1. Introduction
Construction and operation of buildings accounted for 36% of worldwide energy demand and for 37% of energy-related
emissions in 2020 [
1]. As per the impact assessment for the Climate Target Plan 2030, residential and services buildings should reduce their GHG emissions by 60%, compared to 2015 [
2]. Previous studies show that buildings can use 20–40% less energy if poor HVAC control strategies are detected and improved and if more up-to-date HVAC controllers are developed [
3,
4,
5]. To curb energy consumption, some buildings, especially the most modern and large ones, feature automation systems, such as Building Management Systems (BMSs), which monitor and control the HVAC, mechanical and electrical equipment. HVAC systems usually account for 40% of the energy used in buildings [
6], and if lighting is included, this figure can reach 70% [
7]. The recast Energy Performance of Buildings Directive (EPBD) [
8] has spurred on the installation of services, such as building automation, smart meters and control systems, that can ensure high energy savings. Collecting, monitoring and processing HVAC data through the above services helps to detect potential sources of energy waste and faults using FDD techniques, namely, analytical tools enabling the detection of faults in HVAC systems and which provide useful information to plan troubleshooting strategies. Faulty HVAC components account for no less than 30% of the energy used in commercial buildings [
9] and this share can be reduced using FDD.
According to Kim and Katipamula [
9] FDD methods for building systems can be based (1) on qualitative models, such as rules or qualitative physics; (2) on quantitative models, such as detailed or simplified physical models; and (3) on process history. Quantitative models use algebraic and differential equations that describe the behavior of the systems. Differences between actual measurements and results of these models mark faults. However, solving the underlying equations often requires much effort. HVAC processes are always multivariable, and nonlinear, and involve complex heat and mass transfer. Moreover, validating quantitative models requires detailed experimental data about the building physics and the setup of each system. This makes building quantitative models and using them time-consuming. Quantitative models are very useful for retrofit analysis or for defining renovation strategies [
10].
Qualitative models build sets of rules or qualitative equations on a priori knowledge of the systems under study. In rule-based techniques, thresholds are derived by analyzing monitoring data. Qualitative models can be used for real-time control; e.g., for model predictive control [
11,
12]. They are simple and easy to develop and use. However, they are often tailored to a given system or process, so they are hard to apply to other systems or processes.
Methods based on process history tap the vast amount of sensor data from automation systems, such as BMSs. These methods are cost-effective and can achieve accurate, real-time control of the building systems without in-depth knowledge of the physics of the system or process. Unlike previous models, methods based on process history are highly dependent on the quality of the data provided. Similarly to qualitative models, methods based on process history are often hard to apply outside the data range used to build them.
As quantitative and qualitative models were not viable here, methods based on process history were examined instead. They often rely on supervised learning models (classification for discrete predictors, regression for continuous ones); in other words, they often rely on models requiring labeled data. Methods based on process history can also use unsupervised learning models (e.g., clustering, dimensionality reduction, association rules), these being models using unlabeled data. However, evaluating the performance of these models is case-dependent; thus, they were ignored here.
A labeled dataset is a set of structured data consisting of input and output variables. The latter are termed “label” or “labeled data”. The label can be binary for fault detection and binary fault diagnosis (i.e., whether a data sample is normal or faulty) or multiclass for multiclass fault diagnosis (i.e., whether a data sample marks different health states of a machine or process; e.g., normal, faulty or recovering operation in the case of three classes).
A key challenge in developing methods based on process history is the lack of labeled data, due to the fact that labeling often requires human experts and so collecting enough labeled data to classify faults is time- and resource-consuming. Moreover, samples could be incorrectly labeled [
13]. Supervised learning-based FDD of HVAC systems use the following: Support Vector Machines (SVMs) [
14,
15,
16], decision trees [
15,
16], gradient boosted trees [
14,
17], random forests [
14,
16,
17], shallow neural networks [
15], deep feedforward neural networks [
15,
18], Recurrent Neural Networks (RNNs) [
17,
19]. Zhou et al. [
15] compared the performance of SVMs, decision trees, clustering (unsupervised method), shallow and deep neural networks to diagnose faults in a variable refrigerant flow system. The SVM model proved to be the best for diagnosing single faults (here, the training dataset included only one fault class), while deep neural networks excelled at diagnosing multiple faults (here, the training dataset included several fault classes). The dynamics of the system and faults related to it were neglected.
Shahnazari et al. [
19] used RNNs. Their method could isolate faults in HVAC systems without the need for plant fault history, mechanistic models or expert rules. However, performance was not extensively compared among different RNNs.
Mirnaghi and Haghighat [
13] noted that supervised learning-based FDD of HVAC systems was more suitable for steady-state conditions than transient ones. Moreover, they noted that FDD should neglect faulty samples from older HVAC components, as well as the first months or year of operation of HVAC components. This helps in selecting proper case studies.
Available datasets of building systems often include a small amount of labeled data and a large amount of unlabeled data. Semi-supervised learning models can leverage such datasets. Moreover, supervised learning models can seldom identify novel faults [
13], unlike semi-supervised learning models. Dey et al. [
20] used SVM to classify normal and faulty patterns in a terminal unit of an HVAC system. The SVM was trained on historical (i.e., labeled) data. The SVM models outperformed
k-NN classifiers trained and tested on the same data.
To tackle the imbalanced training data problem for AHU FDD (i.e., datasets including a large amount of normal samples and a small amount of anomalies) Yan et al. [
21] developed a semi-supervised method using SVM as the base classifier. Samples with confidence levels (classification probabilities) higher than a threshold were pseudo-labeled and added to the training dataset to improve the SVM performance at the next training iteration. The proposed method outperformed existing semi-supervised methods.
Fan et al. [
22] and Fan et al. [
23] used the same dataset as Yan et al. [
21] and adopted a similar approach using three-layer neural networks for both fault diagnosis (16-class classification task) and unseen fault detection. Unseen (unknown) faults are those which are not in training datasets. Many combinations of semi-supervised learning parameters, these being the number of labeled data (per class), minimum confidence score for pseudo-labeling, learning rate, and maximum number of model updates, were examined. To better detect unseen faults, large confidence thresholds and learning rates were suggested.
Elnour et al. [
24] developed and validated a semi-supervised attack detection method based on isolation forests for a simulated multi-zone HVAC system.
Li et al. [
25] addressed the problem of data scarcity using semi-generative adversarial networks (GANs). However, the proposed method could not diagnose unknown faults in the examined system. Moreover, two different types of faults occurring simultaneously could not be diagnosed.
Martinez-Viol et al. [
26] developed a parameter transfer learning approach, in which a reference classifier was trained on data from the source domain and the weights and biases of the reference classifier were used to initialize the classifier for the target domain. The target domain was trained on target data resembling source data. This study proved that transfer learning in HVAC FDD tasks required a high degree of similarity between source and target domains.
Albayati et al. [
27] used data collected from a rooftop HVAC unit under normal operating conditions. Five classes of faults were analyzed. Multiple faults could occur at once. Two semi-supervised models were developed: model 1 used SVM as the supervised method, and
k-NN labeling as the unsupervised method; model 2 used SVM as the supervised method, and clustering as the unsupervised method. These models classified the minority class in imbalanced datasets more accurately than the supervised model used as baseline. However, the datasets were small: datasets 1 and 2 included 3336 and 2099 samples, respectively. Thus, the applicability of the developed semi-supervised models on larger datasets was not assessed.
Mirnaghi and Haghighat [
13] noted that semi-supervised learning-based FDD of HVAC systems required adjusting hyperparameters to different setups of the systems. This type of FDD also required a large amount of normal operation data, which needed to be available beforehand. Overall, semi-supervised learning-based FDD calls for more automation and enough monitored variables to fully define the operating status of the system.
Key Objectives
This work aimed to develop two types of models that perform FDD of proven, well run-in HVAC systems in non-residential buildings:
- 1.
predictive models that can forecast transient states;
- 2.
classification models that can be trained on partially labeled datasets with a small number of variables.
