
A New Use Strategy of Artificial Intelligence Algorithms for Energy Optimization in Plastic Injection Molding



Abstract
1. Introduction
2. Materials and Methods
2.1. Plastic Injection Molding
2.2. Machine Learning
2.2.1. Supervised Learning Algorithms
- Regression;
- Classification.
2.2.2. Unsupervised Learning Algorithms
2.3. Neural Networks
- The number of layers: single-layer or multilayer;
- The presence of feedback: feed-forward (without feedback) or recurrent (with feedback).
2.4. AI Applied to Plastic Injection Molding
- It addresses the challenge of limited (or zero) labeled data by using an unsupervised learning approach;
- It provides decision-makers with insights into potential factors through anomaly clustering and visualization.
- Time constraints: Manually labeling each data point is a tedious and time-consuming process, especially with large datasets;
- Financial burden: The effort required to label all the records translates to substantial labor costs, making it financially impractical for most factories;
- Expertise requirements: Accurate labeling often necessitates domain knowledge and expertise to correctly identify and categorize defects.
3. Experiments and Results
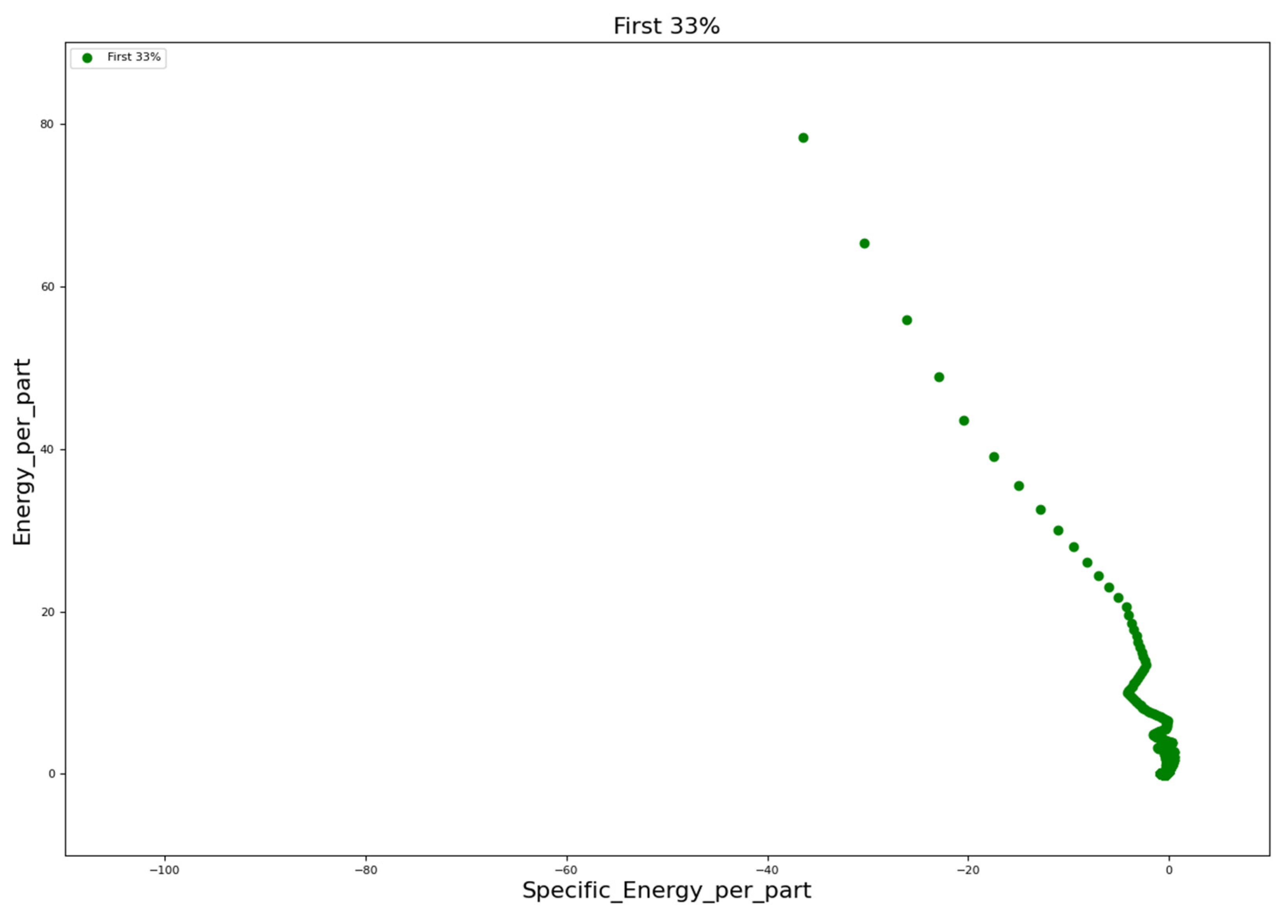
3.1. Energy Consumption Analysis
- Cluster 0 (blue): characterized by low specific energy and high energy per part. This could represent the production of parts with short molding cycles;
- Cluster 1 (orange): shows higher specific energy and medium–high energy per part. This might indicate the production with medium molding cycles.
