Abstract
Mine water inrush is a significant environmental catastrophe during the coal mining process, and the timely discrimination of the source of water inrush is the key to ensuring safe production in coal mines. This work suggests a mine water inrush—belief rule base (MWI-BRB) source discrimination model to overcome the interpretability and performance issues with conventional models. MWI-BRB firstly automatically constructs the reference values of prerequisite attributes using the Sum of Squared Errors—K-means++ algorithm, which effectively combines expert knowledge and data-driven methods, and solves the limitation of the traditional belief rule base model relying on specialist knowledge. Secondly, the hierarchical incremental structure solves the rule explosion problem caused by complex features while using XGBoost to select features. Finally, in the inference process, the model adopts an evidential reasoning algorithm to realize transparent causal inference, guaranteeing the model’s interpretability and transparency. The Penalized Covariance Matrix Adaptation Evolution Strategy algorithm optimizes the model parameters to increase the discriminative accuracy of the model even more. Experimental results on a real coal mine dataset (a total of 67 samples from Hebei, China, covering four water inrush sources) demonstrate that the proposed MWI-BRB achieves 95.23% accuracy, 95.23% recall, and 95.36% F1-score under a 7:3 training–testing split with parameter tuning performed via leave-one-out cross-validation. The near-identical values across accuracy, recall, and F1-score reflect the balanced nature of the dataset and the robustness of the model across different evaluation metrics. Compared with baseline models, MWI-BRB’s accuracy and recall are 4.78% higher than BPNN and 9.52% higher than KNN, RF, and XGBoost; its F1-score is 4.85% higher than BPNN, 10.64% higher than KNN, 10.19% higher than RF, and 9.65% higher than XGBoost. Moreover, the model maintains high interpretability. In conclusion, the MWI-BRB model can realize efficient and accurate water inrush source discrimination in complex environments, which provides a feasible technical solution for the prevention and control of mine water damage.
1. Introduction
One of the most significant accidents that occurs during the building and production of mines is mine water inrush, which has many different and complicated causes, such as surface water leakage, pressured aquifers, and old air [1,2]. The water inrush event exhibits a sudden onset and a significant magnitude, which might endanger miners’ lives and safety in addition to halting production and causing financial loss. The frequency and extent of water inrush disasters in mines have dramatically increased as mining depth and hydrogeological conditions have become more complex [3,4]. In response to the mine water inrush disaster, timely preventive and control measures are the key to ensuring the safe production of the mine. However, due to the diversity of the causes of water inrush and the complexity of the water sources, the implementation of preventive and control measures relies on the accurate discrimination of the sources of water inrush [5].
Conventional techniques for identifying the origins of water in mine water inrush mostly involve isotope tracking, the dynamic monitoring of water temperature, water chemistry, water level, and GIS-based approaches [6,7,8,9,10]. Groundwater chemistry accurately reflects the fundamental properties of its ions, enabling the effective assessment of the source of water inrush. For early water inrush source discrimination, many researchers combine machine learning or deep learning techniques with water chemistry features. Dong et al. discriminated four major water recharge sources in the Wuhai mining area, China, by Fisher extracted features combined with an SVM classifier [11]. Using four cross-validation rules, Yang et al. trained a random forest mine inrush water source discrimination model for mine inrush water accidents in the Pingdingshan Coalfield [12]. This offers a fresh perspective on mine inrush water discrimination. In order to increase the precision of mine water inrush accident prediction, Ye, Z. et al. created a deep learning-based ISMOTE mine water inrush discrimination model [13]. However, there are limitations in the way machine learning and deep learning techniques can be combined with water chemistry characterization. First, some methods, such as support vector machines [14] and deep learning models [15], are poorly interpretable “black-box” models, and it is difficult for mine safety personnel to trust the results of the models in discriminating the source of water inrush. Second, although techniques such as decision trees and plain Bayesian classifiers are interpretable [16], these kinds of models are data-driven, and it is difficult to collect large-scale data for mine water inrush scenarios. Therefore, a small dataset with an interpretable model is needed to discriminate the water inrush source.
In this study, we introduce the BRB into the mine water inrush scenario to solve the problem of poor interpretability of the previous mine water inrush source discrimination model. BRB is a “white-box” modeling strategy based on the IF-THEN rule [17], which has good interpretability. In addition, BRB can fuse expert knowledge in the domain into the model, a feature that eliminates the need for large-scale datasets as training samples for BRB models. Currently, BRBs have been successfully applied to many high-precision realistic scenarios, such as fault detection in the aerospace industry [18,19], intrusion detection in the field of cyber security [20,21], clinical decision support [22], project risk assessment [23], and Complex System Health Status Assessment [24,25].
However, there are two main problems associated with the application of BRB to mine water inrush source determination. The first is the manual initialization of reference values based on expert knowledge, which may limit the model’s structure and parameters. This constraint can reduce the model’s ability to capture complex states, resulting in poor performance. Secondly, the complexity of aquifer hydrochemical characterization leads to an increase in the number of BRB prerequisite attributes when oriented toward mine water inrush source discrimination scenarios. Given that the Cartesian product algorithm determines the BRB rules, the increase in premise attributes will lead to a proliferation of BRB rules, resulting in a rule explosion. It will have a detrimental impact on the model’s performance and restrict the use of expert knowledge to some extent. Traditional BRB models are usually difficult to comprehensively capture the diversity and dynamics of the water chemistry characteristics of water inrush sources, resulting in poor performance in the problem of water inrush source discrimination. In addition, due to the dynamic nature of the environment in which water inrush sources in mines are discriminated, the model parameters need to be continuously optimized to adapt to the changes, and it is difficult for traditional parameter optimization methods to provide an effective solution.
This paper proposes the Mine Water Inflow Source Identification Model MWI-BRB based on Auto-Deep-BRB to address the aforementioned issues. Its innovation manifests in three aspects: firstly, the application of the SSE-KPP algorithm to automatically construct reference values, reducing reliance on subjective expert initialization; secondly, the design of a hierarchical BRB framework effectively mitigates the rule explosion problem while preserving feature interaction relationships. Thirdly, the integration of the ER inference mechanism with P-CMA-ES optimization technology balances interpretability and accuracy, resolving the longstanding trade-off between transparency and performance. These innovations collectively advance the theoretical methodology for mine water inrush identification, providing a practical solution for safety management in complex mining environments. The principal contributions of this paper are as follows:
- An Auto-Deep-BRB-based mine water inrush source discrimination model, MWI-BRB, is established, which can accurately discriminate mine water inrush sources while ensuring the best balance of accuracy and interpretability.