These models should be:
2. Materials and Methods
2.1. Case Study Building
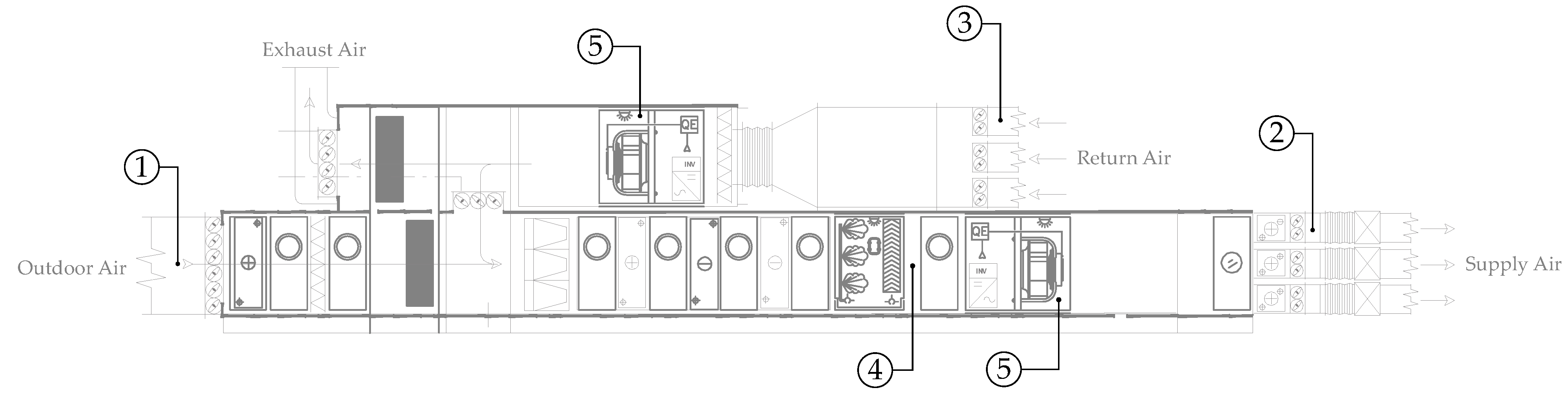
The case study building was the Energy Center, an office building in Turin, Italy (see
Figure 1). This building is described in Becchio et al. [
28] and Di Già and Papurello [
29]. It has five floors, including a basement. The basement houses car parking, laboratories and technical rooms. The first floor houses an exposition hall, which runs through all four above-ground floors, an auditorium and a research laboratory. From the second to the fourth floor, the building houses offices and meeting rooms for companies and start-ups. The following two energy vectors cover most of the energy demand of the building: (1) electricity, through the connection to the medium-voltage grid; and (2) heat, through the connection to the district heating network of Turin. The building is equipped with HVAC systems and with a BMS that controls and manages the entire facility and its equipment.
2.2. Case Study AHU
AHUs bring in outdoor air, control its parameters and feed it to the building’s ductwork for distribution. The controlled parameters are variables, such as temperature, humidity, speed and quality, that ensure the air supplied provides thermo-hygrometric comfort in the room, according to standards such as ISO 7730:2005 [
30], EN 16798-1:2019 [
31] and ASHRAE 55-2020 [
32]. Five all-air recirculating, modular AHUs condition indoor air in the Energy Center. The AHUs monitor the concentration of pollutants in the return air to condition room air and ensure it meets air quality standards. The flow rate of supply air is varied based on Volatile Organic Compounds (VOCs) in the return air, which is partially replaced by outdoor air to replenish oxygen and to remove pollutants and carbon dioxide. The remaining return air is mixed with fresh air and recirculated to reduce energy consumption. Each AHU independently controls one of the following thermal zones:
- 1.
laboratories (basement);
- 2.
lobby (from ground floor to third floor);
- 3.
auditorium (ground floor);
- 4.
offices (first, second and third floors).
More specifically,
- 1.
a terminal reheat/cooling AHU in the basement serves the laboratories;
- 2.
a terminal reheat/cooling AHU in the basement serves the lobby;
- 3.
a terminal reheat/cooling AHU on the roof serves offices in the northwest wing;
- 4.
a terminal reheat/cooling AHU on the roof serves offices in the northeast wing;
- 5.
a single-zone AHU on the roof serves the auditorium.
Single-zone and terminal reheat/cooling AHUs are defined in Seyam [
33]. The single-zone AHUs supply the required sensible and latent heating/cooling load to ensure local thermal comfort. The terminal reheat/cooling AHUs supply the required latent heating/cooling load and most of the sensible heating/cooling load. The zone terminal units, such as ceiling radiant panels, supply the remaining part of the sensible heating/cooling load to ensure local thermal comfort.
The AHU serving offices in the northeast wing was analyzed here. It provides the most consistent and complete monitoring data among all AHUs. This AHU conditions air on all three floors of the office area, in both winter and summer.
Figure 2 shows the front section of the AHU serving offices in the northeast wing.
Understanding the AHU’s winter operation helped to do the following:
assign a different importance to each feature in the dataset;
interpret FDD results;
perform inspection and maintenance only if need be;
set physics-based thresholds for confirming or rejecting anomalies identified by data-driven FDD methods; and
focus on a specific stage of the AHU between two or more sensors.
2.3. Dataset
AHU monitoring data, see
Section 2.2, was collected by the Energy Center BMS. Ideally, the sensors and meters in the AHUs measure temperature, humidity, pressure, flow rate and energy. Nevertheless, only temperature and humidity sensors are installed in most AHUs. Pressure, flow rate and energy meters are expensive and optional for HVAC control. Yan et al. [
21] used a feature selection algorithm to identify key features for AHU FDD in winter and summer datasets. In the current study, features included air temperatures and humidity in different stages of the AHUs. The dataset contained the following 11 features from the AHU serving offices in the northeast wing:
- 1.
timestamp;
- 2.
temperatures of return, supply and outdoor air;
- 3.
relative humidity of return, supply and outdoor air;
- 4.
the temperature setpoint of the return air;
- 5.
the saturation temperature in the humidifier (see
Figure 2);
- 6.
energy and power supplied to the fans.
Data was acquired every 15 min. The AHU’s winter operation differs from its summer operation. To reduce the number of seasonal models to be developed, data from winter 2019–2020 and from winter 2020–2021 were used here.
With so few variables available, and with scant knowledge of the control of the AHU at hand, physics-based methods and rule-based methods were ruled out; instead, data-driven methods were used.
The dataset was preprocessed.
If fewer than 16 samples of a feature were missing in a row, the missing samples were piecewise-linearly interpolated. If more than 16 samples of a feature were missing in a row, data cleaning was applied.
Features were standardized by removing the mean and by scaling to unit variance.
The number of samples in the preprocessed dataset was 33,984.
2.4. ML Methods
Two types of ML models trained and tested on the multivariable dataset above were the following: (1) supervised models; and (2) semi-supervised models. Both types are designed to detect multiple classes of faults in the same observation. The supervised models capture the system dynamics and detect faults in time sequences. Conversely, the semi-supervised models neglect the system dynamics.
