Towards A Taxonomy of Uncertainties: Analysing Sources of Spatio-Temporal Uncertainty on the Example of Non-Standard German Corpora


Abstract
1. Introduction
1.1. Research Framework and Context
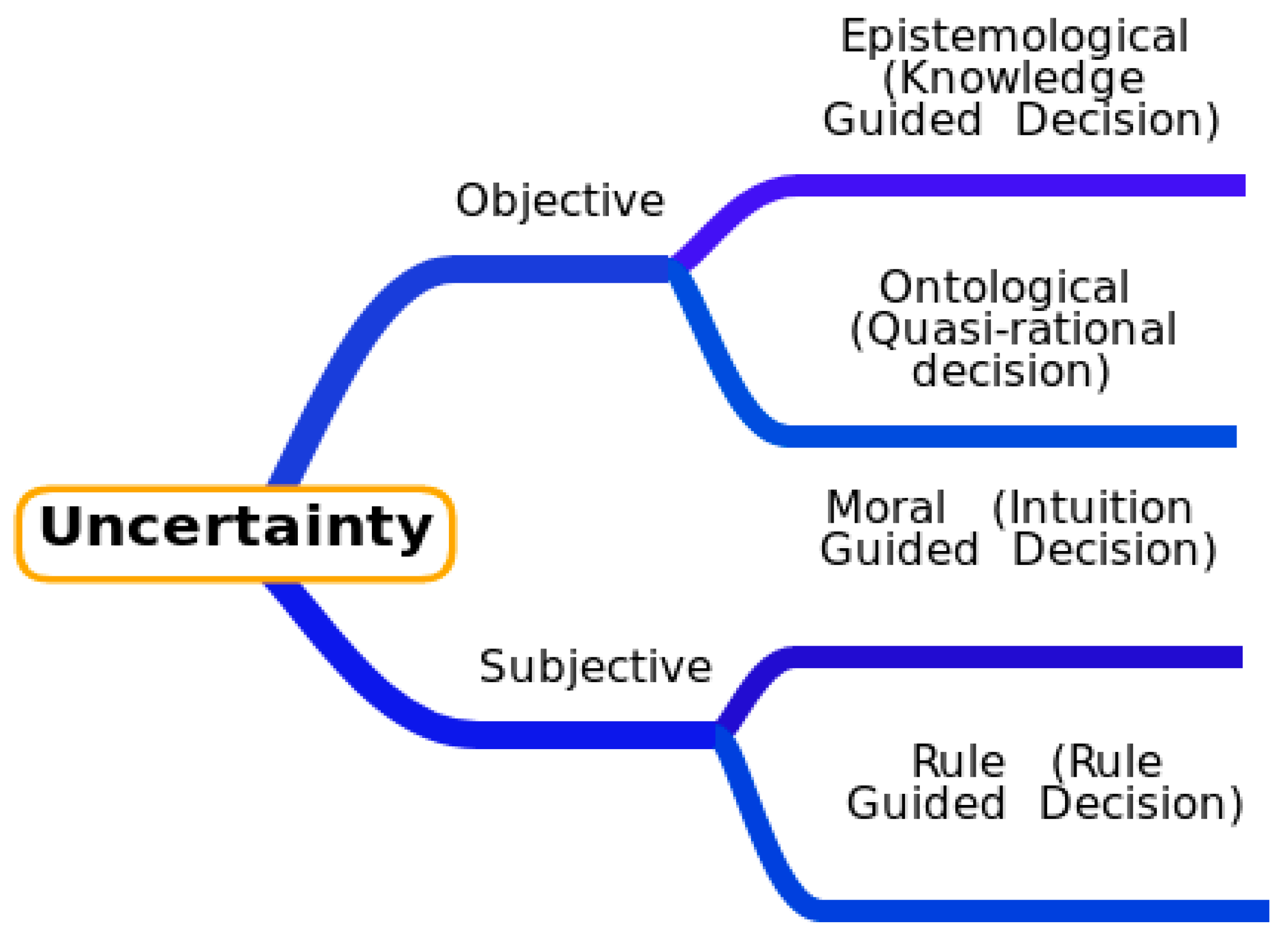
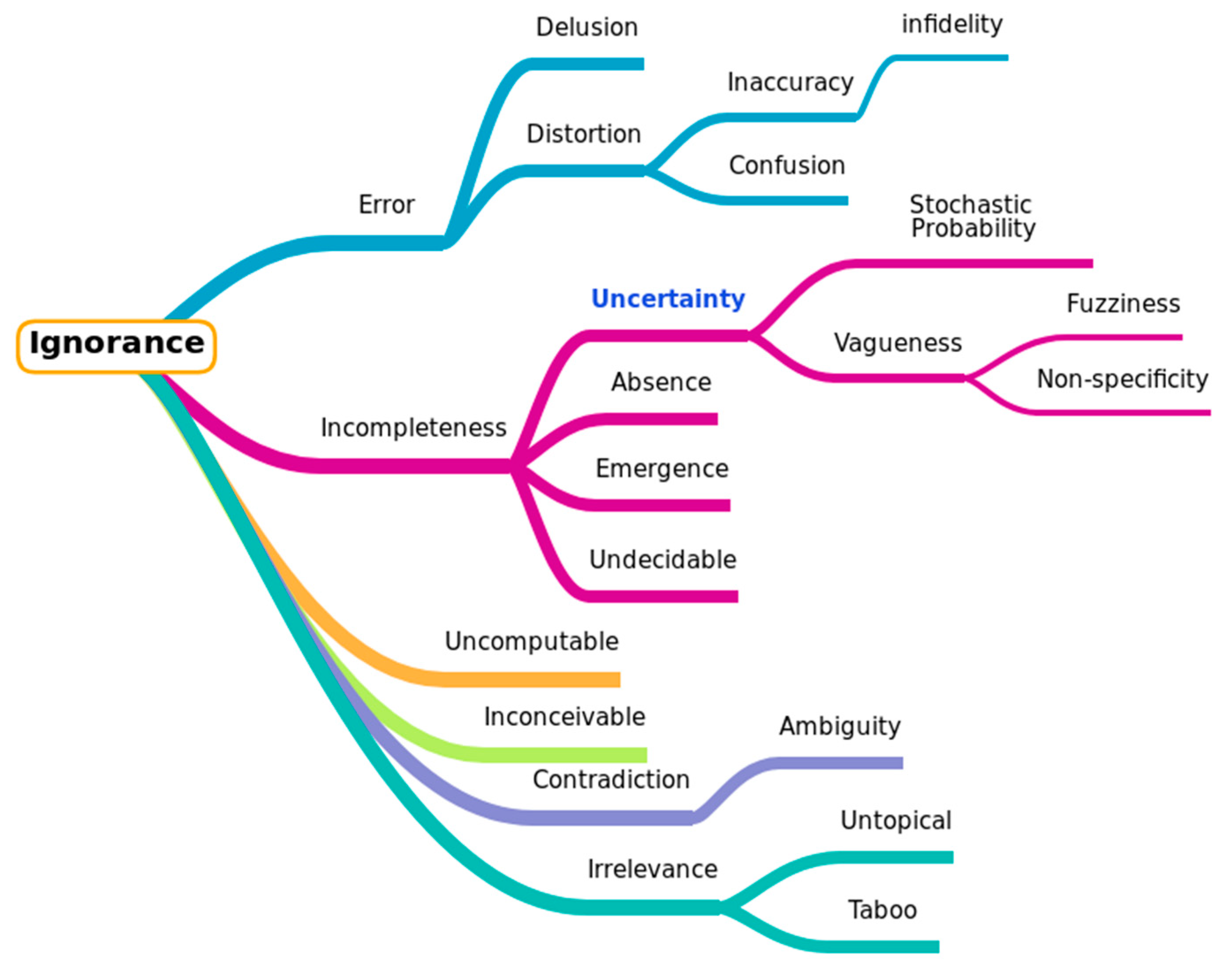
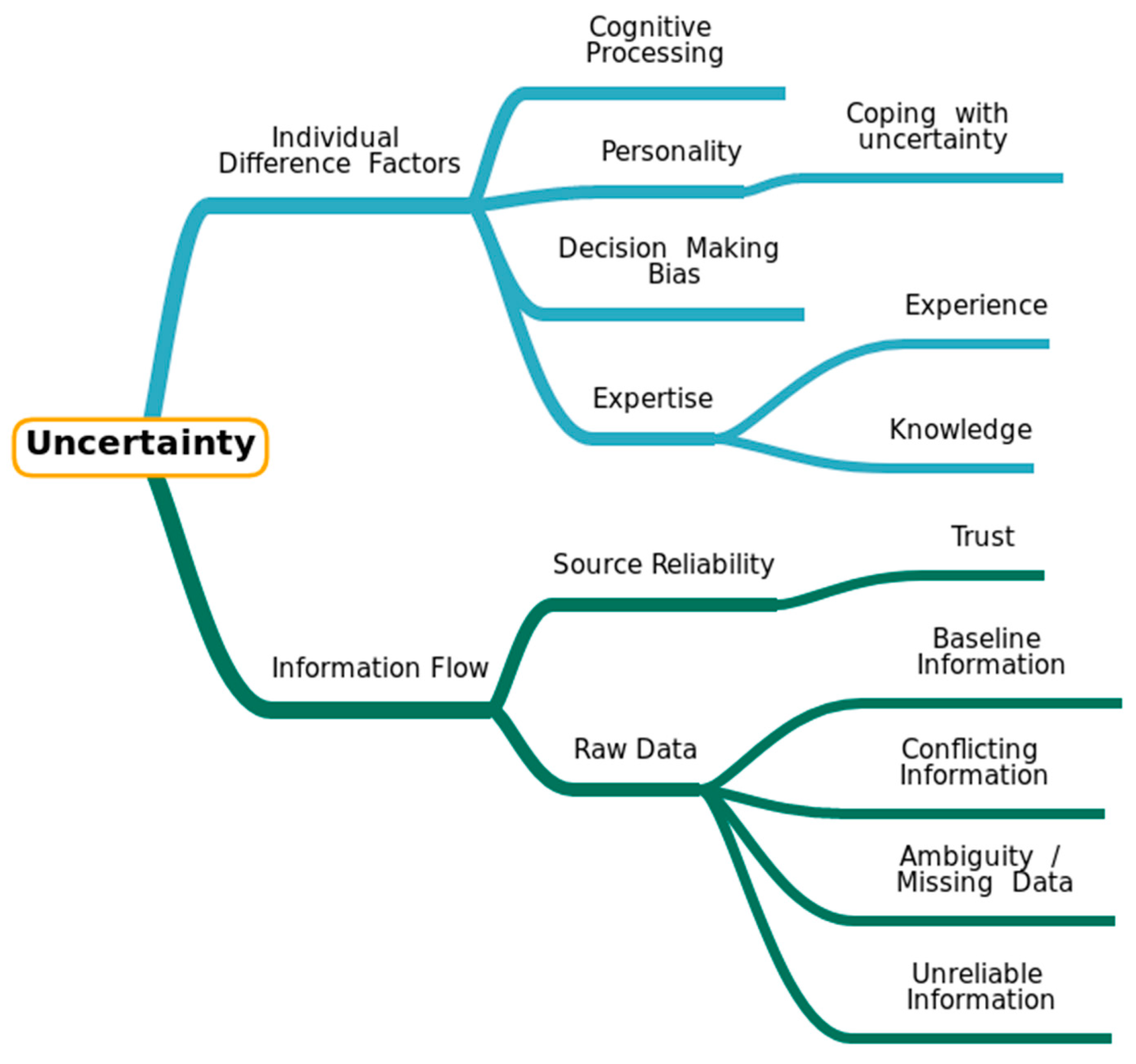
