
A Lightweight Multi-Scale Object Detection Framework for Shrimp Meat Quality Control in Food Processing



Abstract
1. Introduction
- Ensuring the accuracy and consistency of detection in artificial vision systems poses challenges due to reliance on experiential and subjective judgment. Factors such as fatigue can compromise detection rates and consistency, potentially resulting in substandard products reaching the market. This situation not only jeopardizes consumer health but also undermines the company’s reputation and brand value.
- As production expands, repetitive labor-intensive tasks lead to heightened labor costs and administrative complexities. The escalating labor expenses in today’s economic landscape directly erode enterprises’ profit margins and competitive edge.
- The substantial variations in characteristic scales among various shrimp categories, coupled with their nuanced local defects, contribute to diminished detection efficacy and elevated rates of false positives and false negatives for operators. These challenges not only compromise product quality uniformity but also hamper production line efficiency, rendering it inadequate to meet the demands of large-scale processing. Consequently, this scenario impacts production output and market supply capacity for enterprises.
- The ADown module is an innovative downsampling method that substitutes conventional convolution, maintaining essential features while decreasing parameters and computational expenses.
- DSISConv and MSISConv are convolutional methods that selectively incorporate information at two scales and multiple scales, respectively. DSISConv is combined with C3K2 to create C3K2–DSIS, enhancing adaptive multi-scale feature extraction for enhanced detection of defects across varying sizes.
- The LMSISD detector head, based on MSISConv, integrates multi-scale feature fusion and lightweight network design to enhance detection performance.
- Bidirectional knowledge distillation is an enhanced method of distillation that facilitates lightweight student models in acquiring crucial features from teacher models, leading to high accuracy while maintaining minimal parameter complexity.
2. Related Works
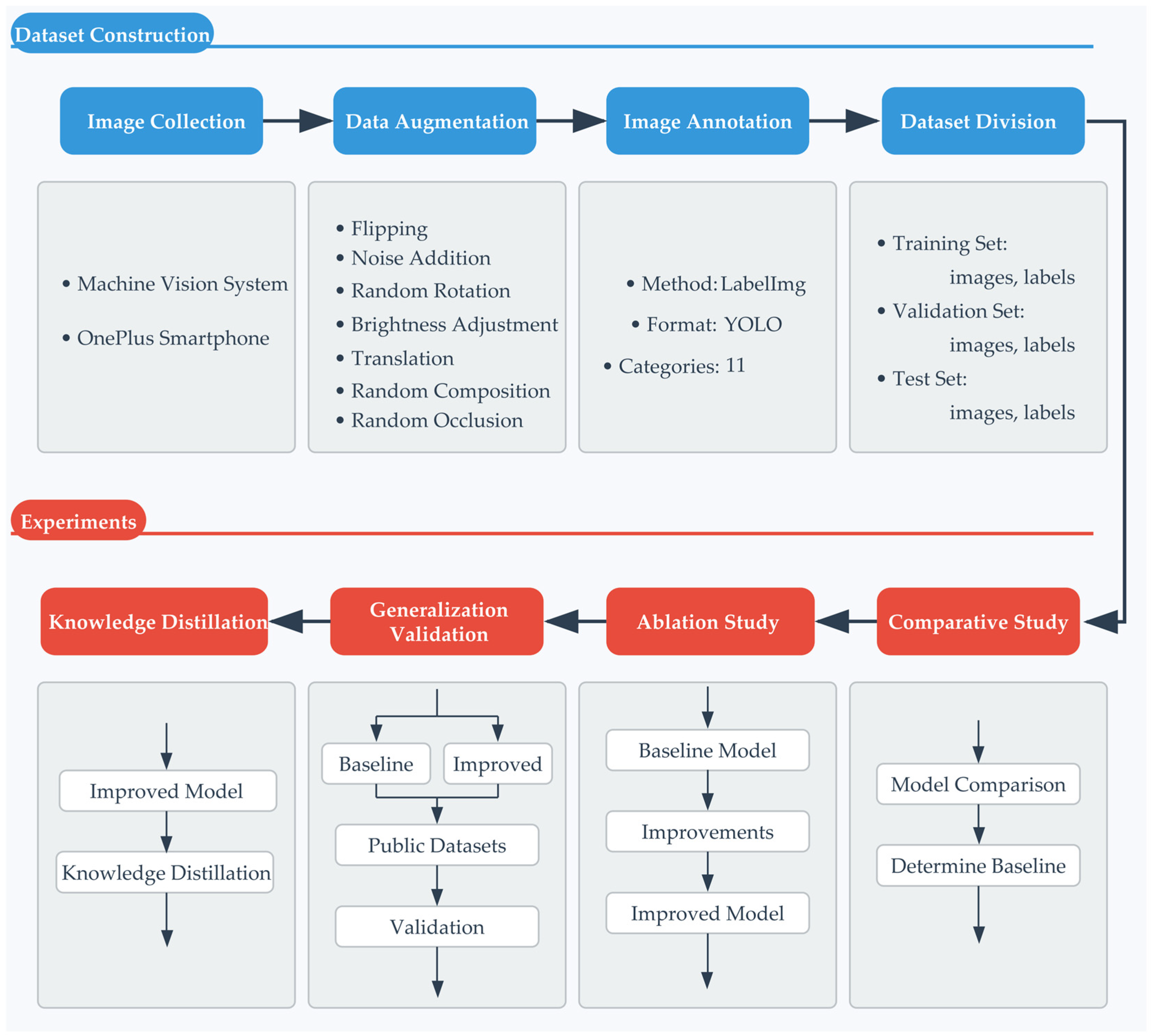
2.1. Experimental Workflow Overview
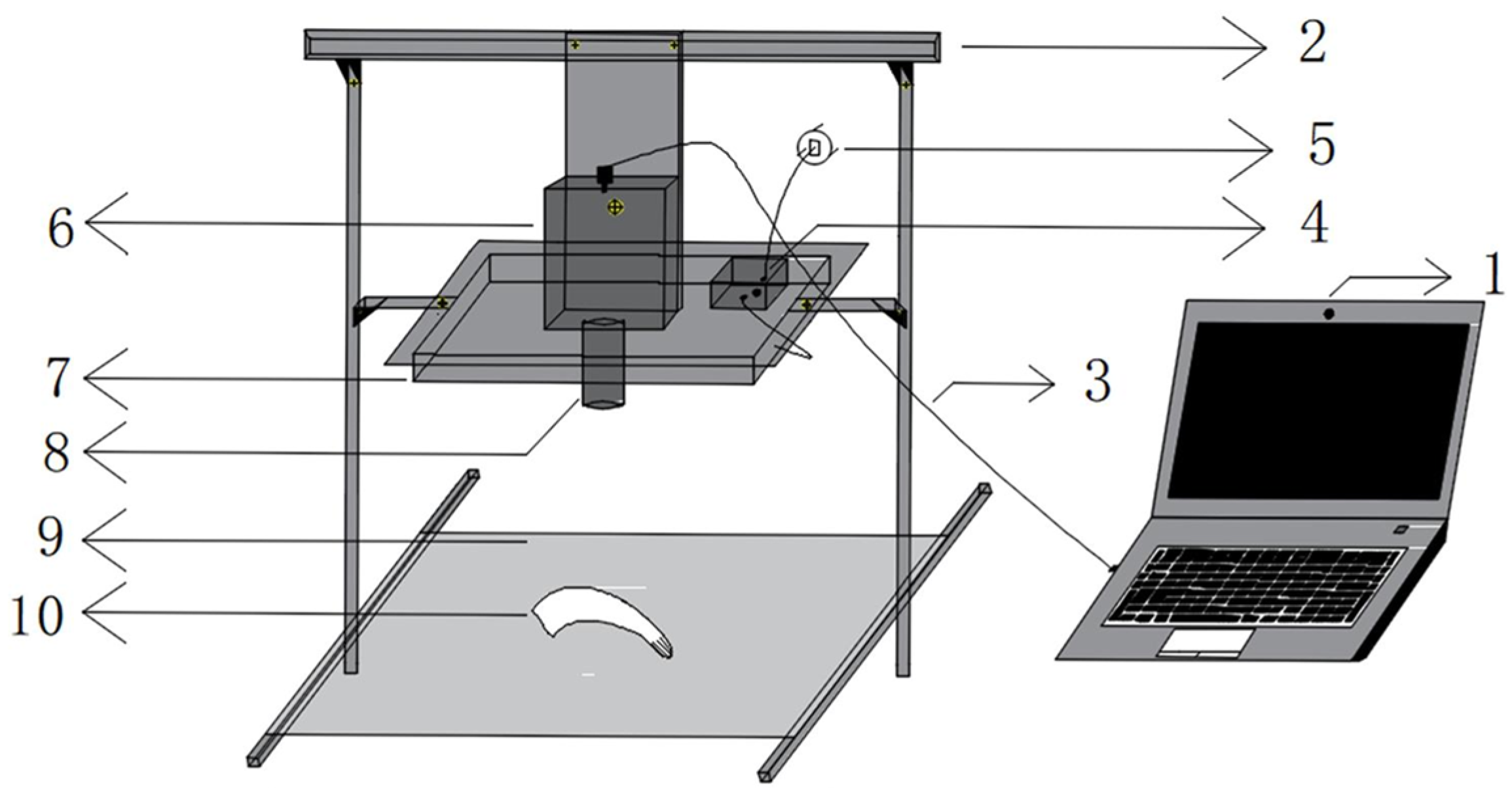
2.2. Experimental Materials
- Quality-defect category: This category included samples exhibiting dehydration and discoloration, damage, incomplete shell removal, incomplete intestinal gland removal, or the presence of shell fragments or appendages (Figure 2a–e), totaling five subcategories;
- Primary processed products: This category comprised fu rong shrimp balls, butterfly shrimp, and butterfly shrimp meat (Figure 2f–h), totaling three subcategories;
- Fully peeled category: This category of shrimp meat has the shell completely removed, and was further subdivided by size into small, medium, and large types (Figure 2i), totaling three subcategories.
