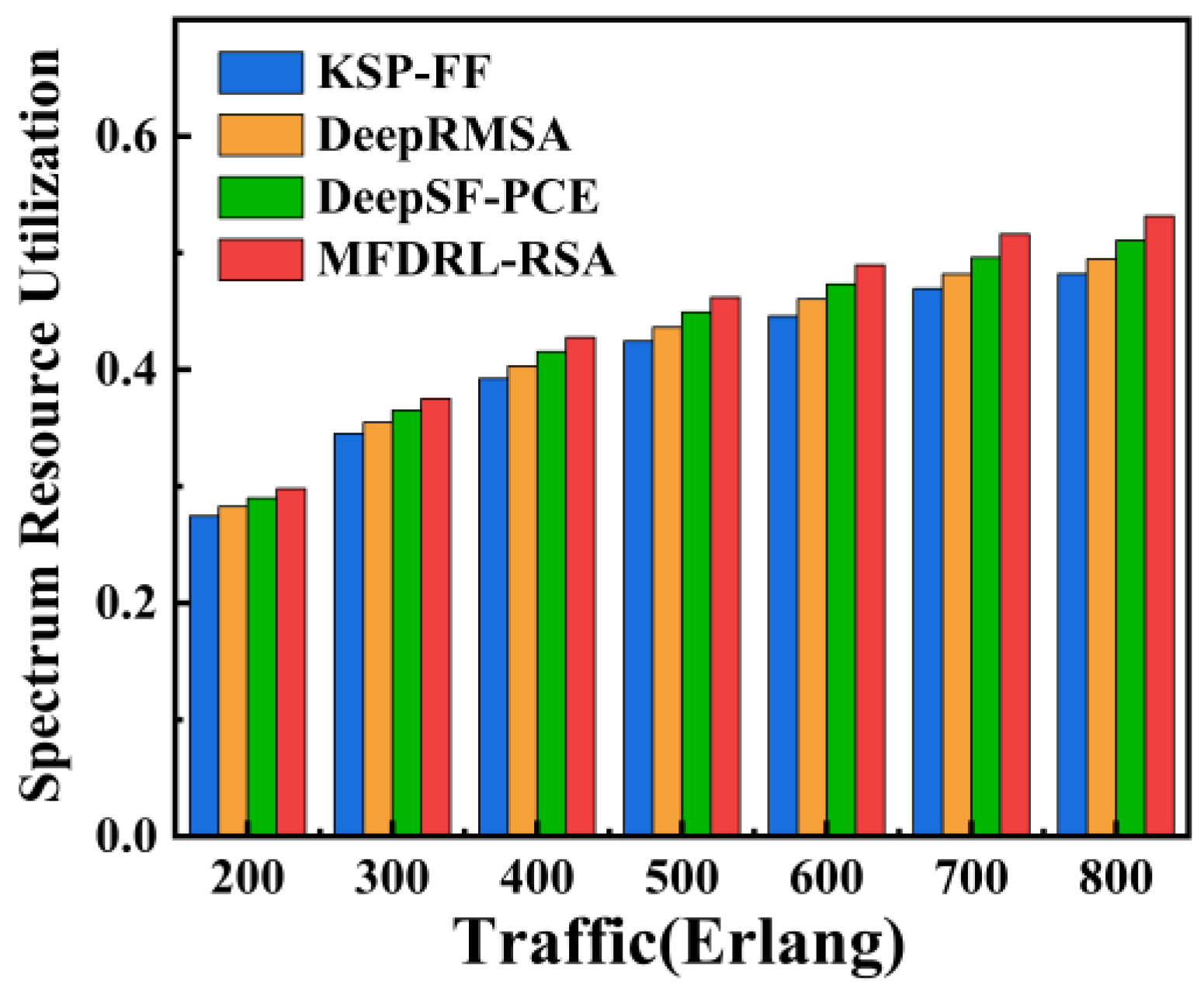
4.2. Simulation Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MFDRL-RSA | Multi-link fragmentation deep reinforcement learning-based routing and spectrum allocation algorithm |
| EONs | Elastic optical networks |
| RSA | Routing and spectrum allocation |
| DRL | Deep reinforcement learning |
| BFN | Breadth-first numbering |
| FS | Frequency slot |
| TAM | Traversing the adjacency matrix |
| AC | Actor-critic |
| KSP-FF | k shortest path and first-fit |
| FF | First-fit |
References
- Kumar, K.S.; Kalaivani, S.; Ibrahim, S.P.S.; Swathi, G. Traffic and fragmentation aware algorithm for routing and spectrum assignment in Elastic Optical Network (EON). Opt. Fiber Technol. 2023, 81, 103480. [Google Scholar] [CrossRef]
- Lechowicz, P.; Tornatore, M.; Włodarczyk, A.; Walkowiak, K. Fragmentation metrics and fragmentation-aware algorithm for spectrally/spatially flexible optical networks. J. Opt. Commun. Netw. 2020, 12, 133–145. [Google Scholar] [CrossRef]
- Kitsuwan, N.; Akaki, K.; Pavarangkoon, P.; Nag, A. Spectrum allocation scheme considering spectrum slicing in elastic optical networks. J. Opt. Commun. Netw. 2021, 13, 169–181. [Google Scholar] [CrossRef]
- Mandloi, A. Routing and dynamic core allocation with fragmentation optimization in EON-SDM. Opt. Fiber Technol. 2024, 83, 103658. [Google Scholar]
- Mei, J.; Wang, X.; Zheng, K.; Boudreau, G.; Bin Sediq, A.; Abou-Zeid, H. Intelligent radio access network slicing for service provisioning in 6G: A hierarchical deep reinforcement learning approach. IEEE Trans. Commun. 2021, 69, 6063–6078. [Google Scholar] [CrossRef]
- He, Q.; Wang, Y.; Wang, X.; Xu, W.; Li, F.; Yang, K.; Ma, L. Routing optimization with deep reinforcement learning in knowledge defined networking. IEEE Trans. Mob. Comput. 2023, 23, 1444–1455. [Google Scholar] [CrossRef]
- Qureshi, K.I.; Lu, B.; Lu, C.; Lodhi, M.A.; Wang, L. Multi-agent DRL for Air-to-Ground Communication Planning in UAV-enabled IoT Networks. Sensors 2024, 24, 6535. [Google Scholar] [CrossRef]
- Wang, S.; Yuen, C.; Ni, W.; Guan, Y.L.; Lv, T. Multiagent deep reinforcement learning for cost- and delay-sensitive virtual network function placement and routing. IEEE Trans. Commun. 2022, 70, 5208–5224. [Google Scholar] [CrossRef]
- Hernández-Chulde, C.; Casellas, R.; Martínez, R.; Vilalta, R.; Muñoz, R. Experimental evaluation of a latency-aware routing and spectrum assignment mechanism based on deep reinforcement learning. J. Opt. Commun. Netw. 2023, 15, 925–937. [Google Scholar] [CrossRef]
- Xu, L.; Huang, Y.C.; Xue, Y.; Hu, X. Hierarchical reinforcement learning in multi-domain elastic optical networks to realize joint RMSA. J. Lightw. Technol. 2023, 41, 2276–2288. [Google Scholar] [CrossRef]
- Tanaka, T.; Shimoda, M. Pre-and post-processing techniques for reinforcement-learning-based routing and spectrum assignment in elastic optical networks. J. Opt. Commun. Netw. 2023, 15, 1019–1029. [Google Scholar] [CrossRef]
