Lensless Image Restoration Based on Multi-Stage Deep Neural Networks and Pix2pix Architecture

Abstract
:1. Introduction
2. Lensless Imaging System
2.1. Theoretical Model
2.2. Calibration
2.3. Image Reconstruction
3. Proposed Method
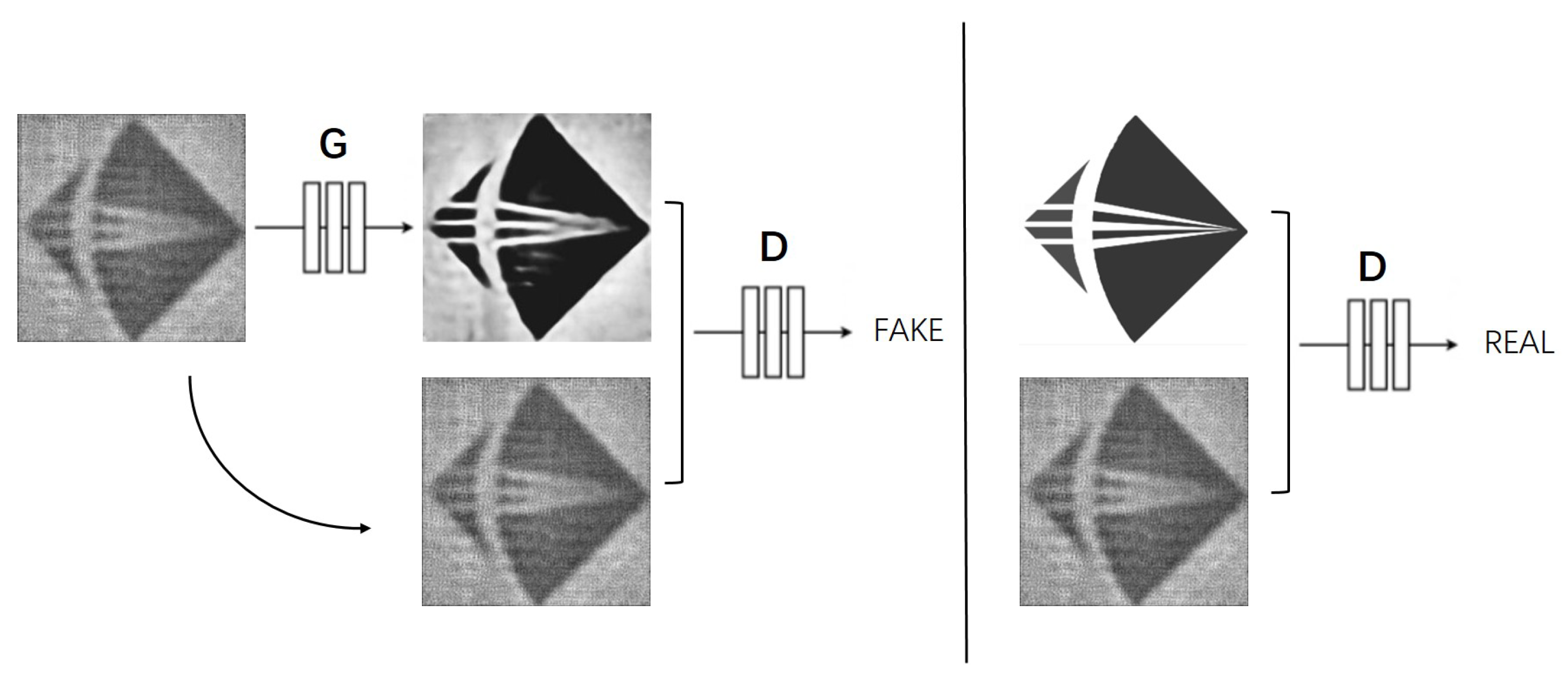
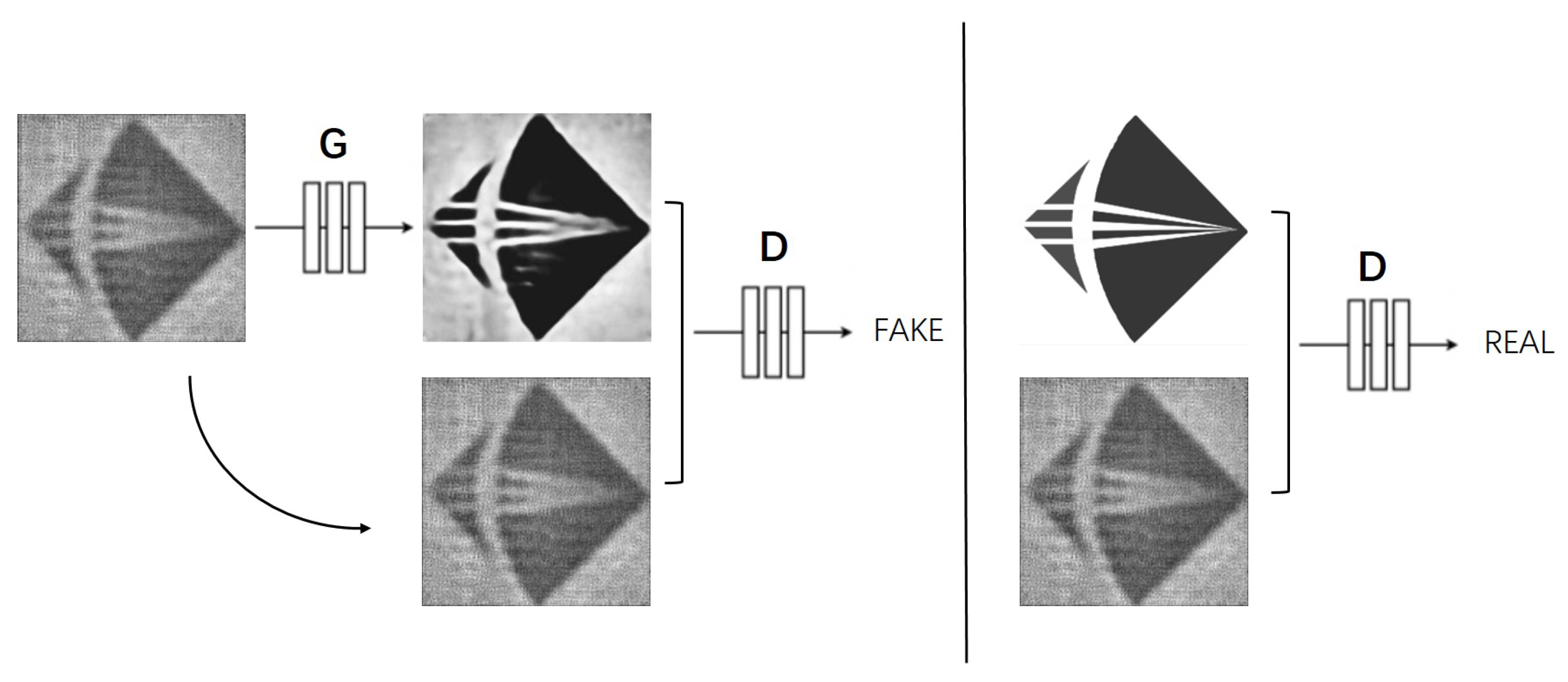
3.1. Generate Adversarial Network Structure: Pix2pix
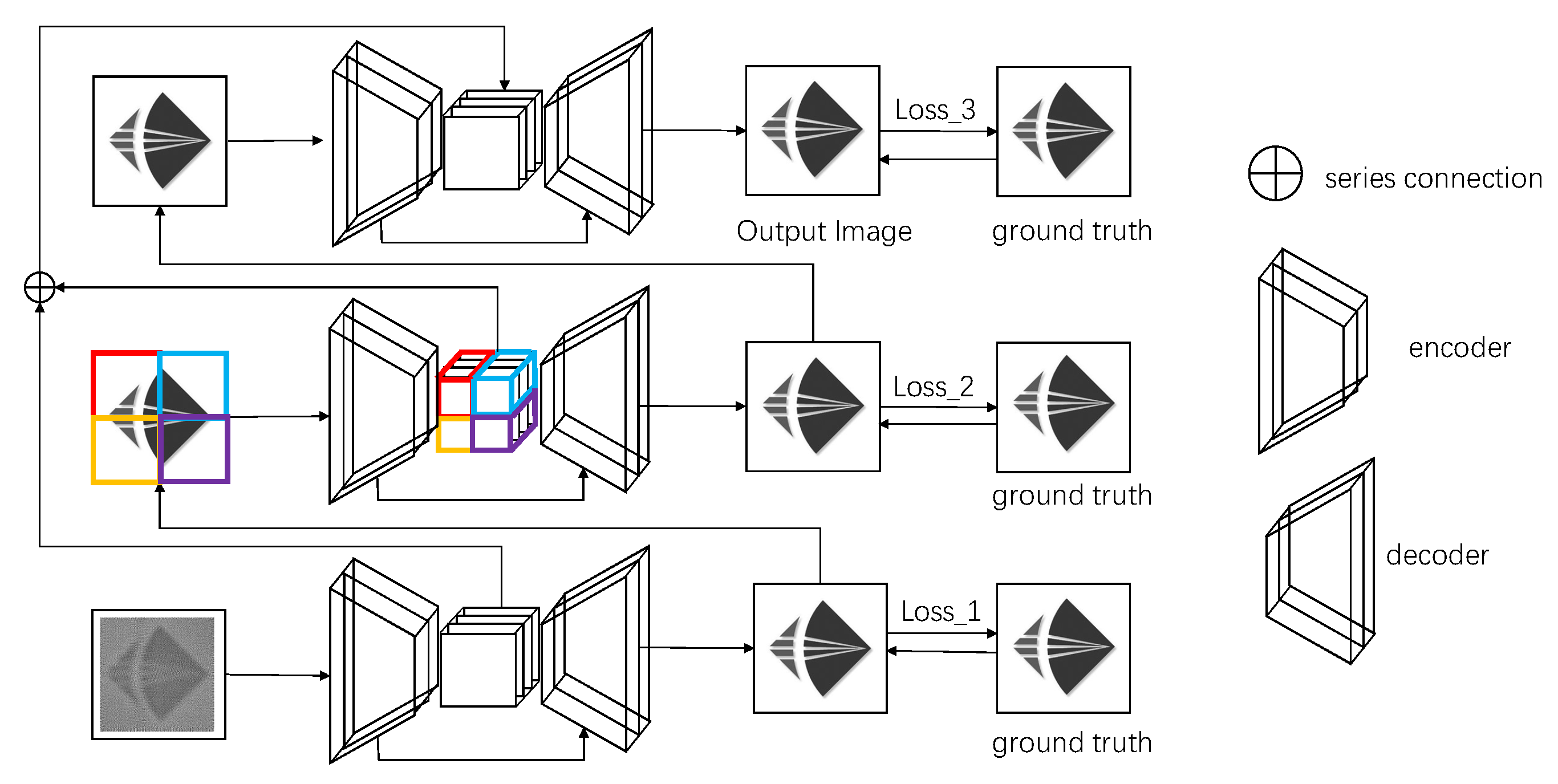
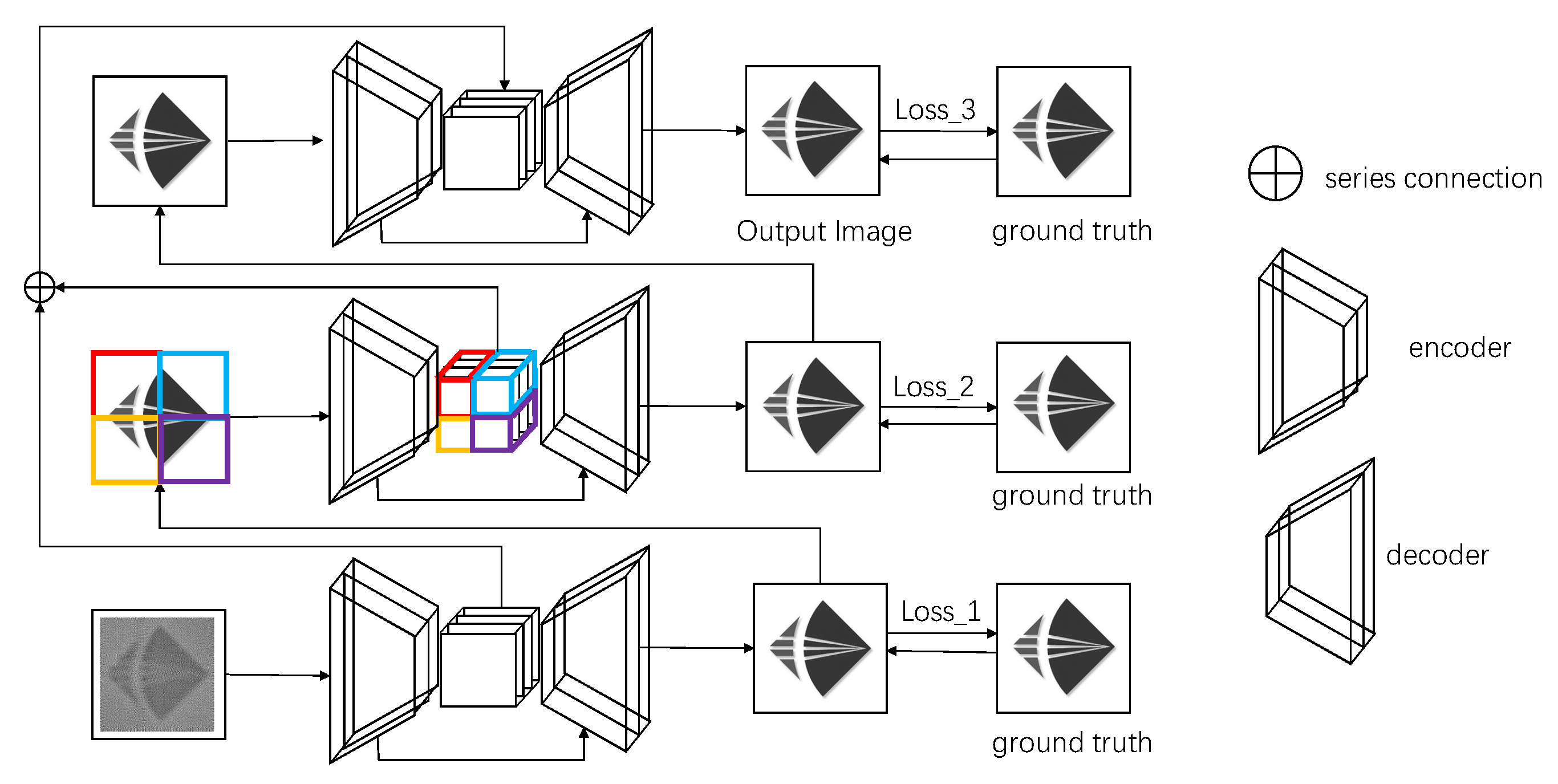
3.2. Multi-Stage Architecture
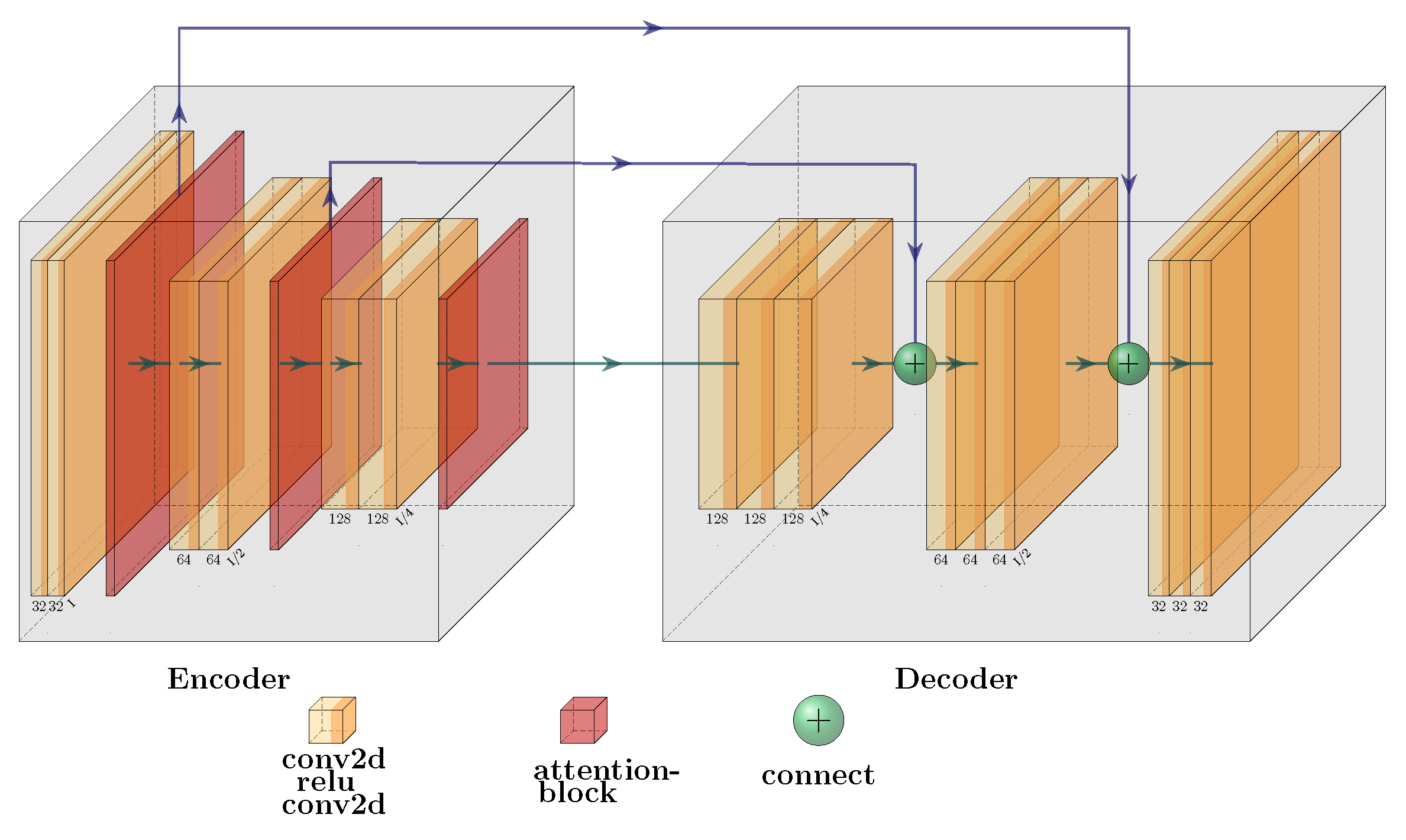
3.3. Encoder and Decoder Architecture
3.4. Loss Function
3.5. Supervision Module
4. Experimental Results and Analysis
4.1. Dataset
4.2. Experimental Details
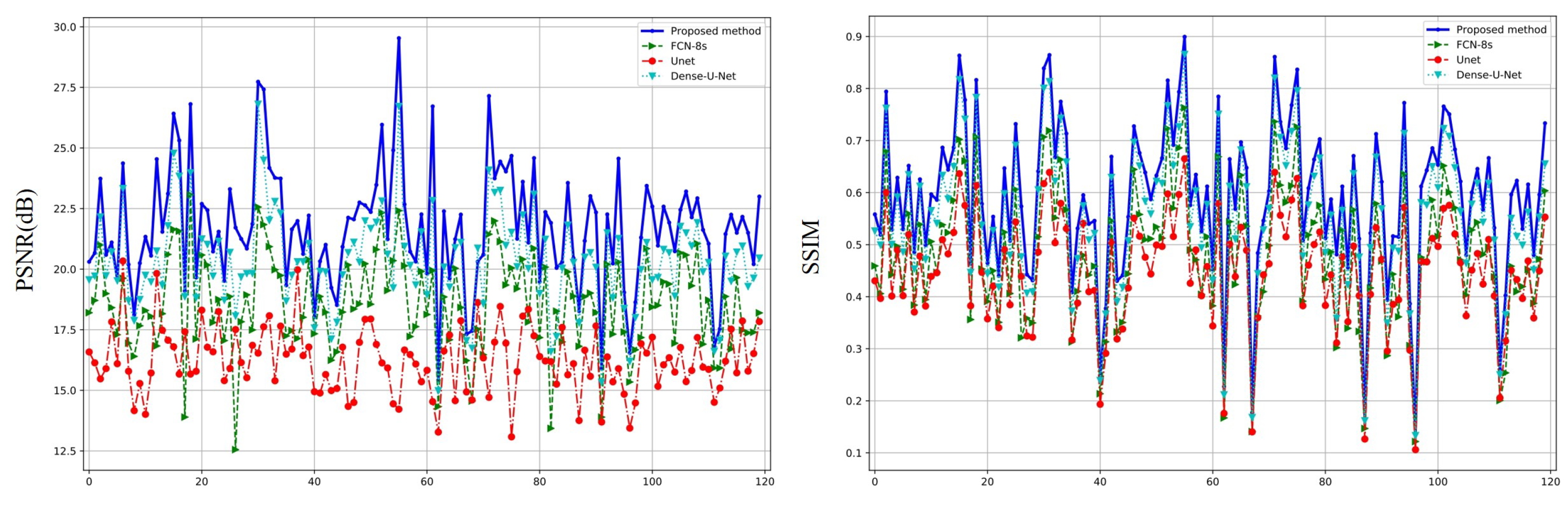
4.3. Comparison with Other Algorithms
4.4. Ablation Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Boominathan, V.; Adams, J.K.; Asif, M.S.; Avants, B.W.; Robinson, J.T.; Baraniuk, R.G.; Sankaranarayanan, A.C.; Veeraraghavan, A. Lensless Imaging: A computational renaissance. IEEE Signal Process. Mag. 2016, 33, 23–35. [Google Scholar] [CrossRef]
- Xiong, Z.; Melzer, J.E.; Garan, J.; McLeod, E. Optimized sensing of sparse and small targets using lens-free holographic microscopy. Opt. Express 2018, 26, 25676–25692. [Google Scholar] [CrossRef] [PubMed]
- Ozcan, A.; McLeod, E. Lensless Imaging and Sensing. Annu. Rev. Biomed. Eng. 2016, 18, 77–102. [Google Scholar] [CrossRef]
