Abstract
Superheat degree (SD) is an important indicator for identifying the status of aluminum electrolytic cells. The fire hole video of the aluminum electrolytic cell captured by an industrial camera is an important basis for identifying SD. This article proposes a novel method that VideoMamba enhances with attention and learnable Fourier transform (CFVM) for SD identification. With a lower computational complexity and feature extraction capabilities comparable to transformers, VideoMamba offers the CFVM model a stronger feature extraction basis. The channel attention mechanism (CAM) block can achieve information exchange between channels. Through matrix eigenvalue manipulation, the learnable nonlinear Fourier transform (LNFT) block may guarantee stable convergence of the model. Furthermore, the LNFT block can efficiently use mixed frequency domain channels to capture global dependency information. The model is trained using the aluminum electrolysis fire hole dataset. Compared with recent fire hole identification models that primarily rely on neural networks, the method proposed in this paper is based on the concept of state space modeling, offering lower model complexity and enhanced feature extraction capability. Experimental results demonstrate that the proposed model achieves competitive performance in fire hole video identification tasks, reaching an identification accuracy of 85.7% on the test set.
1. Introduction
The electrolytic cell is the main equipment for aluminum electrolysis. And there are various field effects and coexisting states in its surroundings, making it a complex reactor. The operating status of the electrolytic cell not only reflects the state of aluminum production but also affects the quality, energy, material, and labor cost of aluminum. Therefore, the operating status of the electrolytic cell needs to be monitored in real-time [1]. The operational status of electrolytic cells using superheat degree (SD) reaction in industry. When SD is too low, the solubility of deteriorates, leading to an increase in the anodic effect and current loss; when SD is too high, the current efficiency decreases, which affects the quality of aluminum and the lifespan of the electrolytic cell. Maintaining SD within a normal range is necessary to improve the current efficiency and stabilize the aluminum production efficiency. SD is defined as the difference between the electrolyte temperature and the initial crystallization temperature. The electrolyte temperature can be directly measured using a temperature sensor, while the initial crystallization temperature cannot be obtained directly through the sensor but can be obtained through experimental approaches. Nevertheless, industrial SD measurement demands speed and precision, which experimental approaches cannot provide.
At aluminum electrolysis production sites, workers generally rely on visual inspection to identify SD states. This process depends on their experience in observing color changes, fluctuations, and other visual characteristics of the electrolyte at the fire hole. However, manual observation presents several limitations: (1) Due to the absence of a standardized system for SD identification, subjectivity and varying levels of expertise among workers often lead to inconsistent results. (2) Environmental factors such as smoke, residue, and high temperatures around the fire hole can hinder observation, making continuous monitoring difficult and potentially causing missed or delayed identifications. (3) Manual observation is experience-based but such knowledge is difficult to formalize and effectively pass on. These challenges impact the stability and operational efficiency of the aluminum electrolysis industry. In recent years, many researchers have begun to apply deep learning methods to the task of SD state identification during the production process. By training models on multi-source data collected in real industrial settings, deep learning approaches can effectively identify and monitor SD states. In this study, fire hole videos captured during aluminum electrolysis are used as the primary data source for training the model, enabling the accurate and automated identification of SD states.
At first, video tasks were mostly modeled using a dual stream CNN structure [2], which used two sub-networks to extract information from both the temporal and spatial dimensions. Due to the inability of CNN to effectively capture long-term dependencies, many scholars have combined CNN with LSTM [3,4] to compensate for this drawback and achieve more accurate predictions. As 3D networks have become more popular, networks like I3D [5], C3D [6], and P3D [7] have been developed one after the other and have shown some potential in real-world applications. Nevertheless, issues like excessive processing resource usage and a lack of local information capture remain with the aforementioned video modeling techniques. Many academics have started using transformers [8] for video work since its inception. When it comes to video understanding tasks, models based on transformer architecture, like video transformer network (VTN) [9], TimeSformer [10], vision transformer (ViT) [11], and video vision transformer (ViViT) [12] each have unique advantages. However, attention mechanisms cause transformers to have a high computational cost. The Mamba, a rising star, overcomes transformers’ computational complexity issue while processing lengthy sequence data and has modeling capabilities that are on par with transformers. Mamba adopts a selection scan mechanism to remove redundant content, retain key information, and improve data processing efficiency. It also uses a hardware-aware algorithm to achieve a significant increase in computing speed on high-performance GPUs through scanning operations. Vision Mamba [13] and VideoMamba [14], improved based on Mamba [15], have achieved excellent results in video understanding tasks. However, when applying VideoMamba to identify SD in aluminum electrolytic cells, the identification effect did not meet expectations. After analyzing the structure of VideoMamba, it was found that the model lacks information interaction between different channels. And from the training results of the fire hole video in VideoMamba, it is observed that there is a problem of non-convergence during the training process. The above two reasons result in lower accuracy of the VideoMamba for SD identification.
In order to address the issues of insufficient model structure and unstable training in current SD identification methods for electrolytic cells, this paper proposes an improved model based on VideoMamba. On the basis of the original framework, this model integrates a channel attention mechanism and a learnable nonlinear Fourier transform block to enhance the information exchange between feature channels and effectively improve the convergence problem of the model during training. The main contributions of this article are as follows:
- (1)
- Combining the channel attention mechanism (CAM) block enhances the selective attention ability of the model to different channel features, thereby improving the modeling effect and expression ability of multidimensional video features.
- (2)
- Adding a learnable nonlinear Fourier transform (LNFT) block significantly alleviates the problems of gradient vanishing and exploding during training by constraining the eigenvalues of the state matrix A in VideoMamba to negative real numbers, effectively improving the convergence speed and stability of the model.
- (3)
- The proposed model is based on state space models, which is different from the mainstream neural network fire hole video identification methods in recent years. The experimental results show that this method exhibits better performance in both identification accuracy and robustness, and has strong practical application potential.
The outline of this article is as follows. In the Section 2, the related work of this article is introduced. In the Section 3, the model structure of VideoMamba enhanced with attention and learnable Fourier transform (CFVM) for SD identification proposed in this paper is detailed. In the Section 4, this method is discussed and compared with other methods to verify its superiority. The Section 5 presents the conclusion of this article.
2. Related Work
2.1. Research on Superheat Degree State Identification
The data collected during the aluminum electrolysis production process can be broadly categorized into two types: fire hole video data and production process data. The fire hole video data are real-time video recordings captured by industrial cameras. These videos intuitively reflect dynamic features such as surface fluctuations and color changes of the electrolyte, which can reveal the evolving trend of SD states in the electrolysis process. As such, fire hole videos provide critical visual information for the intelligent identification and monitoring of SD conditions in aluminum electrolysis. The process data are multidimensional and multivariate time-series data that record key operational parameters of the electrolytic cells. This type of data typically includes, but is not limited to, cell voltage, cell current, mole ratio, electrolyte level, and aluminum level. These variables are closely related to the operating status and energy conversion processes within the electrolytic cell, showing valuable quantitative indicators of the internal state of the system.
In recent years, researchers have employed deep learning methods to extract features from fire hole video data or production process data for the purpose of SD state identification or fault detection in aluminum electrolysis [16,17,18,19]. Zhao [16] proposed a SD identification method based on a 3D convolutional neural network. Firstly, the ORB and RANSAC algorithms are used to estimate the global motion parameters of the fire hole image, and based on the estimation results, the image is cropped to a fixed size to generate identification samples with different combinations of consecutive frames. Secondly, the identification samples are placed into a 3D convolutional neural network for training. Three-dimensional convolutional neural networks are capable of self-learning motion features in fire hole videos, overcoming the limitations of traditional manual feature extraction methods such as limited feature types and low accuracy. Lei [17] combined convolutional neural network (CNN) with extreme learning machine (ELM) to construct a CNN-ELM SD soft sensing model. This model utilizes CNN to extract deep features, and establishes an electrolyte temperature soft sensing model for image and data fusion by fusing features with texture features, amplitude features, etc. Jiang [18] proposed a novel SD measurement method based on kernel extreme learning machine (K-ELM). By selecting a set of input variables based on expert knowledge, they proposed a new activation function and regularization term within the ELM framework to construct IG-SSELM, which is applied to the identification of SD states in the aluminum industry. Yue [19] not only proposed an unbalance double hierarchy hesitant linguistic Petri net (UDHHLPN) to represent knowledge parameter values but also proposed the hybrid averaging UDHHLTS, aiming to enhance the accuracy and efficiency of SD state identification. The aforementioned research methods effectively address the limitations of traditional manual SD state identification, such as high subjectivity, poor real-time performance, and lack of consistency. These approaches enable the continuous and uninterrupted monitoring of the aluminum electrolysis production process, thereby contributing significantly to the enhancement of system intelligence and the advancement of industrial modernization in the aluminum electrolysis sector.
Building upon the aforementioned research foundations, this study selects fire hole video data as the primary basis for modeling. Compared with production process data, fire hole videos offer a more intuitive and dynamic representation of the actual operating state of the electrolyte within the electrolytic cell, thereby providing richer and more informative features.
2.2. Channel Attention Mechanism
The attention mechanism (AM) was initially applied in the field of natural language processing. Its core idea is to simulate the human visual focusing process, enabling models to dynamically assign weights to different parts of the input based on their importance, thereby enhancing the ability to model key information and improve predictive performance. The channel attention mechanism (CAM) is a specific implementation of this concept in computer vision tasks and has been widely applied in convolutional neural networks (CNNs). By modeling the interdependencies among feature channels, it automatically learns the relative importance of each channel in feature representation, and reassigns weights to emphasize informative channels while suppressing redundant ones. In comparison, the general attention mechanism is often employed for modeling dependencies in sequential or spatial dimensions, whereas CAM is more suitable for capturing inter-channel relationships in high-dimensional data such as images and videos, thereby improving the representational capacity of multidimensional inputs.
The CAM has been widely applied in image-based and video-based model construction, effectively improving the overall performance of the model by enhancing the representation ability of key feature channels. Chen et al. [20] proposed an interactive learning and multi-channel attention mechanism-based weakly supervised colorectal histopathology image classification approach (IL-MCAM). In the automatic learning (AL) stage, a multi-channel attention mechanism model is used to extract multi-channel features for classification. Luo et al. [21] proposed a deep fully convolutional network with channel attention mechanism (CAM-DFCN) for semantic segmentation of high-resolution aerial images. By adding CAM in the decoder, the model adaptively weights feature map channels to enhance discriminative feature selection and better balance semantic and spatial location information, thereby improving prediction accuracy. Yan et al. [22] proposed a cloud detection algorithm based on multi-scale inputs and dual-channel attention mechanisms. The dual-channel attention mechanism in this model can focus on band information and angle information based on the reconstructed multi-scale data.
