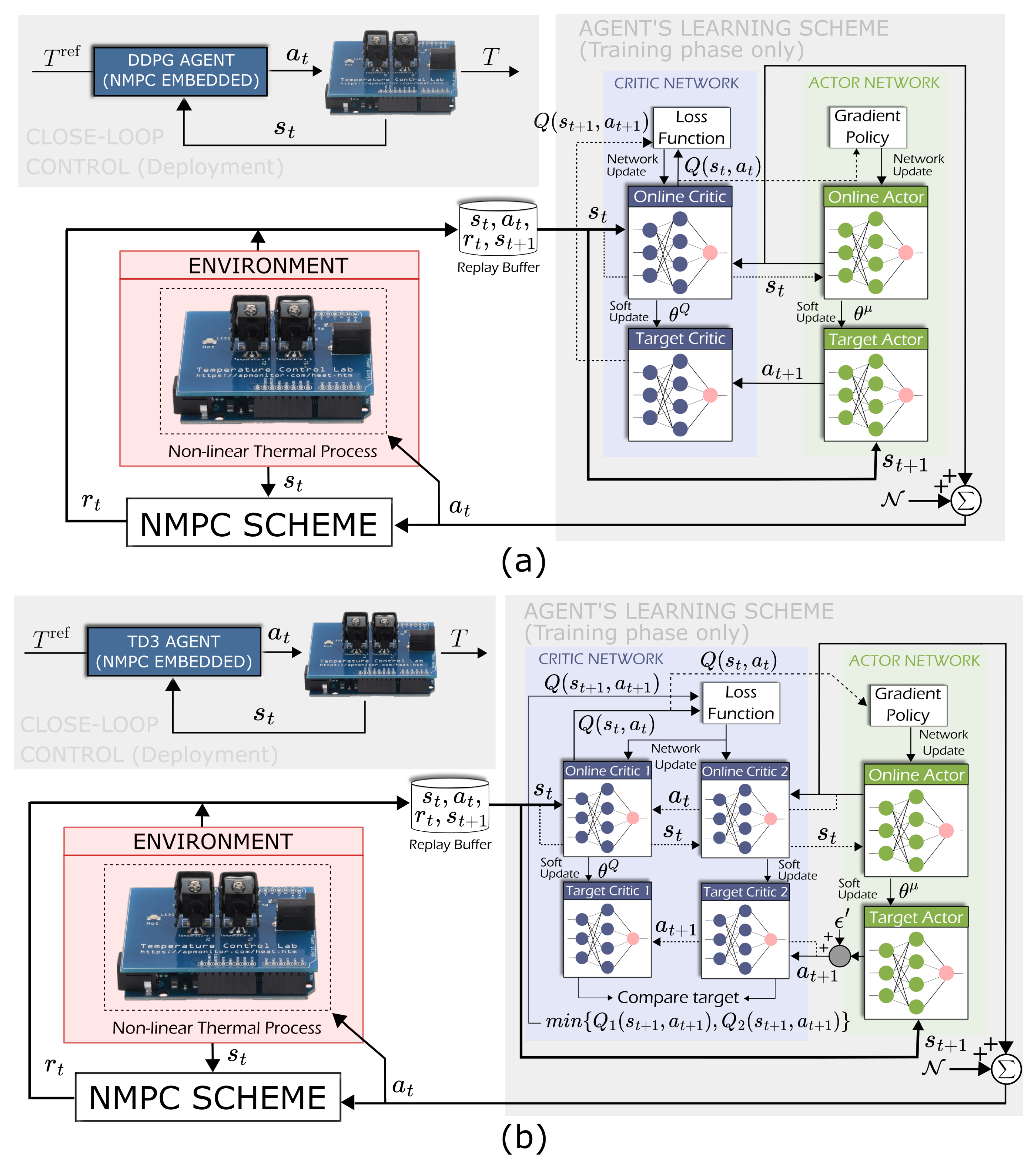
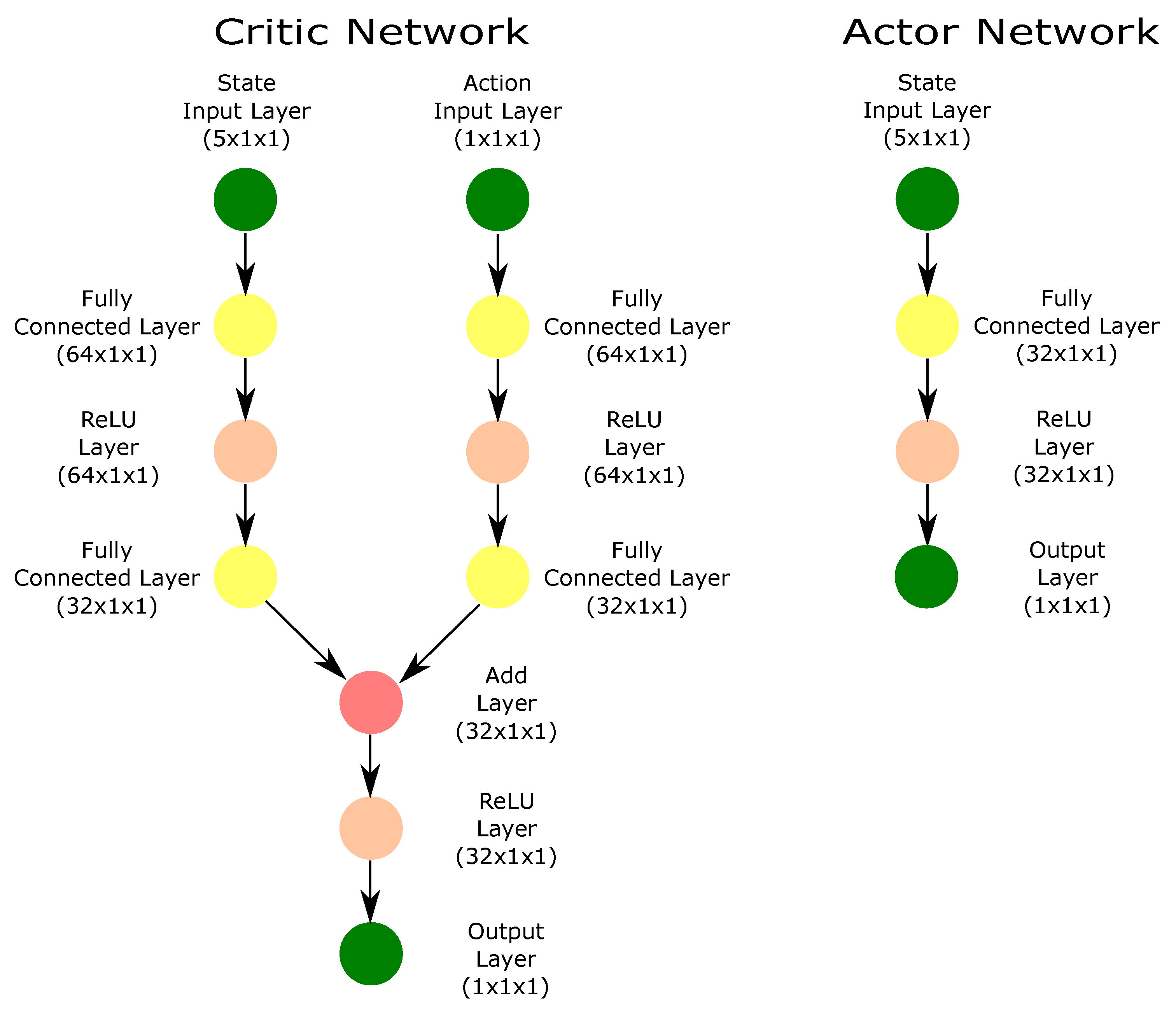
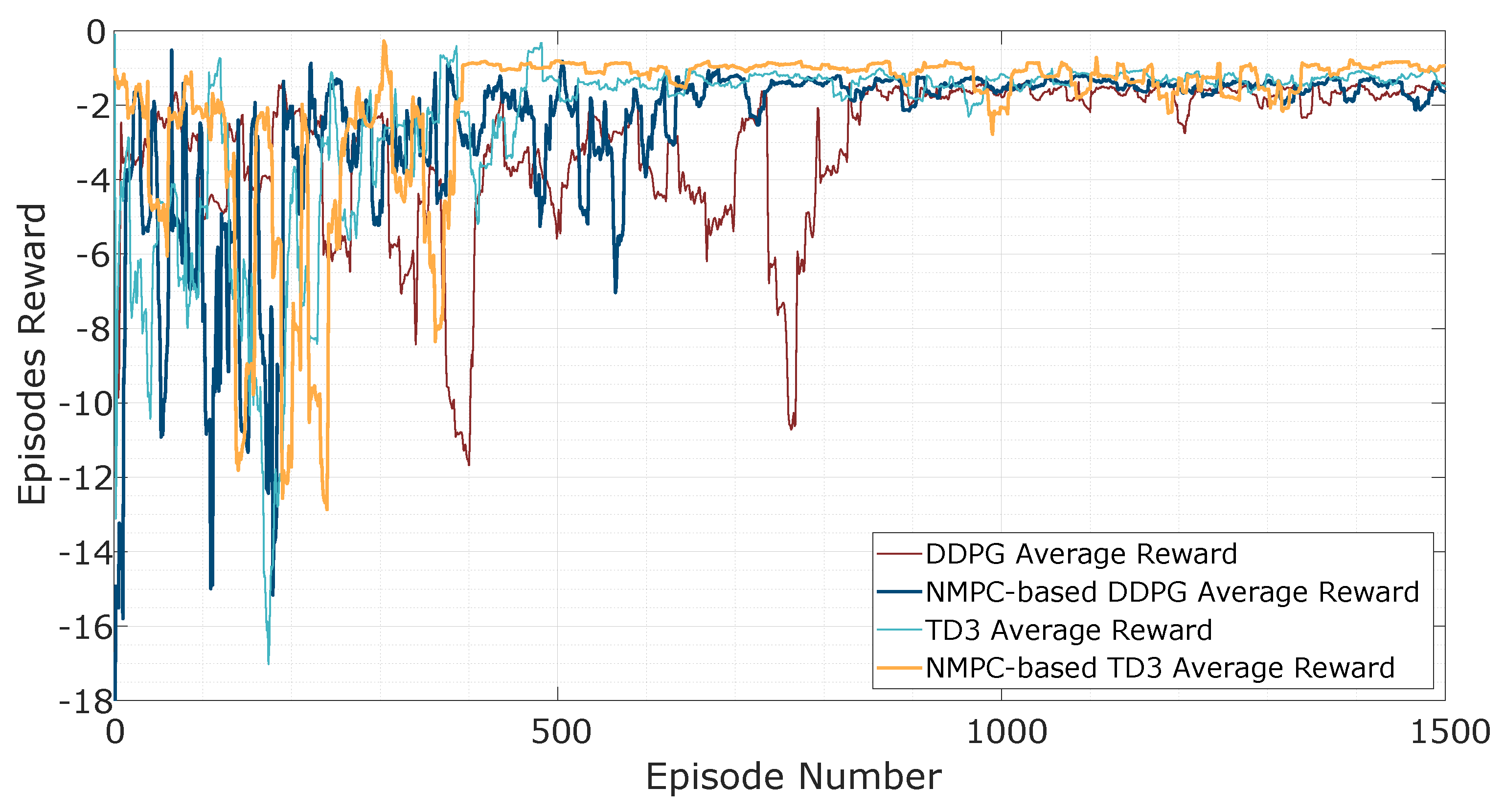
In this section, a control strategy for thermal processes with time delays is presented, integrating NMPC with AC reinforcement learning strategies. Within this framework, NMPC works as a policy generator, providing the trajectory tracking and disturbance rejection objectives to guide the AC agent throughout the learning process. The reward function is derived from the cost function typically formulated in the NMPC optimization problem, ensuring that the AC agent learns to evaluate control actions based on the