
Solutions of Feature and Hyperparameter Model Selection in the Intelligent Manufacturing


Abstract
:1. Introduction
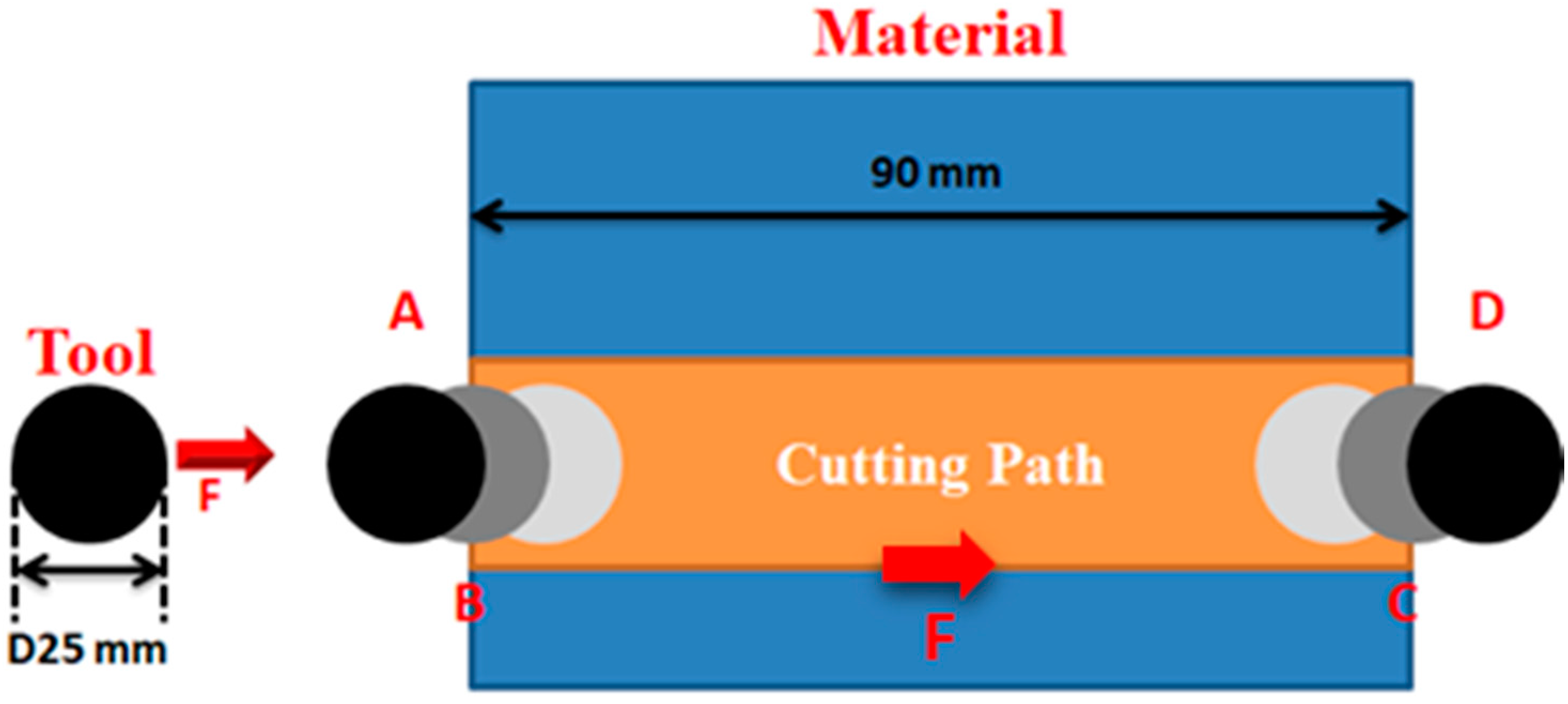
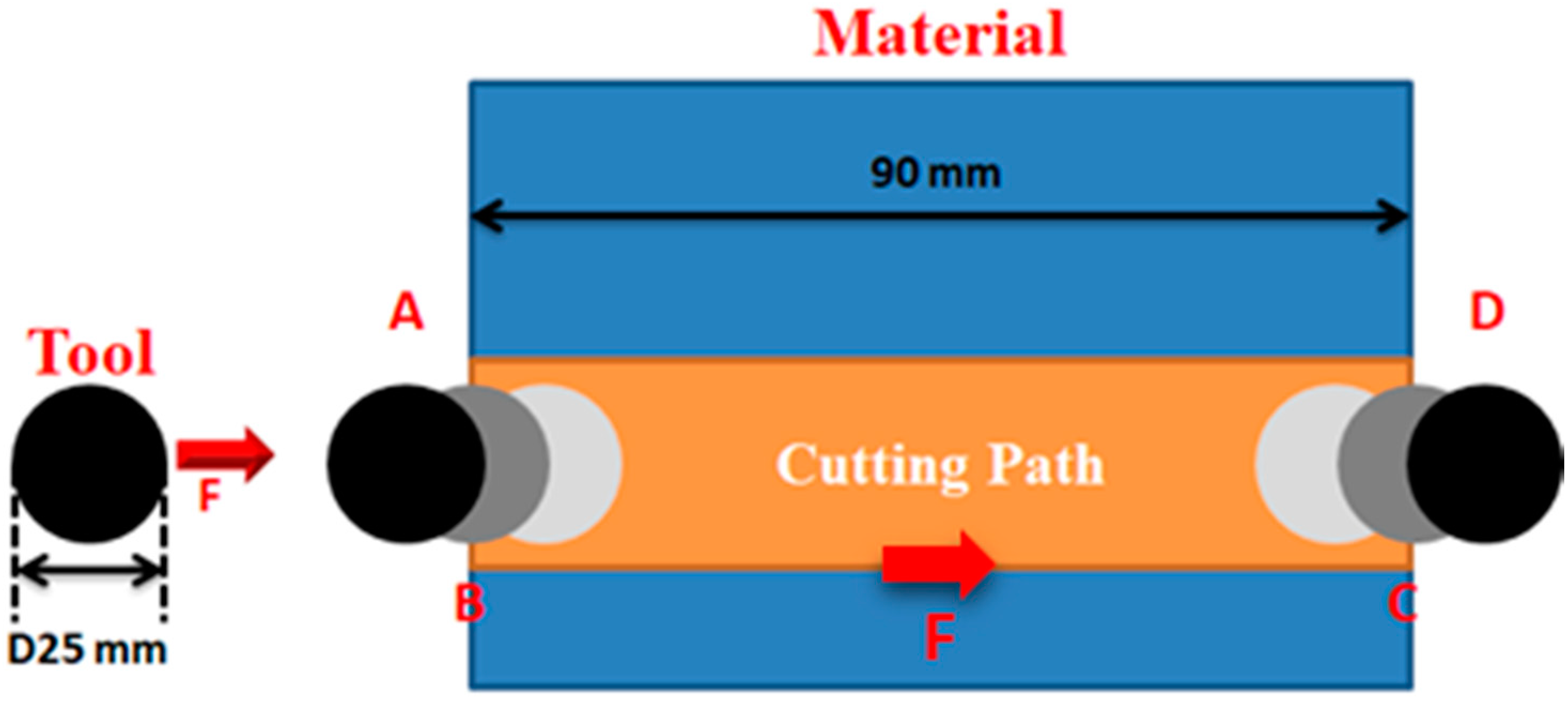
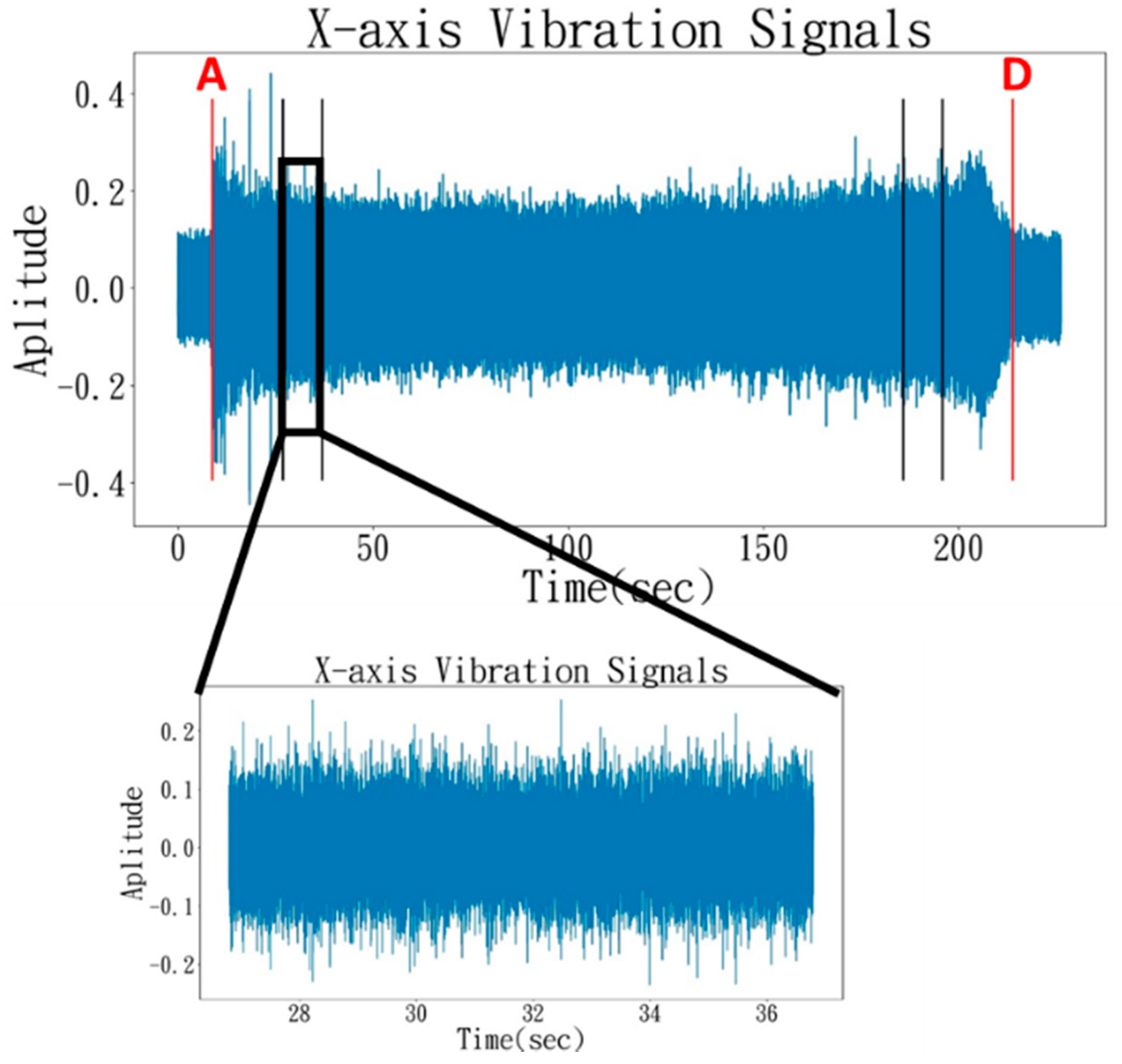
2. Experimental Setup
3. Sensors and Features Selection System
3.1. Methodology
3.1.1. Correlation Coefficient
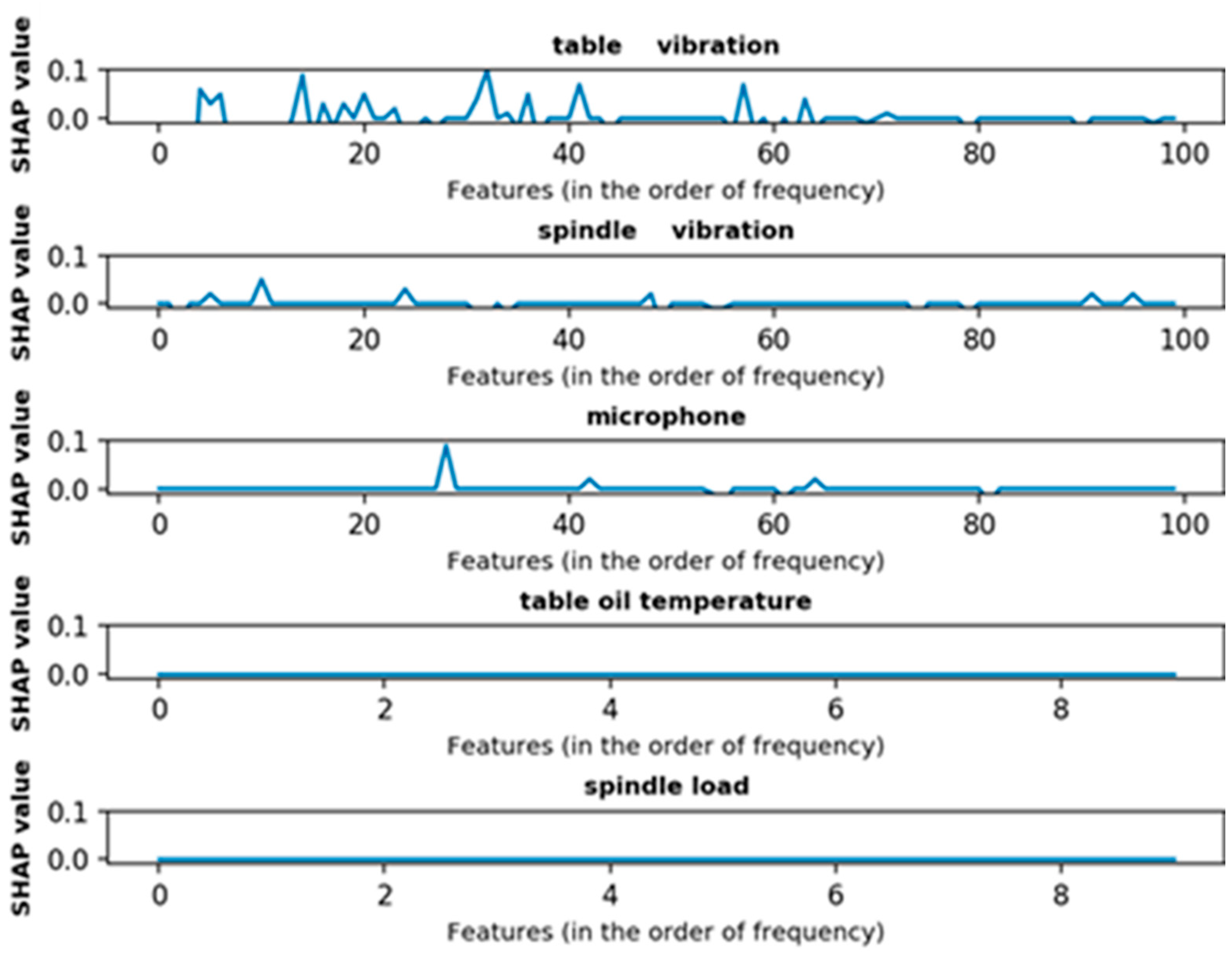
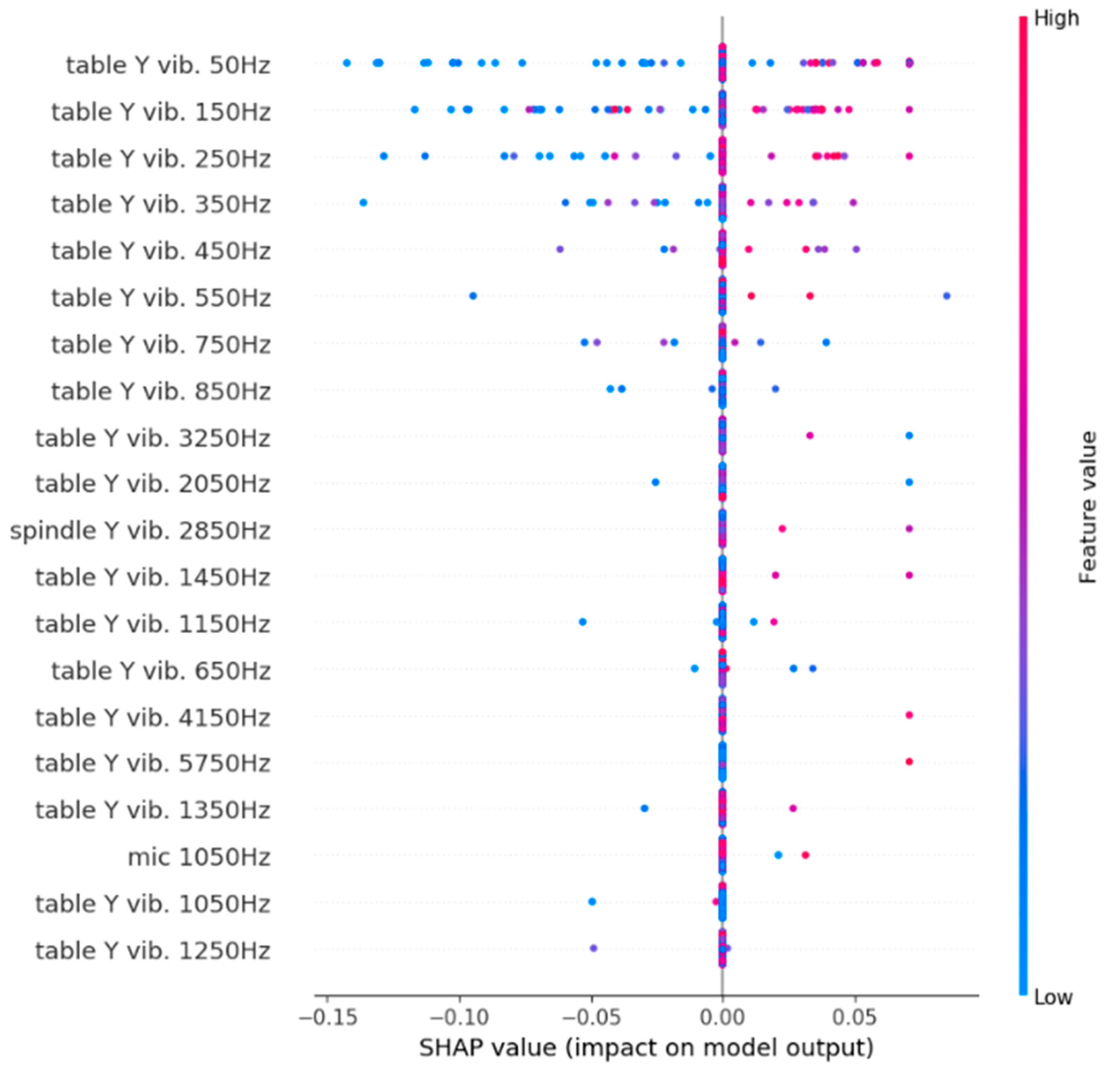
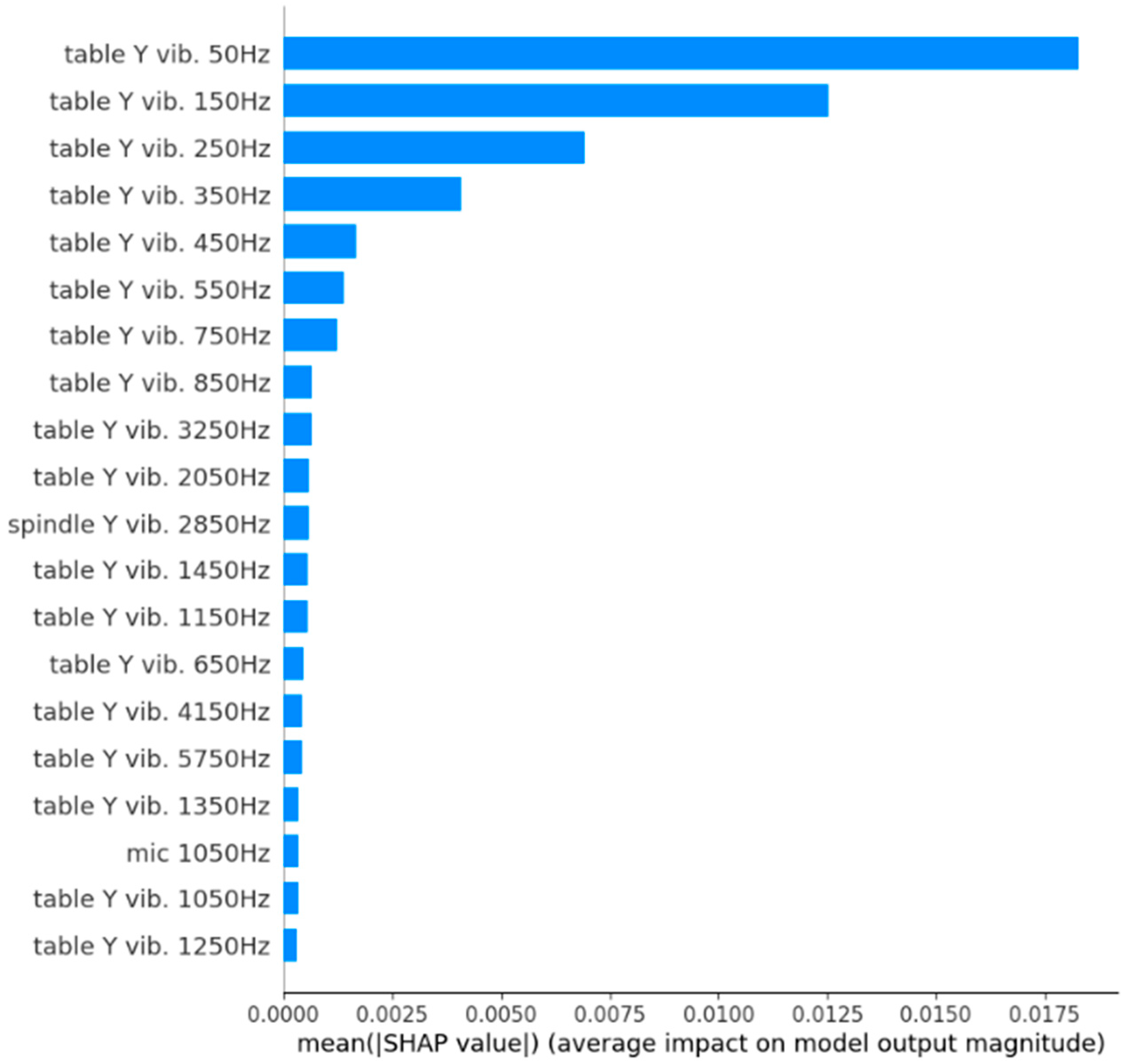
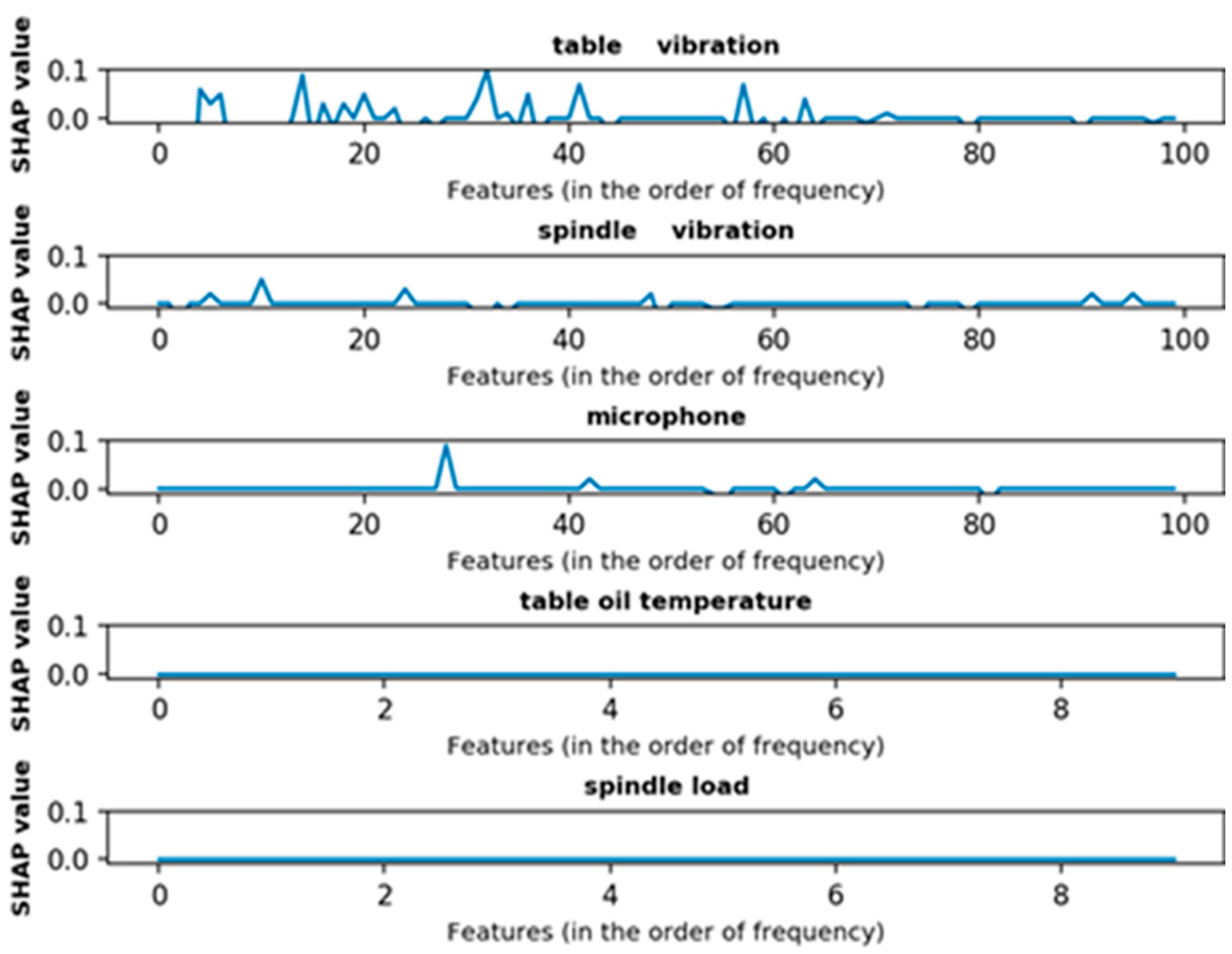
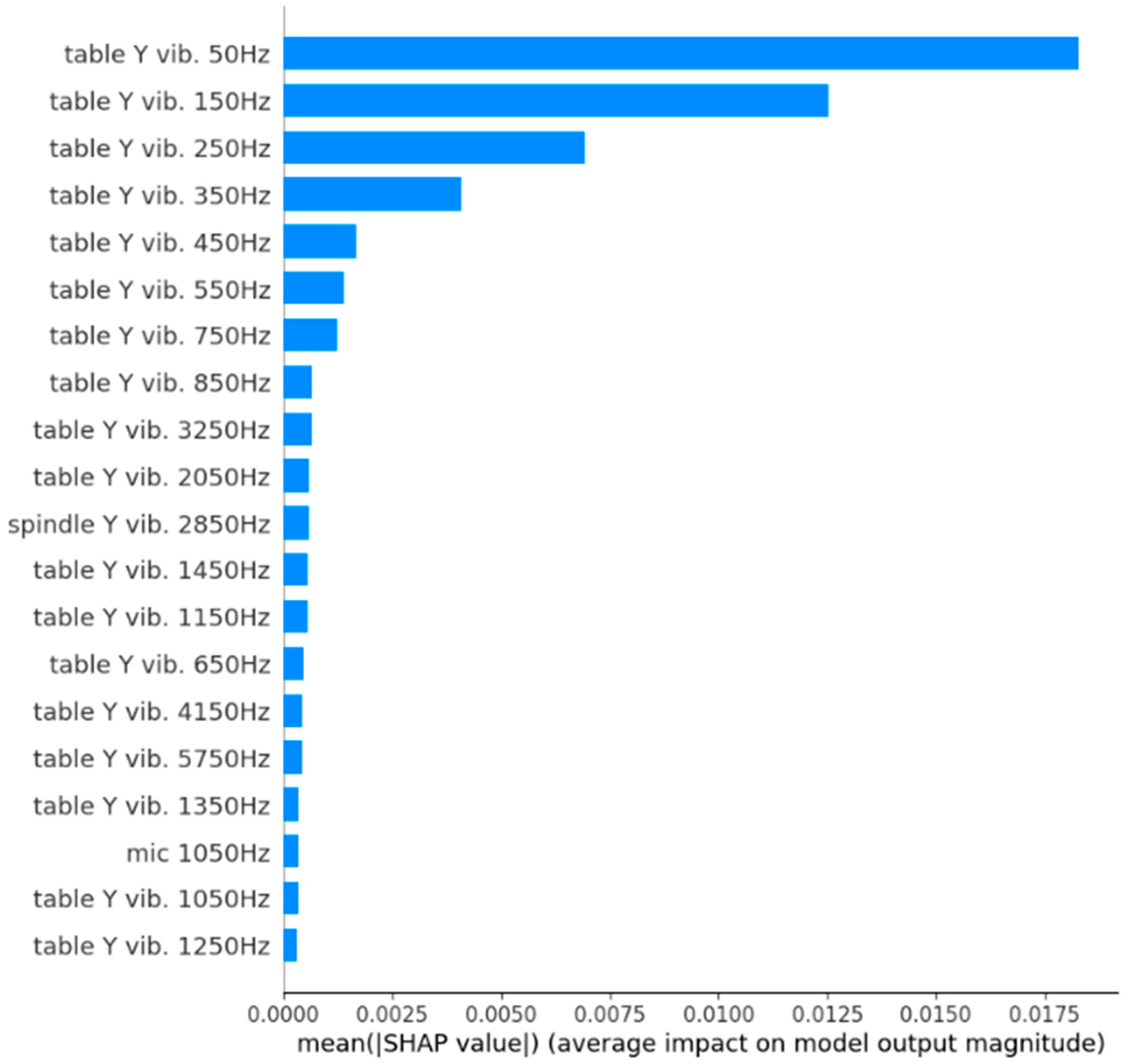
3.1.2. Shapley Additive ExPlanations (SHAP)
3.2. Results
4. Hyperparameters Optimization with Tree-Structured Parzen Estimator (TPE)
4.1. Methodology
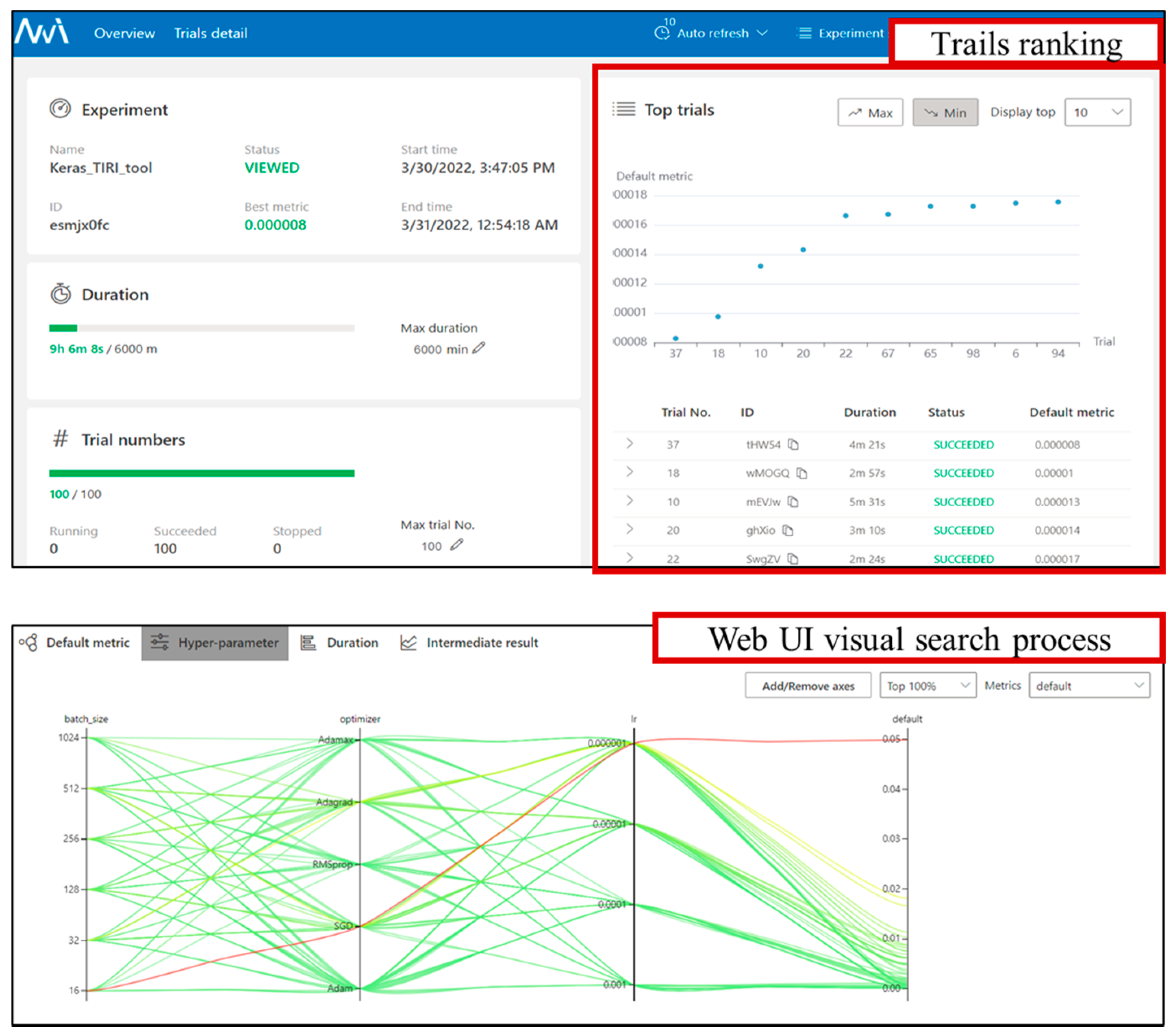
4.2. Cloud Service of Automated HPO
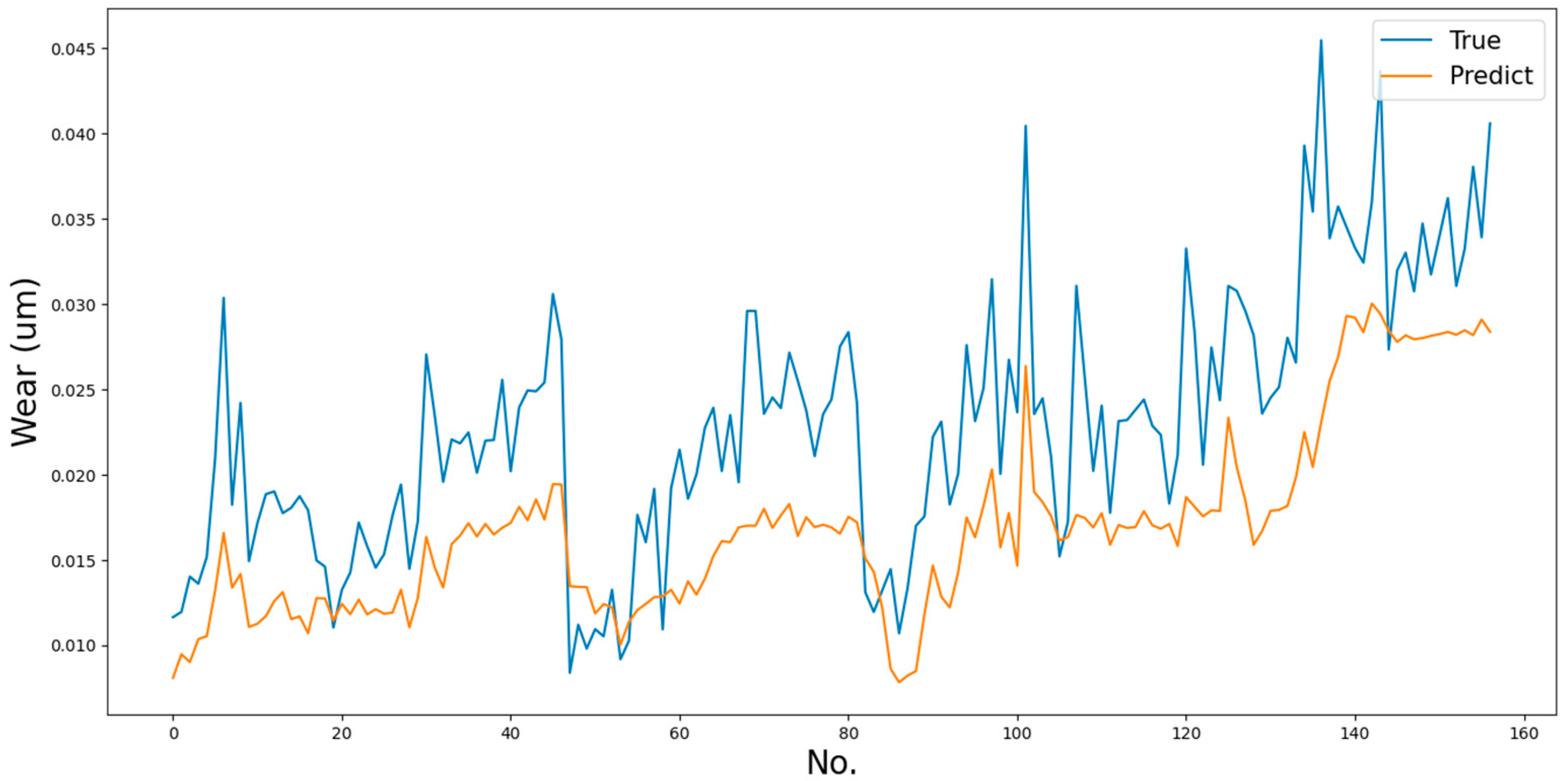
4.3. Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef] [Green Version]