The channel attention mechanism enhances model performance while maintaining commendable computational efficiency. In comparison, the spatial attention mechanism, although capable of emphasizing critical regions, exhibits certain limitations when applied to video sequences, resulting in relatively lower classification accuracy. The self-attention mechanism demonstrates a stronger capacity for global modeling. However, it entails considerable overhead in terms of computational complexity, parameter count, and training time, which may impose substantial burdens in real-world deployment scenarios with constrained resources. In contrast, the channel attention mechanism achieves a more favorable balance between emphasizing essential channel features and managing model complexity, thereby effectively improving the generalization capability and stability of the model.
Based on the above research, this study proposes the integration of a channel attention mechanism block into the existing model architecture. The goal is to improve the capacity of the model to identify the relevance of multidimensional variables, hence increasing its effectiveness in retrieving crucial information from fire hole video data.
2.3. Discrete Fourier Transform
The discrete Fourier transform (DFT) is a useful technique for translating finite-length discrete signals from the time domain to the frequency domain. The basic idea is to decompose a discrete-time signal into a superposition of sine waves and cosine waves in order to study its distribution across different frequency components. Specifically, given a finite length sequence , the DFT is used to transform the time domain signal into a frequency domain signal as shown in Formula (1). Among them, N is the number of sampling points within the period, and is the transformed frequency domain signal. K is the spectral sampling point. DFT can decompose a signal into the superposition of sine waves and cosine waves of different frequencies as shown in Formula (2). Therefore, the transformed is divided into two parts: the real part and the imaginary part. The inverse Fourier transform (IDFT) can transform a given frequency domain signal into a time domain signal as shown in Formula (3):
For a given time domain input X and its corresponding frequency domain signal obtained using DFT, according to the convolution theorem, the convolution operation of X in the time domain can be completely equivalent to the product operation of in the frequency domain. The equivalent formula is shown in Formula (4). Among them, ∗ represents the convolution operation, and · represents the product operation. and B represent the complex weights and biases of the time domain, while and represent the complex weights and biases of the frequency domain
2.4. State Space Models
The state space model (SSM) [23] is a sequence model that can be applied to deep learning. The concept of SSM is based on a continuous system. In a set of equations representing a continuous system, a first-order differential equation (representing continuous-time system) or difference equation (representing discrete-time system) is used to represent the evolution of the internal state of the system, while another equation is used to describe the relationship between the system state and output. In short, the system uses implicit latent states to map a one-dimensional function or sequence . Usually, SSM models the input data using ordinary differential equations (ODEs) as shown in Formula (5):
Among them, represents the evolution matrix of the system, and are the projection matrices. Mamba is a version obtained by adding discretization to the ODEs mentioned above. Mamba uses a time scale parameter to transform continuous parameters into corresponding discrete parameters . There are many discretization methods. Usually, the zero-order hold (ZOH) method is used as shown in Formula (6). The discretized ODE is shown in Formula (7):
Mamba incorporates a selective scan mechanism as the core of its state space model (SSM), and is therefore referred to as S6. The selective scan mechanism can automatically identify and remove redundant information in long time series, significantly reducing the computational burden of the model. More importantly, it can extract key features from time series more effectively, thereby enhancing the ability of model to capture sequence patterns. Through this improvement, Mamba not only outperforms traditional methods in computational efficiency but also exhibits higher stability and accuracy in handling complex time series tasks. This ability gives it significant advantages in application scenarios that require the efficient extraction of time series information.
Almost all SSMs have linear time invariance (LTI). After adding the selective scan mechanism, a length dimension L will be added to all Mamba parameters, and the model will change from time invariant to time varying. At this point, the input data are , and the parameters , , and have also changed, demonstrating that the model has good adaptive weight modulation capability.
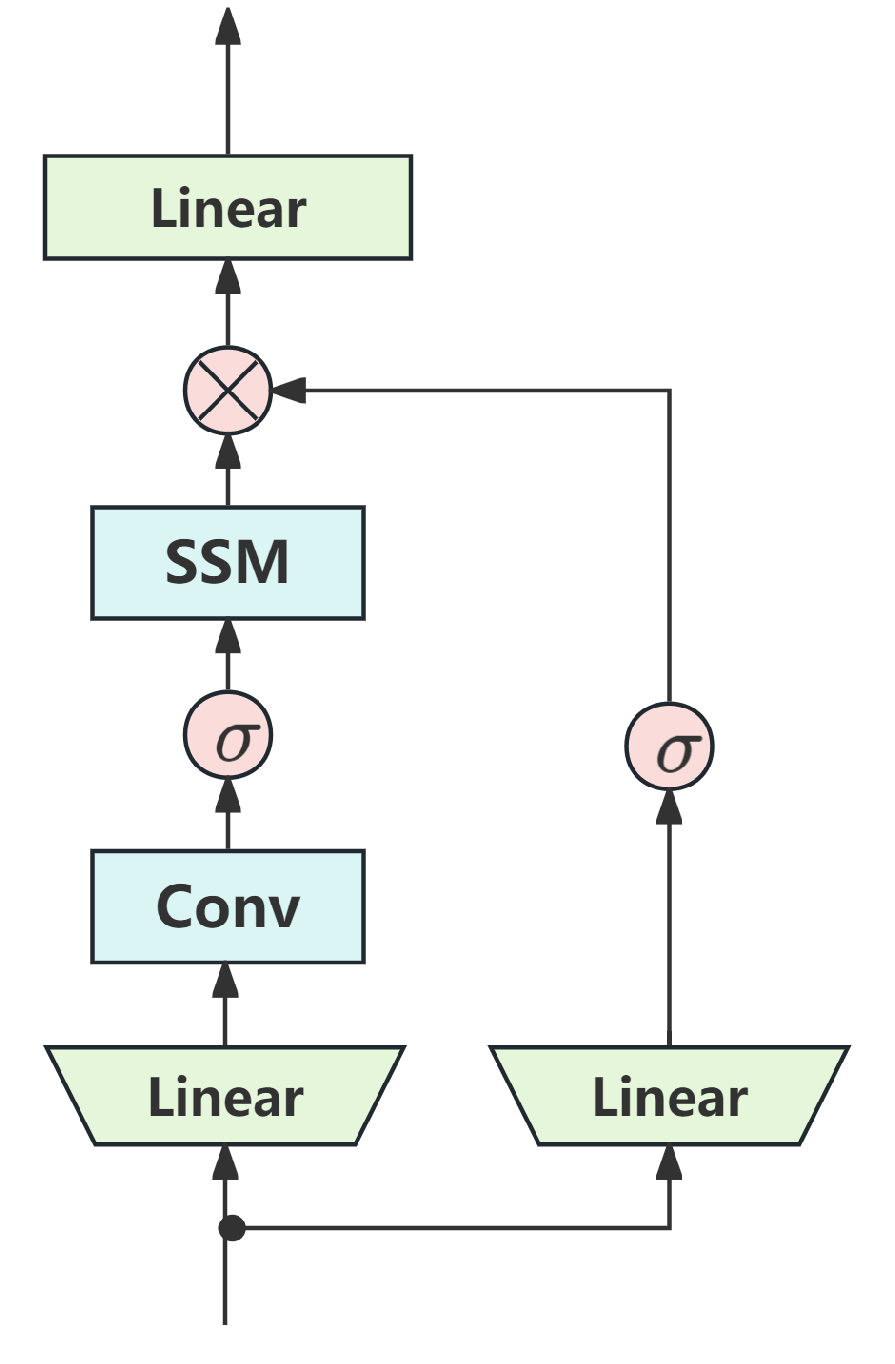
As shown in Figure 1, the unidirectional Mamba block is primarily designed for one-dimensional sequence tasks, such as time-series analysis and text identification. Among them, represents a nonlinear activation function, and ⊗ represents nonlinear multiplication. The structural inspiration for the Mamba block is mainly based on the H3 architecture and gate multilayer perceptron (MLP). The Mamba architecture achieves standardization and residual connection interleaving by repeatedly stacking Mamba blocks.
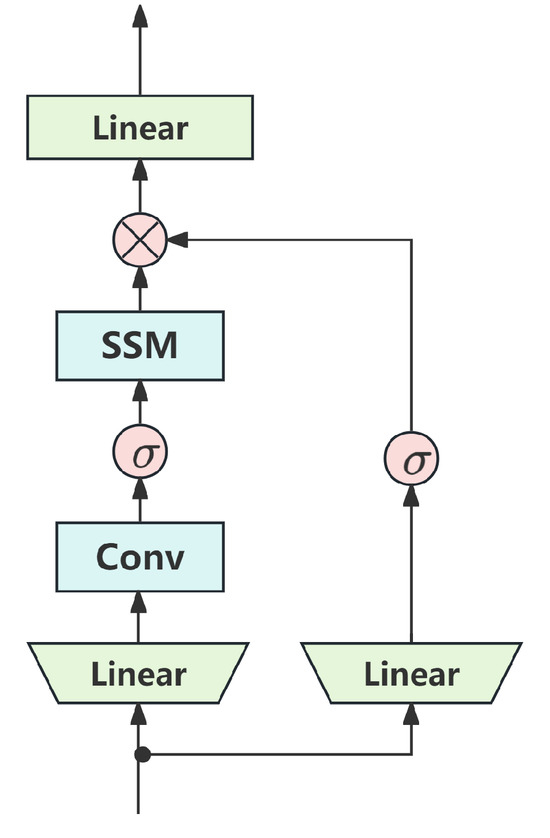
Figure 1.
The structure of the Mamba block.
