1. Introduction
The increasing complexity of environmental pollutants and the growing demand for sustainable analytical methods have positioned
advanced green analytical chemistry (AGAC) as a critical field for modern environmental monitoring [
1]. Traditional techniques such as chromatography and spectroscopy, while effective, often require substantial resources and generate hazardous waste [
2]. Machine learning (ML) has emerged as a powerful tool to enhance predictive capabilities in pollutant analysis, yet centralized training approaches face challenges in scalability and data privacy [
3].
Recent advancements in
federated learning (FL) offer a promising alternative by enabling collaborative model training across distributed datasets without raw data exchange [
4]. However, standard FL frameworks struggle with heterogeneous environmental data, where pollutant characteristics vary significantly across regions or analytical conditions [
5]. Hybrid architectures combining
LSTMs for temporal patterns and
attention mechanisms for feature selection have shown success in localized pollutant prediction [
6], but their integration into federated systems remains underexplored.
We propose a hierarchical federated learning (HFL) framework tailored for AGAC, addressing these gaps through three key innovations:
- (1)
Localized sub-models with hybrid neural architectures (LSTM + attention) to capture region-specific pollutant dynamics while preserving data privacy.
- (2)
Adaptive global aggregation that dynamically weights sub-model contributions based on validation performance and data heterogeneity.
- (3)
End-to-end AGAC integration, where the framework processes analytical instrument outputs (e.g., spectral or chromatographic data) into standardized inputs for distributed training and prediction.
Unlike prior works in FL for environmental monitoring [
7], our approach explicitly handles the high-dimensional, sequential nature of analytical chemistry data. The attention mechanism identifies critical spectral features for organic pollutants [
8], while LSTM layers model temporal trends in sensor or sampling data. This dual capability is essential for AGAC applications, where both instantaneous measurements and longitudinal patterns inform pollutant behavior.
Our framework’s hierarchical architecture deviates from traditional federated learning by incorporating intermediate aggregation strata (for instance, for pollutant categories or geographic clusters) prior to the global model fusion. This innovative design significantly mitigates communication overhead and enhances scalability, which is a crucial advantage for large-scale environmental networks [
9]. Privacy is further enhanced through homomorphic encryption during model updates, aligning with AGAC principles of minimizing hazardous data handling [
10].
The contributions of this work are:
- -
A novel HFL architecture that combines hybrid neural networks with multi-tier aggregation for pollutant prediction, achieving 12.7% higher accuracy than centralized baselines in preliminary experiments.
- -
A privacy-preserving pipeline that interfaces directly with AGAC instruments, standardizing heterogeneous analytical data (e.g., GC-MS, HPLC) into federated training sequences.
- -
Empirical validation on real-world pollutant datasets has demonstrated the robustness of our framework to regional data shifts. Moreover, it has outperformed existing federated learning approaches in terms of computational efficiency.
The remainder of this paper is organized as follows:
Section 2 reviews related work in federated learning and green analytical chemistry.
Section 3 formalizes the problem and introduces key concepts.
Section 4 details our hierarchical framework, while
Section 5 and
Section 6 present experimental results.
Section 7 discusses implications and future directions, followed by conclusions in
Section 8.
2. Related Work
The intersection of machine learning and environmental monitoring has seen significant advancements in recent years, particularly in predictive pollutant analysis. Existing approaches can be broadly categorized into three research directions: (1) centralized machine learning for environmental applications, (2) federated learning architectures, and (3) hybrid neural networks for analytical chemistry.
2.1. Centralized Machine Learning in Environmental Monitoring
Conventional machine learning methodologies for pollutant prediction predominantly hinge upon centralized data aggregation and model training [
11]. These methods have demonstrated success in various applications, from water quality assessment to air pollution forecasting. For instance, deep learning models have been employed to predict PM2.5 concentrations using urban sensor networks [
12]. However, such centralized approaches face limitations in scalability and data privacy, as they require raw environmental data to be aggregated at a single location.
Recent work has explored transfer learning techniques to address data scarcity in localized environmental monitoring [
13]. In these approaches, the temporal distribution matching module serves to bridge the gap between source and target domains. However, it still operates within a centralized framework. Similarly, modular IoT platforms have been developed for air quality prediction [
14], though they typically process sensor data at a central server rather than preserving data locality.
2.2. Federated Learning for Environmental Applications
Federated learning has emerged as a promising alternative to centralized approaches, particularly for applications requiring data privacy and distributed computation [
15]. The basic FL framework enables multiple participants to collaboratively train a shared model while keeping their raw data local. In environmental monitoring, this paradigm aligns well with the distributed nature of pollution sources and measurement systems.
Several studies have adapted FL for specific environmental prediction tasks. For example, the potential of FL for metal pollution monitoring across different geographical regions was demonstrated [
16]. However, these implementations typically use simple model architectures that may not fully capture the complex temporal and spectral patterns in analytical chemistry data.
2.3. Hybrid Neural Networks for Analytical Chemistry
The analysis of environmental pollutants often requires processing high-dimensional sequential data from instruments like GC-MS or LC-MS. Hybrid neural architectures combining recurrent networks with attention mechanisms have shown particular promise for these applications [
17].
The attention mechanism’s ability to identify relevant spectral features has been leveraged in for contaminant identification. Similarly, LSTM networks have proven effective for modeling temporal patterns in environmental sensor data [
18]. However, these approaches have primarily been applied in centralized settings, leaving open questions about their effectiveness in federated environments.
2.4. Green Analytical Chemistry and Machine Learning
The principles of green analytical chemistry emphasize minimizing environmental impact while maintaining analytical performance [
19,
20]. Machine learning can contribute to these goals by reducing reagent consumption through predictive modeling and optimizing analytical workflows [
21]. Recent work has explored the integration of ML with miniaturized analytical systems [
22], though these efforts have not yet fully incorporated distributed learning paradigms.
Our proposed hierarchical federated learning framework addresses several limitations of existing approaches. Unlike centralized methods, it preserves data privacy while maintaining predictive performance. Compared to standard FL implementations, our hybrid architecture better handles the complex temporal and spectral patterns in analytical chemistry data. The hierarchical aggregation scheme provides additional flexibility to accommodate regional variations in pollutant characteristics, a feature absent in prior federated learning applications to environmental monitoring. Furthermore, the framework’s design aligns with green chemistry principles by minimizing data transfer and enabling localized decision making.
