1. Introduction
Student engagement refers to the extent to which students are interested or involved in their learning and how they are linked to other students, their classes, and their institutions [
1]. Three dimensions of student engagement have been identified [
2]: (1) behavioural engagement, represented by behavioural norms, such as attendance and involvement; (2) emotional engagement, represented by emotions, such as enjoyment, interest, and a sense of belonging; and, (3) cognitive engagement, represented by investing more time in learning beyond that required [
2]. This study focuses on behavioural and cognitive engagement.
Student engagement has received significant attention in the literature since the 1990s [
3], particularly in terms of its value for learning and achievement [
4]. Trowler believes that “
the value of engagement is no longer questioned” [
3] (p. 4). Student engagement is considered to be a predictor of student performance [
5,
6] and one of the main factors behind students’ boredom, alienation, low performance, and high dropout rates [
5]. The literature shows that higher education institutions (HEIs) are facing a critical problem with low-level student engagement. Several teaching methods, tools, and strategies have been developed to solve this problem. For example, with the significant increase in the number of internet users and mobile phone owners, there has been great interest in employing these devices in class and outside of class to improve student participation [
7,
8] and, currently, chatbots are being used in education [
9].
According to [
3], a large proportion of the student engagement literature reports studies in the United States (US) and Australia, with most of the research focusing on the implementation of the National Survey of Student Engagement (NSSE). [
10] studied the linkage between student engagement and student learning. The study sample consisted of 1058 students from 14 universities and colleges and used the NSSE survey instrument to collect the data. The instrument consists of 70 items that evaluate the effort and time that students spend on educational activities. The results of the study show that student engagement is only one factor that affects student performance.
The UK represents a small proportion of existing literature [
3] on student engagement. For example, [
3] concentrated on specific aspects of learning, including tools (learning management systems), techniques (particular feedback), or approaches to specific situations (inductions for distance learners). Moreover, [
3] surveyed students to measure their perceptions of these specific aspects. In UK studies on student engagement, the sample size is usually small, and the survey focuses on the experiences of a single class of a single module at a particular level.
A chatbot is a conversational agent and a computer program that can conduct a conversation with the user while using natural language speech [
11]. ELIZA [
12] is considered to be one of the earliest created chatbots [
13]; it was developed in the 1960s by Joseph Weizenbaum to simulate a psychotherapist in clinical treatment [
9,
12]. The idea was straightforward, and it used a keyword matching approach [
9]. ELIZA accepts input text, analyses it, and then produces responses by applying the reassembly rules that come with input decomposition [
13]. ELIZA’s responses show concern for users. However, it has no memory to retain the conversation, and it is unable to become involved in any targeted types of negotiation or collaboration. ELIZA’s syntactic language processing has been dramatically developed. Thus, a large number of chatbot language processes have been created.
Chatbots are also referred to as ‘artificial conversational entities’ (ACEs) or ‘conversational systems’. Currently, well-known examples of chatbots are Amazon Alexa, Siri on iPhone, Cortana, and Google Assistant [
14]. Although chatbots seem to work intelligently by interpreting users’ input before providing answers, some chatbots merely scan the keywords that are inputted and respond with the most suitable matching keyword replies from their databases [
15]. Although chatbots are a fundamental and straightforward application of artificial intelligence (AI), they are critical due to their various applications and potential uses.
Chatbots can be used as a powerful tool for teaching and educating students. They can work as a language tutor, as in the example known as Sofia. Additionally, they can assist with the teaching of mathematics and help users to solve algebra problems, as with the Pari and Mathematica chatbots. Moreover, they help medical students by simulating patients and providing responses during interviews with medical students; an example of this type of chatbot is the Virtual Patient bot (VPbot) [
16].
Using chatbots in education can have many benefits for students and teachers, as presented by [
17], including: (1) they make learning more enjoyable, as students feel more relaxed and comfortable and enjoy chatting with chatbots more than their teachers or peers in traditional teaching [
9,
17]; (2) they support continuous learning, as chatbots enable students to repeat and view the same learning materials many times without feeling tired or bored, in contrast to teachers [
9,
17]; (3) they enhance student motivation by offering a new way of learning that attracts students [
9,
17]; and, (4) they enhance students’ listening and reading abilities [
9,
17].
Chatbots can be used in health intervention approaches. The study by [
18] aimed to assess whether chatbots are suitable for use in mental health interventions. The study was conducted in Australia, and the participants were adults aged between 18 and 25 years old, specifically those with high alcohol consumption. A chatbot was created to carry out an essential assessment of the participants’ alcohol drinking habits and to specify the health risk level. Moreover, it educated users regarding alcohol use. Seventeen participants evaluated the usability of the chatbot and their user satisfaction; the overall results show that the users had strong positive perceptions of the intervention. The main limitations of the study were the small sample size and the lack of a control group [
18].
Chatbots can be a source of entertainment, alleviating boredom [
16]. Mistuku and Jessie Humani are chatbots that fulfil the human need for social interaction and entertainment [
19]. Chatbots can be used to kill time when people are bored, as reported by [
19]. Some chatbots are used for small talk and socialising, such as A.L.I.C.E. and Cleverbot [
19]. Chatbots can be great tools for retrieving information [
17]. They can provide answers to questions, like “when?”, “what?”, “where?”, and “how?”, in a conversational setting. Therefore, many businesses use them for question-answer services [
16]. Chatbots can also be used to provide user assistance via various interfaces, such as Siri on iPhones [
16].
Moreover, chatbots can provide customer services. Many websites contain frequently asked question (FAQ) pages, which contain answers to common issues that concern users. However, when the FAQ page contains many addressed issues, it becomes impractical for users to read through the many distinct entries to find the one that they are searching for. Moreover, the user might not feel confident regarding the terms used to address the issues on the page. Therefore, in website design, chatbots can be used to address these problems by creating a conversational interface for the FAQ page [
20]. Further studies are needed to develop chatbots that allow users to give feedback on how their queries have been addressed by such chatbots [
20].
Personas are a design tool for creating a conversational system. However, in this study, the conversational system will interact differently based on the students’ persona type, which means that the conversational system is based on personas and it is referred to as a persona-based conversational system. Personas can be created from existing data or no data, or data can be collected to create the personas [
21]. A study by [
21] created personas for a training organisation, so the data attributes were related to professional certification and training experiences. Data-driven personas have several advantages over traditional methods [
21]. (1) Personas can be created based on real customer data, so the generated personas are acceptable to the client. (2) The attributes of the collected data can be carefully selected to support the purpose of creating personas. (3) The collected dataset can have a significant number of records. Data-driven personas can be created from qualitative data, quantitative data, or both [
21,
22,
23]. Generally, personas are qualitative in nature [
23]; however, this study focuses on quantitative data-driven personas. According to [
24], qualitative data-driven personas that are built based on a few interviews do not validly represent the real groups, and the generated personas are not considered to be appropriate decision-making instruments. On the other hand, if personas are created based on quantitative data and statistical analysis, they represent valid personas [
23], as in our study.
After analysing the literature, a literature gap has been identified: no previous study has investigated the use of context-based and personas-based conversational systems in HEIs to enhance student engagement. Therefore, this study aims to enhance undergraduate student engagement while using a context-based and personas-based conversational system (chatbots) using design science research that covers three iterations: (1) personas elicitation, (2) survey and SEFMs, and (3) chatbot interaction analysis. In the first iteration, student groups and personas are identified using the K-means clustering method, which is applied to two datasets. Before that, three methods are used to identify the optimal value of K: the elbow, gap statistic, and silhouette methods. K-means clustering is a clustering method that is used to divide a dataset (e.g., student data) into groups based on a specified number. The results present groups that have similar attributes or features, so, in this study, students in the same groups have similar features and they differ from students in other groups.
The contribution of this paper is that it proposes a straightforward and applicable quantitative data-driven persona development method (DDPDM) that can be used in higher education institutions (HEIs) to identify student groups and personas from existing data. It could help other researchers and practitioners to propose tools or techniques to enhance student engagement and thus performance based on different student personas. In addition, we propose eight undergraduate student personas that are mainly based on student engagement and performance data. This study, alongside our future improvements, could help in the development of new forms of pedagogical practices that rely on virtual learning environments (VLEs) and chatbots instead of (or in combination with) traditional teaching approaches.
The remainder of the paper is structured, as follows:
Section 2 discusses previous work related to this research.
Section 3 describes the materials and methods that are used to pre-process the data.
Section 4 presents the analysis and results of the two data analysis, starting with identifying the optimal value of
K and then applying
K-means clustering to the two datasets.
