1. Introduction
In the last ten years, the modern process industry has become more complex and large scale, and its requirements for safety performance, product quality and economic benefits have been increasing. In particular, the importance of monitoring the safety and environmental footprint in the process industry has become increasingly prominent. The collection of massive sensor data and low dependence on accurate mathematical models and expert knowledge make the data-driven approach gain more and more attention in academia and industry [
1]. Multivariate statistical process monitoring (MSPM), as a widely used method, can extract key features in data for process monitoring [
2,
3].
The high-dimensional data collected by different sensors can reflect the running status of the process and how to effectively extract feature information has become a key step in fault detection. Principal component analysis (PCA) extracts feature information by maximizing global variance to reduce dimensionality [
4], and neighborhood preserving embedding (NPE) is based on manifold learning [
5], which reduces dimensionality by keeping the local structure of data points and their neighbors unchanged. As the representatives of multivariate statistical algorithms, they have been widely used in chemical process monitoring. In recent years, fault detection schemes based on global information or local information have developed rapidly. Consider that the sample of industrial processes at different times is not statistically independent, but there is a certain correlation. Ku et al. [
6] first proposed Dynamic Principal Component Analysis (DPCA), which uses the PCA to build models by constructing augmented data matrices at current and past times, taking into account the time-series correlation between variables, and improving the fault detection effect. Miao et al. [
7] proposed Time Series Extended Neighbor Embedding (TNPE), which uses the nearest time neighborhood in the time window to linearly reconstruct the current sample to extract features that can preserve the timing correlation of the samples. Of course, many scholars consider both global information and local information. Zhang et al. [
8] combined Principal Component Analysis (PCA) and Locality Preserving Projections (LPP) to propose a global-local structure analysis model (GLSA) for fault detection, which significantly improves the detection performance. Since then, there have been many similar combined methods [
9,
10].
However, the actual industrial processes not only have dynamic characteristics but also generally have a complex nonlinear relationship. The method to find the projection matrix to obtain features is more suitable for the process with a linear relationship, such as TNPE and the GLSA. Therefore, we need to consider the nonlinear characteristics of industrial processes further. In recent years, the nonlinear dimension reduction techniques have been improved mainly from the following aspects: (1) PCA, (2) slice inverse regression (SIR), (3) active subspace (AS), (4) manifold learning, and (5) the neural network. Nonlinear extension methods based on slice inverse regression, such as kernel SIR, and extension methods based on active subspace, such as Active Manifolds (AMs), were proposed and showed excellent nonlinear feature extraction ability to achieve the purpose of dimensionality reduction. However, most of their methods need to be used under the supervision of the output variable y, or a hypothetical output model is required. Therefore, they are less used in industrial process fault detection and are more suitable for soft sensing [
11,
12,
13]. The extended methods based on PCA and manifold learning have been widely used in fault detection. In recent years, the deep neural network has also begun to be widely used in industrial process monitoring due to their excellent nonlinear feature extraction capabilities, and even further combined with manifold learning and other methods. Cui et al. [
14] proposed an ensemble local kernel principal component analysis (ELKPCA), which took into account the global-local structure information of the data and used kernel functions to deal with nonlinear problems. On the other hand, due to the deep neural network can better extract nonlinear features of high-dimensional data, they have gained significant attention in the field of process monitoring in recent years. Zhao et al. [
15] proposed a neighborhood preserving neural network (NPNN) based on NPE, so that the nonlinear features that were extracted from high-dimensional data can still maintain local reconstruction better and greatly improve the fault detection ability of the NPE algorithm. Autoencoders (AE), as one of the representatives of neural networks, is a model that reduces dimensionality and extracts nonlinear features from data by minimizing the reconstruction errors of input and output. Stacked sparse autoencoders (SSAE) can build deep models by stacking multiple AEs to extract deeper and more important features from the data. For dealing with the nonlinear dynamic characteristics of the process, Zhu et al. [
16] proposed a recursive stacked denoising autoencoder (RSDAE) to extract nonlinear dynamic features and static features and successfully applied them to fault detection. Compared with the kernel method [
17], which requires designing the kernel function artificially, the characteristics of deep neural network automatic learning parameters to extract features make it a popular method to deal with the problem of fault detection in nonlinear processes [
18,
19].
Due to the complicated nonlinear relationship between industrial process variables, there is also a time-series correlation between samples at different times. Considering the sample at a specific moment, its temporal neighborhood or spatial neighborhood can interact with it, so its neighborhood can be used to assist in fault detection. In this paper, a temporal-spatial neighborhood enhanced sparse stack autoencoder (TS-SSAE) is proposed for dynamic nonlinear process monitoring. In a time window, TS-SSAE finds the spatial neighborhoods of the current sample by k-nearest neighbors algorithm (KNN), and reconstruct the neighborhoods by serial correlation weight with the current time, then combine the current sample as the input of the stack sparse autoencoder. Similarly, for the temporal neighborhood, the spatial similarity to the current sample is chosen as a weight to reconstruct the neighborhoods, and then the current sample is combined as the input of the stack sparse autoencoder. Neighborhood reconstruction improves the separability of samples while achieving smooth denoising. The combination of the current sample and the neighborhood reconstruction as input makes the extracted features contain essential information about the current moment and the neighborhood. If the relationship between the current moment and the neighborhood changes, the extracted features will be different. Then, considering the spatial-temporal characteristics of the two neighborhood information, Bayesian theory is used to integrate the and statistics constructed by the two networks, respectively, for fault detection. Finally, a numerical case and the Tennessee Eastman process benchmark are used to demonstrate the effectiveness of the proposed algorithm.