- Systematic initial labeling was first performed on all 6186 original images;
- A comprehensive review was conducted, focusing on refining samples with intricate visual characteristics or unclear boundaries.
- A stratified random sampling approach was employed to verify the accuracy of category labels and bounding boxes by sampling the labeling results of all categories at a 10% sampling ratio.
2.3. YOLOv11 Network Structure
- The Conv module utilized stride-2 convolution for efficient downsampling and initial feature extraction.
- The C3K2 module extends the traditional C2f module by incorporating variable kernel sizes and channel separation strategies, thereby enhancing feature representation capacity.
- The SPPF (spatial pyramid pooling fast) module provides an optimized version of traditional SPP, efficiently capturing contextual information at multiple scales with reduced computational cost.
- The C2PSA module integrates the cross-stage partial (CSP) architecture with the polarized self-attention (PSA) mechanism, enhancing the network’s capacity to perceive features across different scales.
3. Methods
3.1. Improved Network Architecture of ADL-YOLO
3.1.1. Adown Module
- Input processing involves passing the input feature graph through an average pooling layer (AvgPool2d) with a 3 × 3 pooling kernel, a step size of 2, and a padding of 1. This operation computes the average of pixel values in each window to generate a smoothed feature map.
- Channel separation involves dividing the average pooled feature map into two parallel branches based on the channel dimension. If the input feature map has channels, each branch will have channels.
- The initial branch processing involves a convolutional layer with a stride of 2 and a 3 × 3 kernel size, facilitating downsampling of the feature map. This convolutional layer accommodates input channels and output channels.
- The second branch undergoes the following processing steps: initially, it employs a MaxPool2d layer with a pooling kernel size of 2 × 2 and a stride of 2, selecting the maximum value from each window as the output. Subsequently, the maximally pooled output is passed through a standard convolutional layer with a convolution kernel size of 3 × 3 and a stride of 1, maintaining the channel count at .
- Feature fusion involves combining feature maps from two branches, each with a size half that of the original input, through concatenation along the channel dimension to create the ultimate output feature map. The output feature map retains the original number of channels, denoted .
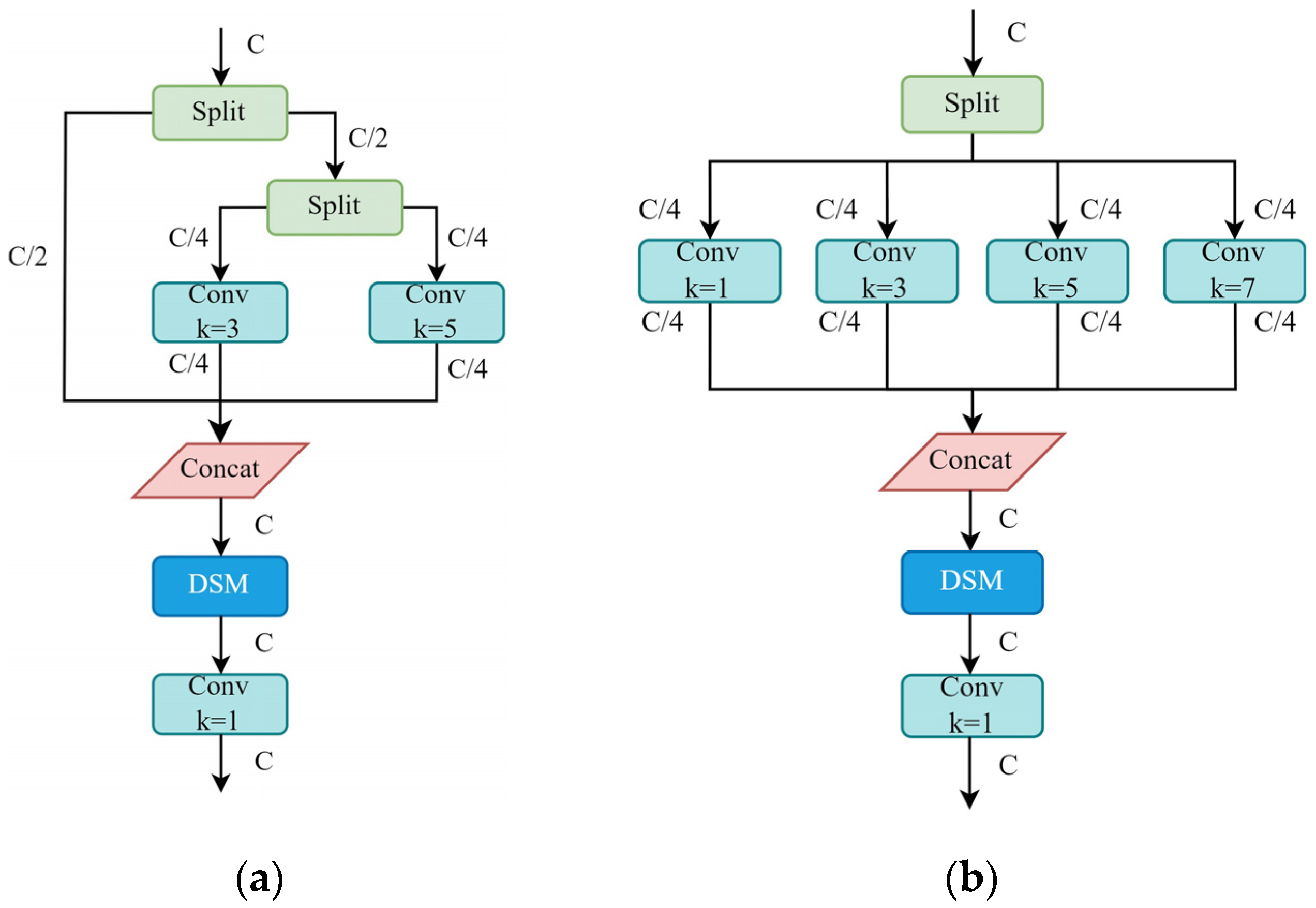
3.1.2. DSISConv and MSISConv Modules
- Dual-Scale Convolution (DSConv)
- 2.
