Conceptualization and Non-Relational Implementation of Ontological and Epistemic Vagueness of Information in Digital Humanities †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Uncertain Information in Humanities Fields
1.2. Existing Approaches Outside Humanities
1.3. Theoretical Framework
- Ontological vagueness, or imprecision, which refers to things in the world that are not clear-cut, such as the boundaries of a hill;
- Epistemic vagueness, or uncertainty, which refers to situations where our knowledge about something is unclear or incomplete.
1.4. ConML
2. Materials and Methods
2.1. Expressing Imprecision and Uncertainty with ConML
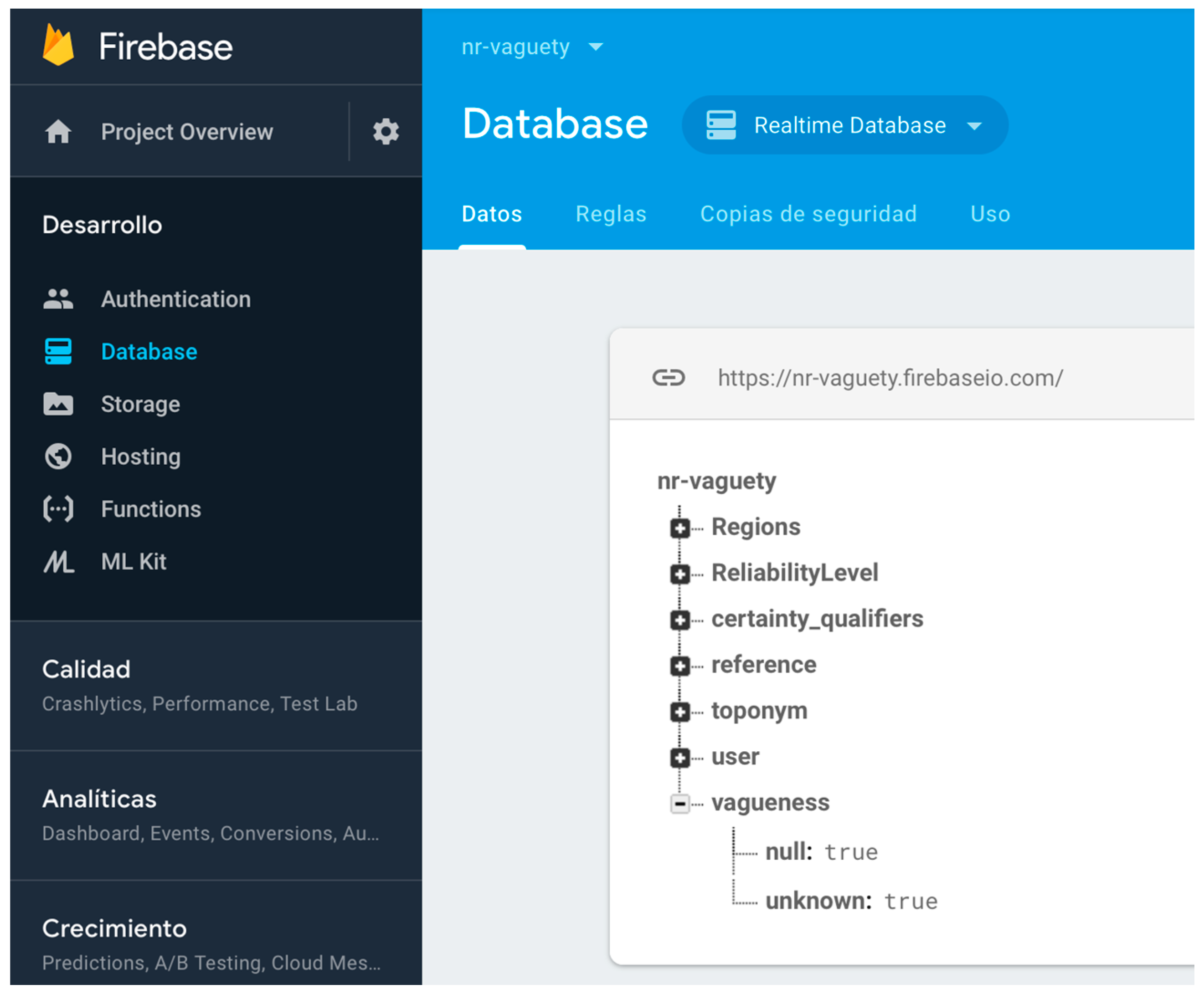
2.1.1. Null and Unknown Semantics
- Null, which indicates ontological absence; b.Protection¬Level = null means that no protection level has been established for b;
- Unknown, which indicates epistemic absence; b.Protection¬Level = unknown means that a protection level has been established for b, but we do not know what it is.
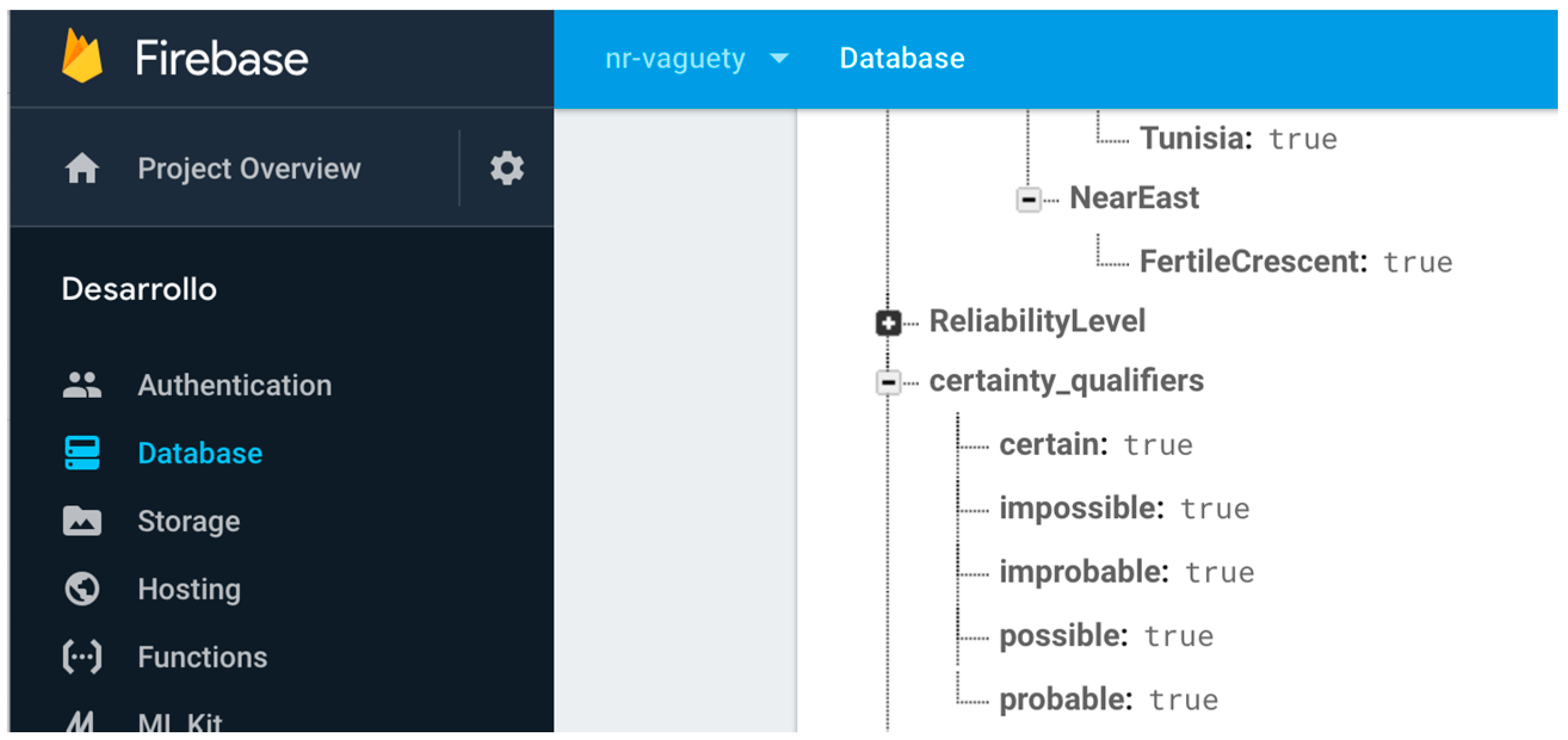
2.1.2. Certainty Qualifiers
- Certain. The expressed fact is known to be true. This is indicated by an asterisk * sign;
- Probable. The expressed fact is probably true. This is indicated by a plus + sign;