The rest of the article is organized as follows. Firstly, the structure of SSAE is introduced in
Section 2, and the TS-SSAE model is proposed in
Section 3. In
Section 4, the fault detection scheme based on the TS-SSAE model is described. In
Section 5, a neighborhood reconstruction experiment is used to show the reconstruction effect. A numerical case and the Tennessee-Eastman process are used to evaluate the algorithm. In
Section 6, some conclusions are listed.
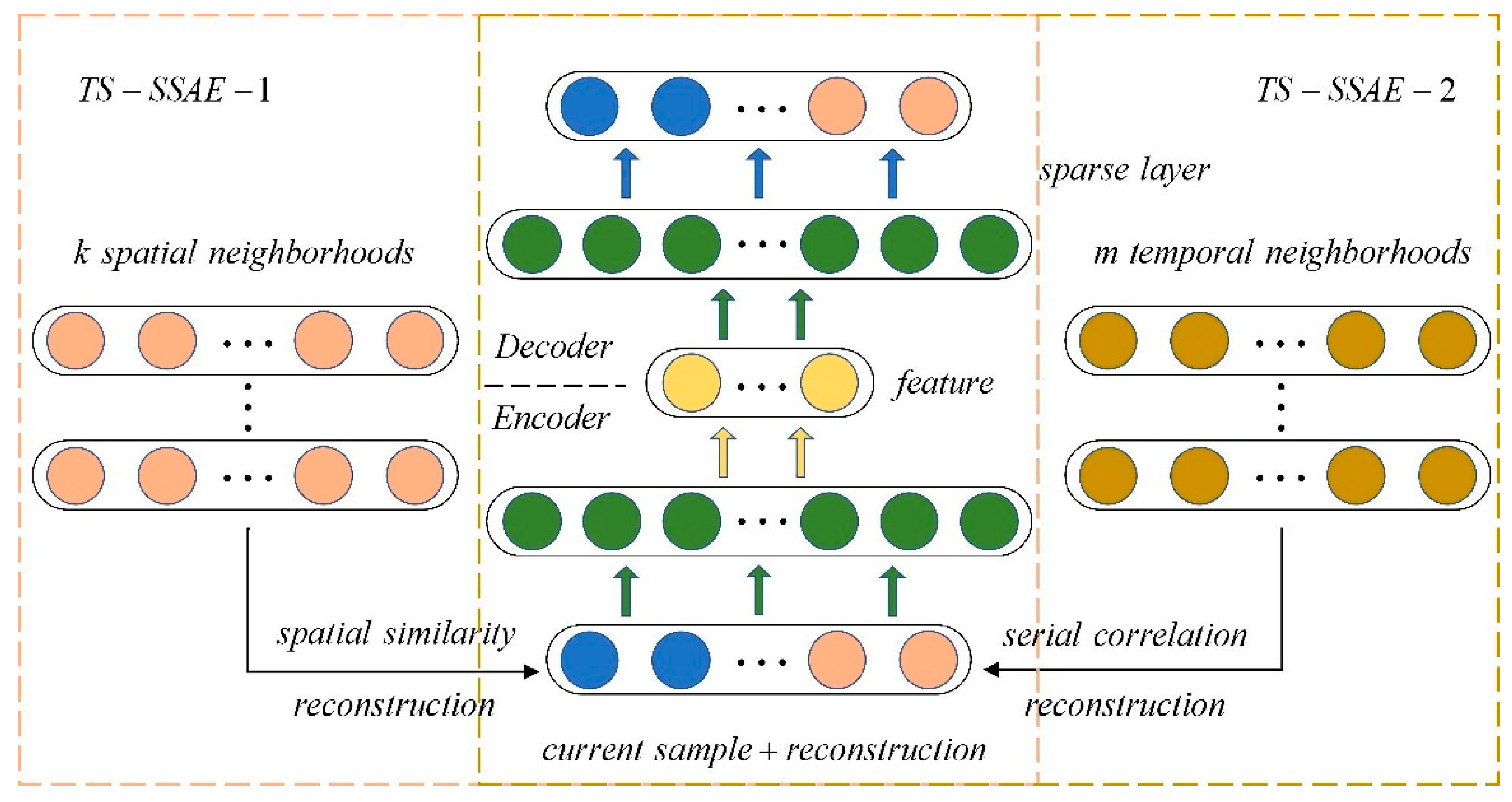
3. Temporal-Spatial Neighborhood Enhanced Sparse Stack Autoencoder (TS-SSAE)
In the industrial process, for the current sample, there are spatial neighborhoods and temporal neighborhoods. Spatial neighborhoods refer to a number of samples with the minimum distance from the current sample in the sample feature space. The distance can generally be measured by Manhattan distance, Euclidean distance, etc. Temporal neighborhoods refer to the multiple samples whose sampling time is closest to the current time. The NPE or TNPE algorithm extracts features by keeping the linear reconstruction relationship of the spatial or temporal neighborhoods and the current sample unchanged to reduce the dimension. Therefore, extracting features by considering the relationship between the neighborhood and the current sample is an effective method for fault detection. Considering that there are complex dynamic nonlinear relationships in industrial processes, some algorithms, such as TNPE, are only suitable for linear processes by constructing projection matrices; most neural networks, such as NPNN, which consider neighborhoods, do not consider the time correlation. Therefore, TS-SSAE is proposed in this paper. For the spatial neighborhood selected within the time window, the timing constraint with the current sample is considered. For the temporal neighborhood, the spatial similarity with the current sample is also considered. Then, the neighborhood reconstruction information and the sample at the current time are combined as an input of SSAE to extract important information of the current sample and the neighborhood. The proposed algorithm can be divided into two parts according to the neighborhood object, which will be described in detail below.