Section 5 discusses the results and interprets the decision of combining the two data analysis results in one. The paper is then summarised in
Section 6, which includes limitations of the study, suggestions for further research, and speculates on future directions.
2. Related Work
Initially, with the popularity of user-centred design (UCD), the usability of systems, websites, and products were improved [
25,
26,
27]. User-centred design is also referred to as ‘customer-centred design’ or ‘human-centred design’ and it is a type of design that brings customers or users into the design process [
26,
27]. UCD has spread widely. However, there has been some frustration that is related to the design of modern products. Many corporations have failed to focus on consumer needs as the most important aspect of the design process [
27]. Therefore, many design processes have failed to reach the target users or consumers [
27,
28,
29]. The well-documented usability issues of products, systems, and websites prove that current product design processes need improvement. For example, many products are returned because they are difficult to use, or the users are unable to use their preferred features [
26].
Personas provide a solution to some of the problems with the current UCD approach. The ‘persona’ concept was proposed by [
29] as a design process methodology [
30]. Personas are not real people but imaginary archetypes of actual users [
30]. A persona is defined as “
a precise description of a hypothetical user and what s/he wishes to accomplish” [
21] (p. 1). A persona is also referred to as a ‘target customer characterisation’, ‘profile’, or ‘user archetype’ [
31]. Persona development is an alternative method for representing and communicating users’ needs [
26]. There is much research in the literature that discusses persona templates [
32,
33], creating personas [
34,
35,
36] and what they are suitable for [
22,
30,
31,
36]—in particular, using personas for interface and interaction design has attracted great attention [
31]. Persona development as a design technique is becoming increasingly popular, as it presents the main users’ features to be used for product design and marketing [
35]. Additionally, it is an efficient way to improve users’ experiences with products and services [
31]. Moreover, personas provide product designers with powerful representations of target consumers [
26].
Furthermore, using personas has other benefits: (1) providing a better understanding of users, (2) providing design requirements at an early stage, (3) requiring design thinking, (4) focusing on users’ goals, requirements and characteristics, (5) facilitating stakeholder communication, and (6) including political and social factors in design decisions [
37]. However, according to [
21], there are a few problems with personas development, including creating personas that are not based on first-hand datasets [
36], which is not the case in this study. Moreover, personas can be unreliable if they do not have a clear relationship with the data, such as if they were designed by a committee [
36].
Chatbots have been utilised in educational domains for different purposes [
38], such as introducing students to concepts. A study by [
39] used chatbots to introduce students to AI and conversation concepts, rather than the creation of chatbots. Using Turi to build the chatbots, the students were able to create several instances of the chatbot Program O. This was done to enhance their understanding of AI concepts, such as call–response conversations. The interactions with the chatbots were written in AI Markup Language (AIML). Each student could construct these instances by modifying AIML statements. Moreover, the students could conduct conservations with their own chatbots or other students’ chatbots. The teachers liked the idea and provided positive feedback [
39].
Another study by [
40] showed how chatbots could be utilised in education to teach socially intelligent computing principles to undergraduate students studying introductory computer science courses. The students created a project while using the Java programming language that enabled collaboration between the individual chatbots that they created: whenever a question could not be handled by the first chatbot, it searched for an answer from other chatbots, and so on [
40].
Chatbots can enable self-guided learning in an educational context. They can provide feedback on a large number of activities for students across a whole semester. This is done using AI techniques and applying natural language processing features and machine learning algorithms [
41]. Chatbots can provide students and teachers with progress reports, including student performance, test results, and the easiest and most difficult parts of the course. Chatbots can then send personalised notifications to individual students to suggest specific quizzes and send warnings to teachers about the students who are struggling in their studies. The results of one study showed that 72% of the students thought that chatbots could assist them in engaging more with the course. Almost all of the students (94%) recommended using testing chatbots for other modules at the university [
41].
Chatbots have been utilised in distinct scenarios to make people interested in computer science for decades [
42]. Worldwide, young students have a lack of engagement in computer science. For example, in Argentina, only 4000 computer science students graduate per year, which is half the amount that is needed by the national industry, while there are 15,000 economics graduates and 10,000 law graduates [
43,
44]. Therefore, [
34] created an innovative way to introduce high school students to computer science while using chatbots and ALICE, which is a well-known education tool. The chatbots taught students basic concepts, such as conditions, variables, and finite state automata, to name a few. The chatbots provided automatic formative assessments to the students while using finite state automata and pattern matching. Formative feedback was immediately generated when errors occurred. The researchers studied the effectiveness of using chatbots on student engagement while using two observational studies: (1) a compulsory in-classroom pilot course across 15 lessons, conducted in three high schools, and (2) an online nationwide contest with at least 10,000 participants. Students’ engagement indicators were measured, such as attendance, enthusiasm, task completion, willingness, and self-reported interest. The study results indicated enhanced student engagement; girls reported more interest than boys, and they were more willing to use chatbots to learn more [
42,
44]. Regarding the online contest, the percentage of students who completed their tasks with chatbots was five times higher than those who used ALICE.
A study by [
45] explored whether a development model of units of learning (UoLs), supported by authoring tools, allowed for better usability of resources for high school teachers. The study used design science research as the main design research method and it used the
K-means algorithm.
K-means clustering was used to identify user groups. Two groups were identified: participants with strong technology skills and participants with poor technology skills. This was achieved based on quantitative data, such as effort times, task completion, the occurrence of errors in tasks, and aid requests. The study covered three iterations. In the first iteration, data were collected from questionnaires, interviews, and documents. In the second and third iterations, data were collected from questionnaires and non-participant observations. The results of the study show that the usability, reusability, creation, and editing of educational resources by high school teachers can be improved by integrating authoring tools and Learning Management System (LMSs).
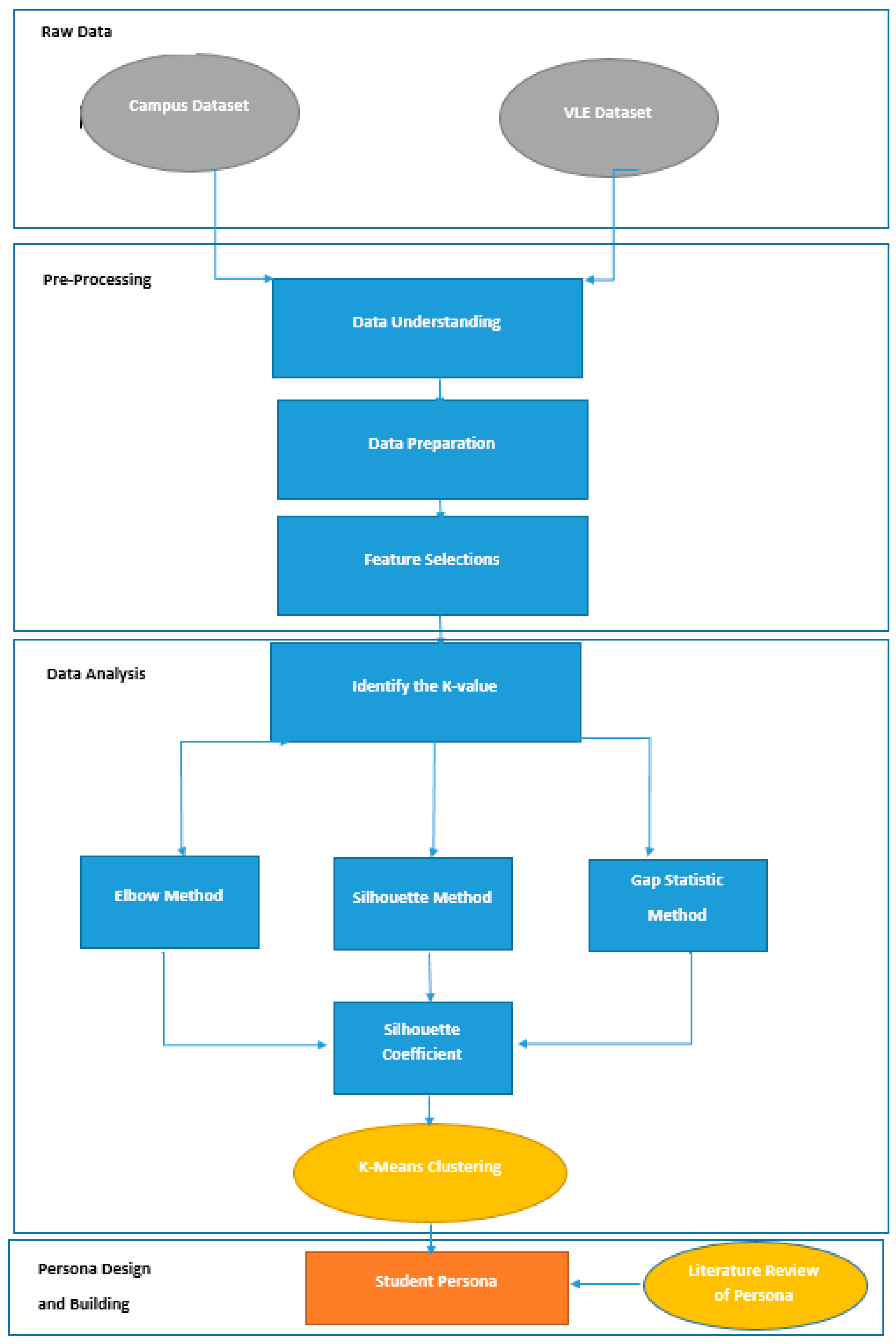
3. Materials and Methods
The design science research (DSR) methodology is the principal research methodology used in this study to create and evaluate an innovative artefact that enables UK HEIs to solve one of their key problems [
46]: low levels of student engagement. The DSR approach is adapted from [
47] to meet the research’s aim and objectives in each iteration. A valid information system (IS) research process is conducted through the building and evaluation of the designed artefact [
46].
