Hybrid Self-Attention Transformer U-Net for Fourier Single-Pixel Imaging Reconstruction at Low Sampling Rates


Abstract
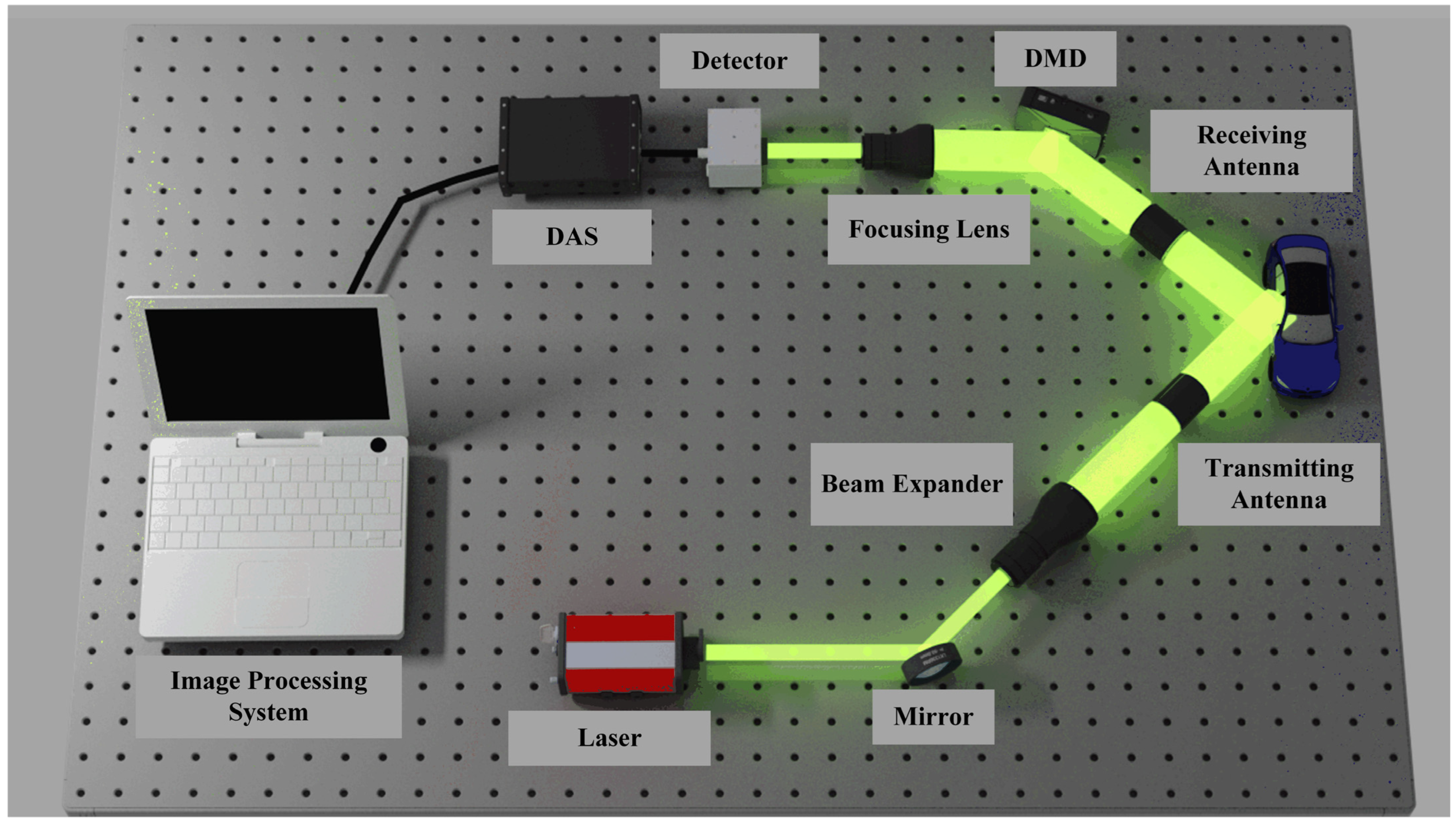
1. Introduction
- (1)
- It introduces the Transformer architecture to enhance global modeling capabilities in FSPI reconstruction tasks, effectively improving image detail restoration and overall reconstruction quality.
