Low-Illumination Image Enhancement Based on Deep Learning Techniques: A Brief Review


Abstract
1. Introduction
2. Classification of Low Illumination Image Enhancement Methods
2.1. Supervised Learning Methods
2.1.1. End-to-End Methods
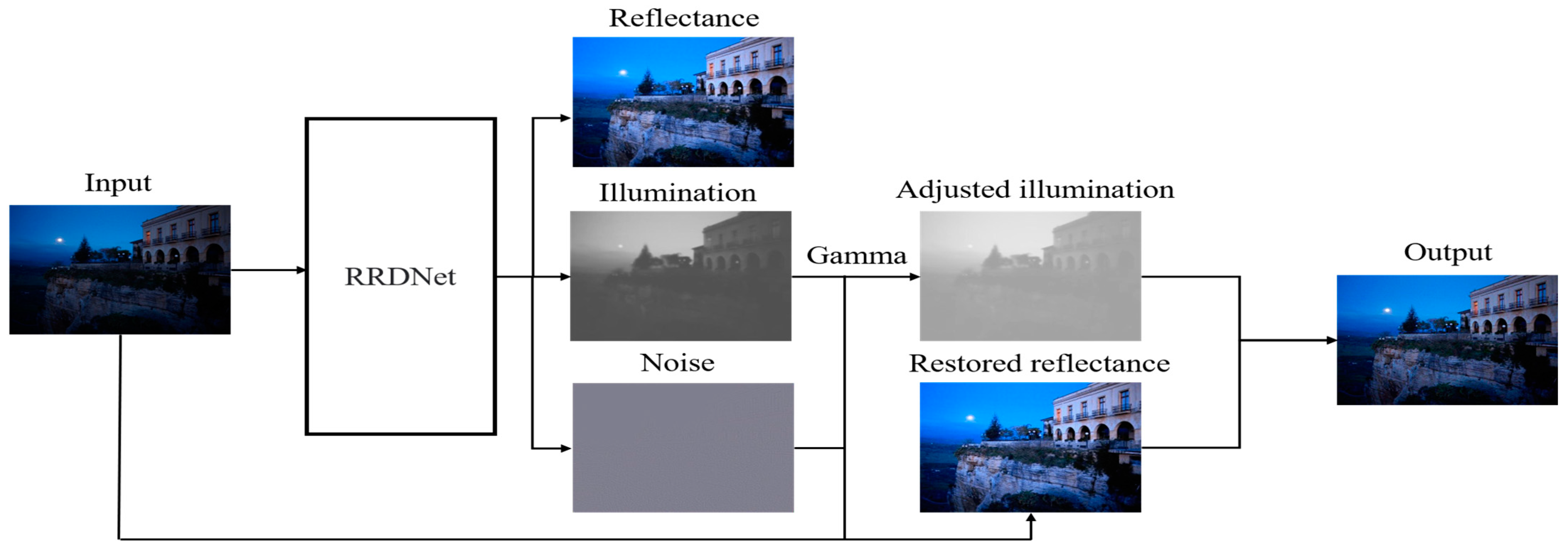
2.1.2. Deep Retinex-Based Methods
2.1.3. Deep Transformer-Based Methods
2.2. Unsupervised Learning Methods
2.3. Semi-Supervised Learning Methods
2.4. Zero-Shot Learning Methods
3. Low-Illumination Image Datasets
4. Image Quality Assessment
4.1. Objective Evaluation Indices
4.2. Subjective Evaluation Indices
4.3. Summary
5. Algorithm Comparisons and Result Analysis
5.1. Subjective Analysis
5.2. Objective Analysis
5.3. Low-Illumination Face Detection Performance
5.4. Time Complexity
5.5. Summary
6. Conclusions
- (1)
- Most of the existing low-illumination image datasets are single images in the natural environment, and the number of paired image datasets with reference is small. The low illuminance/standard light image pairs composed by the synthetic method often have deviations. Still, artificial labels often fail to avoid the influence of physical factors; the brands are inaccurate, and so on. The existing data sets are not suitable for high-level visual tasks and often fail to meet the requirements of high-level visual tasks. They often fail to meet the requirements of high-level visual tasks. Therefore, enhancing the low-illumination image dataset is also a direction of future research.
- (2)
- The existing objective evaluation indicators are used in other research fields, such as image fog removal, rain removal, noise reduction, etc. These metrics are not designed for low-light image enhancement, and these evaluation metrics are far from achieving the natural perception effect of human beings. The quality of objective indicators is often different from the evaluation of human eyes, so it is urgent to design objective evaluation indicators for low-illumination image enhancement.
- (3)
- From a series of algorithm effects, it can be seen that the algorithms with fusion and model framework often have better generalization ability, and the unsupervised learning methods are more robust and stable than the supervised learning methods. However, the purpose of low-illumination image enhancement algorithms is to prepare for higher-level visual tasks. Hence, the current research aims to make universal low-illumination image enhancement algorithms that can serve higher-level visual tasks.