- Multi-Scale Convolution (MSConv)
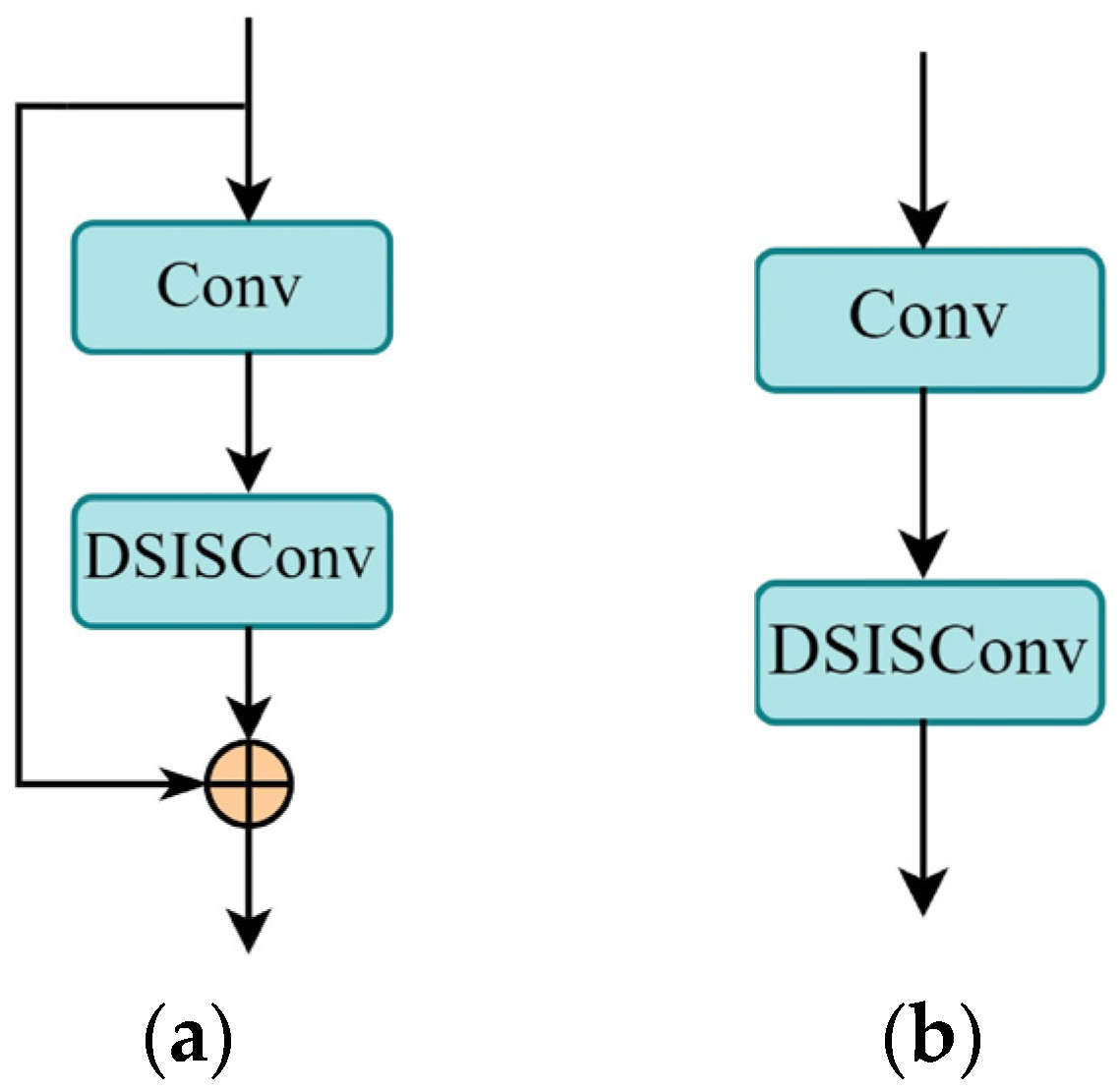
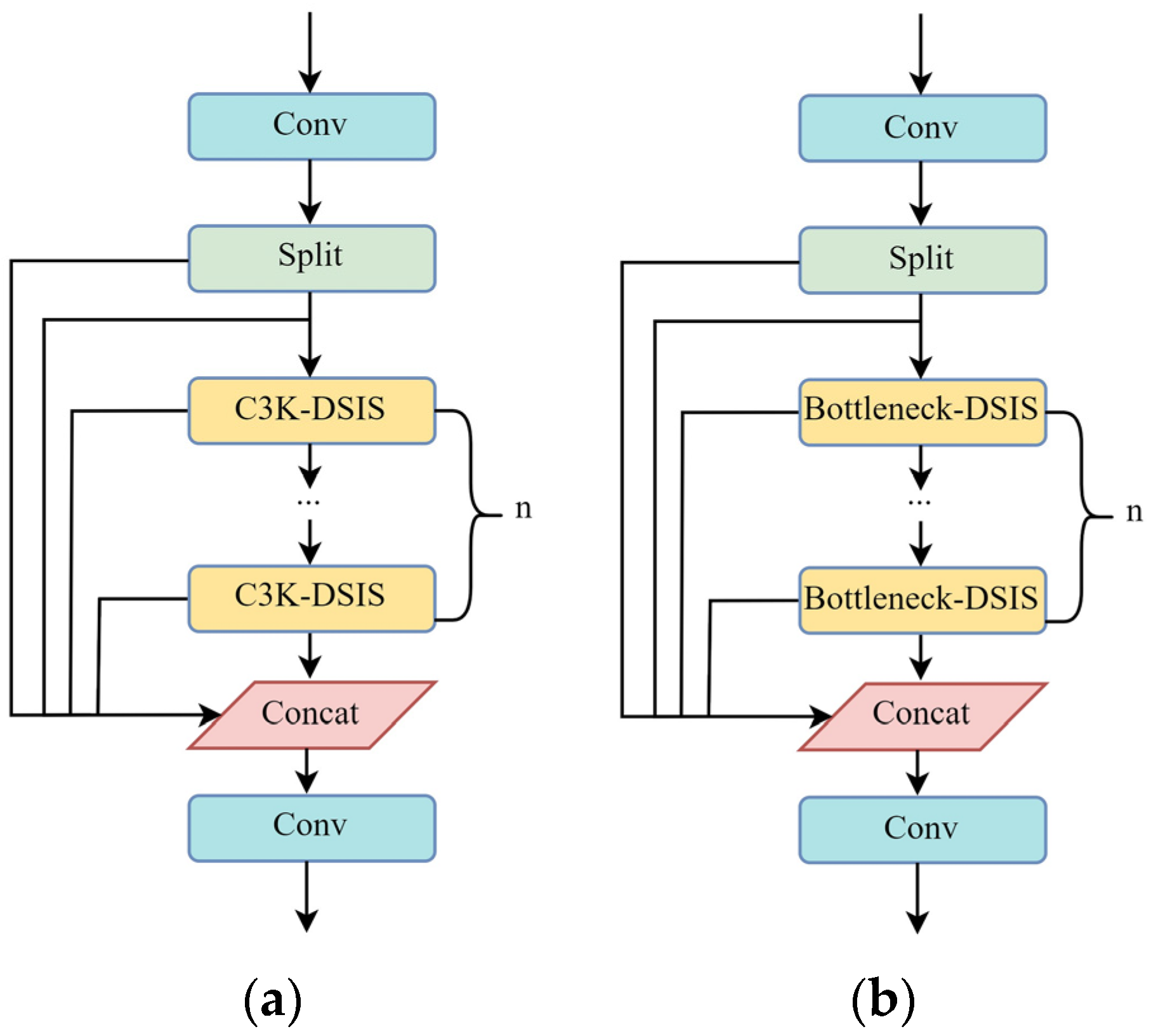
3.1.3. C3K2–DSIS Module
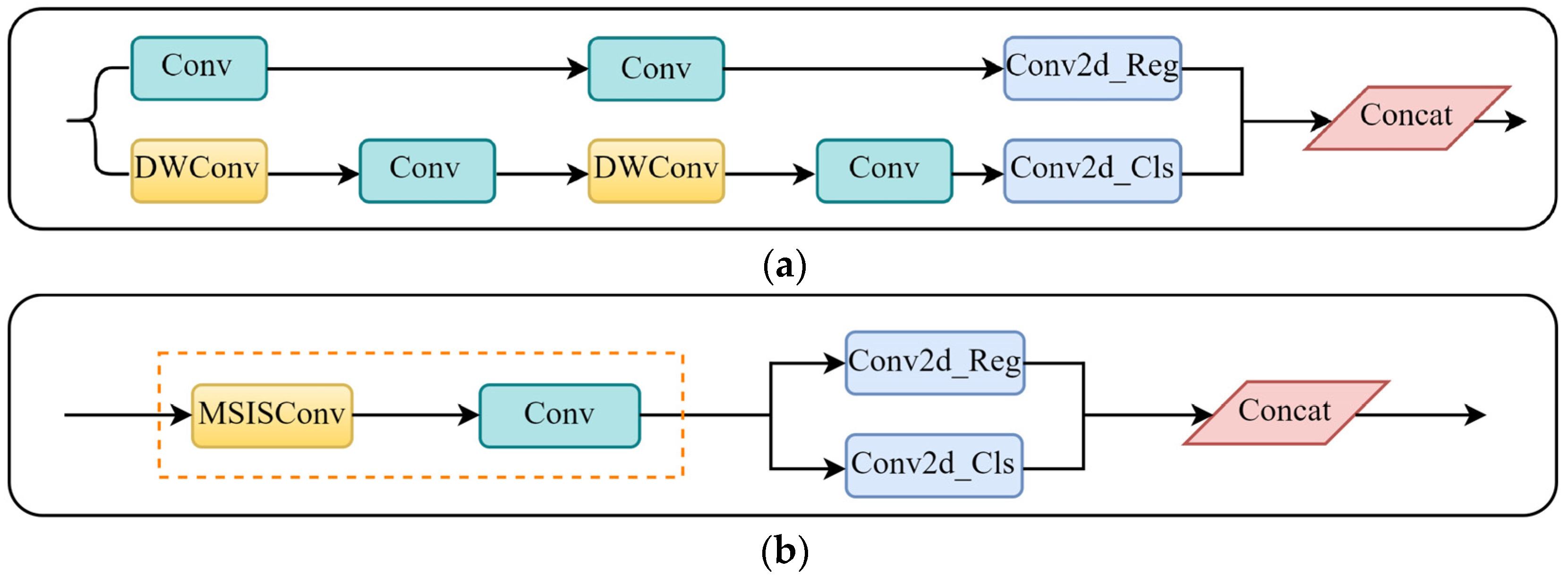
3.1.4. Lightweight Multi-Scale Information Selection Detection Head (LMSISD)
- Parameter sharing in LMSISD, influenced by RetinaTrack, involves sharing parameters across various scale prediction branches (P3, P4, P5). In contrast, the conventional YOLOv11 detector head employs distinct convolutional layers for each scale of feature maps in P3, P4, and P5.
