

Defect Identification of 316L Stainless Steel in Selective Laser Melting Process Based on Deep Learning


Abstract
1. Introduction
2. Materials and Methods
2.1. Samples Used in the Experiments
2.2. Dataset Production
2.3. Experimental Equipment
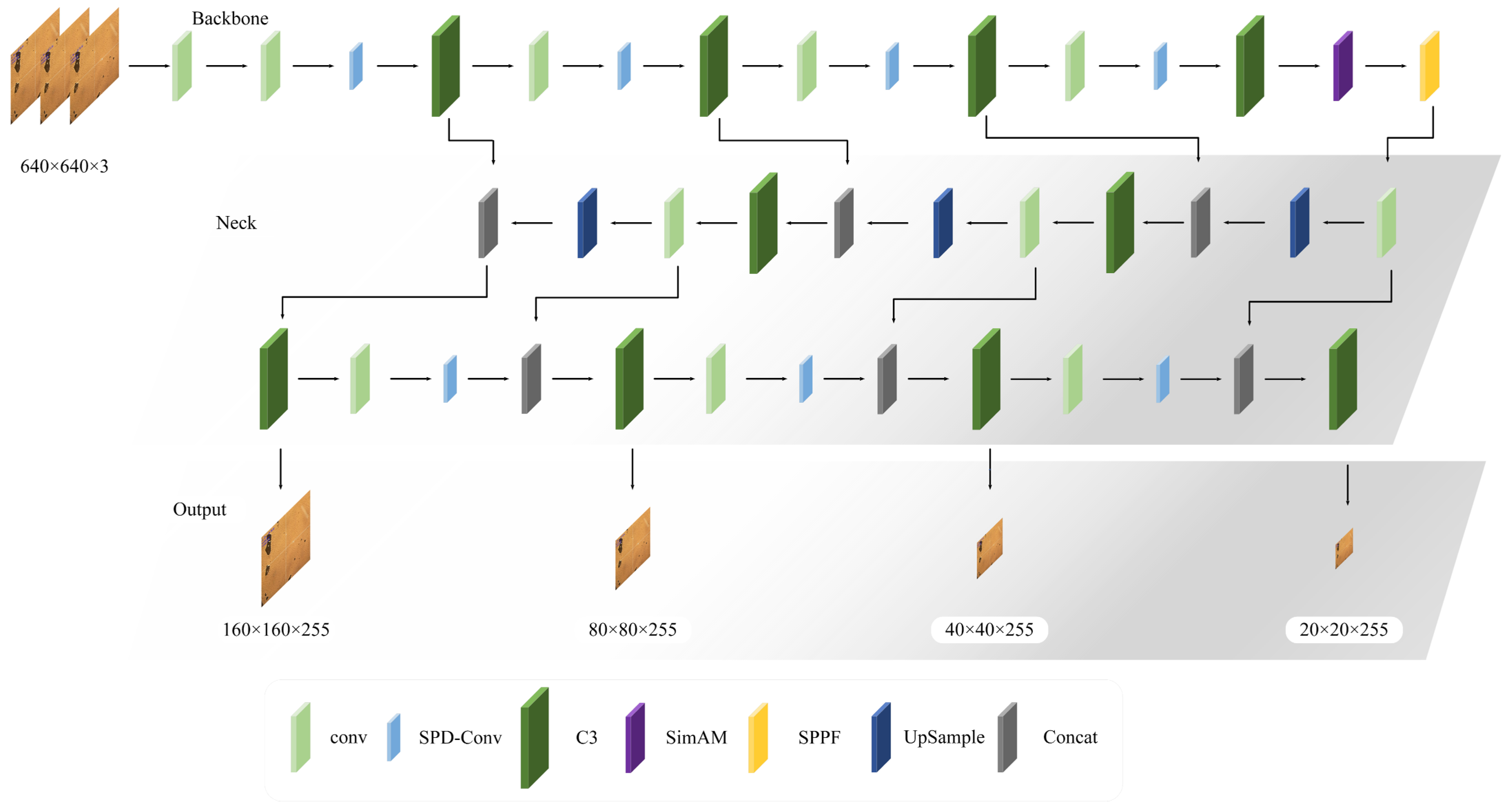
2.4. SLM Defect Detection of 316L Material Based on YOLOv5
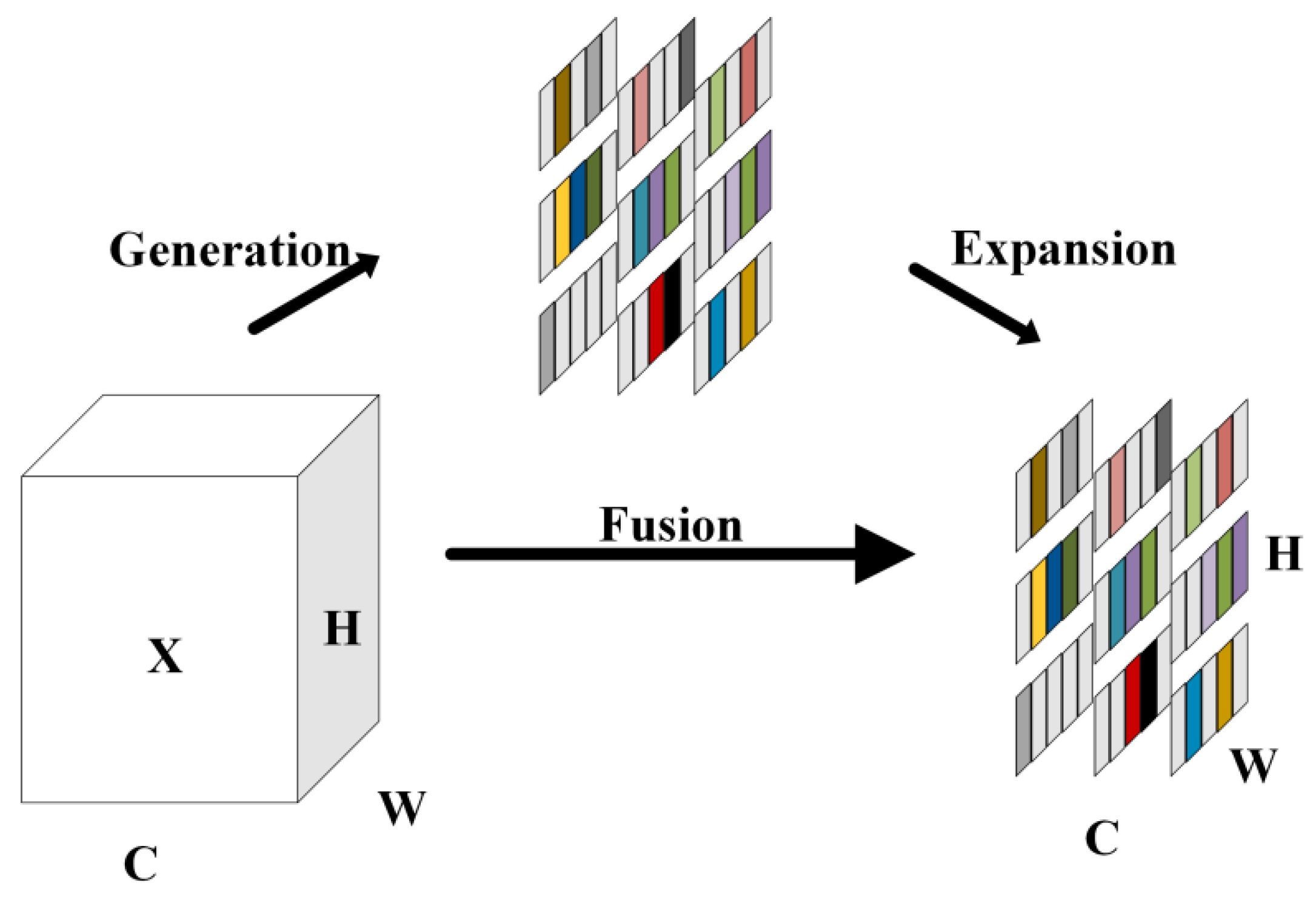
2.4.1. Small Target Detection Layer
2.4.2. Similarity Attention Module
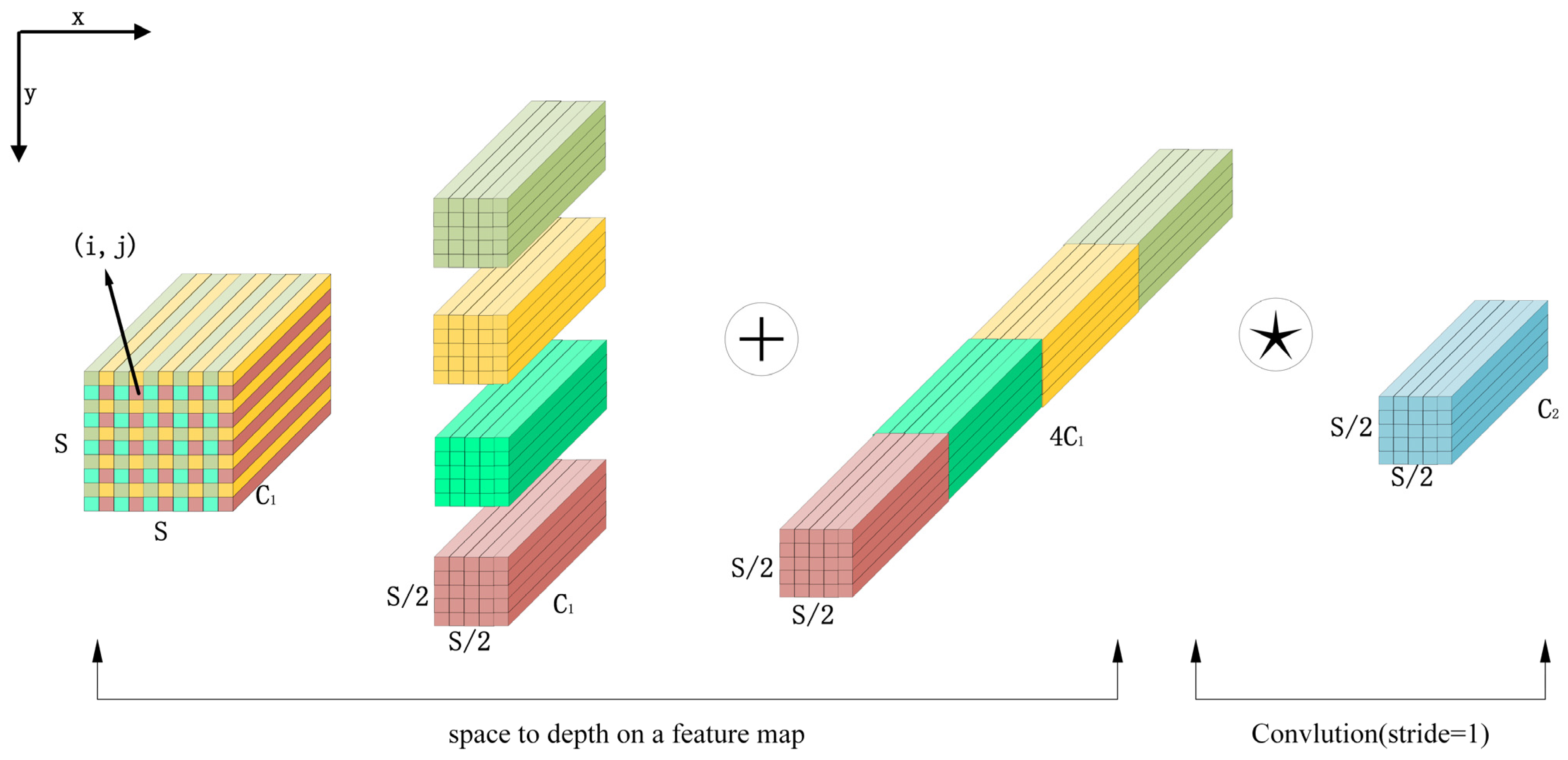
2.4.3. SDP-Conv
3. Results and Discussion
3.1. Model Evaluation Index
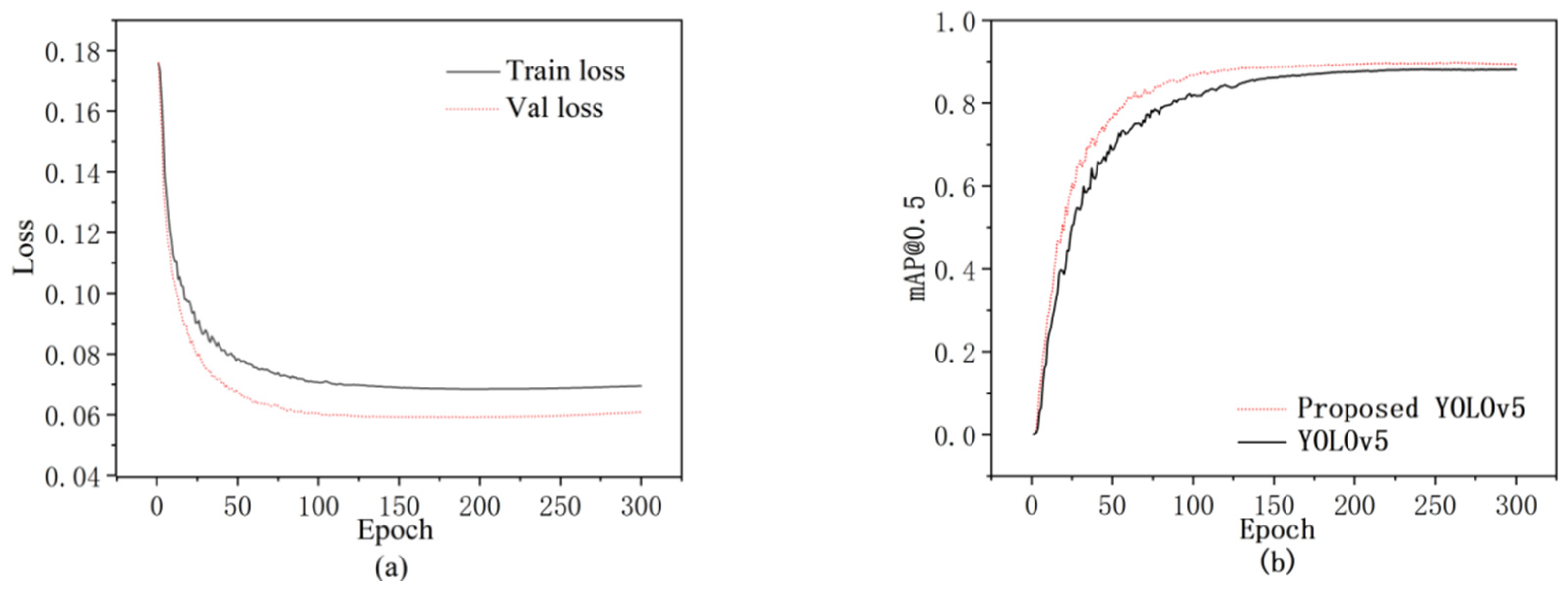
3.2. Results and Analysis
3.3. Performance Comparison of Different Models
4. Conclusions and Future Research
4.1. Conclusions
4.2. Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Frazier, W.E. Metal additive manufacturing: A review. J. Mater. Eng. Perform. 2014, 23, 1917–1928. [Google Scholar] [CrossRef]
- Lewandowski, J.J.; Seifi, M. Metal Additive Manufacturing: A Review of Mechanical Properties. Annu. Rev. Mater. Res. 2016, 46, 151–186. [Google Scholar] [CrossRef]
- Haribaskar, R.; Kumar, T.S. Defects in Metal Additive Manufacturing: Formation, Process Parameters, Postprocessing, Challenges, Economic Aspects, and Future Research Directions. 3D Print. Addit. Manuf. 2023, 9, 165–183. [Google Scholar] [CrossRef]
