

Performance Evaluation of Chiller Fault Detection and Diagnosis Using Only Field-Installed Sensors

Abstract
:1. Introduction
- (1)
- Whether mainstream data-driven FDD methods can still achieve the expected performance when relying solely on features obtained from sensors universally installed on-site is investigated;
- (2)
- For each fault, insights into the optimal FDD performance achievable by data-driven models using solely field-installed sensors are provided;
- (3)
- The conclusions drawn provide guidance on whether additional sensor installations are necessary, serving as a reference for optimizing the cost–benefit ratio in chiller FDD.
2. Methods and Materials
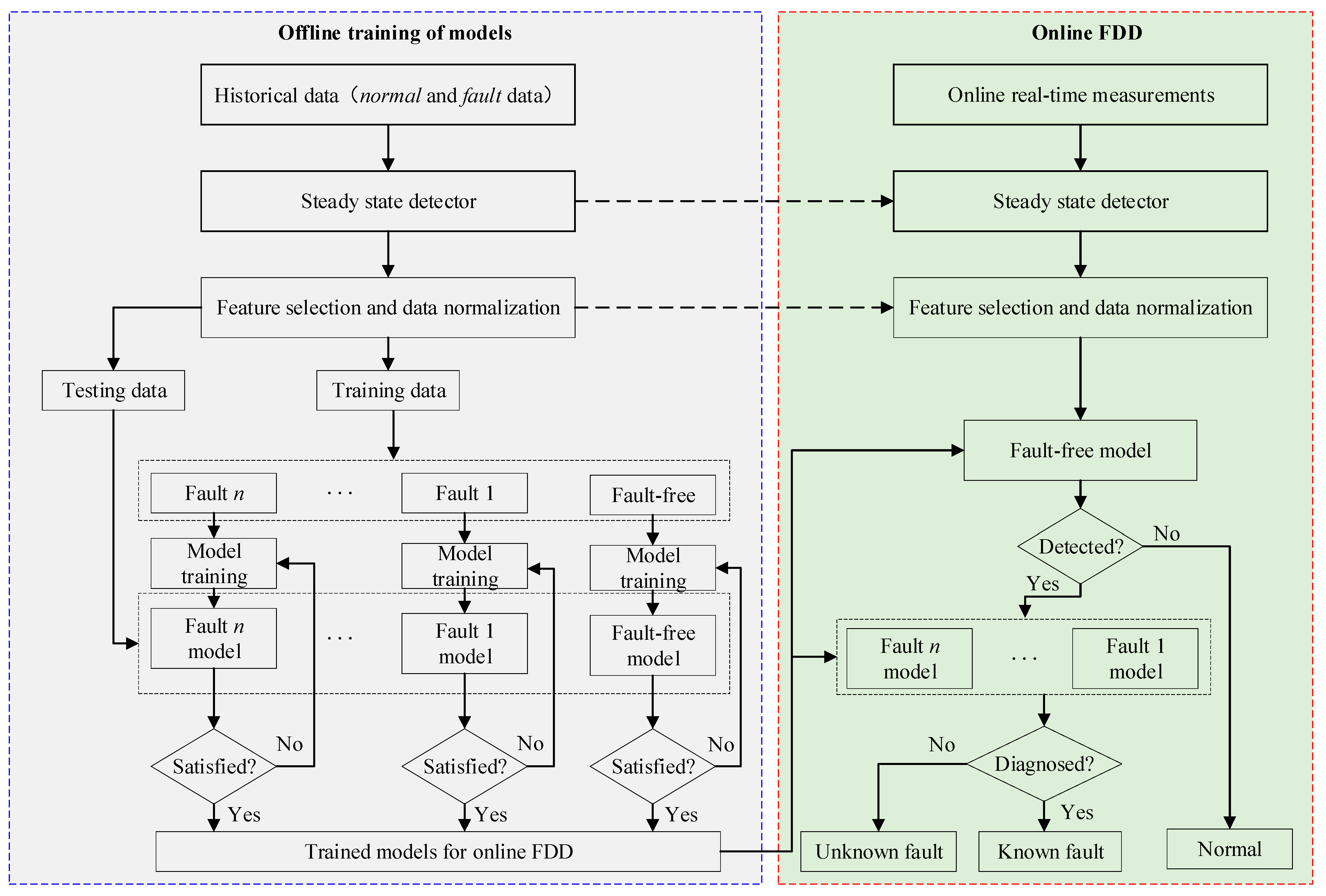
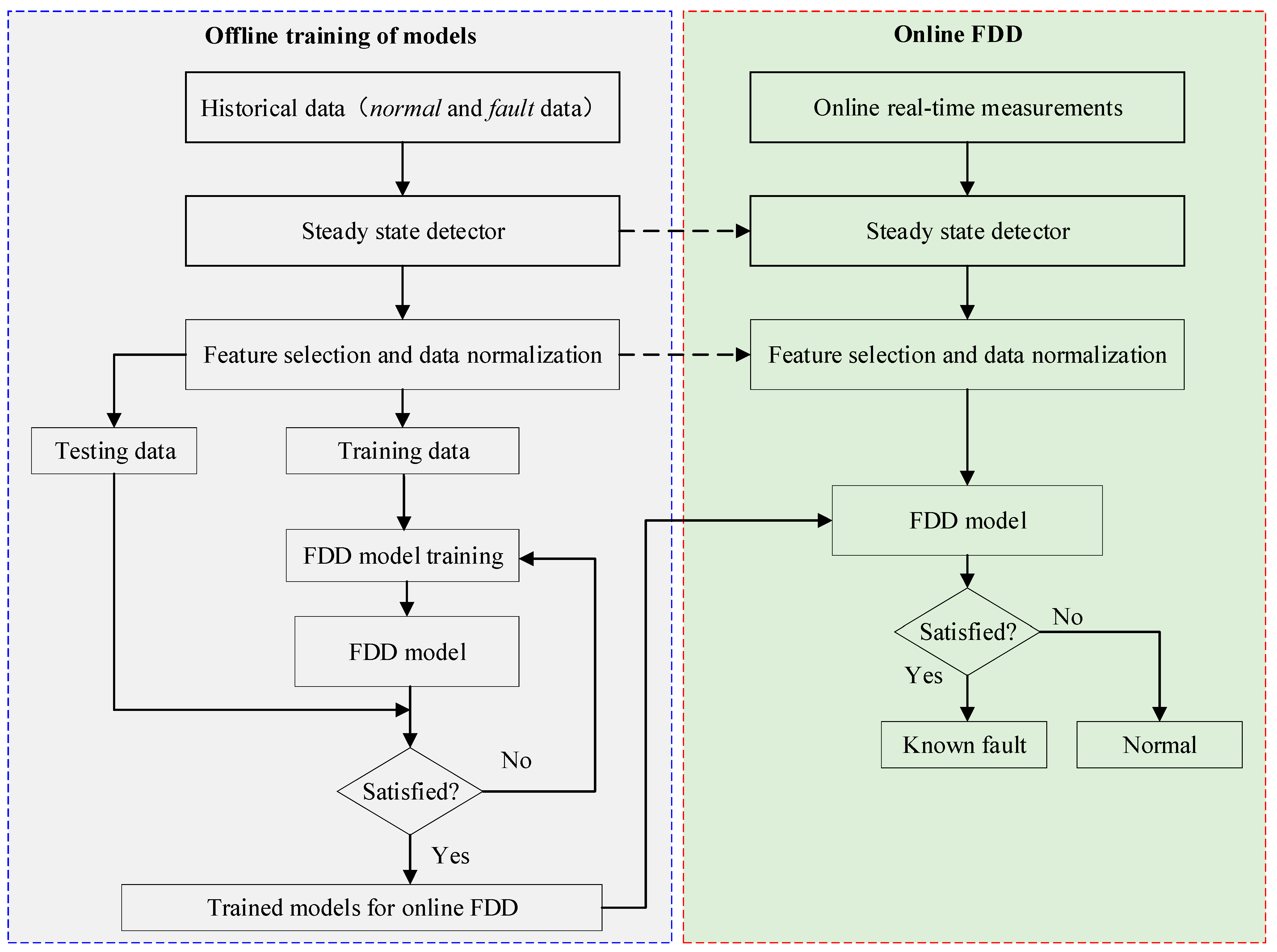
2.1. Frameworks of Data-Driven FDD Methods
2.1.1. One-Class Classification
2.1.2. Multi-Class Classification
2.2. Investigation of Field Chiller Onboard Sensors
2.3. Experimental Data and Model Evaluation
2.3.1. Experimental Data
2.3.2. Feature Selection and Data Pre-Processing
2.3.3. Development of Foundational FDD Models
3. Results and Discussions
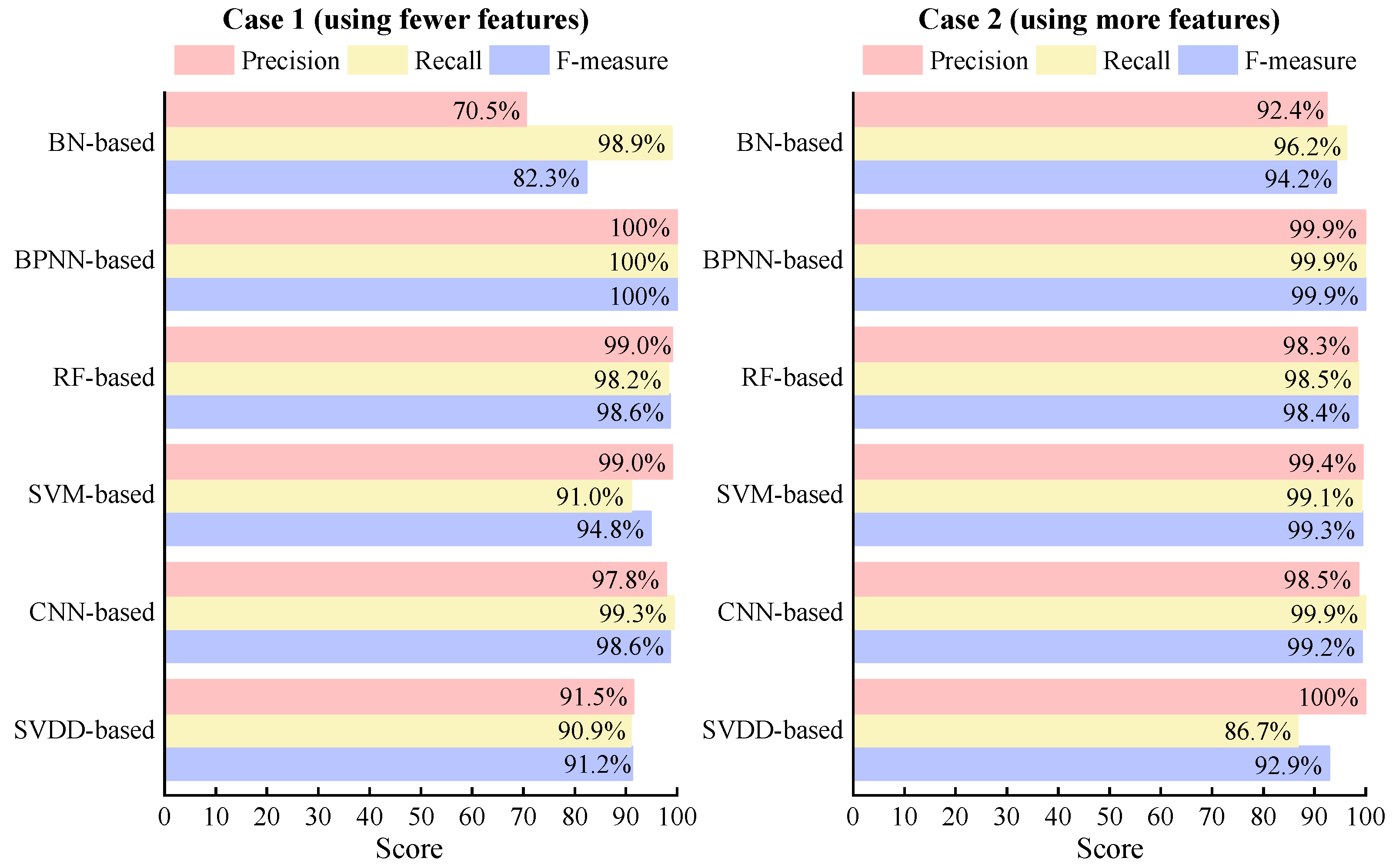
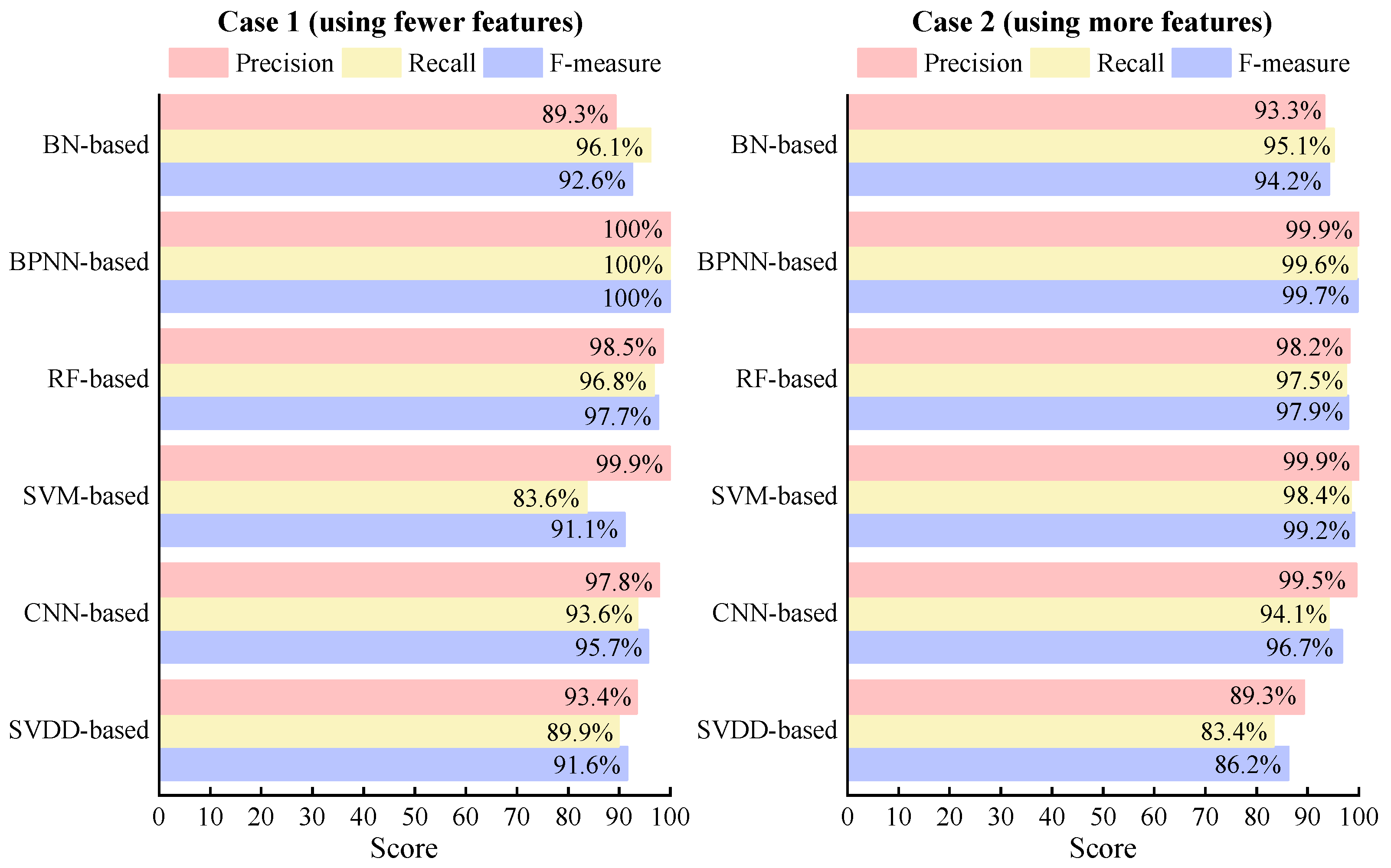
