
Where Is My Mind (Looking at)? A Study of the EEG–Visual Attention Relationship

 , , , , , and
, , , , , and
Abstract
:1. Introduction
2. Related Work
2.1. Deep Learning Approaches for EEG Processing
- The use of convolutional neural networks (CNN) has been considered to extract feature from EEG signals. One of the best known models is EEGNet presented by Lawhern et al. [9]. This network aims to estimate motor movements and detect evoked potentials (specific pattern in electrophysiological signals seen after stimuli apparition) through a sequence of convolution filters with learnable kernels. These kernels extract the spatial and/or temporal features from the signal according to the considered shape (x-axis representing the time evolution and y-axis representing the considered channels).
- One of the other methods considered to process EEG is the use of graph networks. With this approach, the EEG is considered as a graph (with vertices corresponding to electrodes and edges being proportional to their distance) evolving over time. The method based on Regularized Graph Neural Networks proposed by Zhong et al. [10] presents the best results for emotion estimation from EEG.
- Another approach that has already been considered for a wide range of application in EEG processing is based on recurrent neural networks (RNN). These kinds of networks have already proven their ability to extract the spatial [11] and temporal [12] information from brain activity signals. In the work of Bashivan et al. [12], Bashivan et al. consider a model composed of a different layer of CNN and RNN to estimate motor movements from EEG.
