
Automatic Delineation of Resistivity Contrasts in Magnetotelluric Models Using Machine Learning

 , , ,
, , ,  and
and 
Abstract
1. Introduction
2. Methods
2.1. Collection and Preparation of Resistivity Data
2.2. Data Augmentation
2.3. Image Preprocessing and Image Conversion and Restructuring
- -
- p and q are pixel locations in the image.
- -
- S is the neighborhood of pixel p.
- -
- Gs (ǁp-qǁ) is the spatial Gaussian kernel that decreases the influence of distant pixels in the spatial domain.
- -
- Gr (ǁIp-Iqǁ) is the range Gaussian kernel, which decreases the influence of pixels with different intensities (resistivity values).
- -
- Wp is the normalization factor.
2.4. Segmentation Using K-Means Clustering
- Initialize the number of clusters k, and the center.
- For each pixel of an image, the Euclidean distance d between the center and each pixel of an image is calculated using the relationship given below:
- Assign all the pixels to the nearest center based on distance d.
- After all the pixels have been assigned, the new position of the center is recalculated using the relationship given below:
3. Results
3.1. Cropping, Rotation, and Flipping
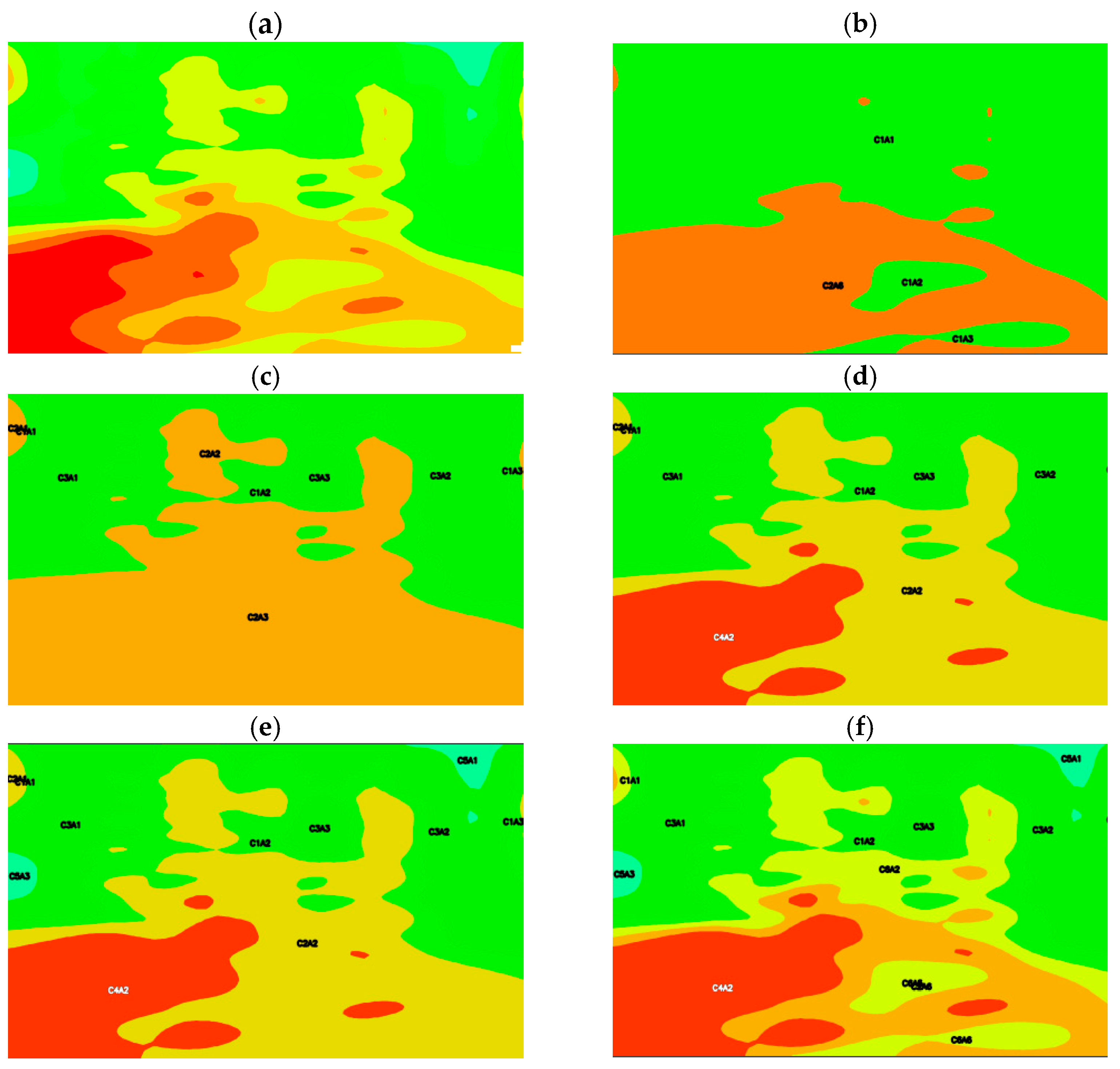
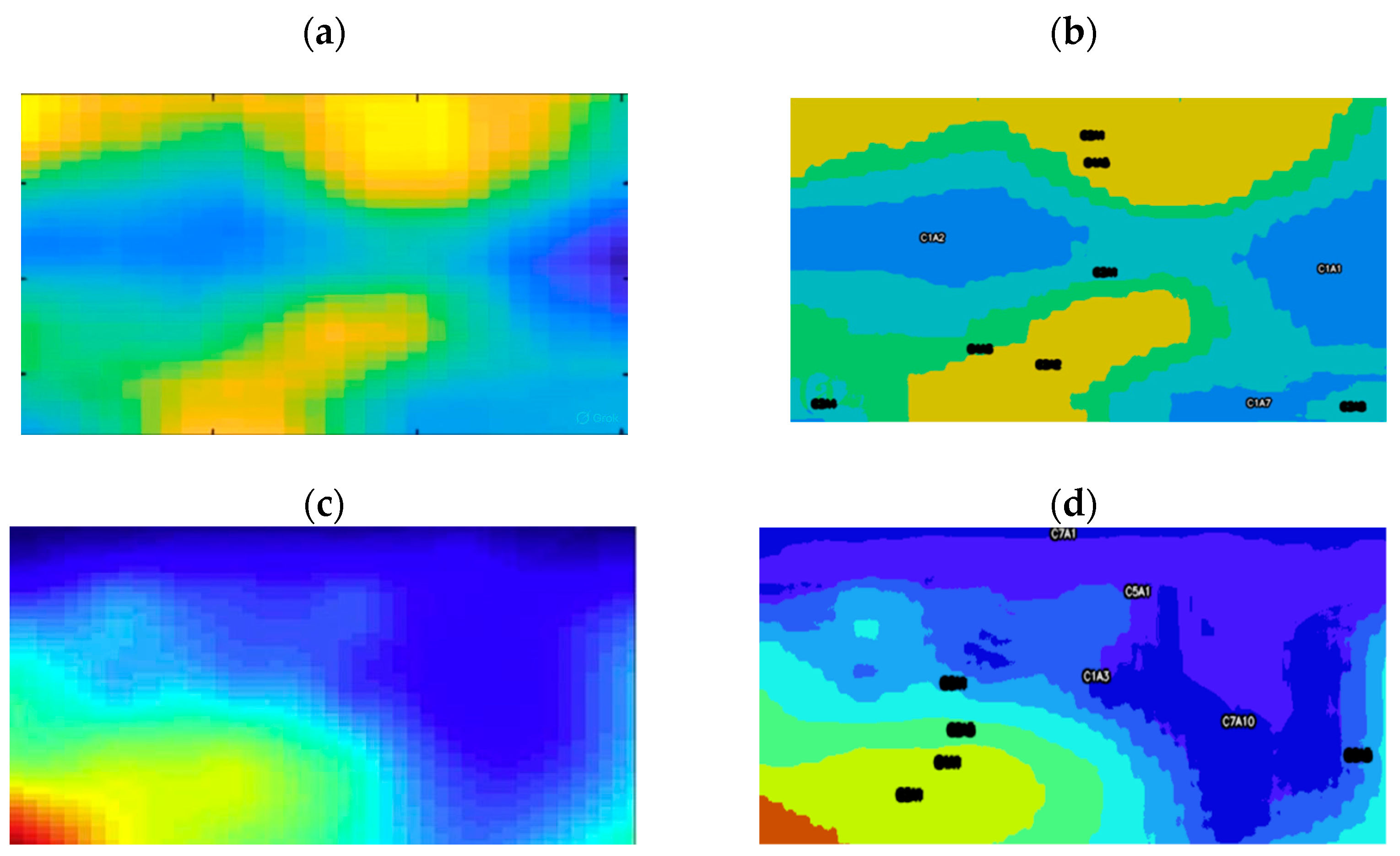
3.2. Classification by Resistivity Ranges Using K-Means
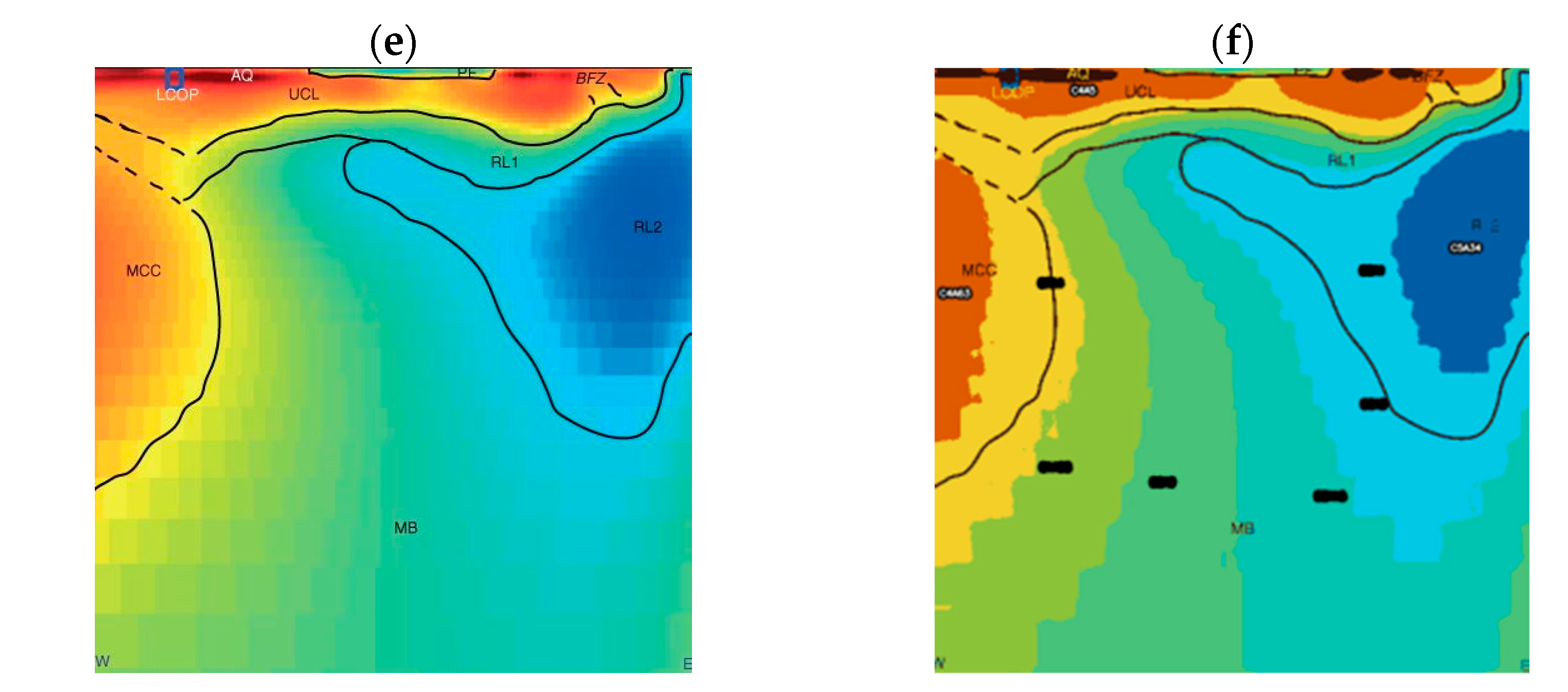
3.3. Model Validation and Generalization Capability
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chave, A.D.; Jones, A.G. The Magnetotelluric Method: Theory and Practice; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Simpson, F.; Bahr, K. Practical Magnetotellurics; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Rycroft, M.J.; Harrison, R.G.; Nicoll, K.A.; Mareev, E.A. An overview of Earth’s global electric circuit and atmospheric conductivity. Planet. Atmos. Electr. 2008, 137, 83–105. [Google Scholar]