- (2)
- It designs a Hybrid Self-Attention Transformer Module that integrates spatial window self-attention and channel self-attention mechanisms, achieving stronger global context modeling and significantly enhancing feature perception and representation capabilities.
- (3)
- It proposes a Feature Fusion Module that dynamically adjusts the weight allocation between shallow spatial features and deep semantic features, enabling more precise and efficient multi-level feature fusion.
2. Methods
2.1. Fourier Single-Pixel Imaging
2.2. Network Architecture
2.2.1. Hybrid Self-Attention Transformer Module
2.2.2. Feature Fusion Module
2.3. Loss Function of HATU
3. Experimental Results and Analysis
3.1. Dataset Preparation and Training Process
3.2. Comparison of Image Reconstruction Performance
3.3. Experiments on Generalization Ability
3.4. Ablation Experiments
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wu, Q.Y.; Yang, J.Z.; Hong, J.Y.; Meng, Z.; Zhang, A.-N. An Edge Detail Enhancement Strategy Based on Fourier Single-Pixel Imaging. Opt. Lasers Eng. 2024, 172, 107828. [Google Scholar] [CrossRef]
- Jiang, P.; Liu, J.; Wang, X.; Fan, Y.; Yang, Z.; Zhang, J.; Zhang, Y.; Jiang, X.; Yang, X. Fourier Single-Pixel Imaging Reconstruction Network for Unstable Illumination. Opt. Laser Technol. 2025, 186, 112695. [Google Scholar] [CrossRef]
- Lu, T.; Qiu, Z.; Zhang, Z.; Zhong, J. Comprehensive Comparison of Single-Pixel Imaging Methods. Opt. Lasers Eng. 2020, 134, 106301. [Google Scholar] [CrossRef]
- Gibson, G.M.; Johnson, S.D.; Padgett, M.J. Single-Pixel Imaging 12 Years on: A Review. Opt. Express 2020, 28, 28190–28208. [Google Scholar] [CrossRef]
- Olivieri, L.; Gongora, J.S.T.; Peters, L.; Cecconi, V.; Cutrona, A.; Tunesi, J.; Tucker, R.; Pasquazi, A.; Peccianti, M. Hyperspectral Terahertz Microscopy via Nonlinear Ghost Imaging. Optica 2020, 7, 186–191. [Google Scholar] [CrossRef]
- Ma, Y.; Yin, Y.; Jiang, S.; Li, X.; Huang, F.; Sun, B. Single Pixel 3D Imaging with Phase-Shifting Fringe Projection. Opt. Lasers Eng. 2021, 140, 106532. [Google Scholar] [CrossRef]
- Jiang, H.; Li, Y.; Zhao, H.; Li, X.; Xu, Y. Parallel Single-Pixel Imaging: A General Method for Direct–Global Separation and 3d Shape Reconstruction under Strong Global Illumination. Int. J. Comput. Vis. 2021, 129, 1060–1086. [Google Scholar] [CrossRef]
- Tao, C.; Zhu, H.; Wang, X.; Zheng, S.; Xie, Q.; Wang, C.; Wu, R.; Zheng, Z. Compressive Single-Pixel Hyperspectral Imaging Using RGB Sensors. Opt. Express 2021, 29, 11207–11220. [Google Scholar] [CrossRef]
- Deng, Q.; Zhang, Z.; Zhong, J. Image-Free Real-Time 3-D Tracking of a Fast-Moving Object Using Dual-Pixel Detection. Opt. Lett. 2020, 45, 4734–4737. [Google Scholar] [CrossRef]
- Zha, L.; Shi, D.; Huang, J.; Yuan, K.; Meng, W.; Yang, W.; Jiang, R.; Chen, Y.; Wang, Y. Single-Pixel Tracking of Fast-Moving Object Using Geometric Moment Detection. Opt. Express 2021, 29, 30327–30336. [Google Scholar] [CrossRef]
- Wu, J.; Hu, L.; Wang, J. Fast Tracking and Imaging of a Moving Object with Single-Pixel Imaging. Opt. Express 2021, 29, 42589–42598. [Google Scholar] [CrossRef]
- Ma, S.; Liu, Z.; Wang, C.; Hu, C.; Li, E.; Gong, W.; Tong, Z.; Wu, J.; Shen, X.; Han, S. Ghost Imaging LiDAR via Sparsity Constraints Using Push-Broom Scanning. Opt. Express 2019, 27, 13219–13228. [Google Scholar] [CrossRef] [PubMed]
