Abstract
Pattern recognition techniques form the heart of most, if not all, incoherent linear shift-invariant systems. When an object is recorded using a camera, the object information is sampled by the point spread function (PSF) of the system, replacing every object point with the PSF in the sensor. The PSF is a sharp Kronecker Delta-like function when the numerical aperture (NA) is large with no aberrations. When the NA is small, and the system has aberrations, the PSF appears blurred. In the case of aberrations, if the PSF is known, then the blurred object image can be deblurred by scanning the PSF over the recorded object intensity pattern and looking for pattern matching conditions through a mathematical process called correlation. Deep learning-based image classification for computer vision applications gained attention in recent years. The classification probability is highly dependent on the quality of images as even a minor blur can significantly alter the image classification results. In this study, a recently developed deblurring method, the Lucy-Richardson-Rosen algorithm (LR2A), was implemented to computationally refocus images recorded in the presence of spatio-spectral aberrations. The performance of LR2A was compared against the parent techniques: Lucy-Richardson algorithm and non-linear reconstruction. LR2A exhibited a superior deblurring capability even in extreme cases of spatio-spectral aberrations. Experimental results of deblurring a picture recorded using high-resolution smartphone cameras are presented. LR2A was implemented to significantly improve the performances of the widely used deep convolutional neural networks for image classification.
1. Introduction
Images are one of the necessary forms of data in the modern era. They are used to capture a variety of physical projections ranging from scientific images to personal memories. Nevertheless, the recorded images are not always in the ideal composition and often require post-processing techniques to enhance their quality. These techniques include brightness and contrast enhancement, saturation and chromaticity adjustments, and artificial high dynamic range image creation, which are now accessible through smartphone applications [1,2]. With the recent developments in diffractive lenses and metalenses, it is highly likely that future cameras will utilize such flat lenses for digital imaging [3,4]. Two main problems foreseen with the above lenses are their sensitivity to wavelength changes and technical challenges in manufacturing such lenses with a large diameter. In addition to the above, spatio-spectral aberrations are expected, as with any imaging lens. The recorded information in a linear, shift-invariant incoherent imaging system can be expressed as , where O is the object function, PSF is the point spread function, N is the noise, and ‘’ is a 2D convolutional operator. The task is to extract O from I as close as possible to reality. As seen from the equation, if PSF is a sharp Kronecker Delta-like function, then I is a copy of O with a minimum feature size given as ~λ/NA. However, due to aberrations and limited NA, the recorded information is not an exact copy of O but a modified version. The modified version is the blurred image. Therefore, computational post-processing is required to correct the recorded information of spatial and spectral aberrations digitally. In addition to spatio-spectral aberrations, there are other areas and situations where deblurring is essential. Like with human vision, where there is the least distance of distinct vision (LDDV), there is a distance limit beyond which it is difficult to image an object with the maximum resolution of a smartphone camera. In such cases, the recorded image appears blurred. It is necessary to develop computational imaging solutions to the above problems.
Deblurring can be achieved by numerous techniques such as Lucy-Richardson algorithm (LRA), matched filter (MF), phase-only filter (PoF), Weiner filter (WF), regularized filter algorithm (RFA), non-linear reconstruction (NLR), etc. [5,6,7]. In our previous studies [5,6], we thoroughly investigated the performances of the above algorithms and found that NLR had a better performance than LRA, MF, PoF, WF, and RFA. In the above studies, severe distortion was obtained using thin scatterers. Recently, NLR was implemented to deblur images recorded with focusing errors when imaging with Cassegrain objective lenses at the Australian Synchrotron and the performance was not satisfactory. Therefore, in that research work, NLR was combined with LRA to create a new deblurring method called the Lucy-Richardson-Rosen algorithm (LR2A) [8,9,10].
LR2A was then successfully implemented to deblur images recorded using a refractive lens with focusing errors with a narrow bandwidth incoherent light source (~20 nm) [11]. In this study, LR2A was applied to blurred images recorded with white light which is spatially as well as temporally incoherent with a broad bandwidth using latest smart phone cameras. This is a significant step as the proposed method can be used to extend the LDDV of smart phones. In all the previous studies, the deblurring methods were implemented in invasive mode. In this study, we demonstrate both invasive as well as non-invasive modes of operation. There are, of course, numerous methods of deblurring developed for different applications [12]. Since it was already established that NLR had a better performance than the commonly used deblurring methods and LR2A evolved from NLR and LRA, in this manuscript, the performance of LR2A was compared only with the parent methods NLR and LRA.
Deep-learning-based pattern recognition methods gradually overtook signal-processing-based pattern recognition approaches in recent years [5,13]. In deep learning, in the first training step, where the network is trained using a large data set, focused images are used. The performances of deep-learning methods are affected by the degree of blur and distortion occurring during recording. It was proven that invasive indirect imaging methods have abilities to deblur images in the presence of stronger distortion in comparison to non-invasive approaches [14]. Most of the imaging situations are linear by nature, and so, it is possible to apply invasive and non-invasive methods wherever possible. Therefore, deblurring approaches can improve the performances of deep-learning methods. If the aberrations of the imaging system are thoroughly studied and understood, it is possible to apply even non-invasive methods that can use synthetic PSFs obtained from scalar diffraction formulation for deblurring images. The concept figure is shown in Figure 1.