3.1. Fault Detection Results Using Foundational Models
3.2. Fault Diagnosis Results Using Foundational Models
3.2.1. Overall Fault Diagnosis Performance
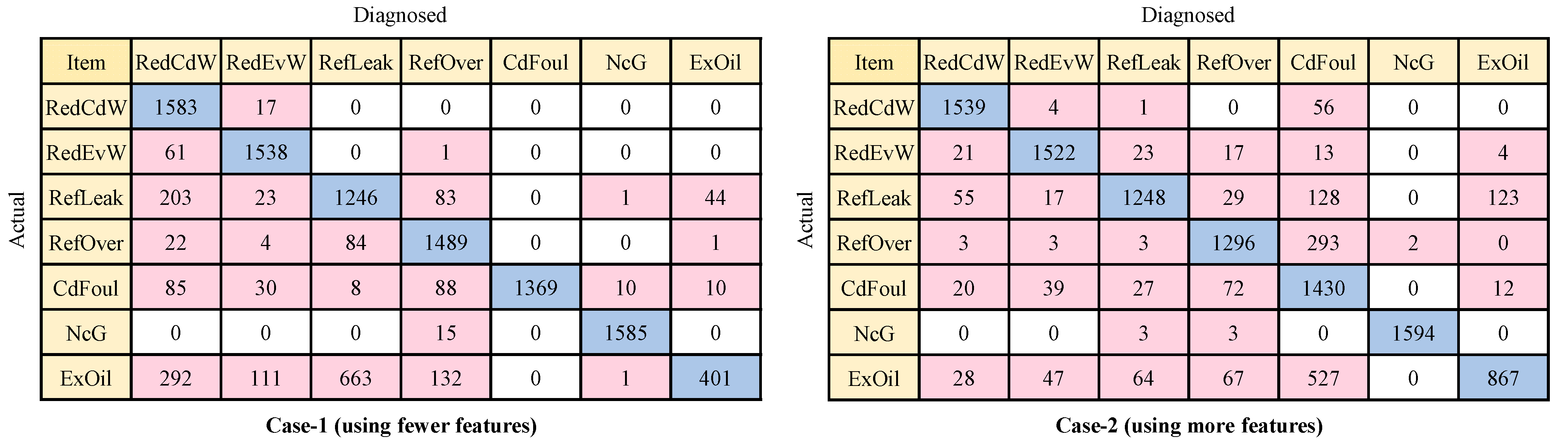
3.2.2. Individual Fault Diagnosis Performance
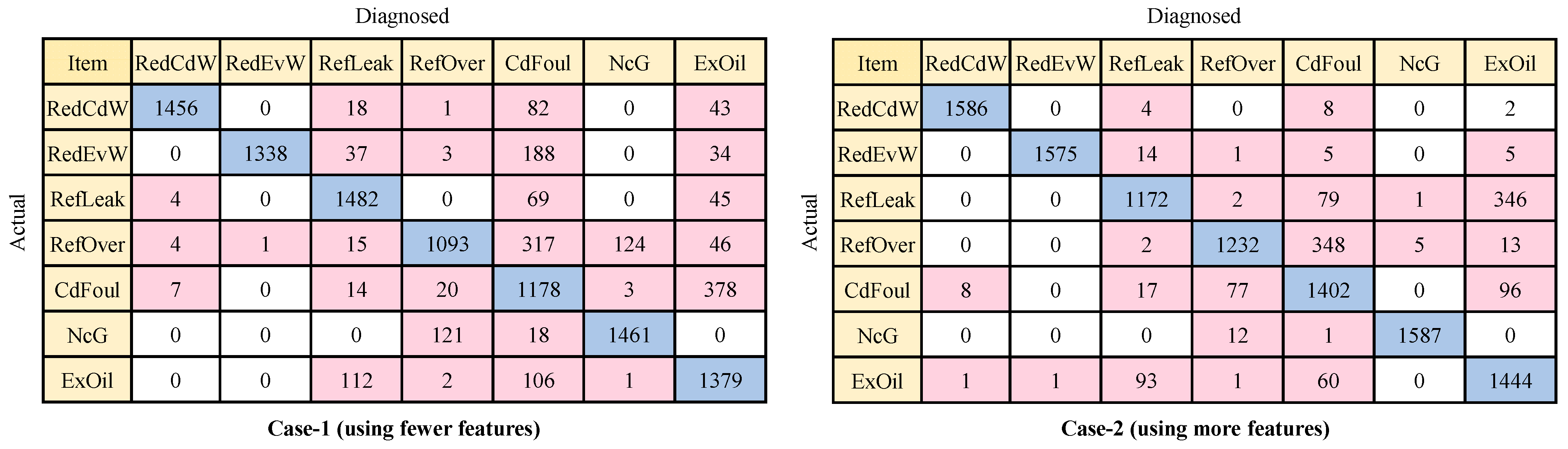
- (1)
- When utilizing only the features obtainable from field sensors, different data-driven methods yield diverse diagnostic results for different fault types. Considering both Case 1 and Case 2, almost all foundational FDD methods achieve F-measures over 80% for all seven faults. However, only a few foundational FDD methods achieve F-measures over 90% for all seven faults. This suggests that the features available in the field are feasible to obtain acceptable diagnostic performance for the seven typical faults but may not be sufficient to achieve excellent diagnostic performance. Further improvement might require additional features to enhance the diagnostic capabilities;
- (2)
- Based on the number of FDD methods with F-measures over 90% for each fault, when using only features obtainable from field sensors, RedCdW, RedEvW, and NcG are the easiest faults to diagnose. All six foundational