Firstly, the original process data matrix is defined as
, where
n is the number of samples, and
m is the number of variables. Considering the dynamic characteristics of the process, the current sample can only use historical samples and samples of future moments cannot be obtained. Therefore, the time window L is defined as a time delay window, L = 2k is generally selected, and k is the number of spatial neighbors selected [
23]. The TS-SSAE algorithm is composed of TS-SSAE-1 and TS-SSAE-2, and their neighborhood information is different. In TS-SSAE-1, for the current sample
, KNN is used to select k spatial neighbors from the time window L=
; they can be represented as
, and
represents the
ith spatial neighbor of the current sample
,
, which represents the time deviation from the current moment. There is a dynamic relationship between the sample in the appropriate time window and the current moment, and these neighbors have the smallest Euclidean distance from
, so they can be considered to have a high correlation with
[
24,
25]. Since the construction of the neighborhood expansion matrix will increase the dimension of the variable, in this paper, we propose to reconstruct neighbors by time or space weight for using neighborhood information to assist in fault detection at the current time. The specific steps of TS-SSAE-1 are as follows:
(1) Calculate the time weight. For the spatial neighbors
, we consider the serial correlation in the time scale. First, the time distance between each neighbor and the current sample
is calculated, and then the time weight can be constructed. The time distance can be defined as Equation (4),
considers the degree of time deviation of all k spatial neighbors, and convert it to the serial correlation contribution of the
ith neighbor to the current sample. What is more, the Gaussian kernel function is introduced to strengthen the time constraints at different times. Finally, the time weight is defined as Equation (5), and the weight of each neighbor is represented as
, the sum of the weights is set to be 1.
Based on the time weight
, the spatial neighbors can be reconstructed as Equation (6):
The reconstructed sample , obtained by Equation (6), means that the neighbors with high similarity are reconstructed by time serial correlation to expand the current sample as the neighborhood feature.
(2) Construct a TS-SSAE model. A TS-SSAE-1 model is based on the spatial neighbors, and the serial correlation is used as time weight to reconstruct neighbors for expanding the current sample
.Therefore, it also considers the topological structure of time and space. The input at the current time can be represented as
