1. Introduction
The operation optimization of complex industrial processes is a dynamic multi-objective optimization problem. These problems cover industrial areas such as steel, chemicals, and energy. Specifically, they address operation optimization problems under uncertain environments in production processes, with production metrics as the optimization objectives and controllable variables as the decision variables. They consider changing factors in production processes, operational metrics, and constraints on production metrics, establishing dynamic models for solving these problems. Unlike static models, these objectives and constraints change over time, similar to how the Pareto set (PS) and Pareto front (PF) in dynamic multi-objective optimization problems (DMOPs) can change over time. Therefore, similar to studying dynamic multi-objective optimization algorithms (DMOAs), our goal is to rapidly and effectively track these movements’ Pareto Set and Pareto Front in complex industrial processes.
In reality, this is a challenging problem because researchers cannot easily create the dynamic models for relevant operating variables. Traditionally, controllers in various complex industrial systems are based on mechanism models. Therefore, dynamic control strategies often rely on the dynamic characteristics of mathematical models of physical systems. Given the dynamic features of a particular system, different control systems can be designed to counteract disturbances applied to the system. This operation simplifies external interferences in industrial systems through assumptions, which are then extended to complex nonlinear systems. However, these approximations and simplifications could be more practical and limit the performance of these systems. Due to the complexity of industrial production processes, traditional mechanism modeling methods are no longer sufficient to provide references for the dynamic optimization and control of production processes. Therefore, establishing dynamic models for the optimization of operational metrics in complex industrial production processes, while ensuring production objectives and promptly optimizing control when the system undergoes dynamic changes, has become an urgent problem in the current context.
The emergence of the big data age has somewhat mitigated the difficulties associated with dynamic multi-objective optimization problems. With the advancement of industrial automation, many sensors are being applied in complex industrial processes. Massive industrial data are crucial in industrial control, leading industrial informatization and intelligence developments. These data are integrated into various aspects of industrial design, processes, production, and management, enabling intelligent functions such as description, diagnosis, prediction, decision-making, and control in industrial systems. In reference [
1], combining the advantages and applications of data-driven methods with the benefits and necessities of dynamic optimization has been emphasized. This integration supports the secure and rapid development of complex industrial systems. It not only enables high-precision and real-time predictions but also forms the application foundation for the dynamic operational optimization of future industrial systems. Specifically, recent issues in industrial systems include state monitoring and fault detection for system equipment, the prediction of critical parameters in the production process, and the monitoring and prediction of product quality, among others. Data-driven modeling and dynamic optimization control of problems in industrial production processes through the analysis of historical or real-time measurement data have gained widespread attention across various industries. References [
2,
3,
4,
5] systematically summarize data-driven predictions in different industrial systems, revealing the characteristics and effects of various prediction methods in different industrial sectors. These prediction methods have played a significant role in the dynamic optimization and control of complex industrial processes. They can enhance the production safety index in industrial processes, reduce the maintenance and operation costs of industrial equipment, and improve industrial production efficiency.
In addition, system dynamics is also an effective solution for handing complex industrial processes. Its core is to model and analyze the feedback loop and time delay in the system to reveal the inherent dynamic behavior and complexity of the system. That is to say, system dynamics pays more attention to the dynamic characteristics of the whole and the interaction between the elements, which is the key to determining the behavior of dynamic systems. Different from the traditional modeling methods, system dynamics considers the influence of the time delay of a decision or action on the system so that it can be used to deal with complex dynamic behaviors such as nonlinearity and historical dependence. However, system dynamics models usually require a deep understanding of the system’s internal structure and dynamic behavior. This requires specialized knowledge and skills, and building such a model can be complex and time-consuming. Therefore, verifying a system dynamics model is usually difficult because it requires complex simulations and experiments. In summary, although the results of system dynamics models usually have good interpretability, it may be more difficult to establish these models when the internal structure and dynamic behavior of a system are very complex.
Data-driven control strategies are different from system dynamics. Data-driven methods can usually learn patterns directly from a large amount of historical data without the need for in-depth understanding of the internal structure and dynamic behavior of a system and are more suitable for dealing with problems such as large amounts of data, high dimensionality, and complex internal structures. Their emergence has rapidly transformed the direction of the traditional industrial control field. This transformation has helped overcome the inherent limitations of mechanism models when applied to dynamic optimization problems, reducing the control system’s dependence on the internal structure of traditional models. Additionally, due to the abundance of data, numerous heterogeneous data sources, and the temporal properties of data, data-driven strategies have found widespread application in complex industrial processes such as petrochemicals and steel metallurgy. Currently, it has become common practice to combine data-driven strategies with traditional multi-objective optimization methods to address these new dynamic optimization challenges, and the latest developments in this field are summarized in references [
6,
7,
8,
9]. Given the backdrop of industrial big data, these references provide strategies for dynamic data-driven optimization. Researchers like Jin and Wang have discussed the importance of dynamic data-driven optimization in industrial production processes, emphasizing real-time model updates, which serve as a reference for future work in dynamic data-driven optimization.
From the perspective of rapidly increasing data volumes, early industrial processes typically employed mechanism modeling methods. As the volume of data grows beyond a certain extent, models that combine mechanism analysis with data-driven approaches tend to be more accurate than traditional mechanism models. In recent years, industrial big data technologies have experienced rapid development, leading to a significant increase in data volumes. Using data-driven models and methods can produce good results.
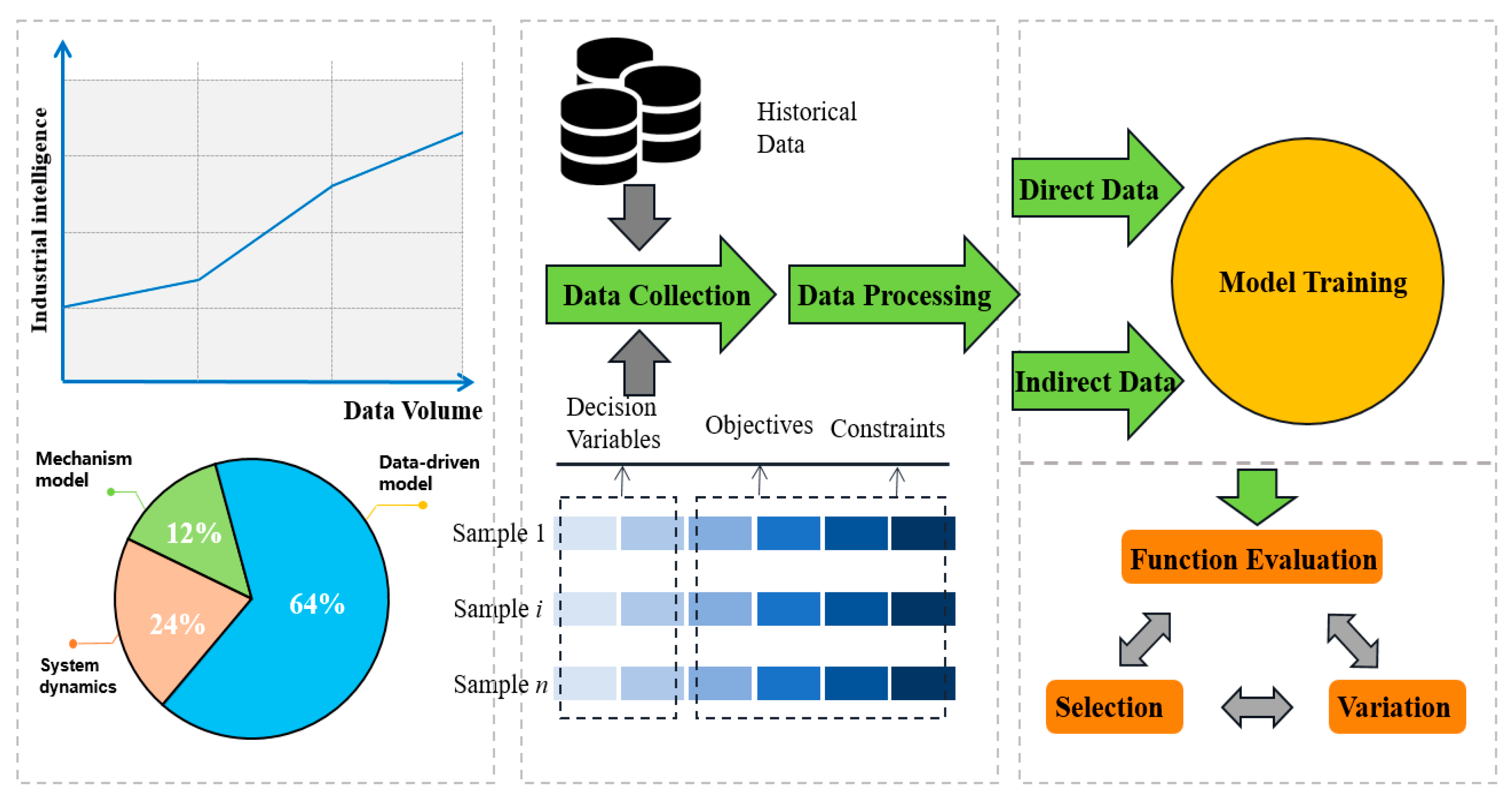
In this paper, the existing literature is analyzed and organized. Currently, 12% of the research focuses on mechanism modeling, 24% on system dynamics modeling, and 64% on data-driven modeling. This also reflects the advantages and broad application of data-driven strategies.
Figure 1 illustrates the steps involved in the study of operation optimization based on a data-driven strategy with the increase in data volume and the development of industrial intelligence. The first stage is the data acquisition phase, the first step in industrial intelligence and operational optimization. Modern industrial equipment is usually equipped with various sensors and monitoring systems, which can collect operating data in real-time, including equipment status, production parameters, energy consumption data, environmental data, etc. The second is the data preprocessing stage. This part mainly preprocesses the collected original data, including data cleaning, outlier detection, data standardization, and missing value processing, to facilitate subsequent analysis and modeling. The last part is the training and solving of the model. According to the specific objectives and problems, the appropriate machine learning or deep learning algorithm is selected to establish a data-driven prediction and optimization model. The specific process is shown in the following
Figure 1.
Data-driven dynamic multi-objective optimization is a research method that combines data-driven methods and multi-objective optimization. This method has become an essential tool for solving challenges in complex industrial production processes. Theoretically, it combines the wide adaptability of multi-objective optimization, the flexibility of dynamic optimization, and the accuracy of data-driven modeling. This enables the model to deal with dynamic and multi-objective optimization problems in the real world and uses a large amount of data to establish and optimize the model to improve the accuracy and reliability of the model’s predictions and decision-making. From a practical point of view, this method has significant advantages in improving decision-making quality, system performance, enhancing system adaptability, and discovering new knowledge. It can help decision-makers make optimal trade-offs between multiple objectives and improve the quality and efficiency of decision-making. At the same time, it can be applied to various complex industrial systems to improve the performance and efficiency of the system by optimizing operating parameters and strategies. In addition, the dynamic optimization model can adjust the decision-making strategy according to real-time data so that the system can better adapt to environmental changes. Through the data-driven optimization process, we can also find the rules and knowledge hidden in the data and provide new insights for industrial production and management.