- Everett, M.E. Near-Surface Applied Geophysics; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar]
- Spichak, V.V. Advances in electromagnetic techniques for exploration, prospecting, and monitoring of hydrocarbon deposits. First Break 2018, 36, 75–81. [Google Scholar] [CrossRef]
- Liu, W.; Lü, Q.; Yang, L.; Lin, P.; Wang, Z. Application of sample-compressed neural network and adaptive-clustering algorithm for magnetotelluric inverse modeling. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1540–1544. [Google Scholar] [CrossRef]
- Lin, W.; Yang, B.; Han, B.; Hu, X. A review of subsurface electrical conductivity anomalies in magnetotelluric imaging. Sensors 2023, 23, 1803. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Craven, J.A.; Tschirhart, V. Retrieval of Subsurface Resistivity from Magnetotelluric Data Using a Deep-Learning-Based Inversion Technique. Minerals 2023, 13, 461. [Google Scholar] [CrossRef]
- Christopherson, K.R. Applications of magnetotellurics to petroleum exploration in Papua New Guinea: A model for frontier areas. Lead. Edge 1991, 10, 21–27. [Google Scholar] [CrossRef]
- Gallardo, L.A.; Meju, M.A. Joint two-dimensional cross-gradient imaging of magnetotelluric and seismic traveltime data for structural and lithological classification. Geophys. J. Int. 2007, 169, 1261–1272. [Google Scholar] [CrossRef]
- Yin, C. Inherent nonuniqueness in magnetotelluric inversion for 1D anisotropic models. Geophysics 2003, 68, 138–146. [Google Scholar] [CrossRef]
- Muñoz, G.; Rath, V. Beyond smooth inversion: The use of nullspace projection for the exploration of non-uniqueness in MT. Geophys. J. Int. 2006, 164, 301–311. [Google Scholar] [CrossRef]
- Park, S.K. Mantle heterogeneity beneath eastern California from magnetotelluric measurements. J. Geophys. Res. Solid Earth 2004, 109, B9. [Google Scholar] [CrossRef]
- Plotkin, V. Inversion of heterogeneous anisotropic magnetotelluric responses. Russ. Geol. Geophys. 2012, 53, 829–836. [Google Scholar] [CrossRef]