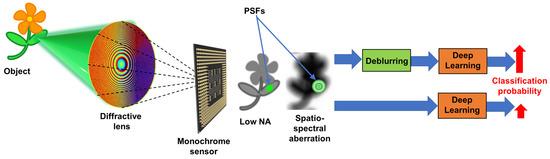
Figure 1.
Schematic of the deblurring assisted deep learning method. An object is focused by a diffractive lens and recorded by a monochrome sensor. A lens with a small NA records an image with a low resolution. Spatio-spectral aberrations blur the image. The blurred image is deblurred and sent into a deep-learning network for image classification.
The manuscript consists of eight sections. The methodology is presented in the Section 2. The simulation results are presented in the Section 3. The Section 4 contains the results of the optical experiments. An introduction to pretrained deep-learning networks is given in the Section 5. The deep-learning experiments are presented in the Section 6. In the Section 7, the results are discussed. The conclusion and future perspectives of the study are presented in the Section 8.
2. Materials and Methods
Deep-learning-based image classification methods are highly sensitive to image blur. There are numerous deblurring techniques developed to process the captured distorted information into high-resolution images [15,16,17]. One straightforward approach to deblurring is given as , where ‘’ is a 2D correlational operator and O′ is the reconstructed image. As seen, the object information is sampled by with some background noise. The above method of reconstruction is commonly called the MF, which generates significant background noise, and in many cases, a PoF or a WF was used to improve the signal-to-noise ratio [18]. All the above filters work on the fundamental principle of pattern recognition, where the PSF is scanned over the object intensity, and every time a pattern matching is achieved, a peak is generated. In this way, the object information is reconstructed. The NLR method of deblurring can be expressed as , where α and β were tuned between −1 and 1 until a minimum entropy is obtained [7]. Even though NLR has a wide applicability range involving different optical modulators, the resolution is limited by the autocorrelation function [19]. This imposes a constraint on the nature of PSF and, therefore, on the type of aberrations that can be corrected. So, NLR is expected to work better with PSFs with intensity localizations than PSFs that are blurred versions of point images.
Another widely used deconvolution method is the iterative Lucy-Richardson algorithm (LRA) [8,9]. The (n + 1)th solution is given as , where PSF′ is the flipped version and complex conjugate of PSF. The loop begins with an initial guess which is I, and gradually converges to the maximum likelihood solution. Unlike NLR, the resolution of LRA is not constrained by the autocorrelation function. However, LRA has only a limited application range and cannot be implemented for a wide range of optical modulators such as NLR. Recently, a new deconvolution method LR2A was developed by replacing the correlation in LRA by NLR [10]. The schematic of the reconstruction method is shown in Figure 2. The algorithm begins with a convolution between the PSF and I, with I as the initial guess coefficient, which results in I′. The ratio between the two matrices I and I′ was correlated with the PSF, and this correlation is replaced by NLR, and the resulting residue is multiplied to the first guess, and this process is continued until a maximum likelihood solution is obtained. The deblurred images obtained from NLR, LRA, and LR2A are then fed into the pretrained deep-learning networks instead of blurred images for image classification.
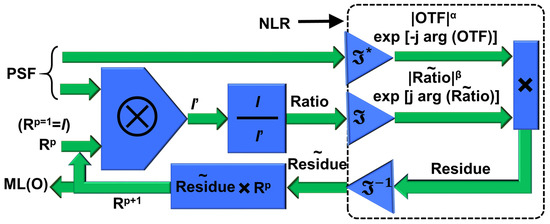
Figure 2.
Schematic of LR2A algorithm; OTF—Optical transfer function; p—number of iterations; ⊗—2D convolutional operator; —refers to complex conjugate following a Fourier transform; Rp is the nth solution, when n = 1, Rp = I.
3. Simulation Studies
In the present work, LR2A was used to deblur images captured using lenses with low NA and spatial and spectral aberrations. Furthermore, we compared the results with the parent benchmarking algorithms, such as LRA and NLR, to verify their effectiveness. The simulation was carried out in MATLAB with a matrix size of 500 × 500 pixels, pixel size of 8 µm, and central wavelength of λ = 632.8 nm. The object and image distances were set as 30 cm. A diffractive lens was designed with a focal length of f = 15 cm for the central wavelength with the radius of the zones given as , where s is the order of the zone. This diffractive lens is representative of both diffractive as well as metalens that works based on the Pancharatnam Berry phase [20]. A standard test object ‘Lena’ in greyscale was used for this study.
In the first study, the NA of the system was varied by introducing an iris in the plane of the diffractive lens and varying its’ diameter. The images of the PSF and object intensity distributions for the radius of the aperture R = 250, 125, 50, and 25 pixels are shown in Figure 3. Deblurring results with NLR (α = 0.2, β = 1) are shown in Figure 3. The deblurring results of LRA and LR2A are shown for the above cases, where the number of iterations p required for LRA was at least 10 times that of LR2A, with the last case requiring 100 for LRA and only 8 for LR2A (α = 0, β = 0.9). Comparing the results of NLR, LRA, and LR2A, it appeared that the performances of LRA and LR2A were similar, while NLR did not deblur due to a blurred autocorrelation function.

