
VideoMamba Enhanced with Attention and Learnable Fourier Transform for Superheat Identification



Abstract
1. Introduction
- (1)
- Combining the channel attention mechanism (CAM) block enhances the selective attention ability of the model to different channel features, thereby improving the modeling effect and expression ability of multidimensional video features.
- (2)
- Adding a learnable nonlinear Fourier transform (LNFT) block significantly alleviates the problems of gradient vanishing and exploding during training by constraining the eigenvalues of the state matrix A in VideoMamba to negative real numbers, effectively improving the convergence speed and stability of the model.
- (3)
- The proposed model is based on state space models, which is different from the mainstream neural network fire hole video identification methods in recent years. The experimental results show that this method exhibits better performance in both identification accuracy and robustness, and has strong practical application potential.
2. Related Work
2.1. Research on Superheat Degree State Identification
2.2. Channel Attention Mechanism
2.3. Discrete Fourier Transform
2.4. State Space Models
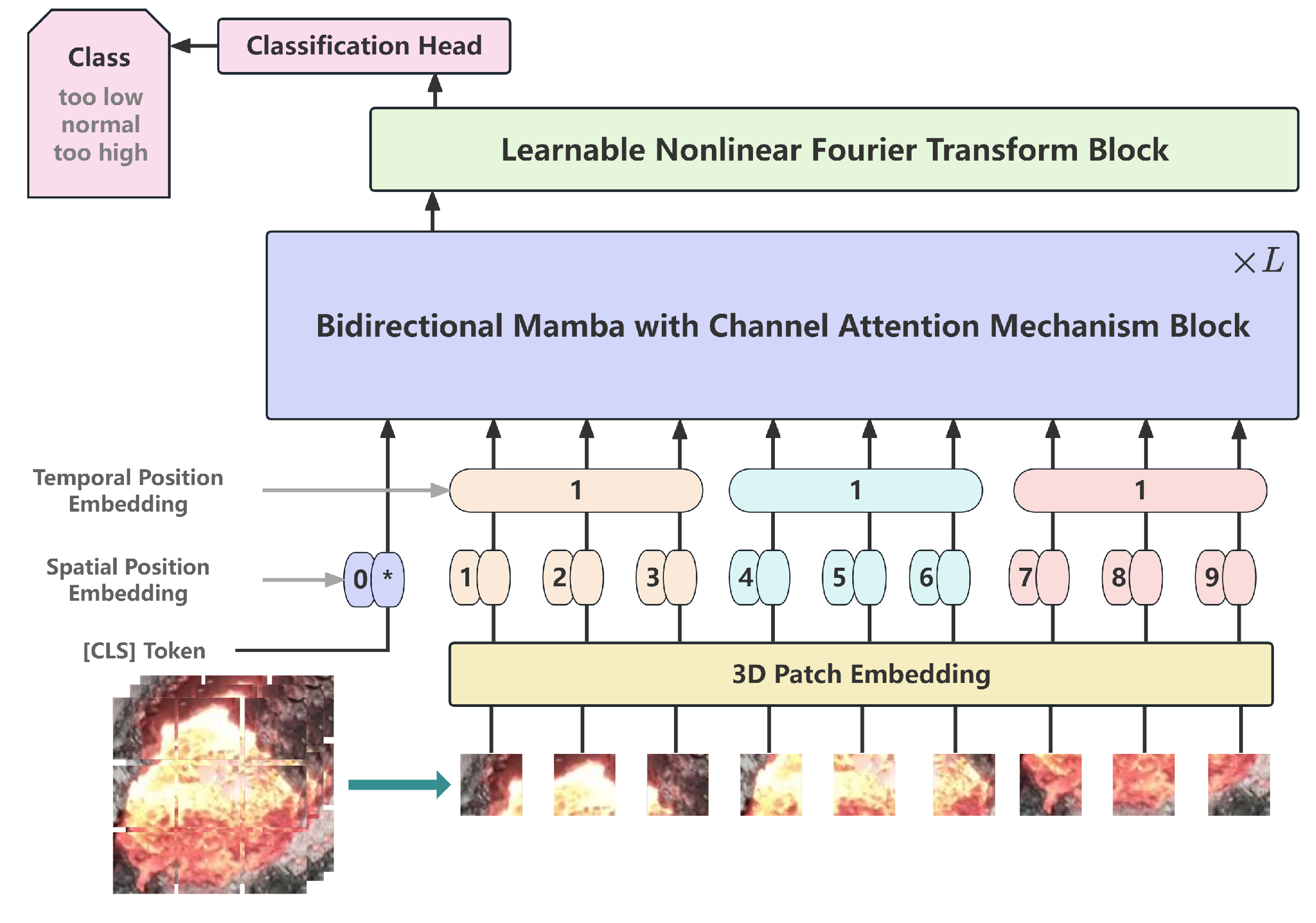
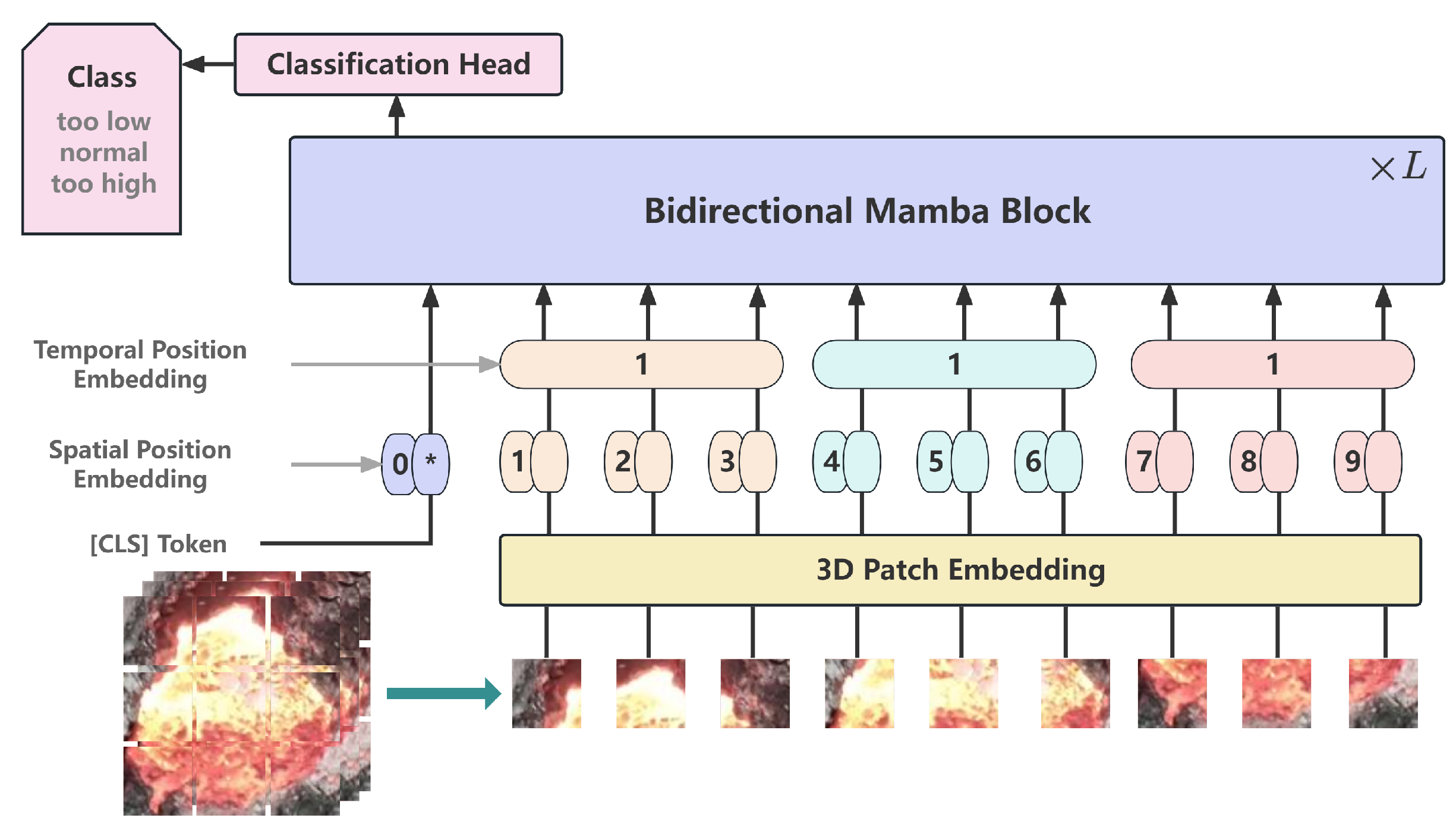
3. The Proposed Method
3.1. VideoMamba
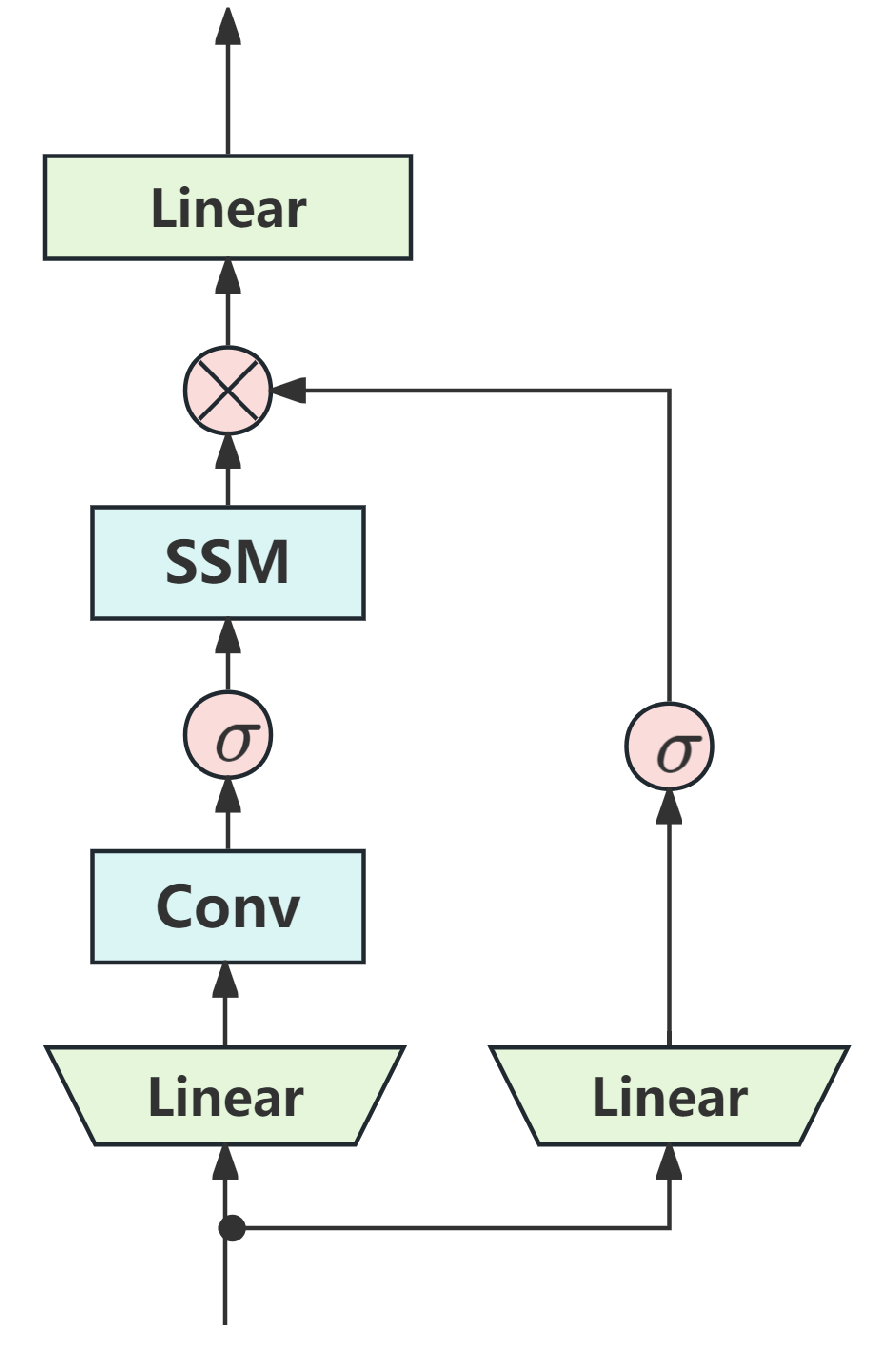
3.2. Bidirectional Mamba with Channel Attention Mechanism Block
3.3. Learnable Nonlinear Fourier Transform Block
4. Results and Discussion