- The SSE-KPP algorithm, which constructs the set of reference values based on the technique of automatic determination of reference values, counteracts the disadvantages of creating models from expert knowledge. This approach contributes to the automatic modeling of the model.
- Introducing a deep structure for dealing with complex features to enhance the model’s ability to deal with complex relationships between different features, while further solving the rule explosion problem caused by the number of features.
2. Problem Description
The primary obstacles to mine water inrush discrimination (MWID) are identified and examined in this section. Traditional models frequently exhibit limitations when working with complicated indicators, particularly in terms of transparency and interpretability, despite the availability of numerous approaches. For both study and practice, a deeper comprehension of the underlying principles and processes of model outcomes is essential. Therefore, it is crucial to construct predictive models that balance accuracy and interpretability. This study proposes the Mine Water Inflow Discrimination Model (MWI-BRB) based on Auto-Deep-BRB. To enhance both model accuracy and interpretability, five key issues must be addressed, as illustrated in Figure 1.
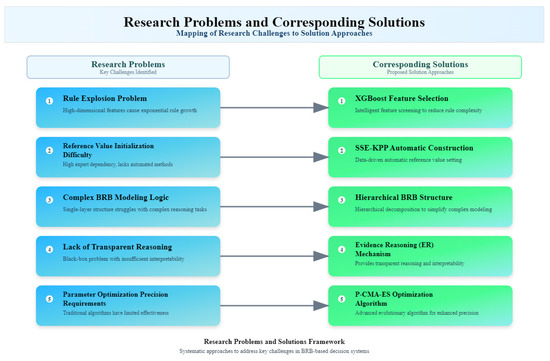
Figure 1.
Research problems and corresponding solutions.
At the data level, the rule explosion problem caused by a large number of hydrochemical features needs to be addressed. This requires selecting the most influential features to simplify the model without losing discriminative capability.
At the data level, the influence of each feature of mine water chemistry on the identification of water inrush is analyzed. The features with higher weights are selected, and the importance of feature ranking is as follows:
where represents the original dataset, is the feature selection algorithm, is the key parameter of the feature selection algorithm, and represents the feature dataset after feature selection.
Another issue lies in the initialization of reference values, which traditionally depends heavily on expert knowledge and lacks systematic construction. To address this, an automatic reference value construction approach is required to enhance reproducibility and reduce subjectivity.
In the BRB model, each rule is composed of important parameters such as premise attribute, premise attribute reference value, and so on. Determining the premise attribute reference value is the most critical step in initializing the BRB model. Traditionally, BRB premise attribute reference values are determined by expert knowledge; however, limited expert knowledge may restrict the performance of the model.
To address this issue, the effective reference values in the dataset are extracted by means of data mining algorithms, which can effectively mine the association information of data features from different perspectives. The process of initializing BRB premise attribute reference be defined as:
where denotes the initial parameters required for MWI-BRB modeling, denotes the data mining algorithm, and denotes the data mining algorithm parameters.
In addition, the complexity of BRB modeling logic makes it difficult to achieve efficient and transparent reasoning, which highlights the need for structural improvements in the rule base.
The discrimination model for mine water inrush sources should take into account both the modeling logic and consider many features caused by the explosion of the single-layer BRB rule problem. For this problem, the proposed solution is described below:
represents the result of discriminating mine water inrush sources.
Furthermore, the lack of interpretability in traditional BRB reasoning reduces trust in the results, emphasizing the necessity of adopting a transparent inference mechanism.
The BRB model requires an interpretable reasoning process, which is achieved through the use of evidential teasoning (ER), a reasoning mechanism that effectively integrates and processes evidence from multiple sources of heterogeneous data while taking into account conflicts and synergies among the evidence. By comprehensively analyzing and assessing the validity and applicability of every piece of evidence, a detailed and precise reasoning process is achieved.
where represents the ER inference mechanism and symbolizes the collection of parameters required for the process of inference.
Finally, parameter optimization remains a crucial step to balance model accuracy and computational efficiency, requiring an effective optimization strategy.
BRB is not only interpretable but also has significant nonlinear modeling capability. Initial parameters, such as reference values of premise attributes, when creating traditional BRB models, experts choose the premise attribute weights and rule weights, which are fuzzy and uncertain, and these parameters may be inaccurate and need to be optimized by P-CMA-ES. An overview of the optimization process is shown below:
where represents the P-CMA-ES optimization function, represents the set of parameters to be optimized, and represents the optimal set of parameters.
3. Construction of the MWI-BRB Model for Discriminating Water Inrush Sources in Mines
The construction process of the MWI-BRB model, which is a highly interpretable and credible model for identifying the mine water inrush sources, is depicted in Figure 2. The construction process is as follows:
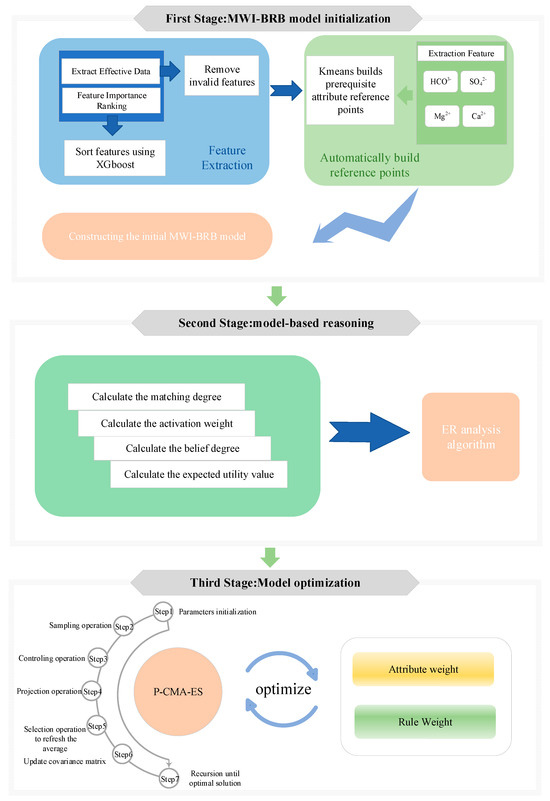
Figure 2.
The construction process of the model.
