
A Novel Temporal Fusion Channel Network with Multi-Channel Hybrid Attention for the Remaining Useful Life Prediction of Rolling Bearings



Abstract
1. Introduction
2. Methodology
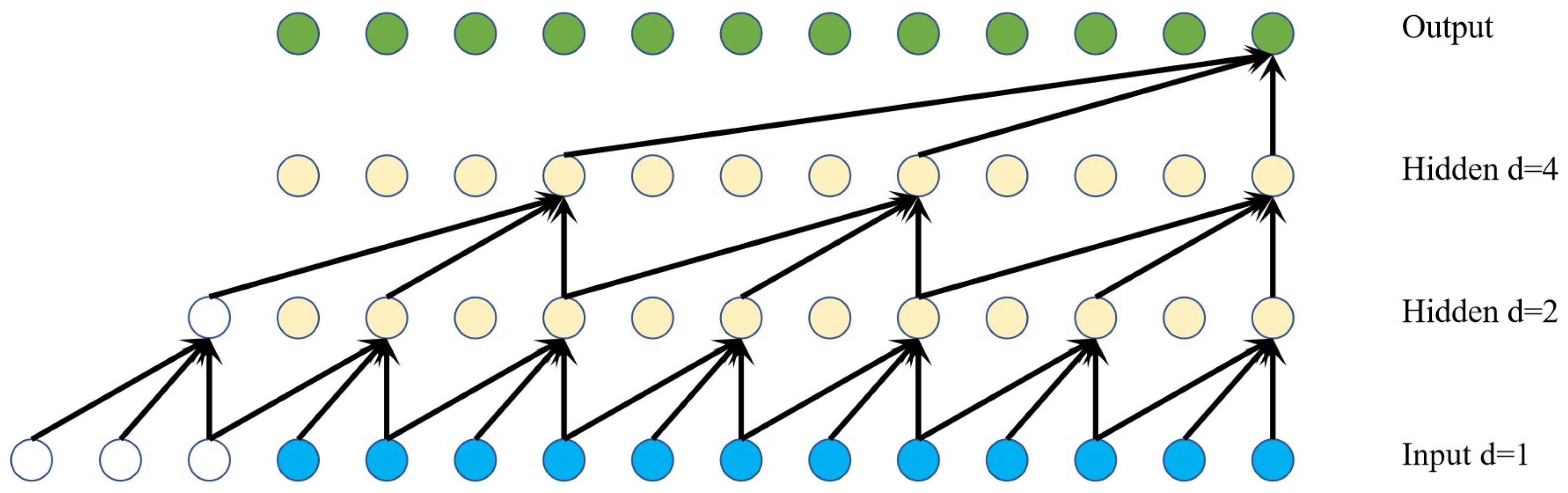
2.1. Temporal Convolutional Network
2.1.1. Dilated Convolution
2.1.2. Causal Convolution
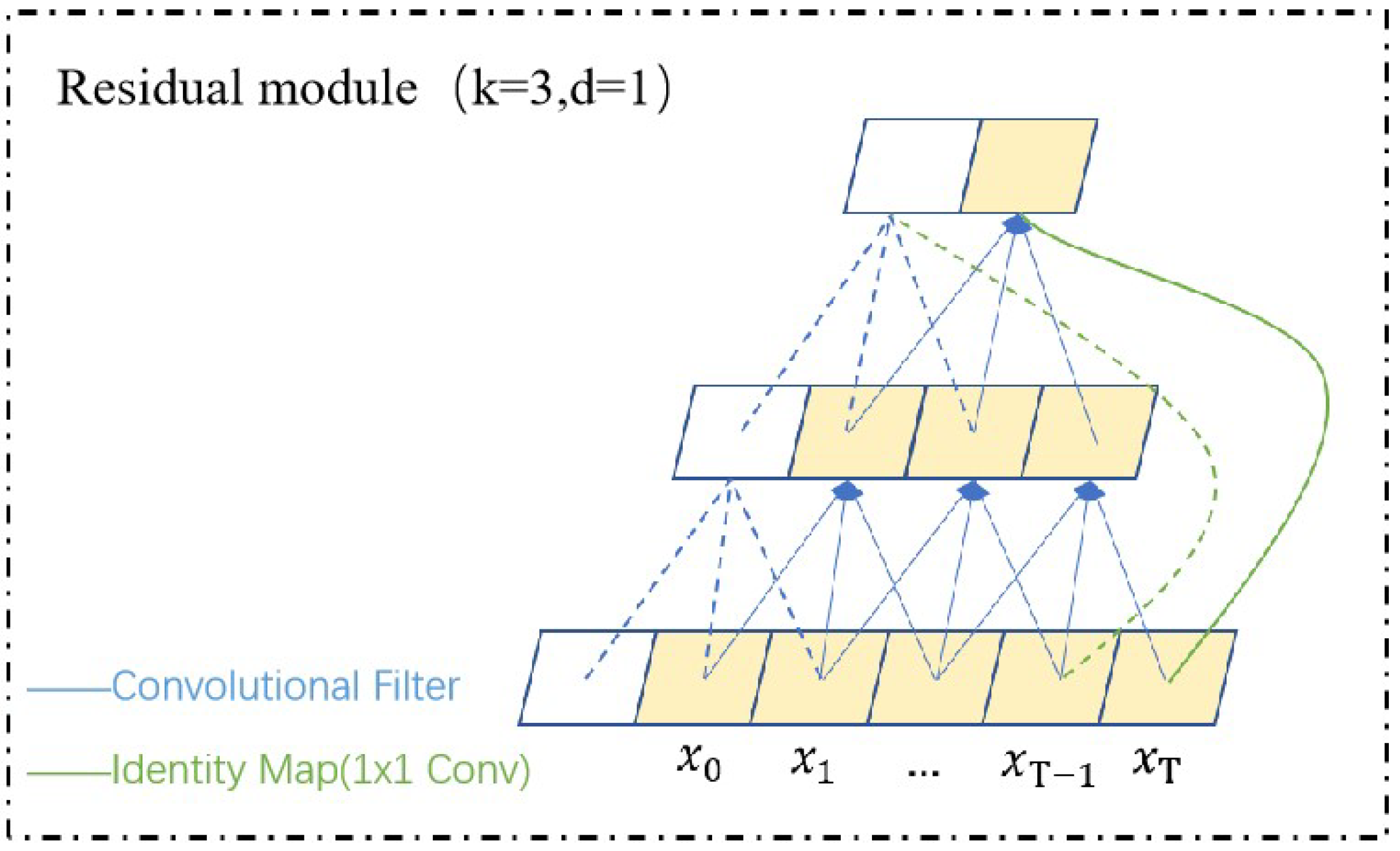
2.1.3. Residual Connection
2.2. Attention Mechanism
2.2.1. Channel Attention
2.2.2. Self-Attention Mechanism
3. RUL Prediction Method Based on MCHA-TFCN
3.1. Key Ideas
3.2. Data Processing
3.3. Construction of Prediction Model MCHA-TFCN
3.3.1. Design of Feature Fusion Module
3.3.2. Feature Fusion Network Construction
| Algorithm 1 RUL prediction method based on MCHA-TFCN | |
| Input: | Training set data for a single working condition: , and corresponding labels Y. |
| Output: | MCHA-TFCN model trained under a single working condition. |
| Training: | |
| 1 | Initialize the network parameters of the feature acquisition module and MCHA-TFCN. |
| 2 | for epochs , max do: |
| 3 | Input training data in batch order into the model to be trained. |
| 4 | Extract time domain and multi-scale depth features, and output a multi-dimensional feature sequence to be fused. |
| 5 | During the network forward propagation process, Formulas (18) and (19) are used to weight the input features, and Formulas (20) and (21) are used to perform feature fusion. |
| 6 | Calculate the loss of the predicted result and the actual label (MSELoss). |
| 7 | Use the Adam method to back-propagate and update the model parameters. |
| 8 | end for |
| 9 | Save the trained network structure. |
| Test: | |
| 10 | Input the test data into the model to obtain the prediction results . |
| 11 | Evaluate the prediction effect of the model based on the evaluation index (RMSE). |
4. Verification
4.1. Dataset Description
4.2. Implementation Details
4.3. Effect Verification
4.4. RUL Estimation Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nieto, P.J.G.; García-Gonzalo, E.; Lasheras, F.S.; de Cos Juez, F.J. Hybrid PSO–SVM-based method for forecasting of the remaining useful life for aircraft engines and evaluation of its reliability. Reliab. Eng. Syst. Saf. 2015, 138, 219–231. [Google Scholar] [CrossRef]