- Hu, B.; Yang, J.; Li, J.; Li, S.; Bai, H. Intelligent Control Strategy for Transient Response of a Variable Geometry Turbocharger System Based on Deep Reinforcement Learning. Processes 2019, 7, 601. [Google Scholar] [CrossRef] [Green Version]
- Tchakoua, P.; Wamkeue, R.; Ouhrouche, M.; Slaoui-Hasnaoui, F.; Tameghe, T.A.; Ekemb, G. Wind Turbine Condition Monitoring: State-of-the-Art Review, New Trends, and Future Challenges. Energies 2014, 7, 2595–2630. [Google Scholar] [CrossRef] [Green Version]
- Majumder, S.; Mondal, T.; Deen, M.J. Wearable Sensors for Remote Health Monitoring. Sensors 2017, 17, 130. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Li, W. Multisensor Feature Fusion for Bearing Fault Diagnosis Using Sparse Autoencoder and Deep Belief Network. IEEE Trans. Instrum. Meas. 2017, 66, 1693–1702. [Google Scholar] [CrossRef]
- Liu, T.; Zhu, K. Intelligent robust milling tool wear monitoring via fractal analysis of cutting force. In Proceedings of the 2017 13th IEEE Conference on Automation Science and Engineering (CASE), Xi’an, China, 20–23 August 2017; pp. 1254–1259. [Google Scholar]