- Wei, Z.; Su, X.; Zhu, W. Lensless Computational Imaging with Separable Coded Mask. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 614–617. [Google Scholar] [CrossRef]
- Kuo, G.; Antipa, N.; Ng, R.; Waller, L. DiffuserCam: Diffuser-Based Lensless Cameras. In Proceedings of the Imaging and Applied Optics 2017 (3D, AIO, COSI, IS, MATH, pcAOP), San Francisco, CA, USA, 26–29 June 2017; Optica Publishing Group: Washington, DC, USA, 2017; p. CTu3B.2. [Google Scholar] [CrossRef]
- Boominathan, V.; Adams, J.K.; Robinson, J.T.; Veeraraghavan, A. PhlatCam: Designed Phase-Mask Based Thin Lensless Camera. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1618–1629. [Google Scholar] [CrossRef] [PubMed]
- DeWeert, M.J.; Farm, B.P. Lensless coded-aperture imaging with separable Doubly-Toeplitz masks. Opt. Eng. 2015, 54, 1–9. [Google Scholar] [CrossRef]
- Antipa, N.; Kuo, G.; Ng, R.; Waller, L. 3D DiffuserCam: Single-Shot Compressive Lensless Imaging. In Proceedings of the Imaging and Applied Optics 2017 (3D, AIO, COSI, IS, MATH, pcAOP), San Francisco, CA, USA, 26–29 June 2017; Optica Publishing Group: Washington, DC, USA, 2017; p. CM2B.2. [Google Scholar] [CrossRef]
- Tan, J.; Niu, L.; Adams, J.K.; Boominathan, V.; Robinson, J.T.; Baraniuk, R.G.; Veeraraghavan, A. Face Detection and Verification Using Lensless Cameras. IEEE Trans. Comput. Imaging 2019, 5, 180–194. [Google Scholar] [CrossRef]