- Psuj, G. Multi-sensor data integration using deep learning for characterization of defects in steel elements. Sensors 2018, 18, 292. [Google Scholar] [CrossRef] [PubMed]
- Alzhanov, N.; Tariq, H.; Amrin, A.; Zhang, D.; Spitas, C. Modelling and simulation of a novel nitinol-aluminium composite beam to achieve high damping capacity. Mater. Today Commun. 2023, 35, 105679. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, S.; Cao, R.; Xu, D.; Fan, Y. A rolling bearing fault diagnosis method based on the WOA-VMD and the GAT. Entropy 2023, 25, 889. [Google Scholar] [CrossRef]
- Pecht, M.; Gu, J. Physics-of-failure-based prognostics for electronic products. Trans. Inst. Meas. Control 2009, 31, 309–322. [Google Scholar] [CrossRef]
- Yu, W.; Tu, W.; Kim, I.Y.; Mechefske, C. A nonlinear-drift-driven Wiener process model for remaining useful life estimation considering three sources of variability. IEEE Trans. Instrum. Meas. 2021, 212, 107631. [Google Scholar] [CrossRef]
- Soualhi, A.; Medjaher, K.; Zerhouni, N. Bearing health monitoring based on Hilbert–Huang transform, support vector machine, and regression. Trans. Inst. Meas. Control 2014, 64, 52–62. [Google Scholar] [CrossRef]
- Cui, L.; Wang, X.; Wang, H.; Ma, J. Research on remaining useful life prediction of rolling element bearings based on time-varying Kalman filter. IEEE Trans. Instrum. Meas. 2019, 69, 2858–2867. [Google Scholar] [CrossRef]
- Aggab, T.; Vrignat, P.; Avila, M.; Kratz, F. Remaining useful life estimation based on the joint use of an observer and a hidden Markov model. J. Risk Reliab. 2022, 236, 676–695. [Google Scholar] [CrossRef]
- Gao, D.; Huang, M. Prediction of remaining useful life of lithium-ion battery based on multi-kernel support vector machine with particle swarm optimization. J. Power Electron. 2017, 17, 1288–1297. [Google Scholar]
- Wang, C.; Lu, N.; Cheng, Y.; Jiang, B. A data-driven aero-engine degradation prognostic strategy. IEEE Trans. Cybern. 2019, 51, 1531–1541. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.; Liu, R.; Zio, E. Remaining useful life prediction based on a double-convolutional neural network architecture. IEEE Trans. Ind. Electron. 2019, 66, 9521–9530. [Google Scholar] [CrossRef]