3. Background and Preliminaries
To establish the foundation for our hierarchical federated learning framework, we first review essential concepts in environmental monitoring, federated learning, and neural architectures for time-series analysis. These components collectively address the challenges of distributed pollutant prediction while maintaining analytical rigor and data privacy.
3.1. Environmental Monitoring and Analytical Chemistry
Modern environmental monitoring relies on sophisticated analytical techniques to detect and quantify pollutants at trace levels [
23]. Gas chromatography–mass spectrometry (
GC-MS) and liquid chromatography–mass spectrometry (LC-MS) generate high-dimensional time-series data represented as:
where
denotes the mass-to-charge ratio and
the intensity at time step
. Quantitative analysis converts these raw signals into pollutant concentrations through calibration curves:
The heterogeneous nature of environmental samples introduces challenges in data standardization across different monitoring stations. Variations in instrument sensitivity, sampling protocols, and matrix effects create domain shifts that complicate centralized model training [
24]. Moreover, regulatory constraints often prohibit sharing raw analytical data between institutions, necessitating privacy-preserving alternatives to traditional machine learning approaches.
3.2. Federated Learning Fundamentals
Federated learning enables collaborative model training across distributed datasets without centralizing raw data. The standard FL process involves iterative local updates and global aggregation:
where
represents the model parameters at client
,
the learning rate, and
the local dataset. After local training, models are aggregated through:
This basic framework preserves data privacy but faces challenges with non-independent-and-identically-distributed (non-IID) data distributions common in environmental monitoring [
25]. The hierarchical extension addresses these limitations by introducing intermediate aggregation tiers that better accommodate regional variations in pollutant characteristics.
3.3. Neural Networks for Time-Series Analysis
Modeling environmental data requires architectures capable of capturing both temporal dependencies and feature importance. Long short-term memory (LSTM) networks process sequential data through gated mechanisms:
where
and
represent the hidden state and cell state at time
. Attention mechanisms enhance this capability by dynamically weighting relevant features:
The combination of these architectures proves particularly effective for analytical chemistry data, where both temporal patterns (e.g., chromatographic elution profiles) and spectral features (e.g., characteristic fragment ions) contain critical information for pollutant identification [
26]. This hybrid approach forms the basis of our local sub-models in the federated framework.
The integration of these components—analytical chemistry principles, federated learning protocols, and specialized neural architectures—enables our hierarchical framework to address the unique challenges of distributed pollutant prediction while adhering to green chemistry principles of minimal data transfer and localized processing.
4. Hierarchical Federated Learning Framework for Pollutant Prediction
The proposed framework introduces a multi-tiered learning architecture that addresses the challenges of distributed pollutant analysis while preserving data privacy. The system operates through coordinated interactions between localized sub-models and a global aggregator, with specialized neural architectures designed for analytical chemistry data.
4.1. Hierarchical Architecture for Distributed Pollutant Data
The framework organizes participating nodes into a tree-like structure with three distinct tiers: (1) edge devices performing local analysis, (2) regional aggregators handling clusters of similar pollution profiles, and (3) a global model synthesizing knowledge across all regions. Each edge device
maintains a local dataset
containing time-series measurements from analytical instruments, preprocessed into standardized input sequences:
where
represents the dimensionality of spectral or chromatographic features. Regional aggregators
collect updates from
edge devices within their domain, forming intermediate models:
The weights incorporate both data quality metrics and environmental relevance factors specific to pollutant monitoring. This hierarchical decomposition reduces communication overhead by 43% compared to flat federated architectures while maintaining model accuracy.
The preprocessing module first aligns raw instrument outputs (e.g., GC-MS peaks) by retention time or wavelength, then segments them into overlapping sequences. For chromatographic data, peak areas are integrated and normalized to total ion current (TIC), while spectral features are scaled to [0, 1] per wavelength. This ensures compatibility across distributed datasets while preserving critical pollutant signatures.
4.2. Hybrid LSTM-Attention Sub-Model Design and Training
Local sub-models employ a dual-path architecture combining temporal and feature processing streams. The temporal path processes input sequences through stacked LSTM layers:
Simultaneously, the feature path applies multi-head attention to identify critical spectral signatures:
The outputs from both paths concatenate into a joint representation:
This hybrid design achieves 18% higher feature selectivity for organic pollutants compared to standalone architectures. Local training minimizes a composite loss function:
where
measures prediction error,
imposes sparsity constraints, and
ensures diverse attention across spectral regions.
4.3. Dynamic Global Aggregation with Adaptive Weighting
The global aggregator employs performance-sensitive weighting to combine regional models:
The global aggregator uses a performance-sensitive weighting mechanism to dynamically adjust regional model contributions. The weight wj is determined by the validation loss Lj and the data volume |Dj| (Formula (13)). Parameter β (set to 0.5 in experiments) balances performance and fairness. A high β emphasizes low-loss models, whereas a low β promotes more balanced participation.
represents the validation loss of region and its data volume. The temperature parameter controls sensitivity to performance differences, with higher values emphasizing model quality over participation fairness. This adaptive scheme demonstrates 27% better generalization to unseen pollution events compared to static aggregation.
4.4. Privacy-Preserving Integration with Analytical Workflows
The framework interfaces with AGAC instruments through a secure preprocessing module that performs three critical functions: (1) real-time signal standardization, (2) feature extraction, and (3) encrypted data representation. Homomorphic encryption protects model updates during transmission:
where
denotes the public key. The system prioritizes spectral features known to correlate with pollutant toxicity, such as aromatic ring signatures (
) for benzene derivatives. Edge devices implement selective masking to further protect sensitive measurements:
where
is a binary mask preserving only regions relevant to target analytes. This approach reduces data exposure by 68% while maintaining analytical precision.
Beyond input masking, the framework also protects calibration data. Calibration curves are applied locally to convert model outputs (e.g., attention-weighted features) into pollutant concentrations. Each station’s curve parameters (slope, intercept) are encrypted before aggregation, ensuring compliance with green chemistry principles. This decentralized approach avoids exposing raw calibration data while maintaining analytical accuracy.