- Over the last years, an emerging method has been considered: the use of a generative adversarial network (GAN) for EEG processing. GAN is a family of neural networks where two networks (i.e., generator and discriminator) are trained in an adversarial manner: the discriminator aims at detecting if a given modality has been artificially generated or corresponds to the ground truth, and the generator tries to fool the discriminator by generating modalities very close to reality [13]. GANs have already been used for generating images representing thoughts and/or dreams [14,15]. Although this research field is still under development, the authors have high hopes that one day, it will be possible to visualize our thoughts or dreams.
2.2. EEG-Based Attention Estimation
2.3. Visual Saliency Estimation
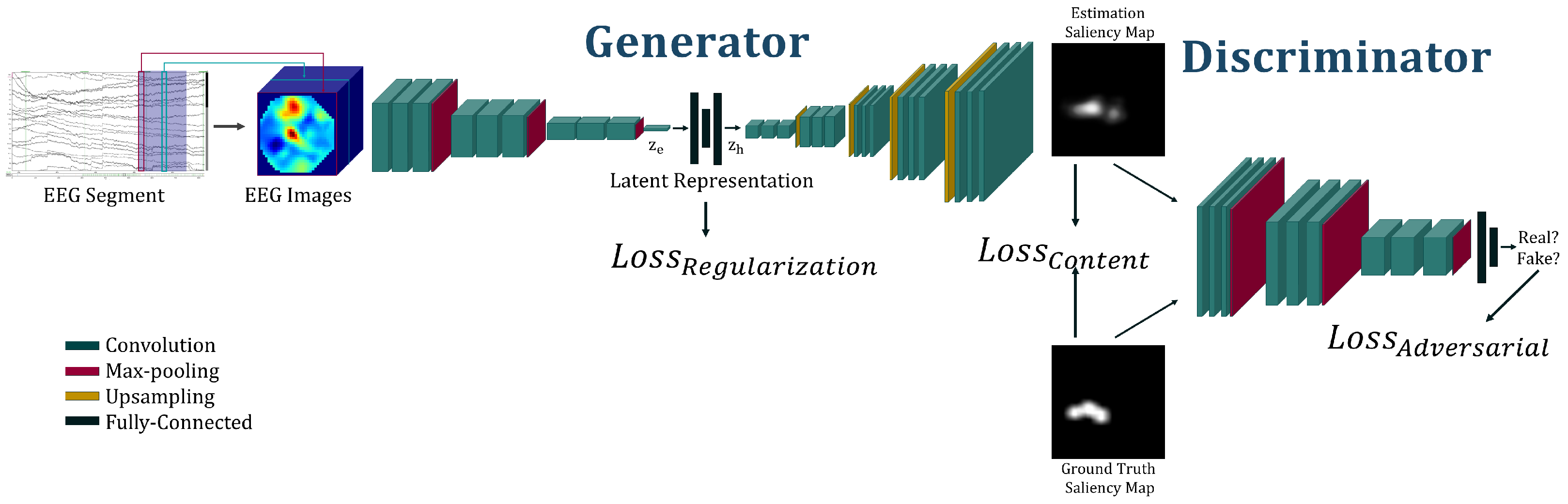
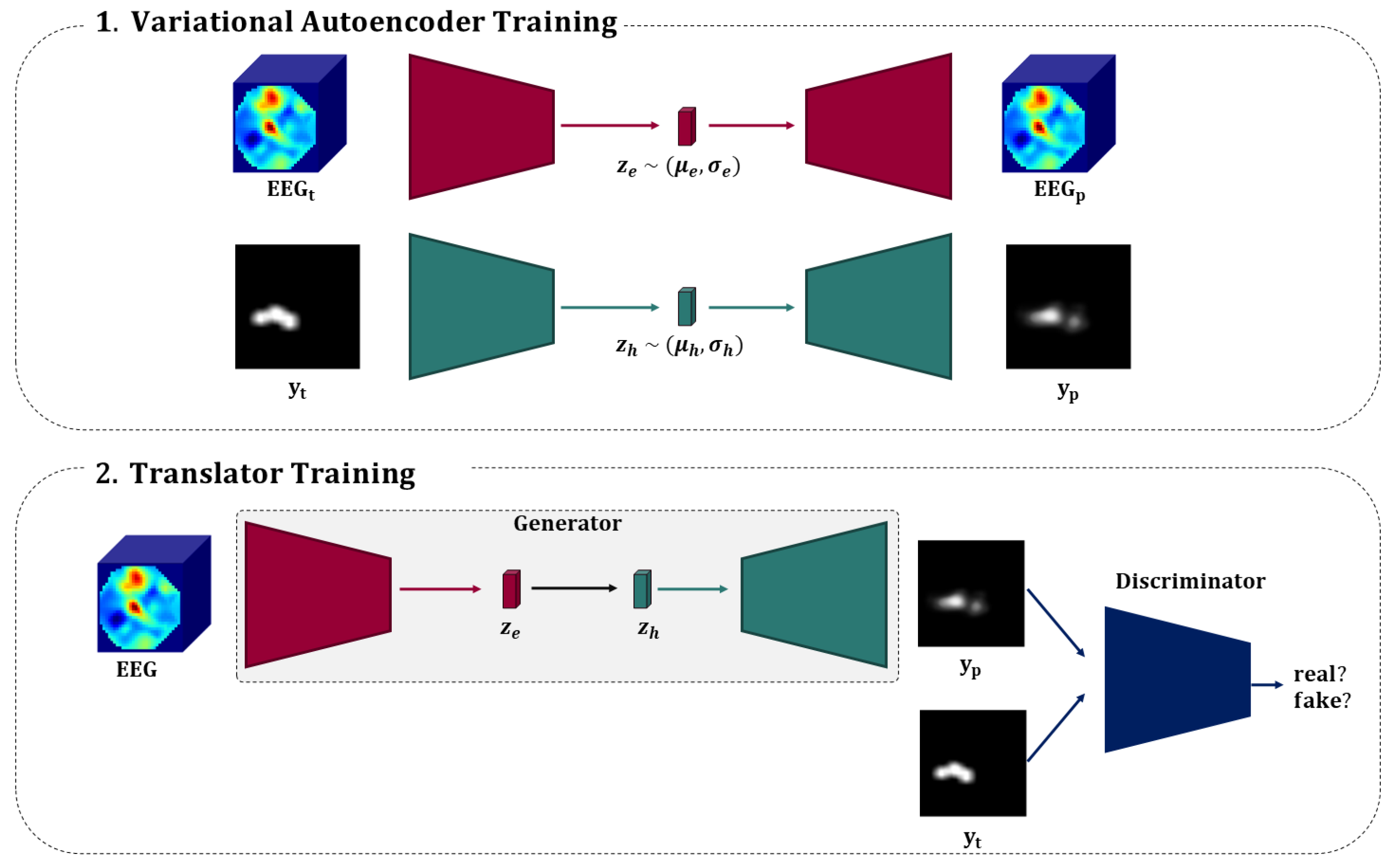
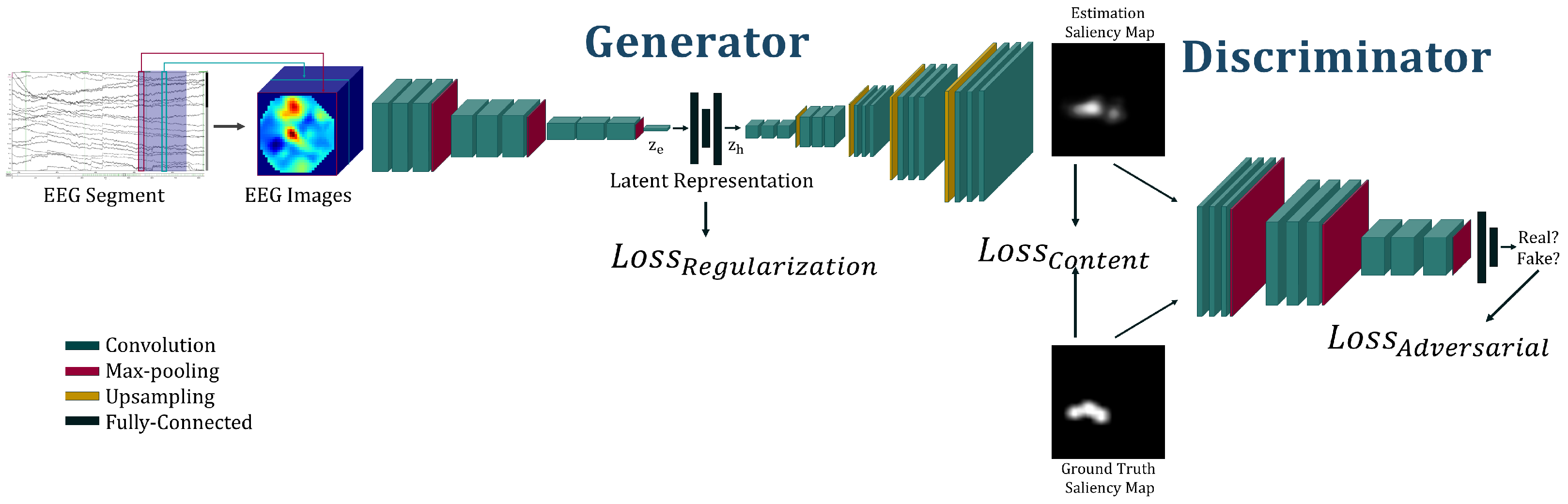
3. Proposed Method
- A variational autoencoder (VAE) aiming to represent the saliency images in a shorter subspace called latent space. This VAE will have two roles: recreating the saliency images that represent the participant visual attention; and representing the images in a completed and continuous latent space [21].
- A VAE aiming to represent the EEG in the latent space. As for the previous model, the aim of EEG VAE is also to minimize the error between the EEG and its reconstruction and to create a continuous and completed representation of the signals in the corresponding latent space.
- A GAN binding the EEG and map latent space with the help of the two VAEs already described. In addition, a discriminator is also used to classify the images from synthetic (i.e., created by our model) vs. real (i.e., real saliency maps created from eye-tracking recording).
3.1. Autoencoding Saliency Map
3.2. Autoencoding EEG Signals
- Separating the total recording in trials leading to an array of dimension .
- For each trial, downsampling the signals after low-pass filtering to extract the general signal evolution and to ignore the artefacts contribution. Preprocessing is at the same time applied to remove the noise and remaining artefacts.
- From the regular electrode position on the scalp, an azimuthal projection is applied to represent their location in a 2D frame.
- The samples composing the trials are taken separately. These samples are projected in a 2D coordinate frame as mentioned at the previous step, and a bicubic interpolation is applied to consider a continuous representation of information. The process is repeated for all the samples, and each projection is concatenated to lead to an image with a number of channels corresponding to the number of temporal samples after the signal downsampling.
