Abstract
The pandemic caused by the 2019 coronavirus disease has marked a total change in the development of society. Since then, its effects have been visible in people, both in work, education and psychological areas. There are many jobs and organizations that have set out to identify the reality of people after the pandemic and how the pandemic has affected their daily lives. To do this, countries have organized data and statistics collection campaigns that allow investigating the new needs of people. With this, instruments such as surveys have become more relevant and valid to know what these needs are. However, the analysis processes must guarantee answers that are able to determine the direct impact that each question has on people’s feelings. This work proposes a framework to determine the incidence values of surveys based on their categories and questions and how they capture the reality of people in areas such as education, the impact of work, family and the stress generated by the pandemic. With the results obtained, each element and category that the population considers a consequence of COVID-19 that affects the normal development of life has been identified.
1. Introduction
Currently, society is going through a period of adaptation to a new normality in most countries, due to the pandemic caused by the Coronavirus disease 2019 (COVID-19). The pandemic forced governments to carry out long isolations and quarantines to somehow control the spread of COVID-19 [1]. During the isolation, both organizations and people found themselves with the need to change the way they carry out their different activities. At the labor level, during 2020–2021, teleworking, which is an old concept, but which had not had greater penetration in the business environment, took greater emphasis [2]. The causes are diverse, however, one of those that has defined the use of teleworking in a normal environment is the lack of existing control by the company towards the worker. With the pandemic, teleworking came into force in many organizations and those that did not accept it, due to technical or administrative resources, may have been affected financially, causing an increase in unemployment [3]. Similarly, personal interaction had to adopt other models and tools to be executed. The tools used both at work and affective levels have been provided by information and communication technologies (ICTs) [4]. ICTs in the period of the pandemic have been updated in such a way that they respond to the needs of society and have improved both in accessibility and usability [5].
The continuity of different personal and work activities is just one of the problems that society has faced during the pandemic. According to previously reviewed works, several factors have been identified that have defined the problems of society during the pandemic. Among the factors identified are interpersonal relationships, the economy, the use of ICTs, psychology, health, etc. This undoubtedly marks a new reality that society is facing and implies changes for a post-pandemic stage [6]. It is important to consider that certain sectors of society generated assertive changes during the pandemic and that these changes will continue in the development of their activities. For example, one of the sectors or environments that underwent rapid change in response to isolation is higher education. Since, the beginning of the pandemic, universities had to find a way to continue academic activities quickly [7]. The answer to this need was given by ICTs with the use of video conferencing platforms, as well as learning management systems (LMS). There are works that have analyzed the level of learning in an educational model with a radical and abrupt change in its execution and identified that student learning was the most affected [8,9]. However, the universities worked on their academic models and learning methodologies, including taking experiences and guidelines from online education to better adapt to the needs of students during isolation. With the course of the pandemic and the lifting of several biosafety measures, universities have not taken a step back and have identified a competitive advantage in ICTs to create a new educational model such as hybrid education [10].
Companies, like universities, have changed the way they develop their business core. For example, companies have modified the way in which certain positions are executed to give priority to teleworking and reduce operating costs [11]. Similarly, companies have seen in the penetration of the internet and social networks a broad market niche where they can offer their products, brands, or services. Proof of this is the increase occurred in eCommerce during the pandemic, making this market model an option for the birth of new companies or for small or medium-sized companies to remain in the market [12]. eCommerce represents an advantage over the traditional market and the factors that determine its use have been the subject of new studies with an analytical vision based on what today’s consumer requires [13].
This work analyzes data acquisition instruments based on the analysis of the phenomenon of the consequences of COVID-19 in people’s daily lives and the problems they face after such prolonged isolation. The data acquisition method was through surveys that contribute to the area and population where the analysis was carried out. In addition, similar works that have identified the most relevant factors that intervene in the development of people in a post-pandemic environment are considered. The data obtained were processed by means of information technology (IT) tools, to later be analyzed by means of data analytics processes and tools.
2. Materials and Methods
For the development of the method, it is important to define the problem to be solved in this work and identify the environment where it is executed. In the same way, it is necessary to establish the theoretical foundation used to define the analysis structure that is used, to generate knowledge about the initial data.
2.1. Definition of the Problem
In the 2020–2021 period, the health of society was exposed due to COVID-19, which, in addition to the numerous losses of life, brought with it several problems that have caused a significant change in people’s lives. The changes span from the way people carry out their activities to the way they relate or interact with each other. The governments of several countries implemented various isolation and quarantine mechanisms to stop the advance of the pandemic [2]. This is the main cause of the change in the actions of society, where people have looked to IT for the necessary tools to solve the means of communication and somehow reduce the impact of isolation [14].
However, communication is not the only problem generated by COVID-19; there are other problems that are categorized into economic and social effects. In the economy, the results are visible: several companies had to close their businesses, exponentially increasing poverty rates [15,16]. On the other hand, the companies that did not close were forced to reduce their personnel or subject them to a reduction in salaries, with different governments approving this type of resolution [17,18,19]. On a social level, confinement has brought with it problems such as an increase in domestic violence, alcohol, and drug use, family and psychological problems, depression, etc. Even when governments have generated plans that allow monitoring of the effects of the pandemic, there are people that have not filed complaints or have simply been ignored by the authorities. This work seeks to identify the problems derived from the pandemic to determine which are the factors that have the greatest impact on people’s daily lives [20].
2.2. Environment Identification
This work is carried out in Ecuador and data from studies that have been previously carried out on the real situation during the pandemic are taken as a reference. To evaluate the method and make the analysis effective, the sample has been segmented and takes as reference the population of a university in the city of Quito. This university has about 10,000 students and 1200 faculty and staff. This is a private university; however, its tuition costs are aligned with a middle-class income, this being the sector to be measured.
Ecuador is a country with 17,511,000 inhabitants, and the COVID-19 crisis has left a strong impact on the living conditions of citizens. The loss of life was the factor with the greatest impact during the pandemic and the provinces with the highest population density were the most affected. The health crisis also significantly affected fundamental aspects of the well-being of people, such as income, employment, access to education, human development, and the emotional state of people. According to several studies reviewed, Ecuador until 2019 experienced a significant reduction in poverty to the point that in 2004 it stood at 54.6%, and at the end of 2018 the percentage of poverty stood at 24.2% [21,22,23]. However, because of the pandemic, the indices presented a sharp drop in economic growth, registering at −6.3% in 2020 [24]. The economic data give a starting point at a general level for this work, where most of the problems derive from the economy of the country.
2.3. Method for Data Analysis
The design of the method is composed of several stages to generate a scalable architecture that guarantees the results of the analysis. To meet these requirements, it is necessary to start from the selection of the sample to the creation of a data analysis model like those used in business intelligence.
2.3.1. Sample Selection
The population that participated in this study belongs to a university community made up of 11,200 people; in addition, the way in which the data were obtained is through surveys. The volume of data obtained from the surveys is high and can lead to other analyzes that require greater granularity. However, for this work, the population has been segmented to evaluate the method and obtain guaranteed results.