Figure 3.
Deblurring results of NLR, LRA, and LR2A for different radii of the aperture R = 250, 125, 50, and 25 pixels.
In the next study, once again, spatial aberrations in the form of focusing errors were introduced into the system. The imaging condition (1/u + 1/v = 1/f), where u and v are object and image distances, was disturbed by changing u to u + Δz, where Δz = 0, 25 mm, 50 mm, 75 mm, and 100 mm. The images of the PSF, object intensity patterns, and deblurring results with NLR, LRA, and LR2A are shown in Figure 4. It was evident that the results of NLR were better than LRA, and the results of LR2A were better than both for large aberrations. However, when Δz = 25 mm, LRA was better than NLR, once again, due to the blurred autocorrelation function.
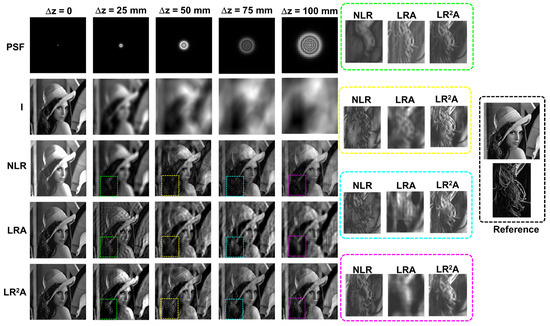
Figure 4.
Deblurring results of NLR, LRA, and LR2A for different axial aberrations values Δz = 0, 25, 50, 75, and 100 mm.
To understand the effects of spectral aberrations, the illumination wavelength was varied from the design wavelength as λ = 400 nm, 500 nm, 600 nm, and 700 nm. Since the optical modulator was a diffractive lens, unlike a refractive lens, it exhibited severe chromatic aberrations. The images of the PSFs, object intensity patterns, and deblurring results with NLR, LRA, and LR2A are shown in Figure 5. As seen from the figures, the results obtained from LR2A were significantly better than LRA and NLR. Another interesting observation can be made from the results. When the intensity distribution was concentrated in a small area, LRA performed better than NLR and vice versa. In all cases, the optimal value of LR2A aligned with one of the cases of NLR or LRA. For concentrated intensity distributions, the results of LR2A aligned towards LRA; in other cases, the results of LR2A aligned with NLR. In all cases, LR2A performed better than NLR and LRA. It must be noted that in the case of focusing error due to change in distance and wavelength, the deblurring with different methods improved the results. However, for the first case, when the lateral resolution was low due to low NA, the deblurring methods did not improve the results as expected.
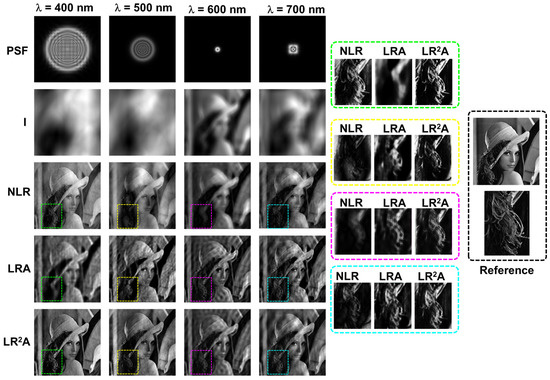
Figure 5.
Deblurring results of NLR, LRA, and LR2A for different wavelengths λ = 400, 500, 600, and 700 nm resulting in different chromatic aberrations.
From the results shown in Figure 3, Figure 4 and Figure 5, it is seen that the performance of LR2A was better than LRA and NLR. The number of possible solutions for LR2A was higher than that of NLR and LRA. The control parameter in the original LRA was limited to one, which was the number of iterations p. The number of control parameters of NLR was two—α and β resulting in a total of m2 solutions, where m is the number of states from (αmin, βmin) to (αmax, βmax). The number of control parameters in LR2A was m2p. Quantitative studies were carried out next for two cases that were aligned towards the solutions of NLR and LRA using structural similarity (SSIM) and mean square error (MSE).
The data from the first column of Figure 5 were used for quantitative comparative studies. As seen from the results in Figure 6, the maximum SSIM obtained using LRA, NLR, and LR2A were 0.595, 0.75, and 0.86, respectively. The minimum value of the MSE for LRA, NLR, and LR2A were 0.028, 0.01, and 0.001, respectively. The above values confirmed that LR2A performed better than both LRA and NLR and NLR better than LRA. The regions of overlap between SSIM and MSE reassured the validity of this analysis.
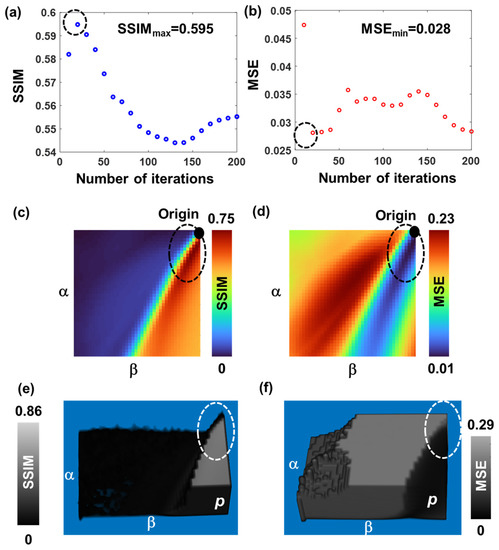
Figure 6.