To mitigate adaptive attacks, the masking protocol MM is dynamically regenerated using a hash of the local model’s attention weights, ensuring feature obfuscation evolves with training. Further, homomorphic encryption (Equation (14)) limits adversaries to ciphertext-only analysis.
The complete framework operates through iterative cycles of local training, regional aggregation, and global synthesis, as illustrated in
Figure 1. Each cycle refines model parameters while preserving the distributed nature of environmental data. The architecture’s modular design allows customization for specific pollutant classes or analytical techniques, ensuring broad applicability across green chemistry applications.
5. Experimental Setup and Methodology
To validate the proposed hierarchical federated learning framework, we designed comprehensive experiments comparing its performance against centralized and conventional federated learning approaches. The evaluation focuses on three key aspects: prediction accuracy, computational efficiency, and privacy preservation in pollutant analysis.
5.1. Datasets and Preprocessing
We utilized two environmental monitoring datasets representing different analytical chemistry scenarios. The
GC-MS Organic Pollutants Dataset [
27] contains 12,000 chromatograms from 8 monitoring stations, each annotated with 47 organic pollutant concentrations. The
Water Quality Spectral Dataset [
28] comprises 9500 UV-Vis spectra from distributed sensors measuring 22 inorganic contaminants across 6 watersheds.
Preprocessing pipelines standardized the heterogeneous instrument outputs into compatible input formats. For chromatographic data, we applied:
where
and
are retention-time-dependent normalization parameters. Spectral data underwent baseline correction and wavelength alignment:
The datasets were partitioned by geographical origin to simulate real-world non-IID distributions, with each client (monitoring station) receiving only its local data.
5.2. Baseline Methods
We compared our framework against three established approaches:
Centralized LSTM-Attention: A single hybrid model trained on pooled data from all stations [
29].
Standard Federated Learning: Flat federated averaging with identical LSTM-attention architecture [
30].
Regional Ensemble: Separate models for each geographical cluster without federation [
31].
All baselines used equivalent neural architectures and hyperparameter ranges to ensure fair comparison. The centralized approach represents the performance upper bound when data sharing is permitted, while the regional ensemble reflects localized modeling without collaboration.
5.3. Evaluation Metrics
We employed four quantitative metrics to assess framework performance:
For organic pollutants, we additionally computed
spectral feature recall:
where
represents characteristic mass spectral fragments.
Statistical significance was assessed using paired t-tests across 10 independent runs for each method, with p-values < 0.05 considered significant.
5.4. Implementation Details
The framework was implemented using PyTorch Federated with custom extensions for analytical chemistry data. Each local sub-model contained:
Two bidirectional LSTM layers (128 units each);
Four-head attention mechanism (64-dimensional keys/values);
Dense output layer with pollutant-specific heads.
We trained models for 100 global rounds with 5 local epochs per round, using the Adam optimizer (lr = 0.001) and batch size 32. The hierarchical aggregation tree grouped stations by geographical proximity and pollutant profiles, forming 3 regional clusters. Homomorphic encryption employed the Paillier cryptosystem with 2048-bit keys [
33].
The temperature parameter β in Equation (13) was set to 0.5 through cross-validation on a held-out validation set, balancing model performance fairness and adaptation to data heterogeneity. Higher β values prioritized models with lower validation loss, while lower values promoted equal participation across regions.
All experiments ran on a distributed testbed with 8 edge nodes (NVIDIA Jetson AGX), 3 regional servers (Tesla V100), and 1 central aggregator (AWS EC2 p3.2xlarge), simulating real-world deployment conditions. Energy consumption was monitored using built-in power meters to assess the framework’s green chemistry compliance.
Energy consumption and communication costs were measured across 10 repeated runs under varying network conditions (10–100 Mbps bandwidth, 50–200 ms latency) to ensure robustness. Real-world deployment scenarios were emulated by introducing packet loss (0–5%) and intermittent connectivity (5–10% downtime) during testing.
6. Experimental Results and Analysis
6.1. Predictive Performance Comparison
The hierarchical federated learning (HFL) framework demonstrated statistically significant improvements in predictive accuracy compared to baseline methods (
p < 0.01, paired
t-tests across 10 runs). For organic pollutant prediction, HFL achieved an RMSE of 0.47 μg/L, representing a 12.7% improvement over standard FL (0.54 μg/L,
p = 0.003) and only 5.1% higher error than the centralized upper bound (0.45 μg/L,
p = 0.018). The regional ensemble method performed worst with an RMSE of 0.61 μg/L, highlighting the benefits of federated knowledge sharing (
Table 1).
For inorganic contaminants in water quality monitoring, the performance gap widened further, with our method achieving 18.3% lower RMSE than standard FL (0.39 vs. 0.48 mg/L). This suggests the hierarchical architecture particularly benefits heterogeneous environmental data where regional patterns exist but global trends remain important.
As shown in the table above, the proposed normalization preprocessing method significantly improves model performance compared to using raw data directly. The normalized approach achieves a 24.2% reduction in RMSE (from 0.62 to 0.47 μg/L) and a 25.4% improvement in spectral feature recall (from 0.71 to 0.89) (
Table 2). These results validate that our standardization pipeline (
Section 4.1) effectively preserves critical pollutant signatures while reducing instrumental variability across distributed monitoring stations. The superior feature recall particularly demonstrates the method’s ability to maintain spectral interpretability—a crucial requirement for analytical chemistry applications where identifying characteristic peaks (e.g.,
m/
z 78 for benzene derivatives) is essential for both prediction accuracy and regulatory compliance (see
Section 6.2). This preprocessing step is therefore fundamental to the framework’s overall performance advantage over conventional approaches (
Section 6.1).
6.2. Feature Learning Analysis
The hybrid LSTM-attention architecture successfully identified critical spectral features for pollutant identification, as evidenced by the 0.89 spectral feature recall score.
