
Estimation of Properties of Petrodiesel—Biodiesel Mixtures Using an Artificial Neural Network

 , , ,
, , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Materials and Reagents
2.2. Methods
3. Results and Discussion
- Readability (g): 0.001;
- Repeatability (std. dev) (g): 0.001;
- Linearity (g): ±0.002.
4. Correlation of the Densities of the Studied Blends with Their Properties by Using an Artificial Neural Network
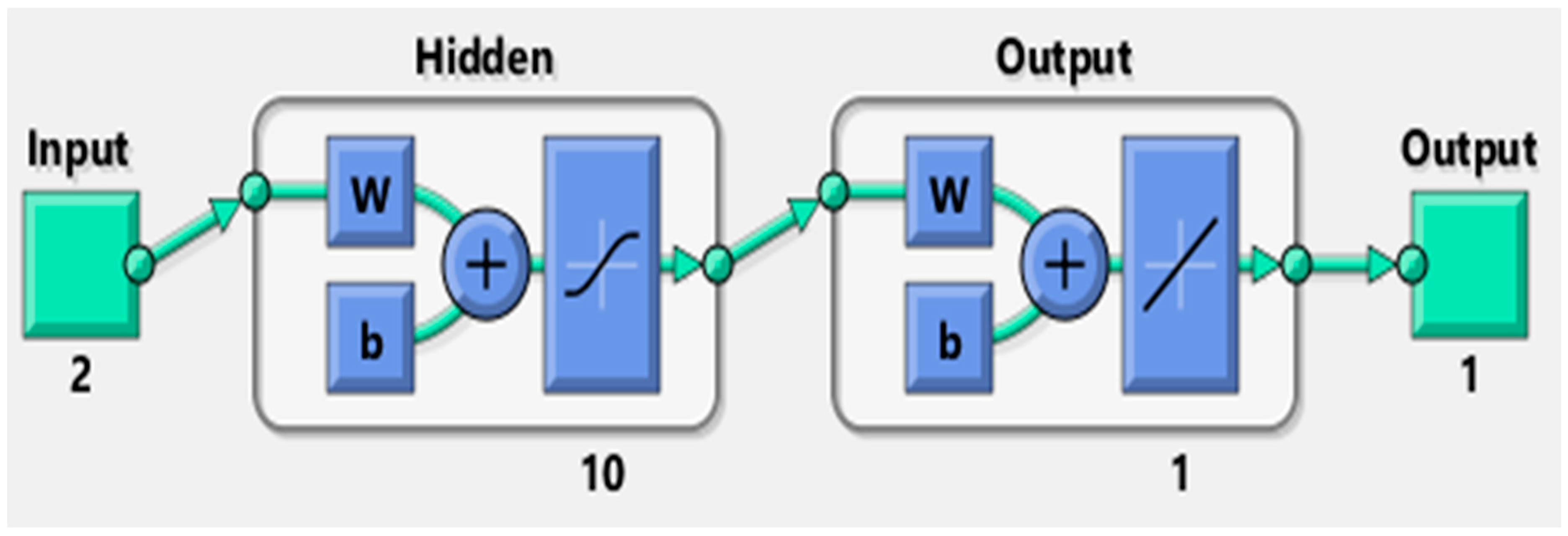
4.1. Artificial Neural Network
- The training data set consists of 30 samples, which suggests that employing two or more hidden layers would be excessive. A single hidden layer can yield similar results while requiring less computational power. Additionally, utilizing only one hidden layer reduces the likelihood of overfitting.
- The experimental data exhibit low uncertainty, indicating consistency; therefore, it is unnecessary to have a significantly high number of neurons in the hidden layer.
- With a limited number of inputs (2) and outputs (1), the hidden layer’s role is to process values from the input layer and relay the results to the output layer. A greater number of inputs typically necessitates having more neurons in the hidden layer.
4.2. Artificial Neural Network Modeling
- A clear determination of input and output data.
- Saving the existing experimental data in a file, under the Matlab accepted format. This step is the creation of the training database.
- Creating the ANN: In this step, a few important parameters of the artificial neural network are being set, and the rest of the creation process is handled by Matlab.
- Training the ANN: In this process, it is essential to utilize the created neural network, because the data from the training database are utilized in order to obtain the future correlations, and the training process links the database to the neural network.