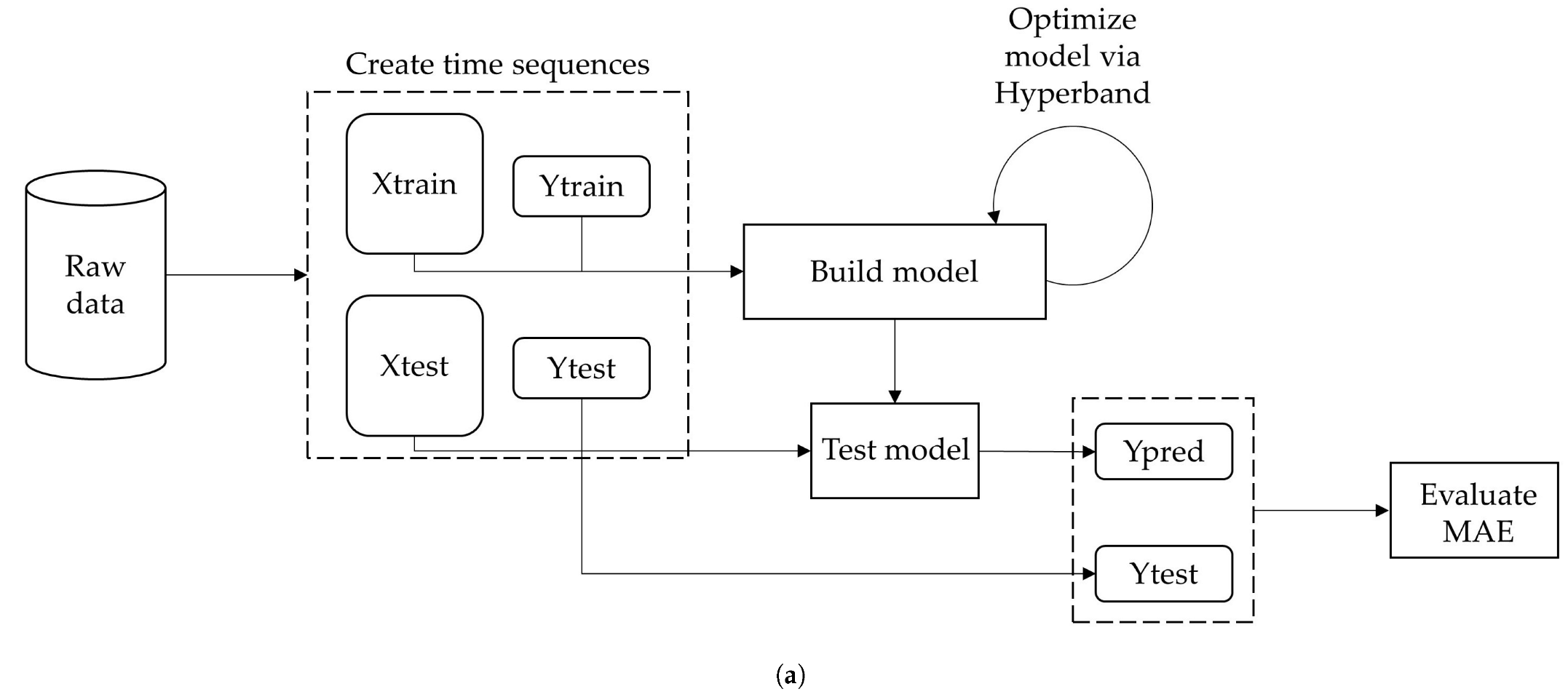
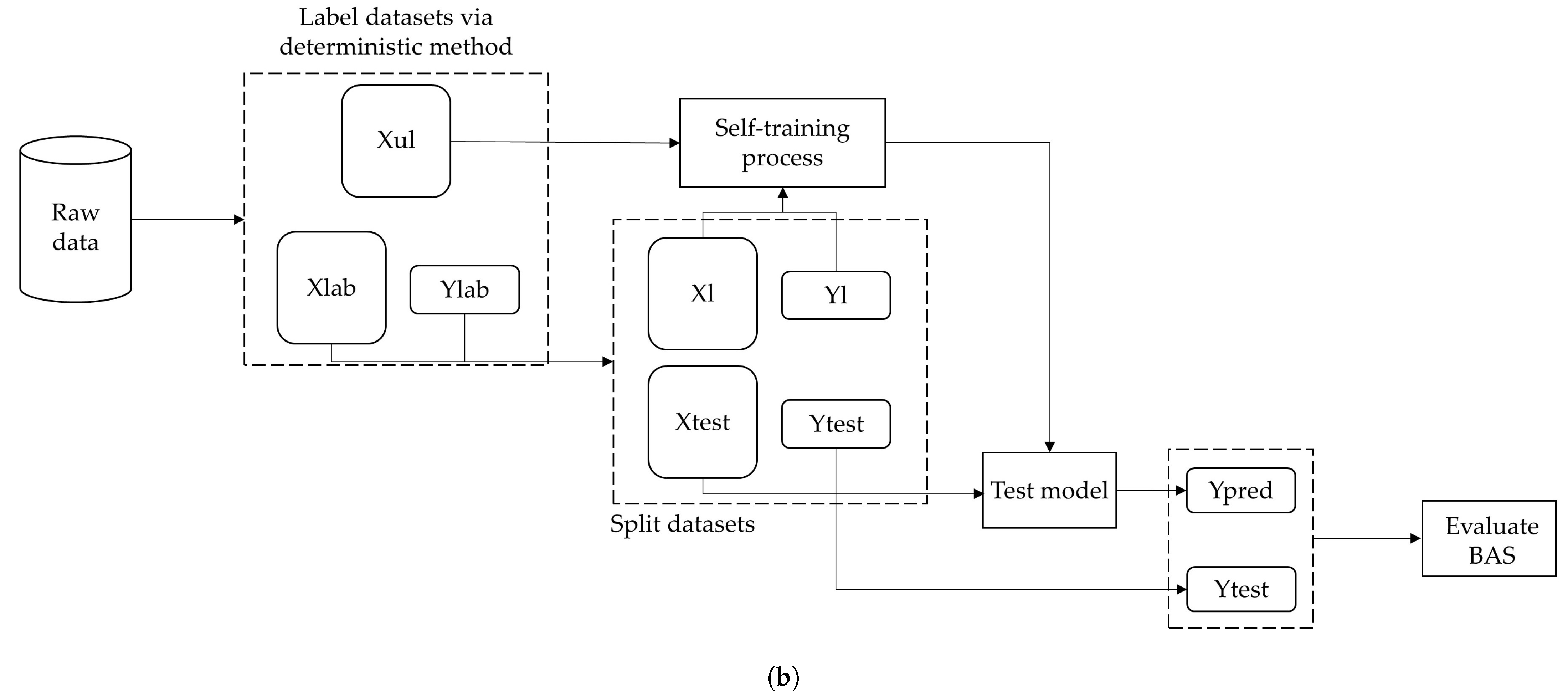
Figure 3 shows the flowchart of the FDD workflow for each type of model.
2.5. Supervised Method
The supervised model implemented adopts a Multi-Input Multi-Output (MIMO) approach. In this complex scenario, all variables in a given time window (here, one day) are fed into the model, which outputs their predicted values. This approach aims to spot variable-wise reconstruction errors that could be related to faults. The predicted time sequences can be used to detect anomalies because, if the actual time sequences are compared with the predicted ones, the actual samples that greatly differ from the predicted ones are labeled as anomalies. Reconstruction errors are evaluated through metrics: Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE) and Root Mean Square Error (RMSE). The MAE is computed as:
The RMSE is computed as:
where
is the actual sample of features
i at time
t.
is the reconstructed sample of features
i at time
t.
is the number of samples.