In general, data-driven dynamic multi-objective optimization provides an effective tool for understanding and optimizing complex dynamic systems. This has significant theoretical and practical value for promoting the development of industrial intelligence and intelligent manufacturing and solving many challenges in complex industrial production processes. Driven by artificial intelligence, digital twins, cloud computing, and industrial big data analysis of production processes, this data-driven strategy is becoming a new focus of global competition, leading new directions in industrial layout and providing essential support for the rapid and stable development of complex industries.
The research work for this review mainly focuses on five aspects:
- (1)
How to establish dynamic operation optimization models based on data-driven modeling;
- (2)
How to detect the concept drift in time series and solve the problem;
- (3)
How to detect dynamic environmental changes;
- (4)
How to adapt to these changes and find new Pareto-based optimal solutions;
- (5)
How to evaluate the performance of dynamic multi-objective optimization algorithms.
The rest of this paper is structured as follows.
Section 2 describes the characteristics and challenges of complex industrial systems, focusing on the dynamic problem in the optimization control of different industries.
Section 3 introduces the concept of dynamic multi-objective optimization, emphasizes state-of-the-art time series predicting models, summarizes a new concept of drift detection methods, and introduces model update methods to solve various challenges.
Section 4 reviews recent developments in dynamic change detection and response methods.
Section 5 delves into examining the efficacy of optimization strategies and reviews the latest performance measures in dynamic multi-objective optimization problems. Finally, the challenges and future directions of data-driven dynamic operation optimization in complex industrial systems are discussed.
2. Review of Dynamic Problems in Complex Industrial Processes
Many factors in complex industrial systems, such as solid nonlinearity, multivariable coupling, dynamic changes in operating conditions, and unknown industrial progress and processes, make further control and optimization of industrial systems very difficult. Different industrial systems have different priorities and evaluation indicators; specific analyses are needed for different industrial processes. Therefore, understanding the production process of complex industries and analyzing it independently and in a customized manner plays an essential role in the monitoring, control, and optimization of complex industrial systems.
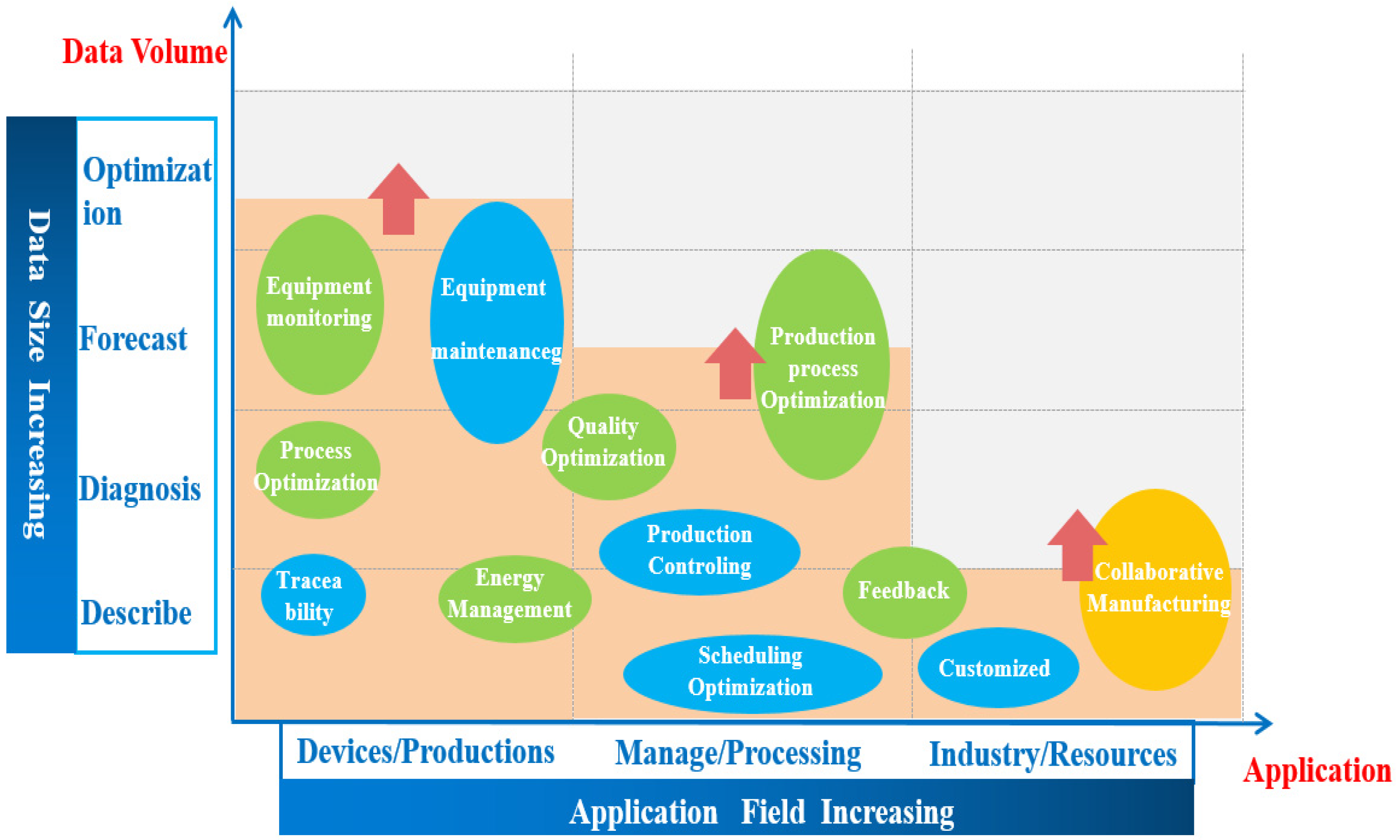
Taking an industrial process in a complex industry as an example, this paper analyzes and discusses different industrial production processes and puts forward operation optimization problems in different processing industries. In recent years, with the rapid development of the industrial Internet, the scope of application of industrial data modeling is expanding. With the deepening concentration of data analysis, the scope of application of data-driven modeling is also developing towards diagnosis and prediction. From the initial solution of energy consumption problems to the predictive maintenance of production equipment to the optimization of production processes, data-driven modeling plays a vital role.
Figure 2 is the application of data-driven modeling in complex industrial processes under the rapid development of data volumes.
Industrial systems are becoming increasingly complex, and safety-related accidents occasionally occur. Significant hazards and frequent accidents highlight the necessity of condition monitoring. The complex industrial model based on data-driven optimization refers to equipment operation data such as for manufacturing, processing, equipping, and testing as part of the production process. It then extracts these data by establishing real-time and comprehensive data acquisition systems. The data are aggregated, calculated, and analyzed in the cloud. This enables condition monitoring, early warning prediction, and industrial equipment performance optimization. The rapid development of big industrial data is significant for controlling and optimizing complex industrial production processes.
Table 1 shows that monitoring and controlling issues in complex industrial processes have become increasingly crucial in recent years. In the steel industry, most scholars focus on enhancing the quality of strip steel, specifically improving steel performance. The pressing need is to increase production efficiency while ensuring steel quality. In the chemical industry, researchers primarily concentrate on predicting crucial parameters in chemical production processes and the safe and rational management of chemical pollutants. Clearly, process control in the chemical industry is vital for energy conservation and enhancing production efficiency. Simultaneously, the safe disposal of chemical pollutants is a significant concern. Most researchers are interested in petroleum production and dynamic risk prediction. As a critical energy source promoting rapid development, petroleum necessitates ensuring safe production while maintaining production efficiency. This leads to researchers addressing issues related to fault detection in oil extraction equipment and oil quality monitoring, proposing corresponding solutions. Additionally, with the growing environmental awareness of industrial processes, wastewater discharge and treatment in the petroleum and chemical industries have become crucial aspects worthy of attention.
However, efficiency is crucial while striving to simplify processes and reduce operational costs. Pursuing higher efficiency can sometimes conflict with achieving the required production quality. Therefore, striking an appropriate balance is crucial. Moreover, production processes often face a trade-off between efficiency and resource utilization. Maximizing efficiency might lead to increased resource consumption, whereas prioritizing resource conservation may negatively impact overall productivity. Ensuring sustained, high-quality production while minimizing resource consumption is a significant challenge. Addressing these challenges requires complex, intelligent technologies and optimization methods. Artificial intelligence, machine learning, and advanced control algorithms are critical in analyzing complex data from various devices and providing real-time insights into the production process. By leveraging these technologies, industrial factories can optimize their operations, make data-driven decisions, and balance efficiency, quality, and resource utilization.
The combinatorial optimization problem in the industrial production process must also be discussed. Combinatorial optimization problems involve finding the optimal solution in a set of possible solutions. These problems usually involve scheduling, path selection, resource allocation, and other aspects, which are the critical problems to be solved in industrial production processes. Due to the variability in customer demands, hybrid manufacturing systems (HMSs) have gained interest from academic and industrial sectors. An HMS, which merges traditional manufacturing units with functional areas, enhances adaptability in terms of fulfilling customer requirements. For example, in production scheduling, it is often necessary to determine the order and time of production to maximize production efficiency or minimize production costs. This involves a typical combinatorial optimization problem: arranging the order and time of production to achieve the optimization goal under the given production task and resource constraints. Omer Faruk Yilmaz et al. [
81] explored a multi-objective scheduling problem in HMS and proposed an optimization model to achieve three objectives: (i) minimization of average flow time, (ii) reducing the maximum number of workers, and (iii) minimization of the maximum number of workers changing. Later, Omer Faruk Yilmaz et al. [
82] studied an integrated dual-objective u-shaped assembly line balancing and part-feeding a problem based on the heterogeneity of workers. An optimization model was established to express the problem to be solved. Experiments show that by improving workers’ skill levels, the quality of Pareto optimal solutions increased by 30% in comparative indicators.
In summary, the data-driven dynamic multi-objective optimization method can be combined with combinatorial optimization techniques to find the optimal solution that satisfies multiple optimization objectives by searching and learning from many possible solutions. At the same time, dynamic optimization can also deal with time-varying optimization problems so that the solution can adapt to changes in the production environment. Therefore, incorporating combinatorial optimization problems into a data-driven dynamic multi-objective optimization framework will help us better understand and solve practical industrial production problems.
3. Model of Operational Optimization
From the existing research in production, traditional static optimization systems often struggle to meet practical needs, given that real-world problems are typically dynamic. In complex industrial production processes, control systems inevitably face various environmental changes, such as dynamic variations in critical process parameters and environmental variables. These changes often result in alterations in the optimal values of operational metrics. Therefore, establishing reasonable dynamic optimization models based on these variations and adjusting operational metrics promptly when dynamic changes occur are crucial for maintaining production efficiency.