- The statistical distribution of the images set has also been normalized around a mean of 0 and a standard deviation of 1.
3.3. Generator Network Mapping the Latent-Space Distributions
3.4. Training Methodology
4. Experiments
4.1. Dataset Acquisition
4.2. Implementation Details
4.3. Metrics and Evaluation
- The area under curve (AUC) representing the area under the receiver operating characteristic (ROC) curve. In the case of visual saliency estimation, the AUC has been adapted to suit with the problematic by considering a changing threshold for class estimation from a value between 0 and 1 (corresponding to saliency value). This adapted AUC is sometimes also called AUC-Judd [1].
- The Normalized Scanpath Saliency (NSS) is a straightforward method to evaluate the model’s ability to predict the visual attention map. It consists of the measurement of the distance between the normalized around 0 ground-truth saliency map and the model estimation [28].
- The binary cross-entropy (BCE) [29] computing the distance between the prediction and the ground truth value in binary classification. Our problematic may be considered as a binary classification if we consider each pixel as a probability of being watched or not, this is the reason that we have also considered this metric.
- The Pearson’s Correlation Coefficient (CC) is a linear correlation coefficient measuring the correlation between the ground truth and model estimation distributions [30].
5. Results and Discussion
5.1. Quantitative Analysis
5.2. Effect of the Adversarial Training
5.3. Qualitative Analysis
5.4. Experimental Study Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Riche, N.; Duvinage, M.; Mancas, M.; Gosselin, B.; Dutoit, T. Saliency and human fixations: State-of-the-art and study of comparison metrics. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1153–1160. [Google Scholar]
- Droste, R.; Jiao, J.; Noble, J.A. Unified image and video saliency modeling. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 419–435. [Google Scholar]
- Pan, J.; Ferrer, C.C.; McGuinness, K.; O’Connor, N.E.; Torres, J.; Sayrol, E.; Giro-i Nieto, X. Salgan: Visual saliency prediction with generative adversarial networks. arXiv 2017, arXiv:1701.01081. [Google Scholar]
- Ravì, D.; Wong, C.; Deligianni, F.; Berthelot, M.; Andreu-Perez, J.; Lo, B.; Yang, G.Z. Deep learning for health informatics. IEEE J. Biomed. Health Inform. 2016, 21, 4–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Seo, H.J.; Milanfar, P. Nonparametric bottom-up saliency detection by self-resemblance. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 45–52. [Google Scholar]
- Duncan, J.; Humphreys, G.; Ward, R. Competitive brain activity in visual attention. Curr. Opin. Neurobiol. 1997, 7, 255–261. [Google Scholar] [CrossRef]
- Busch, N.A.; VanRullen, R. Spontaneous EEG oscillations reveal periodic sampling of visual attention. Proc. Natl. Acad. Sci. USA 2010, 107, 16048–16053. [Google Scholar] [CrossRef] [Green Version]
- Lotte, F.; Bougrain, L.; Cichocki, A.; Clerc, M.; Congedo, M.; Rakotomamonjy, A.; Yger, F. A review of classification algorithms for EEG-based brain–computer interfaces: A 10 year update. J. Neural Eng. 2018, 15, 031005. [Google Scholar] [CrossRef] [Green Version]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef] [Green Version]
- Zhong, P.; Wang, D.; Miao, C. EEG-based emotion recognition using regularized graph neural networks. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Li, Y.; Wang, L.; Zheng, W.; Zong, Y.; Qi, L.; Cui, Z.; Zhang, T.; Song, T. A novel bi-hemispheric discrepancy model for eeg emotion recognition. IEEE Trans. Cogn. Dev. Syst. 2020, 13, 354–367. [Google Scholar] [CrossRef]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Goodfellow, I. Nips 2016 tutorial: Generative adversarial networks. arXiv 2016, arXiv:1701.00160. [Google Scholar]