- Possible. The expressed fact is possibly true. This is indicated by a tilde ~ sign;
- Improbable. The expressed fact is probably not true. This is indicated by a minus − sign;
- Impossible. The expressed fact is known to be not true. This is indicated by an exclamation ! sign.
2.1.3. Abstract Enumerated Items
2.1.4. Arbitrary Time Resolution
3. Results
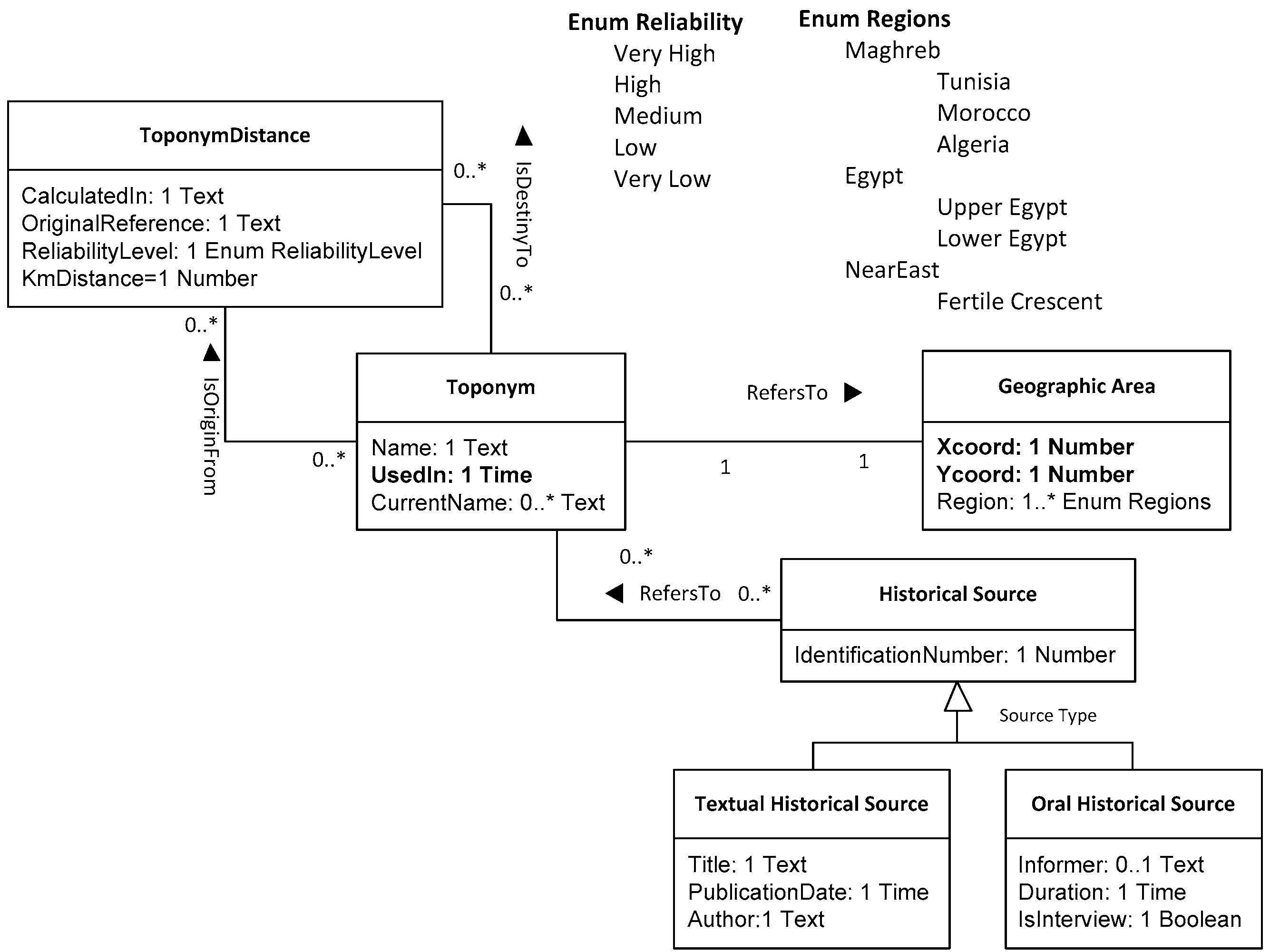
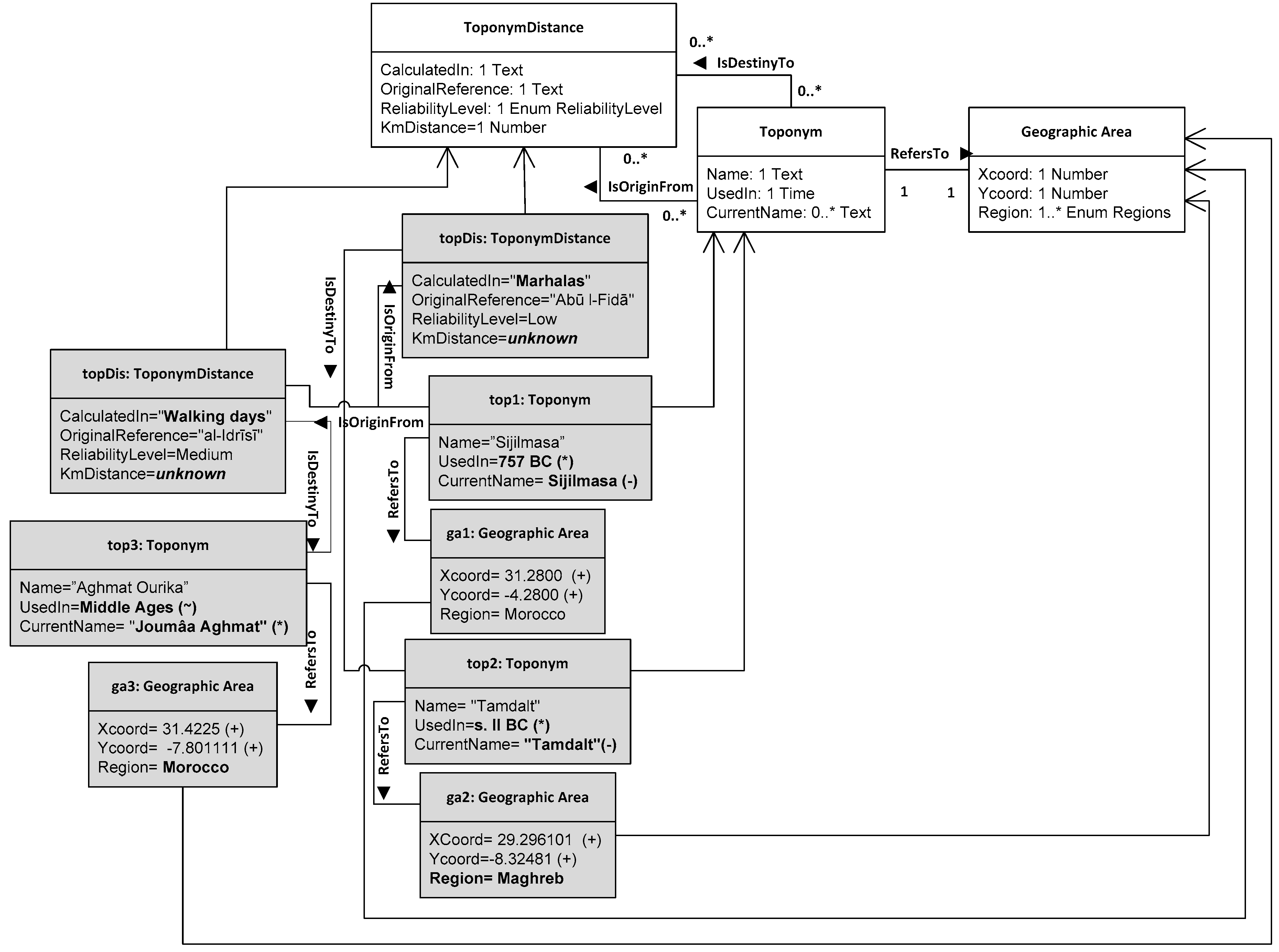
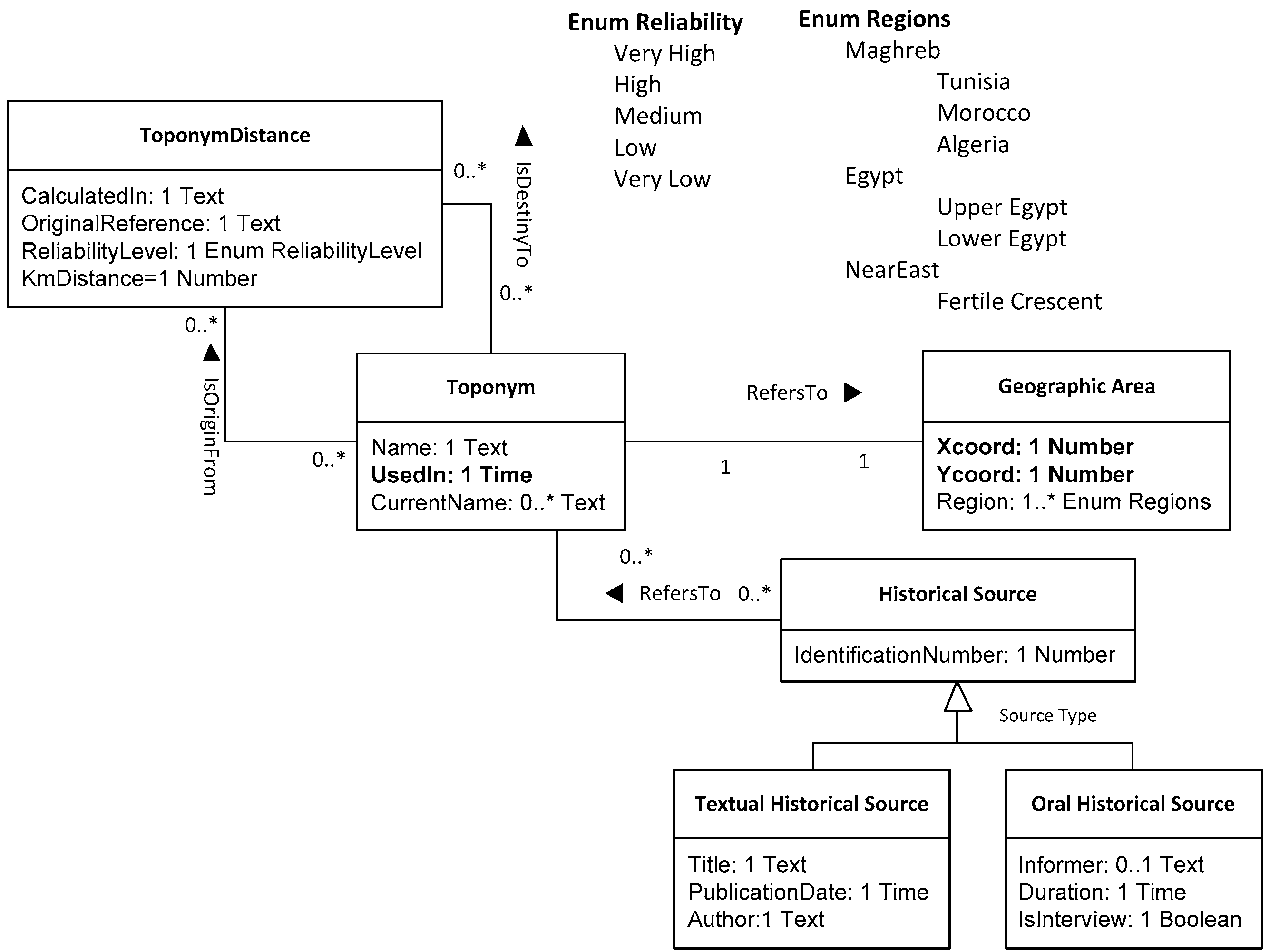
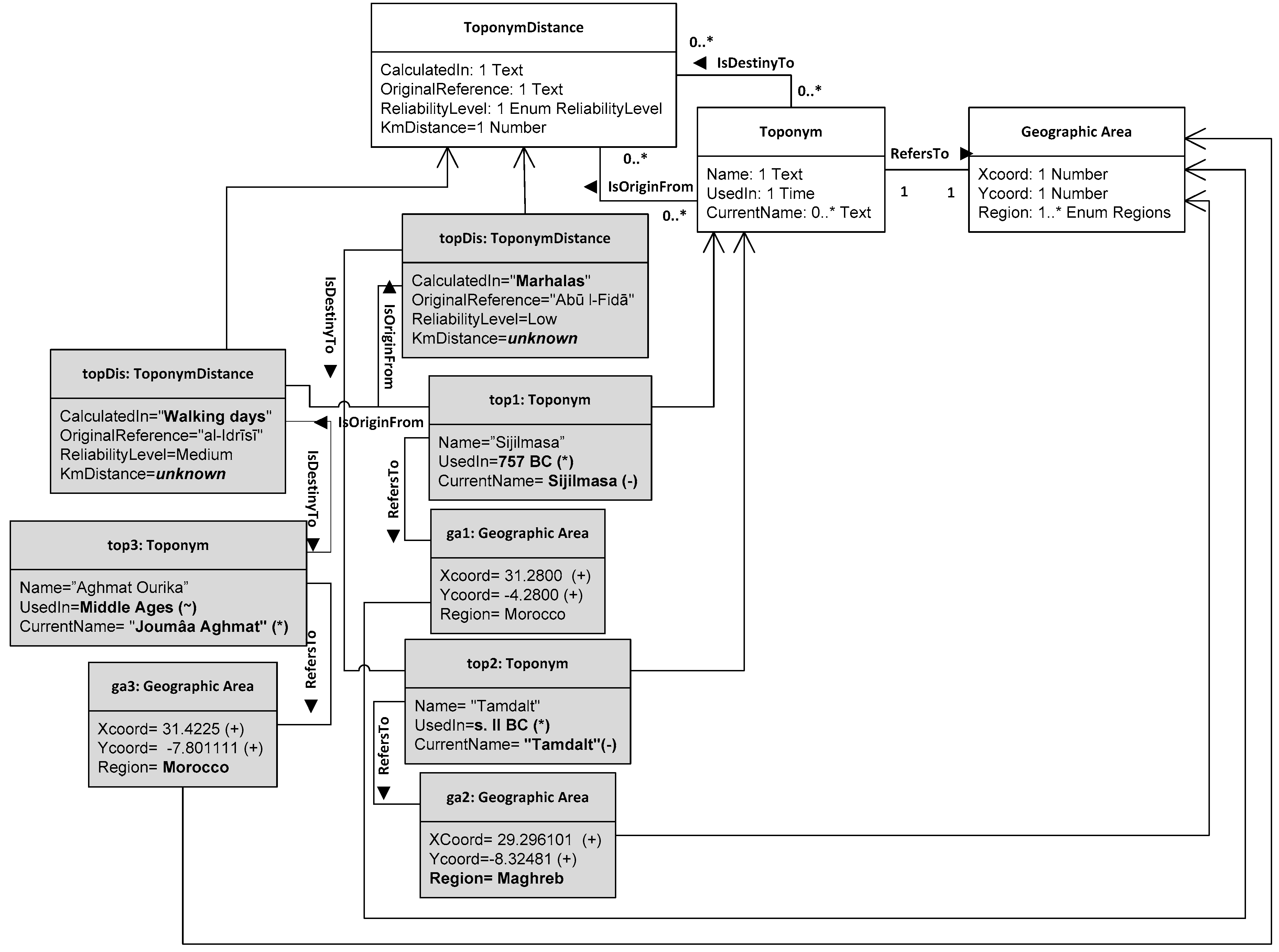
3.1. Case Study and Resultant Models
- Toponym: proper name referring to a geographical place. No vagueness is involved;
- ToponymDistance: relative distance between two toponyms. This class also holds information related to the reliability of the distance estimation as a separate attribute;
- GeographicArea: location of the place referred to by a toponym. If a toponym is still in use, the corresponding geographic area is epistemologically vague but known; if not, the geographic area may be estimated from the historical sources;
- HistoricalSource: any manifestation of a testimony, (textual such as letters, publications, and bibliographical references) or oral testimonies (formal or informal) that allows the reconstruction, analysis, and interpretation of historical events.