3. The Proposed Method
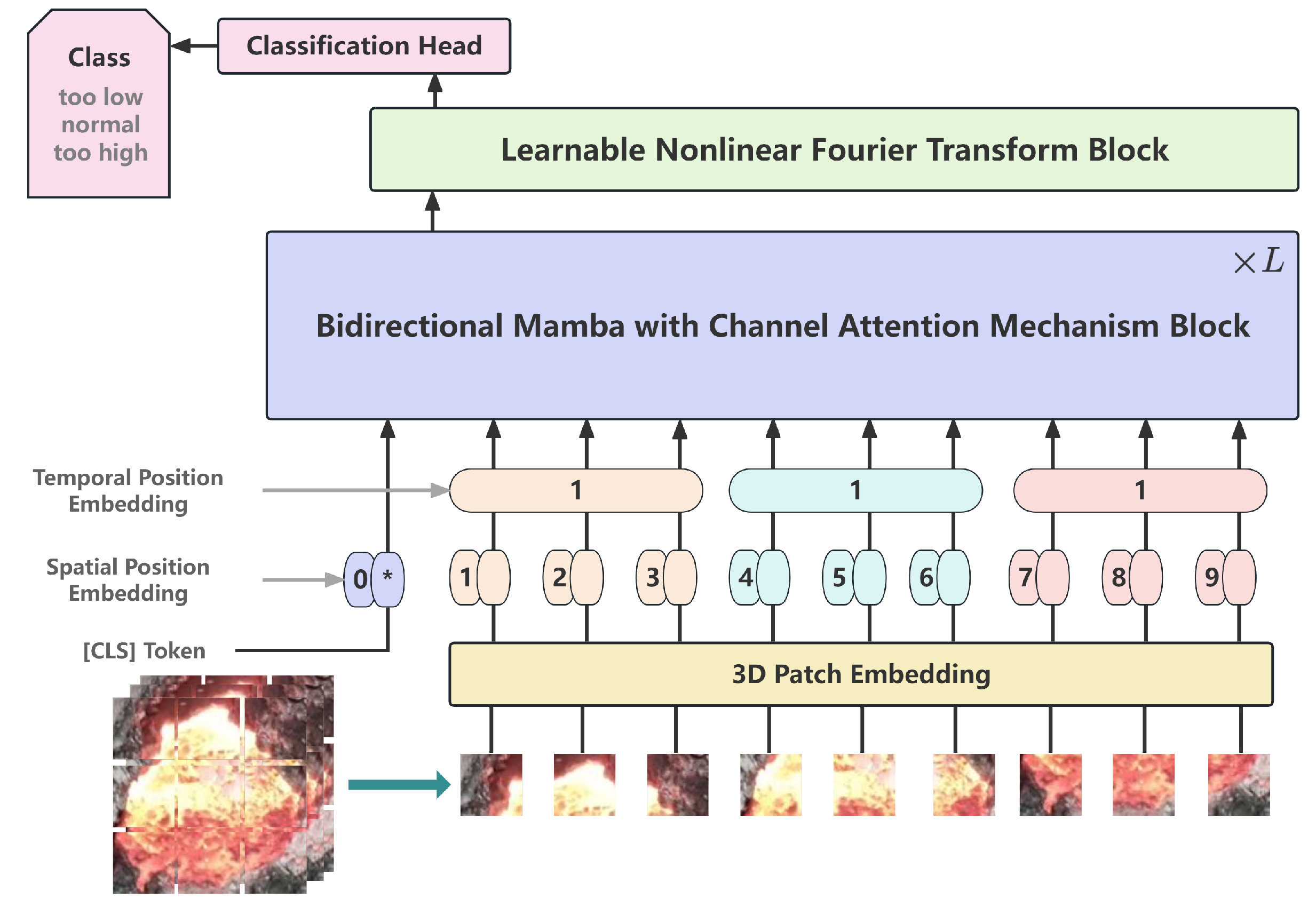
This article proposes a novel method that VideoMamba enhanced with attention and learnable Fourier transform (CFVM) to fully utilize the fire hole videos of aluminum electrolysis for SD state identification. The structure is shown in Figure 2. This model is based on the VideoMamba architecture that overcomes the limitations of existing 3D convolutional neural networks and ViT. As shown in the comparison with the original VideoMamba architecture [14] in Figure 3 and Figure 4, this study performs several key enhancements. Specifically, Figure 3 illustrates the detailed structure of the bidirectional Mamba block used in the overall architecture presented in Figure 4. To facilitate more effective information exchange across different feature channels, a channel attention mechanism (CAM) [24] is integrated into the bidirectional Mamba (B-Mamba) block, resulting in a new BC-Mamba (bidirectional mamba with channel attention) block. Furthermore, a learnable nonlinear Fourier transform (LNFT) block is appended after the BC-Mamba block, which contributes to improved model convergence and overall performance.
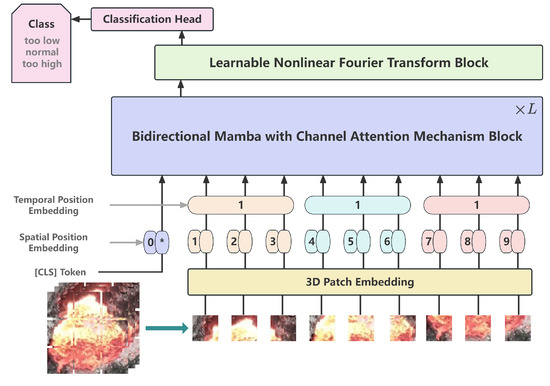
Figure 2.
The structure of VideoMamba enhanced with attention and learnable Fourier transform for superheat identification (CFVM) Model.
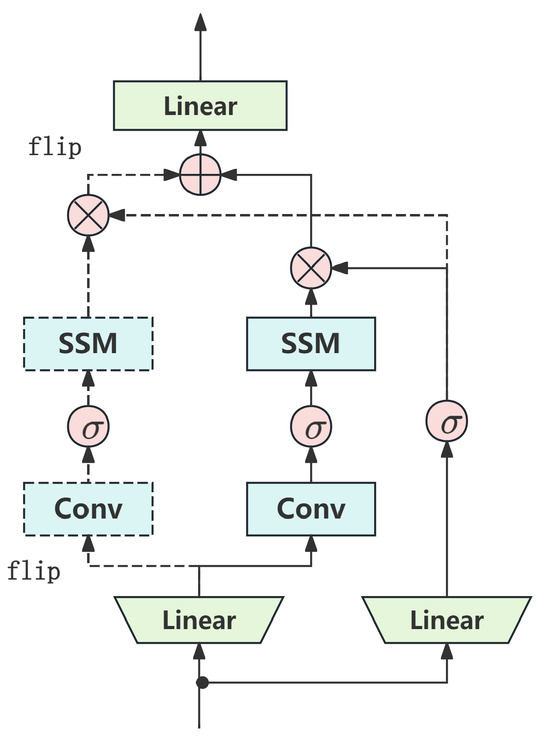
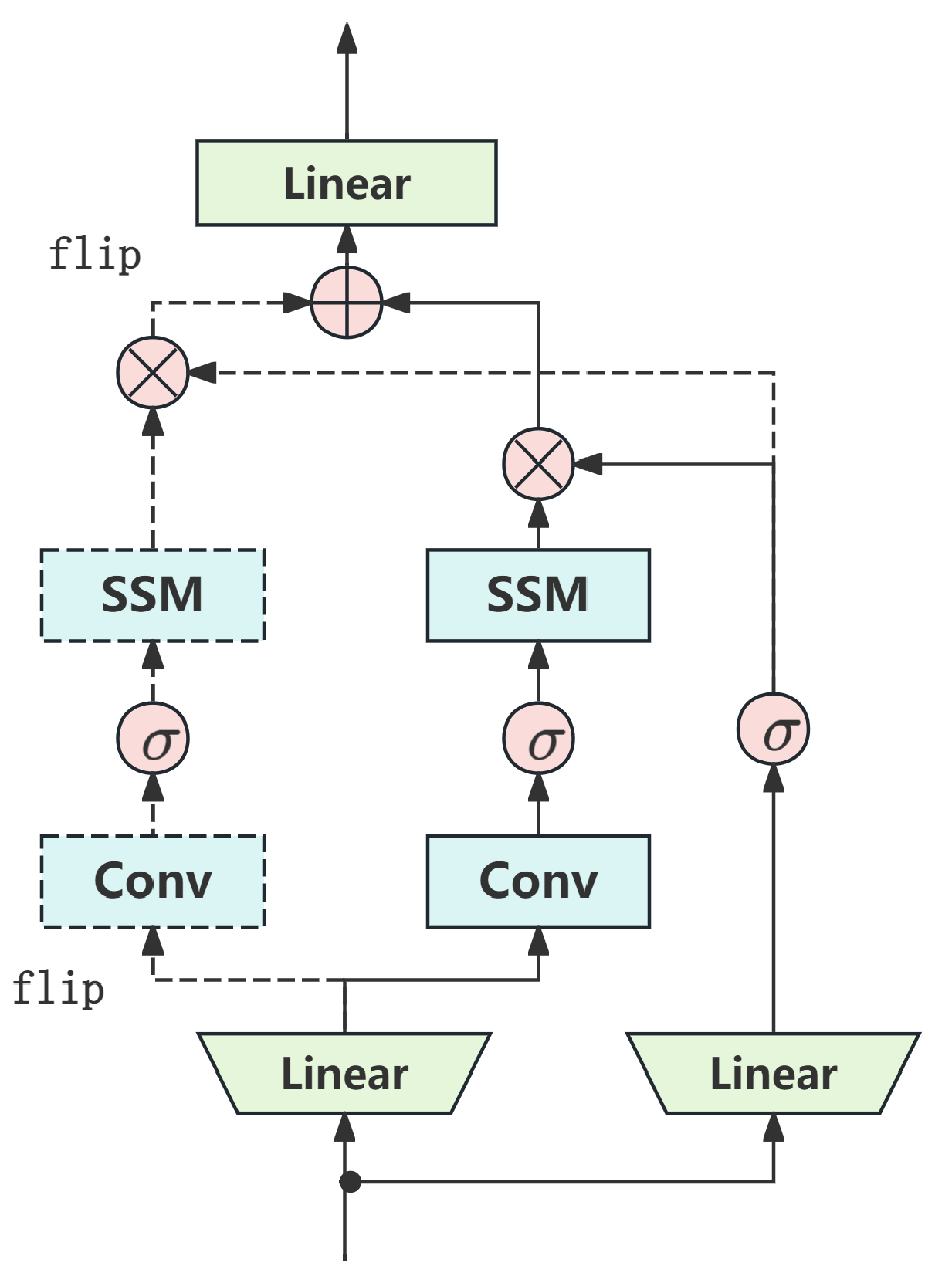
Figure 3.
The structure of the bidirectional Mamba (B-Mamba) block.