- Verifying the training efficiency: This step is crucial, as it provides insight into the accuracy of the future correlations that will be derived from the neural network. The more effective the training process, the more accurate these future correlations will be, in relation to the data from the training database.
- Number of neurons in the hidden layer: Ranging from 1 to 20;
- Training algorithms: Levenberg–Marquardt, Bayesian Regularization, and Scaled Conjugate Gradient.
4.3. Data Collection and Selection, Creating the Training Database
- The biodiesel content, in volume %, of the same mixtures (the cases in which the mixtures had 0% biodiesel and 100% biodiesel were also taken into consideration).
4.4. ANN Model Analysis
- The necessary data for the training database were converted into a form that was agreeable to the Matlab software.
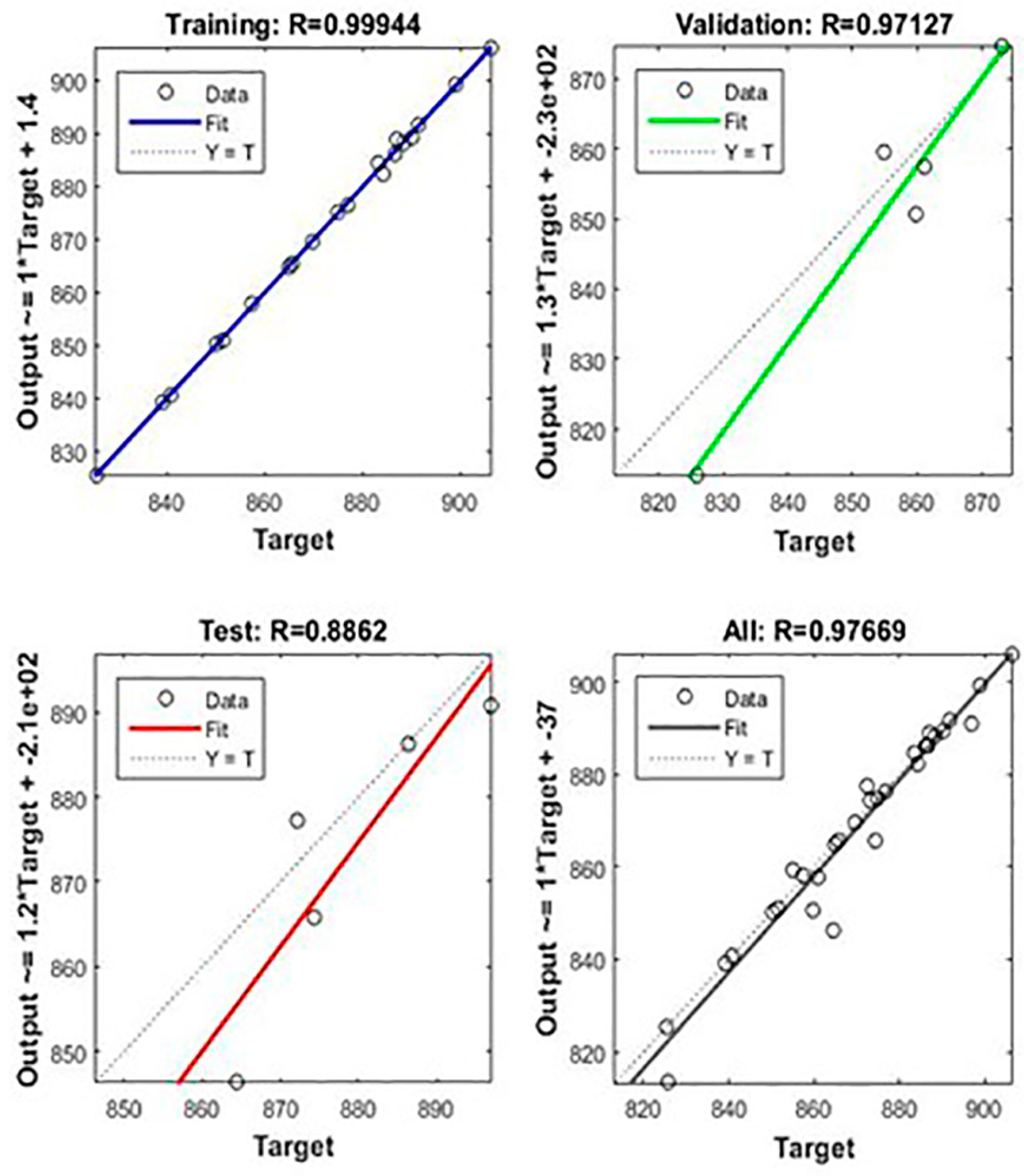
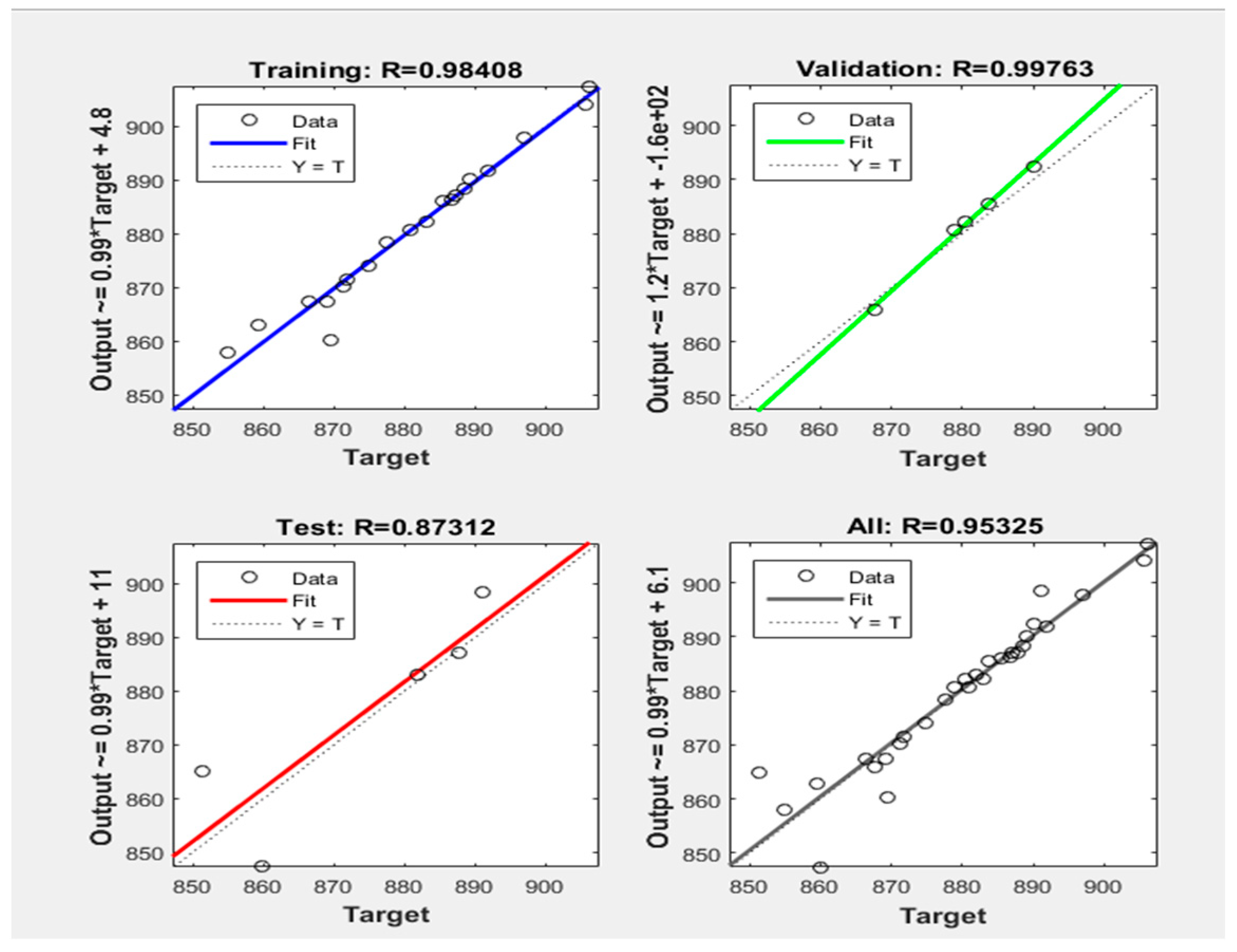
- The division of the training data into the three categories was 70% training data, 15% validation data, and 15% testing data. The data division was random.
- The network had one hidden layer. Ten neurons were enough for this experiment. There is not a general rule to determine the optimum number of neurons, so this number was determined through trial and error.
- As to the training algorithm, the Levenberg–Marquardt algorithm was chosen. The reasons behind this choice are its fast execution speed, fast convergence, and accuracy in training [13,14,53,54]. However, this algorithm requires more memory than the other training algorithms offered by Matlab, the Bayesian Regularization and the Scaled Conjugate Gradient [52].
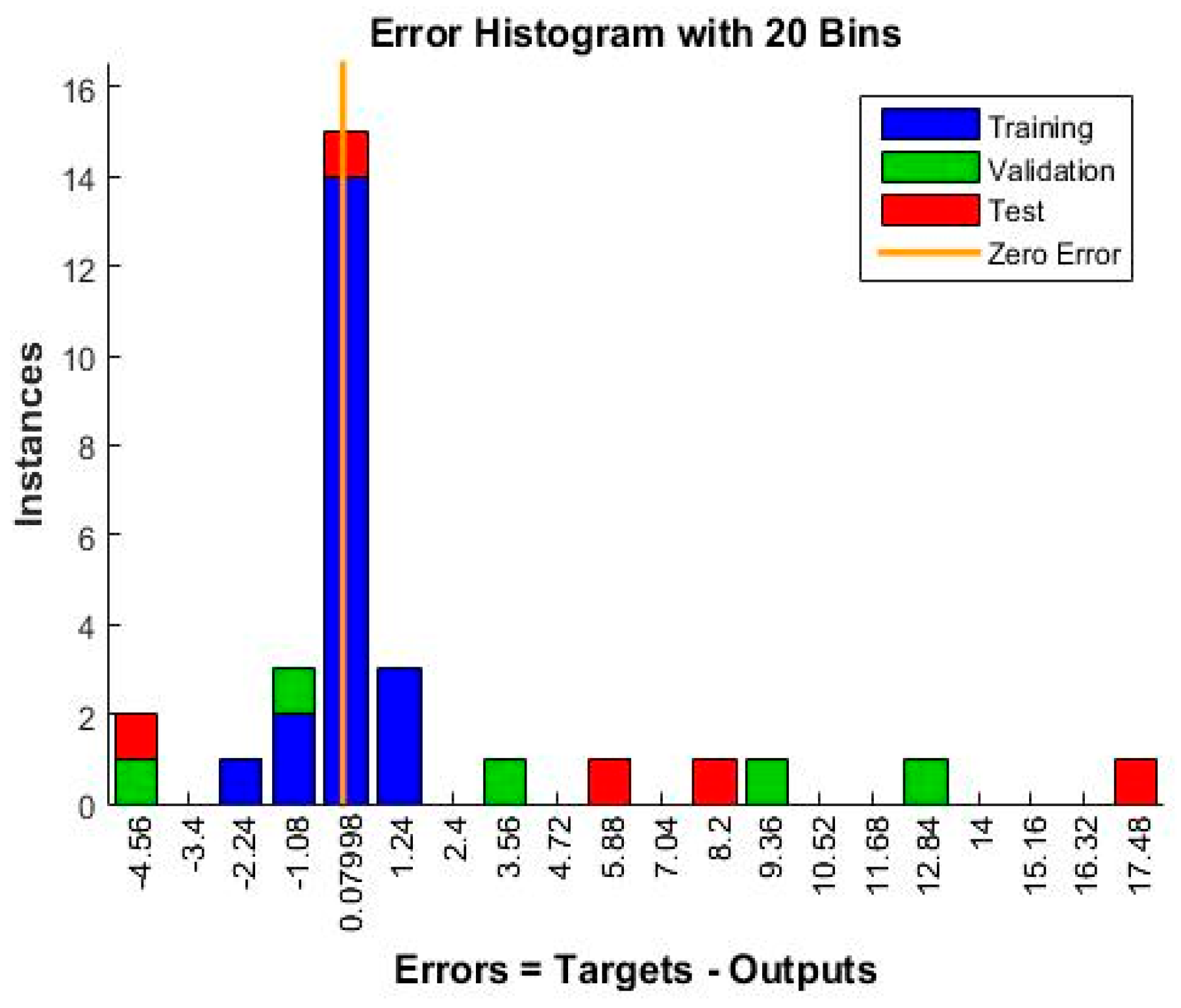
- To evaluate the error performance, meaning to determine when the training should end, the mean squared normalized error algorithm was used.