- Tirupattur, P.; Rawat, Y.S.; Spampinato, C.; Shah, M. Thoughtviz: Visualizing human thoughts using generative adversarial network. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 950–958. [Google Scholar]
- Palazzo, S.; Spampinato, C.; Kavasidis, I.; Giordano, D.; Shah, M. Generative adversarial networks conditioned by brain signals. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3410–3418. [Google Scholar]
- Liang, Z.; Hamada, Y.; Oba, S.; Ishii, S. Characterization of electroencephalography signals for estimating saliency features in videos. Neural Netw. 2018, 105, 52–64. [Google Scholar] [CrossRef] [PubMed]
- Cao, Z.; Chuang, C.H.; King, J.K.; Lin, C.T. Multi-channel EEG recordings during a sustained-attention driving task. Sci. Data 2019, 6, 1–8. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, W.L.; Lu, B.L. A multimodal approach to estimating vigilance using EEG and forehead EOG. J. Neural Eng. 2017, 14, 026017. [Google Scholar] [CrossRef] [PubMed]
- Kummerer, M.; Wallis, T.S.; Bethge, M. Saliency benchmarking made easy: Separating models, maps and metrics. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 770–787. [Google Scholar]
- Kroner, A.; Senden, M.; Driessens, K.; Goebel, R. Contextual encoder–decoder network for visual saliency prediction. Neural Netw. 2020, 129, 261–270. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Stephani, T.; Waterstraat, G.; Haufe, S.; Curio, G.; Villringer, A.; Nikulin, V.V. Temporal signatures of criticality in human cortical excitability as probed by early somatosensory responses. J. Neurosci. 2020, 40, 6572–6583. [Google Scholar] [CrossRef]
- Salvucci, D.D.; Goldberg, J.H. Identifying fixations and saccades in eye-tracking protocols. In Proceedings of the 2000 Symposium on Eye Tracking Research & Applications, Gardens, FL, USA, 6–8 November 2000; pp. 71–78. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE 29th Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Delvigne, V.; Ris, L.; Dutoit, T.; Wannous, H.; Vandeborre, J.P. VERA: Virtual Environments Recording Attention. In Proceedings of the 2020 IEEE 8th International Conference on Serious Games and Applications for Health (SeGAH), Vancouver, BC, Canada, 12–14 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–7. [Google Scholar]
- Oostenveld, R.; Praamstra, P. The five percent electrode system for high-resolution EEG and ERP measurements. Clin. Neurophysiol. 2001, 112, 713–719. [Google Scholar] [CrossRef]
- Francis, N.; Ante, J.; Helgason, D. Unity Real-Time Development Platform. Available online: https://unity.com/ (accessed on 26 January 2022).
- Peters, R.J.; Iyer, A.; Itti, L.; Koch, C. Components of bottom-up gaze allocation in natural images. Vis. Res. 2005, 45, 2397–2416. [Google Scholar] [CrossRef] [Green Version]
- Cox, D.R. The regression analysis of binary sequences. J. R. Stat. Soc. Ser. B 1958, 20, 215–232. [Google Scholar] [CrossRef]
- Bylinskii, Z.; Judd, T.; Oliva, A.; Torralba, A.; Durand, F. What do different evaluation metrics tell us about saliency models? IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 740–757. [Google Scholar] [CrossRef] [Green Version]
- Judd, T.; Durand, F.; Torralba, A. A Benchmark of Computational Models of Saliency to pRedict Human Fixations. 2012. Available online: https://saliency.tuebingen.ai/results.html (accessed on 3 March 2022).