- Cluster 2 (gray): exhibits the highest specific energy and the lowest energy per part. This likely refers to the production of parts that require more demanding process parameters (e.g., higher temperatures, longer cooling times). Black points are displayed due to overlapping of gray points.
- Graph 1 (green) can be referred to as the transient phase of the heating energy used to melt the plastic material and maintain the mold temperature. The pattern is similar to Cluster 1, suggesting a strong correlation between the heating energy and the total energy consumption;
- Graph 2 (orange) and Graph 3 (red) can be referred to as the stationary and final phases of the molding process with a total energy consumption that is quite stable.
3.2. Analysis of Processing Parameters Influencing Energy Consumption
- Bottleneck: this refers to the central part of an autoencoder, where the data’s dimensionality was minimized. This reduction forced the network to learn a compressed representation of the data, retaining the most relevant information for reconstruction;
- Dense: it used fully connected layers (dense layers) in both the encoder and the decoder. Each neuron was connected to all the neurons in the preceding and subsequent layers. This type of autoencoder is suited for tabular or structured data, where there are no spatial relationships. Since we were using only the encoding part of the signal, this type of autoencoder corresponded to a Multi-Layer Perceptron Regressor.
- ActCntPrt: the number of pieces remaining to complete production;
- ActCntCyc: the actual cycle counter;
- @ActCntPrtLeft: the number of pieces remaining to complete production;
- @ActMaterialNeeds: the material requirement to complete production;
- @ActTimWrk: the total time spent on production up to this moment;
- @ActEnergyPerPrt.1: the energy consumption per individual piece [Wh].
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ávila-Cedillo, J.; Borja, V.; López-Parra, M.; Ramírez-Reivich, A.C. Energy Consumption Analysis of ABS Plastic Parts Injected in a Hybrid Injection Moulding Machine. Int. J. Sustain. Eng. 2019, 12, 115–122. [Google Scholar] [CrossRef]
- Aminabadi, S.S.; Tabatabai, P.; Steiner, A.; Gruber, D.P.; Friesenbichler, W.; Habersohn, C.; Berger-Weber, G. Industry 4.0 In-Line AI Quality Control of Plastic Injection Molded Parts. Polymers 2022, 14, 3551. [Google Scholar] [CrossRef] [PubMed]
- Silva, B.; Marques, R.; Faustino, D.; Ilheu, P.; Santos, T.; Sousa, J.; Rocha, A.D. Enhance the Injection Molding Quality Prediction with Artificial Intelligence to Reach Zero-Defect Manufacturing. Processes 2023, 11, 62. [Google Scholar] [CrossRef]
- Al-Ahmad, M.; Yang, S.; Qin, Y. Integrating Machine Learning with Machine Parameters to Predict Plastic Part Quality in Injection Moulding. MATEC Web Conf. 2024, 401, 08011. [Google Scholar] [CrossRef]
- Lee, S.; Yun, Y.; Park, S.; Oh, S.; Lee, C.; Jeong, J. Two Phases Anomaly Detection Based on Clustering and Visualization for Plastic Injection Molding Data. Procedia Comput. Sci. 2022, 201, 519–5266. [Google Scholar] [CrossRef]
- Jung, H.; Jeon, J.; Choi, D.; Park, A.J.Y. Application of Machine Learning Techniques in Injection Molding Quality Prediction: Implications on Sustainable Manufacturing Industry. Sustainability 2021, 13, 4120. [Google Scholar] [CrossRef]
- Ogorodnyk, O.; Martinsen, K. Monitoring and Control for Thermoplastics Injection Molding a Review. Procedia Cirp 2018, 67, 380–385. [Google Scholar] [CrossRef]
- Polenta, A.; Tomassini, S.; Falcionelli, N.; Contardo, P.; Dragoni, A.F.; Sernani, P. A Comparison of Machine Learning Techniques for the Quality Classification of Molded Products. Information 2022, 13, 272. [Google Scholar] [CrossRef]
- Farooque, R.; Asjad, M.; Rizvi, S.J.A. A Current State of Art Applied to Injection Moulding Manufacturing Process—A Review. Mater. Today Proc. 2020, 43, 441–446. [Google Scholar]
- Ghadoui, M.E.L. Intelligent Energy-Based Product Quality Control in the Injection Molding Process. In Proceedings of the E3S Web of Conferences; EDP Sciences: Ullis, France, 2023; Volume 469. [Google Scholar] [CrossRef]
- EL Ghadoui, M.; Mouchtachi, A.; Majdoul, R. A Hybrid Optimization Approach for Intelligent Manufacturing in Plastic Injection Molding by Using Artificial Neural Network and Genetic Algorithm. Sci. Rep. 2023, 13, 21817. [Google Scholar] [CrossRef] [PubMed]
- Nasteski, V. An Overview of the Supervised Machine Learning Methods. Horizons. B 2017, 4, 51–62. [Google Scholar] [CrossRef]
