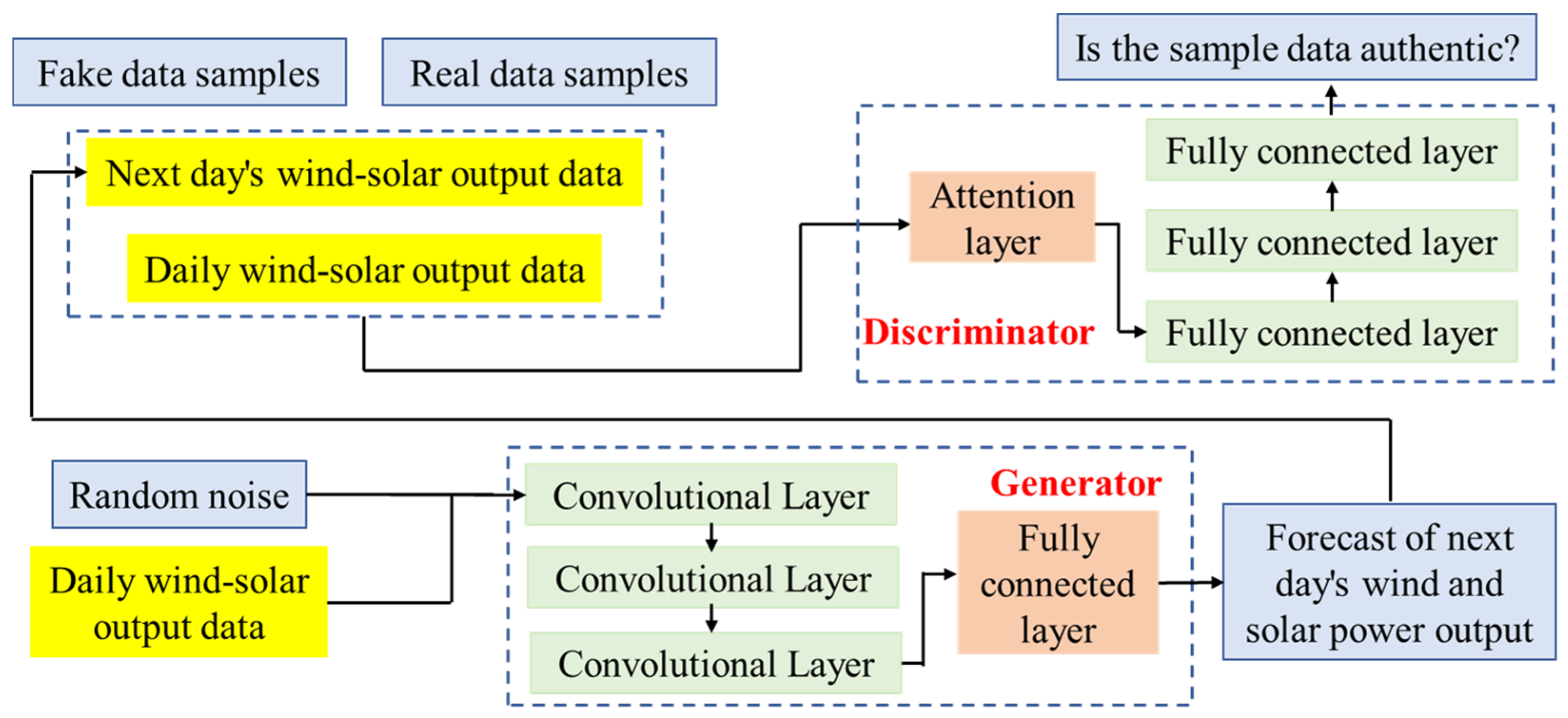
4.1. Effectiveness Validation of Scenario Generation
Firstly, the actual wind and solar power output data from a certain region in Xinjiang is used as the dataset, as shown in
Figure 2 below. The data are preprocessed through cleaning, normalization, and other operations to ensure data quality. The method proposed in this paper is compared with the following two methods:
M1: Historical Data Resampling, which randomly selects samples from historical data as predictions for future scenarios;
M2: Monte Carlo Simulation, which generates future wind and solar power output scenarios based on the statistical characteristics of historical data using the Monte Carlo method.
The comparison results of evaluation indicators for scenario generation using different methods are shown in
Table 2 below.