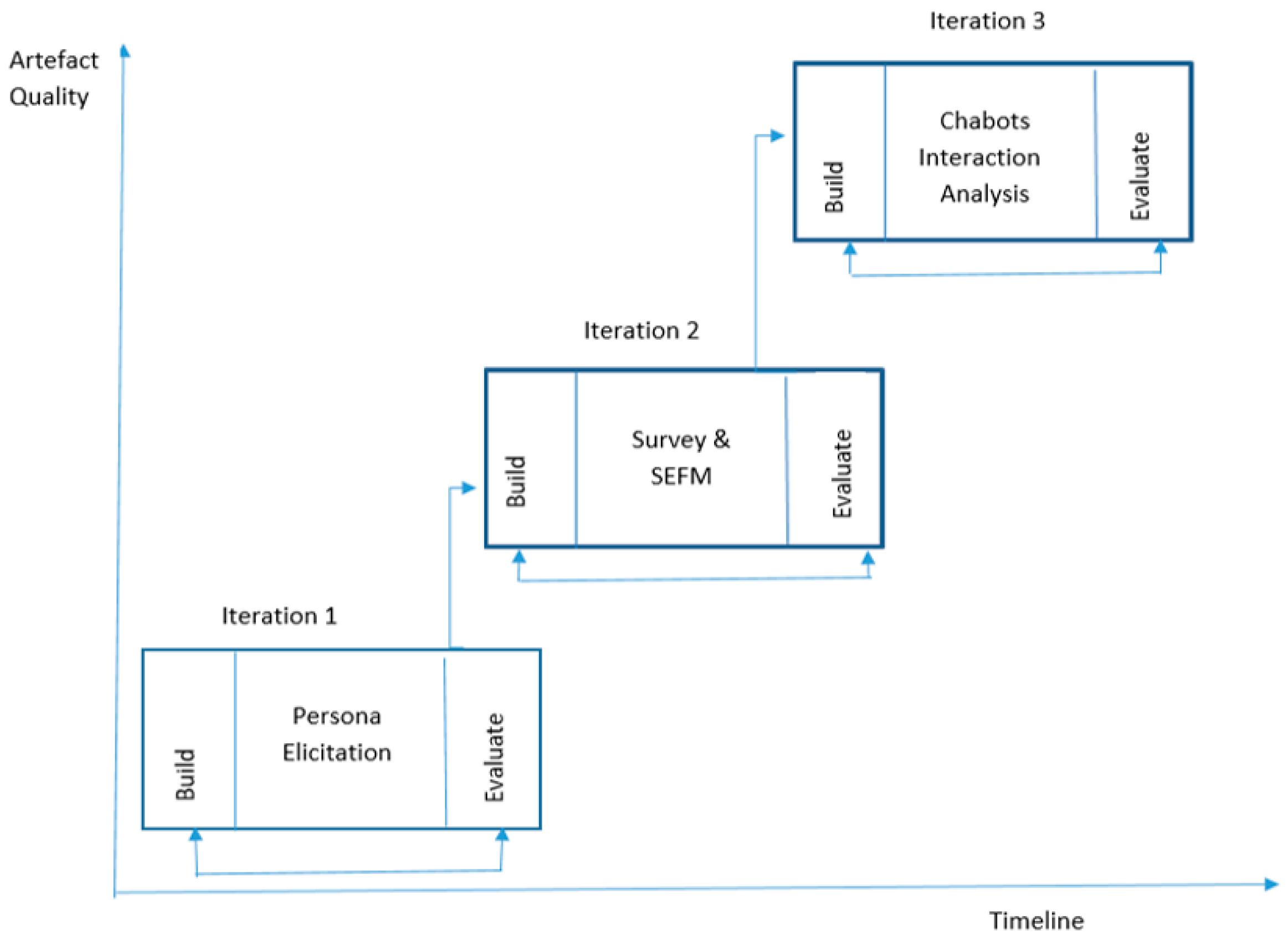
The core idea of this research is to enhance student engagement at HEIs while using a conversational system. This is achieved using three iterations, as shown in
Figure 1. The first iteration, personas elicitation, aims to identify student groups at Brunel University London using machine learning, particularly
K-means clustering. The results of the data analysis and the literature review form a persona template and students personas. The second iteration involves conducting a survey and developing SEFMs. This is achieved using a questionnaire, which will be designed based on the literature review and persona elements from the first iteration. The third iteration, chatbot interaction analysis, aims to study the effectiveness of using a chatbot in enhancing student engagement. This iteration includes designing and building chatbots that will enhance student engagement.
This paper focuses on the first iteration, personas elicitation, and the second two iterations will be conducted shortly after. Each iteration is performed in five phases: (1) problem awareness, (2) suggestions, (3) development, (4) evaluation, and (5) conclusion [
47]. Firstly, awareness of the research problem is developed through a literature review. This involves reviewing and analysing the literature on mobile educational technology, student engagement, and the state of the art of chatbot use in HEIs.
Secondly, the suggestions phase is fundamentally a creative step where a new idea is proposed to address the problem through the design of an appropriate framework. The first iteration covers utilising a machine learning framework to identify student groups on campus and build student personas. The second iteration covers building SEFMs by identifying the factors that affect student engagement. The third iteration uses the knowledge that was identified from the results of the previous two iterations to design and develop a chatbot prototype. In addition, there is a suggestion of establishing an experiment to measure the effectiveness of using this conversational system in enhancing student engagement.
Thirdly, the development phase is carried out through the development of the research artefacts, as represented by constructs, models, methods, and instantiations. In the first iteration, the artefacts are personas models and the DDPDM. In the second iteration, the artefacts are constructed in the form of a survey and SEFMs. In the third iteration, the artefact is a chatbot, which is a form of instantiation.
Fourthly, the evaluation phase focuses on evaluating and assessing the developed artefacts in the previous step in terms of effectiveness, reliability, validity, and usability [
48]. The results of the first iteration, the student persona models, are evaluated in the second iteration with different student data. The results of the second iteration, the SEFMs, are evaluated regarding their reliability and validity using structural equation modelling (SEM). The result of the third iteration, the chatbot, is evaluated in terms of its usability using the System Usability Scale (SUS) and its effectiveness in enhancing student engagement while using pre- and post-tests.
Finally, the conclusion phase is about concluding and writing up the design research cycle, starting from understanding the problem in the domain space and ending with summarising the research findings. In addition, it assesses the limitations of the solutions and develops suggestions for future work.
Overall, the research method is DSR, and a certain method is used to achieve the aim of the iteration in each iteration. For example, in the first iteration, K-means clustering is the main research method that assists in identifying student groups at Brunel University London, and the results of the clustering are used to form a persona template and personas for undergraduate students. The first iteration is described in the following section.
3.2. K-Means Clustering and Identifying the Number of Clusters (K)
Clustering methods are used in this study to identify the groups of students and extract the students’ attributes to build the personas. Clustering refers to the task of grouping a set of objects so that objects in the same group are similar to each other but different from objects in other groups [
31,
37]. Clustering is unsupervised learning that does not require any training data before using it [
50], unlike classification [
51]. Several clustering algorithms have been proposed in the literature, such as
K-means clustering [
52,
53,
54]. Hartigan describes this in detail [
55]. The
K-means clustering method is the most popular and widely used clustering algorithm due to its simplicity [
56]. Besides, it is robust, fast, and easy to understand. It has good performance when there is no noisy data or outliers but is unsuitable for categorical data [
57]. Therefore, it suits the two datasets in this study.