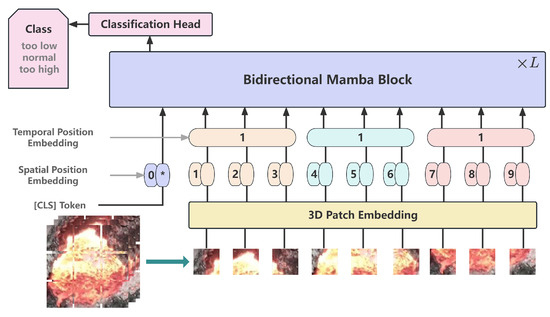
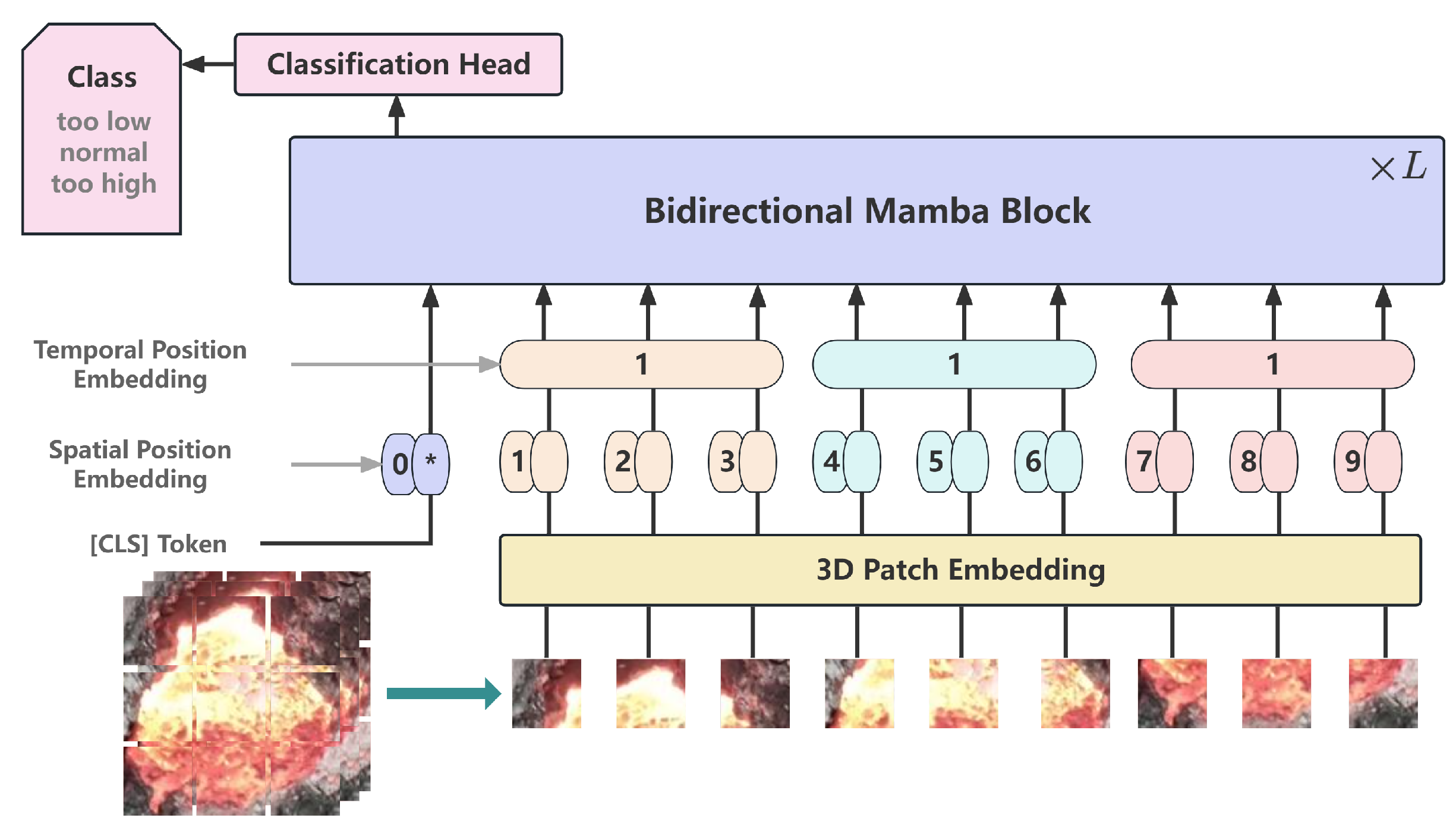
Figure 4.
The structure of VideoMamba.
3.1. VideoMamba
The unidirectional Mamba block, as illustrated in Figure 1, is primarily designed for one-dimensional sequential data, where its core mechanism utilizes a unidirectional state space model (SSM) to aggregate information along the sequence. However, when applied to two-dimensional image sequences or three-dimensional video data, this unidirectional modeling exhibits limited information flow, making it difficult to capture complex spatial structures and multidimensional dependencies. To address this limitation, this paper uses a bidirectional mamba (B-Mamba) structure as shown in Figure 3. Unlike the unidirectional Mamba block, B-Mamba incorporates both forward and backward SSM branches within each layer to simultaneously process visual sequences in both directions. This symmetric architecture not only enhances the capacity to capture contextual information but also significantly improves its ability to model long-range dependencies across spatiotemporal dimensions.
The overall framework of VideoMamba [14] is shown in Figure 4. To conduct a specific analysis of the framework, VideoMamba first uses 3D convolution to project the input video , generating L non-overlapping spatiotemporal patches , where , , and H and W represent the height and width of the fire hole video frames, respectively. Afterwards, place the learnable classification token at the beginning of the sequence. Add learnable spatial position embedding and temporal position embedding to form a new input token sequence for the VideoMamba encoder as shown in Formula (8):
We add learnable spatial position embedding and temporal position embedding to preserve the spatiotemporal information of the input data. Afterwards, the generated token sequence X is passed through L stacked B-Mamba blocks, and finally passed through a classification header containing linear layers to output the final classification token.
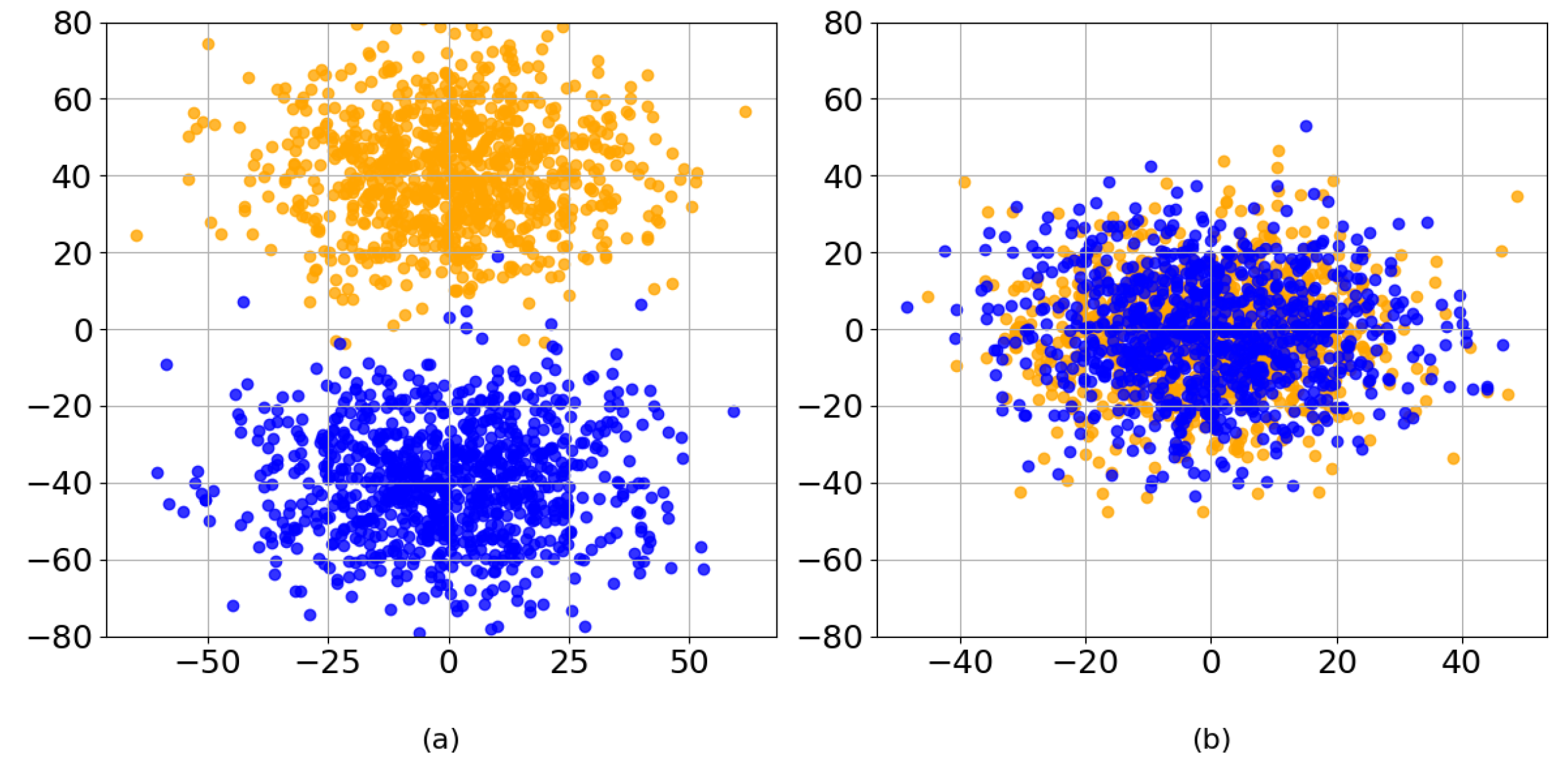
To evaluate the feature extraction capability of VideoMamba, this study presents the alignment process between the latent representations of fire hole videos and the model-generated features as illustrated in Figure 5. In this figure, yellow dots represent the features extracted from the fire hole videos, while blue dots represent the features learned by the model. Figure 5a shows the distribution of the two types of features at the beginning of training, whereas Figure 5b illustrates their distribution after training. The progressive alignment of these features over time indicates that the latent representations of the fire hole videos and those generated by the network gradually converge, demonstrating the strong feature extraction capability of VideoMamba. In addition, VideoMamba achieves a 6× improvement in processing speed and requires 40× less GPU memory for long video sequences, highlighting its low time and space complexity [14].
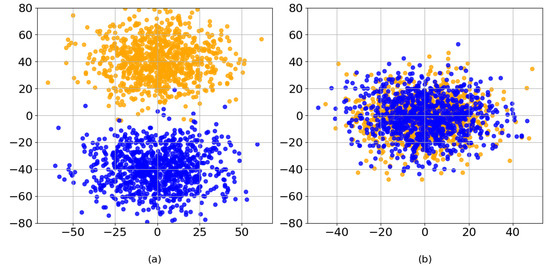
Figure 5.
The alignment process between the latent representations of fire hole videos and the model-generated features. The yellow dots represent the features extracted from the fire hole videos, and the blue dots represent the features learned by the model. (a) The state before training. (b) The state after training.