- Shi, W.; Huang, Z.; Huang, H.; Hu, C.; Chen, M.; Yang, S.; Chen, H. LOEN: Lensless opto-electronic neural network empowered machine vision. Light. Sci. Appl. 2022, 11, 121. [Google Scholar] [CrossRef]
- Adams, J.K.; Boominathan, V.; Avants, B.W.; Vercosa, D.G.; Ye, F.; Baraniuk, R.G.; Robinson, J.T.; Veeraraghavan, A. Single-frame 3D fluorescence microscopy with ultraminiature lensless FlatScope. Sci. Adv. 2017, 3, e1701548. [Google Scholar] [CrossRef] [PubMed]
- Satat, G.; Tancik, M.; Raskar, R. Lensless Imaging With Compressive Ultrafast Sensing. IEEE Trans. Comput. Imaging 2017, 3, 398–407. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Asif, M.S.; Ayremlou, A.; Sankaranarayanan, A.; Veeraraghavan, A.; Baraniuk, R.G. Flatcam: Thin, lensless cameras using coded aperture and computation. IEEE Trans. Comput. Imaging 2016, 3, 384–397. [Google Scholar] [CrossRef]
- Nguyen Canh, T.; Nagahara, H. Deep Compressive Sensing for Visual Privacy Protection in FlatCam Imaging. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 3978–3986. [Google Scholar] [CrossRef]
- Tan, J. Face Detection and Verification with FlatCam Lensless Imaging System. Ph.D. Thesis, Rice University, Houston, TX, USA, 2018. [Google Scholar]
- Anushka, R.L.; Jagadish, S.; Satyanarayana, V.; Singh, M.K. Lens less Cameras for Face Detection and Verification. In Proceedings of the 2021 6th International Conference on Signal Processing, Computing and Control (ISPCC), Solan, India, 7–9 October 2021; pp. 242–246. [Google Scholar] [CrossRef]