N is the number of features.
Through a time sequence generator, a time window of size l is shifted over the input time series by one time step forward, so that all samples in the window become an input sequence, while the m samples after the window become the corresponding output sequence. All future sequences form the output of the model. In this way, a labeled dataset suitable for supervised methods is obtained.
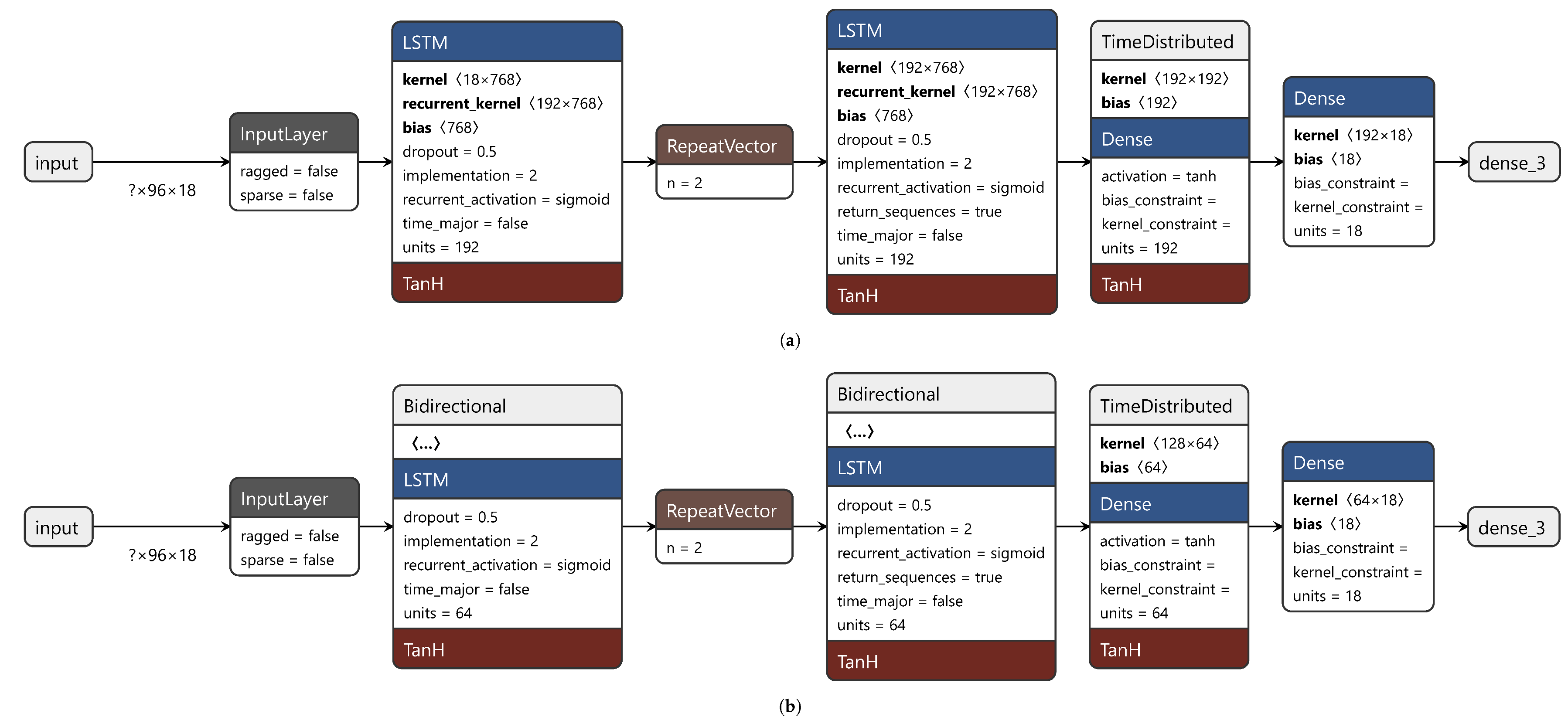
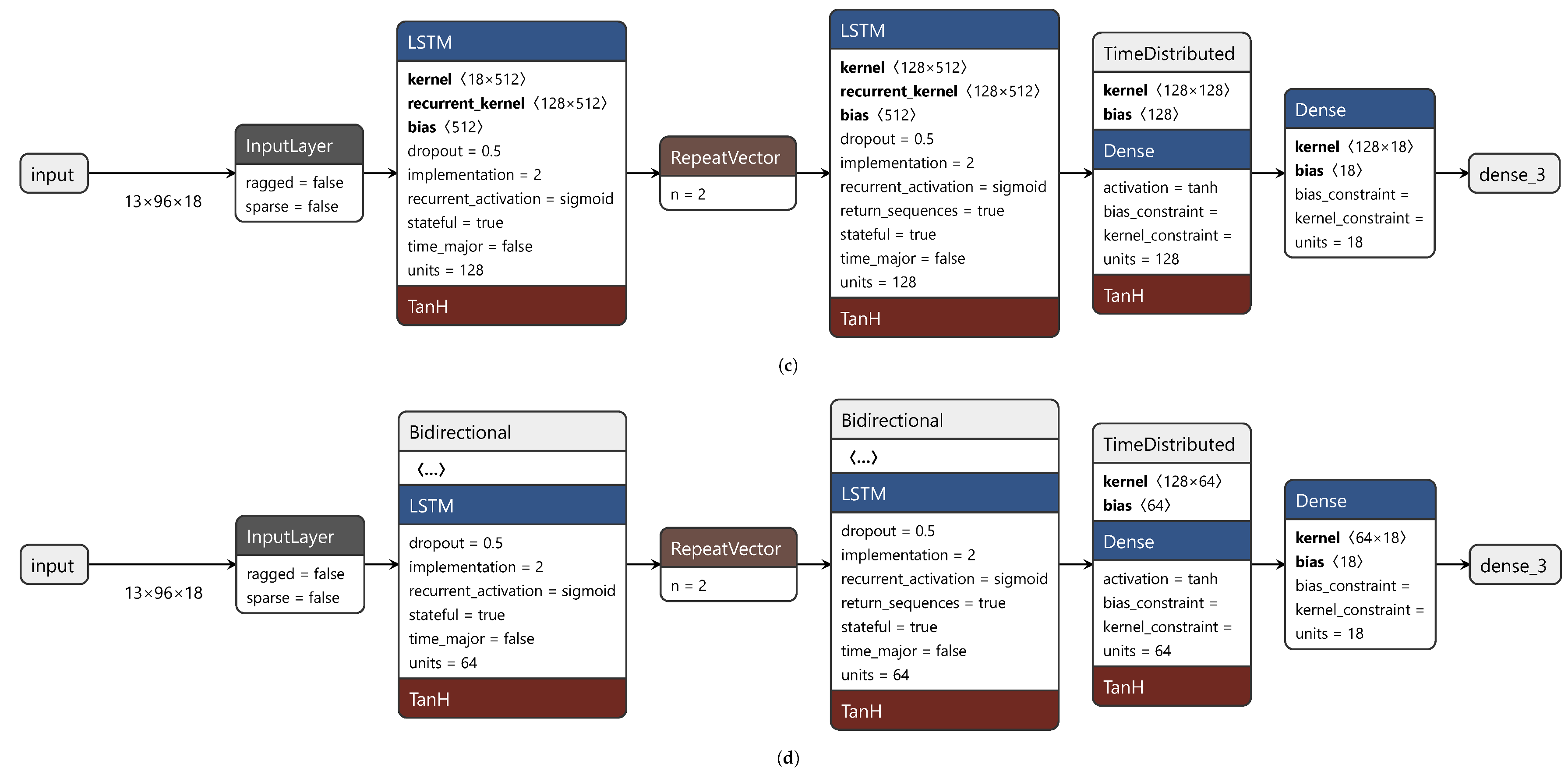
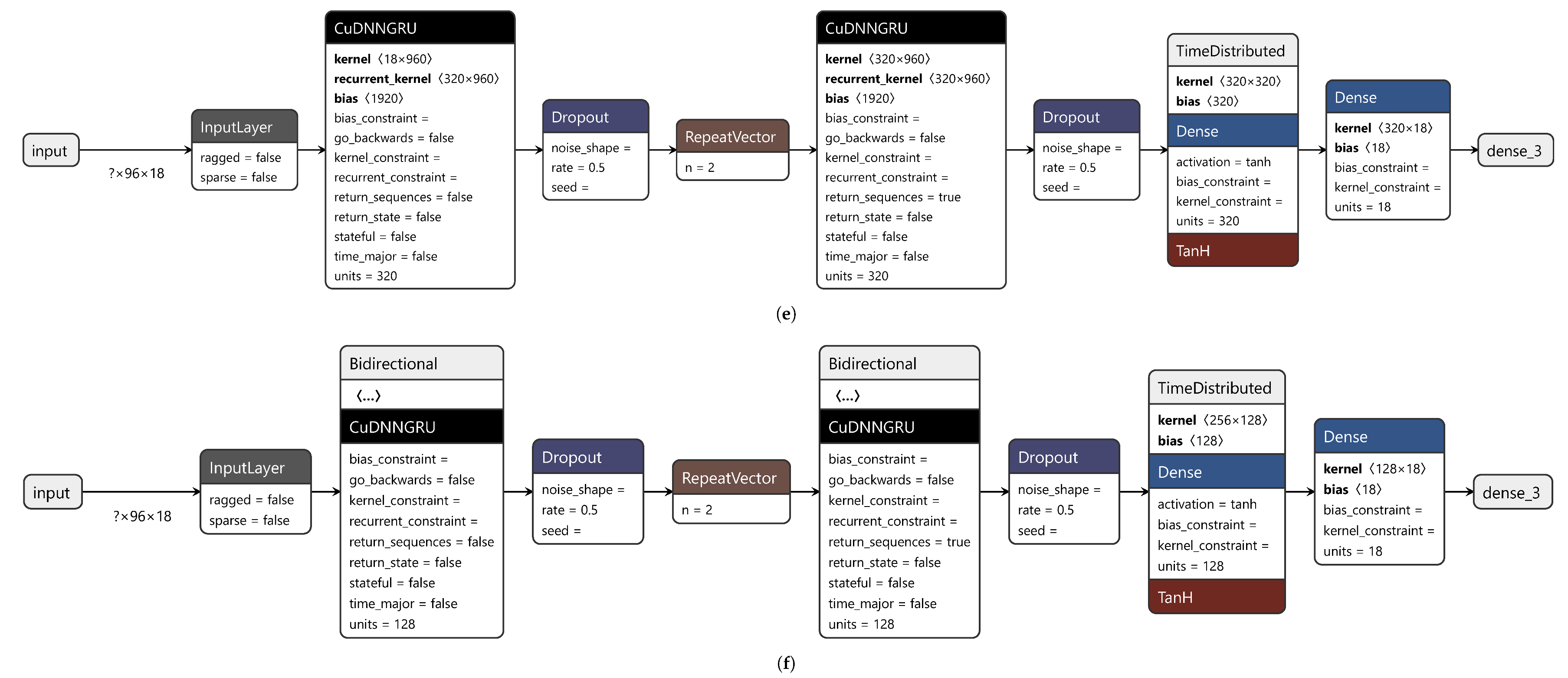
This study stemmed from the poor performance of traditional statistical methods, such as Vector AutoRegression (VAR). Its MAE on the test dataset is equal to 0.23 and too low for FDD in HVAC systems. Therefore, this study analyzed the performance of some RNNs applied to a labeled dataset. Specifically, the hidden layers consisted of Long Short-Term Memory (LSTM) cells and of Gated Recurrent Unit (GRU) cells. LSTMs have hidden states (short-term memory) and cell states (long-term memory), while GRUs only have hidden states.
