Exploiting Past Users’ Interests and Predictions in an Active Learning Method for Dealing with Cold Start in Recommender Systems †



Abstract
:1. Introduction
- Passive collaborative filtering techniques learn from sporadic users’ ratings; hence learning new users preferences is slow [5]. Other techniques propose correlations between users and/or items by using the users/items attributes [6], such as content-based [7] and hybrid methods [8]. However, dealing with such features slows down the process and adds complexity and domain dependency.
- Active techniques interact with the new users in order to retrieve a small set of ratings that allows to learn the users’ preferences. A naive but extended approach is to question users about their interests and get their answers [9]. Such questions may include: ‘Do you like this movie?’, with possible answers such as: ‘Yes, I do’; ‘No, I do not’; ‘I have not seen it’. In fact, this process can be applied for cold-users in a sign-up process (a.k.a. Standard Interaction Model) or for warm-users (a.k.a. Conversational and Collaborative Model) where users can provided new preferences to the system; hence the system can better learn all users preferences [1].
2. Related Work in Active Learning
2.1. Personalization of Questionnaires and Strategies in Active Learning
- Popularity, Variance and Coverage. Most popular items tend to have higher number of ratings, and thus they are more recognized. Popularity-based questionnaires increase the “ratability” [15] of candidate items in order to obtain a larger number of feedbacks, although very particular interests of new user preferences, out of popular items, are not captured. In addition, items with low rating variances are less informative. Thus, variance-based questionnaires show the uncertainty of the system about the prediction of an item [16]. In addition, the item’s coverage (i.e., number of users related to this item) can lead to creating interesting ratings’ correlation patterns between users.