- Other training parameters (epoch, error goal, etc.) were automatically adjusted by Matlab.
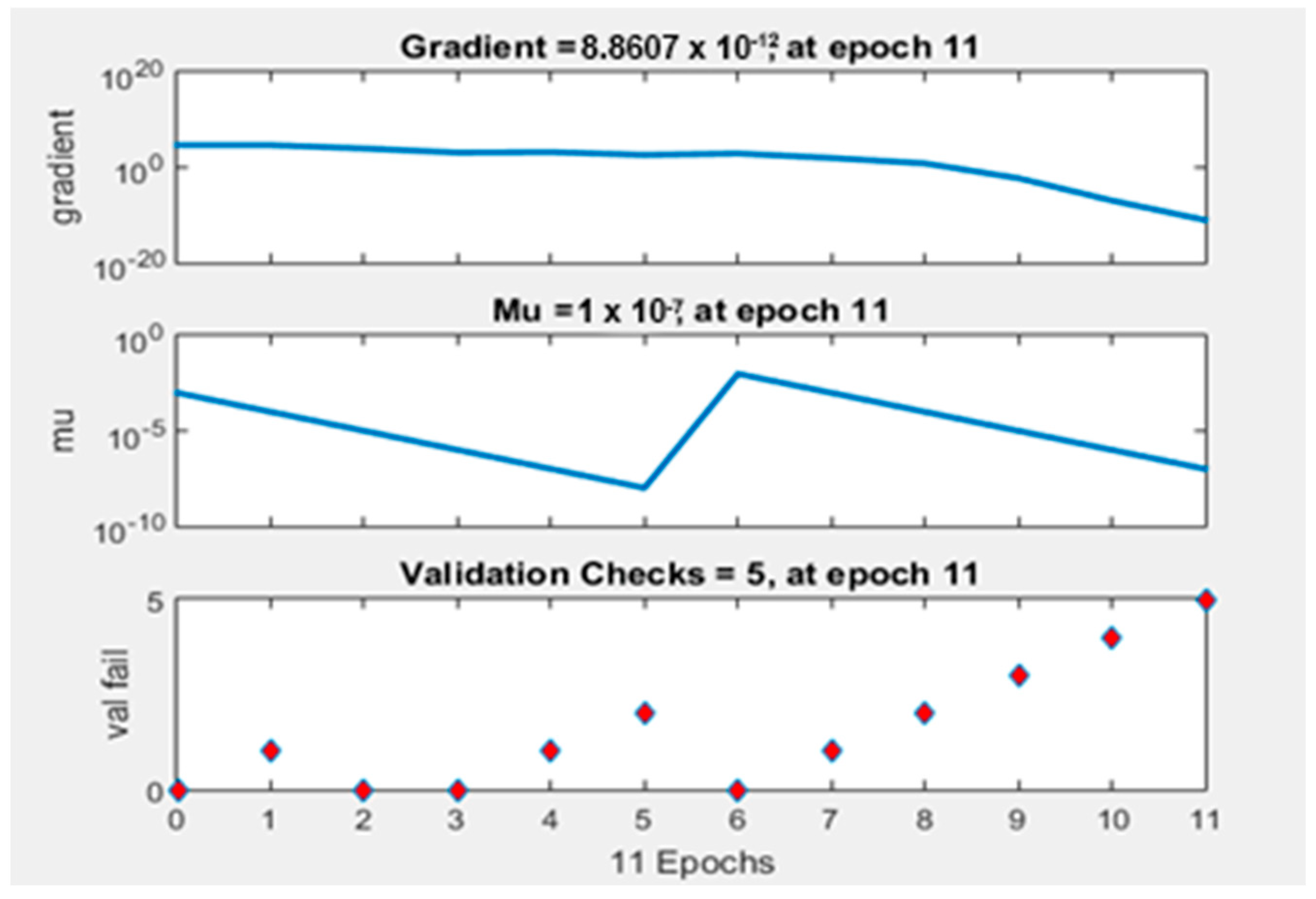
4.5. Neural Network Training, Training Efficiency
4.6. Network Prediction of the Mixtures’ Densities
- The artificial neural network had been trained using the training database regarding the petrodiesel—palm biodiesel blends.
- For each blending created, three estimations had been made. To offset the importance of the random factor induced by the ANN training, multiple estimations are necessary. Because there is no known rule to choose the number of estimations, it was determined through trial and error. In this case, three estimations are enough. Between estimation steps, the network was re-trained using the same training database, to ensure another random distribution of the training data. Without the re-training, the artificial neural network would have given the same estimations, no matter how many times the ANN had been used.
- The value taken into account for comparison with the determined values is the arithmetic mean of the three estimations specified at the above point.
- The calculated errors are expressed using two units of measure: kg/m3 and percent. The formulas for the two types of errors are as follows:
- The above steps were repeated for the other two training databases.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kokkinos, N.C.; Emmanouilidou, E. Waste-to-Energy: Applications and Perspectives on Sustainable Aviation Fuel Production. In Renewable Fuels for Sustainable Mobility. Energy, Environment, and Sustainability; Shukla, P.C., Belgiorno, G., Blasio, G.D., Agarwal, A.K., Eds.; Springer: Singapore, 2023. [Google Scholar] [CrossRef]
- Moser, B.R. Influence of extended storage on fuel properties of methyl esters prepared from canola, palm, soybean and sunflower oils. Renew. Energy 2011, 36, 1221–1226. [Google Scholar] [CrossRef]
- Can, O.; Baklacioglu, T.; Ozturk, E.; Turan, O. Artificial neural networks modeling of combustion parameters for a diesel engine fueled with biodiesel fuel. Energy 2022, 247, 123473. [Google Scholar] [CrossRef]
- Sajjadi, B.; Raman, A.A.A.; Arandiyan, H. A comprehensive review on properties of edible and non-edible vegetable oil-based biodiesel: Composition, specifications and prediction models. Renew. Sustain. Energy Rev. 2016, 63, 62–92. [Google Scholar] [CrossRef]
- Betiku, E.; Ajala, S.O. Modeling and optimization of Thevetia peruviana (yellow oleander) oil biodiesel synthesis via Musa paradisiacal (plantain) peels as a heterogeneous base catalyst: A case of artificial neural network vs. response surface methodology. Ind. Crop. Prod. 2014, 5, 314–322. [Google Scholar] [CrossRef]
- EN14214; Automotive Fuels—Fatty Acid Methyl Esters (FAME) for Diesel Engines—Requirements and Test Methods. CEN: Brussels, Belgium, 2009.