The core idea of
K-means clustering is to define
K centroids for
K clusters. It is recommended to choose
K centroids that are far away from each other to simplify the process of creating the cluster. After that, each data point is assigned to the nearest centroid until no data points are left. These data points and their centroid form a cluster. For each
K cluster, a new centroid is recalculated, and then each data point is reassigned to the nearest centroid to form a new
K cluster. This step is repeated until no changes are noticed–until the
K centroids do not change [
56]. The
K-means algorithm forms clusters in such a way that each data point has the minimum square error between the point in the cluster (itself) and its cluster mean, as shown in Equation (1).
K-means methods aim to obtain the minimum sum of the squared error in all the
K clusters, as shown in Equation (2).
Let
X be the set of data points
X = {
x1,
x2,
x3,……..,
xn} and V be the set of centres V = {
v1,
v2,…….,
vc}. The algorithmic steps for
K-means clustering are as follows [
57]:
Select ‘C’ centroids, cluster centres, randomly.
Compute the distances between each data point in set X and the cluster centroids. Assign each data point to a cluster that has the minimum distance from the point to the centroid.
Re-compute the new cluster centre using the formula, as shown in Equation (3):
where ‘ci’ represents the total number of data points in the Ith cluster.
Assuming that
X = {
x1,
x2,
x3,….,
xn} is the set of data points and
V = {
v1,
v2,…
vc} is the set of centres, the similarity or regularity of the data items is measured while using a distance metric. Some of the popular distance metrics to calculate the difference between two points
p (
x1,
y1) and
p (
x2,
