Abstract
Large Language Models (LLMs) are increasingly proposed to personalize healthcare delivery, yet their real-world readiness remains uncertain. We conducted a systematic literature review to assess how LLM-based systems are designed and used to enhance patient engagement and personalization, while identifying open challenges these tools pose. Four digital libraries (Scopus, IEEE Xplore, ACM, and Nature) were searched, yielding 3787 studies; 16 met the inclusion criteria. Most studies, published in 2024, span different types of motivations, architectures, limitations and privacy-preserving approaches. While LLMs show potential in automating patient data collection, recommendation/therapy generation, and continuous conversational support, their clinical reliability is limited. Most evaluations use synthetic or retrospective data, with only a few employing user studies or scalable simulation environments. This review highlights the tension between innovation and clinical applicability, emphasizing the need for robust evaluation protocols and human-in-the-loop systems to guide the safe and equitable deployment of LLMs in healthcare.
1. Introduction
The paradigm of modern medicine is undergoing a profound transformation, moving beyond precision diagnosis to a new frontier: deeply personalized patient interactions [1,2,3]. This vision aims to create a healthcare experience not only tailored to an individual’s biology but also continuously adaptive to their context, behavior, personality, and expressed needs [4,5]. This shift is driven by the advent of Large Language Models (LLMs) [6,7], a class of AI systems uniquely capable of understanding, synthesizing, and engaging in natural language. Their potential to process complex multimodal data [8] and sustain personalized conversations opens new possibilities: from responsive therapeutic agents to empathetic, longitudinal support systems [7,9,10,11,12]. These capabilities promise a transition toward more collaborative, patient-centered models of care.
However, as the exploration of this new frontier grows, the landscape of research has become fragmented. Efforts to build LLM-driven personalized systems span diverse clinical contexts and technical strategies, making it difficult to discern a clear path forward [13,14,15,16]. Several gaps remain in the current body of research. There is limited understanding of the specific clinical and patient-centered needs driving the development of these models. Furthermore, the field is still exploring multiple architectural pathways and techniques, with no single approach yet emerging as a standard. The challenge of ensuring patient data privacy is still a major concern, and fundamental limitations continue to hinder the safe and effective integration of these tools into real-world clinical practice.
To address these unresolved issues, including the limited understanding of clinical and patient-centered needs, the diversity of emerging approaches, and the persistent challenges of privacy and real-world integration, we present a systematic literature review (SLR) on Large Language Models (LLMs) in Personalized Healthcare. Our goal is to map the current state of the field, identify prevailing trends, and highlight the methodological, ethical, and practical barriers that must be overcome. By analyzing motivations, architectural approaches such as Retrieval-Augmented Generation (RAG) and multi-agent frameworks, and developments in privacy-preserving techniques, this review directly responds to the gaps identified above. Ultimately, we expose the tension between rapid innovation and clinical reliability, underscoring the need for robust evaluation protocols and human-in-the-loop systems to guide safe and equitable deployment.
2. Literature Review
This systematic literature review was conducted following the PRISMA 2020 guidelines [17], which provide a standardized approach for ensuring transparency and completeness in reporting systematic reviews.
2.1. PICOC Criteria
To define the scope and boundaries for our literature review, we employed the PICOC framework proposed by Peterson et al. [18,19]. The specific components used in this study are summarized in Table 1.

Table 1.
PICOC components used to define the research scope.
By decomposing the research problem into core dimensions according to the PICOC framework—target population, intervention type, expected outcomes, and contextual boundaries—this study formulated six research questions that directly reflect the objectives of this review. These questions address a fundamental gap in digital health: the understanding of the applications and challenges of LLMs in healthcare. The aforementioned questions are as follows:
- RQ1: What are the main motivations for using LLMs in personalized healthcare systems focused on personalization?
- –
- This question addresses the lack of consolidated understanding about the specific clinical and patient-centered needs that drive the development of LLM-powered systems. By identifying motivations, the study clarifies whether current research aligns with real-world healthcare demands.
- RQ2: What LLM-based techniques and architectures are proposed for personalized healthcare systems?
- –
- This question responds to the landscape of technical strategies, where no clear standard has emerged. It allows us to map the architectural pathways under exploration and assess their suitability for healthcare personalization.
- RQ3: How are user characteristics and data incorporated into the personalized LLM frameworks?
- –
- Given the gap in integrating multimodal and contextual patient information, this question investigates how existing systems embed clinical records, conversational history, and sensor data into personalization pipelines.
- RQ4: How is the effectiveness of LLM-based healthcare systems evaluated?
- –
- As most evaluations rely on synthetic or retrospective data, this question aims to examine whether robust, clinically relevant evaluation frameworks are being employed.
- RQ5: What challenges and limitations are identified in the use of LLMs for personalization in healthcare?
- –
- This question is motivated by the uncertainty surrounding the reliability, fairness, and clinical safety of these systems. It explores recurring obstacles that hinder real-world deployment.
- RQ6: How are security, privacy, and trust aspects addressed in the use of LLMs for personalized healthcare with sensitive health data?
- –
- Because privacy remains a central barrier to adoption, this question investigates the strategies currently employed to safeguard sensitive information, a critical prerequisite for safe implementation.
2.2. Search Strategy
A comprehensive search was conducted across IEEE Xplore, Scopus, Nature Portfolio, and the ACM Digital Library, focusing on publications from 2020 to 2025. No language restrictions were applied. Keywords were initially combined using the ’OR’ Boolean operator for each specific concept. Subsequently, these concept-specific keyword sets were linked using the ’AND’ Boolean operator to refine the query logic and ensure relevance.
The final search query was designed based on the PICOC criteria. The terms for each component were grouped using parentheses and joined with Boolean operators, as follows: (“patient*” OR “healthcare user*”) AND (“large language model*” OR “LLM*” OR “generative AI” OR “conversational AI” OR “conversational agent*”) AND (“patient engagement” OR “user-focused” OR “human-centric” OR “personaliz*” OR “recommend*”) AND (“telehealth” OR “telemedicine” OR “digital health” OR “e-health” OR “health*”).
2.3. Inclusion and Exclusion Criteria
Clear inclusion and exclusion criteria were defined prior to the screening process to ensure a rigorous and transparent selection of studies as follows:
2.3.1. Inclusion Criteria
- Population: Scientific publications that describe, propose, or evaluate the use of LLMs for personalized healthcare.
- Intervention: Use of LLMs or conversational AI systems with a declared personalization component. This includes:
- –
- Prompt engineering tailored to user input,
- –
- Fine-tuning or RLHF (Reinforcement Learning from Human Feedback) on patient data,
- –
- Context injection (e.g., EHRs, chat history, user profiles),
- –
- Personalized recommendation algorithms,
- –
- RAG.
- Comparison: Not applicable.
- Outcomes: Studies reporting on personalization impact (e.g., patient engagement, satisfaction, safety, clinical outcomes).
- Context: Explicit healthcare-related settings, including clinical care, hospital care, and digital health applications.