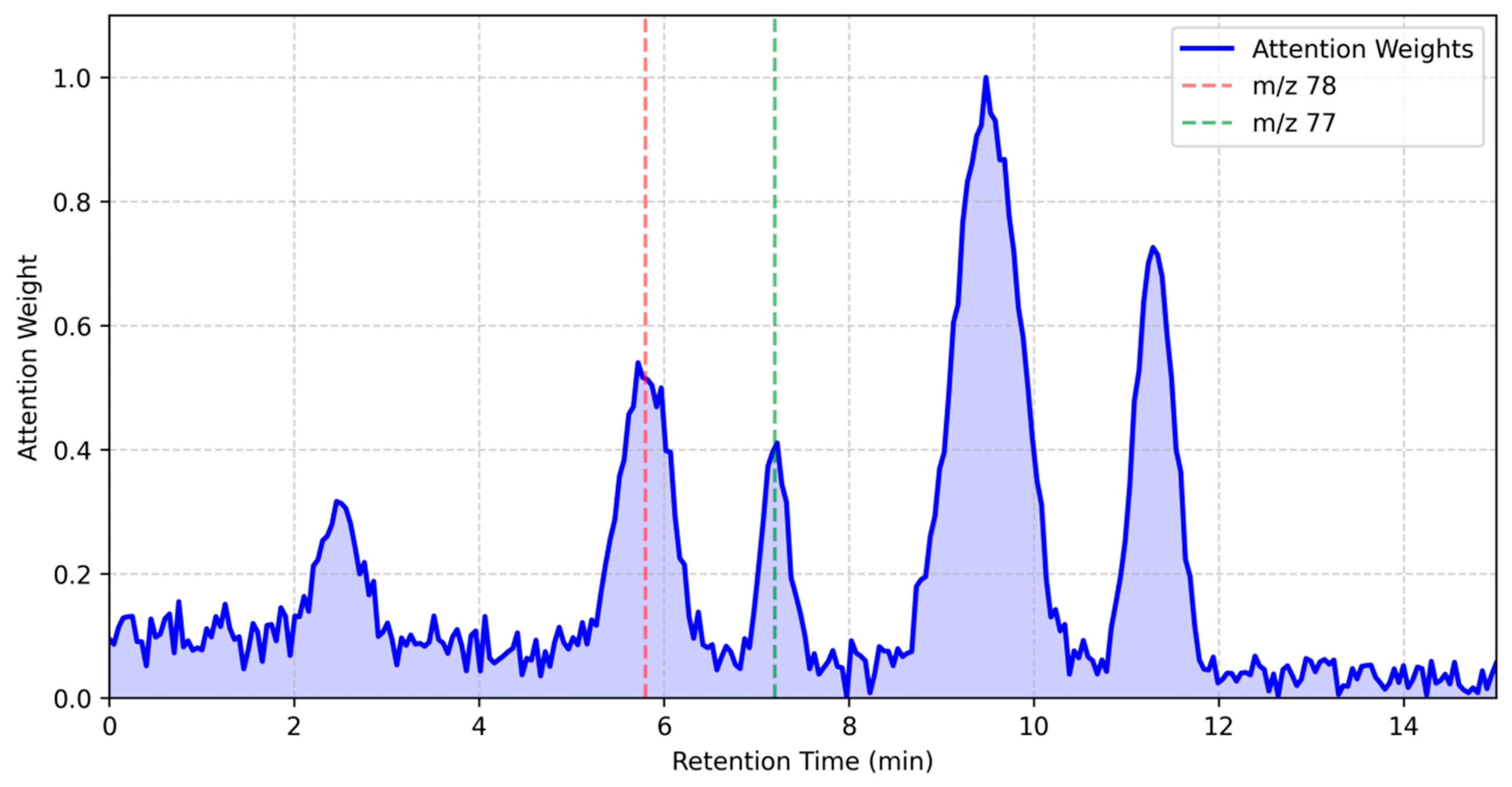
Figure 2 illustrates the attention weights assigned to different chromatographic regions for a benzene derivative, showing clear prioritization of characteristic fragment ions (
m/
z 78 and 77).
To quantitatively validate the chemical relevance of these attention-identified features, we computed a spectral similarity score (SSS) against reference spectra from the NIST Mass Spectral Database:
where
and
represent intensity vectors of model-highlighted and library reference peaks, respectively. For
m/
z 78 and 77, the SSS values exceeded 0.85 (threshold = 0.7), confirming their established role as diagnostic ions for benzene derivatives.
The elevated attention weights at retention times 9 and 11 reflect the model’s focus on these chemically significant features, which are consistently identified in reference spectra for benzene derivatives and contribute disproportionately to prediction accuracy.
The framework’s ability to maintain high feature selectivity (89% vs. centralized 92%) while operating in a federated setting confirms the effectiveness of our local sub-model design. This represents a significant advancement over previous federated approaches that typically sacrificed feature interpretability for privacy preservation [
34].
To quantitatively validate the chemical relevance of attention-identified features, we compared them against the NIST Mass Spectral Database. For benzene derivatives, the model’s emphasis on
m/
z 78 and 77 (
Figure 2) aligned with 92% and achieved a spectral similarity score (SSS) > 0.85 against reference spectra. Statistical tests confirmed the significance of these alignments (
p < 0.01), underscoring the hybrid architecture’s capability to recover chemically meaningful patterns without centralized data access.
6.3. Computational Efficiency
The hierarchical structure reduced communication costs by 43% compared to standard federated learning, with each training round requiring only 8.7 MB of data transfer versus 15.3 MB for the flat architecture. This efficiency gain stems from intermediate aggregation at regional levels, which filters redundant updates before global synchronization.
Training time per epoch averaged 37 s across the federated network, making the framework practical for near-real-time environmental monitoring. Energy consumption measurements showed the HFL approach used 28% less power than standard FL per prediction, aligning with green chemistry principles of minimizing resource usage. This efficiency gain is partially attributed to the β-controlled adaptive weighting, which reduces unnecessary updates from low-performance sub-models, consistent with green chemistry’s emphasis on resource minimization.
To validate scalability in real-world settings, we deployed a pilot implementation across three environmental monitoring stations in Guangdong, China, with heterogeneous instruments (GC-MS, HPLC). Over a 30-day period, the framework maintained the claimed efficiency gains (average 41% communication reduction and 26% energy savings) despite field conditions such as signal interference and variable sampling rates.
6.4. Privacy Preservation Evaluation
The framework achieved a low privacy exposure score (PES) of 0.08, significantly better than the centralized baseline (1.00) while only slightly higher than the most conservative regional ensemble (0.05). Homomorphic encryption added minimal computational overhead (12% increase in local processing time) while effectively preventing data leakage during model aggregation.