- Yu, M.; Li, Y.; Tian, F. Responses of functional brain networks while watching 2D and 3D videos: An EEG study. Biomed. Signal Process. Control 2021, 68, 102613. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Generator | ||
|---|---|---|
| Network Part | Layer | Int/Out Channels |
| EEG Encoder | Conv2D-3 | 401/256 |
| Conv2D-3 | 256/256 | |
| Conv2D-3 | 256/256 | |
| Conv2D-3 | 256/256 | |
| Maxpool-2 | 256/256 | |
| Conv2D-3 | 256/512 | |
| Conv2D-3 | 512/512 | |
| Conv2D-3 | 512/512 | |
| Maxpool-2 | 512/512 | |
| Conv2D-3 | 512/512 | |
| Conv2D-3 | 512/512 | |
| Flattening Layer | ||
| Linear | 512/256 | |
| Linear | 256/64 | |
| Distrib. FC | Linear | 64/64 |
| Sampling Layer | ||
| Noise Cat | 64/128 | |
| Linear | 128/256 | |
| Linear | 256/64 | |
| Saliency Decoder | Linear | 64/512 |
| UnFlattening Layer | ||
| Upsampling-2 | 512/512 | |
| Conv2D-3 | 512/512 | |
| Conv2D-3 | 512/512 | |
| Conv2D-3 | 512/512 | |
| Upsampling-3 | 512/512 | |
| Conv2D-3 | 512/256 | |
| Conv2D-3 | 256/256 | |
| Conv2D-3 | 256/256 | |
| Upsampling-3 | 256/256 | |
| Conv2D-3 | 256/128 | |
| Conv2D-3 | 128/128 | |
| Conv2D-3 | 128/128 | |
| Upsampling-3 | 128/128 | |
| Conv2D-3 | 128/64 | |
| Conv2D-3 | 64/64 | |
| Conv2D-3 | 64/64 | |
| Upsampling-2 | 64/64 | |
| Conv2D-3 | 64/4 | |
| Conv2D-3 | 4/4 | |
| Conv2D-3 | 4/1 |
| Discriminator | |
|---|---|
| Layer | Int/Out Channels |
| Conv2D-3 | 1/3 |
| Conv2D-3 | 3/32 |
| Conv2D-3 | 32/32 |
| Conv2D-3 | 32/32 |
| Maxpool-2 | 32/32 |
| Conv2D-3 | 32/64 |
| Conv2D-3 | 64/64 |
| Conv2D-3 | 64/64 |
| Maxpool-2 | 64/64 |
| Conv2D-3 | 64/128 |
| Conv2D-3 | 128/128 |
| Conv2D-3 | 128/128 |
| Maxpool-2 | 128/128 |
| Conv2D-3 | 128/256 |
| Conv2D-3 | 256/256 |
| Conv2D-3 | 256/256 |
| Flattening Layer | |
| Linear | 256/64 |
| Linear | 64/1 |
| Modality | Approach | AUC | NSS | CC |
|---|---|---|---|---|
| EEG | Our method (1) | 0.697 | 1.9869 | 0.383 |
| Our method (2) | 0.574 | 1.6891 | 0.251 | |
| Images | UNISAL [2] | 0.877 | 2.3689 | 0.7851 |
| SalGAN [3] | 0.8498 | 1.8620 | 0.6740 | |
| SSR [5] | 0.7064 | 0.9116 | 0.2999 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Delvigne, V.; Tits, N.; La Fisca, L.; Hubens, N.; Maiorca, A.; Wannous, H.; Dutoit, T.; Vandeborre, J.-P. Where Is My Mind (Looking at)? A Study of the EEG–Visual Attention Relationship. Informatics 2022, 9, 26. https://doi.org/10.3390/informatics9010026
Delvigne V, Tits N, La Fisca L, Hubens N, Maiorca A, Wannous H, Dutoit T, Vandeborre J-P. Where Is My Mind (Looking at)? A Study of the EEG–Visual Attention Relationship. Informatics. 2022; 9(1):26. https://doi.org/10.3390/informatics9010026
Chicago/Turabian StyleDelvigne, Victor, Noé Tits, Luca La Fisca, Nathan Hubens, Antoine Maiorca, Hazem Wannous, Thierry Dutoit, and Jean-Philippe Vandeborre. 2022. "Where Is My Mind (Looking at)? A Study of the EEG–Visual Attention Relationship" Informatics 9, no. 1: 26. https://doi.org/10.3390/informatics9010026
APA StyleDelvigne, V., Tits, N., La Fisca, L., Hubens, N., Maiorca, A., Wannous, H., Dutoit, T., & Vandeborre, J.-P. (2022). Where Is My Mind (Looking at)? A Study of the EEG–Visual Attention Relationship. Informatics, 9(1), 26. https://doi.org/10.3390/informatics9010026