- The MSISConv module was integrated into the detection head structure to process feature maps from three resolutions (80 × 80, 40 × 40, and 20 × 20) before the final prediction layer.
- Decoupled header architecture: LMSISD employs a decoupled framework that segregates the classification and regression tasks into autonomous branches, enabling each branch to independently manage its feature representation.
3.2. Bidirectional Complementary Knowledge Distillation
4. Experimental
4.1. Datasets
4.2. Experimental Environment
4.3. Evaluation Metrics
4.4. Experimental Results and Analysis
- In the independent evaluation phase assessing the efficacy of enhancement modules (Section 4.4.2 and Section 4.4.3), two fundamental modules underwent scrutiny employing the control variable method within the recognized benchmark model. Firstly, the impact of the ADown downsampling module on reducing model weight was assessed (Section 4.4.2). Secondly, the enhancement in performance of the C3K2–DSIS module in multi-scale feature extraction was validated (Section 4.4.3).
- During the validation phase of module assembly performance (Section 4.4.4 and Section 4.4.5), following the independent evaluation results, the study delved deeper into the benefits of module synergy and integration. The research systematically assessed the collective performance of various downsampling modules when combined with C3K2–DSIS and LMSISD (Section 4.4.4). DSISConv and MSISConv were integrated into the C3K2 structure and lightweight detector head, respectively. This process involved constructing different model variants and conducting a comprehensive comparative analysis to unveil the most effective configuration and its underlying synergy mechanism (Section 4.4.5).
- During the refinement evaluation phase of the ablation experiment (Section 4.4.6 and Section 4.4.7), the efficacy and rationale of each optimization approach were assessed using a refined analysis method. Initially, the optimal embedding position of the module within the network architecture was determined through hierarchical ablation experiments employing C3K2–DSIS (Section 4.4.6). Subsequently, systematic ablation experiments were conducted to quantify the specific impact of each enhanced module on the overall performance, offering a detailed foundation for optimization decisions (Section 4.4.7).
4.4.1. Performance Comparison of Object Detection Algorithms on the Custom Dataset
4.4.2. Comparison of Detection Performance with Different Downsampling Modules
4.4.3. Comparison of Detection Performance with Improved C3K2 Modules
4.4.4. Performance Comparison of Different Downsampling Modules Combined with C3K2–DSIS and LMSISD
4.4.5. Performance Comparison of Model Variants Based on DSISConv and MSISConv
4.4.6. Hierarchical Ablation Study of C3K2–DSIS
4.4.7. Ablation Study of Improved Modules
4.4.8. Generalization Validation on Public Datasets
4.4.9. Knowledge Distillation Experiment
4.5. Visual Analysis of Results
5. Discussion
5.1. Comparison of ADL-YOLO with Existing Detection Methods
5.2. Working Mechanisms and Synergistic Effect Analysis of Core Modules
5.3. Limitations
5.4. Industrial Application Potential
5.5. Future Work
- Multi-regional data validation and model generalization: Expanding the sampling range to multiple processing facilities across China’s major coastal production areas to assess the impact of geographic location and processing technology differences on detection performance, further validating ADL-YOLO’s adaptability and stability across diverse production environments.
- Extension to other aquatic product detection: Applying the ADL-YOLO framework to quality inspection of fish fillets, squid, and other aquatic products with more complex texture and shape characteristics. Through transfer learning and domain adaptation techniques, the model can efficiently adapt to new food categories, expanding its application scope.
- Domain transfer adaptation enhancement: Investigating model performance stability under varying backgrounds, different shrimp species, and camera parameter conditions. Introducing adversarial training and meta-learning techniques to enhance model robustness in changing environments, particularly developing more universally applicable detection models for species variations across different geographic regions.
- Practical deployment and performance verification across diverse edge computing platforms: Implementing system performance evaluation of ADL-YOLO on various edge computing devices, including Jetson series (Xavier NX, Orin Nano), RK3588 NPU, and Raspberry Pi, verifying its inference speed and resource utilization performance in actual hardware environments.
5.6. Artificial Intelligence Technology Application
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- FAO. The State of World Fisheries and Aquaculture 2024; Food and Agriculture Organization of the United Nations: Rome, Italy, 2024; Available online: https://www.fao.org/documents/card/en/c/cc9840en (accessed on 27 March 2025).