- Asif, M.S.; Ayremlou, A.; Veeraraghavan, A.; Baraniuk, R.; Sankaranarayanan, A. FlatCam: Replacing Lenses with Masks and Computation. In Proceedings of the 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), Santiago, Chile, 7–13 December 2015; pp. 663–666. [Google Scholar] [CrossRef]
- Tan, J.; Boominathan, V.; Veeraraghavan, A.; Baraniuk, R. Flat focus: Depth of field analysis for the FlatCam lensless imaging system. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 6473–6477. [Google Scholar] [CrossRef]
- Khan, S.S.; Adarsh, V.; Boominathan, V.; Tan, J.; Veeraraghavan, A.; Mitra, K. Towards photorealistic reconstruction of highly multiplexed lensless images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7860–7869. [Google Scholar]
- Zhou, H.; Feng, H.; Hu, Z.; Xu, Z.; Li, Q.; Chen, Y. Lensless cameras using a mask based on almost perfect sequence through deep learning. Opt. Express 2020, 28, 30248–30262. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Feng, H.; Xu, W.; Xu, Z.; Li, Q.; Chen, Y. Deep denoiser prior based deep analytic network for lensless image restoration. Opt. Express 2021, 29, 27237–27253. [Google Scholar] [CrossRef]
- Asif, M.S. Lensless 3D Imaging Using Mask-Based Cameras. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 6498–6502. [Google Scholar] [CrossRef]
