
Discrimination of High Impedance Fault in Microgrids: A Rule-Based Ensemble Approach with Supervised Data Discretisation

 ,
,  ,
,  and
and 
Abstract
1. Introduction
- To identify and differentiate HIFs from other transients in a solar PV-integrated MG and IEEE 13 bus network models, a heterogeneous-based voting ensemble model is recommended.
- Applying the discrete wavelet transform (DWT) technique, the features are retrieved from HIF and other transient signals of the MG network.
- Using the supervised discretisation method, the extracted features from the DWT analysis are discretised before learning the ensemble and rule-based individual classifiers.
- The proposed ensemble model’s effectiveness is evaluated by comparing classification accuracy, the successive rate of HIFs, and performance indices (PI) for the ensemble and rule-based individual classifiers under STC and weather intermittency of solar PV in an islanded MG network.
- The proposed ensemble model’s classification accuracy and success rate of HIF are analysed under the noisy environment of even signals.
- A classification study for HIFs and other transients in the IEEE 13 bus standard network is also considered to validate the effectiveness of the suggested ensemble model.
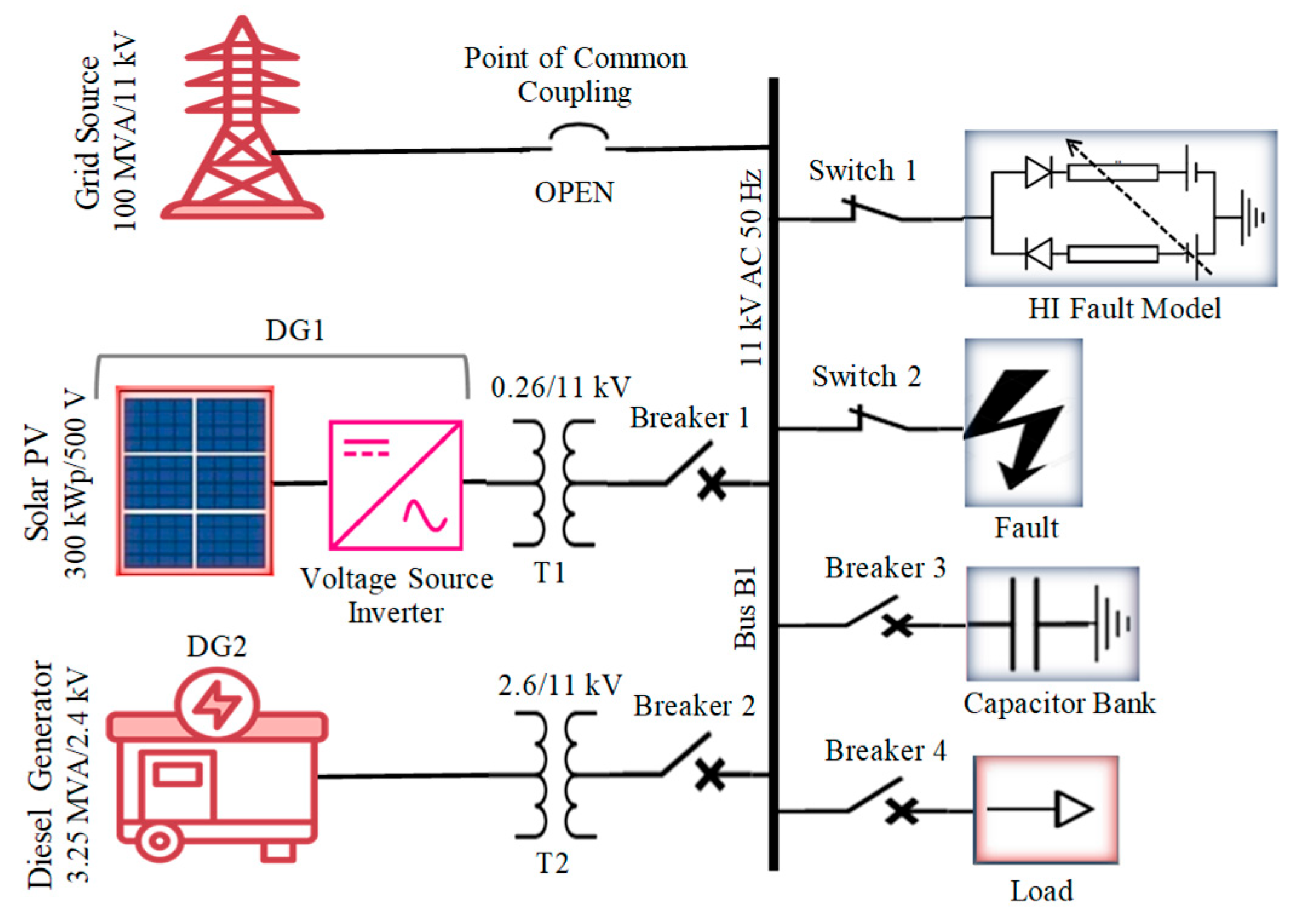
2. Models Studied: PV Connected MG and IEEE 13 Bus Network
- Mode of MG operation: Islanded (point of common coupling breaker open in Grid side);
- Distributed generation source (DG1): Solar PV 300 kWp rated capacity with the implementation of two converters (DC–DC boost converter (280 V/500 V) and DC–AC Inverter (500 V DC/260V AC)) and interconnecting Transformer T1 (0.260 kV/11 kV);
- Distributed generation source (DG2): Diesel engine generator (3.25 MVA, 2.6 kV) with interconnecting transformer T2 (2.6 kV/11 kV);
- Interconnected AC load capacity: maximum 2400 kW (11 kV);
- Maximum capacity of interconnected capacitor bank: maximum 600 kVAR (11 kV);
- Low impedance (LI) faults introduction (line to ground (LG), line to line ground (LLG), all three lines to ground (LLLG), and line to line (LL)) with varying values of fault resistance;
- High-impedance fault (HIF) model configuration: Configured with anti-parallel diodes (D1 and D2), variable resistors (R1 and R2), and variable voltage sources (V1 and V2).