- Tsanaktsidis, C.G.; Spinthoropoulos, K.G.; Christidis, S.G.; Sariannidis, N. Mathematical models for calculating the density of petroleum diesel fuel/biodiesel blends. Chem. Technol. Fuels Oil 2013, 49, 399–405. [Google Scholar] [CrossRef]
- Hoang, A.T.; Nižetić, S.; Ong, H.C.; Tarelko, W.; Pham, V.V.; Le, T.H.; Chau, M.Q.; Nguyen, X.P. A review on application of artificial neural network (ANN) for performance and emission characteristics of diesel engine fueled with biodiesel-based fuel. Sustain. Energy Technol. Assess. 2021, 47, 101416. [Google Scholar] [CrossRef]
- Jahirul, M.I.; Rasul, M.G.; Brown, R.J.; Senadeera, W.; Hosen, M.A.; Haque, R.; Saha, S.C.; Mahlia, T.M.I. Investigation of correlation between chemical composition and properties of biodiesel using principal component analysis (PCA) and artificial neural network (ANN). Renew. Energy 2021, 168, 632–646. [Google Scholar] [CrossRef]
- Rocabruno-Valdés, C.I.; Ramírez-Verduzco, L.F.; Hernández, J.A. Artificial neural network models to predict density, dynamic viscosity and cetane number of biodiesel. Fuel 2015, 147, 9–17. [Google Scholar] [CrossRef]
- Kumar, J.; Bansal, A. Selection of Best Neural Network for Estimating Properties of Diesel-Biodiesel Blends. In Proceedings of the 6th WSEAS Int. Conf. on Artificial Intelligence, Knowledge Engineering and Data Bases, Corfu Island, Greece, 16–19 February 2007; pp. 136–141. Available online: https://dl.acm.org/doi/abs/10.5555/1348485.1348509 (accessed on 28 May 2025).
- Kumar, J.; Bansal, A. Application of artificial neural network to predict properties of diesel—Biodiesel blends. Kathmandu Univ. J. Sci. Eng. Technol. 2010, 6, 98–103. [Google Scholar] [CrossRef]
- Balabin, R.M.; Lomakina, E.I.; Safieva, R.Z. Neural network (ANN) approach to biodiesel analysis: Analysis of biodiesel density, kinematic viscosity, methanol and water contents using near-infrared (NIR) spectroscopy. Fuel 2011, 90, 2007–2015. [Google Scholar] [CrossRef]
- Giwa, S.O.; Adekomaya, S.O.; Adama, K.O.; Mukaila, M.O. Prediction of selected biodiesel fuel properties using artificial neural network. Front. Energy 2015, 9, 433–445. [Google Scholar] [CrossRef]
- Mejia, J.D.; Salgado, N.; Orrego, C.E. Effect of blends of Diesel and Palm-Castor biodiesels on viscosity, cloud point and flash point. Ind. Crop. Prod. 2013, 43, 791–797. [Google Scholar] [CrossRef]
- Omidvarborna, H.; Kumar, A.; Kim, D.S. NOX emissions from low-temperature combustion of biodiesel made of various feedstocks and blends. Fuel Process. Technol. 2015, 140, 113–118. [Google Scholar] [CrossRef]
- Zhang, Y.; Duan, L.; Esmaeili, H. A review on biodiesel production using various heterogeneous nanocatalysts: Operation mechanisms and performances. Biomass Bioenergy 2022, 158, 106356. [Google Scholar] [CrossRef]
- Gheorghe, C.G.; Pântea, O.; Matei, V.; Bomboș, D.; Borcea, A.F. Testing the biodegradation of contaminated water with petroleum products Through conventional treatment in comparison with treatment through biological sludge enriched with activated charcoal. Rev. Chim. 2011, 62, 655–658. [Google Scholar]
- Cursaru, D.; Neagu, M.; Bogatu, L. Investigations on the oxidation stability of biodiesel synthesized from different vegetable oils. Rev. Chim. 2013, 64, 438–441. [Google Scholar]
- Dey, S.; Reang, N.M.; Das, P.K.; Deb, M. Comparative study using RSM and ANN modeling for performance-emission prediction of CI engine fuelled with bio-diesohol blends: A fuzzy optimization approach. Fuel 2021, 292, 120356. [Google Scholar] [CrossRef]
- Hirner, F.S.; Hwang, J.; Bae, C.; Patel, C.; Gupta, T.; Agarwal, A.K. Nanostructure characterization of soot particles from biodiesel and diesel spray flame in a constant volume combustion chamber. Fuel 2019, 235, 130–149. [Google Scholar] [CrossRef]
- Babu, D.; Karvembu, R.; Anand, R. Impact of split injection strategy on combustion, performance and emissions characteristics of biodiesel fuelled common rail direct injection assisted diesel engine. Energy 2018, 165, 577–592. [Google Scholar] [CrossRef]
- Aydına, M.; Uslub, S.; Çelikb, M.B. Performance and emission prediction of a compression ignition engine fueled with biodiesel-diesel blends: A combined application of ANN and RSM based optimization. Fuel 2020, 269, 117472. [Google Scholar] [CrossRef]
- Pourhoseini, S.H.; Mahboub, M.N.; Hosseini, E.; Alimoradi, A. A comparative exploration of thermal, radiative and pollutant emission characteristics of oil burner flame using palm oil biodiesel-diesel blend fuel and diesel fuel. Energy 2021, 217, 119338. [Google Scholar] [CrossRef]
- Kumar, P.V.; Ashok, B.; Kumar, M.S.; Vignesh, R.; Bhasker, J.P.; Kumar, A.N. Evaluation of performance, emissions and combustion attributes of CI engine using palmyra biodiesel blend with distinct compression ratios, EGR rates and nano-particles. Fuel 2022, 321, 124092. [Google Scholar] [CrossRef]
- Navaneeth, P.V.; Suraj, C.K.; Mehta, P.S.; Anand, K. Predicting the effect of biodiesel composition on the performance and emission of a compression ignition engine using a phenomenological model. Fuel 2021, 293, 120453. [Google Scholar] [CrossRef]
- Hosamani, B.R.; Doddi, S.; Puthani, P. Assessment of density and kinematic viscosity of two methyl ester blends at elevated temperatures. Mater. Today Proc. 2022, 56, 1588–1593. [Google Scholar] [CrossRef]
- Thomas, A. Fatts and Fatty Acids, in Ullmann’s Encyclopedia of Industrial Chemistry, 6th ed.; Wiley-VCH Verlag GmbH & Co. KgaA: Weinheim, Germany, 2002. [Google Scholar] [CrossRef]