- Mohanta, N.; Singh, R.K.; Sharma, A.K. Online Monitoring System for Tool Wear and Fault Prediction Using Artificial Intelligence. In Proceedings of the 2020 International Conference on Contemporary Computing and Applications (IC3A), Lucknow, India, 5–7 February 2020; pp. 310–314. [Google Scholar]
- Fu, Y.; Gao, Z.; Liu, Y.; Zhang, A.; Yin, X. Actuator and Sensor Fault Classification for Wind Turbine Systems Based on Fast Fourier Transform and Uncorrelated Multi-Linear Principal Component Analysis Techniques. Processes 2020, 8, 1066. [Google Scholar] [CrossRef]
- Gao, Z.; Liu, X. An Overview on Fault Diagnosis, Prognosis and Resilient Control for Wind Turbine Systems. Processes 2021, 9, 300. [Google Scholar] [CrossRef]
- Zhu, Q.; Sun, B.; Zhou, Y.; Sun, W.; Xiang, J. Sample Augmentation for Intelligent Milling Tool Wear Condition Monitoring Using Numerical Simulation and Generative Adversarial Network. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Givnan, S.; Chalmers, C.; Fergus, P.; Ortega-Martorell, S.; Whalley, T. Anomaly Detection Using Autoencoder Reconstruction upon Industrial Motors. Sensors 2022, 22, 3166. [Google Scholar] [CrossRef]
- Wang, A.; Li, Y.; Yao, Z.; Zhong, C.; Xue, B.; Guo, Z. A Novel Hybrid Model for the Prediction and Classification of Rolling Bearing Condition. Appl. Sci. 2022, 12, 3854. [Google Scholar] [CrossRef]
- Cai, W.; Zhang, W. A hybrid information model based on long short-term memory network for tool condition monitoring. J. Intell. Manuf. 2020, 31, 1497–1510. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Proc. Adv. Neural Inf. Process. Syst. 2017, 30, 4765–4774. [Google Scholar]
- Cohen, S.; Ruppin, E.; Dror, G. Feature Selection Based on the Shapley Value. In Proceedings of the 19th International Joint Conference on Artificial Intelligence (IJCAI’05), Edinburgh, UK, 30 July–5 August 2005; pp. 665–670. [Google Scholar] [CrossRef]