same performance criteria that govern the baseline controller. The AC agent, implemented through either the deep deterministic policy gradient (DDPG) or twin delayed deep deterministic policy gradient (TD3) methods, assesses control performance by measuring how effectively the thermal process tracks the reference trajectory while simultaneously adapting to disturbances and system uncertainties in real time.
The integration is not only aimed at improving the agent’s learning efficiency but also at enabling adaptive control adjustments based on feedback from the process. Moreover, the proposed controller eliminates the need to compute a terminal cost during the control execution, which is typically required in NMPC and can be computationally intensive for nonlinear system dynamics. By leveraging AC-based approaches, the proposed method enhances adaptability to model uncertainties and varying process conditions, ensuring that the control strategy remains effective even in unpredictable operating environments. In addition, the combination of NMPC and AC strategies is designed to reinforce robust control performance while preserving system stability.
4.2. Nonlinear Model Predictive Control-Driven Reward Strategy
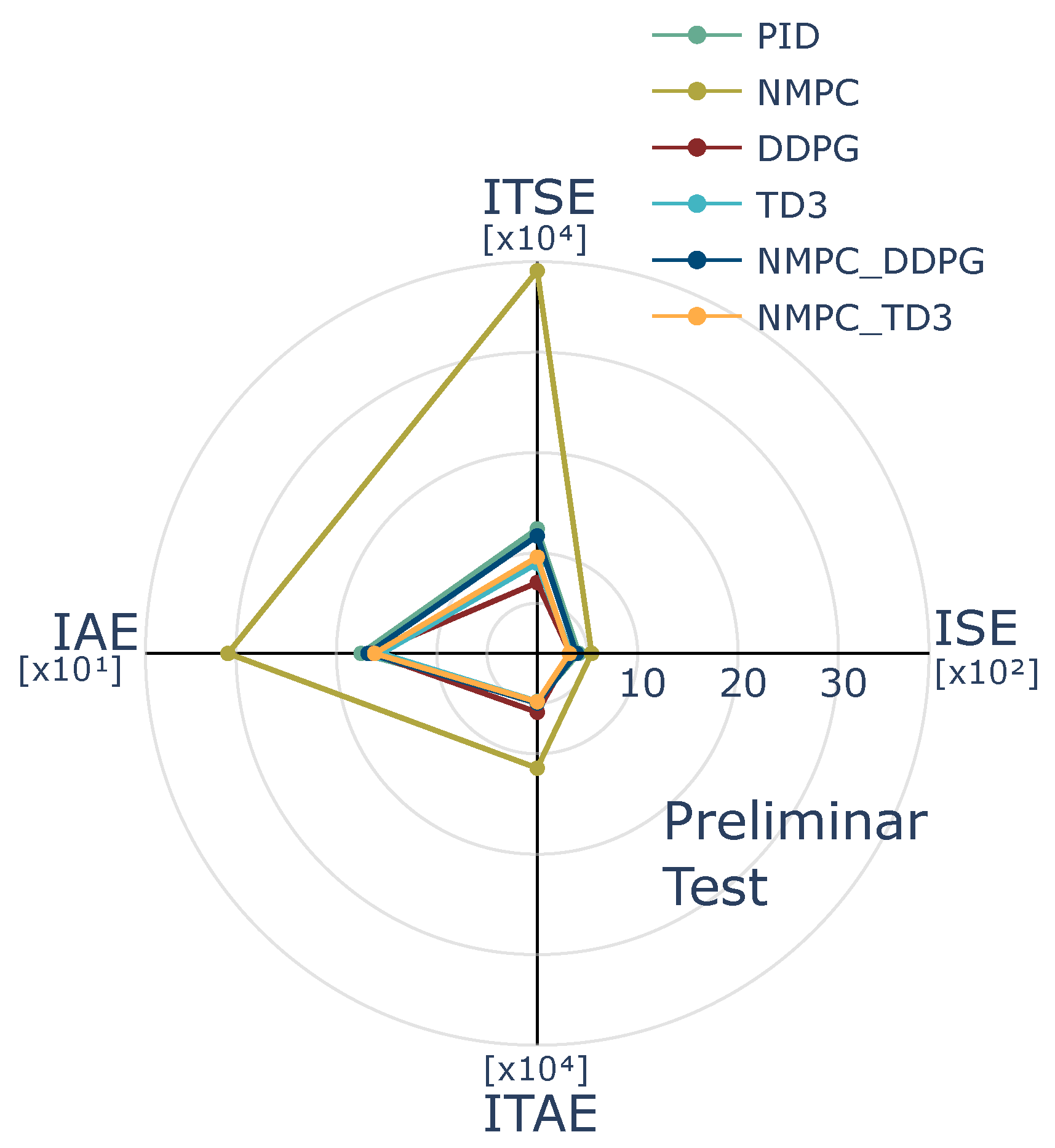