- The network model (operating voltage 4.16 kV) is connected to the source of main grid (100 MVA, 4.16 kV, 50 Hz);
- A 300 kWp capacity of solar PV unit is connected at bus node 680 of network model;
- The interconnecting transformer (300 kVA, 0.26 kV/4.16 kV) integrates the solar PV unit (which includes a boost converter (DC–DC) and voltage source inverter (DC–AC)) at bus node number 680 of the IEEE 13-bus network.
3. Configuration of Studied High Impedance (HI) Fault Model
4. Overview of the Classification Process
5. Initial Processing of Event Signals and Dataset
5.1. Decomposing Signals Using Discrete Wavelet Transform (DWT) Method
5.2. Feature Discretisation
- First, the continuous values of features (XN) are converted into k discrete intervals {[dI0, dI1], [dI1, dI2], …, (dIK-1, dIK]}, in that dI0 and dIK are the minimum and maximum values of the feature X.
- Then, to discretise feature XN, the data are sorted by increasing the value of the feature.
- In the given dataset of DS, with the consideration of feature XN and cut point TP, the class entropy which is partitioned with TP (random select) can be expressed as
6. Classification Methodology
6.1. Decision Table (DT)
6.2. Java Repeated Incremental Pruning (JRIP)
6.3. Partial Decision Tree (PART)
6.4. Proposed Ensemble Classifier
- Training dataset TDS is partitioned into 10 equally sized subsets using the 10-fold cross-validation method: TDS = (TDS1, TDS2, TDS3, …, TDSK); (k = 10).
- Three rule-based classifiers, such as DT (RC1), JRIP (RC2), and PART (RC3) (N = 3), are trained in the initial stage of classification.
- The rule of voting technique “average of probabilities” is applied and described as [45]:
7. Results and Discussion
7.1. Results of DWT Analysis
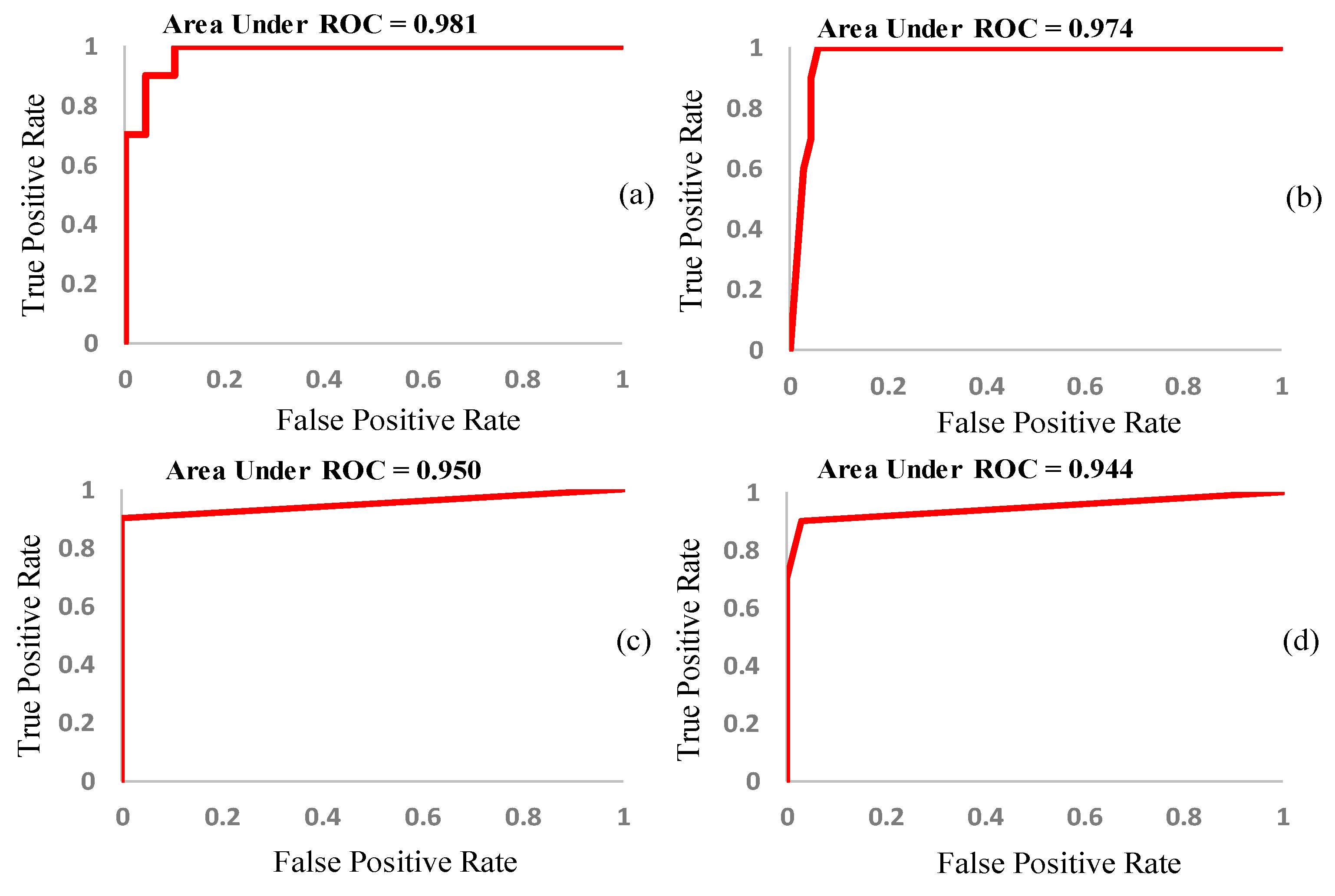
7.2. Results of Classification and Performance Analysis
7.2.1. Classification Results: PV Connected MG (At STC of Solar PV)
7.2.2. Classification Results: IEEE 13 Bus Power Network (At STC of Solar PV)
7.2.3. Results of Performance Measures in PV Connected MG Model (At STC of Solar PV)
7.2.4. Classification Results: PV Connected MG at Weather Intermittency of Solar PV
7.2.5. Classification Results: PV Connected MG Under Noisy Environment of Event Signals
7.2.6. Comparison Between Proposed Voting Ensemble Approach to Existing Methods
8. Conclusions
- Under the STC of solar PV in PV-connected MG, the suggested ensemble classifier with the absence of feature discretisation attains higher classification accuracy (95%) and success rate of HIF (93.3%) than rule-based classifiers and other ML classifiers. Furthermore, the suggested ensemble classifier with the implementation of feature discretisation provides excellent results of accuracy (98.75%) and success rate of HIF (95%) compared to rule-based classifiers and other ML classifiers.