y2) are Euclidean distance [
58,
59], Manhattan distance [
57,
59], Chebyshev distance [
57], and Minkowski distance [
57,
59], as shown in Equations (47), respectively. In this study, Euclidean distance is used to measure the centre of a new cluster, because it is suitable for continuous data [
60]; see Equation (8).
Clustering results vary based on the number of cluster parameters. Thus, the main challenge of using clustering is to identify the right number of clusters before performing the clustering [
56]. The developer can query the end user to provide the number to address this issue for the
K-means method. However, this is not always feasible, as the end user might not be familiar with the domain knowledge of each dataset. Therefore, some statistical methods have been proposed to estimate the number of clusters, such as the elbow method [
56,
61], the silhouette method [
56], and the gap statistic method [
62].
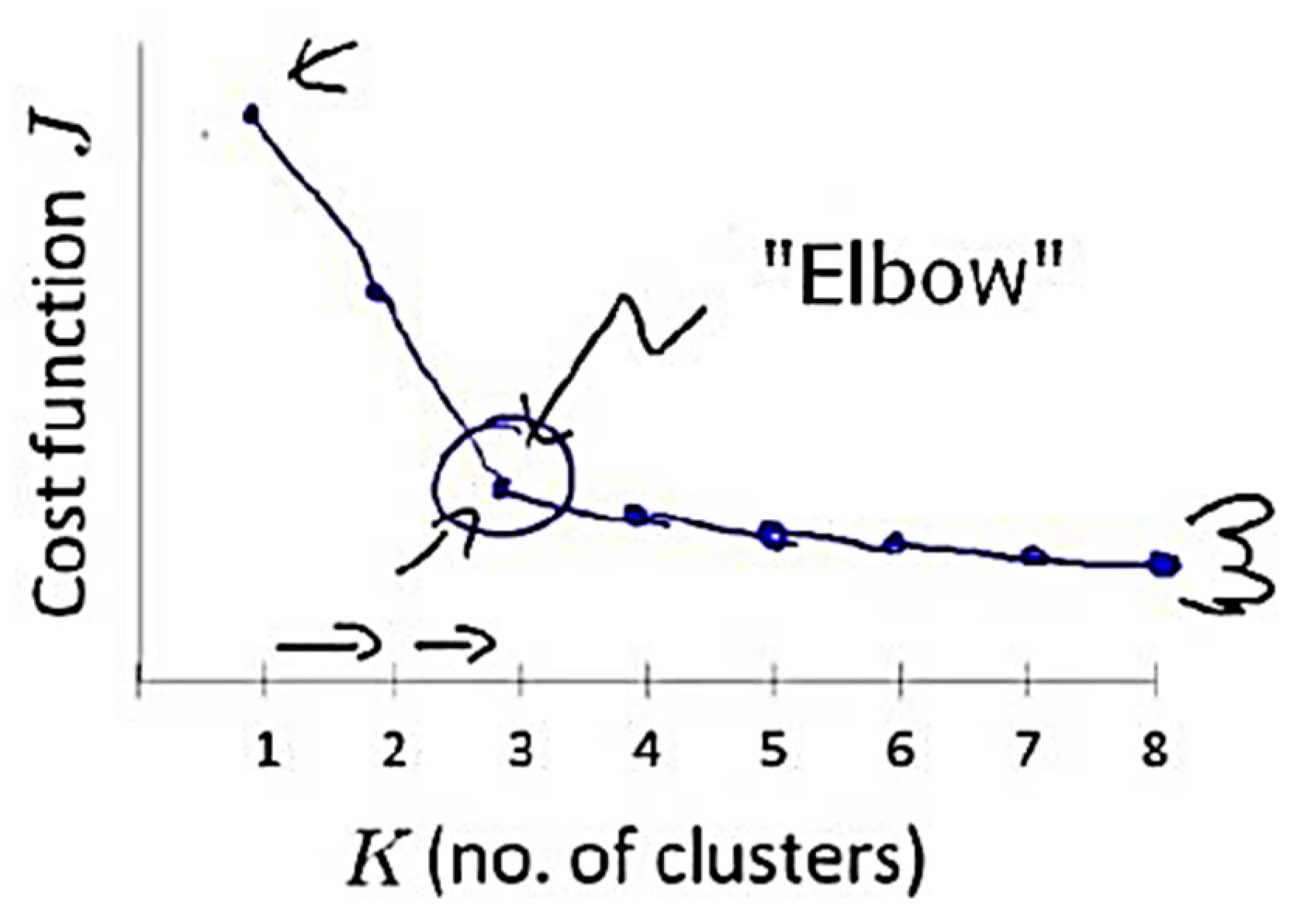
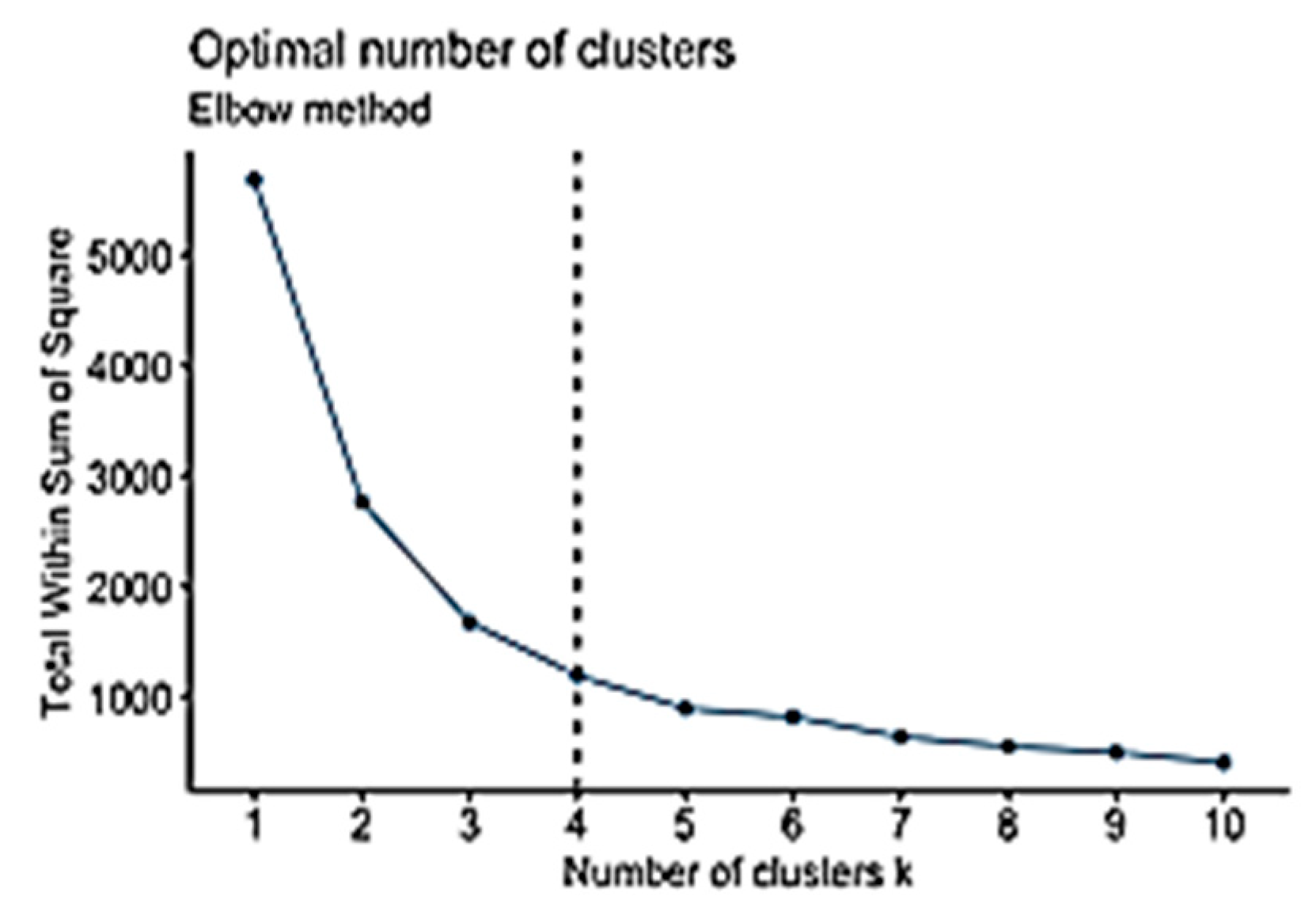
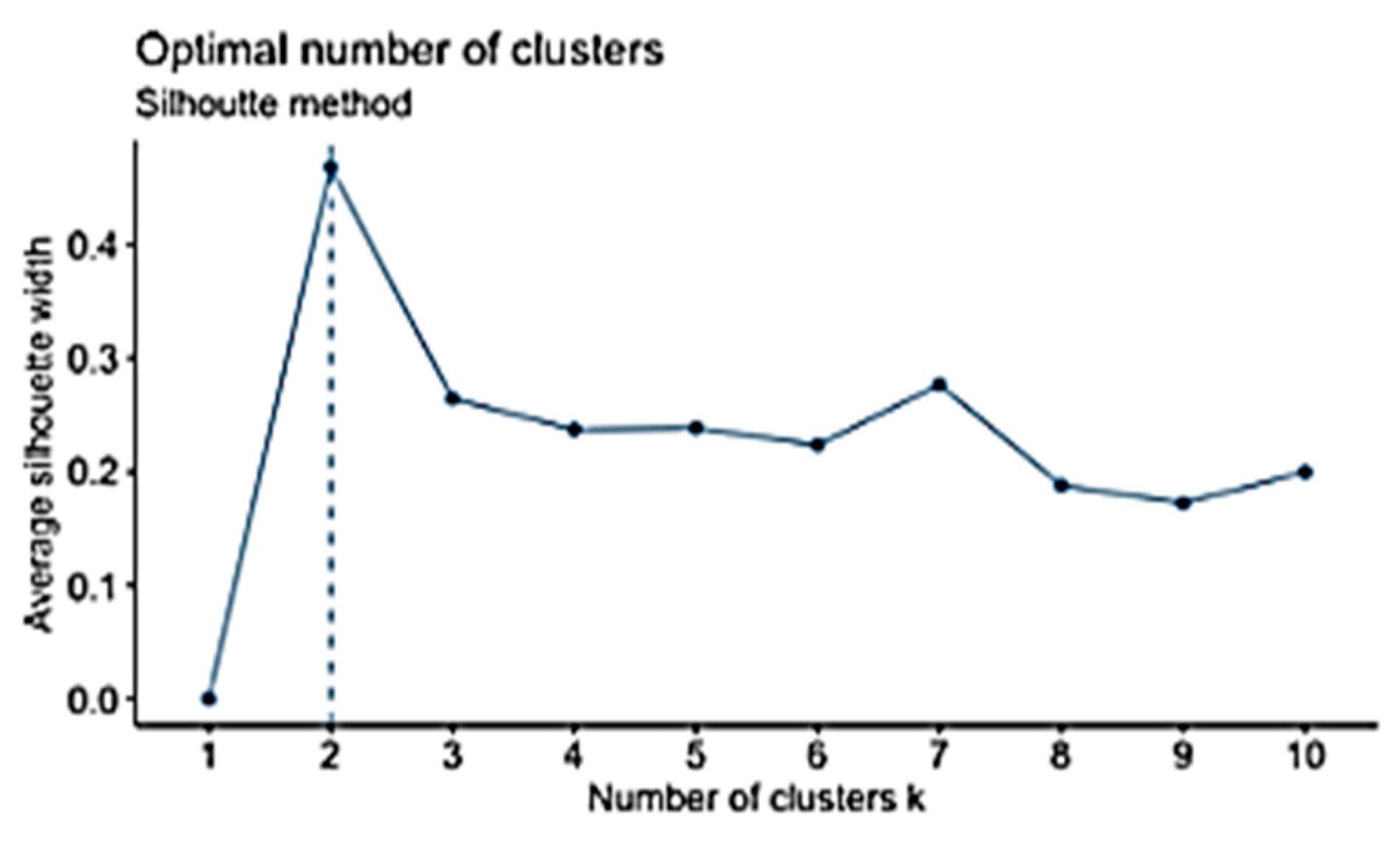
The elbow method is considered to be the oldest method for determining the appropriate number of clusters for a dataset. The elbow method is a visual method that starts with
K = 2, increments
K by 1 in each iteration, and computes the
K clusters and the cost that comes with the training. With each value of
K, the cost declines dramatically and eventually reaches a plateau, and this identifies the
K value (
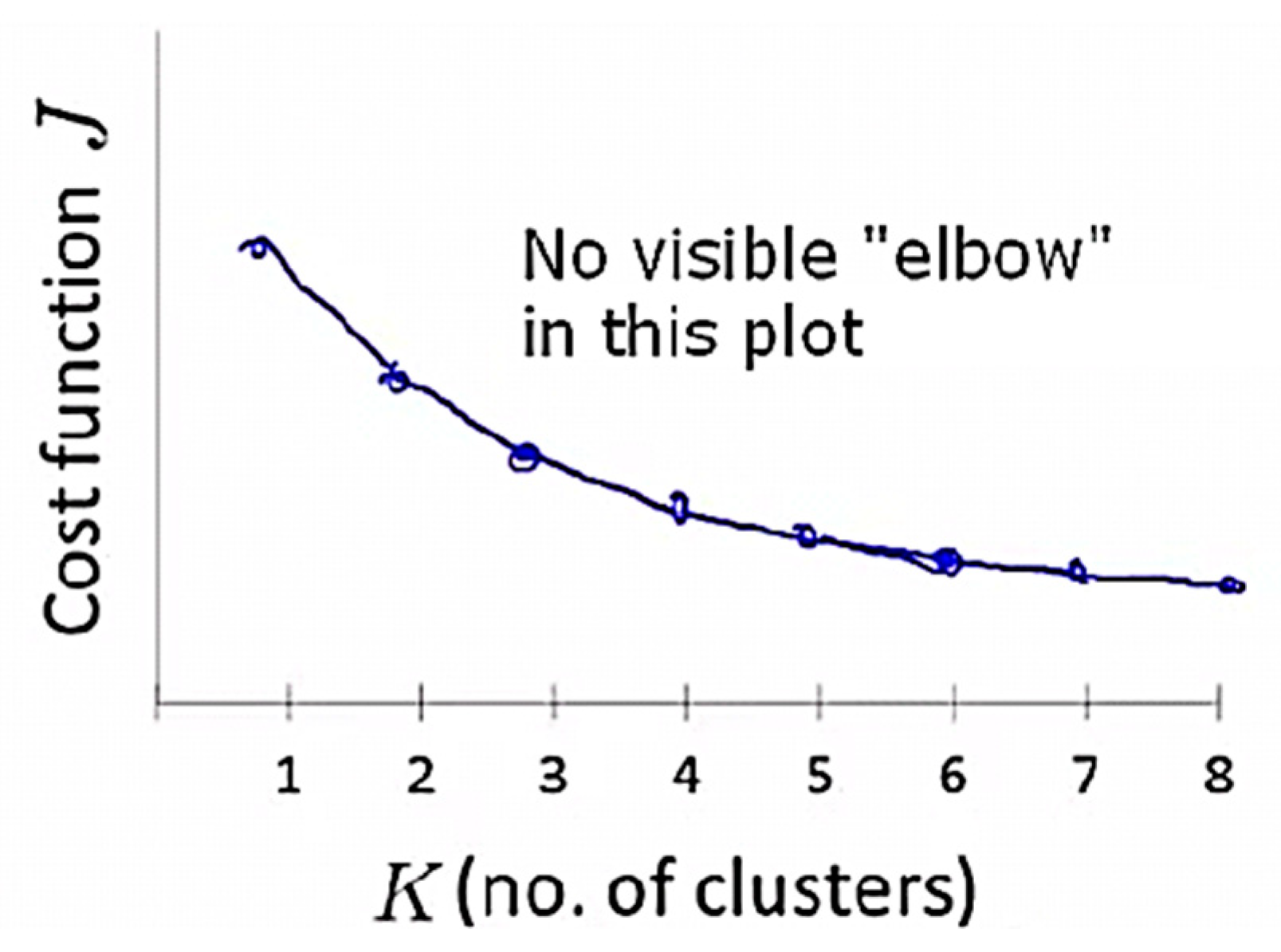
Figure 2). However, a limitation of the elbow method is that there might be no clear elbow or more than one elbow, as shown in
Figure 3 [
56,
62]. The elbow method is calculated while using the sum of squared errors [
61], as shown in Equation (9).