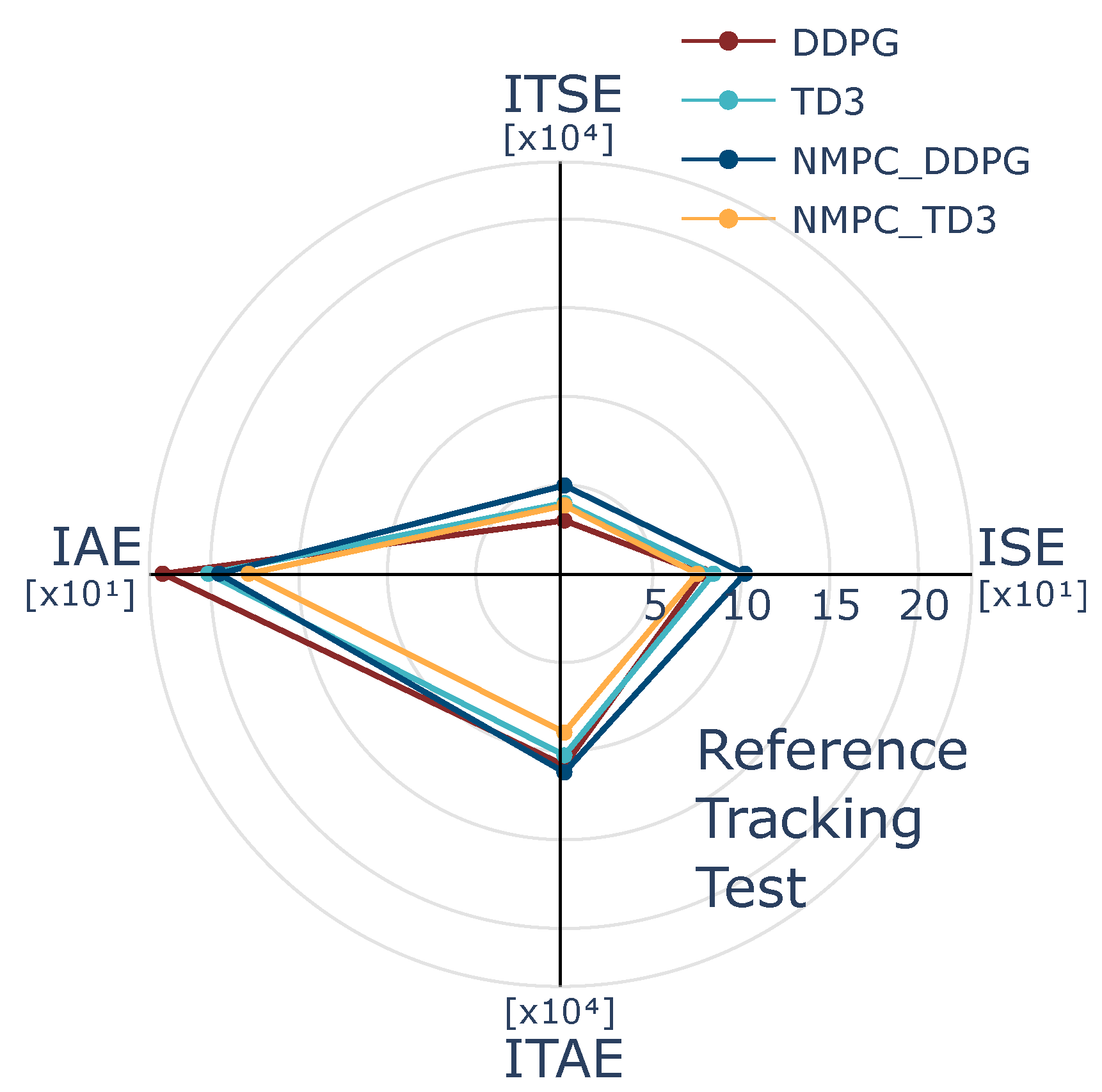
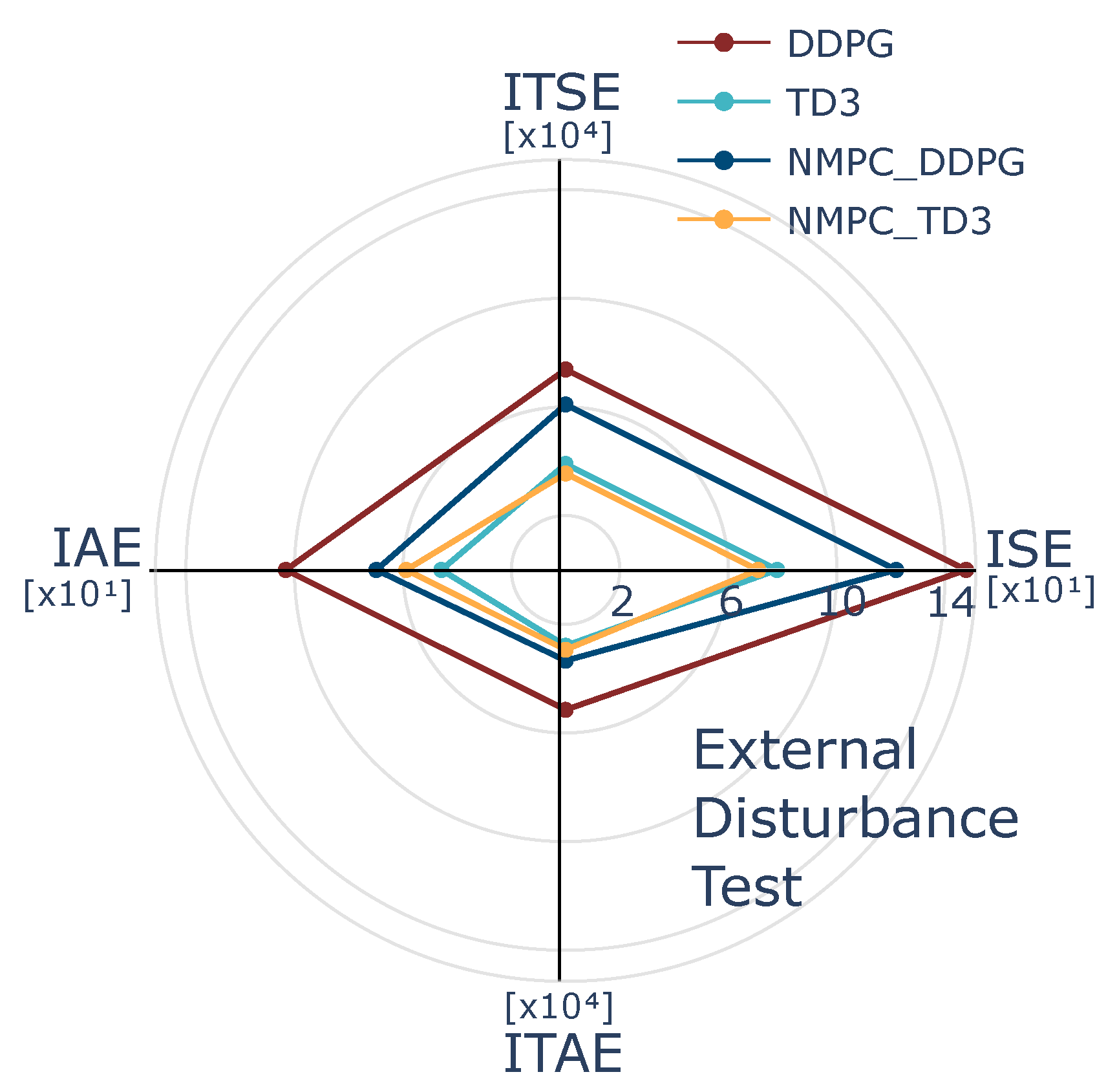
To optimize long-term reward returns in alignment with control objectives, the proposed reward function is formulated based on a NMPC cost function, prioritizing the minimization of both tracking errors and control effort. The agent is designed to improve trajectory tracking accuracy while efficiently regulating control inputs, ensuring robust performance against external disturbances and model uncertainties. Moreover, the agent dynamically adapts the learning to varying process conditions, mitigating the influence of disturbances during control execution. Consequently, the reward function is defined as the minimization of a stage cost function associated with a nominal NMPC problem, explicitly formulated to achieve the desired control objectives. Since the agent is trained using this reward function, the NMPC objectives are implicitly addressed through the minimization of trajectory tracking errors and control effort, subject to feasible state and input constraints. By integrating the reward function within the DRL framework, the proposed approach preserves the advantageous properties of NMPC while leveraging DRL techniques to enhance robustness against disturbances and uncertainties.