3.1. Establishment of the Model
A dynamic multi-objective optimization problem (DMOP) refers to an optimization problem with multiple objectives, where these objectives or constraints change over time. The mathematical representation of DMOPs can be expressed as follows:
where
m represents the total number of objectives, while
p and
q denote the quantities of equity as well as inequity constraints, respectively.
is the decision space,
t is the discrete time and
is the time space.
is the objective function vector that assesses the answer
x at a certain time
t.
It is important to note that in dynamic multi-objective optimization problems, (1) decision variables (such as the number of optimized effective variables) change over time. (2) Over time, the objective functions also undergo modifications. (3) Both decision variables and functions are reliant on their preceding environmental values. This concept, known as parameter or function state time-dependency, implies that functions or parameters are delineated by factoring in the present state and previous values/states. (4) The environment continually adapts due to the constraints that vary with time. Additionally, it should be clarified that:
- (1)
Operational optimization aims at ensuring the global optimal production metrics.
- (2)
All operational metrics serve as decision variables.
- (3)
In practical terms, operational metrics must align with production conditions and constraints to yield products of acceptable quality. Such conditions and constraints constitute what are referred to as boundary constraints for decision variables.
Data-driven strategies solve to the dynamic changes in variables encountered in complex industrial production processes. Currently, employing data-driven models to establish objective functions has become common in complex industrial systems, as depicted in
Figure 3. A comprehensive data-driven model includes data collection, data processing, feature selection, and model selection. Each of these steps is critically important. Through these processes, the model can better adapt to dynamic changes in complex industries, thus enhancing production efficiency and ensuring product quality. This approach helps companies meet real-world demands effectively and manage dynamic changes in the production process efficiently.
In addition, when using a data-driven model as an objective function, it is crucial to consider dynamic issues precisely because key variables in complex industries change over time. Detecting and handling these changes requires selecting appropriate methods. Modeling based on time series data effectively addresses this concern. Time series models can capture and analyze the dynamic behavior of systems over time. This approach aids in the understanding of inherent patterns, trends, and periodicity in complex industrial systems, enabling better predictions of the system’s future states and performance.
3.2. Time Series-Based Modeling
In recent years, the extensive application of time series-based modeling tools has been attributed to complex industrial processes’ temporal complexity and high dimensionality. Time series predicting methods represent a form of regression prediction. The basic principles include two aspects: first, recognizing continuity in the development of phenomena by using historical time series data for statistical analysis in order to deduce the developmental patterns of events; second, taking into account the randomness caused by accidental factors, eliminating the influence of random fluctuations, and conducting statistical analysis using historical data. Essentially, this approach involves making predictions about future changes by analyzing the patterns observed in the past.
The most fundamental predicting methods based on time series include simple moving average, weighted moving average, moving average with a trend, and weighted moving average with a trend. These methods typically assign weights to the data from different times within the same moving window and then use averaging techniques to predict future values. However, these traditional time series prediction models often fail to effectively extract sufficiently significant features from the data, leading to lower prediction accuracy.
In recent years, deep learning techniques have surpassed traditional models in numerous time series prediction tasks. Deep neural networks have effectively tackled time series prediction problems, enabling accurate prediction of critical parameters in intricate industrial processes. Owing to their ability to automatically learn and understand the temporal dependencies inherent in time series data, they have emerged as efficient solutions. However, existing time series prediction methods, including recurrent neural network (RNN), long short-term memory network (LSTM), gated recurrent unit (GRU), and conv-LSTM, while demonstrating excellent performance in multiple application domains, have their limitations and drawbacks. As shown in
Table 2, researchers have been actively working on innovative solutions to overcome these issues, conducting in-depth studies and implementing innovations tailored to different application scenarios and problem natures.
Firstly, traditional RNN encounters the issue of vanishing gradients or exploding gradients when dealing with long sequences. This limitation restricts its ability to model long-term dependencies effectively. In order to tackle this problem, LSTM and GRU were introduced. They incorporated gating mechanisms, effectively capturing long-term dependencies in sequences. However, they still face challenges related to complex training and significant computational resource consumption.
Researchers have proposed various improvements and variant models for these issues, such as bidirectional LSTM and attention mechanisms. These models, which introduce new architectures or techniques, have enhanced the performance and efficiency of the models. In their study, Sarkar et al. [
83] proposed introducing a novel ensemble learning model known as GATE to improve the precision and robustness of time series prediction. The GATE model integrates the strengths of RNN, LSTM, and conv-LSTM. The approach employs an unsupervised learning technique with a guiding network to direct the collective output.
Furthermore, to mitigate the issue of overfitting in deep learning models, GATE implemented an optimization strategy that involves adapting the sample loss function and weight update function for each model inside the ensemble structure. The SeriesNet model, proposed by Shen et al. [
84], learns the features of time series data at different intervals, extracting multi-scale and multi-level features. This leads to improved prediction accuracy compared to models using fixed time intervals. Wang et al. [
85] presented a new algorithm called BiDiPLS-LSTM, which uses DiPLS to process both forward and backward time series data. This approach extracts dynamic latent variables (DLV) from the most predictable data for the target variable. The dynamic features from both forward and backward data are then used as new inputs for the LSTM network, enhancing the accuracy of time series prediction. Wen et al. [
86] proposed a model called LSTM-attention-LSTM. This model uses two LSTM models as an encoder and a decoder, with an attention mechanism between them. The attention mechanism allows the model to calculate the interrelationships between sequence data, overcoming limitations of encoder–decoder models and improving prediction for sequences with long time steps. Finally, Wang et al. [
87] introduced a method called attention-based dynamic inner partial least squares long short-term memory (ADiPLS-LSTM). This method uses DiPLS to extract dynamic features from selected data, and an attention mechanism to determine the importance of response features. The dynamic features, multiplied by the attention mechanism results, are used as inputs for LSTM. This approach utilizes both recent and long-term essential data, leading to more accurate prediction results.
Table 2.
Improvement strategies for traditional models.
Table 2.
Improvement strategies for traditional models.
| Existing Problem | Method | Year |
|---|
| Vanishing or exploding gradients | Long Short-Term Memory network (LSTM) | 1997 |
| Gated Recurrent Unit (GRU) | 2014 |
| Computational resource consumption | Bidirectional LSTM | 1999 |
| Attention mechanisms | 2014 |
| Overfitting | GATE [83] | 2023 |
| | BiDiPLS-LSTM [85] | 2023 |
| Low accuracy | LSTM-attention-LSTM [86] | 2023 |
| | ADiPLS-LSTM [87] | 2023 |
Moreover, although several existing models can make predictions, there is a need for novel methodologies to address lengthy time series prediction challenges. The incorporation of attention mechanisms has introduced novel vistas in precise time series prediction. Recent studies have applied Transformer-based solutions to long time series prediction tasks, yielding excellent results. In reference [
88], a simple Transformer model was enhanced by incorporating convolutional networks and skip connections between tree levels, improving the accuracy of long time series predictions. The Transformer outperformed LSTM in terms of accuracy and computational efficiency in multiple experiments, making it one of the most popular neural network prediction models. Nevertheless, some obstacles have been recognized by researchers when it comes to the Transformer model. These issues hinder its direct utilization in tasks involving the prediction of extended time sequences due to factors such as quadratic spatiotemporal difficulty, high memory consumption, and inherent limitations associated with encoder–decoder designs. As shown in
Table 3, some new strategies have been proposed to solve these problems.
Regarding the loosely coupled nature of the Transformer, Wang et al. [
89] suggested the TCCT algorithm model. This model incorporated the cross-stage partial attention (CSPAttention) technique, merging cross-stage partial network (CSPNet) with the self-attention mechanism, which reduced computational demands by 30% and diminished memory requirements by half. Despite these advancements in addressing the loosely coupled issue, some Transformer constraints remained, such as neglecting potential sequence correlations and the confined scalability of the encoder–decoder framework during enhancement. As a solution to these constraints, Su alongside others [
90] developed the adaptive graph convolutional network for Transformer-based long sequence time series prediction algorithm model (AGCNT). The AGCNT model successfully represents the relationships between sequences in multivariate long sequence time prediction problems, while mitigating the issue of memory limits.
In addition, introducing a self-attention mechanism [
91] has enhanced algorithm performance. The self-attention mechanism is a refined attention model succinctly described as a self-learning representation process. Nonetheless, the self-attention mechanism’s computational expense is proportionally squared to the sequence length, leading to reduced computational efficiency, sluggish processing speeds, and elevated training expenditures in Transformer models. In addition, the significant computational overhead presents obstacles to the model’s application, particularly in predicting extended time-series data in intricate industries.
To mitigate these issues, experts have created an efficient algorithmic model, known as Informer, for long-series time predictions. This framework draws inspiration from the Transformer model [
92]. The Informer model utilizes the ProbSparse self-attention mechanism, effectively reducing temporal complexity and improving the alignment of sequence dependencies. As a result, it boosts the overall performance and reliability of the model. Liu et al. [
93] utilized the Informer algorithm model to make predictions regarding motor bearing vibrations. Additionally, they introduced a time series prediction approach that leverages random search techniques to optimize the Informer algorithm model. Additionally, to enhance the computational efficiency of long time series, Zhu et al. [
94] combined the model with CNN. This enhanced the regional performance of Informer and improved its learning capabilities, reducing computational costs and memory usage.
Table 3.
Improvement strategies.
Table 3.
Improvement strategies.
| Existing Problem | Method | Year |
|---|
| High memory consumption | TCCT [89] | 2022 |
| Confined scalability | AGCNT [90] | 2021 |
| Sluggish processing speeds | Informer [93] | 2022 |
| Informer-CNN [94] | 2023 |
Today, the widespread use of the Informer model has made the precise prediction of long time series in complex industrial processes possible. Over the past few years, numerous innovative algorithm models have emerged in addition to Informer, as shown in
Table 4. For instance, a model called FEDformer was introduced by Wen et al. [
95] in 2022. This model adeptly applies trend decomposition by assimilating seasonal trends, thus capturing a comprehensive time series perspective. Another model is Autoformer, suggested by Xu et al. [
96], which leverages a profound decomposition structure to extract more predictable components from intricate time series while selectively concentrating on previously unnoticed reliable time dependencies. Furthermore, the Pyraformer model was put forward by Liao et al. [
97], which resorts to a pyramidal self-attention mechanism to seize temporal features at various scales and curtails computation time and memory usage during the execution of high-precision single-step and extended multi-step predicting tasks. Most recently, the Triformer model was presented by Guo et al. [
98]. This model substitutes the original attention algorithm with the patch attention algorithm, puts forward triangular contraction modules as a fresh pooling technique, and harnesses a lightweight variable modeling methodology, thus empowering the model to seize features between disparate variables.
In summary, researchers in long-time series prediction actively address existing challenges and limitations, continually advancing the field. Tailoring their approaches to specific problem characteristics, they propose various innovative methods and technologies to enhance predictive performance, improve model stability, and increase computational efficiency, effectively tackling complex tasks related to time series data prediction. These new methods and innovations open up broader prospects for applying time series prediction across various domains.