Variants such as Bidirectional LSTM (BiLSTM) and Bidirectional GRU (BiGRU) were investigated, which add a backward LSTM (GRU) layer to a traditional forward LSTM (GRU) layer. The original input sequence is fed into the forward layer, while the reversed sequence is fed into the backward layer. The outputs of both layers can be combined in several ways, such as concatenation or element-wise sum, average or multiplication. Here concatenation was selected. Bidirectional versions were designed to overcome the shortcomings of traditional versions. They preserve the input information from both past and future at a given time interval, and, hence, long-term relationships are better captured.
Moreover, the different performance of stateless and stateful networks was examined. Sequence-processing models can be stateless or stateful. Stateless models use sequences of identically distributed and independent training samples, while stateful models consider time dependence between batches. In stateless models, the states of the model are reset each time a new batch is processed. This forces the model to forget the states learned from previous batches. In stateful models, the training batches are assumed to be related to one another. Thus, propagating the learned internal states from one batch to another is useful, as the model better captures the time dependence. As batch size increases, stateless models tend to approach stateful models. Stateful models require batches to be time-sorted, so they can be seen as one sequence, and, hence, shuffling (changing the order of training batches) is not allowed.
This section describes the elements that made up the final network. The network consisted of an input layer, an output layer, and an arbitrary number of intermediate hidden layers. Each layer had a specific activation function. Here, six RNNs were trained and tested. The developed RNNs used the hyperbolic tangent (tanh) as the activation function. This choice enabled the use of the cuDNN implementation, which sped up training [
34]. The activation function of the output layer was linear as predicting sequences is a regression problem. The batch size was set to 64 for stateless models and to 13 for stateful models. Stateful models need a batch size that divides the training dataset into equal-size batches. The maximum number of epochs was set to 500. However, to prevent overfitting, an early stopping scheme was set and a dropout of 0.5 was applied to hidden layers as a regularization technique. The input features are listed in
Section 2.3. However, 18 input features were used, because timestamps were replaced by hours and one-hot encoded days of the week. The input size was (96, 18). The sequence length was 96 as the time span considered was 24 h and data was measured and collected every 15 min; hence, 96 measurements spanned a full day’s cycle. The output size was (2, 18). The sequence length was 2 as the model should predict how variables evolve 30 min ahead.
As stated above, this study compared the performance of six variants of a model. This model was an encoder–decoder RNN, which combines the strengths of an autoencoder with those of an RNN. Between two RNN (LSTM or GRU) layers lies a Repeat Vector layer, which allows for a dimensionality reduction of the problem; namely, from 3D to 2D. The RNN layer before the Repeat Vector layer outputs a vector of 2D encoded variables. This vector is decoded by the Repeat Vector layer, which outputs 3D vectors. One of their three dimensions is the number of time steps to be predicted. The network ends with a Time Distributed layer and a Dense layer, which outputs the prediction.
The six variants were:
- 1.
stateless LSTM;
- 2.
stateless BiLSTM;
- 3.
stateful LSTM;
- 4.
stateful BiLSTM;
- 5.
stateless GRU;
- 6.
stateless BiGRU.
Each model was trained and tuned on three hyperparameters: (1) number of hidden layers; (2) number of neurons per hidden layer; (3) L1 and L2 activity regularization in the input layer.
Table 1 lists candidate values of these hyperparameters. The Hyperband algorithm of the Keras Tuner [
35] automatically tuned the hyperparameters.
The models were trained using Adam as optimizer and using MAE as metrics and as the loss function. The initial dataset was split into training and test datasets, using a 70:30 split ratio. The data split was not random but along time, as the model had to predict the future and keep memory of the past.
As stated above, the reconstruction errors and performance of the models were evaluated using three metrics: MAE, MAPE and RMSE. Conversely, the anomaly detection was evaluated using the absolute error from Equation (
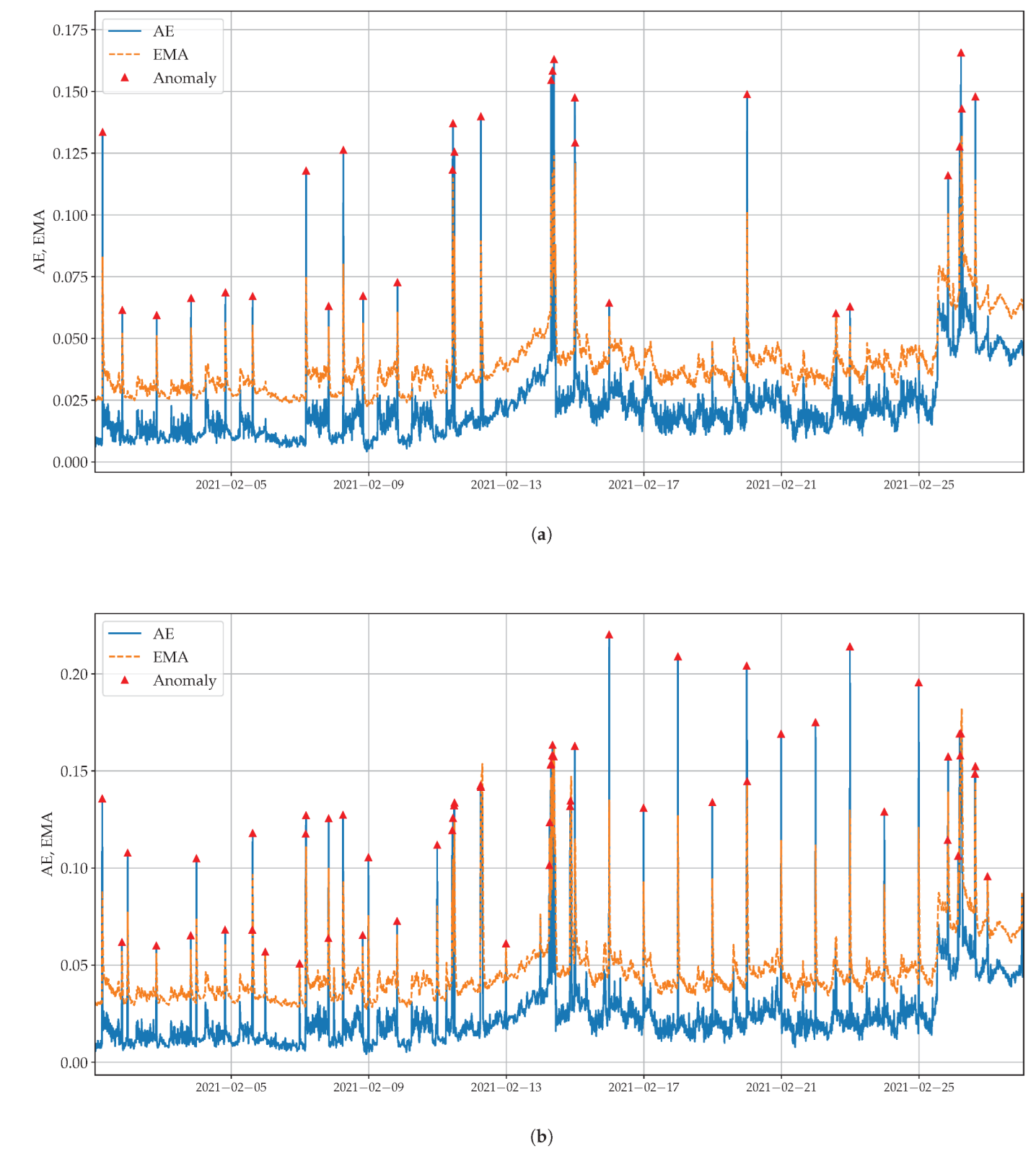
1). This prevented the model from being particularly sensitive to noise, thus, causing false positives. For example, RMSE errors were squared before being averaged, which gave more weight to larger errors. As the data showed seasonal trends, anomalies were detected using a dynamic threshold; namely, using the Exponential Moving Average (EMA) in Equation (
4):
where
is the value of absolute error at time
n;
is the EMA at time
;
is a smoothing parameter. Here,
. A higher
gave more weight to the absolute error and made the threshold more sensitive to seasonality. Dynamic thresholds are more sensitive to data behavior than static thresholds.