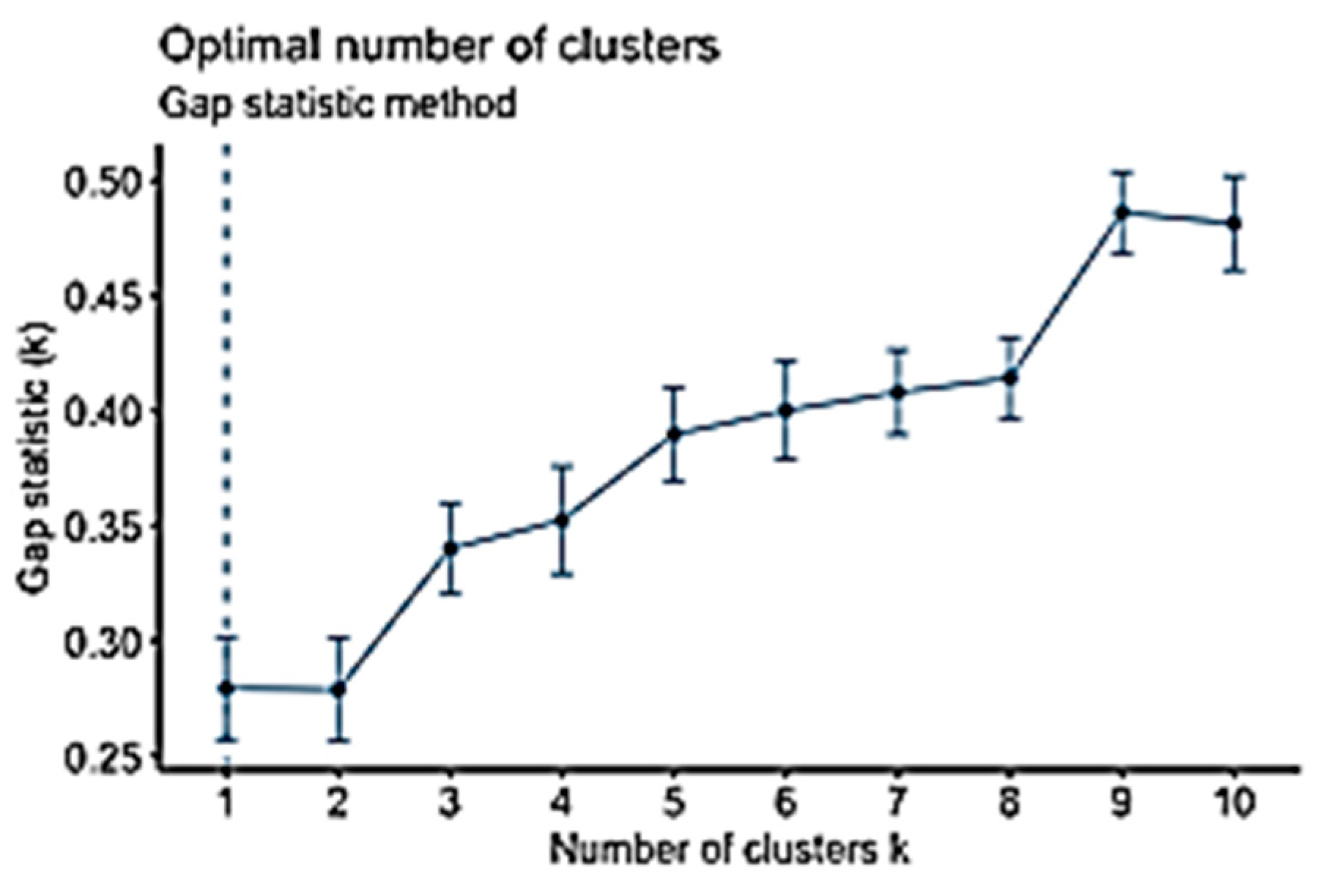
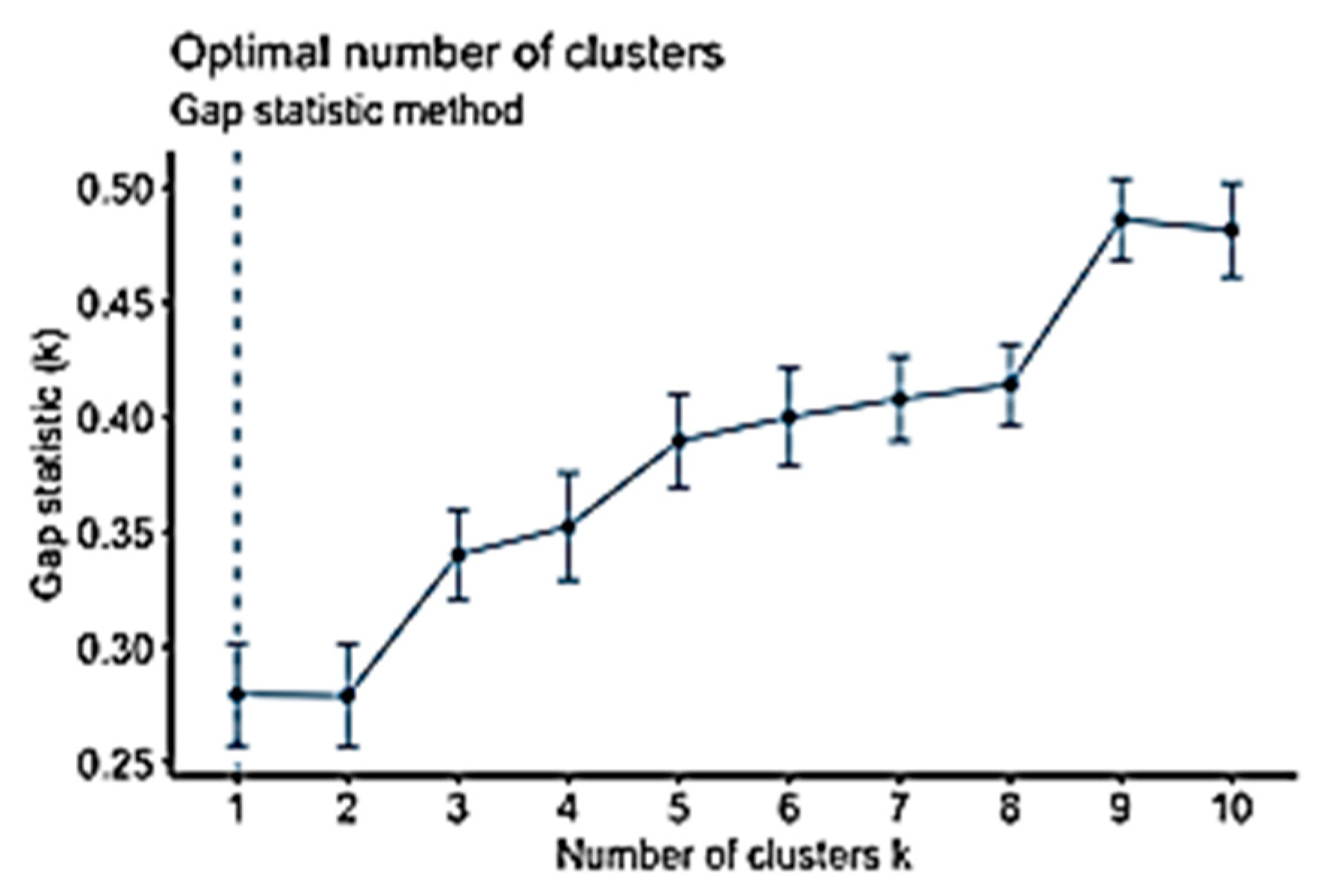
The gap statistic method is another method that is used to identify the most suitable number of clusters; it is designed to work with any clustering method [
62]. It compares
with
as shown in Equation (10). Accordingly, the estimation of the
K value is computed using the following equation [
62]:
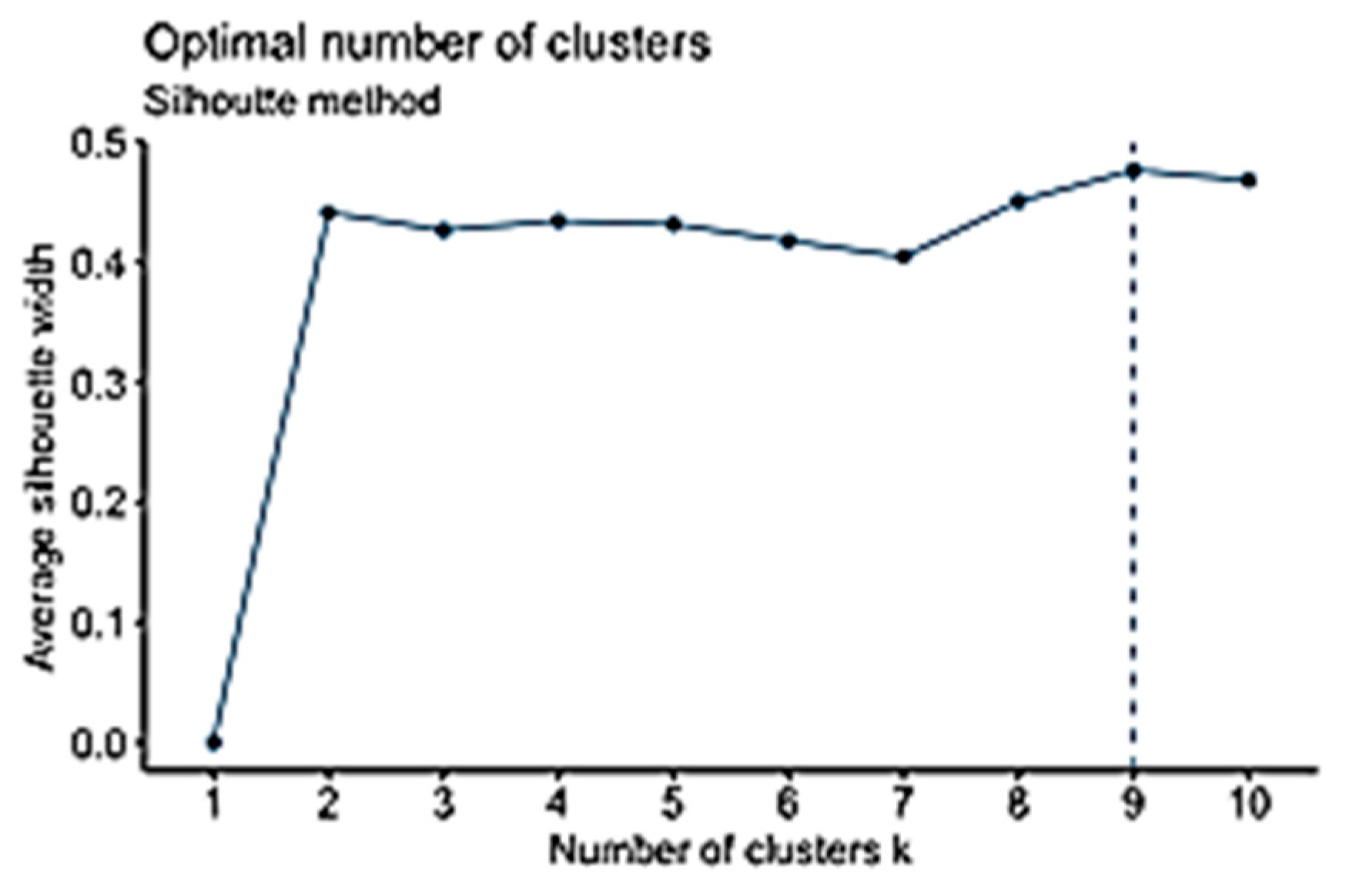
The silhouette method is a new graphical method developed for partitioning technique [
63], such as
K-Means, to clearly identify separated clusters [
64]. Its core idea is based on clusters’ tightness and separation [
64]. It compares within-cluster distances to between-cluster distances. The higher the number, the more it fits. One of the strong points of the silhouette method is that the actual partition of the object does not depend on the clustering algorithms that have been used to obtain it, but on the actual partitions on the objects, as shown in Equation (11).