3.2. Implementatio
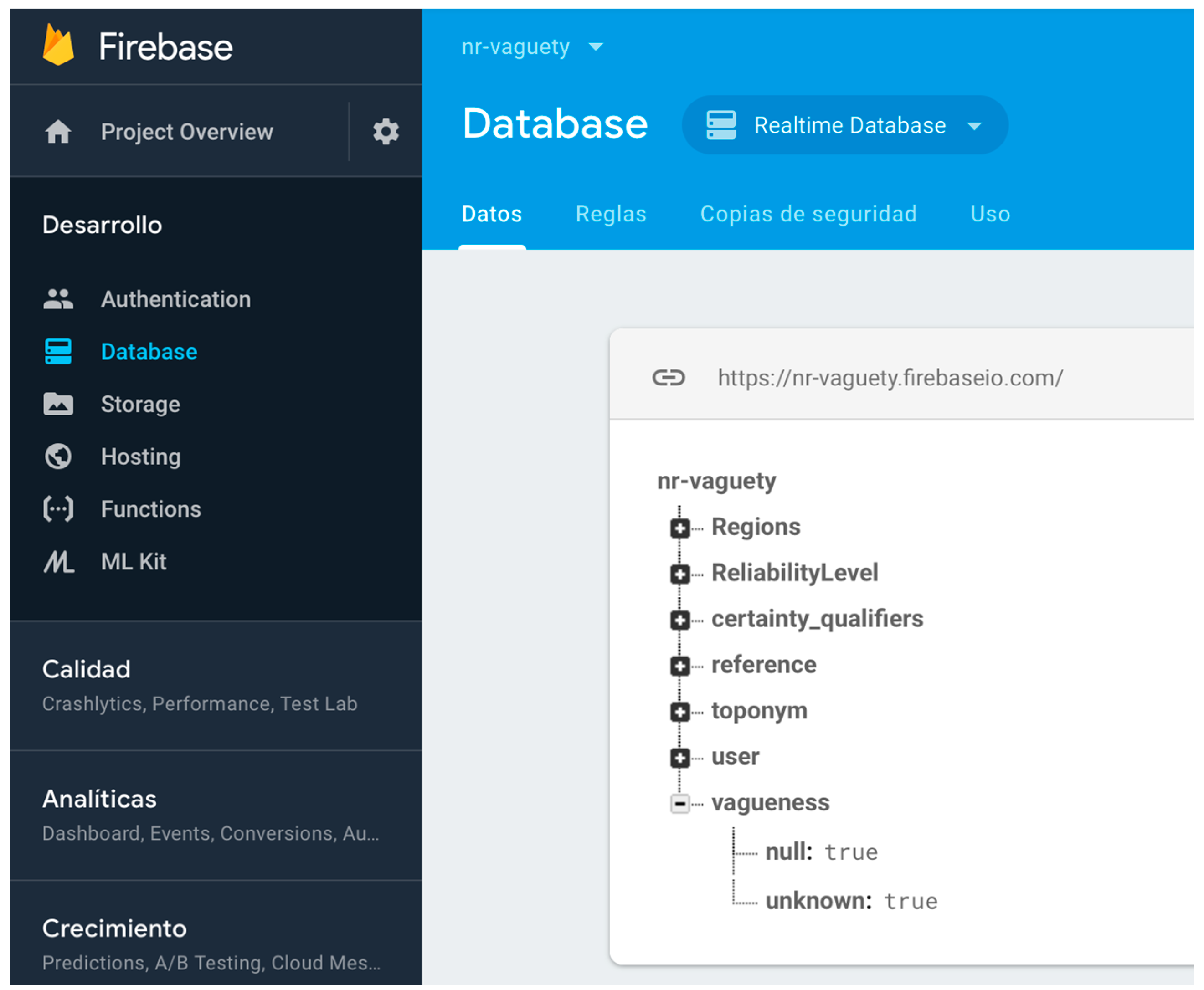
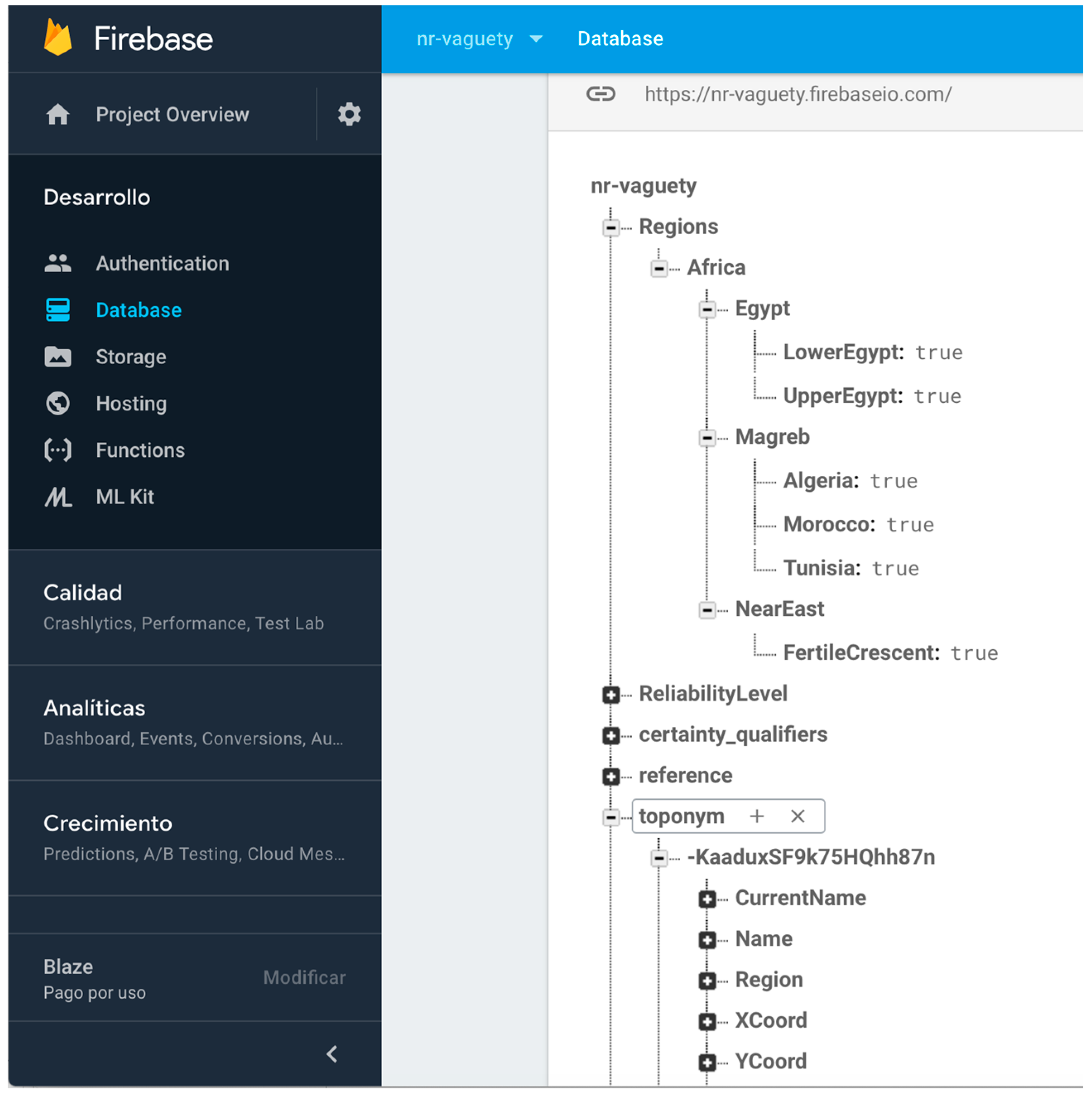
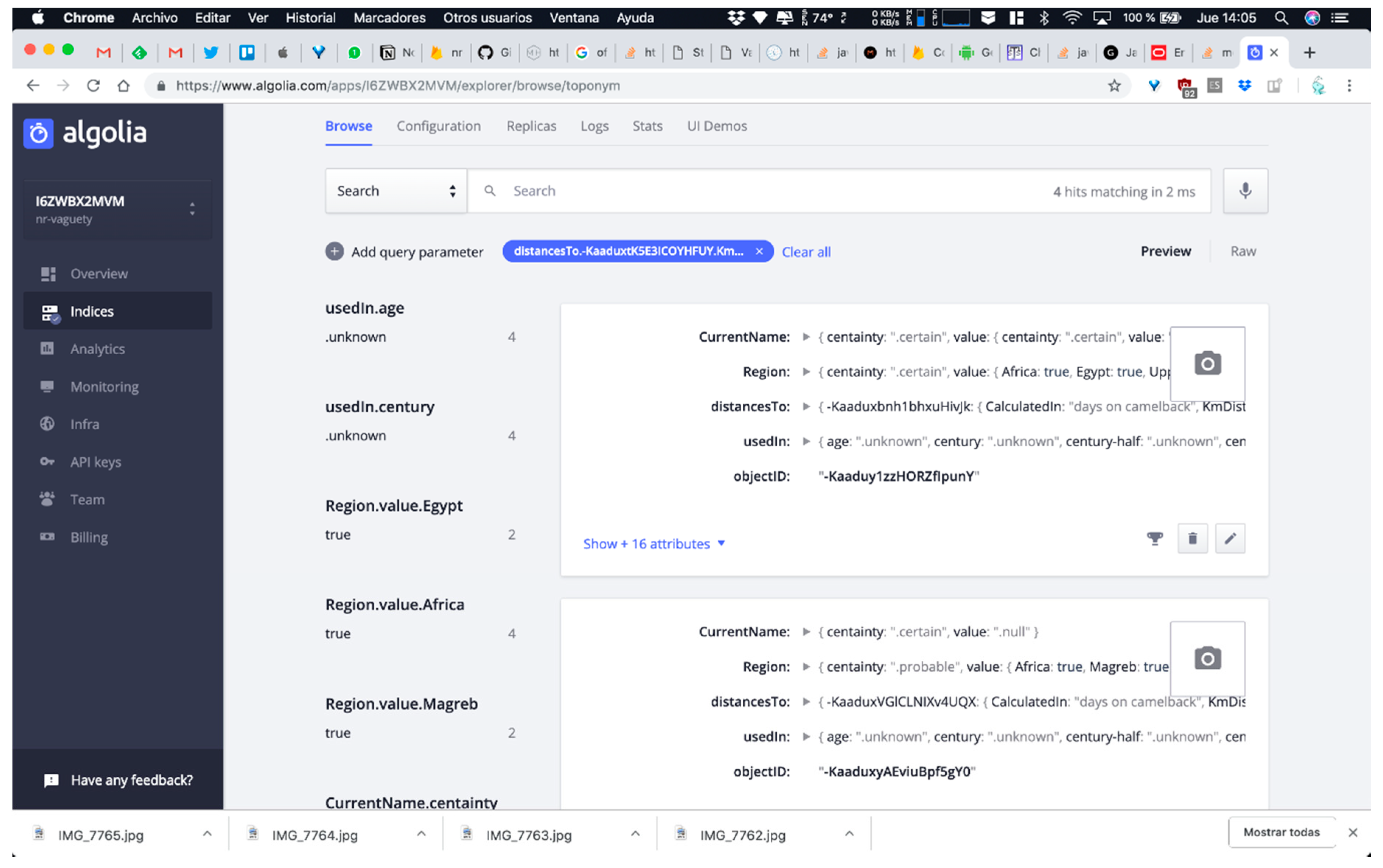
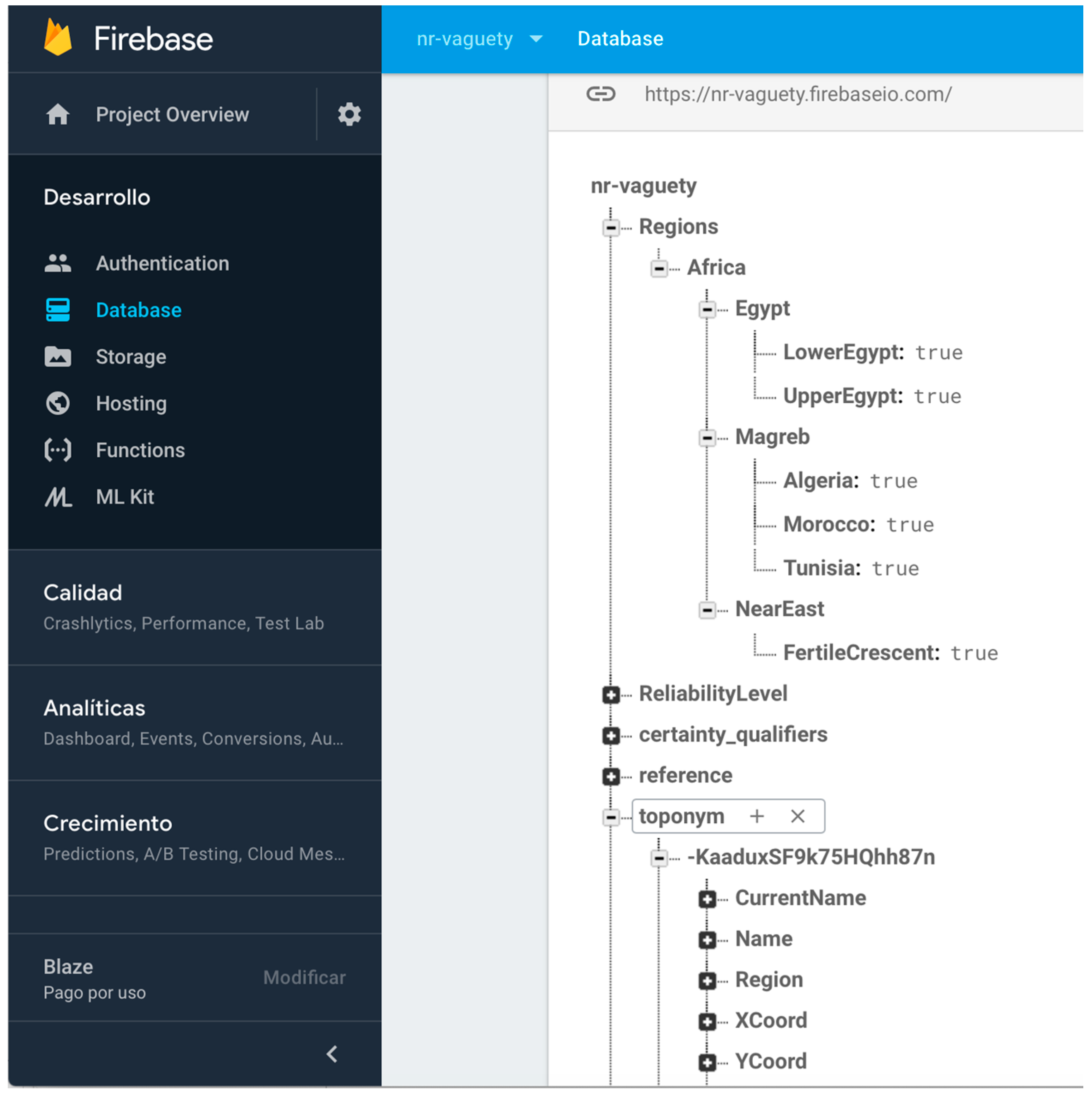
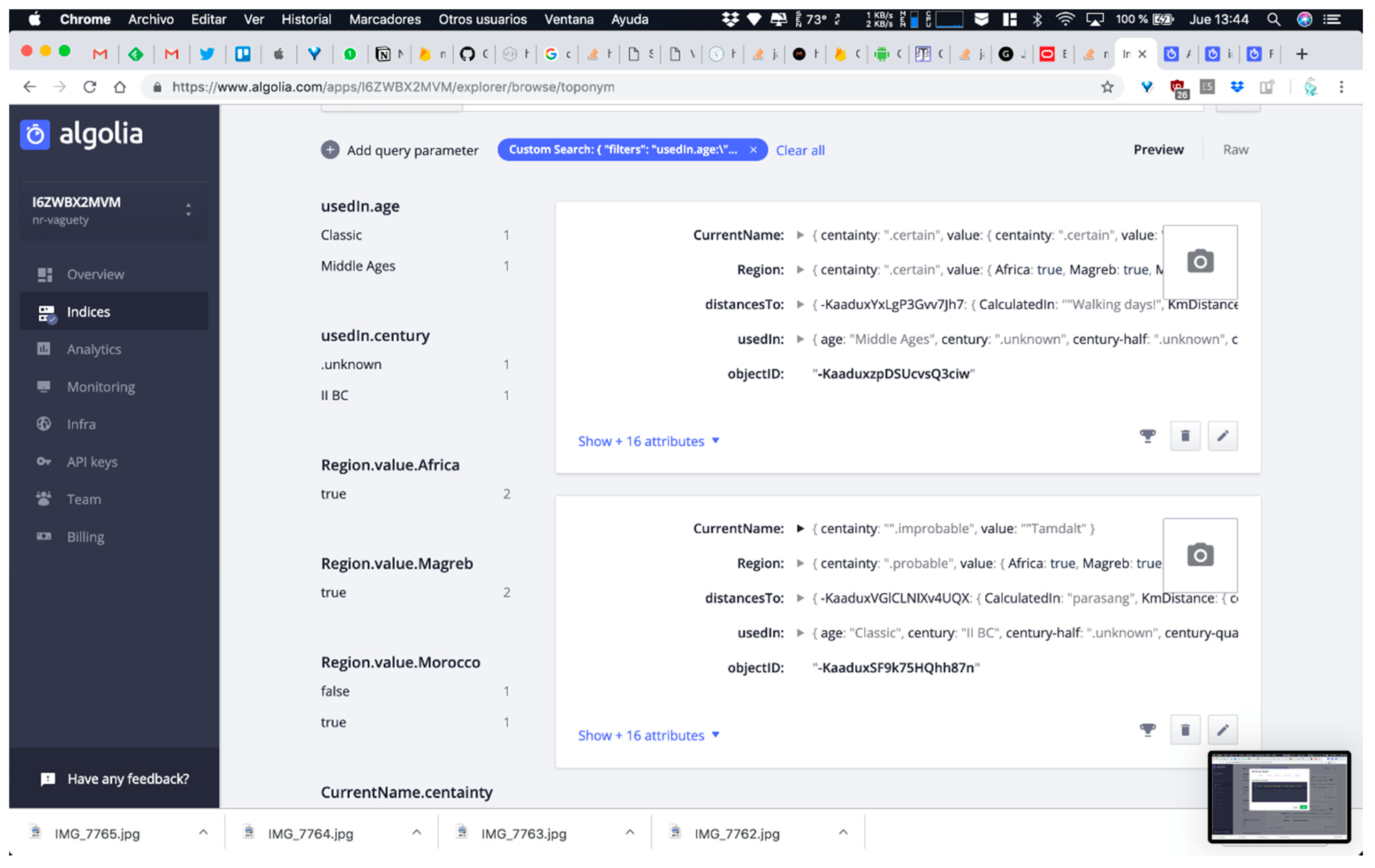
- Null and unknown semantics. Most of the non-relational systems do not allow one to create specific reserved words that could implement the need for null and unknown semantic for expressing vagueness. Some systems use numeric values such as zero, negatives values, or empty strings to represent null and/or unknown values. Other values are sometimes used as “magic” values for these semantics. However, these practices often introduce ambiguity and confusion, as zero and empty strings may constitute acceptable values for associated attributes. It is also common practice to create specific informational objects in the database structure for null or unknown semantics. This is a possible solution in systems where the object structure is still supported, such as MongoDB [48]. However, this solution is not possible in all non-relational systems. As we need specific semantics elements for representing absence of facts and absence of information universally, we have defined a node in our non-relational structure for each of them, encapsulating in specific references in the non-relational software systems the semantic required. Figure 3 shows the non-relational node and the key-value structures defined for null and unknown semantics and their use in a specific toponym information description in DICTOMAGRED.