- Step 1: Describe and rank the water ion concentration features that have an impact on mine water inrush source discrimination, eliminate the less significant features, and direct the discrimination model’s attention to the features that have the biggest impact on the outcomes.
- Step 2: Determine the reference value of prerequisite attributes when constructing the MWI-BRB model through a data mining algorithm based on the selected features, and effectively mine the correlation information between data features.
- Step 3: Construct the MWI-BRB model based on the important features identified in Step 1 and the prerequisite attribute reference values identified in Step 2. The MWI-BRB model ranks the selected features according to the feature importance and combines them with the corresponding prerequisite attribute references in turn according to the feature importance to construct the MWI-BRB that is integrated by multiple single-layer BRB units.
- Step 4: Create workable algorithms for inference and optimization to increase the mine water inrush source discrimination model’s accuracy even more.
- Step 5: Apply the optimized mine water inrush model to the realistic scenario.
As shown in Figure 2, the first stage of feature extraction is detailed in Section 3.1; the automatic model construction initializes the prerequisite attribute reference values in Section 3.2. In Section 3.3, the MWI-BRB construction is demonstrated; in Section 3.4, the second inference stage is explained; and in Section 3.5, the third optimization stage is explained.
3.1. Selection of Characteristics Affected by Sudden Water Source in Mines
Limiting the number of premise attributes can effectively solve the rule explosion problem. However, too few premise attributes tend to cause the model not to have enough rules to deal with the water inrush source discrimination problem [26]. Therefore, we use XGBoost for feature selection, which can better cope with the nonlinear relationship between the signs and more accurately capture the true importance of the features. The XGBoost process is described below:
where is the predicted value, is the structure of the decision tree, and is the tree space.
(12) is the objective function of XGBoost, (13) describes the loss function of XGBoost, and (14) is the gain function
3.2. Automatically Builds Prerequisite Attribute Reference Points
The reference values of prerequisite attributes are the basis for constructing the MWI-BRB model. Usually, the reference values of prerequisite attributes in BRB models are manually initialized by domain experts [27,28]. However, relying solely on domain expert knowledge to determine the reference value in MWID can make the constructed MWI-BRB have certain limitations and affect the model’s accuracy [29,30]. Since the BRB model runs according to the belief rule, concurrently, the BRB model run involves being able to effectively match the samples with the reference value when constructing the model [31]. Therefore, determining the reference value in the high-frequency region of the data samples can effectively ensure the matching of the reference value with the samples when the BRB model is run.
Data mining algorithms are able to extract the distribution characteristics of prerequisite attributes from complex datasets and effectively mine the key regions and boundary points of the data. Clustering algorithms are able to classify the prerequisite attributes into a number of clustering centers and extract these clustering centers as reference values, which can reflect the attribute value of high-frequency regions. Therefore, this study introduces a clustering enhancement algorithm of SSE-KPP to extract the reference values for constructing the MWI-BRB model. The algorithm utilizes iterative analysis of sample data and mining potential relationships in the data to construct the reference values. Figure 3 depicts the algorithm’s primary flow. SSE-KPP is able to discriminate the cluster centers more accurately to get the reference value by constraining the output of KMeans++ by least squares and error.
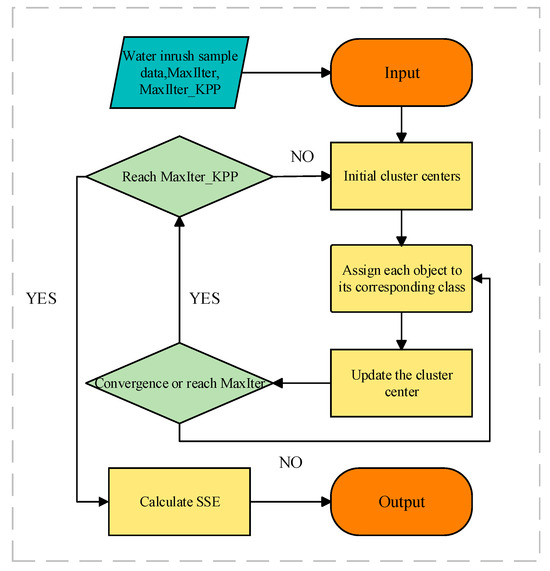
Figure 3.
The main flow of SSE-KPP.
The determination of some reference values needs to be determined according to the actual scenario, and according to Sun et al. [32], the minimum number of reference values is 2. However, due to the complexity of the mine water inrush source discrimination scenario, it is difficult to form a comprehensive matching pair of reference values and samples by taking 2 reference values for each prerequisite attribute. From the hydrochemical mechanism perspective, the concentration of characteristic ions in aquifers often exhibits multi-peak distributions and abrupt changes, which cannot be effectively represented by only 2–3 reference values. Moreover, when the number of reference values is too small, the fuzzy grades of attributes (e.g., “low/medium/high”) become uneven, and small threshold shifts may lead to biased rule activation. By adopting 4 reference values, the attribute space can be divided into more balanced fuzzy intervals (e.g., “low/relatively low/relatively high/high”), which enhances the stability of rule triggering and avoids bias caused by boundary effects. On the other hand, assigning more than 4 reference values would sharply increase the number of rules and lead to rule explosion, thereby reducing interpretability. In line with extensive field experience from coal mine water inrush discrimination practice, domain experts generally adopt 3–4 representative intervals to distinguish aquifers. Therefore, setting 4 reference values in this study provides a rational compromise: it adequately captures the heterogeneity of hydrochemical indicators, ensures balanced fuzzy partitioning, and maintains computational feasibility and model transparency.
3.3. The Modeling Process of the MWI-BRB
The complex mine water inrush source discrimination problem will result in severe combinatorial explosion issues if all features are entered simultaneously into a single-layer BRB to build the model. In order to solve this problem, MWI-BRB utilizes deep structure layering to gradually realize the prediction of water inrush sources in mines [33], enters the features into MWI-BRB, and builds the BRB unit incrementally based on the features’ relative importance. It ensures both the problem of model combination explosion and the rationality of MWI-BRB modeling. As shown in Figure 4.
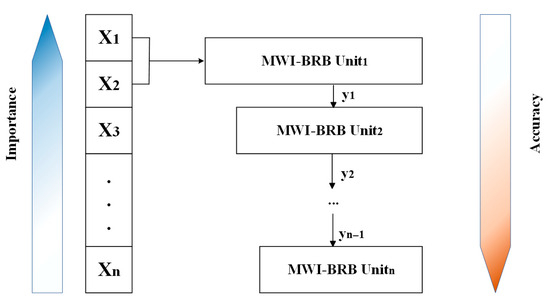
Figure 4.
