
Biologically Plausible Boltzmann Machine



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
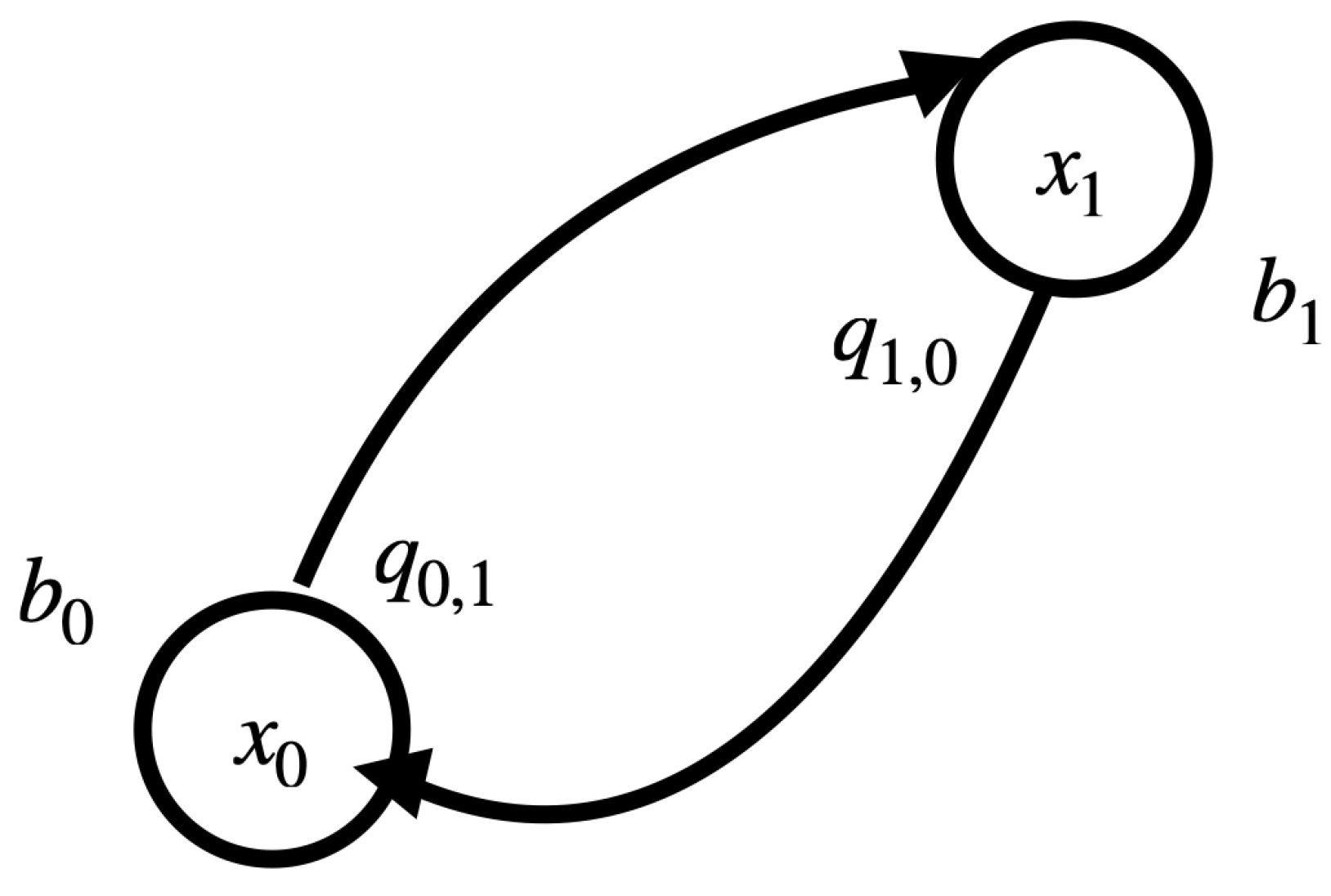
2.1. The Boltzmann Machine