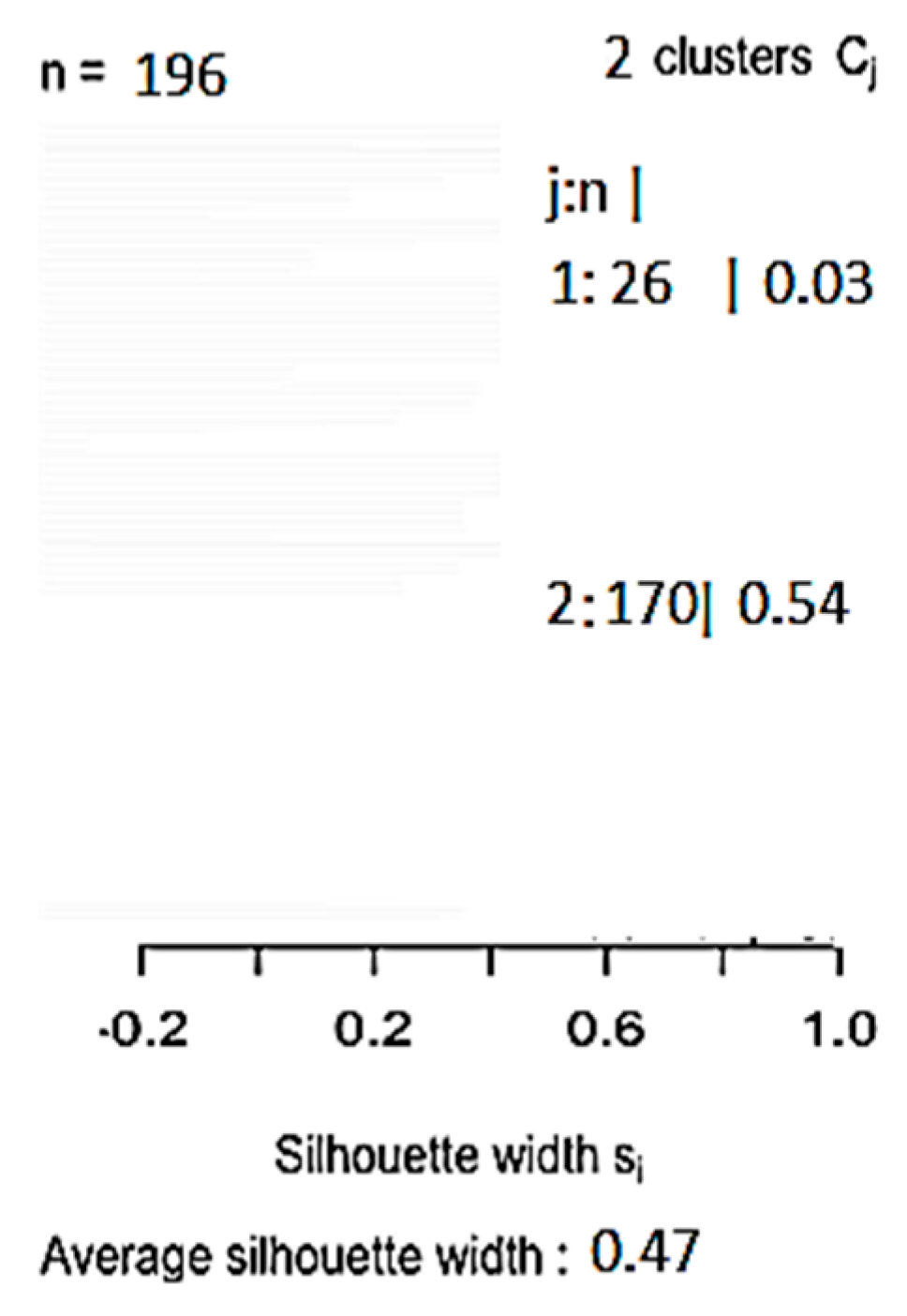
Average silhouette width is used to evaluate the cluster validity and find the optimal value of
K [
63]. Silhouette Coefficient for
K clusters is the average silhouette width of mentioned
K-clusters [
65]. The silhouette width, which was introduced by Kaufman and Rousseuw [
66], is a well-balanced coefficient that has good performance. The silhouette width s(i) presents the difference between the within-cluster tightness and disconnection from the rest. The silhouette width s(i) for the entity
i €
I is defined in Equation (8). The silhouette width value ranges from −1 to 1, as shown in Equation (12). Set
I is well structured when the silhouette width value is close to 1, and it is misleading when the silhouette width value is close to −1. However, when the value is 0, it means that the entity could be assigned to another cluster [
56].