3.3. Concept Drift of Time Series
In the current era, with the rapid advancement of industrial intelligence, there has been a substantial increase in the volume of data, which are becoming increasingly complex in their sources. This situation makes data distribution highly susceptible to change. Such circumstances can easily lead to concept drift, directly affecting the efficacy of predictive models. Concept drift in time series is a phenomenon wherein data change over time. For time series mining, when concept drift occurs, the performance measures of the established models deteriorate over time, potentially resulting in model failure. Consequently, the accurate detection and assessment of concept drift are pivotal aspects of time series-related mining. Detecting concept drift has recently emerged as a prominent research focus in the academic community.
Various methods are available for detecting concept drift, each with unique advantages and limitations. Some common methods include those based on statistical measures, supervised learning approaches, unsupervised learning methods, ensemble techniques, and deep learning-based methods. While these methods have played a crucial role in addressing data concept drift, they also come with their respective constraints and shortcomings. Researchers have actively engaged in in-depth investigations and innovations to tackle these challenges. They have proposed several enhanced techniques tailored to different application scenarios and the nature of the problems, aiming to improve the accuracy of concept drift detection.
In recent years, practical concept drift detection algorithms have been developed to identify multiple concept drifts. Notable examples include the one class drift detector (OCDD) [
99], a sliding-window algorithm with an identification method based on multi-sliding windows (CDT_MSW) [
100], and the Kolmogorov–Smirnov test detector (KSWIN) [
101]. Furthermore, two additional density-based clustering methods are worth noting, namely DCSNE [
102] and Re-DBSCAN [
103].
OCDD uses two sliding windows to hold new and old data. It uses a classifier to detect outliers in these windows, and the percentage of outliers found is used to trigger a drift signal. This makes it especially suitable for detecting abrupt and incremental drift. CDT_MSW also has two windows, with the critical distinction being its ability to detect the precise location and duration of concept drift. This enables the algorithm to ascertain the specific concept drift type occurring effectively.
KSWIN, by implementing the “Kolmogorov–Smirnov test”, identifies instances of concept drift, a technique rooted in supervised learning. Algorithms for recognizing unsupervised concept drift include LD3 [
104], STUDD [
105], and CDCMS [
106]. With a focus on label-dependent sorting for detecting concept drift in multi-label classifications, LD3 is particularly well-suited to mutation and incremental drift scenarios. STUDD, conversely, forms a support model (students) to mimic the actions of the primary model (teacher), leveraging the teacher’s predictions for new instances while monitoring student imitation loss to spot concept drift. This method is beneficial for abrupt, gradual, and incremental drift scenarios. CDCMS employs innovative clustering and diversity-focused memory management tactics in model space strategies to handle concept drift, demonstrating remarkable efficacy in managing abrupt and recurring drift scenarios.
DCSNE is a density-based clustering method. In this approach, Maheshwari et al. [
102] introduced neighbor entropy to identify similarities. Another density-based method is Re-DBSCAN, which was proposed by Miyata et al. [
103], and detects the source of drift by updating the k-distribution map, thereby expediting the modification of the learning model.
Moreover, deep learning methods have been widely employed in drift detection. These approaches can learn intricate feature representations from data but typically require substantial data for training and may be sensitive to hyperparameters. This underscores the need for distinct detection methods tailored to different types of concept drift (e.g., instance drift, concept drift) and diverse application domains. Consequently, researchers have proposed specialized drift detection algorithms for specific issues. For instance, Ding et al. [
107] addressed the issue of Transformer’s inability to adapt to concept drift. They proposed a distribution-adaptive concept drift adaptation method (CDAM) to adjust the learning rate dynamically. CDAM aims to optimize the new model on new concept data while entirely using old data through online learning strategies. Additionally, they introduced a square root sparse self-attention method to decrease the algorithm’s time complexity.
It is essential to point out that many concept drift detection algorithms tend to require more memory or have slower detection speeds. To tackle this problem, DMDDM [
108] was developed. This algorithm has significantly improved the detection speed of concept drift, effectively overcoming the challenges associated with cost and execution time. This development marks a notable advancement in unsupervised learning and concept drift detection.
When conducting time series prediction, addressing this issue becomes critical once the presence of concept drift is detected. Concept drift can lead to a deterioration in model performance, necessitating measures to maintain the accuracy and reliability of the model. Currently, deep learning models typically adapt to concept drift through model updates.
3.4. Model Updates
There are various methods available for addressing concept drift, given the challenges posed by changes in data distribution or patterns over time. Researchers have developed a multitude of strategies and techniques to tackle these challenges. One of the most important and widely discussed approaches is online model updating. This method allows the model to adjust itself dynamically during runtime. Online learning algorithms and incremental learning techniques are effective means to achieve this objective, as they can continuously adapt to new data without interrupting the model’s operation.
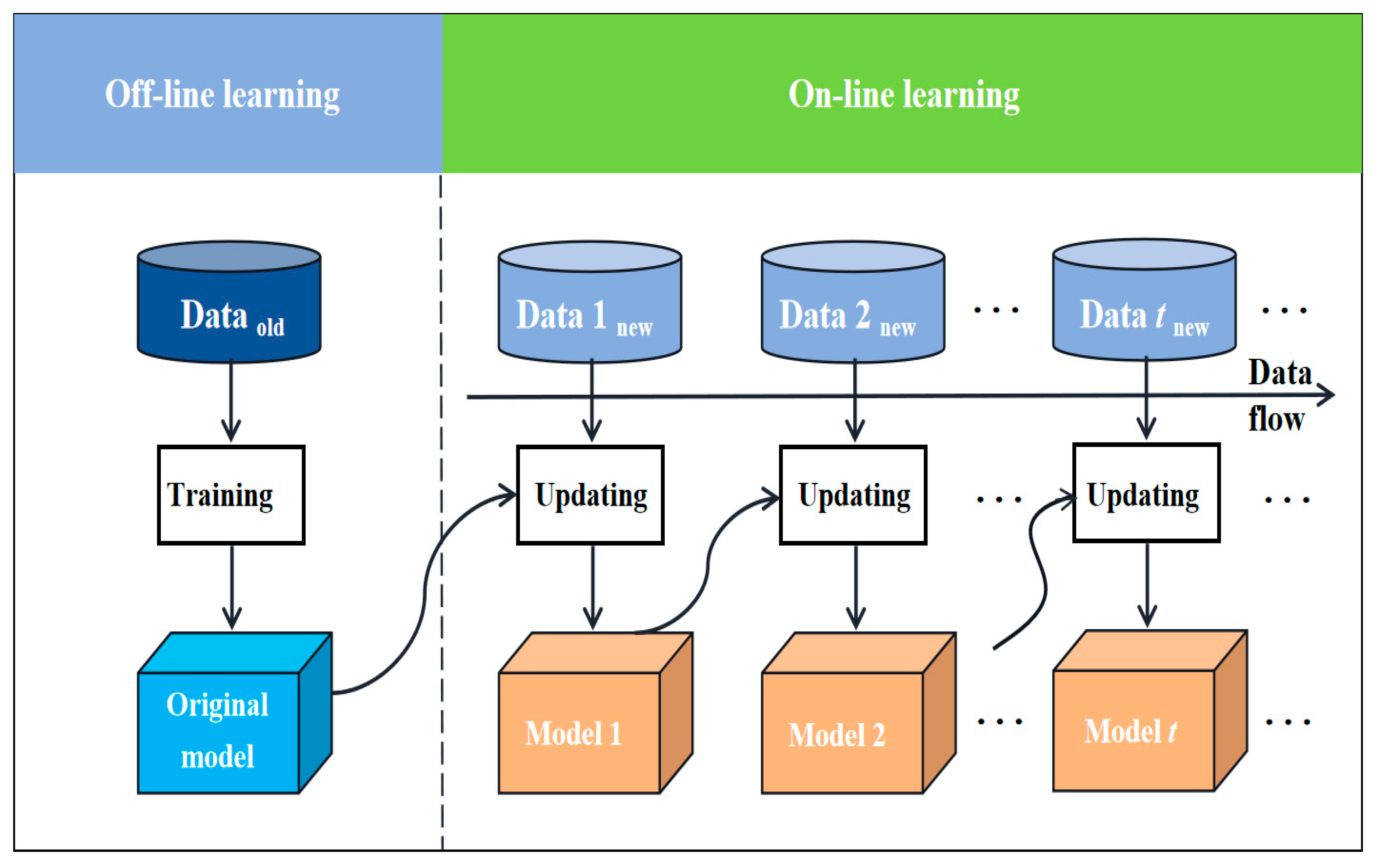
Therefore, to implement online model updating, it is imperative to develop a dynamic model that is driven by data and incorporates online learning approaches. The structure diagram of an online learning framework is illustrated in
Figure 4.
represents the offline data. Original model represents the model trained by offline data.
represents the data updated in real time with data flow. Compared with traditional offline learning, online learning has more advantages. Online learning processes less data and saves a lot of training time. The model has scalability—acquiring running data updates based on the constructed model. Conversely, offline learning retrains the model with all the data, which not only loses the information of the original model but also consumes a great deal time.
Currently, online updating models have been widely applied in various fields, including fault monitoring, medical diagnosis, and industrial monitoring. These models can enhance prediction stability, robustness, and performance by continuously adapting to the concept drift of data. The development of online learning has played a pivotal role in advancing industrial digitization, significantly reducing errors caused by concept drift in complex industrial processes and continually improving model accuracy. As a result, many scholars have started exploring and practically applying the field of online learning. Recent experiments have demonstrated that data-driven models in online learning enable online updates of the model and eliminate the need to retrain the model. This is particularly valuable for the control and optimization of complex industrial processes. Consequently, online model updating is an essential strategy for addressing concept drift issues, which holds significant importance for data-driven applications.
On the other hand, during the application of online learning in industrial systems, the introduction of incremental learning can further enhance the model’s ability to update online. The vision of incremental learning is that the system can achieve incremental learning when new data arrives in a stream, and new categories or tasks appear simultaneously. That is, while retaining the old knowledge, it can better adapt to new areas and learn new knowledge. In recent years, incremental learning has been significantly adopted in complex process industries. This mainly includes the following two forms [
109]:
Task incremental learning: This implies that data arrival at distinct time intervals corresponds to separate tasks, while data pertaining to the same job can be received collectively. In the production process of a complex industry, all the data in the current production process can be obtained. When new data arrives as a data stream, the output of the latest and old data are independent, and the multi-head network can realize the model.
Class incremental learning: This refers to data that arrives at varying times and belongs to distinct categories, yet all pertaining to the same task. Class incremental learning requires the model to perform single-head output and can increase the output category. Compared with task incremental learning, the cross-interference between data pre- and post-implementation of category incremental learning is notably more intricate and pronounced. Correspondingly, due to the complexity and diversity of industrial production processes, when new data arrives in a data stream, the model needs first to determine which task the latest data belongs to and its category, so there is only one output unit. This method is more complex than task incremental learning.