- (4)
- Low-illumination video enhancement is a method to decompose the video into frames, enhance the decomposed image, and then fuse it. However, it is difficult for various algorithms to achieve the speed of 30 frames per second. How to speed up the algorithms without weakening the enhancement effect still needs further research.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ackar, H.; Abd Almisreb, A.; Saleh, M.A. A review on image enhancement techniques. Southeast Eur. J. Soft Comput. 2019, 8, 42–48. [Google Scholar] [CrossRef]
- Fang, M.; Li, H.; Lei, L. A review on low light video image enhancement algorithms. J. Chang. Univ. Sci. Technol. 2016, 39, 56–64. [Google Scholar]
- Yan, X.; Liu, T.; Fu, M.; Ye, M.; Jia, M. Bearing Fault Feature Extraction Method Based on Enhanced Differential Product Weighted Morphological Filtering. Sensors 2022, 22, 6184. [Google Scholar] [CrossRef]
- Wang, W.; Yuan, X.; Wu, X.; Liu, Y. Fast image dehazing method based on linear transformation. IEEE Trans. Multimed. 2017, 19, 1142–1155. [Google Scholar] [CrossRef]
- Yu, J.; Li, D.-p.; Liao, Q.-m. Color constancy-based visibility enhancement of color images in low-light conditions. Acta Autom. Sin. 2011, 37, 923–931. [Google Scholar]
- Sun, Y.; Li, M.; Dong, R.; Chen, W.; Jiang, D. Vision-Based Detection of Bolt Loosening Using YOLOv5. Sensors 2022, 22, 5184. [Google Scholar] [CrossRef] [PubMed]
- Yan, X.; Jia, M. Bearing fault diagnosis via a parameter-optimized feature mode decomposition. Measurement 2022, 203, 112016. [Google Scholar] [CrossRef]
- Wang, Y.-F.; Liu, H.-M.; Fu, Z.-W. Low-light image enhancement via the absorption light scattering model. IEEE Trans. Image Process. 2019, 28, 5679–5690. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, J.; Wan, Z.; Zhang, D.; Jiang, D. Rotor Fault Diagnosis Using Domain-Adversarial Neural Network with Time-Frequency Analysis. Machines 2022, 10, 610. [Google Scholar] [CrossRef]
- Li, W.; Zhu, D.; Shao, W.; Jiang, D. Modeling of Internal Geometric Variability and Statistical Property Prediction of Braided Composites. Materials 2022, 15, 5332. [Google Scholar] [CrossRef]
- Abdullah-Al-Wadud, M.; Kabir, M.H.; Dewan, M.A.A.; Chae, O. A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Yang, Y.; Zhuang, Z.; Yu, Y. Defect removal and rearrangement of wood board based on genetic algorithm. Forests 2021, 13, 26. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, Y.; Liu, Z.; Zhuang, Z.; Wang, X.; Gou, B. Crack Detection Method for Engineered Bamboo Based on Super-Resolution Reconstruction and Generative Adversarial Network. Forests 2022, 13, 1896. [Google Scholar] [CrossRef]
- Stark, J.A. Adaptive image contrast enhancement using generalizations of histogram equalization. IEEE Trans. Image Process. 2000, 9, 889–896. [Google Scholar] [CrossRef]
- Land, E.H.; McCann, J.J. Lightness and retinex theory. Josa 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Liu, J.; Xu, D.; Yang, W.; Fan, M.; Huang, H. Benchmarking low-light image enhancement and beyond. Int. J. Comput. Vis. 2021, 129, 1153–1184. [Google Scholar] [CrossRef]
- Dai, Q.; Pu, Y.-F.; Rahman, Z.; Aamir, M. Fractional-order fusion model for low-light image enhancement. Symmetry 2019, 11, 574. [Google Scholar] [CrossRef]
- Ma, R.; Zhang, S. An improved color image defogging algorithm using dark channel model and enhancing saturation. Optik 2019, 180, 997–1000. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. Msr-net: Low-light image enhancement using deep convolutional network. arXiv 2017, arXiv:1711.02488. [Google Scholar]
- Tao, L.; Zhu, C.; Xiang, G.; Li, Y.; Jia, H.; Xie, X. LLCNN: A convolutional neural network for low-light image enhancement. In Proceedings of the the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the the BMVC, Newcastle, UK, 3–6 September 2018; p. 4. [Google Scholar]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Yu, R.; Liu, W.; Zhang, Y.; Qu, Z.; Zhao, D.; Zhang, B. Deepexposure: Learning to expose photos with asynchronously reinforced adversarial learning. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3291–3300. [Google Scholar]