2.2. The Maximum Entropy Principle
2.3. Maximum Entropy Boltzmann Machine
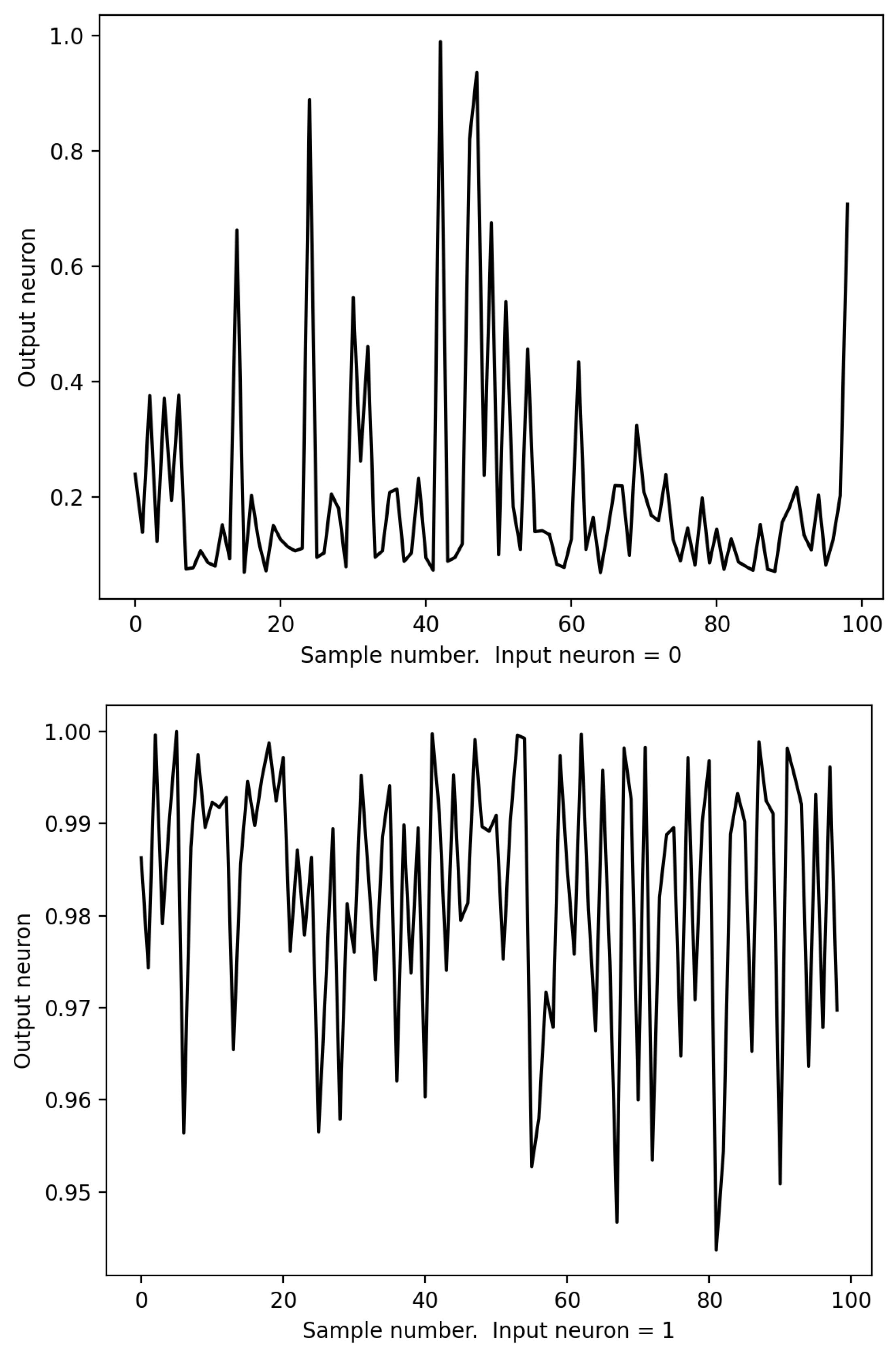
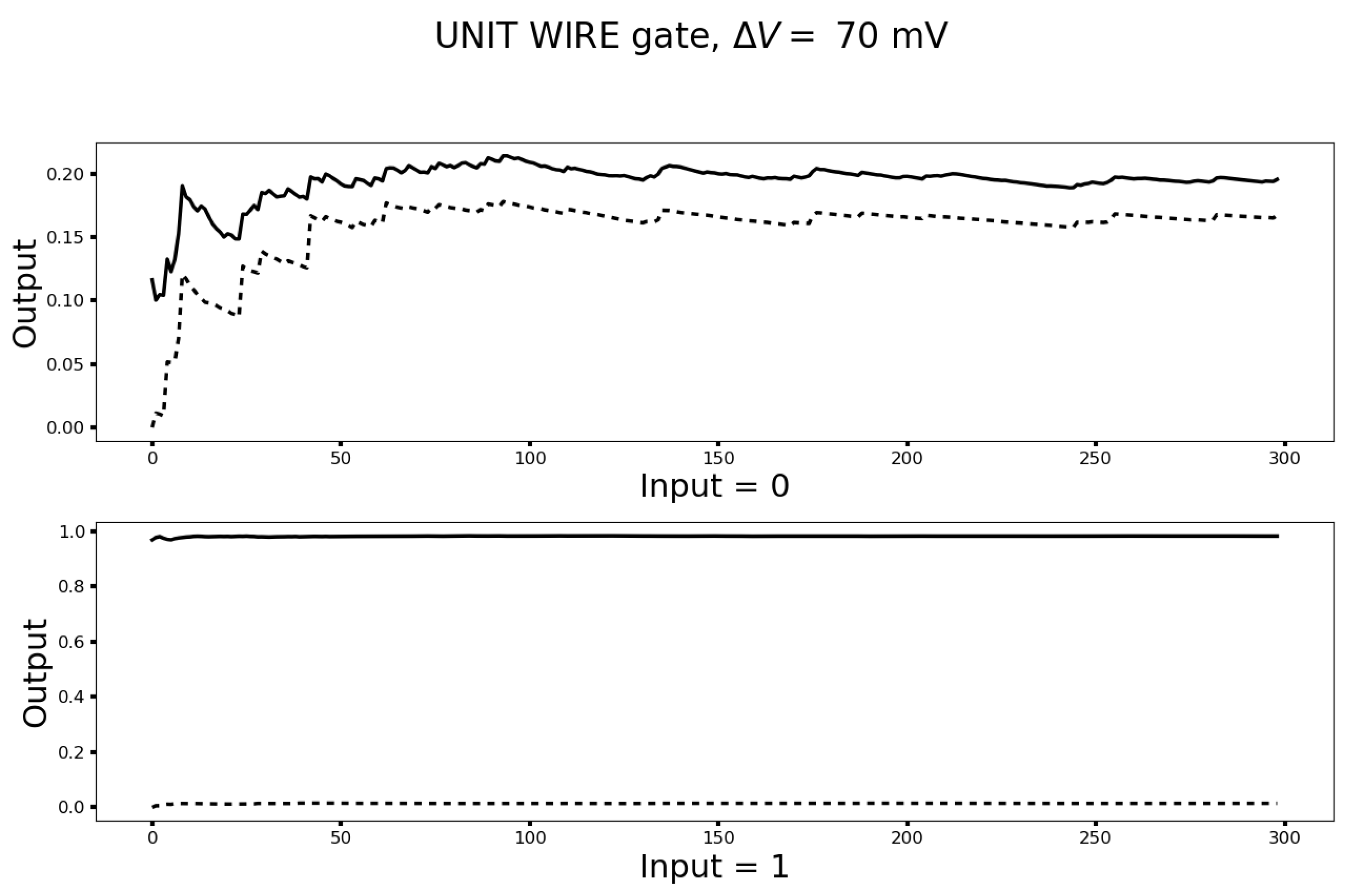