How to store and use the critical parameters of data and the model in in the training process of incremental learning is a problem that most scholars have been studying and solving in recent years, which is also one of the problems that must be solved in developing big industrial data. Yu [
110] designed a BCNN model with an incremental learning ability using the model expansion method. When new data arrives, the parameters of the original model remain unchanged, but learn new knowledge by adding network nodes and training node parameters with the new data. The model has been verified to perform well in two Tennessee Eastman Process and Three-Phase Flow Facility cases and has been applied in industrial process fault diagnosis. Li et al. [
111] designed an incremental deep convolution calculation model using the regularization method. They proved that the model performs well in the feature learning of big industrial data on datasets such as CIFRA and CUAVE. In addition, Chen et al. [
112] proposed an online learning GA-BP model using the data review method. Experiments proved that adding new data to the training set every time can enhance prediction accuracy.
With the recent increased interest in incremental learning, continual learning, and catastrophic forgetting, these approaches have also received more attention. Researchers have made many attempts to avoid catastrophic forgetting and seek the plasticity-stability balance of the model. However, many problems can still be solved by applying incremental learning to complex industrial systems. Improving the model’s stability and reducing the data’s storage space requirements while improving the model’s accuracy are the main problems to be solved in future complex industrial production processes.
In summary, the existing modeling methods and model update strategies based on time series provide the foundation for optimizing model construction. After establishing an optimized model, an important challenge lies in finding an adequate quantity of evenly dispersed and representative dynamic Pareto optimal solutions.
4. Optimization Model Solving
An ideal dynamic multi-objective optimization algorithm should have two essential components: change detection and change response. Since the environment of complex industrial processes constantly changes, DMOPs vary at each time interval. Therefore, change detection and change response strategies are crucial for addressing DMOPs.
4.1. Change Detection
When the time variable changes, algorithms need to promptly detect changes in the objective functions and respond according to different types of changes. They must address the optimized problem following the adjustment and employ multi-objective optimization techniques to find the DPF and DPS through iterative population iterations efficiently. In practice, DMOPs can be viewed as static MOPs under discrete temporal variables, translating complex dynamic characteristics into static processing for convenience and ease of handling. However, this has clear disadvantages, namely slow processing speeds and no guarantee of timeliness. When dealing with environments with high change frequencies, DMOPs often fail to quickly track the Pareto front, leading to poor algorithm performance. Therefore, for an ideal DMOA, an appropriate change response mechanism is crucial in handling DMOPs.
Understanding the presence of environmental changes is vital because it affects how DMOAs adapt to changes during the search. The most popular change detection approach in DMOPs is reassessing some random members of the population. However, many researchers believe that population-based change detection approaches play a significant role. Recently, several emerging detection strategies, as illustrated in
Table 5, have been widely adopted in response to various changes.
- (1)
Random Reassessment:
The strategy of randomly reassessing a subset of the populace at the outset of each generation is a prevalent change detection method in DMOPs. Jiang et al. [
117] recognized that approaches like random reassessment of population proportions and its derivatives detect changes only after the population has completed an entire generational cycle, which might delay change responses. To address this, Jiang and Yang [
114] introduced the steady-state change detection (SSCD) method. Throughout each generation, SSCD arbitrarily picks certain population individuals who have experienced steady-state evolution to act as sensors for sequential change detection. If any of these sensors identify a change, the remaining unutilized sensors are abandoned, and immediate measures are implemented to react. This method facilitates more rapid responses to changes. The findings indicate that, when compared with top-tier methods, the proposed algorithm presents significant competitiveness in dynamic multi-objective optimization.
- (2)
Population Detection:
When there is uncertainty in the target values of the environment, this problem is observed in environments that are not easily detectable. Gee and Tan [
115] recently proposed a method that combines statistical approaches for detecting subtle environmental changes using statistical tests. This method implements statistical tests such as
the Kolmogorov–Smirnov test [
118] or
the Wilcoxon-Mann–Whitney test [
119] to determine if there is a significant difference between the prior and current populations. If such a difference is found, this is seen as a detected change. This method has shown superior performance in change detection tasks compared to existing methods [
116].
Additionally, a two-stage change detection test [
115] has been proposed. This testing method uses an inverse model in its first stage to inspect possible changes in the landscape of the objective function. In the second stage, it is re-evaluated using a fixed number of individuals within the population. Like SSCD, this method can identify alterations between two generations.
In summary, applying change detection whenever possible is reasonable for efficiency in computing. When there are observable environmental changes, utilizing multiple detectors aids the optimization algorithm in intelligently determining actions, i.e., responding only when a change is detected, thus saving the computational cost of unnecessary operations.
It is worth noting that random reassessment incurs the minimum computational cost, followed by population detection. Due to the frequent usage of these methods independently, there needs to be more comparative research showcasing their advantages and disadvantages.
4.2. Change Response
The decision and objective space of DMOPs can change in various ways over time. Generally, if the environment changes during the search process, the algorithm will lose competitiveness because the problem may undergo more alterations before discovering novel solutions. Hence, ensuring the timely provision of a high-quality starting population following dynamic environmental changes is paramount. This is at the core of algorithm design, meaning DMOAs should respond to detected or known environmental changes and take action accordingly.
Due to the short periods of stability in DMOPs, DMOAs must respond rapidly to changes and handle them appropriately before the following change occurs. To enhance the tracking performance of DMOAs, maintaining population diversity and providing knowledge are two commonly used and effective approaches. This is because a diverse population provides the necessary evolutionary dynamics for DMOAs, and useful knowledge accelerates population convergence, saving computational resources and time. Maintaining population diversity (i.e., the spatial distribution of individuals) concerns the spatial characteristics of evolutionary information, while providing knowledge (including past or predicted individuals or data) primarily considers the temporal characteristics of evolutionary information in DMOPs.
According to reference [
120], existing DMOAs can mainly be categorized into five types:
- (1)
DMOAs based on diversity;
- (2)
DMOAs based on population;
- (3)
DMOAs based on memory;
- (4)
DMOAs based on prediction;
- (5)
DMOAs based on transfer learning.
Most diversity-based and population-based DMOAs primarily focus on the quality of evolutionary information in the spatial dimension. In contrast, most prediction-based and memory-based DMOAs briefly consider the quality of evolutionary information in the temporal dimension. Although good population diversity helps DMOAs enhance the driving force for population evolution, it might slow down population convergence. Similarly, providing more knowledge (i.e., promising individuals) can expedite convergence but might dampen the evolutionary dynamics in new environments. This is because the sampling capability of existing algorithms is limited, meaning the population size restricts DMOAs from generating more data. Therefore, preserving and utilizing the spatiotemporal attributes of evolutionary information is crucial to enhancing DMOAs’ tracking performance.
4.2.1. DMOAs Based on Diversity
Environmental changes typically harm population diversity as they can lead to varying degrees of diversity loss. Therefore, a natural idea is to counteract this loss by introducing additional diversity when changes occur or are detected.
Table 6 presents the latest approaches related to increasing diversity.
When changes are detected, such as injecting randomly generated solutions or performing hypermutations on existing solutions, the diversity within the population can be immediately increased. Initially, migration schemes were studied in dynamic multi-objective environments [
122]. In each generation, migration was introduced to replace some population members, providing surplus diversity to counteract the loss when the environment changed. Different migration schemes for DMOPs were described, leading to the derivation of diversity generators based on generalized migration. The experimental results demonstrated that the efficacy of this generator was superior to single elite or random migration schemes. Later, Li et al. [
123] introduced a two-archive system in which one archive focused on preserving diversity while the other focused on managing population convergence. Cui et al. [
124] introduced two archive strategies: one archive maintains the algorithm’s convergence, and the other maintains its diversity, effectively balancing convergence and diversity. These archives evolved together and were designed to handle varying numbers of objective functions as they changed over time. Comprehensive experiments are conducted on various benchmark problems with a time-dependent number of objectives. Empirical results fully demonstrate the effectiveness of our proposed algorithm. The computing inefficiency of this design has been resolved in the cited reference [
136]. The computing efficiency has increased by 30%.
Sun et al. [
125] recently suggested implementing arbitrary solutions across diverse regions of the objective space, affirming a well-spread distribution of introduced solutions within the population. The method’s efficacy is confirmed by contrasting it with four cutting-edge evolutionary algorithms on 12 test functions. The experimental data underscores the capability of our proposed algorithm to adequately map the fluctuating Pareto fronts and predict the moving Pareto set’s location proficiently. Ahrari et al. [
126] introduced a genetic-based adaptive mutation operator to enhance population variety deliberately. The efficacy of this variation operator is evaluated against five other prevalent ones on 42 dynamic multi-objective test problems. Numerical comparisons highlight its exceptional learning capacity. Similarly, in reference [
137], an effective adaptive precision-controllable mutation operator was introduced to utilize or investigate the search space and employ a modest generation strategy that mimics isotropic magnetic particles to preserve diversity. When these novel methods are effectively synchronized, DMOAs have achieved promising results.
Furthermore, in reference [
128], a constraint-based MOPA called CDCBM (constraint-based dynamic constraint boundary method) was proposed. This algorithm assists the population during the evolutionary process by dynamically changing constraint boundaries, continuously searching for promising infeasible solutions between the unconstrained Pareto front (UPF) and the constrained Pareto front (CPF). It offers additional evolutionary paths for the primary population, improving convergence and variety. In reference [
129], D-MOPSO was introduced, addressing the shortcomings of PSO in terms of convergence and diversity. In the D-MOPSO variation, the fluctuation in the population’s size was resource-dependent, tied to the archive’s available resources, thereby facilitating an adaptive population size adjustment. Particles were introduced in this model through local perturbations to bolster the exploration of these particles. Conversely, applying non-dominated sorting coupled with population density regulation safeguards against uncontrolled population expansion, thereby maintaining an optimal population size.
Building upon these ideas, Huang and Zhang [
130] proposed an explosive mutation approach to counter the proclivity of populations trapped in local optima. The explosive mutation operates like fireworks, spreading outward from a point and capturing some nearby points as well as some distant ones. It has proven effective in preventing local optima and maintaining population diversity. Additionally, optimizing the equilibrium between the convergence and diversity of solutions is a crucial concern. Improvements regarding iterative formulas and parameter tuning have also been made to enhance algorithmic performance. To maintain diversity while not explicitly responding to continually changing environments, Yu et al. [
138] introduced a diversity maintenance strategy (DMS) to enhance the accuracy of predictions. It stochastically generates a variety of individuals inside the adjacent Pareto set region, enhancing population diversity. When contrasted with three alternative prediction methodologies on test instances, the method exhibits competitive prowess in convergence, diversity, and rapid responsiveness to environmental shifts.