- Robert, T.; Thome, N.; Cord, M. HybridNet: Classification and Reconstruction Cooperation for Semi-supervised Learning. In Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 158–175. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, Q.; Fu, C.-W.; Shen, X.; Zheng, W.-S.; Jia, J. Underexposed photo enhancement using deep illumination estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6849–6857. [Google Scholar]
- Jiang, H.; Zheng, Y. Learning to see moving objects in the dark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7324–7333. [Google Scholar]
- Zhang, L.; Zhang, L.; Liu, X.; Shen, Y.; Zhang, S.; Zhao, S. Zero-shot restoration of back-lit images using deep internal learning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1623–1631. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. Eemefn: Low-light image enhancement via edge-enhanced multi-exposure fusion network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 13106–13113. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 12–16 October 2020; pp. 1780–1789. [Google Scholar]
- Fan, M.; Wang, W.; Yang, W.; Liu, J. Integrating semantic segmentation and retinex model for low-light image enhancement. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2317–2325. [Google Scholar]
- Lu, K.; Zhang, L. TBEFN: A two-branch exposure-fusion network for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4093–4105. [Google Scholar] [CrossRef]
- Wang, L.-W.; Liu, Z.-S.; Siu, W.-C.; Lun, D.P. Lightening network for low-light image enhancement. IEEE Trans. Image Process. 2020, 29, 7984–7996. [Google Scholar] [CrossRef]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Munir, F.; Azam, S.; Jeon, M. LDNet: End-to-End Lane Detection Approach usinga Dynamic Vision Sensor. arXiv 2020, arXiv:2009.08020. [Google Scholar] [CrossRef]
- Lim, S.; Kim, W. DSLR: Deep stacked Laplacian restorer for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4272–4284. [Google Scholar] [CrossRef]
- Hai, J.; Xuan, Z.; Yang, R.; Hao, Y.; Zou, F.; Lin, F.; Han, S. R2rnet: Low-light image enhancement via real-low to real-normal network. arXiv 2021, arXiv:2106.14501. [Google Scholar] [CrossRef]
- Li, J.; Feng, X.; Hua, Z. Low-light image enhancement via progressive-recursive network. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4227–4240. [Google Scholar] [CrossRef]
- Qiao, Z.; Xu, W.; Sun, L.; Qiu, S.; Guo, H. Deep Semi-Supervised Learning for Low-Light Image Enhancement. In Proceedings of the 2021 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 23–25 October 2021; pp. 1–6. [Google Scholar]
- Wei, X.; Zhang, X.; Li, Y. Tsn-ca: A two-stage network with channel attention for low-light image enhancement. In Proceedings of the International Conference on Artificial Neural Networks, Beijing, China, 5–7 November 2022; pp. 286–298. [Google Scholar]
- Wei, X.; Zhang, X.; Wang, S.; Cheng, C.; Huang, Y.; Yang, K.; Li, Y. BLNet: A Fast Deep Learning Framework for Low-Light Image Enhancement with Noise Removal and Color Restoration. arXiv 2021, arXiv:2106.15953. [Google Scholar]
- Zhao, Z.; Xiong, B.; Wang, L.; Ou, Q.; Yu, L.; Kuang, F. Retinexdip: A unified deep framework for low-light image enhancement. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1076–1088. [Google Scholar] [CrossRef]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Yang, W.; Wang, W.; Huang, H.; Wang, S.; Liu, J. Sparse gradient regularized deep retinex network for robust low-light image enhancement. IEEE Trans. Image Process. 2021, 30, 2072–2086. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Loy, C.C. Learning to enhance low-light image via zero-reference deep curve estimation. arXiv 2021, arXiv:2103.00860. [Google Scholar] [CrossRef]