Comparison of SSIM (a) LRA, (c) NLR and (e) LR2A and MSE for (b) LRA, (d) NLR and (f) LR2A for spectral aberration with Δλ = 232.8 nm corresponding to first column of Figure 5. The number of iterations is p. The dotted circles indicate the regions of highest SSIM and lowest MSE.
4. Optical Experiments
Smart phones, even with all the advanced lens systems and software, suffer from certain limitations. One such limitation is the LDDV. In such cases, the blurred images can be deblurred using LR2A. A preliminary invasive study was carried out on simple objects consisting of a few points using a quasi-monochromatic light source and a single refractive lens [11]. However, the performance was not high due to the weak intensity distributions from a pinhole, scattering, and experimental errors. In this study, the method was evaluated again in both invasive as well as non-invasive mode. In invasive mode, the PSF was obtained from the recorded image of the object from isolated points and by creating a guide star in the form of a point object added to the object. In non-invasive mode, the PSF was synthesized within the computer for different spatio-spectral aberrations using Fresnel propagation as described in Section 3. To examine the method for practical applications, we projected a test image—Lena—on a computer monitor and captured it using two smartphone cameras (Samsung Galaxy A71 with 64-megapixel (f/1.8) primary camera and Oneplus Nord 2CE with 64-megapixel (f/1.7) primary camera). The object projection was adjusted to a point where the device’s autofocus software could no longer adjust the focus. To record PSF, a small white dot was added to the image and was then extracted manually. The images were recorded ~4 cm from the screen with different point sizes, 0.3, 0.4, and 0.5 cm, respectively. They were then fed back to our algorithm and reconstructed using LR2A (α = 0.1, β = 0.98, and two iterations). The recorded raw images and the reconstructed ones of the hair region of the test sample are shown in Figure 7. Line data were extracted from the images as indicated by the lines and plotted for comparison. In all the cases, LR2A improved the image resolution. What appeared in the recorded image as a single entity could be clearly discriminated as multiple entities using LR2A, indicating a significant performance as seen in the plots where a single peak was replaced by multiple peaks.
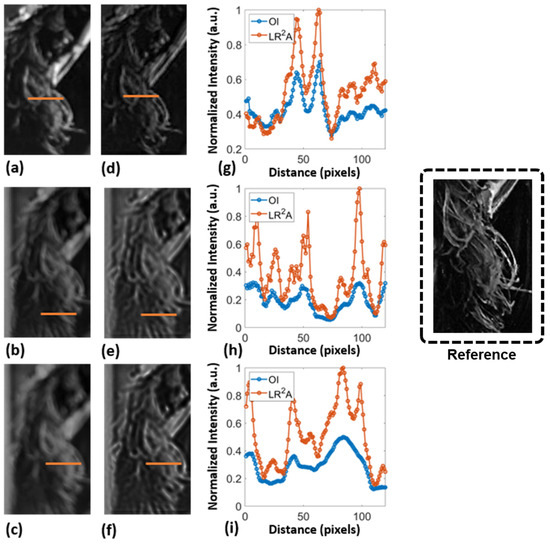
Figure 7.
Images recorded using a smartphone (a) using a Samsung Galaxy A7 (b,c) using a Oneplus Nord 2CE with different point sizes of (0.4 and 0.5 cm). (d–f) are corresponding LR2A deblurred images. Line data (orange line) from the cropped images were plotted and given in (g–i).
For non-invasive mode, the Lena image was displayed on the monitor and recorded using Samsung Galaxy A7. The images of the fully resolved image and blurred image due to recording close to the screen are shown in Figure 8a,b respectively. One of the reconstruction results using NLR (α = 0, β = 0.9), LRA (ten iterations). and LR2A (α = 0, β = one and three iterations) are shown in Figure 8c–e, respectively. The image of the synthesized PSF using scalar diffraction formulation is shown in Figure 8f. Two areas with interesting features are magnified for all the three cases. The results indicate a better quality of reconstruction with LR2A. The image could not be completely deblurred but can be improved without invasively recording PSF. The deblurred images were sharper and contained more information than the blurred image. The proposed method can be converted into an application for deblurring images recorded using smart phone cameras.
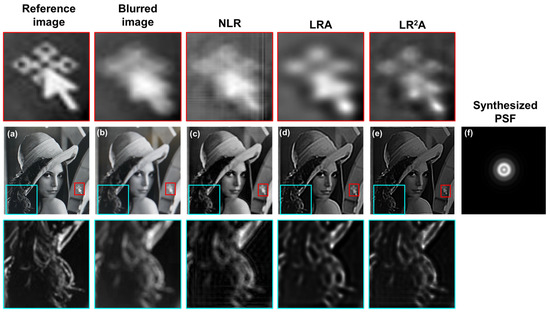
Figure 8.
Deblurring of blurred images using NLR, LRA, and LR2A using synthetic PSF. (a) Reference image, (b) blurred image. Deblurring results by (c) NLR, (d) LRA and (e) LR2A. (f) Synthetic PSF.