2.3.2. Exclusion Criteria
- Studies outside the health domain (e.g., education, marketing).
- Systems not based on LLMs (e.g., rule-based bots, FAQ engines).
- Editorials, opinion pieces, protocols without results, or non-peer-reviewed sources (e.g., white papers, preprints).
2.4. Search Results
The search strategy returned a total of 3787 records: 904 from Scopus, 582 from the ACM Digital Library, 229 from IEEE Xplore, and 900 from Nature. Results from Scopus, IEEE Xplore, and Nature were sorted by their relevance ranking. In contrast, for the ACM Digital Library, which lacks relevance sorting, we utilized “citation” sorting. Table 2 presents the number of studies that passed the initial screening per database.
Table 2.
Results after screening by database.
To manage reviewer workload and mitigate the inclusion of low-relevance entries, we adopted a pragmatic saturation rule: screening for each database was discontinued after 50 consecutive records failed to meet the eligibility criteria. For example, screening in the Nature database was halted after the ninth page of results, once no further relevant studies were identified. In contrast, all results from IEEE Xplore were reviewed due to the smaller result set, yielding 30 records deemed potentially eligible for further assessment.
Figure 1 presents a PRISMA 2020 flow diagram summarizing the study selection process. Of the 3787 records initially identified, 3702 entries were excluded based on the saturation rule, followed by the exclusion of five duplicates. The remaining 80 records underwent title and abstract screening using the Rayyan systematic review platform, which resulted in the exclusion of 51 additional articles. After an initial screening round, Cohen’s [20] between two reviewers was 0.23 (“slight” agreement). During a calibration session, Reviewer 2 re-examined all the papers they had initially marked for inclusion but that Reviewer 1 had excluded; Reviewer 2 revised nine decisions to exclusion. As a result, agreement improved from 59% to 71%, increasing Cohen’s from ‘slight’ to ‘moderate.’ Twenty-nine full-text articles were assessed for eligibility, and 13 were excluded due to incorrect outcome (n = 6), non-target population (n = 5), or inappropriate study design (n = 2). The final synthesis included 16 studies, detailed in Table 3 and Table 4.
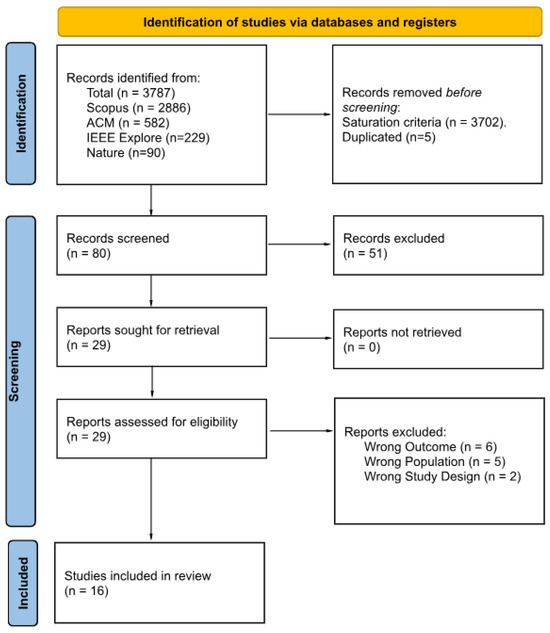
Figure 1.
PRISMA 2020 flow diagram of the study selection process.
Table 3.
Articles used in the study: Overview, domain, and user data employed.
Table 4.
Articles used in the study: Key techniques, evaluation, and security.
2.5. Data Extraction
A structured data extraction form was developed to collect information from each included study relevant to our research questions. Metadata for each study (e.g., title, authors, year, abstract, journal, and keywords) was initially collected through exports from Scopus and managed using Zotero, a tool for organizing, citing, and sharing research sources. These records facilitated the organization of references and the identification of duplicates.
However, to address the research questions, a second round of manual extraction was conducted from the full texts. The extraction process was guided by the research questions RQ1–RQ6. For each included study, we recorded structured responses corresponding to each RQ in a spreadsheet.
To characterize the intellectual landscape of this emerging field, we conducted a bibliometric analysis of the 16 included publications using VOSviewer 1.6.20. The following three key patterns emerged:
- Temporal Concentration: All the papers were published after 2024, confirming the recent and accelerating nature of LLM applications in healthcare.
- Publication Sources: 64% of papers appeared in conference proceedings, signaling an exploratory phase, while the presence in high-impact journals highlights rising academic interest.
- Keyword Co-occurrence: Terms such as “large language model(s)” and “natural language processing” were dominant, with strong connections to “mHealth” and “remote patient monitoring”, reflecting a primary application context in digital remote care.
Institutional contributions were primarily led by the United States, followed by South Asia. These findings underscore the need for methodological depth, cross-contextual evaluation, and geographical diversification in future research. Importantly, the extracted dataset now provides the foundation for answering RQ1–RQ6 in the Results section, ensuring that the synthesis of motivations, architectures, evaluation methods, and challenges remains tightly coupled to the evidence base.
3. Results
Given the nature of our systematic review, this section aims to answer the questions discussed in the methodology phase. An overview of the distribution of evaluation methodologies, data sources, motivations, techniques, and privacy measures is presented in Figure 2, providing a visual synthesis of the evidence base before addressing each research question.
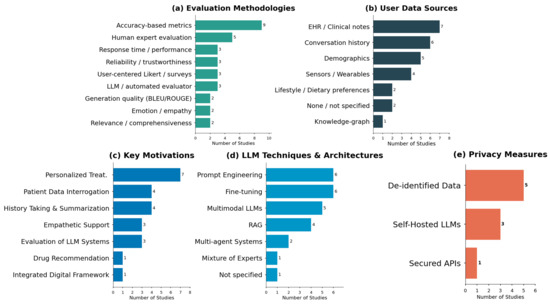
Figure 2.
Distribution of evaluation methodologies (a), data sources (b), motivations (c), LLM techniques (d), and privacy measures (e) in personalized healthcare applications.
3.1. RQ1: What Are the Main Motivations for Using LLMs in Personalized Healthcare Systems Focused on Personalization?
To address our first research question (RQ1) concerning the motivations for using LLMs in personalized healthcare, our analysis of the selected literature reveals a clear landscape of current research priorities. The findings, summarized in Table 5, are categorized into four key areas.
Table 5.
Grouping of selected studies by key motivations for using LLMs in healthcare systems.
The predominant application area, representing a significant portion of the reviewed literature, is personalized treatment in the clinical area. This body of work moves beyond generalized clinical guidelines, leveraging the deep analytical capabilities of LLMs to engineer medical recommendation systems. These systems are designed to deliver highly individualized care by processing vast and complex patient data. Their applications span a broad spectrum of clinical interactions, including:
- Drug Recommendations: Tailoring pharmaceutical prescriptions based on individual patient profiles, genetic predispositions, and historical responses to treatments.
- Personalized Treatment Plans and Diagnosis: Assisting clinicians in formulating bespoke care pathways and refining diagnostic accuracy.