- Entropy. This strategy uses information theories, such as the Shannon’s Theory [17], to measure the dispersion of items ratings and hence to evaluate items informativeness. This technique tends to select rarely known items. In addition, entropy and popularity are correlated, and they are very influenced by the users’ ratability (capacity of users to know/rate the proposed items) [9].
- Optimization. The system selects the items from those new feedbacks that may improve the prediction error rate, such as MAE or RMSE. Indeed, this is a very important aspect in recommender systems since error reduction is directly related to users’ satisfaction [1]. Other strategies may focus on the influence of queried item evaluations (influence based [18]), the user partitioning generated by these evaluations (user clustering [19], decision trees [20]) or simply analyze the impact of the given rating for future predictions (impact analysis [21]).
2.2. Active Learning for Collaborative Filtering
3. Background and Notation
4. Active Learning Decision Trees
4.1. Decision Trees in Small Datasets
4.2. Warm-Users Predictions in Decision Trees
4.3. The Decision Trees Algorithms
4.3.1. Non Supervised Decision Trees for Active Learning
| Algorithm 1 Non-supervised decision tree algorithm | |
| 1: | functionBuildDecisionTree(, , currentTreeLevel) |
| 2: | for rating in do |
| 3: | accumulate statistics for i in node t using |
| 4: | end for |
| 5: | for candidate item j in do |
| 6: | for in do |
| 7: | obtain |
| 8: | split into 3 child nodes based on j |
| 9: | find the child node where u has moved into |
| 10: | for rating in do |
| 11: | accumulate statistics for i in node using |
| 12: | end for |
| 13: | end for |
| 14: | derive statistics for j in node from the and statistics |
| 15: | candidate error: = + + |
| 16: | end for |
| 17: | discriminative item = |
