Development and Application of a Data-Driven System for Sensor Fault Diagnosis in an Oil Processing Plant

 , , ,
, , , 
Abstract
:1. Introduction
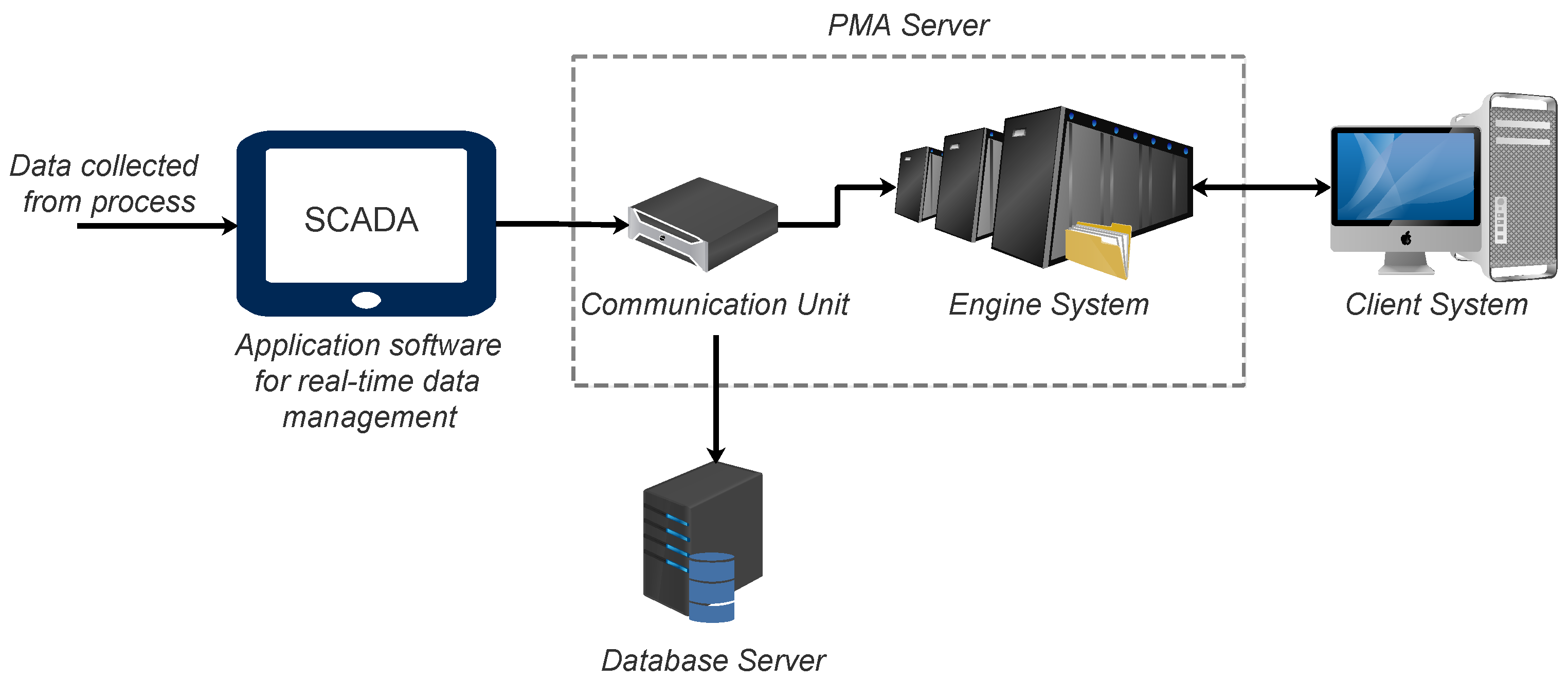
2. PMA: A System for Process Monitoring
2.1. Online PMA System and Remote PMA System
2.2. Theoretical Background
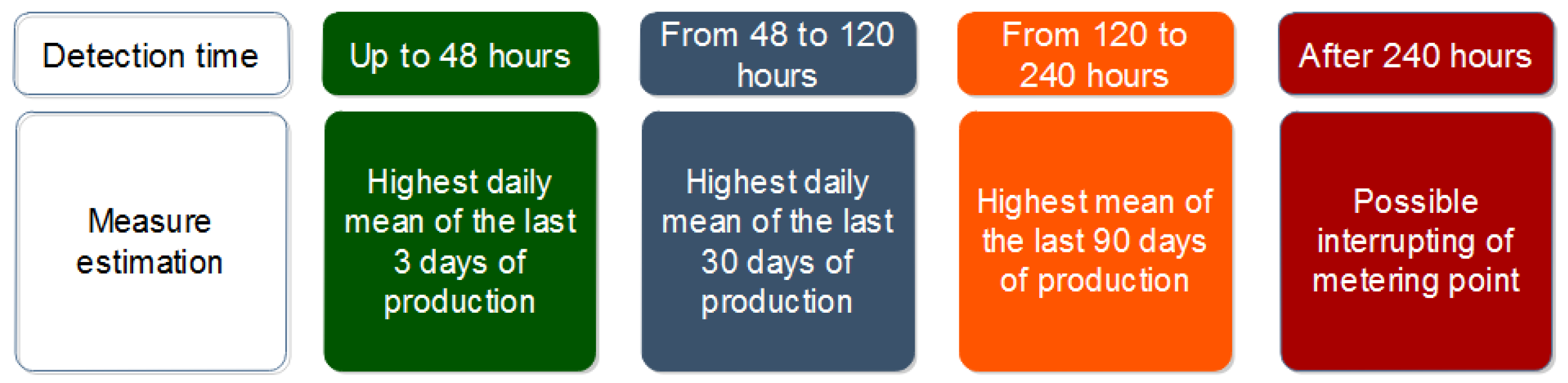
2.3. Alarm System
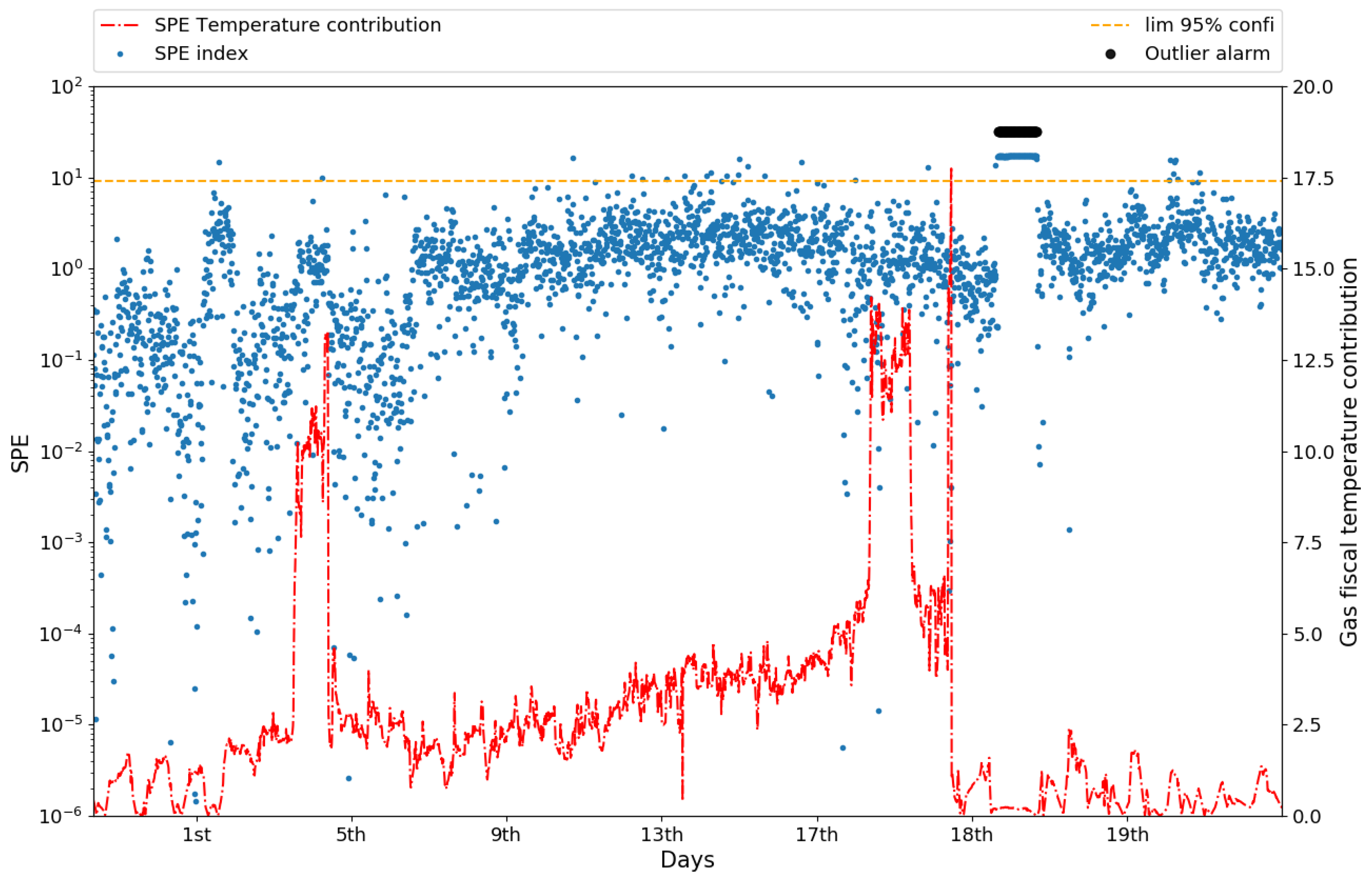
Outlier Alarm
- Index for prediction error: a measure of model prediction accuracy.
- Index for the y variable: a measure of the relevance of the response variable versus the model construction data.
- Index for the x variable: a measure of the relevance of the selected input variables versus the model construction data.
3. Real Case Application
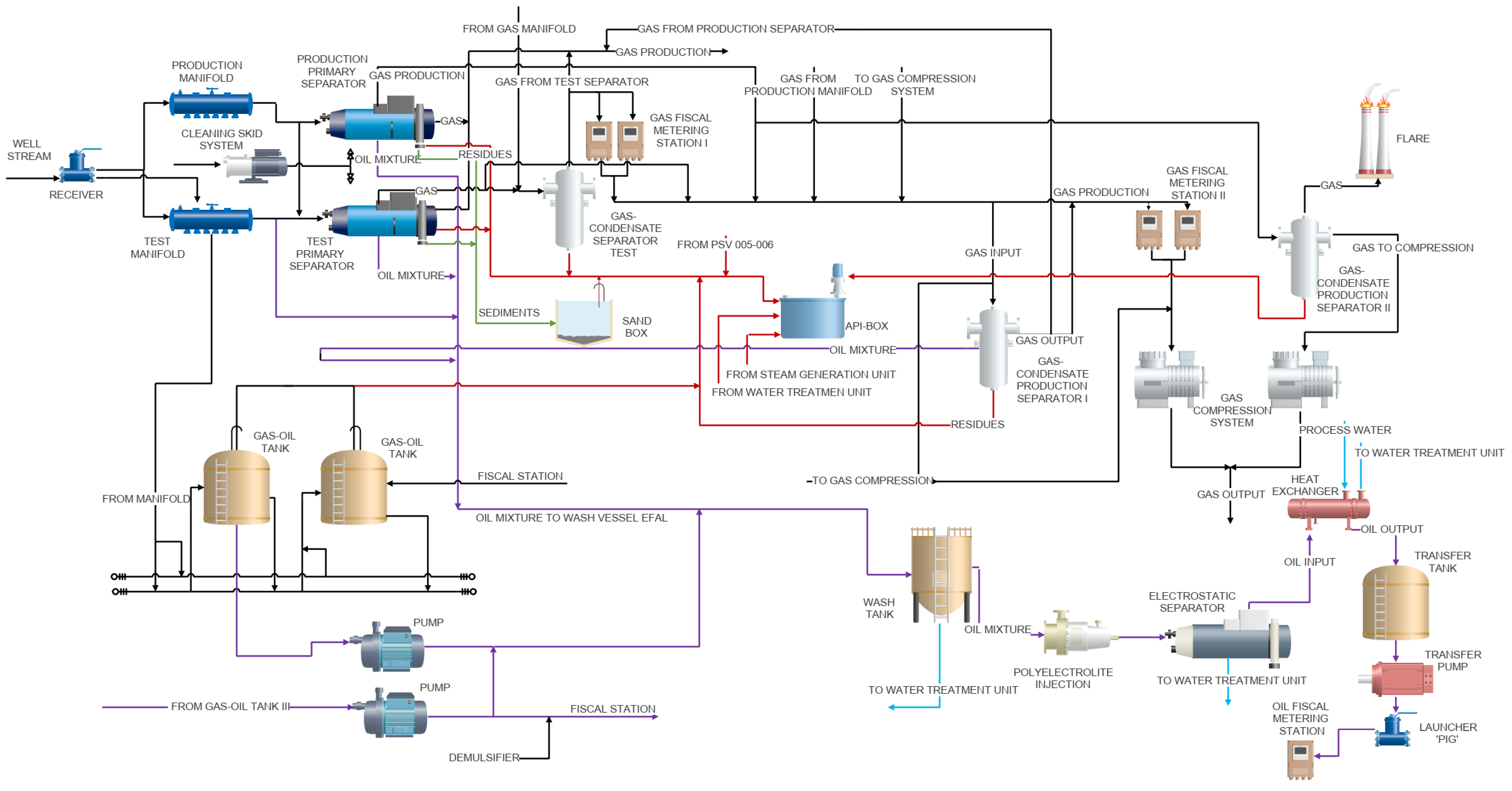
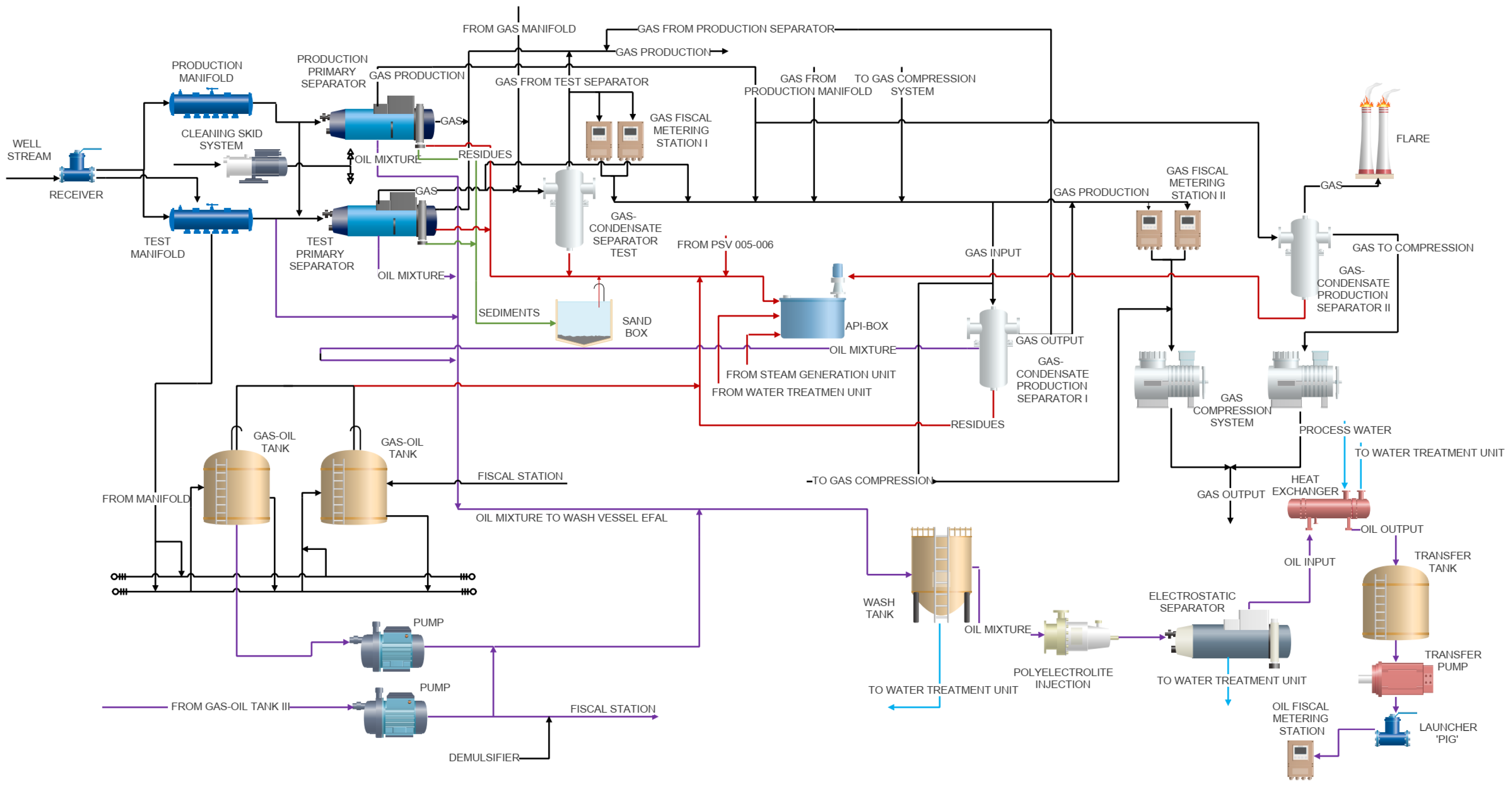
3.1. Oil and Gas Fiscal Metering Station
3.2. Fault Description
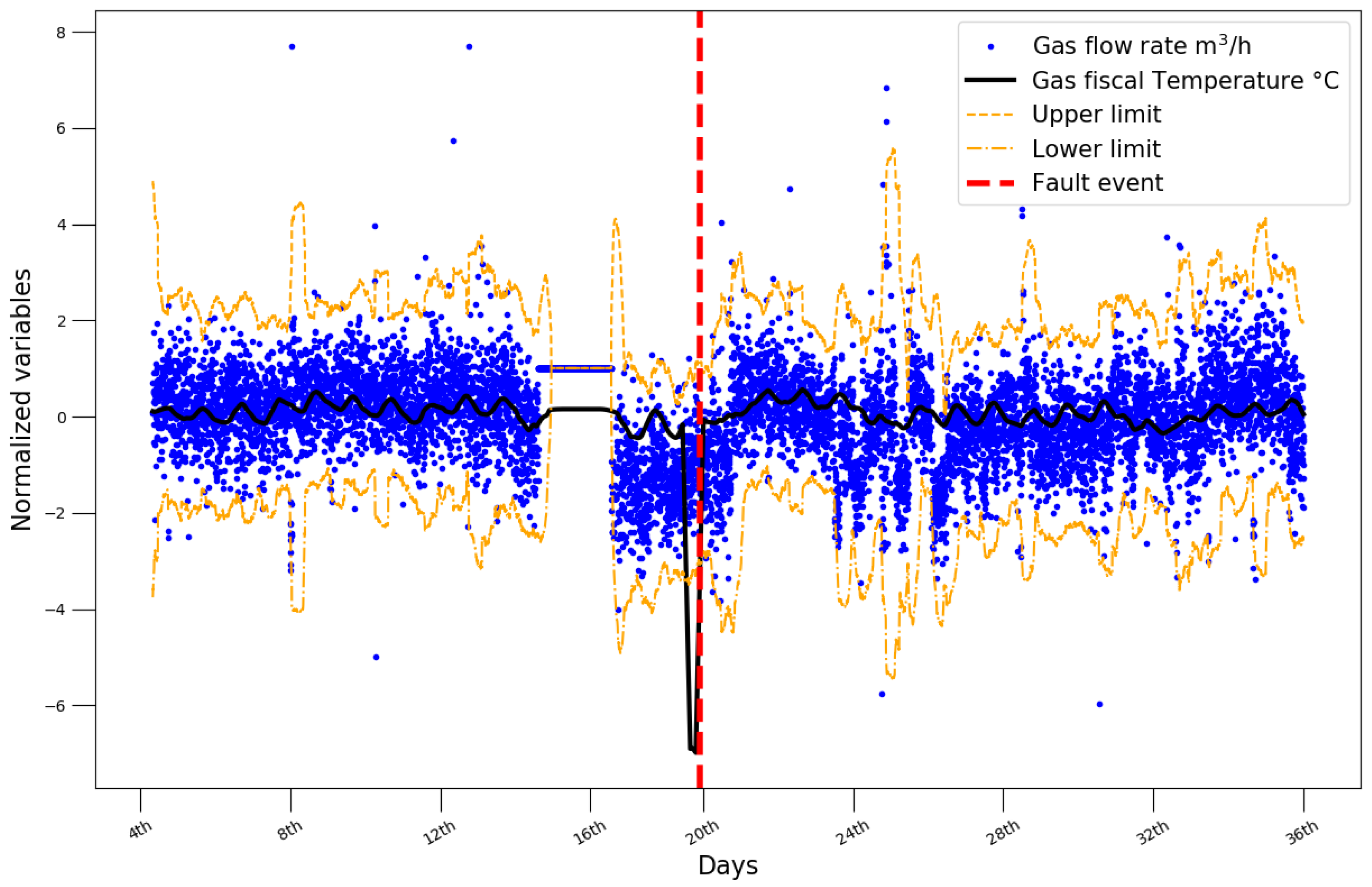
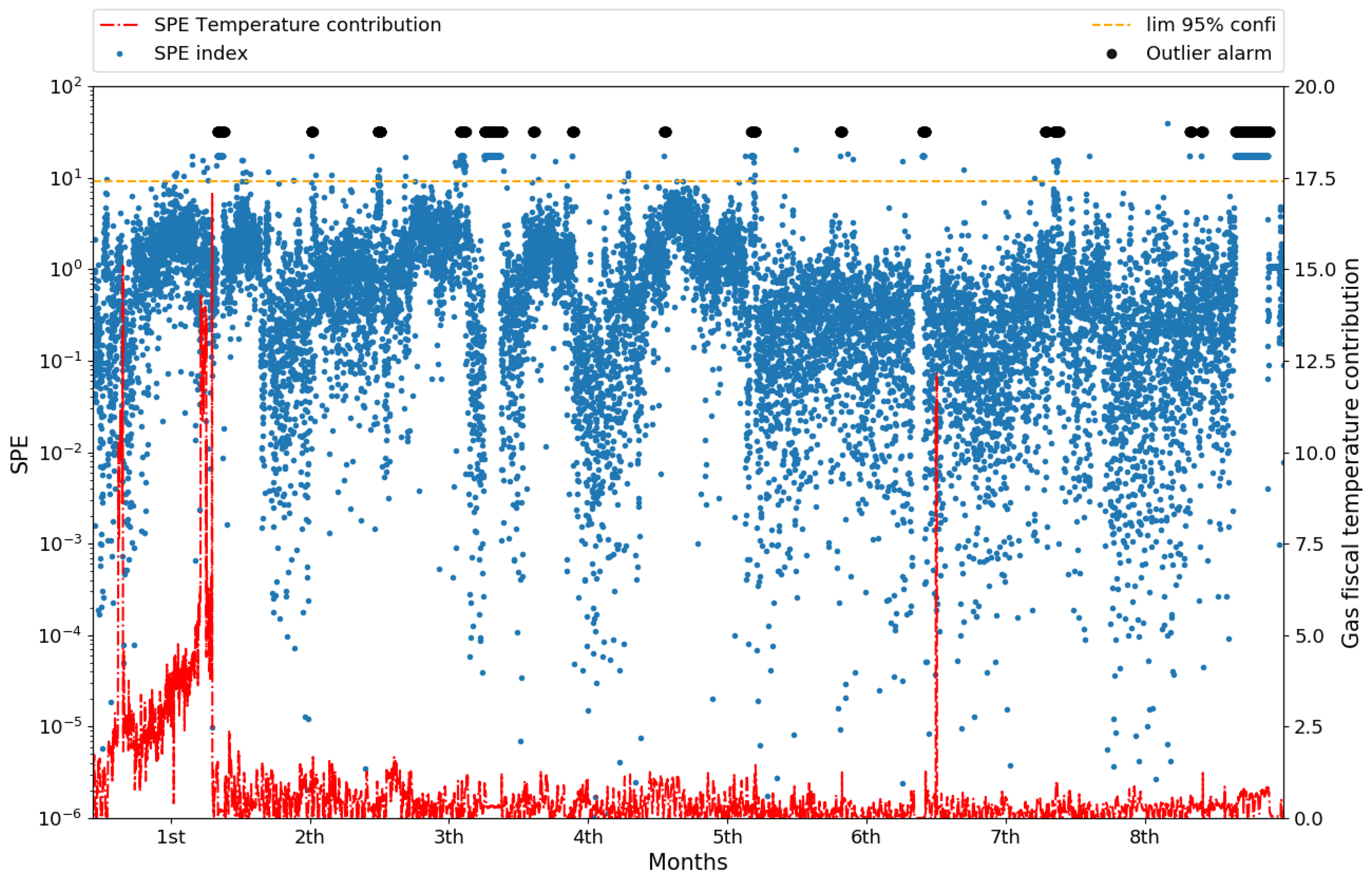
4. Results
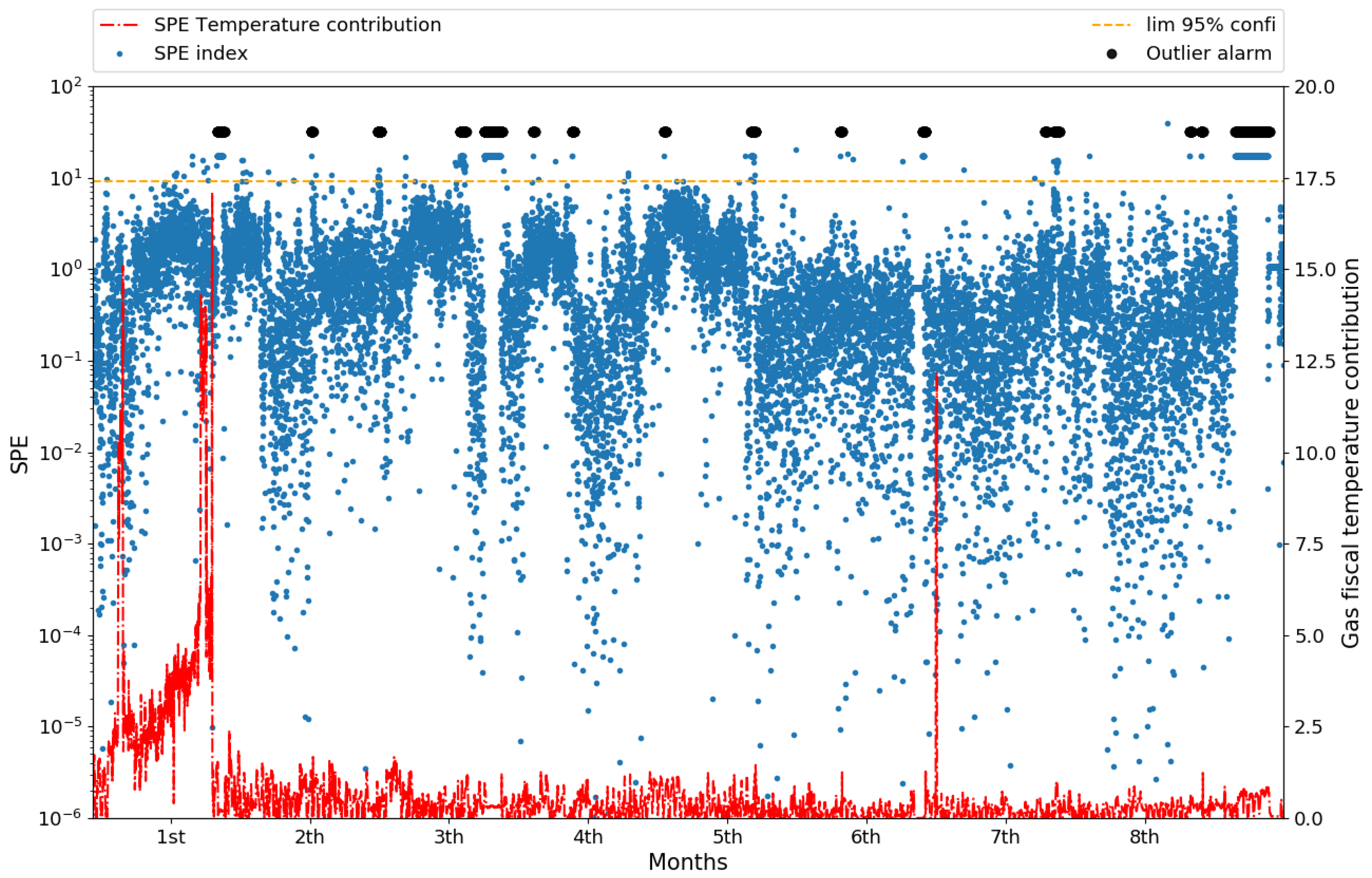
4.1. Monitoring and Fault Diagnosis Results
4.2. Current Status
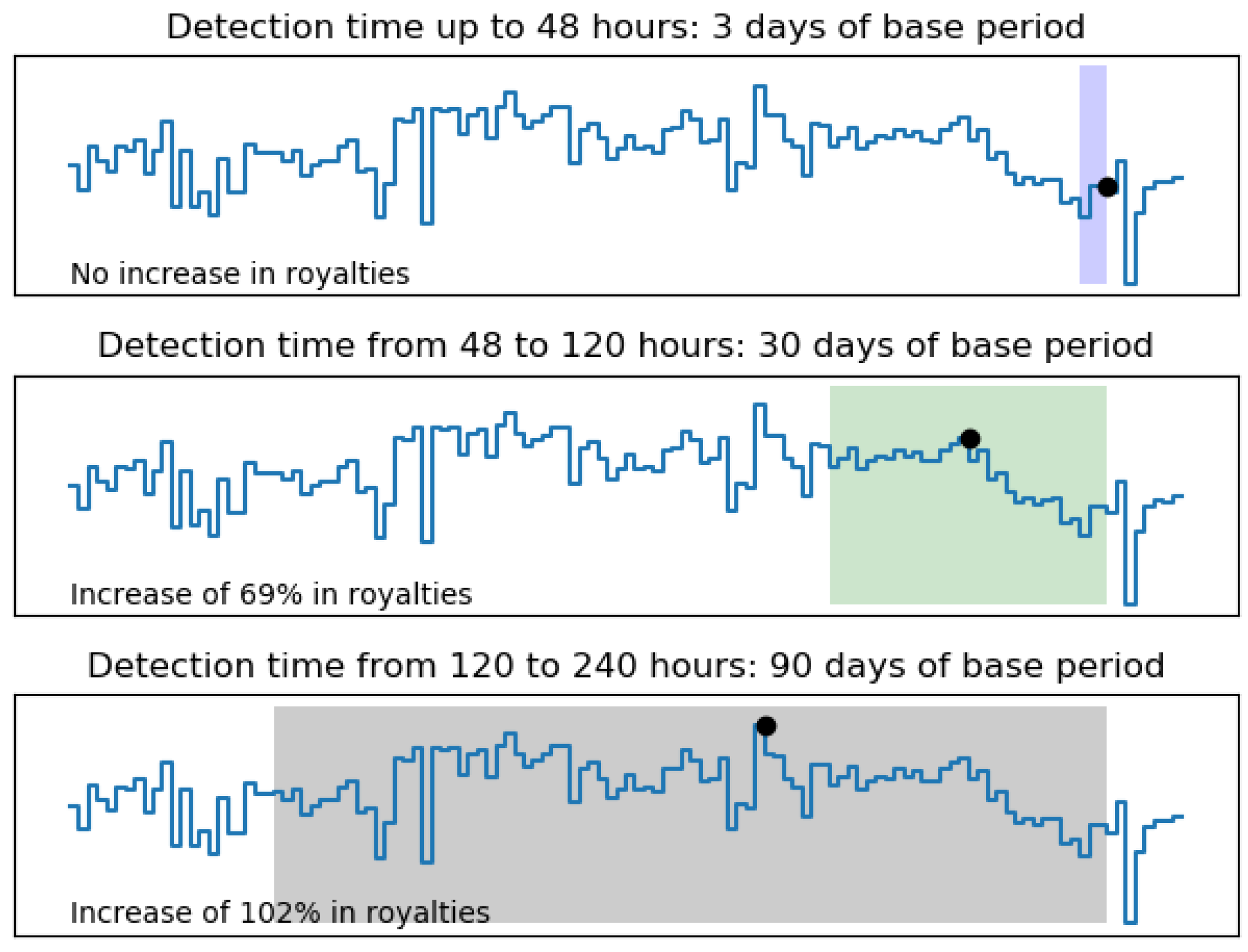
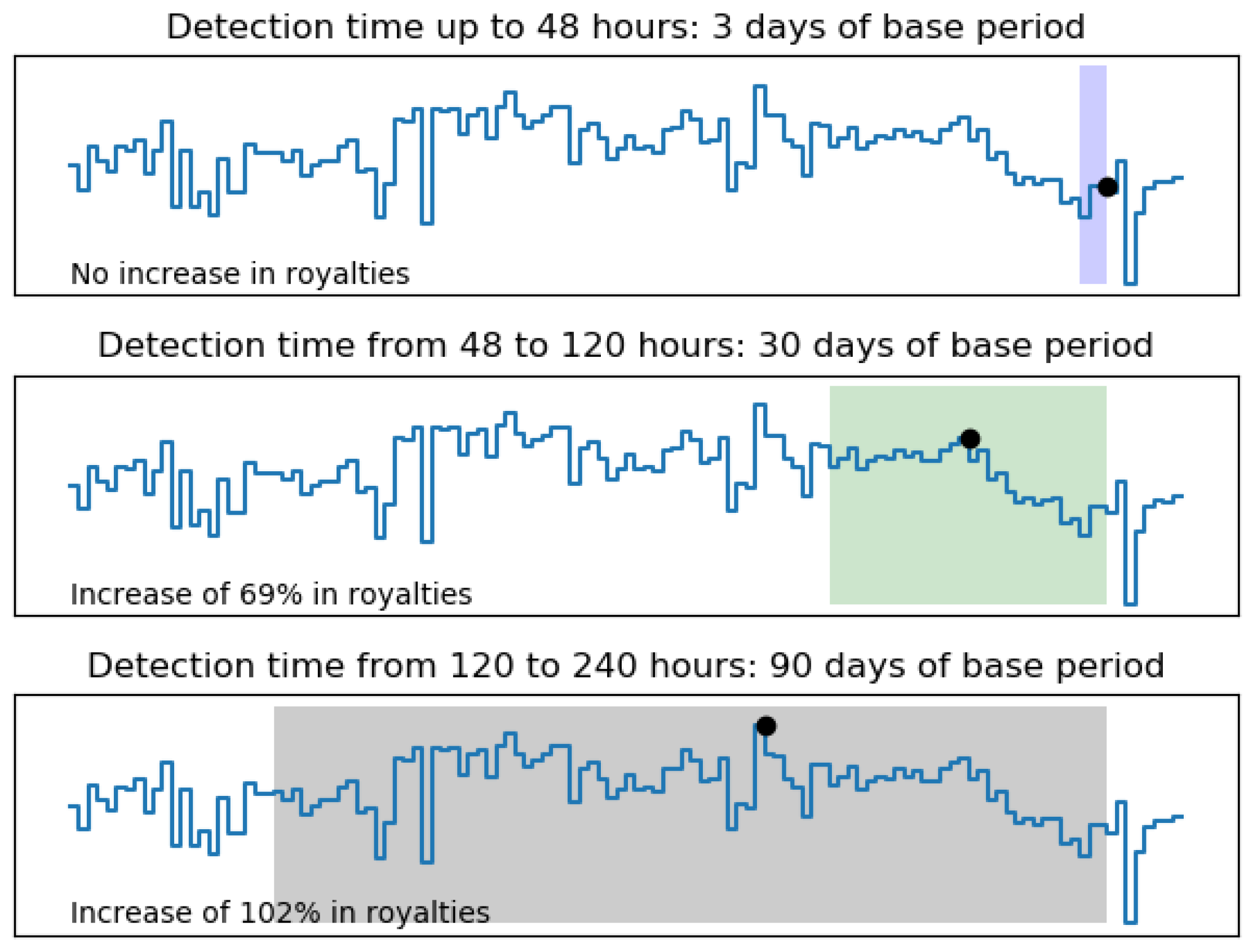
4.3. Economic Analysis Remarks
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CVA | Canonical Variate Analysis |
| CBM | Conditional-Based Maintenance |
| FDD | Fault Detection and Diagnosis |
| PMA | Predictive Maintenance Application |
| RVM | Relevant Vector Machines |
| SVD | Singular-Value Decomposition |
| SPE | Square Prediction Error |
| PDC | Partial Decomposition Contribution |
| PFD | Process Flow Diagram |
| PCA | Principal Components Analysis |
References
- Russell, E.L.; Chiang, L.; Braatz, R. Data-Driven Methods for Fault Detection and Diagnosis in Chemical Processes; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Gao, Z.; Cecati, C.; Ding, S.X. A Survey of Fault Diagnosis and Fault-Tolerant Techniques—Part I: Fault Diagnosis With Model-Based and Signal-Based Approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef]