, and
will be used as input for SSAE, the objective function is shown in Equation (7), and the sparsity restriction makes the extracted middle-layer features contain the most important information about the current sample and the reconstructed neighborhood.
The left part of Equation (7) is the reconstruction error of the autoencoder, and it should be noted that the sparsity parameter in the KL distance mentioned above is used as a hyperparameter, its choice has a greater impact on the result, and its value will be changed for a different dataset. Therefore, L1 regularization is applied to the hidden layer at each moment to avoid the design of hyperparameters. The objective function is the right part of Equation (7), is the weight that controls the sparsity penalty, is the output of the jth hidden layer, is the input of the jth hidden layer, and is also the output of the j-1th layer.
In TS-SSAE-1, the spatial neighborhood is the main body, but the temporal neighbors of have a more apparent serial correlation with , the addition of temporal neighborhood information will be beneficial to deal with dynamic problems. In TS-SSAE-2, the temporal neighbor is used to reconstruct neighborhood information. First, for the current sample , select m temporal neighbors in the time window L; they can be represented as . The algorithm steps are as follows:
(1) Calculate spatial weights. For the temporal neighbors
of the current sample
, we consider the similarity in the spatial scale. The spatial similarity is defined by Equation (8), and then the spatial weights are calculated according to Equation (9). The introduction of spatial similarity makes the reconstructed samples take into account the correlation between time and space at the same time. The defined reconstruction expression is shown in Equation (10):
(2) Construct the TS-SSAE model. Similar to the TS-SSAE-1 section above,
will be the input of SSAE, its objective function is the same as Equation (7), and the structure of TS-SSAE model is shown in
Figure 2.
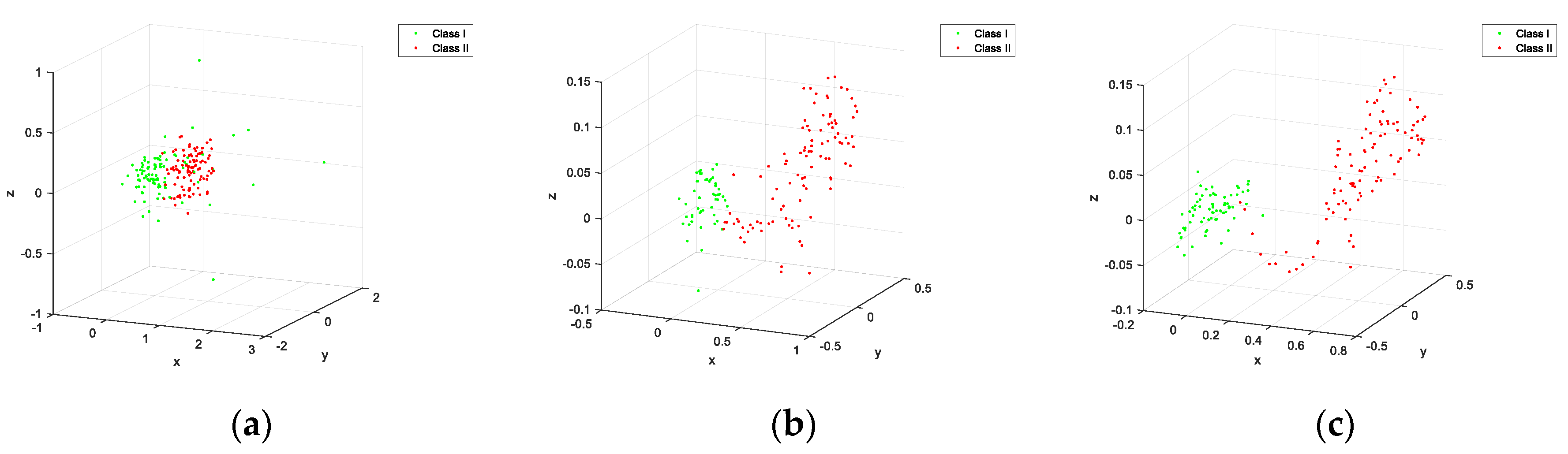
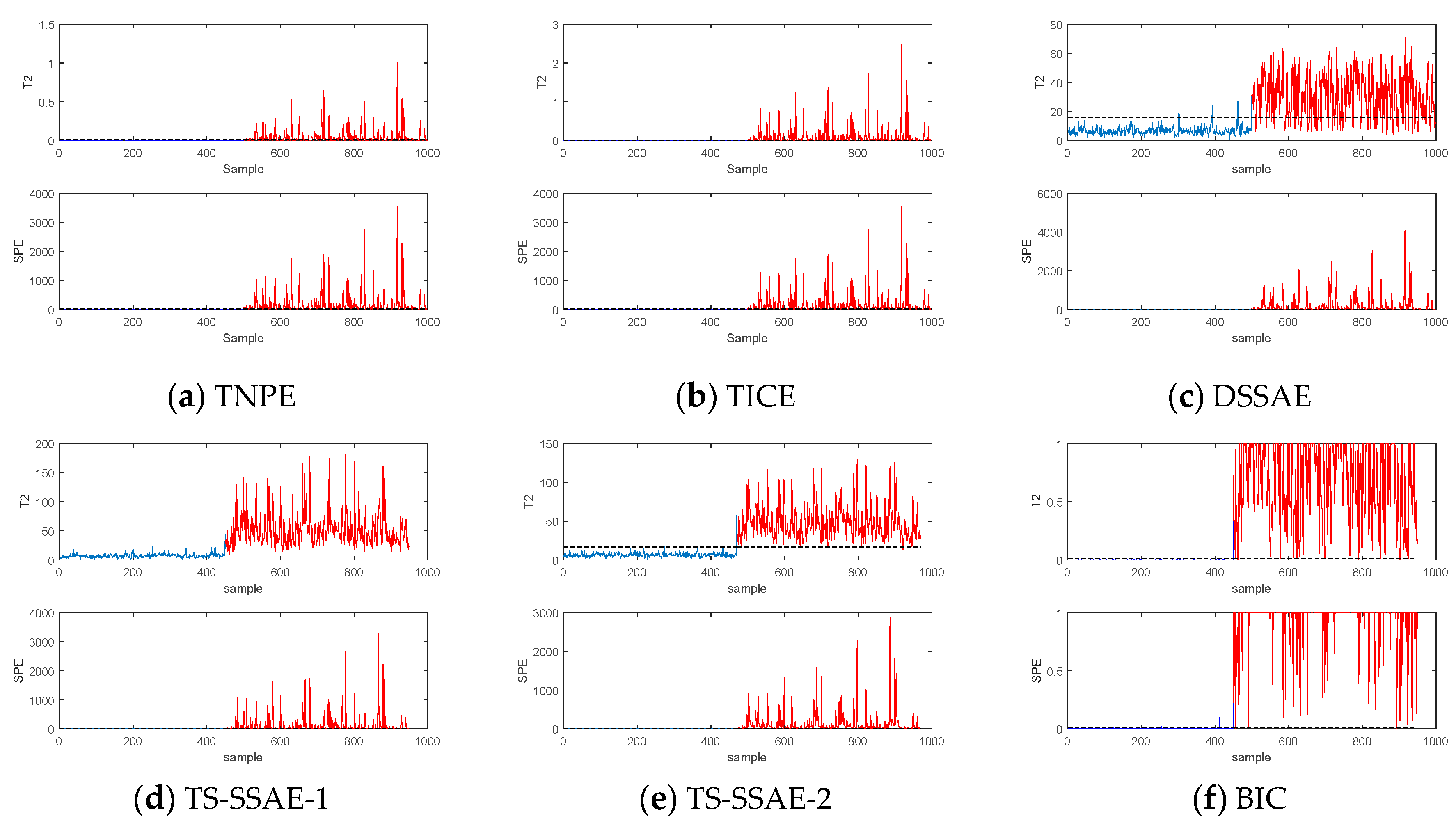
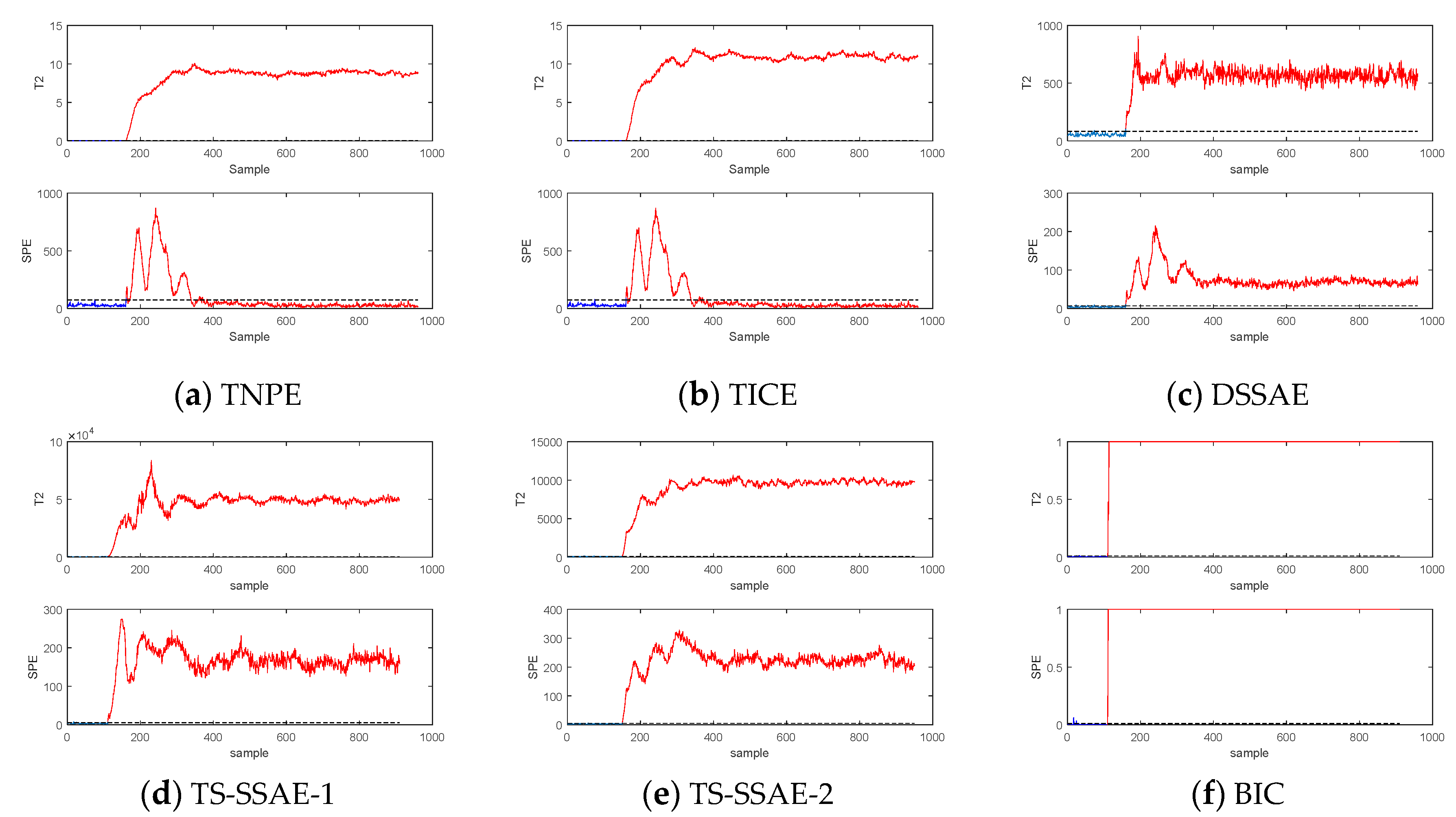
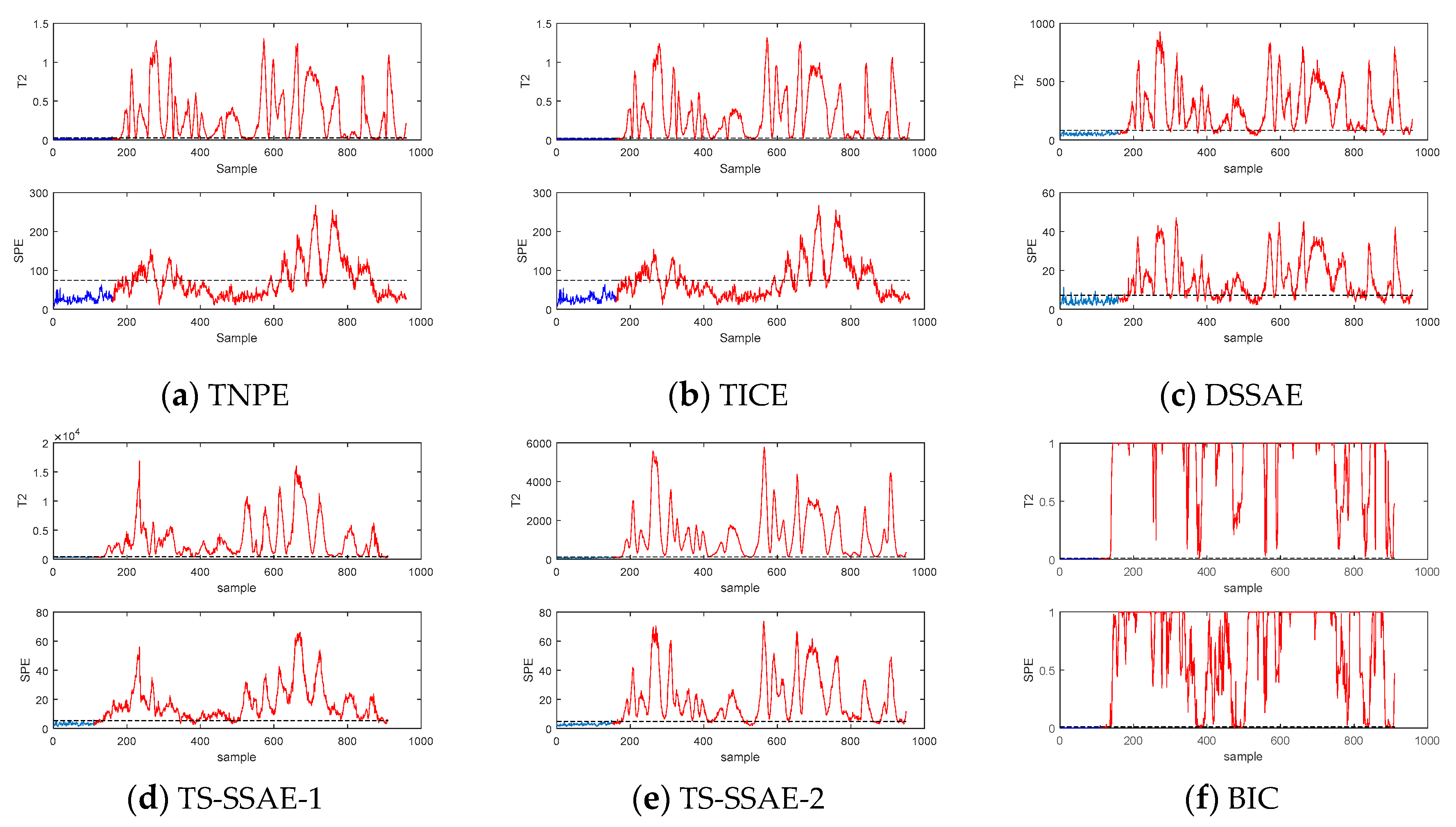