| 18: | compute by using item prediction average |
| 19: | if currentTreeLevel < maxTreeLevel then |
| 20: | create 3 child nodes based on ratings |
| 21: | for child in child nodes do |
| 22: | exclude from |
| 23: | BuildDecisionTree(, , currentTreeLevel +1) |
| 24: | end for |
| 25: | end if |
| 26: | return |
| 27: | end function |
4.3.2. Supervised Decision Trees for Active Learning
| Algorithm 2 Supervised decision tree algorithm | |
| 1: | functionBuildDecisionTree(, , , , currentTreeLevel) |
| 2: | for user u∈ do |
| 3: | compute on and |
| 4: | end for |
| 5: | for candidate item j from do |
| 6: | split into 3 child nodes based on j |
| 7: | for user u∈ do |
| 8: | find the child node where u has moved into |
| 9: | compute on and |
| 10: | |
| 11: | end for |
| 12: | end for |
| 13: | aggregate all |
| 14: | discriminative item = |
| 15: | compute by using item prediction average |
| 16: | if currentTreeLevel < maxTreeLevel and then |
| 17: | create 3 child nodes based on based on ratings |
| 18: | for child in child nodes do |
| 19: | exclude from |
| 20: | BuildDecisionTree(, , , , currentTreeLevel+1) |
| 21: | end for |
| 22: | end if |
| 23: | return |
| 24: | end function |
4.4. Complexity of the Algorithm and Time Analysis
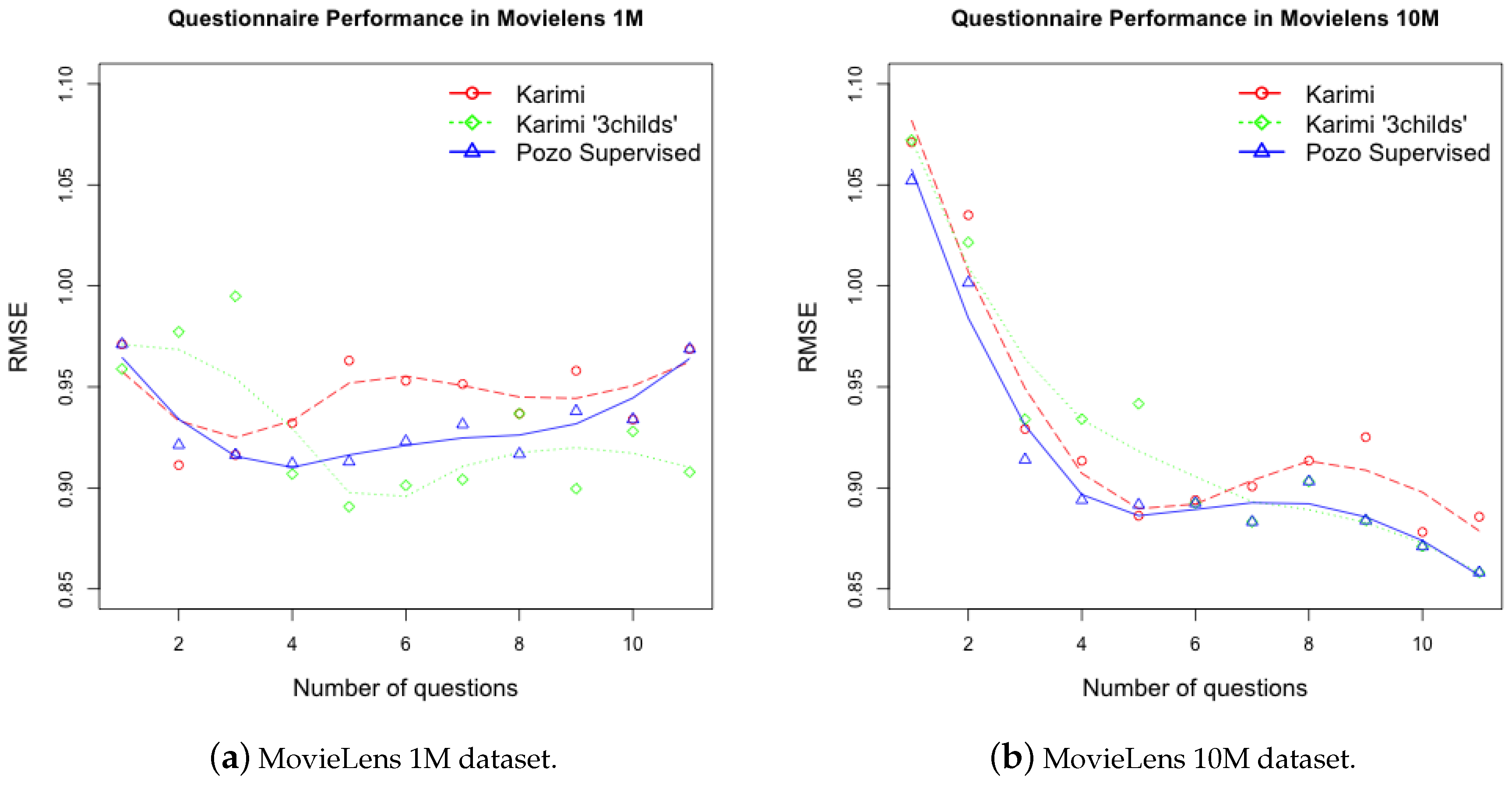
5. Experimentation
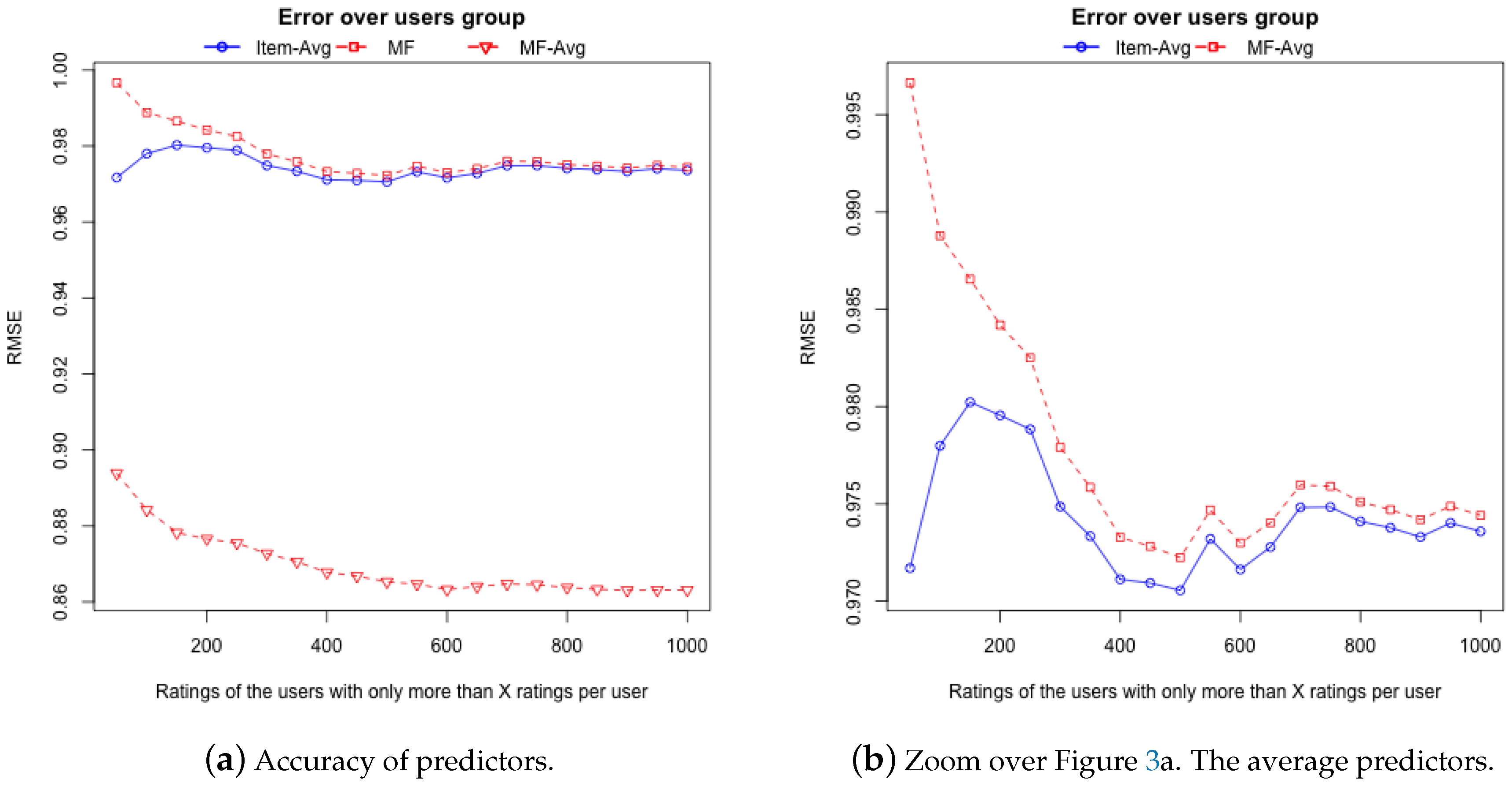
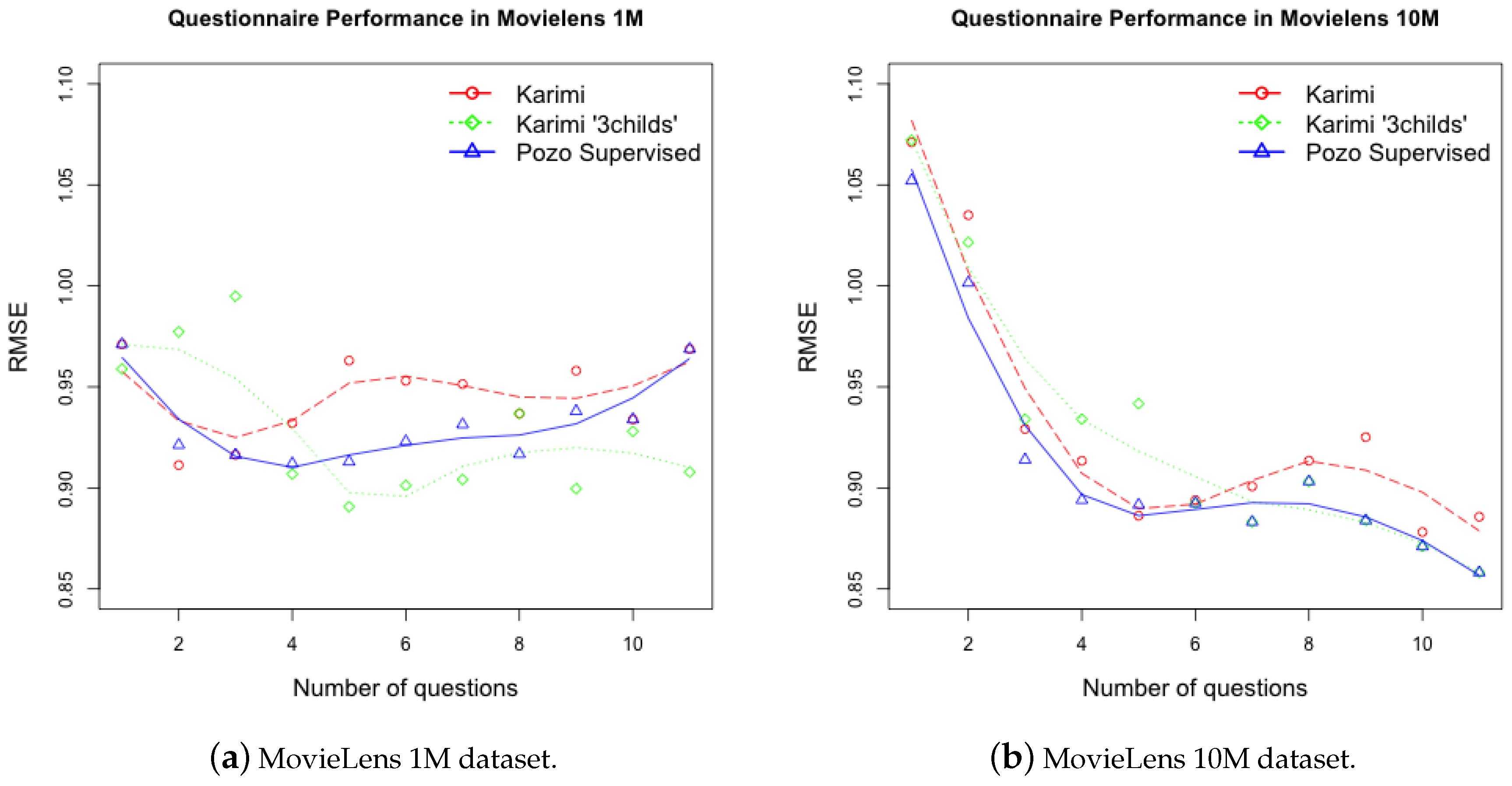
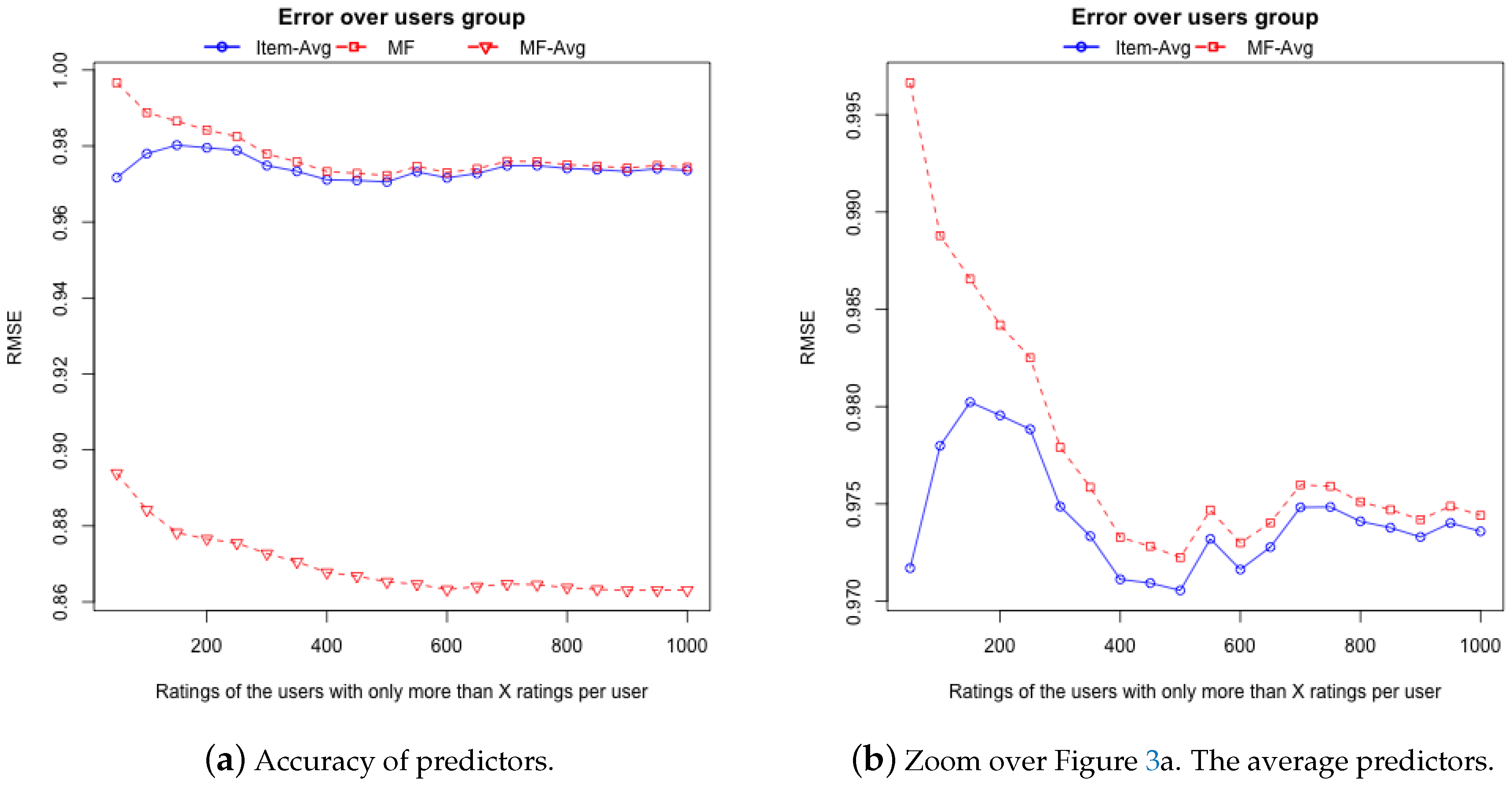
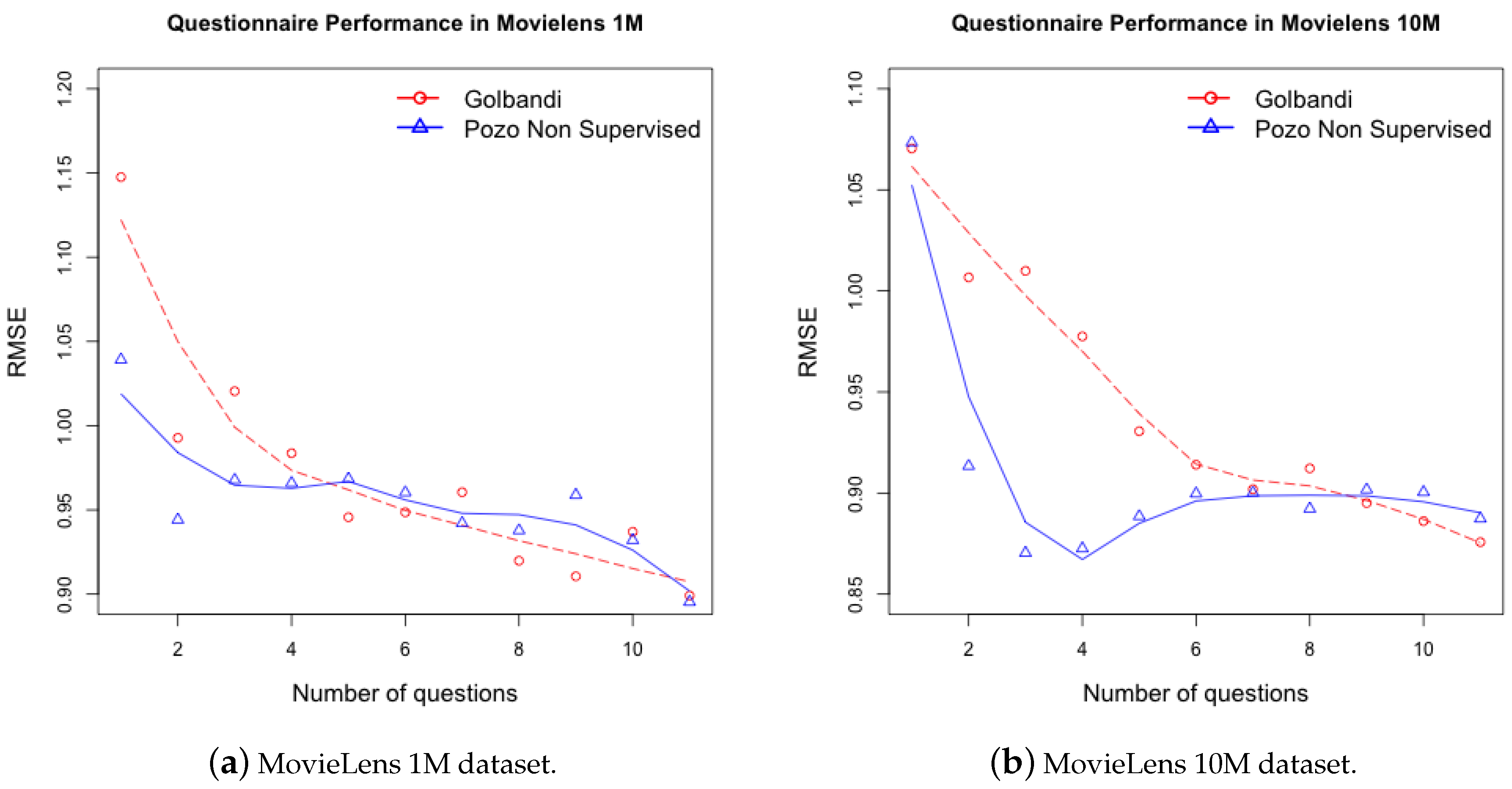
5.1. Non Supervised Decision Trees
5.2. Supervised Decision Trees
5.3. Time Analysis
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Rubens, N.; Elahi, M.; Sugiyama, M.; Kaplan, D. Active learning in recommender systems. In Recommender Systems Handbook; Springer: Berlin, Germany, 2015; pp. 809–846. [Google Scholar]
- Elahi, M.; Ricci, F.; Rubens, N. Active Learning in Collaborative Filtering Recommender Systems. In E-Commerce and Web Technologies; Springer: Berlin, Germany, 2014; pp. 113–124. [Google Scholar]