2.4. Implementation of the Unit Wire
3. Results
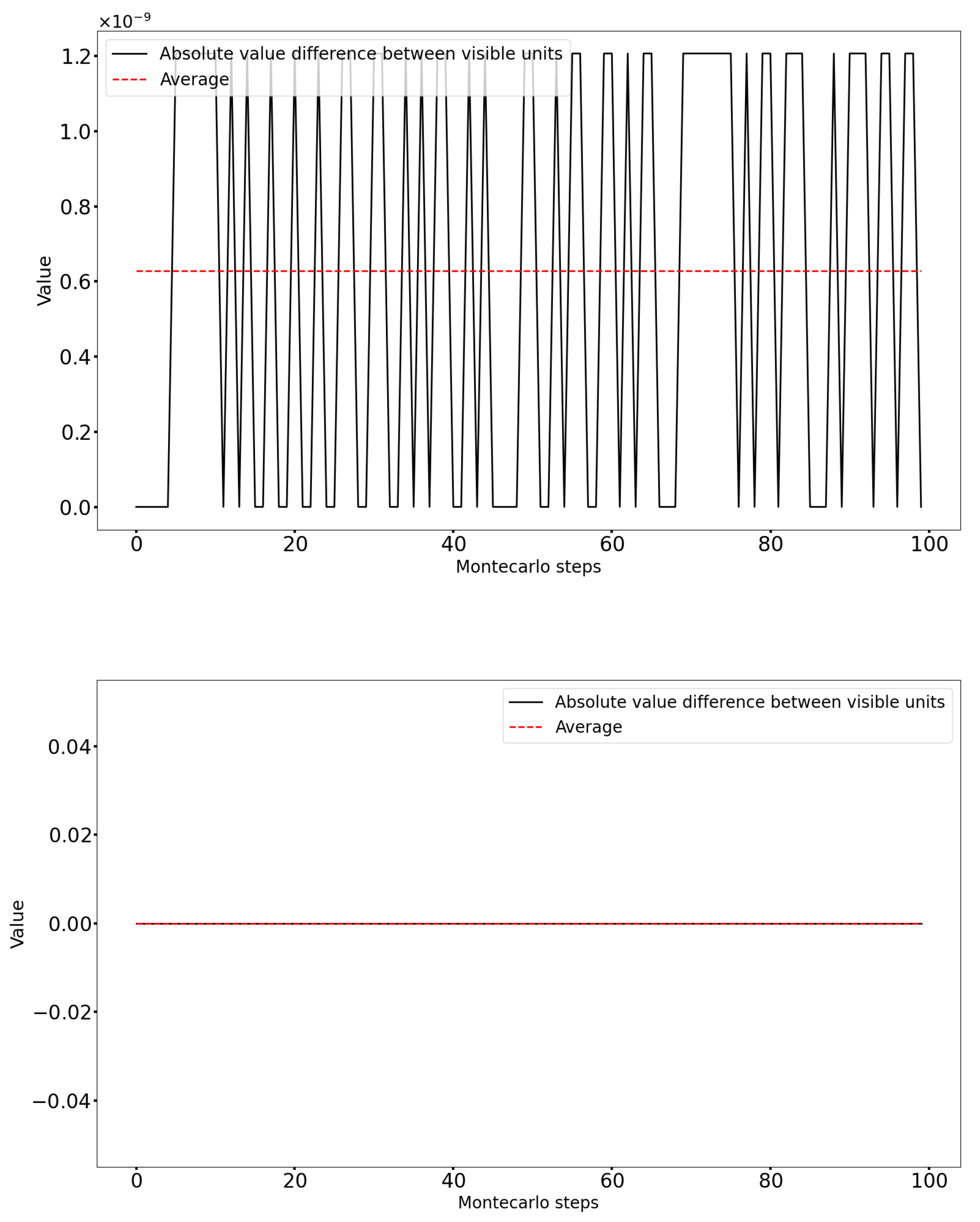
3.1. Statistical Mechanics for a Physical Realization of a Boltzmann Machine