The cost function
J that captures the integral control objectives of trajectory tracking and control effort is detailed in Equation (
22), where
and
comprise the nominal system states and control input (i.e., disturbance-free), respectively.
is the prediction horizon, and
is the control horizon. To compute the control input
, an optimization problem (OP) associated with the nominal system dynamics in Equation (
1) is proposed by
with:
subject to:
where
and
represent the state prediction and control horizon, respectively. The term
l denotes the stage cost function that captures the control objectives, whereas
denotes the terminal cost function, which was incorporated during the training phase to ensure stability of the closed-loop system by penalizing deviations from the desired terminal state. While the terminal cost
played a critical role in shaping the NMPC-generated trajectories used for training, its explicit design and evaluation were not required during policy execution. Specifically, once the DRL policy was learned, the terminal cost was no longer explicitly evaluated at runtime. Instead, the agent learned from the terminal state trajectories within the control policy through reward shaping and repeated exposure to NMPC-guided episodes, enabling the execution of a stable control policy without requiring online computation of
. To ensure feasibility throughout the optimization process and meet the control requirements of the thermal system described in Equation (
1), the agent first verifies that the state constraints
and control input constraints
are satisfied. Such constraints are given by
The stage cost function
l encompasses the control objectives of the NMPC controller, which are integrated into the DRL framework for learning tracking and regulation capabilities through exploration and exploitation of the environment, including the minimization of tracking errors and the smoothing of the control input effort. Such a cost function can be described as follows:
where
and
denote state and control input set points, respectively, which are fixed for each episode but changed throughout the training process. In general, weights
S and
R denote positive definite symmetric matrices which provide the ability to tune nominal control performance through the balance between the tracking error and control input effort. It is worth noting that the matrix
is often challenging to compute for nonlinear systems without introducing increased conservativeness, and thus, it is treated as a design parameter. Additionally, due to the inherent non-convexity of the optimization problem caused by nonlinear model constraints, global optimality cannot be guaranteed.
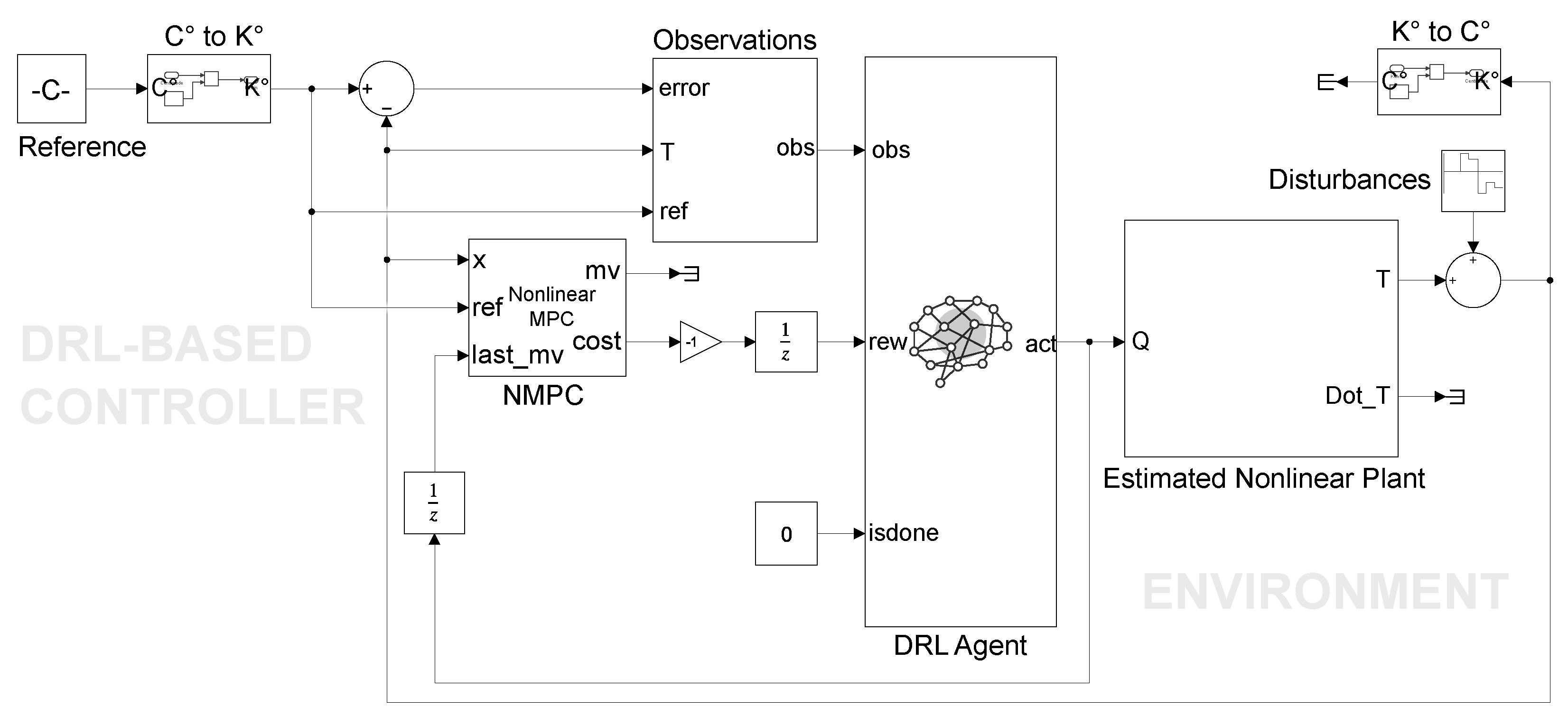
From the DRL perspective, the agent is designed to learn from the nonlinear model following the control objectives raised in an NMPC scheme. Indeed, the control objective for the agent is to use an internal optimization process while adjusting the reward policy according to the stage cost function of the NMPC. The NMPC works as a policy generator, while the DRL strategies evaluate the learning process. Thus, the optimization process incorporates the state
and action
constraints into the learning process, as defined in Equation (
24) and Equation (
25), respectively, and they are specified as follows:
Given that the agent’s goal is to iteratively optimize the NMPC objectives in terms of tracking and disturbance rejection, the optimization problem described in Equation (
22) can be reformulated to integrate the NMPC cost function within a reward policy iteration framework. However, rather than directly optimizing the cost function
J as part of the DRL process, the reward function is designed to ensure that the agent achieves at least the same control objectives that the NMPC strategy targets. This ensures that the learning process remains aligned with the NMPC framework while avoiding the need for building a simultaneous control framework that accounts for additional compensatory or corrective control actions. Specifically, the agent aims to minimize the cost function