FDD methods achieve F-measures over 90% for these three faults. RefLeak, CdFoul, and ExOil are relatively easier to diagnose, with five or four foundational methods achieving F-measures over 90% for each of them. On the other hand, RefOver is the most challenging fault to diagnose, with only three foundational methods achieving F-measures over 90%;
- (3)
- Upon analyzing the confusion matrix, it is evident that there is significant confusion between RefOver and CdFoul faults. For instance, for BN-, SVM-, and CNN-based methods, 293, 348, and 349 RefOver samples, respectively, were misdiagnosed as CdFoul. According to the experimental results [45], certain features used, such as , , and , exhibit similar changing trends when RefOver and CdFoul faults occur, and this similarity has a notable negative impact on the BN-, SVM-, and CNN-based methods. Therefore, it is necessary to supplement additional features for effective diagnosis of RefOver;
- (4)
- Further analysis reveals that when using the same feature combination, such as using features from either Case 1 or Case 2, the six foundational data-driven methods achieve different results in fault detection and diagnosis. Some methods show better FDD performance than the others. For example, in Case 1, the fault detection accuracy of the BN-based method is 18.5% higher than that of the CNN-based method, and the fault diagnosis accuracy of the BPNN-based method is 17.6% higher than that of the BN-based method. This indicates that different methods may have different optimal feature combinations to achieve the best FDD performance. This also highlights the necessity of feature selection for each method separately. Therefore, it is advisable to individually choose the optimal feature combination for each FDD method.
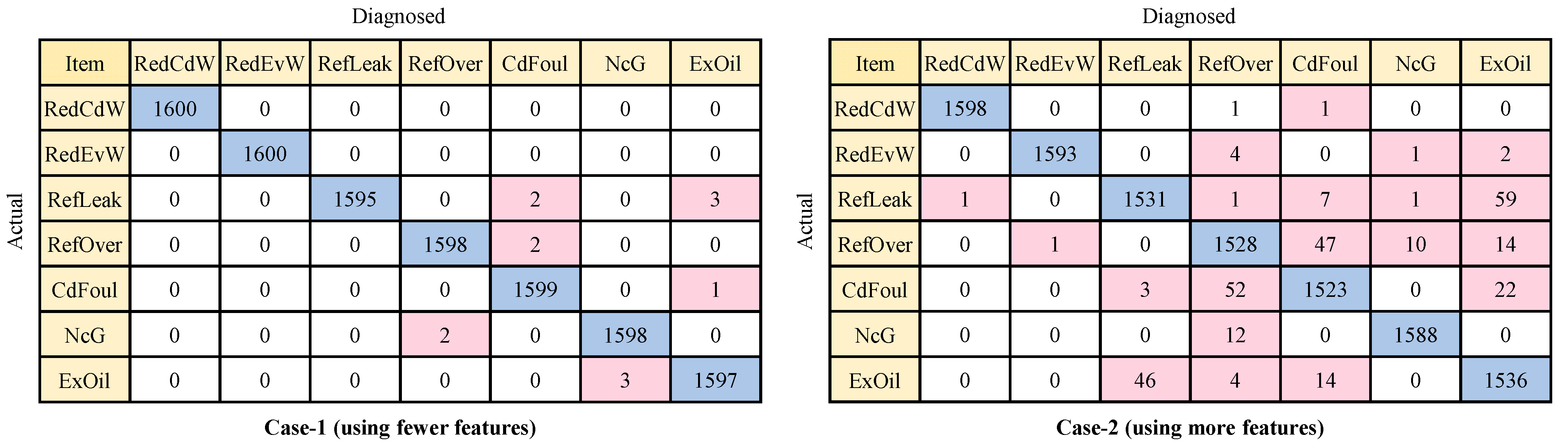
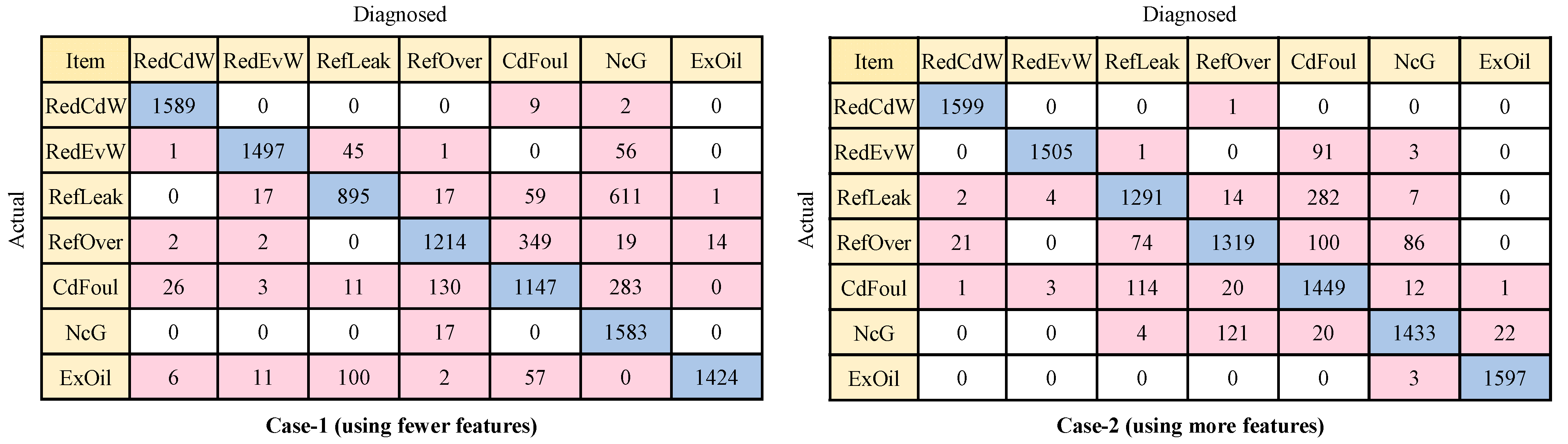
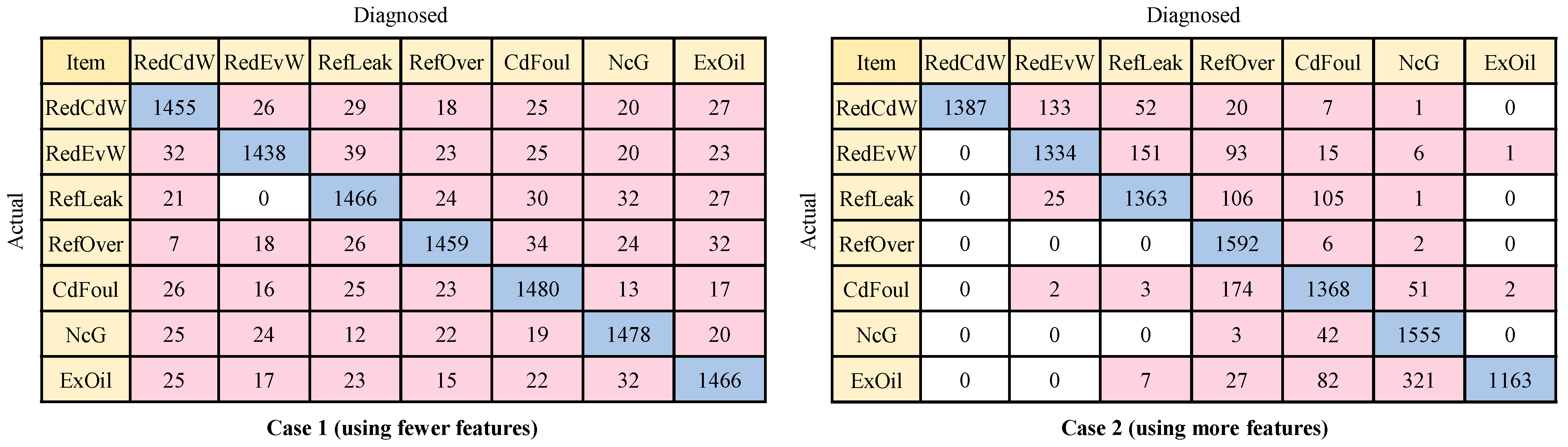
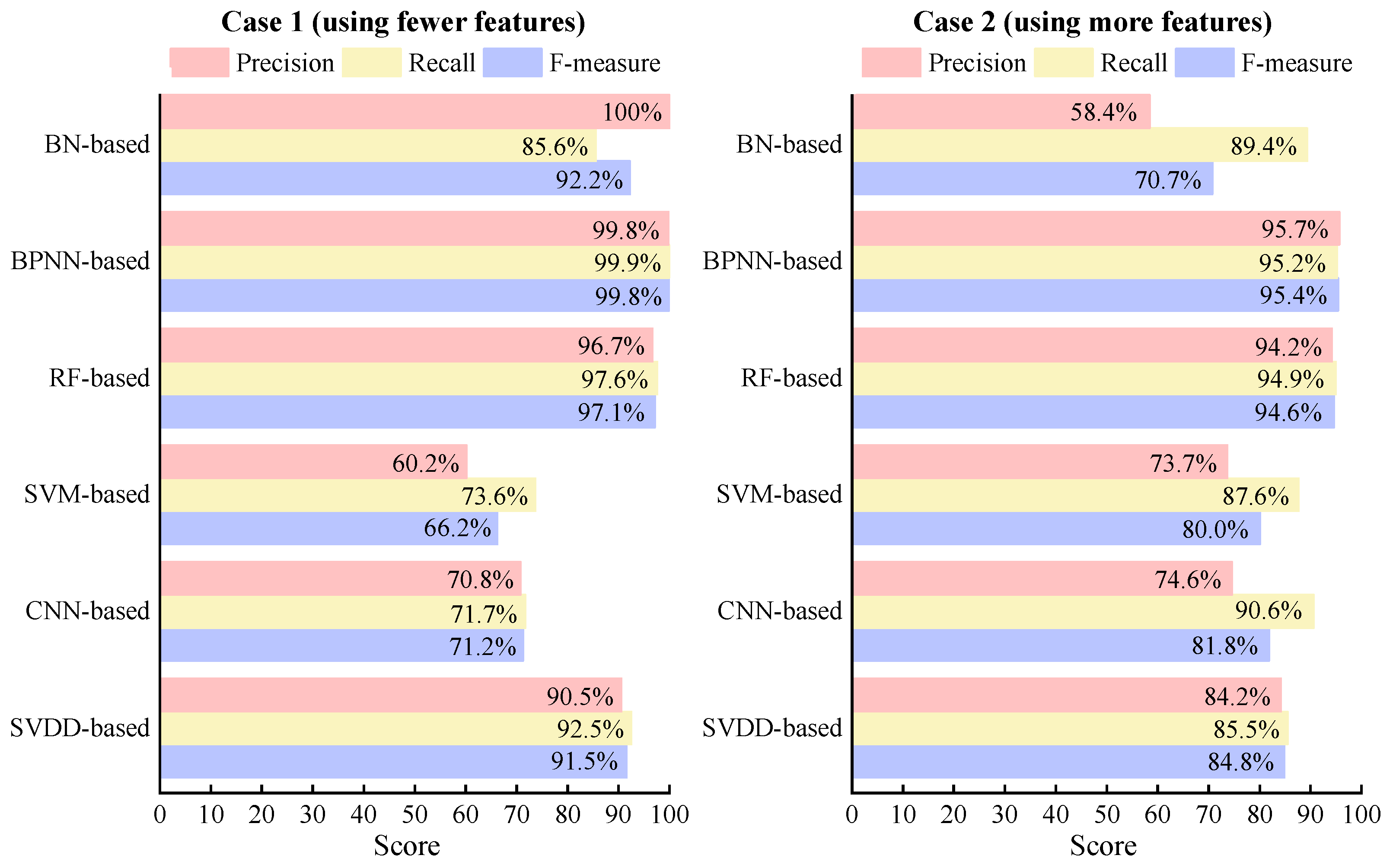
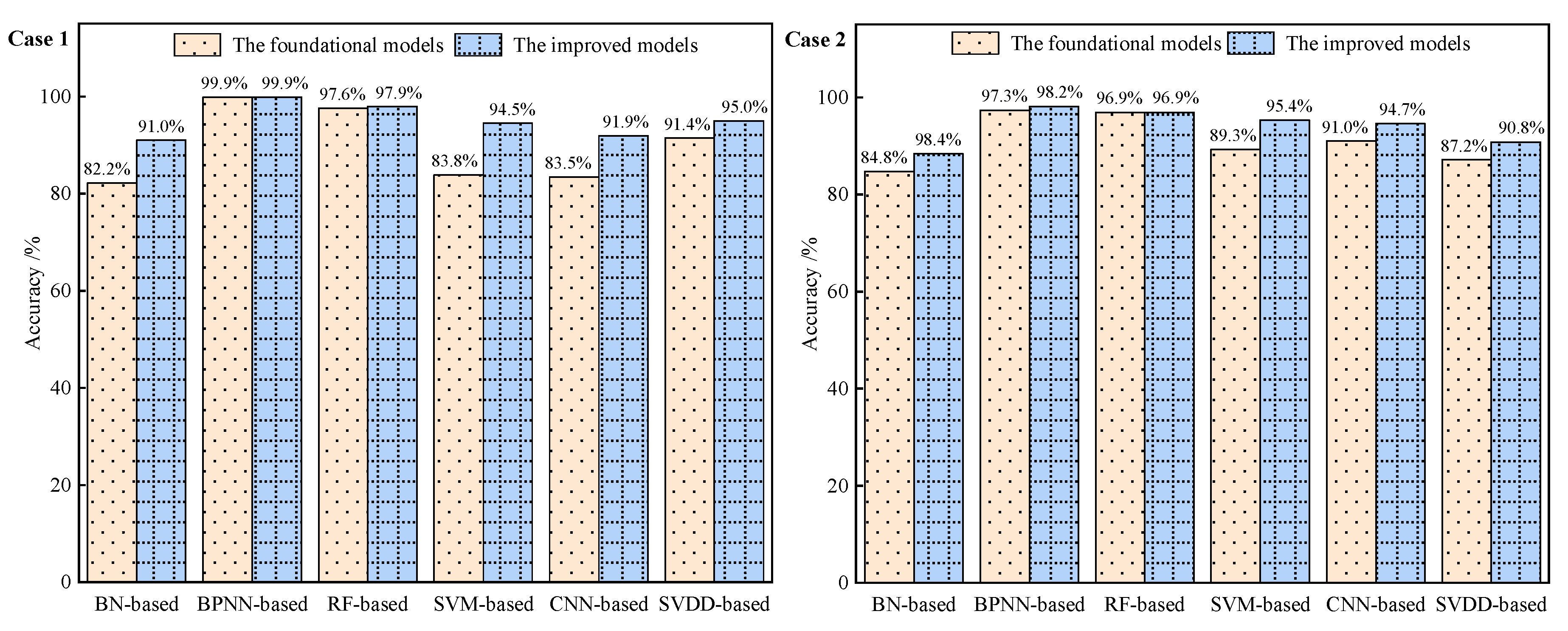
3.3. Fault Diagnosis Results Using Improved Models
3.4. Discussions
4. Conclusions
- (1)
- For these foundational models, considering the overall FDD performance, using features commonly available in the field is adequate to achieve acceptable FDD performance, such as accuracies or F-measures exceeding 80%. However, it falls short of obtaining excellent FDD performance, defined