3.2. Bidirectional Mamba with Channel Attention Mechanism Block
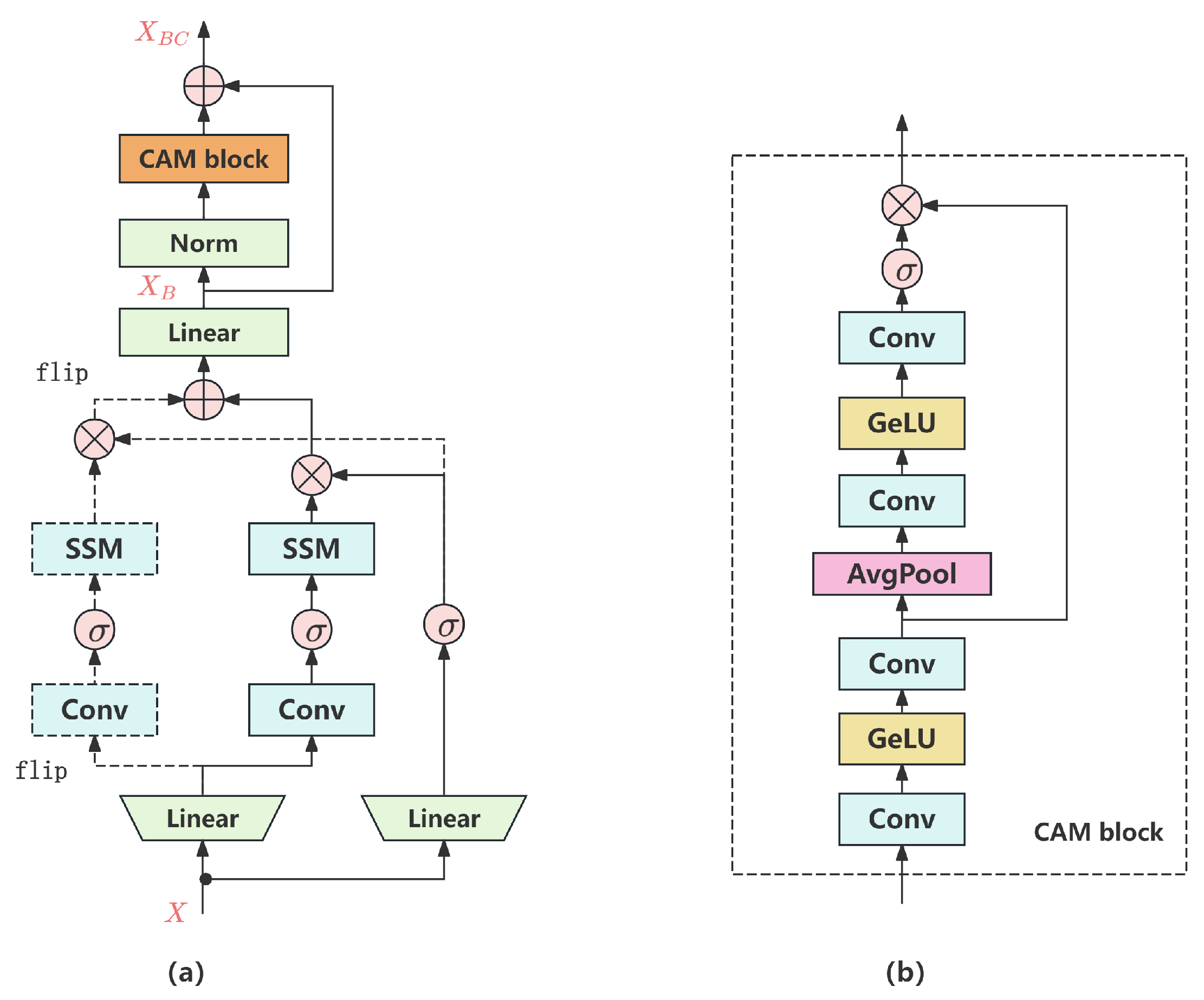
In the VideoMamba architecture, S6 processes multidimensional data separately for each channel, resulting in the model being unable to effectively capture the dependency relationships between different channels. This flaw limits the performance of the model when dealing with complex data. To overcome this issue, this paper proposes an improved solution by adding CAM in the B-Mamba block. The newly constructed bidirectional Mamba with channel attention mechanism (BC-Mamba) block can integrate information between different channels, extract dependency relationships between channels, and more fully utilize the potential information of input data. The structure of the BC-Mamba block is shown in Figure 6. In Figure 6a, the new input token sequence X undergoes bidirectional SSM and linear projection to obtain the output . After normalization, enters the CAM block. Finally, is added to the output information of CAM to obtain as shown in Formula (9). The specific structure of the CAM block is shown in Figure 6b.
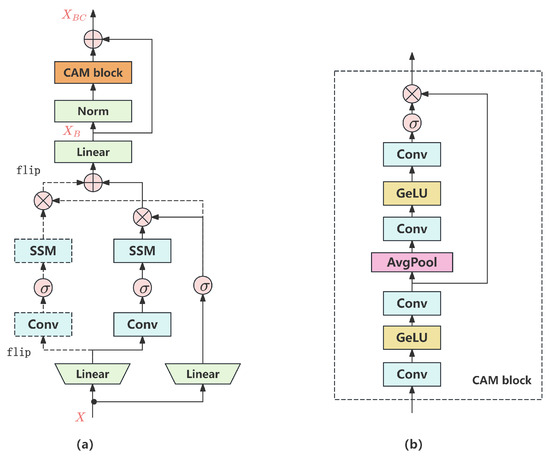
Figure 6.
The structure of the bidirectional Mamba with channel attention mechanism (BC-Mamba) block. (a) The structure of the BC-Mamba block. (b) The structure of the channel attention mechanism (CAM) block.
The CAM models the interdependencies among feature channels by assigning adaptive weight coefficients to each channel, thereby emphasizing informative channels while suppressing redundant or irrelevant features. Essentially, it performs a weighted reconstruction of the feature maps, enabling the network to dynamically adjust its focus. This allows for the more effective extraction of task-relevant salient features, particularly when processing video or multimodal inputs, and enhances the ability of the model to identify target patterns. Moreover, by prioritizing meaningful information during feature representation, the CAM helps to mitigate the influence of noise, thereby improving the robustness and generalization performance of the model under variable input conditions:
3.3. Learnable Nonlinear Fourier Transform Block
Mamba, as the most widely used SSM architecture, has shown excellent performance in handling tasks related to text, speech, sequences, and more. But when Mamba expanded into the field of video understanding, it showed instability. For example, VideoMamba suffers from non-convergence issues when training on video datasets. Some articles [25] have shown that the stability of SSM depends on the matrix A in the system of equations. When all eigenvalues of matrix A are negative real numbers, the SSM exhibits stability. Therefore, this article proposes the Fourier transform [26] and a nonlinear learnable layer to form a learnable nonlinear Fourier transform (LNFT) block.
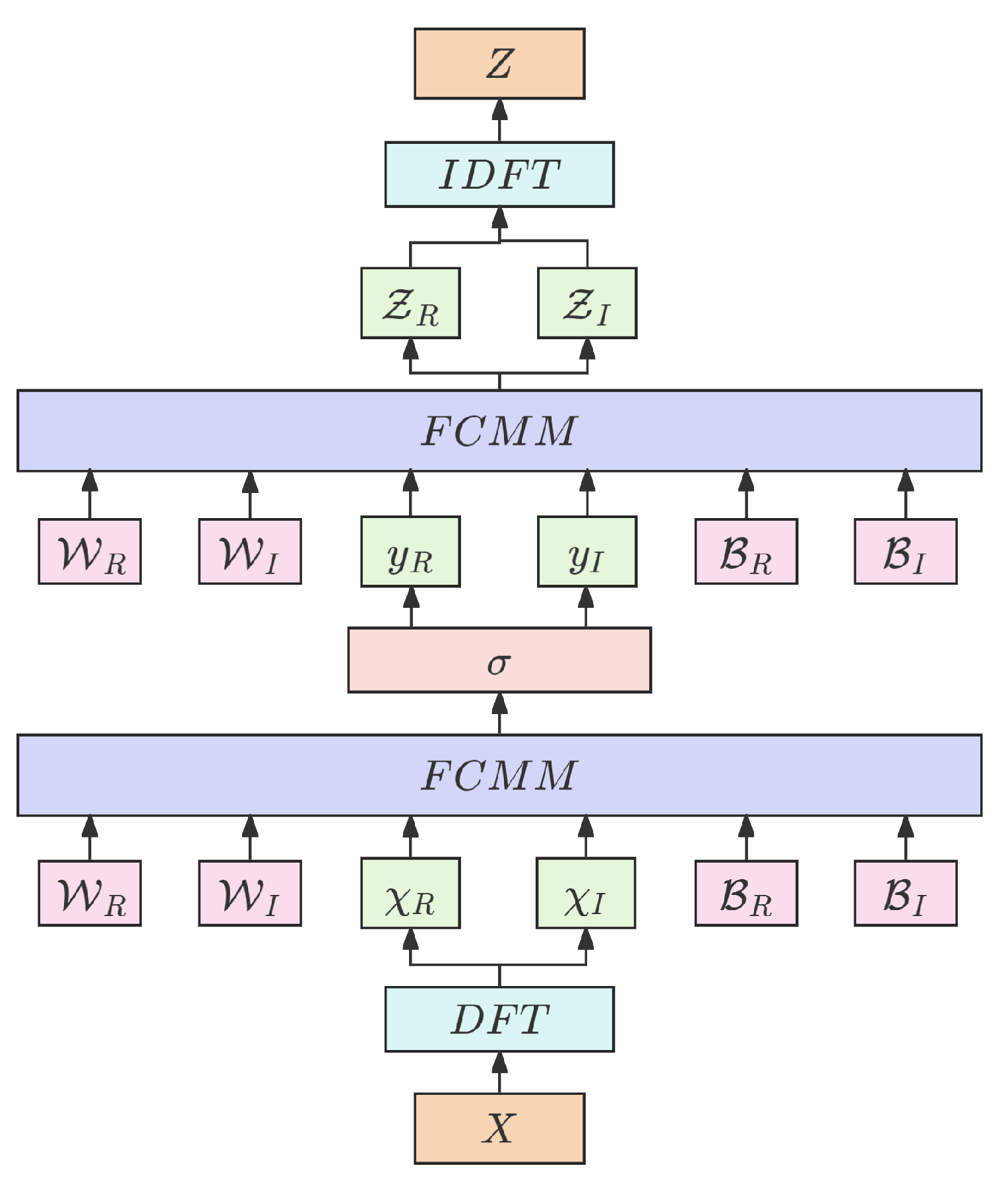
The function of the LNFT block is to manipulate the eigenvalues of matrix A to be negative real numbers, ensuring the stability of VideoMamba. In addition, the LNFT block can also mix channel information in the frequency domain, achieve information communication between different channels, and effectively extract global information from complex data. Its specific structure is shown in Figure 7. The input of the LNFT block is the l-th time node . After undergoing the discrete Fourier transform (DFT), obtains its own frequency domain component . and are the real and imaginary parts of , respectively. and are the real and imaginary parts of the complex weight matrix in the frequency domain, respectively. and are the real and imaginary parts of the complex biases in the frequency domain. After the above frequency domain information is calculated twice by the FCMM layer, the output is obtained. Among them, and are the real and imaginary parts of , respectively.