J, but rather than directly computing optimal control inputs at each iteration, it relies on a reward function derived from the optimized NMPC cost as follows:
where
represents the stage cost, penalizing both tracking errors and control effort, while
accounts for the terminal cost function addressed to ensure the system stability along the training process. These cost functions are given by
It is worth mentioning that, although the DRL agent does not explicitly solve an optimization problem at each time step, the NMPC remains active throughout the learning process. Consequently, the training stage inherently involves optimization steps for each learning episode; however, the training process remained feasible within practical time constraints. To accelerate the learning process and improve convergence, reward shaping is incorporated by adding an additional shaped reward
, which provides intermediate feedback on the trajectory tracking improvement and control smoothness. Then, the final reward function is expressed as
where
is a weighting factor that balances the influence of the NMPC cost function and the shaped reward
. This shaped reward enables residual learning, allowing the agent to learn from both the global NMPC cost function
J and the local trajectory improvements provided by
, thereby effectively reducing the dependence on frequent NMPC evaluations. The parameter
was selected through a heuristic approach to balance the influence of the NMPC-based reward and the shaped reward
r. To this end, a set of candidate values within the range [0, 1], incremented by 0.1, was evaluated during preliminary simulations. These simulations assessed control performance and stability in terms of cumulative reward and sensitivity to the shaped reward. Based on this assessment,
was identified as the suitable value to be fixed, as it consistently yielded smooth learning and improved trajectory tracking with reduced oscillatory responses during early training. The shaped reward can be defined as a function of the instantaneous tracking error
and control input effort
:
where
and
are positive constants that regulate the penalization of the actual tracking errors and control effort, respectively. The tracking error
and the deviation of the control input from the previous input
are given by:
To improve convergence and learning with the proposed shaped rewards, NMPC generates optimal control sequences for a set of representative initial conditions. These precomputed solutions initialize the policy and value function approximations for the DRL agent, particularly during the early exploration phase. This approach reduces computational overhead while ensuring near-optimal performance and control feasibility. As the DRL agent learns the control policy, the need for real-time NMPC optimization is reduced, allowing the system to operate with minimal computational cost.
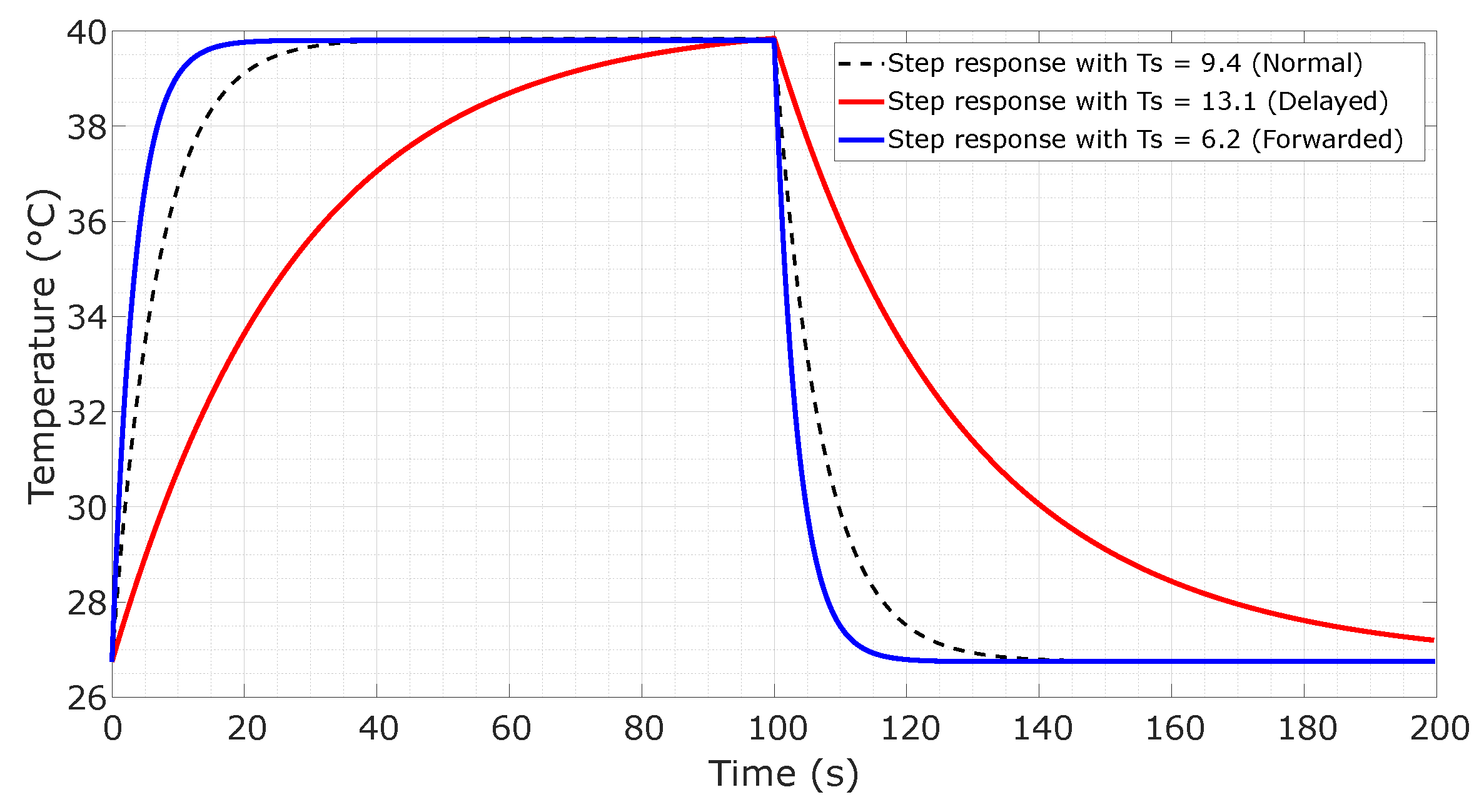
The constraint values and NMPC parameters used in the NMPC-based reward policy function, following tuning for the thermal process, are presented in
Table 3. The computational burden of the proposed control agent typically escalates by increasing the prediction horizon
and control horizon
. However, selecting a relatively small
can degrade control performance, as the agent may fail to adequately learn tracking and regulation. Conversely, an excessively large
limits the ability to execute timely control actions, which is particularly unfavorable given the inherently long time delay in the thermal system dynamics. To address these trade-offs, the horizon lengths were chosen to balance three critical aspects: (i) efficient agent training, (ii) feasibility for real-time implementation, and (iii) robust control performance, particularly under long and variable time delays characteristic of the thermal process. Since the thermal system exhibits relatively slow reaction dynamics in response to reference changes, a confident horizon length was enough to ensure stability. For consistency across all NMPC-based strategies, the prediction and control horizons were set to