- Su, X.; Khoshgoftaar, T.M. A survey of collaborative filtering techniques. Adv. Artif. Intell. 2009, 2009, 421425. [Google Scholar] [CrossRef]
- Golbandi, N.; Koren, Y.; Lempel, R. Adaptive bootstrapping of recommender systems using decision trees. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 595–604. [Google Scholar]
- Karimi, R.; Freudenthaler, C.; Nanopoulos, A.; Schmidt-Thieme, L. Comparing prediction models for active learning in recommender systems. In Proceedings of the LWA 2015 Workshops: KDML, FGWM, IR, and FGDB, Trier, Germany, 7–9 October 2015. [Google Scholar]
- Kantor, P.B.; Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems Handbook; Springer: Berlin, Germany, 2011; p. 848. [Google Scholar]
- Peis, E.; del Castillo, J.M.; Delgado-López, J. Semantic recommender systems. Analysis of the state of the topic. Hipertext. Net 2008, 6, 1–5. [Google Scholar]
- Karim, J. Hybrid system for personalized recommendations. In Proceedings of the International Conference on Research Challenges in Information Science (RCIS), Marrakesh, Morocco, 28–30 May 2014; pp. 1–6. [Google Scholar]
- Rashid, A.M.; Albert, I.; Cosley, D.; Lam, S.K.; McNee, S.M.; Konstan, J.A.; Riedl, J. Getting to know you: Learning new user preferences in recommender systems. In Proceedings of the 7th International Conference on Intelligent User Interfaces, San Francisco, CA, USA, 13–16 January 2002; pp. 127–134. [Google Scholar]
- Pilászy, I.; Tikk, D. Recommending new movies: even a few ratings are more valuable than metadata. In Proceedings of the Third ACM Conference on Recommender Systems, New York, NY, USA, 22–25 October 2009; pp. 93–100. [Google Scholar]
- Harpale, A.S.; Yang, Y. Personalized active learning for collaborative filtering. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 20–24 July 2008; pp. 91–98. [Google Scholar]