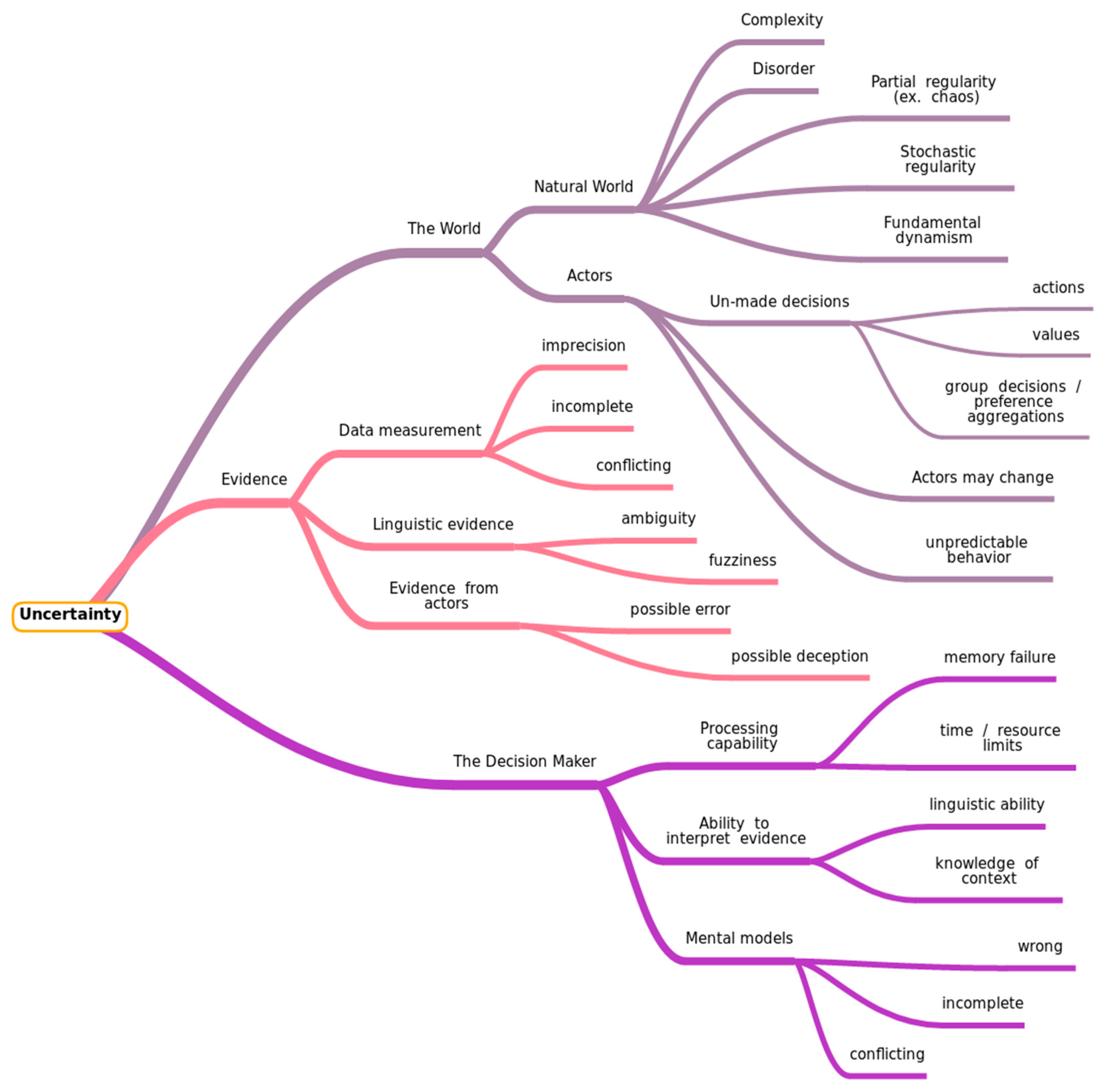
1.2. Taxonomies of Uncertainty: A Concise Overview
1.3. Uncertainty in (Digital) Humanities
2. Materials and Methods
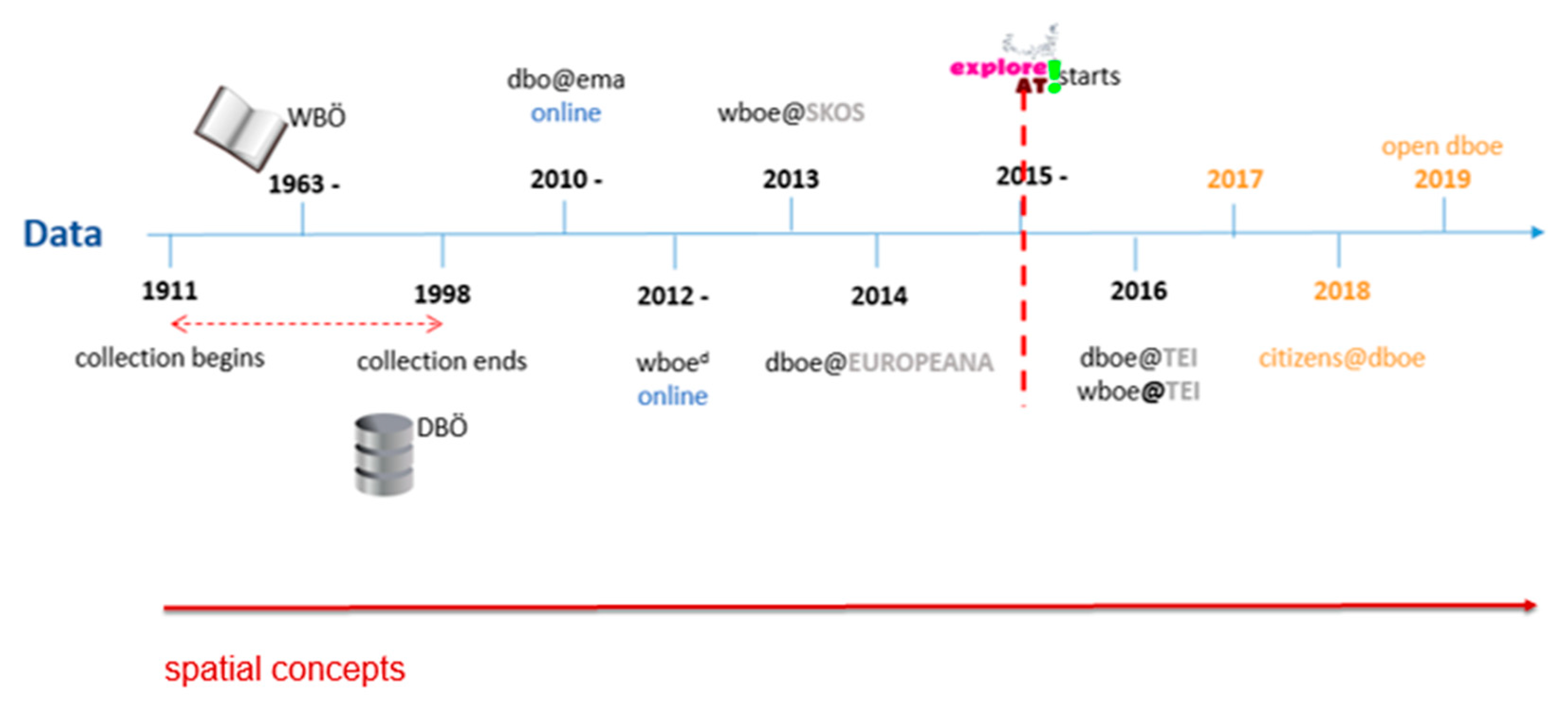
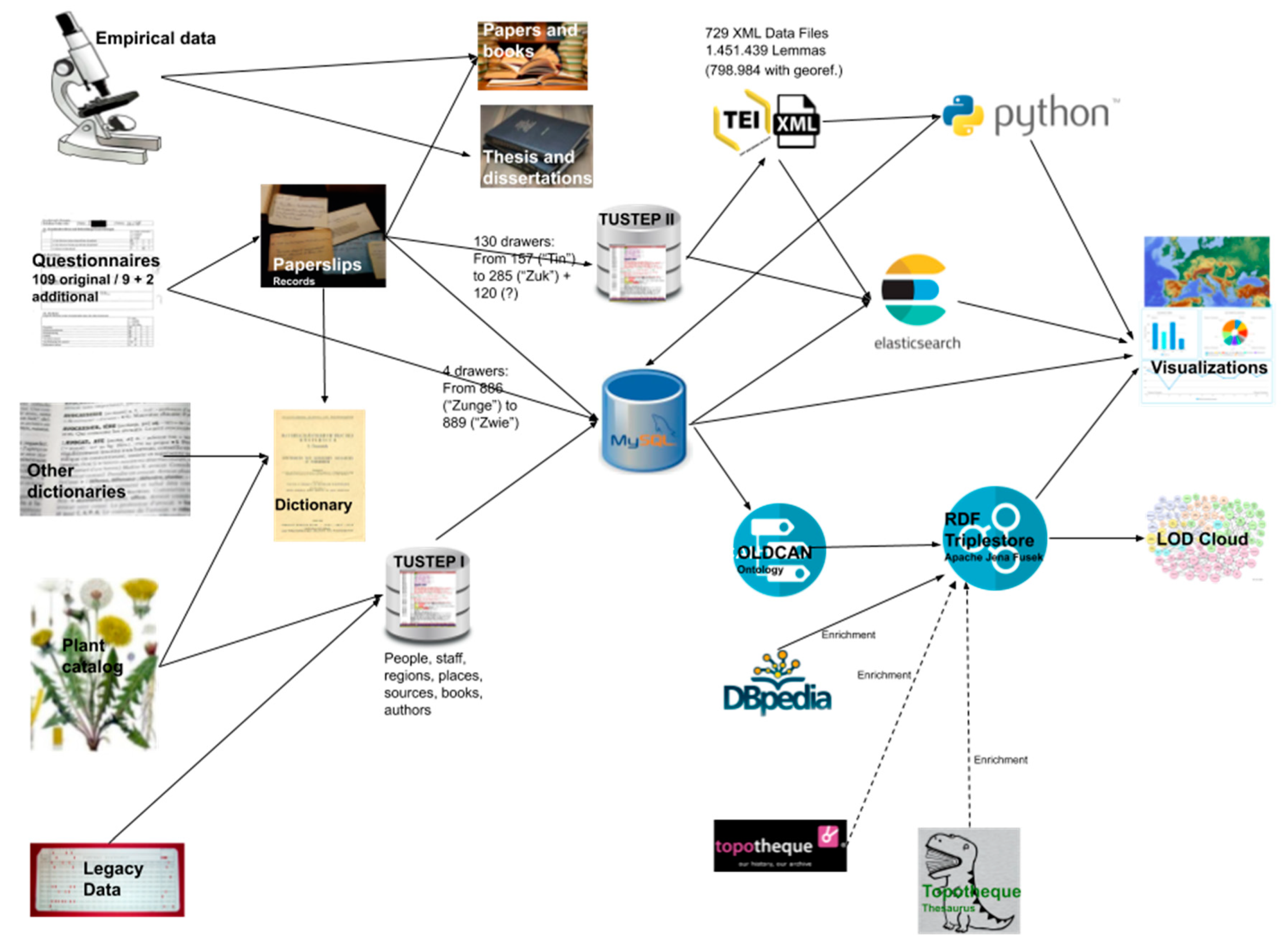
2.1. Materials and Data Description
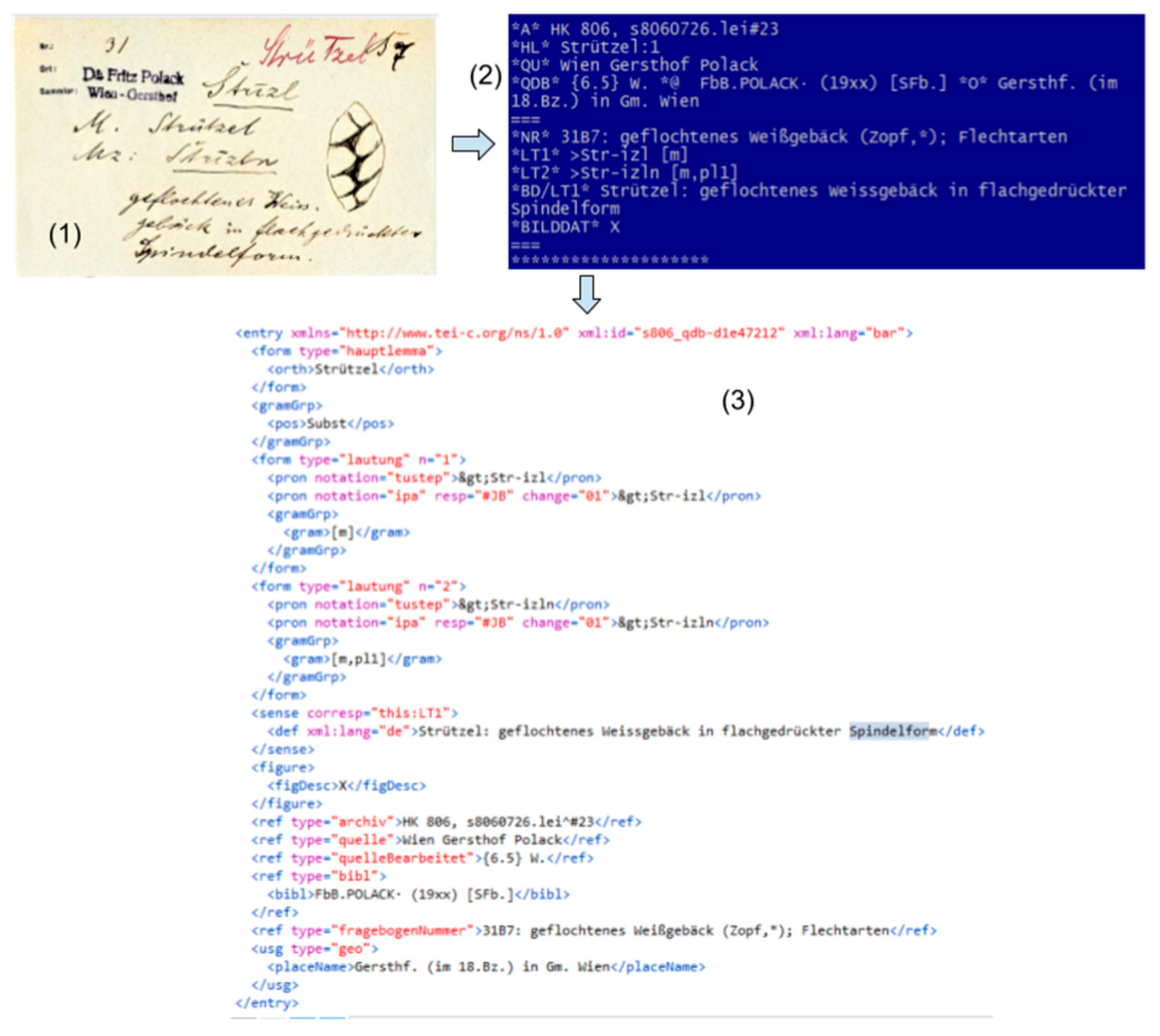