5. Pretrained Deep-Learning Networks
Deep-learning experiments rely on the quality of the training data sets which, in many cases, may be blurred due to different types of aberrations. In many deep-learning-based approaches, adding a diverse data sets consisting of focused and blurred images may affect the convergence of the network. In such cases, it might be useful to attach a signal-processing-based deblurring method to reduce the time of training, data sets, and improve classification. In this study, deep-learning experiments were carried out for classification of images with diverse spatio-spectral aberrations with LRA, NLR, and LR2A. A “bell pepper” image was blurred for different spatio-spectral aberrations and deblurred using the above algorithms LRA, NLR, and LR2A. The images obtained from LR2A were much clearer with sharper edges and fine details in comparison to the other two algorithms. The NLR method resulted in an image reconstruction that was slightly oversmoothed, with some loss of fine details. The LRA method produced a better result than NLR, but it was relatively slower than the other two methods, and the improvement was not as significant as it was with LR2A. Overall, LR2A was the most effective in removing the blur and preserving the fine details in the image.
Several pretrained deep-learning networks such as squeezenet, inceptionv3, densenet201, mobilenetv2, resnet18, resnet50, resnet101, xception, inceptionresnetv2, shufflenet, nasnetmobile, nasnetlarge, darknet19, darknet53, efficientnetb0, alexnet, vgg16, vgg19, and GoogLeNet were tested to validate the efficiency of LR2A [21]. Pretrained networks are highly complex neural networks trained on enormous datasets of images, allowing them to recognize a wide range of objects and features in images. MATLAB offers a variety of these models that can be used for image classification, each with its own unique characteristics and strengths. One such model is Darknet53, a neural network architecture used for object detection. Comprised of 53 layers, this network is known for its high accuracy in detecting objects. It first came to prominence in the revolutionary YOLOv3 object detection algorithm. Another powerful model is EfficientNetB0, a family of neural networks specifically designed for performance and efficiency. This model uses a unique scaling approach that balances model depth, width, and resolution, producing significant results in image classification tasks.
InceptionResNetV2 is another noteworthy model, combining the Inception and ResNet modules to create a deep neural network that is both accurate and efficient. It first gained widespread recognition in the ImageNet Large Scale Visual Recognition Challenge of 2016, where it achieved state-of-the-art performance in the classification task. NASNetLarge and NASNetMobile are additional models that were discovered using neural architecture search (NAS). These models are highly adaptable, with the flexibility to be customized for a wide range of image classification tasks. Finally, ResNet101 and ResNet50 are neural network architectures that belong to the ResNet family of models. With 50 and 101 layers, respectively, these models were widely used in image classification tasks and are renowned for achieving state-of-the-art performance on many benchmark datasets. Overall, the diverse range of pretrained models available in MATLAB provides a wealth of possibilities for performing complex image classification tasks. Detailed analysis of different networks and computational algorithms such as NLR, LRA, and LR2A are given in the Supplementary Materials. GoogLeNet is a convolutional neural network developed by researchers at Google, which is one of the widely used methods for image classification [22].
6. Deep-Learning Experiments
Feeding a focused image is as important as feeding a correct image into the deep learning-network for optimal performance. This is because a blur can cause significant distortion to an image that may be mistaken for another image. A trained Google net in MATLAB accepts only color images (RGB) with a size of 224 × 224 for classification. In this experiment, a color test image, “bell pepper”, was used. The red, green, and blue channels were extracted from the color image and chromatic aberrations of a diffractive lens was applied for a central wavelength λc = 550 nm, and the resulting blurred images were fused back into a color image. A significantly high aberration was applied to test the limits of the deblurring algorithm. The blurred color image can be written as , where R, G, B are the red, green, and blue channels. The blurred image was then analyzed using the pretrained GoogLeNet. The schematic of the process of applying blur to different color channels and obtaining blurred color image and the analysis results from GoogLeNet are shown in Figure 9. GoogLeNet classified the blurred “bell pepper” image as jellyfish with more than 70% probability and spotlight, scuba diver, projector, and traffic light with reduced probabilities.
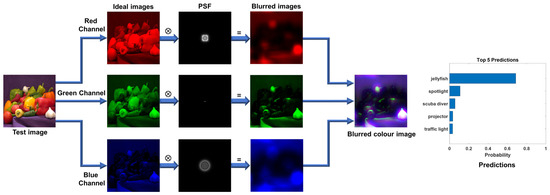
Figure 9.
Method of applying chromatic aberrations to a color image and classification of the resulting blurred image using GoogLeNet.
The deblurring methods NLR, LRA, LR2A were applied to different color channels and after deblurring, the channels were fused to obtain the deblurred color image. The above process is shown in Figure 10. As seen, NLR and LRA reduced the blur to some extent but the deblurred image was not classified as “bell pepper” even within 3% probability. However, the results obtained for LR2A had “bell pepper” as one of the possibilities, which shows that LR2A is a better candidate than LRA and NLR for improving the classification probabilities of pre-trained deep-learning networks when the images are blurred.