- Chaaya, G.; Metais, E.; Abdo, J.B.; Chiky, R.; Demerjian, J.; Barbar, K. Evaluating Non-personalized Single-Heuristic Active Learning Strategies for Collaborative Filtering Recommender Systems. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 593–600. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, S.H.; Zha, H. Functional matrix factorizations for cold-start recommendation. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 25–29 July 2011; pp. 315–324. [Google Scholar]
- Karimi, R.; Freudenthaler, C.; Nanopoulos, A.; Schmidt-Thieme, L. Active learning for aspect model in recommender systems. In Proceedings of the Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; pp. 162–167. [Google Scholar]
- Carenini, G.; Smith, J.; Poole, D. Towards more conversational and collaborative recommender systems. In Proceedings of the 8th International Conference on Intelligent User Interfaces, Miami Beach, FL, USA, 12–15 January 2003; pp. 12–18. [Google Scholar]
- Boutilier, C.; Zemel, R.S.; Marlin, B. Active collaborative filtering. In Proceedings of the Nineteenth Conference on Uncertainty in Artificial Intelligence, Acapulco, Mexico, 7–11 August 2003; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2002; pp. 98–106. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. ACM Sigm. Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Rubens, N.; Sugiyama, M. Influence-based collaborative active learning. In Proceedings of the 2007 ACM Conference on Recommender Systems, Minneapolis, MN, USA, 19–20 October 2007; pp. 145–148. [Google Scholar]
- Rashid, A.M.; Karypis, G.; Riedl, J. Learning preferences of new users in recommender systems: An information theoretic approach. ACM Sigk. Explor. Newslett. 2008, 10, 90–100. [Google Scholar] [CrossRef]
- Golbandi, N.; Koren, Y.; Lempel, R. On bootstrapping recommender systems. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, Canada, 26–30 October 2010; pp. 1805–1808. [Google Scholar]