- Zhu, R.; Feng, H.; Xiong, Y.; Zhan, L.; Xu, F. All-Fiber Reflective Single-Pixel Imaging with Long Working Distance. Opt. Laser Technol. 2023, 158, 108909. [Google Scholar] [CrossRef]
- Guo, Z.; He, Z.; Jiang, R.; Li, Z.; Chen, H.; Wang, Y.; Shi, D. Real-Time Three-Dimensional Tracking of Distant Moving Objects Using Non-Imaging Single-Pixel Lidar. Remote Sens. 2024, 16, 1924. [Google Scholar] [CrossRef]
- He, R.; Zhang, S.; Li, X.; Kong, T.; Chen, Q.; Zhang, W. Vector-Guided Fourier Single-Pixel Imaging. Opt. Express 2024, 32, 7307–7317. [Google Scholar] [CrossRef]
- Dai, Q.; Yan, Q.; Zou, Q.; Li, Y.; Yan, J. Generative Adversarial Network with the Discriminator Using Measurements as an Auxiliary Input for Single-Pixel Imaging. Opt. Commun. 2024, 560, 130485. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, H.; Zhou, M.; Jiao, S.; Zhang, X.-P.; Geng, Z. Adaptive Super-Resolution Networks for Single-Pixel Imaging at Ultra-Low Sampling Rates. IEEE Access 2024, 12, 78496–78504. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhou, W.; Fan, M.; Wu, Q.; Zhang, K. Deformable Perfect Vortex Wave-Front Modulation Based on Geometric Metasurface in Microwave Regime. Chin. J. Electron. 2025, 34, 64–72. [Google Scholar] [CrossRef]
- Rizvi, S.; Cao, J.; Zhang, K.; Hao, Q. Improving Imaging Quality of Real-Time Fourier Single-Pixel Imaging via Deep Learning. Sensors 2019, 19, 4190. [Google Scholar] [CrossRef]
- Rizvi, S.; Cao, J.; Zhang, K.; Hao, Q. Deringing and Denoising in Extremely Under-Sampled Fourier Single Pixel Imaging. Opt. Express 2020, 28, 7360–7374. [Google Scholar] [CrossRef]
- Yang, X.; Jiang, P.; Jiang, M.; Xu, L.; Wu, L.; Yang, C.; Zhang, W.; Zhang, J.; Zhang, Y. High Imaging Quality of Fourier Single Pixel Imaging Based on Generative Adversarial Networks at Low Sampling Rate. Opt. Lasers Eng. 2021, 140, 106533. [Google Scholar] [CrossRef]
- Yang, X.; Jiang, X.; Jiang, P.; Xu, L.; Wu, L.; Hu, J.; Zhang, Y.; Zhang, J.; Zou, B. S2O-FSPI: Fourier Single Pixel Imaging via Sampling Strategy Optimization. Opt. Laser Technol. 2023, 166, 109651. [Google Scholar] [CrossRef]
- Chang, X.; Wu, Z.; Li, D.; Zhan, X.; Yan, R.; Bian, L. Self-Supervised Learning for Single-Pixel Imaging via Dual-Domain Constraints. Opt. Lett. 2023, 48, 1566–1569. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wen, Y.; Ma, Y.; Peng, W.; Lu, Y. Optimizing Under-Sampling in Fourier Single-Pixel Imaging Using GANs and Attention Mechanisms. Opt. Laser Technol. 2025, 187, 112752. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer v2: Scaling up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Rad, M.S.; Bozorgtabar, B.; Marti, U.-V.; Basler, M.; Ekenel, H.K.; Thiran, J.-P. Srobb: Targeted Perceptual Loss for Single Image Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Liu, Y.; Chen, H.; Chen, Y.; Yin, W.; Shen, C. Generic Perceptual Loss for Modeling Structured Output Dependencies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 10–25 June 2021. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object Representations for Fine-Grained Categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Palubinskas, G. Image Similarity/Distance Measures: What Is Really behind MSE and SSIM? Int. J. Image Data Fusion 2017, 8, 32–53. [Google Scholar] [CrossRef]