- Wu, M.; Ye, Q.; Mu, J.; Fu, Z.; Han, Y. Remaining Useful Life Prediction via a data-driven deep learning fusion model–CALAP. IEEE Access 2023, 11, 112085–112096. [Google Scholar] [CrossRef]
- Du, X.; Jia, W.; Yu, P.; Shi, Y.; Gong, B. RUL prediction based on GAM–CNN for rotating machinery. J. Braz. Soc. Mech. Sci. Eng. 2023, 45, 142. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Song, Y.; Gao, S.; Li, Y.; Jia, L.; Li, Q.; Pang, F. Distributed attention-based temporal convolutional network for remaining useful life prediction. IEEE Internet Things J. 2020, 8, 9594–9602. [Google Scholar] [CrossRef]
- Zeng, X.; Yang, C.; Liu, J.; Zhou, K.; Li, D.; Wei, S.; Liu, Y. Remaining useful life prediction for rotating machinery based on dynamic graph and spatial–temporal network. Meas. Sci. Technol. 2022, 34, 035102. [Google Scholar] [CrossRef]
- Liang, H.; Cao, J.; Zhao, X. Multi-sensor data fusion and bidirectional-temporal attention convolutional network for remaining useful life prediction of rolling bearing. Meas. Sci. Technol. 2023, 34, 105126. [Google Scholar] [CrossRef]
- Nie, L.; Xu, S.; Zhang, L. Multi-Head Attention Network with Adaptive Feature Selection for RUL Predictions of Gradually Degrading Equipment. Actuators 2023, 12, 158. [Google Scholar] [CrossRef]
- Ren, L.; Liu, Y.; Huang, D.; Huang, K.; Yang, C. MCTAN: A novel multichannel temporal attention-based network for industrial health indicator prediction. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 6456–6467. [Google Scholar] [CrossRef]
- Van Den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7 September 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 5 July 2016; pp. 770–778. [Google Scholar]
- Cao, Y.; Ding, Y.; Jia, M.; Tian, R. A novel temporal convolutional network with residual self-attention mechanism for remaining useful life prediction of rolling bearings. Reliab. Eng. Syst. Saf. 2021, 215, 107813. [Google Scholar] [CrossRef]
- Bahdanau, D. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–7 December 2017. [Google Scholar]