- Liu, J.; Luo, W.; Yang, X.; Wu, L. Robust Model-Based Fault Diagnosis for PEM Fuel Cell Air-Feed System. IEEE Trans. Ind. Electron. 2016, 63, 3261–3270. [Google Scholar] [CrossRef] [Green Version]
- Isermann, R. Model-based fault-detection and diagnosis: Status and applications. Annu. Rev. Control 2005, 29, 71–85. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Yin, K.; Kavuri, S.N. A review of process fault detection and diagnosis: Part I: Quantitative model-based methods. Comput. Chem. Eng. 2003, 27, 293–311. [Google Scholar] [CrossRef]
- Gharahbagheri, H.; Imtiaz, S.A.; Khan, F.I. Application of Bayesian network for root cause diagnosis of chemical process fault. In Proceedings of the 2017 Indian Control Conference (ICC), Guwahati, India, 4–6 January 2017; pp. 188–193. [Google Scholar] [CrossRef]
- Yuan, T.; Qin, S.J. Root cause diagnosis of plant-wide oscillations using Granger causality. J. Process Control 2014, 24, 450–459. [Google Scholar] [CrossRef]
- Chen, H.S.; Zhao, C.; Yan, Z.; Yao, Y. Root Cause Diagnosis of Oscillation-Type Plant Faults Using Nonlinear Causality Analysis. IFAC-PapersOnLine 2017, 50, 13898–13903. [Google Scholar] [CrossRef]
- Li, G.; Qin, S.J.; Yuan, T. Data-driven root cause diagnosis of faults in process industries. Chemom. Intell. Lab. Syst. 2016, 159, 1–11. [Google Scholar] [CrossRef]
- Ragab, A.; El-Koujok, M.; Poulin, B.; Amazouz, M.; Yacout, S. Fault diagnosis in industrial chemical processes using interpretable patterns based on Logical Analysis of Data. Expert Syst. Appl. 2018, 95, 368–383. [Google Scholar] [CrossRef]