To define the population included in the analysis, the calculation of the most representative sample was applied. Equation (1) presents the formula for calculating the representative sample [25], where the parameters are the following:
- N = 500; Population size;
- Z = 1.96; Confidence level (statistical parameter), corresponds to a confidence interval of 95%;
- p = 50%; Percentage of the population that has the desired attribute;
- q = 50%; Percentage of the population that does not have the desired attribute;
- e = 3%; Maximum accepted estimation error.
Representative sample size calculation:
Once the calculation is made, it is obtained that the representative population is 974.36 individuals; for this work, the data from the surveys of 974 individuals are considered.
2.3.2. Survey Generation
Surveys are the main resource of this work; therefore, their design is based on the identification of the categories to be measured. In each category, several questions are integrated that allow identifying the feelings of the respondent [26]. Generally, survey questions are designed to elicit as much real information from respondents, therefore they must be clear, direct, and objective [27]. The response model is presented by levels of acceptance or rejection; in this way, the respondent does not generate a state of annoyance or discomfort that punishes the veracity of the answers. An example of the type of question used in this work is the following: “Rate your degree from 1 to 5 according to the following statements that are related to the experience that a person has had in confinement, where 1 means “completely alone” and 5 means “I have not been confined for work reasons”.
The categories with which this analysis is carried out have been identified in similar works that serve as a theoretical framework for this research [28,29,30]. The categories included in the study are numbered below [31,32,33,34,35]:
- Education;
- Stress;
- Emotional health;
- Labor impact;
- Family impact.
In addition to the categories identified for analysis, it is important to establish that general demographic data were established in all the surveys and that they are important for segmenting the population. For example, within the data collected are sex, age, degree of study, mail, etc. These data have not been included in this analysis because the priority has been given to the general population. However, in the next stage of the analysis, these data take on greater relevance to define strategies that contribute to satisfying the needs expressed in the surveys by the chosen population.
2.3.3. Data Analysis Model
The data analysis model follows the architecture indicated in the flowchart presented in Figure 1. The process begins with the identification of the question that needs to be answered, for example, “What are the variables that have the greatest impact on the economic status of people, after COVID-19?” To answer this question, the process begins with the identification of the variables that enter the analysis [36]. The variables are identified through the review of previous works and with the variables found in the categories of the generated surveys.
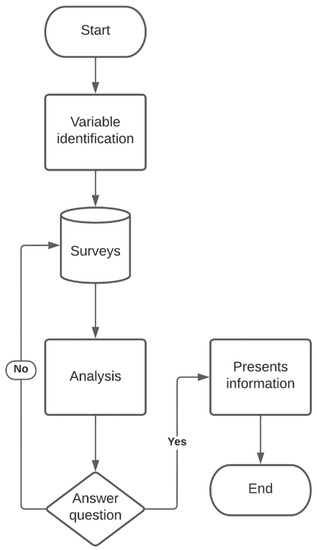
Figure 1.
Flowchart for the description of the stages of the data analysis architecture in surveys.
Each variable is made up of several questions that acquire information about people’s feelings. In the first stage, the data extracted and processed from the surveys carried out are analyzed by means of data analysis tools [37]. In the next stage, the validation of the results is carried out, and if they give an answer to the question posed, the ones that have the greatest incidence in each category are presented and the process is finished. For the analysis of the data, in this work a statistical product and service solution (SPSS v. 27.0) was used, as this tool manages a complete format for the statistical analysis of data. SPSS was used to perform data capture and analysis to create tables and graphs with complex data. SPSS is known for its ability to handle large volumes of data and can perform text analysis among other formats. SPSS is used for a wide range of statistical analyses, such as descriptive statistics, bivariate statistics, regression, factor analysis, and graphing of data.
3. Results
In the results, the method is evaluated, through the application of a case study with the data extracted from surveys carried out on the population indicated in the previous section.
3.1. Sample Selection
The selection of the sample corresponds to the most significant population of the university where this study is carried out. A university has an environment like a small city, and its variety in the society that integrates these environments allows establishing clear ideas of what happens in environments with greater population density and larger size. According to the data obtained by executing the formula of the most representative population, the ideal number of respondents is 974 individuals. However, this work seeks to include all sectors of the university population, therefore, the surveys have been carried out in all university areas, including administrative, academic, students, maintenance personnel, etc. By having a variety of population sectors, it is possible to obtain a clear idea of the consequences of COVID-19 in people’s daily lives.
3.2. Generation of Surveys
For the generation of the surveys, the guidelines established in several of the reviewed works have been adopted as they seek to obtain quality data through these tools [38,39]. In these works, it is established that for the development of a survey it is important to define if it can offer precision, classification, and valuable conclusions about the object of study. However, to obtain these characteristics it is necessary to comply with seven steps that allow the development, administration, and analysis of a survey; these steps are:
- Defining if a survey is the right tool;
- Select the type of survey;
- Define the universe and sample;
- Design the questionnaire;
- Apply the quiz;
- Use the appropriate software to process the data;
- Write reports on findings and conclusions.
In addition to the steps to follow in the development of the survey, there are other important parameters that must be included in the generation of the survey, for example, the time it takes for the respondent to answer the questionnaire. The time of the development of the survey has a direct influence on the motivation of the respondent and the veracity of their answers. The response time of the survey depends on the number of questions, this being another important parameter that must be considered in its design. According to the works reviewed [40,41,42], a multiple-choice survey should contain 10 or fewer questions to maintain survey motivation and response quality. With these guidelines, several surveys were designed that seek to obtain data on the categories identified in the method. Next, each category is presented with four questions whose data have been included in the analysis. This limitation in the number of questions per category is mainly due to the space of the document; the sources have considered the development of 10 questions for each survey, which implies a response time that varies between 5 and 10 min for the respondent. The questions are as objective as possible and have been programmed with precision to obtain answers that represent the reality of the feelings of the population surveyed.
- Education
- a.
- How happy are you with the apps/platforms used for distance learning? (1 not at all, 2, 3, 4, 5 a lot)
- b.
- Evaluate your distance learning experience so far? (1 not at all, 2, 3, 4, 5 a lot)
- c.
- Do you feel that communication is fluid between students and teachers? (1 not at all, 2, 3, 4, 5 a lot)
- d.
- How much time do you dedicate each day on average to distance education?
- 1–3 h
- 3–5 h
- 5–7 h
- 7–10 h
- More than 10 h
- Stress
- a.
- Over the last few days, in relation to the situation triggered by COVID-19, what are you feeling?
- 1.
- I am afraid of losing my job, (1 not at all, 2, 3, 4, 5 a lot)
- 2.
- I think it is likely that I will lose my job soon, (1 not at all, 2, 3, 4, 5 a lot)
- b.
- How worried are you about the impact of COVID-19? On the health of household members, (1 not at all, 2, 3, 4, 5 a lot)
- c.
- How anxious are you about the relationship between your child/children due to physical and social distancing? (1 not at all, 2, 3, 4, 5 very much)
- d.
- How do you think the economic situation will be in the coming months? (1 worst, 2, 3, 4, 5 best)
- Emotional health
- a.
- During the last few days, how often have I felt
- 1.
- Scared, (1 not at all, 2, 3, 4, 5 a lot)
- 2.
- Nervous, (1 not at all, 2, 3, 4, 5 a lot)
- 3.
- Disgusted, (1 not at all, 2, 3, 4, 5 very much)
- 4.