The TS-SSAE model considers the information of the distance in the time scale for spatial neighbors, and the spatial constraints for the temporal neighbors, both of which take into account spatial-temporal information, so they are suitable for feature extraction in dynamic processes. Besides, three points need to be explained here: (1) Neighbor reconstruction samples are used as input, which is equivalent to each neighbor being used as input at the same time, and each neighbor is given an importance coefficient and then shares the weight of the input layer. Therefore, the method of using neighborhood reconstruction as input can be considered to extract important information of each neighborhood in some way. (2) The two neighborhood weighted reconstructions mentioned above can improve the separability of sample points and achieve smooth denoising. So, it can be used as supplementary information of
to reflect the different characteristics of each sample. The specific effect can be shown by the dataset constructed in
Section 5. (3) For dynamic processes, dynamic data with similar sampling times have small changes, so the time neighborhood of the data may also be its spatial neighborhood. Obviously, for different dynamic processes, the overlap of the two neighborhoods is also different. However, the number of temporal neighborhoods and spatial neighborhoods selected in this paper are different. Even if the number of overlaps is large, since the weights of the two kinds of neighborhood reconstruction samples consider the time scale and the space scale, respectively, they will still provide different features.
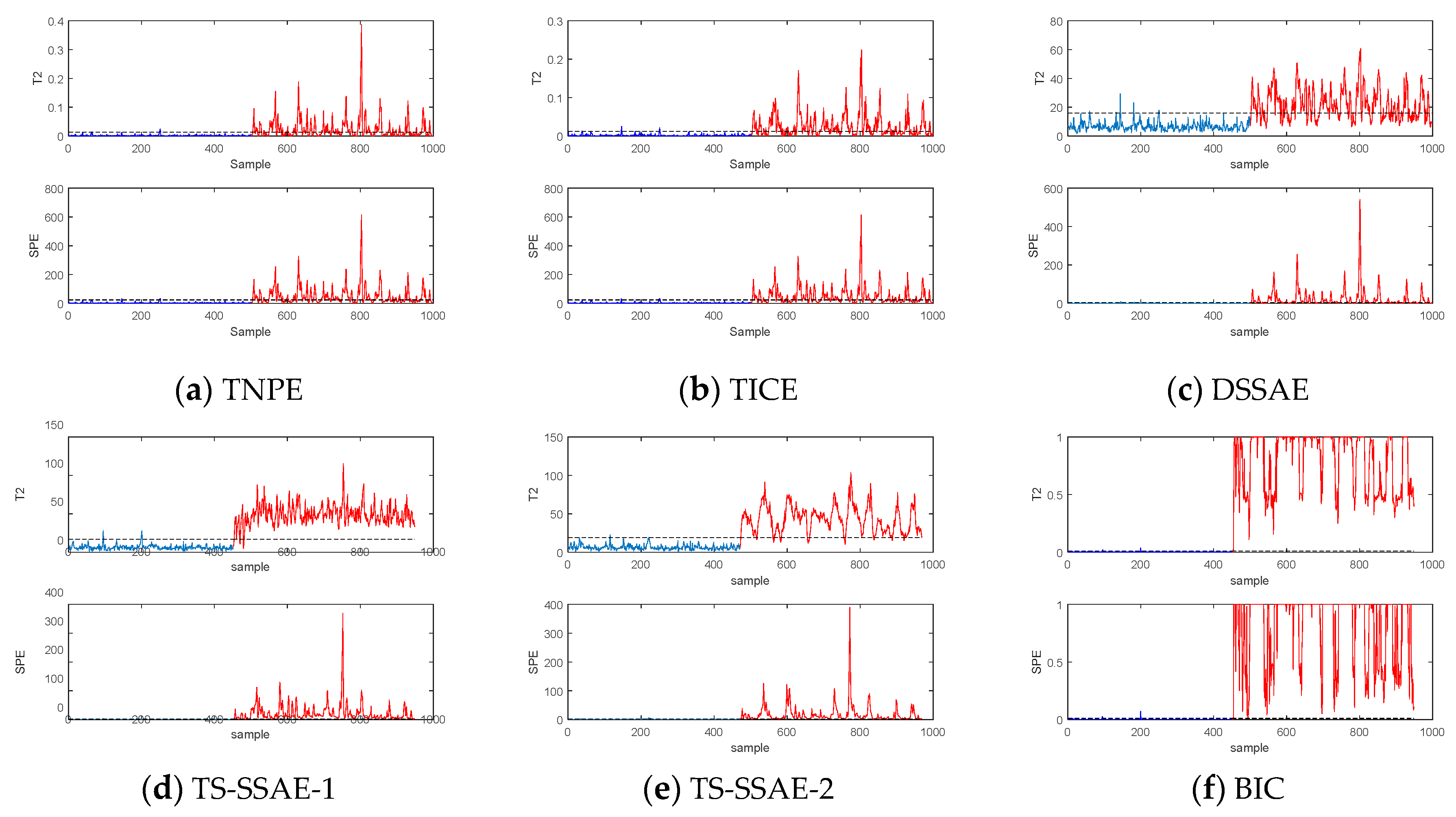
4. Fault Detection Based on TS-SSAE
In this chapter, the TS-SSAE model proposed above is used for fault detection, the
statistic is constructed by using the features of the middle layer, and the
SPE statistic is also constructed by residual features. Finally, kernel density estimation (KDE) is used to establish control limits for fault detection. It is worth mentioning that the introduction of neighborhood reconstruction makes SSAE extract the correlation features between
and neighbors, and reconstructed samples that integrate the characteristics of spatial and temporal neighbors provide richer information for
. When the fault occurs at the sampling time t, and the relationship between
and the spatial-temporal neighbors changes, the obvious change of reconstructed samples will change the features extracted from the network for fault detection, which is also consistent with the separability mentioned above. Considering the temporal and spatial characteristics of the data in both parts of TS-SSAE, the Bayesian fusion strategy is used to integrate the two
statistics and two
SPE statistics to improve detection performance. We assume that the offline process dataset can be represented as
. According to the above algorithm, TS-SSAE-1 reconstructs the spatial neighbors to
and then makes
the input of SSAE, the extracted middle layer feature is