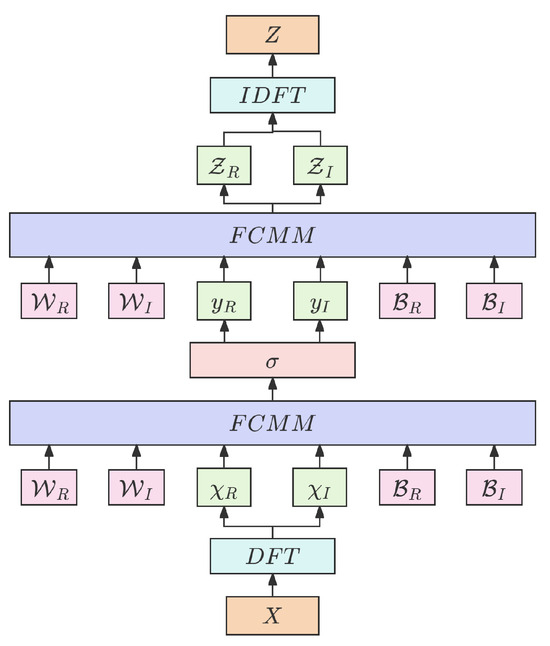
Figure 7.
The structure of a learnable nonlinear Fourier transform (LNFT) block.
This block improves the stability of the state space model by including a nonlinear activation function . Nonlinear activation functions may establish nonlinear stability restrictions in the frequency domain, limiting the capacity of the model to gain and gradient changes. Simultaneously, it can reduce high-frequency components, which improves system convergence to some extent. After undergoing inverse discrete Fourier transform (IDFT), is transformed into time domain . Finally, the output spanning L time nodes is integrated to generate the overall output . Both DFT and IDFT are executed along the channel dimension. This process can be represented by Formulas (10)–(14):
Apply the frequency domain channel matrix multiplication (FCMM) layer to the channel dimensions of input X and weight matrix , using Formula (15). represents the number of blocks in the channel, and represents the number of subchannels in each block. Arrange the channels in the pattern to form a block diagonal matrix. The result will generate a mixed feature vector . ⋄ represents the channel matrix multiplication operation in the frequency domain. The FCMM layer achieves frequency domain mixing by separately calculating the real and imaginary parts of frequency components. This method not only fully extracts global information from data but also provides sufficient justification for computing resources:
4. Results and Discussion
This article trains the proposed model on a preprocessed dataset of aluminum electrolysis fire hole videos. And the training results are compared with those of other models that performed well during the same period, verifying the effectiveness and superiority of CFVM in SD identification. In addition, ablation experiments are conducted on CFVM to verify the necessity of different modules in the model.
4.1. Data Preprocessing
The fire hole videos are obtained by using an industrial camera to capture the fire hole of the aluminum electrolysis cell in the factory. The fire hole videos used in this article are all MP4 files with a frame rate of 30 fps and a resolution of 1920 × 1080, mainly sourced from a domestic aluminum electrolysis factory. After the videos are captured, three experienced workers identify their SD state and ultimately adopt the idea of having more votes. According to the different states of SD, the videos are divided into three categories: too low, normal, and too high.
The initial fire hole video frame contains a large number of background areas unrelated to the fire hole, as shown in Figure 8a. This article removes the background part from the fire hole video to obtain a complete and clear fire hole area in the video, in order to better extract fire hole features in the model and achieve better identification performance. In order to comprehensively reflect the changes in the color, fluctuation, and other features of electrolytes in a fire hole video, 16 frames are extracted at equal intervals from a fire hole video. After removing the background area, the video is regenerated as shown in Figure 8b.

Figure 8.
The initial fire hole video frame (a) and processed fire hole video frame (b).
The experimental dataset used in this article consists of 1089 labeled fire hole videos. The final resolution of the fire hole video dataset is 256 × 256. About 30% of the fire hole videos are used as the test set, and about 70% of the fire hole videos are used as the train set. There are a total of 762 samples in the train set, including 177 samples with too low SD, 395 samples with normal SD, and 190 samples with too high SD. There are a total of 327 samples in the test set, including 76 samples with too low SD, 170 samples with normal SD, and 81 samples with too high SD.
4.2. Experimental Results
CFVM, the method proposed in this article, includes the CAM and LNFT blocks and is built on the VideoMamba foundation. It is challenging to attain optimal performance with CFVM if it is trained end-to-end. The main reason for this problem is that the CAM block is embedded in the BC-Mamba structure. When BC-Mamba performs a bidirectional propagation, the attention mechanism of the CAM block will perform a calculation. Due to the high computational complexity of the attention mechanism, directly conducting end-to-end training in models containing CAM blocks, LNFT blocks, and SSM architectures will significantly increase the computational burden, not only reducing the training efficiency but also potentially affecting the final identification accuracy of the model [27]. To address this issue, this article adopts a two-stage training strategy. Firstly, pre-train the CAM block independently to obtain optimal weight parameters, enabling it to effectively extract channel dependencies. Secondly, during the CFVM training process, pre-trained CAM weights are directly loaded to improve the convergence speed and identification performance of the model without significantly increasing computational resource consumption.
In order to verify the effectiveness of the CFVM method in the fire hole classification task, this paper conducts comparative experiments with current advanced classification methods. Specifically, we select ResNet [28], long-term recurrent convolutional network (LRCN) [29], convolutional 3D network (C3D) [30], SS-ELM [31], two-stream inflated 3D convnet (two-stream I3D) [32], Deep Belief Network (DBN) [33], dual-stream multidimensional network (DM) [34], and CFVM proposed in this article, comparing this method’s performance on SD classification tasks. The experimental results are shown in Table 1. From the data, it can be seen that the classification accuracy of ResNet, LRCN, C3D, and SS-ELM on SD tasks is all below 80%, indicating relatively poor performance. The classification accuracy of two-stream I3D, DBN, DM, and CFVM all exceeded 80%, indicating their good applicability in this task. Among them, CFVM further improved the classification performance, with a 5% increase in SD identification accuracy compared to two-stream I3D, a 3.6% increase compared to DBN, and a 1.5% increase compared to DM. This result indicates that CFVM has higher accuracy compared to video classification models of the same period and achieves better performance in SD identification tasks.

Table 1.
Comparison of CFVM network and other technologies on the fire hole video dataset.
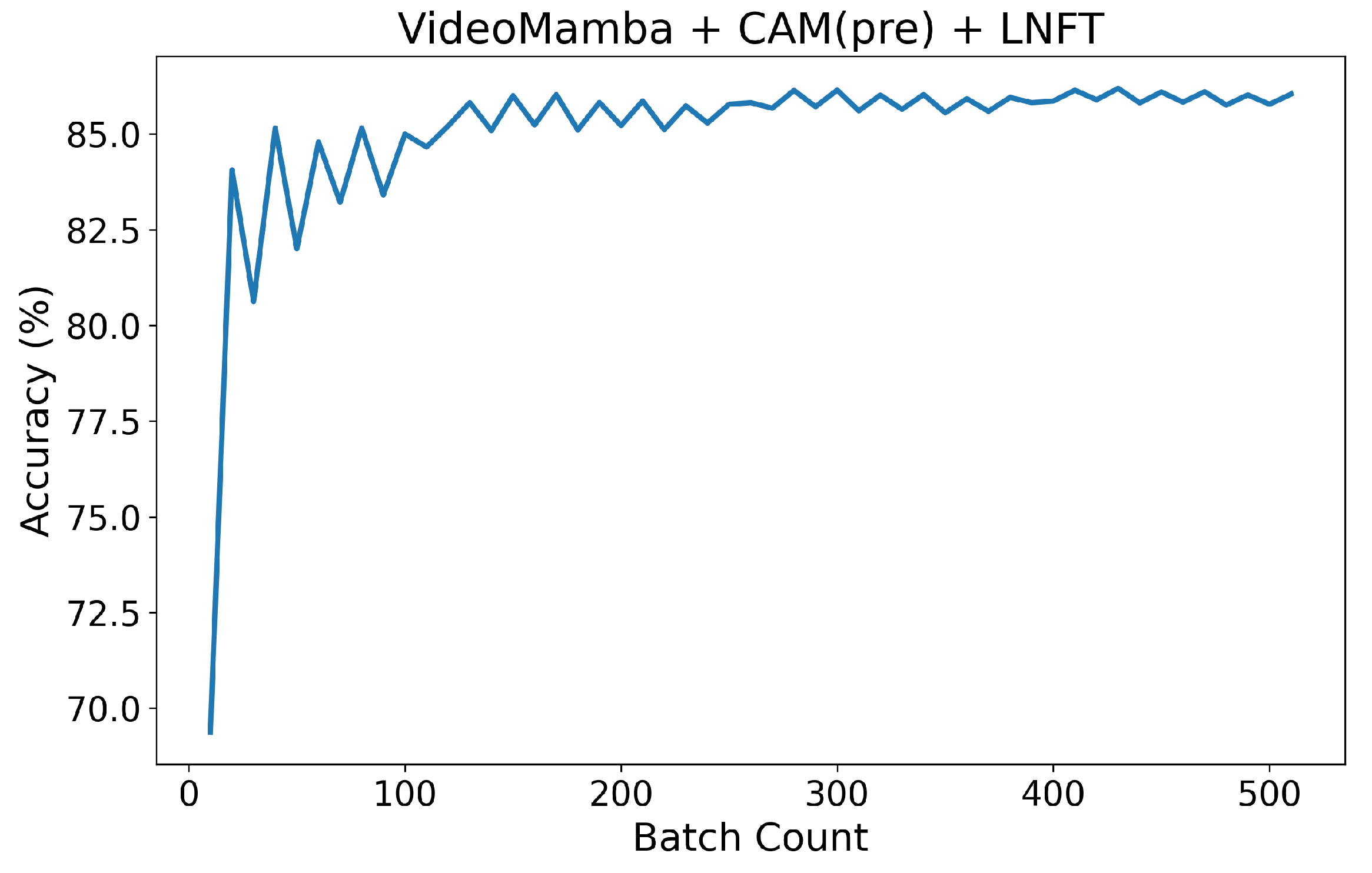
Figure 9 shows the test set results obtained after training the CFVM network using the fire hole dataset. Due to the fact that the model training results obtained in Figure 9 and Figure 10 are both based on the Videomamba architecture, the curves are roughly similar. However, due to differences in the model improvements, the training results presented in these figures are not identical. Figure 9 and Figure 10d share the same model structure, but the model in Figure 9 adopts a pre-training strategy, resulting in faster training speed and better classification performance. This further verifies the effectiveness of the pre-training strategy proposed in this study.