- Chan, T.; Esedoglu, S.; Park, F.; Yip, A. Total variation image restoration: Overview and recent developments. In Handbook of Mathematical Models in Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 17–31. [Google Scholar]
- Eckstein, J.; Yao, W. Augmented Lagrangian and alternating direction methods for convex optimization: A tutorial and some illustrative computational results. RUTCOR Res. Rep. 2012, 32, 44. [Google Scholar]
- Tihonov, A.N. Solution of incorrectly formulated problems and the regularization method. Sov. Math. 1963, 4, 1035–1038. [Google Scholar]
- Bae, D.; Jung, J.; Baek, N.; Lee, S.A. Lensless Imaging with an End-to-End Deep Neural Network. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Republic of Korea, 1–3 November 2020; pp. 1–5. [Google Scholar]
- Pan, X.; Chen, X.; Takeyama, S.; Yamaguchi, M. Image reconstruction with transformer for mask-based lensless imaging. Opt. Lett. 2022, 47, 1843–1846. [Google Scholar] [CrossRef]
- Wu, J.; Cao, L.; Barbastathis, G. DNN-FZA camera: A deep learning approach toward broadband FZA lensless imaging. Opt. Lett. 2021, 46, 130–133. [Google Scholar] [CrossRef] [PubMed]
- Boominathan, V.; Robinson, J.T.; Waller, L.; Veeraraghavan, A. Recent advances in lensless imaging. Optica 2022, 9, 1–16. [Google Scholar] [CrossRef]