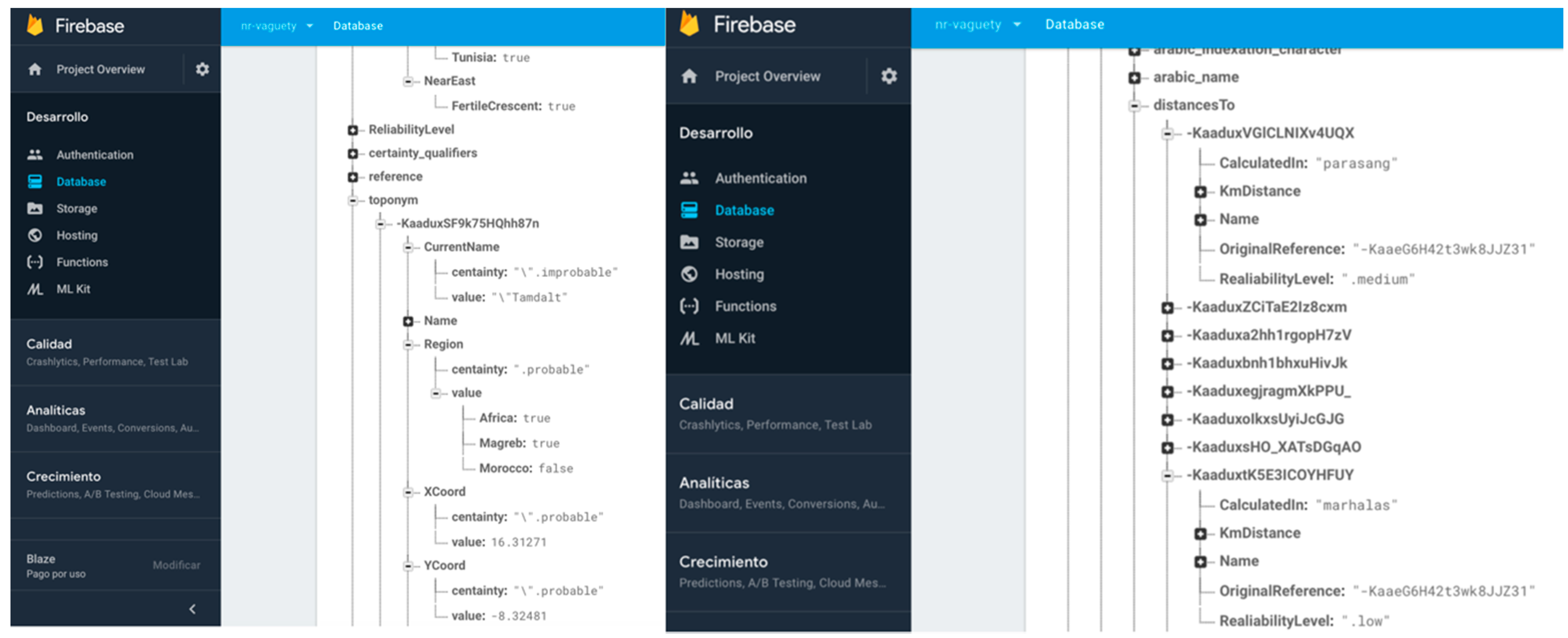
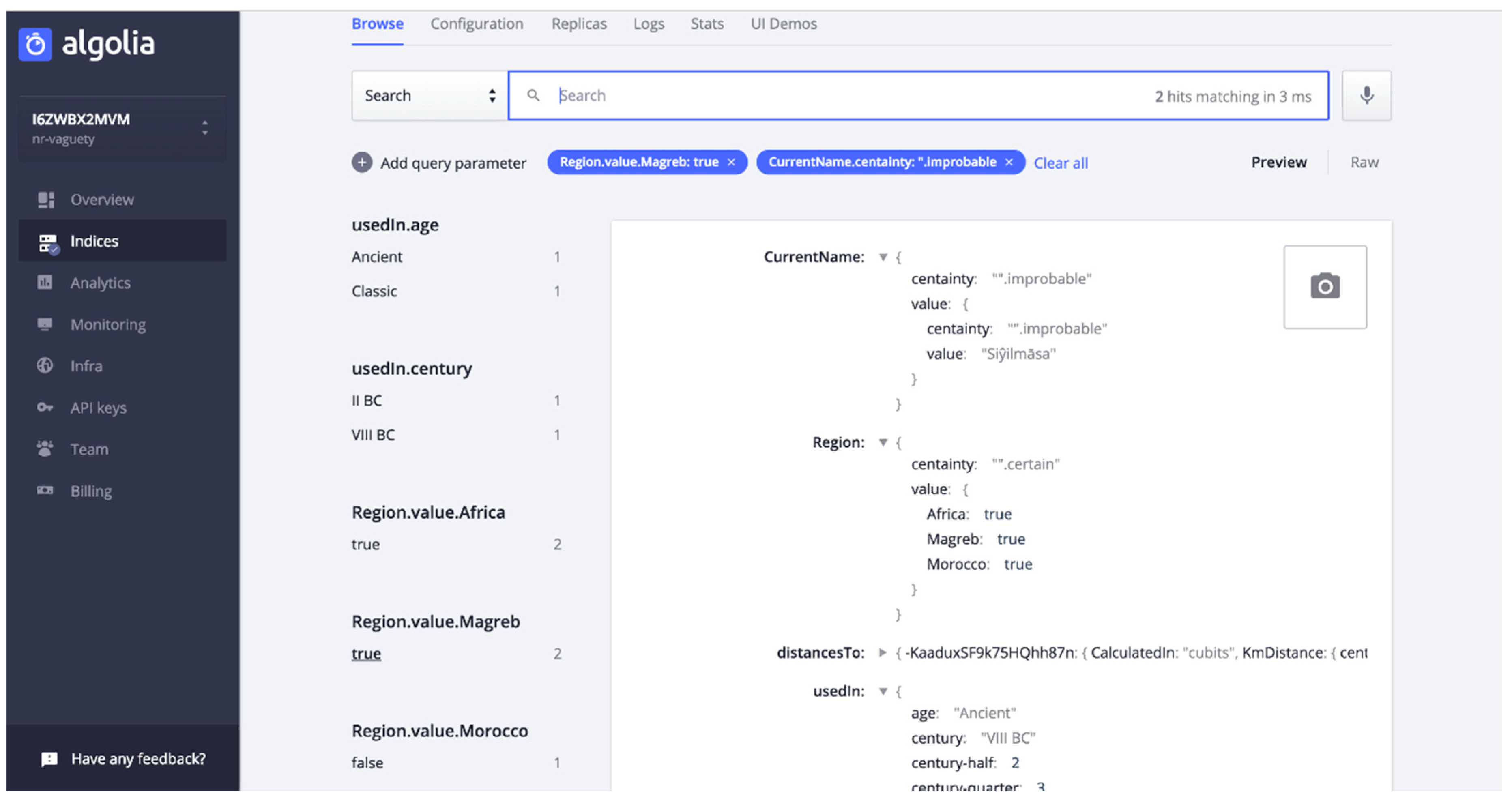
- Certainty qualifiers. As we previously detailed, a certainty qualifier offers some “extra” information about a specific value of an attribute defined in the conceptual model (i.e., in b.Height = 34 (~), “34” is the value and the certainty qualifier indicates extra information; we are not very sure about the height given value). Thus, it is necessary to firstly define in the non-relational structure the certainty qualifiers as specific references that we can add to any key-value previously defined. A node with all possible certainty qualifiers is defined as part of the non-relational structure, separated from any other information node. With this solution, it is possible to correlate another key-value structure to the value “34” itself (following the example), for indicating the certainty qualifier. Figure 4 shows the nodes added and their use in a specific toponym information description in DICTOMAGRED.