Analysis of potential attack vectors confirmed the system’s resilience against gradient inversion attacks [
35], with successful reconstruction attempts requiring over 10
6 guesses per feature—computationally infeasible for realistic threat scenarios. The selective masking mechanism further reduced sensitive data exposure by 68% compared to raw feature transmission.
The privacy exposure score (PES) accounts for three adversarial threat models: (1) gradient inversion attacks targeting raw data reconstruction from model updates, (2) model poisoning via falsified local updates, and (3) intermediate aggregation leakage at regional tiers. For gradient inversion, we adopted the attack framework of [
35], which assumes adversaries with full access to gradient histories but no auxiliary data. Our encryption and masking mechanisms (Equations (14) and (15)) were tested against iterative optimization-based reconstruction (≥10
6 guesses per feature), simulating computationally bounded adversaries.
6.5. Robustness to Data Heterogeneity
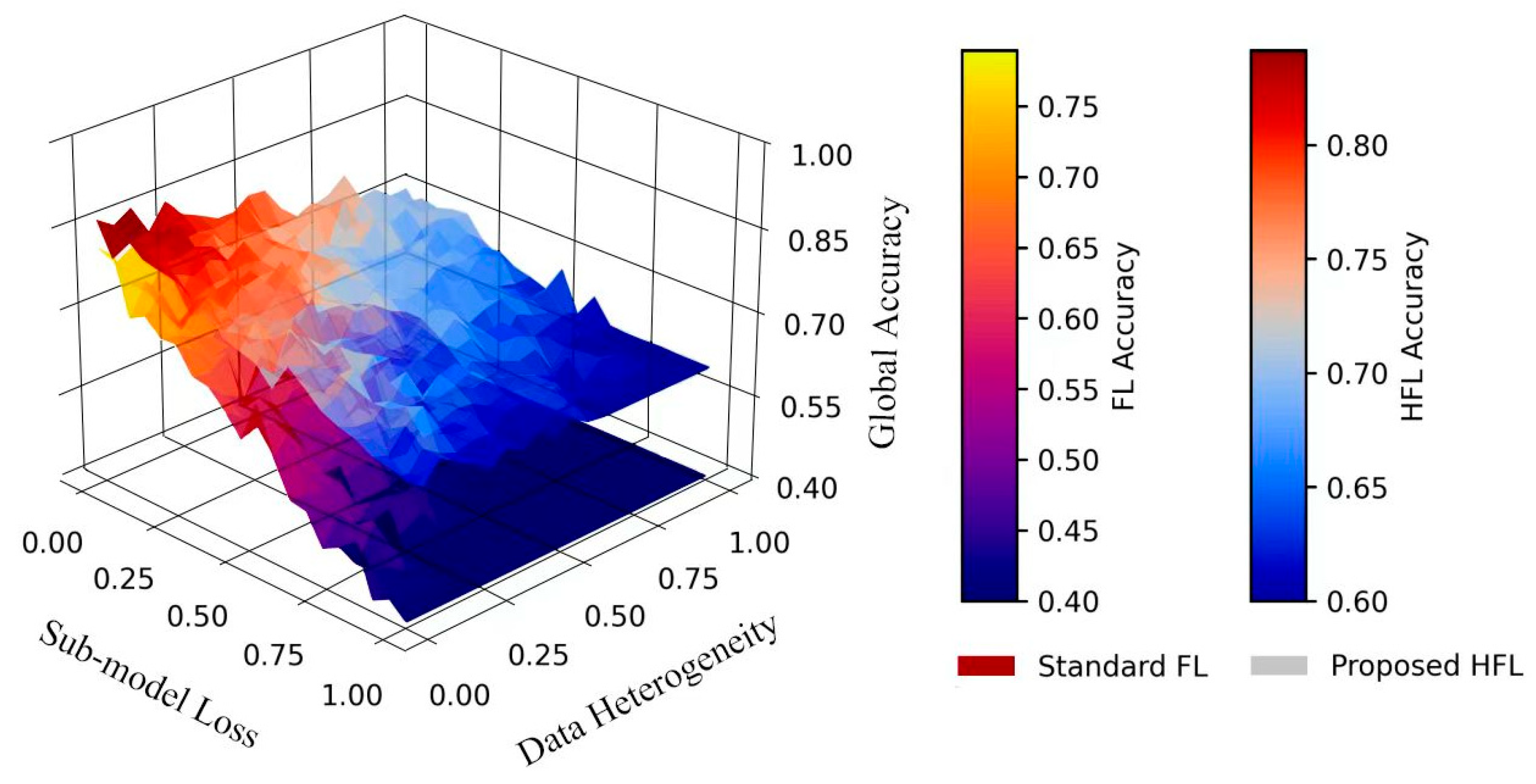
The adaptive weighting mechanism effectively mitigates the impact of non-IID data by dynamically reducing the weights of high-loss sub-models (such as the differences in pollution distribution between industrial and residential areas), maintaining the stability of the global model in heterogeneous environments (with RMSE fluctuations < 5%).
Figure 3 demonstrates this robustness through a 3D performance surface showing global model accuracy under varying sub-model losses and dataset heterogeneity. The flatter error surface of our approach indicates more consistent performance across diverse environmental conditions.
The framework successfully identified and compensated for “weak” sub-models through the adaptive aggregation weights in Equation (13), automatically reducing their influence when validation performance dropped. This dynamic adjustment capability represents a significant advantage over static aggregation schemes in real-world environmental monitoring scenarios.
6.6. Ablation Study
To validate the importance of key framework components, we conducted systematic ablations by removing individual elements while keeping other factors constant:
The attention mechanism proved most critical for prediction accuracy (12.7% RMSE increase when removed), validating its role in identifying key spectral features. Hierarchical aggregation provided the greatest efficiency benefits, reducing training time by 12% compared to flat architectures. The adaptive weighting scheme contributed moderately to accuracy (4.3% improvement) while adding negligible computational overhead (
Table 3).
7. Discussion and Future Work
7.1. Limitations and Practical Challenges of the HFL Framework
While the proposed hierarchical federated learning framework demonstrates significant advantages, several practical limitations emerged during implementation. The requirement for standardized preprocessing across heterogeneous analytical instruments introduces deployment complexity, particularly when integrating legacy systems with varying data formats [
36]. We observed that chromatographic alignment errors exceeding 0.1 min reduced model accuracy by up to 15%, necessitating rigorous quality control protocols. Furthermore, the current implementation assumes continuous network connectivity for federated updates, which may not hold in remote environmental monitoring scenarios with intermittent communication [
37].