- Under the weather intermittency of solar PV in PV connected MG, the ensemble classifier with the use of the feature discretisation approach attains a higher accuracy (more than 96%) and success rate of HIF (more than 94%).
- Results of performance analysis clearly indicate that the proposed ensemble classifier outperforms rule-based classifiers, both with and without discretisation of features, and a notable improvement in performance level is achieved with feature discretisation.
- Proposed ensemble classifier efficacy is verified by discriminating HIFs and other transients in a bench work model of the IEEE 13 bus network. With the absence of feature discretisation, the ensemble model attains a higher accuracy (93.4%) and a higher success rate of HIF (94.2%). The classification accuracy and success rate of HIF both were improved by 2.5% while training the ensemble classifier with features of discretisation.
- The proposed ensemble classifier also performs well in terms of the accuracy and success rate of HIF even when event signals are included with high amounts of noise.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hatziargyriou, N. (Ed.) Microgrids: Architectures and Control; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Manohar, M.; Koley, E.; Ghosh, S. Reliable protection scheme for PV integrated microgrid using an ensemble classifier approach with real-time validation. IET Sci. Meas. Technol. 2018, 12, 200–208. [Google Scholar] [CrossRef]
- Swarna, K.S.; Vinayagam, A.; Ananth, M.B.; Kumar, P.V.; Veerasamy, V.; Radhakrishnan, P. A KNN based random subspace ensemble classifier for detection and discrimination of high impedance fault in PV integrated power network. Measurement 2022, 187, 110333. [Google Scholar] [CrossRef]
- Ghaderi, A.; Mohammadpour, H.A.; Ginn, H.L.; Shin, Y.-J. High-Impedance Fault Detection in the Distribution Network Using the Time-Frequency-Based Algorithm. IEEE Trans. Power Deliv. 2015, 30, 1260–1268. [Google Scholar] [CrossRef]
- Chaitanya, B.K.; Yadav, A.; Pazoki, M. An intelligent detection of high-impedance faults for distribution lines integrated with distributed generators. IEEE Syst. J. 2019, 14, 870–879. [Google Scholar] [CrossRef]
- Wang, S.; Payman, D. On the use of artificial intelligence for high impedance fault detection and electrical safety. IEEE Trans. Ind. Appl. 2020, 56, 7208–7216. [Google Scholar] [CrossRef]
- Szmajda, M.; Górecki, K.; Mroczka, J. DFT Algorithm analysis in low-cost power quality measurement systems based on a DSP processor. In Proceedings of the 2007 9th International Conference on Electrical Power Quality and Utilisation, Barcelona, Spain, 9–11 October 2007; pp. 1–6. [Google Scholar]
- Santoso, S.; Grady, W.M.; Powers, E.J.; Lamoree, J.; Bhatt, S.C. Characterization of distribution power quality events with fourier and wavelet transforms. IEEE Trans. Power Deliv. 2000, 15, 247–254. [Google Scholar] [CrossRef]
- Gu, Y.H.; Bollen, M.H.J. Time-frequency and time-scale domain analysis of voltage disturbances. IEEE Trans. Power Deliv. 2000, 15, 1279–1284. [Google Scholar] [CrossRef]
- Ge, B.; Wu, X.; Liu, Y.; Zhang, Z.; Yang, F. Influence research of renewable energy application on power quality detection. IOP Conf. Ser. Earth Environ. Sci. 2018, 168, 012033. [Google Scholar]
- Zhao, F.; Yang, R. Power quality disturbance recognition using S-transform. In Proceedings of the 2006 IEEE Power Engineering Society General Meeting, Montreal, QC, Canada, 18–22 June 2006; p. 7. [Google Scholar]
- Veerasamy, V.; Wahab, N.I.A.; Ramachandran, R.; Thirumeni, M.; Subramanian, C.; Othman, M.L.; Hizam, H. High-impedance fault detection in mediumvoltage distribution network using computational intelligence-based classifiers. Neural Comput. Appl. 2019, 31, 9127–9143. [Google Scholar] [CrossRef]
- Radhakrishnan, P.; Ramaiyan, K.; Vinayagam, A.; Veerasamy, V. A stacking ensemble classification model for detection and classification of power quality disturbances in PV integrated power network. Measurement 2021, 175, 109025. [Google Scholar] [CrossRef]
- Veerasamy, V.; Wahab, N.I.A.; Othman, M.L.; Padmanaban, S.; Sekar, K.; Ramachandran, R.; Islam, M.Z. LSTM recurrent neural network classifier for high impedance fault detection in solar PV integrated power system. IEEE Access 2021, 9, 32672–32687. [Google Scholar] [CrossRef]
- Lustgarten, J.L.; Gopalakrishnan, V.; Grover, H.; Visweswaran, S. Improving classification performance with discretisation on biomedical datasets. AMIA Annu. Symp. Proc. 2008, 2008, 445–449. [Google Scholar] [PubMed]
- Witten, I.H.; Frank, E. Data mining: Practical machine learning tools and techniques with Java implementations. ACM Sigmod. Record. 2002, 31, 76–77. [Google Scholar] [CrossRef]