- Mello, C.E.; Aufaure, M.A.; Zimbrao, G. Active learning driven by rating impact analysis. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 341–344. [Google Scholar]
- Karimi, R.; Freudenthaler, C.; Nanopoulos, A.; Schmidt-Thieme, L. Non-myopic active learning for recommender systems based on matrix factorization. In Proceedings of the Conference on Information Reuse and Integration (IRI), San Diego, CA, USA, 4–6 August 2017; pp. 299–303. [Google Scholar]
- Karimi, R.; Freudenthaler, C.; Nanopoulos, A.; Schmidt-Thieme, L. Towards optimal active learning for matrix factorization in recommender systems. In Proceedings of the 2011 23rd IEEE International Conference on Tools with Artificial Intelligence (ICTAI), Boca Raton, FL, USA, 7–9 November 2011; pp. 1069–1076. [Google Scholar]
- Karimi, R.; Freudenthaler, C.; Nanopoulos, A.; Schmidt-Thieme, L. Exploiting the characteristics of matrix factorization for active learning in recommender systems. In Proceedings of the Sixth ACM Conference on Recommender Systems, Dublin, Ireland, 9–13 September 2012; pp. 317–320. [Google Scholar]
- Karimi, R. Active learning for recommender systems. KI Künstliche Intell. 2014, 28, 329–332. [Google Scholar] [CrossRef]
- Kohrs, A.; Merialdo, B. Improving collaborative filtering for new users by smart object selection. In Proceedings of the International Conference on Media Features (ICMF), Florence, Italy, 8–9 May 2001. [Google Scholar]
- Jin, R.; Si, L. A bayesian approach toward active learning for collaborative filtering. In Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, Arlington, WV, USA, 7–11 July 2004; pp. 278–285. [Google Scholar]
- Rendle, S.; Schmidt-Thieme, L. Online-updating regularized kernel matrix factorization models for large-scale recommender systems. In Proceedings of the 2008 ACM Conference on Recommender Systems, Pittsburgh, PA, USA, 19–21 June 2008; pp. 251–258. [Google Scholar]