- Seepaul, R.; Small, I.M.; Devkota, P.; Sintim, H.Y.; Mulvaney, M.J.; George, S.; Leon, R.G.; Paula-Moraes, S.V.; Esquivel, I.L.; Bennett, R.; et al. Carinata, the Sustainable Crop for a Bio-Based Economy: Production Recommendations for the Southeastern United States, SS-AGR-384; University of Florida: Gainesville, FL, USA, 2023. [Google Scholar] [CrossRef]
- Mohdaly, A.A.A.; Ramadan, M.F. Characteristics, composition and functional properties of seeds, seed cake and seed oil from different Brassica carinata genotypes. Food Biosci. 2022, 48, 100752. [Google Scholar] [CrossRef]
- Li, J.; Su, Y.; Shapiro, C.A.; Schachtman, D.P.; Wang, X. Phosphate deficiency modifies lipid composition and seed oil production in camelina. Plant Sci. 2023, 330, 111636. [Google Scholar] [CrossRef]
- Mansuri, S.; Bakhshabadi, H.; Moghimi, M.; Tahmasebi, A.; Gharekhani, M. Evaluating the physicochemical properties of camelina (Camelina sativa) seed oil obtained through optimized ultrasonic-assisted extraction. Ultrason. Sonochemistry 2025, 118, 107371. [Google Scholar] [CrossRef] [PubMed]
- Aslam, M.M.; Khan, A.A.; Cheema, H.M.N.; Hanif, M.A.; Azeem, M.W.; Azmat, M.A. Novel mutant camelina and jatropha as valuable feedstocks for biodiesel production. Sci. Rep. 2020, 10, 21868. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Shadloo, M.S.; Nasiri, H.; Maleki, A.; Karimipour, A.; Tlili, I. Prediction of viscosity of biodiesel blends using various artificial model and comparison with empirical correlations. Renew. Energy 2020, 153, 1296–1306. [Google Scholar] [CrossRef]
- Pitchaiah, S.; Juchelkov, D.; Sathyamurthy, R.; Atabani, A.E. Prediction and performance optimisation of a DI CI engine fuelled diesel–Bael biodiesel blends with DMC additive using RSM and ANN: Energy and exergy analysis. Energy Convers. Manag. 2023, 292, 117386. [Google Scholar] [CrossRef]
- Mahmodi, K.; Mostafaei, M.; Mirzaee-Ghaleh, E. Detecting the different blends of diesel and biodiesel fuels using electronic nose machine coupled ANN and RSM methods. Sustain. Energy Technol. Assess. 2021, 51, 101914. [Google Scholar] [CrossRef]
- Zikri, J.M.; Sani, M.S.M.; Rashid, M.F.F.A.; Muriban, J.; Prayogo, G.S. Predictive modeling and optimization of noise emissions in a palm oil methyl ester-fueled diesel engine using response surface methodology and artificial neural network integrated with genetic algorithm. Int. J. Thermofluids 2025, 26, 101103. [Google Scholar] [CrossRef]
- Mishra, S.; Bukkarapu, K.R.; Krishnasamy, A. A composition based approach to predict density, viscosity and surface tension of biodiesel fuel. Fuel 2021, 285, 119056. [Google Scholar] [CrossRef]
- Xue, S.; Hou, K.; Zhang, Z.; Liu, H.; Zhu, C.; Liu, X.; He, M. General models for prediction densities and viscosities of saturated and unsaturated fatty acid esters. J. Mol. Liq. 2021, 341, 117374. [Google Scholar] [CrossRef]
- Dantas, M.B.; de Biodiesel, B. Estabilidade Térmica e Oxidativa e Monitoramento Durante Armazenamento. Master’s Thesis, Universidade Federal da Paraíba, João Pessoa, Brazil, 2010. [Google Scholar]
- Bandbafha, H.H.; Kumar, D.; Singh, B.; Shahbeig, H.; Lam, S.S.; Aghbashlo, M.; Tabatabaei, M. Biodiesel antioxidants and their impact on the behavior of diesel engines: A comprehensive review. Fuel Process. Technol. 2022, 232, 107264. [Google Scholar] [CrossRef]
- Ramírez-Verduzco, L.F.; García-Flores, B.E.; Rodríguez-Rodríguez, J.E. Prediction of the density and viscosity in biodiesel blends at various temperatures. Fuel 2011, 90, 1751–1761. [Google Scholar] [CrossRef]
- Knothe, G. Some aspects of biodiesel oxidative stability. Fuel Process. Technol. 2007, 88, 669–677. [Google Scholar] [CrossRef]
- Freire, L.M.S.; Filho, J.R.C.; Moura, C.V.R.; Soledade, L.E.B.; Stragevitch, L.; Cordeiro, A.M.T.M.; Santos, I.M.G.; Souza, A.G. Evaluation of the oxidative stability and flow properties of quaternary mixtures of vegetable oils for biodiesel production. Fuel 2012, 95, 126–130. [Google Scholar] [CrossRef]
- Park, J.Y.; Kim, D.K.; Lee, J.P.; Park, S.C.; Kim, Y.J.; Lee, J.S. Blending effects of biodiesels on oxidation stability and low temperature flow properties. Bioresour. Technol. 2008, 99, 1196–1203. [Google Scholar] [CrossRef]
- Alvisoa, D.; Záratea, C.; Durieza, T. Modeling of vegetable oils cloud point, pour point, cetane number and iodine number from their composition using genetic programming. Fuel 2021, 284, 119026. [Google Scholar] [CrossRef]
- Esteban, B.; Riba, J.R.; Baquero, G.; Rius, A.; Puig, R. Temperature dependence of density and viscosity of vegetable oils. Biomass Bioenergy 2012, 42, 164–171. [Google Scholar] [CrossRef]
- Folayan, A.J.; Anawe, P.A.L.; Aladejare, A.E.; Ayeni, A.O. Experimental investigation of the effect of fatty acids configuration, chain length, branching and degree of unsaturation on biodiesel fuel properties obtained from lauric oils, high-oleic and high-linoleic vegetable oil biomass. Energy Rep. 2019, 5, 793–806. [Google Scholar] [CrossRef]
- Brahma, S.; Nath, B.; Basumatary, B.; Das, B.; Saikia, P.; Patir, K.; Basumatary, S. Biodiesel production from mixed oils: A sustainable approach towards industrial biofuel production. Chem. Eng. J. Adv. 2022, 10, 100284. [Google Scholar] [CrossRef]
- Gülüm, M.; Bilgin, A. Density, flash point and heating value variations of corn oil biodiesel–diesel fuel blends. Fuel Process. Technol. 2015, 134, 456–464. [Google Scholar] [CrossRef]
- Holman, J.P. Experimental Methods for Engineers, 7th ed.; McGraw-Hill: New York, NY, USA, 2001. [Google Scholar]
- MathWorks Inc. MATLAB R2015a Help System; MA, USA, 2015; Available online: http://www.mathworks.com/ (accessed on 2 March 2025).