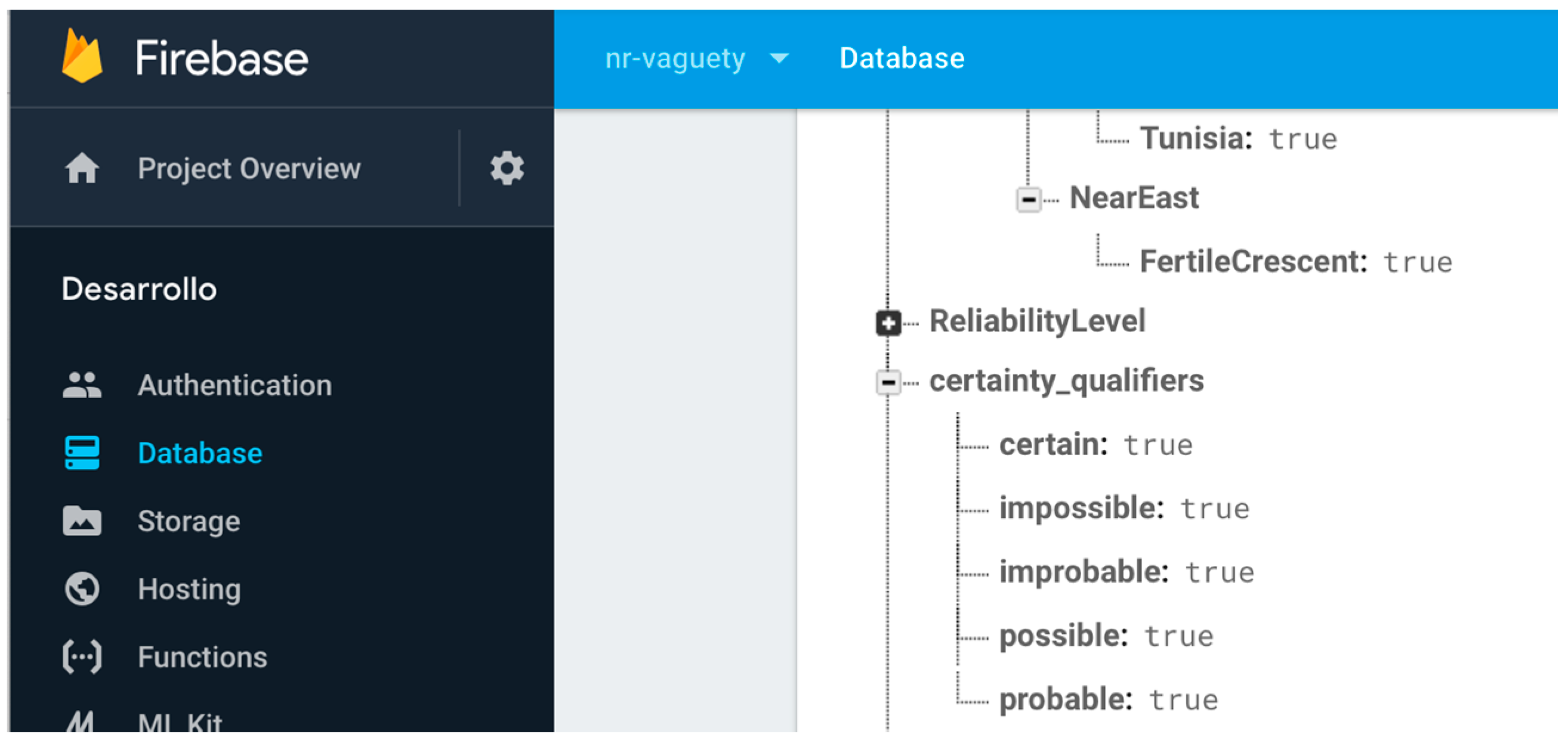
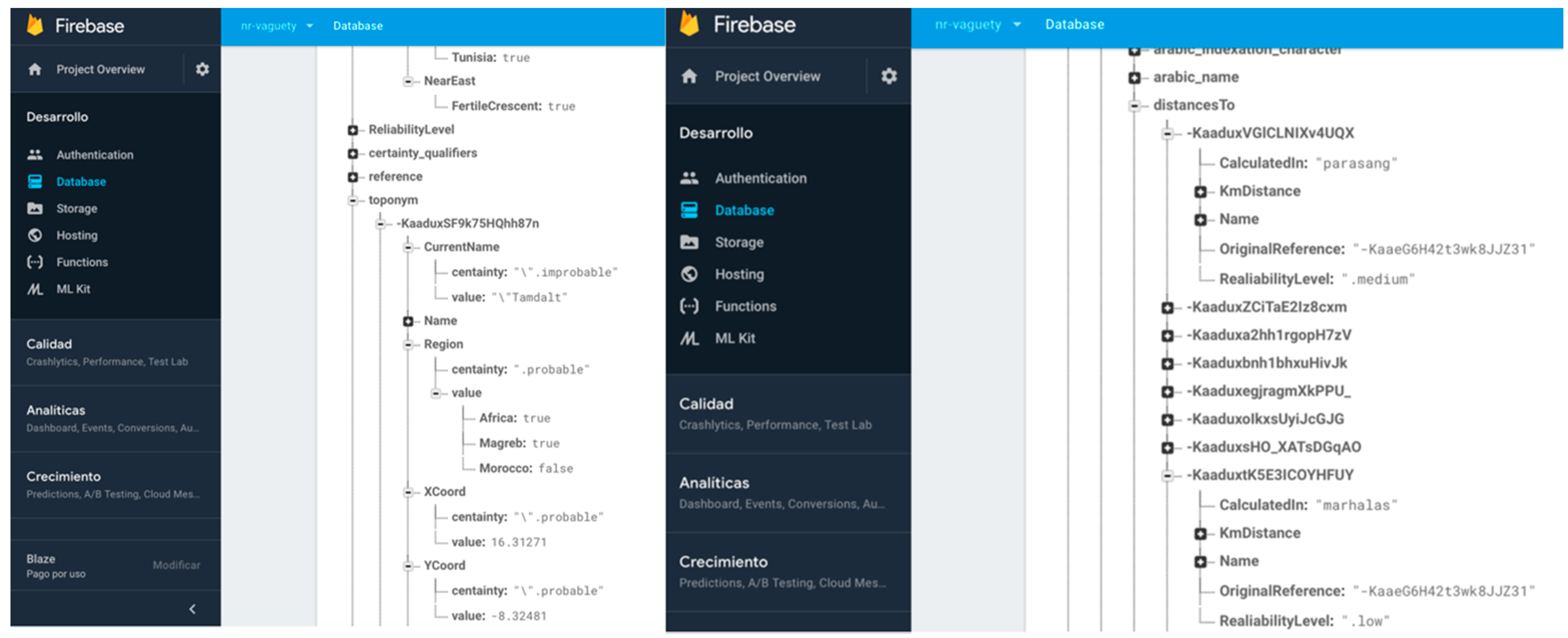
- Abstract enumerated items. Some systems use numeric values for representing levels of abstraction in a hierarchical structure of items. Other values are sometimes used as ad hoc formatted values for these semantics, as chains of strings separated by special characters like “.” or “/” for representing the entire path of the enumerated item value (Region = Magreb.Morocco). However, these practices often introduce ambiguity and confusion in the information, as they may constitute acceptable values for the associated attributes or responds to arbitrary implementation decisions. It is also common practice to create implement abstract enumerated items as in the previous certainty qualifiers mechanism, defining a hierarchical node in the non-relational structure and putting the most concrete value of the hierarchy (Region = Morocco). Then, the software system iterates this node in order to obtain at what level of abstraction the value is described. The final possibility is to define the hierarchical node but putting as Boolean values of the attribute all the levels involved (Magreb = true; Morocco = true). Both last solutions follow a non-relational structure and are operational for implementing abstract enumerated items. However, iterating the node each time we want to solve the abstraction information is inefficient in non-relational environments, so finally we chose the Boolean values structure. Figure 5 shows the non-relational node defined for the regions enumerated type and their items, and their use in a specific toponym information description in DICTOMAGRED.
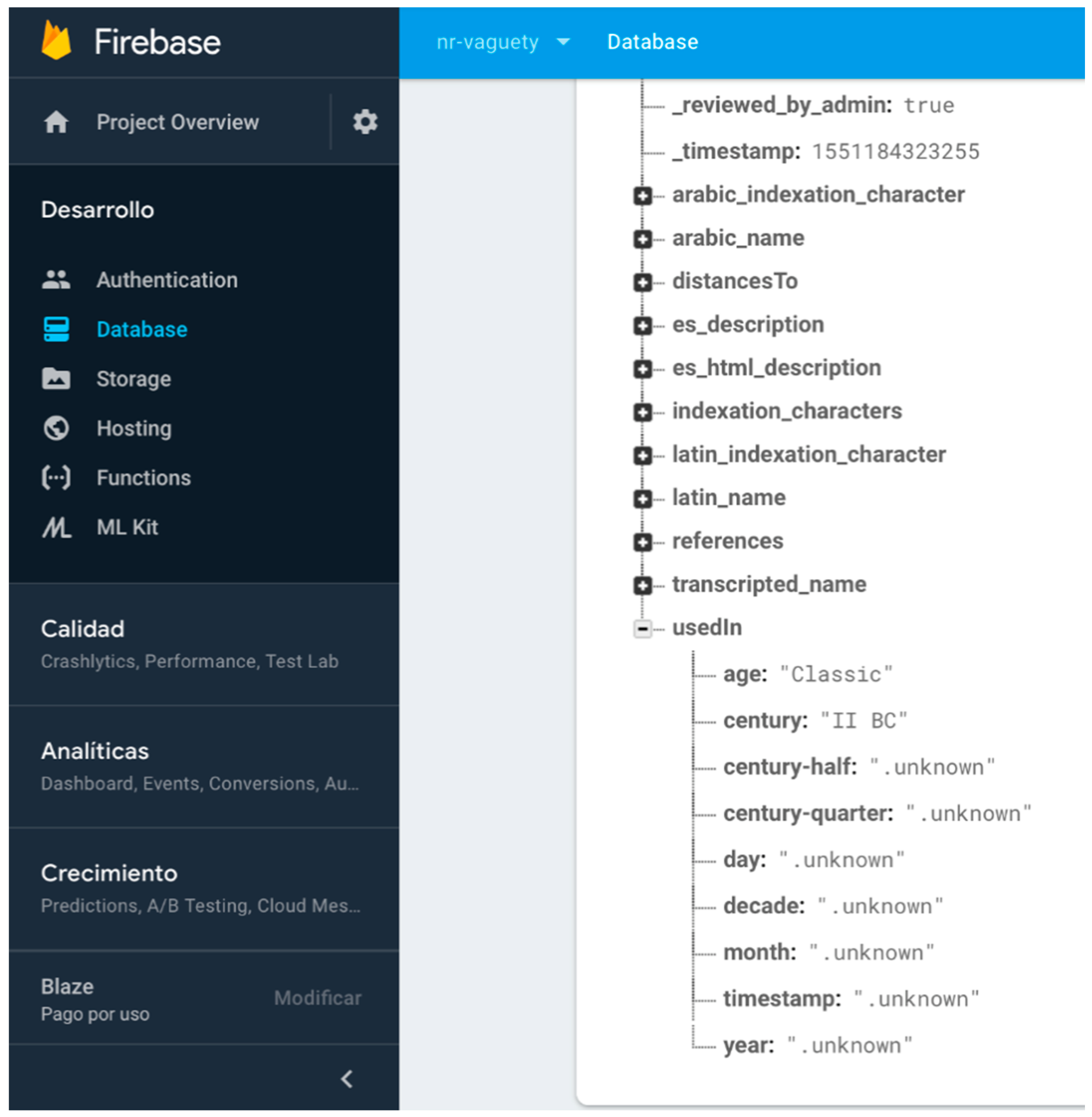
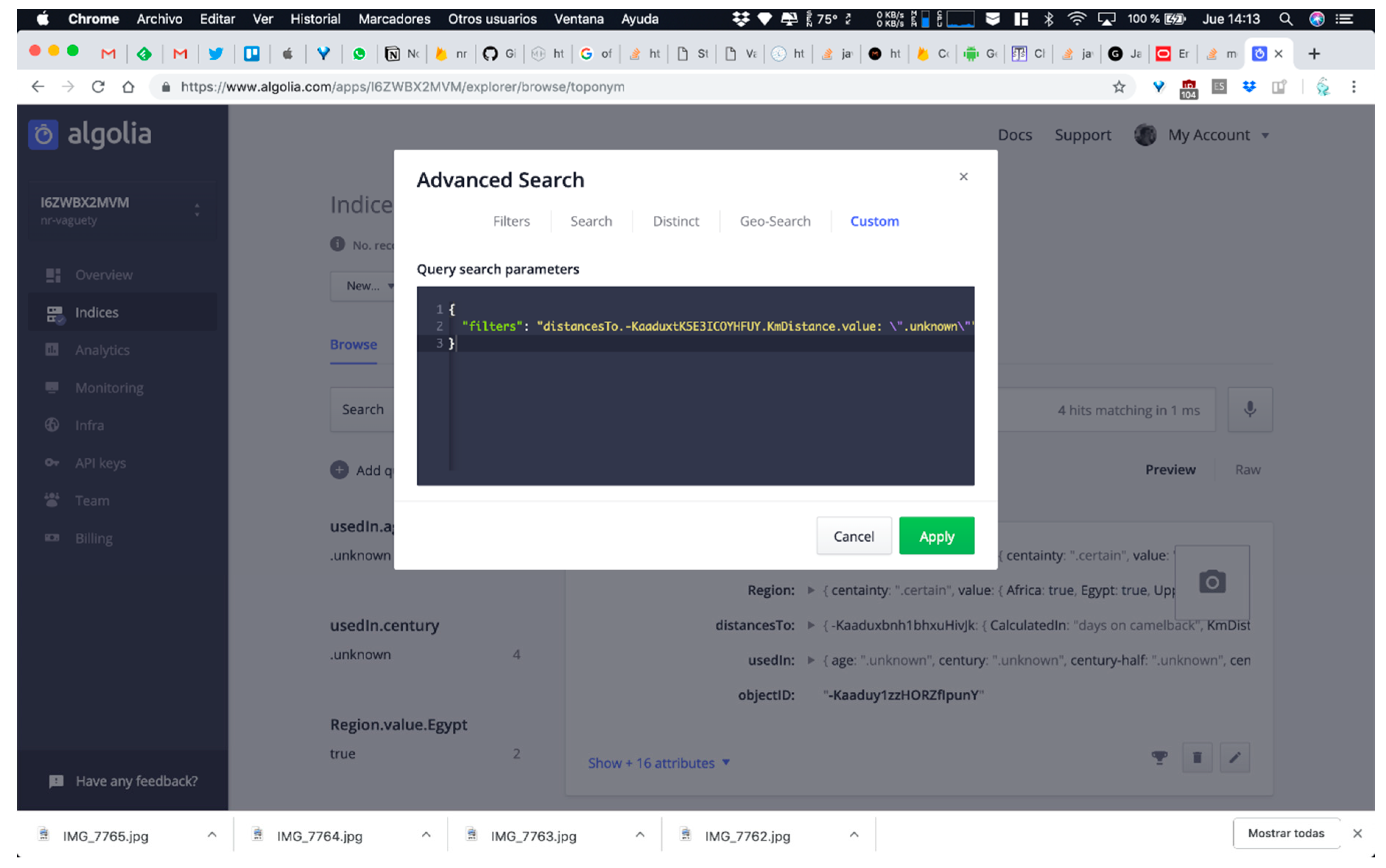
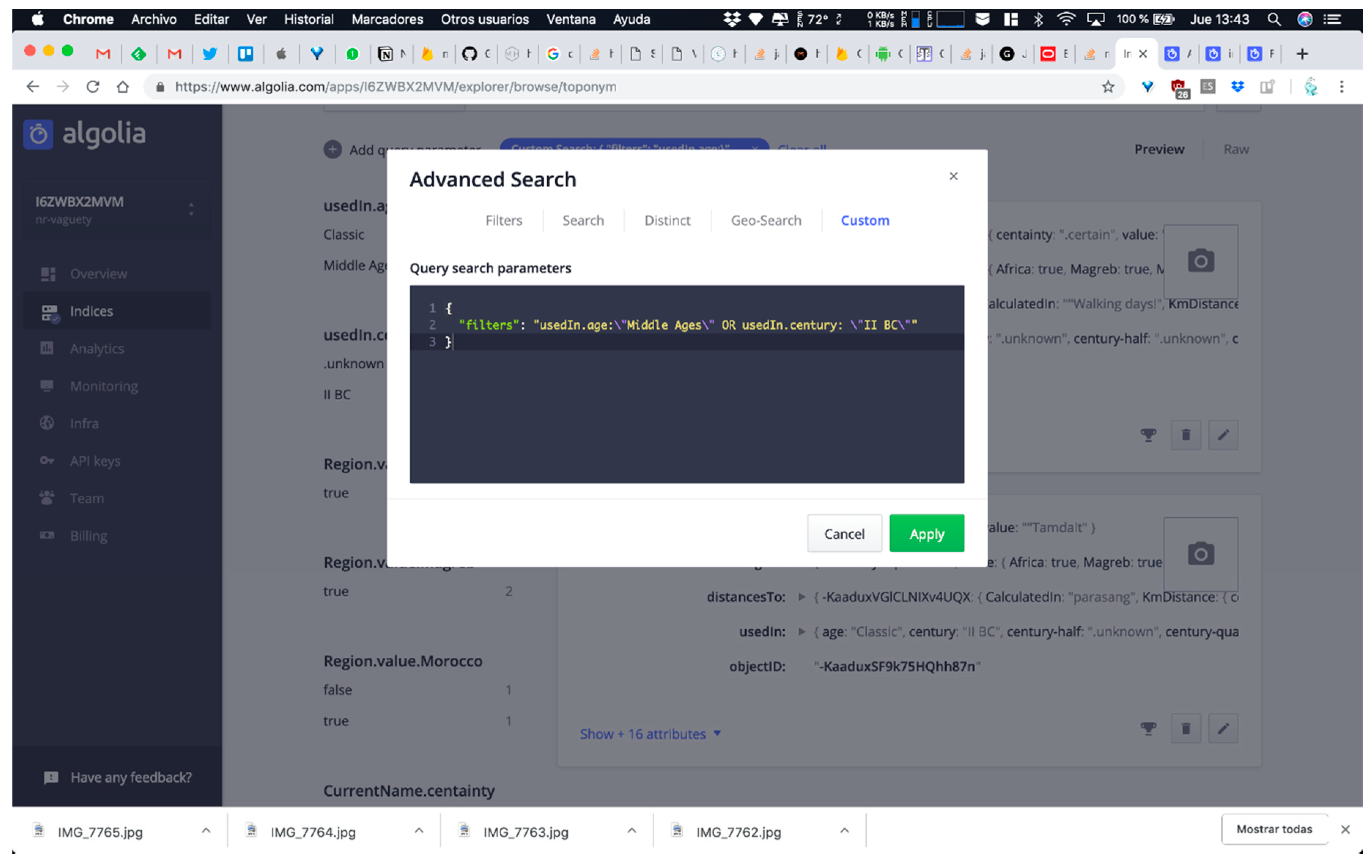
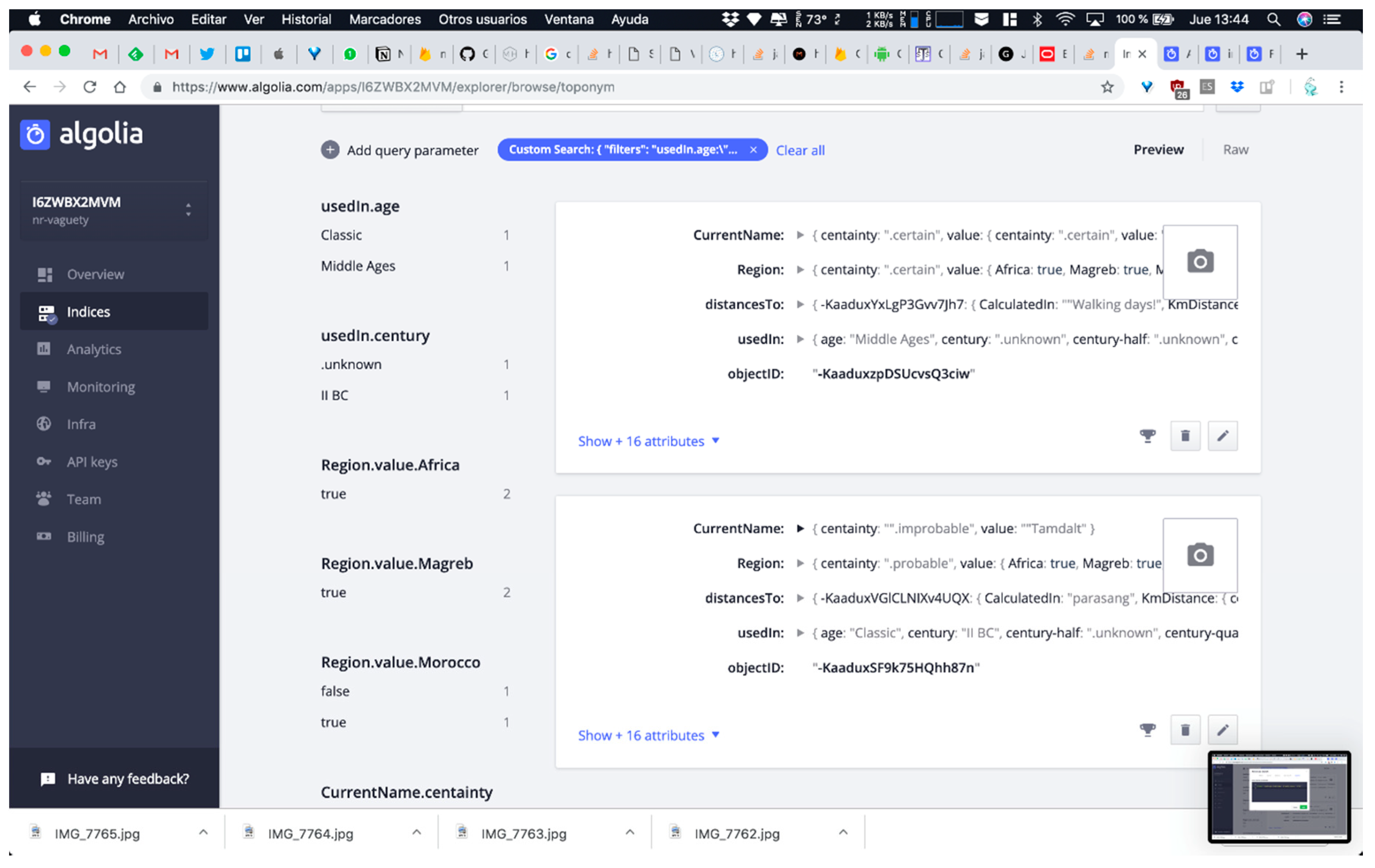