MWI-BRB deep structure.
3.4. Model Reasoning Process
The core of the MWI-BRB inference mechanism is Evidence Reasoning (ER), which is used to deal with problems of uncertainty, multi-source information fusion, and fuzzy decision-making. The ER inference process generates the final confidence distribution for the target variable by combining the evidence information from multiple rules. There are typically five phases in the MWI-BRB theoretical inference process: input transformation, rule aggregation, match normalization, rule activation weight calculation, and utility calculation.
- A reference value distribution is created from the supplied data.where is defined as the attribute’s reference value. The distribution level of the reference value is denoted by .
- 2.
- Calculating the matching degree involves the following steps: the reference value distribution is used to determine the matching degree.where the attribute normalized weights are denoted by . The matching degree of the rule is denoted by .
- 3.
- Calculation of rule activation weights: Rules need to be activated or not by activation weights which are calculated as follows:
The activation weight of the rule is represented by .
- 4.
- The following is the computational technique for the rule aggregation process. This generates the ultimate belief dispersion by combining all existing rules:where indicates the degree of belief in the outcome. An intermediate parameter is indicated by .
The confidence level distribution obtained is as follows:
where the input vector is denoted by .
- 5.
- The following formula is used to determine the final utility of .where represents the value of utility.
3.5. Model Optimization Process
In the mine water inrush source discrimination model based on the belief rule base (BRB), the design of the belief rules and the determination of the system parameters are crucial to the performance of the model. To achieve the optimal effect of mine water inrush source discrimination, several parameters in the MWI-BRB system need to be optimized, such as rule weights, fuzzification parameters, and belief distributions of the rules. The search space of these parameters is usually high-dimensional, nonlinear and may have local optimal solutions, so efficient global optimization methods are needed to solve them. For this reason, in this paper, P-CMA-ES, Penalized Covariance Matrix Adaptation Evolution Strategy (P-CMA-ES, Penalized Covariance Matrix Adaptation Evolution Strategy) is used to optimize the parameters in the MWI-BRB model.
The following steps are included in the P-CMA-ES optimization process.
- Step 1: Establish the basic P-CMA-ES settings and the first parameters that need to be optimized.where the starting mean value is denoted by and the first vector of parameters to be optimized by .
- Step 2: Establish the limitations and the objective function. MSE, which is computed as, indicates the modeling accuracy of BRB.
If is the BRB’s diagnostic result, is the system’s actual output, and is the amount of observation data.
According to the formulation given above, the following are the limitations and the goal of the function:
- Step 3: To create the aggregate, carry out the sampling procedure.
The standard deviation is represented by , and the step length is indicated by , which indicates the th response in the generation. The matrix of covariance in the generation is represented by the letter .
- Step 4: To meet the limits, carry out the projection operation.where is the number of parameters that are part of the solution’s equal requirement ; can be used to symbolize the hyperplane; The parameter vector is represented by , and the number of equality constraints in the solution is indicated by .
- Step 5: Use selection to update the mean according to , where stands for the solution’s weight coefficient. In the generation, represents the solution out of solutions. The overall size of the progeny is indicated by .
- Step 6: The covariance matrix is refined through adaptation.where the step size is changed using the calculation below:where the learning rates are denoted by and , the evolutionary path by , and the evolutionary path’s retrospective time by .
- Step 7: Iteratively continue the process until the ideal response is discovered. Next, the ideal BRB is created.
4. Case Study
To demonstrate the excellent precision and interpretability of MWI-BRB in scenarios involving mine water inrush source discrimination, this study uses water inrush data from a coal mine in Hebei, China, as a case study. The dataset used for the experiments is presented in Section 4.1; the importance of discriminating water inrush source features is analyzed in Section 4.2. The use of the SSE-KPP algorithm to determine the values of the prerequisite attributes for the MWI-BRB model is presented. In Section 4.3, the construction of the MWI-BRB model is described in Section 4.4, and the experimental results of the MWI-BRB model are discussed in Section 4.5.
4.1. Dataset
The dataset used in this study is the water quality analysis results ledger data of a coal mine in Hebei, China. The hydrogeology of this coal mine is complex, and the problem of mine water emergence has been the main factor affecting normal mining. In this study, this mine is used as a classic water-surge mine, and after research and analysis, the mine water-surge is mainly from four sources: Goaf water, Ordovician limestone water, 12 coal seam sandstone fracture water, and 13 coal seam sandstone fracture water. In the experimental setup, we divide the experimental data into the training set and the test set at a ratio of 7:3.
It is worth noting that due to the considerable difficulty and inherent hazards involved in collecting water samples during actual mining operations, the existing dataset remains relatively small, comprising a total of 67 samples. Despite this limited sample size, the dataset remains highly representative of typical water inflow scenarios and has been widely adopted in similar hydrogeological studies.
4.2. Feature Importance Analysis
In this section, feature selection is accomplished by ranking the importance of each hydrochemical feature of the aquifer by XGBoost, and the feature importance is shown in Figure 5. Since the importance coefficient of Na+ is much smaller than other features, the initial five characteristics are chosen as inputs, i.e., X1, X2, X3, X4, and X5 are , , , , and , respectively.
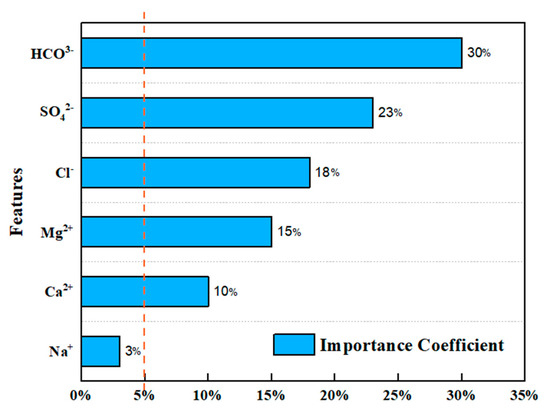
Figure 5.
Importance ranking of features.
4.3. Selection of Characteristics Affected by Water Inrush Source in Mines
In this section, the construction of the reference values set for the prerequisite attributes is described. The reference values for each characteristic comprise the data’s highest and lowest values, and the SSE-KPP technique is used to construct the remaining reference points. To guarantee the robustness of the optimization, the SSE-KPP iteration count (MaxIter) was set at 150. Table 1 describes in detail the reference values determined by SSE-KPP for X1, X2, X3, X4, and X5.