Song et al. [
131] suggested strategies, such as adapting the size of subpopulations, that effectively solved problems with many features. In the reference [
132], population diversity is preserved through the simulation of magnetic particles, which rapidly gravitate toward the Pareto front within the existing environment. Typically, strategies for maintaining diversity employ the Pareto-optimal solution set from the optimization issue in the previous environment as the initial population within the present environment. In a different approach, Zou et al. [
133] implemented an auxiliary strategy to preserve diversity, upholding two archives concentrating on convergence and diversity, respectively. Additionally, interval mapping strategies were designed to ensure diverse solutions. Building on this, Liang et al. proposed a novel approach [
134]. In this reference, decision variables were divided into three parts, employing approaches to maintain, predict, and introduce diversity, generating high-quality offspring individuals to expedite population convergence. Diversity maintenance approaches perform well for DMOPs with weak variations. Nevertheless, if the optimal solutions derived from past contexts diverge from the actual Pareto front in the present environment, it can result in subpar problem-tracking performance.
However, despite their effectiveness, many of the strategies mentioned above offer a single response to shifts in environmental conditions, often overlooking the potential benefit of utilizing new available environmental information. In contrast, one study [
135] integrates evolutionary algorithms with dynamic strategies, offering two distinct responses to environmental changes—the restart strategy (RS) and adjustment strategy (AS). The restart strategy uses minimal new environmental information and local search to reinitialize the population closer to the anticipated Pareto solutions in the new environment after environmental changes. This strategy is beneficial for rapidly responding to environmental changes, and it is expected to speed up the algorithm’s convergence rate. On the other hand, the adjustment strategy modifies the current population with high-quality solutions after obtaining more precise environmental information. This method helps to ensure that the solutions remain relevant and quality-controlled. The proposed algorithm was subjected to various test instances with different change dynamics. The experimental results indicate that this algorithm performs competitively in dynamic multi-objective optimization compared to the leading approaches.
These diversity-based methods may be the simplest way to address environmental changes. The application and effectiveness of them are contingent upon the extent of environmental changes encountered. Put simply, the extent of diversity required to be introduced or preserved is directly linked to the magnitude of the alterations. Minor adjustments are required if population diversity changes are small, whereas significant adjustments are needed if the changes are substantial. This principle also applies to diversity maintenance techniques.
4.2.2. DMOAs Based on Population
The application of multiple-population-based methods offers benefits for preserving population variety. When multiple interacting sub-populations are dispersed in the search space, it is less likely to lose significant diversity under changing environmental conditions. This method is especially beneficial when there are fluctuations in the environment in specific search regions while others remain constant. This section elaborates on different methods for creating multiple populations, with the overall number determined by the objectives and the number of decision variables.
Xu et al. [
139] postulated a cooperative coevolution algorithm based on similarity to address dynamic multi-objective optimization problems (DMOPs). They considered the interval nature of objective values and grouped decision variables based on the inherent similarity between these variables and interval parameters. This approach allows for a more refined and accurate analysis of the data. To handle each group of decision variables, sub-populations are employed with two response strategies. This dual-strategy approach can lead to more effective and accurate solutions for DMOPs. The algorithm was applied to eight benchmark optimization instances and a multi-period portfolio selection problem and compared with five cutting-edge evolutionary algorithms. The experimental findings indicate that the new algorithm is highly competitive in most optimization instances.
In reference [
140], the RPCR algorithm is introduced. After environmental changes occur, RPCR first initializes the population in the new environment through steps such as population partition, predicting population centers, and individual generation. This measure is implemented to guarantee that most of the initial population is located inside the viable zone, promoting swift convergence. Furthermore, a modification mechanism is introduced during the optimization process to maintain population diversity. Likewise, the population is first partitioned into multiple sub-populations. The centroid of each sub-population in the new environment is projected separately. The new population is based on estimated center Gaussians and uniform distributions to enhance convergence speed. Furthermore, to preserve population variety, a modification method is implemented. This strategy detects which reference points are not associated with any individuals and generates some individuals around these points. This method addresses DMOPs and is compared to constrained and unconstrained DMOAs with enhancements. Statistical results demonstrate that this algorithm effectively addresses real DMOPs.
Reference [
141] introduced a novel algorithm for tackling DMOPs. This algorithm, referred to as a multi-group collaborative PSO, is characterized by the collaboration of multiple groups. Each group focuses on different objectives and maintains an external archive that facilitates information sharing among the groups. This multi-group collaboration structure fosters a higher level of diversity among the groups. Each group can focus on specific objectives, and through the external archives, they can share their findings and progress with the other groups. This collaborative approach allows for a more comprehensive and diverse exploration of potential solutions in the problem space, potentially leading to better optimization results. The algorithm has been assessed on a dynamic problem test suite with varying numbers of objectives and different levels of change severity. The experimental findings demonstrate that the algorithm competes effectively with other typical, state-of-the-art dynamic multi-objective algorithms, successfully finding well-diversified and well-converged solution sets in dynamic environments.
While improving the quality of population evolution in the search space is an effective approach to solving DMOPs, sampled populations may need more knowledge. To mitigate this issue, researchers have proposed various approaches to preserve or generate time-related individuals (i.e., historical or predicted data/individuals). These approaches aid DMOAs in rapidly discovering high-quality solution sets. Examples include approaches based on memory and predictive memory.
4.2.3. DMOAs Based on Memory
Memory in solving DMOPs is a critical method for managing environmental changes. This approach capitalizes on the concept of “learning from the past”. As the optimization algorithm processes data and evolves, certain solutions from previous environments may prove beneficial in new or changed environments, particularly if the new environment bears similarities to past ones. Specific solutions from the evolving population are selectively stored in a “memory” database to utilize this. When a change occurs in the environment, or a similar problem is encountered, these stored solutions can be retrieved and reintegrated into the population. This method allows the algorithm to effectively adapt to changes by leveraging past solutions that have proven effective, potentially improving the efficiency and accuracy of the problem-solving process.
Bechikh et al. [
142] proposed a D-NSGAII using a memory-based approach to expedite population convergence. Additionally, unlike previous studies, the archive size in D-NSGAII can fluctuate depending on the magnitude of environmental alterations. Du et al. [
143] represent an innovative application of memory-based methods in DMOAs. They modified the squirrel search algorithm and incorporated it within the framework of DMOAs. The resulting decomposition-based algorithm breaks down the more significant, complex optimization problem into smaller, simpler subproblems. The critical feature of this new algorithm is its use of memory-based techniques, which enable it to simulate and adapt to environmental changes for a part of the population. DMOPs’ test functions demonstrate that the DMOISSA/D-P&M algorithm outperforms other dynamic multi-objective optimization algorithms. It exhibits superior convergence and distribution and enhanced abilities to handle environmental changes.
Several studies acknowledge that past environmental knowledge and search experiences aid in creating new environments. The reference [
144] formulates a dynamic environmental evolution model that catalogs environmental data and the population’s search experiences post-environmental alterations. This accumulated data and experiences are subsequently employed to direct the search within the new environment. Ding et al. [
145] proposed an evolutionary algorithm to manage fluctuating constraints and objective functions. This includes innovative mating and environmental selection operators that adaptively permit feasible and unfeasible solutions within the population. In change scenarios, solutions previously obtained are reutilized, drawing on the information derived from the new environment. When a change is detected, the change response strategy employs some old solutions combined with randomly generated solutions to reinitialize the population—the steady-state update method—to enhance the retained previous solutions. The experimental results demonstrate that the proposed test problems effectively distinguish the performance of various algorithms. Moreover, the new algorithm proves to be highly competitive in solving DMOPs compared to state-of-the-art algorithms.
Additionally, some studies indicate that memory-based methods have been relatively underexplored despite their significant success in DMOPs. Zheng et al. [
146] reported a novel memory strategy involving a combined harvester memory. Furthermore, the Pareto memory strategy (PMS) includes a method that preserves an optimal set of solutions by reutilizing elite answers that have been recognized before. The algorithm’s performance has been greatly improved. However, inaccuracies may arise in predicting the population’s evolutionary trajectory when the population has yet to achieve complete convergence.
Therefore, memory-based approaches might need to be more accurate in some cases of environmental change. It is important to note that predictive methods also rely on past solutions. To avoid confusion between these two methods, this section only reviews methods that directly use past solutions without relying on predictive models of the new environment.
4.2.4. DMOAs Based on Prediction
Predictive approaches are designed to guide population evolution after each environmental change through prediction mechanisms, enabling a rapid response to new changes. When environmental changes exhibit predictable patterns, researchers use prediction models to predict new PS or PF by relying on previous PS/PF approximations. At the present stage, predictive models have been top-rated in the field of DMOPs and can be defined as follows: [
147]:
where
Xi represents the predicted solutions in new environment, and Predicting is a specific predictive model that operates on past approximate
PS from a previous environment. Predicting can be either linear or nonlinear, relying on the intricacy of environmental changes.
Table 7 summarizes the latest prediction models in DMOPs.
Predicting specific individuals is an effective approach to addressing DMOPs such as centroids and inflection points. Their aim is to provide promising individuals (i.e., knowledge) across the temporal dimension. Reference [
148] presented a combined predicting method. This method utilized the Takagi–Sugeno fuzzy nonlinear regression model and linear multi-step prediction, following PPS principles. It was used for predicting the centers and manifolds of PS, which were then used for reinitializing the population. A hybrid population prediction strategy, based on fuzzy logic and one-step prediction, was proposed in reference [
149]. It extrapolated the new PS trajectory from the previous PS approximation, enhancing the speed of tracking changes in the PF. There was also an exploration of the use of multiple prediction models to enhance the accuracy of the prediction.
In reference to [
150], a grey prediction model was created for population prediction, as mentioned. The method employs cluster centroids from the prior environment to create initial populations in the current environment. The task utilizes the prediction model to reset a population segment in the subsequent environment. The empirical results demonstrate that the algorithm can effectively and efficiently handle dynamic environments, tracking the varying Pareto optimal set (POS) and Pareto optimal front (POF). Moreover, it outperforms several selected state-of-the-art algorithms on most test problems, showing superior performance.
Jin et al. [
151] introduced a multi-predictive model to predict population trends. A model selection strategy was devised, involving detecting the change type in PS and applying the most appropriate predictive model for the observed type. When environmental changes caused consecutive problem statements to be dissimilar, using a single PS center to build a population to approximate the new PS was useless. This constraint was resolved by implementing a multi-directional prediction technique. PS was approximated by dividing it into various sub-populations according to reference locations. Each sub-population in the new environment was then reset based on the centers anticipated by the model. Similarly, Gong et al. [
152] introduced a multi-directional prediction method for predicting several points on the PS.
Li et al. [
153] utilized the feedforward central method to predict individuals with potential in the novel environment. In reference [
154], differential prediction using the difference between two consecutive population centers from previous environments was employed to generate new individuals when detected changes different to previous ones. In contrast, in reference [
140], the previously stored data were utilized to restore the new setting following a modification. The RPCR algorithm initially predicts the locations of subpopulation centers and subsequently constructs a new population centered around these projected locations. Yang et al. [
125] presented a multi-region cooperative differential evolution algorithm (MRCDMO), introduced a decomposition-based multi-region prediction (MRP) to predict the movement trends of centroids, and suggested a multi-region diversity maintenance strategy to enhance population diversity. The method’s performance was validated by comparing four cutting-edge evolutionary algorithms with 12 test functions. The experimental results reveal that our proposed algorithm can effectively cover the changing PF and efficiently predict the location of the moving PS.