Observing the above table, it can be found that the CGAN performs better than both the historical data resampling method and the Monte Carlo method in generating wind and solar power output scenarios, based on the Mean Squared Error (MSE) and Mean Absolute Error (MAE) as well as the distribution fitting accuracy. Through the mutual competition between the generator and the discriminator, CGAN can learn and simulate complex data distributions. In power systems, wind and solar power output (such as from wind turbines and photovoltaic panels) is influenced by various factors, resulting in highly uncertain and random output data. CGAN can capture these complex data characteristics and generate wind and solar power output scenarios that are closer to real-world conditions. Compared to traditional GANs, CGAN introduces conditional variables, making the generation process more controllable. In power system dispatching, these conditional variables can include time, weather, geographical location, etc., ensuring that the generated scenarios are more aligned with actual conditions.
The historical data resampling method mainly relies on historical data and may not fully cover all possible scenarios. In contrast, CGAN can generate new and diverse scenarios, thereby increasing the richness and representativeness of the dataset. Over-reliance on historical data may lead to overfitting, where the model fits historical data well but has poor prediction capabilities for new data. By generating new data samples, CGAN helps to mitigate the overfitting problem. The Monte Carlo method estimates probability distributions through a large number of random samples, which can be computationally expensive. In contrast, CGAN learns data distributions through neural networks and can generate a large number of samples more quickly, improving computational efficiency. The Monte Carlo method may not accurately capture the complex characteristics of data distribution in some cases, leading to low-precision scenarios. However, through deep learning techniques, CGAN can more accurately simulate data distributions and generate more precise scenarios. CGAN can generate scenarios that are very close to the real data distribution, thus performing excellently in terms of distribution fitting. Since the scenarios generated by CGAN are closer to real-world conditions, their MSE and MAE values are typically lower when compared to real data.
4.2. Economic Analysis
The 24 h of a day are divided into peak, flat, and off-peak periods, with specific divisions and corresponding electricity prices listed in
Table 3. The various cost information for EVs is shown in
Table 4. The number of EVs in the VPP is 1000, with an initial state of charge following a normal distribution
N(0.5, 0.12). The maximum charging power and discharging power for each EV is 10 kW, and the charging and discharging efficiencies are 90%. The expected state of charge at the beginning of a trip is 0.85. To prevent overcharging of EVs, the minimum and maximum states of charge are set to 0.2 and 0.9, respectively. To more intuitively demonstrate the effect of scheduling, two different scenarios are set here: ordered scheduling and unordered scheduling.
Scenario 1: Unordered charging of EVs.
Scenario 2: Ordered charging of EVs participating in VPP scheduling.
A comparison of the number of EVs on the grid during unordered charging (Scenario 1) and the EVs participating in demand response charging based on electricity prices (Scenario 2) is shown in
Figure 3.
The comparison between the EV load during unordered charging (Scenario 1) and the EV load when participating in demand response based on electricity prices (Scenario 2) is shown in
Figure 4.
Observing the above figure, we can find that in Scenario 2, during peak hours, the number of EVs charging decreases, resulting in a reduction of 14.56 MW in EV charging load compared to unordered charging; during flat hours, the EV charging load decreases by 9.40 MW compared to unordered charging, and the economic benefit of the VPP increases by USD 867.54 after demand response; during off-peak hours, the number of EVs charging increases, leading to an increase of 31.51 MW in EV charging load compared to unordered charging. Therefore, EV participation in demand response can reduce EV charging load during peak hours and shift it to off-peak hours. Active participation of EV users in demand response can change the EV charging time and charging power, which not only increases the economic benefit of the VPP but also reduces the “peak on peak” phenomenon caused by a large number of EVs charging simultaneously. During the operation of the VPP, there is a deviation between the planned output and the actual output, and the VPP needs to pay a corresponding penalty cost to the system.