- Zheng, C.; Shi, D.; Shi, W. Adaptive Unfolding Total Variation Network for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4439–4448. [Google Scholar]
- Zhang, F.; Li, Y.; You, S.; Fu, Y. Learning temporal consistency for low light video enhancement from single images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 20–25 June 2021; pp. 4967–4976. [Google Scholar]
- Sharma, A.; Tan, R.T. Nighttime visibility enhancement by increasing the dynamic range and suppression of light effects. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 20–25 June 2021; pp. 11977–11986. [Google Scholar]
- Wu, W.; Weng, J.; Zhang, P.; Wang, X.; Yang, W.; Jiang, J. URetinex-Net: Retinex-Based Deep Unfolding Network for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 5901–5910. [Google Scholar]
- Tu, Z.; Talebi, H.; Zhang, H.; Yang, F.; Milanfar, P.; Bovik, A.; Li, Y. Maxim: Multi-axis mlp for image processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 5769–5780. [Google Scholar]
- Fan, C.-M.; Liu, T.-J.; Liu, K.-H. Half Wavelet Attention on M-Net+ for Low-Light Image Enhancement. arXiv 2022, arXiv:2203.01296. [Google Scholar]
- Dong, X.; Xu, W.; Miao, Z.; Ma, L.; Zhang, C.; Yang, J.; Jin, Z.; Teoh, A.B.J.; Shen, J. Abandoning the Bayer-Filter To See in the Dark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 17431–17440. [Google Scholar]
- Zheng, D.; Zhang, X.; Ma, K.; Bao, C. Learn from Unpaired Data for Image Restoration: A Variational Bayes Approach. arXiv 2022, arXiv:2204.10090. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward Fast, Flexible, and Robust Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 5637–5646. [Google Scholar]
- Cotogni, M.; Cusano, C. TreEnhance: A Tree Search Method For Low-Light Image Enhancement. Pattern Recognit. 2022, 136, 109249. [Google Scholar] [CrossRef]
- Liang, J.; Xu, Y.; Quan, Y.; Shi, B.; Ji, H. Self-Supervised Low-Light Image Enhancement Using Discrepant Untrained Network Priors. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7332–7345. [Google Scholar] [CrossRef]
- Jin, Y.; Yang, W.; Tan, R.T. Unsupervised night image enhancement: When layer decomposition meets light-effects suppression. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 24–28 October 2022; pp. 404–421. [Google Scholar]
- Wang, H.; Xu, K.; Lau, R.W. Local color distributions prior for image enhancement. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 24–28 October 2022; pp. 343–359. [Google Scholar]
- Wang, T.; Zhang, K.; Shen, T.; Luo, W.; Stenger, B.; Lu, T. Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method. arXiv 2022, arXiv:2212.11548. [Google Scholar]
- Xu, X.; Wang, R.; Fu, C.-W.; Jia, J. SNR-Aware Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 17714–17724. [Google Scholar]
- Wang, W.; Wei, C.; Yang, W.; Liu, J. Gladnet: Low-light enhancement network with global awareness. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 751–755. [Google Scholar]
- Ravirathinam, P.; Goel, D.; Ranjani, J.J. C-LIENet: A multi-context low-light image enhancement network. IEEE Access 2021, 9, 31053–31064. [Google Scholar] [CrossRef]
- Cui, Z.; Li, K.; Gu, L.; Su, S.; Gao, P.; Jiang, Z.; Qiao, Y.; Harada, T. Illumination Adaptive Transformer. arXiv 2022, arXiv:2205.14871. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. pp. 213–229. [Google Scholar]
- Fu, Y.; Hong, Y.; Chen, L.; You, S. LE-GAN: Unsupervised low-light image enhancement network using attention module and identity invariant loss. Knowl. -Based Syst. 2022, 240, 108010. [Google Scholar] [CrossRef]
- Ni, Z.; Yang, W.; Wang, S.; Ma, L.; Kwong, S. Towards unsupervised deep image enhancement with generative adversarial network. IEEE Trans. Image Process. 2020, 29, 9140–9151. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Shao, Y.; Sun, Y.; Zhu, K.; Gao, C.; Sang, N. Unsupervised low-light image enhancement via histogram equalization prior. arXiv 2021, arXiv:2112.01766. [Google Scholar]