- Excited, (1 not at all, 2, 3, 4, 5 very much)
- 5.
- Active, (1 not at all, 2, 3, 4, 5 a lot)
- b.
- During the period of the pandemic, how often (many days, quite a few days, some days, never) have you felt…?
- 1.
- Bad for having little interest or pleasure in doing things
- 2.
- Down, depressed, or hopeless
- 3.
- Nervous, anxious, or very upset (with the nerves on edge)
- 4.
- Unable to stop or control worry
- 5.
- Everything is fine
- c.
- In relation to the coronavirus and its consequences during the last year, could you tell me how many times (many, quite a few, some, or none or almost none) you…?
- 1.
- You have had unwanted unpleasant thoughts or memories about the coronavirus and its consequences
- 2.
- You have had nightmares or images related to the coronavirus
- 3.
- You have felt distressed or overwhelmed by thoughts or memories about the coronavirus
- 4.
- You have tried to avoid bothersome thoughts or memories about the coronavirus
- 5.
- Thoughts, memories, or images about the coronavirus have disrupted your work or daily tasks
- d.
- Have you been worried that anxiety attacks can have negative consequences on your health? (1 not at all, 2, 3, 4, 5 a lot)
- Labor impact
- a.
- What economic impact have you felt during the pandemic?
- 1.
- I have lost my job
- 2.
- My employer is at risk of bankruptcy
- 3.
- My employer has reduced my working day due to a lack of demand
- 4.
- I have a new job or business opportunity
- 5.
- I have significantly increased my savings or reduced my debt because I spend less
- b.
- Which of the following best describes the impact of COVID-19 on your ability to meet your financial obligations or essential needs, such as rent or mortgage payments, utilities, and groceries?
- 1.
- Big impact
- 2.
- Moderate impact
- 3.
- Minor impact
- 4.
- No impact
- 5.
- Too early to tell
- c.
- What is the main source of income in your household currently?
- Now we have no sources of income
- Government aid program
- Bank loans or debts
- Temporary work/payment according to hours worked
- Formal paid work of one or more members of the household
- d.
- How has COVID-19 affected the economic situation of your household?
- It has completely affected it (reduction of 76% or more of our income)
- Affected because the prices of essential items and services have risen
- Affected because now I have more expenses than before the crisis (masks, alcohol, cleaning, technology for distance education, etc.)
- Has not affected
- It has improved
- Family impact
- Have you noticed a significant increase in your home that you consider detrimental in any of the following areas?
- Strong arguments or fights with household members
- Excessive alcohol consumption
- Excessive use of technology by children (tablet, mobile, TV)
- Excessive use of technology by children (tablet, mobile, TV)
- I have not noticed a detrimental increase in these areas
- Have you noticed any change or modification in the way of being or behaving of your children during the period of the pandemic? (1 not at all, 2, 3, 4, 5 a lot)
- What kind of changes in your children have you observed during the pandemic period?
- Changes in the way they behave
- Changes in the way of relating at home with parents
- Mood swings
- Changes in lifestyle
- Sleep changes
- Regarding the way you appear to others during the pandemic period, have you noticed that your children or grandchildren who live with you…?
- They are less sociable
- They have a low tolerance for others
- They prefer to spend time alone
- They are more social
- There are no changes
3.3. Analysis of Data
The analysis of the data obtained from the surveys begins with the identification of the need that is sought to be answered, for example, the first need identified in this work is to determine the consequences of COVID-19 in the workplace of people. To identify the consequences, the data obtained in the category “employment impact” have been taken [43,44,45]. To determine the degree of influence that the people surveyed consider having the greatest impact, a factorial analysis is applied to the data [46,47,48]. The analysis is developed in two groups; in the first group, the data obtained through the four questions that are detailed in the generation of surveys are considered. In the second group, we work with the 10 original questions that have been raised for the survey, as the purpose is to evaluate the results with different amounts of data.
The factorial analysis can be applied to the data of all the categories; however, the first analysis was carried out by category, to clearly identify the results and without errors in their interpretation. The survey data corresponds to 974 individuals and the questions that are presented are four for the first run of the analysis, which results in 3986 responses obtained. In Table 1, to present the fields that are being used, the headers that allow each question to be identified and the first 20 answers are presented. This segmentation is only informative, since all the data are considered in the analysis. The data of the questions have values between 1 and 5; considering that the questions are of the multiple-choice type, this is the conditioning factor that establishes the indicated range of values.

Table 1.
Data obtained on the labor impact of people in COVID-19 with a survey with four multiple-choice questions with answers valued with ranges of 1–5.
In the factorial analysis with the segmented data of four questions, the following results are obtained. In Table 2, the values of the correlation matrix are presented; in the matrix from left to right the values that are presented diagonally, the constant and the correlation values. According to the values obtained, the existing correlation is weak, however, the analysis continues to determine the main characteristics. The table shows the relationships between the expressed meanings of different aspects for individuals. The 1.000 line from top left to bottom right is the primary tilt, showing that each factor in each case connects with itself. This network is balanced, with a similar connection that appears above the tilt principle being a perfect representation of those below the corner-to-corner primary. In this result, the correlations with different questions are not representative or their relationship is too low.
Table 2.
Correlation matrix indicating the coefficients of connection between the factors in a survey with four questions.
Another important result is the Kaiser, Meyer and Olkin (KMO) test that is presented in Table 3. The KMO relates the correlation coefficients between the variables Xj Xh and ajh. The closer the KMO result is to 1, the more it implies that the relationship between the variables is high. In this analysis it is important to consider that we are evaluating only one category with four questions. This implies that the analysis tool takes the questions as variables and the results are focused on defining the relationship that exists between them to evaluate the category of labor impact. According to the KMO concept that establishes the ranges of the coefficients as a significant set, the closer to 1 the value obtained from the KMO test implies that the relationship between the variables is high. If KMO ≥ 0.9, the test is very good; notable for KMO ≥ 0.8; median for KMO ≥ 0.7; low for KMO ≥ 0.6; and very low for KMO < 0.5. Per the results of KMO and the Bartlett’s test, the values are low according to the figure that is presented from the analysis. However, it is necessary to continue with the analysis to identify which are the variables that suppose a greater percentage of relationship and how to decide about surveys as a tool in data acquisition.
Table 3.
The KMO and Bartlett values obtained to test whether the partial correlations between the variables are small.
Table 4 presents the communalities; this table is important because the information it provides allows establishing the contribution that each question has to the object analyzed. The closer it is to 1, the stronger the contribution or incidence it has with the object of study. The values obtained from the four questions are generally low and according to the absolute values established for the analysis, all values below 0.30 are considered as questions that have no contribution to the analysis. With this conceptualization, questions two and three, since they do not contribute to the analysis, can be removed from the process; however, questions one and four remain within the limit of the set value, so that they are considered as questions that contribute to the study. With the information obtained so far, it is possible to determine that the survey does not fit the necessary parameters to be considered valid and the questions should be readjusted. As this is the first analysis where only four questions have been considered to evaluate the method, the evaluation of the results continues. The value for this analysis is 0.507; this value is low for KMO, therefore, this analysis can be rejected directly considering that the analysis does not have a linear statistical dependence. However, in the sphericity test the result obtained is 0.723, which is a suitable value for the application of the factor analysis model. With this consideration, the analysis continues, but the values are kept under observation and verified with the results of the calculation of the total explained variance. If the values of the analysis in the following stages are maintained, it will be deleted, and it is assumed that there is no relationship between the variables.