- Trunzer, E.; Wu, C.; Guo, K.; Vermum, C.; Vogel-Heuser, B. Data-Driven Approach to Support Experts in the Identification of Operational States in Industrial Process Plants. In Proceedings of the IECON 2018 44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3096–3101. [Google Scholar] [CrossRef]
- Askarian, M.; Benítez, R.; Graells, M.; Zarghami, R. Data-based fault detection in chemical processes: Managing records with operator intervention and uncertain labels. Expert Syst. Appl. 2016, 63, 35–48. [Google Scholar] [CrossRef] [Green Version]
- Lv, F.; Wen, C.; Bao, Z.; Liu, M. Fault diagnosis based on deep learning. In Proceedings of the 2016 American Control Conference (ACC), Boston, MA, USA, 6–8 July 2016; pp. 6851–6856. [Google Scholar] [CrossRef]
- Qian, Y.; Li, X.; Jiang, Y.; Wen, Y. An expert system for real-time fault diagnosis of complex chemical processes. Expert Syst. Appl. 2003, 24, 425–432. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.N.; Yin, K. A review of process fault detection and diagnosis: Part III: Process history based methods. Comput. Chem. Eng. 2003, 27, 327–346. [Google Scholar] [CrossRef]
- Isermann, R. Process fault detection based on modeling and estimation methods—A survey. Automatica 1984, 20, 387–404. [Google Scholar] [CrossRef]
- Gertler, J.J. Survey of model-based failure detection and isolation in complex plants. IEEE Control Syst. Mag. 1988, 8, 3–11. [Google Scholar] [CrossRef]
- Frank, P.M. Fault diagnosis in dynamic systems using analytical and knowledge-based redundancy: A survey and some new results. Automatica 1990, 26, 459–474. [Google Scholar] [CrossRef]
- Isermann, R. Supervision, fault-detection and fault-diagnosis methods—An introduction. Control Eng. Pract. 1997, 5, 639–652. [Google Scholar] [CrossRef]
- Maurya, M.R.; Paritosh, P.K.; Rengaswamy, R.; Venkatasubramanian, V. A framework for on-line trend extraction and fault diagnosis. Eng. Appl. Artif. Intell. 2010, 23, 950–960. [Google Scholar] [CrossRef]