- Byun, S.; Moussavinik, H.; Balasingham, I. Fair allocation of sensor measurements using Shapley value. In Proceedings of the 2009 IEEE 34th Conference on Local Computer Networks, Zurich, Switzerland, 20–23 October 2009; pp. 459–466. [Google Scholar] [CrossRef]
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An explainable machine learning framework for intrusion detection systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Serin, G.; Sener, B. Review of tool condition monitoring in machining and opportunities for deep learning. Int. J. Adv. Manuf. Technol. 2020, 109, 953–974. [Google Scholar] [CrossRef]
- Liu, W.; Luo, F.; Liu, Y.; Ding, W. Optimal Siting and Sizing of Distributed Generation Based on Improved Nondominated Sorting Genetic Algorithm II. Processes 2019, 7, 955. [Google Scholar] [CrossRef] [Green Version]
- Real, E.; Liang, C.; So, D.; Le, Q. AutoML-Zero: Evolving Machine Learning Algorithms from Scratch. In Proceedings of the 37th International Conference on Machine Learning (ICML 2020), Vienna, Austria, 12–18 July 2020. [Google Scholar]
- Tsiakmaki, M.; Kostopoulos, G.; Kotsiantis, S.; Ragos, O. Implementing AutoML in Educational Data Mining for Prediction Tasks. Appl. Sci. 2020, 10, 90. [Google Scholar] [CrossRef] [Green Version]
- Lin, M.; Wang, P.; Sun, Z.; Chen, H.; Sun, X.; Qian, Q.; Li, H.; Jin, R. Zen-NAS: A Zero-Shot NAS for High-Performance Deep Image. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 337–346. [Google Scholar]
- Chen, M.; Peng, H.; Fu, J.; Ling, H. AutoFormer: Searching Transformers for Visual Recognition. In Proceedings of the 2021 IEEE CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Luo, Z.; He, Z.; Wang, J.; Dong, M.; Huang, J.; Chen, M.; Zheng, B. AutoSmart: An Efficient and Automatic Machine Learning framework for Temporal Relational Data. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, KDD ’21, Singapore, 14–18 August 2021; pp. 3976–3984. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. In Proceedings of the 24th International Conference on Neural Information Processing Systems, NIPS’11, Granada, Spain, 12–15 December 2011; pp. 2546–2554. [Google Scholar]
- Hutter, F.; Hoos, H.H.; Leyton-Brown, K. Sequential Model-Based Optimization for General Algorithm Configuration. In Proceedings of the 5th international conference on Learning and Intelligent Optimization, LION’05, Athens, Greece, 20–25 June 2021; pp. 507–523. [Google Scholar]
- Swersky, K.; Duvenaud, D.; Snoek, J.; Hutter, F.; Osborne, M.A. Raiders of the lost architecture: Kernels for Bayesian optimization in conditional parameter spaces. In Proceedings of the NIPS Workshop on Bayesian Optimization in Theory and Practice (BayesOpt’13), Lake Tahoe, NV, USA, 10 December 2013. [Google Scholar]
- Neural Network Intelligence, April 2021. Available online: https://github.com/microsoft/nni (accessed on 28 February 2022).