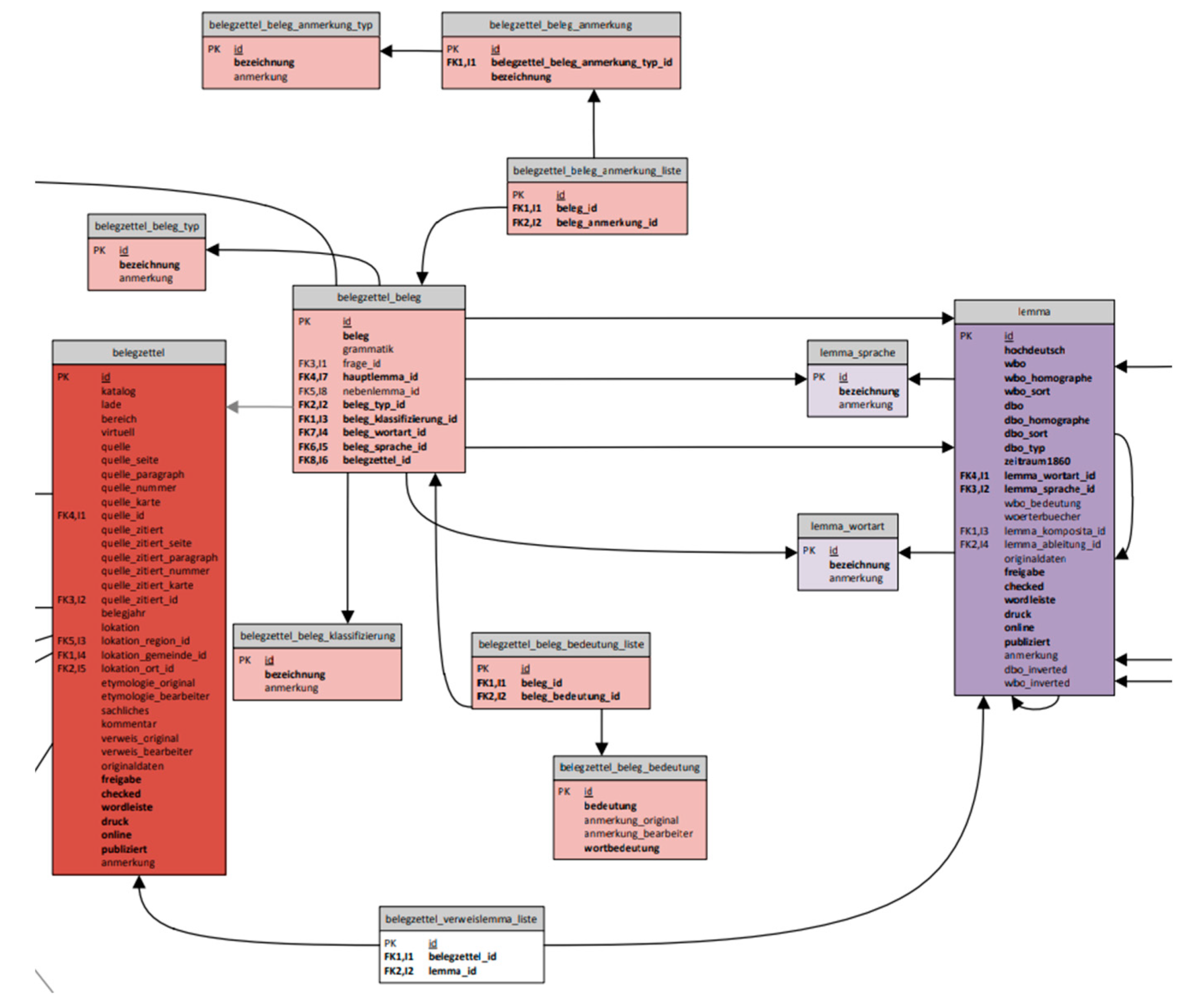
2.2. Data Transformation and Process Description
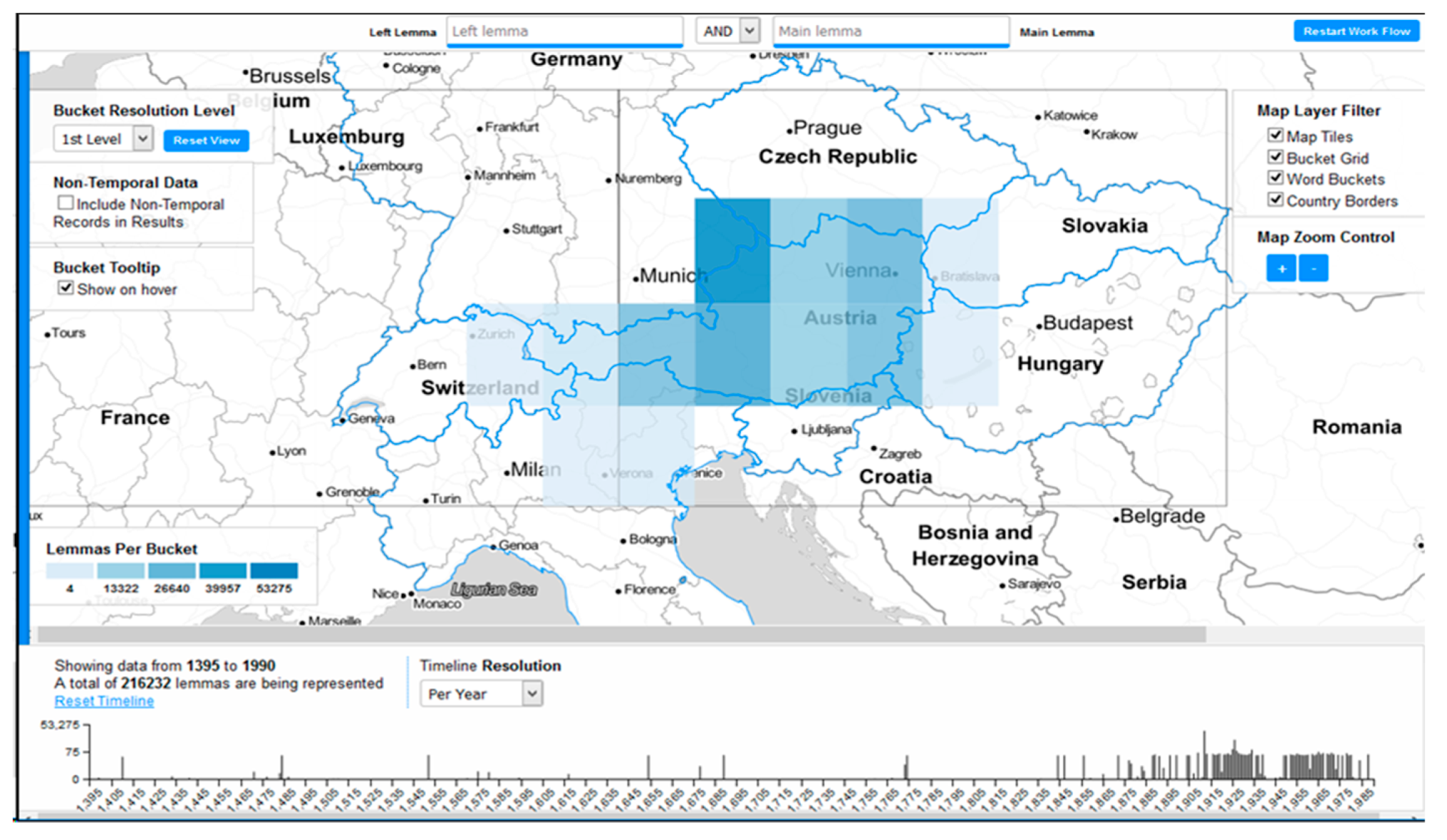
2.3. Spatial and Temporal Dimensions in the DBÖ: A Review
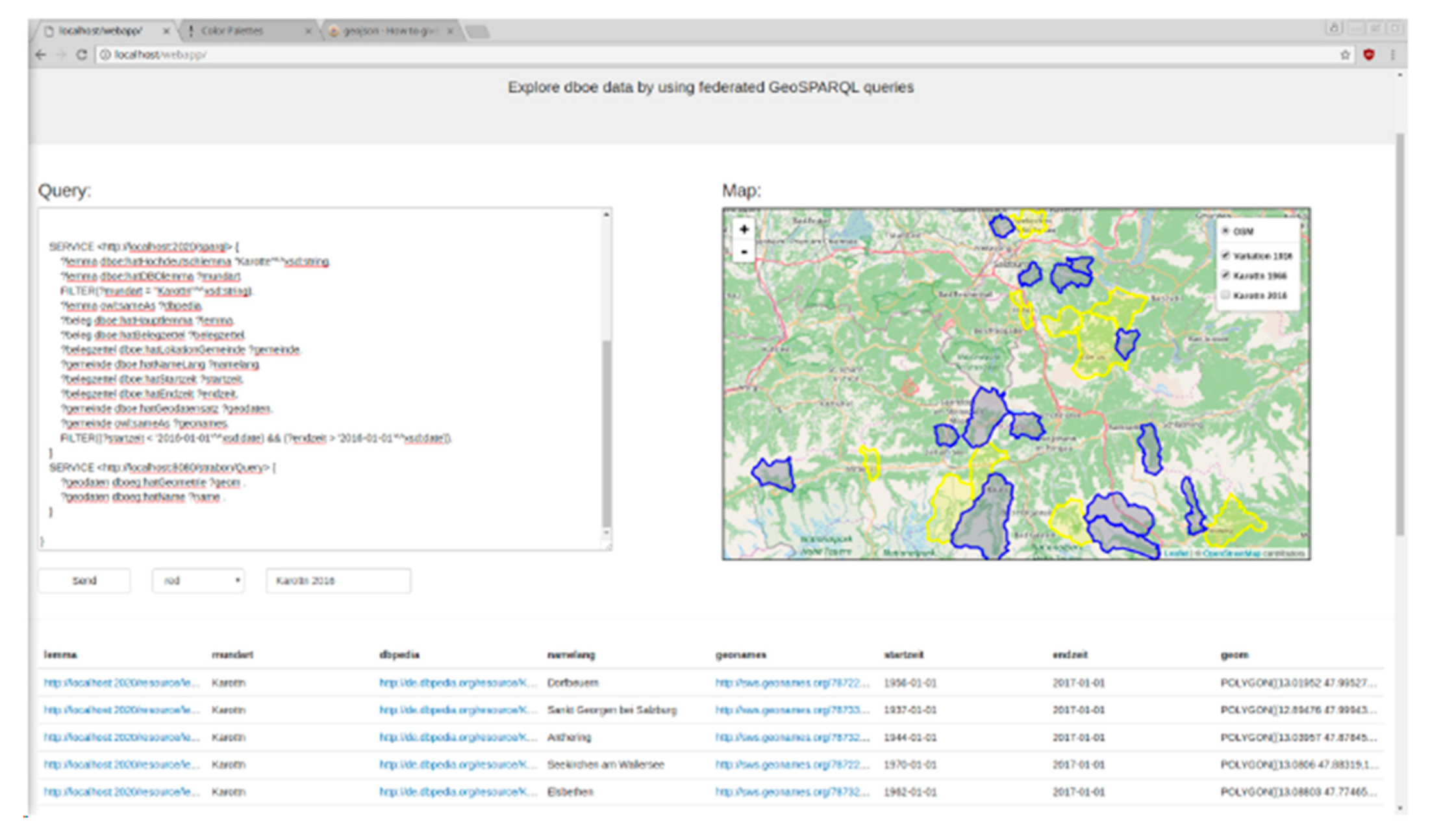
2.4. Methods
3. Results
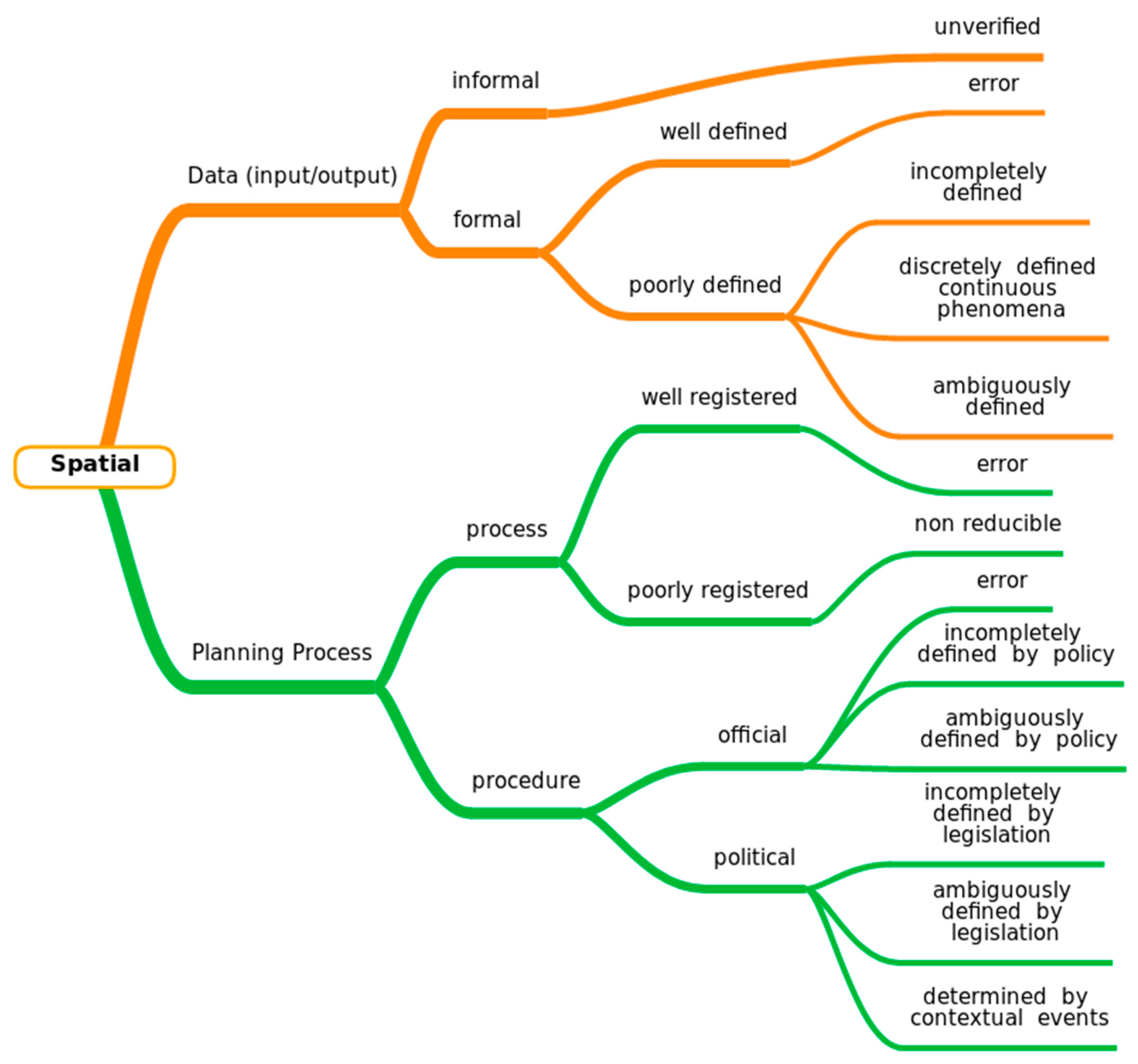