In reference [
155], SVM was used to address changes in the environment effectively. The classifier relies on both randomly generated solutions and prior solutions as input data, classifying them into two distinct categories: “good” and “bad”. Individuals deemed “favorable” are assimilated into the populace to acclimate to the new surroundings. In addition, Liao et al. [
156] proposed a prediction method based on ensemble learning. This method comprises three prediction models, encompassing both linear and nonlinear models. The model is a derivative of autoregressive models applied to the overall centroid or the knee solutions on the PF. By leveraging the elite learning prediction strategy (ELPS), the reinitialized population can adapt to various environmental changes and enhance its prediction accuracy and robustness. Compared with other state-of-the-art prediction strategies on the benchmark test suite, the experimental results indicate that ELPS performs better in handling dynamic multi-objective optimization problems.
At the current stage, predictive approaches have attracted considerable attention among researchers. Nevertheless, in most prediction methods, the solutions employed to build prediction models and the anticipated solutions are expected to adhere to the same distribution. In other words, they satisfy the independent and identically distributed assumption. However, differences exist between training solutions and predicted solutions. Given this, the study [
157] employed an inverse model to predict the population in a new environment using quantile information on the population. Recently, Yang et al. [
158] introduced a feature information prediction method for DMOPs. A joint distribution adaptation model was employed to ascertain the distribution of solutions following environmental alterations, which served as the basis for generating the new population in the modified environment. Gong et al. [
159] devised a multi-model prediction method to address feature change types, including translation, rotation, and combination issues. This method offers a notable advantage over previous prediction methods in effectively addressing the majority of DMOPs.
In the TMO [
162], historical information evolved in previous dynamic environments was used for partial population initialization to find the PS in the current environment quickly. Clearly, the prediction model provides potential directions for subsequent evolutionary exploration. To evaluate the performance of the developed algorithm, they compared the proposed prediction strategies with three single prediction methods across 11 dynamic benchmark functions. The experimental results suggest that ensemble prediction methods exhibit greater robustness than single prediction models and are highly effective in addressing dynamic robust multi-objective optimization problems.
In addition to the abovementioned approaches, reinforcement learning approaches have also been reasonably employed. Tang et al. [
160] introduced a reinforcement learning strategy that determines actions to be conducted in response to changes based on the severity of those changes. This method allows for reasonable decision-making regarding change responses. Nevertheless, the method’s capacity to remain in many states could be improved, resulting in the possibility of imprecise change responses. Another group of researchers, including Li et al. [
161], introduced a reinforcement learning method that categorizes environmental changes into mild, moderate, and severe states. This method employs three strategies: knee-based prediction, centroid-based prediction, and local search. A sequence of activities is selected depending on the provided state to steer the population towards the new PF.
Although prediction models have a wide range of applications, they unavoidably come with projected mistakes, which can affect the precise direction of the optimization process. From a statistical standpoint, the solution set chosen to build the prediction model and the set of solutions anticipated by the model must follow the assumption of independent and identically distributed data. However, this assumption overlooks that the data may be uneven. Given this, Huang et al. [
163] proposed transfer learning strategies to address environmental challenges.
4.2.5. DMOAs Based on Transfer Learning
Transfer learning is an effective approach to assist DMOAs in tracking time-varying solution sets. For instance, when the environment changes, a high-quality initial population can be generated through transfer learning approaches (Tr). Multiple experiments have shown that using transfer learning to track time-varying solution sets can quickly find good solutions in different optimization environments. In recent years, transfer learning has garnered growing interest because of its capacity to leverage past data to direct evolutionary searches.
Recently, several transfer learning-based methods have been suggested for dynamic situations to address different problems. In reference [
164], Feng et al. utilized an autoencoder-based evolutionary search to generate promising individuals. Experimental results confirmed that this method outperformed three other prediction-based DMOAs. Wang et al. [
165] introduced a regression transfer learning model that incorporates SVR to predict the PS of DMOPs. They compared the algorithm with three state-of-the-art algorithms using benchmark functions. The experimental results suggest that our algorithm can significantly improve the performance of static multi-objective optimization algorithms. Notably, it exhibits competitiveness in terms of convergence and diversity.
The latest reference [
166] introduced a novel method: cluster-based regression transfer learning (CRTL). This method is bifurcated into two segments: selection based on clusters and regression transfer based on clusters. After that, to increase prediction precision, the benefit of cluster centroids is harnessed to construct a robust regression transfer model using TrAdaboost.R2. Ultimately, the new environment prediction and regression transfer model creates a superior initial population. Huang et al. [
167] proposed a multi-objective dynamic learning strategy based on transfer learning. Using transfer learning, they learned the PS from neighboring historical environments and generated an initial population. The experimental findings indicate that this method expedites the convergence of a population in novel settings and precisely follows the best possible solutions. Li et al. [
168] utilized transfer learning to address computationally intensive DMOPs and employed alternative auxiliary evolutionary algorithms. Moreover, the process of establishing agent models is swiftly launched by applying transfer learning, which involves transferring pre-existing training data to the current environment. This enables DMOAs to better adapt to new environments.
Additionally, Li et al. [
169] advocated for incorporating transfer learning methodologies into optimization algorithms, noting the substantial advantages this could have in tracing the shifting PS/PF of DMOPs. They applied a domain adaptation strategy to build a predictive model that learns to uncover PS from the anticipated population. This concept and a few other tactics have been utilized to estimate distribution algorithms to tackle DMOPs. More recently, Wang et al. [
170] showed that the complexity involved in forming predictive models could be minimized, thereby enhancing the initial idea. As a result, they introduced a manifold transfer learning method for DMOPs. This novel method predicts new PS using the optimal individuals selected from solution sets predicted in former environments, considerably reducing the need for heavy computations. Liu [
171] suggested a combination of the PPS with transfer learning to enhance prediction. The experimental results suggest that the algorithm outperforms PPS and Tr-DMOEA on the test problems, indicating superior overall performance. In the study from reference [
172], transfer learning was utilized to enhance prediction accuracy using inflection points.
Multiple studies have indicated that transfer learning methodologies show promising results in resolving DMOPs characterized by significant and cyclical fluctuations. Nonetheless, the usage of transfer learning in handling DMOPs is relatively nascent. Present transfer learning methods often necessitate extended training durations, posing a considerable impediment for certain DMOPs. One contributing factor to this slow process is that existing transfer learning methods generally attain knowledge reutilization by probing potential spaces, which demands additional parameter configurations, utilizes more computational resources, results in squandering resources in pursuit of subpar individuals, and considerably elevates the risk of negative transfer [
173]. Should the knowledge of these superior individuals be transferred, it could lay the groundwork for more precise and efficient prediction models for implementing DMOPs in various complex and real-world scenarios.
Some existing references have tackled the issues mentioned in the research. In reference [
174], high-quality solutions filtered through pre-search approaches alleviate negative transfer issues. Guo et al. introduced a method for solving DMOPs via individual transfer learning. This strategy, in contrast to current methods, selectively excludes certain high-quality individuals with significant variability. In reference [
175], Yao introduced a novel transfer learning method, TCD-DMOA. Unlike existing approaches, it optimizes population quality using a clustered difference strategy to reduce data differences between target and source domains. Based on this, transfer learning techniques are applied to expedite the establishment of the initial population. The TCD-DMOA has an advantage in minimizing negative transfer by increasing the similarity between the source and target domains, resulting in improved algorithm performance. Guan et al. [
176] pointed out that conventional transfer learning might not be suitable for solving certain types of DMOPs, so they investigated different kernel functions in transfer learning. Subsequently, many other transfer learning-based methods have been suggested to improve the tracking performance of DMOAs. For instance, an imbalanced transfer learning approach, KT, generates high-quality inflection points to guide population evolution.
In summary, each change response strategy has its pros and cons. Hybrid change response approaches often outperform single methods. Recent research has increasingly supported this notion. For instance, Wang et al. [
171] suggested using a hybrid of the PPS and transfer learning to improve prediction. In reference [
175], Yao et al. proposed a novel response mechanism that combines a clustering difference method with transfer learning. This method reduces the possibility of negative transfer. The TradaBoost is employed to construct a prediction model. This model produces an excellent starting population and carries out multiple-objective optimization. This method can be applied to any population-oriented multi-objective optimization algorithm, resulting in notable enhancements in performance.
Therefore, for a new DMOP, researchers can initiate their process by implementing diversity-based methods and progressively integrate various change response ways until the algorithm’s performance aligns with the specified requirements.
5. Performance Evaluation and Analysis
DMOPs in complex industrial processes are a challenging class of problems. They often involve finding optimal solutions among multiple objective functions, which may change over time. When addressing these problems, the introduction of performance measures is crucial. On the one hand, performance measures can objectively assess the efficacy of various algorithms in solving DMOPs, helping determine which algorithm is more efficient in addressing specific issues. On the other hand, the nature of different problems may vary, so performance measures aid in comparing algorithm performance across diverse problem instances to identify which problems are more challenging. Furthermore, due to the dynamic nature of complex industries, problems may change over time. Appropriate performance measures can monitor the evolution of problems and determine when adjustments to algorithms or strategies are needed.
In dynamic multi-objective optimization, there are numerous performance measures to use. This section begins by presenting the assessment measures typically used for DMOPs. Additionally, it includes the most recent performance evaluation methods that have been presented in recent years. However, the selection of measurements is typically contingent upon the problem’s characteristics and the study’s objectives. Based on their characteristics, the commonly used performance measures for DMOPs can be broadly classified into three groups [
147], as shown in
Table 8: convergence, diversity, and dynamics measures.
Convergence measures focus on assessing the convergence of algorithms. DMOPs aim to indicate how and when the algorithm converges to the PF before environmental changes occur. Thus far, some performance measures have been formulated based on static measures. Producing such measures entails assessing the algorithm’s convergence at each time the environment terminates using static convergence measures and calculating the arithmetic mean to represent the algorithm’s convergence performance in a dynamic environment. These measures include GD, IGD, etc.
In addition to the simple “averaging” approach, several new approaches are used to measure the convergence of DMOAs. In reference [
177], the normalized generational distance is used to measure convergence. Zhang introduced the convergence rate (CR) [
180] as a statistical convergence marker grounded on coverage. The concept of optimal sub-pattern assignment (OSPA) was suggested by Bouvry et al. [
183], operating as an expanded version of the Hausdorff distance, to appraise how close the estimated PF is to the actual PF concerning localization and cardinality.
Diversity measures quantify the degree of diversity among approximate solutions in the objective space. Again, the “averaging” method can be employed for static diversity measurements of DMOAs. In fact, spacing measures [
117] that assess solution uniformity have been extended in this manner in several DMOAs. Another instance is maximum spread [
182], which quantifies the degree of approximation and has been enhanced to mitigate mistakes.