- Kaufman, L.; Lischinski, D.; Werman, M. Content-Aware Automatic Photo Enhancement. In Proceedings of the Computer Graphics Forum, Reims, France, 25–29 April 2022; pp. 2528–2540. [Google Scholar]
- Lee, C.; Lee, C.; Lee, Y.-Y.; Kim, C.-S. Power-constrained contrast enhancement for emissive displays based on histogram equalization. IEEE Trans. Image Process. 2011, 21, 80–93. [Google Scholar]
- Lee, C.; Lee, C.; Kim, C.-S. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef]
- Wang, S.; Zheng, J.; Hu, H.-M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef]
- Yu, F.; Xian, W.; Chen, Y.; Liu, F.; Liao, M.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving video database with scalable annotation tooling. arXiv 2018, arXiv:1805.04687. [Google Scholar]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the exclusively dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Q.; Do, M.N.; Koltun, V. Seeing motion in the dark. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 3185–3194. [Google Scholar]
- Wang, W.; Wang, X.; Yang, W.; Liu, J. Unsupervised Face Detection in the Dark. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 5, 1250–1266. [Google Scholar] [CrossRef]
- Tan, X.; Xu, K.; Cao, Y.; Zhang, Y.; Ma, L.; Lau, R.W. Night-time scene parsing with a large real dataset. IEEE Trans. Image Process. 2021, 30, 9085–9098. [Google Scholar] [CrossRef]
- Wei, K.; Fu, Y.; Yang, J.; Huang, H. A physics-based noise formation model for extreme low-light raw denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 12–16 October 2020; pp. 2758–2767. [Google Scholar]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3496–3504. [Google Scholar]
- Li, C.; Guo, C.; Han, L.-H.; Jiang, J.; Cheng, M.-M.; Gu, J.; Loy, C.C. Low-light image and video enhancement using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9396–9416. [Google Scholar] [CrossRef] [PubMed]
- Singh, A.; Gupta, K. A contrast enhancement technique for low light images. AIP Conf. Proc. 2016, 1715, 020057. [Google Scholar]
- Dong, X.; Pang, Y.; Wen, J. Fast efficient algorithm for enhancement of low lighting video. In ACM SIGGRAPH 2010 Posters; Association for Computing Machinery: New York, NY, USA, 2010; p. 1. [Google Scholar]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Kellman, P.; McVeigh, E.R. Image reconstruction in SNR units: A general method for SNR measurement. Magn. Reson. Med. 2005, 54, 1439–1447. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Xu, X.; Lin, H.; Xinyan, Y. Low-illumination image enhancement method based on a fog-degraded model. J. Image Graph. 2017, 22, 1194–1205. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Sheikh, H.R.; Bovik, A.C.; De Veciana, G. An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Trans. Image Process. 2005, 14, 2117–2128. [Google Scholar] [CrossRef] [PubMed]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Ignatov, A.; Kobyshev, N.; Timofte, R.; Vanhoey, K.; Van Gool, L. Wespe: Weakly supervised photo enhancer for digital cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 691–700. [Google Scholar]
- Zhu, J.; Wang, Z. Low-illumination surveillance image enhancement based on similar scenes. Comput. Appl. Softw. 2015, 32, 203–205. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.-P.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2782–2790. [Google Scholar]
- Ma, C.; Yang, C.-Y.; Yang, X.; Yang, M.-H. Learning a no-reference quality metric for single-image super-resolution. Comput. Vis. Image Underst. 2017, 158, 1–16. [Google Scholar] [CrossRef]
- Ke, J.; Wang, Q.; Wang, Y.; Milanfar, P.; Yang, F. Musiq: Multi-scale image quality transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5148–5157. [Google Scholar]