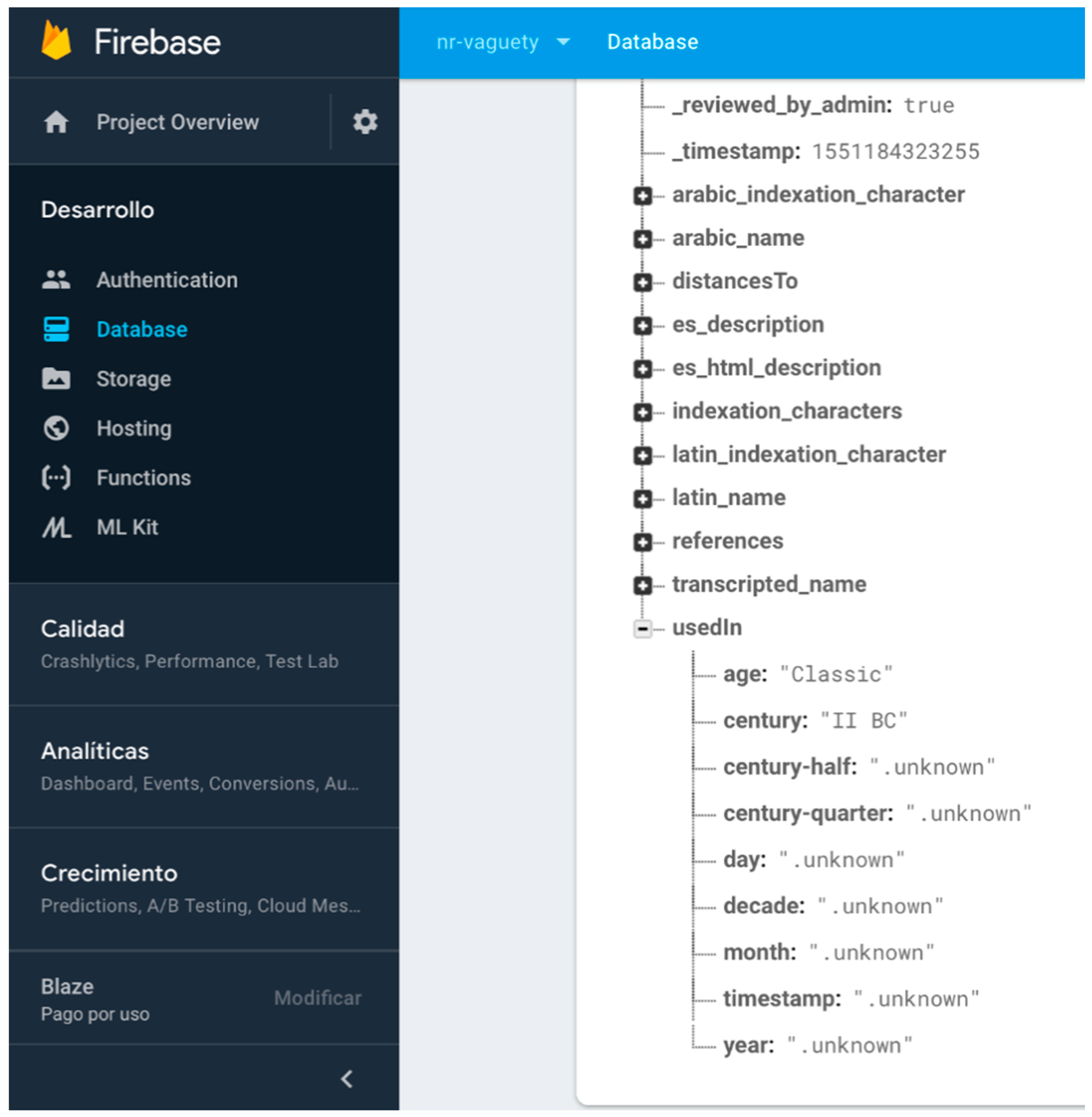
- Arbitrary time resolution. Most of the non-relational systems use the timestamp mechanism to represent temporal values (number of milliseconds after 1st January 1970). The need for representing previous dates at any granularity level in digital humanities makes timestamps use impossible for humanities information. There are some non-relational systems, such as MongoDB [48], that present specific data types for dates but with a very rigid format guided by ISO 8601 standards, which also presents other problems for humanities information, such as absence of support of Julian calendar or problems in data conversions between other date systems, such as Hegira (used in DICTOMAGRED project), Chinese calendar, etc. These limitations encouraged us to implement class library supporting the arbitrary resolution inherent to the time data type in ConML, which allows for some of the most usual forms of time representation, including simple and incomplete dates (and times), years, decades, and centuries. Now, we have implemented part of the functionalities of the class library in the non-relational environment for DICTOMAGRED. Similar to the certainty qualifiers implementation, we have defined a node in the non-relational structure with a hierarchical conceptualization of vagueness points in a timeline that we want to manage (years, decades, centuries, time eras, etc.). Then, we included a key-value structure referring to the specific point in time used for solved a given value. For instance, UsedIn = middle ages contains a key-value structure indicating that the value “middle ages” needs to be interpreted as the “Age” level of granularity in time. Figure 6 shows the non-relational node defined for the arbitrary time resolution, and its use in a specific toponym information description in DICTOMAGRED.