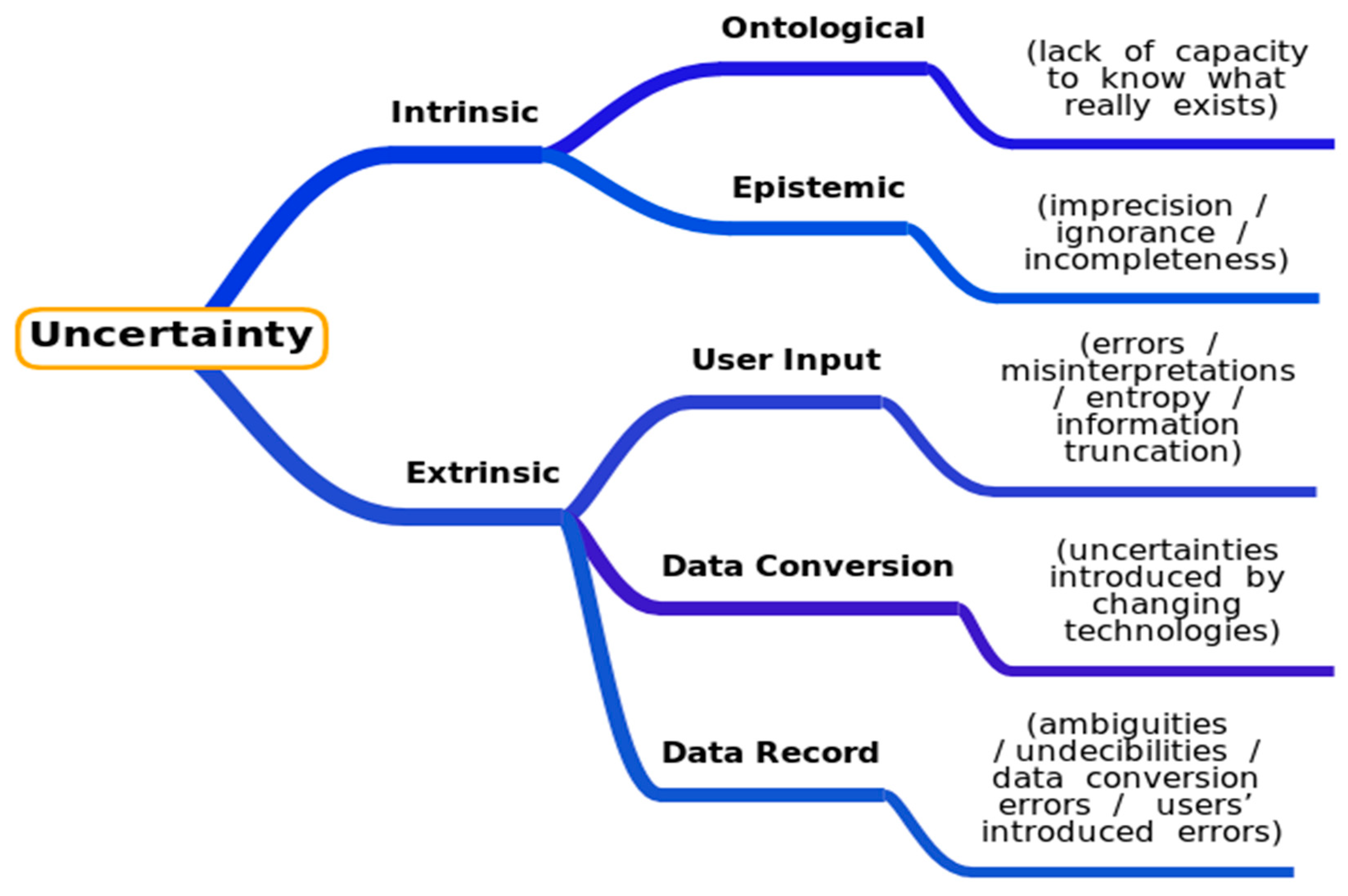
3.1. Uncertainty in DBÖ—A Specific Taxonomy
3.2. Uncertainty in DBÖ—Examples
3.2.1. Spatial/Intrinsic/Ontological
3.2.2. Spatial/Intrinsic/Epistemic
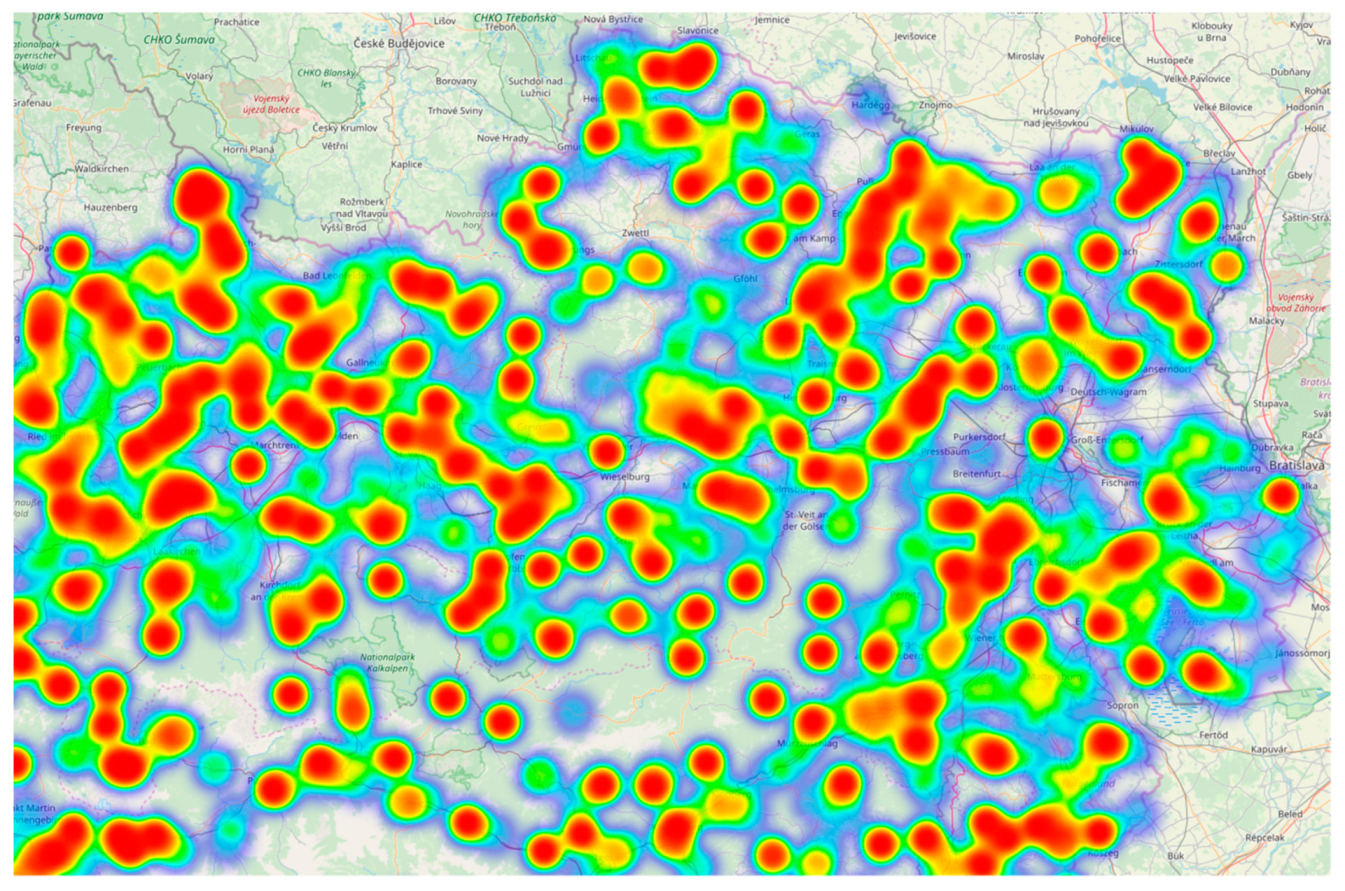
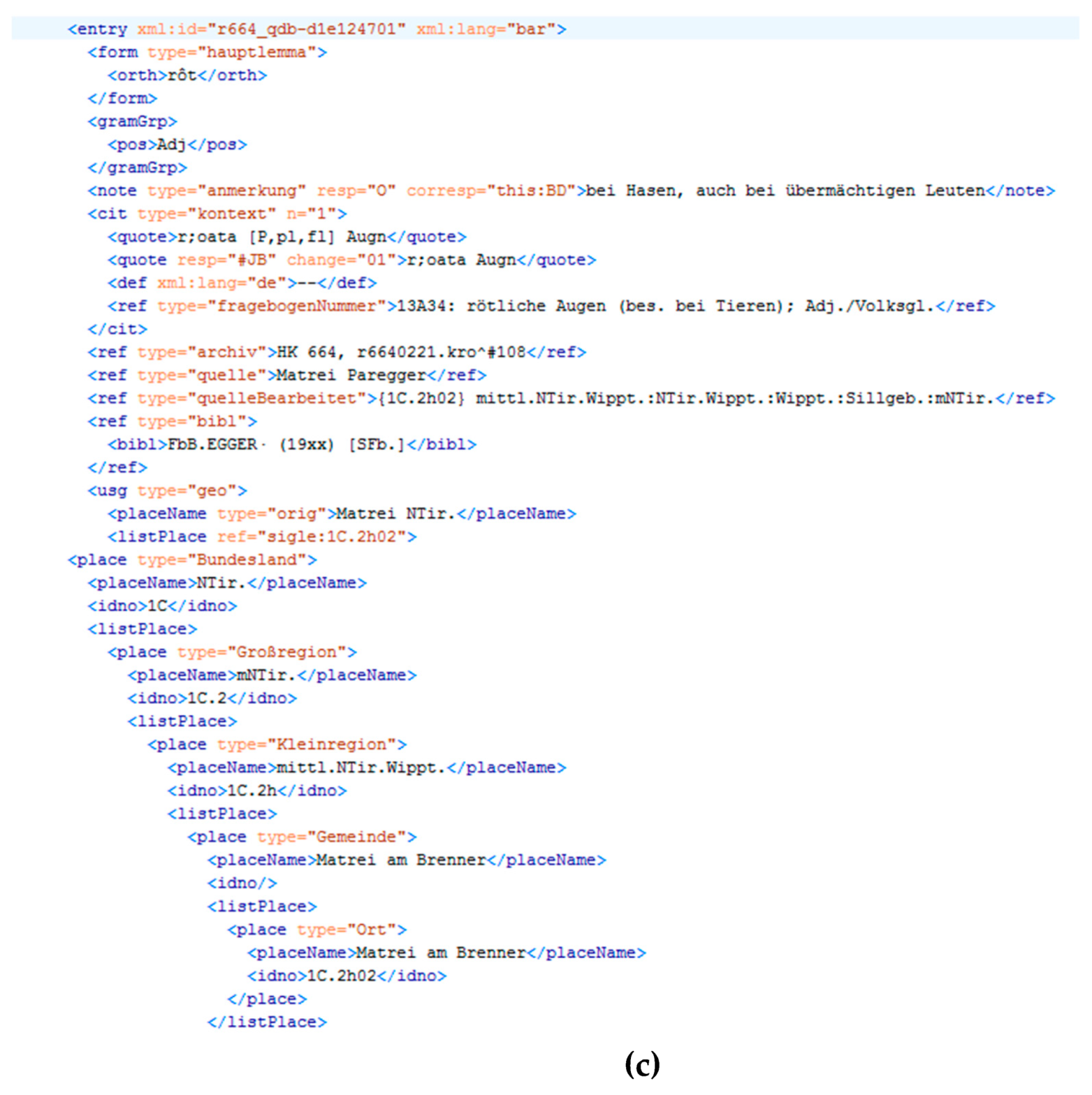
3.2.3. Spatial/Extrinsic/User Input
- The correct location is “Unterinn” and not “Matrei”. The error caused a wrong assignment, thus the standardised source in TUSTEP and later in the TEI/XML file (see below) is not correct. The data typist was probably mistaken, as the collectors in Matrei and in Unterinn have similar names (Egger/Paregger).