as accuracies or F-measures exceeding 90%. This conclusion provides valuable information for users/manufacturers with limited or no budget regarding the best diagnostic performance achievable using the current mainstream data-driven methods;
- (2)
- While the improved models result in enhanced diagnostic performance, they are accompanied by increased computational costs and longer training times. The findings indicate that after model optimization, all six models exhibited improved diagnostic performance, with the maximum improvement reaching 10.7% (SVM in Case 1). However, it is important to note that the training time significantly increased, ranging from 5 to 11 times;
- (3)
- Not all typical chiller faults require additional features to achieve excellent FDD performance. Based on the number of FDD methods with F-measures exceeding 90%, the faults of RedCdW, RedEvW, and NcG are the easiest to diagnose even without supplementing additional features. However, the fault of RefOver is the most challenging, with only three foundational methods achieving F-measures over 90%. The conclusion emphasizes the necessity of supplementing additional features for a more precise diagnosis of RefOver, providing valuable guidance for users/manu facturers aiming to enhance FDD performance;
- (4)
- Moreover, each method may require a distinct optimal feature combination to attain the best FDD performance. The impact of information redundancy within the feature set varies among different methods, with effects that can be either negative or positive. Consequently, it is crucial to individually choose the optimal feature combination for each method.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FDD | fault detection and diagnosis |
| HVAC | heating, ventilating, and air conditioning |
| RedCdW | reduced condenser water flow |
| RedEvW | reduced evaporator water flow |
| RefLeak | refrigerant leakage |
| RefOver | refrigerant overcharge |
| CdFoul | condenser fouling |
| NcG | non-condensable gas in refrigerant |
| ExOil | excess oil |
| BN | Bayesian network |
| BPNN | back-propagation neural network |
| RF | random forest |
| SVM | support vector machine |
| CNN | convolutional neural network |
| SVDD | support vector data description |
References
- Nalley, S. Annual Energy Outlook 2021; Energy Information Administration: Washington, DC, USA, 2021.