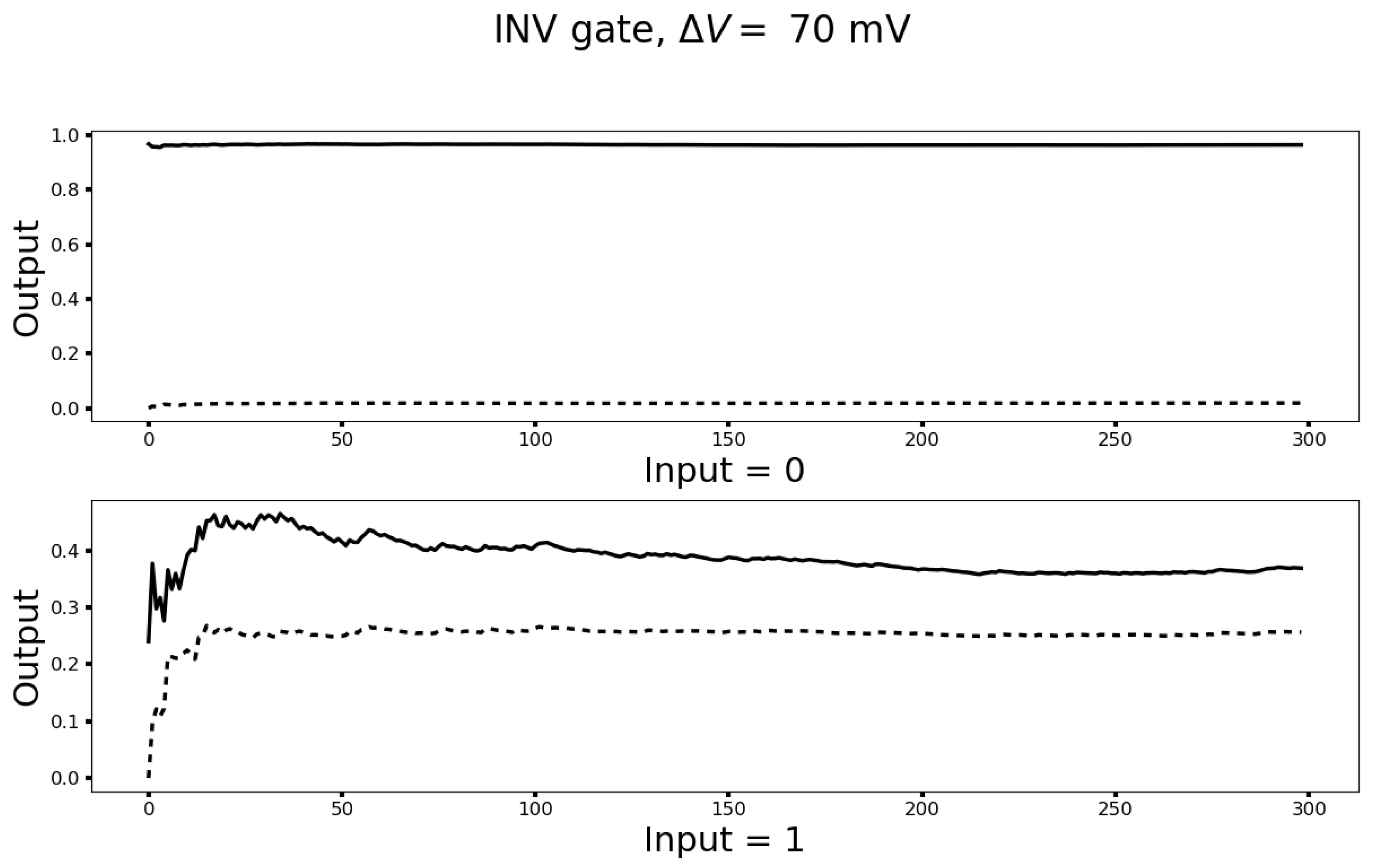
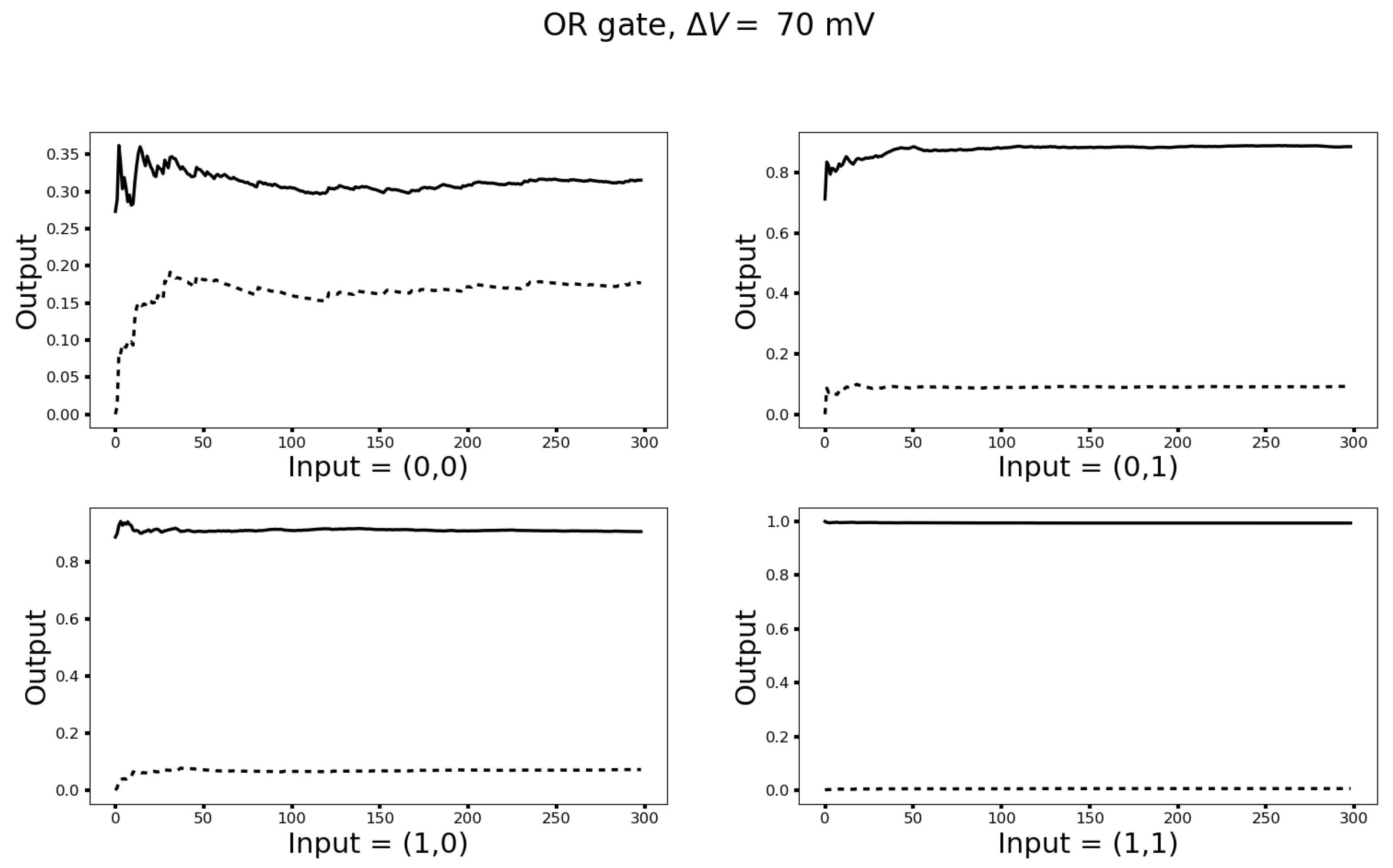
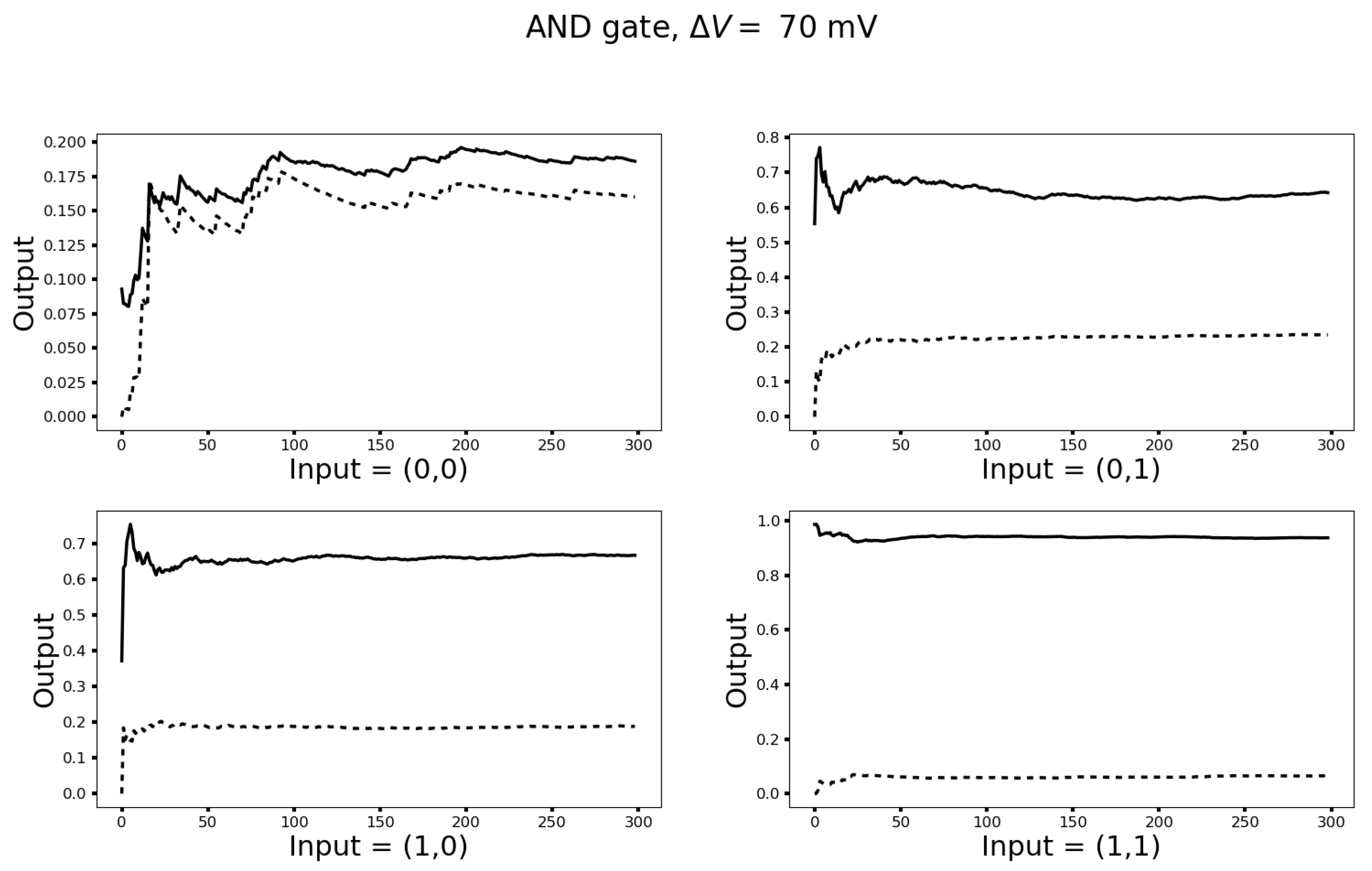
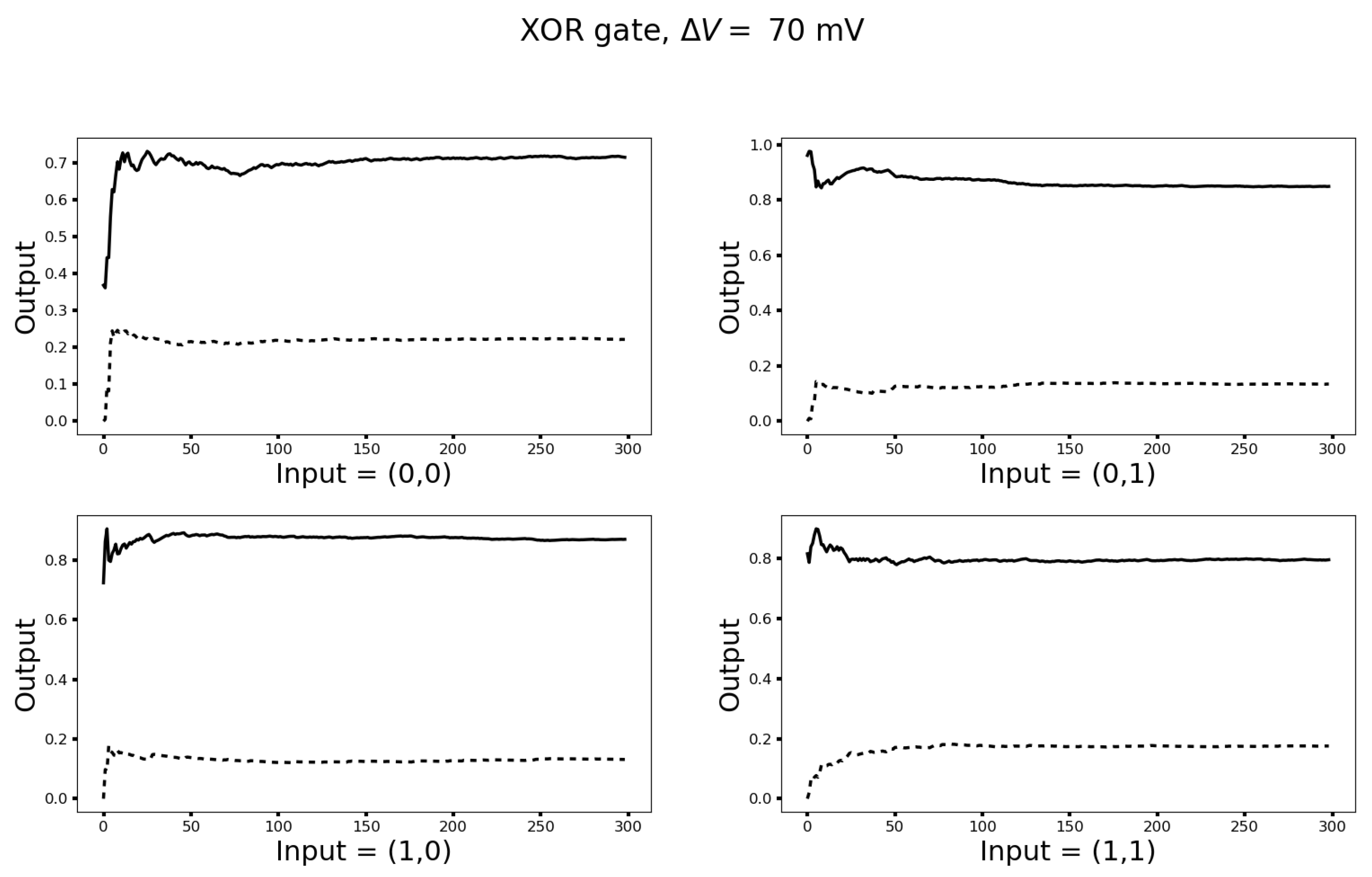