- Liu, H.; Hussain, F.; Tan, C.L.; Dash, M. Discretisation: An enabling technique. Data Min. Knowl. Discov. 2002, 6, 393–423. [Google Scholar] [CrossRef]
- Toulabinejad, E.; Mirsafaei, M.; Basiri, A. Supervised discretisation of continuous-valued attributes for classification using RACER algorithm. Expert Syst. Appl. 2023, 244, 121203. [Google Scholar] [CrossRef]
- Sekar, K.; Mohanty, N.K.; Sahoo, A.K. High impedance fault detection using wavelet transform. In Proceedings of the Technologies for Smart-City Energy Security and Power (ICSESP), Bhubaneswar, India, 28–30 March 2018; pp. 1–6. [Google Scholar]
- Baqui, I.; Zamora; Mazón, J.; Buigues, G. High impedance fault detection methodology using wavelet transform and artificial neural networks. Electr. Power Syst. Res. 2011, 81, 1325–1333. [Google Scholar] [CrossRef]
- Yang, M.T.; Gu, J.C.; Guan, J.L.; Cheng, C.Y. Evaluation of algorithms for high impedance faults identification based on staged fault tests. In Proceedings of the IEEE Power Engineering Society General Meeting, Montreal, QC, Canada, 18–22 June 2006; p. 8. [Google Scholar]
- Sarlak, M.; Shahrtash, S.M. SVM-based method for high-impedance faults detection in distribution networks. COMPEL-Int. J. Comput. Math. Electr. Electron. Eng. 2011, 30, 431–450. [Google Scholar] [CrossRef]
- Sahoo, S.; Baran, M.E. A method to detect high impedance faults in distribution feeders. In Proceedings of the T&D Conference and Exposition, 2014 IEEE PES, Chicago, IL, USA, 14–17 April 2014; pp. 1–6. [Google Scholar]
- Veerasamy, V.; Abdul Wahab, N.I.; Vinayagam, A.; Othman, M.L.; Ramachandran, R.; Inbamani, A.; Hizam, H. A novel discrete wavelet transform-based graphical language classifier for identification of high-impedance fault in distribution power system. Int. Trans. Electr. Energy Syst. 2020, 30, e12378. [Google Scholar] [CrossRef]
- Abohagar, A.A.; Mustafa, M.W.; Al-geelani, N.A. Hybrid algorithm for detection of high impedance arcing fault in overhead transmission system. Int. J. Electron. Electr. Eng. 2012, 2, 18. [Google Scholar]
- Samantaray, S.R.; Panigrahi, B.K.; Dash, P.K. High impedance fault detection in power distribution networks using time–frequency transform and probabilistic neural network. IET Gener. Transm. Distrib. 2008, 2, 261–270. [Google Scholar] [CrossRef]
- Mishra, M.; Rout, P. Detection and Classification of Micro-grid Faults Based on HHT and Machine Learning Techniques. IET Gener. Transm. Distrib. 2017, 12, 388–397. [Google Scholar] [CrossRef]
- Kavi, M.; Mishra, Y.; Vilathgamuwa, M. Challenges in high impedance fault detection due to increasing penetration of photovoltaics in radial distribution feeder. In Proceedings of the 2017 IEEE Power & Energy Society General Meeting, Chicago, IL, USA, 16–20 July 2017; pp. 1–5. [Google Scholar]
- Niu, G.; Han, T.; Yang, B.S.; Tan, A.C.C. Multi-agent decision fusion for motor fault diagnosis. Mech. Syst. Signal Process. 2007, 21, 1285–1299. [Google Scholar] [CrossRef]
- Azizi, R.; Seker, S. Microgrid fault detection and classification based on the boosting ensemble method with the Hilbert-Huang transform. IEEE Trans. Power Deliv. 2021, 37, 2289–2300. [Google Scholar] [CrossRef]
- Mishra, P.K.; Yadav, A.; Pazoki, M. A novel fault classification scheme for series capacitor compensated transmission line based on bagged tree ensemble classifier. IEEE Access 2018, 6, 27373–27382. [Google Scholar] [CrossRef]
- Balakrishnan, P.; Gopinath, S. A new intelligent scheme for power system faults detection and classification: A hybrid technique. Int. J. Numer. Model. Electron. Netw. Devices Fields 2020, 33, e2728. [Google Scholar] [CrossRef]
- Samantaray, S.R. Ensemble decision trees for high impedance fault detection in power distribution network. Int. J. Electr. Power Energy Syst. 2012, 43, 1048–1055. [Google Scholar] [CrossRef]
- Vinayagam, A.; Veerasamy, V.; Tariq, M.; Aziz, A. Heterogeneous learning method of ensemble classifiers for identification and classification of power quality events and fault transients in wind power integrated microgrid. Sustain. Energy Grids Netw. 2022, 31, 100752. [Google Scholar] [CrossRef]
- Farid, D.M.; Al-Mamun, M.A.; Manderick, B.; Nowe, A. An adaptive rule-based classifier for mining big biological data. Expert Syst. Appl. 2016, 64, 305–316. [Google Scholar] [CrossRef]
- Azim, R.; Li, F.; Xue, Y.; Starke, M.; Wang, H. An islanding detection methodology combining decision trees and Sandia frequency shift for inverter-based distributed generations. IET Gener. Transm. Distrib. 2017, 11, 4104–4113. [Google Scholar] [CrossRef]