- Fu, Y.; Downey, A.R.; Yuan, L.; Zhang, T.; Pratt, A.; Balogun, Y. Machine learning algorithms for defect detection in metal laser-based additive manufacturing: A review. J. Manuf. Process. 2022, 75, 693–710. [Google Scholar] [CrossRef]
- Zhang, L.; Fu, Z.; Guo, H.; Sun, Y.; Li, X.; Xu, M. Multiscale Local and Global Feature Fusion for the Detection of Steel Surface Defects. Electronics 2023, 12, 3090. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, Q.; Wu, C.; Pan, J.; Qi, H. Improved faster-RCNN-based inspection of hydraulic cylinder internal surface defects. In Proceedings of the 3rd International Conference on Artificial Intelligence, Automation, and High-Performance Computing (AIAHPC 2023), Wuhan, China, 31 March–2 April 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12717, pp. 201–208. [Google Scholar]
- Yixuan, L.; Dongbo, W.; Jiawei, L.; Hui, W. Aeroengine Blade Surface Defect Detection System Based on Improved Faster RCNN. Int. J. Intell. Syst. 2023, 2023, 1992415. [Google Scholar] [CrossRef]
- Khalfaoui, A.; Badri, A.; Mourabit, I.E.L. Comparative study of YOLOv3 and YOLOv5’s performances for real-time person detection. In Proceedings of the 2nd International Conference on Innovative Research in Applied Science, Engineering and Technology (IRASET), Meknes, Morocco, 3–4 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–5. [Google Scholar]