and
, respectively.
Remark 1. It is worth highlighting that the terminal cost function, embedded within the NMPC-based reward formulation, was used exclusively during the training phase. Its role was to guide the agent toward stable trajectory generation, leveraging the long-term control objectives associated with NMPC. While a terminal cost term is conventionally included to guarantee theoretical stability under specific model formulations [45], the proposed approach avoids the need for explicit terminal evaluation at runtime. Instead, closed-loop stability emerges from the agent’s learned policy, shaped through repeated exposure to NMPC-generated trajectories and rewards that penalize deviations from the reference. During training, the agent effectively internalized terminal state behavior by being penalized for persistent tracking errors in response to reference variations and external disturbances, thereby ensuring stable performance during deployment without online computation of the terminal cost function . In addition, this approach enabled the proposed controllers to adapt the thermal dynamics to time-varying conditions without need of additional compensatory control actions to mitigate errors induced by disturbances or model uncertainties. Such perturbations were also inherently addressed by the agent as part of the training process, thereby enhancing the robustness of the control strategy. 4.3. Randomized Episodic Training Approach
To train the AC-based learning models, the thermal dynamics described in Equation (
2) were incorporated into the environment, with the system states being represented by the observations
o from Equation (
21), and the control action
a followed the formulation in
Section 4.1. The objective of the AC-based framework is to develop an adaptive control agent, independent of its specific learning architecture and capable of accurately tracking reference temperature trajectories while mitigating uncertainties and disturbances inherent to the thermal process. To achieve such a goal, external variability was intentionally introduced into the exploration and exploitation phases by means of a reference shift parameter that changed episodically, randomly changing based on a uniform probability distribution. This strategy was incorporated to enhance exploration under variable reference conditions, as they changed while tracking over time, thus preventing systematic error accumulations in the reward function and mitigating potential estimation biases. Specifically, considering minimum and maximum temperature values and actions that must satisfy the state and control input constraints outlined in
Table 2, two previously normalized variables were integrated into the training process: (i) an episodic reference temperature variable
, which varied across training episodes for all admissible control inputs, and (ii) an episodic disturbance variable
, which spanned the largest feasible disturbance range. The training parameterization is defined in terms of a randomly generated parameter
, such that the episodic variables are structured as follows:
where
denotes the target training temperature, used to train the agent in tracking time-varying reference trajectories. Likewise,
represents the initial temperature for each training episode, allowing the agent to adapt effectively to varying system conditions. To further enhance robust control performance and strengthen the control system’s ability to reject disturbances, a new episodic parameter is also incorporated into the learning process, as described below:
where
is a stochastic parameter that represents a variable disturbance during training. Similarly, the parameter
p stands for the largest feasible bound of disturbances. Note that alternative observations and reward formulations may be used; however, the proposed reward function is suited for achieving satisfactory performance in practice for the delayed thermal process.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}