- Venkatasubramanian, V.; Rengaswamy, R.; Kavuri, S.N. A review of process fault detection and diagnosis: Part II: Qualitative models and search strategies. Comput. Chem. Eng. 2003, 27, 313–326. [Google Scholar] [CrossRef]
- Ge, Z.; Song, Z.; Gao, F. Review of Recent Research on Data-Based Process Monitoring. Ind. Eng. Chem. Res. 2013, 52, 3543–3562. [Google Scholar] [CrossRef]
- Qin, S.J. Survey on data-driven industrial process monitoring and diagnosis. Annu. Rev. Control 2012, 36, 220–234. [Google Scholar] [CrossRef]
- Yin, S.; Ding, S.X.; Haghani, A.; Hao, H.; Zhang, P. A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman process. J. Process Control 2012, 22, 1567–1581. [Google Scholar] [CrossRef]
- Nor, N.M.; Hassan, C.R.C.; Hussain, M.A. A review of data-driven fault detection and diagnosis methods: Applications in chemical process systems. Rev. Chem. Eng. 2019, 1–40. [Google Scholar] [CrossRef]
- Wong, P.K.; Yang, Z.; Vong, C.M.; Zhong, J. Real-time fault diagnosis for gas turbine generator systems using extreme learning machine. Neurocomputing 2014, 128, 249–257. [Google Scholar] [CrossRef]
- Namburu, S.M.; Chigusa, S.; Prokhorov, D.; Qiao, L.; Choi, K.; Pattipati, K. Application of an Effective Data-Driven Approach to Real-time time Fault Diagnosis in Automotive Engines. In Proceedings of the 2007 IEEE Aerospace Conference, Big Sky, MT, USA, 3–10 March 2007; pp. 1–9. [Google Scholar] [CrossRef]
- Patan, K.; Parisini, T. Identification of neural dynamic models for fault detection and isolation: The case of a real sugar evaporation process. J. Process Control 2005, 15, 67–79. [Google Scholar] [CrossRef]