- There is also an error in the meaning—it is not “übermächtigen Leuten” (overpowering people), but “übernächtigen Leuten” (people that are tired out). As it almost sounds true and is not all that far-fetched, it is easy to overlook.These interpretations have introduced both spatial and linguistic errors in the collection.
3.2.4. Spatial/Extrinsic/Data Conversion
3.2.5. Spatial/Extrinsic/Data Record
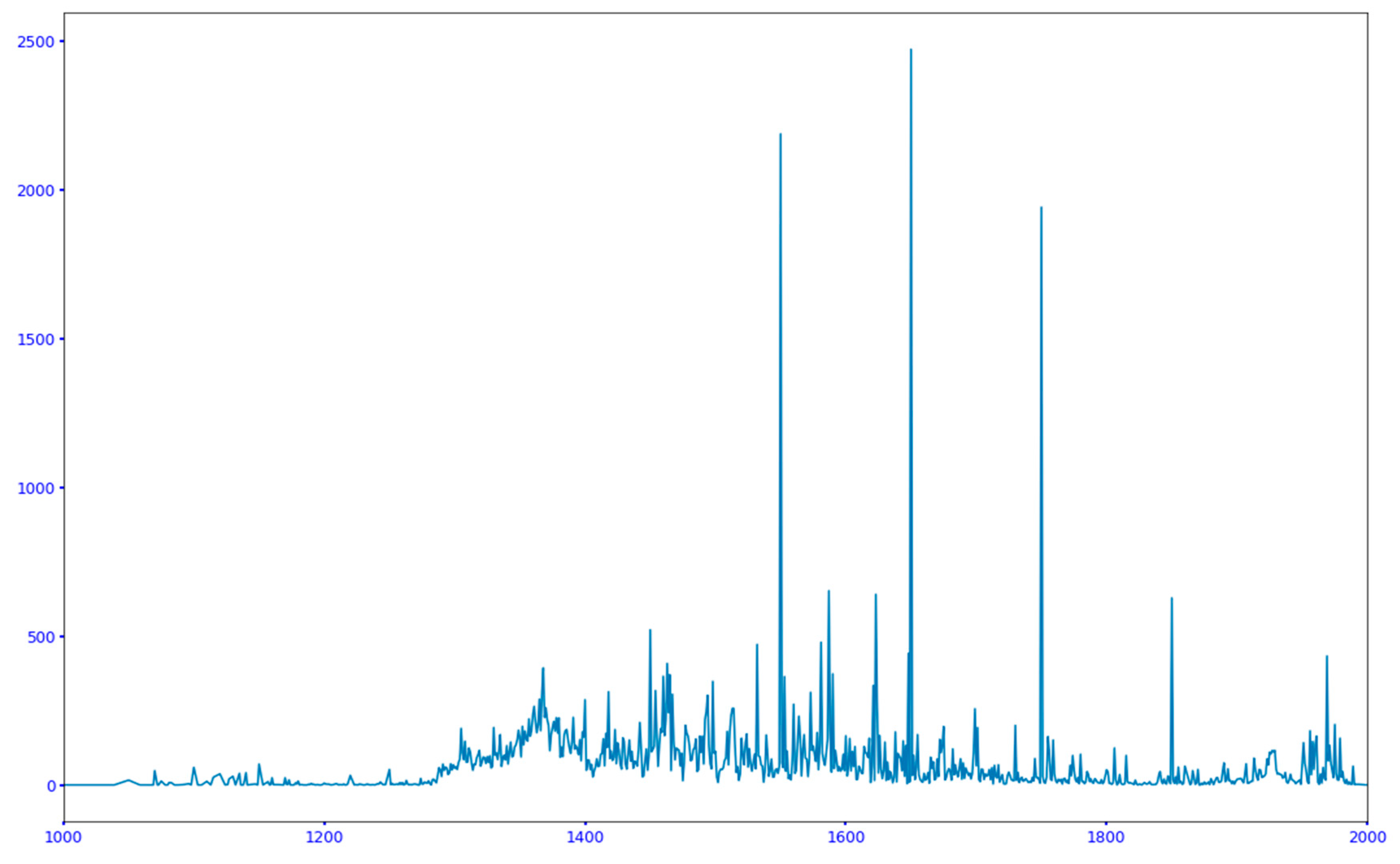
3.2.6. Temporal/Intrinsic/Ontological and Epistemic
- Reference to day (e.g., “11. 8. 1735”); month (e.g., “Juli 1927!”); year (e.g., “1465”; “a. 1630”) or century (e.g., “15. Jh.”).
- Imprecise reference (e.g., “Mitte d. 15. Jh.”, “1608; 1651 [?]”, “vor 2. Weltkrieg”, “Biedermeierzeit”, “Vorkriegszeit” or “nach 1. Weltkrieg”) (Figure 19).
3.2.7. Temporal/Extrinsic/User Input
3.2.8. Temporal/Extrinsic/Data Conversion and Data Record
3.2.9. Linguistic/Intrinsic/Ontological
3.2.10. Linguistic/Intrinsic/Epistemic
3.2.11. Linguistic/Extrinsic/User Input
3.2.12. Linguistic/Extrinsic/Data Conversion
3.2.13. Linguistic/Extrinsic/Data Record
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Nowotny, H.; Scott, P.B.; Gibbons, M.T. Re-Thinking Science: Knowledge and the Public in An Age of Uncertainty; John Wiley & Sons: New York, NY, USA, 2013. [Google Scholar]
- Nowotny, H. The Cunning of Uncertainty; Polity Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Nowotny, H. The radical openness of science and innovation. Why uncertainty is inherent in the openness towards the future. EMBO Rep. 2015, 16, 1601–1604. [Google Scholar] [CrossRef] [PubMed]
- Dow, S.C. Uncertainty about Uncertainty. In Foundations for New Economic Thinking; Palgrave Macmillan: London, UK, 2012; pp. 72–82. [Google Scholar]
- Downey, H.K.; Slocum, J.W. Uncertainty: Measures, Research, and Sources of Variation. Acad. Manag. J. 1975, 18, 562–578. [Google Scholar]
- Taylor, J. Introduction to Error Analysis, the Study of Uncertainties in Physical Measurements, 2nd ed.; University Science Books: New York, NY, USA, 1997. [Google Scholar]
- Kuhlthau, C.C. A principle of uncertainty for information seeking. J. Doc. 1993, 49, 339–355. [Google Scholar] [CrossRef]
- Shackle, G.L.S. Uncertainty in Economics and Other Reflections; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Weiss, C. Expressing scientific uncertainty. Law Probab. Risk 2003, 2, 25–46. [Google Scholar] [CrossRef]
- Stigler, S.M. The History of Statistics: The Measurement of Uncertainty before 1900; Harvard University Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Bammer, G.; Smithson, M. (Eds.) Uncertainty and Risk. Multidisciplinary Perspectives; Earthscan: London, UK, 2008. [Google Scholar]
- Stirling, A. Risk, Uncertainty and Precaution: Some Instrumental Implications from the Social Sciences. In Negotiating Environmental Change: New Perspectives from the Social Sciences; Berkhout, F., Leach, M., Scoones, I., Eds.; Edward Elgar Publishing: Cheltenham, UK, 2003; pp. 33–76. [Google Scholar]
- Austrian Academy of Sciences. ACDH. Methods and Innovation. Core Unit 4. Available online: https://www.oeaw.ac.at/acdh/about/core-units/core-unit-4 (accessed on 28 June 2019).
- Open Innovation. ÖAW—Exploration Space. Available online: http://openinnovation.gv.at/portfolio/oeaw-exploration-space/ (accessed on 28 June 2019).