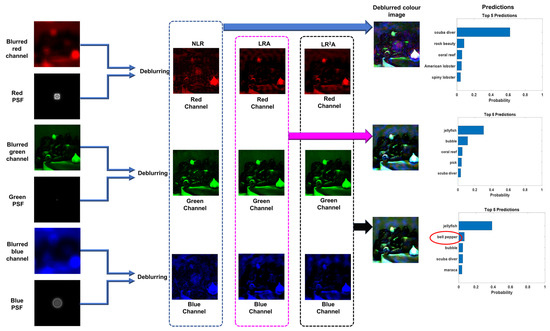
Figure 10.
Method of deblurring different color channels using LRA, NLR, and LR2A, fusing them into a color image and classification of the resulting deblurred image using GoogLeNet. The red circle indicates that the second most probable case is bell pepper when LR2A was used.
Since it is established from the results shown in Figure 10 that LR2A performed better than NLR and LRA, in the next experiment, with different types of aberrations, only classification results for blurred image (BI) were compared with those obtained for LR2A. Blurred and deblurred images obtained from LR2A of the test object were loaded, and its classification was carried out. The results obtained for a typical case of blur and the deblurred images are shown in Figure 11a,b, respectively. It can be seen from Figure 11a that GoogLeNet could not identify “bell pepper” and classified it as a spotlight. In fact, the label ‘bell pepper’ did not appear in the top 25 classification labels (25th with the probability of 0.3%), whereas for the LR2A reconstructed, the classification results were improved by multifold, and the classification probability was about 36%. Few other blurring cases were also considered (Figure 8c A (R = 100 pixels), B (R = 200 pixels), C (Δz = 0.37 mm), D (Δz = 0.38 mm), and E (Δz = 0.42 mm), F (Δλ = 32.8 nm), G (Δλ = 132.8 nm). In all the cases, image classification probability was significantly improved for LR2A.
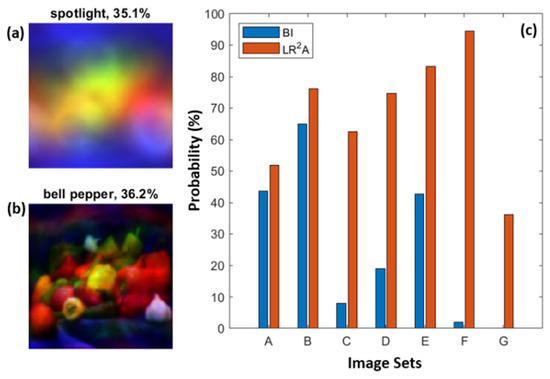
Figure 11.
Image classification using GoogLeNet deep learning module (a) object intensity for image at Δλ = 132.8 nm, (b) deblurred image using LR2A (a,c) classification probabilities of blurred images (BI) vs. deblurred images (LR2A).
7. Discussion
The study presented here linked imaging technology and deep learning in a new light. In most of the previous studies [23,24,25], deep learning was presented as a tool to improve imaging. In this study, for the first time, we showed the possibility to improve the classification performance of deep-learning networks with optical and signal-processing tools. The data used for training deep-learning networks and the original data were often assumed to be without aberrations, which is not the case in reality. From this study, it was quite clear that even minor spatio-spectral aberrations can affect the performances of deep-learning networks significantly. By attaching a robust deblurring method to a deep-learning network, it is possible to improve the performance significantly in the presence of aberrations.
The above idea is different from developing deep-learning methods to deblur blurred images. Even in such cases, if the input dataset consists of both blurred and focused images, fitting over diverse datasets with a deep-learning network is a challenging task. In recent years, physics-informed deep-learning methods were gaining attention [26]. The proposed method can be applied in a similar fashion as a blurred image can be detected by observing the strengths of high spatial frequencies and the probability of classification [27,28].
LR2A is a recently developed deblurring algorithm which was demonstrated so far only with spatially incoherent but temporally coherent illumination and only invasively [10,11]. In this study, for the first time, LR2A was implemented for white light illumination and using latest smart phones in both invasive as well as non-invasive modes. In the non-invasive approach demonstrated, the synthetic PSFs were obtained by scalar diffraction formulation. The method was implemented on datasets with aberrations for many deep-learning networks. The performance of deblurring assisted GoogLeNet for datasets with spatio-spectral aberrations is presented. The performances of about 19 pre-trained deep-learning networks were evaluated for NLR, LRA, and LR2A and the detailed results are presented in the Supplementary Materials. In all the cases, it was evident that LR2A significantly improved classification performance compared to NLR and LRA. It is true that there are numerous deblurring methods developed for various applications, and comparing all the existing methods is not realistic. Since, it was well-established that NLR performed better than commonly used deblurring methods such as MF, PoF, WF, and RFA, in this study, the comparison was made only with the parent methods, namely LRA and NLR.