- Wang, J.; Che, B.; Sun, C. Spatiotemporal variations in shrimp aquaculture in China and their influencing factors. Sustainability 2022, 14, 13981. [Google Scholar] [CrossRef]
- Lee, D.J.; Xiong, G.M.; Lane, R.M.; Zhang, D. An Efficient Shape Analysis Method for Shrimp Quality Evaluation. In Proceedings of the 2012 12th International Conference on Control Automation Robotics & Vision (ICARCV), Guangzhou, China, 5–7 December 2012; pp. 865–870. [Google Scholar]
- Zhang, D.; Lillywhite, K.D.; Lee, D.J.; Tippetts, B.J. Automatic shrimp shape grading using evolution constructed features. Comput. Electron. Agric. 2014, 100, 116–122. [Google Scholar] [CrossRef]
- Liu, Z.; Jia, X.; Xu, X. Study of shrimp recognition methods using smart networks. Comput. Electron. Agric. 2019, 165, 104926. [Google Scholar] [CrossRef]
- Zhou, C.; Yang, G.; Sun, L.; Wang, S.; Song, W.; Guo, J. Counting, locating, and sizing of shrimp larvae based on density map regression. Aquac. Int. 2024, 32, 3147–3168. [Google Scholar] [CrossRef]
- Hu, W.; Wu, H.; Zhang, Y.; Zhang, S.; Lo, C. Shrimp recognition using ShrimpNet based on convolutional neural network. J. Ambient. Intell. Humaniz. Comput. 2020, 1–8. [Google Scholar] [CrossRef]
- Liu, Z.H. Soft-shell Shrimp Recognition Based on an Improved AlexNet for Quality Evaluations. J. Food Eng. 2020, 266, 109698. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, S.; Li, E.; Yang, G.; Liang, Z.; Tan, M. MD-YOLO: Multi-scale Dense YOLO for small target pest detection. Comput. Electron. Agric. 2023, 213, 108233. [Google Scholar] [CrossRef]
- Tao, H.; Zheng, Y.; Wang, Y.; Qiu, J.; Stojanovic, V. Enhanced feature extraction YOLO industrial small object detection algorithm based on receptive-field attention and multi-scale features. Meas. Sci. Technol. 2024, 35, 105023. [Google Scholar] [CrossRef]
- Li, Y.-L.; Feng, Y.; Zhou, M.-L.; Xiong, X.-C.; Wang, Y.-H.; Qiang, B.-H. DMA-YOLO: Multi-scale object detection method with attention mechanism for aerial images. Vis. Comput. 2023, 40, 4505–4518. [Google Scholar] [CrossRef]
- Cao, Y.; Li, C.; Peng, Y.; Ru, H. MCS-YOLO: A Multiscale Object Detection Method for Autonomous Driving Road Environment Recognition. IEEE Access 2023, 11, 22342–22354. [Google Scholar] [CrossRef]
- Wang, S.; Hao, X. YOLO-SK: A lightweight multiscale object detection algorithm. Heliyon 2024, 10, e24143. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Liu, X.; Ma, J.; Su, W.; Li, H. Real-Time Steel Surface Defect Detection with Improved Multi-Scale YOLO-v5. Processes 2023, 11, 1357. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, S.; Zhan, R.; Wang, W.; Zhang, J. LMSD-YOLO: A Lightweight YOLO Algorithm for Multi-Scale SAR Ship Detection. Remote. Sens. 2022, 14, 4801. [Google Scholar] [CrossRef]
- Peng, S.; Fan, X.; Tian, S.; Yu, L. Ps-yolo: A small object detector based on efficient convolution and multi-scale feature fusion. Multimed. Syst. 2024, 30, 241. [Google Scholar] [CrossRef]
- Su, Z.; Yu, J.; Tan, H.; Wan, X.; Qi, K. MSA-YOLO: A Remote Sensing Object Detection Model Based on Multi-Scale Strip Attention. Sensors 2023, 23, 6811. [Google Scholar] [CrossRef]
- Li, J.; Sun, H.; Zhang, Z. A Multi-Scale-Enhanced YOLO-V5 Model for Detecting Small Objects in Remote Sensing Image Information. Sensors 2024, 24, 4347. [Google Scholar] [CrossRef]
- Glenn, J. YOLOv8. GitHub. 2023. Available online: https://docs.ultralytics.com/models/yolov8/ (accessed on 27 March 2025).
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Cui, Y.; Ren, W.; Cao, X.; Knoll, A. Focal network for image restoration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 13001–13011. [Google Scholar]
- Workspace. Potato Detection Dataset (Open Source Dataset). Roboflow Universe. 2024. Available online: https://universe.roboflow.com/workspace-tedkk/potato-detection-phjcg (accessed on 28 November 2024).
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Ahmed, H.A.; Muhammad Ali, P.J.; Faeq, A.K.; Abdullah, S.M. An Investigation on Disparity Responds of Machine Learning Algorithms to Data Normalization Method. ARO-Sci. J. KOYA Univ. 2022, 10, 29–37. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Glenn, J. YOLOv5. GitHub. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 27 March 2025).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Glenn, J. YOLO11. GitHub. 2024. Available online: https://github.com/ultralytics/ultralytics (accessed on 27 March 2025).
- Lyu, C.; Zhang, W.; Huang, H.; Zhou, Y.; Wang, Y.; Liu, Y.; Zhang, S.; Chen, K. RTMDet: An Empirical Study of Designing Real-Time Object Detectors. arXiv 2022, arXiv:2212.07784. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding Yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wu, T.; Tang, S.; Zhang, R.; Cao, J.; Zhang, Y. Cgnet: A light-weight context guided network for semantic segmentation. IEEE Trans. Image Process. 2020, 30, 1169–1179. [Google Scholar] [CrossRef]
- Xu, G.; Liao, W.; Zhang, X.; Li, C.; He, X.; Wu, X. Haar wavelet downsampling: A simple but effective downsampling module for semantic segmentation. Pattern Recognit. 2023, 143, 109819. [Google Scholar] [CrossRef]