- Cheenkachorn, K. Predicting properties of biodiesel using statistical models and artificial neural networks. In Proceedings of the Joint International Conference on Sustainable Energy and Environment, Hua Hin, Thailand, 1–2 June 2004; pp. 176–179. [Google Scholar]
- Meng, X.; Jia, M.; Wang, T. Neural network prediction of biodiesel kinematic viscosity at 313K. Fuel 2014, 121, 133–140. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tests | Sample | Method | ||
|---|---|---|---|---|
| Palm Oil | Brassica carinata Oil | Camelina Oil | ||
| Density (at 20 °C, kg/m3) | 919.6 | 914.5 | 918.1 | EN ISO 3838 |
| Refractive index (at 20 °C) | 1.4638 | 1.4740 | 1.4754 | ASTM D-1218 |
| Viscosity (at 40 °C, mm2/s) | 39.47 | 68.56 | 25.32 | EN ISO 3104 |
| Saponification index (mg KOH/g) | 172.21 | 174.51 | 182.14 | EN ISO 3657 |
| Iodine value (g I2/100 g) | 59.12 | 96.12 | 146.70 | EN-14111 |
| Total acidity number (mg KOH/g) | 2.17 | 0.79 | 1.38 | ASTM D-1980 |
| Cloud point (°C) | 28 | 4 | −11 | ASTM D-2500 |
| Property, u.m. | Density (at 20 °C, kg/m3) | Refractive Index (at 20 °C) | Total Acidity Number, (mg KOH/g) | Iodine Value, (g I2/100 g) | Cloud Point, (°C) | Flash Point, (°C) |
|---|---|---|---|---|---|---|
| Petrodiesel, experimental data | 896.9 | 1.4756 | 0.5 | 8.585 | <−25 | 71 |
| Petrodiesel, Standard value | 820–845 | - | - | - | −10 | <55 |
| Tests | Biodiesel Sample | Standard Value | Method | ||
|---|---|---|---|---|---|
| Palm | Brassica Carinata | Camelina | EN 14214 | ||
| Density (at 20 °C, kg/m3) | 864.9 | 883.6 | 970.9 | 860–900 | EN ISO 3838 |
| Refractive index (at 20° C) | 1.4483 | 1.4570 | 1.4575 | - | ASTM D-1218 |
| Viscosity (at 40 °C, mm2/s) | 18.49 | 24.37 | 4.09 | 3.5–5 | EN ISO 3104 |
| Saponification index (mg KOH/g) | 171.41 | 173.82 | 181.76 | - | EN ISO 3657 |
| Iodine value (g I2/100 g) | 55.90 | 92.41 | 141.9 | <120 | EN-14111 |
| Total acidity number (mg KOH/g) | 1.24 | 1.37 | 1.07 | <0.5 | ASTM D-1980 |
| Cloud point (°C) | 38,4 | 4 | 2.5 | Report | ASTM D-2500 |
| Cetane number | 65.56 | 56.90 | 44.39 | >51 | Calculated |
| Sample | Blend 1 | Blend 2 | Blend 3 | Biodiesel | Petrodiesel |
|---|---|---|---|---|---|
| Density at 15 °C | 42.2352 | 41.9724 | 41.6220 | 41.5920 | 42.4203 |
| Density at 20 °C | 42.0549 | 41.9248 | 41.4043 | 41.3868 | 42.1876 |
| Density at 25 °C | 41.9398 | 41.8698 | 41.1966 | 41.2592 | 42.0174 |
| Density at 30 °C | 41.8473 | 41.6871 | 41.0465 | 41.0164 | 41.9348 |
| Density at 35 °C | 41.5695 | 41.5069 | 40.7437 | 40.7812 | 41.6370 |
| Density at 40 °C | 41.2917 | 41.3743 | 40.4084 | 40.3983 | 41.1366 |
| Sample | Blend 1 | Blend 2 | Blend 3 | Biodiesel | Petrodiesel |
|---|---|---|---|---|---|
| Density at 15 °C | 42.4052 | 42.0424 | 41.9949 | 41.9799 | 42.4203 |
| Density at 20 °C | 42.0625 | 41.9423 | 41.8998 | 41.8547 | 42.1876 |
| Density at 25 °C | 41.9599 | 41.8397 | 41.7847 | 41.7021 | 42.0174 |
| Density at 30 °C | 41.8122 | 41.7772 | 41.7346 | 41.5595 | 41.9348 |
| Density at 35 °C | 41.5469 | 41.4919 | 41.4544 | 41.4268 | 41.6370 |
| Density at 40 °C | 41.5019 | 41.2492 | 41.0465 | 41.2617 | 41.1366 |
| Sample | Blend 1 | Blend 2 | Blend 3 | Biodiesel | Petrodiesel |
|---|---|---|---|---|---|
| Density at 15 °C | 42.4603 | 42.7606 | 42.9633 | 44.2245 | 42.4203 |
| Density at 20 °C | 42.2476 | 42.6630 | 42.8782 | 44.0393 | 42.1876 |
| Density at 25 °C | 41.9998 | 42.4253 | 42.5954 | 43.8942 | 42.0174 |
| Density at 30 °C | 41.9248 | 42.3327 | 42.3652 | 43.5739 | 41.9348 |
| Density at 35 °C | 41.7597 | 41.9498 | 42.1024 | 43.3036 | 41.6370 |
| Density at 40 °C | 41.2291 | 41.3843 | 41.6671 | 43.1035 | 41.1366 |
| Sample | Blend 1 | Blend 2 | Blend 3 | Biodiesel | Petrodiesel |
|---|---|---|---|---|---|
| Density at 15 °C | 899.0 | 888.3 | 874.3 | 873.1 | 906.2 |
| Density at 20 °C | 891.6 | 886.4 | 865.6 | 864.9 | 896.9 |
| Density at 25 °C | 887.0 | 884.2 | 857.3 | 859.8 | 890.1 |
| Density at 30 °C | 883.3 | 876.9 | 851.3 | 850.1 | 886.8 |
| Density at 35 °C | 872.2 | 869.7 | 839.2 | 840.7 | 874.9 |
| Density at 40 °C | 861.1 | 864.4 | 825.8 | 825.4 | 854.9 |
| Sample | Blend 1 | Blend 2 | Blend 3 | Biodiesel | Petrodiesel |
|---|---|---|---|---|---|
| Density at 15 °C | 905.6 | 891.1 | 889.2 | 888.6 | 906.2 |
| Density at 20 °C | 891.9 | 887.1 | 885.4 | 883.6 | 896.9 |
| Density at 25 °C | 887.8 | 883.0 | 880.8 | 877.5 | 890.1 |
| Density at 30 °C | 881.9 | 880.5 | 878.8 | 871.8 | 886.8 |
| Density at 35 °C | 871.3 | 869.1 | 867.6 | 866.5 | 874.9 |
| Density at 40 °C | 869.5 | 859.4 | 851.3 | 859.9 | 854.9 |
| Sample | Blend 1 | Blend 2 | Blend 3 | Biodiesel | Petrodiesel |
|---|---|---|---|---|---|
| Density at 15 °C | 907.8 | 919.8 | 927.9 | 978.3 | 906.2 |