- Wang, X.; Li, Y.; Xu, Y.; Liu, X.; Zheng, T.; Zheng, B. Remaining useful life prediction for aero-engines using a time-enhanced multi-head self-attention model. Aerospace 2023, 10, 80. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 1 July 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Zhang, W.; Ma, H.; Luo, Z.; Li, X. Data alignments in machinery remaining useful life prediction using deep adversarial neural networks. Knowl.-Based Syst. 2020, 197, 105843. [Google Scholar] [CrossRef]
- Wang, Y.; Deng, L.; Zheng, L.; Gao, R.X. Temporal convolutional network with soft thresholding and attention mechanism for machinery prognostics. J. Manuf. Syst. 2021, 60, 512–526. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Layer | Setting Value |
|---|---|---|
| 1 | Linear | 2560, 256 |
| 2 | BatchNorm1d | 256 |
| 3 | Tanh | / |
| 4 | Dropout | 0.2 |
| 5 | Linear | 256, 1 |
| 6 | PReLU | / |
| Task | Conditions | Train | Test |
|---|---|---|---|
| Task-I | Load (N): 4000; Speed (r/min): 1800 | B1_1-B1_2 | B1_3-B1_7 |
| Task-II | Load (N): 4200; Speed (r/min): 1650 | B2_1-B2_2 | B2_3-B2_7 |
| Task-III | Load (N): 5000; Speed (r/min): 1500 | B3_1-B3_2 | B3_3 |
| Module | Input-Size | Output-Size |
|---|---|---|
| Feature input | 32, 2, 2560 | 16, 32, 1, 2560 |
| MCHA-TFCN-I | 16, 32, 1, 2560 | 8, 32, 32, 2560 |
| MCHA-TFCN-II | 8, 32, 32, 2560 | 4, 32, 128, 2560 |
| MCHA-TFCN-III | 4, 32, 128, 2560 | 2, 32, 64, 2560 |
| MCHA-TFCN-IV | 2, 32, 64, 2560 | 32, 32, 2560 |
| AdaptiveAvgPool1d | 32, 32, 2560 | 32, 1, 2560 |
| Hyper-Parameter | Input-Size |
|---|---|
| Batch size | 32 |
| Max epochs | 300 |
| Initial learning rate | 0.1 |
| Gamma | 0.1 |
| Milestones | 10, 100, 150, 200 |
| Number of features to be fused | |
| Kernel sizes of multiscale conv1d layers | |
| Strides of multiscale conv1d layers | 1, 1, 2, 2 |
| Hidden channel list of MCHA-TFCN | [32, 128, 64, 32] |
| Self-attention | |
| Dropout rate | 0.2 |
| Test | RMSE | |||
|---|---|---|---|---|
| TCN(1) | TCN(2) | TCN-SA | MCHA-TFCN | |
| 1–3 | 0.355 | 0.194 | 0.157 | 0.109 |
| 1–4 | 0.303 | 0.115 | 0.105 | 0.044 |
| 1–5 | 0.209 | 0.188 | 0.130 | 0.118 |
| 1–6 | 0.220 | 0.155 | 0.139 | 0.126 |
| 1–7 | 0.097 | 0.150 | 0.109 | 0.057 |