- Li, X.; Wang, C.; Ju, H.; Li, Z. Surface Defect Detection Model for Aero-Engine Components Based on Improved YOLOv5. Appl. Sci. 2022, 12, 7235. [Google Scholar] [CrossRef]
- Inbar, O.; Shahar, M.; Gidron, J.; Cohen, I.; Menashe, O.; Avisar, D. Analyzing the secondary wastewater-treatment process using Faster R-CNN and YOLOv5 object detection algorithms. J. Clean. Prod. 2023, 416, 137913. [Google Scholar] [CrossRef]
- Thuan, D. Evolution of Yolo Algorithm and Yolov5: The State-of-the-Art Object Detection Algorithm. Bachelor’s Thesis, Oulu University of Applied Sciences, Oulu, Finland, 2021. [Google Scholar]
- Cherkasov, N.; Ivanov, M.; Ulanov, A. Weld Surface Defect Detection Based on a Laser Scanning System and YOLOv5. In Proceedings of the 2023 International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Sochi, Russia, 15–19 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 851–855. [Google Scholar]
- Wang, K.; Teng, Z.; Zou, T. Metal defect detection based on YOLOv5. J. Phys. Conf. Ser. 2022, 2218, 012050. [Google Scholar] [CrossRef]
- Lu, D.; Muhetae, K. Research on algorithm of surface defect detection of aluminum profile based on YOLO. In Proceedings of the International Conference on Image, Signal Processing, and Pattern Recognition (ISPP 2023), Changsha, China, 24–26 February 2023; SPIE: Bellingham, WA, USA, 2023; Volume 12707, pp. 317–323. [Google Scholar]
- Xiao, D.; Xie, F.T.; Gao, Y.; Ni Li, Z.; Xie, H.F. A detection method of spangle defects on zinc-coated steel surfaces based on improved YOLO-v5. Int. J. Adv. Manuf. Technol. 2023, 128, 937–951. [Google Scholar] [CrossRef]
- Zhao, H.; Wan, F.; Lei, G.; Xiong, Y.; Xu, L.; Xu, C.; Zhou, W. LSD-YOLOv5: A Steel Strip Surface Defect Detection Algorithm Based on Lightweight Network and Enhanced Feature Fusion Mode. Sensors 2023, 23, 6558. [Google Scholar] [CrossRef] [PubMed]
- Brennan, M.C.; Keist, J.S.; Palmer, T.A. Defects in Metal Additive Manufacturing Processes. J. Mater. Eng. Perform. 2021, 30, 4808–4818. [Google Scholar] [CrossRef]
- Hossain, S.; Anzum, H.; Akhter, S. Comparison of YOLO (v3, v5) and MobileNet-SSD (v1, v2) for Person Identification Using Ear-Biometrics. Int. J. Comput. Digit. Syst. 2023, 15, 1259–1271. [Google Scholar] [CrossRef] [PubMed]
- Yusuf, S.M.; Gao, N. Influence of energy density on metallurgy and properties in metal additive manufacturing. Mater. Sci. Technol. 2017, 33, 1269–1289. [Google Scholar] [CrossRef]