- Patient Data Interrogation: Developing intelligent chatbots that allow patients to query their health records and receive understandable, personalized insights.
- History Taking and Summarization: Automating the collection of comprehensive patient histories and generating concise summaries of complex medical narratives. LLMs can engage in nuanced dialogs to extract patient histories, maintaining diagnostic quality under time constraints, or analyze records to recommend appropriate drugs.
For instance, LLMs can engage in nuanced dialogs to extract comprehensive patient histories, maintaining diagnostic quality under time constraints [22], or analyze a patient’s records to recommend appropriate drugs with greater accuracy, addressing gaps in individualized treatment selection [29]. These systems process complex patient data to predict treatment outcomes and suggest interventions tailored to specific patient profiles.
A second emerging domain is personalized empathetic support [10,11,24]. This area explores a more humanistic application of LLMs, focusing on building conversational interfaces endowed with the capacity for emotional recognition and empathetic response. For instance, So et al. [10] proposed an LLM-based voice interaction framework specifically designed for elderly care, aiming to alleviate loneliness. Another notable example is MindBot, a conversational agent developed for mental health support [11].
Although represented by a single study, Rahman et al. [28] integrated digital-hospital framework illustrates the architectural complexity required to embed personalized LLM agents into enterprise-scale health information systems.
Crucially, addressing the second facet, our review identified a dedicated and growing category for the Evaluation of Personalized LLM Systems. The existence of this category highlights a maturing field, recognizing that traditional Natural Language Processing (NLP) metrics are insufficient for high-stakes medical applications.
Beyond specific application areas, a transversal insight derived from these studies underscores the transformative potential of LLMs through their unparalleled capacity to analyze and interpret vast, complex datasets at scale. For instance, recent investigations have demonstrated the efficacy of advanced NLP frameworks and LLMs in deriving actionable insights from unstructured clinical notes [23]. This capability enables a granular understanding of individual patient profiles far beyond the scope of traditional analytical methods.
3.2. RQ2: What LLM-Based Techniques and Architectures Are Proposed to Personalized Healthcare Systems?
Table 6 summarizes six technique classes identified in the 16 studies. We organize the discussion in ascending order of architectural complexity. The most prevalent approaches involve adapting pre-trained models through prompt engineering and fine-tuning. These techniques represent the basis for specializing LLMs for personalized healthcare.
Table 6.
Frequency of LLM techniques in personalized healthcare literature.
Prompt engineering has evolved from simple queries into a critical discipline for shaping LLM behavior. Its importance is recognized as a methodological factor, with studies highlighting that the choice of prompting technique, such as zero-shot, few-shot, or chain-of-thought [30,31,32], significantly impacts performance [16]. More than just a technical step, it serves as a collaborative designtool. In the CRAFT-MD framework, for example, prompts for different AI agents were iteratively developed with clinicians to align model behavior with clinical expectations [22]. At its most advanced, prompt engineering becomes a mechanism for eliciting complex reasoning, using multi-part prompts that combine role-playing, directives, and chain-of-thought to guide LLMs through creative clinical tasks [23].
Complementing prompt engineering, Fine-tuning is equally critical for tailoring LLMs to the specific nuances of healthcare. While prompting guides a model’s existing knowledge, fine-tuning modifies the model’s internal parameters by continuing its training on smaller, domain-specific datasets. This is essential for adapting models to specialized medical jargon, understanding unique patient cohort data, or developing a consistent, empathetic tone for patient-facing applications. For instance, Balakrishna et al. [29] detail the use of fine-tuned models on medical datasets to enhance a drug recommendation system. Similarly, the development of domain-specific medical LLMs, such as Med-PaLM2 [33], exemplifies this approach, achieving state-of-the-art results on benchmarks like MedQA through extensive fine-tuning, as highlighted by Kumar et al. and Fang et al. [9,21]. Future work should report parameter-efficient variants (LoRA, adapters) and alignment via RLHF.
A core architectural pattern, identified in four studies, is the widespread adoption of RAG to overcome the inherent limitations of LLMs, such as knowledge cutoffs and the risk of hallucination [34]. At its fundamental level, RAG grounds model responses in curated, reliable sources, like clinical guidelines or electronic health records, by retrieving relevant information before generating a response. This is a crucial safety feature for healthcare applications [13,27].
However, the RAG paradigm itself is evolving to handle the increasing complexity of health data. In systems designed for holistic patient summaries, RAG serves as an orchestration framework, retrieving facts from a diverse spectrum of data [28]. Pushing this boundary further, a graph-augmented RAG approach enhances standard retrieval with a hierarchical knowledge graph, demonstrating how the architecture can be augmented to handle intricate, structured health data like wearable sensor readings more effectively [26]. This progression from foundational to augmented RAG highlights a critical trend towards creating more contextually aware and reliable personalized healthcare systems.
Beyond adapting and grounding single models, a significant trend is the design of complex, multi-component systems. This includes the integration of diverse data types through Multimodal LLM and the distribution of tasks among Multi-Agent Systems.
The expansion into holistic multimodal systems is an architectural evolution, enabling the integration of data far beyond text. This began with enhancing user interaction via speech recognition [10] and is rapidly expanding to incorporate continuous physiological data streams from wearables [9]. These next-generation systems synthesize medical images, text, and real-time patient data within a unified framework, often by pairing LLMs with specialized components like Vision Transformers for native image processing [13,15].
Concurrently, a key innovation is the move towards Multi-Agent Systems, where distinct AI components collaborate on specialized roles [35]. One primary application is in creating robust evaluation frameworks, where one LLM generates insights and another acts as an automated ’peer-reviewer’ [26]. This concept scales dramatically in architectures that simulate entire clinical environments with AI patient, evaluator, and clinician agents [22].
Operationally, this paradigm leads to systems like a “next-generation virtual hospital” built upon an ensemble of diverse, specialized models (LLMs, SLMs, VLMs) orchestrated under a unified framework [28]. This approach, sometimes overlapping with Mixture of Experts (MoE) architectures [15], demonstrates a strategic shift from relying on a single generalist model to engineering coordinated specialists for a truly holistic and multimodal understanding of the patient.
3.3. RQ3: How Are User Characteristics and Data Incorporated into the Personalized LLM Frameworks?
Given the central role of data, healthcare projects benefit from multi-layered data pipelines. The most prevalent data sources are traditional Electronic Health Records (EHR) and unstructured clinical notes and rich conversational history. A primary approach involves grounding the LLM in the patient’s formal medical history. For example, Balakrishna et al. [29] feed patient health records and clinical notes into their model to generate personalized drug recommendations. This concept is extended in systems like the e-Health Assistant [13], which ingests a comprehensive corpus of clinical documents and medication history to function as a question-answering system for both patients and clinicians. Similarly, Kumar et al. [21] construct a comprehensive patient profile within the Personalized Treatment Recommendation System: the fine-tuned Med-PaLM2 model considers an array of patient-specific factors—prior medical history, EHR data, genetic information, and lifestyle factors—and produces recommendations based on this profile. Additionally, the system considers genetic information alongside EHR data and lifestyle factors to produce highly specific treatment recommendations. As shown in Table 7, EHR and clinical notes represent the most frequently employed data sources, appearing in seven studies, followed closely by conversation history in six studies.