Table 4.
Communalities matrix, a sum of the squared factorial weights in each of the rows.
Table 5 presents the results of the total calculation of the explained variance. In the analysis, it is expected that in the minimum accumulated total, the instrument (survey) explains 50% of the phenomenon, something that was not obtained in the analysis. Therefore, with the results obtained so far, it is shown that the instrument under the current conditions is not capable of explaining the phenomenon.
Table 5.
Percentage of explained variance.
For the next stage of the analysis, six questions are included in the survey, which address the labor impact of COVID-19. Table 6 presents the results of the descriptive statistics. In this table it is important to verify the mean values of each question, the standard deviation and the number of participants that have been included in the analysis. These are the 974 respondents, which is the most representative sample calculated from the total population and there is no lack of data.
Table 6.
Analysis of the descriptive statistics application with 10 questions.
Table 7 presents the matrix of correlations. In Figure 2, the graph of the matrix is established to clearly visualize the relationships between the questions considered. The correlation relationship existing about each question is still low; however, in the analysis with orthogonal components where “Varimax” is used when the relationships are low, it significantly improves the relationships between the questions. This is reinforced by the graph in the following figure. In this, the existing incidence is clearly identified for each question, and it is even possible to observe the questions that have a negative value with respect to the different reagents of the survey. In the correlation matrix, both in the rows and columns, question has been replaced by Q to maintain an adequate space within the table format. For example, Question 1 = Q 1, Question 2 = Q 2, etc.
Table 7.
Correlation matrix, calculation of the relationship between each pair in each cell, expressed with a number ranging from 0 to 1.
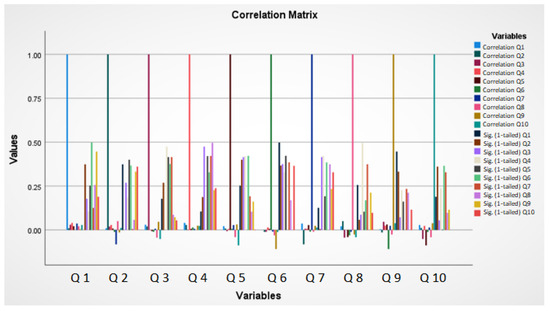
Figure 2.
Graph of the correlation matrix with 10 questions for the identification of incidence in each analyzed factor.
Table 8 presents the values of communalities, according to the resulting values; when integrating all the questions of the survey, the contribution values of each question increase significantly in relation to the first analysis. The contribution value in questions two and three has increased, to the point that they exceed the 0.30 assigned to the analysis of the absolute value. There are even questions with values that exceed 0.60, improving the incidence of the questions in the analysis of the phenomenon. To improve the effectiveness of the analysis, it is possible to eliminate the questions with low values and reprocess the data to verify the results. In this stage, to evaluate the method, the analysis of the results continues, maintaining the 10 questions and carrying out a comparison with the results of the first analysis.
Table 8.
Calculation of communalities, a sum of the squared factorial weights in each of the rows.
With the increase in the values of the communalities of the questions, values less than 0.5 are considered as questions with less relation in the contribution to the evaluation of the category. Therefore, questions 3, 4 and 5 become part of a deeper analysis in the following results.
In Table 9, the total variance explained in its fifth component or generated dimension achieves a percentage that exceeds 50%, reaching 54.481%. This means that the instrument in the second analysis with all the questions included can explain the phenomenon, therefore, the instrument is valid to continue with the analysis.
Table 9.
Calculation of the total explained variance with five components in an accumulated percentage of 54.481%.
Table 10 shows the matrix of rotated components; in this analysis something unique is obtained and that is that the results have been classified into five factors or dimensions. According to the theoretical logic of the analysis, all the questions belong to one dimension, so it is expected that the results and contributions of these maintain the dimensionality. The reason for the results obtained specifically focuses on the fact that several of the questions are being misunderstood by the respondents and that in the design of the questionnaire it was not considered that certain questions are evaluating two or more categories.
Table 10.
Rotated component array.
For a dimension to be considered valid, it needs at least three questions to feed into it or be directly related. The table shows that this relationship and contribution of at least three questions does not exist. However, there are questions that have negative values; these will be eliminated from the analysis to modify the influence value of the remaining questions. A similar process will be carried out with the questions with low values in the contribution to each dimension.
Figure 3 shows graphically the incidence of the rotated components in each dimension. With this information, the analysis is modified by eliminating the factors that have the least incidence in the dimensions. By means of the rotating components and their matrix formalism, new axes can be considered that represent the cloud of points that form the original variables. Thus, the projection of the point cloud on the components serves to interpret the relationship between the different variables. In the point cloud, it is observed how each question affects the components on each axis and it is possible to determine the elements that can be eliminated from the analysis.
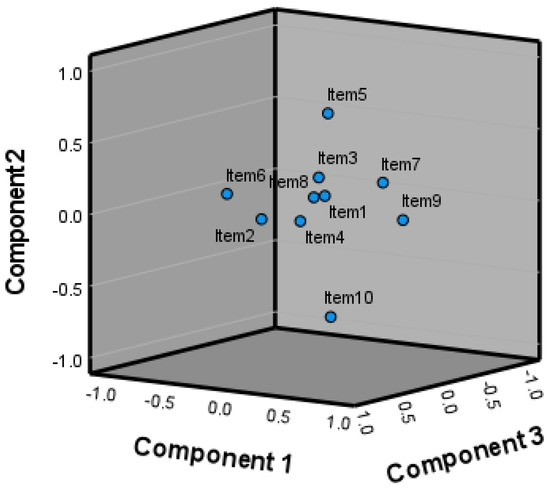
Figure 3.
Graphic representation of the incidence of the rotated components in each dimension. In the figure, each analyzed question has been represented as “Item”; this change has been made so as not to overload the labels and so that the point cloud can be viewed clearly. The changeset is: Question1 = Item1, Question2 = Item2, etc.
Figure 4a presents the results of the rotated component matrix with two components or dimensions. To reach this result, questions 2, 5, 6, 8 and 10 have been separated from the analysis. These questions were separated in a staggered manner to observe each existing variation in the analysis process.
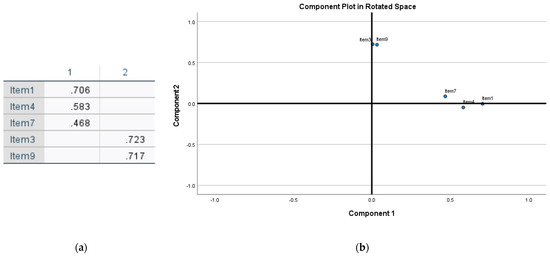
Figure 4.
Rotated components. (a) Convergence between iterations in rotated components; (b) graph of components rotated in space.