, and the reconstructed output is
. Similarly, TS-SSAE-2 takes the reconstructed temporal neighborhood
as input, the feature of the middle layer is
, and the reconstructed output is
, where d1 and d2 are the dimensions of the middle layer of the two networks. Considering that the calculation of the neighborhood requires samples in the time window L, for the online sample
, it is also necessary to set the time window and select the corresponding spatial-temporal neighborhood. Then, the pre-processed x1 and x2 are used as input into the two offline-trained SSAE models to obtain the feature representation
and
, and the reconstructed feature
and
. Then, the
and
statistics corresponding to
can be constructed as Equations (11)–(13):
where
i = 1,2, represents the detection results of TS-SSAE-1 and TS-SSAE-2, respectively, and Equation (13) represents the covariance of the feature layer of the offline training set.
The establishment of statistical control limit is an important factor to determine whether a fault occurs. There are two main ways to determine the control limit. One is to calculate the control limit by the empirical distribution under a certain confidence level,
, when the feature variable obeys the Gaussian distribution [
26,
27]. The other is determined by kernel density estimation (KDE). KDE is a procedure for fitting a data set with a suitable smooth probability density function (PDF) from a set of random samples. It is used widely for estimating PDFs, especially for univariate random data [
28]. The
and
SPE statistics are both univariate, although the process characterized by these statistics is multivariate. Therefore, KDE is widely used to establish control limits in recent studies [
15,
28,
29]. In this paper, due to the complexity of the nonlinear transformation (for example, different activation functions have large differences), it is impossible to assume the feature layer distribution obtained by the neural network, that is, the feature distribution is unknown and does not necessarily obey the Gaussian distribution. Therefore, KDE is adopted in this paper to determine the control limits of
and
statistics, which can be denoted as
[
30].
In TS-SSAE, the spatial neighborhood reconstruction sample and the temporal neighborhood reconstruction sample represent different neighborhood information. Although the two types of neighborhoods may have a certain amount of overlap, the weight of the spatial neighborhood is based on the serial correlation, the weights of temporal neighborhoods take into account the spatial similarity, which means that their weights are determined according to different criteria. Moreover, the two parts of neighborhood reconstruction information consider the spatial and temporal neighborhood characteristics of