- Monakhova, K.; Yurtsever, J.; Kuo, G.; Antipa, N.; Yanny, K.; Waller, L. Learned reconstructions for practical mask-based lensless imaging. Opt. Express 2019, 27, 28075–28090. [Google Scholar] [CrossRef] [PubMed]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Dong, H.; Neekhara, P.; Wu, C.; Guo, Y. Unsupervised image-to-image translation with generative adversarial networks. arXiv 2017, arXiv:1701.02676. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Mao, X.; Shen, C.; Yang, Y.B. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5978–5986. [Google Scholar]
- Das, S.D.; Dutta, S. Fast deep multi-patch hierarchical network for nonhomogeneous image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 482–483. [Google Scholar]
- Schuler, C.J.; Hirsch, M.; Harmeling, S.; Schölkopf, B. Learning to deblur. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1439–1451. [Google Scholar] [CrossRef] [PubMed]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8174–8182. [Google Scholar]
- Zhang, K.; Luo, W.; Zhong, Y.; Ma, L.; Stenger, B.; Liu, W.; Li, H. Deblurring by realistic blurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2737–2746. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Chen, C.; Huang, B.; Luo, Y.; Ma, J.; Jiang, J. Multi-scale progressive fusion network for single image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8346–8355. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar] [CrossRef]