- Zhang, X.; Song, Y.; Song, T.; Yang, D.; Ye, Y.; Zhou, J.; Zhang, L. LDConv: Linear deformable convolution for improving convolutional neural networks. Image Vis. Comput. 2024, 149, 105190. [Google Scholar] [CrossRef]
- Sunkara, R.; Luo, T. No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2022, Grenoble, France, 19–23 September 2022; Part III. pp. 443–459. [Google Scholar]
- Shi, D. TransNeXt: Robust Foveal Visual Perception for Vision Transformers. arXiv 2024, arXiv:2311.17132. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Song, Y.; Zhou, Y.; Qian, H.; Du, X. Rethinking Performance Gains in Image Dehazing Networks. arXiv 2022, arXiv:2209.11448. [Google Scholar]
- Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang, Z.; Huang, T.; Wang, Y.; Wang, C. Rethinking Mobile Block for Efficient Attention-based Models. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 1389–1400. [Google Scholar]
- Li, S.; Wang, Z.; Liu, Z.; Tan, C.; Lin, H.; Wu, D.; Chen, Z.; Zheng, J.; Li, S.Z. Moganet: Multi-order gated aggregation network. In Proceedings of the Twelfth International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Li, J.; Wen, Y.; He, L. SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 6153–6162. [Google Scholar]
- Li, Q.; Jin, S.; Yan, J. Mimicking very efficient network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6356–6364. [Google Scholar]
- Shu, C.; Liu, Y.; Gao, J.; Yan, Z.; Shen, C. Channel-wise knowledge distillation for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 20221; pp. 5311–5320. [Google Scholar]
- Du, Y.; Wei, F.; Zhang, Z.; Shi, M.; Gao, Y.; Li, G. Learning to prompt for open-vocabulary object detection with vision-language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14084–14093. [Google Scholar]
- Mobahi, H.; Farajtabar, M.; Bartlett, P.L. Self-Distillation Amplifies Regularization in Hilbert Space. In Proceedings of the Annual Conference on Neural Information Processing Systems 2020 (NeurIPS 2020), Virtual, 6–12 December 2020. [Google Scholar]
- Liu, B.-Y.; Chen, H.-X.; Huang, Z.; Liu, X.; Yang, Y.-Z. ZoomInNet: A Novel Small Object Detector in Drone Images with Cross-Scale Knowledge Distillation. Remote Sens. 2021, 13, 1198. [Google Scholar] [CrossRef]
- Yang, L.; Zhou, X.; Li, X.; Qiao, L.; Li, Z.; Yang, Z.; Wang, G.; Li, X. Bridging Cross-task Protocol Inconsistency for Distillation in Dense Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 17175–17184. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Zhang, Z.; Yang, Y.; Xu, X.; Liu, L.; Yue, J.; Ding, R.; Lu, Y.; Liu, J.; Qiao, H. GVC-YOLO: A Lightweight Real-Time Detection Method for Cotton Aphid-Damaged Leaves Based on Edge Computing. Remote Sens. 2024, 16, 3046. [Google Scholar] [CrossRef]
- Xu, J.; Pan, F.; Han, X.; Wang, L.; Wang, Y.; Li, W. Edgetrim-YOLO: Improved trim YOLO framework tailored for deployment on edge devices. In Proceedings of the 2024 4th International Conference on Computer Communication and Artificial Intelligence (CCAI), Xi’an, China, 24–26 May 2024; pp. 113–118. [Google Scholar]
- Kang, J.; Cen, Y.; Cen, Y.; Wang, K.; Liu, Y. CFIS-YOLO: A Lightweight Multi-Scale Fusion Network for Edge-Deployable Wood Defect Detection. arXiv 2025, arXiv:2504.11305. [Google Scholar]
- Huang, Y.; Liu, Z.; Zhao, H.; Tang, C.; Liu, B.; Li, Z.; Wan, F.; Qian, W.; Qiao, X. YOLO-YSTs: An Improved YOLOv10n-Based Method for Real-Time Field Pest Detection. Agronomy 2025, 15, 575. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Train | Val | TrainVal | Test | ||||
|---|---|---|---|---|---|---|---|---|
| Images | Objects | Images | Objects | Images | Objects | Images | Objects | |
| VOC2007 | 2501 | 6301 | 2510 | 6307 | 5011 | 12,608 | 4952 | 12,032 |
| VOC2012 | 5717 | 13,609 | 5823 | 13,841 | 11,540 | 27,450 | — | — |
| VOC07+12 | 16,551 | 40,058 | 4952 | 12,032 | — | — | — | — |
| Hyperparameters | Configuration | ||
|---|---|---|---|
| Custom | Potato Detection | VOC07+12 | |
| Epochs | 200 | 200 | 500 |
| Batch | 32 | 32 | 8 |
| Image Size | 640 | 640 | 640 |
| Optimizer | SGD | SGD | SGD |
| lr0 | 0.01 | 0.01 | 0.01 |
| lrf | 0.01 | 0.01 | 0.01 |
| Close mosaic | 0 | 0 | 0 |
| Weight decay | 0.0005 | 0.0005 | 0.0005 |
| Patience | 100 | 100 | 100 |
| Momentum | 0.9 | 0.9 | 0.937 |
| Workers | 10 | 10 | 10 |
| Learning rate decay | Linear decay | Linear decay | Linear decay |
| Scheduler | LambdaLR | LambdaLR | LambdaLR |
| Model | /% | /% | mAP50 /% | mAP50-95 /% | FPS (Frames/s) | Ms /MB | GFLOPs | Params | |
|---|---|---|---|---|---|---|---|---|---|
| Anchor-Based One-Stage: | |||||||||
| SSD300 [30] | 81.9 | 79.0 | 85.6 | 59.6 | 51.8 | 212.00 | 30.926 | 25,083,000 | — |
| RetinaNet−R50−FPN [31] | 72.4 | 69.3 | 76.4 | 52.8 | 21.6 | 312.00 | 179.000 | 36,537,000 | — |
| YOLOv3−tiny [32] | 93.1 | 91.0 | 94.6 | 71.3 | 271.7 | 16.60 | 12.900 | 8,689,792 | 0.104 |
| YOLOv5n [33] | 94.1 | 92.8 | 96.0 | 74.0 | 282.5 | 3.67 | 4.200 | 1,774,048 | 0.486 |
| YOLOv7−tiny [34] | 91.8 | 92.5 | 95.5 | 75.3 | 253.8 | 11.70 | 13.100 | 6,034,656 | 0.334 |
| Anchor-Free One-Stage: | |||||||||
| YOLOv8n [19] | 93.1 | 93.6 | 96.1 | 78.9 | 347.2 | 5.95 | 8.100 | 3,007,793 | 0.674 |
| YOLOv9t [20] | 92.0 | 93.7 | 96.5 | 79.1 | 207.5 | 5.82 | 10.700 | 2 620 850 | 0.600 |