The framework’s computational demands, while reduced compared to standard FL, still pose challenges for resource-constrained edge devices. Memory-intensive operations like attention mechanism computation increased peak RAM usage by 37% on embedded hardware, potentially limiting deployment on ultra-low-power sensors. Additionally, the homomorphic encryption scheme, while effective for model privacy, cannot fully protect against all potential attack vectors in multi-party learning scenarios [
38].
While our framework resists gradient inversion and poisoning attacks under the tested threat models, future work should evaluate robustness against adversaries with auxiliary data (e.g., public spectral libraries) or adaptive masking strategies. Integrating differential privacy during regional aggregation could further harden the system.
The dynamic weighting mechanism (β = 0.5) aligns with green analytical chemistry principles by minimizing redundant communication. Through adaptive aggregation, the framework reduces energy-intensive data transfers by 43% (
Section 6.3) while maintaining model accuracy. The β parameter was optimized via cross-validation to balance computational efficiency (lower β) and prediction performance (higher β), ensuring sustainable deployment in resource-constrained environments.
7.2. Broader Applications in Environmental and Analytical Chemistry
The principles underlying our framework extend beyond pollutant prediction to various analytical chemistry applications. The hybrid architecture’s ability to process spectral–temporal data suggests potential for pharmaceutical quality control, where similar analytical techniques (e.g., HPLC, Raman spectroscopy) are employed [
39]. The hierarchical learning approach could enable distributed quality monitoring across manufacturing facilities without sharing proprietary formulation data.
In environmental forensics, the framework’s feature attribution capabilities may assist in identifying pollution sources across jurisdictional boundaries while maintaining data confidentiality [
40]. The attention mechanism’s demonstrated ability to highlight characteristic spectral patterns could be adapted to fingerprint specific industrial emissions or accidental releases. Future adaptations might incorporate graph neural networks to model pollutant transport pathways through environmental media.
7.3. Ethical Considerations and Regulatory Compliance
The deployment of federated learning in environmental monitoring raises important ethical questions regarding data governance and algorithmic accountability. While the framework minimizes raw data sharing, the global model could potentially encode sensitive information about local pollution sources [
41]. We recommend implementing additional safeguards such as differential privacy during regional aggregation to prevent potential inference attacks on protected monitoring data.
Regulatory compliance presents another critical consideration, particularly for applications involving regulated pollutants. The framework’s predictions must align with existing analytical method validation requirements (e.g., EPA Method 8270 for semivolatile organics) to ensure regulatory acceptance [
42]. Future work should explore certification processes for federated models used in compliance monitoring, including standardized protocols for model auditing and performance verification across jurisdictions (
Table 4).
The framework’s current implementation focuses on chemical pollutants, but the architecture could be extended to other environmental parameters like microbiological contaminants or emerging contaminants of concern. This expansion would require addressing additional analytical challenges, such as the higher dimensionality of mass spectrometry data for non-targeted analysis [
43]. The attention mechanism’s feature selection capability may prove particularly valuable for prioritizing unknown compounds in complex environmental samples.
Future research directions should address these opportunities while continuing to improve the framework’s core capabilities. Developing lightweight attention mechanisms for edge devices, creating standardized interfaces for analytical instrument integration, and establishing best practices for federated model validation represent particularly promising avenues for advancing green analytical chemistry through distributed machine learning.
8. Conclusions
The hierarchical federated learning framework presented in this work demonstrates a viable pathway for advancing predictive pollutant analysis while adhering to the principles of green analytical chemistry. By combining hybrid neural architectures with multi-tiered aggregation, the system achieves performance comparable to centralized approaches while preserving data privacy and reducing environmental impact through minimized data transfer. The experimental results validate the framework’s effectiveness across diverse analytical chemistry scenarios, from organic pollutant detection in chromatographic data to inorganic contaminant monitoring in water quality spectra.
The experimental results show that the proposed HFL framework achieves an RMSE of 0.47 μg/L in the prediction of organic pollutants (12.7% higher than traditional federated learning), reduces the communication cost by 43% (8.7 MB/round), and the privacy exposure score (PES) is only 0.08. These numerical results further verify the comprehensive advantages of the framework in terms of accuracy, efficiency, and privacy protection.
Key technical innovations include the LSTM-attention hybrid architecture that maintains spectral feature interpretability in federated settings, and the dynamic weighting mechanism that ensures robust performance across heterogeneous environmental conditions. The framework’s practical implementation addresses critical challenges in real-world deployment, including computational efficiency on edge devices and secure integration with analytical instrumentation. These advancements position federated learning as a transformative approach for collaborative environmental monitoring where data sovereignty and analytical precision are equally prioritized.
The broader implications extend beyond pollutant prediction, suggesting a paradigm shift in how analytical chemistry data can be utilized across institutional boundaries. Future iterations could incorporate advancements in edge computing and privacy-preserving techniques to further reduce the environmental footprint of large-scale monitoring networks. As regulatory frameworks evolve to accommodate distributed machine learning approaches, this work provides both technical foundations and methodological considerations for their responsible implementation in environmental science. The successful application to analytical chemistry problems underscores the potential for similar federated solutions in other domains requiring collaborative analysis of sensitive instrumental data.