- Dehghani, H.; Vahidi, B.; Naghizadeh, R.A.; Hosseinian, S.H. Power quality disturbance classification using a statistical and wavelet-based hidden Markov model with Dempster–Shafer algorithm. Int. J. Electr. Power Energy Syst. 2013, 47, 368–377. [Google Scholar] [CrossRef]
- Ares, B.; Morán-Fernández, L.; Bolón-Canedo, V. Reduced precision discretisation based on information theory. Procedia Comput. Sci. 2022, 207, 887–896. [Google Scholar] [CrossRef]
- Jamali, S.; Ranjbar, S.; Bahmanyar, A. Identification of faulted line section in microgrids using data mining method based on feature discretisation. Int. Trans. Electr. Energy Syst. 2020, 30, e12353. [Google Scholar] [CrossRef]
- Huang, J.; Ling, S.; Wu, X.; Deng, R. GIS-based comparative study of the bayesian network, decision table, radial basis function network and stochastic gradient descent for the spatial prediction of landslide susceptibility. Land 2022, 11, 436. [Google Scholar] [CrossRef]
- Pham, B.T.; Luu, C.; Van Phong, T.; Nguyen, H.D.; Van Le, H.; Tran, T.Q.; Ta, H.T.; Prakash, I. Flood risk assessment using hybrid artificial intelligence models integrated with multi-criteria decision analysis in Quang Nam Province, Vietnam. J. Hydrol. 2021, 592, 125815. [Google Scholar] [CrossRef]
- Mala, I.; Akhtar, P.; Ali, T.J.; Zia, S.S. Fuzzy rule based classification for heart dataset using fuzzy decision tree algorithm based on fuzzy RDBMS. World Appl. Sci. J 2013, 28, 1331–1335. [Google Scholar]
- Mazid, M.M.; Ali, A.S.; Tickle, K.S. Input space reduction for rule based classification. WSEAS Trans. Inf. Sci. Appl. 2010, 7, 749–759. [Google Scholar]
- Ozturk Kiyak, E.; Tuysuzoglu, G.; Birant, D. Partial Decision Tree Forest: A Machine Learning Model for the Geosciences. Minerals 2023, 13, 800. [Google Scholar] [CrossRef]
- Chaudhary, A.; Kolhe, S.; Kamal, R. A hybrid ensemble for classification in multiclass datasets: An application to oilseed disease dataset. Comput. Electron. Agric. 2016, 124, 65–72. [Google Scholar] [CrossRef]
- Muniyandi, A.P.; Rajeswari, R.; Rajaram, R. Network anomaly detection by cascading k-Means clustering and C4.5 decision tree algorithm. Procedia Eng. 2012, 30, 174–182. [Google Scholar] [CrossRef]
- Waqar, H.; Bukhari, S.B.A.; Wadood, A.; Albalawi, H.; Mehmood, K.K. Fault identification, classification, and localization in microgrids using superimposed components and Wigner distribution function. Front. Energy Res. 2024, 12, 1379475. [Google Scholar] [CrossRef]
- Grcić, I.; Pandžić, H. High-Impedance Fault Detection in DC Microgrid Lines Using Open-Set Recognition. Appl. Sci. 2024, 15, 193. [Google Scholar] [CrossRef]
- Fahim, R.; Shahriar; Sarker, S.K.; Muyeen, S.M.; Sheikh, M.R.I.; Das, S.K. Microgrid fault detection and classification: Machine learning based approach, comparison, and reviews. Energies 2020, 13, 3460. [Google Scholar] [CrossRef]
- Pan, P.; Mandal, R.K.; Akanda, M.M.R.R. Fault classification with convolutional neural networks for microgrid systems. Int. Trans. Electr. Energy Syst. 2022, 2022, 8431450. [Google Scholar] [CrossRef]
- Singh, O.J.; Winston, D.P.; Babu, B.C.; Kalyani, S.; Kumar, B.P.; Saravanan, M.; Christabel, S.C. Robust detection of real-time power quality disturbances under noisy condition using FTDD features. Autom. Časopis Autom. Mjer. Elektron. Računarstvo Komun. 2019, 60, 11–18. [Google Scholar]
- Narasimhulu, N.; Kumar, D.V.A.; Kumar, M.V. Detection of High Impedance Faults Using Extended Kalman Filter with RNN in Distribution System. J. Green Eng. 2020, 10, 2516–2546. [Google Scholar]
- Patnaik, B.; Mishra, M.; Bansal, R.C.; Jena, R.K. MODWT-XGBoost based smart energy solution for fault detection and classification in a smart microgrid. Appl. Energy 2021, 285, 116457. [Google Scholar] [CrossRef]
- Shihabudheen, K.V.; Gupta, S. Detection of high impedance faults in power lines using empirical mode decomposition with intelligent classification techniques. Comput. Electr. Eng. 2023, 109, 108770. [Google Scholar]
- Vinayagam, A.; Suganthi, S.T.; Venkatramanan, C.B.; Alateeq, A.; Alassaf, A.; Aziz, N.F.A.; Mansor, M.H.; Mekhilef, S. Discrimination of high impedance fault in microgrid power network using semi-supervised machine learning algorithm. Ain Shams Eng. J. 2025, 16, 103187. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High Impedance Fault | ||||
|---|---|---|---|---|
| Range of Resistance Values (R1 and R2) | Range of Voltage Level (V1 and V2) | Characteristics of HIF Current | Method of Variation | Type of Surface |
| 0.12 kΩ to 1.2 kΩ | 0.5 kV to 3.2 kV | High current and sustained arc | Resistance values varied randomly | Wet soil |