, so we choose to integrate the feature statistics
and the residual statistics
SPE extracted from the two parts of the network, respectively, in this paper, hoping to consider the influence of different neighborhoods more comprehensively. The integration method adopts the Bayesian fusion strategy. In this strategy, N and F represent normal conditions and fault conditions. The following takes
as an example, integrates its detection results, and converts statistics into fault probability through Bayesian formulas [
31,
32,
33]. The fault probability can be obtained by Equation (14).
where
i = 1,2, represents the monitoring results of the two networks, and
can be represented by Equation (15).
In the above equation, and are, respectively, set as and , where is the confidence level. They are the prior probabilities of the process being normal and abnormal.
For a new sample, we can only obtain its conditional probabilities
and
according to its statistics. Moreover, what we expect is such a situation. Under normal conditions, the statistics of the samples will be less than the control limit, and the larger their deviation, the better, because this means a lower false alarm rate. That is,
has a higher probability below the control limit, and a smaller probability when it is higher than the control limit. Under abnormal conditions, the sample statistics will be higher than the control limit. Similarly, the larger the deviation, the better, which means that the algorithm has excellent fault detection capabilities. Furthermore, considering the uncertainty of the failure and the normalized property of the probability, we can assume that
has the following trend. When the statistic is lower than the control limit, there is a low probability, and when it is higher than the control limit, the probability is larger, and after reaching a certain peak, it starts to decrease slowly. Therefore, we define the conditional probability as Equations (16) and (17):
Equation (17) indicates that with as the variable obeys the chi-square distribution of as the degree of freedom. and can be determined according to the actual situation. However, it is necessary to make the distribution of the two conditional probabilities intersect near the control limit, so that the probability of occurrence under normal conditions and the probability of occurrence under abnormal conditions can be balanced at the control limit. In this paper, we set as 5 and as 0.5.