Moreover, multiple diversity measures have been formulated through varying methods. The PL [
178] was constructed to consider the morphology and organization of the problem’s PF, increasing the diversity evaluation’s precision. In reference [
184], the principle of information entropy was incorporated in the development of diversity measures. Araújo et al. [
185] introduced two diversity measures to evaluate the quality of approximate solutions. Furthermore, a recent study [
186] has adapted the IGD to assess the level of variety within a population.
Subsequently, some researchers discovered that a measure could effectively assess several facets of algorithmic performance and belong to the categories of the measures mentioned above. Such a measure is referred to as a hybrid measure. Among the most acclaimed hybrid measures is hypervolume [
179]. This measure computes the volume contained within non-dominated solutions and a reference point. Due to its succinct evaluation of both diversity and convergence, hypervolume has garnered significant popularity in static multi-objective optimization. In a similar vein, the “averaging” method can be utilized in conjunction with hypervolume and the hypervolume difference measure (MHVD) [
189] to assess the mean performance of algorithms amidst diverse environmental modifications.
Despite years of effort, effectively assessing the performance of DMOAs remains a challenging problem, and some issues still need to be solved. The “averaging” approach used to adapt static performance measurements to DMOPs is the simplest approach. Two commonly used measures in multi-objective optimization are the mean inverted generational distance (MIGD) and the mean hypervolume (MHV), extensively utilized in evaluating DMOPs. Nevertheless, as stated in reference [
117], calculating the average of several changes may not accurately represent the actual performance of the algorithm under consideration. Therefore, algorithm comparisons based on arithmetic mean measurements may be biased. Furthermore, given that the majority of performance measures for DMOAs originate from static measures, with only a handful of exceptions used to evaluate dynamic handling capacities, the examination of algorithm responses to changes needs to be more addressed. At present, there is a demand for a broader array of dynamic performance measures to scrutinize the performance of algorithms methodically. In recent years, some researchers have been working in this direction.
For DMOPs in complex industrial systems, the different dynamic characteristics that various industrial processes may possess often lead to problems changing over time. Consequently, it is crucial to introduce relevant evaluation measures for analyzing an algorithm’s capacity to handle such dynamics. Camara et al. [
187] proposed two measurement approaches to address this need. Jiang and Yang [
117] introduced measures for measuring algorithm robustness in dynamic environments. Additionally, due to the importance of change detection in DMOAs, some research has focused on change detection. Dynamic measures surrounding change detection investigate success rate, associated costs [
113], and timeliness [
191].
In the latest publication, as found in reference [
192], Javidan Kazemi Kordestani et al. propose a duo of
fitness adaptation speed and
alpha accuracy measures. A comparative study was subsequently carried out among various cutting-edge algorithms on a moving peaks benchmark using these proposed measures and a range of other performance metrics. The goal was to highlight the relative benefits of the newly introduced measures.
Furthermore, it is crucial to acknowledge that evaluating the efficiency of algorithms designed to solve DOMPs poses a challenge due to the fluctuating nature of fitness over time. Commonly used performance indicators for DOMPs do not sufficiently consider continuous fitness changes, potentially resulting in a biased interpretation of performance. Similarly, these measures cannot equitably compare performance across instances of identical problem types or diverse problem categories due to the absence of performance value normalization. A large number of these measures also operate on the assumption of normally distributed input data values, though, in practice, the prerequisites for data normality still need to be met. Additionally, most measures often overlook the concept of performance fluctuation over time.
In reference [
193], Pampara et al. introduced a novel performance measure for DOMPs, the
relative error distance. This measure aims to evaluate the proximity of an algorithm’s performance to the optimal state by calculating the multi-dimensional distance between the vector and the theoretical point of the best possible performance. One of the key strengths of this new measure is that it does not operate on the assumption of normally distributed performance data across fitness changes. It is robust against fitness changes and effectively amalgamates performance variance across fitness changes into a single scalar value. This makes it easier to compare algorithms using established nonparametric statistical methods. By overcoming the limitations of traditional performance measures, the
relative error distance provides a more accurate and comprehensive evaluation of an algorithm’s performance on DOMPs. Its ability to adjust to fitness changes and capture performance variance over time makes it a significant tool in dynamic optimization problems.
Additionally, it is crucial to consider computational complexity when evaluating DMOAs. Due to the specific aspects related to changes in DMOPs, DMOAs incur additional computational costs, extra time complexity, the number of fitness evaluations for checking fitness differences, and change responses. Therefore, the number of change detections and change responses in most DMOAs is non-negligible. To ensure that no changes are missed, continuous monitoring of change detection in each generation of evolution is also a direction for developing future performance measures.
6. Conclusions
The rapid advancement of global industrial intelligence has facilitated the widespread application of industrial big data technology and artificial intelligence technology. Ensuring safety in industrial production systems while enhancing production efficiency is an urgent requirement for international sustainability. Hence, it is crucial to efficiently harness the continuously expanding industrial data to regulate the safety and stability of intricate industrial operations.
This paper analyzes the DMOPs in complex industrial processes in recent years and provides a perspective on solving them. Initially, the paper outlines the challenges of complex industrial processes and proposes approaches to address these issues. It highlights the significance of data-driven modeling for dynamic operational optimization and introduces a time-series model based on time-varying parameters in real industrial production. Furthermore, the paper presents the latest change detection and change response approaches, enabling the model to track the dynamic Pareto front and seek optimal solutions.
In addition, there are some important considerations. In the context of change detection and response, we observe that hybrid change response approaches often outperform single approaches, as they can handle a wider variety of dynamic characteristics. Recent research has increasingly demonstrated the effectiveness of hybrid strategies. Data-driven optimization algorithms simplify the search for solutions in DMOPs, reducing the complexity of change responses. Meanwhile, deep learning models enhance change responses, and deep learning techniques such as transfer learning have proven effective in learning from dynamic environments and adapting to high-frequency environmental changes. However, new environmental detection approaches are still needed. Developing competitive environmental detection approaches to address the intensity and frequent occurrence of environmental changes in highly complex DMOPs while preserving computational resources by detecting “redundant information” between detection time slots remains a significant task for the future.
Regarding performance evaluation measures, most performance measures in DMOPs are adaptations from static measures to accommodate DMOPs solutions. These adjustments do not consistently yield the desired results in practical application as they need comprehensive measurements of the algorithm’s responsiveness and adaptability to environmental changes. In recent years, several newly proposed performance measures, such as fitness adaptation speed, alpha accuracy, and relative error distance, have focused on the dynamic responsiveness of algorithms. Nevertheless, establishing performance measures in DMOPs remains a substantial and open challenge, requiring different dynamics-based measures to achieve more dynamic performance evaluation.
Lastly, it is worth noting that the dynamic and robust multi-objective optimization concept is often referenced in numerous optimization and learning studies. However, it needs a precise and universally accepted definition. Robustness refers to the capacity to sustain optimal outcomes in multiple environmental variations. While robustness has been introduced to address DMOPs, the approaches for addressing these issues still need to be explored. Therefore, this research direction holds vast prospects and merits further in-depth exploration.





{kind=link}
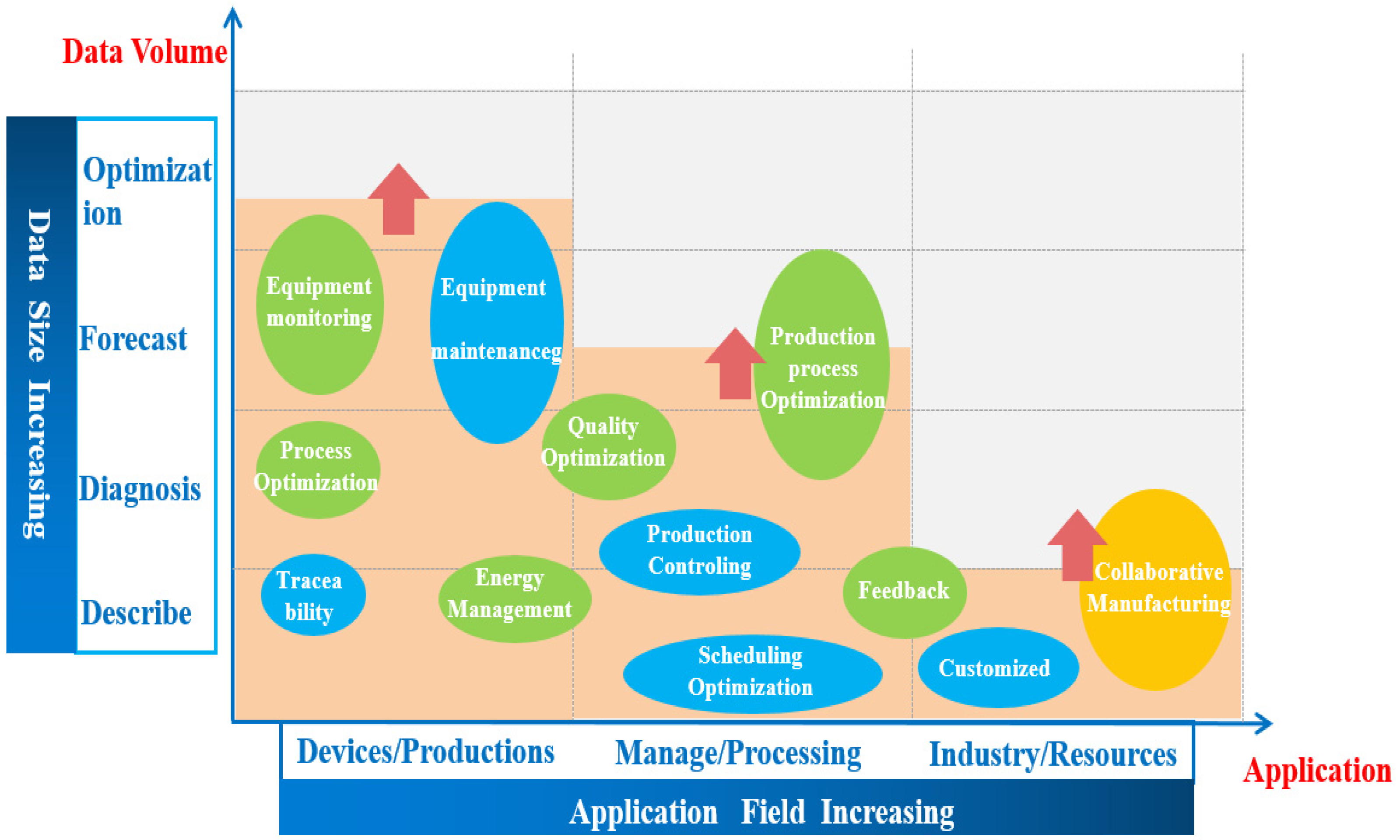{kind=link}
{kind=link}
{kind=link}