Table 1.
MWI-BRB prerequisite attribute reference values.
4.4. Construction of MWI-BRB
Considering the five characteristics chosen in Section 4.2. and the reference values determined in Section 4.3, the MWID model is constructed. As shown in Figure 6, a single-layer BRB suffers from an exponential increase in the number of rules as the number of input features grows. Specifically, if n features are simultaneously considered, and each feature is associated with m reference values, the total number of rules required in a single-layer BRB reaches mn, which leads to a severe rule explosion problem. This not only increases the computational complexity but also makes the integration of expert knowledge less feasible. In contrast, the proposed layered BRB structure incrementally introduces features according to their importance ranking. By decomposing the modeling process into multiple submodules, each with only a small subset of features, the total number of rules is significantly reduced. As illustrated in Figure 6, the layered design effectively controls the rule growth while maintaining the discriminative capacity of the model, thereby achieving a balance between accuracy and interpretability.
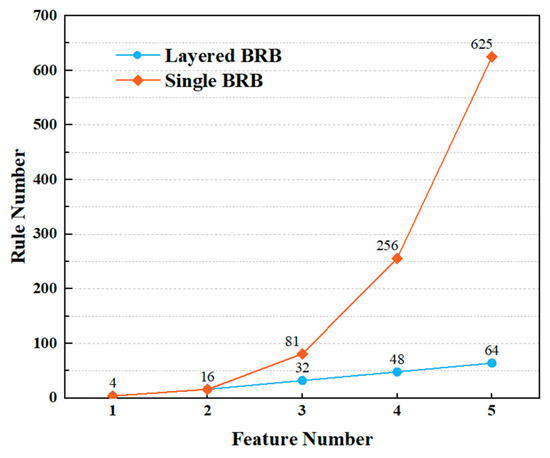
Figure 6.
Comparison of single-layer and deep structural rule sets.
In order to solve the problem of combinatorial explosion, MWI-BRB adopts the design of a deep BRB. The MWID is divided into four processes, in the MWI-BRB sub-module BRB1, the features X1, and X2 with the highest feature importance ranking are input to the module BRB1 as the premise attributes to get the discrimination result y1, the BRB2 module outputs y2 with y1 and X3 as the premise attributes, the BRB3 module outputs the result y3 with the output result y2 and X4 of BRB2 as the premise attributes. Finally, y3 and X5 are input to BRB4 to get the final discriminative result y4.
The hierarchical BRB structure is theoretically grounded in the need to mitigate the rule explosion that arises in single-layer BRBs when modeling high-dimensional input spaces. By incrementally introducing features into successive submodules, the model adopts a divide-and-conquer strategy that reduces combinatorial complexity while retaining interpretability. The ordering of features within this hierarchy is guided by the importance ranking obtained from XGBoost, which is a widely validated method capable of capturing nonlinear dependencies and providing stable feature importance scores. High-importance features are allocated to the earlier submodules so that the most discriminative information is prioritized, while lower-importance features are progressively incorporated in later stages, thereby avoiding the dominance of weak signals over strong ones.
Based on the setup in Section 4.3, the four sub-modules BRB1, BRB2, BRB3, and BRB4 of MWI-BRB are trained and tested, and the results of the four sub-modules on the sudden water discernment of the mine water inrush sources are compared with the real results as shown in Figure 7.
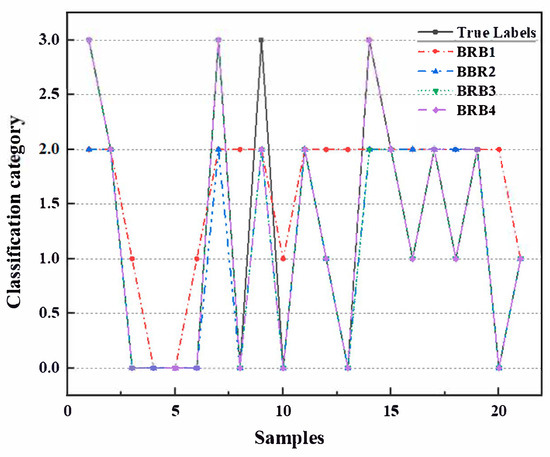
Figure 7.
Results of the discrimination of the mine water inrush source.
4.5. Discussion of MWI-BRB Results
This study addresses the effectiveness of the MWI-BRB deep structure in Section 4.5.1. The effectiveness of the MWI-BRB layered structure. The MWI-BRB is contrasted with current techniques in Section 4.5.2. Comparison of the model with other models.
4.5.1. The Effectiveness of the MWI-BRB Layered Structure
MWI-BRB inputs the two most important features, X1 and X2, into the model after feature selection to form the BRB1 submodule for mine water source discrimination. Subsequently, on the basis of the initial mine water inrush source discrimination results, new BRB sub-modules are formed by inputting the features in order of their importance into the model, which gradually improves the model’s accuracy Each level of sub-modules of MWI-BRB can effectively mine attribute features; meanwhile, each level of sub-modules has the ability to be trained to realize the hierarchical optimization of the mine water burst source discrimination results.
In order to comprehensively evaluate the overall performance of the MWI-BRB, various performance metrics, including accuracy, precision, recall, and F1-Score, were used to comprehensively evaluate the MWI-BRB. Figure 8 visualizes the results of MWI-BRB and the effect of hierarchical lifting through the confusion matrix.
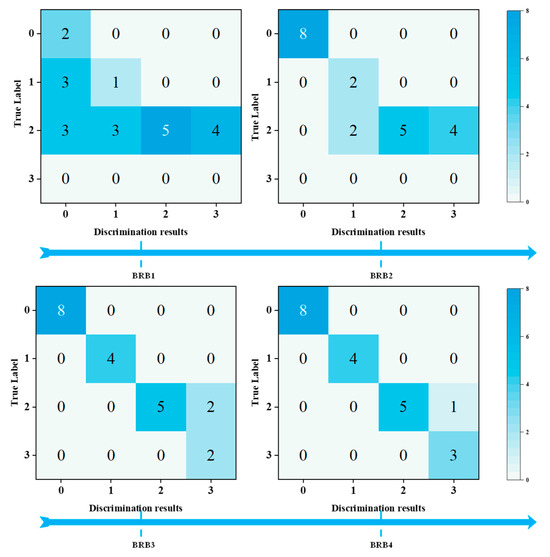
Figure 8.