- Karimi, R.; Wistuba, M.; Nanopoulos, A.; Schmidt-Thieme, L. Factorized decision trees for active learning in recommender systems. In Proceedings of the 2013 IEEE 25th International Conference on Tools with Artificial Intelligence (ICTAI), Limassol, Cyprus, 10–12 November 2014; pp. 404–411. [Google Scholar]
- Karimi, R.; Nanopoulos, A.; Schmidt-Thieme, L. A supervised active learning framework for recommender systems based on decision trees. User Model. User Adapt. Interact. 2015, 25, 39–64. [Google Scholar] [CrossRef]
- Narayanan, A.; Shmatikov, V. Robust de-anonymization of large sparse datasets. In Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 18–21 May 2008; pp. 111–125. [Google Scholar]
- Zhou, Y.; Wilkinson, D.; Schreiber, R.; Pan, R. Large-scale parallel collaborative filtering for the netflix prize. In Algorithmic Aspects in Information and Management; Springer: Berlin, Germany, 2008; pp. 337–348. [Google Scholar]
- Fahim, M.; Baker, T.; Khattak, A.M.; Alfandi, O. Alert me: Enhancing active lifestyle via observing sedentary behavior using mobile sensing systems. In Proceedings of the 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom), Dalian, China, 12–15 October 2017; pp. 1–4. [Google Scholar]
- Fahim, M.; Baker, T. Knowledge-Based Decision Support Systems for Personalized u-lifecare Big Data Services. In Current Trends on Knowledge-Based Systems; Alor-Hernández, G., Valencia-García, R., Eds.; Springer: Berlin, Germany, 2017; pp. 187–203. [Google Scholar]
- Lemire, D.; Maclachlan, A. Slope One Predictors for Online Rating-Based Collaborative Filtering. In Proceedings of the 2005 SIAM International Conference on Data Mining, Newport Beach, CA, USA, 21–23 April 2005; Volume 5, pp. 1–5. [Google Scholar]
- Koren, Y.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: Berlin, Germany, 2011; pp. 145–186. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| R | Set of ratings |
| P | Set of predictions |
| u | User |
| i | Item |
| Rating of user u in item i | |