- Sabzi, H.E.; Maeng, S.; Liang, X.; Simonelli, M.; Aboulkhair, N.T.; Rivera-Díaz-del-Castillo, P.E.J. Controlling crack formation and porosity in laser powder bed fusion: Alloy design and process optimization. Addit. Manuf. 2020, 34, 101360. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Vostrikov, A.; Chernyshev, S. Training sample generation software. In Intelligent Decision Technologies 2019, Proceedings of the 11th KES International Conference on Intelligent Decision Technologies (KES-IDT 2019), St. Julian’s, Malta, 17–19 June 2019; Springer: Singapore, 2019; Volume 2, pp. 145–151. [Google Scholar]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Powder Size (μm) | Power (W) | Scanning Speed (mm/s) | Layer Thickness (μm) | Hatch Distance (μm) |
|---|---|---|---|---|
| 50–150 | 200 | 1000 | 50 | 120 |
| Parameters | Configure |
|---|---|
| Operating system | Windows 11 |
| Deep learning framework | Pytorch 1.10 |
| Programming language | Python 3.6 |
| GPU-accelerated environment | CUDA 10.2 |
| GPU | GeForce RTX 2060 s 8 G |
| CPU | AMD Ryzen 7 5700X 8-Core Processor @3.40 GHz |
| Experiment No. | Precision (%) | Recall (%) | mAP@0.5 (%) | Model Size (MB) |
|---|---|---|---|---|
| 1 | 92.1 | 93.1 | 88.1 | 65.9 |
| 2 | 94.3 | 93.7 | 88.9 | 92.2 |
| 3 | 95.6 | 94.1 | 89.4 | 92.2 |
| 4 | 96.3. | 94.6 | 89.8 | 110.7 |