- Hu, J.; Tse, P.W. A Relevance Vector Machine-Based Approach with Application to Oil Sand Pump Prognostics. Sensors 2013, 13, 12663–12686. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bang, M.; Engelsgaard, S.S.; Alexandersen, E.K.; Skydt, M.R.; Shaker, H.R.; Jradi, M. Novel real-time model-based fault detection method for automatic identification of abnormal energy performance in building ventilation units. Energy Build. 2019, 183, 238–251. [Google Scholar] [CrossRef]
- Lei, J.; Liu, C.; Jiang, D. Fault diagnosis of wind turbine based on Long Short-term memory networks. Renew. Energy 2019, 133, 422–432. [Google Scholar] [CrossRef]
- Chen, K.; Laghrouche, S.; Djerdir, A. Fuel cell health prognosis using Unscented Kalman Filter: Postal fuel cell electric vehicles case study. Int. J. Hydrogen Energy 2019, 44, 1930–1939. [Google Scholar] [CrossRef]
- Fuente, M.; Vega, P. Neural networks applied to fault detection of a biotechnological process. Eng. Appl. Artif. Intell. 1999, 12, 569–584. [Google Scholar] [CrossRef]
- Li, L.; Luo, H.; Ding, S.X.; Yang, Y.; Peng, K. Performance-based fault detection and fault-tolerant control for automatic control systems. Automatica 2019, 99, 308–316. [Google Scholar] [CrossRef]
- Li, C.; Zhao, D.; Mu, S.; Zhang, W.; Shi, N.; Li, L. Fault diagnosis for distillation process based on CNN-DAE. Chin. J. Chem. Eng. 2019, 27, 598–604. [Google Scholar] [CrossRef]
- Marseguerra, M.; Ricotti, M.E.; Zio, E. Neural Network-Based Fault Detections in a Pressurized Water Reactor Pressurizer. Nucl. Sci. Eng. 1996, 124, 339–348. [Google Scholar] [CrossRef]
- Persin, S.; Tovornik, B. Real-time implementation of fault diagnosis to a heat exchanger. Control Eng. Pract. 2005, 13, 1061–1069. [Google Scholar] [CrossRef]
- Choi, K.; Namburu, S.M.; Azam, M.S.; Luo, J.; Pattipati, K.R.; Patterson-Hine, A. Fault diagnosis in HVAC chillers. IEEE Instrum. Meas. Mag. 2005, 8, 24–32. [Google Scholar] [CrossRef]