- Di Giuseppe, M.G.; Troiano, A.; Troise, C.; De Natale, G. k-Means clustering as tool for multivariate geophysical data analysis. An application to shallow fault zone imaging. J. Appl. Geophys. 2014, 101, 108–115. [Google Scholar] [CrossRef]
- Kumar, E.B.; Thiagarasu, V. Color channel extraction in RGB images for segmentation. In Proceedings of the 2nd International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 19–20 October 2017; pp. 234–239. [Google Scholar]
- Rajinikanth, V.; Couceiro, M. RGB histogram based color image segmentation using firefly algorithm. Procedia Comput. Sci. 2015, 46, 1449–1457. [Google Scholar] [CrossRef]
- Kulkarni, N. Color thresholding method for image segmentation of natural images. Int. J. Image Graph. Signal Process. 2012, 4, 28. [Google Scholar] [CrossRef]
- Henderson, J.; Purves, S.J.; Fisher, G.; Leppard, C. Delineation of geological elements from RGB color blending of seismic attribute volumes. Lead. Edge 2008, 27, 342–350. [Google Scholar] [CrossRef]
- Savelonas, M.A.; Veinidis, C.N.; Bartsokas, T.K. Computer Vision and Pattern Recognition for the Analysis of 2D/3D Remote Sensing Data in Geoscience: A Survey. Remote Sens. 2022, 14, 6017. [Google Scholar] [CrossRef]
- Zeeb, C.; Göckus, D.; Bons, P.; Al Ajmi, H.; Rausch, R.; Blum, P. Fracture flow modelling based on satellite images of the Wajid Sandstone, Saudi Arabia. Hydrogeol. J. 2010, 18, 1699. [Google Scholar] [CrossRef]
- Rubanga, D.P.; May-Cuevas, S.A.; Arvelyna, Y.; Shimada, S. Fracture-fault detection using deep learning with stepwise elimination from satellite images in Djibouti. GEOMATE J. 2023, 25, 241–248. [Google Scholar]
- Koike, K.; Nagano, S.; Kawaba, K. Construction and analysis of interpreted fracture planes through combination of satellite-image derived lineaments and digital elevation model data. Comput. Geosci. 1998, 24, 573–583. [Google Scholar] [CrossRef]