| YOLOv10n [21] | 93.1 | 91.8 | 95.5 | 78.3 | 431.0 | 5.48 | 8.200 | 2,698,706 | 0.583 |
| RT−DETR−R18 [35] | 94.6 | 93.7 | 95.1 | 77.2 | 100.2 | 38.60 | 57.000 | 19,885,884 | 0.282 |
| YOLOv11n [36] | 93.4 | 94.0 | 96.1 | 78.9 | 328.9 | 5.21 | 6.300 | 2,584,297 | 0.690 |
| RTMDet−Tiny [37] | 91.1 | 90.8 | 95.0 | 76.3 | 25.7 | 83.30 | 8.033 | 4,876,000 | — |
| YOLOX−tiny [38] | 92.6 | 90.9 | 95.0 | 74.1 | 56.8 | 65.70 | 7.579 | 5,036,000 | — |
| Anchor-Based Two-Stage: | |||||||||
| Faster−RCNN −R50−FPN [39] | 94.0 | 92.6 | 95.9 | 76.6 | 19.6 | 363.00 | 179.000 | 41,339,000 | — |
| Module | /% | /% | mAP50 /% | mAP50-95 /% | FPS (Frames/s) | Ms /MB | GFLOPs | Params | |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv11n (Baseline) | 93.4 | 94.0 | 96.1 | 78.9 | 328.9 | 5.21 | 6.3 | 2,584,297 | 0.566 |
| Context Guided [40] | 93.6 | 93.7 | 96.9 | 79.6 | 282.5 | 7.07 | 8.9 | 3,528,873 | 0.632 |
| HWD [41] | 93.8 | 94.1 | 96.7 | 79.0 | 306.7 | 4.52 | 5.5 | 2,215,657 | 0.675 |
| LDConv [42] | 91.6 | 91.7 | 95.6 | 77.7 | 246.3 | 4.43 | 5.5 | 2,170,247 | 0.047 |
| SPDConv [43] | 94.0 | 93.2 | 96.7 | 79.5 | 303.0 | 9.01 | 10.6 | 4,574,953 | 0.565 |
| SRFD [43] | 93.6 | 94.2 | 96.5 | 79.0 | 217.4 | 5.21 | 7.6 | 2,555,977 | 0.445 |
| ADown [20] | 92.8 | 94.4 | 96.6 | 79.4 | 310.6 | 4.31 | 5.3 | 2,105,065 | 0.695 |
| Module | /% | /% | mAP50 /% | mAP50-95 /% | FPS (Frames/s) | Ms /MB | GFLOPs | Params | |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv11n (Baseline) | 93.4 | 94.0 | 96.1 | 78.9 | 328.9 | 5.21 | 6.3 | 2,584,297 | 0.629 |
| C3k2–Faster [44] | 92.2 | 91.7 | 95.8 | 78.2 | 324.7 | 4.65 | 5.8 | 2,290,145 | 0.579 |
| C3k2–Faster–EMA [44,45] | 91.9 | 92.2 | 95.7 | 77.1 | 274.7 | 4.70 | 5.9 | 2,294,929 | 0.372 |
| C3k2–gConv [46] | 89.8 | 90.5 | 94.9 | 76.2 | 325.0 | 4.59 | 5.7 | 2,251,809 | 0.295 |
| C3k2–iRMB [47] | 92.8 | 92.5 | 95.8 | 76.8 | 297.6 | 4.95 | 6.0 | 2,437,201 | 0.392 |
| C3k2–MogaBlock [48] | 89.5 | 89.3 | 94.4 | 75.7 | 241.5 | 5.30 | 6.7 | 2,570,120 | −0.148 |
| C3k2–SCcConv [49] | 93.7 | 93.4 | 96.4 | 79.1 | 310.6 | 5.00 | 6.2 | 2,467,049 | 0.660 |
| C3K2–DSIS | 94.0 | 94.3 | 96.8 | 78.9 | 331.1 | 5.14 | 6.3 | 2,511,285 | 0.728 |
| Module | /% | /% | mAP50 /% | mAP50-95 /% | FPS (Frames/s) | Ms /MB | GFLOPs | Params | |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv11n (Baseline) | 93.4 | 94.0 | 96.1 | 78.9 | 328.9 | 5.21 | 6.3 | 2,584,297 | 0.536 |
| +Context Guided + B + C | 93.9 | 93.5 | 96.6 | 79.2 | 238.0 | 7.55 | 8.5 | 3,723,630 | 0.412 |
| +HWD + B + C | 94.6 | 93.3 | 96.5 | 79.3 | 267.4 | 5.00 | 5.1 | 2,410,414 | 0.559 |
| +LDConv + B + C | 91.4 | 91.4 | 95.3 | 77.6 | 225.2 | 4.91 | 5.1 | 2,365,004 | 0.025 |
| +SPDConv + B + C | 93.0 | 93.7 | 96.8 | 79.3 | 278.0 | 9.49 | 10.2 | 4,769,710 | 0.431 |
| +SRFD + B + C | 93.1 | 94.3 | 96.4 | 79.5 | 207.0 | 5.69 | 7.2 | 2,750,734 | 0.413 |
| +ADown + B + C | 94.3 | 95.0 | 96.9 | 80.2 | 299.4 | 4.79 | 4.9 | 2,299,822 | 0.792 |
| Module | /% | /% | mAP50 /% | mAP50-95 /% | FPS (Frames/s) | Ms /MB | GFLOPs | Params | |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv11n (Baseline) | 93.4 | 94.0 | 96.1 | 78.9 | 328.9 | 5.21 | 6.3 | 2,584,297 | 0.050 |
| AMD-YOLO | 93.4 | 94.2 | 97.0 | 79.7 | 275.0 | 4.38 | 4.4 | 2,082,126 | 0.343 |
| ADL-YOLO | 94.3 | 95.0 | 96.9 | 80.2 | 299.4 | 4.79 | 4.9 | 2,299,822 | 0.610 |
| ADD-YOLO | 93.7 | 94.7 | 96.9 | 79.5 | 287.4 | 4.27 | 4.4 | 2,030,798 | 0.416 |
| AMM-YOLO | 94.6 | 94.7 | 97.1 | 79.7 | 281.0 | 4.91 | 4.9 | 2,351,150 | 0.470 |
| Replace Layer | /% | /% | mAP50 /% | mAP50-95 /% | FPS (Frames/s) | Ms /MB | GFLOPs | Params | |
|---|---|---|---|---|---|---|---|---|---|
| 2, 4, 6, 8, 13, 16, 19, 22 | 95.1 | 93.9 | 97.0 | 79.8 | 257.73 | 4.85 | 4.7 | 2,266,719 | 0.307 |
| 4, 6, 8, 13, 16, 19, 22 | 93.0 | 94.6 | 96.9 | 79.7 | 259.07 | 4.83 | 4.7 | 2,266,864 | 0.203 |
| 6, 8, 13, 16, 19, 22 | 94.4 | 94.9 | 97.1 | 80.0 | 270.27 | 4.82 | 4.8 | 2,268,949 | 0.537 |
| 8, 16, 19, 22 | 94.7 | 94.5 | 97.0 | 80.0 | 271.74 | 4.80 | 4.8 | 2,286,444 | 0.477 |
| 8, 19, 22 | 93.8 | 94.7 | 96.7 | 79.5 | 279.33 | 4.79 | 4.9 | 2,288,529 | 0.140 |
| 8, 19 | 93.5 | 95.1 | 97.0 | 80.2 | 292.40 | 4.82 | 4.9 | 2,325,035 | 0.565 |
| 19, 22 | 93.9 | 94.7 | 96.8 | 80.1 | 290.70 | 4.82 | 4.9 | 2,325,035 | 0.407 |
| 8, 22 | 94.3 | 95.0 | 96.9 | 80.2 | 299.4 | 4.79 | 4.9 | 2,299,822 | 0.625 |
| ADown | C3K2–DSIS | LMSISD | /% | /% | mAP50 /% | mAP50-95 /% | FPS (Frames/s) | Ms /MB | GFLOPs | Params | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 93.4 | 94.0 | 96.1 | 78.9 | 328.9 | 5.21 | 6.3 | 2,584,297 | 0.116 | |||
| √ | 92.8 | 94.4 | 96.6 | 79.4 | 310.6 | 4.31 | 5.3 | 2,105,065 | 0.344 | ||
| √ | 94.0 | 94.3 | 96.8 | 78.9 | 331.1 | 5.14 | 6.3 | 2,511,285 | 0.369 | ||
| √ | 93.6 | 93.9 | 96.8 | 79.4 | 290.7 | 5.77 | 6.0 | 2,852,066 | 0.176 | ||
| √ | √ | 94.6 | 94.2 | 96.7 | 79.6 | 318.5 | 4.24 | 5.2 | 2,032,053 | 0.539 | |
| √ | √ | 94.1 | 94.7 | 96.9 | 79.8 | 294.1 | 4.86 | 5.0 | 2,372,834 | 0.490 | |
| √ | √ | 94.2 | 94.3 | 96.9 | 79.6 | 297.6 | 5.70 | 5.9 | 2,779,054 | 0.354 | |
| √ | √ | √ | 94.3 | 95.0 | 96.9 | 80.2 | 299.4 | 4.79 | 4.9 | 2,299,822 | 0.642 |
| Group | Dataset | Model | mAP50/% | mAP50-95/% | GFLOPs | Params |
|---|---|---|---|---|---|---|