- Wandl-Vogt, E.; Kieslinger, B.; O’Connor, A.; Theron, R. exploreAT! Perspektiven einer Transformation am Beispiel eines lexikographischen Jahrhundertprojekts. In DHd2015. Von Daten zu Erkenntnissen. 23. bis 27. Februar 2015, Graz. Book of Abstracts; Austrian Centre for Digital Humanities: Wien, Austrian.
- Abgaz, Y.; Dorn, A.; Piringer, B.; Wandl-Vogt, E.; Way, A. Semantic Modelling and Publishing of Traditional Data Collection Questionnaires and Answers. Information 2018, 9, 297. [Google Scholar] [CrossRef]
- Benito, A.; Losada, A.G.; Therón, R.; Dorn, A.; Seltmann, M.; Wandl-Vogt, E. A Spatio-temporal Visual Analysis Tool for Historical Dictionaries. In Proceedings of the Fourth International Conference on Technological Ecosystems for Enhancing Multiculturality, Salamanca, Spain, 2–4 October 2016. [Google Scholar]
- Benito, A.; Losada, A.G.; Therón, R.; Dorn, A.; Wandl-Vogt, E. Creating Meaningful Narratives in Collections of Historical Lexical Data. GI Forum 2018, 6, 50–57. [Google Scholar] [CrossRef][Green Version]
- Dorn, A.; Wandl-Vogt, E.; Abgaz, Y.; Benito Santos, A.; Therón, R. Unlocking Cultural Conceptualisation in Indigenous Language Resources: Collaborative Computing Methodologies. In Proceedings of the LREC 2018 Workshop “CCURL2018—Sustainable Knowledge Diversity in the Digital Age”, Miyazaki, Japan, 12 May 2018. [Google Scholar]
- Open Innovation Strategy for Austria; Federal Ministry of Science, Research and Economy (bmwfw) and Federal Ministry for Transport, Innovation and Technology (bmvit): Vienna, Austria, 2015.
- Wandl-Vogt, E. Wie man ein Jahrhundertprojekt zeitgemäß hält: Datenbankgestützte Dialektlexikografie am Institut für Österreichische Dialekt- und Namenlexika (I DINAMLEX) (mit 10 Abbildungen). In Bausteine zur Wissenschaftsgeschichte von Dialektologie/Germanistischer Sprachwissenschaft im 19. und 20. Jahrhundert. Beiträge zum 2. Kongress der Internationalen Gesellschaft für Dialektologie des Deutschen; Ernst, P., Ed.; Praesens Verlag: Wien, Austria, 2008; pp. 93–112. [Google Scholar]
- Welcome to the PROVIDEDH CHIST-ERA Project Site. Available online: https://providedh.eu (accessed on 28 June 2019).
- Theron, R.; Wandl-Vogt, E.; Edmond, J.; Mazurek, C. Progressive Visual Decision Making for Digital Humanities (PROVIDEDH): Conceptual outline and first results. In Proceedings of the European Association for Digital Humanities Conference (EADH 2018), Galway, Ireland, 7–9 December 2018. [Google Scholar]
- Fisher, P.; Comber, A.; Wadsworth, R. Approaches to Uncertainty in Spatial Data. In Qualité de l’Information Géographique (Traité IGAT); Devillers, R., Jeansoulin, R., Eds.; Hermes/Lavoisier: Paris, France, 2005; pp. 9–64. [Google Scholar]
- Therón, R.; Losada, A.G.; Benito, A.; Santamaría, R. Toward supporting decision-making under uncertainty in digital humanities with progressive visualization. In Proceedings of the Sixth International Conference on Technological Ecosystems for Enhancing Multiculturality, Salamanca, Spain, 24–26 October 2018. [Google Scholar]
- Benito, A.; Rodriguez, A.; Therón, R. Visual approaches to uncertainty in DH. Presentation at the workshop “Uncertainties in Humanities Research Datasets”, Maynooth, Ireland, 6 March 2019. co-hosted by the Humanities Research Institute at Maynooth University, the Trinity College Dublin Centre for Digital Humanities and the consortium members of the PROVIDEDH project. [Google Scholar]
- Galbraith, J.K. The Age of Uncertainty; Houghton Mifflin: Boston, MA, USA, 1977. [Google Scholar]
- Regan, H.M.; Colyvan, M.; Burgman, M.A. A taxonomy and treatment of uncertainty for ecology and conservation biology. Ecol. Appl. 2002, 12, 618–628. [Google Scholar] [CrossRef]
- Fox, R.C. Medical Uncertainty Revisited. In Handbook of Social Studies in Health and Medicine; Albrecht, G.L., Fitzpatrick, R., Scrimshaw, S.C., Eds.; SAGE Publishing: Thousand Oaks, CA, USA, 2000; pp. 409–425. [Google Scholar]
- Hoffmann, V.H.; Trautmann, T.; Schneider, M. A taxonomy for regulatory uncertainty—application to the European Emission Trading Scheme. Environ. Sci. Policy 2008, 11, 712–722. [Google Scholar] [CrossRef]
- New World Encyclopedia. “Uncertainty”. Available online: http://www.newworldencyclopedia.org/p/index.php?title=Uncertainty&oldid=993112 (accessed on 28 June 2019).
- Smithson, M. Ignorance and Uncertainty: Emerging Paradigms; Springer Science & Business Media: Berlin, Germany, 2012. [Google Scholar]
- Bammer, G.; Smithson, M.; Goolabri Group. The Nature of Uncertainty. In Uncertainty and Risk: Multidisciplinary Perspectives; Smithson, M., Bammer, G., Eds.; Routledge: Abingdon, UK, 2012; pp. 289–303. [Google Scholar]
- Shattuck, L.G.; Lewis Miller, N.; Kemmerer, K.E. Tactical Decision Making Under Conditions of Uncertainty: An Empirical Study. In Proceedings of the Human Factors and Ergonomics Society. Annual Meeting, San Antonio, TX, USA, 19–23 October 2009. [Google Scholar]
- Diehl, A.; Yang, B.; Das, R.D.; Chen, S.; Andrienko, G.; Andrienko, N.; Dransch, D.; Keim, D. User-Uncertainty: A Human-Centred Uncertainty Taxonomy for VGI through the Visual Analytics Workflow. In Proceedings of the VGI Geovisual Analytics Workshop, colocated with BDVA 2018, Konstanz, Germany, 19 October 2018. [Google Scholar]
- Lovell, B.E. A Taxonomy of Types of Uncertainty. Ph.D. Dissertation, Portland State University, Portland, OR, USA, 1995. [Google Scholar]
- Vullings, W.; de Vries, M.; de Borman, L. Dealing with uncertainty in spatial planning. In Proceedings of the 10th AGILE International Conference on Geographic Information Science, Aalborg, Denmark, 13–17 August 2007. [Google Scholar]
- Cressie, N.; Wikle, C.K. Statistics for Spatio-Temporal Data; John Wiley & Sons: New York, NY, USA, 2015. [Google Scholar]
- Aigner, W.; Miksch, S.; Müller, W.; Schumann, H.; Tominski, C. Visualizing time-oriented data—A systematic view. Comput. Graph. 2007, 31, 401–409. [Google Scholar] [CrossRef]
- Kissling, W.D.; Ahumada, J.A.; Bowser, A.; Fernandez, M.; Fernández, N.; Alonso Garcia, E.; Guralnick, R.P.; Isaac, N.J.B.; Kelling, S.; Los, W.; et al. Building essential biodiversity variables (EBVs) of species distribution and abundance at a global scale. Biol. Rev. 2018, 93, 600–625. [Google Scholar] [CrossRef] [PubMed]
- Binder, F.; Entrup, B.; Schiller, I.; Lobin, H. Uncertain about Uncertainty: Different ways of processing fuzziness in digital humanities data. In Proceedings of the Digital Humanities 2014 Conference Abstracts EPFL—UNIL, Lausanne, Switzerland, 8–12 July 2014. [Google Scholar]
- Edmond, J. Managing Uncertainty in the Humanities: Digital and Analogue Approaches. In Proceedings of the Sixth International Conference on Technological Ecosystems for Enhancing Multiculturality, Salamanca, Spain, 24–26 October 2018. [Google Scholar]
- Track 13. Uncertainty in Digital Humanities. Available online: https://2018.teemconference.eu/uncertainty-digital-humanities (accessed on 28 June 2019).
- Martin-Rodilla, P.; Gonzalez-Perez, C. Representing Imprecise and Uncertain Knowledge in Digital Humanities: A Theoretica l Framework and ConML Implementation with a Real Case Study. In Proceedings of the Sixth International Conference on Technological Ecosystems for Enhancing Multiculturality, Salamanca, Spain, 24–26 October 2018. [Google Scholar]
- Senabre Hidalgo, E. Dotmocracy and Planning Poker for Uncertainty Management in Collaborative Research: Two Examples of Co-creation Techniques Derived from Digital Culture. In Proceedings of the Sixth International Conference on Technological Ecosystems for Enhancing Multiculturality, Salamanca, Spain, 24–26 October 2018. [Google Scholar]
- Wandl-Vogt, E.; Dorn, A.; Piringer, B. The unknThe unknown and the uncertain. A data discovery journey from an analogous data collection to an interactive exploration space. In Proceedings of the First European Association for Digital Humanities Conference (EADH 2018), Galway, Ireland, 7–9 December 2018. [Google Scholar]
- Fisher, P.F. Models of uncertainty in spatial data. Geogr. Inf. Syst. 1999, 1, 191–205. [Google Scholar]
- Couclelis, H. The Certainty of Uncertainty: GIS and the Limits of Geographic Knowledge. Trans. GIS 2003, 7, 165–175. [Google Scholar] [CrossRef]
- Fusco, G.; Caglioni, M.; Emsellem, K.; Merad, M.; Moreno, D.; Voiron-Canicio, C. Questions of uncertainty in geography. Environ. Plan. A Econ. Space 2017, 49, 2261–2280. [Google Scholar] [CrossRef]
- Züfle, A.; Trajcevski, G.; Pfoser, D.; Renz, M.; Rice, M.T.; Leslie, T.; Delamater, P.; Emrich, T. Handling Uncertainty in Geo-Spatial Data. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017. [Google Scholar]
- GIS-Wörterbuch. Available online: https://support.esri.com/en/other-resources/gis-dictionary/term/9ac5d78f-2a00-4c24-81ba-346ad51bf302 (accessed on 28 June 2019).
- Wörterbuch der bairischen Mundarten in Österreich (WBÖ). In Bayerisches Wörterbuch: I; Verlag der Österreichischen Akademie der Wissenschaften: Wien, Austria, 1970.