- Talebi, H.; Milanfar, P. NIMA: Neural image assessment. IEEE Trans. Image Process. 2018, 27, 3998–4011. [Google Scholar] [CrossRef]
- Fang, Y.; Zhu, H.; Zeng, Y.; Ma, K.; Wang, Z. Perceptual quality assessment of smartphone photography. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3677–3686. [Google Scholar]
- Li, J.; Wang, Y.; Wang, C.; Tai, Y.; Qian, J.; Yang, J.; Wang, C.; Li, J.; Huang, F. DSFD: Dual shot face detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5060–5069. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Method | Training Data | Test Data | Evaluation Metrics | Platform |
|---|---|---|---|---|---|
| 2017 | LLNet | Gamma corrected image processing | Self-Selected | PSNR SSIM | Theano |
| 2017 | MSR-Net | Open-source data set | MEF NPE VV | SSIM NIQE | Caffe |
| 2017 | LLCNN | Gamma corrected image processing | Self-Selected | PSNR SSIM LOE SNM | --- |
| 2018 | MBLLEN | VOC | Self-Selected | PSNR SSIM AB VIF LOE TOMI | TensorFlow |
| 2018 | RetinexNet | LOL | VV MEF LIME NPE DICM | --- | TensorFlow |
| 2018 | SCIE | SCIE | SCIE | PSNR FSIM | Caffe&Matlab |
| 2018 | DeepExposure | MIT-Adobe FiveK | MIT-Adobe FiveK | MSE PSNR | TensorFlow |
| 2018 | Chen et al. | SID | SID | PSNR SSIM | TensorFlow |
| 2018 | HybirdNet | Places | CIFAR-10 STL-10 SVHN | --- | Caffe |
| 2019 | EnlightenGAN | Unpaired real images | NPE LIME MEF DICM VV BBD-100K ExDARK | NIQE | PyTorch |
| 2019 | KinD | LOL | LOL NPE LIME MEF | PSNR SSIM LOE NIQE | TensorFlow |
| 2019 | KinD++ | LOL | DICM LIME MEF NPE | PSNR SSIM LOE NIQE | TensorFlow |
| 2019 | DeepUPE | Homemade image pair | MIT-Adobe FiveK | PSNR SSIM | --- |
| 2019 | SMOID | SMOID | SMOID | PSNR SSIM MSE | TensorFlow |
| 2019 | EXCNet | real images | IEpsD | CDIQA LOD | PyTorch |
| 2020 | EEMEFN | SID | SID | PSNR SSIM | PyTorch |
| 2020 | Zero-DCE | SICE | SICE NPE LIME MEF DICM VV DARK FACE | PNSR SSIM | PyTorch |
| 2020 | DRBN | LOL | LOL | PSNR SSIM | PyTorch |
| 2020 | SemanticRetinex | analog image | self-selected | PSNR SSIM NIQE | --- |
| 2020 | TBEFN | SCIE LOL | SCIE LOL DICM MEF NPE VV | PSNR SSIM NIQE | TensorFlow |
| 2020 | DLN | analog image | LOL | PSNR SSIM NIQE | PyTorch |
| 2020 | RRDNet | --- | PE LIME MEF DICM | NIQE CPCQI | PyTorch |
| 2020 | LDNet | --- | DVS | --- | PyTorch |
| 2020 | DSLR | MIT-Adobe FiveK | MIT-Adobe FiveK self-selected | PSNR SSIM NIQMC NIQE BTMQI CaHDC | PyTorch |
| 2021 | R2RNet | LSRW | LOL LIME DICM NPE MEF VV | PSNR SSIM FSIM MAE GMSD NIQE | PyTorch |
| 2021 | PRIEN | MEF LOL Brightening-Train | LIME NPE MEF VV | PSNR SSIM LOE TMQI | PyTorch |
| 2021 | TSN-CA | LOL | LOL LIME DICM MEF NPE | PSNR SSIM VIF LPIPS FSIM UQI | --- |
| 2021 | BLNet | LOL | LOL LIME DICM MEF | --- | PyTorch |
| 2021 | RetinexDIP | --- | DICM ExDark Fusion LIME NASA NPE VV | NIQE NIQMC CPCQI | PyTorch |
| 2021 | RUAS | MIT-Adobe FiveKLOL | LOL MIT-Adobe FiveK DarkFace ExtremelyDarkFace | PSNR SSIM LPIPS | PyTorch |
| 2021 | Retinex-Net | New-LOL | New-LOL NPE DICM VV | PSNR SSIM UQI | PyTorch |
| 2021 | Zero-DCE++ | SICE | NPE LIME MEF DICM VV | PSNR SSIM MAE #P FLOPS | PyTorch |
| 2021 | UTVNet | ELD | SID | PSNR SSIM Params LPIPS MACs | PyTorch |
| 2021 | Zhang et al. | DAVIS | DAVIS | PSNR SSIM MABD | PyTorch |
| 2021 | Sharma et al. | HDR-Real SID Color-Constancy | HDR-Real | PSNR SSIM | PyTorch |
| 2022 | URetinex-Net | VV LIME VV DICM ExDark | LOL SICE MEF | PSNR SSIM MAE LPIPS | PyTorch |
| 2022 | MAXIM | LOL MIT-Adobe FiveK | LOL MIT-Adobe FiveK | PSNR SSIM | TensorFlow |
| 2022 | M-Net+ | LOL MIT-Adobe FiveK | LOL MIT-Adobe FiveK | PSNR SSIM LPILS | PyTorch |
| 2022 | Dong et al. | MCR | SID MCR | PSNR SSIM | PyTorch |
| 2022 | LUD-VAE | LUD-VAE | LOL | PSNR SSIM LPILS | PyTorch |
| 2022 | SCI | --- | MIT-Adobe FiveK LSRW | PSNR SSIM DE EME LOE NIQE | PyTorch |