| 0.8 kΩ to 2.2 kΩ | 3.5 kV to 6.5 kV | Moderate current build-up and arc | Voltage +/−5% Resistance +/−10% | Grass |
| 1.5 kΩ to 3 kΩ | 4.2 kV to 7.5 kV | Low, intermittent arc sustain | step change +/−10% in R1/R2 per half cycle | Asphalt wet |
| 2.3 kΩ to 4 kΩ | 5.2 kV to 8.5 kV | Low current and arc extinction frequent | R1/R2 values randomly varied every 2 ms | Dry soil |
| 3 kΩ to 5.2 kΩ | 6.2 kV to 10 kV | sporadic arc and very low current (less than 5 amps) | R1/R2 values randomly varied every 10 ms | Dry concrete |
| Low Impedance (LI) Fault | ||||
| Varying fault resistances between 8 Ω and 115 Ω in various time steps | ||||
| Capacitor switching transient (CST) | ||||
| Switching on capacitor between 200 kVAR and 600 kVAR in different time steps | ||||
| Load switching transient (LST) | ||||
| Switching on load between 500 kW and 2400 kW in different time steps | ||||
| Range | Number of Subset | Class |
|---|---|---|
| {-inf–50,350,000} | 12 | Capacitor switching transient (CST) |
| {50,350,000–50,800,000} | 5 | High iImpedance fault (HIF) |
| {50,800,000–55,250,000} | 10 | Load switching transient (LST) |
| {55,250,000–2,924,850,000} | 3 | High impedance fault (HIF) |
| {2,924,850,000–5,805,000,000} | 10 | Normal |
| {5,805,000,000–5,885,000,000} | 4 | Line to line ground (LLG) |
| {5,885,000,000–5,955,000,000} | 11 | Line to ground (LG) |
| {5,955,000,000–6,000,000,000} | 9 | Line to line (LL) |
| {6,000,000,000–6,600,000,000} | 6 | All the lines to ground (LLLG) |
| {6,600,000,000–inf} | 10 | All the lines to ground (LLLG) |
| DT Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 87.5 | 83.3 |
| 0 | 96 | 12 | 0 | 12 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 20 | 100 | 0 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 8 | 0 | 0 | 108 | 4 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 20 | 0 | 10 | 90 | 0 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 0 | 0 | 100 | 8 | 12 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 12 | 108 | 0 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 2 | 118 | PS8 | CST | ||
| JRIP Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 88.75 | 85 |
| 0 | 112 | 0 | 8 | 0 | 0 | 0 | 0 | PS2 | LG | ||
| 12 | 0 | 108 | 0 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 14 | 106 | 0 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 0 | 0 | 12 | 100 | 8 | 0 | 0 | PS5 | LL | ||
| 4 | 0 | 4 | 10 | 0 | 102 | 0 | 0 | PS6 | HIF | ||
| 12 | 0 | 0 | 0 | 0 | 12 | 96 | 0 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 12 | 108 | PS8 | CST | ||
| PART Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 91.25 | 90 |
| 0 | 120 | 0 | 0 | 0 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 0 | 108 | 12 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 0 | 112 | 8 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 0 | 0 | 4 | 116 | 0 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 12 | 0 | 108 | 0 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 12 | 96 | 12 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 12 | 12 | 96 | PS8 | CST | ||
| Voting Ensemble Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 95 | 93.3 |
| 0 | 120 | 0 | 0 | 0 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 0 | 120 | 0 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 0 | 112 | 8 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 0 | 12 | 0 | 108 | 0 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 8 | 0 | 112 | 0 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 6 | 110 | 4 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 10 | 110 | PS8 | CST | ||
| DT Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 91.25 | 85.8 |
| 0 | 108 | 0 | 0 | 12 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 8 | 107 | 5 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 12 | 0 | 0 | 108 | 0 | 0 | 0 | 0 | PS4 | LLLG | ||
| 12 | 12 | 0 | 0 | 96 | 0 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 0 | 0 | 103 | 5 | 12 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 6 | 114 | 0 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 120 | PS8 | CST | ||
| JRIP Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 92.5 | 87.5 |
| 0 | 108 | 0 | 0 | 12 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 8 | 112 | 0 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 10 | 110 | 0 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 12 | 0 | 10 | 98 | 0 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 0 | 0 | 105 | 12 | 3 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 115 | 5 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 120 | PS8 | CST | ||
| PART Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 93.75 | 91.6 |