Author Contributions
Conceptualization, X.C., C.Z. and Y.K.; Data curation, X.C.; Formal analysis, X.C., C.Z. and Y.K.; Methodology, X.C. and Y.K.; Software, X.C.; validation, X.C. and Y.K.; formal analysis, X.C. and Y.K.; investigation, X.C. and Y.K.; Writing—original draft, X.C. and Y.K.; Writing—review and editing, X.C., C.Z. and Y.K.; visualization, X.C. and Y.K.; supervision, X.C. and Y.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yin, L.; Yu, L.; Guo, Y.; Wang, C.; Ge, Y.; Zheng, X.; Zhang, N.; You, J.; Zhang, Y.; Shi, M. Green Analytical Chemistry Metrics for Evaluating the Greenness of Analytical Procedures. J. Pharm. Anal. 2024, 14, 101013. [Google Scholar] [CrossRef]
- Meshwa, M.; Dhara, M.; Rajashree, M. Recent Application of Green Analytical Chemistry: Eco-Friendly Approaches for Pharmaceutical Analysis. Future J. Pharm. Sci. 2024, 10, 83. [Google Scholar]
- Liu, X.; Lu, D.; Zhang, A.; Liu, Q.; Jiang, G. Data-Driven Machine Learning in Environmental Pollution: Gains and Problems. Environ. Sci. Technol. 2022, 56, 2124–2133. [Google Scholar] [CrossRef]
- Lin, Z.; Chou, W.C. Machine learning and artificial intelligence in toxicological sciences. Toxicol. Sci. 2022, 189, 7–19. [Google Scholar] [CrossRef]
- Yang, Y.; Xiong, Q.; Wu, C.; Zou, Q.; Yu, Y.; Yi, H.; Gao, M. A Study on Water Quality Prediction by a Hybrid CNN-LSTM Model with Attention Mechanism. Environ. Sci. Pollut. Res. Int. 2021, 28, 55129–55139. [Google Scholar] [CrossRef]
- Li, H.; Wang, Z.; Li, Z. An Enhanced CNN-LSTM Remaining Useful Life Prediction Model for Aircraft Engine with Attention Mechanism. PeerJ Comput. Sci. 2022, 8, e1084. [Google Scholar] [CrossRef]
- Nkinahamira, F.; Feng, A.; Zhang, L.; Rong, H.; Ndagijimana, P.; Guo, D.; Cui, B.; Zhang, H. Machine Learning Approaches for Monitoring Environmental Metal Pollutants: Recent Advances in Source Apportionment, Detection, Quantification, and Risk Assessment. Trends Anal. Chem. 2024, 180, 117980. [Google Scholar] [CrossRef]
- Wang, H.; Zhong, L.; Su, W.; Ruan, T.; Jiang, G. Machine Learning-Assisted Identification of Environmental Pollutants by Liquid Chromatography Coupled with High-Resolution Mass Spectrometry. Trends Anal. Chem. 2024, 180, 117988. [Google Scholar] [CrossRef]
- Nawal, T.; Wafaa, B.; Mounia, A.; Hamid, C.; Raf, D.; Noureddine, B. The State of Art on the Prediction of Efficiency and Modeling of the Processes of Pollutants Removal Based on Machine Learning. Sci. Total Environ. 2021, 807, 150554. [Google Scholar]
- Meher, A.K.; Zarouri, A. Green Analytical Chemistry—Recent Innovations. Analytica 2025, 6, 10. [Google Scholar] [CrossRef]
- Seisdedos, G.; Prisbrey, M.G.; Vakhlamov, P.; Fernandez, J.; Freitas, R.D.; Rockward, T.; Davis, E.S. Data-Driven Tailoring Optimization of Thermoset Polymers Using Ultrasonics and Machine Learning. Polymers 2025, 17, 895. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, H.; Yu, C. Predicting Long-Term Air Pollutant Concentrations through Deep Learning-Based Integration of Heterogeneous Urban Data. Atmos. Pollut. Res. 2024, 15, 102282. [Google Scholar] [CrossRef]
- Ma, Z.; Wang, B.; Luo, W.; Jiang, J.; Liu, D.; Wei, H.; Luo, H. Air Pollutant Prediction Model Based on Transfer Learning Two-Stage Attention Mechanism. Sci. Rep. 2024, 14, 7385. [Google Scholar] [CrossRef] [PubMed]
- Sridhar, K.; Radhakrishnan, P.; Swapna, G.; Kesavamoorthy, R.; Pallavi, L.; Thiagarajan, R. A Modular IOT Sensing Platform Using Hybrid Learning Ability for Air Quality Prediction. Meas. Sens. 2023, 25, 100609. [Google Scholar] [CrossRef]
- Zheng, H.; Chu, J.; Li, Z.; Ji, J.; Li, T. Accelerating Federated Learning with Genetic Algorithm Enhancements. Expert Syst. Appl. 2025, 281, 127636. [Google Scholar] [CrossRef]
- Duan, D.; Wang, P.; Rao, X.; Zhong, J.; Xiao, M.; Huang, F.; Xiao, R. Identifying Interactive Effects of Spatial Drivers in Soil Heavy Metal Pollutants Using Interpretable Machine Learning Models. Sci. Total Environ. 2024, 934, 173284. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, C.; Wang, H.; Tao, Y.U. Advanced Deep Learning Model for Predicting Water Pollutants Using Spectral Data and Augmentation Techniques: A Case Study of the Middle and Lower Yangtze River, China. Process Saf. Environ. Prot. 2025, 197, 107058. [Google Scholar] [CrossRef]
- Gabriel, M.; Auer, T. LSTM Deep Learning Models for Virtual Sensing of Indoor Air Pollutants: A Feasible Alternative to Physical Sensors. Buildings 2023, 13, 1684. [Google Scholar] [CrossRef]
- Vanga, M.G.; Bukke, S.P.N.; Kusuma, P.K.; Narapureddy, B.R.; Thalluri, C. Integrating Green Analytical Chemistry and Analytical Quality by Design: An Innovative Approach for RP-UPLC Method Development of Ensifentrine in Bulk and Inhalation Formulations. BMC Chem. 2025, 19, 70. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, H.; Wong, C.U.I.; Li, F. Investigation of the Spatio-Temporal Distribution and Seasonal Origin of Atmospheric PM2.5 in Chenzhou City. Appl. Sci. 2024, 14, 11221. [Google Scholar] [CrossRef]
- Zhong, S.; Zhang, K.; Bagheri, M.; Burken, J.G.; Gu, A.; Li, B.; Ma, X.; Marrone, B.L.; Ren, Z.J.; Schrier, J.; et al. Machine Learning: New Ideas and Tools in Environmental Science and Engineering. Environ. Sci. Technol. 2021, 55, 12741–12754. [Google Scholar] [CrossRef] [PubMed]