- Okada, N.; Maekawa, Y.; Owada, N.; Haga, K.; Shibayama, A.; Kawamura, Y. Automated identification of mineral types and grain size using hyperspectral imaging and deep learning for mineral processing. Minerals 2020, 10, 809. [Google Scholar] [CrossRef]
- Sudharsan, S.; Hemalatha, R.; Radha, S. A survey on hyperspectral imaging for mineral exploration using machine learning algorithms. In Proceedings of the 2019 International Conference on Wireless Communications Signal Processing and Networking (WiSPNET), Chennai, India, 21–23 March 2019; pp. 206–212. [Google Scholar]
- Vibhute, A.D.; Kale, K.; Dhumal, R.K.; Mehrotra, S. Soil type classification and mapping using hyperspectral remote sensing data. In Proceedings of the 2015 International Conference on Man and Machine Interfacing (MAMI), Bhubaneswar, India, 17–19 December 2015; pp. 1–4. [Google Scholar]
- Demanet, D.; Pirard, E.; Renardy, F.; Jongmans, D. Application and processing of geophysical images for mapping faults. Comput. Geosci. 2001, 27, 1031–1037. [Google Scholar] [CrossRef]
- Chave, A.D.; Thomson, D.J. A bounded influence regression estimator based on the statistics of the hat matrix. J. R. Stat. Soc. Ser. C Appl. Stat. 2003, 52, 307–322. [Google Scholar] [CrossRef]
- Bibby, H.; Caldwell, T.; Brown, C. Determinable and non-determinable parameters of galvanic distortion in magnetotellurics. Geophys. J. Int. 2005, 163, 915–930. [Google Scholar] [CrossRef]
- Shijie, J.; Ping, W.; Peiyi, J.; Siping, H. Research on data augmentation for image classification based on convolution neural networks. In Proceedings of the 2017 Chinese Automation Congress (CAC), Tianjin, China, 20–22 October 2017; pp. 4165–4170. [Google Scholar]