| 0 | 112 | 8 | 0 | 0 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 12 | 108 | 0 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 0 | 112 | 8 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 0 | 8 | 12 | 100 | 0 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 6 | 0 | 110 | 4 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 118 | 2 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 120 | PS8 | CST | ||
| Voting Ensemble Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 98.75 | 95 |
| 0 | 120 | 0 | 0 | 0 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 0 | 118 | 2 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 0 | 118 | 2 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 0 | 2 | 0 | 118 | 0 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 6 | 0 | 114 | 0 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 120 | 0 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 120 | PS8 | CST | ||
| SVM Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 87.9 | 85.0 |
| 0 | 100 | 8 | 8 | 4 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 8 | 106 | 6 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 4 | 108 | 8 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 8 | 12 | 8 | 92 | 0 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 6 | 0 | 102 | 12 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 10 | 104 | 6 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 8 | 112 | PS8 | CST | ||
| MLP-NN Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 90.0 | 86.6 |
| 0 | 112 | 8 | 0 | 0 | 0 | 0 | 0 | PS2 | LG | ||
| 8 | 0 | 112 | 0 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 8 | 8 | 104 | 0 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 0 | 0 | 8 | 104 | 8 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 4 | 8 | 0 | 104 | 4 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 12 | 100 | 8 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 6 | 6 | 108 | PS8 | CST | ||
| SVM Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 91.5 | 86.6 |
| 0 | 108 | 4 | 4 | 4 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 6 | 108 | 6 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 4 | 108 | 8 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 4 | 6 | 4 | 106 | 0 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 6 | 0 | 104 | 10 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 6 | 108 | 6 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 0 | 4 | 116 | PS8 | CST | ||
| MLP-NN Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 92.7 | 88.3 |
| 0 | 116 | 4 | 0 | 0 | 0 | 0 | 0 | PS2 | LG | ||
| 6 | 0 | 114 | 0 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 8 | 6 | 106 | 0 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 0 | 0 | 6 | 106 | 8 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 4 | 6 | 0 | 106 | 4 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 6 | 110 | 4 | PS7 | LST | ||
| 0 | 0 | 0 | 0 | 0 | 4 | 4 | 112 | PS8 | CST | ||
| Without Discretisation | ||||
|---|---|---|---|---|
| Classifiers | Correctly Classified Instances | Incorrectly Classified Instances | Overall Accuracy (%) | HIF Success Rate (%) |
| DT | 840 | 120 | 87.5 | 83.3 |
| JRIP | 852 | 108 | 88.75 | 85 |
| PART | 876 | 84 | 91.25 | 90 |
| SVM | 844 | 116 | 87.9 | 85 |
| MLP-NN | 864 | 96 | 90 | 86.6 |
| Ensemble | 912 | 48 | 95 | 93.3 |
| With Discretisation | ||||
| DT | 876 | 84 | 91.25 | 85.8 |
| JRIP | 888 | 72 | 92.5 | 87.5 |
| PART | 900 | 60 | 93.75 | 91.6 |
| SVM | 878 | 82 | 91.5 | 86.6 |
| MLP-NN | 890 | 70 | 92.7 | 88.3 |
| Ensemble | 948 | 12 | 98.75 | 95 |
| Voting Ensemble Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 93.4 | 94.2 |
| 0 | 120 | 0 | 0 | 0 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 0 | 118 | 2 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 8 | 112 | 0 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 0 | 0 | 0 | 106 | 6 | 8 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 0 | 0 | 113 | 7 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 8 | 104 | 8 | PS7 | LST | ||
| 0 | 0 | 8 | 0 | 8 | 0 | 0 | 104 | PS8 | CST | ||
| Voting Ensemble Classifier | Accuracy (%) | HIF Success Rate (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| PS1 | PS2 | PS3 | PS4 | PS5 | PS6 | PS7 | PS8 | Class | |||
| 120 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | PS1 | Normal | 95.8 | 96.6 |
| 0 | 120 | 0 | 0 | 0 | 0 | 0 | 0 | PS2 | LG | ||
| 0 | 0 | 120 | 0 | 0 | 0 | 0 | 0 | PS3 | LLG | ||
| 0 | 0 | 6 | 114 | 0 | 0 | 0 | 0 | PS4 | LLLG | ||
| 0 | 0 | 0 | 0 | 112 | 8 | 0 | 0 | PS5 | LL | ||
| 0 | 0 | 0 | 0 | 0 | 116 | 4 | 0 | PS6 | HIF | ||