8. Summary and Conclusions
LR2A is a recently developed computational reconstruction method that integrates two well-known algorithms, namely LRA and NLR [10]. In this study, LR2A was implemented for the deblurring of images simulated with spatial and spectral aberrations and with a limited numerical aperture. In every case, LR2A was found to perform better than both LRA and NLR. In the cases where the energy was concentrated in a smaller area, LRA performed better than NLR and vice versa. However, in all cases, LR2A aligned towards one of NLR or LRA and was better than both. The convergence rate of LR2A was also at least an order better than LRA, and in some cases, the ratio of the number of iterations between LRA and LR2A was >50 times, which is significant. It must be noted that LR2A uses the same approach as LRA, which is estimation of the maximum likelihood solution. However, the estimation speed is faster than LRA due to the replacement of MF by NLR in LRA and offers a better estimation. In some cases of reconstruction, the signal strength appears weaker than the original signal due to the tuning of α and β to non-unity values. We believe that these preliminary results are promising, and LR2A can be an attractive tool for pattern recognition applications and image deblurring in incoherent linear shift-invariant imaging systems. There are certain challenges in implementing LR2A (and LRA) as supposed to NLR. In NLR, the optimal values of α and β can be blindly obtained at the minima of entropy, which is not the case in LR2A. Additionally, NLR is quite stable with non-changing values of α and β unless a significant change was made to the experiment. This was not the case with LR2A, as it was highly sensitive to even minor changes in PSF, object, and experimental conditions. Dedicated research is needed in the future to develop a fast method to find the optimal values of α, β, and number of iterations in the case of LR2A. In the current study, the values of α and β were obtained intuitively.
In this study, LR2A was demonstrated for the first time with spatially and temporally incoherent illumination, making it applicable for wider applications. Optical experiments were carried out using the camera of smartphones, and the recorded images were significantly enhanced with LR2A. This approach enables imaging beyond the LDDV of smart phone cameras. Deep-learning-based image classification is highly sensitive to the quality of images, as even a minor blur can affect the classification probability significantly. In this study, the invasive and non-invasive LR2A-based deblurring was shown to improve the classification probability. A significant improvement was also observed in the case of deep-learning-based image classification. The current research outcome also indicates the need for an integrated approach involving signal processing, optical methods, and deep learning to achieve optimal performance [29].
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/photonics10040396/s1.
Author Contributions
Conceptualization, V.A., R.S., S.J., I.S. and A.J.; methodology, V.A., R.S., I.S., A.J. and P.P.A.; deep learning experiments, A.J. and P.P.A.; software, A.J., I.S., V.A., P.P.A., A.S.J.F.R. and S.G.; validation, F.G.A., A.B., D.S., S.H.N., M.H., T.K. and A.P.I.X.; resources, V.A. and S.J.; smart phone experiments, V.A., P.P.A., S.G., A.S.J.F.R. and A.J.; writing—original draft preparation, V.A., P.P.A. and A.J.; writing—review and editing, all the authors; supervision, V.A., R.S. and S.J.; project administration, V.A., R.S. and S.J.; funding acquisition, V.A., R.S. and S.J.; All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by European Union’s Horizon 2020 research and innovation programme grant agreement No. 857627 (CIPHR) and ARC Linkage LP190100505 project.
Institutional Review Board Statement
Not Applicable.
Informed Consent Statement
Not Applicable.
Data Availability Statement
The data can be obtained from the authors upon reasonable request.
Acknowledgments
The authors thank Tiia Lillemaa for the administrative support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Peng, X.; Gao, L.; Wang, Y.; Kneip, L. Globally-Optimal Contrast Maximisation for Event Cameras. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3479–3495. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Liang, J.; Zhang, M. A degradation model for simultaneous brightness and sharpness enhancement of low-light image. Signal Process. 2021, 189, 108298. [Google Scholar] [CrossRef]
- Kim, J.; Seong, J.; Yang, Y.; Moon, S.-W.; Badloe, T.; Rho, J. Tunable metasurfaces towards versatile metalenses and metaholograms: A review. Adv. Photon. 2022, 4, 024001. [Google Scholar] [CrossRef]
- Pan, M.Y.; Fu, Y.F.; Zheng, M.J.; Chen, H.; Zang, Y.J.; Duan, H.G.; Li, Q.; Qiu, M.; Hu, Y.Q. Dielectric metalens for miniaturized imaging systems: Progress and challenges. Light Sci. Appl. 2022, 11, 195. [Google Scholar] [CrossRef]