- Hore, A.; Ziou, D. Image Quality Metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010. [Google Scholar]
- Setiadi, D.R.I.M. PSNR vs SSIM: Imperceptibility Quality Assessment for Image Steganography. Multimed. Tools Appl. 2021, 80, 8423–8444. [Google Scholar] [CrossRef]
- Tanchenko, A. Visual-PSNR Measure of Image Quality. J. Vis. Commun. Image Represent. 2014, 25, 874–878. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- Gu, Z.; Ma, Q.; Gao, X.; You, J.W.; Cui, T.J. Direct Electromagnetic Information Processing with Planar Diffractive Neural Network. Sci. Adv. 2024, 10, eado3937. [Google Scholar] [CrossRef]
- Gao, X.; Gu, Z.; Ma, Q.; Chen, B.J.; Shum, K.-M.; Cui, W.Y.; You, J.W.; Cui, T.J.; Chan, C.H. Terahertz Spoof Plasmonic Neural Network for Diffractive Information Recognition and Processing. Nat. Commun. 2024, 15, 6686. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Rate | Method | SSIM | PSNR | RMSE | LPIPS |
|---|---|---|---|---|---|
| 1% | FSPI | 0.525 | 19.751 | 0.1041 | 0.5803 |
| DCAN | 0.559 | 20.145 | 0.0996 | 0.5471 | |
| FSPI-Gan | 0.585 | 20.323 | 0.0944 | 0.4798 | |
| HATU (Ours) | 0.614 | 20.760 | 0.0882 | 0.3631 | |
| % | FSPI | 0.631 | 22.056 | 0.0803 | 0.4672 |
| DCAN | 0.672 | 22.647 | 0.0751 | 0.4207 | |
| FSPI-Gan | 0.713 | 23.303 | 0.0699 | 0.3631 | |
| HATU (Ours) | 0.732 | 23.556 | 0.0638 | 0.3197 | |
| 5% | FSPI | 0.698 | 23.399 | 0.0692 | 0.4041 |
| DCAN | 0.736 | 24.026 | 0.0645 | 0.3517 | |
| FSPI-Gan | 0.772 | 24.652 | 0.0595 | 0.2953 | |
| HATU (Ours) | 0.793 | 25.041 | 0.0537 | 0.2632 | |
| 10% | FSPI | 0.791 | 25.483 | 0.0551 | 0.3091 |
| DCAN | 0.814 | 25.808 | 0.0529 | 0.2577 | |
| FSPI-Gan | 0.855 | 26.943 | 0.0468 | 0.2099 | |
| HATU (Ours) | 0.867 | 27.432 | 0.0399 | 0.1878 |
| Method | Parameters (M) | FLOPs (G) | Inference Time (ms) |
|---|---|---|---|
| FSPI | / | / | / |
| DCAN | 0.19 | 3.07 | 1.39 |
| FSPI-Gan | 79.85 | 14.66 | 21.28 |
| HATU (Ours) | 8.79 | 24.81 | 19.54 |
| Method | SSIM | PSNR | RMSE | LPIPS |
|---|---|---|---|---|
| HATU | 0.614 | 20.760 | 0.0882 | 0.3631 |
| (1) | 0.565 | 20.201 | 0.0973 | 0.4967 |
| (2) | 0.571 | 20.284 | 0.0957 | 0.4755 |
| (3) | 0.606 | 20.660 | 0.0904 | 0.4028 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Zhang, H.; Zou, B.; Wu, L. Hybrid Self-Attention Transformer U-Net for Fourier Single-Pixel Imaging Reconstruction at Low Sampling Rates. Photonics 2025, 12, 568. https://doi.org/10.3390/photonics12060568
Chen H, Zhang H, Zou B, Wu L. Hybrid Self-Attention Transformer U-Net for Fourier Single-Pixel Imaging Reconstruction at Low Sampling Rates. Photonics. 2025; 12(6):568. https://doi.org/10.3390/photonics12060568
Chicago/Turabian StyleChen, Haozhen, Hancui Zhang, Bo Zou, and Long Wu. 2025. "Hybrid Self-Attention Transformer U-Net for Fourier Single-Pixel Imaging Reconstruction at Low Sampling Rates" Photonics 12, no. 6: 568. https://doi.org/10.3390/photonics12060568
APA StyleChen, H., Zhang, H., Zou, B., & Wu, L. (2025). Hybrid Self-Attention Transformer U-Net for Fourier Single-Pixel Imaging Reconstruction at Low Sampling Rates. Photonics, 12(6), 568. https://doi.org/10.3390/photonics12060568