- Khorasani, Y.; Rahbar, A.G.; Alizadeh, B. A novel adjustable defragmentation algorithm in elastic optical networks. Opt. Fiber Technol. 2024, 82, 103615. [Google Scholar] [CrossRef]
- Bao, B.; Yang, H.; Yao, Q.; Yu, A.; Chatterjee, B.C.; Oki, E.; Zhang, J. SDFA: A service-driven fragmentation-aware resource allocation in elastic optical networks. IEEE Trans. Netw. Serv. Manag. 2021, 19, 353–365. [Google Scholar] [CrossRef]
- Chen, X.; Li, B.; Proietti, R.; Lu, H.; Zhu, Z.; Ben Yoo, S.J. DeepRMSA: A deep reinforcement learning framework for routing, modulation and spectrum assignment in elastic optical networks. J. Lightw. Technol. 2019, 37, 4155–4163. [Google Scholar] [CrossRef]
- Yan, W.; Li, X.; Ding, Y.; He, J.; Cai, B. DQN with prioritized experience replay algorithm for reducing network blocking rate in elastic optical networks. Opt. Fiber Technol. 2024, 82, 103625. [Google Scholar] [CrossRef]
- Gonzalez, M.; Condon, F.; Morales, P.; He, J.; Cai, B. Improving multi-band elastic optical networks performance using behavior induction on deep reinforcement learning. In Proceedings of the 2022 IEEE Latin-American Conference on Communications (LATINCOM), Rio de Janeiro, Brazil, 30 November–2 December 2022; Volume 1, pp. 1–6. [Google Scholar]
- Errea, J.; Djon, D.; Tran, H.Q.; Verchere, D.; Ksentini, A. Deep reinforcement learning-aided fragmentation-aware RMSA path computation engine for open disaggregated transport networks. In Proceedings of the 2023 International Conference on Optical Network Design and Modeling (ONDM), Coimbra, Portugal, 8–11 May 2023; Volume 1, pp. 1–3. [Google Scholar]
- Johari, S.S.; Taeb, S.; Shahriar, N.; Chowdhury, S.R.; Tornatore, M.; Boutaba, R.; Mitra, J.; Hemmati, M. DRL-assisted reoptimization of network slice embedding on EON-enabled transport networks. IEEE Trans. Netw. Serv. Manag. 2023, 20, 800–814. [Google Scholar] [CrossRef]
- Etezadi, E.; Natalino, C.; Diaz, R.; Lindgren, A.; Melin, S.; Wosinska, L.; Monti, P.; Furdek, M. Deep reinforcement learning for proactive spectrum defragmentation in elastic optical networks. J. Opt. Commun. Netw. 2023, 15, E86–E96. [Google Scholar] [CrossRef]
- Shimoda, M.; Tanaka, T. Mask RSA: End-to-end reinforcement learning-based routing and spectrum assignment. In Proceedings of the European Conference on Optical Communication (ECOC), Bordeaux, France, 13–16 September 2021. [Google Scholar]
- Tang, B.; Huang, Y.C.; Xue, Y.; Song, H.; Xu, Z. Heuristic reward design for deep reinforcement learning-based routing, modulation and spectrum assignment of elastic optical networks. IEEE Commun. Lett. 2022, 26, 2675–2679. [Google Scholar] [CrossRef]
- Asiri, A.; Wang, B. Deep Reinforcement Learning for QoT-Aware Routing, Modulation, and Spectrum Assignment in Elastic Optical Networks. J. Lightw. Technol. 2025, 43, 42–60. [Google Scholar] [CrossRef]
- Wang, Y.; Cao, X.; Pan, Y. A study of the routing and spectrum allocation in spectrum-sliced elastic optical path networks. In Proceedings of the 2011 Proceedings IEEE Infocom, Shanghai, China, 10–15 April 2011; Volume 1, pp. 1503–1511. [Google Scholar]