- Ng, S.H.; Anand, V.; Katkus, T.; Juodkazis, S. Invasive and Non-Invasive Observation of Occluded Fast Transient Events: Computational Tools. Photonics 2021, 8, 253. [Google Scholar] [CrossRef]
- Vijayakumar, A.; Jayavel, D.; Muthaiah, M.; Bhattacharya, S.; Rosen, J. Implementation of a speckle-correlation-based optical lever with extended dynamic range. Appl. Opt. 2019, 58, 5982–5988. [Google Scholar] [CrossRef]
- Rai, M.; Vijayakumar, A.; Rosen, J. Non-linear adaptive three-dimensional imaging with interferenceless coded aperture correlation holography (I-COACH). Opt. Express 2018, 26, 18143–18154. [Google Scholar] [CrossRef]
- Lucy, L.B. An iterative technique for the rectification of observed distributions. Astron. J. 1974, 79, 745. [Google Scholar] [CrossRef]
- Richardson, W.H. Bayesian-Based Iterative Method of Image Restoration. J. Opt. Soc. Am. 1972, 62, 55–59. [Google Scholar] [CrossRef]
- Anand, V.; Han, M.; Maksimovic, J.; Ng, S.H.; Katkus, T.; Klein, A.; Bambery, K.; Tobin, M.J.; Vongsvivut, J.; Juodkazis, S.; et al. Single-shot mid-infrared incoherent holography using Lucy-Richardson-Rosen algorithm. Opto-Electron. Sci. 2022, 1, 210006. [Google Scholar]
- Praveen, P.A.; Arockiaraj, F.G.; Gopinath, S.; Smith, D.; Kahro, T.; Valdma, S.-M.; Bleahu, A.; Ng, S.H.; Reddy, A.N.K.; Katkus, T.; et al. Deep Deconvolution of Object Information Modulated by a Refractive Lens Using Lucy-Richardson-Rosen Algorithm. Photonics 2022, 9, 625. [Google Scholar] [CrossRef]
- Wang, R.; Tao, D. Recent progress in image deblurring. arXiv 2014, arXiv:1409.6838 2014. [Google Scholar]
- Bai, X.; Wang, X.; Liu, X.; Liu, Q.; Song, J.; Sebe, N.; Kim, B. Explainable deep learning for efficient and robust pattern recognition: A survey of recent developments. Pattern Recognit. 2021, 120, 108102. [Google Scholar] [CrossRef]
- Rosen, J.; Vijayakumar, A.; Kumar, M.; Rai, M.R.; Kelner, R.; Kashter, Y.; Bulbul, A.; Mukherjee, S. Recent advances in self-interference incoherent digital holography. Adv. Opt. Photon. 2019, 11, 1–66. [Google Scholar] [CrossRef]
- Padhy, R.P.; Chang, X.; Choudhury, S.K.; Sa, P.K.; Bakshi, S. Multi-stage cascaded deconvolution for depth map and surface normal prediction from single image. Pattern Recognit. Lett. 2019, 127, 165–173. [Google Scholar] [CrossRef]
- Riad, S.M. The deconvolution problem: An overview. Proc. IEEE 1986, 74, 82–85. [Google Scholar] [CrossRef]
- Starck, J.L.; Pantin, E.; Murtagh, F. Deconvolution in astronomy: A review. Publ. Astron. Soc. Pac. 2002, 114, 1051. [Google Scholar] [CrossRef]
- Horner, J.L.; Gianino, P.D. Phase-only matched filtering. Appl. Opt. 1984, 23, 812–816. [Google Scholar] [CrossRef] [PubMed]
- Smith, D.; Gopinath, S.; Arockiaraj, F.G.; Reddy, A.N.K.; Balasubramani, V.; Kumar, R.; Dubey, N.; Ng, S.H.; Katkus, T.; Selva, S.J.; et al. Nonlinear Reconstruction of Images from Patterns Generated by Deterministic or Random Optical Masks—Concepts and Review of Research. J. Imaging 2022, 8, 174. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, S.; Li, L.; Cui, T.J. Spin-Controlled Multiple Pencil Beams and Vortex Beams with Different Polarizations Generated by Pancharatnam-Berry Coding Metasurfaces. ACS Appl. Mater. Interfaces 2017, 9, 36447–36455. [Google Scholar] [CrossRef]
- Arora, G.; Dubey, A.K.; Jaffery, Z.A.; Rocha, A. A comparative study of fourteen deep learning networks for multi skin lesion classification (MSLC) on unbalanced data. Neural Comput. Appl. 2022, 1, 27. [Google Scholar] [CrossRef]
- Tang, P.; Wang, H.; Kwong, S. G-MS2F: GoogLeNet based multi-stage feature fusion of deep CNN for scene recognition. Neurocomputing 2017, 225, 188–197. [Google Scholar] [CrossRef]
- Gassenmaier, S.; Küstner, T.; Nickel, D.; Herrmann, J.; Hoffmann, R.; Almansour, H.; Afat, S.; Nikolaou, K.; Othman, A.E. Deep Learning Applications in Magnetic Resonance Imaging: Has the Future Become Present? Diagnostics 2021, 11, 2181. [Google Scholar] [CrossRef]
- Lee, J.; Jun, S.; Cho, Y.; Lee, H.; Kim, G.B.; Seo, J.B.; Kim, N. Deep Learning in Medical Imaging: General Overview. Korean J. Radiol. 2017, 18, 570–584. [Google Scholar] [CrossRef] [PubMed]
- Barbastathis, G.; Ozcan, A.; Situ, G. On the use of deep learning for computational imaging. Optica 2019, 6, 921. [Google Scholar] [CrossRef]
- Wei, W.; Tang, P.; Shao, J.; Zhu, J.; Zhao, X.; Wu, C. End-to-end design of metasurface-based complex-amplitude holograms by physics-driven deep neural networks. Nanophotonics 2022, 11, 2921. [Google Scholar] [CrossRef]
- Ali, U.; Mahmood, M.T. Analysis of Blur Measure Operators for Single Image Blur Segmentation. Appl. Sci. 2018, 8, 807. [Google Scholar] [CrossRef]
- Golestaneh, S.A.; Karam, L.J. Spatially-Varying Blur Detection Based on Multiscale Fused and Sorted Transform Coefficients of Gradient Magnitudes. arXiv 2017, arXiv:1703.07478. [Google Scholar]
- Lin, X.; Rivenson, Y.; Yardimci, N.T.; Veli, M.; Luo, Y.; Jarrahi, M.; Ozcan, A. All-optical machine learning using diffractive deep neural networks. Science 2018, 361, 1004–1008. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).