- Natarajan, S.; Srinivasan, R. Multi-model based process condition monitoring of offshore oil and gas production process. Chem. Eng. Res. Des. 2010, 88, 572–591. [Google Scholar] [CrossRef]
- Li, G.; Qin, S.J.; Ji, Y.; Zhou, D. Reconstruction based fault prognosis for continuous processes. Control Eng. Pract. 2010, 18, 1211–1219. [Google Scholar] [CrossRef]
- Hwang, H.J. Introduction to a Condition-based Maintenance Solution for Offshore Platforms. In Proceedings of the Twenty-Fifth International Ocean and Polar Engineering Conference, Kona, HI, USA, 21–26 June 2015; International Society of Offshore and Polar Engineers: Mountain View, CA, USA, 2015. [Google Scholar]
- Hwang, H.; Lee, J.; Hwang, J.; Jun, H. A study of the development of a condition-based maintenance system for an LNG FPSO. Ocean Eng. 2018, 164, 604–615. [Google Scholar] [CrossRef]
- Ly, C.; Tom, K.; Byington, C.S.; Patrick, R.; Vachtsevanos, G.J. Fault diagnosis and failure prognosis for engineering systems: A global perspective. In Proceedings of the 2009 IEEE International Conference on Automation Science and Engineering, Bangalore, India, 22–25 August 2009; pp. 108–115. [Google Scholar] [CrossRef]
- Thorsen, O.V.; Dalva, M. A survey of faults on induction motors in offshore oil industry, petrochemical industry, gas terminals, and oil refineries. IEEE Trans. Ind. Appl. 1995, 31, 1186–1196. [Google Scholar] [CrossRef]
- Zhang, L.; Hu, J. Safety prognostic technology in complex petroleum engineering systemsf: Progress, challenges and emerging trends. Pet. Sci. 2013, 10, 486–493. [Google Scholar] [CrossRef]
- Cibulka, J.; Ebbesen, M.K.; Hovland, G.; Robbersmyr, K.G.; Hansen, M.R. A Review on Approaches for Condition Based Maintenance in Applications with Induction Machines Located Offshore. Model. Identif. Control 2012, 33, 69–86. [Google Scholar] [CrossRef]