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3149–3157. [Google Scholar]
- Bergstra, J.; Komer, B.; Eliasmith, C.; Yamins, D.; Cox, D.D. Hyperopt: A python library for model selection and hyperparameter optimization. Comput. Sci. Discov. 2015, 8, 014008. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool Number | Spindle Speed (rpm) | Feed Rate (mm/min) | Depth (mm) | Number of Path |
| 1 | 800 | 40 | 0.3 | 33 |
| 2 | 600 | 20 | 0.3 | 20 |
| 3 | 400 | 20 | 0.3 | 35 |
| 4 | 800 | 20 | 0.3 | 75 |
| Sensor | Frequency Range | Install Location |
|---|---|---|
| Accelerometer | 0–8 kHz | Spindle |
| Accelerometer | 0–8 kHz | Worktable |
| Condense Microphone | 0–20 kHz | Spindle |
| Thermocouple | 1 Hz | Worktable |
| Spindle load | 24 Hz | - |
| Sensor | Highly Correlated r > 0.7 | Moderately Correlated 0.7 > r > 0.4 | Highly Correlated ρ > 0.7 |
|---|---|---|---|
| Accelerometer on worktable | 1651 | 1703 | 0 |
| Accelerometer on spindle | 12,544 | 32,549 | 1002 |
| Condense microphone | 1380 | 1075 | 0 |
| Thermocouple | 1 | 0 | 0 |
| Spindle load | 1 | 0 | 0 |
| Features | Largest SHAP Value | Features | Smallest SHAP Value | ||
|---|---|---|---|---|---|
| table | 3250 Hz | 0.1 | table | 150 Hz | −0.56 |
| table | 1450 Hz | 0.09 | table | 250 Hz | −0.46 |
| spindle | 2850 Hz | 0.09 | table | 350 Hz | −0.26 |
| table | 4150 Hz | 0.07 | table | 50 Hz | −0.24 |
| table | 5750 Hz | 0.07 | table | 750 Hz | −0.08 |
| table | 450 Hz | 0.06 | table | 850 Hz | −0.06 |
| table | 650 Hz | 0.05 | table | 1050 Hz | −0.05 |
| table | 2050 Hz | 0.05 | table | 1250 Hz | −0.05 |
| table | 3650 Hz | 0.05 | table | 1550 Hz | −0.05 |
| mic | 1050 Hz | 0.05 | table | 3750 Hz | −0.05 |
| table | 3150 Hz | 0.04 | mic | 250 Hz | −0.05 |
| table | 6350 Hz | 0.04 | mic | 4950 Hz | −0.05 |
| table | 550 Hz | 0.03 | table | 2450 Hz | −0.04 |
| table | 1650 Hz | 0.03 | table | 6050 Hz | −0.04 |
| No. | Batch Size | Optimizer | Learning Rate |
|---|---|---|---|
| 1 | 16 | Adam | 0.001 |
| 2 | 32 | SGD | 0.0001 |
| 3 | 128 | RMSprop | 0.00001 |
| 4 | 256 | Adagrad | 0.000001 |
| 5 | 512 | Adamax |
| Tool Number | MSE | MAPE | MAE |
|---|---|---|---|
| 1 * | 0.000193 | 19.919 | 0.00369 |
| 2 | 0.000306 | 24.348 | 0.00477 |
| 3 | 0.000363 | 26.017 | 0.00493 |
| 4 | 0.000460 | 26.767 | 0.00503 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, C.-Y.; Huang, C.-Y.; Chiang, Y.-H. Solutions of Feature and Hyperparameter Model Selection in the Intelligent Manufacturing. Processes 2022, 10, 862. https://doi.org/10.3390/pr10050862
Wang C-Y, Huang C-Y, Chiang Y-H. Solutions of Feature and Hyperparameter Model Selection in the Intelligent Manufacturing. Processes. 2022; 10(5):862. https://doi.org/10.3390/pr10050862
Chicago/Turabian StyleWang, Chung-Ying, Chien-Yao Huang, and Yen-Han Chiang. 2022. "Solutions of Feature and Hyperparameter Model Selection in the Intelligent Manufacturing" Processes 10, no. 5: 862. https://doi.org/10.3390/pr10050862
APA StyleWang, C.-Y., Huang, C.-Y., & Chiang, Y.-H. (2022). Solutions of Feature and Hyperparameter Model Selection in the Intelligent Manufacturing. Processes, 10(5), 862. https://doi.org/10.3390/pr10050862