3.2. The Unit Wire Revisited
| Algorithm 1 Pseudo-code for Monte Carlo sampling from the maximum entropy distribution. |
|
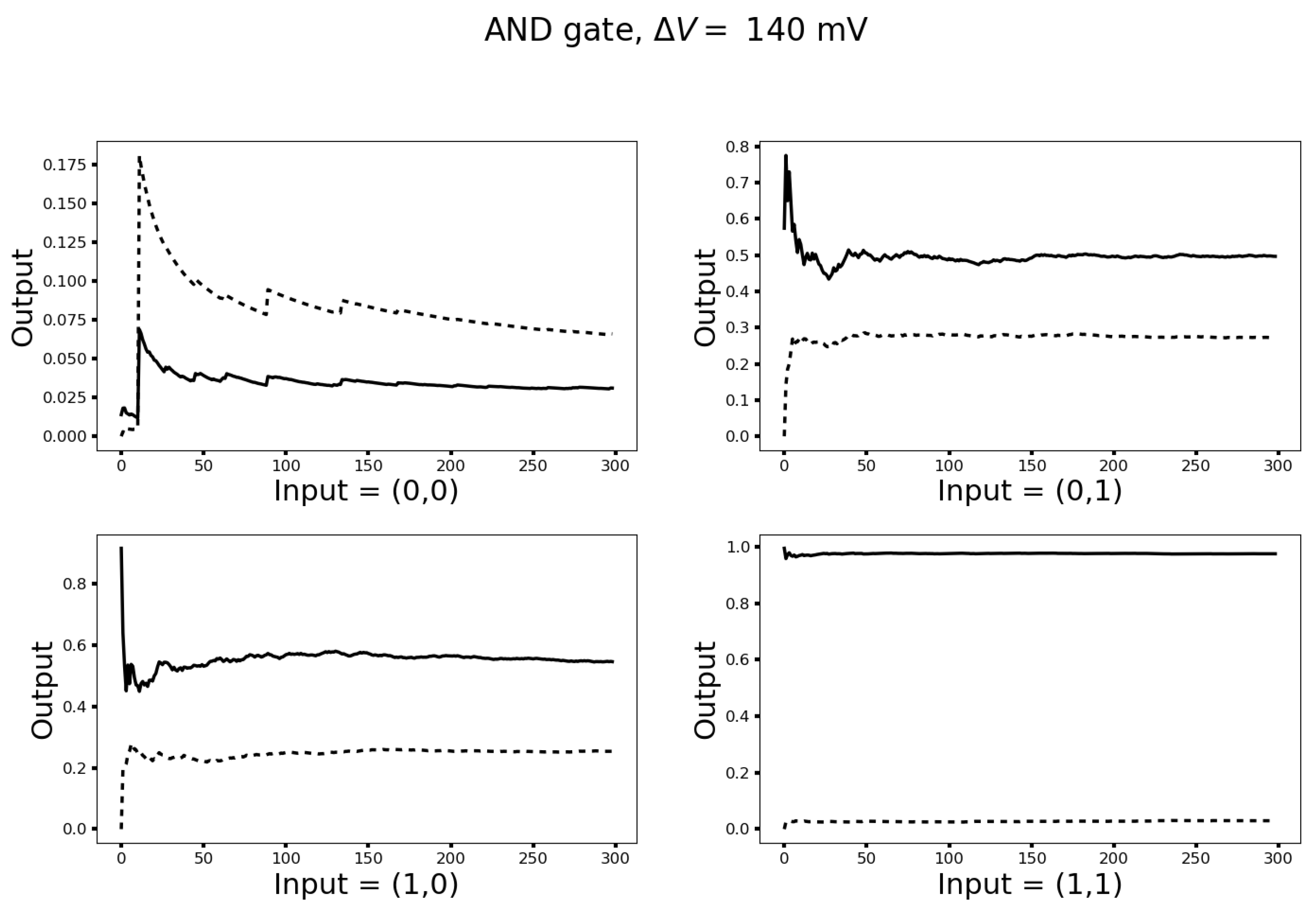