- Gowid, S.; Dixon, R.; Ghani, S. Profitability, reliability and condition based monitoring of LNG floating platforms: A review. J. Nat. Gas Sci. Eng. 2015, 27, 1495–1511. [Google Scholar] [CrossRef] [Green Version]
- Reis, M.S.; Gins, G. Industrial Process Monitoring in the Big Data/Industry 4.0 Era: From Detection, to Diagnosis, to Prognosis. Processes 2017, 5, 35. [Google Scholar] [CrossRef]
- Jackson, J.E.; Mudholkar, G.S. Control Procedures for Residuals Associated with Principal Component Analysis. Technometrics 1979, 21, 341–349. [Google Scholar] [CrossRef]
- Ku, W.; Storer, R.H.; Georgakis, C. Disturbance detection and isolation by dynamic principal component analysis. Chemom. Intell. Lab. Syst. 1995, 30, 179–196. [Google Scholar] [CrossRef]
- Rato, T.; Reis, M. Advantage of Using Decorrelated Residuals in Dynamic Principal Component Analysis for Monitoring Large-Scale Systems. Ind. Eng. Chem. Res. 2013, 52, 13685–13698. [Google Scholar] [CrossRef]
- Negiz, A.; Çinar, A. PLS, balanced, and canonical variate realization techniques for identifying VARMA models in state space. Chemom. Intell. Lab. Syst. 1997, 38, 209–221. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal component analysis. Technometrics 2002, 45, 276. [Google Scholar] [CrossRef]
- Röhr, M.; Gittins, R. Canonical Analysis—A Review with Applications in Ecology (Biomathematics, vol. 12), Springer-Verlag, Berlin–Heidelberg– New York –Tokyo 1985, 351 S., 16 Abb., DM 128,–. Biom. J. 1988, 30, 249–250. [Google Scholar] [CrossRef]
- Schaper, C.; Larimore, W.; Seborg, D.; Mellichamp, D. Identification of chemical processes using canonical variate analysis. Comput. Chem. Eng. 1994, 18, 55–69. [Google Scholar] [CrossRef]
- Alcala, C.; Qin, S.J. Analysis and generalization of fault diagnosis methods for process monitoring. J. Process Control 2011, 21, 322–330. [Google Scholar] [CrossRef]
- Nelson, L.S. The Shewhart Control Chart-Tests for Special Causes. J. Qual. Technol. 1984, 16, 237–239. [Google Scholar] [CrossRef]