2.6. Semi-Supervised Method
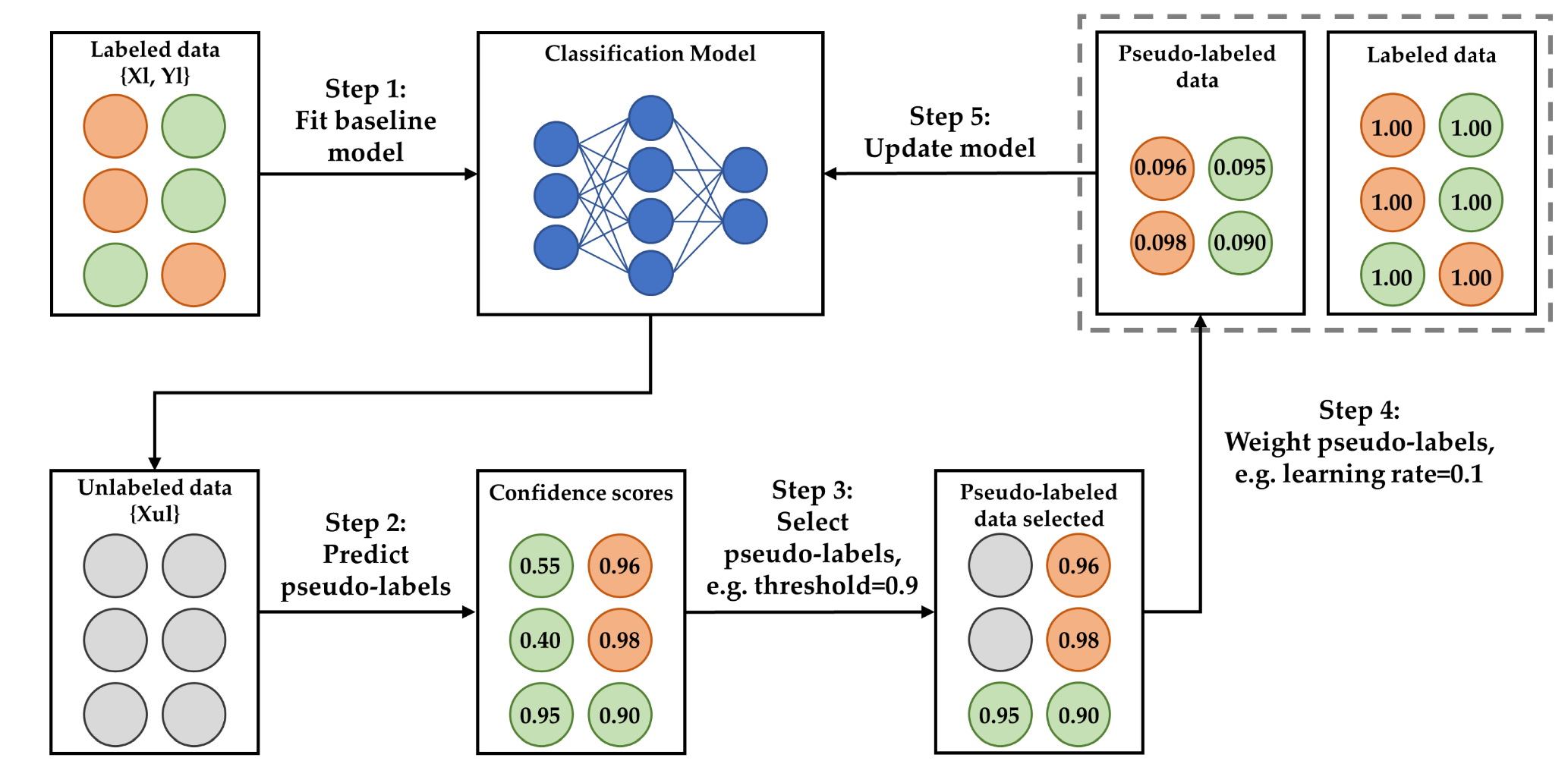
The semi-supervised FDD method implemented built on Fan et al. [
23]. There, the self-training strategy was an iterative training process for developing semi-supervised neural networks.
- 1.
In Step 1, the initial classifier (baseline model) was developed from the small amount of labeled data at hand. Input and output data were termed
and
, respectively. The train–test split ratio of the labeled dataset for training and testing the classifier at the first learning iteration was set to 20:80. In this way, a consistent test dataset was obtained and its size could be compared with the training dataset, which grew in size during the self-training iterations. The input features are listed in
Section 2.3. However, timestamps were replaced by days of the week.
- 2.
In Step 2. the classifier was tested on the unlabeled data, termed , to generate pseudo-labels.
- 3.
In Step 3, a learning parameter, termed confidence threshold, was introduced to select the pseudo-labels and only pseudo-labels with a relatively high confidence were kept to update the model in the next learning iteration. For example, given a confidence threshold of 0.9, only pseudo-labels with a confidence score of 0.9 or more were kept because they were reliable.
- 4.
In Step 4, a learning parameter, termed learning rate, which ranged from 0 to 1, was introduced to specify the training weights of the pseudo-labeled data. For example, given a learning rate of 0.1, the weight of a pseudo-labeled data sample with a confidence score of 0.92 was 0.092 (i.e., ) in the next learning iteration. Initial data samples were weighted 1.