| Density at 20 °C | 899.3 | 915.9 | 924.5 | 970.9 | 896.9 |
| Density at 25 °C | 889.4 | 906.4 | 913.2 | 965.1 | 890.1 |
| Density at 30 °C | 886.4 | 902.7 | 904.0 | 952.3 | 886.8 |
| Density at 35 °C | 876.8 | 887.4 | 893.5 | 941.5 | 874.9 |
| Density at 40 °C | 858.6 | 864.8 | 876.1 | 933.5 | 854.9 |
| Sample | Blend 1 | Blend 2 | Blend 3 | Biodiesel | Petrodiesel |
|---|---|---|---|---|---|
| Density at 15 °C | 5.99 × 106 | 6.03 × 10−6 | 6.09 × 10−6 | 6.10 × 10−6 | 5.96 × 10−6 |
| Density at 20 °C | 6.02 × 10−6 | 6.04 × 10−6 | 6.13 × 10−6 | 6.14 × 10−6 | 6.00 × 10−6 |
| Density at 25 °C | 6.04 × 10−6 | 6.05 × 10−6 | 6.17 × 10−6 | 6.16 × 10−6 | 6.03 × 10−6 |
| Density at 30 °C | 6.06 × 10−6 | 6.08 × 10−6 | 6.20 × 10−6 | 6.21 × 10−6 | 6.04 × 10−6 |
| Density at 35 °C | 6.10 × 10−6 | 6.12 × 10−6 | 6.26 × 10−6 | 6.25 × 10−6 | 6.09 × 10−6 |
| Density at 40 °C | 6.15 × 10−6 | 6.14 × 10−6 | 6.33 × 10−6 | 6.33 × 10−6 | 6.18 × 10−6 |
| Sample | Blend 1 | Blend 2 | Blend 3 | Biodiesel | Petrodiesel |
|---|---|---|---|---|---|
| Density at 15 °C | 5.96 × 10−6 | 6.02 × 10−6 | 6.03 × 10−6 | 6.03 × 10−6 | 5.96 × 10−6 |
| Density at 20 °C | 6.02 × 10−6 | 6.04 × 10−6 | 6.05 × 10−6 | 6.05 × 10−6 | 6.00 × 10−6 |
| Density at 25 °C | 6.04 × 10−6 | 6.06 × 10−6 | 6.07 × 10−6 | 6.08 × 10−6 | 6.03 × 10−6 |
| Density at 30 °C | 6.06 × 10−6 | 6.07 × 10−6 | 6.07 × 10−6 | 6.11 × 10−6 | 6.04 × 10−6 |
| Density at 35 °C | 6.11 × 10−6 | 6.12 × 10−6 | 6.12 × 10−6 | 6.13 × 10−6 | 6.09 × 10−6 |
| Density at 40 °C | 6.12 × 10−6 | 6.16 × 10−6 | 6.20 × 10−6 | 6.16 × 10−6 | 6.18 × 10−6 |
| Sample | Blend 1 | Blend 2 | Blend 3 | Biodiesel | Petrodiesel |
|---|---|---|---|---|---|
| Density at 15 °C | 5.96 × 10−6 | 5.91 × 10−6 | 5.88 × 10−6 | 5.71 × 10−6 | 5.96 × 10−6 |
| Density at 20 °C | 5.99 × 10−6 | 5.92 × 10−6 | 5.89 × 10−6 | 5.73 × 10−6 | 6.00 × 10−6 |
| Density at 25 °C | 6.03 × 10−6 | 5.96 × 10−6 | 5.93 × 10−6 | 5.75 × 10−6 | 6.03 × 10−6 |
| Density at 30 °C | 6.04 × 10−6 | 5.98 × 10−6 | 5.97 × 10−6 | 5.79 × 10−6 | 6.04 × 10−6 |
| Density at 35 °C | 6.09 × 10−6 | 6.04 × 10−6 | 6.01 × 10−6 | 5.83 × 10−6 | 6.09 × 10−6 |
| Density at 40 °C | 6.17 × 10−6 | 6.14 × 10−6 | 6.09 × 10−6 | 5.86 × 10−6 | 6.18 × 10−6 |
| 15 | 20 | 25 | 30 | 35 | 40 |
| 5 | 5 | 5 | 5 | 5 | 5 |
| 899 | 891.6 | 887 | 883.3 | 872.2 | 861.1 |
| Blending Number | Determined Value (D) | Estimation | Mean Estimation (M) | Error (D − M) | Error (%) | ||
|---|---|---|---|---|---|---|---|
| #1 | #2 | #3 | |||||
| 1 | 899.0 | 897.5 | 901.2 | 898.3 | 899.0 | 0.0 | 0.0 |
| 2 | 888.3 | 883.2 | 894.3 | 891.3 | 889.6 | −1.3 | −0.1 |
| 3 | 874.3 | 875.4 | 889.8 | 887.7 | 884.3 | −10.0 | −1.1 |
| 4 | 873.1 | 876.4 | 879.3 | 884.6 | 880.1 | −7.0 | −0.8 |
| 5 | 906.2 | 875.6 | 890.2 | 874.4 | 880.1 | 26.1 | 2.9 |
| 6 | 891.6 | 856.7 | 877.9 | 860.5 | 865.0 | 26.6 | 3.0 |
| 7 | 886.4 | 886.3 | 899.3 | 889.8 | 891.8 | −5.4 | −0.6 |
| 8 | 865.6 | 878.8 | 891.0 | 884.4 | 884.7 | −19.1 | −2.2 |
| 9 | 864.9 | 872.9 | 879.8 | 880.8 | 877.8 | −12.9 | −1.5 |
| 10 | 896.9 | 876.1 | 860.3 | 876.6 | 871.0 | 25.9 | 2.9 |
| 11 | 887.0 | 875.0 | 873.4 | 868.0 | 872.1 | 14.9 | 1.7 |
| 12 | 884.2 | 848.4 | 865.7 | 856.3 | 856.8 | 27.4 | 3.1 |
| 13 | 857.3 | 874.5 | 897.4 | 873.4 | 881.8 | −24.5 | −2.9 |
| 14 | 859.8 | 875.1 | 888.1 | 866.5 | 876.6 | −16.8 | −2.0 |
| 15 | 890.1 | 868.4 | 871.0 | 859.5 | 866.3 | 23.8 | 2.7 |
| 16 | 883.3 | 875.4 | 847.7 | 850.6 | 857.9 | 25.4 | 2.9 |
| 17 | 876.9 | 897.5 | 856.1 | 839.5 | 864.4 | 12.5 | 1.4 |
| 18 | 851.3 | 883.2 | 849.4 | 826.0 | 852.9 | −1.6 | −0.2 |
| 19 | 850.1 | 875.4 | 841.9 | 873.0 | 863.4 | −13.3 | −1.6 |
| 20 | 886.8 | 876.4 | 845.6 | 865.0 | 862.3 | 24.5 | 2.8 |
| 21 | 872.2 | 875.6 | 842.6 | 859.8 | 859.3 | 12.9 | 1.5 |
| 22 | 869.7 | 856.7 | 802.2 | 850.0 | 836.3 | 33.4 | 3.8 |
| 23 | 839.2 | 886.3 | 786.3 | 840.7 | 837.8 | 1.4 | 0.2 |
| 24 | 840.7 | 878.8 | 786.0 | 863.2 | 842.7 | −2.0 | −0.2 |
| 25 | 874.9 | 872.9 | 903.4 | 905.9 | 894.1 | −19.2 | −2.2 |
| 26 | 861.1 | 876.1 | 899.3 | 896.2 | 890.5 | −29.4 | −3.4 |
| 27 | 864.4 | 875.0 | 902.5 | 890.9 | 889.5 | −25.1 | −2.9 |
| 28 | 825.8 | 848.4 | 902.2 | 887.2 | 879.3 | −53.5 | −6.5 |
| 29 | 825.4 | 874.5 | 903.0 | 873.8 | 883.8 | −58.4 | −7.1 |
| 30 | 854.9 | 875.1 | 887.2 | 855.6 | 872.6 | −17.7 | −2.1 |
| Blending Number | Determined Value (D) | Estimation | Mean Estimation (M) | Error (D − M) | Error (%) | ||
|---|---|---|---|---|---|---|---|
| #1 | #2 | #3 | |||||
| 1 | 905.6 | 902.7 | 902.5 | 907.4 | 904.2 | 1.4 | 0.2 |
| 2 | 891.1 | 891.2 | 891.7 | 900.5 | 894.5 | −3.4 | −0.4 |
| 3 | 889.2 | 886.4 | 886.7 | 890.5 | 887.9 | 1.3 | 0.1 |
| 4 | 888.6 | 882.9 | 882.6 | 882.5 | 882.7 | 5.9 | 0.7 |