| Predicted rating of user u in item i | |
| t | Current node of the tree |
| Set of ratings in node t | |
| Set of predictions in node t | |
| Set of users in node t | |
| Set of items in node t | |
| Set of user’s ratings in node t | |
| Set of item’s ratings in node t | |
| Set of user’s predictions in node t | |
| Set of item’s predictions in node t |
| Property | MovieLens 1M | MovieLens 10M | Netflix |
|---|---|---|---|
| Users | 6040 | 71,567 | 480,000 |
| Items | 3900 | 10,681 | 17,000 |
| Ratings | 1 million | 10 millions | 100 millions |
| Sparsity | 0.042% | 1.308% | 1.225% |
| Scale | Integer 1–5 | 1–5 by 0.5 | Integer 1–5 |
| Statistic | MovieLens 1M | MF1 | MovieLens 10M | MF2 |
|---|---|---|---|---|
| 1st Quartile | 3.00 | 3.18 | 3.00 | 3.13 |
| Median | 4.00 | 3.66 | 4.00 | 3.58 |
| Mean | 3.58 | 3.58 | 3.51 | 3.51 |
| 3rd Quartile | 4.00 | 4.05 | 4.00 | 3.96 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pozo, M.; Chiky, R.; Meziane, F.; Métais, E. Exploiting Past Users’ Interests and Predictions in an Active Learning Method for Dealing with Cold Start in Recommender Systems. Informatics 2018, 5, 35. https://doi.org/10.3390/informatics5030035
Pozo M, Chiky R, Meziane F, Métais E. Exploiting Past Users’ Interests and Predictions in an Active Learning Method for Dealing with Cold Start in Recommender Systems. Informatics. 2018; 5(3):35. https://doi.org/10.3390/informatics5030035
Chicago/Turabian StylePozo, Manuel, Raja Chiky, Farid Meziane, and Elisabeth Métais. 2018. "Exploiting Past Users’ Interests and Predictions in an Active Learning Method for Dealing with Cold Start in Recommender Systems" Informatics 5, no. 3: 35. https://doi.org/10.3390/informatics5030035
APA StylePozo, M., Chiky, R., Meziane, F., & Métais, E. (2018). Exploiting Past Users’ Interests and Predictions in an Active Learning Method for Dealing with Cold Start in Recommender Systems. Informatics, 5(3), 35. https://doi.org/10.3390/informatics5030035