- Ioffe, S. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Rama, J.; Nalini, C.; Kumaravel, A. Image pre-processing: Enhance the performance of medical image classification using various data augmentation technique. Accent. Trans. Image Process. Comput. Vis. 2019, 5, 7. [Google Scholar] [CrossRef]
- Lin, T.H.; Way, D.L.; Shih, Z.C.; Tai, W.K.; Chang, C.C. An efficient structure-aware bilateral texture filtering for image smoothing. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2016; Volume 35, pp. 57–66. [Google Scholar]
- Yadav, G.; Maheshwari, S.; Agarwal, A. Contrast limited adaptive histogram equalization based enhancement for real time video system. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–20 September 2014; pp. 2392–2397. [Google Scholar]
- Khan, S.S.; Ahmad, A. Cluster center initialization algorithm for K-means clustering. Pattern Recognit. Lett. 2004, 25, 1293–1302. [Google Scholar] [CrossRef]
- Dhanachandra, N.; Manglem, K.; Chanu, Y.J. Image segmentation using K-means clustering algorithm and subtractive clustering algorithm. Procedia Comput. Sci. 2015, 54, 764–771. [Google Scholar] [CrossRef]
- Salihah, A.-N.A.; Yusoff, M.; Zeehaida, M. Colour image segmentation approach for detection of malaria parasites using various colour models and k-means clustering. WSEAS Trans. Biol. Biomed. 2013, 10, 41–55. [Google Scholar]
- Szeliski, R. Shape from Rotation; Citeseer: Cambridge, MA, USA, 1990. [Google Scholar]
- Beka, T.I.; Smirnov, M.; Bergh, S.G.; Birkelund, Y. The first magnetotelluric image of the lithospheric-scale geological architecture in central Svalbard, Arctic. Norway Polar Res. 2015, 34, 26766. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | Zone | Num. Pixels | Area (km2) | Percentage (%) |
|---|---|---|---|---|
 | C1A1 | 12,792 | 1364.19 | 0.83 |
| C1A2 | 225,623 | 24,061.40 | 14.58 |
| C1A3 | 13,412 | 1430.31 | 0.87 |
 | C2A6 | 274,717 | 29,296.99 | 17.76 |
 | C3A1 | 145,568 | 15,523.99 | 9.41 |
| C3A2 | 210,648 | 22,464.40 | 13.61 |
| C3A3 | 29,927 | 3191.54 | 1.93 |