3.3. Query-Based Vagueness Resolution Results
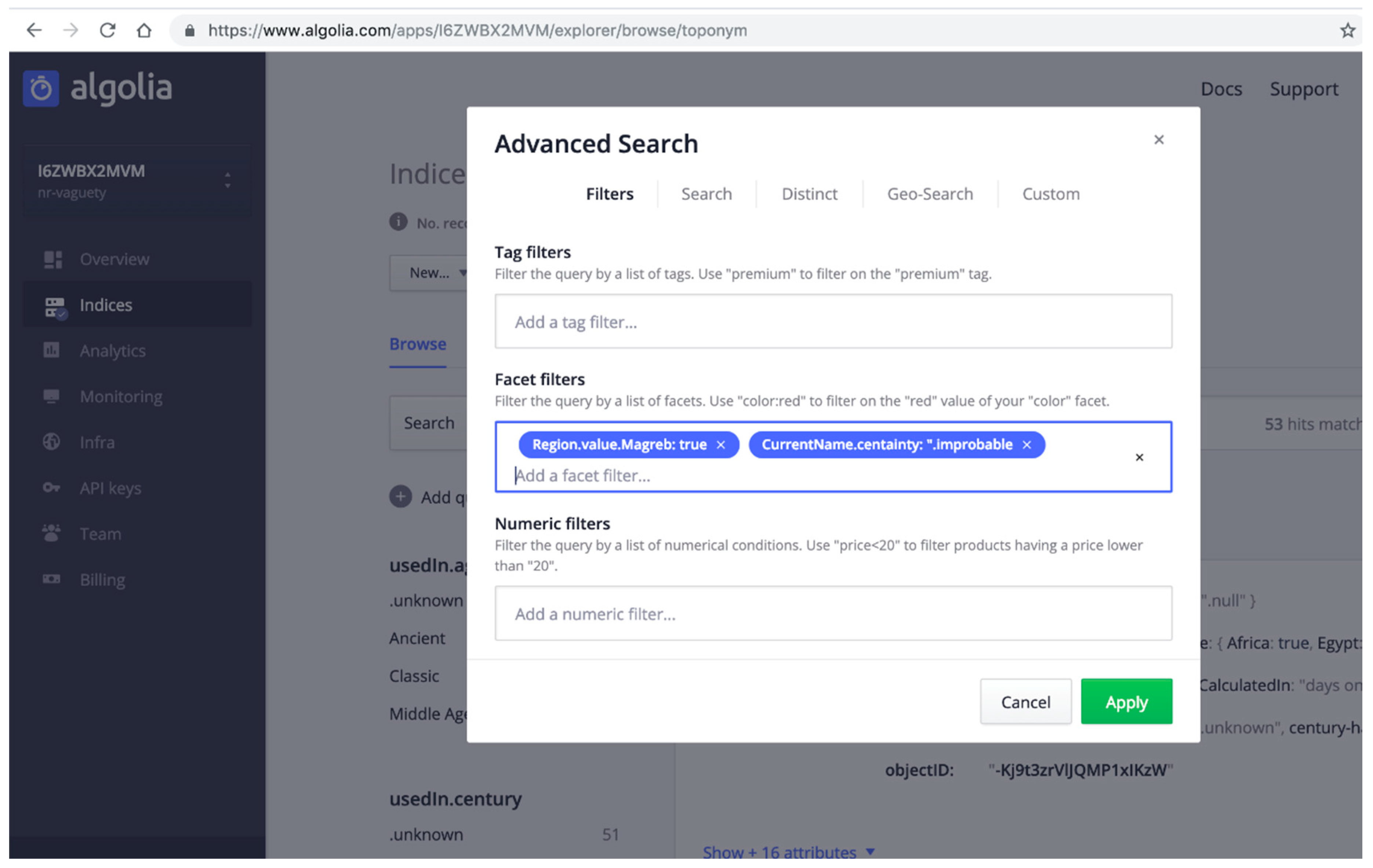
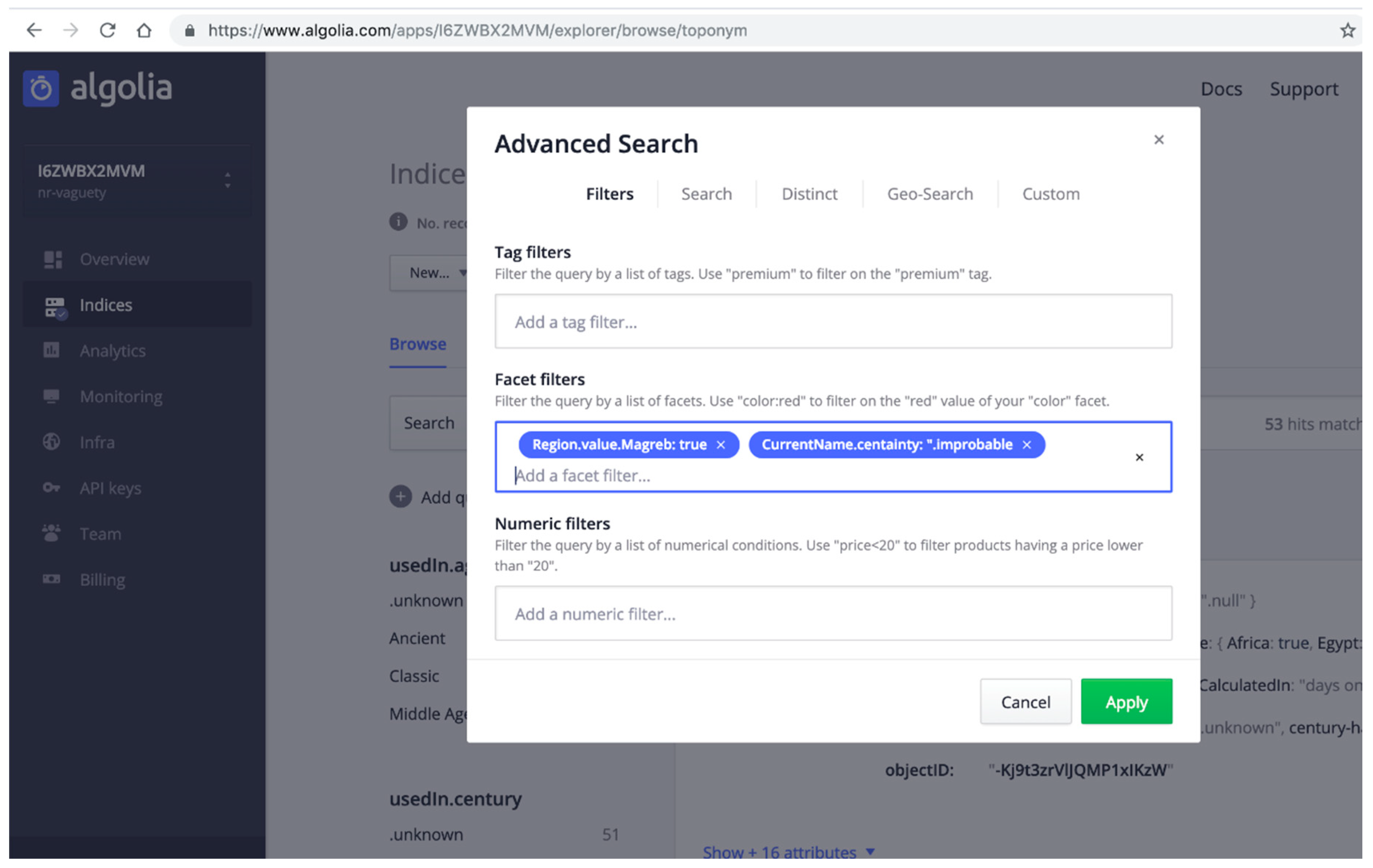
- QUERY A: Searching for all Dictomagred toponyms located in Maghreb region whose CurrentName is improbable. This means that the toponym is probably not in use regarding current maps of populations and cities. QUERY A involves tow vagueness mechanisms: abstract enumerated items to solve the hierarchical levels of the information about the regions attribute, and certainty qualifiers to evaluate what values of the current name present an improbable qualifier.
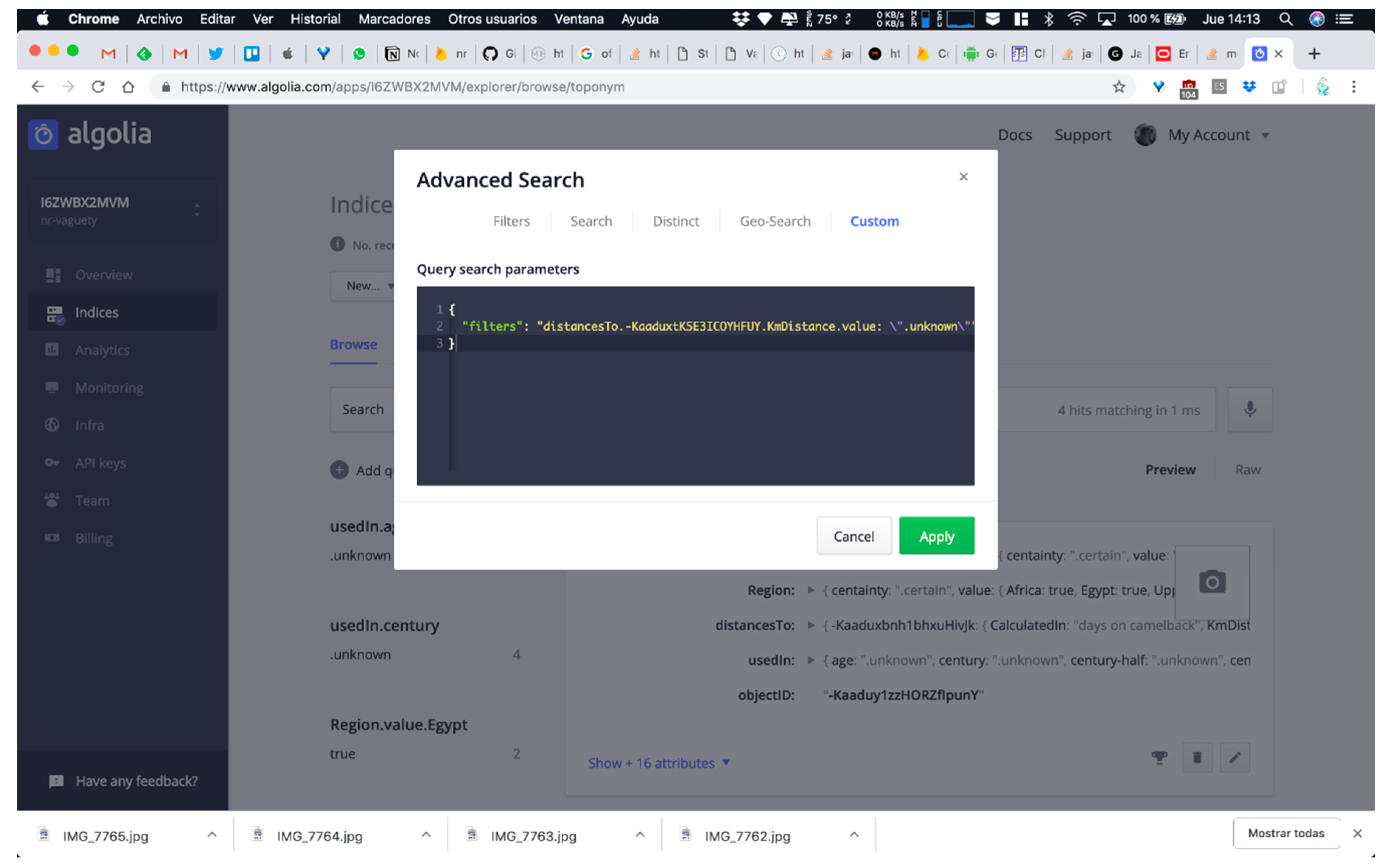
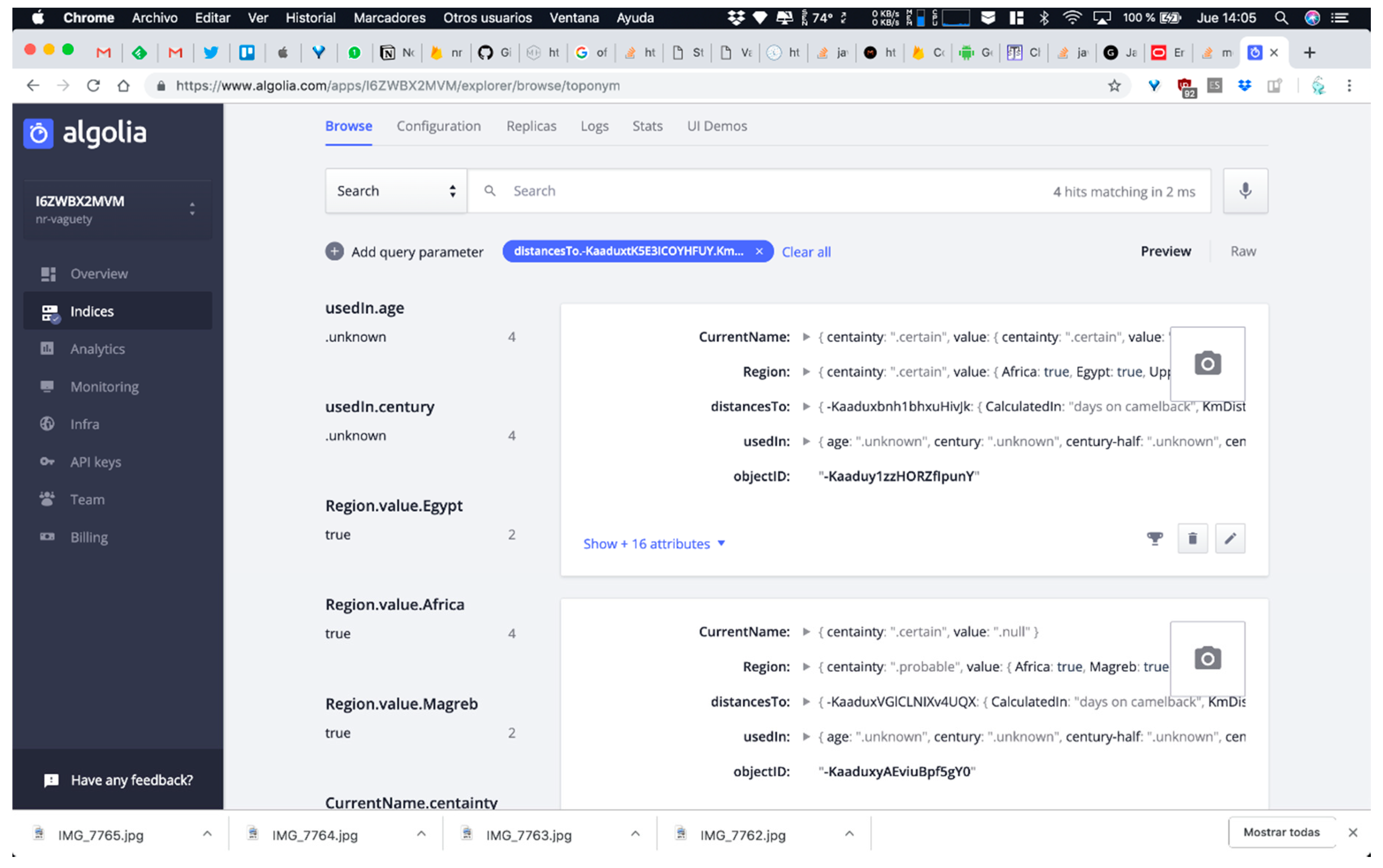
- QUERY B: Searching for all DICTOMAGRED toponyms whose distance from Sijilmasa is unknown. This means that the system evaluates the instances of ToponymDistance where KmDistance is unknown and shows the correspondence toponyms involved in these instances as origin or destinies. This query allows us to test the resolution of unknown references.