4.1. Data Preprocessing
4.2. Experimental Results
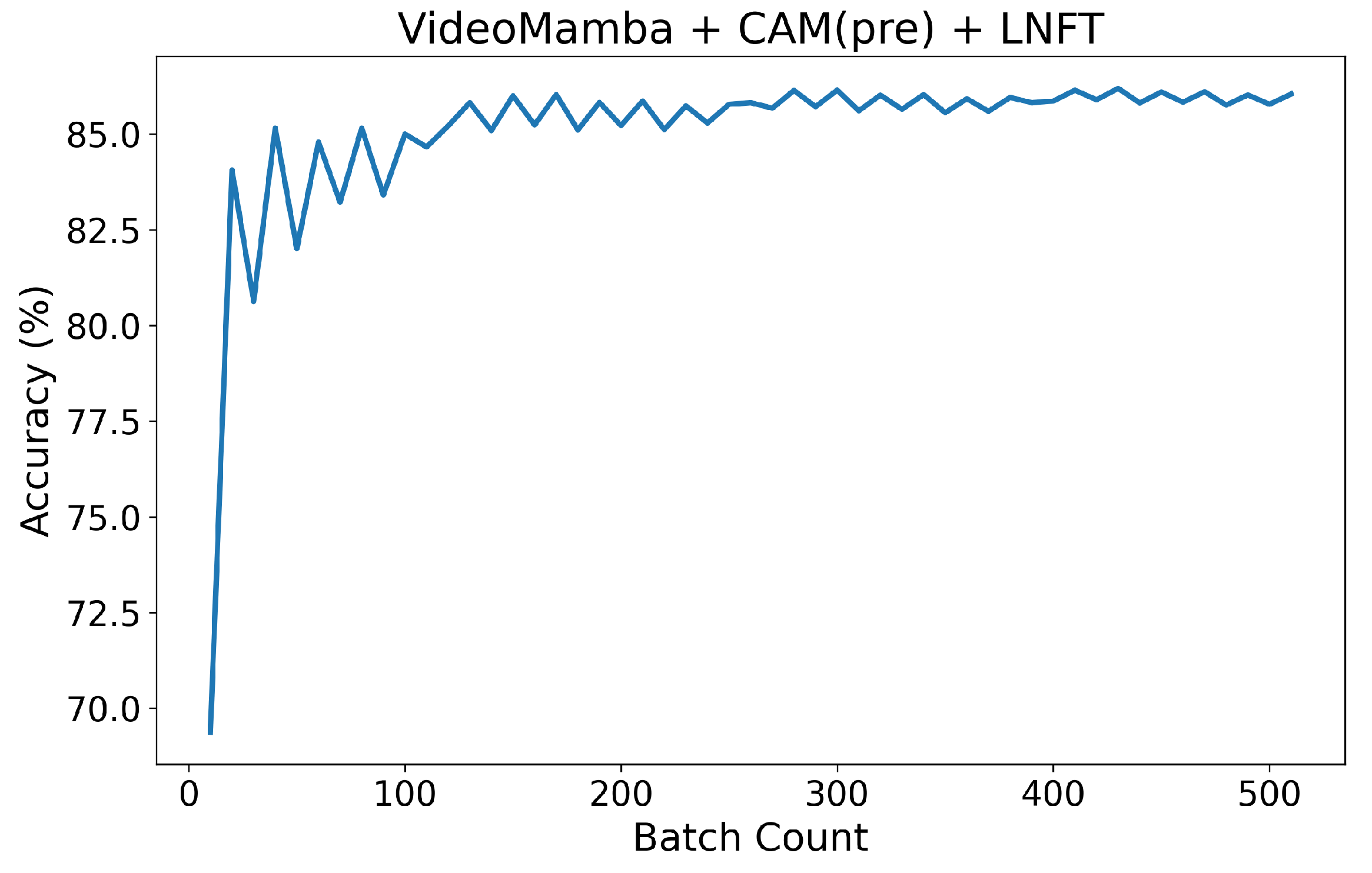
4.3. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Deng, Z.; Chen, X.; Xie, S.; Xie, Y.; Zhang, H. Semi-supervised Discriminative Projective Dictionary Pair Learning and Its Application to Industrial Process. IEEE Trans. Ind. Inform. 2023, 19, 3119–3132. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Wang, J.; Yuan, Q.; Yang, Z. CNN-LSTM Model for Recognizing Video-Recorded Actions Performed in a Traditional Chinese Exercise. IEEE J. Transl. Eng. Health Med. 2023, 11, 351–359. [Google Scholar] [CrossRef] [PubMed]
- Bai, H.; Yao, R.; Zhang, W.; Zhong, Z.; Zou, H. Power Quality Disturbance Classification Strategy Based on Fast S-Transform and an Improved CNN-LSTM Hybrid Model. Processes 2025, 13, 743. [Google Scholar] [CrossRef]
- Wu, Q.; Zhu, A.; Cui, R.; Wang, T.; Hu, F.; Bao, Y.; Snoussi, H. Pose-Guided Inflated 3D ConvNet for action recognition in videos. Signal Process. Image Commun. 2021, 91, 116098. [Google Scholar] [CrossRef]
- Qu, W.; Zhu, T.; Liu, J.; Li, J. A time sequence location method of long video violence based on improved C3D network. J. Supercomput. 2022, 78, 19545–19565. [Google Scholar] [CrossRef]
- Wei, J.; Wang, H.; Yi, Y.; Li, Q.; Huang, D. P3D-CTN: Pseudo-3D Convolutional Tube Network for Spatio-Temporal Action Detection in Videos. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 300–304. [Google Scholar] [CrossRef]