In dimension one, two questions with values higher than 0.5 and one question with a lower value have been obtained. In dimension two we have the contribution of two questions, both exceeding 0.7, i.e., a high value of influence. With these results, the next step will be to eliminate the question with the greatest influence in dimension two. Generally, this process is carried out considering that the question with the greatest influence in another dimension can influence the questions so that they contribute to the dimension that it points to. Therefore, in dimensions other than those expected, it is ideal to eliminate the questions with the greatest influence, the opposite of the process to be followed in the analyzed dimension. In the graph of Figure 4b the questions that are contributing to dimension two are observed, according to the coordinate axis question 3 is the one that is closest to dimension two, while question 9 tends to dimension one. In the following analysis, the question is separated from the analysis to obtain a single dimension.
Table 11 shows the questions with the values they contribute to the dimension; these questions are considered for the total analysis. However, this process is replicated in each of the categories identified in the previous sections, but the difference is that in the following analysis it is carried out with the 10 questions, taking as a reference that in the analysis with four initial questions it did not explain the phenomenon.
Table 11.
Main component of the analysis, incidence values by identified question.
After the total analysis of the dimensions, the results have identified the most significant questions for each category. Table 12 presents the questions identified by category. In the first row, the names of each category identified for the analysis are established, therefore, category 1 = labor impact, category 2 = education, category 3 = emotional health, category 4 = family impact and category 5 = stress.
Table 12.
Questions identified by category with the greatest influence on the instrument.
Below are the questions in each category that have had the greatest impact on the phenomenon analyzed:
- Labor impact
- 1.
- What economic impact have you felt during the pandemic?
- I have lost my job
- My employer is at risk of bankruptcy
- My employer has reduced my working day due to lack of demand
- I have a new job or business opportunity
- I have significantly increased my savings or reduced my debt because I spend less
- 3.
- What is the main source of income in your household currently?
- Now we have no sources of income
- Government aid program
- Bank loans or debts
- Temporary work/payment according to hours worked
- Formal paid work of one or more household members
- 4.
- How has COVID-19 affected the economic situation of your household?
- It has completely affected it (reduction of 76% or more of our income)
- Affected because the prices of essential questions and services have risen
- Affected because now I have more expenses than before the crisis (masks, alcohol, cleaning, technology for distance education, etc.)
- Has not affected
- It has improved
- 7.
- How many people work and contribute to the expenses in your household?
- None
- A person
- Two people
- At least 3 people
- Everyone works
- Education
- 5.
- How effective has learning during COVID-19 been for you?
- It has not been effective at all
- Slightly effective
- Moderately effective
- Very effective
- Extremely effective
- 7.
- How helpful has the school or university been in providing resources for learning at home?
- Not useful at all
- Slightly useful
- Moderately helpful
- Very useful
- Extremely helpful
- 9.
- How well could you manage time while distance learning? (Consider 5 extremely well and 1 not at all)
- Emotional health
- 5.
- In relation to the coronavirus and its consequences during the last year, could you tell me how many times (many, quite a few, some, or none or almost none) you?
- You have had unwanted unpleasant thoughts or memories about the coronavirus and its consequences
- You have had nightmares or images related to the coronavirus
- You have felt distressed or overwhelmed by thoughts or memories about the coronavirus
- You have tried to avoid bothersome thoughts or memories about the coronavirus
- Thoughts, memories, or images about the coronavirus have disrupted your work or daily tasks
- 6.
- Have you been worried that anxiety attacks can have negative consequences on your health? (1 not at all, 2, 3, 4, 5 a lot)
- 7.
- How often have you cried because of the pandemic? (1 not at all, 2, 3, 4, 5 a lot)
- Family impact
- 4.
- Have you noticed any change in the way of being or behaving of your children during the period of the pandemic? (1 not at all, 2, 3, 4, 5 a lot)
- 5.
- What type of changes in your children have you observed during the period of the pandemic?
- None
- Changes in the way you behave
- Changes in the way you appear to others
- Changes in the way of relating at home with parents
- Mood swings
- 6
- Regarding changes in the way of relating at home with their children who live with their parents/grandparents, during the pandemic to the present?
- They are more disobedient
- They are more irritable
- They isolate easily
- Protest about anything
- They are always “stuck” to their parents
- Stress
- 4
- How do you think the economic situation will be in the coming months? (1 same, 2, 3, 4, 5 best)
- 5
- From the beginning of the COVID-19 pandemic and until now, could you tell me how many times (many, quite a few, some, or none or almost none) have you?
- You have felt hopeless about the future
- You have felt irritable, angry, angry, or aggressive
- Have you felt overwhelmed or stressed?
- Have you felt restless or restless?
- Everything stays normal
- 7
- Since the beginning of the COVID-19 pandemic and until now, have you felt bad about having?
- Back pain
- Headaches
- Palpitations or feel like your heart is racing
- Feeling tired or low on energy
- Sleeping problems
Once the questions were identified, it was possible to carry out an analysis to determine the existing relationship between the questions of all the dimensions and give the analysis greater validity. The questions identified with the greatest influence in each category have been stored to create a bank of questions and refine the instrument that can explain the phenomenon.
4. Discussion
During the pandemic and in the year 2022, many works have been published that have analyzed the state of people in various areas. However, extracting the data requires a great effort for researchers, since it depends on the quality of the data to reach reliable conclusions, attached to the reality of a population [49,50,51].
Surveys have become the preferred instrument for data collection by different organizations and research groups. Currently there are even tools and guides that allow the design of increasingly efficient surveys. However, during the review of similar works it was detected that there is an in-depth analysis of the results obtained, but in very few works was a clear analysis of the influence value of each question on the variables analyzed carried out. It has even been identified that organizations that carry out surveys to offer different services to the population after COVID-19 create a mix of questions without categorizing them. When carrying out a survey in this way, there are several problems that can result in false positives [52,53,54].
There are many models that allow generating survey questions and presenting them objectively. However, this is not the only parameter to consider, since the veracity of the answers depends on the interpretation that the respondent has of each question [55,56,57]. Therefore, as in previous work, the authors participated in several surveys available on the internet, where it was found that in several of these, in addition to mixing the questions of different circumstances, the time it takes to finish them is very high, generating demotivation in completing the survey.
In this work we have sought to define the current state of a population by means of obtaining data with surveys. The difference from several of the works reviewed is because the analysis is provided with a process that allows establishing the incidence value of each question in relation to its category. In this way, it is possible to verify the validity of the instrument through a statistical analysis that comprehensively determines how the reagents affect each stage of the analysis. This process is necessary when dealing with survey data and even more so when the population where it is carried out is large. Even in this factor, the proposed method uses a model that allows establishing the most representative population, giving greater validity to the analysis [58,59,60]. After the analysis, the questions with the highest incidence in each of the analyzed dimensions were identified and presented to the user to improve the instrument or create a single survey capable of correctly evaluating several dimensions.
The framework presented in this work aims to publicize a process by which it is possible to improve the design of surveys and even more so in such critical aspects as the consequences of COVID-19 on society. However, being so dependent on the data obtained directly from the people surveyed is a limitation, since there is always a range of error that must be dealt with in data collection. There are works and guides that allow the design of surveys that are a real contribution to research and this work includes this information. However, when replicating the proposed method, it is necessary to include surveys appropriate to the analyzed population, to guarantee the results.