- Câmara, M.M. Técnicas de Identificação Voltadas Para a Otimização de Processos em Tempo Real. Ph.D. Thesis, Universidade Federal do Rio de Janeiro/COPPE/Programa de Engenharia Química, Rio de Janeiro, Brazil, 2018. (In Portuguese). [Google Scholar]
- Diretora Geral da Agência Nacional do Petróleo, Gás Natural e Biocombustíveis. Resolução ANP Nº 18 DE 27/03/2014. 2014. Available online: http://legislacao.anp.gov.br/?path=legislacao-anp/resol-anp/2014/marco&item=ranp-18–2014 (accessed on 8 April 2019).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Type | Number of Variables | Units |
|---|---|---|
| Flow rate | 40 | m/h |
| Temperature | 11 | C |
| Controller output | 2 | % |
| Pressure differential | 8 | kPa |
| Pressures | 21 | kPa |
| Levels | 2 | m |
| Relative density | 9 | - |
| Basic Sediment and water | 6 | % |
| Electric current | 9 | mA |
| Valve aperture | 4 | % |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Clavijo, N.; Melo, A.; Câmara, M.M.; Feital, T.; Anzai, T.K.; Diehl, F.C.; Thompson, P.H.; Pinto, J.C. Development and Application of a Data-Driven System for Sensor Fault Diagnosis in an Oil Processing Plant. Processes 2019, 7, 436. https://doi.org/10.3390/pr7070436
Clavijo N, Melo A, Câmara MM, Feital T, Anzai TK, Diehl FC, Thompson PH, Pinto JC. Development and Application of a Data-Driven System for Sensor Fault Diagnosis in an Oil Processing Plant. Processes. 2019; 7(7):436. https://doi.org/10.3390/pr7070436
Chicago/Turabian StyleClavijo, Nayher, Afrânio Melo, Maurício M. Câmara, Thiago Feital, Thiago K. Anzai, Fabio C. Diehl, Pedro H. Thompson, and José Carlos Pinto. 2019. "Development and Application of a Data-Driven System for Sensor Fault Diagnosis in an Oil Processing Plant" Processes 7, no. 7: 436. https://doi.org/10.3390/pr7070436