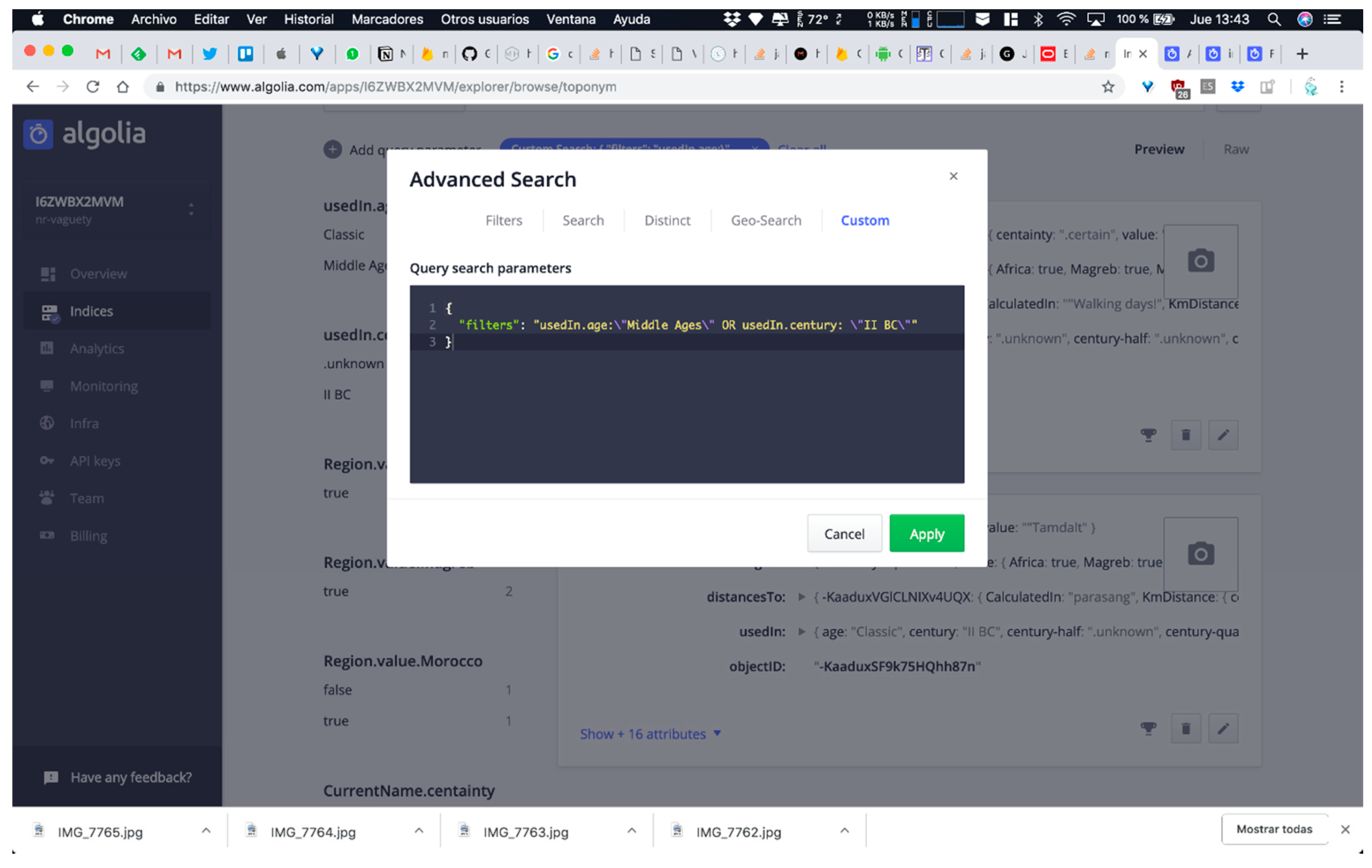
- QUERY C: Searching for all toponyms used in middle ages or in the second century B.C. This means that the software system has to query UsedIn attribute value at two levels of abstraction for solving the query employed arbitrary time resolution (note that both points in time present different levels of granularity and neither of them adjusts to classic timestamps of data formats employed in ISO 8601 standard or similar references).
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ackoff, R.L. From data to wisdom. J. Appl. Sys. Anal. 1988, 16, 3–9. [Google Scholar]
- Ciula, A.; Eide, Ø. Modelling in digital humanities: Signs in context. Digit. Scholarsh. Humanit. 2016, 32 (Suppl. 1), i33–i46. [Google Scholar] [CrossRef]
- Gonzalez-Perez, C. Information Modelling for Archaeology and Anthropology: Software Engineering Principles for Cultural Heritage; Springer International Publishing: Berlin, Germany, 2018. [Google Scholar] [CrossRef]
- Europeana. Europeana Project 2008–2015 [26/04/2016]. Available online: http://www.europeana.eu/ (accessed on 22 March 2019).
- ARIADNE. ARIADNE Project 2013. Available online: http://ariadne-infrastructure.eu/ (accessed on 22 March 2019).
- DARIAH-EU. Digital Research Infrastructure for the Arts and Humanities (DARIAH) 2007–2015 [26/04/2016]. Available online: https://dariah.eu/ (accessed on 22 March 2019).
- Incipit. ConML Technical Specification. ConML 1.4.4 2015. Available online: http://www.conml.org/Resources_TechSpec.aspx (accessed on 22 March 2019).
- Flanders, J.; Jannidis, F. Data modeling. In A New Companion to Digital Humanities; Schreibman, S., Siemens, R., Unsworth, J., Eds.; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Flanders, J.; Jannidis, F. Knowledge Organization and Data Modeling in the Humanities. Available online: https://www.wwp.northeastern.edu/outreach/conference/kodm2012/flanders_jannidis_datamodeling.pdf (accessed on 22 March 2019).
- Hedges, M. Grid-enabling humanities datasets. Digit. Humanit. Q. 2009, 3, 4. [Google Scholar]
- Linked Data. Available online: http://linkeddata.org/ (accessed on 22 March 2019).
- Chen, P.P.-S. The entity-relationship model: Toward a unified view of data. In Readings in Artificial Intelligence and Databases; Elsevier: Amsterdam, The Netherlands, 1988; pp. 98–111. [Google Scholar]
- W3C. RDF Schema 1.1. W3C Recommendation 25 February 2014. Available online: https://www.w3.org/TR/rdf-schema/ (accessed on 22 March 2019).
- Hunter, A.; Liu, W. Representing and Merging Uncertain Information in XML: A Short Survey. Available online: http://www0.cs.ucl.ac.uk/staff/A.Hunter/papers/saj.pdf (accessed on 22 March 2019).
- Consortium, T. Text Enconding Initiative (TEI) 2016. Available online: http://www.tei-c.org/index.xml (accessed on 22 March 2019).
- Isaksen, L.; Simon, R.; Barker, E.T.E.; de Soto Cañamares, P. Pelagios and the emerging graph of ancient world data. In Proceedings of the 2014 ACM conference on Web science, Bloomington, IN, USA, 23–26 June 2014; pp. 197–201. [Google Scholar]
- Commons, P. Pelagios Commons WebSite (Pelagios 6 Project). Available online: http://commons.pelagios.org/ (accessed on 22 March 2019).
- Gonzalez-Perez, C.; Martín-Rodilla, P. Teaching Conceptual Modelling in Humanities and Social Sciences. Digit. Humanit. Mag. 2017, 1, 408–416. [Google Scholar]
- Chirico, R.D.; Frenkel, M.; Diky, V.V.; Marsh, K.N.; Wilhoit, R.C. ThermoML—An XML-Based Approach for Storage and Exchange of Experimental and Critically Evaluated Thermophysical and Thermochemical Property Data. 2. Uncertainties. J. Chem. Eng. Data 2003, 48, 1344–1359. [Google Scholar] [CrossRef]
- ISO. ISO 21127:2006 Information and Documentation—A Reference Ontology for the Interchange of Cultural Heritage Information 2006. Available online: https://www.iso.org/standard/34424.html (accessed on 22 March 2019).
- De Runz, C.; Desjardin, E.; Piantoni, F.; Herbin, M. Using Fuzzy Logic to Manage Uncertain Multi-modal Data in an Archaeological GIS. Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.108.7063 (accessed on 22 March 2019).
- Tolle, K.; Wigg-Wolf, D. Uncertainty … ? ECFN Meeting 2014—Basel Goethe University 2014. Available online: http://ecfn.fundmuenzen.eu/images/Tolle_Wigg-Wolf_Uncertainty.pdf (accessed on 6 May 2019).
- Christensen-Dalsgaard, B.; Castelli, D.; Jurik, B.A.; Lippincott, J. Research and Advanced Technology for Digital Libraries. In Proceedings of the 12th European Conference, ECDL 2008, Aarhus, Denmark, 14–19 September 2008. [Google Scholar]
- Van Ruymbeke, M.; Hallot, P.; Billen, R. Enhancing CIDOC-CRM and compatible models with the concept of multiple interpretation. Remote Sens. Spat. Inf. Sci. 2017, 4, 287. [Google Scholar] [CrossRef]
- Ore, C.-E.; Eide, Ø. TEI and cultural heritage ontologies: Exchange of information? Lit. Linguist. Comput. 2009, 24, 161–172. [Google Scholar] [CrossRef]
- PROVIDEDH. PROgressive VIsual DEcision-Making in Digital Humanities (PROVIDEDH) Project 2019. Available online: https://providedh.eu (accessed on 22 March 2019).
- ISO/IEC. Information Technology—Object Management Group Unified Modeling Language (OMG UML) Part 1: Infrastructure. ISO/IEC 19505-1:2012. Available online: https://www.iso.org/standard/32624.html (accessed on 22 March 2019).
- Malta, M.C.; González-Blanco, E.; Cantón, C.M.; Del Rio, G. A Common Conceptual Model for the Study of Poetry in the Digital Humanities. Available online: https://dh2017.adho.org/abstracts/148/148.pdf (accessed on 22 March 2019).
- Lacerda, M.J.; Crespo, L.G. Interval predictor models for data with measurement uncertainty. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017. [Google Scholar]
- Zadeh, L.A. Fuzzy logic = computing with words. IEEE Trans. Fuzzy Syst. 1996, 4, 103–111. [Google Scholar] [CrossRef]
- Zadeh, L.A. A Summary and Update of “Fuzzy Logic”. In Proceedings of the 2010 IEEE International Conference on Granular Computing, San Jose, CA, USA, 14–16 August 2010. [Google Scholar]
- Bouchon-Meunier, B. Strengths of Fuzzy Techniques in Data Science. Available online: https://hal.sorbonne-universite.fr/hal-01676195/document (accessed on 22 March 2019).
- Zhou, H.; Wang, J.-Q.; Zhang, H.-Y. Multi-criteria decision-making approaches based on distance measures for linguistic hesitant fuzzy sets. J. Oper. Res. Soc. 2018, 69, 661–675. [Google Scholar] [CrossRef]
- Faizi, S.; Rashid, T.; Sałabun, W.; Zafar, S.; Wątróbski, J. Decision making with uncertainty using hesitant fuzzy sets. Int. J. Fuzzy Sys. 2018, 20, 93–103. [Google Scholar] [CrossRef]
- OMG. Project Portal for OMG® Uncertainty Modeling (UM) 2017. Available online: http://www.omgwiki.org/uncertainty/doku.php?id=Home (accessed on 22 March 2019).
- Yue, T.; Ali, S.; Selic, B. Standardizing Uncertainty Modeling at OMG. Available online: http://www.cister.isep.ipp.pt/ae2016/presentations/utest2.pdf (accessed on 22 March 2019).
- Xiao, J.; Pinel, P.; Pi, L.; Aranega, V.; Baron, C. Modeling uncertain and imprecise information in process modeling with UML. In Proceedings of the Fourteenth International Conference on Management of Data (COMAD), Mumbai, India, 17–19 December 2008. [Google Scholar]
- Jackson, C.H.; Bojke, L.; Thompson, S.G.; Claxton, K.; Sharples, L.D. A framework for addressing structural uncertainty in decision models. Med. Decis. Mak. 2011, 31, 662–674. [Google Scholar] [CrossRef] [PubMed]
- Ottomanelli, M.; Wong, C.K. Modelling uncertainty in traffic and transportation systems. Transportmetrica 2011, 7, 1–3. [Google Scholar] [CrossRef]
- Sarma, A.D.; Benjelloun, O.; Halevy, A.; Nabar, S.; Widom, J. Representing uncertain data: Models, properties, and algorithms. VLDB 2009, 18, 989–1019. [Google Scholar] [CrossRef]
- Martín-Rodilla, P.; Gonzalez-Perez, C. Assessing the learning curve in archaeological information modelling: Educational experiences with the Mind Maps and Object-Oriented paradigms. In Proceedings of the 45th Computer Applications and Quantitative Methods in Archaeology (CAA 2017), Atlanta, GA, USA, 13–16 March 2017. [Google Scholar]
- IEMYR. Instituto de Estudios Medievales y Renacentistas y de Humanidades Digitales IEMYRhd 2018. Available online: http://iemyr.usal.es/ (accessed on 22 March 2019).
- Dictomagred. DICTOMAGRED: Diccionario de Toponimia Magrebí 2018. Available online: https://dictomagred.usal.es/ (accessed on 22 March 2019).
- Rodríguez, M.A.M. Paisajes, espacios y objetos de devoción en el Islam. Available online: https://dialnet.unirioja.es/servlet/libro?codigo=708334 (accessed on 22 March 2019).
- Sharp, J.; McMurtry, D.; Oakley, A.; Subramanian, M.; Zhang, H. Data Access for Highly-Scalable Solutions: Using SQL, NoSQL, and Polyglot Persistence; Microsoft Patterns & Practices: Redmond, DC, USA, 2013. [Google Scholar]
- De Freitas, M.C.; Souza, D.Y.; Salgado, A.C. Conceptual Mappings to Convert Relational into NoSQL Databases. In Proceedings of the 18th International Conference on Enterprise Information Systems, Rome, Italy, 25–28 April 2016. [Google Scholar]
- What are NoSQL Databases? Available online: https://aws.amazon.com/nosql/ (accessed on 22 March 2019).
- MongoDB. Available online: https://www mongodb com/ (accessed on 22 March 2019).
- Inc. G. Firebase 2019 [01/03/2019]. Available online: https://firebase.google.com/ (accessed on 22 March 2019).
- Abramova, V.; Bernardino, J. NoSQL databases: MongoDB vs cassandra. In Proceedings of the International C* Conference on Computer Science and Software Engineering, Porto, Portugal, 10–12 July 2013. [Google Scholar]
- Algolia. Algolia Website 2019. Available online: https://www.algolia.com/ (accessed on 22 March 2019).
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martin-Rodilla, P.; Gonzalez-Perez, C. Conceptualization and Non-Relational Implementation of Ontological and Epistemic Vagueness of Information in Digital Humanities. Informatics 2019, 6, 20. https://doi.org/10.3390/informatics6020020
Martin-Rodilla P, Gonzalez-Perez C. Conceptualization and Non-Relational Implementation of Ontological and Epistemic Vagueness of Information in Digital Humanities. Informatics. 2019; 6(2):20. https://doi.org/10.3390/informatics6020020
Chicago/Turabian StyleMartin-Rodilla, Patricia, and Cesar Gonzalez-Perez. 2019. "Conceptualization and Non-Relational Implementation of Ontological and Epistemic Vagueness of Information in Digital Humanities" Informatics 6, no. 2: 20. https://doi.org/10.3390/informatics6020020
APA StyleMartin-Rodilla, P., & Gonzalez-Perez, C. (2019). Conceptualization and Non-Relational Implementation of Ontological and Epistemic Vagueness of Information in Digital Humanities. Informatics, 6(2), 20. https://doi.org/10.3390/informatics6020020