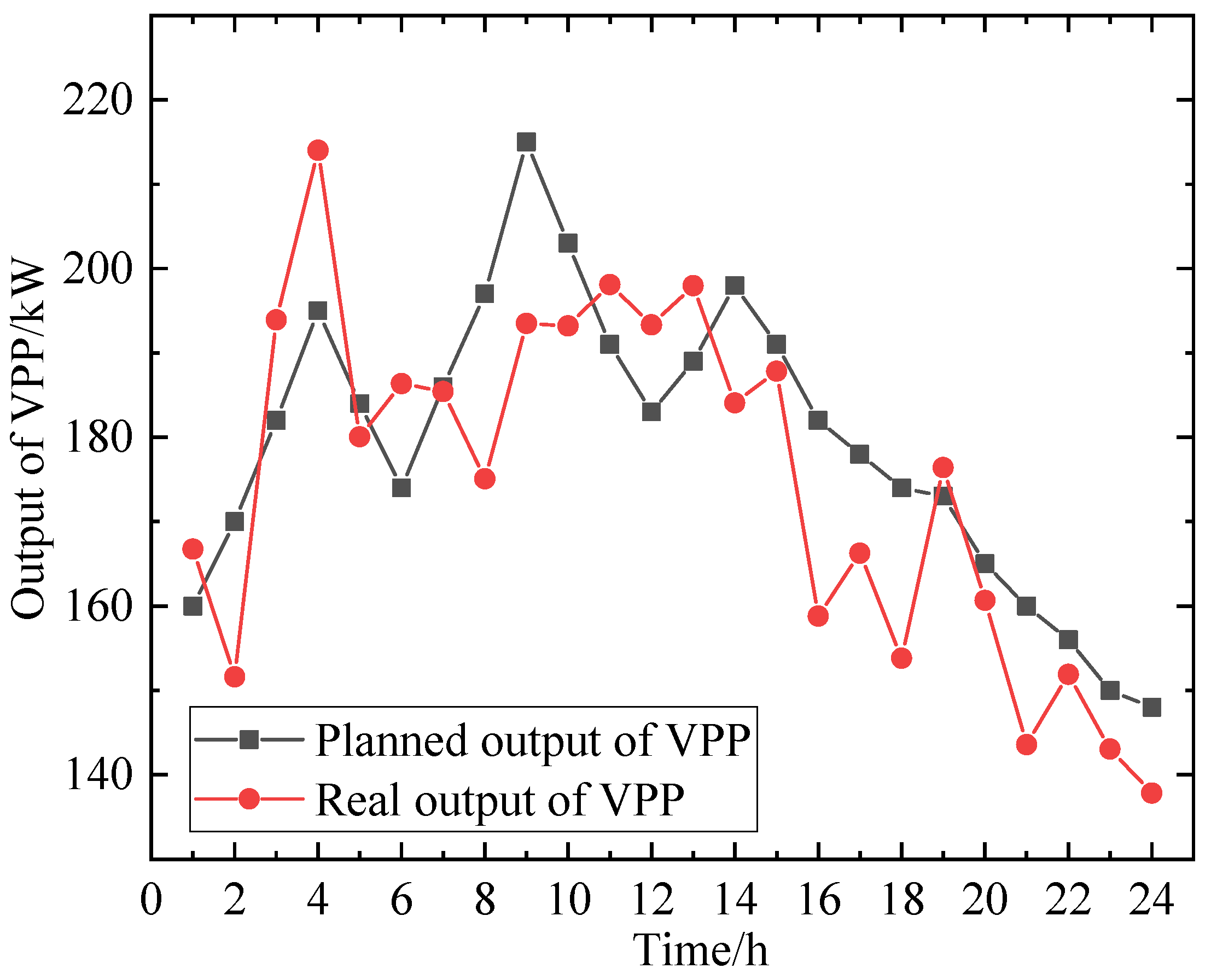
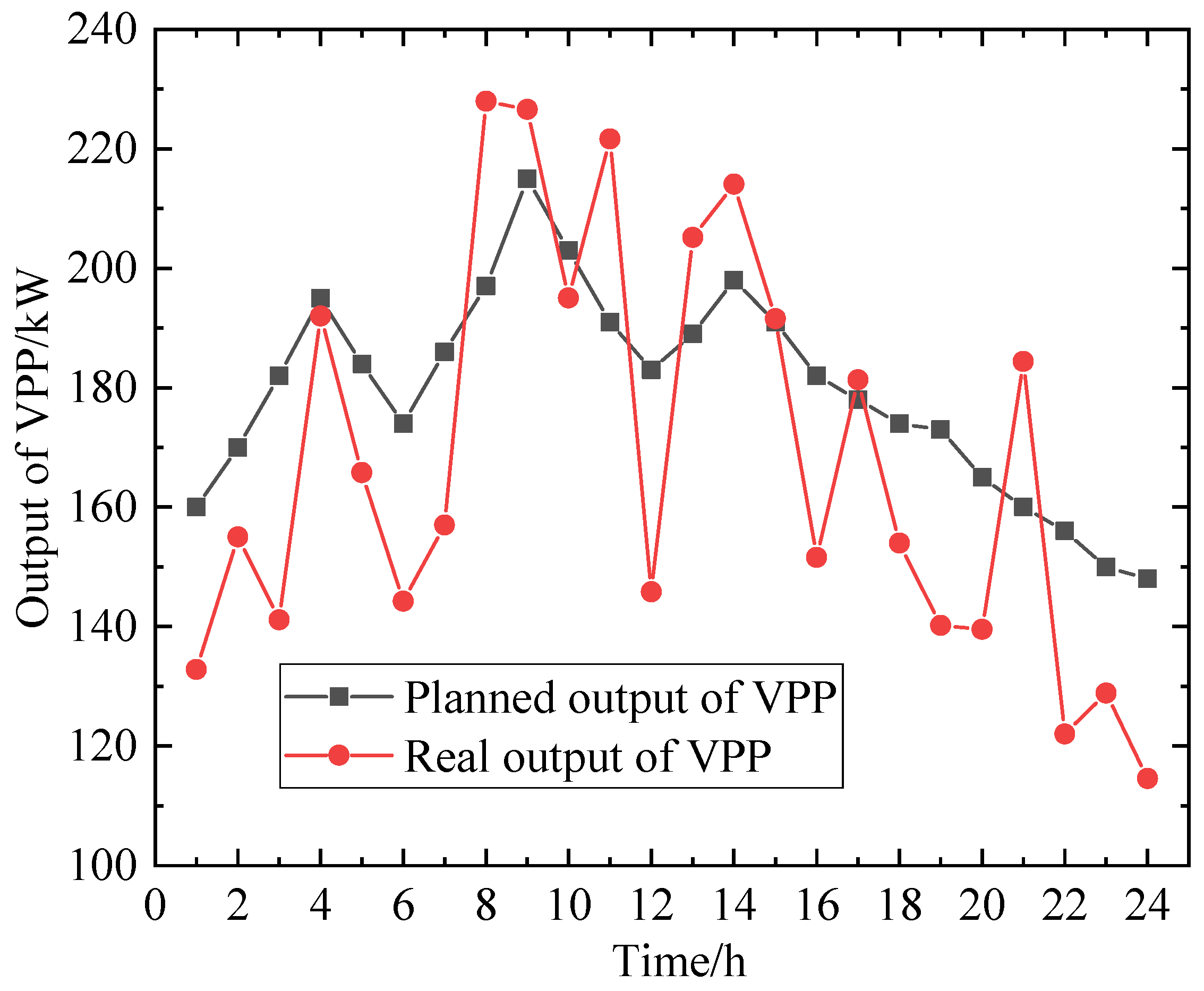
Figure 5 shows a comparison of the planned output and actual output of the VPP when EVs do not participate in its scheduling, with an overall output deviation of 9.26%.
Figure 6 shows a comparison of the planned output and actual output of the VPP when EVs participate in its scheduling, with an overall deviation of 5.16%. By comparing these figures, it can be seen that EV participation in VPP scheduling helps to reduce the deviation between planned and actual output, improve the flexibility of internal scheduling within the VPP, and reduce penalty costs for the VPP.
To further demonstrate the effectiveness and feasibility of the proposed method, we have added comprehensive comparisons with currently prevalent approaches, including traditional PSO algorithms [
43], deep reinforcement learning algorithms [
44,
45], and simulated annealing algorithms [
46,
47]. The comparative evaluation focuses on three key metrics: computation time, renewable energy accommodation rate, and single-scheduling computation time. The detailed comparative results are presented in
Table 5 below.