- Li, Q.; Wang, G.; Li, X.; Yu, C.; Bao, Q.; Wei, L.; Li, W.; Ma, H.; Si, F. Robust Dynamic Modeling of Bed Temperature in Utility Circulating Fluidized Bed Boilers Using a Hybrid CEEMDAN-NMI–iTransformer Framework. Processes 2025, 13, 816. [Google Scholar] [CrossRef]
- Neimark, D.; Bar, O.; Zohar, M.; Asselmann, D. Video Transformer Network. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 3163–3172. [Google Scholar]
- Chen, Z.; Wang, S.; Yan, D.; Li, Y. A Spatio- Temporl Deepfake Video Detection Method Based on TimeSformer-CNN. In Proceedings of the 2024 Third International Conference on Distributed Computing and Electrical Circuits and Electronics (ICDCECE), Ballari, India, 26–27 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Jing, Y.; Wang, F. TP-VIT: A Two-Pathway Vision Transformer for Video Action Recognition. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2185–2189. [Google Scholar] [CrossRef]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. ViViT: A Video Vision Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 6836–6846. [Google Scholar]
- Zhang, H.; Zhu, Y.; Wang, D.; Zhang, L.; Chen, T.; Wang, Z.; Ye, Z. A Survey on Visual Mamba. Appl. Sci. 2024, 14, 5683. [Google Scholar] [CrossRef]
- Li, K.; Li, X.; Wang, Y.; He, Y.; Wang, Y.; Wang, L.; Qiao, Y. VideoMamba: State Space Model for Efficient Video Understanding. In Proceedings of the Computer Vision—ECCV 2024, Milan, Italy, 29 September–4 October 2024; Springer Nature: Cham, Switzerland, 2025; pp. 237–255. [Google Scholar] [CrossRef]