- Arbeitsplan und Geschäftsordnung für Das Bayerisch-Österreichische Wörterbuch; Archive of the Austrian Academy of Sciences: Vienna, Austria, 1912.
- Piringer, B.; Wandl-Vogt, E.; Abgaz, Y.; Lejtovicz, K. Exploring and exploiting biographical and prosopographical information as common access layer for heterogeneous data facilitating inclusive, gender- symmetric research. In Proceedings of the Biographical Data in a Digital World, Linz, Austria, 6–7 November 2017. [Google Scholar]
- Scholz, J.; Hrastnig, E.; Wandl-Vogt, E. A Spatio-Temporal Linked Data Representation for Modeling Spatio-Temporal Dialect Data. In Proceedings of the Workshops and Posters at the 13th International Conference on Spatial Information Theory (COSIT), L’Aquila, Italy, 4–8 September 2017. [Google Scholar]
- Schopper, D.; Bowers, J.; Wandl-Vogt, E. dboe@TEI: Remodelling a database of dialects into a rich LOD resource. In Proceedings of the Text Encoding Initiative Conference, Lyon, France, 28–31 October 2015. [Google Scholar]
- Wandl-Vogt, E. Datenbank der Bairischen Mundarten in Österreich @ Electronically Mapped. Projektbeschreibung. 2012. Available online: https://dboema.acdh.oeaw.ac.at/projekt/beschreibung/ (accessed on 28 June 2019).
- Wandl-Vogt, E. Von der Karte zum Wörterbuch—Überlegungen zu einer räumlichen Zugriffsstruktur für Dialektwörterbücher dargestellt am Beispiel des Wörterbuchs der bairischen Mundarten in Österreich (WBÖ). In Proceedings of the Atti del XII Congresso Internazionale di Lessicografia, Torino, Italia, 6–9 September 2006. [Google Scholar]
- Wandl-Vogt, E. Mapping Dialects. Die Karte als primäre Zugriffsstruktur für Dialektwörterbücher. Wiener Schriften Geographie Kartographie 2006, 17, 87–89. [Google Scholar]
- Wandl-Vogt, E.; Kop, C.; Nickel, J.; Scholz, J. Database of Bavarian Dialects (DBÖ) electronically mapped (dbo@ema). A System for Archiving, Maintaining and Field Mapping of Heterogeneous Dialect Data for the Compilation of Dialect Lexicons. In Proceedings of the XIII Euralex International Congress, Barcelona, Spain, 15–19 July 2008. [Google Scholar]
- Scholz, J.; Bartelme, N.; Fliedl, G.; Hassler, M.; Mayr, H.C.; Nickel, J.; Vöhringer, J.; Wandl-Vogt, E. Mapping Languages—Erfahrungen aus dem Projekt dbo@ema. In Proceedings of the Angewandte Geoinformatik 2008—Beiträge zum 20. AGIT-Symposium, Salzburg, Austria, 2–4 July 2008. [Google Scholar]
- Bartelme, N.; Scholz, J. Geoinformationstechnologien zur Analyse des Raum- und Zeitbezugs bei Dialektwörtern. In Fokus Dialekt Analysieren—Dokumentieren—Kommunizieren; Bergmann, H., Glauninger, M.M., Wandl-Vogt, E., Winterstein, S., Eds.; Georg Olms Verlag: Hildesheim, Germany, 2010; pp. 65–78. [Google Scholar]
- Scholz, J.; Lampoltshammer, T.J.; Bartelme, N.; Wandl-Vogt, E. Spatial-temporal Modeling of Linguistic Regions and Processes with Combined Indeterminate and Crisp Boundaries. In Progress in Cartography. Lecture Notes in Geoinformation and Cartography; Gartner, G., Jobst, M., Huang, H., Eds.; Springer: Cham, Switzerland, 2016; pp. 133–151. [Google Scholar]
- Hrastnig, E. A Linked Data approach for Digital Humanities. Master’s Thesis, Technische Universität Graz, Graz, Austria, January 2018. [Google Scholar]
- Collection Explorer. Available online: https://exploreat.acdh-dev.oeaw.ac.at/exploreAT-collectionexplorer (accessed on 28 June 2019).
- GitHub. Acdh-Oeaw/Exploreat-Collectionexplorer. Available online: https://github.com/acdh-oeaw/exploreAT-collectionexplorer (accessed on 28 June 2019).
- Smith, B. Fiat Objects. Topoi 2001, 20, 131–148. [Google Scholar] [CrossRef]
- Rill, B. Böhmen und Mähren. In Geschichte im Herzen Mitteleuropas; Casimir Katz Verlag: Gernsbach, Germany, 2006. [Google Scholar]
- GeoPy. Available online: https://geopy.readthedocs.io/en/stable/# (accessed on 28 June 2019).
- Welcome to Nominatim. Available online: https://nominatim.openstreetmap.org/ (accessed on 28 June 2019).
- Wikipedia. The Free Encyclopedia. “Date Format by Country”. Available online: https://en.wikipedia.org/wiki/Date_format_by_country (accessed on 28 June 2019).
- Dobrin, L.; Sicoli, M. Why cultural meanings matter in endangered language research. In Reflections on Language Documentation 20 Years after Himmelmann 1998; McDonnell, B., Berez-Kroeker, A.L., Holton, G., Eds.; University of Hawaii Press: Honolulu, HI, USA, 2018; pp. 41–54. [Google Scholar]
- Belew, A.; Chen, Y.; Campbell, L.; Barlow, R.; Hauk, B.; Heaton, R.; Walla, S. The World’s Endangered Languages and their Status. In Cataloguing the World’s Endangered Languages; Campbell, L., Belew, A., Eds.; Routledge: Abingdon, UK, 2018; pp. 85–249. [Google Scholar]
- International Phonetic Alphabet. Available online: http://www.internationalphoneticalphabet.org/ipa-sounds/ipa-chart-with-sounds (accessed on 28 June 2019).
- Reichel, S. Handbuch zum Zeichensatz SMFTeuthonista. 2003. Available online: https://web.archive.org/web/20040724105759/http://www.sprachatlas.phil.unierlangen.de/materialien/Teuthonista_Handbuch.pdf (accessed on 28 June 2019).
- Bachmaier, R.; Kramer, U. Symbole der Wiener Teuthonista und der IPA im Vergleich. 2009. Available online: https://web.archive.org/web/20120306040434/http://www.oeaw.ac.at/dinamlex/Teutho_IPA.pdf (accessed on 28 June 2019).
- UTF-8 Encoding Table and Unicode Characters. Available online: https://www.utf8-chartable.de/unicode-utf8-table.pl (accessed on 28 June 2019).
- About the Unicode® Standard. Available online: https://unicode.org/standard/standard.html (accessed on 28 June 2019).
- Character Set Encoding Basics. Available online: https://scripts.sil.org/cms/scripts/page.php?site_id=nrsi&item_id=IWS-Chapter03#79e846db (accessed on 28 June 2019).
- Funtowicz, S.; Ravetz, J. Post-normal science. In Companion to Environmental Studies; Castree, N., Hulme, M., Proctor, J.D., Eds.; Routledge: Abingdon, UK, 2018; pp. 443–447. [Google Scholar]



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| XML/TEI Files | MySQL Records | |||
|---|---|---|---|---|
| Number of Entries | 2,416,499 | 65,839 | ||
| Number of lemmas | Total | Unique | Total | Unique |
| • Original mainlemmas | 1,315,183 | 197,123 | 98,272 | 39,853 |
| • Original additional lemma | 112,309 | 42,432 | 14,842 | 9874 |
| • Normalized mainlemmas | 1,314,494 | 191,691 | - | - |
| • Normalized additionallemma | 112,236 | 40,069 | - | - |
| • Entries with no lemmas | 115,516 | 0 | ||
| Number of Locations | Total | Unique | Unique | |
| • Bundesland | 1,316,889 | 9 | - | |
| • Großregion | 1,296,722 | 32 | 415 | |
| • Kleinregion | 1,286,463 | 323 | ||
| • Gemeinde | 1,198,447 | 1146 | 3058 | |
| • Ort | 1,198,447 | 1145 | 19,946 | |
| • Ort (without associated Gemeinde) | 395,186 | 24,788 | - | |
| With Location | Without Location | With Location | Without Location | |
| Entries vs location | 1,712,705 | 703,794 | 7333 | 58,506 |
| Time span of entries | Oldest | Newest | Oldest | Newest |
| 1010 | 2008 | 1196 | 2012 | |
| Uncertainties | |||||
|---|---|---|---|---|---|
| Intrinsic | Extrinsic | ||||
| Ontological | Epistemic | User Input | Data Conversion | Data Record | |
| Dimensions | (lack of capacity to know what really exists) | (imprecision/ignorance/incompleteness) | (errors/misinterpretations/entropy/information truncation) | (uncertainties introduced by changing technologies) | (ambiguities/undecibilities/data conversion errors/users’ introduced errors) |
| Spatial |
|
|
|
|
|
| Temporal |
|
|
| ||
| Linguistic |
|
|
| ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rocha Souza, R.; Dorn, A.; Piringer, B.; Wandl-Vogt, E. Towards A Taxonomy of Uncertainties: Analysing Sources of Spatio-Temporal Uncertainty on the Example of Non-Standard German Corpora. Informatics 2019, 6, 34. https://doi.org/10.3390/informatics6030034
Rocha Souza R, Dorn A, Piringer B, Wandl-Vogt E. Towards A Taxonomy of Uncertainties: Analysing Sources of Spatio-Temporal Uncertainty on the Example of Non-Standard German Corpora. Informatics. 2019; 6(3):34. https://doi.org/10.3390/informatics6030034
Chicago/Turabian StyleRocha Souza, Renato, Amelie Dorn, Barbara Piringer, and Eveline Wandl-Vogt. 2019. "Towards A Taxonomy of Uncertainties: Analysing Sources of Spatio-Temporal Uncertainty on the Example of Non-Standard German Corpora" Informatics 6, no. 3: 34. https://doi.org/10.3390/informatics6030034
APA StyleRocha Souza, R., Dorn, A., Piringer, B., & Wandl-Vogt, E. (2019). Towards A Taxonomy of Uncertainties: Analysing Sources of Spatio-Temporal Uncertainty on the Example of Non-Standard German Corpora. Informatics, 6(3), 34. https://doi.org/10.3390/informatics6030034