- Yao, X.; Liu, M.; Su, X.; Zhu, W. Influence of exposure time on image reconstruction by lensless imaging technology. In Proceedings of the 2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 15–17 April 2022; pp. 1978–1981. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 5–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, P.; Su, X.; Liu, M.; Zhu, W. Lensless computational imaging technology using deep convolutional network. Sensors 2020, 20, 2661. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System Parameters | |
|---|---|
| Distance to target | 30 cm |
| Mask pattern | m-sequence |
| Sensor size | 23.04 mm × 23.04 mm |
| Camera model | vc-25mc-m30 |
| Scene | 5120 × 5120 × 1 |
| Mask size | 15.3 mm × 15.3 mm |
| Algorithm | Model Parameter Size/K | Time/s |
|---|---|---|
| FCN-8s | 131,269 | 0.043 |
| U-Net | 3950 | 0.046 |
| Dense-U-Net | 338,828 | 0.079 |
| MARN-1-stage | 7125 | 0.065 |
| MARN-2-stage | 14,250 | 0.097 |
| MARN-3-stage | 50,697 | 0.149 |
| Algorithm | MSE | PSNR/dB | SSIM |
|---|---|---|---|
| Previous work | 105.4972 | 8.2982 | 0.0098 |
| FCN-8s | 94.6699 | 18.5603 | 0.4803 |
| U-Net | 86.2329 | 16.2278 | 0.4484 |
| Dense-U-Net | 89.3149 | 20.3110 | 0.5565 |
| MARN-1-stage | 88.9985 | 20.2235 | 0.5033 |
| MARN-2-stage | 82.5377 | 21.3704 | 0.5798 |
| MARN-3-stage | 80.7181 | 21.7335 | 0.5930 |