MWI-BRB deep structure confusion matrix results.
The accuracy and adaptability of the discrimination findings are increased by MWI-BRB’s ability to more accurately capture the essential characteristics influencing the discrimination of water inrush sources in mines through the superposition of deep structures.
Figure 9 displays the precision and recall of MWI-BRB on the discrimination outcomes of mine water inrush sources. The results obtained by MWI-BRB are deemed credible due to their 100% accuracy and recall on the discrimination of Goaf water, Ordovician limestone water, and 12 coal seam sandstone fracture water, and their 75% accuracy and 83% recall on coal seam sandstone fracture water demonstrate the reliability of the MWI-BRB’s discrimination results.
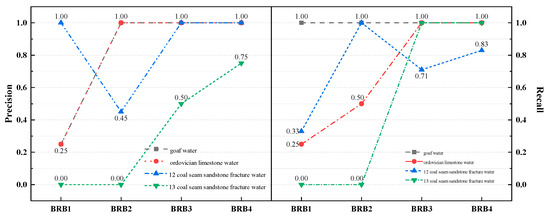
Figure 9.
Results of MWI-BRB on the discrimination of water inrush sources in mines.
It should be noted that MWI-BRB achieved 100% accuracy and recall for Goaf water, Ordovician limestone water, and 12 coal seam sandstone fracture water. While this may appear overly optimistic, it can be explained by two factors. First, the dataset used in this study is relatively small, containing only 67 samples in total, which increases the likelihood of obtaining perfect performance in certain categories. Second, the hydrochemical features of these three water sources exhibit strong separability, with low intra-class variability and high inter-class differences, making them easier to discriminate. In contrast, the 13 coal seam sandstone fracture water samples display higher internal variability and partial overlap with other categories, which explains the lower recognition rates observed for this class. Importantly, the train-test split (7:3 ratio) was conducted strictly at the sample level with no overlap between training and testing data, and baseline models trained on the same splits did not achieve perfect results. This indicates that the 100% performance is not due to data leakage, but rather reflects both the small dataset size and the distinctiveness of the three well-separated classes.
4.5.2. Comparison of the Model with Other Models
In this section, in order to analyze the effectiveness of MWI-BRB, MWI-BRB is compared with Back Propagation Neural Network (BPNN) [34], K Nearest Neighbors (KNN) [35], Random Forest (RF) [36], and XGBoost [37], and the hyperparameters of the compared models are shown in Table 2.
Table 2.
Hyperparameter settings for contrast models.
To ensure the fairness and reproducibility of the comparison experiments, the hyperparameters of BPNN, KNN, RF, and XGBoost were carefully tuned prior to reporting the results in Table 2. Specifically, we adopted a grid search strategy combined with leave-one-out cross-validation on the training set to determine the optimal parameters of each model. The search ranges were designed according to commonly used settings in previous studies and adjusted to balance computational efficiency and predictive accuracy. For instance, the number of hidden units and learning rate of BPNN were selected by evaluating candidate values [5, 10, 20] and [0.001, 0.005, 0.01], respectively; the number of neighbors for KNN was tuned within [3, 5, 7]; and the maximum depth of RF and XGBoost was explored within [2, 4, 6, 10]. The final settings listed in Table 2 correspond to the configurations that achieved the best performance on the validation folds, ensuring that the reported results represent fair and optimized baselines for comparison with the proposed MWI-BRB model.
The evaluation metrics used in this study, including accuracy, recall, and F1-score, are calculated based on the comparison between predicted and actual labels. Specifically:
is defined as the proportion of correctly predicted instances among all instances:
measures the proportion of correctly predicted positive instances among all actual positive instances:
is the harmonic mean of precision and recall, providing a balance between them:
where True Positive () denotes correctly predicted positive samples, True Negative () denotes correctly predicted negative samples, False Positive () denotes negative samples incorrectly predicted as positive, and False Negative () denotes positive samples incorrectly predicted as negative. These metrics were calculated for all models included in the comparison to ensure consistency.
The comparison results are shown in Table 3. In comparison to a number of other models, the parameter-optimized MWI-BRB has higher metrics, MWI-BRB model’s accuracy is 95.23% compared to BPNN improved by 4.78%, compared to KNN, RF, and XGBoost improved by 9.52%, and in the recall reached 95.23% compared to the other models improved, respectively, by 4.78%, 9.52%, 9.52%, 9.52%, and F1-Score of 95.36% improved 4.85%, 10.64%, 10.19%, and 9.65% compared to other models, respectively.
Table 3.
Model comparison results.
BPNN, KNN, RF, and XGBoost by data-driven discriminative mine water inrush source in the data-driven model, the data-driven model shows significant advantages in modeling complex systems through the efficient processing capability of multidimensional data. Being able to automatically learn potential patterns and laws from data, they reduce the reliance on a priori assumptions and possess greater flexibility and adaptability. Nonetheless, such models have serious data quality issues, and it is difficult to collect large-scale data for mine water inrush scenarios. In contrast, MWI-BRB integrates expert knowledge and data and performs better in this scenario. The model iteratively enhances expert knowledge as its basis through a transparent inference mechanism and optimization processes that support the model’s interpretability and performance enhancement. This is accomplished by fusing optimization methods with historical data.
Overall, the MWI-BRB proposed in this study has more significant advantages over other models in MWID:
- The MWI-BRB model can more accurately combine expert knowledge to discriminate the source of mine water inrush by considering the importance of the features for discriminating the source of water inrush and determining the reference value for MWI-BRB modeling through the SSE-KPP data mining algorithm.
- MWI-BRB enhances the model’s ability to explore the potential information of the input features and promotes the understanding of the relationship between the features through the hierarchical progressive processing mechanism. According to Figure 9. MWI-BRB considerably enhances the model’s performance layer by layer, it can be concluded.
- MWI-BRB, compared with models such as BPNN, has higher accuracy compared with other methods. Combining expert knowledge to determine the inference rules and employing the ER algorithm as the method for inference, it has high interpretability and can vividly demonstrate how inputs and outcomes are causally related.