- Chen, K.; Chen, B.; Liu, C.; Li, W.; Zou, Z.; Shi, Z. RSMamba: Remote Sensing Image Classification with State Space Model. IEEE Geosci. Remote Sens. Lett. 2024, 21, 8002605. [Google Scholar] [CrossRef]
- Zhao, S.; Xie, Y.; Yue, W.; Chen, X. A Machine Learning Method for State Identification of Superheat Degree with Flame Interference. In Proceedings of the 10th International Symposium on High-Temperature Metallurgical Processing, San Antonio, TX, USA, 10–14 March 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 199–208. [Google Scholar] [CrossRef]
- Lei, Y.; Chen, X.; Min, M.; Xie, Y. A semi-supervised Laplacian extreme learning machine and feature fusion with CNN for industrial superheat identification. Neurocomputing 2020, 381, 186–195. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, P.; Lei, Y. A Novel Superheat Identification of Aluminum Electrolysis with Kernel Semi-supervised Extreme Learning Machine. J. Phys. Conf. Ser. 2020, 1631, 012005. [Google Scholar] [CrossRef]
- Yue, W.; Hou, L.; Wan, X.; Chen, X.; Gui, W. Superheat Degree Recognition of Aluminum Electrolysis Cell Using Unbalance Double Hierarchy Hesitant Linguistic Petri Nets. IEEE Trans. Instrum. Meas. 2023, 72, 2511815. [Google Scholar] [CrossRef]
- Chen, H.; Li, C.; Li, X.; Rahaman, M.M.; Hu, W.; Li, Y.; Liu, W.; Sun, C.; Sun, H.; Huang, X.; et al. IL-MCAM: An interactive learning and multi-channel attention mechanism-based weakly supervised colorectal histopathology image classification approach. Comput. Biol. Med. 2022, 143, 105265. [Google Scholar] [CrossRef] [PubMed]