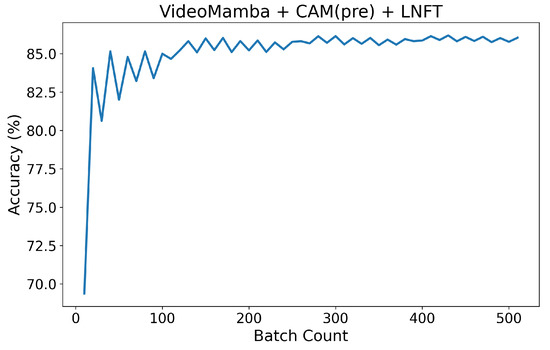
Figure 9.
Test result of the CFVM model to identify SD state.
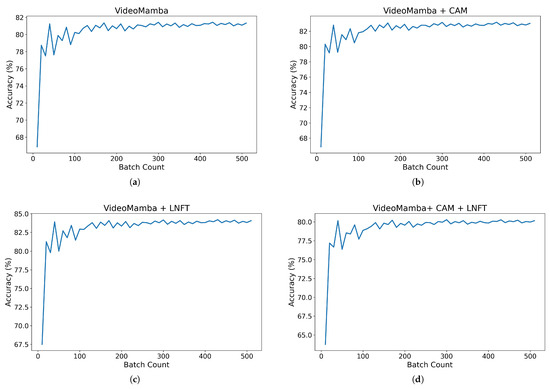
Figure 10.
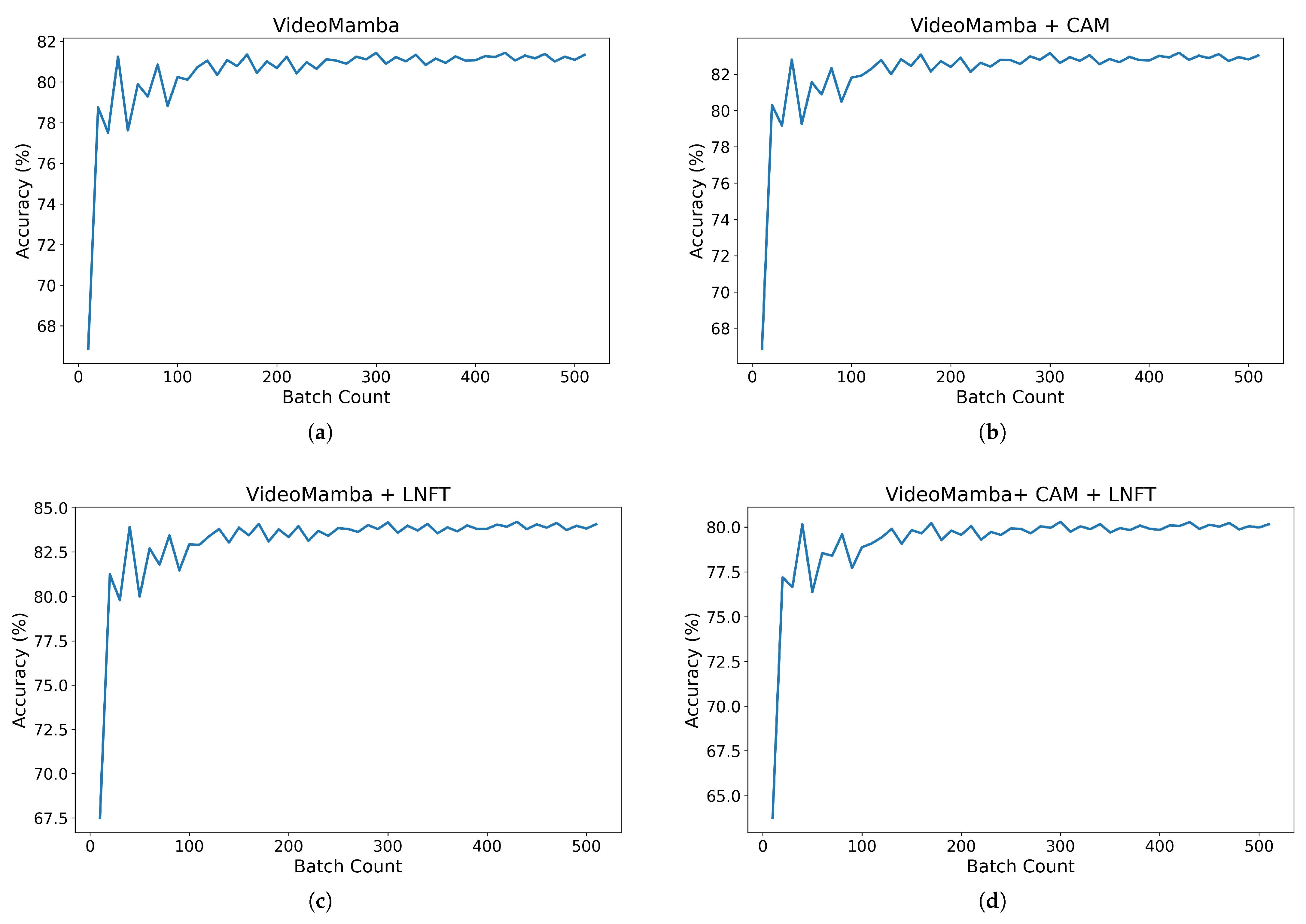
Test results for identifying SD status through different module combinations. (a) The test results of only VideoMamba identifying SD status. (b) The test results of VideoMamba + CAM identifying SD status. (c) The test results of VideoMamba + LNFT identifying SD status. (d) The test results of VideoMamba + CAM + LNFT identifying SD status.
ResNet is mainly used for image classification, while the SD state identification of fire hole videos requires extracting dynamic features such as color changes, fluctuation amplitude, and frequency of electrolytes. LRCN combines convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to model temporal dependencies. The network structures of ResNet and LRCN are relatively simple and cannot fully capture the deep features of videos, resulting in poor classification performance. C3D enhances the ability to extract temporal information by adding convolution in the time dimension based on 2D convolutional networks. SS-ELM is suitable for training evaluation models on large-scale datasets, so the training effect on small-scale data in this paper is poor. Two-stream I3D further optimizes the C3D structure by extending the 2D network to a 3D network and adopting a dual stream structure: the RGB branch extracts the appearance features of static frames (spatial flow), and the optical flow branch extracts the temporal features between frames (temporal flow). However, 3D networks have high computational complexity, a large number of parameters, and high requirements for data scale and training resources. In the limited size of the fire hole video dataset, the training performance of C3D and two-stream I3D does not exceed that of DM, DBN, and CFVM. DBN training is slow and not suitable for time-series data, so this method is not the optimal choice for fire hole video data. DM adopts a dual branch structure of efficient flow and precision flow, with RGB and optical flow as inputs. Unfortunately, DM cannot model the information dependency relationships between channels. Therefore, the identification accuracy is slightly lower than CFVM. Overall, CFVM models the information dependencies between channels through CAM and LNFT transformations, extracts global information, and achieves stable convergence in model training, achieving excellent performance in SD identification tasks.
In Table 1, all models are evaluated using k-fold cross-validation with k = 5. Specifically, the train set is divided into five subsets; during each iteration, one subset is used as the test set, while the remaining four are used for training. This process is repeated five times, and the average result is taken as the final performance metric for each model. This method effectively mitigates the sensitivity of the model to data partitioning, thereby enhancing the reliability and generalizability of the experimental results. In the accuracy metric, not only is the average accuracy displayed, but the corresponding standard deviation is also provided to more comprehensively reflect the consistency and stability of the model performance. The p-value, derived from significance testing, is used to assess the statistical difference between each model and the proposed model. The results show that all p-values are less than 0.05, and most of them are below 0.01. It indicates that the CFVM model outperforms the others with statistical significance:
Moreover, to further evaluate the stability of each model, the mean absolute error (MAE) (Formula (16)) is employed as a performance metric. Here, n denotes the number of accuracy values obtained from the k-fold cross-validation, represents the accuracy from the i-th fold, and is the average accuracy across all k folds. As shown in Table 1, MAE generally decreases as model complexity increases, showing that the prediction stability improves accordingly. CFVM achieves the lowest MAE among all models, indicating the smallest prediction error and the highest stability.
In conclusion, the experimental results demonstrate that the proposed model consistently outperforms existing mainstream methods in terms of accuracy, error control, and statistical significance, thereby offering superior practical value and broader application potential.
4.3. Ablation Experiments
To verify the effectiveness of each block in the CFVM method, we conduct ablation experiments as shown in Table 2. From Table 2, we can see that using VideoMamba (Figure 10a) alone to train fire hole videos achieves an accuracy rate of approximately 81.7%. Compared to VideoMamba, the accuracy of VideoMamba + CAM (Figure 10b) and VideoMamba + LNFT (Figure 10c) is increased by approximately 1.5% and 2.2%, respectively. Therefore, the above three sets of experimental data validate the effectiveness of the CAM block and LNFT block in SD identification. However, as shown in Table 2, the training time for the VideoMamba + CAM combination is nearly four times longer than that of either VideoMamba or VideoMamba + LNFT. Furthermore, the number of training epochs required for VideoMamba + CAM + LNFT (Figure 10d) is approximately fifteen times that of the final model. These results show that training the attention mechanism within CAM blocks from scratch significantly increases the computational complexity of the model, thereby demanding substantially more training time. The more complex the model incorporating CAM blocks becomes, the greater the training time required.
Table 2.
Ablation experiments on the fire hole video dataset.
As shown in Table 3, this study investigates the impact of different attention mechanisms by integrating the channel attention mechanism, spatial attention mechanism, and self-attention mechanism into the VideoMamba framework. The experimental results demonstrate that incorporating the channel attention mechanism yields an accuracy of 83.2%, which is significantly higher than the 82.4% achieved by the model with only the spatial attention mechanism. This indicates that enhancing feature representation along the channel dimension is more effective for the current classification task. Although the self-attention mechanism slightly improves the accuracy to 83.3%, it comes at the cost of increased computational complexity, a larger number of parameters, and longer training time. Therefore, considering the trade-off between model performance and computational overhead, the channel attention mechanism emerges as a more efficient and deployable choice, and is thus adopted as the final attention module in this work.