In the results obtained, it is observed that in the first analysis where four questions were considered, the percentage of the variance explained in Table 5 is sufficient to determine that the validity of the survey is not adequate. With a single component and with the accumulated percentage of 26.670%, the tool is not enough to answer the study phenomenon. This undoubtedly marks a reference and a guide to improve the contextualization of the survey and of the questions both in number and quality. These results in the first instance are not what is expected in a traditional survey, since, when defining that the fewer the number of questions in a survey, the veracity and quality of the answers improves, this is not entirely true. This first result is the basis for including the surveys that have 10 questions in the entire analysis. In Table 9, it is observed that the accumulated percentage is greater than 50% in five components, therefore, the analysis was continued, in addition to accepting the validity of the tool to respond to the study phenomenon. In the works reviewed, this validation does not exist and the data from the surveys are taken as valid answers, which becomes a problem when generating evaluations in populations with greater density where the results obtained do not adhere to the analyses generated.
5. Conclusions
The versatility of ICT allows people and organizations to create novel ways to acquire information about a phenomenon, a system, or a population. However, it is important to establish processes that validate these data acquisition models and instruments. Surveys are currently widely used instruments in this area, but it is important to establish processes that allow validating the instrument, as well as each of the items included in it. By aligning the design of the survey to an analysis process that validates each stage of this, it is possible to guarantee the results and identify the percentages of incidence that each question has in relation to its dimension.
With the analysis carried out by means of the proposed method, it has been determined that the quality of the surveys does not depend on the number of questions, but on the perspective of the respondent, time, and motivation. Even when this seems logical or easy to determine, it needs analytical support that allows establishing the existing relationships between dimensions and questions of the surveys. In addition, graphically establishing the incidence of the questions in the different dimensions allows the survey to be correctly aligned.
To ensure proper use of rapid survey data, reporting should include clear information on survey objectives, reference periods, methodology, sampling frame and design, population target, and other data quality issues. Furthermore, when the rapid survey is not representative of the general population, the results should be reported with explicit reference to the specific groups or areas covered. The results of the survey reveal the need for programs and actions to alleviate the problems observed and delve into the specific difficulties of the most vulnerable populations, such as those who have been ill or have lost loved ones, and those who have lost their jobs.
An important feature of rapid surveys is the use of a relatively short questionnaire dealing only with essential topics. In the context of the COVID-19 pandemic, rapid surveys are likely needed to capture essential information on a variety of topics. When one of the objectives is the measurement of employed persons in a specific reference period, it will be necessary to include several questions to adequately identify employed persons, given the great diversity of jobs that people can carry out.
This work, even though it aims to identify the validity of the surveys that seek to answer a phenomenon, depends mainly on the answers obtained for each question. This can be considered as a limitation, so to eliminate the risk that there are answers that do not adhere to reality, it is important to follow a clear process in the design of the surveys. In our design we have clearly established guidelines taken from different reviewed works which have been cited to provide readers with the possibility of reviewing these works and arrive at a survey design that guarantees the results expected.
A factorial analysis using data from surveys carried out on a population that is barely overcoming a pandemic can bring with it several anomalies in the responses. One cause of this is the stress caused by confinement or by the same causes that we analyze in this work. This can affect data quality; therefore, it is important to establish a mechanism that determines the validity of the survey and questions. However, there are cases in which actions are taken with direct data from a survey, simply by performing basic filters to clean the data. This, without a doubt, is a point of failure, so it is necessary to establish how each factor influences the reality of the population. For this reason, the results obtained in our work are not something that was expected or that could be identified with the naked eye, but it has been necessary to carry out several analyses of each survey and review each of the established questions to determine its impact on the population and, according to them, establish which are the variables with the greatest influence on the phenomenon under study.
Our proposal is adapted to the current needs of different fields of study since today the development of surveys and data collection with the use of these tools has become commonplace. Therefore, there must be a base that refers to the incidence factors that each question has and with this information improve the questions and the quality of the data that make up the analysis. With the pandemic, the penetration of the internet in society has improved notably, as has the accessibility and use of the web; therefore, we must pay attention to the extraction of information to assess these channels and there are several statistical models that can establish new needs in the educational and scientific field that generate new opportunities to use and improve this work.
Author Contributions
W.V.-C. contributed to the following: the conception and design of the study, acquisition of data, analysis, and interpretation of data, drafting the article, and approval of the submitted version. The authors I.O.-G. and J.G.-O. contributed to the study by design, conception, interpretation of data, and critical revision. S.S.-V. made the following contributions to the study: analysis and interpretation of data, approval of the submitted version. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rios-Campos, C.; Campos, P.R.; Delgado, F.C.; Ramírez, I.M.; Hubeck, J.A.; Fernández, C.J.; Vega, Y.C.; Méndez, M.C. COVID-19 and Universities in Latin America. South Fla. J. Dev. 2021, 2, 577–585. [Google Scholar] [CrossRef]