Table 7.
Types of characteristics and user data employed.
Complementing these formal records, conversational history serves as a dynamic source of personalization. For instance, the voice agent proposed by So et al. [10] employs personalized memory mechanisms, retaining details from prior interactions to inform subsequent responses. This personalization becomes even more adaptive in systems like MindBot [11], which performs real-time sentiment analysis on user input.
Moving beyond static records and text, a significant trend is the integration of dynamic data, primarily from sensors and wearables. This approach grounds personalization in continuous physiological and behavioral monitoring. A salient example is PhysioLLM [9], which directly integrates biometric data streams, such as sleep quality, physical activity, and heart rate, from a user’s device. This equips the LLM with a dynamic, quantitative understanding of the user’s health, enabling it to render complex physiological trends intelligible to the user.
And, finally, the use of an integrated knowledge graph represents an effort to provide LLMs with structured, semantically rich context, moving beyond raw data to pre-processed relational information, thus enhancing the model’s reasoning capabilities. It is also noteworthy that two studies did not specify the data used, highlighting an area for improvement in methodological reporting.
3.4. RQ4: How Are the Effectiveness of LLM-Based Healthcare Systems Evaluated?
To address our fourth research question (RQ4) on how the effectiveness of LLM-based personalized healthcare systems is evaluated, our analysis identified a multi-layered landscape of assessment methodologies, as detailed in Table 8. The findings reveal that evaluation is not a monolithic process but a composite of approaches spanning clinical accuracy, technical performance, user experience, and automated frameworks. We organize our discussion around three primary themes: the core evaluation of clinical performance, the assessment of user-centric and qualitative dimensions, and the emerging paradigm of scalable, automated evaluation.
Table 8.
Frequency of evaluation approaches in LLM-based personalized healthcare studies.
The cornerstone of evaluation in this high-stakes domain remains the assessment of clinical correctness. Accuracy-based metrics are the most prevalent evaluation approach, appearing in nine of the reviewed studies [11,12,15,16,21,22,25,28,29]. These metrics typically measure whether the LLM’s output (e.g., diagnosis, recommendation) aligns with established medical facts or ground truth, mostly with datasets.
Crucially, this quantitative assessment is frequently complemented by human expert evaluation, the second most common approach. This synergy is vital for moving beyond simple right-or-wrong checks to appraise clinical nuance and safety. For instance, Ref. [25] conducted a large-scale evaluation on 10,000 real emergency department cases, where human doctors assessed LLM recommendations for accuracy, sensibility, and specificity. This highlights a best practice of using expert judgment to validate model performance in complex, real-world scenarios. Alongside accuracy, other performance-oriented metrics such as response time [12,16,29] and fundamental generation quality (e.g., BLEU/ROUGE) [21,27] are also employed, though they are often seen as secondary to clinical validity.
Recognizing that personalization extends beyond clinical accuracy, a significant body of work evaluates the system’s impact on the end-user. User-centered Likert scales and surveys [9,16,23] are a key method for this. For example, Fang et al. [9] deployed a personalized smartwatch system to 24 users, using pre/post-surveys to demonstrate that the personalized LLM led to a significantly deeper user understanding and motivation compared to a baseline chatbot.
This user-centric focus is further refined through more granular metrics. Studies assess the relevance, comprehensiveness, and actionability of the LLM’s advice [9,26], ensuring the guidance is not only correct but also useful and understandable to the patient. Moreover, as these systems become more interactive, the evaluation of emotion and empathy in responses [11,16] is emerging as a critical factor for patient engagement and trust. Finally, the overarching concept of reliability and trustworthiness [11,16,22] is assessed, capturing a holistic measure of the system’s dependability from both a technical and user perspective.
While effective, manual expert evaluation presents significant scalability challenges. Addressing this, an emerging trend is the use of an LLM as an automated evaluator [9,14,22]. This approach leverages a powerful model (e.g., GPT-4) to systematically rate the output of another LLM, offering a scalable alternative to human assessment.
The CRAFT-MD framework by Johri et al. [22] exemplifies this paradigm. It operationalizes evaluation through an “AI Grader” agent that assesses diagnostic accuracy, with medical experts validating only a subset of interactions. This hybrid approach achieves remarkable efficiency, processing 10,000 multi-turn conversations in 48–72 h, a task estimated to require over 1150 h of human effort. Similarly, Subramanian et al. [26] used a second LLM to rate their primary model on dimensions like relevance and actionability, demonstrating that automated evaluation can assess nuanced qualitative criteria, not just correctness. This shift towards automated, yet human-validated, frameworks represents a critical step towards the rigorous and scalable evaluation required for the widespread adoption of personalized LLM systems in healthcare.
3.5. RQ5: What Challenges and Limitations Are Identified in the Use of LLMs for Personalization in Healthcare?
While promising, the deployment of LLMs for personalized healthcare faces substantial limitations, particularly concerning their reasoning capabilities. A primary challenge is the context-dependent fragility of their diagnostic performance, as established by Johri et al. [22]. Using the CRAFT-MD framework, they demonstrated a statistically significant impairment in the accuracy of models like GPT-4 and LLaMA-2-7b when required to synthesize information from a multi-turn, conversational exchange. This performance stands in sharp contrast to their capabilities when presented with the same clinical facts in a pre-processed, structured vignette, underscoring a misalignment between LLMs and the dynamic nature of real-world clinical data acquisition.
Furthermore, this issue of suboptimal reasoning extends beyond data formatting challenges. Even when provided with structured clinical notes, LLMs can exhibit flawed clinical judgment. For instance, Williams et al. [25] found that the diagnostic accuracy of GPT-3.5 and GPT-4 Turbo was significantly lower than that of a resident physician, by 24% and 8%, respectively. This performance deficit was attributed to the models’ tendency towards overly cautious recommendations, leading to a high rate of false-positive suggestions for clinical intervention.
This demonstrated technical unreliability directly fuels the third major barrier: justifiable clinician skepticism. The apprehension of medical professionals is not merely theoretical. A recent study found that while endocrinologists perceived a high utility in AI tools, they rated tasks requiring autonomous synthesis of patient data, AI-driven message triage, and real-time data interpretation as carrying a significant risk of harm [23]. This illustrates that the very tasks where automation is most desired are those where clinicians are most cautious, precisely because of the potential for direct impact on patient safety. Therefore, the path to clinical integration is gated not only by the need to overcome fundamental technical deficiencies in reasoning and robustness but also by the critical imperative to build justifiable trust with the end-users.