| 2022 | TreEnhance | LOL MIT-Adobe FiveK | LOL MIT-Adobe FiveK | PSNR SSIM LPILS DeltaE | PyTorch |
| 2022 | Liang et al. | --- | LOL LIME NPE MEF DICM | NIQE ARISM NIQMC PSNR SSIM | PyTorch |
| 2022 | Jin et.al | LOL | Dark ZurichLOL LOL-Real | PSNR SSIM MSE LPIPS | PyTorch |
| 2022 | LCDPNet | MIT-Adobe FiveK MSEC LOL | MSEC LOL | PSNR SSIM | PyTorch |
| 2022 | LLFormer | UHD-LOL | UHD-LOL LOLMIT-Adobe FiveK | PSNR SSIM MAE LPIPS | PyTorch |
| 2022 | SNR-Aware | LOL SID SMID | LOL SID SMID SDSD | PSNR SSIM | PyTorch |
| Date | Dataset | Paired/Unpaired | Image/Video | No. of Images | Synthetic/Real |
|---|---|---|---|---|---|
| 2011 | MIT-Adobe FiveK [73] | Paired | Image | 5000 | Real |
| 2012 | MEF [74] | Unpaired | Image | 17 | Real |
| 2013 | DICM [75] | Unpaired | Image | 69 | Real |
| 2013 | NPE [76] | Unpaired | Image | 85 | Real |
| 2017 | LIME [77] | Unpaired | Image | 10 | Real |
| 2017 | DPED [41] | Paired | Image | 22,000 | Real |
| 2018 | SID [26] | Paired | Image | 5094 | Real |
| 2018 | LOL [24] | Paired | Image | 500 | Synthetic+Real |
| 2018 | BDD-100k [78] | Unpaired | Video | 10,000 | Real |
| 2018 | SICE [23] | Paired | Image | 5002 | Real |
| 2019 | ExDark [79] | Unpaired | Image | 7363 | Real |
| 2019 | SMOID [32] | Paired | Video | 202 | Real |
| 2019 | DRV [80] | Unpaired | Video | 179 | Real |
| 2020 | DarkFace [81] | Unpaired | Image | 6000 | Real |
| 2020 | NightCity [82] | Unpaired | Image | 4297 | Real |
| 2020 | ELD [83] | Paired | Image | 480 | Real |
| 2021 | LLVIP [84] | Paired | Image | 30,976 | Real |
| 2021 | LSRW [42] | Paired | Image | 5650 | Synthetic+Real |
| 2021 | VE-LOL-L [16] | Paired | Image | 2500 | Synthetic+Real |
| 2021 | VE-LOL-H [16] | Unpaired | Image | 10,940 | Real |
| 2021 | LoLi-Phone [85] | Unpaired | Image+Video | 55,148 | Real |
| --- | VV | Unpaired | Image | 24 | Real |
| Abbreviation | Full-/Non-Reference |
|---|---|
| MSE (Mean Square Error) [86,87] | Full-Reference |
| MAE (Mean Absolute Error) [88] | Full-Reference |
| SNR (Signal to Noise Ratio) [89] | Full-Reference |
| PSNR (Peak-Signal to Noise Ratio) [90] | Full-Reference |
| LPIPS (Learned Perceptual Image Patch Similarity) [91] | Full-Reference |
| IFC (Information Fidelity Criterion) [92] | Full-Reference |
| VIF (Visual Information Fidelity) [93] | Full-Reference |
| SSIM (Structural Similarity Index) [94] | Full-Reference |
| IE (Information Entropy) [95] | Non-Reference |
| NIQE (Natural Image Quality Evaluator) [96] | Non-Reference |
| LOE (Lightness Order Error) [97] | Full-Reference |
| PI (Perceptual Index) [98] | Non-Reference |
| MUSIQ (Multi-scale Image Quality Transformer) [99] | Non-Reference |
| NIMA (Neural Image Assessment) [100] | Non-Reference |
| SPAQ (Smartphone Photography Attribute and Quality) [101] | Non-Reference |
| Method | NIQE↓ | IE↑ | LOE↓ |
|---|---|---|---|
| Input | 3.015 | 6.381 | 0 |
| LLNet 1 | 2.986 | 7.382 | 167.051 |
| RetinexNet 2 | 2.783 | 6.854 | 621.855 |
| MBLLEN 3 | 3.432 | 7.408 | 47.448 |
| EnlightenGAN 4 | 2.403 | 7.515 | 311.282 |
| ExCNet 5 | 2.386 | 7.413 | 206.526 |
| RRDNet 6 | 2.768 | 7.119 | 41.711 |
| DRBN 7 | 3.312 | 7.481 | 464.876 |
| TBEFN 8 | 2.693 | 7.097 | 158.634 |
| Zero-DCE++ 9 | 2.490 | 7.438 | 246.028 |
| ICENet 10 | 3.331 | 7.517 | 115.913 |
| KinD++ 11 | 2.426 | 7.292 | 347.293 |
| Sci 12 | 4.068 | 7.562 | 61.257 |
| URetinexNet 13 | 3.429 | 7.432 | 109.214 |
| LCDPNet 14 | 2.756 | 7.336 | 157.570 |
| Method | PSNR↑ | SSIM↑ | MSE (×103)↓ | NIQE↓ | IE↑ | LOE↓ |
|---|---|---|---|---|---|---|
| Input | 6.503 | 0.094 | 14.546 | 4.282 | 4.761 | 0 |
| LLNet | 14.963 | 0.726 | 2.074 | 4.001 | 6.576 | 250.756 |
| RetinexNet | 14.940 | 0.689 | 2.085 | 2.595 | 6.543 | 619.658 |
| MBLLEN | 20.334 | 0.790 | 0.602 | 3.261 | 7.146 | 172.254 |
| EnlightenGAN | 12.378 | 0.687 | 3.761 | 2.683 | 7.134 | 364.849 |
| ExCNet | 13.794 | 0.597 | 2.715 | 2.352 | 6.497 | 175.605 |