| Algorithm | Supervision Module | Attention Module | MSE | PSNR | SSIM |
|---|---|---|---|---|---|
| MARN-1-stage | √ | 94.4483 | 18.9328 | 0.4418 | |
| MARN-2-stage | √ | 86.9825 | 20.5046 | 0.5556 | |
| MARN-3-stage | √ | 84.4851 | 21.0566 | 0.5805 | |
| MARN-3-stage | √ | 87.9114 | 20.4234 | 0.5635 | |
| MARN-1-stage | √ | √ | 88.9985 | 20.2235 | 0.5033 |
| MARN-2-stage | √ | √ | 82.5377 | 21.3704 | 0.5798 |
| MARN-3-stage | √ | √ | 80.7181 | 21.7335 | 0.5930 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, M.; Su, X.; Yao, X.; Hao, W.; Zhu, W. Lensless Image Restoration Based on Multi-Stage Deep Neural Networks and Pix2pix Architecture. Photonics 2023, 10, 1274. https://doi.org/10.3390/photonics10111274
Liu M, Su X, Yao X, Hao W, Zhu W. Lensless Image Restoration Based on Multi-Stage Deep Neural Networks and Pix2pix Architecture. Photonics. 2023; 10(11):1274. https://doi.org/10.3390/photonics10111274
Chicago/Turabian StyleLiu, Muyuan, Xiuqin Su, Xiaopeng Yao, Wei Hao, and Wenhua Zhu. 2023. "Lensless Image Restoration Based on Multi-Stage Deep Neural Networks and Pix2pix Architecture" Photonics 10, no. 11: 1274. https://doi.org/10.3390/photonics10111274
APA StyleLiu, M., Su, X., Yao, X., Hao, W., & Zhu, W. (2023). Lensless Image Restoration Based on Multi-Stage Deep Neural Networks and Pix2pix Architecture. Photonics, 10(11), 1274. https://doi.org/10.3390/photonics10111274