Another limitation is that when the LLMs are faced with wearable data, current LLMs are not optimized to interpret complex medical sensor data or longitudinal records on their own. Some researchers [26] claim that straightforward approaches like prompting an LLM with raw wearable data often fail to yield meaningful insights: the models struggle with multi-dimensional, temporal information, necessitating elaborate pre-processing or augmentation frameworks as a workaround.
Moreover, issues of bias and fairness linger in the background: a personalized system might inadvertently reflect or even amplify biases present in its training data, a concern raised by [16], potentially giving less accurate or inappropriate recommendations to certain patient groups if not carefully managed.
3.6. RQ6: How Are Security, Privacy, and Trust Aspects Addressed in the Use of LLMs for Personalized Healthcare with Sensitive Health Data?
The challenge of ensuring privacy when using LLMs with sensitive health data is being addressed through a spectrum of strategies, ranging from fundamental data-level anonymization to complete architectural control over the AI models themselves, as detailed in Table 9.
Table 9.
Security and privacy aspects.
The most foundational and prevalent strategy is the use of rigorously de-identified data. This approach is consistently applied across research, whether using certified institutional datasets [25], public benchmarks like MIMIC (Medical Information Mart for Intensive Care) [21,28] secondary patient portal communications [23], or multimodal records from remote health studies [26]. By systematically stripping Personal Health Information (PHI), these methods often allow Institutional Review Boards (IRBs) to classify the work as non-human subjects research, thereby waiving the need for additional, explicit patient consent. This forms the ethical and regulatory bedrock for much of the current research in the field.
Moving beyond data preparation, a second layer of protection addresses the security of the technical infrastructure. For studies leveraging powerful, third-party models, a common practice is to use secure, HIPAA-compliant Application Programming Interfaces (APIs), such as those offered by Microsoft Azure, to create a protected pipeline for data in transit [25].
However, to completely mitigate the risks associated with any third-party data transmission, the most robust strategy involves achieving full architectural sovereignty. This privacy-by-design approach is exemplified by [13], who developed a personalized chatbot where the LLM is self-hosted on hospital-controlled infrastructure [13,28]. By combining this with end-to-end encryption for all communications, they ensure that no patient data ever leaves the trusted local environment, thus eliminating reliance on external vendors and providing the highest level of confidentiality.
In essence, the field is navigating a continuum of privacy solutions, from securing the data itself for retrospective research to architecting entirely self-contained systems for live clinical applications, reflecting a growing maturity in addressing these critical concerns.
4. Discussion
LLM adoption in personalized healthcare is advancing rapidly, with efforts aimed at improving efficiency, enhancing diagnosis and treatment, and broadening access. This has driven a shift from text-only to multimodal systems, supported by techniques such as RAG, multi-agent orchestration, and advanced prompting, while privacy is addressed through de-identification, self-hosting, and provider-level safeguards. Yet clinical performance remains uneven, and clinician skepticism is justified. These contrasting dynamics create fundamental tensions between efficiency and specificity, sophistication and privacy practicality, and evaluation adequacy and clinical reliability, which frame the following discussion.
- Efficiency vs. specificityA central tension emerging from our analysis is the conflict between the motivation for operational efficiency and the observed clinical performance limitations of current LLMs. A key promise is that these models can alleviate clinician workload through automation, for example, by triaging patient messages or suggesting interventions [23,28]. Yet, empirical evidence demonstrates that these same models, particularly when using straightforward prompts, exhibit dangerously low specificity, tending to over-recommend actions like hospital admission or antibiotic prescription [25]. This creates a paradox: a tool designed to save time could dramatically increase it by flooding clinicians with a high volume of false-positive alerts that require manual verification. Suggesting that, without substantial improvements in clinical calibration, LLMs may paradoxically contribute to the very problem of clinician burnout they are intended to mitigate.
- Sophistication vs. privacy practicalityA second critical tension exists between the drive for technical sophistication and the imperative for data privacy. The most advanced architectures identified, such as multimodal systems and those using complex RAG frameworks, achieve personalization by accessing rich, detailed, and often longitudinal patient data. However, the gold-standard privacy solutions for live clinical deployment, such as self-hosting and end-to-end encryption, while robust, introduce substantial computational, financial, and operational burdens, including on-premise hardware, compliance audits, and dedicated IT maintenance, which may limit adoption to only well-resourced institutions. This creates a potential scalability dilemma: the most powerful and personalized models may be accessible only to well-resourced institutions capable of managing such complex, private infrastructure. Meanwhile, simpler, de-identification-based privacy measures used in most research are ill-suited for real-time applications where patient identity is intrinsic to the task, highlighting a complex trade-off between model capability and practical, secure implementation.
- Evaluation adequacy vs. clinical reliabilityA central limitation in current LLM-for-health research is not merely how inputs are engineered but how effectiveness is evaluated. Conventional NLP metrics (e.g., accuracy) poorly capture what matters in clinical and patient-facing contexts, namely truthfulness, non-redundancy, contextual relevance, and downstream safety. As a result, systems may appear robust in benchmark settings yet remain clinically fragile in real conversational workflows. We argue for a shift toward domain-calibrated evaluation that combines (i) expert-in-the-loop judgments on content quality [36], (ii) risk- and safety-aware measures (e.g., harmfulness, uncertainty, and selective abstention), and (iii) user-centered and workflow-sensitive outcomes (e.g., time-to-understanding, perceived trust, and cognitive effort).
To broaden the geographical and practical lens beyond our systematic corpus, we examined two recent South American studies that speak directly to personalization, safety, and usability in patient-facing LLM systems. The first presents MarIA, a GPT-3.5 conversational assistant for diabetes self-care that systematically varies empathy, dialog style, and personalization, reporting higher engagement and safe interactions in a 35-patient evaluation with expert review [37]. The second evaluates LLM-generated medication directions under the national e-prescribing standard, showing that calibrated prompts, especially bias mitigation, improve adequacy and acceptability, with open- and closed-source models achieving similar adequacy but distinct hallucination profiles across scenarios [38]. Together, these findings reinforce our implications that prompt engineering is one of the levers for patient engagement and that context-aware evaluation (clinical workflow, regulation, and bias) enables cost-sensitive deployment in low-resource settings. These works were consulted post-screening to enrich geographical perspective and were not included in the quantitative synthesis.
Design Implications
The challenges in deploying LLM-powered systems are not merely algorithmic but are deeply rooted in the sociotechnical context of healthcare. Drawing from the tensions, we distill five core design implications to guide the development of future personalized healthcare systems.
- Minimize Friction and Integrate into Clinical Workflows.For any AI tool to be adopted, it must seamlessly integrate into the fast-paced, high-stakes environment of clinical practice. This means embedding LLM-powered suggestions directly within existing interfaces, such as the Electronic Health Record (EHR) note-entry screen, to avoid disruptive context-switching. Furthermore, information must be presented in concise, structured formats that clinicians can parse quickly, using summaries or bullet points instead of dense paragraphs to reduce cognitive load [39].