 | C4A2 | 238,898 | 25,477.10 | 15.44 |
 | C5A1 | 16,483 | 1757.82 | 1.07 |
| C5A3 | 11,180 | 1192.28 | 0.72 |
 | C6A2 | 250,254 | 26,688.15 | 16.17 |
| C6A5 | 39,458 | 4207.97 | 2.55 |
| C6A6 | 41,249 | 4398.97 | 2.67 |
| Cluster | Zone | Geological Interpretation |
|---|---|---|
| C1A1 | Clay |
| C1A2 | Clay |
| C1A3 | Clay |
| C2A6 | Sandstone bearing oil |
| C3A1 | Shale |
| C3A2 | Shale |
| C3A3 | Shale |
| C4A2 | High-saturation hydrocarbon-bearing sandstone |
| C5A1 | Fresh Water |
| C5A3 | Fresh Water |
| C6A2 | Sandstone |
| C6A5 | Sandstone |
| C6A6 | Sandstone |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Herrera Ríos, E.; Marulanda, M.; Arboleda, H.; Soule, G.; Lucuara, E.; Jaramillo, D.; Cardona, A.; Taborda, E.A.; Cortés, F.B.; Franco, C.A. Automatic Delineation of Resistivity Contrasts in Magnetotelluric Models Using Machine Learning. Processes 2025, 13, 2263. https://doi.org/10.3390/pr13072263
Herrera Ríos E, Marulanda M, Arboleda H, Soule G, Lucuara E, Jaramillo D, Cardona A, Taborda EA, Cortés FB, Franco CA. Automatic Delineation of Resistivity Contrasts in Magnetotelluric Models Using Machine Learning. Processes. 2025; 13(7):2263. https://doi.org/10.3390/pr13072263
Chicago/Turabian StyleHerrera Ríos, Ever, Mateo Marulanda, Hernán Arboleda, Greg Soule, Erika Lucuara, David Jaramillo, Agustín Cardona, Esteban A. Taborda, Farid B. Cortés, and Camilo A. Franco. 2025. "Automatic Delineation of Resistivity Contrasts in Magnetotelluric Models Using Machine Learning" Processes 13, no. 7: 2263. https://doi.org/10.3390/pr13072263
APA StyleHerrera Ríos, E., Marulanda, M., Arboleda, H., Soule, G., Lucuara, E., Jaramillo, D., Cardona, A., Taborda, E. A., Cortés, F. B., & Franco, C. A. (2025). Automatic Delineation of Resistivity Contrasts in Magnetotelluric Models Using Machine Learning. Processes, 13(7), 2263. https://doi.org/10.3390/pr13072263