- Building Energy Conservation Research Center of Tsinghua University. China Building Energy Conservation Annual Development Report; China Building Industry Press: Beijing, China, 2021. [Google Scholar]
- Wang, Z.; Wang, L.; Ma, A.; Liang, K.; Song, Z.; Feng, L. Performance evaluation of ground water-source heat pump system with a fresh air pre-conditioner using ground water. Energy Convers. Manag. 2019, 188, 250–261. [Google Scholar] [CrossRef]
- Katipamula, S.; Brambley, M.R. Review Article: Methods for Fault Detection, Diagnostics, and Prognostics for Building Systems—A Review, Part I. HVACR Res. 2005, 11, 3–25. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, T.; Zhang, X.; Zhang, C. Artificial intelligence-based fault detection and diagnosis methods for building energy systems: Advantages, challenges and the future. Renew. Sustain. Energy Rev. 2019, 109, 85–101. [Google Scholar] [CrossRef]
- Mirnaghi, M.S.; Haghighat, F. Fault detection and diagnosis of large-scale HVAC systems in buildings using data-driven methods: A comprehensive review. Energy Build. 2020, 229, 110492. [Google Scholar] [CrossRef]
- Wei, Y.; Zhang, X.; Shi, Y.; Xia, L.; Pan, S.; Wu, J.; Han, M.; Zhao, X. A review of data-driven approaches for prediction and classification of building energy consumption. Renew. Sustain. Energy Rev. 2018, 82, 1027–1047. [Google Scholar] [CrossRef]
- Kim, W.; Katipamula, S. A review of fault detection and diagnostics methods for building systems. Sci. Technol. Built Environ. 2018, 24, 3–21. [Google Scholar] [CrossRef]
- Shi, Z.; O’Brien, W. Development and implementation of automated fault detection and diagnostics for building systems: A review. Autom. Constr. 2019, 104, 215–229. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, L.; Li, Y.; Shi, Y.; Gao, X.; Hu, Y. A review of computing-based automated fault detection and diagnosis of heating, ventilation and air conditioning systems. Renew. Sustain. Energy Rev. 2022, 161, 112395. [Google Scholar] [CrossRef]
- Chen, Z.; O’Neill, Z.; Wen, J.; Pradhan, O.; Yang, T.; Lu, X.; Lin, G.; Miyata, S.; Lee, S.; Shen, C.; et al. A review of data-driven fault detection and diagnostics for building HVAC systems. Appl. Energy 2023, 339, 121030. [Google Scholar] [CrossRef]
- Borda, D.; Bergagio, M.; Amerio, M.; Masoero, M.C.; Borchiellini, R.; Papurello, D. Development of Anomaly Detectors for HVAC Systems Using Machine Learning. Processes 2023, 11, 535. [Google Scholar] [CrossRef]
- Gao, Y.; Miyata, S.; Akashi, Y. Automated fault detection and diagnosis of chiller water plants based on convolutional neural network and knowledge distillation. Build. Environ. 2023, 245, 110885. [Google Scholar] [CrossRef]
- Gao, J.; Han, H.; Ren, Z.; Fan, Y. Fault diagnosis for building chillers based on data self-production and deep convolutional neural network. J. Build. Eng. 2021, 34, 102043. [Google Scholar] [CrossRef]
- Han, H.; Zhang, Z.; Cui, X.; Meng, Q. Ensemble learning with member optimization for fault diagnosis of a building energy system. Energy Build. 2020, 226, 110351. [Google Scholar] [CrossRef]
- Fan, Y.; Cui, X.; Han, H.; Lu, H. Feasibility and Improvement of Fault Detection and Diagnosis Based on Factory-Installed Sensors for Chillers. Appl. Therm. Eng. 2020, 164, 114506. [Google Scholar] [CrossRef]
- Ebrahimifakhar, A.; Kabirikopaei, A.; Yuill, D. Data-driven fault detection and diagnosis for packaged rooftop units using statistical machine learning classification methods. Energy Build. 2020, 225, 110318. [Google Scholar] [CrossRef]
- van de Sand, R.; Corasaniti, S.; Reiff-Stephan, J. Data-driven fault diagnosis for heterogeneous chillers using domain adaptation techniques. Control. Eng. Pract. 2021, 112, 104815. [Google Scholar] [CrossRef]
- Zhao, Y.; Xiao, F.; Wen, J.; Lu, Y.; Wang, S. A robust pattern recognition-based fault detection and diagnosis (FDD) method for chillers. HvacR Res. 2014, 20, 798–809. [Google Scholar] [CrossRef]
- Chen, K.; Wang, Z.; Gu, X.; Wang, Z. Multicondition operation fault detection for chillers based on global density-weighted support vector data description. Appl. Soft Comput. 2021, 112, 107795. [Google Scholar] [CrossRef]
- Zhang, C.; Peng, K.; Dong, J. An incipient fault detection and self-learning identification method based on robust SVDD and RBM-PNN. J. Process Control. 2020, 85, 173–183. [Google Scholar] [CrossRef]
- Wang, Z.; Liang, B.; Guo, J.J.; Wang, L.; Tan, Y.; Li, X. Fault diagnosis based on residual–knowledge–data jointly driven method for chillers. Eng. Appl. Artif. Intell. 2023, 125, 106768. [Google Scholar] [CrossRef]
- Wang, Z.; Liang, B.; Guo, J.J.; Wang, L.; Tan, Y.; Li, X.; Zhou, S. Fault Diagnosis Based on Fusion of Residuals and Data for Chillers. Processes 2023, 11, 2323. [Google Scholar] [CrossRef]
- Ng, K.H.; Yik, F.W.H.; Lee, P.; Lee, K.; Chan, D. Bayesian Method for HVAC Plant Sensor Fault Detection and Diagnosis. Energy Build. 2020, 228, 110476. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Y.; Zhang, C.; Luo, J.; Zhang, X. A knowledge-guided and data-driven method for building HVAC systems fault diagnosis. Build. Environ. 2021, 198, 107850. [Google Scholar] [CrossRef]
- Liu, Z.; Huang, Z.; Wang, J.; Yue, C.; Yoon, S. A novel fault diagnosis and self-calibration method for air-handling units using Bayesian Inference and virtual sensing. Energy Build. 2021, 250, 111293. [Google Scholar] [CrossRef]
- Li, P.; Anduv, B.; Zhu, X.; Jin, X.; Du, Z. Across working conditions fault diagnosis for chillers based on IoT intelligent agent with deep learning model. Energy Build. 2022, 268, 112188. [Google Scholar] [CrossRef]
- Choi, Y.; Yong, S. Autoencoder-driven fault detection and diagnosis in building automation systems: Residual-based and latent space-based approaches. Build. Environ. 2021, 203, 108066. [Google Scholar] [CrossRef]
- Yoo, Y.-J. Fault Detection Method Using Multi-mode Principal Component Analysis Based on Gaussian Mixture Model for Sewage Source Heat Pump System. Int. J. Control. Autom. Syst. 2019, 17, 2125–2134. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, H.; Guo, Y.; Wang, J.; Li, G.; Shen, L. Sensor fault detection and diagnosis for a water source heat pump air-conditioning system based on PCA and preprocessed by combined clustering. Appl. Therm. Eng. 2019, 160, 114098. [Google Scholar] [CrossRef]