- Build Trust Through Verifiable Transparency.Clinician and patient trust is not granted by default; it must be earned. Given the propensity of LLMs to “hallucinate,” systems must be designed to be transparent and their claims verifiable. This involves implementing layered explainability, providing a simple answer by default but offering deeper context like confidence scores or links to source evidence. A critical aspect is to visually and semantically distinguish between factual data and probabilistic inferences, helping users calibrate their reliance [40,41].
- Design for Co-Piloting, Not Autopiloting.The most effective and safest role for LLMs in healthcare is that of a “co-pilot” that augments human expertise. Designers must thus conceive systems that function as intelligent co-pilots, not autopilots, offering meaningful choices [42]. This philosophy requires designing for effective human–AI collaboration upholding human agency to question, edit, or override any AI-generated output. Systems must also gracefully handle the ambiguity of clinical language, allowing clinicians to correct misinterpretations and refine the model’s understanding through dialog [40,43,44].
- Embed Equity and Mitigate Bias by Design.LLM-based systems risk amplifying existing health disparities if biases present in their training data are not proactively addressed. This requires implementing standardized frameworks to regularly audit for performance disparities across different demographic groups. Prioritizing accessibility, through plain language and multilingual support, and co-design with diverse patient communities, is crucial to ensure equitable outcomes [45].
- Uphold Privacy as a Foundational Design Constraint.The sensitive nature of patient data requires that privacy be treated as a non-negotiable design constraint. This involves practicing data minimization and designing workflows that use only essential data. Transparent communication about data usage, in accordance with regulations like HIPAA, is vital to ensure privacy is upheld as a foundational and visible constraint.
5. Gaps and Challenges
Addressing the tensions identified in this literature review requires a research agenda that is dynamically adaptive to the rapid evolution of LLM technology. We propose that the path forward is structured around four interconnected pillars, as illustrated in Figure 3. The following discussion unpacks the critical gaps in current research that motivate each pillar of this agenda.
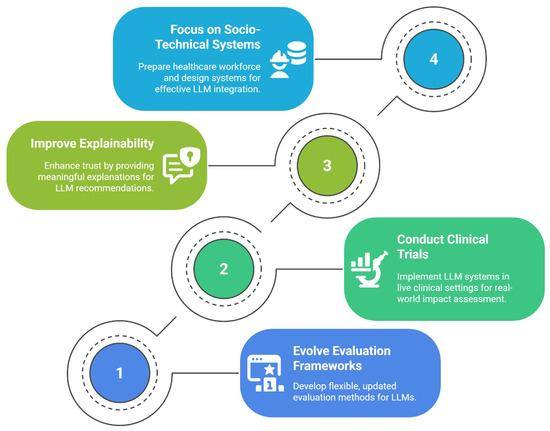
Figure 3.
A proposed four-pillared research agenda.
The first pillar of this agenda, Evolving Evaluation Frameworks, is motivated by the fact that the field’s current evaluation methods are fundamentally misaligned with clinical reality. Because the capabilities of LLMs evolve rapidly, evaluation frameworks must go beyond static benchmarks. The field requires methodological infrastructure that is flexible, modular, and continuously updated, capable of testing new models across evolving metrics such as factuality, empathy, bias, and safety. Rather than fixed leaderboards, this calls for iterative pipelines with reproducibility, versioning, and clinician-in-the-loop refinement.
The necessity of the second pillar, conducting clinical trials, arises from a significant gap between in silico validation and real-world clinical utility. The majority of studies evaluated in this review rely on retrospective, de-identified datasets, testing LLMs on static, historical information [23,25]. While essential for initial development, this methodology fails to address the complexities of prospective, longitudinal implementation. Future research must therefore move towards pilot and clinical trials that deploy these systems in live clinical workflows, measuring their impact not only on diagnostic accuracy but also on real-world outcomes such as consultation time, clinician workload, and, most importantly, patient safety.
The third pillar, the need to improve explainability, is a direct response to the significant trust deficit identified among clinicians [23,25]. Bridging this gap requires more than higher AUROC scores; it calls for clinically meaningful explainability. A critical research gap exists in identifying and testing which XAI methods, from chain-of-thought rationales to counterfactual risk explanations, can effectively improve clinician calibration and decision confidence without introducing new biases.
Finally, the fourth pillar, the call to focus on socio-technical systems, addresses the gap between model-centric research and the realities of clinical practice. As LLMs evolve in complexity, research must extend beyond the models themselves. This necessitates designing systems with a human-in-the-loop philosophy that facilitates, rather than replaces, human expertise. A critical component of this research is workforce preparedness, investigating the core competencies clinicians need to effectively supervise and correct LLM output, a crucial step towards ensuring safe and effective integration.
6. Conclusions, Limitations and Future Work
Our systematic literature review deconstructs the paradigm shift of LLMs in personalized healthcare, revealing a field defined by a critical duality. On one hand, technological innovation is immense, with sophisticated architectures enabling personalized clinical treatments and empathetic support systems that promise to redefine patient care. On the other hand, this progress is met with a persistent clinical fragility. The underlying models still struggle with the core imperatives of reliability and nuanced reasoning when faced with complex, real-world clinical data. This gap between technical capability and clinical readiness fosters a justified skepticism among clinicians, creating a barrier to safe and effective adoption.
6.1. Limitations of This SLR
Our synthesis is constrained by the current evidence base. The majority of included studies rely on retrospective or synthetic data and report task-level metrics rather than prospective, workflow-embedded outcomes. Substantial heterogeneity in tasks and evaluation metrics weakened cross-study comparability. Furthermore, the literature is skewed toward high-income, English-language settings, with underrepresentation of LMIC contexts and social determinants of health, constraining the generalizability of our findings. Finally, selective publication may bias the available evidence toward positive results.
6.2. Future Work
Moving forward requires a significant paradigm shift, away from demonstrating purely technical feasibility and toward ensuring clinical safety and real-world utility. This necessitates a move beyond retrospective, in silico validation to an agenda rooted in prospective clinical trials and the development of dynamic evaluation frameworks that prioritize safety, fairness, and clinical nuance over simple accuracy metrics. Concurrently, future work must deepen its focus on the socio-technical aspects of deployment by prioritizing clinically meaningful XAI to build trust and designing robust human-in-the-loop systems that augment, rather than replace, clinical expertise. Critically, for personalization to be equitable, this research must explore how LLMs can reason over contextual data like SDOH, ensuring these powerful technologies narrow, rather than widen, existing health disparities.
6.3. Concluding Remarks
Ultimately, the success of LLMs in healthcare will not be defined by the autonomy of the models themselves, but by the quality of the collaboration they facilitate between the machine and the clinician. Realizing this synergistic future requires a sustained, interdisciplinary effort anchored in scientific rigor, ethical responsibility, and an unwavering commitment to patient well-being. The journey is only beginning, and it must be pursued with as much caution as ambition.