5. Conclusions
In this study, we propose an interpretable Mine Water Inrush Discrimination (MWID) model, termed MWI-BRB, based on an auto-deep belief rule base framework. The model is designed to address the dual challenges of accurately identifying water inrush sources and providing transparent reasoning for the decision process. To enhance model performance and interpretability, we employ the SSE-KPP algorithm for automatic construction of reference values, XGBoost for systematic feature selection, and a hierarchical deep BRB structure for knowledge representation and inference. Compared with conventional machine learning methods—including BPNN, KNN, RF, and XGBoost—MWI-BRB demonstrates superior predictive accuracy while maintaining interpretability. Specifically, the proposed approach effectively overcomes two major limitations inherent to existing methodologies: (1) traditional water inrush source discrimination models often function as “black boxes,” providing limited insight into their decision logic; and (2) conventional BRB models rely heavily on expert-defined parameters and are prone to rule explosion as the number of variables increases. By addressing these issues, MWI-BRB not only achieves strong discriminative power but also enables transparent, reasoning-driven decision support, which is critical for practical mine safety management and hazard prevention.
Despite these advantages, the present model still exhibits certain limitations. Its performance relies on the availability and quality of hydrochemical data, and the generalizability of the approach has not yet been fully verified across diverse geological conditions. In addition, the computational cost of multi-layer BRB structures may increase with the expansion of input features. Future research will therefore focus on more concrete validation and model improvements. Specifically, we plan to evaluate the MWI-BRB model on multi-mine datasets to assess its spatial generalizability and perform temporal generalization tests using historical time-series data to examine its robustness over different mining periods. Furthermore, we aim to enhance the model’s interpretability, improve data adaptability by integrating broader historical datasets and domain knowledge, and optimize computational efficiency. These efforts will expand the applicability of MWI-BRB and strengthen its reliability in real-world mining environments.
Author Contributions
Conceptualization, Z.J.; Methodology, Z.J. and H.L.; Software, H.L.; Validation, H.L.; Formal analysis, Z.J. and Y.T.; Writing—review & editing, H.L.; Visualization, Z.J. and Y.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
We would like to thank the editor for their constructive comments.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations, nomenclature and Greek symbols are used in this manuscript:
| MWID | Mine Water Inrush Discrimination |
| MWI-BRB | Mine Water Inrush—Belief Rule Base |
| BRB | Belief Rule Base |
| ER | Evidential Reasoning |
| P-CMA-ES | Penalized Covariance Matrix Adaptation Evolution Strategy |
| SSE-KPP | Sum of Squared Errors—K-means++ |
| BPNN | Back Propagation Neural Network |
| KNN | K-Nearest Neighbor |
| XGBoost | Extreme Gradient Boosting |
| Nomenclature | |
| X1 | |
| X2 | |
| X3 | |
| X4 | |
| X5 | |
| y1 | Output the result of the BRB1 sub-module |
| y2 | Output the result of the BRB2 sub-module |
| y3 | Output the result of the BRB3 sub-module |
| y4 | Final discrimination result of the MWI-BRB model |
| n | Number of features |
| m | Number of reference values for each prerequisite attribute |
| Predicted result of the BRB model | |
| The structure of the decision tree | |
| The tree space | |
| Matrix required for confidence distribution calculation | |
| The value of utility | |
| Greek Symbols | |
| The attribute normalized weights | |
| The matching degree of the rule | |
| The activation weight of the rule | |
| Degree of belief in the outcome | |
| An intermediate parameter | |
References
- Li, B.; Wu, H.; Liu, P.; Fan, J.; Li, T. Construction and application of mine water inflow prediction model based on multi-factor weighted regression: Wulunshan Coal Mine case. Earth Sci. Inform. 2023, 16, 1879–1890. [Google Scholar] [CrossRef]
- Cheng, W.; Yin, H.; Dong, F.; Li, Y.; Guo, Q.; Wang, Y. Hydrochemical characteristics, cross-layer pollution and environmental health risk of groundwater system in coal mine area: A case study of Jiangzhuang coal mine. Environ. Geochem. Health 2024, 46, 523. [Google Scholar] [CrossRef]
- Wang, X.; Xu, Z.; Sun, Y.; Zheng, J.; Zhang, C.; Duan, Z. Construction of multi-factor identification model for real-time monitoring and early warning of mine water inrush. Int. J. Min. Sci. Technol. 2021, 31, 853–866. [Google Scholar] [CrossRef]
- Cui, M.; Huang, P.; Hu, Y.; Chai, S.; Zhang, Y.; Li, Y. Application of dynamic weight in coal mine water inrush source identification. Environ. Earth Sci. 2024, 83, 69. [Google Scholar] [CrossRef]
- Li, W.; Wang, L.; Ye, Z.; Liu, Y.; Wang, Y. A dynamic combination algorithm based scenario construction theory for mine water-inrush accident multi-objective optimization. Expert Syst. Appl. 2024, 238, 121871. [Google Scholar] [CrossRef]
- Dai, G.; Xue, X.; Xu, K.; Dong, L.; Niu, C. A GIS-based method of risk assessment on no. 11 coal-floor water inrush from Ordovician limestone in Hancheng mining area, China. Arab. J. Geosci. 2018, 11, 714. [Google Scholar] [CrossRef]
- Jiang, Q.; Zhao, W.; Zheng, Y.; Wei, J.; Wei, C. A source discrimination method of mine water-inrush based on 3d spatial interpolation of rare classes. Arch. Min. Sci. 2019, 64, 321–333. [Google Scholar]
- He, C.-Y.; Zhou, M.-R.; Yan, P.-C. Application of the Identification of Mine Water Inrush with LIF Spectrometry and KNN Algorithm Combined with PCA. Spectrosc. Spectr. Anal. 2016, 36, 2234–2237. [Google Scholar]