| RRDNet | 8.885 | 0.334 | 8.406 | 3.498 | 6.016 | 109.657 |
| DRBN | 15.182 | 0.663 | 1.972 | 4.043 | 7.051 | 203.220 |
| TBEFN | 14.234 | 0.681 | 2.453 | 2.911 | 6.904 | 322.813 |
| Zero-DCE++ | 11.197 | 0.395 | 4.936 | 3.034 | 6.465 | 277.180 |
| ICENet | 12.250 | 0.553 | 3.873 | 3.803 | 5.999 | 156.514 |
| KinD++ | 14.983 | 0.683 | 2.064 | 3.082 | 6.364 | 636.400 |
| Sci | 10.683 | 0.454 | 5.557 | 3.140 | 5.922 | 123.624 |
| URetinexNet | 18.550 | 0.614 | 0.908 | 3.408 | 6.465 | 145.845 |
| LCDPNet | 13.946 | 0.651 | 2.621 | 3.459 | 6.678 | 309.153 |
| Method | PSNR↑ | SSIM↑ | MSE (×103)↓ | NIQE↓ | IE↑ | LOE↓ |
|---|---|---|---|---|---|---|
| Input | 7.610 | 0.144 | 9.015 | 6.240 | 5.238 | 0 |
| LLNet | 18.739 | 0.567 | 0.869 | 3.845 | 7.215 | 385.358 |
| RetinexNet | 17.303 | 0.609 | 1.209 | 4.383 | 7.081 | 743.301 |
| MBLLEN | 16.305 | 0.567 | 1.523 | 3.236 | 7.409 | 163.754 |
| EnlightenGAN | 20.332 | 0.643 | 0.602 | 3.268 | 7.375 | 343.028 |
| ExCNet | 19.261 | 0.679 | 0.771 | 3.052 | 7.772 | 166.688 |
| RRDNet | 11.396 | 0.373 | 4.716 | 3.217 | 6.525 | 104.375 |
| DRBN | 20.331 | 0.669 | 0.603 | 3.664 | 7.190 | 413.652 |
| TBEFN | 19.151 | 0.731 | 0.791 | 3.164 | 7.007 | 398.717 |
| Zero-DCE++ | 14.914 | 0.310 | 2.098 | 3.035 | 7.197 | 454.495 |
| ICENet | 17.751 | 0.678 | 1.092 | 4.364 | 7.294 | 152.807 |
| KinD++ | 17.026 | 0.678 | 1.290 | 4.028 | 7.349 | 615.748 |
| Sci | 15.345 | 0.666 | 1.899 | 4.086 | 7.235 | 138.523 |
| URetinexNet | 23.038 | 0.814 | 0.323 | 3.517 | 7.172 | 193.717 |
| LCDPNet | 20.270 | 0.721 | 0.611 | 3.067 | 7.239 | 249.273 |
| Method | PSNR↑ | SSIM↑ | MSE (×103)↓ | NIQE↓ | IE↑ | LOE↓ |
|---|---|---|---|---|---|---|
| Input | 9.812 | 0.267 | 6.790 | 5.172 | 5.130 | 0 |
| LLNet | 21.823 | 0.821 | 0.427 | 3.392 | 7.016 | 381.035 |
| RetinexNet | 16.008 | 0.656 | 1.630 | 2.795 | 6.552 | 624.638 |
| MBLLEN | 20.380 | 0.712 | 0.596 | 2.815 | 7.292 | 132.327 |
| EnlightenGAN | 19.682 | 0.726 | 0.699 | 2.753 | 7.078 | 777.351 |
| ExCNet | 18.694 | 0.733 | 0.878 | 2.579 | 7.231 | 419.8283 |
| RRDNet | 16.177 | 0.736 | 1.568 | 2.474 | 6.636 | 94.710 |
| DRBN | 21.401 | 0.841 | 0.471 | 3.276 | 6.884 | 762.254 |
| TBEFN | 21.351 | 0.831 | 0.476 | 2.750 | 6.514 | 478.2779 |
| Zero-DCE++ | 21.591 | 0.578 | 0.451 | 2.420 | 6.653 | 489.985 |
| ICENet | 22.991 | 0.776 | 0.327 | 3.941 | 6.719 | 579.937 |
| KinD++ | 19.711 | 0.797 | 0.695 | 2.900 | 6.610 | 694.534 |
| Sci | 22.928 | 0.775 | 0.331 | 3.870 | 6.808 | 205.172 |
| URetinexNet | 17.019 | 0.769 | 1.292 | 3.737 | 6.782 | 201.452 |
| LCDPNet | 27.070 | 0.892 | 0.128 | 3.212 | 6.966 | 346.545 |
| Method | Running Time |
|---|---|
| LLNet | 4.021 |
| RetinexNet | 0.469 |
| MBLLEN | 3.975 |
| EnlightenGAN | 0.012 |
| ExCNet | 12.748 |
| RRDNet | 78.386 |
| DRBN | 0.935 |
| TBEFN | 0.120 |
| Zero-DCE++ | 0.747 |
| ICENet | 4.203 |
| KinD++ | 1.322 |
| Sci | 0.931 |
| URetinexNet | 2.467 |
| LCDPNet | 1.630 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, H.; Zhu, H.; Fei, L.; Wang, T.; Cao, Y.; Xie, C. Low-Illumination Image Enhancement Based on Deep Learning Techniques: A Brief Review. Photonics 2023, 10, 198. https://doi.org/10.3390/photonics10020198
Tang H, Zhu H, Fei L, Wang T, Cao Y, Xie C. Low-Illumination Image Enhancement Based on Deep Learning Techniques: A Brief Review. Photonics. 2023; 10(2):198. https://doi.org/10.3390/photonics10020198
Chicago/Turabian StyleTang, Hao, Hongyu Zhu, Linfeng Fei, Tingwei Wang, Yichao Cao, and Chao Xie. 2023. "Low-Illumination Image Enhancement Based on Deep Learning Techniques: A Brief Review" Photonics 10, no. 2: 198. https://doi.org/10.3390/photonics10020198
APA StyleTang, H., Zhu, H., Fei, L., Wang, T., Cao, Y., & Xie, C. (2023). Low-Illumination Image Enhancement Based on Deep Learning Techniques: A Brief Review. Photonics, 10(2), 198. https://doi.org/10.3390/photonics10020198