Author Contributions
G.d.P.S., methodology—developed the systematic literature review protocol, including search strategy, inclusion/exclusion criteria, and data extraction framework; formal analysis—synthesized study results, identified research gaps, and formulated the taxonomy and discussion; writing—original draft—prepared the initial manuscript, ensuring accuracy and completeness. G.M., supervision—provided oversight, strategic guidance, and methodological input throughout the study; writing—review and editing—critically reviewed and refined the manuscript. D.S., supervision—offered academic and technical oversight for the research; writing—review and editing—revised the manuscript for clarity, coherence, and scientific rigor. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data is contained within the article. Further inquiries can be directed to the corresponding author.
Acknowledgments
The authors would like to thank the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LLM | Large Language Models |
| SLR | Systematic Literature Review |
| ROUGE | Recall-Oriented Understudy for Gisting Evaluation |
| RAG | Retrieval-augmented generation |
| SDOH | Social Determinants of Health |
| LMIC | Low- and Middle-Income Countries |
| EHR | Electronic Health Record |
| NLP | Natural Language Processing |
| API | Application Programming Interface |
| MoE | Mixture of Experts |
| XAI | Explainable Artificial Intelligence |
| HIPAA | Health Insurance Portability and Accountability Act |
| PICOC | Population, Intervention, Comparison, Outcome, Context |
| RQ | Research Question |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| RLHF | Reinforcement Learning from Human Feedback |
| BLEU | Bilingual Evaluation Understudy |
| AUROC | Area Under the Receiver Operating Characteristic |
| VLM | Visual Language Models |
| SLM | Small Language Models |
| PHI | Personal Health Information |
| MIMIC | Medical Information Mart for Intensive Care |
References
- Louca, S. Personalized medicine—A tailored health care system: Challenges and opportunities. Croat. Med. J. 2012, 53, 211–213. [Google Scholar] [CrossRef] [PubMed]
- Cinti, C.; Trivella, M.G.; Joulie, M.; Ayoub, H.; Frenzel, M. The Roadmap toward Personalized Medicine: Challenges and Opportunities. J. Pers. Med. 2024, 14, 546. [Google Scholar] [CrossRef]
- Vicente, A.M.; Ballensiefen, W.; Jönsson, J.I. How personalised medicine will transform healthcare by 2030: The ICPerMed vision. J. Transl. Med. 2020, 18, 180. [Google Scholar] [CrossRef]
- Chunara, R.; Gjonaj, J.; Immaculate, E.; Wanga, I.; Alaro, J.; Scott-Sheldon, L.A.J.; Mangeni, J.; Mwangi, A.; Vedanthan, R.; Hogan, J. Social Determinants of Health: The Need for Data Science Methods and Capacity. Lancet Digit. Health 2024, 6, e235–e237. [Google Scholar] [CrossRef]
- Onnela, J.P. Opportunities and challenges in the collection and analysis of digital phenotyping data. Neuropsychopharmacology 2021, 46, 45–54. [Google Scholar] [CrossRef] [PubMed]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2024, arXiv:2303.08774. [Google Scholar]
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of Artificial General Intelligence: Early Experiments with GPT-4. arXiv 2023, arXiv:2303.12712. [Google Scholar] [CrossRef]
- Yin, S.; Fu, C.; Zhao, S.; Li, K.; Sun, X.; Xu, T.; Chen, E. A Survey on Multimodal Large Language Models. Natl. Sci. Rev. 2024, 11, nwae403. [Google Scholar] [CrossRef]
- Fang, C.M.; Danry, V.; Whitmore, N.; Bao, A.; Hutchison, A.; Pierce, C.; Maes, P. PhysioLLM: Supporting Personalized Health Insights with Wearables and Large Language Models. In Proceedings of the 2024 IEEE EMBS International Conference on Biomedical and Health Informatics (BHI), Houston, TX, USA, 10–13 November 2024; pp. 1–8. [Google Scholar] [CrossRef]
- So, K.; Kim, H.J.; Shin, D.S.; Sim, J.A.; Lee, J.J.; Duong, D.; Meisinger, K.; Won, D.O. A Conversational Interaction Framework Using Large Language Models for Personalized Elderly Care. In Proceedings of the 2025 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–14 January 2025; pp. 1–2. [Google Scholar] [CrossRef]
- Kambare, S.M.; Jain, K.; Kale, I.; Kumbhare, V.; Lohote, S.; Lonare, S. Design and Evaluation of an AI-Powered Conversational Agent for Personalized Mental Health Support and Intervention (MindBot). In Proceedings of the 2024 International Conference on Sustainable Communication Networks and Application (ICSCNA), Theni, India, 11–13 December 2024; pp. 1394–1402. [Google Scholar] [CrossRef]
- Akilesh, S.; Abinaya, R.; Dhanushkodi, S.; Sekar, R. A Novel AI-based Chatbot Application for Personalized Medical Diagnosis and Review Using Large Language Models. In Proceedings of the 2023 International Conference on Research Methodologies in Knowledge Management, Artificial Intelligence and Telecommunication Engineering (RMKMATE), Chennai, India, 1–2 November 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Pap, I.A.; Oniga, S. eHealth Assistant AI Chatbot Using a Large Language Model to Provide Personalized Answers through Secure Decentralized Communication. Sensors 2024, 24, 6140. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, S.; Han, X.; Baldwin, T.; Cohn, T.; Frermann, L. Evaluating debiasing techniques for intersectional biases. arXiv 2021, arXiv:2109.10441. [Google Scholar] [CrossRef]
- Cai, H. Multimodal Hybrid Healthcare Recommendation System Based on ERT-MOE and Large Language Model Enhancement. In Proceedings of the 2024 4th International Conference on Electronic Information Engineering and Computer Communication (EIECC), Wuhan, China, 13–15 December 2024; pp. 1222–1226. [Google Scholar] [CrossRef]
- Abbasian, M.; Khatibi, E.; Azimi, I.; Oniani, D.; Shakeri Hossein Abad, Z.; Thieme, A.; Sriram, R.; Yang, Z.; Wang, Y.; Lin, B.; et al. Foundation Metrics for Evaluating Effectiveness of Healthcare Conversations Powered by Generative AI. Npj Digit. Med. 2024, 7, 82. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. PLoS Med. 2021, 18, e1003583. [Google Scholar] [CrossRef] [PubMed]
- Kitchenham, B.; Pearl Brereton, O.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic literature reviews in software engineering—A systematic literature review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for Conducting Systematic Mapping Studies in Software Engineering: An Update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Kumar, G. A Doctor Assistance Tool: Personalized Healthcare Treatment Recommendations Journey from Deep Reinforcement Learning to Generative AI. In Proceedings of the 2024 3rd Edition of IEEE Delhi Section Flagship Conference (DELCON), New Delhi, India, 21–23 November 2024; pp. 1–9. [Google Scholar] [CrossRef]