| Category | YOLOV5 | Proposed YOLOv5 |
|---|---|---|
| LOF | 90.4 | 91.1 |
| Unmelted Powder | 89.6 | 90.2 |
| Keyhole | 83.2 | 86.3 |
| Model Name | P (%) | R (%) | mAP@0.5 (%) | Model Size (MB) | Detect Time (ms) |
|---|---|---|---|---|---|
| Faster R-CNN | 86.4 | 88.7 | 80.9 | 108 | 119.7 |
| SSD300 | 68.6 | 75.4 | 70.4 | 93.1 | 74.3 |
| YOLOv5 | 92.1 | 93.1 | 88.1 | 65.9 | 27.1 |
| Proposed YOLOv5 | 96.3. | 94.6 | 89.8 | 110.7 | 34.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, W.; Gan, X.; He, J. Defect Identification of 316L Stainless Steel in Selective Laser Melting Process Based on Deep Learning. Processes 2024, 12, 1054. https://doi.org/10.3390/pr12061054
Yang W, Gan X, He J. Defect Identification of 316L Stainless Steel in Selective Laser Melting Process Based on Deep Learning. Processes. 2024; 12(6):1054. https://doi.org/10.3390/pr12061054
Chicago/Turabian StyleYang, Wei, Xinji Gan, and Jinqian He. 2024. "Defect Identification of 316L Stainless Steel in Selective Laser Melting Process Based on Deep Learning" Processes 12, no. 6: 1054. https://doi.org/10.3390/pr12061054
APA StyleYang, W., Gan, X., & He, J. (2024). Defect Identification of 316L Stainless Steel in Selective Laser Melting Process Based on Deep Learning. Processes, 12(6), 1054. https://doi.org/10.3390/pr12061054