- Pramono, C.A.; Manurung, A.H.; Heriyati, P.; Kosasih, W. Analysis of the Influence of Entrepreneurship Capability, Agility, Business Transformation, Opportunity on Start-up Behavior in Ecommerce Companies in Indonesia during the COVID-19 Pandemic. WSEAS Trans. Bus. Econ. 2021, 18, 1103–1112. [Google Scholar] [CrossRef]
- Lyttelton, T.; Zang, E.; Musick, K. Telecommuting and Gender Inequalities in Parents’ Paid and Unpaid Work before and during the COVID-19 Pandemic. J. Marriage Fam. 2022, 84, 230–249. [Google Scholar] [CrossRef]
- Fleet, G.J. Evidence for Stalled ICT Adoption and the Facilitator ECommerce Adoption Model in SMEs. J. Acad. Bus. World 2012, 6, 7–18. [Google Scholar]
- Lai, C.-T.; Chang, H.-H.; Lee, K.-T.; Huang, J.-Y.; Lee, W.-P. Predicting Drug Side Effects Using Data Analytics and the Integration of Multiple Data Sources. IEEE Access 2017, 5, 20449–20462. [Google Scholar] [CrossRef]
- Garín-Muñoz, T.; López, R.; Pérez-Amaral, T.; Herguera, I.; Valarezo, A. Models for Individual Adoption of ECommerce, EBanking and EGovernment in Spain. Telecommun. Policy 2019, 43, 100–111. [Google Scholar] [CrossRef] [Green Version]
- Villegas-Ch., W.; García-Ortiz, J.; Román-Cañizares, M.; Sánchez-Viteri, S. Proposal of a Remote Education Model with the Integration of an ICT Architecture to Improve Learning Management. PeerJ Comput. Sci. 2021, 7, e781. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Sánchez-Viteri, S.; Román-Cañizares, M. Academic Activities Recommendation System for Sustainable Education in the Age of COVID-19. Informatics 2021, 8, 29. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Román-Cañizares, M.; Palacios-Pacheco, X. Improvement of an Online Education Model with the Integration of Machine Learning and Data Analysis in an LMS. Appl. Sci. 2020, 10, 5371. [Google Scholar] [CrossRef]
- Villegas-Ch., W.; Palacios-Pacheco, X.; Roman-Cañizares, M. Applied Sciences Analysis of Educational Data in the Current State of University Learning for the Transition to a Hybrid Education Model. Appl. Sci. 2021, 11, 2068. [Google Scholar] [CrossRef]
- Lone, S.; Favero, I.; Quaglieri, L.; Packiaraja, S. European Ecommerce Report 2019; Ecommerce Foundation: Chandigarh, India, 2019. [Google Scholar]
- Arora, S. Devising E-Commerce and Green Ecommerce Sustainability. Int. J. Eng. Dev. Res. 2019, 7, 206–210. [Google Scholar]
- Huang, R. Ecommerce in Rural Areas and Environmental Sustainability: The Last-Mile Delivery. In Proceedings of the 16th Wuhan International Conference on E-Business, WHICEB 2017, Wuhan, China, 26–28 May 2017. [Google Scholar]
- Troyer, E.A.; Kohn, J.N.; Hong, S. Are We Facing a Crashing Wave of Neuropsychiatric Sequelae of COVID-19? Neuropsychiatric Symptoms and Potential Immunologic Mechanisms. Brain Behav. Immun. 2020, 87, 34–39. [Google Scholar] [CrossRef]
- Donthu, N.; Gustafsson, A. Effects of COVID-19 on Business and Research. J. Bus. Res. 2020, 117, 284–289. [Google Scholar] [CrossRef]
- Fairlie, R. The Impact of COVID-19 on Small Business Owners: Evidence from the First Three Months after Widespread Social-Distancing Restrictions. J. Econ. Manag. Strategy 2020, 29, 727–740. [Google Scholar] [CrossRef]
- Fernández-Aranda, F.; Casas, M.; Claes, L.; Bryan, D.C.; Favaro, A.; Granero, R.; Gudiol, C.; Jiménez-Murcia, S.; Karwautz, A.; le Grange, D.; et al. COVID-19 and Implications for Eating Disorders. Eur. Eat. Disord. Rev. 2020, 28, 239–245. [Google Scholar] [CrossRef]
- Sønderskov, K.M.; Dinesen, P.T.; Santini, Z.I.; Østergaard, S.D. The Depressive State of Denmark during the COVID-19 Pandemic. Acta Neuropsychiatr. 2020, 32, 226–228. [Google Scholar] [CrossRef] [Green Version]
- Egbert, A.R.; Cankurtaran, S.; Karpiak, S. Brain Abnormalities in COVID-19 Acute/Subacute Phase: A Rapid Systematic Review. Brain Behav. Immun. 2020, 89, 543–554. [Google Scholar] [CrossRef]
- Du, J.; Dong, L.; Wang, T.; Yuan, C.; Fu, R.; Zhang, L.; Liu, B.; Zhang, M.; Yin, Y.; Qin, J.; et al. Psychological Symptoms among Frontline Healthcare Workers during COVID-19 Outbreak in Wuhan. Gen. Hosp. Psychiatry 2020, 67, 144–145. [Google Scholar] [CrossRef]
- Luna, A.L.; Ramírez Chávez, G.; Reyes, G.J.M. Analysis of Poverty in Ecuador, Period 2017–2018. Scielo 2020, 12, 363–368. [Google Scholar]
- Stiftung, B. BTI 2022 Country Report Ecuador; BTI: Quito, Ecuador, 2022. [Google Scholar]
- García Álvarez, S.; Almeida Guzmán, P. Analysis of Poverty in Ecuador, Period 2017–2018-Rev-2; Universidad de Cienfuegos: Quito, Ecuador, 2021. [Google Scholar]
- International Monetary Fund. World Economic Outlook, October 2020 (Spanish Edition): A Long and Difficult Ascent; INTL Monetary Fund: Washington, DC, USA, 2021; ISBN 9781513561868. [Google Scholar]
- Jiang, Y.; Zhao, L.; Beer, M.; Wang, L.; Zhang, J. Dominant Failure Mode Analysis Using Representative Samples Obtained by Multiple Response Surfaces Method. Probabilistic Eng. Mech. 2020, 59, 103005. [Google Scholar] [CrossRef]
- Lasa, N.B.; Benito, J.G.; Montesinos, D.H.; Manterola, A.G.; Sánchez, J.P.E.; García, J.L.P.; Germán, M.Á.S. Las Consecuencias Psicológicas de la COVID-19 Y el Confinamiento Informe de Investigación; Servicio de Publicaciones de la Universidad del País Vasco: Bilbao, Spain, 2020. [Google Scholar]
- A Prospective Survay of Patients’ Satisfaction with Urethral Reconstructive Surgery—ScienceDirect. Available online: https://www.sciencedirect.com/science/article/abs/pii/S0022534718343933 (accessed on 24 April 2022).
- Pollard, M.S.; Tucker, J.S.; Green, H.D. Changes in Adult Alcohol Use and Consequences during the COVID-19 Pandemic in the US. JAMA Netw. Open 2020, 3, e2022942. [Google Scholar] [CrossRef]
- Kujawa, A.; Green, H.; Compas, B.E.; Dickey, L.; Pegg, S. Exposure to COVID-19 Pandemic Stress: Associations with Depression and Anxiety in Emerging Adults in the United States. Depress. Anxiety 2020, 37, 1280–1288. [Google Scholar] [CrossRef]
- Müller, C.; Mildenberger, T. Facilitating Flexible Learning by Replacing Classroom Time with an Online Learning Environment: A Systematic Review of Blended Learning in Higher Education. Educ. Res. Rev. 2021, 34, 100394. [Google Scholar] [CrossRef]
- Karataş, M.A.-K. COVID-19 Pandemisinin Toplum Psikolojisine Etkileri ve Eğitime Yansımaları. J. Turk. Stud. 2020, 15, 1–13. [Google Scholar] [CrossRef]
- Engzell, P.; Frey, A.; Verhagen, M. Learning Inequality during the COVID-19 Pandemic; University of Oxford: Oxford, UK, 2020. [Google Scholar]