- Zhang, C.; Wang, P. Fuzzy logic system assisted sensing resource allocation for optical fiber sensing and communication integrated network. Sensors 2022, 22, 7708. [Google Scholar] [CrossRef]
- Chen, X.; Xu, Z.; Wu, Y.; Wu, Q. Heuristic algorithms for reliability estimation based on breadth-first search of a grid tree. Reliab. Eng. Syst. Saf. 2023, 232, 109083. [Google Scholar] [CrossRef]
- Liao, J.; Zhao, J.; Gao, F.; Li, G.Y. Deep learning aided low complex breadth-first tree search for MIMO detection. IEEE Trans. Wirel. Commun. 2023, 23, 6266–6278. [Google Scholar] [CrossRef]
- Zhou, C.; Huang, B.; Hassan, H.; Fränti, P. Attention-based advantage actor-critic algorithm with prioritized experience replay for complex 2-D robotic motion planning. J. Intell. Manuf. 2023, 34, 151–180. [Google Scholar] [CrossRef]
- Wang, H.; Gao, W.; Wang, Z.; Zhang, K.; Ren, J.; Deng, L.; He, S. Research on Obstacle Avoidance Planning for UUV Based on A3C Algorithm. J. Mar. Sci. Eng. 2023, 12, 63. [Google Scholar] [CrossRef]
- Wang, S.; Song, R.; Zheng, X.; Huang, W.; Liu, H. A3C-R: A QoS-oriented energy-saving routing algorithm for software-defined networks. Future Internet 2025, 17, 158. [Google Scholar] [CrossRef]
- Labao, A.B.; Martija, M.A.M.; Naval, P.C. A3C-GS: Adaptive moment gradient sharing with locks for asynchronous actor–critic agents. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1162–1176. [Google Scholar] [CrossRef]
- National Science Foundation. NSFNET: The Birth of the Commercial Internet. Available online: https://www.nsf.gov/impacts/internet (accessed on 3 June 2025).
- SNDlib—Survivable Network Design Library. Cost239 Topology. Available online: https://sndlib.zib.de/network.jsp?topology=cost239 (accessed on 3 June 2025).
- Vincent, R.J.; Ives, D.J.; Savory, S.J. Scalable capacity estimation for nonlinear elastic all-optical core networks. J. Light. Technol. 2019, 37, 5380–5391. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| m | Modulation Format | Reach (km) |
|---|---|---|
| 1 | BPSK | 5000 |
| 2 | QPSK | 2500 |
| 3 | 8QAM | 1250 |
| 4 | 16QAM | 625 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, J.; Su, Y.; Cheng, J.; Shang, T. Multi-Link Fragmentation-Aware Deep Reinforcement Learning RSA Algorithm in Elastic Optical Network. Photonics 2025, 12, 634. https://doi.org/10.3390/photonics12070634
Jiang J, Su Y, Cheng J, Shang T. Multi-Link Fragmentation-Aware Deep Reinforcement Learning RSA Algorithm in Elastic Optical Network. Photonics. 2025; 12(7):634. https://doi.org/10.3390/photonics12070634
Chicago/Turabian StyleJiang, Jing, Yushu Su, Jingchi Cheng, and Tao Shang. 2025. "Multi-Link Fragmentation-Aware Deep Reinforcement Learning RSA Algorithm in Elastic Optical Network" Photonics 12, no. 7: 634. https://doi.org/10.3390/photonics12070634
APA StyleJiang, J., Su, Y., Cheng, J., & Shang, T. (2025). Multi-Link Fragmentation-Aware Deep Reinforcement Learning RSA Algorithm in Elastic Optical Network. Photonics, 12(7), 634. https://doi.org/10.3390/photonics12070634