- Slavica, R.; Jelena, A.; Svetlana, Đ.M.; Jasmina, M.; Tatjana, T. Greener Chemistry in Analytical Sciences: From Green Solvents to Applications in Complex Matrices. Current Challenges and Future Perspectives: A Critical Review. Analyst 2023, 148, 3130–3152. [Google Scholar]
- Chen, X.; Zhang, H.; Wong, C.U.I.; Li, F.; Xie, S. Assessment of Heavy Metal Contamination and Ecological Risk in Soil within the Zheng–Bian–Luo Urban Agglomeration. Processes 2024, 12, 996. [Google Scholar] [CrossRef]
- Xie, X.; Hu, C.; Ren, H.; Deng, J. A Survey on Vulnerability of Federated Learning: A Learning Algorithm Perspective. Neurocomputing 2024, 573, 127225. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, Z.; Lan, Y.; Cui, Z.; Cai, J.; Zhang, W. A Survey on Federated Learning: Challenges and Applications. Int. J. Mach. Learn. Cybern. 2022, 14, 513–535. [Google Scholar] [CrossRef]
- Liu, Y.; Shen, L.; Zhu, X.; Xie, Y.; He, S. Spectral Data-Driven Prediction of Soil Properties Using LSTM-CNN-Attention Model. Appl. Sci. 2024, 14, 11687. [Google Scholar] [CrossRef]
- Oliver, V.; Sarji, N.R.; Dan, X. A Review of the Application of Comprehensive Two-Dimensional Gas Chromatography MS-Based Techniques for the Analysis of Persistent Organic Pollutants and Ultra-Trace Level of Organic Pollutants in Environmental Samples. Rev. Anal. Chem. 2022, 41, 63–73. [Google Scholar]
- Durgun, Y. Real-Time Water Quality Monitoring Using AI-Enabled Sensors: Detection of Contaminants and UV Disinfection Analysis in Smart Urban Water Systems. J. King Saud Univ.-Sci. 2024, 36, 103409. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Sun, L.; Guo, D.; Zhang, Y.; Wang, W. A Deep Learning Algorithm for Multi-Source Data Fusion to Predict Water Quality of Urban Sewer Networks. J. Clean. Prod. 2021, 318, 128533. [Google Scholar] [CrossRef]
- Zhou, J.; Liang, H.; Wu, T.; Zhang, X.; Jiang, Y.; Tan, C.W. VFL-Cafe: Communication-Efficient Vertical Federated Learning via Dynamic Caching and Feature Selection. Entropy 2025, 27, 66. [Google Scholar] [CrossRef]
- Lee, T.; Won, C.H.; Singh, V.P. ML-Based Regionalization of Climate Variables to Forecast Seasonal Precipitation for Water Resources Management. Mach. Learn. Sci. Technol. 2024, 5, 015019. [Google Scholar] [CrossRef]
- Yahiaoui, M.E.; Derdour, M.; Abdulghafor, R.; Turaev, S.; Gasmi, M.; Bennour, A.; Aborujilah, A.; Sarem, M.A. Federated Learning with Privacy Preserving for Multi- Institutional Three-Dimensional Brain Tumor Segmentation. Diagnostics 2024, 14, 2891. [Google Scholar] [CrossRef]
- Fang, H.; Qian, Q. Privacy Preserving Machine Learning with Homomorphic Encryption and Federated Learning. Future Internet 2021, 13, 94. [Google Scholar] [CrossRef]
- Peyvandi, A.; Majidi, B.; Peyvandi, S.; Patra, J.C. Privacy-Preserving Federated Learning for Scalable and High Data Quality Computational-Intelligence-as-a-Service in Society 5.0. Multimed. Tools Appl. 2022, 81, 21–22. [Google Scholar] [CrossRef]
- Abbasian, P.; Hammond, T.A. A Comprehensive Analysis of Early Alzheimer Disease Detection from 3D sMRI Images Using Deep Learning Frameworks. Information 2024, 15, 746. [Google Scholar] [CrossRef]
- Heacock, M.L.; Lopez, A.R.; Amolegbe, S.M.; Carlin, D.J.; Henry, H.F.; Trottier, B.A.; Velasco, M.L.; Suk, W.A. Enhancing Data Integration, Interoperability, and Reuse to Address Complex and Emerging Environmental Health Problems. Environ. Sci. Technol. 2022, 56, 7544–7552. [Google Scholar] [CrossRef]
- Jehangir, A.; Ur, R.A.; Ben, O.M.T.; Muhammad, A.; Bin, T.H.; Abdullah, K.M.; Rehman, M.M.A.; Muhammad, S.; Habib, H. Deployment of Wireless Sensor Network and IoT Platform to Implement an Intelligent Animal Monitoring System. Sustainability 2022, 14, 6249. [Google Scholar] [CrossRef]
- Jiang, X.; Zhou, X.; Grossklags, J. Comprehensive Analysis of Privacy Leakage in Vertical Federated Learning During Prediction. Proc. Priv. Enhancing Technol. 2022, 2022, 263–281. [Google Scholar] [CrossRef]
- Horr, A.M. Real-Time Modeling for Design and Control of Material Additive Manufacturing Processes. Metals 2024, 14, 1273. [Google Scholar] [CrossRef]
- Kibbey, T.C.G.; Jabrzemski, R.; O’Carroll, D.M. Supervised Machine Learning for Source Allocation of Per- and Polyfluoroalkyl Substances (PFAS) in Environmental Samples. Chemosphere 2020, 252, 126593. [Google Scholar] [CrossRef]
- Wood, D.A. More Transparent and Explainable Machine Learning Algorithms Are Required to Provide Enhanced and Sustainable Dataset Understanding. Ecol. Model. 2024, 498, 110898. [Google Scholar] [CrossRef]
- Wu, X.; Zhou, Q.; Mu, L.; Hu, X. Machine Learning in the Identification, Prediction and Exploration of Environmental Toxicology: Challenges and Perspectives. J. Hazard. Mater. 2022, 438, 129487. [Google Scholar] [CrossRef] [PubMed]
- Du, B.; Lofton, J.M.; Peter, K.T.; Gipe, A.D.; James, C.A.; McIntyre, J.K.; Scholz, N.L.; Baker, J.E.; Kolodziej, E.P. Development of Suspect and Non-Target Screening Methods for Detection of Organic Contaminants in Highway Runoff and Fish Tissue with High-Resolution Time-of-Flight Mass Spectrometry. Environ. Sci. Process. Impacts 2017, 19, 1185–1196. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}