The improved PSO algorithm demonstrates significant advantages in convergence iterations compared to traditional PSO, deep reinforcement learning (DRL), and simulated annealing (SA) algorithms, requiring only 145 iterations to converge, a 54.7% reduction from traditional PSO’s 320 iterations. This improvement stems from the combined effect of dynamic inertia weight adjustment and multi-population cooperative search strategies: early-stage high inertia weights expand global search scope to avoid local optima, while mid-to-late stages employ refined local searches by the exploitation group based on global optima transmitted from the exploration group. The piecewise linear decreasing weight strategy effectively balances exploration-exploitation trade-offs. In contrast, traditional PSO suffers from search oscillations due to fixed inertia weights. DRL requires 500 training epochs to balance policy network exploration and exploitation. SA needs 800 iterations due to slow annealing temperature decay, with its random inferior-solution acceptance further impeding efficiency.
Regarding renewable energy accommodation rate, the improved PSO achieves 92.6%, attributable to the exploration group’s active identification of high-potential scenarios (e.g., wind power output peaks) and the exploitation group’s precise matching via the projected gradient method for infeasible solution repair. Dynamic penalty functions enhance grid security constraint handling, reducing renewable curtailment. While DRL captures temporal correlations through Q-learning networks, its adaptability to extreme fluctuations is limited by training data coverage. Traditional PSO sacrifices the accommodation rate due to single-objective cost optimization bias, whereas SA struggles to stably approach high-accommodation solutions due to strong randomness.
In user cost reduction, the improved PSO delivers a 23.8% decrease, outperforming traditional PSO, DRL, and SA. Its multi-objective optimization framework coordinates accommodation and cost targets via the weighted sum method, with GPU parallel computing enabling real-time evaluation of thousands of EVs’ charging/discharging costs for rapid, low-cost solution screening. Though DRL implicitly learns price-time-user behavior relationships, it requires extensive cost-labeled training data. Traditional PSO fails to resolve multi-objective conflicts due to single-objective limitations, while SA lacks directional search mechanisms for efficient cost optimization.
For single-scheduling computation time, the improved PSO requires merely 4.2 s, a marked advantage. This results from GPU parallelization, distributing fitness calculations across 1024 CUDA cores and solution-space pruning that eliminates 15–20% invalid regions based on historical data. Traditional PSO suffers from serial full-space search inefficiency. DRL is constrained by policy network inference latency and environment interaction overhead. SA cannot parallelize sequential neighborhood solution generation. These innovations enable the improved PSO to meet microgrid real-time requirements while ensuring scheduling precision, offering an efficient solution for high-dimensional nonlinear-constrained problems.
Simulation results demonstrate that when EV penetration reaches 20%, the proposed strategy can improve the system power factor from an initial 0.82 to 0.95 while reducing key bus voltage fluctuations from ±8.5% to ±2.3%. Specifically, during peak photovoltaic output periods (11:00–13:00), the EV cluster actively provides 12.3 Mvar of capacitive reactive power through four-quadrant regulation, increasing the bus voltage from 0.91 p.u. to 1.03 p.u. while reducing total voltage harmonic distortion (THD) from 7.2% to 3.8%. Notably, under extreme wind power output drop conditions (25% reduction during 14:30–14:45), the EV dynamic reactive power support system injects 9.8 Mvar of reactive power within 420 ms, restoring the fault node voltage from 0.87 p.u. to 0.96 p.u. For an in-depth evaluation of different scenarios, we established
Table 6 and
Table 7.
Table 6 data shows that as EV penetration increases from 15% to 35%, the system’s average power factor improves linearly from 0.85 to 0.98, with each 10% penetration increase reducing harmonic THD by approximately 1.2 percentage points.
Table 7 quantifies dynamic responses under three typical disturbances: (1) During three-phase load mutation (+40%), the improved PSO algorithm-based dynamic reactive power allocation reduces voltage imbalance from 8.7% to 2.1%. (2) In photovoltaic islanding switching, EV reactive power compensation shortens the voltage sag duration to 180 ms. (3) During nighttime charging peaks, coordinated charging phase angles of 300 EVs reduce the regional grid’s inductive reactive power demand by 62%. These results validate the superiority of EV clusters as flexible reactive power compensation resources. Their distributed characteristics enable more precise voltage regulation (with spatial resolution reaching distribution transformer level) than centralized devices, while the intelligent scheduling algorithm resolves the contradiction between response speed and control accuracy in traditional compensation devices, improving dynamic response rates by 2–3 times, providing a new technical pathway for coordinated power quality optimization in VPP environments.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}