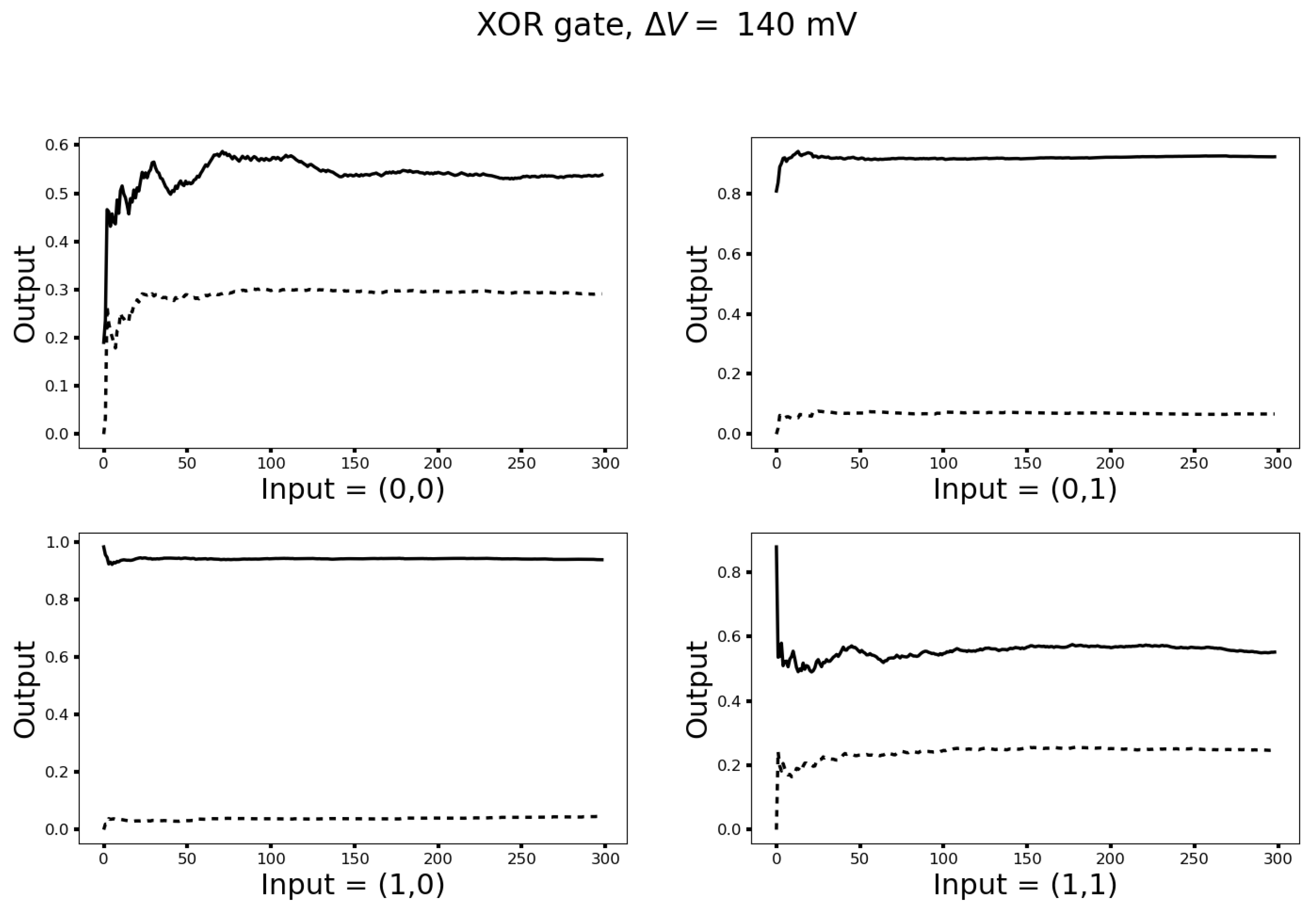
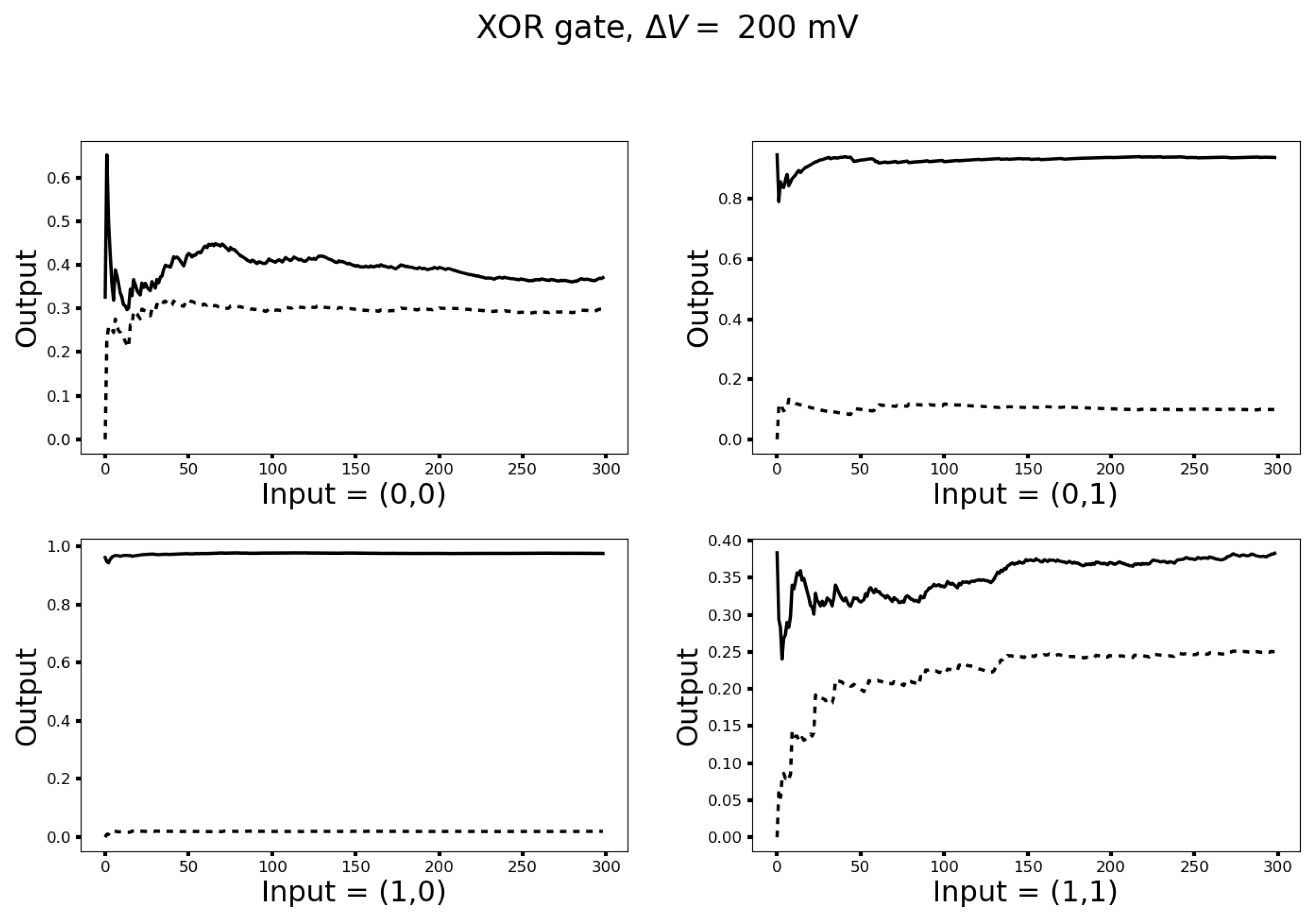
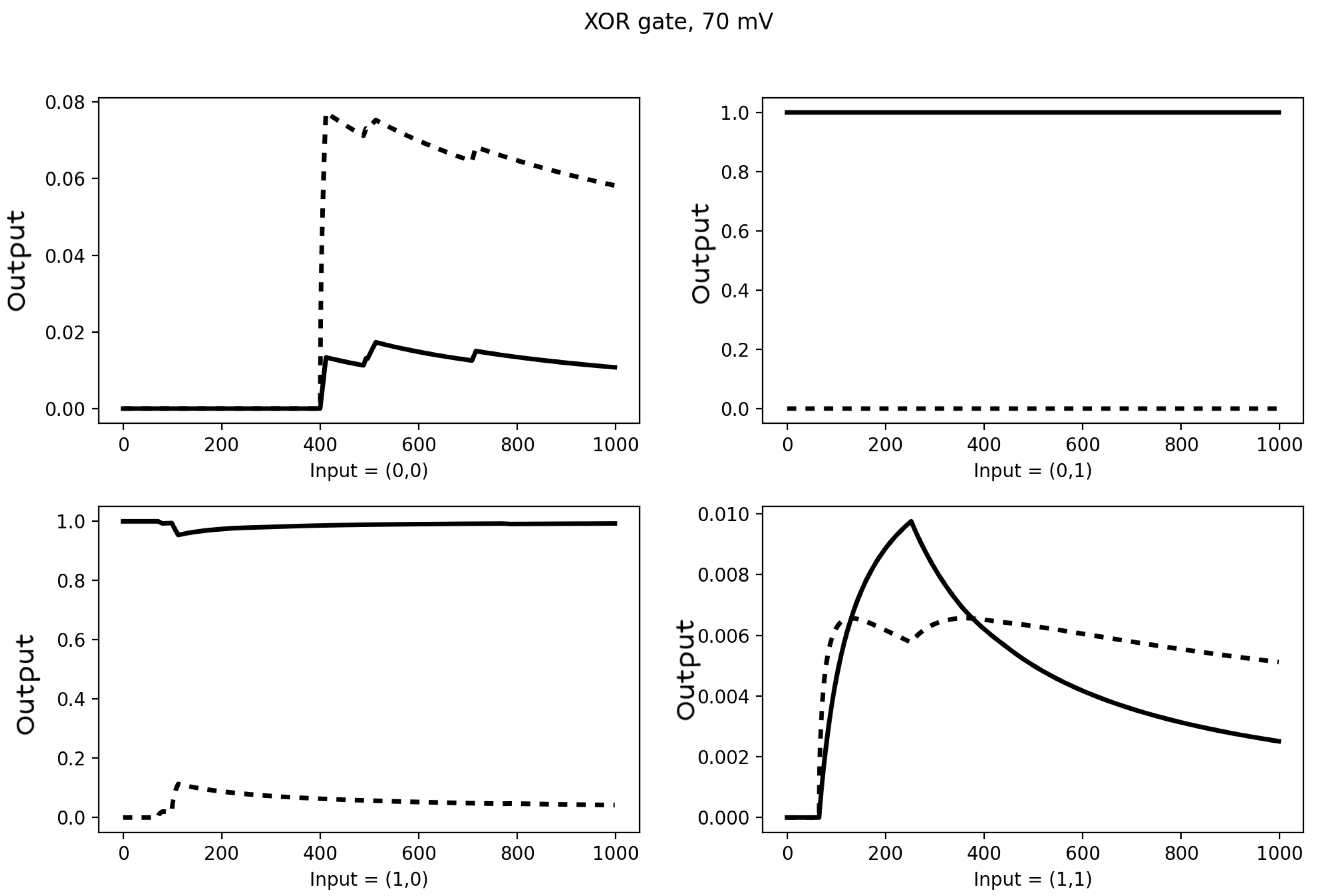
3.3. Turing Completeness
3.4. Networks with Hidden Neurons and Cyclical Connections for Machine Learning
- 1
- Give an initial connectivity matrix and initial bits for the hidden units for each sequence in D.