- 5.
In Step 5, the whole self-training was rerun to update the classifier.
Figure 4 shows the self-training process.
The self-training strategy was based on three learning parameters: (1) the confidence threshold for the selection of pseudo-labeled data; (2) the learning rate for using the pseudo-labeled data; and (3) the number of learning iterations.
Table 2 lists candidate values of these parameters.
As stated in Fan et al. [
22], a small confidence threshold enabled the selection of more pseudo-labels for the self-training process and, hence, the model could exploit unlabeled data more efficiently. Conversely, a high confidence threshold removed unreliable pseudo-labels, to strengthen the self-training process.
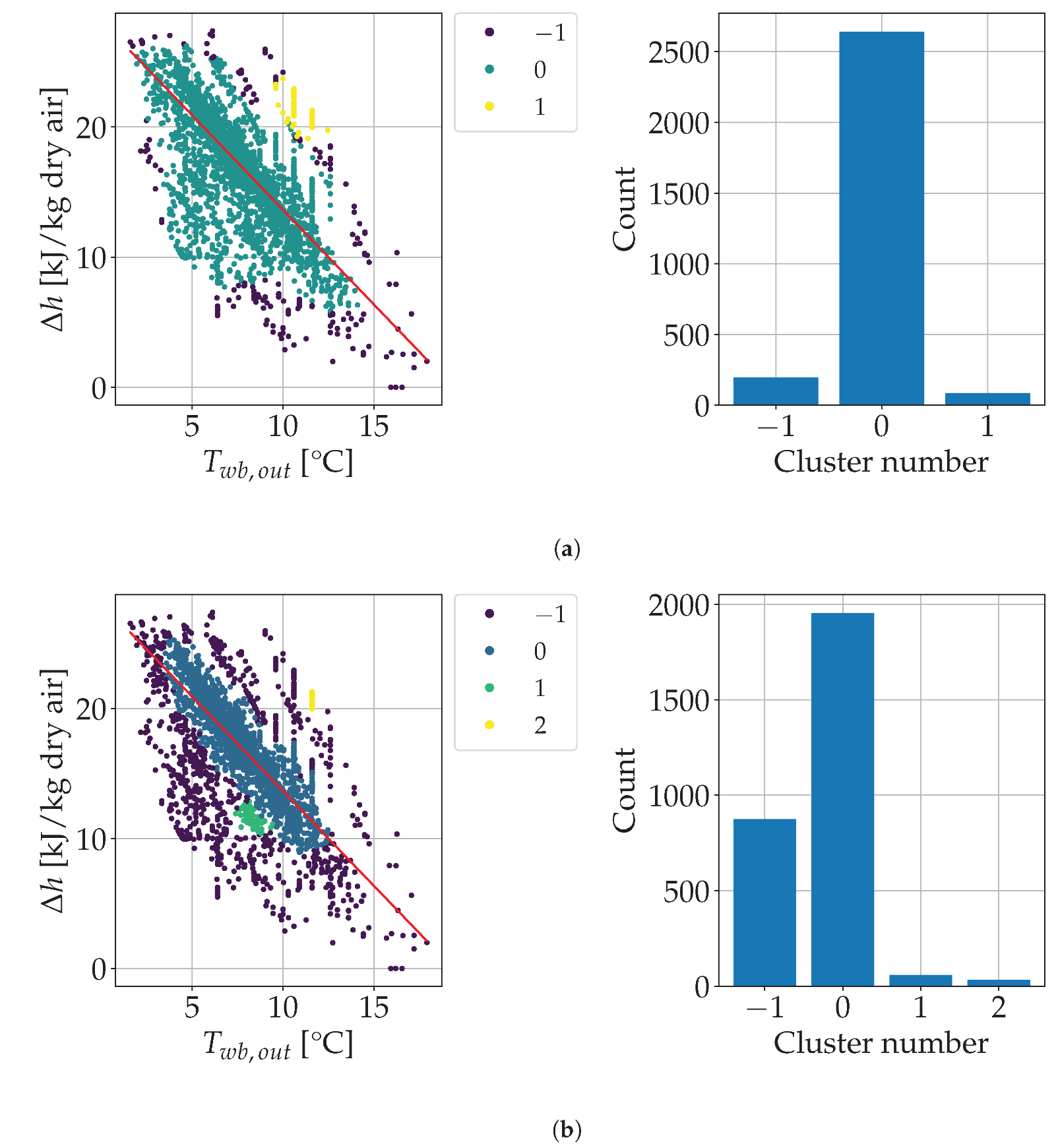
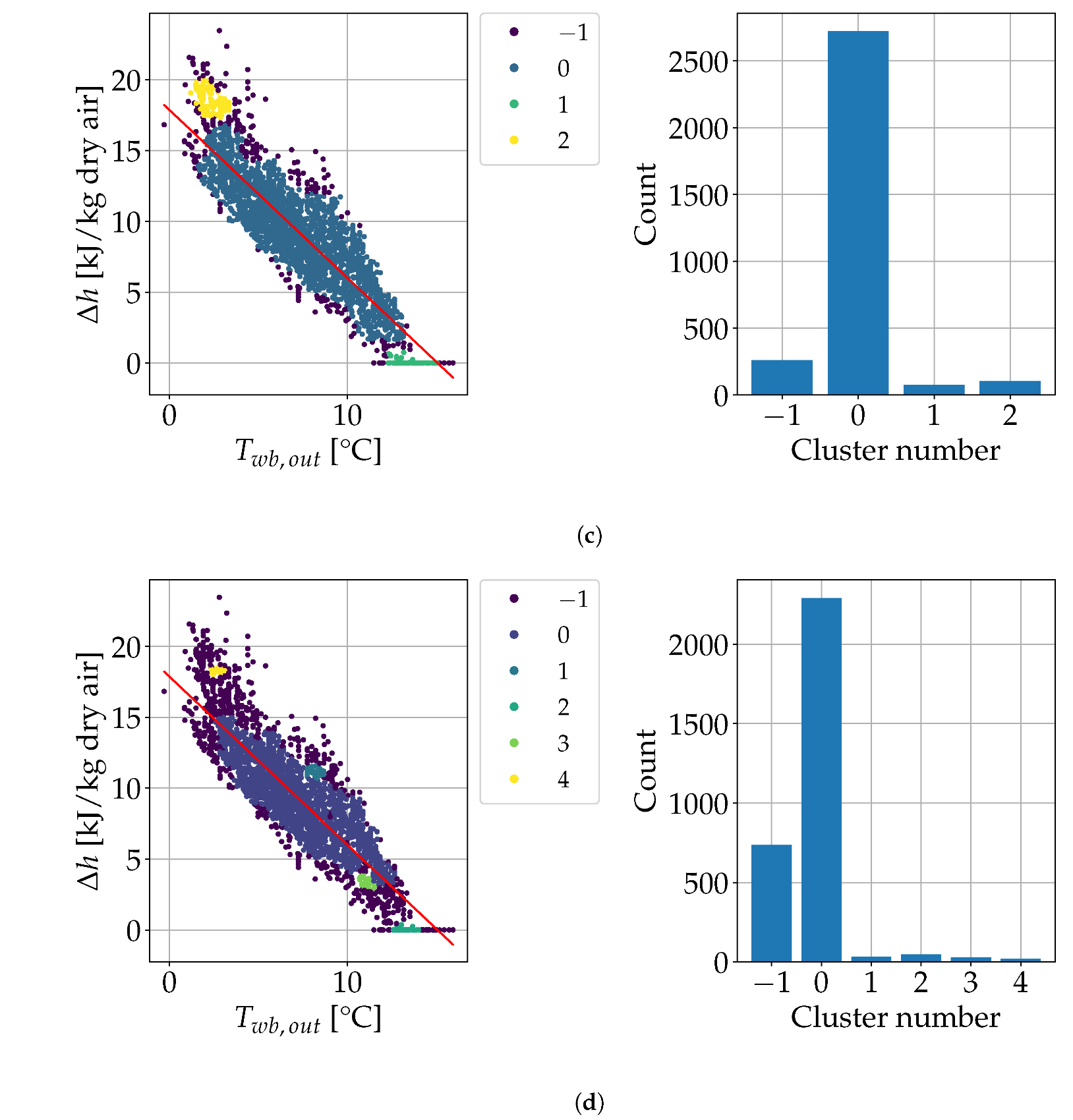
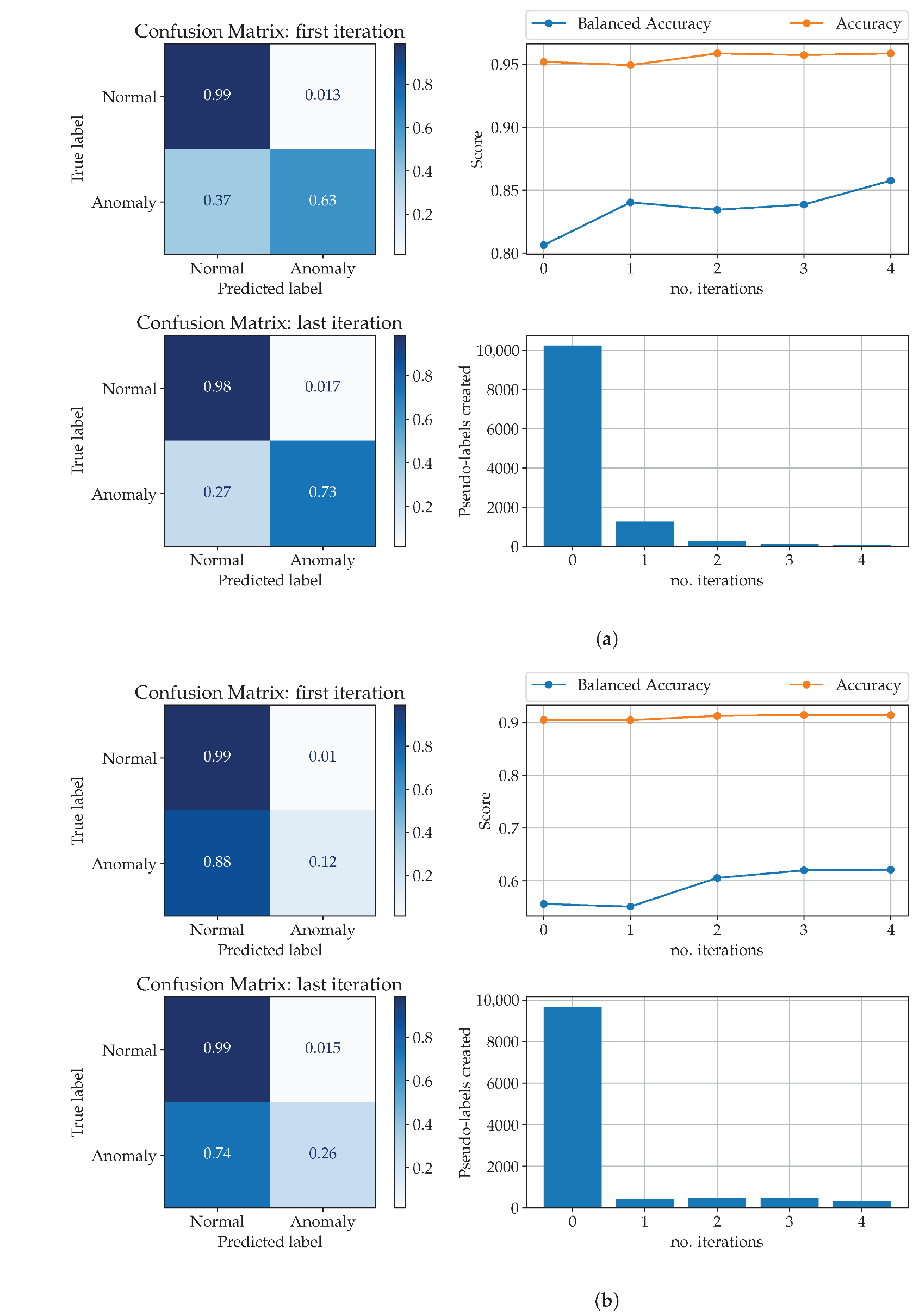
The self-training strategy assumed a subset of labeled data was available. The labeled data size was 1.16–9.26% of the data size, depending on the labeled data availability per fault [
23]. In this study, however, labeled data was missing and, hence, a mix of deterministic methods and clustering was used to label data (i.e., to detect anomalous and normal HVAC data) to start the self-training strategy. The size of the initial labeled dataset thus obtained was equal to 13.8% of the whole dataset, which was deemed enough to label the unlabeled dataset.