Finally, the monitoring results of the new samples in the two parts of TS-SSAE,
and
,
and
are gained, then the fault probability is weighted to obtain the final fused probabilistic statistics
and
, as shown in Equation (18) [
31,
33]. The control limit of both is
. Once the statistics of the Bayesian Inference Combination (
BIC) exceed the control limit, the fault is considered to happen.
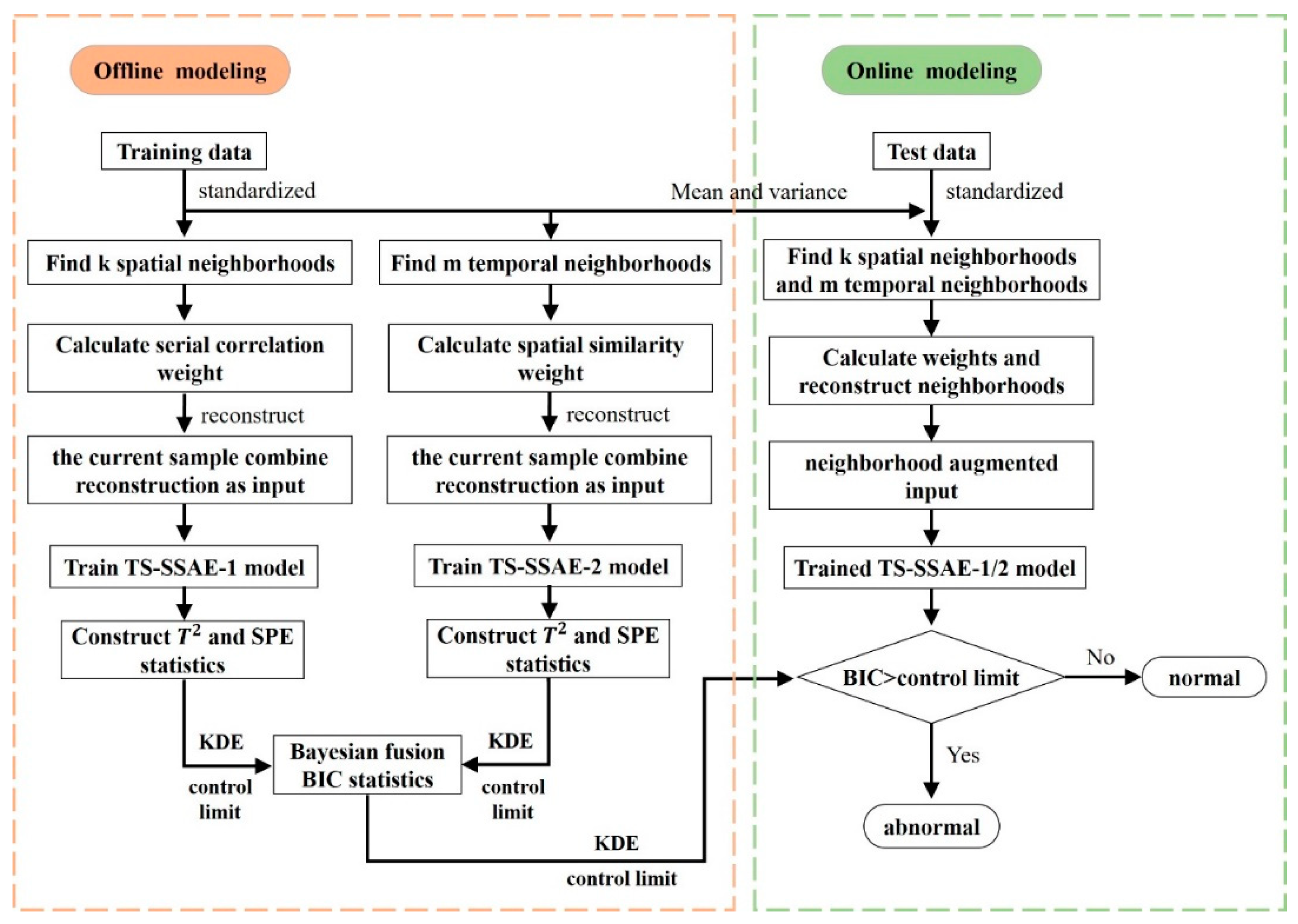
The steps of using the TS-SSAE algorithm for fault detection are summarized as follows.
Figure 3 shows the flowchart of proposed method for fault detection.
4.1. Offline Modeling Steps
Step 1. The training sample data set is collected under normal conditions and standardizes it.
Step 2. Select the appropriate time window L and obtain the spatial neighborhood for each offline sample according to the KNN, and calculate the neighborhood reconstruction . Then, obtain the temporal neighborhood based on the serial correlation, and calculate the neighborhood reconstruction .
Step 3. Use the combined sample as input to train the SSAE model, which can be recorded as TS-SSAE-1, and obtain the feature of middle layer and reconstructed output . Similarly, the second SSAE is trained with the combined sample as input, which is denoted as TS-SSAE-2, and the features and are obtained.
Step 4. Calculate their statistics and SPE respectively, and calculate their control limit by kernel density estimation (KDE). Finally, BIC is obtained by using Bayesian fusion strategy.
4.2. Online Monitoring Steps
Step 1. The test sample is standardized.
Step 2. Obtain the temporal and spatial neighbors within the time window L, and calculate the neighborhood reconstruction and according to Equation (2).
Step 3. and are input into the TS-SSAE-1 and TS-SSAE-2 trained in the offline step (3), respectively, and then the feature , and the reconstructed feature , can be obtained.
Step 4. According to Equations (11) and (12), two sets of and statistics are calculated, respectively, and the final fused probabilistic statistics and are also calculated. When , a fault is detected.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}