- Luo, H.; Chen, C.; Fang, L.; Zhu, X.; Lu, L. High-Resolution Aerial Images Semantic Segmentation Using Deep Fully Convolutional Network with Channel Attention Mechanism. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3492–3507. [Google Scholar] [CrossRef]
- Yan, Q.; Liu, H.; Zhang, J.; Sun, X.; Xiong, W.; Zou, M.; Xia, Y.; Xun, L. Cloud Detection of Remote Sensing Image Based on Multi-Scale Data and Dual-Channel Attention Mechanism. Remote Sens. 2022, 14, 3710. [Google Scholar] [CrossRef]
- Islam, M.M.; Bertasius, G. Long Movie Clip Classification with State-Space Video Models. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2022; pp. 87–104. [Google Scholar] [CrossRef]
- Gao, X.; Du, J.; Liu, X.; Jia, D.; Wang, J. Object Detection Based on Improved YOLOv10 for Electrical Equipment Image Classification. Processes 2025, 13, 529. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Verghese, G. Signals, Systems and Inference; Pearson: New York City, NY, USA, 2010. [Google Scholar]
- Benkedjouh, T.; Zerhouni, N.; Rechak, S. Deep Learning for Fault Diagnosis based on short-time Fourier transform. In Proceedings of the 2018 International Conference on Smart Communications in Network Technologies (SaCoNeT), El Oued, Algeria, 27–31 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 288–293. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-Term Recurrent Convolutional Networks for Visual Recognition and Description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2625–2634. [Google Scholar]