| 0 | 0 | 0 | 0 | 0 | 4 | 108 | 8 | PS7 | LST | ||
| 0 | 0 | 6 | 0 | 4 | 0 | 0 | 110 | PS8 | CST | ||
| Results | PV Connected MG | IEEE 13 Bus Network | Features Discretisation |
|---|---|---|---|
| Classification accuracy (%) | 95.0 | 93.4 | without |
| HIF success rate (%) | 93.3 | 94.2 | |
| Classification accuracy (%) | 98.75 | 95.8 | with |
| HIF success rate (%) | 95 | 96.6 |
| Without Feature Discretisation | |||||||||
| Class Labels | Events | DT | JRIP | PART | VOTING | ||||
| Classified Instances | Classified Instances | Classified Instances | Classified Instances | ||||||
| Correct | Incorrect | Correct | Incorrect | Correct | Incorrect | Correct | Incorrect | ||
| PS1 | Normal | 120 | 0 | 120 | 0 | 120 | 0 | 120 | 0 |
| PS2 | LG | 100 | 20 | 109 | 11 | 118 | 2 | 118 | 2 |
| PS3 | LLG | 96 | 24 | 110 | 10 | 110 | 10 | 118 | 2 |
| PS4 | LLLG | 102 | 18 | 102 | 18 | 104 | 16 | 110 | 10 |
| PS5 | LL | 90 | 28 | 96 | 24 | 114 | 6 | 104 | 16 |
| PS6 | HIF | 96 | 24 | 99 | 21 | 105 | 15 | 108 | 12 |
| PS7 | LST | 102 | 18 | 90 | 30 | 95 | 25 | 106 | 14 |
| PS8 | CST | 112 | 8 | 102 | 18 | 98 | 22 | 106 | 14 |
| Overall accuracy (%) | 85.2 | 86.25 | 90 | 92.7 | |||||
| HIF Success Rate (%) | 80 | 82.5 | 87.5 | 90 | |||||
| With Feature Discretisation | |||||||||
| Class Labels | Events | DT | JRIP | PART | VOTING | ||||
| Classified Instances | Classified Instances | Classified Instances | Classified Instances | ||||||
| Correct | Incorrect | Correct | Incorrect | Correct | Incorrect | Correct | Incorrect | ||
| PS1 | Normal | 120 | 0 | 120 | 0 | 120 | 0 | 120 | 0 |
| PS2 | LG | 108 | 12 | 116 | 4 | 120 | 0 | 120 | 0 |
| PS3 | LLG | 102 | 18 | 114 | 6 | 114 | 6 | 120 | 0 |
| PS4 | LLLG | 106 | 14 | 106 | 14 | 105 | 15 | 116 | 4 |
| PS5 | LL | 100 | 20 | 104 | 16 | 118 | 2 | 116 | 4 |
| PS6 | HIF | 101 | 19 | 104 | 16 | 109 | 11 | 113 | 7 |
| PS7 | LST | 104 | 16 | 98 | 22 | 98 | 22 | 110 | 10 |
| PS8 | CST | 114 | 6 | 102 | 18 | 100 | 20 | 110 | 10 |
| Overall Accuracy (%) | 89 | 90 | 92 | 96.3 | |||||
| HIF Success Rate (%) | 84.2 | 86.6 | 90.8 | 94.2 | |||||
| Class Events | No Noise | 20 dB | 40 dB | 50 dB | |||
|---|---|---|---|---|---|---|---|
| Accuracy | Mis-Classified Instances | Accuracy | Mis-Classified Instances | Accuracy | Mis-Classified Instances | Accuracy | |
| PS1 | 100 | 5 | 96 | 4 | 97 | 1 | 99 |
| PS2 | 100 | 6 | 95 | 2 | 98 | 1 | 99 |
| PS3 | 98.33 | 6 | 95 | 4 | 97 | 2 | 98 |
| PS4 | 98.33 | 5 | 96 | 4 | 97 | 1 | 99 |
| PS5 | 98.33 | 14 | 88 | 13 | 89 | 10 | 92 |
| PS6 | 95 | 14 | 88 | 11 | 91 | 10 | 92 |
| PS7 | 100 | 13 | 89 | 13 | 89 | 11 | 91 |
| PS8 | 100 | 8 | 93 | 10 | 92 | 7 | 94 |
| Overall Accuracy | 98.75% | 92.5% | 93.75% | 95.5% | |||
| Success rate of HIF | 95% | 88% | 91% | 92% | |||
| Ref. Year | Classifiers | Type of Network | HIF | Symmetrical/ Asymmetrical Faults | Switching Transients | Analysis with Noise Exposure | Overall Accuracy (%) and Computational Cost |
|---|---|---|---|---|---|---|---|
| [52] 2020 | RNN | Radial distribution network | √ | X | √ | X | 91.6 and high |
| [53] 2021 | XGBoost | IEEE 13 bus network | √ | √ | X | √ | 97.22 and moderate |
| [3] 2022 | Random subspace ensemble | IEEE 13 bus network | √ | √ | √ | √ | 93.0 and moderate |
| [54] 2023 | LSTM | IEEE 30 bus network | √ | √ | √ | X | 97.74 and very high |
| [55] 2025 | Semi-supervised | PV connected MG | √ | √ | √ | X | 92.5 and Moderate |
| Proposed | Voting ensemble | PV connected MG and IEEE 13 bus network | √ | √ | √ | √ | 98.75 and below moderate |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vinayagam, A.; Balaji, S.S.; R, M.; Mishra, S.; Alshamayleh, A.; C, B. Discrimination of High Impedance Fault in Microgrids: A Rule-Based Ensemble Approach with Supervised Data Discretisation. Processes 2025, 13, 1751. https://doi.org/10.3390/pr13061751
Vinayagam A, Balaji SS, R M, Mishra S, Alshamayleh A, C B. Discrimination of High Impedance Fault in Microgrids: A Rule-Based Ensemble Approach with Supervised Data Discretisation. Processes. 2025; 13(6):1751. https://doi.org/10.3390/pr13061751
Chicago/Turabian StyleVinayagam, Arangarajan, Suganthi Saravana Balaji, Mohandas R, Soumya Mishra, Ahmad Alshamayleh, and Bharatiraja C. 2025. "Discrimination of High Impedance Fault in Microgrids: A Rule-Based Ensemble Approach with Supervised Data Discretisation" Processes 13, no. 6: 1751. https://doi.org/10.3390/pr13061751
APA StyleVinayagam, A., Balaji, S. S., R, M., Mishra, S., Alshamayleh, A., & C, B. (2025). Discrimination of High Impedance Fault in Microgrids: A Rule-Based Ensemble Approach with Supervised Data Discretisation. Processes, 13(6), 1751. https://doi.org/10.3390/pr13061751