- Naeem, S.; Ali, A.; Anam, S.; Ahmed, M.M. An Unsupervised Machine Learning Algorithms: Comprehensive Review. Int. J. Comput. Digit. Syst. 2023, 13, 911–921. [Google Scholar] [CrossRef] [PubMed]
- Niu, W.J.; Feng, Z.K.; Feng, B.F.; Min, Y.W.; Cheng, C.T.; Zhou, J.Z. Comparison of Multiple Linear Regression, Artificial Neural Network, Extreme Learning Machine, and Support Vector Machine in Deriving Operation Rule of Hydropower Reservoir. Water 2019, 11, 88. [Google Scholar] [CrossRef]
- Alzubi, J.; Nayyar, A.; Kumar, A. Machine Learning from Theory to Algorithms: An Overview. J. Phys. Conf. Ser. 2018, 1142, 012012. [Google Scholar] [CrossRef]
- Mingoti, S.A.; Lima, J.O. Comparing SOM Neural Network with Fuzzy C-Means, K-Means and Traditional Hierarchical Clustering Algorithms. Eur. J. Oper. Res. 2006, 174, 1742–1759. [Google Scholar] [CrossRef]
- Wu, Y.C.; Feng, J.W. Development and Application of Artificial Neural Network. Wirel. Pers. Commun. 2018, 102, 1645–1656. [Google Scholar] [CrossRef]
- Li, P.; Pei, Y.; Li, J. A Comprehensive Survey on Design and Application of Autoencoder in Deep Learning. Appl. Soft Comput. 2023, 138, 110176. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Area of Interest | KPI Addressed | AI Approach | PRO’S | CON’S |
|---|---|---|---|---|---|
| [2] | fully automated closed-loop injection molding | AI control to adjust machine parameters | ResNet-18 CNN | High precision in defect detection and parameter adjustment; supports zero-defect manufacturing | Limited to specific parameters; needs high-quality sensor data |
| [3] | zero-defect manufacturing, sustainability | Overall Equipment Effectiveness (OEE), downtime reduction | Data augmentation, human-in-the-loop labeling | Reduces defective parts and environmental impact; increases OEE and process efficiency | High initial implementation costs; dependence on real-time data integration |
| [4] | machine parameter optimization | Defect rate, production efficiency | Logistic regression, random forest, gradient boosting | High classification accuracy (>98%), robust analysis of sensor data | Potential overfitting, requires extensive sensor setup |
| [5] | anomaly detection in injection molding | Detection rate, system robustness | Clustering, visualization | Enhances anomaly detection precision through clustering; adaptable to different datasets | Requires significant computational resources |
| [6] | sustainable manufacturing | Accuracy, precision, recall, F1-score | Decision trees, regression models, autoencoders | Autoencoder performs best; highlights temperature and time as key factors affecting quality | Selection of algorithms depends heavily on input data quality |
| [7] | process monitoring and control | Quality consistency, system adaptability | Various machine learning methods | Comprehensive overview of monitoring technologies; real-time application | Broad scope lacks specific implementation details |
| [8] | quality classification for molded products | Classification accuracy, error rates | Random forest, neural networks, support vector machines | Provides comparative performance of different algorithms; flexible setup | Accuracy depends on the size and diversity of training datasets |
| [9] | process optimization in injection molding | Defect minimization, mechanical properties | Artificial neural networks, genetic algorithms, Taguchi methods | Comprehensive overview of optimization techniques; highlights significant process parameters such as cooling time and holding pressure | Variability in process parameters reduces general applicability; limited specific experimental results |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pascoschi, G.; De Filippis, L.A.C.; Decataldo, A.; Dassisti, M. A New Use Strategy of Artificial Intelligence Algorithms for Energy Optimization in Plastic Injection Molding. Processes 2024, 12, 2798. https://doi.org/10.3390/pr12122798
Pascoschi G, De Filippis LAC, Decataldo A, Dassisti M. A New Use Strategy of Artificial Intelligence Algorithms for Energy Optimization in Plastic Injection Molding. Processes. 2024; 12(12):2798. https://doi.org/10.3390/pr12122798
Chicago/Turabian StylePascoschi, Giovanni, Luigi Alberto Ciro De Filippis, Antonio Decataldo, and Michele Dassisti. 2024. "A New Use Strategy of Artificial Intelligence Algorithms for Energy Optimization in Plastic Injection Molding" Processes 12, no. 12: 2798. https://doi.org/10.3390/pr12122798
APA StylePascoschi, G., De Filippis, L. A. C., Decataldo, A., & Dassisti, M. (2024). A New Use Strategy of Artificial Intelligence Algorithms for Energy Optimization in Plastic Injection Molding. Processes, 12(12), 2798. https://doi.org/10.3390/pr12122798