| Avg | 0.237 | 0.151 | 0.128 | 0.091 |
| Test | RMSE | |||
|---|---|---|---|---|
| TCN(1) | TCN(2) | TCN-SA | MCHA-TFCN | |
| 2–3 | 0.409 | 0.227 | 0.230 | 0.102 |
| 2–4 | 0.346 | 0.106 | 0.164 | 0.117 |
| 2–5 | 0.216 | 0.187 | 0.176 | 0.099 |
| 2–6 | 0.257 | 0.218 | 0.142 | 0.104 |
| 2–7 | 0.293 | 0.183 | 0.248 | 0.108 |
| Avg | 0.304 | 0.184 | 0.190 | 0.106 |
| Test | CNN-LSTM | DANN | TCN-SA | Bi-TACN | MCHA-TFCN |
|---|---|---|---|---|---|
| 1–3 | 0.126 | 0.335 | 0.117 | 0.090 | 0.109 |
| 1–4 | 0.107 | 0.251 | 0.085 | 0.113 | 0.044 |
| 1–5 | 0.152 | 0.216 | 0.086 | 0.090 | 0.118 |
| 1–6 | 0.154 | 0.209 | 0.101 | 0.016 | 0.126 |
| 1–7 | 0.129 | 0.192 | 0.129 | 0.149 | 0.057 |
| Avg | 0.127 | 0.222 | 0.104 | 0.114 | 0.091 |
| Test | CNN-LSTM | DANN | TCN-SA | Bi-TACN | MCHA-TFCN |
|---|---|---|---|---|---|
| 2–3 | 0.174 | 0.168 | 0.230 | 0.203 | 0.102 |
| 2–4 | 0.136 | 0.106 | 0.064 | 0.137 | 0.117 |
| 2–5 | 0.150 | 0.228 | 0.150 | 0.176 | 0.099 |
| 2–6 | 0.167 | 0.237 | 0.154 | 0.142 | 0.104 |
| 2–7 | 0.183 | 0.192 | 0.263 | 0.248 | 0.108 |
| Avg | 0.162 | 0.186 | 0.172 | 0.181 | 0.106 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.; Jiang, J.; Qi, H.; Zhang, D.; Han, X. A Novel Temporal Fusion Channel Network with Multi-Channel Hybrid Attention for the Remaining Useful Life Prediction of Rolling Bearings. Processes 2024, 12, 2762. https://doi.org/10.3390/pr12122762
Wang C, Jiang J, Qi H, Zhang D, Han X. A Novel Temporal Fusion Channel Network with Multi-Channel Hybrid Attention for the Remaining Useful Life Prediction of Rolling Bearings. Processes. 2024; 12(12):2762. https://doi.org/10.3390/pr12122762
Chicago/Turabian StyleWang, Cunsong, Junjie Jiang, Heng Qi, Dengfeng Zhang, and Xiaodong Han. 2024. "A Novel Temporal Fusion Channel Network with Multi-Channel Hybrid Attention for the Remaining Useful Life Prediction of Rolling Bearings" Processes 12, no. 12: 2762. https://doi.org/10.3390/pr12122762
APA StyleWang, C., Jiang, J., Qi, H., Zhang, D., & Han, X. (2024). A Novel Temporal Fusion Channel Network with Multi-Channel Hybrid Attention for the Remaining Useful Life Prediction of Rolling Bearings. Processes, 12(12), 2762. https://doi.org/10.3390/pr12122762