| 5 | 906.2 | 872.1 | 872.3 | 871.9 | 872.1 | 34.1 | 3.8 |
| 6 | 891.9 | 868.3 | 859.7 | 846.1 | 858.0 | 33.9 | 3.8 |
| 7 | 887.1 | 896.4 | 895.0 | 904.9 | 898.8 | −11.7 | −1.3 |
| 8 | 885.4 | 887.1 | 888.4 | 898.1 | 891.2 | −5.8 | −0.7 |
| 9 | 883.6 | 883.1 | 883.5 | 887.6 | 884.7 | −1.1 | −0.1 |
| 10 | 896.9 | 880.2 | 880.1 | 879.8 | 880.0 | 16.9 | 1.9 |
| 11 | 887.8 | 870.3 | 871.6 | 869.5 | 870.5 | 17.3 | 2.0 |
| 12 | 883.0 | 858.3 | 857.0 | 846.2 | 853.8 | 29.2 | 3.3 |
| 13 | 880.8 | 890.0 | 887.8 | 916.8 | 898.2 | −17.4 | −2.0 |
| 14 | 877.5 | 883.4 | 885.1 | 899.9 | 889.5 | −12.0 | −1.4 |
| 15 | 890.1 | 880.4 | 880.4 | 886.0 | 882.3 | 7.8 | 0.9 |
| 16 | 881.9 | 878.1 | 878.2 | 877.5 | 877.9 | 4.0 | 0.4 |
| 17 | 880.5 | 868.0 | 871.0 | 868.0 | 869.0 | 11.5 | 1.3 |
| 18 | 878.8 | 841.4 | 853.9 | 852.4 | 849.2 | 29.6 | 3.4 |
| 19 | 871.8 | 892.8 | 837.6 | 911.5 | 880.6 | −8.8 | −1.0 |
| 20 | 886.8 | 884.0 | 836.6 | 900.4 | 873.7 | 13.1 | 1.5 |
| 21 | 871.3 | 880.4 | 848.3 | 891.5 | 873.4 | −2.1 | −0.2 |
| 22 | 869.1 | 872.4 | 871.7 | 879.0 | 874.4 | −5.3 | −0.6 |
| 23 | 867.6 | 865.1 | 866.3 | 868.2 | 866.5 | 1.1 | 0.1 |
| 24 | 866.5 | 861.8 | 859.8 | 863.4 | 861.7 | 4.8 | 0.6 |
| 25 | 874.9 | 908.8 | 909.6 | 912.9 | 910.4 | −35.5 | −4.1 |
| 26 | 869.5 | 895.4 | 895.4 | 903.9 | 898.2 | −28.7 | −3.3 |
| 27 | 859.4 | 890.2 | 889.9 | 893.7 | 891.3 | −31.9 | −3.7 |
| 28 | 851.3 | 886.2 | 885.9 | 885.5 | 885.9 | −34.6 | −4.1 |
| 29 | 859.9 | 874.3 | 873.4 | 874.5 | 874.1 | −14.2 | −1.6 |
| 30 | 854.9 | 873.8 | 862.1 | 850.5 | 862.1 | −7.2 | −0.8 |
| Blending Number | Determined Value (D) | Estimation | Mean Estimation (M) | Error (D − M) | Error (%) | ||
|---|---|---|---|---|---|---|---|
| #1 | #2 | #3 | |||||
| 1 | 907.8 | 908.78 | 911.90 | 908.40 | 909.7 | −1.9 | −0.2 |
| 2 | 919.8 | 904.13 | 907.80 | 905.85 | 905.9 | 13.9 | 1.5 |
| 3 | 927.9 | 895.89 | 896.29 | 897.80 | 896.7 | 31.2 | 3.4 |
| 4 | 978.3 | 887.49 | 888.79 | 890.98 | 889.1 | 89.2 | 9.1 |
| 5 | 906.2 | 875.75 | 881.33 | 880.64 | 879.2 | 27.0 | 3.0 |
| 6 | 899.3 | 857.83 | 862.99 | 859.47 | 860.1 | 39.2 | 4.4 |
| 7 | 915.9 | 918.00 | 920.07 | 918.17 | 918.7 | −2.8 | −0.3 |
| 8 | 924.5 | 908.68 | 916.76 | 915.01 | 913.5 | 11.0 | 1.2 |
| 9 | 970.9 | 902.73 | 905.10 | 906.59 | 904.8 | 66.1 | 6.8 |
| 10 | 896.9 | 893.07 | 896.57 | 897.96 | 895.9 | 1.0 | 0.1 |
| 11 | 889.4 | 880.59 | 887.78 | 886.24 | 884.9 | 4.5 | 0.5 |
| 12 | 906.4 | 863.59 | 870.20 | 865.01 | 866.3 | 40.1 | 4.4 |
| 13 | 913.2 | 928.50 | 927.62 | 928.84 | 928.3 | −15.1 | −1.7 |
| 14 | 965.1 | 919.90 | 925.34 | 924.96 | 923.4 | 41.7 | 4.3 |
| 15 | 890.1 | 917.75 | 914.91 | 916.16 | 916.3 | −26.2 | −2.9 |
| 16 | 886.4 | 905.24 | 906.48 | 905.72 | 905.8 | −19.4 | −2.2 |
| 17 | 902.7 | 891.86 | 897.65 | 892.27 | 893.9 | 8.8 | 1.0 |
| 18 | 904.0 | 875.02 | 883.96 | 871.29 | 876.8 | 27.2 | 3.0 |
| 19 | 952.3 | 980.09 | 978.88 | 978.58 | 979.2 | −26.9 | −2.8 |
| 20 | 886.8 | 971.10 | 970.97 | 970.83 | 971.0 | −84.2 | −9.5 |
| 21 | 876.8 | 969.63 | 965.87 | 964.59 | 966.7 | −89.9 | −10.3 |
| 22 | 887.4 | 958.04 | 954.67 | 952.28 | 955.0 | −67.6 | −7.6 |
| 23 | 893.5 | 941.32 | 937.10 | 941.83 | 940.1 | −46.6 | −5.2 |
| 24 | 941.5 | 931.97 | 933.47 | 931.67 | 932.4 | 9.1 | 1.0 |
| 25 | 874.9 | 906.91 | 903.92 | 899.68 | 903.5 | −28.6 | −3.3 |
| 26 | 858.6 | 902.69 | 899.31 | 897.52 | 899.8 | −41.2 | −4.8 |
| 27 | 864.8 | 894.90 | 888.91 | 889.84 | 891.2 | −26.4 | −3.1 |
| 28 | 876.1 | 888.39 | 882.90 | 884.73 | 885.3 | −9.2 | −1.1 |
| 29 | 933.5 | 875.66 | 877.12 | 875.42 | 876.1 | 57.4 | 6.2 |
| 30 | 854.9 | 855.43 | 859.76 | 854.73 | 856.6 | −1.7 | −0.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Doicin, B.; Duşescu-Vasile, C.M.; Onuţu, I.; Băjan, M.; Bomboș, D.; Vasilievici, G. Estimation of Properties of Petrodiesel—Biodiesel Mixtures Using an Artificial Neural Network. Processes 2025, 13, 1769. https://doi.org/10.3390/pr13061769
Doicin B, Duşescu-Vasile CM, Onuţu I, Băjan M, Bomboș D, Vasilievici G. Estimation of Properties of Petrodiesel—Biodiesel Mixtures Using an Artificial Neural Network. Processes. 2025; 13(6):1769. https://doi.org/10.3390/pr13061769
Chicago/Turabian StyleDoicin, Bogdan, Cristina Maria Duşescu-Vasile, Ion Onuţu, Marian Băjan, Dorin Bomboș, and Gabriel Vasilievici. 2025. "Estimation of Properties of Petrodiesel—Biodiesel Mixtures Using an Artificial Neural Network" Processes 13, no. 6: 1769. https://doi.org/10.3390/pr13061769
APA StyleDoicin, B., Duşescu-Vasile, C. M., Onuţu, I., Băjan, M., Bomboș, D., & Vasilievici, G. (2025). Estimation of Properties of Petrodiesel—Biodiesel Mixtures Using an Artificial Neural Network. Processes, 13(6), 1769. https://doi.org/10.3390/pr13061769