| 1 | VOC07+12 | Yolov5n | 74.0 | 46.9 | 4.2 | 1,786,225 |
| 2 | Yolov7-tiny | 79.9 | 55.2 | 13.2 | 6,059,010 | |
| 3 | Yolov8n | 80.9 | 60.2 | 8.1 | 3,009,548 | |
| 4 | Yolov10n | 81.2 | 61.5 | 8.3 | 2,702,216 | |
| 5 | YOLOv11n (Baseline) | 81.5 | 61.3 | 6.3 | 2,586,052 | |
| 6 | ADL-YOLO (Ours) | 82.1 | 62.7 | 4.9 | 2,303,881 | |
| 7 | Potato Detect | Yolov5n | 76.7 | 55.3 | 4.1 | 1,765,930 |
| 8 | Yolov7-tiny | 78.4 | 57.1 | 13.1 | 6,018,420 | |
| 9 | Yolov8n | 79.5 | 60.2 | 8.1 | 3,006,623 | |
| 10 | Yolov10n | 77.7 | 58.7 | 8.2 | 2,696,366 | |
| 11 | YOLOv11n (Baseline) | 79.6 | 60.3 | 6.3 | 2,583,127 | |
| 12 | ADL-YOLO (Ours) | 80.9 | 61.4 | 4.9 | 2,297,116 |
| Model | mAP50 | Aero | Bicycle | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv11n (Baseline) | 81.5 | 87.9 | 90.6 | 78.3 | 74.8 | 68.0 | 88.3 | 91.8 | 90.2 | 65.1 | 82.3 |
| ADL-YOLO | 82.1 | 89.8 | 91.2 | 80.5 | 75.2 | 69.8 | 86.8 | 92.0 | 91.0 | 64.7 | 81.5 |
| Model | Table | Dog | Horse | Moto | Person | Plant | Sheep | Sofa | Train | Tv | |
| YOLOv11n (Baseline) | 78.4 | 86.0 | 91.3 | 88.1 | 88.3 | 53.1 | 80.5 | 78.9 | 89.3 | 79.3 | |
| ADL-YOLO | 77.3 | 87.1 | 91.6 | 88.1 | 88.3 | 58.2 | 82.4 | 78.7 | 89.7 | 79.1 |
| Method | /% | /% | mAP50/% | mAP50-95/% |
|---|---|---|---|---|
| ADL-YOLO-L (Teacher) | 94.3 | 94.9 | 97.1 | 81.4 |
| ADL-YOLO (Student) | 94.3 | 95.0 | 96.9 | 80.2 |
| Feature-Based Distillation | ||||
| Mimic [50] | 94.3 | 94.3 | 97.1 | 79.9 |
| CWD [51] | 94.4 | 94.9 | 96.9 | 79.9 |
| Logits-Based Distillation | ||||
| L1 [52] | 93.7 | 94.9 | 96.7 | 80.0 |
| L2 [53,54] | 94.1 | 94.9 | 97.0 | 80.0 |
| BCKD [55] | 94.2 | 95.8 | 97.1 | 80.3 |
| Feature-Logits-Based Distillation | ||||
| L1 + Mimic | 93.6 | 94.8 | 96.8 | 79.9 |
| L1 + CWD | 94.5 | 95.2 | 97.0 | 80.4 |
| L2 + Mimic | 94.2 | 94.8 | 97.0 | 80.0 |
| L2 + CWD | 94.2 | 95.7 | 97.1 | 80.0 |
| BCKD + Mimic | 94.1 | 95.0 | 97.3 | 80.4 |
| BCKD + CWD | 94.2 | 96.2 | 97.4 | 80.7 |
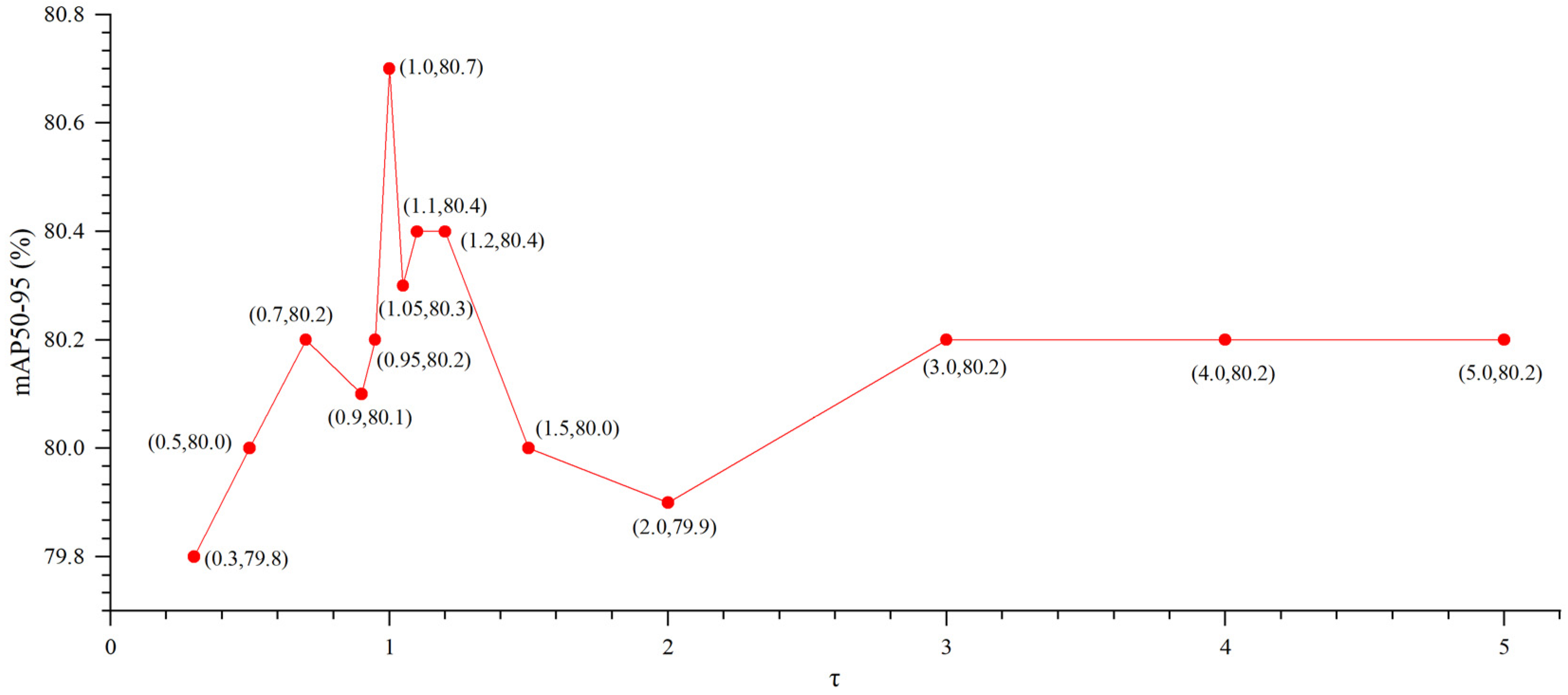
| Group | /% | /% | mAP50/% | mAP50-95/% | |
|---|---|---|---|---|---|
| 1 | 0.3 | 94.1 | 94.5 | 97.0 | 79.8 |
| 2 | 0.5 | 94.0 | 95.5 | 97.2 | 80.0 |
| 3 | 0.7 | 94.1 | 94.6 | 97.0 | 80.2 |
| 4 | 0.9 | 94.2 | 95.7 | 97.4 | 80.1 |
| 5 | 0.95 | 94.7 | 94.5 | 97.1 | 80.2 |
| 6 | 1.0 | 94.2 | 96.2 | 97.4 | 80.7 |
| 7 | 1.05 | 95.1 | 95.1 | 97.4 | 80.3 |
| 8 | 1.1 | 94.2 | 95.5 | 97.2 | 80.4 |
| 9 | 1.2 | 94.6 | 95.2 | 97.2 | 80.4 |
| 10 | 1.5 | 94.7 | 94.8 | 97.2 | 80.0 |
| 11 | 2.0 | 94.1 | 95.7 | 97.0 | 79.9 |
| 12 | 3.0 | 94.8 | 95.7 | 97.1 | 80.2 |
| 13 | 4.0 | 94.2 | 94.9 | 97.2 | 80.2 |
| 14 | 5.0 | 94.2 | 94.9 | 97.1 | 80.2 |
| Group | /% | /% | mAP50/% | mAP50-95/% | ||
|---|---|---|---|---|---|---|
| 1 | 1.0 | 7.5 | 94.2 | 96.2 | 97.4 | 80.7 |
| 2 | 0.5 | 7.5 | 94.0 | 95.1 | 97.2 | 80.2 |
| 3 | 0.1 | 7.5 | 94.8 | 95.1 | 97.3 | 80.0 |
| 4 | 2.0 | 7.5 | 94.2 | 95.2 | 96.8 | 79.7 |
| 5 | 1.0 | 7.0 | 94.3 | 95.3 | 97.0 | 80.2 |
| 6 | 1.0 | 6.9 | 93.8 | 94.6 | 97.1 | 80.2 |
| 7 | 1.0 | 6.8 | 94.4 | 94.6 | 97.2 | 80.4 |
| 8 | 1.0 | 6.7 | 94.6 | 95.2 | 97.2 | 80.3 |
| 9 | 1.0 | 6.6 | 95.3 | 95.0 | 97.2 | 80.1 |
| 10 | 1.0 | 6.4 | 94.6 | 94.8 | 97.2 | 80.3 |
| 11 | 1.0 | 6.3 | 94.4 | 94.6 | 97.0 | 80.1 |
| 12 | 1.0 | 6.2 | 94.5 | 94.9 | 96.9 | 80.0 |
| 13 | 1.0 | 6.1 | 94.2 | 95.0 | 97.2 | 80.3 |
| 14 | 1.0 | 6.0 | 94.0 | 95.5 | 97.2 | 80.4 |
| 15 | 1.0 | 5.5 | 94.2 | 94.3 | 97.0 | 80.1 |
| 16 | 1.0 | 5.0 | 94.1 | 95.6 | 97.0 | 80.2 |
| 17 | 0.1 | 6.1 | 93.5 | 95.5 | 97.1 | 80.3 |
| 18 | 0.1 | 2.0 | 93.7 | 94.7 | 97.1 | 80.0 |
| 19 | 0.1 | 1.0 | 94.3 | 95.0 | 97.1 | 79.9 |
| Model | Params/M | GFLOPs | Ms/MB | Platform | FPS (Frames/s) | References |
|---|---|---|---|---|---|---|
| GVC-YOLO | 2.53 | 6.8 | 5.4 | Jetson Xavier NX | 48.0 | Zhang et al. [57] |
| EdgeTrim-YOLO | 6.40 | 11.0 | 14.9 | RK3588 NPU | 34.6 | Xu et al. [58] |
| YOLO v5n | 1.90 | 4.5 | 4.2 | RK3588 NPU | 59.9 | Xu et al. [58] |
| YOLO v5s | 7.20 | 16.5 | 15.7 | RK3588 NPU | 27.9 | Xu et al. [58] |
| YOLO v5m | 21.2 | 49.0 | 43.0 | RK3588 NPU | 16.0 | Xu et al. [58] |
| CFIS-YOLO | 7.17 | — | 11.21 | SOPHON BM1684X | 135.0 | Kang et al. [59] |
| YOLO-YSTs | 3.02 | 8.8 | 6.5 | Raspberry Pi 4B | 22.0 | Huang et al. [60] |
| ADL-YOLO (Ours) | 2.3 | 4.9 | 4.79 | NVIDIA GeForce RTX 2080 Ti | 299.4 | — |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Chen, J.; Lu, B.-Y.; Hu, S. A Lightweight Multi-Scale Object Detection Framework for Shrimp Meat Quality Control in Food Processing. Processes 2025, 13, 1556. https://doi.org/10.3390/pr13051556
Zhang H, Chen J, Lu B-Y, Hu S. A Lightweight Multi-Scale Object Detection Framework for Shrimp Meat Quality Control in Food Processing. Processes. 2025; 13(5):1556. https://doi.org/10.3390/pr13051556
Chicago/Turabian StyleZhang, Henghui, Jinpeng Chen, Bing-Yuh Lu, and Shaolin Hu. 2025. "A Lightweight Multi-Scale Object Detection Framework for Shrimp Meat Quality Control in Food Processing" Processes 13, no. 5: 1556. https://doi.org/10.3390/pr13051556
APA StyleZhang, H., Chen, J., Lu, B.-Y., & Hu, S. (2025). A Lightweight Multi-Scale Object Detection Framework for Shrimp Meat Quality Control in Food Processing. Processes, 13(5), 1556. https://doi.org/10.3390/pr13051556