- Zhang, H. The Influence of the Ongoing COVID-19 Pandemic on Family Violence in China. J. Fam. Violence 2020, 37, 1–11. [Google Scholar] [CrossRef]
- Gupta, S.; Jawanda, M.K. The Impacts of COVID-19 on Children. Acta Paediatr. Int. J. Paediatr. 2020, 109, 2181–2183. [Google Scholar] [CrossRef]
- Sakshaug, J.W. Impacts of the COVID-19 Pandemic on Labor Market Surveys at the German Institute for Employment Research. Surv. Res. Methods 2020, 14, 229–233. [Google Scholar] [CrossRef]
- Londhe, A.; Rao, P.P. Platforms for Big Data Analytics: Trend towards Hybrid Era. In Proceedings of the 2017 International Conference on Energy, Communication, Data Analytics and Soft Computing (ICECDS), Chennai, India, 1–2 August 2017; pp. 3235–3238. [Google Scholar]
- Bologna, E.; Lopomo, N.; Marchiori, G.; Zingales, M. A Non-Linear Stochastic Approach of Ligaments and Tendons Fractional-Order Hereditariness. Probab. Eng. Mech. 2020, 60, 103034. [Google Scholar] [CrossRef]
- Ramsay, J.O.; Dalzell, C.J. Some Tools for Functional Data Analysis. J. R. Stat. Soc. Ser. B (Methodol.) 1991, 53, 539–561. [Google Scholar] [CrossRef]
- Huang, T.C.K.; Wu, I.L.; Chou, C.C. Investigating Use Continuance of Data Mining Tools. Int. J. Inf. Manag. 2013, 33, 791–801. [Google Scholar] [CrossRef]
- Aghaunor, L.; Fotoh, X. Factors Affecting Ecommerce Adoption in Nigerian Banks. IT Bus. Renew. 2006, 20, 23–28. [Google Scholar]
- Li, X.; Yu, H.; Bian, G.; Hu, Z.; Liu, X.; Zhou, Q.; Yu, C.; Wu, X.; Yuan, T.F.; Zhou, D. Prevalence, Risk Factors, and Clinical Correlates of Insomnia in Volunteer and at Home Medical Staff during the COVID-19. Brain Behav. Immun. 2020, 87, 140–141. [Google Scholar] [CrossRef] [PubMed]
- Janssen, M.; van der Voort, H.; Wahyudi, A. Factors Influencing Big Data Decision-Making Quality. J. Bus. Res. 2017, 70, 338–345. [Google Scholar] [CrossRef]
- Bell, L.; McCloy, R.; Butler, L.; Vogt, J. Motivational and Affective Factors Underlying Consumer Dropout and Transactional Success in ECommerce: An Overview. Front. Psychol. 2020, 11, 1546. [Google Scholar] [CrossRef]
- Musa, S.; Ali, N.B.M.; Miskon, S.B.; Giro, M.A. Success Factors for Business Intelligence Systems Implementation in Higher Education Institutions—A Review; Springer International Publishing: Johor, Malaysia, 2019; Volume 843, ISBN 978-3-319-99006-4. [Google Scholar]
- Lai, J.; Ma, S.; Wang, Y.; Cai, Z.; Hu, J.; Wei, N.; Wu, J.; Du, H.; Chen, T.; Li, R.; et al. Factors Associated with Mental Health Outcomes among Health Care Workers Exposed to Coronavirus Disease 2019. JAMA Netw. Open 2020, 3, e203976. [Google Scholar] [CrossRef]
- Villegas-Ch., W.; Palacios-Pacheco, X.; Ortiz-Garcés, I.; Luján-Mora, S. Management of Educative Data in University Students with the Use of Big Data Techniques. Rev. Iber. Sist. E Tecnol. Inf. 2019, E19, 227–238. [Google Scholar]
- Villegas-Ch, W.; Luján-Mora, S. Systematic Review of Evidence on Data Mining Applied to LMS Platforms for Improving E-Learning. In Proceedings of the International Technology, Education and Development Conference, Valencia, Spain, 6–8 March 2017; pp. 6537–6545. [Google Scholar]
- Villegas-Ch, W.; García-Ortiz, J.; Sánchez-Viteri, S. Identification of the Factors That Influence University Learning with Low-Code/No-Code Artificial Intelligence Techniques. Electronics 2021, 10, 1192. [Google Scholar] [CrossRef]
- Almaiah, M.A.; Al-Khasawneh, A.; Althunibat, A. Exploring the Critical Challenges and Factors Influencing the E-Learning System Usage during COVID-19 Pandemic. Educ. Inf. Technol. 2020, 25, 5261–5280. [Google Scholar] [CrossRef]
- Sanyal, S. Factors Affecting Customer Satisfaction with Ecommerce Websites—An Omani Perspective. In Proceedings of the 2019 International Conference on Digitization (ICD), Sharjah, United Arab Emirates, 18–19 November 2019. [Google Scholar]
- Octora, A.; Kurniawan, H.; Gultom, L.F.; Sundjaja, A.M. The Determinant Factors of Food and Beverage Small and Medium Industries Competitive Advantage That Mediated by E-Commerce Adoption Level in Bogor. Int. J. Emerg. Technol. Adv. Eng. 2021, 11, 1–14. [Google Scholar] [CrossRef]
- Sidpra, J.; Gaier, C.; Reddy, N.; Kumar, N.; Mirsky, D.; Mankad, K. Sustaining Education in the Age of COVID-19: A Survey of Synchronous Web-Based Platforms. Quant. Imaging Med. Surg. 2020, 10, 1422–1427. [Google Scholar] [CrossRef] [PubMed]
- Ferrer-Perez, V.A. Coping with the COVID-19 Pandemic and Itsconsequences from the Vantage Point of Feministsocial Psychology (Afrontando La Pandemia COVID-19 y Sus Consecuencias Desde La PsicologíaSocial Feminista) ((Afrontando La Pandemia COVID-19y Sus Consecuencias Desde La Psicología Socialfeminista)). Int. J. Soc. Psychol. 2020, 35, 639–646. [Google Scholar] [CrossRef]
- Lepin Molina, C. La Familia Ante La Pandemia Del COVID-19. Ius Et Prax. 2020, 23–29. [Google Scholar] [CrossRef]
- Ruthberg, J.S.; Quereshy, H.A.; Ahmadmehrabi, S.; Trudeau, S.; Chaudry, E.; Hair, B.; Kominsky, A.; Otteson, T.D.; Bryson, P.C.; Mowry, S.E. A Multimodal Multi-Institutional Solution to Remote Medical Student Education for Otolaryngology During COVID-19. Otolaryngol. Head Neck Surg. 2020, 163, 707–709. [Google Scholar] [CrossRef]
- Zhu, S.; Wu, Y.; Zhu, C.-Y.; Hong, W.-C.; Yu, Z.-X.; Chen, Z.-K.; Chen, Z.-L.; Jiang, D.-G.; Wang, Y.-G. The Immediate Mental Health Impacts of the COVID-19 Pandemic among People with or without Quarantine Managements. Brain Behav. Immun. 2020, 87, 56–58. [Google Scholar] [CrossRef]
- Bo, H.X.; Li, W.; Yang, Y.; Wang, Y.; Zhang, Q.; Cheung, T.; Wu, X.; Xiang, Y.T. Posttraumatic Stress Symptoms and Attitude toward Crisis Mental Health Services among Clinically Stable Patients with COVID-19 in China. Psychol. Med. 2021, 51, 1052–1053. [Google Scholar] [CrossRef] [Green Version]
- Pregowska, A.; Masztalerz, K.; Garlińska, M.; Osial, M. A Worldwide Journey through Distance Education—From the Post Office to Virtual, Augmented and Mixed Realities, and Education during the COVID-19 Pandemic. Educ. Sci. 2021, 11, 118. [Google Scholar] [CrossRef]
- Tan, H.R.; Chng, W.H.; Chonardo, C.; Ng, M.T.T.; Fung, F.M. How Chemists Achieve Active Learning Online during the COVID-19 Pandemic: Using the Community of Inquiry (CoI) Framework to Support Remote Teaching. J. Chem. Educ. 2020, 97, 2512–2518. [Google Scholar] [CrossRef]
- Lellis-Santos, C.; Abdulkader, F. Smartphone-Assisted Experimentation as a Didactic Strategy to Maintain Practical Lessons in Remote Education: Alternatives for Physiology Education during the COVID-19 Pandemic. Adv. Physiol. Educ. 2020, 44, 579–586. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).