- Johri, S.; Jeong, J.; Tran, B.A.; Schlessinger, D.I.; Wongvibulsin, S.; Barnes, L.A.; Zhou, H.Y.; Cai, Z.R.; Van Allen, E.M.; Kim, D.; et al. An Evaluation Framework for Clinical Use of Large Language Models in Patient Interaction Tasks. Nat. Med. 2025, 31, 77–86. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Chen, M.L.; Rezaei, S.J.; Hernandez-Boussard, T.; Chen, J.H.; Rodriguez, F.; Han, S.S.; Lal, R.A.; Kim, S.H.; Dosiou, C.; et al. Artificial Intelligence Tools in Supporting Healthcare Professionals for Tailored Patient Care. npj Digit. Med. 2025, 8, 210. [Google Scholar] [CrossRef]
- Jaiswal, S.; Lee, J.; Berria, J.; Tanikella, R.; Zolyomi, A.; Ahmad, M.A.; Si, D. Building Personality-Adaptive Conversational AI for Mental Health Therapy. In Proceedings of the 15th ACM International Conference on Bioinformatics, Computational Biology and Health Informatics, Shenzhen, China, 22–25 November 2024; p. 1. [Google Scholar] [CrossRef]
- Williams, C.Y.K.; Miao, B.Y.; Kornblith, A.E.; Butte, A.J. Evaluating the Use of Large Language Models to Provide Clinical Recommendations in the Emergency Department. Nat. Commun. 2024, 15, 8236. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, A.; Yang, Z.; Azimi, I.; Rahmani, A.M. Graph-Augmented LLMs for Personalized Health Insights: A Case Study in Sleep Analysis. In Proceedings of the 2024 IEEE 20th International Conference on Body Sensor Networks (BSN), Chicago, IL, USA, 15–17 October 2024; pp. 1–4. [Google Scholar] [CrossRef]
- Garima, S.; Swapnil, M.; Shashank, S. Harnessing the Power of Language Models for Intelligent Digital Health Services. In Proceedings of the 2024 ITU Kaleidoscope: Innovation and Digital Transformation for a Sustainable World (ITU K), New Delhi, India, 21–23 October 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Rahman, M.A.; Al-Hazzaa, S. Next-Generation Virtual Hospital: Integrating Discriminative and Large Multi-Modal Generative AI for Personalized Healthcare. In Proceedings of the GLOBECOM 2024—2024 IEEE Global Communications Conference, Cape Town, South Africa, 8–12 December 2024; pp. 3509–3514. [Google Scholar] [CrossRef]
- Balakrishna, C.; Yadav, A.; Singh, J.; Saba, M.; Shashikant; Shrivastava, V. Smart Drug Delivery Systems Using Large Language Models for Real-Time Treatment Personalization. In Proceedings of the 2024 2nd World Conference on Communication & Computing (WCONF), Raipur, India, 12–14 July 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large Language Models Are Zero-Shot Reasoners. arXiv 2022, arXiv:2205.11916. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar] [CrossRef]
- Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Amin, M.; Hou, L.; Clark, K.; Pfohl, S.R.; Cole-Lewis, H.; et al. Toward Expert-Level Medical Question Answering with Large Language Models. Nat. Med. 2025, 31, 943–950. [Google Scholar] [CrossRef]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. Acm Trans. Inf. Syst. 2025, 43, 1–55. [Google Scholar] [CrossRef]
- Li, X.; Wang, S.; Zeng, S.; Wu, Y.; Yang, Y. A Survey on LLM-based Multi-Agent Systems: Workflow, Infrastructure, and Challenges. Vicinagearth 2024, 1, 9. [Google Scholar] [CrossRef]
- Ferreira, A.A.; Rocha, L.; Cunha, W.; Machado, A.C.; Campos, J.M.; Jallais, G.; Viana, A.C.F.; Tuler, E.; Araújo, I.; Macul, V.; et al. A comprehensive qualitative analysis of patient dialogue summarization using large language models applied to noisy, informal, non-English real-world data. Sci. Rep. 2025, 15, 31660. [Google Scholar] [CrossRef]
- Silva, V.; Furtado, E.S.; Oliveira, J.; Furtado, V. Engenharia de Prompts em Assistentes Conversacionais para Promoção de Autocuidado baseados em Modelos Amplos de Linguagem. In Proceedings of the Anais do XXIV Simpósio Brasileiro de Computação Aplicada à Saúde (SBCAS 2024), Goiânia, Brazil, 25–28 June 2024; pp. 377–388. [Google Scholar] [CrossRef]
- Reis, Z.S.N.; Pagano, A.S.; Ramos de Oliveira, I.J.; dos Santos Dias, C.; Lage, E.M.; Mineiro, E.F.; Varella Pereira, G.M.; de Carvalho Gomes, I.; Basilio, V.A.; Cruz-Correia, R.J.; et al. Evaluating Large Language Model–Supported Instructions for Medication Use: First Steps Toward a Comprehensive Model. Mayo Clin. Proc. Digit. Health 2024, 2, 632–644. [Google Scholar] [CrossRef]
- Rajashekar, N.C.; Shin, Y.E.; Pu, Y.; Chung, S.; You, K.; Giuffre, M.; Chan, C.E.; Saarinen, T.; Hsiao, A.; Sekhon, J.; et al. Human-Algorithmic Interaction Using a Large Language Model-Augmented Artificial Intelligence Clinical Decision Support System. In Proceedings of the CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 11–16 May 2024; pp. 1–20. [Google Scholar] [CrossRef]
- Park, Y.J.; Pillai, A.; Deng, J.; Guo, E.; Gupta, M.; Paget, M.; Naugler, C. Assessing the research landscape and clinical utility of large language models: A scoping review. Bmc Med. Inform. Decis. Mak. 2024, 24, 72. [Google Scholar] [CrossRef]
- Zhang, Z.; Rossi, R.A.; Kveton, B.; Shao, Y.; Yang, D.; Zamani, H.; Dernoncourt, F.; Barrow, J.; Yu, T.; Kim, S.; et al. Personalization of Large Language Models: A Survey. arXiv 2025, arXiv:2411.00027. [Google Scholar] [CrossRef]
- Schneider, D.; de Almeida, M.A.; Nascimento, M.; Correia, A.; de Souza, J.M. Designing for (Digital) Nomad-AI Interaction. In Proceedings of the International Conference on Computer-Human Interaction Research and Applications, Marbella, Spain, 20–21 October 2025. [Google Scholar]
- Wang, Y.; Zhao, Y.; Petzold, L. Are Large Language Models Ready for Healthcare? A Comparative Study on Clinical Language Understanding. arXiv 2023, arXiv:2304.05368. [Google Scholar] [CrossRef]
- Cai, C.J.; Winter, S.; Steiner, D.; Wilcox, L.; Terry, M. “Hello AI”: Uncovering the onboarding needs of medical practitioners for human-AI collaborative decision-making. Proc. ACM-Hum.-Comput. Interact. 2019, 3, 1–24. [Google Scholar]
- Chen, J.; Liu, Z.; Huang, X.; Wu, C.; Liu, Q.; Jiang, G.; Pu, Y.; Lei, Y.; Chen, X.; Wang, X.; et al. When large language models meet personalization: Perspectives of challenges and opportunities. World Wide Web 2024, 27, 42. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).