- Ullah, A.; Muhammad, K.; Haydarov, K.; Haq, I.U.; Lee, M.; Baik, S.W. One-Shot Learning for Surveillance Anomaly Recognition using Siamese 3D CNN. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Shen, Q.; Ban, X.; Guo, C.; Wang, C. Kernel Semi-supervised Extreme Learning Machine Applied in Urban Traffic Congestion Evaluation. In Proceedings of the Cooperative Design, Visualization, and Engineering, Sydney, NSW, Australia, 24–27 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 90–97. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 6299–6308. [Google Scholar]
- Sheeba, P.T.; Murugan, S. Hybrid features-enabled dragon deep belief neural network for activity recognition. Imaging Sci. J. 2018, 66, 355–371. [Google Scholar] [CrossRef]
- Ning, Z.; Xie, S.; Xie, Y.; Chen, X. Dual-stream multidimensional network for aluminum electrolysis process superheat identification. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2873–2878. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Input Data | Accuracy(%) | MAE | p-Value |
|---|---|---|---|---|
| ResNet | Image | 75.3 (±3.1) | 0.0316 | 0.0022 |
| LRCN | video | 78.2 (±1.4) | 0.0128 | 0.0002 |
| C3D | video | 78.6 (±1.1) | 0.0120 | 0.0001 |
| SS-ELM | video | 79.1 (±0.7) | 0.0064 | 0.0001 |
| Two-Stream I3D | video | 80.7 (±1.1) | 0.0104 | 0.0008 |