- 2
- Generate a candidate connectivity matrix by the use of Equation (22).
- 3
- Sample new sequences of bits by the application of .
- 4
- If the generated new sequences of bits satisfy a suitable improvement criterion over the visible units, then update .
- 5
- Repeat until a suitable convergence criterion is met.
| Algorithm 2 Pseudo-code for the thermalization stage of Monte Carlo sampling from the maximum entropy distribution. |
|
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Bound for the Couplings Fluctuations
References
- Bennett, C.H.; Landauer, R. The fundamental physical limits of computation. Sci. Am. 1985, 253, 48–57. [Google Scholar] [CrossRef]
- Purohit, S.; Margala, M. Investigating the impact of logic and circuit implementation on full adder performance. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2011, 20, 1327–1331. [Google Scholar] [CrossRef]
- Hylton, T.; Conte, T.M.; Hill, M.D. A vision to compute like nature: Thermodynamically. Commun. ACM 2021, 64, 35–38. [Google Scholar] [CrossRef]
- Sherrington, D.; Kirkpatrick, S. Solvable model of a spin-glass. Phys. Rev. Lett. 1975, 35, 1792. [Google Scholar] [CrossRef]
- Wang, W.; Machta, J.; Katzgraber, H.G. Comparing Monte Carlo methods for finding ground states of Ising spin glasses: Population annealing, simulated annealing, and parallel tempering. Phys. Rev. E 2015, 92, 013303. [Google Scholar] [CrossRef] [PubMed]
- Huang, H. Monte Carlo Simulation Methods. In Statistical Mechanics of Neural Networks; Springer: Singapore, 2021; pp. 33–42. [Google Scholar]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Fernandez, L.A.; Pemartin, I.G.A.; Martin-Mayor, V.; Parisi, G.; Ricci-Tersenghi, F.; Rizzo, T.; Ruiz-Lorenzo, J.J.; Veca, M. Numerical test of the replica-symmetric Hamiltonian for correlations of the critical state of spin glasses in a field. Phys. Rev. E 2022, 105, 054106. [Google Scholar] [CrossRef] [PubMed]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Jaynes, E.T. The well-posed problem. Found. Phys. 1973, 3, 477–492. [Google Scholar] [CrossRef]
- Jaynes, E.T. How Does the Brain Do Plausible Reasoning? Springer: Berlin/Heidelberg, Germany, 1988; pp. 1–24. [Google Scholar]
- Laplace, P.S. Pierre-Simon Laplace Philosophical Essay on Probabilities: Translated from the Fifth French Edition of 1825 with Notes by the Translator; Springer: Berlin/Heidelberg, Germany, 1998; Volume 13. [Google Scholar]
- Fredkin, E.; Toffoli, T. Conservative logic. Int. J. Theor. Phys. 1982, 21, 219–253. [Google Scholar] [CrossRef]
- Daube, J.R.; Stead, S.M. Basics of neurophysiology. In Textbook of Clinical Neurophysiology, 3rd ed.; Oxford: New York, NY, USA, 2009; pp. 69–96. [Google Scholar]
- Available online: https://github.com/ArturoBerronesSantos/bioplausBM (accessed on 30 March 2023).
- Kaiser, J.; Borders, W.A.; Camsari, K.Y.; Fukami, S.; Ohno, H.; Datta, S. Hardware-aware in situ learning based on stochastic magnetic tunnel junctions. Phys. Rev. Appl. 2022, 17, 014016. [Google Scholar] [CrossRef]
- Yan, X.; Ma, J.; Wu, T.; Zhang, A.; Wu, J.; Chin, M.; Zhang, Z.; Dubey, M.; Wu, W.; Chen, M.S.W.; et al. Reconfigurable Stochastic neurons based on tin oxide/MoS2 hetero-memristors for simulated annealing and the Boltzmann machine. Nat. Commun. 2021, 12, 5710. [Google Scholar] [CrossRef] [PubMed]
- Nienborg, H.R.; Cohen, M.; Cumming, B.G. Decision-related activity in sensory neurons: Correlations among neurons and with behavior. Annu. Rev. Neurosci. 2012, 35, 463–483. [Google Scholar] [CrossRef] [PubMed]
- Lucia, U. Thermodynamic paths and stochastic order in open systems. Phys. A Stat. Mech. Appl. 2013, 392, 3912–3919. [Google Scholar] [CrossRef]
- Kaniadakis, G. Maximum entropy principle and power-law tailed distributions. Eur. Phys. J. B 2009, 70, 3–13. [Google Scholar] [CrossRef]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berrones-Santos, A.; Bagnoli, F. Biologically Plausible Boltzmann Machine. Informatics 2023, 10, 62. https://doi.org/10.3390/informatics10030062
Berrones-Santos A, Bagnoli F. Biologically Plausible Boltzmann Machine. Informatics. 2023; 10(3):62. https://doi.org/10.3390/informatics10030062
Chicago/Turabian StyleBerrones-Santos, Arturo, and Franco Bagnoli. 2023. "Biologically Plausible Boltzmann Machine" Informatics 10, no. 3: 62. https://doi.org/10.3390/informatics10030062
APA StyleBerrones-Santos, A., & Bagnoli, F. (2023). Biologically Plausible Boltzmann Machine. Informatics, 10(3), 62. https://doi.org/10.3390/informatics10030062