- Hu, F.; Zhou, M.; Yan, P.; Li, D.; Lai, W.; Zhu, S.; Wang, Y. Selection of characteristic wavelengths using SPA for laser induced fluorescence spectroscopy of mine water inrush. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2019, 219, 367–374. [Google Scholar] [CrossRef] [PubMed]
- Zhou, M.-R.; Hu, F.; Yan, P.-C.; Liu, D. Laser Induced Fluorescence Spectrum Analysis of Water Inrush in Coal Mine Based on FCM. Spectrosc. Spectr. Anal. 2018, 38, 1572–1576. [Google Scholar]
- Dong, D.L.; Chen, Z.Y.; Lin, G.; Li, X.; Zhang, R.M.; Ji, Y. Combining the Fisher feature extraction and support vector machine methods to identify the water inrush source: A case study of the Wuhai mining area mine. Water Environ. 2019, 38, 855–862. [Google Scholar] [CrossRef]
- Yang, Z.; Lv, H.; Xu, Z.; Wu, X. Source discrimination of mine water based on the random forest method. Sci. Rep. 2022, 12, 19568. [Google Scholar] [CrossRef]
- Ye, Z.; Shoufeng, T.; Ke, S.; Xia, T. An evaluation of the mine water inrush based on the deep learning of ISMOTE. Nat. Hazards 2023, 117, 1475–1491. [Google Scholar] [CrossRef]
- Dong, D.; Zhang, J. Discrimination Methods of Mine Inrush Water Source. Water 2023, 15, 3237. [Google Scholar] [CrossRef]
- Yin, H.; Zhang, G.; Wu, Q.; Yin, S.; Soltanian, M.R.; Thanh, H.V.; Dai, Z. A deep learning-based data-driven approach for predicting mining water inrush from coal seam floor using micro-seismic monitoring data. IEEE Trans. Geosci. Remote Sens. 2023, 61, 4504815. [Google Scholar] [CrossRef]
- Zhang, N.; Niu, M.; Wan, F.; Lu, J.; Wang, Y.; Yan, X.; Zhou, C. Hazard prediction of water inrush in water-rich tunnels based on random forest algorithm. Appl. Sci. 2024, 14, 867. [Google Scholar] [CrossRef]
- Yang, J.B.; Liu, J.; Wang, J.; Sii, H.S.; Wang, H.W. Belief rule-base inference methodology using the evidential reasoning approach-RIMER. IEEE Trans. Syst. Man Cybern.-Part A Syst. Hum. 2006, 36, 266–285. [Google Scholar] [CrossRef]
- Walker, A.R. Check for updates A Fuzzy Inference System for an Optimal Spacecraft Attitude State Trajectory. In Fuzzy Information Processing; Springer: Cham, Switzerland, 2023; Volume 751, p. 268. [Google Scholar] [CrossRef]
- Dambrosio, L.; Domenico, N.; Pascazio, G. Aerodynamic reverse engineering design using fuzzy logic. J. Phys. Conf. Ser. 2024, 2893, 012130. [Google Scholar] [CrossRef]
- Qian, G.; Li, J.; He, W.; Zhang, W.; Cao, Y. An online intrusion detection method for industrial control systems based on extended belief rule base. Int. J. Inf. Secur. 2024, 23, 2491–2514. [Google Scholar] [CrossRef]
- Li, G.; Wang, Y.; Yang, J.; Li, S.; Li, X.; Mo, H. A Security Situation Prediction Model for Industrial Control Network Based on Explainable Belief Rule Base. Symmetry 2024, 16, 1498. [Google Scholar] [CrossRef]
- Wu, J.; Wang, Q.; Wang, Z.; Zhou, Z. AutoBRB: An automated belief rule base model for pathologic complete response prediction in gastric cancer. Comput. Biol. Med. 2022, 140, 105104. [Google Scholar] [CrossRef]
- Badhon, B.; Chakrabortty, R.K.; Anavatti, S.G.; Vanhoucke, M. IRAF-BRB: An explainable AI framework for enhanced interpretability in project risk assessment. Expert Syst. Appl. 2025, 285, 127979. [Google Scholar] [CrossRef]
- Yin, X.; He, W.; Wang, J.; Peng, S.; Cao, Y.; Zhang, B. Health state assessment based on the Parallel–Serial Belief Rule Base for industrial robot systems. Eng. Appl. Artif. Intell. 2025, 142, 109856. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, Y.; He, W.; Zhang, L.; Wu, R. A new belief rule base model with uncertainty parameters. Reliab. Eng. Syst. Saf. 2025, 256, 110796. [Google Scholar] [CrossRef]
- Hu, G.; He, W.; Sun, C.; Zhu, H.; Li, K.; Jiang, L. Hierarchical belief rule-based model for imbalanced multi-classification. Expert Syst. Appl. 2023, 216, 119451. [Google Scholar] [CrossRef]
- Antonelli, M.; Ducange, P.; Lazzerini, B.; Marcelloni, F. Learning knowledge bases of multi-objective evolutionary fuzzy systems by simultaneously optimizing accuracy, complexity and partition integrity. Soft Comput. 2011, 15, 2335–2354. [Google Scholar] [CrossRef]
- Zhou, Z.J.; Hu, G.Y.; Zhang, B.C.; Hu, C.H.; Zhou, Z.G.; Qiao, P.L. A model for hidden behavior prediction of complex systems based on belief rule base and power set. IEEE Trans. Syst. Man Cybern. Syst. 2017, 48, 1649–1655. [Google Scholar] [CrossRef]
- Wang, W.-X.; Lai, Y.-C.; Grebogi, C. Data-based identification and prediction of nonlinear and complex dynamical systems. Phys. Rep. 2016, 644, 1–76. [Google Scholar] [CrossRef]
- Wen, P.; Zhao, S.; Chen, S.; Li, Y. A generalized remaining useful life prediction method for complex systems based on composite health indicator. Reliab. Eng. Syst. Saf. 2021, 205, 107241. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhao, B.; He, W.; Zhu, H.; Zhou, G. A behavior prediction method for complex system based on belief rule base with structural adaptive. Appl. Soft Comput. 2024, 151, 111118. [Google Scholar] [CrossRef]
- Sun, C.; Yang, R.; He, W.; Zhu, H. A novel belief rule base expert system with interval-valued references. Sci. Rep. 2022, 12, 6786. [Google Scholar] [CrossRef] [PubMed]
- Cao, Y.; Zhou, Z.; Hu, G.; Hu, C.; Tang, S.; Li, G. A new multilayer belief rule base model for complex system modeling. IEEE Syst. J. 2021, 16, 4301–4312. [Google Scholar] [CrossRef]
- Asaad, R.R.; Ali, R.I. Back Propagation Neural Network (BPNN) and sigmoid activation function in multi-layer networks. Acad. J. Nawroz Univ. 2019, 8, 216–221. [Google Scholar] [CrossRef]
- Steinbach, M.; Tan, P.-N. kNN: K-nearest neighbors. In The Top Ten Algorithms in Data Mining; Chapman and Hall/CRC: Boca Raton, FL, USA, 2009; pp. 165–176. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CL, USA, 13–17 August 2016. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).