The deterministic methods above should be based on the energy analysis of the HVAC operation. However, the available data and variables did not allow for a comprehensive energy analysis, as many of the variables needed to describe the physics of the problem, such as mass flow rates, valve states (open/closed) and thermal energy usage, were unknown. Deterministic methods help to compute suitable energy Key Performance Indicators (KPIs). These KPIs describe the overall performance and/or operational criteria of an HVAC system. In this work, the main energy KPI was defined as:
where
is the dry-bulb temperature of outdoor air;
is the relative humidity of outdoor air;
is the dry-bulb temperature of supply air;
is the relative humidity of supply air. Numerator
is the difference between enthalpy of supply air
and enthalpy of outdoor air
. Hence, the numerator gauges the heating provided by the AHU so that air supplied to the room mixes with indoor air and ensures comfort. Denominator
is the linear best fit of enthalpy array
versus temperature array
; that is,
where
a and
b are constants determined from Huber regression, a linear regression technique that is robust to outliers.
is the outdoor wet-bulb temperature, which depends on
and
. Equation (
6) alters the energy signature, that is, the linear best fit of energy demand versus outdoor temperature, to account for outdoor relative humidity, similarly to Krese et al. [
36]. Consequently, the KPI in Equation (
5) compares the energy required to ensure comfort under current conditions (namely, supply and outdoor conditions) with the energy usually required to ensure comfort under current outdoor conditions.
This study stemmed from the poor performance of traditional shallow learning methods, such as Random Forest, whose Balanced Accuracy Score (BAS; see Equation (
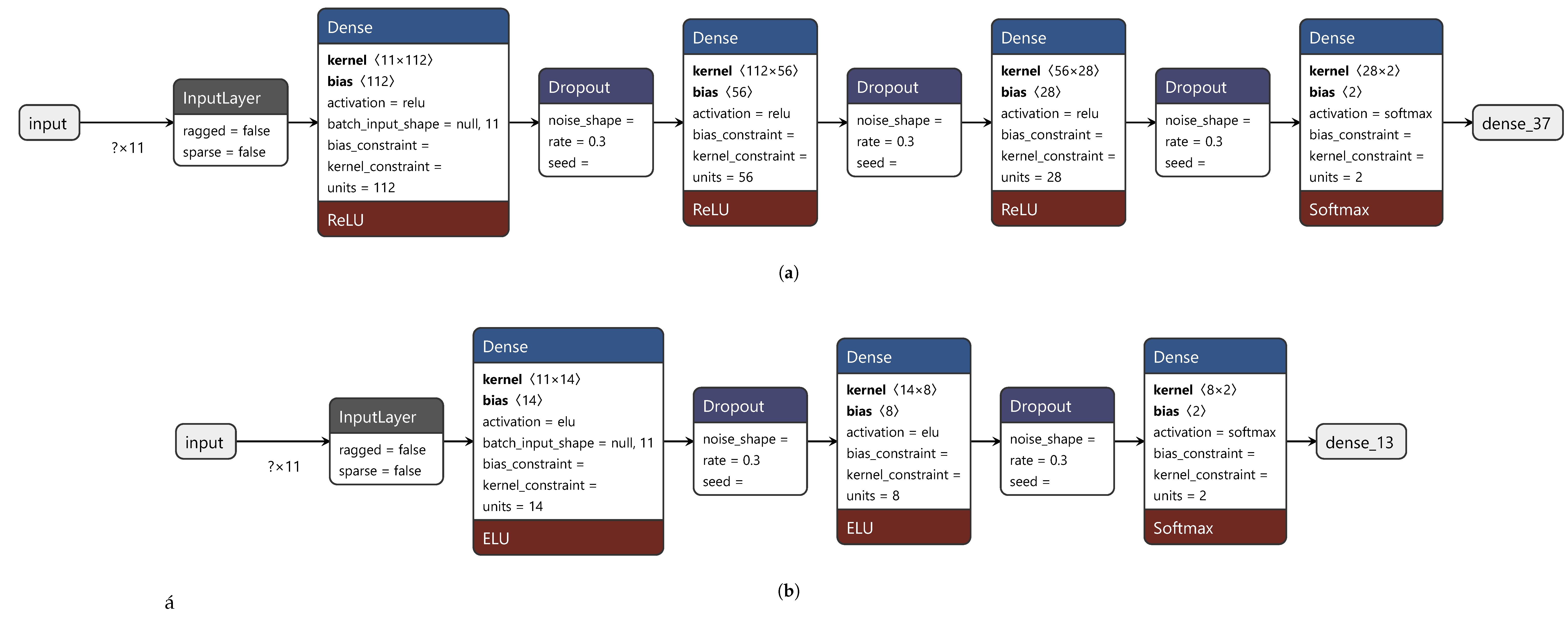
8)) on the test dataset was equal to 0.65 and too low for FDD in HVAC systems. Therefore, this study analyzed the performance of some ANN classifiers. The self-training aimed to train an ANN classifier. The model should classify data samples as related to faulty or normal operation. The output layer of the model contained two neurons and used softmax as the activation function. Hence, the model output the classification probability; i.e., the likelihood that a data sample belonged to each of the two classes (faulty operation, normal operation). This likelihood was taken as the confidence score. The input layer of the classifier took in all features in the dataset at hand (see
Section 2.3) as they were crucial for fault detection. The model was trained using Adam as optimizer, binary cross-entropy as the loss function and accuracy as metrics. The maximum number of epochs was set to 1000. The batch size was set to 64. A dropout of 0.3 was applied to the hidden layers as regularization technique. Moreover, in each learning iteration the model was trained using an early stopping scheme, which stopped the training if the performance of the model on the validation data did not improve after 50 training iterations. Dropout and early stopping prevented overfitting. The model weights from the epoch with the best value of the monitored quantity (here, validation loss) were used in the final model. The validation dataset was the same as the test dataset.
The performance of a classifier depends on the structure of the model and on its hyperparameters. The classifier was trained and tuned on four hyperparameters: (1) activation function; (2) number of hidden layers; (3) number of neurons per hidden layer; (4) L1 and L2 activity regularization in the input layer.
Table 3 lists candidate values of these hyperparameters.
We designed and tested Algorithm 1 to train the classifier:
| Algorithm 1 Function maximized by the differential evolution algorithm. The semi-supervised classifier was trained here. |
- 1:
procedureclassifierAccuracy(set of classifier hyperparameters) - 2:
use current hyperparameters to update the classifier - 3:
for j ∈ sets of learning parameters do - 4:
for k ∈ {1, …, number of learning iterations} do - 5:
run self-training iteration - 6:
compute BAS on the test set - 7:
end for - 8:
save BAS on the test set as j-th BAS - 9:
end for - 10:
return best BAS on the test set at current evaluation - 11:
end procedure
|
The sets of classifier hyperparameters were combinations of lists in
Table 3. The sets of learning parameters were all combinations of lists in
Table 2; i.e., their Cartesian product. A differential evolution algorithm [
37] as implemented in SciPy 1.8 [
38] aimed to maximize the value returned by the procedure in Algorithm 1; i.e., the best BAS on the test set at the last self-training iteration (i.e., at
number of learning iterations), over all sets of learning parameters. To this end, the SciPy algorithm evaluated the procedure up to 180 times, or until relative convergence was met. While doing so, it updated the classifier hyperparameters.
Accuracy Score (AS) and BAS assess the performance of the classifier; i.e., how well it predicts the right class. In binary classification they are defined as:
and
respectively.
are true positives;
are true negatives;
are false positives;
are false negatives.
.
.
is termed sensitivity;
is termed specificity. BAS is used for imbalanced datasets. Both BAS and AS range from 0 to 1; the higher the metrics, the better the classification. The classifier was expected to improve its performance during the self-training iterations so that its (balanced) accuracy score at the last iteration was higher than at the first.
All deep learning models used Keras 2.8 [
39].


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}