| DBN | video | 82.1 (±0.6) | 0.0056 | 0.0001 |
| DM | video | 84.2 (±0.5) | 0.0044 | 0.0032 |
| CFVM(ours) | video | 85.7 (±0.4) | 0.0036 | - |
| VideoMamba | CAM | LNFT | CAM(pre) | Epoches | Accuracy |
|---|---|---|---|---|---|
| ✔ | - | - | - | 15 | 81.7% |
| ✔ | - | - | - | 15 | 81.7% |
| ✔ | ✔ | - | - | 55 | 83.2% |
| ✔ | - | ✔ | - | 15 | 83.9% |
| ✔ | ✔ | ✔ | - | 200 | 79.6% |
| ✔ | - | ✔ | ✔ | 13 | 85.7% |
| VideoMamba | Channel Attention | Spatial Attention | Self-Attention | Accuracy |
|---|---|---|---|---|
| ✔ | ✔ | - | - | 83.2% |
| ✔ | - | ✔ | - | 82.4% |
| ✔ | - | - | ✔ | 83.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Chen, X.; Cen, L.; Yin, Z.; Deng, Z. VideoMamba Enhanced with Attention and Learnable Fourier Transform for Superheat Identification. Processes 2025, 13, 1310. https://doi.org/10.3390/pr13051310
Hu Y, Chen X, Cen L, Yin Z, Deng Z. VideoMamba Enhanced with Attention and Learnable Fourier Transform for Superheat Identification. Processes. 2025; 13(5):1310. https://doi.org/10.3390/pr13051310
Chicago/Turabian StyleHu, Yezi, Xiaofang Chen, Lihui Cen, Zeyang Yin, and Ziqing Deng. 2025. "VideoMamba Enhanced with Attention and Learnable Fourier Transform for Superheat Identification" Processes 13, no. 5: 1310. https://doi.org/10.3390/pr13051310
APA StyleHu, Y., Chen, X., Cen, L., Yin, Z., & Deng, Z. (2025). VideoMamba Enhanced with Attention and Learnable Fourier Transform for Superheat Identification. Processes, 13(5), 1310. https://doi.org/10.3390/pr13051310