- Zhang, C.; Xue, X.; Zhao, Y.; Zhang, X.; Li, T. An improved association rule mining-based method for revealing operational problems of building heating, ventilation and air conditioning (HVAC) systems. Appl. Energy 2019, 253, 113492. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, J.; Liu, C.; Zhu, J.; Lu, J.; Li, Y. Operation Pattern Recognition of the Refrigeration, Heating and Hot Water Combined Air-Conditioning System in Building Based on Clustering Method. Processes 2023, 11, 812. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, D.; Yan, R. Domain adaptation networks with parameter-free adaptively rectified linear units for fault diagnosis under variable operating conditions. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, D.; Zhang, H.; Wang, Q.-G. Dual-path mixed-domain residual threshold networks for bearing fault diagnosis. IEEE Trans. Ind. Electron. 2022, 69, 13462–13472. [Google Scholar] [CrossRef]
- Wang, D.; Yang, J.; Liu, X.; Yang, Q.; Wang, Q. Wavelet neural network approach for fault diagnosis to a chemical reactor. In Proceedings of the 2006 6th World Congress on Intelligent Control and Automation, Dalian, China, 21–23 June 2006; Volume 2, pp. 5764–5768. [Google Scholar]
- Comstock, M.C.; Braun, J.E.; Groll, E.A. The Sensitivity of Chiller Performance to Common Faults. HVACR Res. 2001, 7, 263–279. [Google Scholar] [CrossRef]
- Zhou, Q.; Wang, S.; Xiao, F. A Novel Strategy for the Fault Detection and Diagnosis of Centrifugal Chiller Systems. HVACR Res. 2009, 15, 57–75. [Google Scholar] [CrossRef]
- Bai, X.; Zhang, M.; Jin, Z.; You, Y.; Liang, C. Fault detection and diagnosis for Chiller based on Feature-recognition model and Kernel Discriminant Analysis. Sustain. Cities Soc. 2022, 79, 103708. [Google Scholar] [CrossRef]
- Zhang, L.; Frank, S.; Kim, J.; Jin, X.; Leach, M. A systematic feature extraction and selection framework for data-driven whole-building automated fault detection and diagnostics in commercial buildings. Build. Environ. 2020, 186, 107338. [Google Scholar] [CrossRef]
- Han, H.; Gu, B.; Wang, T.; Li, Z. Important sensors for chiller fault detection and diagnosis (FDD) from the perspective of feature selection and machine learning. Int. J. Refrig. 2011, 34, 586–599. [Google Scholar] [CrossRef]
- Gao, Y.; Han, H.; Ren, Z.X.; Gao, J.; Jiang, S.; Yang, Y. Comprehensive Study on Sensitive Parameters for Chiller Fault Diagnosis. Energy Build. 2021, 251, 111318. [Google Scholar] [CrossRef]
- Yan, K.; Ma, L.; Dai, Y.; Shen, W.; Ji, Z.; Xie, D. Cost-sensitive and Sequential Feature Selection for Chiller Fault Detection and Diagnosis. Int. J. Refrig. 2017, 86, 401–409. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Z.; Gu, X.; He, S.; Yan, Z. Feature selection based on Bayesian network for chiller fault diagnosis from the perspective of field applications. Appl. Therm. Eng. 2018, 129, 674–683. [Google Scholar] [CrossRef]
- Zhao, X.; Yang, M.; Li, H. Field implementation and evaluation of a decoupling-based fault detection and diagnostic method for chillers. Energy Build. 2014, 72, 419–443. [Google Scholar] [CrossRef]
- Comstock, M.C.; Braun, J.E. Development of Analysis Tools for the Evaluation of Fault Detection and Diagnostics for Chillers; ASHRAE Research Project 1043-RP, HL 99-20, Report #4036-3; Purdue University: West Lafayette, IN, USA, 1999. [Google Scholar]
- Rossi, T.M. Detection, Diagnosis, and Evaluation of Fault in Vapor Compressor Cycle Equipment. Ph.D. Thesis, Purdue University, West Lafayette, IN, USA, 1995. [Google Scholar]
- Wang, F. The use of artificial neural networks in a geographical information system for agricultural land-suitability assessment. Environ. Plan. A 1994, 26, 265–284. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Designation | Description | Formulation |
|---|---|---|---|
| 1 | Entering evaporator water temperature | Direct measurement | |
| 2 | Leaving evaporator water temperature | Direct measurement | |
| 3 | Entering condenser water temperature | Direct measurement | |
| 4 | Leaving condenser water temperature | Direct measurement | |
| 5 | Compressor input power | Direct measurement | |
| 6 | Evaporating temperature/pressure | Direct measurement | |
| 7 | Condensing temperature/pressure | Direct measurement | |
| 8 | Refrigerant discharge temperature | Direct measurement |
| No. | Designation | Description | Formulation |
|---|---|---|---|
| 1 | Evaporator water temperature difference | ||
| 2 | Condenser water temperature difference | ||
| 3 | Logarithmic mean temperature difference of evaporator | ||
| 4 | Logarithmic mean temperature difference of condenser | ||
| 5 | Evaporator approach temperature | ||
| 6 | Condenser approach temperature | ||
| 7 | Refrigerant discharge superheat temperature | ||
| 8 | Heat transfer efficiency in saturation section of condenser | ||
| 9 | Heat transfer efficiency in superheat section of condenser | ||
| 10 | Heat transfer efficiency in saturation section of evaporator |
| Case | Models | BN-Based | BPNN-Based | RF-Based | SVN-Based | CNN-Based | SVDD-Based |
|---|---|---|---|---|---|---|---|
| Case 1 | The foundational models | 344.2 s | 344.2 s | 344.2 s | 344.2 s | 344.2 s | 344.2 s |
| The improved models | 2019.4 s | 1749.3 s | 1321.2 s | 1927.3 s | 1141.4 s | 1582.6 s | |
| Case 2 | The foundational models | 382.4 s | 452.8 s | 139.1 s | 316.5 s | 315.4 s | 272.4 s |
| The improved models | 2346.9 s | 2079.3 s | 1658.6 s | 2467.5 s | 1352.1 s | 2049.5 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Guo, J.; Zhou, S.; Xia, P. Performance Evaluation of Chiller Fault Detection and Diagnosis Using Only Field-Installed Sensors. Processes 2023, 11, 3299. https://doi.org/10.3390/pr11123299
Wang Z, Guo J, Zhou S, Xia P. Performance Evaluation of Chiller Fault Detection and Diagnosis Using Only Field-Installed Sensors. Processes. 2023; 11(12):3299. https://doi.org/10.3390/pr11123299
Chicago/Turabian StyleWang, Zhanwei, Jingjing Guo, Sai Zhou, and Penghua Xia. 2023. "Performance Evaluation of Chiller Fault Detection and Diagnosis Using Only Field-Installed Sensors" Processes 11, no. 12: 3299. https://doi.org/10.3390/pr11123299
APA StyleWang, Z., Guo, J., Zhou, S., & Xia, P. (2023). Performance Evaluation of Chiller Fault Detection and Diagnosis Using Only Field-Installed Sensors. Processes, 11(12), 3299. https://doi.org/10.3390/pr11123299