5. Discussion
As presented in
Section 4, the first data analysis produced four personas, based on physical engagement data (attendance) and performance (grade), as shown in
Table 3 and
Table 4. The second data analysis produced two personas, based on virtual engagement (interactions with VLEs) and performance (grade), as shown in
Table 5 and
Table 6. Combining the results of the two data analysis processes produced eight personas, as the two datasets were for second-year computer science students at Brunel University and performance was a common attribute in the two datasets, as shown in
Table 8.
Based on the discussion above, specific and tangible attributes were selected to build the personas. The attributes that fit the conversational system (chatbots) are highlighted and presented in the following personas example (
Figure 19). The next step after identifying the personas template was identifying a typical user and building the personas model for each group to create a persona that represented a real person. Therefore, we needed to calculate the average scores for each cluster. We had already identified the groups and the attributes that distinguished them. We computed the average score for each distinct criterion and chose the record for the student who had the score nearest the average score of the cluster. The user was a typical user, and their data were used to present the persona [
22]. The student persona in
Figure 19 represents a high virtual and physical engagement and performance student persona. Physical engagement is represented by attendance, while virtual engagement is represented by interactions with VLEs.
Finally, this study set out to validate the personas template; the literature identifies several ways of validating the personas. The method in the study by Nunes, Silva, and Abrantes [
77] was chosen due to its realistic way of validating the personas. It involves simply asking experts in the domain about their opinion of the identified persona. In this study, we will ask ten faculty members in the Computer Science Department who teach undergraduate students a few questions. During the discussion, the instructors will confirm whether the attributes that are listed in the proposed personas template are appropriate and whether it is a good representation of the existing computer science students.
The DSR method is conducted in several iterations. The first iteration, personas elicitation, includes designing, building, and evaluating personas by utilising K-means clustering techniques. The outputs of the first iteration are used as inputs in the second iteration, which are persona components, such as age, gender, experience, etc.
The second iteration, a survey and the development of SEFMs, will survey students to identify the factors that affect student engagement, including the persona components. The survey will be designed and built while using the Bristol Online Survey tool and sent to computer science students at Brunel University London by email. SEM will be used to build the SEFMs.
The third iteration, chatbot interaction analysis, will use the inputs from the first two iterations to design, build, and evaluate chatbots that will target several factors of engagement. An experiment will be conducted to measure the effectiveness of using chatbots in enhancing student engagement.
The chatbot development will be done while using Amazon Alexa technology, which contains a client, server, and database. The client will be developed using the JSON programming language; the server side will be developed using the JavaScript programming language. A built-in database, called DynamoDB, will save the interactions between the client and the server. The experiment will be done by installing the Amazon Alexa app on a smartphone or by running the application on an Amazon Alexa Echo device. The experiment will be conducted for second-year computer science students, and pre- and post-tests will be conducted.
6. Conclusions
In conclusion, chatbots are conversational systems that interact with users using text or audio, such as Amazon Alexa, Siri on iPhone, Cortana, and Google Assistant. Chatbots are used in different domains, such as education, health interventions, e-commerce, and entertainment, to name a few. In education, chatbots are used to introduce students to concepts, to enable self-guided learning, and make students interested in certain domains. Using chatbots in education brings many benefits; it supports continuous learning, enhances student motivation, enhances students’ learning and listening skills, and makes learning more enjoyable.
The purpose of this study is to explore how to enhance student engagement in higher education institutions (HEIs) while using a context-based and personas-based conversational system (chatbots). This study uses the DSR method, which was performed in three iterations: personas elicitation, Survey and SEFM, and Chatbots Interaction Analysis. This research paper focuses on the first iteration, personas elicitation, Survey and SEFM, and Chatbots Interaction Analysis. In the first iteration, a DDPDM was proposed to achieve the aim of the first iteration (personas elicitation). Data preparation and data analysis were performed using VBA macros and the R programming language. K-means clustering was the main clustering method that was used in the first iteration. The K-values were identified while using well-known methods: the elbow, silhouette and gap statistic methods. The silhouette coefficient was used to get the optimal value of K. Four popular methods are proposed in the literature to measure the similarity or regularity of the data item: Euclidean distance, Manhattan distance, Chebychev distance, and Minkowski distance. Euclidean distance was chosen because it is a suitable one to the nature of the two datasets.
The first data analysis produced four clusters, namely very low physical engagement and very low performance, high physical engagement and high performance, low physical engagement and high performance, and better physical engagement and low performance. The second data analysis produced two clusters, namely less engaged and more engaged. As the data were collected from second-year computer science students at Brunel University London, and as both datasets had ‘grades’ as a common attribute, the two datasets were combined, which produced eight personas. The undergraduate student persona template was adapted from [
49].
Figure 19 presents an example of an undergraduate student persona. Interestingly, the results of the data analysis show that engagement does not always affect student performance. Besides, active participation does not influence student engagement. There might be other factors that affect student engagement. An interesting finding was that the Gap Statistic method that was used to find the k-values produces
K = 1 in both datasets, which is a meaningless value,
K should be at least equal to 2.
The present iteration makes several noteworthy contributions to the current literature. Initially, it proposed a quantitative DDPDM that mainly uses K-means clustering analysis and three methods to identify the K values: elbow, silhouette, and gap statistic methods. It is an applicable, cheap, and straightforward method when compared to other methods. Moreover, the data analysis produced a university student persona template and eight distinct university student personas. Generally, this paper, alongside the planned future iterations, forms the basis for the development of new forms of pedagogical practices that use VLEs and chatbot technology, either instead of or alongside traditional teaching.
However, there were some limitations to this iteration. Firstly, it used only one variable for measuring the outcome (grades) in the two data analysis processes. In future work, other assessment variables could be assessed, such as the results of individual tests (classroom assessments) [
80], assignments/homework [
80], and lab test. Another limitation of this iteration was that only attendance and interactions with VLEs were used as indicators of engagement (physical and virtual engagement) in the data analysis. However, researchers could measure other engagement indicators, such as enthusiasm, task completion, willingness and self-reported interest.
Future work will cover the second and third iterations: (1) survey and SEFMs and (2) chatbot interaction analysis. Regarding the second iteration (survey and SEFMs), the objective will be to build SEFMs. The problem awareness step will draw on the results of the first iteration. In the suggestions phase, a literature review will be conducted to identify the factors that affect student engagement. In the development phase, a SEFM will be created and it will only include factors that can be tested while using chatbots. The evaluation phase will consist of the validation of the SEFM while using a semi-structured survey that was sent via email to all computer science students at Brunel University London. The data will be analysed using structural equation modelling to produce the final version of the SEFM, which will be fed into the next iteration.
Furthermore, regarding the third iteration (chatbot interaction analysis), the objective will be to evaluate the effectiveness of using chatbots to enhance student engagement. The problem awareness phase will draw from the results of the SEFM. In the suggestions phase, chatbots will be designed and developed, based on the student personas results and the survey and SEFM results (the first and second iterations, respectively). In the development phase, chatbots will be designed and developed to match the requirements that are proposed in the suggestions phase; the code will be written in JavaScript and will run on Amazon Echo devices (Alexa) and mobile devices. In the evaluation phase, the chatbots will be evaluated in terms of usability and effectiveness in enhancing student engagement while using the System Usability Scale (SUS), evaluated pre-test, and post-test.
The expected future contributions are as follows: (1) the data analysis of the semi-structured survey will be used to produce a SEFM, which will be tested by the chatbots. Students motivations, interest, and experience are examples of the data that will be collected in the second iterations; (2) the chatbot interaction analysis iteration will be the main contribution of this study, developing effective and usable chatbots that will enhance student engagement.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}