Table 3.
Comparison of the effects of different attention mechanisms.
The combination of VideoMamba+CAM+LNFT is equivalent to directly training CFVM end-to-end. As the model becomes more complex, the training time also increases. The training time of this combination is nearly 13 times that of the other combinations. Moreover, the final classification performance of this combination is not ideal, and the accuracy is even lower than that of VideoMamba, not exceeding 80%. When we first pre-train the CAM block, we obtain optimal attention weight parameters. After loading the weight parameter, we perform end-to-end training on CFVM. VideoMamba + CAM (pre) + LNFT ultimately achieve an accuracy of 85.7%. Compared to the other four combinations, the accuracy of this combination is improved by at least about 2%. Therefore, this experiment confirms the effectiveness of all proposed components and training methods in improving accuracy.
5. Conclusions
This article proposes a SD identification model based on aluminum electrolytic cell fire hole videos—CFVM. CFVM integrates a channel attention mechanism (CAM) block and a learnable nonlinear Fourier transform (LNFT) block based on the VideoMamba framework to improve SD identification performance. VideoMamba has classification capabilities comparable to transformers, while having lower computational complexity, providing efficient feature extraction capabilities for CFVM. The CAM block achieves information exchange between channels through convolution operations, thereby enhancing feature expression capabilities; the LNFT block is used to model the inter-channel dependencies in the frequency domain and promote stable convergence of the model. This article experimentally demonstrates that CAM and LNFT blocks have a significant effect on improving model accuracy. Our study demonstrates the superiority of the proposed method by comparing it with several recent approaches for fire hole video identification. Through ablation experiments, the effectiveness of each individual module within the framework is validated. Furthermore, the results confirm that the optimal training strategy involves leveraging pre-trained weights, which not only significantly reduces training time but also enhances classification performance. The proposed model, CFVM, achieves an accuracy of 85.7% in SD state identification tasks.
Since CFVM performs exceptionally well in identifying aluminum electrolytic SD, this technique may find use in other video-based industrial state identification domains. Its methods and theoretical framework can help with industrial intelligent control and optimization and serve as a reference for related fields. Furthermore, the electrolyte color changes and fluctuation features are crucial criteria for SD identification in the fire hole video. Further study should be conducted on how to enhance the accuracy of SD identification by combining deep learning techniques with surface features taken from videos.
Author Contributions
Conceptualization, Y.H. and L.C.; Methodology, Y.H., L.C. and Z.D.; Validation, Y.H., Z.Y. and Z.D.; Formal analysis, Z.Y.; Investigation, X.C. and Z.D.; Resources, Z.Y.; Data curation, Y.H.; Writing—original draft, Y.H. and X.C.; Writing—review & editing, Y.H. and L.C.; Supervision, X.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Grant number 62473384 and 62133016), Yunnan Province Science and Technology Planning Project (Grant number 202202AB080017), and Central South University Research Programme of Advanced Interdisciplinary Studies (Grant number 2023QYJC007).
Data Availability Statement
The data used in this article involves operational information related to industrial scenarios and is currently not publicly available. We apologize for any inconvenience caused.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Deng, Z.; Chen, X.; Xie, S.; Xie, Y.; Zhang, H. Semi-supervised Discriminative Projective Dictionary Pair Learning and Its Application to Industrial Process. IEEE Trans. Ind. Inform. 2023, 19, 3119–3132. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Wang, J.; Yuan, Q.; Yang, Z. CNN-LSTM Model for Recognizing Video-Recorded Actions Performed in a Traditional Chinese Exercise. IEEE J. Transl. Eng. Health Med. 2023, 11, 351–359. [Google Scholar] [CrossRef] [PubMed]
- Bai, H.; Yao, R.; Zhang, W.; Zhong, Z.; Zou, H. Power Quality Disturbance Classification Strategy Based on Fast S-Transform and an Improved CNN-LSTM Hybrid Model. Processes 2025, 13, 743. [Google Scholar] [CrossRef]
- Wu, Q.; Zhu, A.; Cui, R.; Wang, T.; Hu, F.; Bao, Y.; Snoussi, H. Pose-Guided Inflated 3D ConvNet for action recognition in videos. Signal Process. Image Commun. 2021, 91, 116098. [Google Scholar] [CrossRef]
- Qu, W.; Zhu, T.; Liu, J.; Li, J. A time sequence location method of long video violence based on improved C3D network. J. Supercomput. 2022, 78, 19545–19565. [Google Scholar] [CrossRef]
- Wei, J.; Wang, H.; Yi, Y.; Li, Q.; Huang, D. P3D-CTN: Pseudo-3D Convolutional Tube Network for Spatio-Temporal Action Detection in Videos. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 300–304. [Google Scholar] [CrossRef]
- Li, Q.; Wang, G.; Li, X.; Yu, C.; Bao, Q.; Wei, L.; Li, W.; Ma, H.; Si, F. Robust Dynamic Modeling of Bed Temperature in Utility Circulating Fluidized Bed Boilers Using a Hybrid CEEMDAN-NMI–iTransformer Framework. Processes 2025, 13, 816. [Google Scholar] [CrossRef]
- Neimark, D.; Bar, O.; Zohar, M.; Asselmann, D. Video Transformer Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3163–3172. [Google Scholar]
- Chen, Z.; Wang, S.; Yan, D.; Li, Y. A Spatio- Temporl Deepfake Video Detection Method Based on TimeSformer-CNN. In Proceedings of the 2024 Third International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Ballari, India, 26–27 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Jing, Y.; Wang, F. TP-VIT: A Two-Pathway Vision Transformer for Video Action Recognition. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2185–2189. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. ViViT: A Video Vision Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 6836–6846. [Google Scholar]
- Zhang, H.; Zhu, Y.; Wang, D.; Zhang, L.; Chen, T.; Wang, Z.; Ye, Z. A Survey on Visual Mamba. Appl. Sci. 2024, 14, 5683. [Google Scholar] [CrossRef]
- Li, K.; Li, X.; Wang, Y.; He, Y.; Wang, Y.; Wang, L.; Qiao, Y. VideoMamba: State Space Model for Efficient Video Understanding. In Proceedings of the Computer Vision—ECCV 2024, Milan, Italy, 29 September–4 October 2024; Springer Nature: Cham, Switzerland, 2025; pp. 237–255. [Google Scholar] [CrossRef]
- Chen, K.; Chen, B.; Liu, C.; Li, W.; Zou, Z.; Shi, Z. RSMamba: Remote Sensing Image Classification with State Space Model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 8002605. [Google Scholar] [CrossRef]
- Zhao, S.; Xie, Y.; Yue, W.; Chen, X. A Machine Learning Method for State Identification of Superheat Degree with Flame Interference. In Proceedings of the 10th International Symposium on High-Temperature Metallurgical Processing, San Antonio, TX, USA, 10–14 March 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 199–208. [Google Scholar] [CrossRef]
- Lei, Y.; Chen, X.; Min, M.; Xie, Y. A semi-supervised Laplacian extreme learning machine and feature fusion with CNN for industrial superheat identification. Neurocomputing 2020, 381, 186–195. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, P.; Lei, Y. A Novel Superheat Identification of Aluminum Electrolysis with Kernel Semi-supervised Extreme Learning Machine. J. Phys. Conf. Ser. 2020, 1631, 012005. [Google Scholar] [CrossRef]
- Yue, W.; Hou, L.; Wan, X.; Chen, X.; Gui, W. Superheat Degree Recognition of Aluminum Electrolysis Cell Using Unbalance Double Hierarchy Hesitant Linguistic Petri Nets. IEEE Trans. Instrum. Meas. 2023, 72, 2511815. [Google Scholar] [CrossRef]
- Chen, H.; Li, C.; Li, X.; Rahaman, M.M.; Hu, W.; Li, Y.; Liu, W.; Sun, C.; Sun, H.; Huang, X.; et al. IL-MCAM: An interactive learning and multi-channel attention mechanism-based weakly supervised colorectal histopathology image classification approach. Comput. Biol. Med. 2022, 143, 105265. [Google Scholar] [CrossRef] [PubMed]
- Luo, H.; Chen, C.; Fang, L.; Zhu, X.; Lu, L. High-Resolution Aerial Images Semantic Segmentation Using Deep Fully Convolutional Network with Channel Attention Mechanism. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3492–3507. [Google Scholar] [CrossRef]
- Yan, Q.; Liu, H.; Zhang, J.; Sun, X.; Xiong, W.; Zou, M.; Xia, Y.; Xun, L. Cloud Detection of Remote Sensing Image Based on Multi-Scale Data and Dual-Channel Attention Mechanism. Remote Sens. 2022, 14, 3710. [Google Scholar] [CrossRef]
- Islam, M.M.; Bertasius, G. Long Movie Clip Classification with State-Space Video Models. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 87–104. [Google Scholar] [CrossRef]
- Gao, X.; Du, J.; Liu, X.; Jia, D.; Wang, J. Object Detection Based on Improved YOLOv10 for Electrical Equipment Image Classification. Processes 2025, 13, 529. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Verghese, G. Signals, Systems and Inference; Pearson: New York City, NY, USA, 2010. [Google Scholar]
- Benkedjouh, T.; Zerhouni, N.; Rechak, S. Deep Learning for Fault Diagnosis based on short-time Fourier transform. In Proceedings of the 2018 International Conference on Smart Communications in Network Technologies (SaCoNeT), El Oued, Algeria, 27–31 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 288–293. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2625–2634. [Google Scholar]
- Ullah, A.; Muhammad, K.; Haydarov, K.; Haq, I.U.; Lee, M.; Baik, S.W. One-Shot Learning for Surveillance Anomaly Recognition using Siamese 3D CNN. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Shen, Q.; Ban, X.; Guo, C.; Wang, C. Kernel Semi-supervised Extreme Learning Machine Applied in Urban Traffic Congestion Evaluation. In Proceedings of the Cooperative Design, Visualization, and Engineering, Sydney, NSW, Australia, 24–27 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 90–97. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 6299–6308. [Google Scholar]
- Sheeba, P.T.; Murugan, S. Hybrid features-enabled dragon deep belief neural network for activity recognition. Imaging Sci. J. 2018, 66, 355–371. [Google Scholar] [CrossRef]
- Ning, Z.; Xie, S.; Xie, Y.; Chen, X. Dual-stream multidimensional network for aluminum electrolysis process superheat identification. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2873–2878. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).